A pilot study of remote cognitive assessment in children using the NIH toolbox participant/examiner app
Berivan Ece, Emily H. Ho, Zutima Tuladhar, Miriam A. Novack, Shaili Ganatra, Anne Zola, Vitali Ustsinovich, Christine W. Hockett, Richard Gershon

TL;DR
This pilot study shows that cognitive assessments for children can be effectively done remotely using a new app, similar to in-person testing.
Contribution
The study introduces a new remote version of the NIH Toolbox Cognition Battery for children, validated for equivalency with in-person assessments.
Findings
Remote and in-person assessments showed considerable consistency in cognitive test scores.
Remote assessments took longer and showed potential practice effects on some measures.
The NIHTB-P/E App is a feasible alternative for administering cognitive assessments to children.
Abstract
The demand for remote assessment tools has increased, yet there is a lack of standardized adaptations for remote administration. This pilot study investigates the equivalency of in-person and remote cognitive assessments using the NIH Toolbox Cognition Battery (NIHTB-CB) among children aged 7 to 17 years. Forty-seven children (51.1% female; Mage = 12.26, SDage= 3.23) were assessed in two formats: in-person at a study site and remotely from home, with the order of assessments counterbalanced. The NIHTB-CB was used for in-person evaluations, while a newly developed version, the NIH Toolbox Participant/Examiner (NIHTB-P/E) App, was used for remote assessments through built-in teleconferencing features. The results showed considerable consistency between in-person and remote scores across all NIHTB-CB tests. Certain differences were noted, including longer test durations for remote…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
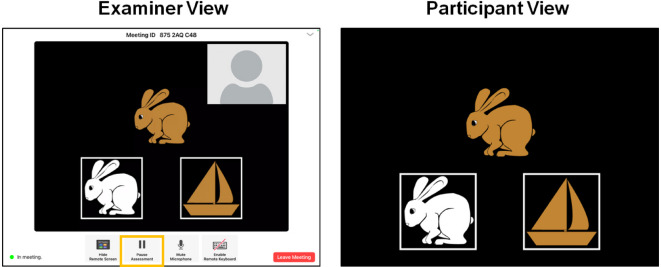 Figure 1
Figure 1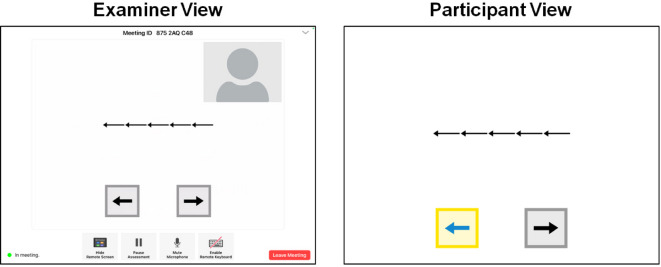 Figure 2
Figure 2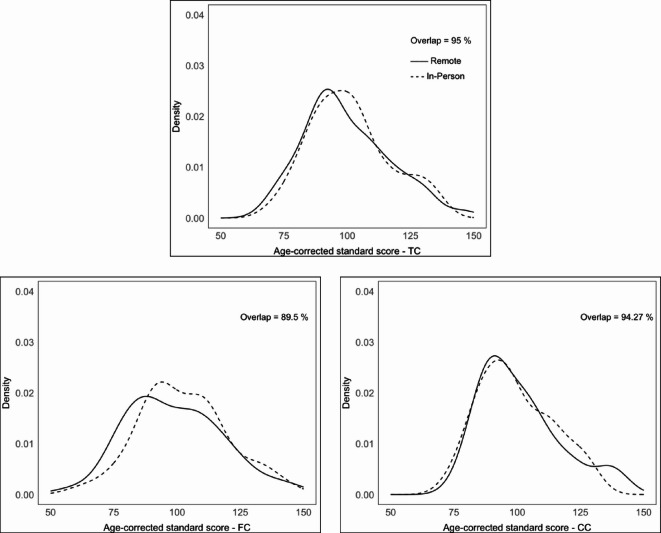 Figure 3
Figure 3- —The Environmental Child Health Outcomes Study
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEEG and Brain-Computer Interfaces · Cognitive Functions and Memory · Infant Development and Preterm Care
Introduction
Cognitive assessment is vital to evaluating cognitive functioning^1^. It is particularly critical during childhood due to its essential role in tracking healthy development, identifying any developmental delays, making accurate and timely diagnoses, and evaluating the effectiveness of treatments and interventions^2–6^. In that respect, cognitive assessments have significant implications for children, ranging from treatment decisions to eligibility for access to resources^3^. Additionally, cognitive abilities have been consistently associated with real-world outcomes, such as social functioning^7^ and physical and mental health^8^as well as educational outcomes including school readiness, early academic skills, language comprehension, reading, vocabulary acquisition, and mathematics^9–11^. Cognitive assessments are also used in research studies to compare outcomes between intervention groups. Therefore, it is crucial to have reliable, valid, and age-appropriate standardized measures to evaluate children’s cognitive functioning, as these tools ensure the quality and accuracy of the assessment process.
