Meta-analysis models relaxing the random-effects normality assumption: methodological systematic review and simulation study
Kanella Panagiotopoulou, Theodoros Evrenoglou, Christopher H Schmid, Silvia Metelli, Anna Chaimani

TL;DR
This paper reviews and compares alternative statistical models for meta-analysis that relax the assumption of normally distributed study effects, finding that some non-normal models perform better in certain scenarios.
Contribution
The study systematically reviews and simulates non-normal random-effects meta-analysis models, providing guidance on when to consider alternatives to the standard normal model.
Findings
Mixture and semi-parametric models better handle latent clustering in study data.
Normal models may give misleading results when heterogeneity or outliers are present.
Alternative models show similar bias but differ in coverage probability, especially with high variance.
Abstract
Random-effects meta-analysis is widely used for synthesizing the studies of a systematic review assuming a normal distribution for the study-specific effects. However, this assumption might not always be plausible. Alternative options have been suggested but not used in published meta-analyses. We conducted a systematic review to identify articles that proposed alternative meta-analysis models assuming non-normal distributions for the random effects, such as skewed or semi-parametric distributions. Subsequently, we performed a simulation study to evaluate the performance of the identified models and to compare them with the normal model. We considered 22 scenarios varying the amount of random-effects variance, the number of included studies, and the shape of the true distribution: normal, skew-normal, and mixture of two normal distributions. For each scenario, we generated 1000…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
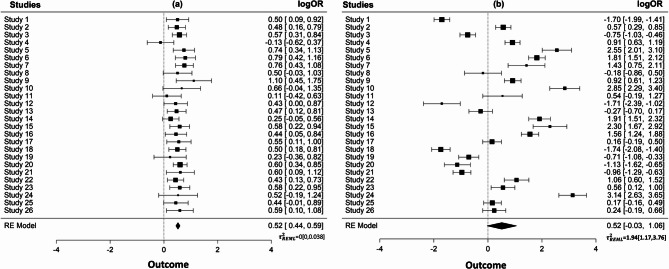 Figure 1
Figure 1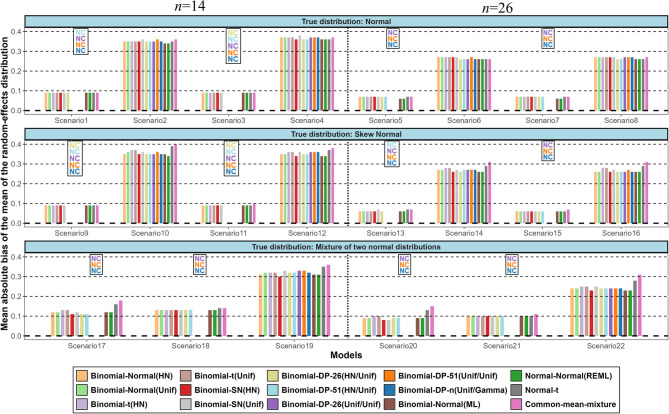 Figure 2
Figure 2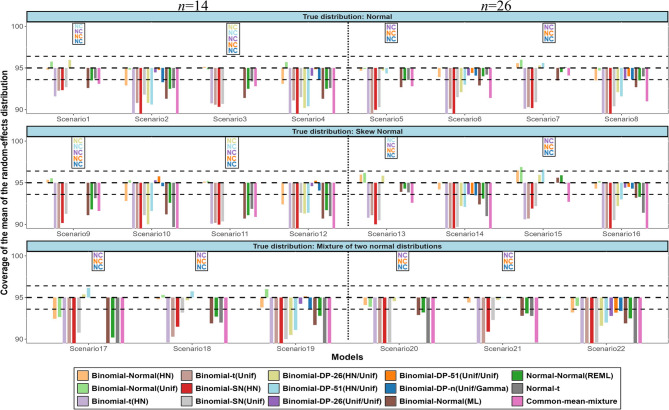 Figure 3
Figure 3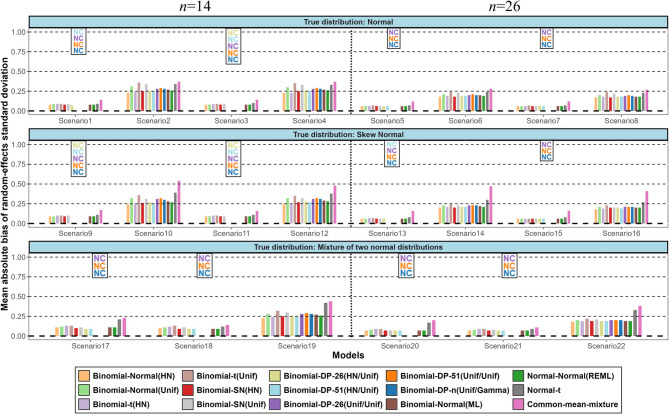 Figure 4
Figure 4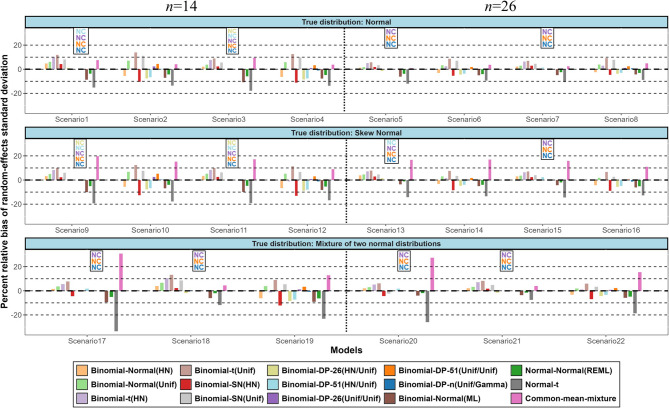 Figure 5
Figure 5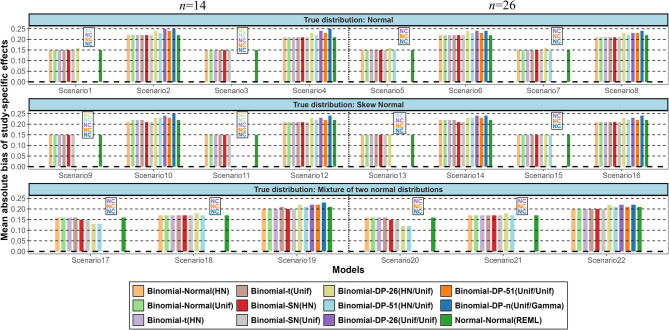 Figure 6
Figure 6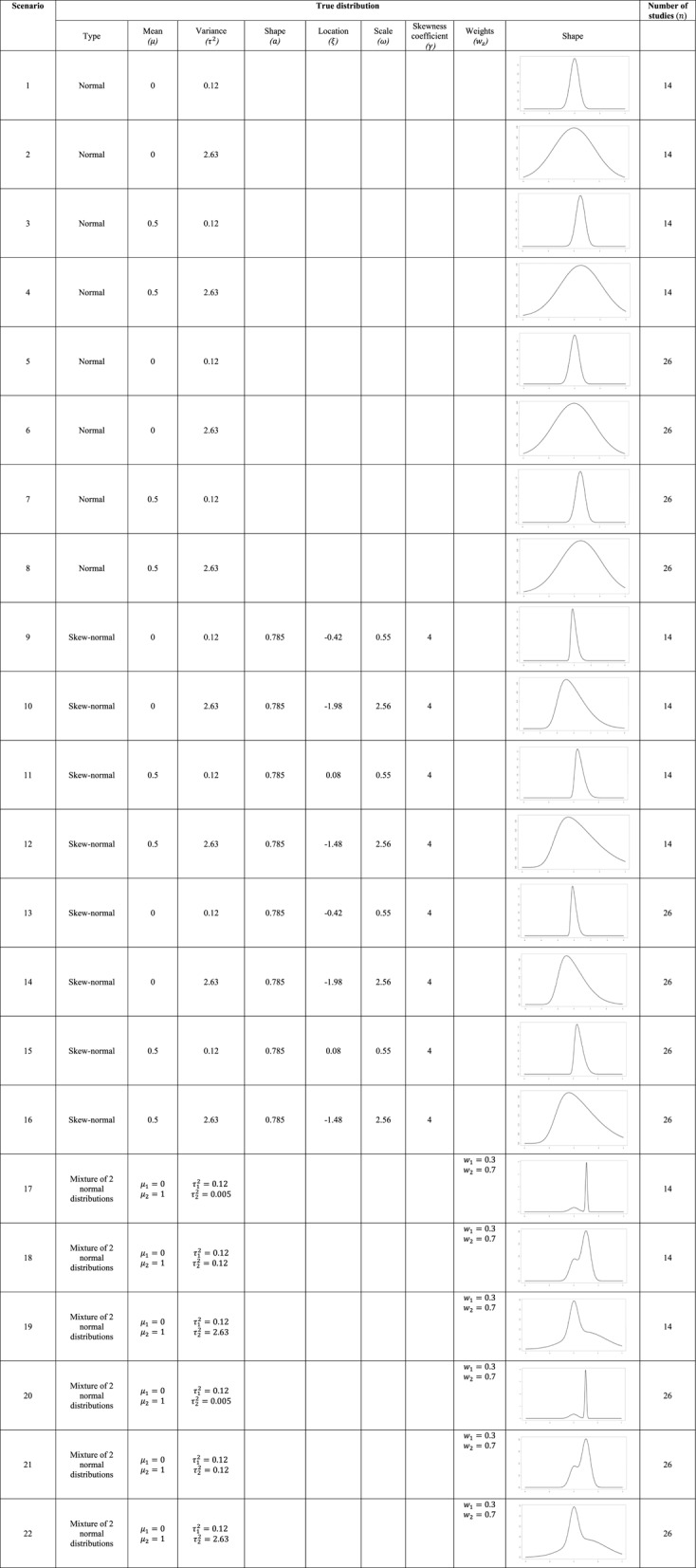 Figure 7
Figure 7- —https://doi.org/10.13039/501100001665Agence Nationale de la Recherche
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Bayesian Methods and Mixture Models · Statistical Methods and Applications
Background
Meta-analysis is the statistical combination of the results from two or more individual studies that meet pre-specified eligibility criteria with an aim to answer a specific research question. It generally requires that studies are sufficiently homogeneous to be synthesized. In the presence of heterogeneity, though, a random-effects model may be used [1]. Conventional random-effects meta-analysis assumes that the underlying effects follow a normal distribution, and thus allows for some variability across the available studies [2]. The Cochrane Handbook states that meta-analyses of very diverse studies can be misleading and the presence of heterogeneity affects the extent to which generalizable conclusions can be formed [3, 4]. However, it is usually unclear how much heterogeneity may be acceptable and how conclusions may be affected in the presence of significant heterogeneity. This leads to a tendency for meta-analysts to ignore the extent of variation of study results and to focus on the estimated mean of the random effects distribution with its confidence interval only, without realizing that as the variance of the effects’ distribution increases, the mean becomes less representative of the studies at hand [5, 6].
Figure 1 presents random-effects meta-analyses of two simulated datasets having binary outcomes in which the study effect measures are log odds ratios. We assigned an underlying normal random-effects distribution with a common mean but different variance: N(0.5,0.0001) and N(0.5,2.63). For both datasets, we assumed equal within-study sample sizes and generated the number of events from a binomial distribution (see also the Data generating mechanism section). The estimated mean in both meta-analyses is 0.52 and, although the confidence interval of the diamond in panel (b) is wider, only marginally crosses the line of no difference. Here, focusing solely on the two point estimates and ignoring the variation between the study-specific effects distributions of these two meta-analyses would probably lead to similar conclusions.
