PSO-DT based BagDT: a robust lightweight ensemble framework for efficient feature selection and DDoS attack detection in IoT environment
J. Jasmine Shirley, M. Priya

TL;DR
This paper introduces a lightweight framework for detecting DDoS attacks in IoT environments using a PSO-DT based Bagged Decision Tree model.
Contribution
The novel PSO-DT-based BagDT ensemble model efficiently selects features and detects DDoS attacks with high accuracy in resource-constrained IoT settings.
Findings
The PSO-DT-based BagDT model achieved 99.96% accuracy in DDoS attack detection.
BagDT improved accuracy by 4.13% and reduced training time by 95.49% compared to other ensemble models.
The model increased throughput by 63.52%, making it suitable for real-time IoT applications.
Abstract
The recent decade has seen enormous growth in the Internet of Things field. This development has significantly expanded the space for cyber-threats, among which the Distributed Denial of Service attacks have become one of the most important and common threats. These attacks might severely disrupt critical services if not detected and handled on time. To provide a reliable and secure IoT environment, accurate and effective mechanisms for detecting DDoS attacks in real-time are the most required. While state-of-the-art deep learning models like CNNs and LSTMs offer high accuracy, their computational overhead often makes them unsuitable for resource-constrained IoT environments. To address this gap, we have proposed a robust hybrid framework, the PSO-DT-based BagDT ensemble model. This model utilizes Particle Swarm Optimization in combination with Decision Tree for effectively finding the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
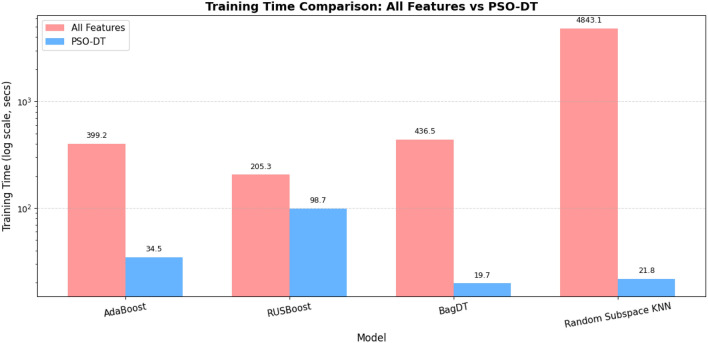 Figure 10
Figure 10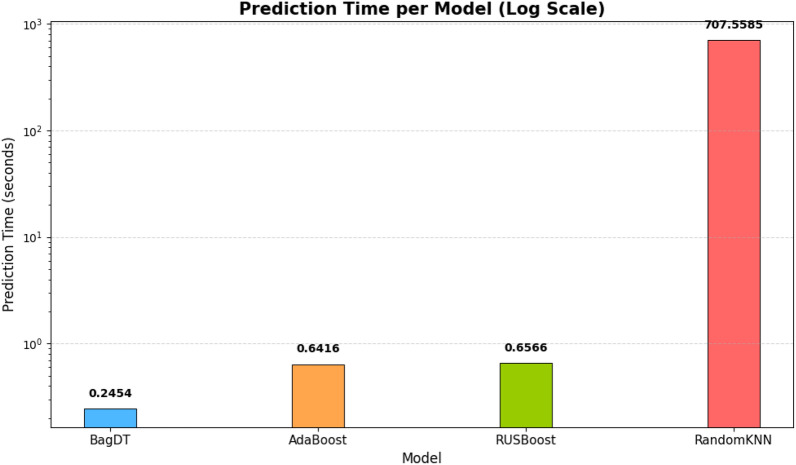 Figure 11
Figure 11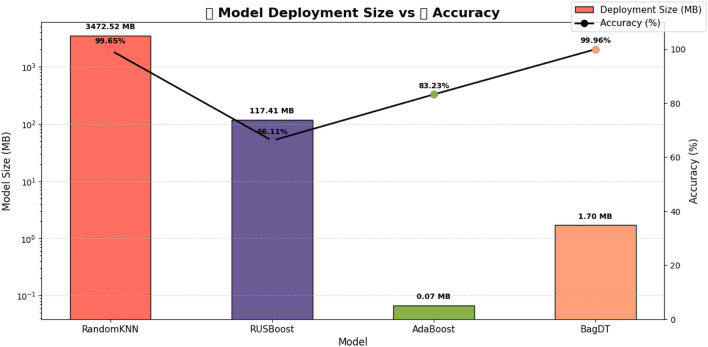 Figure 12
Figure 12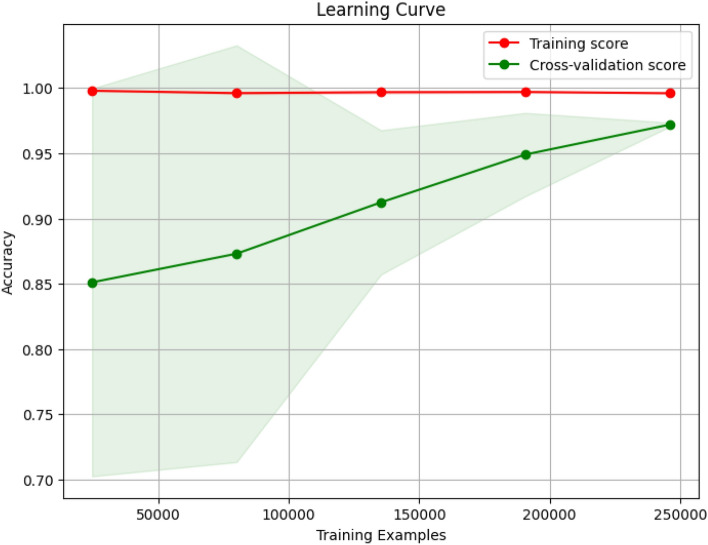 Figure 13
Figure 13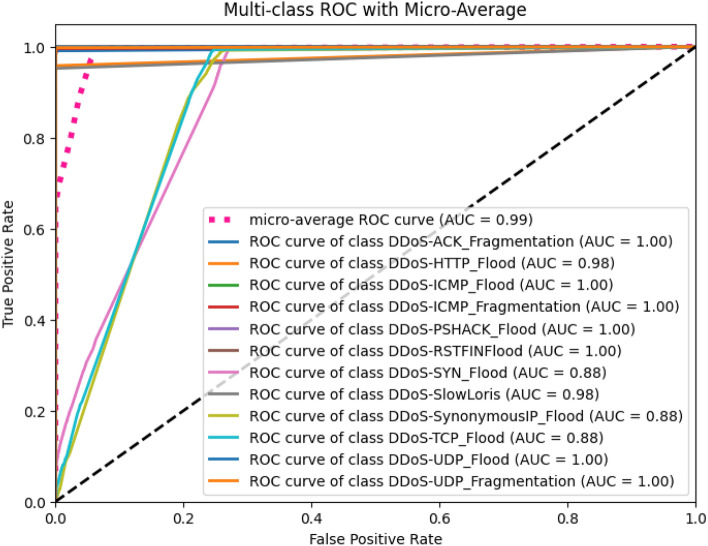 Figure 14
Figure 14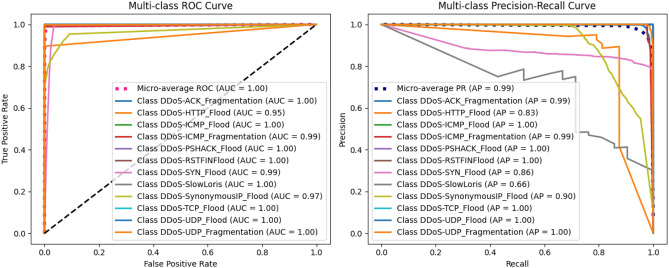 Figure 15
Figure 15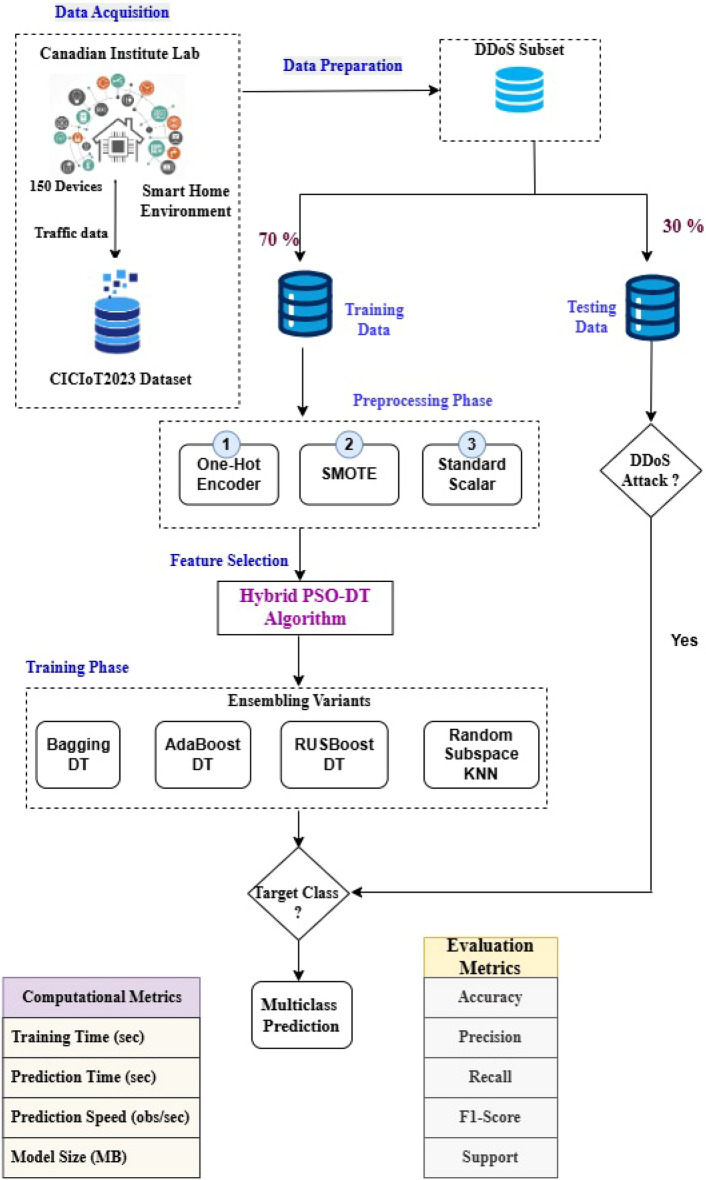 Figure 1
Figure 1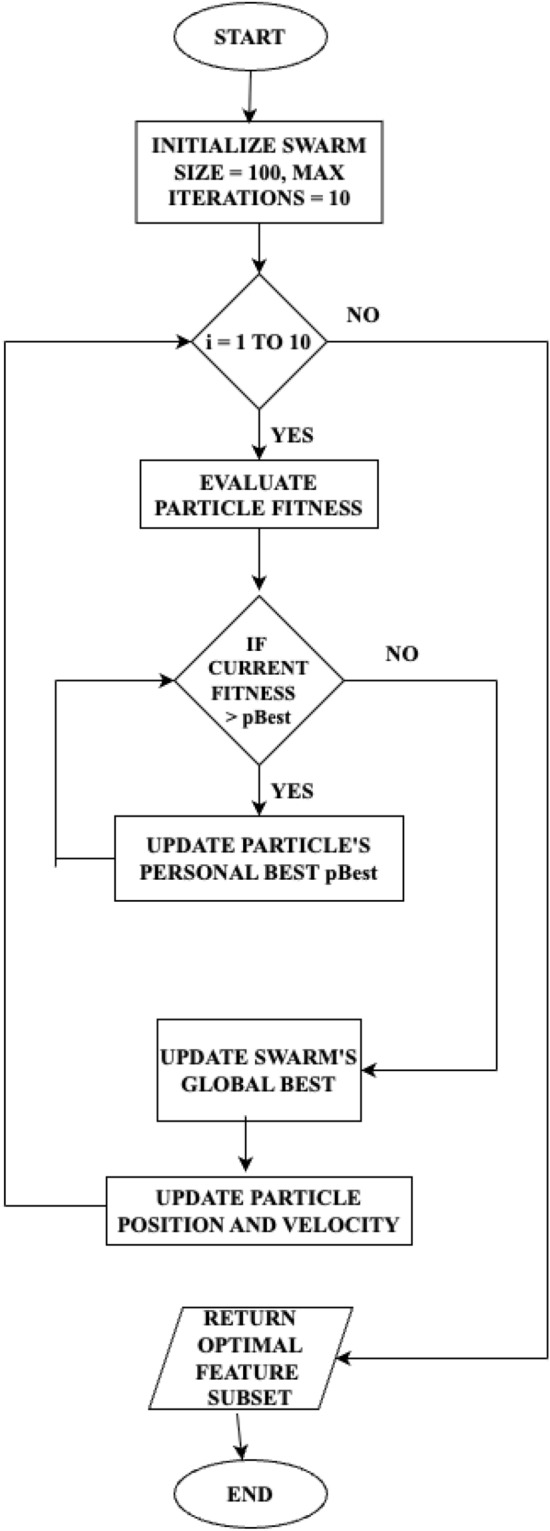 Figure 2
Figure 2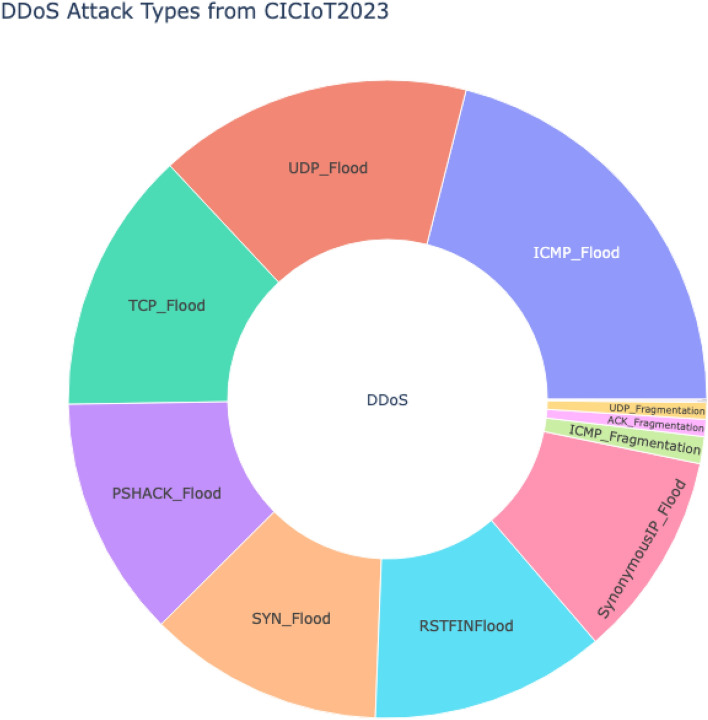 Figure 3
Figure 3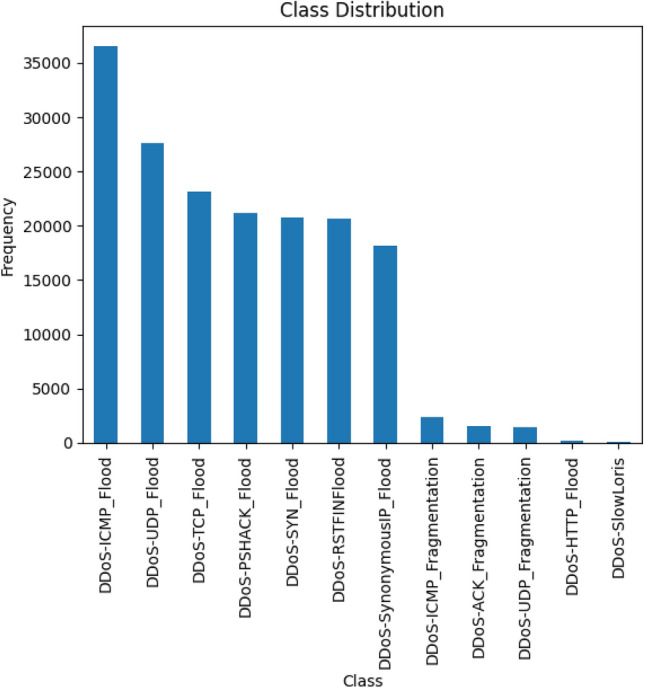 Figure 4
Figure 4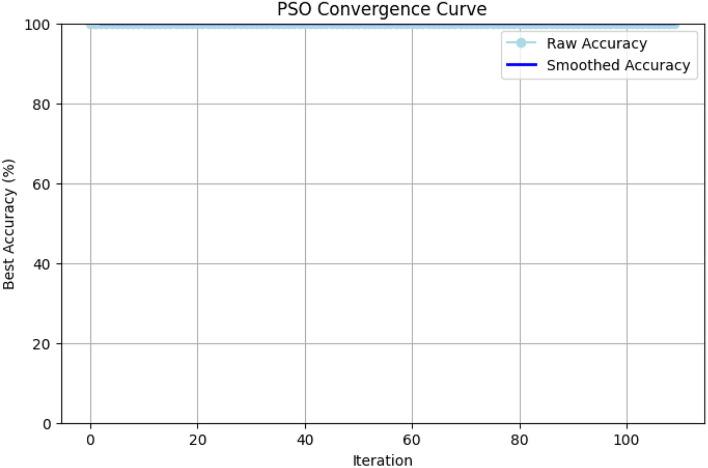 Figure 5
Figure 5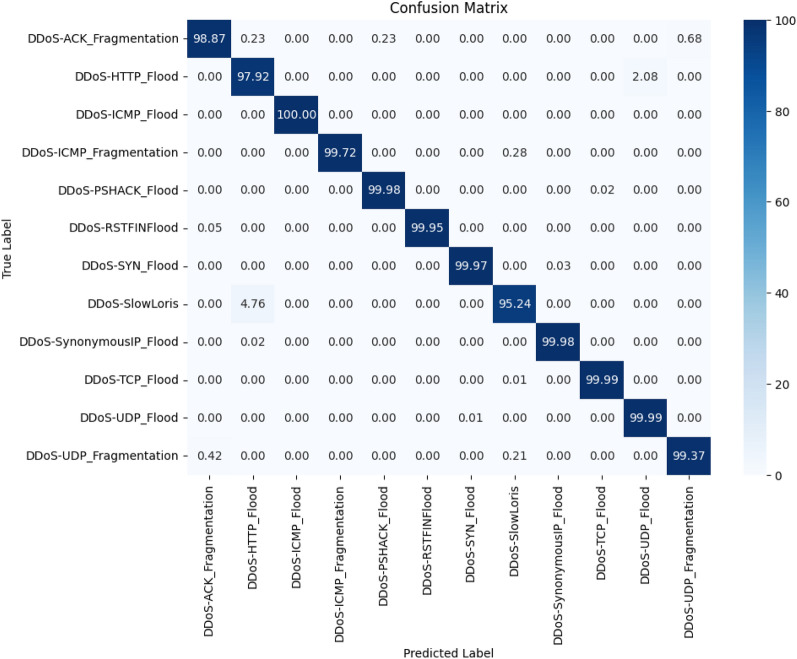 Figure 6
Figure 6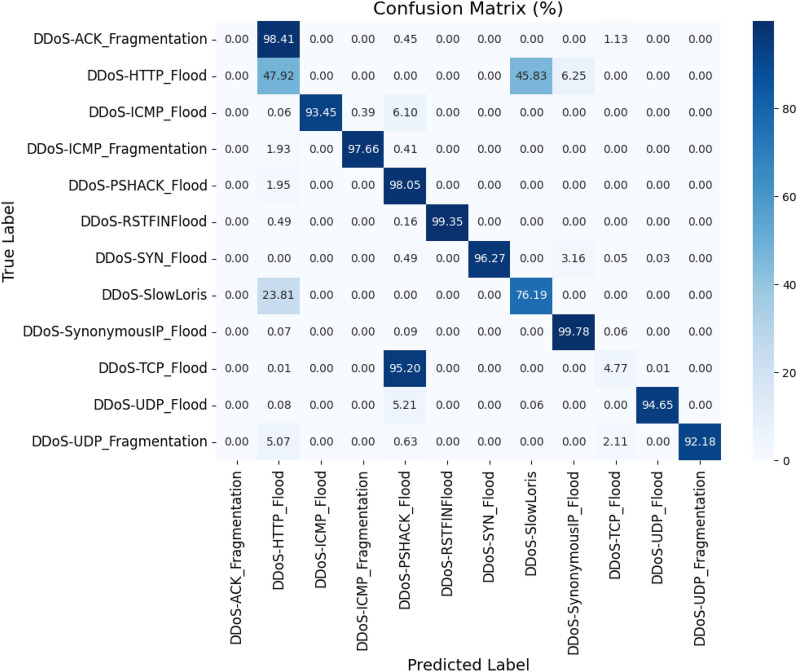 Figure 7
Figure 7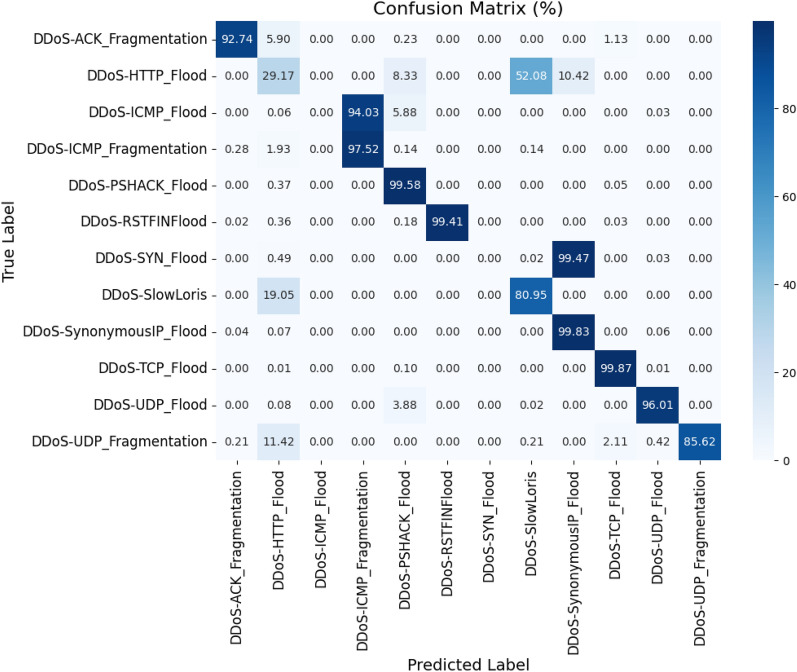 Figure 8
Figure 8 Figure 9
Figure 9 Figure 16
Figure 16 Figure 17
Figure 17- —Vellore Institute of Technology, Vellore
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNetwork Security and Intrusion Detection · Advanced Malware Detection Techniques · Anomaly Detection Techniques and Applications
Introduction
Advancements in technologies like Internet of Things (IoT), Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning have revolutionized how devices interact with each other in the real-world environment. This has widely encouraged industrialists to develop and deploy multiple applications across smart cities, healthcare, agriculture, finance, and home automation. Although there is a positive transformation in the environment, IoT devices are resource-constrained as well as heterogeneous in nature and also lack robust security features. This nature makes them the primary target for cyber threats, especially Distributed Denial of Service (DDoS) attacks. DDoS attacks are those in which the network and the servers are flooded with illegitimate traffic with the help of multiple compromised devices or bots. In certain cases, the IoT devices are hijacked and made to act as botnets like Mirai, Mozi or Torii. These can then be used in launching large-scale DDoS attacks, which can paralyze the infrastructure, disrupt services and hence cause economic damage.