Traditional methods of cognitive assessment in pediatric populations often involve direct interaction between an examiner and a participant, typically conducted in a clinical, research, or educational setting using standardized paper-and-pencil or computerized tests^12–14^. The COVID-19 pandemic, however, interrupted these traditional in-person approaches due to social distancing requirements and restrictions on face-to-face interaction^15–17^ and led researchers to explore alternative assessment strategies. Remote assessment, in which the participant and examiner are in separate locations, has proven to offer several benefits to both researchers and participants. Benefits for researchers include increased efficiency of data collection, increased sample size and diversity, higher generalizability and ecological validity, and cost-effectiveness^18,19^. Benefits for participants include eliminating barriers to participation, such as travel costs and long travel hours, which is particularly helpful for participants residing in remote or hard-to-reach areas^20,21^. Remote testing can reduce attrition in longitudinal studies by increasing the likelihood of participation at multiple time points^21^. Remote assessment can even aid the recruitment of participants living with limited mobility (e.g., physical disabilities) who are underserved when in-person assessment strategies are applied^22^.
Despite numerous benefits, remote assessment is not without its limitations. First, it can be challenging to achieve the same level of standardization remotely as in traditional lab settings^23,24^ because researchers have less control over the testing environment (e.g., distraction). Second, depending on the level of monitoring, participants may engage in dishonest practices, such as taking notes, capturing screenshots, or seeking assistance from third parties. Third, if the remote assessments are administered on participants’ own devices, the assessment can be interrupted by phone calls, notifications, or text messages. Fourth, additional challenges to data safety and transfer exist, especially when Personally Identifiable Information (PII) is involved^25,26^.
The COVID-19 pandemic has also increased interest in the feasibility of remote cognitive assessment in pediatric populations^27,28^. A majority of the feasibility studies focused on the psychometric equivalency between remote and in-person cognitive assessments by using either intelligence scales such as the Wechsler Intelligence Scale for Children, Fifth Edition^29^ or other cognitive tests^27,28,30,31^. Additionally, some recent studies investigated remote cognitive assessment in special populations. In children with specific learning disabilities, for example, remote and in-person assessments of learning skills revealed similar results^32^. Likewise, remote administration of processing speed measures was feasible in children with chronic medical conditions^33^indicating its potential for broader use in clinical practice.
In the current pilot study, we investigate the equivalency of in-person and remote cognitive assessments in healthy children by examining a newly developed application - the NIH Toolbox Participant/Examiner (NIHTB-P/E) App, which leverages the NIH Toolbox for Assessment of Neurological and Behavioral Function Cognition Battery (NIHTB-CB; www.nihtoolbox.org). The NIHTB-CB is a well-established iPad-based measurement system currently deployed in over 1,100 institutions across the world^34–38^. It is used in several large-scale longitudinal studies such as Environmental influences on Child Health Outcomes (ECHO)^39^ and HEALthy Brain and Child Development (HBCD)^40^ is further used in clinical samples, including children with congenital heart defects (CHD)^41^ and those with Pompe disease (PD)^42^. Therefore, providing the remote option of the NIHTB-CB is an important contribution to the field by expanding accessibility, reducing barriers to participation, and enabling more frequent and flexible monitoring of cognitive development in pediatric populations.
Tests within the NIH Toolbox Cognition Battery (NIHTB-CB) span a diverse array of cognitive domains, including working memory,* processing speed*,* language*,* attention*,* executive functioning*, and episodic memory (see Table 1 for constructs, their definitions, corresponding tests, age ranges, and test durations), These tests have been proven useful for predicting cognitive performance across diverse childhood samples^43–46^. The NIHTB-CB measures were designed to be interactive, engaging, and developmentally appropriate and have previously been shown to be reliable and valid compared to similar gold-standard assessments in this age range^45,47^. NIHTB-CB measures have typically been administered in-person; however, they can now be administered remotely via the newly developed NIHTB-P/E app. This app is an iPad-to-iPad assessment system allowing for testing when the examiner and participant are in different locations. Critically, it includes a built-in bi-directional video-conferencing feature (see Figs. 1 and 2) that allows the administration to be experimenter-guided and fully monitored. This supervised remote cognitive assessment is similar to in-person testing due to the real-time interactions between the examiner and the participant through videoconferencing^48^.
Table 1Constructs measured in the NIH toolbox cognition battery and the NIH toolbox participant/examiner app together with their definitions,* corresponding tests*,* age ranges*,* and test durations*.TestConstructDefinitionAge rangeDuration (minutes)List Sorting Working Memory TestWorking memoryThe ability to retain and manipulate information in a temporary storage system7–857Pattern Comparison Processing Speed TestProcessing speedThe amount of time it takes to process a specific amountof information or the amount of information that can be processed within a specified timeframe.7–853Oral Reading Recognition TestLanguage - Oral readingLanguage is a system of symbols such as words that can be used for communication. Reading is the ability to pronounce these symbols.7–853Picture Vocabulary TestLanguage - VocabularyOne’s knowledge of the set of words in a specific language.3–854Flanker Inhibitory Control and Attention TestAttentionThe ability to allocate limited resources to deal with the abundant information in the environment.3–854Dimensional Change Card Sort TestFlanker Inhibitory Control and Attention TestExecutive functionA set of cognitive processes that enable individuals to plan, organize, monitor, and regulate behavior.3–854Picture Sequence Memory TestEpisodic MemoryThe ability to acquire, store and retrieve new information and experiences learned within a specific context and encoded with time-specific information.3–857
Fig. 1. The NIH Toolbox Participant/Examiner App during a live session (DCCS Test).