Fig. 1. Meta-analysis of two simulated sets of studies generated from two normal distributions with the same mean but different variances. The dataset of panel (a) was generated from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N\left(0.5,\:0.0001\right)\:$$\end{document} and that of panel (b) from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:N\left(0.5,\:2.63\right)$$\end{document}
A commonly used approach to explore the variation between studies in meta-analysis is meta-regression. Relative effects are frequently associated with one or more study characteristics (i.e. effect modifiers) which may form distinct subgroups of studies. In such cases, meta-regression can be used to explore subgroup differences. However, while meta-regression can be informative, it is only sufficient when the observed differences across studies can be adequately explained by the included subgroups. It is common that even after accounting for the available covariates, substantial residual heterogeneity between studies to remain (e.g. presence of outliers). In such situations the use of non-normal distributions, such as skewed or bimodal distributions may be considered [7–9].
Despite the aforementioned limitations of the conventional random-effects model, in the vast majority of meta-analyses the variability between studies is modelled through a normal distribution. Potential reasons for this choice are analytical convenience, model simplicity, tradition and software availability. On the other hand, normality can be considered a conservative or robust assumption as it is the ‘maximum entropy’ distribution for given expectation and variance [10]. Other more flexible modeling approaches have been suggested in the literature but, to our knowledge, they have rarely been used in clinical applications [11].
In this article, we review and evaluate several meta-analysis models that make different assumptions about the random-effects distribution. We first performed a systematic review aiming to identify and summarize all available statistical models for meta-analysis that allow alternative non-normal distributions for the random effects. Subsequently, we conducted a simulation study to compare the identified models and assess their performance under different scenarios. The rest of the article is structured as follows: In the Systematic review methods section, we briefly describe the methods of our systematic review and we provide an overview of the identified meta-analysis models. The Simulation study section presents our simulation study and summarizes our findings. In the Selected simulated datasets section, we further compare the evaluated models using specific simulated datasets. Finally, in the Discussion section we discuss the implications of our findings and in the Conclusions section we provide concluding remarks.
Systematic review methods
Search and selection of articles
We searched for published articles presenting or evaluating models for meta-analysis that avoid the assumption of a normal distribution for the random effects. The last search was performed on 14 October 2024.
First, we searched in PubMed using the following search algorithm: (meta-analy*[Title] OR synthesi*[Title]) AND (non-normal*[Title/Abstract] OR mixture[Title/Abstract] OR non-parametric*[Title/Abstract] OR flexible random distribution models[Title/Abstract] OR skewed[Title/Abstract]) AND (model[Title/Abstract] OR approach[Title/Abstract]). Given that some eligible articles might have been published in journals not included in PubMed we further searched in other related journals (such as Journal of the American Statistical Association,* Annals of Statistics*, etc.). Finally, we screened the references of the included articles for potentially additional eligible articles.
Eligible articles were those introducing new meta-analysis models, methodological reviews, simulation studies, or commentaries on the properties and characteristics of the models of interest. Overviews of reviews or articles implementing alternative distributions in other parts of the meta-analysis model (e.g. within-study distribution, control group risk, patient-level data distributions) were excluded. We included only articles published in English. Relevant models for meta-analysis of diagnostic test accuracy studies were eligible. Articles about synthesis of gene association studies were excluded.
From each article, we extracted information about the distributional framework(s) proposed or evaluated. We also extracted the meta-analytic setting and the type of data for which the identified models have been suggested. Finally, the theoretical properties and the performance (if available) of the identified models were also extracted.
Search results
We identified 1278 articles through PubMed out of which 1221 were excluded by screening the titles and the abstracts and 36 after reading the full text. Six additional articles that met our inclusion criteria were identified through hand-searching in specific journals. We ended up with 27 eligible articles involving 24 alternative distributions for the random effects [11–37]. The detailed flow chart is available in Supplementary Fig. 1.