In 2024, a survey was undertaken by Zayo on the insights of DDoS attacks. The report revealed that there was a staggering increase of about 82% in DDoS attacks from 2023 to 2024. The incidents increased from 90,000 to 165,000 attacks^1^. The key insights are as follows.
- The healthcare industry experienced a 223% rise in DDoS attacks as a result of the huge amount of interconnected medical devices.
- The finance and telecom sectors were found to be the most targeted ones due to their nature of high availability.
- The average cost estimated as of now is 2,34,000 dollars per DDoS attack if it lasts for a time frame of 39 minutes, which amounts to 6,000 dollars per minute. The various DDoS attacks that occurred in 2024 alone are as follows.
- In East Asia, a smart city transportation system was brought to a halt due to the SYN flood attack, which is a type of DDoS attack that targeted the traffic lights and surveillance feeds.
- The European manufacturing plants were disrupted by the UDP flood attacks, which exploited the insecure Industrial IoT gateways.
- In North America, one of the public utility grids was temporarily disabled due to a DDoS botnet that exploited the default user credentials that were used in smart meters. These reports and surveys not only portray the scale at which DDoS attacks occur but also portray the diversity of the attack, ranging from TCP SYN floods, UDP floods, and ICMP fragmentation to application-layer attacks such as HTTP floods and Slowloris. These challenges make the traditional detection systems fail in real-time. Moreover, IoT also poses certain challenges that are unique, such as Heterogeneous Protocols, limited resources, high class imbalance and dynamicity of attacks. To handle these challenges, a dynamic attack detection mechanism that can adapt to the requirements needs to be deviced. This motivates researchers across the world to focus on developing ML-based DDoS attack detection schemes and frameworks. Having these in mind, this work focuses on developing an integrated framework based on the ensembling of various machine learning classifiers. The base weak learners are combined and boosted to build a strong prediction model that can adapt according to the situation.
Novelty and contributions
While many studies have applied machine learning to DDoS detection, a significant portion focuses on maximizing accuracy with complex models such as deep neural networks that are ill-suited for the computational and memory constraints of real-world IoT devices. Our research addresses this critical gap by focusing on a lightweight, deployment-ready framework without sacrificing performance. The primary innovations and contributions of this work are as follows
- A Novel Hybrid Feature Selection Algorithm: We introduce a unique feature selection algorithm, PSO-DT, which combines Particle Swarm Optimization with a Decision Tree evaluator. Unlike conventional uses of PSO for hyperparameter tuning, our approach employs it as a wrapper-based feature selector to discover the optimal feature subset. This method significantly reduces data dimensionality, which in turn lowers model complexity and computational cost.