In this pilot study, we tested the equivalency of in-person cognitive assessment by using the NIHTB-CB and remote cognitive assessment via the NIHTB-P/E app. Children ages 7–17 completed the NIHTB-CB tests on an iPad, guided and monitored by a trained examiner using the NIHTB-P/E app. With the support of the bi-directional communication system, we expected no significant differences in test scores between remote cognitive assessment at home by using the NIHTB-P/E app and in-person assessment at the study site utilizing the NIHTB-CB.
Method
Participants
Child-caregiver dyads were recruited across six study sites throughout the United States (i.e., Orlando, FL; Houston, TX; Nashville, TN; Atlanta, GA; Baltimore, MD; and Dallas, TX) as part of a larger study^49^ with specific age, gender, race/education, and mother education targets to ensure demographic diversity (e.g., maximum 60% of each sex, at least 20% of mothers/caregivers with less than a college degree). Participants were screened by a market panel research company based on predetermined inclusion and exclusion criteria. Specifically, the inclusion criteria were: children aged 7–17 years, fluency in English, self-reported adequate internet access, and caregiver willingness to assist with the remote setup. Exclusion criteria, on the other hand, included a current positive COVID-19 test in the child, limited English proficiency in either the caregiver or the child, or a lack of access to an iPad-compatible internet connection. Children with physical impairments that would interfere with the ability to interact with the iPad (e.g., limited upper limb mobility preventing touchscreen use) were not included in this pilot study. A total of 58 child participants between 7 and 17 years old were recruited (48.3% female; Mage = 11.88, SDage = 3.31). Of these participants, 47 (51.1% female; Mage = 12.26, SDage = 3.23) completed both the in-person and remote cognitive batteries a few days apart (M = 3.15; SD = 3.06). While a small number of participants did not complete both sessions, there was no evidence of differential dropout by age group, sex, or mode of test administration. Demographic characteristics of the final sample are displayed in Table 2. Caregivers signed informed consent forms and received $225 for participating in both remote and in-person assessments. Their travel expenses were reimbursed for in-person site visits. The study protocol was approved by the WIRB-Copernicus Group (WCG) Institutional Review Board (IRB Approval #20231258). In addition, the study was conducted in accordance with the Declaration of Helsinki and applicable institutional/national ethical guidelines. Finally, written informed consent was obtained from all participants or their legally authorized representatives prior to study enrollment.
Table 2. Sample characteristics.Characteristic n % Sex Male2348.9Female2451.1 Age 7–12 years2451.113–17 years2348.9 Race White2757.4Black or African American1838.3Other24.3 Ethnicity Not Hispanic or Latino4697.9Hispanic or Latino12.1Total47100
Measures
The NIH toolbox cognition battery (NIHTB-CB)
The NIH Toolbox for Assessment of Neurological and Behavioral Function (NIHTB; www.nihtoolbox.org) is a comprehensive set of computerized measures with four batteries: cognition, emotion, motor, and sensation^37,50^. NIHTB is designed for use across the lifespan (i.e., ages 3 to 85) and has been reported to be a valid and reliable tool in different age groups and populations ranging from healthy adults to patients with neurological disorders^50–52^. The NIHTB-CB is designed to measure a broad range of cognitive abilities, including attention,* episodic memory*,* language (i.e., oral reading* and vocabulary),* working memory*,* executive function*, and processing speed. All tests in the NIHTB-CB are psychometrically validated and normed^50^. Each cognitive test in the battery is further described individually below.
The NIH toolbox participant/examiner app (NIHTB-P/E)
NIH Toolbox Participant/Examiner App (NIHTB-P/E) is a newly developed iPad-to-iPad assessment system that allows for remote cognitive testing when the examiner and participant are in different locations. The NIHTB-P/E app leverages the NIHTB described above. The NIHTB-P/E app was designed for monitored, experimenter-guided assessment and, as such, includes a built-in bi-directional video-conferencing feature. The examiner can observe the participant completing the assessment at all times and has full control over the assessment, including pausing the assessment, terminating the assessment, and moving to a new measure. In turn, the participant is able to complete all measures directly on the iPad in front of them and, if necessary, can communicate with the examiner. Figures 1 and 2 show screenshots of the NIHTB-P/E app, captured during a sample testing session for the Dimensional Change Card Sort Test and the Flanker Inhibitory Control and Attention Test, respectively.
Fig. 2. The NIH Toolbox Participant/Examiner App during a live session (Flanker Test).
The NIHTB-P/E was designed to be adaptable to various iPad models, and as such, testing stimuli are fixed to the stimuli size of the NIHTB-CB, regardless of iPad screen size of either the examiner or participant. Additionally, scores are recorded and calculated locally on the participant’s device after each item (e.g., in a computer adaptive paradigm), maximizing data capture. The NIHTB-CB and NIHTB-P/E app offer parallel versions of standardized normed measures, with the only difference being the remote functionality of the latter system.