Description of the identified models
The identified models can be classified into four main categories based on their random-effects distributional assumptions: (a) skewed extensions of normal and t-distributions, (b) beta distribution (c) mixtures of distributions, and (d) distributions based on Dirichlet Process priors. In the majority of the articles, the proposed model was constructed under the Bayesian framework. In terms of software, most articles provided code but only a few developed an accompanying software package [12, 38–43]. A summary of the characteristics of the eligible articles can be found in Supplementary Table 1. In the following paragraphs, we start by describing the conventional model where a normal distribution is assumed for the random effects and continue with the description of the alternative models identified through our systematic review.
Conventional normal model
Suppose that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Y}_{1},{Y}_{2},\:\dots\:,\:{Y}_{n},$$\end{document} are the observed effect sizes for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} studies in the meta-analysis with corresponding underlying effects denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{1},\dots\:,{\theta\:}_{n}$$\end{document} . The conventional random-effects meta-analysis model assumes for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i=1,\dots\:,n$$\end{document} that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_i\left|\theta_i\right.\sim\;\text N\left(\theta_i,\sigma_i^2\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta_i\sim\text N\left(\mu,\tau^2\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\sigma\:}_{i}^{2}$$\end{document} is the variance of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Y}_{i}$$\end{document} that usually is assumed known, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} is the mean of the random effects’ distribution and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}$$\end{document} is the random-effects variance. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:\mu\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} are also the location and scale parameters respectively. For brevity, we refer to the model of Eq. (1) in the rest of the manuscript simply as the “normal model”.
t-distribution
The simplest way to allow for some extreme effects in meta-analysis (e.g. outlying studies) is to replace the normal distribution in Eq. (1) with a t-distribution [12–14]. In that case Eq. (2),
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta_i\sim t\;\left(\mu,\omega,\nu\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:\mu\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}$$\end{document} are the mean and variance of the t-distribution with scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\omega\:=\sqrt{{\tau\:}^{2}\frac{\left(v-2\right)}{v}}\:$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\nu\:>2$$\end{document} is the degrees of freedom determining the weight of the tails. The t-distribution is similar to the normal but it has more weight in the tails and thus outliers generally tend to be less influential. Beath [15] also developed the R package metaplus [38] and implemented the above t-distribution model.
A multivariate extension of the t-distribution model has been proposed by Bodnar and Bodnar [16] for meta-analysis of multiple outcomes. Comparing the multivariate normal and the multivariate t-distribution models with several prior distributions in simulations and real data applications, resulted in the multivariate-t model yielding consistently wider credible intervals reflecting the influence of heavy tails. The authors also developed an accompanied R package called BayesMultMeta [39].
Skewed extensions of normal and t-distribution
To allow for further flexibility and avoid the assumption of a symmetric distribution, we can employ a skew-normal (SN) or a skewed t-distribution (ST) [12, 13].This requires introducing parameters regulating the skewness of the distribution [44]. Then, in case of a skew-normal distribution, Eq. (1) would be modified into
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{i}\sim\:\:\text{S}\text{N}\left(\xi\:,\omega\:,a\right)$$\end{document}Considering \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:\:$$\end{document} as the mean, the variance and the skewness coefficient of the skew normal distribution, then the location, scale, and shape parameters, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\xi\:$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\omega\:$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:a\:$$\end{document} respectively, are defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\xi\:=\mu\:-\omega\:b\delta\:$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\omega\:=\sqrt{\frac{{\tau\:}^{2}}{[1-{\left(b\delta\:\right)}^{2}]}}\:$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:=\frac{4-\pi\:}2\frac{\left(b\delta\:\right)^3}{{(1-\left(b\delta\:\right)^2)}^3}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b=\sqrt{\frac{2}{\pi\:}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\delta\:=\frac{a}{\sqrt{1+{a}^{2}}}$$\end{document} . The shape parameter and the skewness coefficient regulate the skewness of the skew-normal distribution but the former takes any real value whereas the latter is constrained to the range (− 1,1) [45]. Since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:$$\end{document} is a function of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a$$\end{document} , it ensures that the skewness remains within a fixed interpretable scale. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a\:=\:0$$\end{document} , the above distribution coincides with the normal distribution. Alternatively, a skewed t-distribution can be used, namely
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{i}\sim\text{S}\text{T}(\xi\:,\omega\:,\nu\:,a)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\xi\:$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\omega\:$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a$$\end{document} are again obtained as a function of the mean, the variance and the skewness coefficient of the skewed t-distribution. The above distributions are positively skewed for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a>0$$\end{document} and negatively skewed for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a<0$$\end{document} . Examples of how different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:$$\end{document} can affect the skewness of the distribution are provided in Supplementary Fig. 2.