- Emphasis on Deployment Readiness and Scalability: A key novelty of this paper is the rigorous evaluation of deployment feasibility. We move beyond traditional classification metrics to analyze and optimize for model size (MB), prediction speed (observations/sec), and training time. This focus ensures our proposed model is not just a theoretical success but a practical solution for real-time detection on edge devices.
- An Integrated and Holistic Framework: This work presents a complete, end-to-end framework that cohesively integrates solutions for common challenges in IoT security datasets. It combines automated handling of class imbalance using SMOTE, the novel PSO-DT feature selection, and an efficient Bagged Decision Tree (BagDT) ensemble classifier, resulting in a robust and reproducible system. The rest of the paper is structured as follows. Section “Related works” reviews the works related to DDoS attack detection carried out by researchers in recent years across the world. Section “Background fundamentals” provides a brief introduction to the fundamentals and background needed for a better understanding. Section “Proposed methodology” describes in detail the proposed feature selection algorithm PSO-DT, the integrated framework and the ensemble prediction model PSO-DT based on BagDT. Section “Results and discussions” presents a detailed description of the results obtained for each variant and the comparative analysis of the complete experiment carried out. The paper is finally concluded with challenges, scope and future enhancements.
Related works
The recent decade has seen multiple researchers working on developing novel frameworks for detecting cyber attacks using ML and DL methods. This section discusses the contributions of a few researchers who have performed similar experiments on the data set CICIoT2023 and other similar types. The authors in^2^ aimed to develop a prediction model for detecting cyber attacks using hybrid ML models. Two ensemble techniques were experimented on the dataset, namely voting and stacking, using Logistic Regression (LR), Gaussian Naive Bayes (GNB), and Random Forest (RF) algorithms are used as base learners. Their model utilised pre-processing steps, and hyperparameter optmization was done for improving the performance of the hybrid ML model. The voting-based ensemble learner produced 99% accuracy for binary class classification and 98% for multiclass. Their study did not focus on deployment feasibility, computational complexity and scalability. In^3^, the researchers had proposed an ensemble model using multiple base classifiers, namely LR, Naive Bayes (NB), Support Vector Machine (SVM), K-Nearest Neighbour (KNN) and Multi-Level Perceptron (MLP). They experimented with their proposed ensemble learner on two data sets, namely CICIoT2023 and Edge-IIoTset2023. Experiments were also conducted using variants of ensembling techniques, voting, bagging, boosting and stacking. They interpreted the performance of the ensemble learner using the metrics precision, recall, F1 score and accuracy. They concluded that the boosting-based ensemble technique provided better accuracy of 93% when compared to other variants. These researchers also focused only on measuring the performance of the proposed ensemble model on both data sets where whereas they did not focus on computational complexity or deployment feasibility.