Cognitive tests in the NIHTB-CB and the NIHTB-P/E app
NIH Toolbox Dimensional Change Card Sort Test (DCCS). NIH Toolbox Dimensional Change Card Sort Test^53^ measures cognitive flexibility, which is the ability to adaptively shift between sorting rules for identical stimuli. The original version of DCCS was developed by Zelazo and colleagues^54^ for the first version of the NIHTB-CB. This test is a measure of fluid ability, which is the capacity to acquire new knowledge and to adapt to unfamiliar circumstances. In DCCS, participants are shown two images side by side at the bottom of the screen. In each trial, participants see a cue word - either “shape” or “color” - at the center of the screen, followed by a bivalent target image, which participants sort based on the cued dimension. The sorting rule alternates between “color” and “shape” in a pre-determined order that appears to be pseudo-random. Participants respond by tapping one of the two visual images based on the dimension specified by the presented cue word (see Fig. 1). Scoring is based on both accuracy and reaction time.
NIH Toolbox Flanker Inhibitory Control and Attention Test (Flanker). The NIH Toolbox Flanker Inhibitory Control and Attention Test (Flanker) is a version of the Eriksen Flanker Task^55^ designed to measure attention and inhibitory control^36,53^. Like the DCCS test, Flanker is also considered a measure of fluid ability. In this test, each trial starts with a fixation star in the center of the screen, followed by a blank screen. Next, a row of five stimuli (fish or arrows) appears, pointing left or right (see Fig. 2). Participants are instructed to tap one of two buttons on the bottom of the screen that matches the target stimulus’s direction (the middle fish or arrow). Scoring is based on both accuracy and reaction time.
NIH Toolbox List Sorting Working Memory Test (LSWM). The NIH Toolbox List Sorting Working Memory Test (LSWM) is a sequencing task developed to measure working memory^56^. In this test, which is a measure of fluid ability, participants engage in immediate recall and sequencing of different stimuli presented visually and orally. A set of pictures of different animals and foods are presented with an accompanying audio recording and written text (e.g., dog, apple). The participants are then asked to say the items back in size order (smallest to largest) in two formats, first within a single dimension (either animals or foods, called 1-List) and then in two dimensions (foods, then animals, called 2-List). Scoring is based on the total number of items correct.
NIH Toolbox Pattern Comparison Processing Speed Test (PCPS). The NIH Toolbox Pattern Comparison Processing Speed Test (PCPS) is a measure of fluid ability and developed to assess the speed of processing. It measures how accurately participants can decide whether two side-by-side pictures are the same^51^. When the presented patterns are not identical, they vary on one of three dimensions (i.e., color, quantity, and presence/absence of an image or image component). Participants respond to whether or not the patterns are identical by pressing a “yes” or “no” button. Scoring is based on the total number of items correct.
NIH Toolbox Picture Sequence Memory Test (PSM). The NIH Toolbox Picture Sequence Memory Test (PSM) measures episodic memory by asking participants to recall the order of thematically related pictures of objects and activities^57,58^. It is also considered as a measure of fluid ability. At the beginning of each trial, a fixed spatial order of pictures is displayed in the center of the screen, with an auditory description of an activity that can be described with all the pictures. Immediately following the presentation of a sequence of pictures, the participants are instructed to re-order the stimuli from memory. Participants are asked to recall each sequence twice. The number of presented pictures in a sequence varies between 6 and 18 depending on the age of the participant. Participants are given credit for each adjacent pair of pictures they correctly place (i.e., if pictures in locations 7 and 8 are placed in that order and adjacent to each other anywhere, such as slots 1 and 2, one point is awarded), up to the maximum value for the sequence, which is one less than the sequence length. Scoring is based on an IRT-based score where the number of correct adjacent pairs is transformed into a latent (theta) score, which is then scaled to a normed score.
NIH Toolbox Oral Reading Recognition Test (OR). The NIH Toolbox Oral Reading Recognition Test (OR) employs a Computer Adaptive Testing^59,60^ methodology, requiring active administrator involvement for scoring^60,61^. It measures crystallized abilities, which develop with age and education and increase during childhood before becoming stable in adulthood. The examiner first identifies the educational level of the participant in order to set the appropriate starting point. Respondents are then provided with a word on the screen. The difficulty level of the words is set according to the participant’s age and adaptively increases or decreases in difficulty based on the participant’s performance. Participants are asked to pronounce each word to the best of their ability. Examiners are trained with audio recordings for the word list and a printed pronunciation guide before administering the test. The trained examiner scores the participants’ responses as either “correct” or “incorrect” based on pronunciation accuracy. Pronunciations that did not match the respelling pronunciation guide were evaluated as incorrect. Scoring is based on a combination of correct responses and the difficulty of each item, and a latent (theta) score is produced that is then scaled to normed scores.
NIH Toolbox Picture Vocabulary Test (PVT). The NIH Toolbox Picture Vocabulary Test (PVT) assesses general vocabulary knowledge^60^ using CAT. This test is a measure of crystallized abilities. The examiner first identifies the educational level of the participant in order to set the appropriate starting point. During the test, the participant is presented with four photographic images on the screen and an audio recording that matches one of the four images. Participants are provided as much time as they need to respond and are asked to select the picture that matches most closely based on the recording. The difficulty level of the words is set according to the participant’s age and adaptively increases or decreases in difficulty based on the participant’s performance. Scoring is based on a combination of correct responses and the difficulty of each item, and a latent (theta) score is produced that is then scaled to normed scores.