Based on two simulated datasets – one normal and one skewed scenario – and on two real datasets involving some outliers, Lee and Thompson [13] found small differences in the estimation of the mean and the variance of the normal, skew-normal and skew-t distributions. However, relaxing the normality assumption improved model fit and yielded more skewed predictive distributions. They, additionally, provided bivariate extensions of the above models assuming that the treatment effect and the baseline risk are correlated. A bivariate skew-normal model is also suggested by Negeri and Beyene [17] for meta-analysis of diagnostic test accuracy (DTA) studies to model specificity and sensitivity jointly. Both articles conclude that the non-normal models improve model fit and precision when the data are skewed. However, the complexity added by the extra parameters they involve is a key limitation.
Other skewed distributions
On top of the skew-normal and skewed t-distribution, Noma et al. [12] proposed the use of three alternative skewed distributions:
- The asymmetric Subbotin distribution (type II) [46, 47] being an extension of the symmetric Subbotin distribution, previously proposed for meta-analyses with outliers by Baker and Jackson [14], that can express greater asymmetry and excess kurtosis.
- The Jones–Faddy [48] distribution that involves a kurtosis parameter instead of the degrees of freedom as well as a skewness parameter.
- The sinh-arcsinh distribution [49] that offers increased flexibility as it can express both symmetric and skewed shapes as well as heavy or light tail-weight.
For a detailed description of these distributions, we refer to the original article [12]. The authors applied the above five skewed distributions to two meta-analyses datasets and compared the results with the normal and the t-distribution models. Given that the skewed distributions provided slightly different mean estimates with narrower credible intervals and resulted in more skewed posterior distributions, they suggest using them as a sensitivity analysis and choosing the most suitable model based on model fit criteria (such as DIC [50]). They also developed an R package, called flexmeta [12]which is linked to the rstan [51] package.
Beta distribution
Baker and Jackson [14]apart from the t-, Subbotin, and arcsinh distributions, also considered the use of a beta distribution for the random effects restricted on a constraint interval which results to a short-tailed distribution for meta-analyses that completely lack outliers. The proposed random-effects distribution is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{i}\sim\text{B}\text{e}\text{t}\text{a}({a}_{0},\:{b}_{0})$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{a}_{0}=\mu\:\left(\frac{\mu\:\left(1-\mu\:\right)-{\tau\:}^{2}}{{\tau\:}^{2}}\right)\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{b}_{0}=(1-\mu\:)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left(\frac{\mu\:\left(1-\mu\:\right)-{\tau\:}^{2}}{{\tau\:}^{2}}\right)\:$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{a}_{0},\:{b}_{0}>1$$\end{document} . The authors compare these models in three meta-analyses with different settings: presence of one outlier, several outliers, and no obvious outliers. They conclude that the use of long-tailed distributions significantly reduces the weight of the outlying studies and might be also more appropriate for meta-analyses where publication bias is suspected.
Chen et al. [18] propose a “hybrid” beta-binomial model for DTA meta-analyses that allows combining case-control and cohort studies. For case-control studies, the random effects follow a bivariate Sarmanov beta distribution [52]accounting for correlations between sensitivity and specificity. For cohort studies, a trivariate Sarmanov beta distribution [52] is used to capture correlations between pairs of sensitivity, specificity, and prevalence. Their models are implemented in the R package xmeta [40]. More details can be found in the original article [18].