Further expanding on deep learning approaches, Sumathi et al.^4^ proposed a hybrid model using Long Short-Term Memory (LSTM) and a hybrid Harris Hawks-PSO (HHO-PSO) algorithm for feature selection, demonstrating the power of combining bio-inspired optimization with recurrent neural networks. In a comparative study, the efficacy of several machine learning algorithms for detecting specific attack vectors like the TCP SYN flood was analyzed, highlighting the trade-offs between different models^5^. Other works have also explored deep learning methods^6^ and hybrid frameworks to address the evolving threat landscape in IoT environments. A common thread in much of this research is the focus on sophisticated deep learning architectures, which, while powerful, often do not prioritize the lightweight and deployment-ready characteristics essential for resource-constrained IoT devices^7^ .Table 1. Summary of related works.Ref.ContributionDataset for validationPerformance analysisLimitations^2^Used Hybrid ML Ensemble (Voting, Stacking) of LR, GNB, RFCICIoT2023Accuracy: 99% (binary), 98% (multi-class)No focus on deployment feasibility, computational cost, or scalability^3^Developed an Ensemble model with LR, NB, SVM, KNN, MLP using Voting, Bagging, Boosting, Stacking variantsCICIoT2023, Edge-IIoTset2023Boosting achieved 93% accuracyLacked analysis on deployment feasibility and efficiency^4^Compared Individual ML/DL vs. Ensemble (DNN, RF, DT)CICIoT2023, WSN-DSEnsemble outperformed standalone modelsFocus limited to accuracy, no deployment considerations^5^Developed a Hybrid Stacking Ensemble and Cuckoo Search OptimizationCICIoT2023, KDDCup99, CSE-CIC-IDS2018Accuracy: 99.87% (binary), 98.86% (multi-class)Deployment and complexity not addressed^6^Used Voting Ensemble with RF as Base ModelCICIoT2023F1-Score: 99.75%, FAR: 0.038%No scalability or real-time feasibility assessment^7^Combined Recursive Clustering, Entropy Sampling and ML classifiersCICIoT2023High precision, recall, and F1-scoreFocused mainly on sampling and feature selection^8^Developed a Hybrid deepCLG (CNN, LSTM, GRU, Capsule Net)CICIoT2023, UNSW_NB15Accuracy: 99.82%No attention to resource constraints or deployment aspects
In^8^, the authors compared the performance of individual ML and DL models with the ensemble learner for detecting DDoS and DoS attacks. The three models used in their study are deep neural network (DNN), RF, and decision tree (DT). The performance metrics utilised were precision, recall, F1-score and accuracy. They grouped the total number of 33 attacks in the CICIoT2023 data into 7 major classes for performing the study. The researchers also performed the study on another dataset set namely WSN-DS, which contained four types of DoS attacks. Their experiments concluded that the ensemble approach achieved better accuracy when compared stand stand-alone ML and DL approaches. The authors in^9^ proposed an integrated framework for enhancing the security in an IoT environment using a stacking ensemble approach. To reduce the dimension, they used the Cuckoo search optimization algorithm. They tested their proposed ensemble model on various data sets, which include KDD Cup 99, CSE-CIC-IDS2018, and CICIoT2023. The maximum accuracy achieved on binary classification was 99.87% on the KDD Cup 99 data set. In the case of the multiclass approach, the accuracy achieved was 98.86%. In^10^, the researchers experimented with an ensemble approach based on a voting mechanism. The base learner utilized in this study was RF. The model was experimented on the CICIoT2023 data set. Their model achieved an F1 score of 99.75%. They showed a false alarm rate of 0.038%. In^11^, the authors proposed a recursive clustering method based on K-means for condensing the data and used an entropy-based sampling method for preparing an apt subset of the large data set. They utilized the Monte Carlo entropy technique for selecting the relevant features. The classification was performed using various classifiers, namely RF, LR, KNN, J48, NB and LinearSVC. They utilized precision, recall and F1 measure as evaluation metrics. Their major focus was on developing an effective sampling and feature selection technique for large data sets.
The researchers in^12^ focused on Industrial IoT networks and developed a framework for detecting the traffic irregularities. They proposed a hybrid model named deepCLG. The model is a hybrid version that utilized CNN, long short-term memory (LSTM), and the gated recurrent unit (GRU) and integrates these with a capsule network. The authors analyzed the efficiency of the proposed model on two data sets, CICIoT2023 and UNSW_NB15. The model achieved an accuracy of 99.82%. The authors in^13^ expanded on this research by developing an adaptive intrusion detection system that integrates autoencoders with a feedforward neural network (FNN). This innovative approach demonstrated impressive classification performance against emerging IoT threat vectors. Their Autoencoder-FNN fusion model emphasized effective feature extraction and dimensionality reduction while ensuring high detection accuracy. A summary of the contributions and limitations of the works carried out by the researchers in the same domain is illustrated in the Table 1. The last decade has seen an increasing trend in leveraging ensemble machine learning and deep learning techniques for cyber attack detection, particularly in IoT environments. Most studies have shown that ensemble approaches, especially stacking, voting, and boosting, outperform individual ML or DL models in terms of detection accuracy, precision, recall, and F1-score. Specifically, accuracy values have consistently exceeded 98% in many cases, with some hybrid models even achieving performance close to 99.8%. However, though performance metrics are well explored across these experiments, a common limitation is the lack of attention to deployment feasibility, computational efficiency, and scalability. These aspects are crucial for real-time IoT security systems, especially when operating under constrained environments such as edge or fog computing. The Table 2 illustrates how our proposed framework is unique from other related works discussed in this section.Table 2. Comparative analysis of contributions of proposed work vs related works.AspectProposed workCited studiesFeature SelectionOptimized PSO-DT algorithm for reducing model complexityMostly traditional feature selection or none. Some used entropy-based or Cuckoo searchModel TypeHybrid predictive model (PSO-DT + BagDT) for DDoS attack classification in IoT environmentMajority used stacking, voting, boosting with common ML/DL models (e.g., RF, SVM, DNN)Class Imbalance HandlingUses integrated resampling, encoding and ensemble learning for addressing class imbalanceLimited or no explicit handling of class imbalanceComparative AnalysisProvides detailed evaluation of multiple ensemble variants like AdaBoost, RUSBoost, BagDT, Random Subspace KNN in terms of accuracy, training time, prediction time and deployment feasibilityFocused mostly on accuracy, with limited or no comparison across ensemble variantsDeployment ReadinessAssesses model size, prediction speed (obs/sec), and scalability for real-time useRarely addressed, most studies lacked focus on deployment feasibility or real-world constraintsIoT SpecificityExplicitly designed for IoT environments with network traffic data and real-time constraintsUsed IoT datasets like CICIoT2023, but lacked emphasis on real-time or resource-aware deploymentPerformance MetricsEvaluates both predictive accuracy and operational metrics like speed and scalabilityMainly used accuracy, precision, recall, F1-score, rarely used system level metrics
Background fundamentals
This section provides a brief description of the various fundamental concepts and background required for understanding the proposed framework. The concepts discussed are Bio-inspired algorithms, Ensemble Learning and Particle Swarm Optimization techniques.
Bio-inspired algorithms
The Bio-inspired algorithms are the methods inspired by the natural behaviour, structure and evolution of biological systems in nature. These algorithms are best suited for solving complex and dynamic problems that cannot be solved by mathematical approaches. Usually, researchers use these algorithms for non-linear high-dimensional data^14^. The major characteristics of these algorithms are as follows.
- Since these are nature-inspired, they can adapt themselves to the dynamic environment automatically.
- They generally work in a decentralized manner.
- Since randomness is the key, local minima issues are handled efficiently.