Procedure
Prior to data collection, examiners were trained and certified to administer both the in-person and remote versions of the NIHTB-CB. The order of remote and in-person cognitive assessment sessions was counterbalanced, with half of the participants (randomly selected) first completing the assessments remotely and the other half completing them in person.
For the remote assessments participants were shipped a study kit that included a study iPad pre-loaded with the NIHTB-P/E app, an iPad charger, printed instructions for setup and use, and paper copies of data collection forms to be completed during the remote session. Caregivers were provided with step-by-step instructions on how to enter a meeting code on the NIHTB-P/E app that would connect them to the examiner. Once connected with the examiner on the app, caregivers followed the examiner’s live instructions through the app’s communication system to assist with the final setup process (e.g., adjusting the volume on the iPad).
The setup process on the participant’s end typically took less than five minutes, not including the time to charge the iPad, which families were instructed to do in advance. Once the set-up process was complete, caregivers were instructed not to assist their child with any tests. However, they were allowed to help with technical difficulties, such as connection issues or iPad malfunctions. The examiner could note any deviations from the administration, though there were none recorded regarding the administration of the current reported study. Caregivers were also given the examiner’s contact information in case the examiner was disconnected during the test and needed to rejoin the app. After completing the assessments, participants could return the iPad either in person at the study site or by using a prepaid return shipping label provided in the kit.
Statistical analyses
Individual and composite test scores
Individual test scores were obtained from each of the seven tests in the NIHTB-CB. Composite scores were derived from a specific combination of individual test scores, resulting in three categories: fluid composite (FC),* crystallized composite (CC)*, and total composite (TC) test scores^34,62^. Specifically, the FC test score includes Flanker, Dimensional Change Card Sort, Picture Sequence Memory, List Sorting, and Pattern Comparison Tests while the CC test score includes the Picture Vocabulary and Reading Tests. These composite scores were calculated by averaging the standard scores of the individual tests. Finally, the TC test score is the average of the FC and CC test scores. These composites were empirically derived in prior validation studies of the NIH Toolbox Cognitive Battery and have been used in previous research involving children and adolescents^63^.
Age-corrected standard scores and uncorrected standard scores
For each test, we used two types of test scores: age-corrected standard scores and uncorrected standard scores. Age-corrected standard scores compare each participant’s score to those in the original NIHTB norming study of nationally representative individuals of the same age^36^. A score of 100 indicated performance at the national average for the participant’s age with an SD of 15. Uncorrected standard scores also use a standard score metric (normative mean = 100 and SD = 15), comparing the performance of the test-taker to those in the entire NIHTB normative sample, regardless of age or any other variable. In the present study, all analyses involving test scores were conducted separately for age-corrected and uncorrected standard scores for comparison purposes. Results based on uncorrected standard scores are presented in Table S1 and Table S2 in the supplementary materials.
Finally, analyses involving participants’ age used two age bands: 7- to 12-years and 13- to 17-years, consistent with previous research using the NIHTB-CB in child samples^36,45,64^. We also conducted the analyses by including age as a continuous covariate and obtained consistent results, indicating that our findings are robust regardless of how age is included in the analyses.
Group comparisons
Differences between remote and in-person cognitive assessment scores were compared by conducting a series of Repeated Measures ANOVAs. The mode of administration (remote vs. in-person) was the within-subjects while age group (7-to-12 vs. 13-to-17 years old) and administration order (remote first vs. in-person first) were between-subjects factors. Another series of Repeated Measures ANOVAs examined the within-subjects effect of mode of administration (remote vs. in-person) controlling for age group (7-to-12 vs. 13-to-17 years old) and administration order (remote first vs. in-person first), which were the between-subjects factors on test time in minutes. Bonferroni corrections^65^ were applied to adjust for multiple comparisons, with an alpha level of 0.017 for analyses involving the three composite test scores and 0.007 for analyses involving the seven individual test scores.
Analysis of overlap
To assess the similarity between the empirical distributions of each measure and composite when compared by administration mode (e.g., the percentage overlap in distribution between remote and in-person Pattern Comparison Processing Speed Test), we calculated the overlap between their respective kernel density estimates^66^. This analysis has been used in many contexts in many fields^67,68^is efficient to calculate, makes no assumptions of normality, and is straightforward to interpret. This analysis was done using the ‘overlapping’ package in R 4.2.2^69,70^.
Results
Mode of administration by age group and administration order
Analyses on participants’ individual test scores revealed no significant differences between remote and in-person cognitive assessments (see Table 4). Age group and administration order had no significant effects on performance for individual test scores (see Table 4). However, there was a significant interaction between the mode of administration and the first mode for two of the individual tests: Pattern Comparison Processing Speed Test and Picture Sequence Memory. To be more specific, test scores for remote cognitive assessments were lowest for these two tests when the remote assessment was administered first, whereas they were highest when the in-person cognitive assessment was administered first (see Table 3). As seen in Table 4, no other significant interaction between the mode of administration and the first mode was observed for the remaining individual test scores. Finally, the three-way interaction between mode of administration, age group, and first mode was not significant for individual test scores (see Table 4). Results of the separate analyses for composite test scores are provided in the Supplementary Materials. Specifically, Table S1 presents the means and standard deviations of age-corrected composites test scores by mode of administration, age and first mode and Table S2 presents mean square error (MSE), F and p values together with the effect sizes of the Repeated Measures ANOVAs. As seen in Table S2, results for composite scores generally followed the same pattern observed in individual test scores with significant ModeFirst Mode* interactions for both the fluid and total composites, suggesting higher remote scores when remote testing was the second administration (see Supplementary Table S1).
Table 3Means and standard deviations of age-corrected standard scores by mode of administration,* age and first mode*.7–12 years old13–17 years oldRemote firstIn-person firstMeasureMSDMSDMSDMSD DCCS Remote95.0015.0598.2216.6495.6113.5798.4419.69In-person96.7514.3895.8717.1596.8714.3895.2518.26 Flanker Remote92.659.7691.7818.0091.4813.8593.6915.32In-person98.5811.9586.6115.5192.9015.3592.3811.57 List Sort Remote100.3317.01103.4312.64102.6015.61101.4414.06In-person95.2112.58102.1710.43100.1611.9495.6311.87 Pattern Comparison Remote97.2929.59110.0922.3097.0025.74116.2524.78In-person104.3821.39120.7421.02116.8722.99103.6919.50 Picture Sequence Memory Remote104.3817.49101.3019.4998.0015.54112.3120.16In-person109.0018.05105.7417.23109.4518.81103.4414.48 Oral Reading Remote101.4219.79100.8317.40101.5818.87100.2518.21In-person101.4619.2899.9615.14101.3917.1799.4417.77 Picture Vocabulary Remote102.4613.6799.3913.83101.2313.97100.4413.56In-person99.2512.7997.7411.4498.4811.9798.5612.57
Table 4Comparison of age-corrected standard scores by mode of administration,* age*,* and first mode*.ScoreMSEF p partial ηp² DCCS Mode60.140.8180.3710.019Age6.110.0140.9070.000First mode5.030.0110.9160.000ModeAge218.352.9690.0920.065First modeAge94.170.2130.6470.005ModeFirst mode207.772.8260.1000.062ModeAgeFirst mode54.650.7430.3930.017 Flanker Mode4.050.0450.8330.001Age1,352.824.3460.0430.092First mode71.570.2300.6340.005ModeAge701.357.8070.0080.154First modeAge439.051.4110.2410.032ModeFirst mode163.991.8250.1840.041ModeAgeFirst mode4.750.0530.8190.001 List Sort Mode233.762.3440.1330.052 Age743.142.7780.1030.061 First mode3.930.0150.9040.000ModeAge59.390.5950.4450.014First modeAge326.361.2200.2760.028ModeFirst mode38.050.3810.5400.009ModeAgeFirst mode6.000.0600.8070.001 Pattern Comparison Mode399.722.4950.1220.055Age2,979.413.6060.0640.077First mode533.200.6450.4260.015ModeAge12.930.0810.7780.002First modeAge1,959.842.3720.1310.052ModeFirst mode4,853.3130.299< 0.0010.413ModeAgeFirst mode280.721.7530.1930.039 Picture Sequence Memory Mode0.060.0000.9860.000Age0.320.0010.9780.000First mode424.211.0030.3220.023ModeAge282.311.5540.2190.035First modeAge644.341.5240.2240.034ModeFirst mode2,510.6213.817< 0.0010.243ModeAgeFirst mode177.150.9750.3290.022 Oral Reading Mode15.000.2630.6110.006Age0.820.0010.9710.000First mode22.240.0360.8500.001ModeAge17.580.3080.5820.007First modeAge412.760.6750.4160.015ModeFirst mode8.780.1540.6970.004ModeAgeFirst mode21.340.3740.5440.009 Picture Vocabulary Mode71.881.8750.1780.042Age276.830.9000.3480.020First mode57.880.1880.6670.004ModeAge29.800.7780.3830.018First modeAge224.270.7290.3980.017ModeFirst mode13.960.3640.5490.008ModeAge*First mode13.170.3440.5610.008Note.Effect sizes reported are partial eta squared (partial η²). Benchmarks for interpreting partial η² are: small = 0.0099, medium = 0.0588, and large = 0.1379 based on Richardson (2011)^80^. MSE: Mean Square Error.
Test duration by mode of administration, age group, and administration order
Results indicated a significant main effect of mode of administration on test duration for Dimensional Change Card Sort Test, List Sorting Working Memory, and Picture Sequence Memory tests: Participants took longer to complete these tests in remote administration compared to in-person administration (see Tables 5 and 6). Mode of administration had no effect on the remaining tests of Flanker, Pattern Comparison Processing Speed Test, Oral Reading Recognition, and Picture Vocabulary (see Table 6). Age group had a main effect on test duration for the Pattern Comparison Processing Speed Test, with younger participants completing the test faster than their older counterparts (see Tables 5 and 6). The interaction between the mode of administration and administration order was significant for Pattern Comparison Processing Speed Test and Picture Vocabulary tests (see Table 6). For the Pattern Comparison Processing Speed Test, children completed the test faster in the first administration. More specifically, in-person testing had shorter duration than remote testing when it was conducted first while remote assessment was shorter than in-person one when it was administered first. For the Picture Vocabulary test, duration was the longest when the cognitive assessment was completed remotely as the first measurement. However, remote Picture Vocabulary testing displayed the shortest duration when the first administration mode was in-person. No other significant effects or interactions were observed (see Table 6).