- They are all self-organised, and the solutions are derived from their local behaviours and interactions among the population. The bio-inspired algorithms can be classified as Evolutionary Algorithms (EAs), Swarm Intelligence Algorithms, Artificial Immune Systems (AIS) and Neural and Cellular-Inspired Models. The EAs are based on the principle of Darwin, that is, survival of the fittest, which is simulated by operations like selection, mutation, crossover and reproduction^15^. Few well-known examples are Genetic algorithms^16^, Genetic programming^17^ and Differential evolution^18^. The major applications are in feature selection, training of neural networks and hyperparameter tuning. Swarm Intelligence algorithms are designed by mimicking the collective behaviour of animals like honey bees, ants, birds, lions, whales, fireflies, etc., for achieving an objective. Few popular algorithms are Particle Swarm Optimization (PSO)^19^, Ant Colony Optimization (ACO)^20^, Artificial Bee Colony (ABC)^21^ and Firefly Algorithm^22^. The major applications are in sensor networks for routing problems, detection of cyber attacks and optimized resource allocation. AIS are those techniques that are based on the principle of the human immune system. The inspiration is in the manner the human immune system detects pathogens and neutralizes them. Neural and Cellular-Inspired Models are based on the principle of intelligence at the cellular and brain level. Cellular automata^23^ and Spiking Neural Networks^24^ are well-known examples of these types. The major applications are in image and signal processing, pattern matching and temporal anomaly detection. A summary of the popular bio-inspired algorithms is illustrated in the Table 3. These algorithms can be utilized for a wide range of optimization problems and are domain-independent. They are capable of handling noisy, incomplete as well and dynamic data. Though they have various advantages, they suffer from a few drawbacks like the requirement of high computational resources, complex parameter tuning, slower convergence rate and the global optimum is not guaranteed.Table 3. Summary of popular bio-inspired algorithms.Type of AlgorithmInspirationStrengthsApplicationsGenetic AlgorithmNatural Evolution* Global Search * Flexible* Feature Selection * Optimization problemsParticle Swarm OptimizationBird/Fish Swarming* Fast convergence * Simple* Weighted SumAnt Colony OptimizationAnt Foraging* Very good for paths and combinatorial* Routing * SchedulingArtificial Bee ColonyBee Foraging* Balanced exploration and exploitation* Resource optimizationArtificial Immune SystemImmune Response* Anomaly detection * Memory usage* Network security * Secure IoT environmentFirefly / Bat AlgorithmLight/echolocation* Continuous optimization* Signal classification * Training ML modelsCellular Automata, Spiking Neural NetworksCells/Neurons* Local rules * Spatiotemporal modeling* Complex systems modeling
Ensemble learning
Ensemble Learning (EL) is an advanced ML paradigm, where the output of various weak learners or base models is combined to improve the performance of the final prediction model. This final prediction model is usually a strong learner that combines all the best measures of individual models and is also robust. The reason behind this improved performance is that the variance and bias are reduced, thereby improving the prediction accuracy due to diversity^25^. EL techniques can be of four different types, namely bagging, boosting, stacking and voting. Bagging is a technique in which the data set is divided into multiple subsets, and the training is performed individually on each subset. This mechanism helps in reducing the variance and hence avoids overfitting. The popular base learner used here is the RF or DT. In the case of boosting, the models are utilized to train the dataset sequentially, one after the other. Each model tries to correct the mistakes made by the previous model. This helps in reducing bias, and hence performance of the final model is improved. Usually, algorithms like AdaBoost, Gradient Boosting Machines (GBM), XGBoost, LightGBM and CatBoost are used. In the case of Stacking, the base models are usually heterogeneous. The output of these models is combined using a meta-model, which is usually a weak learner. The outputs of the base learners are used as features for the meta-model. Popularly used meta-learners are LR or a multi-layer perceptron. Voting is a very simple mechanism for combining the outputs of multiple classifiers. There are two types of voting, namely hard and soft voting. In hard voting, the majority output is considered to be the final prediction. In case of soft voting, the final prediction is the average result. A summary of the various EL techniques is illustrated in the Table 4. The major challenge in EL is that they are usually computationally expensive, as multiple models need to be trained. Also, hyperparameter tuning is a challenge.Table 4. Summary of ensemble techniques.MethodFocusBase learners typeAggregation schemeBaggingVarianceHomogeneousAveraging/votingBoostingBiasHomogeneousWeighted sumStackingGeneralizationHeterogeneousMeta-learnerVotingSimplicityAnythingMajority/average
Particle swarm optimization
PSO is an algorithm inspired by the swarming behaviour observed in birds, fish and other social animals^26^. Birds usually flock together to find the presence of food efficiently. Similar to that, in PSO, the particles are initialized to collaborate for finding the solution in an optimized manner. The algorithm was developed by Kennedy and Eberhart. The algorithm works on various terminologies, which are listed as follows.
- Swarm: This term represents the group of particles.
- Particle: This represents the possible solution for the given problem.
- Position: This represents the current location of the particle n and can be represented as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_n$$\end{document} .
- Velocity: This is the speed at which the particle moves in a particular direction and can be represented as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_n$$\end{document} .
- Personal Best: When the particle moves in search of a solution, the best solution or position of the particle n is specified as personal best and can be represented as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\alpha$$\end{document} .
- Global Best: Out of all the solutions found by each particle in the swarm, the best solution is considered as the global best and is represented by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g\alpha$$\end{document} . The entire algorithm is executed for multiple iterations, and the possible solutions are obtained. At every iteration, the position and velocity of every particle are updated using the following equations. The velocity of the particle can be updated using the Eq. (1). In the Eq. (1), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega$$\end{document} represents the balance between exploitation and exploration that is termed as inertia weight, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_2$$\end{document} are the acceleration constants, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ran_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ran_2$$\end{document} are the random numbers generated between the interval 0 and 1.
The position of the particle can be updated or modified using the Eq. (2).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_n(x+1) = y_n(x) + v_n(x+1) \end{aligned}$$\end{document}Initially, a swarm of particles are initialized with some random velocity and position. Then, for each particle in the swarm, the fitness value is estimated using a fitness function. Based on this, the current position of the particle is updated, and if it is better than the previous position, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\alpha$$\end{document} is updated with the new value. Out of all the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\alpha$$\end{document} values, the best is considered to be the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g\alpha$$\end{document} value. The velocity and position of the particles are updated using Eqs. (1) and (2). These steps are repeated till a stopping criterion is reached. The stopping criteria can be a maximum value for iterations or a best fitness value, which is decided by a threshold.
This research has proposed a feature selection algorithm, PSO-DT, based on the PSO algorithm, and a prediction model for detecting DDoS is designed by using an ensemble approach. All the variants are utilized for experimental purposes, and the best variant is decided. The next section discusses about the proposed methodologies.
Proposed methodology
Due to technological advancements in ML, DL and IoT, various smart devices are being installed in real-world environments. These devices are usually installed to remotely monitor the environment and transfer the data via the internet to a centralized cloud framework where some drastic decisions are taken and actuators are initialized. These types of smart devices are usually installed as edge devices and are also heterogeneous. Though there are multiple smart applications in various domains and industries, these are not generally adopted in a wide range of real-time applications. The reason behind this hesitation is the security aspect of these devices, which are resource-constrained and hence need to transmit data over a public network. These networks and data are usually exposed to data threats and data breaches, which might lead to negative impacts. The traditional intrusion detection systems are designed based on some static patterns and cannot adapt to the current dynamic environment. Moreover, the IoT devices are usually smaller in size and lack storage and memory capacity. Hence, having a lightweight model for detecting the attack is most needed. Our proposed integrated framework, PSO-DT-based BagDT, is best suited for this scenario and is illustrated in the Algorithm 1.
Algorithm 1Proposed integrated PSO-DT based BagDT ensemble model
The proposed integrated framework is illustrated in Fig. 1.Figure 1. Hybrid PSO-DT based ensemble framework for DDoS attack detection in IoT environment..
The integrated framework has a total of five phases, namely the data preparation phase, pre-processing phase, feature selection, training phase and testing phase. The data gathered from a set of 150 IoT devices in the CIC Lab is the CICIoT2023 dataset. This dataset is initially prepared in the data preparation phase, where the target classes related to DDoS attacks alone are filtered and separated to form an individual subset. This subset is then tested for NULL values. Since there were no NULL values, the subset was taken as such and split into training and validation data sets using the 70-30 rule. Then the training data set is passed over to the Pre-processing phase, which includes three components. Initially, the data is encoded using the one-hot encoding scheme to convert the categorical data available in the dataset into numerical data so that it can be further utilized for processing. During data visualization, since it was noticed that there was class imbalance, to balance the distribution of classes, the SMOTE oversampling technique is utilized. Then the balanced data set is normalized using the Standard scalar method. The preprocessed training data is then used as input for the proposed PSO-DT feature selection algorithm. The PSO-DT algorithm is illustrated in Algorithm 2. The operational logic of the PSO-based feature selection process is visually detailed in the flowchart in Fig. 2. The selected features are then used for training the four ensemble models, BagDT, AdaBoost, RUSBoost and Random Subspace KNN. The prediction models are evaluated using the evaluation metrics Precision, Recall, F1 score, Support, Training time, Testing Time, Prediction speed in terms of observations per second and model deployment size in MB. Then the models are validated using the validation data. All the models are evaluated and compared with the prediction model MRMR-PCA BagDT model, which was proposed in our previous research. The best model is decided based on accuracy, model size and computational complexity.
Algorithm 2PSO-based feature selection with decision tree
Results and discussions
This section discusses in detail the data set used to experiment, the experimental setup, the hyperparameters used, the results obtained and the discussion on the validation results.
Dataset description
The data set utilized to validate the proposed framework is the real-time data collected at the Canadian Institute of Cyber Security (CIC). The data is generated in the CIC’s IoT lab set up specifically for producing IoT-based security data^27^. The lab was set up with a total of 150 IoT devices deployed all over the laboratory to mimic the real-world environment. Out of these, around 67 devices were utilized to create the attacks, and the remaining 38 were deployed in the network using Zigbee and Z-wave devices. These were further connected to the hubs, which were 5 in number. The various devices interconnected in the lab are smart home devices like cameras, televisions, sensors and micro-controllers. The attacks are produced using various tools and software that are installed in the environment. Various types of attacks were produced and captured, namely DDoS, DoS, Recon, Web-based, Brute-force, Spoofing and Mirai. Each type of attack had sub-sets. The details of all the classes under each category of attack are illustrated in the Table 5.Table 5. Distribution of attack instances across categories and their respective target classes in the dataset.Category of AttackTarget ClassesNumber of InstancesDistributed Denial of ServiceUDP Flood5,412,287SlowLoris23,426RSTFIN Flood4,045,285HTTP Flood28,790ACK Fragmentation285,104ICMP Flood7,200,504PSHACK Flood4,094,755UDP Fragmentation286,925ICMP Fragmentation452,489TCP Flood4,497,667SYN Flood4,059,190SynonymousIP Flood3,598,138Denial of ServiceTCP Flood2,671,445HTTP Flood71,864SYN Flood2,028,834UDP Flood3,318,595ReconPing Sweep2,262OS Scan98,259Vulnerability Scan37,382Port Scan82,284Host Discovery134,378Web-basedSQL Injection5,245Command Injection5,409Backdoor Malware3,218Uploading Attack1,252XSS3,846Browser Hijacking5,859Brute-ForceDictionary Brute Force13,064SpoofingARP Spoofing307,593DNS Spoofing178,911MiraiGREIP Flood751,682Greeth Flood991,866UDPPlain890,576
The proposed framework concentrates on experimenting only with the DDoS category and its corresponding target classes, namely ACK_Fragmentation, HTTP_Flood, ICMP_Flood, ICMP_Fragmentation, PSHACK_Flood, RSTFINFlood, SYN_Flood, SlowLoris, SynonymousIP_Flood, TCP_Flood, UDP_Flood and UDP_Fragmentation as shown in the Fig. 3. The subset has 47 features, of which one is the target class and of categorical type. All other features are numerical and of type float.Figure 2. Flowchart of the PSO-DT feature selection process.Figure 3DDoS attack types for experimentation extracted from CICIoT2023.
Experimental setup
To ensure the transparency and reproducibility of our findings, all experiments were conducted in a consistent computational environment. The hardware and software configurations used for data processing, model training, and evaluation are detailed below.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bullet$$\end{document} All experiments were conducted within the Google Colab environment, which provided a virtual machine equipped with an Intel Xeon CPU (running at 2.20GHz or faster) and 12 GB of system RAM. For accelerated computations where applicable, a Tesla T4 or P100 GPU was utilized. To ensure efficient model training, Scikitlearn’s n jobs=-1 parameter was used to leverage all available CPU cores for parallel processing.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bullet$$\end{document} The entire workflow was implemented in Python version 3.8+. Core functionalities were handled by several key open-source libraries, with the following versions being used.
- Pandas (v1.3.5) was used for data loading and manipulation.
- Scikit-learn (v1.0.2) was utilized for building the ensemble models namely BaggingClassifier, AdaBoostClassifier. Then also for data scaling, and performance metric calculations.
- Imbalanced-learn (v0.8.1) was for applying the SMOTE technique to correct class imbalance.
- Pyswarm (v0.6) was used for implementing the Particle Swarm Optimization algorithm.
- Matplotlib (v3.2.2) and Seaborn (v0.11.2) were utilized for generating all visualizations, including confusion matrices and performance graphs.
Data pre-processing
Data pre-processing began with an integrity check, which confirmed there were no missing values. The primary challenge identified during the initial analysis was a severe class imbalance, as illustrated in the class distribution plot in the Fig. 4.
With a calculated imbalance ratio of over 344:1, the dataset is heavily skewed towards majority classes. Training a model on such an imbalanced dataset can lead to a biased classifier that performs well on frequent attack types but fails to detect rare yet critical threats, rendering it unreliable for real-world security.
To mitigate this, we incorporated the Synthetic Minority Over-sampling Technique (SMOTE) into our framework. SMOTE was specifically chosen over simple over-sampling or under-sampling because it generates new, synthetic data points for the minority classes by interpolating between existing instances. This approach creates a more balanced and robust training set without discarding potentially valuable data or simply overfitting to duplicate samples.Figure 4. Distribution of classes across the dataset.
Since the dataset had categorical features, we used the one-hot encoding technique to encode the categorical features. We decided to keep the numerical features as such. Hence, when numerical features were found, we used the pass-through transformer mechanism to avoid any encoding. For balancing the classes across the training dataset, we used SMOTE. A random state of 42 was initialized for performing this balancing operation. The distribution of classes before and after applying SMOTE is illustrated in Table 6. To normalise both the training and testing data, normalization was performed using the Standard Scalar mechanism.Table 6. Distribution of instances for each class: before vs after SMOTE.Target classBefore applying SMOTEAfter applying SMOTEICMP_Flood25,62925,629UDP_Flood19,25725,629TCP_Flood16,16725,629PSHACK_Flood14,80125,629SYN_Flood14,56625,629RSTFINFlood14,53825,629SynonymousIP_Flood12,75325,629ICMP_Fragmentation165125,629ACK_Fragmentation106425,629UDP_Fragmentation101125,629HTTP_Flood12125,629SlowLoris8525,629
Feature selection
The dataset had a total of 47 features, out of which one is the target class and the other 46 are features correlating to the target class. When all features were utilized for training the data, the time required for training was higher, and it would also require more computational resources. To overcome these issues, we tried to select the best features using the proposed PSO-DT framework, where only 19 features were selected. The fitness score obtained as a result of the proposed PSO-DT feature selection algorithm is illustrated in the Table 7. The algorithm tries to minimize the fitness function, which is defined. Here, since we want to maximize the accuracy, the negative accuracy is considered to be returned as a result. In the feature subset, ‘0’ represents that the feature is not selected and ‘1’ represents that the feature is selected. Hence, a binary mask is utilized. In every iteration, the selected feature subsets are evaluated using the DT classifier with 3-fold cross-validation initially and then again evaluated with 5-fold cross-validation to test the quality of the feature subset. The features which were selected as a result of this phase were Drate, syn_flag_number, rst_flag_number, ack_count, syn_count, fin_count, HTTP, SMTP, IRC, UDP, ICMP, IPv, LLC, AVG, IAT, Number, Magnitude, Covariance and Variance. These selected features were used for training the proposed ensemble models.Table 7. Fitness score for features.FeaturesFitness scoreFeaturesFitness scoreFeaturesFitness scoreflow_duration0.30436109ack_count0.94010189DHCP0.21379606Header_Length0.13199394syn_count0.85842519ARP0.33428846Protocol Type0fin_count0.75775922ICMP0.99799178Duration0.39785963urg_count0.3499426IPv0.67377248Rate0.2021474rst_count0.35770719LLC0.85858186Srate0.49855604HTTP0.60686721Tot sum0.41871924Drate0.76882591HTTPS0.04443177Min0fin_flag_number0.15159532DNS0Max0syn_flag_number0.55217229Telnet0Avg1rst_flag_number0.59178972SMTP0.77489411Std0.11144784psh_flag_number0.13252155SSH0.16439804Tot size0.01078028ack_flag_number0.07472793IRC0.66806486IAT0.62099422ece_flag_number0.18252335TCP0.40778826Number0.78897386cwr_flag_number0.15874875UDP0.77971405Magnitue1Radius0.06808802Covariance0.57125954Variance0.85736812Weight0.44938718
PSO parameter selection
The choice of parameters such as swarm size and the number of iterations directly impacts the balance between the quality of the feature subset found and the computational cost of the search process. In our framework, we selected a swarm size of 100 and a maximum of 10 iterations. This decision was based on established practices and the specific goals of our study. A larger swarm size of 100 was chosen to ensure a comprehensive exploration of the high-dimensional feature space, reducing the risk of the algorithm prematurely converging on a local optimum. The number of iterations was deliberately limited to 10 as a trade-off to maintain computational efficiency. Since our goal is a lightweight and practical framework, an exhaustive, timeconsuming search process was deemed counter-productive. The effectiveness of this choice is demonstrated by the algorithm’s convergence curve, shown in Fig. 5. The convergence curve plots the best fitness score (accuracy) found by the swarm as the search progresses. As illustrated, the algorithm identifies a near-optimal solution with an accuracy of 99.97% almost immediately and shows no further improvement in subsequent iterations. This rapid convergence provides strong evidence that 10 iterations are sufficient to yield a high-quality feature subset without incurring unnecessary computational overhead. This aligns perfectly with our goal of balancing high detection accuracy with efficient deployment.
Classification models
The standalone classification models DT and KNN were ensembled using three approaches, namely bagging, boosting and Random subspace. In the case of boosting, two variations were concentrated, namely AdaBoost and RUSBoost. 5-fold cross-validation was utilized to validate the proposed framework. The models were trained using the feature subset obtained as a result of feature selection from the proposed PSO-DT algorithm. The results obtained are finally compared and validated.
Bagging-based decision tree classifier
Initially, the best solution obtained from the PSO-DT algorithm is taken and masked to be either ‘0’ or ‘1’. When the feature is masked as 1, the feature is considered for training, and when it is masked as 0, it is omitted. A threshold of 0.5 is maintained for the binary mask.Figure 5PSO convergence curve for feature selection.Table 8. Classification report: PSO-DT based bagging DT classifier.Target classPrecisionRecallF1 scoreSupportDDoS-ACK_Fragmentation0.990.990.99441DDoS-HTTP_Flood0.940.980.9648DDoS-ICMP_Flood1.001.001.0010,925DDoS-ICMP_Fragmentation1.001.001.00726DDoS-PSHACK_Flood1.001.001.006409DDoS-RSTFINFlood1.001.001.006131DDoS-SYN_Flood1.001.001.006173DDoS-SlowLoris0.830.950.8921DDoS-SynonymousIP_Flood1.001.001.005436DDoS-TCP_Flood1.001.001.006982DDoS-UDP_Flood1.001.001.008369DDoS-UDP_Fragmentation0.990.990.99473
Then, the final training and testing data sets are reduced by including only the selected features from the binary feature mask. The reduced training set is utilized for training the ensemble of decision trees. Totally 50 decision trees are created and ensembled using the bagging technique. Since faster training is the requirement, all the CPU cores are utilized. The training is then started, and the total time required for training is calculated. Then, using the trained model, the testing data is validated, using which the time required for prediction is calculated in seconds. The classification report is obtained for this model and is illustrated in the Table 8. The confusion matrix for the same is shown in Fig. 6.Figure 6. Confusion matrix: proposed PSO-DT based bagging DT classifier.