Table 5. Means and standard deviations of test durations in minutes by mode of administration and age.RemoteIn-personTestMSDMSD DCCS 7–12 years old5.680.985.240.7913–17 years old5.260.394.920.32Total5.480.775.080.62 Flanker 7–12 years old4.511.683.961.0613–17 years old4.242.013.370.28Total4.381.873.670.83 List Sort 7–12 years old9.232.997.161.5113–17 years old8.712.287.322.34Total8.982.657.241.94 Pattern Comparison 7–12 years old1.650.061.670.0413–17 years old1.710.051.730.04Total1.680.061.700.05 Picture Sequence Memory 7–12 years old8.312.167.461.6613–17 years old8.172.376.450.79Total8.242.246.971.39 Oral Reading 7–12 years old1.830.741.670.8113–17 years old2.171.701.420.53Total2.001.301.550.69 Picture Vocabulary 7–12 years old2.270.982.050.5513–17 years old2.131.291.740.66Total2.201.131.900.62
Table 6Test durations by mode of administration,* age*,* and first mode*.TestMSEF p ηp² DCCS Mode2.57040.023< 0.0010.482Age1.2831.7830.1890.040First mode1.2641.7570.1920.039ModeAge0.0811.2620.2680.028First modeAge5.2527.2990.0100.145ModeFirst mode0.1632.5310.1190.056ModeAgeFirst mode0.0160.2540.6170.006 Flanker Mode5.4744.2980.0440.091Age3.9161.3080.2590.030First mode1.3180.440.5110.01ModeAge0.0040.0030.9570.000First modeAge0.2460.0820.7760.002ModeFirst mode2.8042.2020.1450.049ModeAgeFirst mode0.6380.5010.4830.012 List Sort Mode51.39215.184< 0.0010.261Age0.6370.0880.7690.002First mode0.3810.0520.8200.001ModeAge2.0280.5990.4430.014First modeAge19.6392.7020.1080.059ModeFirst mode7.1452.1110.1530.047ModeAgeFirst mode4.6621.3770.2470.031 Pattern Comparison Mode0.0022.7170.1070.059Age0.05616.762< 0.0010.280First mode0.0030.9690.3300.022ModeAge2.2030.0320.8580.001First modeAge0.0041.3100.2590.030ModeFirst mode0.01725.629< 0.0010.373ModeAgeFirst mode0.0000.6600.4210.015 Picture Sequence Memory Mode19.0688.6950.0050.168Age7.5651.8020.1870.040First mode8.7552.0850.1560.046ModeAge1.0710.4890.4880.011First modeAge2.0260.4820.4910.011ModeFirst mode16.8537.6850.0080.152ModeAgeFirst mode0.2220.1010.7520.002 Oral Reading Mode1.9402.7400.1050.060Age0.0310.0210.8860.000First mode0.3950.2670.6080.006ModeAge0.6710.9480.3360.022First modeAge0.4820.3260.5710.008ModeFirst mode2.7943.9460.0530.084ModeAgeFirst mode0.0490.0700.7930.002 Picture Vocabulary Mode0.6481.8960.1760.042Age1.4491.1580.2880.026First mode2.0261.6180.2100.036ModeAge0.0000.0010.9710.000First modeAge0.1480.1190.7320.003ModeFirst mode3.52710.3130.0030.193ModeAge*First mode0.1170.3410.5620.008Note. Effect sizes reported are partial eta squared (partial η²). Benchmarks for interpreting partial η² are: small = 0.0099, medium = 0.0588, and large = 0.1379 (Richardson, 2011)^80^. MSE: Mean Square Error.
Analysis of overlap
The percentage overlap between remote and in-person distributions of each NIHTB-CB test ranged between 96.61% and 84.21%, indicating the highest overlap for the Flanker test and the lowest for the List Sorting Working Memory test. The mean percentage overlap for all seven tests was 90.72%. The percentage overlap for the fluid, crystallized, and total composite scores was 89.5%, 94.27%, and 95%, respectively. Density plots with the percentage overlap between in-person and remote assessments are presented in Fig. 3 for composite test scores. For individual test scores, density with the percentage overlap between in-person and remote assessments are displayed in Figure S1 in the supplementary materials.
Fig. 3. Density plots with percentage overlap for age-corrected composite test scores.
Discussion
Results of this pilot study show equivalency between in-person and remote test scores, indicating that the NIHTB-P/E app is a feasible option for remote cognitive assessment in children aged 7–17. Introducing standardized remote cognitive assessment methods is critical, as remote assessment has endured in the post-pandemic era^71,72^ and offers a range of potential benefits, including increased diversity and representativeness of research subjects. Increasing sample diversity is essential for research with children as developmental processes can vary depending on geographical location, ethnicity, and socioeconomic status^73–75^. Through remote assessment, children who would otherwise be excluded from studies, such as those living in rural areas, face lower barriers to participation, all of which can help improve the ecological validity of research studies. In addition to these benefits, remote tools like the NIHTB-P/E app can enhance the feasibility of decentralized clinical trials (DCTs)^76,77^ by reducing reliance on in-person site visits. Thus, the remote administration of the NIHTB-CB will support future studies including the decentralized ones.