The training time for training the parameters and ending with a learned model is 21.22 seconds, the time required for prediction is 0.26 seconds, and the model size is 1.70 MB when the proposed PSO-DT-based Bagging DT Classifier is used. The model achieved an accuracy of 99.96%.
AdaBoost-based decision tree classifier
This model uses several weak learners and combines them to arrive at a final strong classifier. This model functions sequentially and tries to correct the mistakes made in the previous round during the next immediate round. The base model, which is a weak learner, is initially defined. The base model considered here is called a decision stump, which is a decision tree with only one split. The tree is considered to be a shallow tree, and the limit for splitting is fixed to be one level. This tree is too weak when used alone, but the Adaboost ensembling approach would boost the performance of the weak learners. This approach also helps in avoiding overfitting. The model is also initialized with a random state of 42, ensuring that the results produced are almost the same every time. The total number of rounds to boost the weak learners is set at 50, which means that the algorithm will sequentially build 50 weak learners. The learning rate is set to 1.0, which allows more aggressive updates and is faster. Using this model, the training dataset is trained using the selected best features from the proposed PSO-DT feature selection algorithm, and the training time required is calculated. Then the validation data is used for predicting the target classes, and the prediction time is also recorded. The results obtained are shown by the confusion matrix in Fig. 7.Figure 7. Confusion matrix: proposed PSO-DT based AdaBoost DT classifier.
The total training time is 34.4733 seconds, and the prediction time is 0.6416 seconds. The model deployment size is 0.0667 MB. The evaluation metrics for the classification performed using this variation of the PSO-DT based Adaboost DT are tabulated in the Table 9.Table 9. Classification report: PSO-DT based AdaBoost DT classifier.Target ClassPrecisionRecallF1 ScoreSupportDDoS-ACK_Fragmentation0.000.000.00441DDoS-HTTP_Flood0.030.480.0648DDoS-ICMP_Flood1.000.930.9710925DDoS-ICMP_Fragmentation0.940.980.96726DDoS-PSHACK_Flood0.450.980.616409DDoS-RSTFINFlood1.000.991.006131DDoS-SYN_Flood1.000.960.986173DDoS-SlowLoris0.370.760.5021DDoS-SynonymousIP_Flood0.961.000.985436DDoS-TCP_Flood0.940.050.096982DDoS-UDP_Flood1.000.950.978369DDoS-UDP_Fragmentation1.000.920.96473
RUSBoost based decision tree classifier
This variation is built using a combination of random undersampling and Adaboost. In this certain classes are removed randomly for balancing the distribution of the samples. The base weak learner used is the decision tree stump with one split. 50 weak learners are initialized to learn the ensemble model. The learning rate is set to 1.0, and hence it is faster. The random state is initialized as 42, similar to the other variants. Then the model is trained using the subset of the training data retrieved from the whole based on the selected features as a result of PSO-DT. The total time required for training is estimated as 98.6793 seconds. Then, using this, the target classes are predicted for the validation data, and the time required for this is 0.6566 seconds. The size of the deployment model is 117.4072 MB. The confusion matrix obtained as a result of this model is shown in Fig. 8.Figure 8. Confusion matrix: proposed PSO-DT based RUSBoost DT classifier.
The precision, recall, F1 score and support values for the classification results concerning each target class are tabulated in the Table 10. This classification model achieved an accuracy of 66.11%.Table 10. Classification report: PSO-DT based RUSBoost DT classifier.Target classPrecisionRecallF1 ScoreSupportDDoS-ACK_Fragmentation0.990.930.96441DDoS-HTTP_Flood0.070.290.1148DDoS-ICMP_Flood0.000.000.0010925DDoS-ICMP_Fragmentation0.060.980.12726DDoS-PSHACK_Flood0.871.000.936409DDoS-RSTFINFlood1.000.991.006131DDoS-SYN_Flood0.000.000.006173DDoS-SlowLoris0.360.810.5021DDoS-SynonymousIP_Flood0.471.000.645436DDoS-TCP_Flood1.001.001.006982DDoS-UDP_Flood1.000.960.988369DDoS-UDP_Fragmentation1.000.860.92473
Random subspace ensemble using KNN bagging classifier
Figure 9. Confusion matrix: proposed PSO-DT based random subspace KNN bagging classifier.
The selected features are used for training and testing the model. The model uses a KNN-based learner, and the final predictions are aggregated using majority voting. The random subspace is initialized to be 0.7, which instructs the model to choose only 70% of the features for the ensemble randomly each time. This helps in introducing diversity among the base models. The training is performed using 50 KNN models, each with a different subset of features, by random sampling. Similarly to all the other variations, the random state is set to 42, and all CPU cores are utilized for training. When the training is performed using this configuration, the total time required for training the data is estimated to be 21.7785 seconds. The inference time required to predict the target classes is 707.5585 seconds. The prediction result obtained can be interpreted from the confusion matrix shown in Fig. 9. The classification results can be evaluated using the metrics precision, recall, F1 score and support value as tabulated in the Table 11. The model achieved an accuracy of 99.65% and the size of the model during deployment would be 3472.5218 MB.Table 11. Classification Report: PSO-DT based Random Subspace KNN Classifier.Target classPrecisionRecallF1 ScoreSupportDDoS-ACK_Fragmentation0.900.900.90441DDoS-HTTP_Flood0.810.900.8548DDoS-ICMP_Flood1.001.001.0010925DDoS-ICMP_Fragmentation0.970.980.97726DDoS-PSHACK_Flood1.001.001.006409DDoS-RSTFINFlood1.001.001.006131DDoS-SYN_Flood1.001.001.006173DDoS-SlowLoris0.340.860.4921DDoS-SynonymousIP_Flood1.001.001.005436DDoS-TCP_Flood1.001.001.006982DDoS-UDP_Flood1.001.001.008369DDoS-UDP_Fragmentation0.910.930.92473
Statistical significance analysis
To provide a rigorous, quantitative validation of our model choices, we conducted a series of paired t-tests on the 5-fold cross-validation accuracy scores of our key classifiers. This analysis formally assesses whether the observed performance differences are statistically significant or merely due to chance. Our null hypothesis (H) for each test was that there is no significant difference in the mean accuracy between the two models being compared, using a significance level of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {p } < 0.05$$\end{document} . First, we compared our proposed Bagging DT (BagDT) ensemble against a standalone Decision Tree (DT) to evaluate the contribution of the ensembling technique itself. Subsequently, we compared the BagDT model against the alternative boosting-based ensembles, RUSBoost and AdaBoost, to validate its superiority. The results are summarized in Table 12. The statistical analysis yielded two critical insights. First, the t-test between the standalone DT and the BagDT ensemble showed no statistically significant difference in accuracy (p = 0.2114). This is a powerful testament to the effectiveness of our PSODT feature selection, which identifies a feature subset so discriminative that even a simple model achieves near-perfect results. In this high-performance context, the primary role of the Bagging ensemble is to provide model robustness and stability by reducing variance, a crucial trait for real-world deployment. Second, the comparisons between BagDT and the boosting variants are definitive. With p-values of 0.0020 (vs. RUSBoost) and 0.0024 (vs. AdaBoost), the results show that the Bagging DT model is statistically significantly more accurate than its boosting-based counterparts. This provides conclusive evidence that our chosen approach is the superior one among the tested ensemble methods, validating its selection for the final framework.Table 12. Paired T-test results for model comparisons (accuracy).Comparison pairMean accuracyt-statisticp-valueResult ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {p} < 0.05$$\end{document} )Standalone DT99.98% ± 0.01%1.48630.2114Not SignificantBagging DT (Ours)99.98% ± 0.01%Bagging DT (Ours)99.98% ± 0.01%-7.21230.0020SignificantRUSBoost79.94% ± 5.56%Bagging DT (Ours)99.98% ± 0.01%-6.82070.0024SignificantAdaBoost78.95% ± 6.16%
Discussion on results
Based on the experimental analysis performed, it is clear that the BagDT Ensemble Model based on the proposed PSO-DT integrated hybrid framework performs better compared to traditional state-of-the-art models, other variants of the ensemble, and the MRMR-PCA BagDT model^28^ proposed by us in our previous work in terms of precision. The comparative analysis of the proposed framework with the state-of-the-art literature techniques can be interpreted from Table 13 given below. The table clearly shows that the proposed model outperforms all the state-of-the-art related works.
The superior performance of the proposed system can be attributed to the effective integration of its core components. The out-performance relative to the other ensemble variants are from fundamental differences in their mechanisms. Our Bagged DT (BagDT) model excels by using bagging, an approach that reduces variance by training decision trees independently on different data subsets. This makes the final model highly robust to noise and outliers within the training data. In contrast, boostingbased models like AdaBoost and RUSBoost, which sequentially focus on misclassified instances, can sometimes overfit to noisy data, leading to lower overall accuracy as seen in our results. While the Random Subspace KNN achieved high accuracy, its massive model size and extremely high prediction delay render it impractical for realtime IoT deployment. Furthermore, as shown in the comparative analysis in Table 13, the proposed framework outperforms published state-of-the-art models primarily through its holistic focus on both accuracy and deployment readiness. All models in this study were evaluated for their multi-class classification capabilities, but our novel PSO-DT feature selection provides a critical advantage by significantly reducing model complexity and training time without compromising performance, a balance not often prioritized in other works.
The proposed hybrid PSO-DT based BagDT Ensemble model outperforms the other ensemble variants in terms of computational aspects and the deployment model size is lesser than others and is illustrated in Table 14.
To specifically address the model’s real-time capabilities and performance under high traffic loads, we analyzed two key latency metrics: Average Detection Delay and Prediction Speed. As shown in Table 15, our proposed PSO-DT BagDT model achieves an ultra-low detection delay of just 4.7 microseconds per packet. This nearinstantaneous classification is essential for timely threat mitigation. Furthermore, the Prediction Speed metric directly addresses the model’s performance in high-traffic IoT environments. With the ability to process over 212,000 observations per second, our model’s throughput significantly exceeds the data rates of most IoT gateways. This ensures that the detection system will not become a network bottleneck, even during peak traffic or a large-scale attack, validating its suitability for demanding real-world deployment.Table 13. Performance analysis-proposed model vs state-of-the-art techniques.Ref.Feature selectionMulti classClass imbalance handledDeployment readyScalableTime and speedAccuracy (%)^2^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 98^3^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 96^4^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 97^5^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 98.96^6^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 99^7^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} Variable^8^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 99.45Proposed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 99.96Table 14. Performance of proposed PSO-DT hybrid ensemble models.Training time (s)Prediction speed observations per sec) ModelAll featuresPSO-DTAll featuresPSO-DTAccuracy (%)AdaBoost399.1734.473329,00081,25983.23RUSBoost205.3398.679322,00079,39866.11BagDT436.4719.679029,0002,12,43299.96Random Subspace KNN4843.121.778518073099.65Table 15High-traffic performance of proposed PSO-DT hybrid ensemble models.ModelAverage detection delay (micro seconds)Model size (MB)Prediction speed (obs/s)AdaBoost12.30.0781,259RUSBoost12.6117.4179,398BagDT4.71.70212,432Random Subspace KNN13571.43472.52730
The major contributions of the proposed hybrid framework for detecting DDoS attacks in an IoT environment are as follows.
- The hybrid framework includes an integrated preprocessing phase, which includes all the steps for handling the class imbalance issues as well as automatic encoding and normalization. The SMOTE is an oversampling technique that creates synthetic samples for the minority class by interpolating between existing minority instances. This reduces overfitting compared to random oversampling. This also improves minority class recall. Since the focus was to have a balance between performance and control, this is the best technique to be used in a real-time environment.
- The proposed PSO-DT feature selection algorithm reduces the feature space by avoiding the need for separate dimensionality reduction techniques like Principal Component Analysis. This not only reduces the dimension but also improves the performance of the model. Since PSO is metaheuristic, it can easily adapt to different datasets and classifiers.
- Among the variants of the ensemble models, the PSO-DT based BagDT requires a lesser training time of 19.679 seconds, as illustrated in the Fig. 10.
- The time required for predicting the occurrence of attack is lesser in the case of the proposed hybrid PSO-DT based BagDT Ensemble model when compared with other variants and can be seen clearly in the Fig. 11.
- Since the prediction model developed has to be deployed in an edge device which is usually size restricted, the size of the model plays a major role and from the Fig. 12 it is evident that the proposed PSO-DT based BagDT is lightweight with better accuracy, lesser training and prediction time. Figure 10. Training time comparison: ALL features vs PSO-DT for ensemble variants.Figure 11. Prediction time analysis: PSO-DT based ensemble variants.Figure 12. Model deployment size vs accuracy plot: tradeoff.
From the experimental analysis conducted, it is clear that the proposed PSO-DT based BagDT Ensemble framework outperforms all the other variants, namely AdaBoost, RUSBoost and Random Subspace KNN. This interpretation is based on the accuracy and model size. In the case of Random Subspace KNN, the accuracy is equivalent to that of BagDT, but it would suffer from deployment issues in a real-time IoT environment since the model size is too high. Also, the time required for training is higher in Random Subspace KNN when compared to BagDT.
Discussion on model generalization and robustness
While direct experimentation on additional datasets provides the ultimate proof of generalization and is a valuable direction for future work, the current study includes several key methodological steps and validation results that strongly support our model’s robustness.Figure 13. Learning curve for the PSO-DT based BagDT model.Figure 14ROC curve for the proposed PSO-DT based BagDT model.
Visualizing generalization with learning curves
To ensure that the proposed model does not overfit the training data, we plotted its learning curve . This curve compares the training score against the 5-fold cross-validation score on unseen data as the number of training samples increases. As shown in Fig. 13, the training and cross-validation scores converge to a high level of accuracy. The minimal gap between the two curves indicates that the model generalizes well to new data and does not suffer from high variance or overfitting. This is a critical validation of our model’s stability.
Evaluating classifier robustness with ROC/AUC
To further evaluate the model’s robustness, we analyzed the Receiver Operating Characteristic (ROC) curve and the Area Under the Curve (AUC), as shown in Fig. 14. All classification thresholds. Our proposed model achieves a near-perfect micro-average AUC of 0.99, confirming its outstanding ability to discriminate between different attack classes and benign traffic. In addition to these visual analytics, our framework’s robustness is supported by the following list.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bullet$$\end{document} Rigorous Internal Validation: The model’s performance was not evaluated on a simple train-test split alone. We employed 5-fold cross-validation during the feature selection and evaluation phases. This technique repeatedly tests the model on different subsets of the data, providing a more reliable estimate of its performance on unseen data and mitigating the risk of overfitting to a specific test set.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bullet$$\end{document} Fundamental Nature of Selected Features: Our PSO-DT algorithm selected features such as packet rates, flag counts, and protocol types. These are not arbitrary characteristics of a single dataset but are fundamental indicators of network behavior and DDoS attacks (e.g., a flood of SYN packets is a universal signature). A model trained on these core features is inherently more likely to be robust across different network environments.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bullet$$\end{document} Comprehensiveness of the CICIoT2023 Dataset: The primary dataset used in this study, CICIoT2023, is a modern, large-scale dataset generated from a complex IoT environment with 150 devices and a wide variety of DDoS attack types. Its diversity and realism make it a strong benchmark for evaluating model performance in a way that is already indicative of real-world applicability.
In summary, while we fully agree that testing on additional public datasets such as Edge-IIoTset or BoT-IoT is an important next step, the rigorous cross-validation, analysis of learning curves, and the fundamental nature of the features selected provide substantial evidence for the generalization capability of our proposed framework.
Performance analysis on imbalanced data
While ROC-AUC provides a comprehensive measure of classifier performance, its interpretation can be overly optimistic on the test sets with a severe class imbalance which is a characteristic of our validation data. In such scenarios, a large number of true negatives can inflate the performance score hence masking potential weaknesses in detecting rare positive classes. To provide a more stringent and insightful evaluation, we therefore supplement our analysis with the Precision-Recall (PR) curve. The PR curve is particularly effective here because it evaluates the trade-off between precision (the fraction of positive predictions that are correct) and recall (the fraction of actual positives that are correctly identified), thus focusing directly on the performance of the rare attack categories. Figure 15 presents both the micro-averaged ROC curve and the corresponding PR curve for our proposed model. The Precision-Recall curve on the right of the Fig. 15 provides a stringent performance evaluation. Our model achieves a micro-averaged Area Under the PR Curve (AUPRC) of 0.99, a near-perfect score indicating high real-world effectiveness. This result confirms that the model maintains exceptional precision and recall, minimizing false alarms while detecting most true attacks. This robust performance, validated with a class imbalance-sensitive metric, proves the framework’s reliability for security scenarios where detecting rare threats is critical.Figure 15. Micro-averaged ROC and precision-recall curves for the proposed model.
Conclusion
This research successfully developed a lightweight and efficient prediction model for real-time DDoS attack detection in IoT environments. The novelty of our PSO-DT feature selection algorithm was clearly demonstrated by its ability to intelligently reduce the feature space, leading to a remarkable 95.49 while simultaneously reducing model complexity. This innovative approach eliminates the need for separate dimensionality reduction steps. Consequently, the final PSO-DT based BagDT model achieved an outstanding accuracy of 99.96 this work’s innovative focus on deployment readiness was validated by the final model’s lightweight footprint of just 1.70 MB, making it highly scalable and suitable for deployment on resource-constrained edge devices. By balancing high classification performance with practical operational metrics, our integrated framework provides a robust solution to a critical challenge in IoT security. Future work will involve analyzing the effectiveness of this framework on a wider variety of datasets to further test its adaptability.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sokkalingam, S. & Ramakrishnan, R. An intelligent intrusion detection system for distributed denial of service attacks: A support vector machine with hybrid optimization algorithm based approach. Concurr. Comput. Pract. Exp.34. 10.1002/cpe.7334 (2022).
- 2Ahmad, Z., Petrovski, A., Arifeen, M., Khan, A. S. & Shah, S. A. Heads: Hybrid ensemble anomaly detection system for internet-of-things networks. In International Conference on Engineering Applications of Neural Networks, 178–190 (Springer, 2024).
- 3Gulzar, Q. & Mustafa, K. Enhancing network security in industrial iot environments: a deepclg hybrid learning model for cyberattack detection. Int. J. Mach. Learn. Cybern. 1–19 (2025).
- 4Khan, M. W. A comprehensive survey of genetic programming applications in modern biological research. Medinformatics (2024).
- 5Dorigo, M. & Stützle, T. Ant colony optimization: overview and recent advances. Handbook of metaheuristics 311–351 (2018).
- 6Shirley, J. J. & Priya, M. Hybrid mrmr-pca bagdt-an effective feature selection based ensemble model for real-time intrusion detection in iot environment. IEEE Access (2024).