The lack of significant differences between in-person and remote scores held across age groups (7–12 and 13–17 years old) and, for the most part, regardless of the order in which the testing modes were administered. Indeed, for five out of the seven tests, no significant differences were observed in scores across the two formats. However, the interaction between the mode of administration and the order of remote versus in-person assessments revealed practice effects for two individual tests: the Pattern Comparison Processing Speed and Picture Sequence Memory tests. More specifically, taking these tests in-person first led to higher scores on the second (remote) session. Interestingly, when the remote assessment was administered first, we did not see an increase in performance in the second (in-person) session. It is important to note that practice effects on these tests may not be specific to this context since previous studies have also reported practice effects for both Pattern Comparison Processing Speed^51^ and Picture Sequence Memory^58^. These effects may be related to familiarity with stimuli and may have more to do with the relatively short time between the remote and in-person administrations in the current study. Overall, current findings indicate that the NIHTB-P/E app, in general, offers a way to reliably assess cognitive abilities in decentralized protocols. It is important to note that this analysis was focused on group-level equivalency between in-person and remote testing, often used in cross-sectional research designs, for example, rather than individual-level measurement agreement. As such, while preliminary findings of our pilot study support the comparability of in-person and remote testing at the group level, future research is needed to investigate whether individuals obtain consistent scores across administrations.
Additionally, we found that test duration was impacted by the mode of administration, with participants taking significantly longer to complete specific tests (i.e., Dimensional Change Card Sort, List Sorting Working Memory, and Picture Sequence Memory) remotely compared to in-person. Age differences affected only the Pattern Comparison Processing Speed test, which was completed faster by younger participants than older ones. The Picture Vocabulary test had the longest duration when administered remotely first and shortest when remote testing followed in-person administration. The Pattern Comparison Processing Speed test, on the other hand, had a shorter duration in the first administration than the second, independent of the mode of administration. These differences, however, had very small effect sizes. Overall, these findings suggest that both administration mode and order have nuanced effects on test duration for the Pattern Comparison Processing Speed and Picture Vocabulary tests, highlighting the importance of considering these factors when interpreting remote versus in-person testing results.
One limitation of the NIHTB-P/E app is that it requires sufficient internet bandwidth and the availability of required technological devices: in this case, an iPad. While these limitations may be an issue by introducing selection bias, systematically excluding individuals lacking access to internet services, technological devices, and technological literacy^78,79^we note that there are many solutions to overcome these challenges. For instance, researchers can send participants iPads with built-in internet service or connect users to locations with adequate internet access, such as libraries. Certainly, our study addressed this limitation by screening participants for internet access and providing iPads for home use. However, these requirements may present significant challenges for larger, multi-site, or national studies involving hundreds or thousands of participants.
Another limitation to note is that although our study demonstrated equivalency between the remotely applied NIHTB-P/E app and the in-person NIHTB-CB, the norm-referenced scores available for the NIHTB are based on data from in-person testing. This creates future opportunities to harmonize assessments across both modes of administration. Finally, the moderate sample size, consistent with the pilot nature of the study, limits the generalizability of the current findings and requires further research with larger samples. While the study provides important preliminary evidence supporting remote administration of the NIHTB-CB, the findings should be interpreted with caution. Larger studies are needed to confirm these results and explore variability across different subgroups and settings.
In conclusion, the NIHTB-P/E app provides a feasible and standardized method for remote administration of the NIHTB-CB to children in varied environments. Although this pilot study had a small sample size that may limit statistical power to detect subtle differences, the findingssuggest that scores obtained remotely are generally comparable to those from traditional in-person methods These preliminary results support the potential utility of the app for remote cognitive assessment with minimal impacts on test duration or performance. This pilot study supports the NIHTB-P/E app’s potential to expand the scope of cognitive assessment research, reducing participant burden.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lezak, M. D., Howieson, D. B., Bigler, E. D. & Tranel, D. Neuropsychological Assessment (Oxford University Press, 2012).
- 2Sternberg, R. J. & Kaufman, S. B. The Nature of Human Intelligence (Cambridge University Press, 2018).
- 3Kaufman, A. S. & Kaufman, N. L. Kaufman Assessment Battery for Children (American Guidance Service, 2015).
- 4Reynolds, C. R. & Fletcher-Janzen, E. (eds) Handbook of Clinical Child Neuropsychology (Springer, 2019).
- 5Sattler, J. M. & Hoge, R. D. Assessment of Children: Cognitive Applications (Sattler, Publisher, Inc., 2006). Jerome M.
- 6Wechsler, D. Wechsler Intelligence Scale for Children (Pearson, 2014).
- 7Peterson, R. K. & Ng, R. The feasibility of remote administration of oral processing speed measures in children with chronic medical conditions. Clin. Neuropsychol. 1–13. 10.1080/13854046.2025.2469337 (2025).10.1080/13854046.2025.246933739996582 · doi ↗ · pubmed ↗
- 8Gershon, R. C. et al. NIH Toolbox for Assessment of Neurological and Behavioral Function. Neurology 80, (2013).10.1212/WNL.0b 013e 3182872 e 5f PMC 366233523479538 · doi ↗ · pubmed ↗