Mixture of distributions
An alternative flexible way to model the random effects is to use a ‘mixture’ of two or more distributions. This approach might be more relevant when the data seem to naturally come from two or more sub-populations or when several outlying studies are present. Mixture models may also allow approximating sufficiently well arbitrary distributions [53]. These models aim to identify latent subgroups of studies (mixture components) and to estimate each subgroup’s mean and variance along with the corresponding mixing proportions. Either different distributions (e.g. a normal distribution and a t-distribution) or the same distribution with different parameters can be employed to the mixture. Hence, a mixture of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} normal distributions is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{i}\sim{w}_{1}\text{N}\left({\mu\:}_{1},{\tau\:}_{1}^{2}\right)+\dots\:+{w}_{k}\text{N}\left({\mu\:}_{k},{\tau\:}_{k}^{2}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{1},\:\dots\:,\:{\mu\:}_{k}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{1}^{2},\:\dots\:,{\tau\:}_{k}^{2}$$\end{document} are the subgroup-specific mean and variance for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:k$$\end{document} subgroups with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}_{1},\dots\:,{w}_{k}$$\end{document} being the corresponding mixing weights with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sum\:_{z=1}^{k}{w}_{z}=1$$\end{document} .
Beath [15] describes a finite mixture model for the random effects for outlier detection. The model considers two normal distributions with common mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:\left({\mu\:}_{c}\right)$$\end{document} and different variances \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{(\tau\:}_{1}^{2},{\tau\:}_{2}^{2})$$\end{document} corresponding to two subgroups of studies representing non-outlying and outlying studies. A bootstrap likelihood ratio test is used to determine whether there are any outliers by comparing models with and without outliers; the outlier studies are identified using posterior predicted probabilities. The weight ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}_{1},\:{w}_{2}$$\end{document} ) of each distribution in the mixture is proportional to the number of studies in the respective subgroup. Here, Eq. (6) becomes
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{i}\sim{w}_{1}\text{N}\left({\mu\:}_{c},{\tau\:}_{1}^{2}\right)+{w}_{2}\text{N}({\mu\:}_{c},{\tau\:}_{2}^{2})\:$$\end{document}and parameters are estimated through an expectation-maximization (EM*)* algorithm [54]. Then, the mean of the mixture distribution is estimated including all studies but with outliers being down-weighted due to the larger variance assumed for their subgroup. An extension of this model incorporating covariates can be used to further explain the observed heterogeneity. Several case studies are provided to point out the importance of identifying and properly modeling outlying studies due to their influence on the estimation of the overall mean of the mixture distribution. The above model has been implemented in the metaplus [38] package in R.
Brown et al. [19] introduce a different two-component normal mixture model where each component is based on a regression model incorporating both individual-participant-level covariates and study-level covariates. The use of two components reflects the presence of two suspected subgroups and mixture weights represent the proportion of studies in each subgroup.
Finucane et al. [20] introduce a semi-parametric density estimation meta-analysis model for dependent study effect sizes with covariates. The proposed model is a finite mixture of normal distributions with weights assigned according to the stick and breaking process (see the Dirichlet Process priors section). This approach leverages information from both aggregate and individual participant data when available.
Zhang et al. [21] propose a latent mixture-based moderator analysis as a way to disentangle the observed heterogeneity without requiring information on the contributing factors. Specifically, they assume a mixture of several normal distributions for the random effects and then they use an automated data-driven algorithm to decompose the mixture components. They suggest this analysis as a useful step prior to standard moderator analysis (e.g. meta-regression), where researchers can then use the resulting components to examine deeper potential moderating effects.
Eusebi et al. [22] also suggest a similar finite mixture model of bivariate normal distributions and they extend their model to incorporate covariates for predicting latent subgroup classification. They apply their proposed model through the Latent GOLD 4.5 software [55].
Lopes et al. [23] suggest the use of a mixture of multivariate normal distributions for longitudinal data incorporating a time component as well as other covariates for which they suspect non-linearity. The random-effects distribution is decomposed into one part that is common across all studies and a second part that is specific to each study and captures the variability between patients within the same study. This results to a distribution for the random effects which depends on the patients’ measurements within studies and on study-level covariates.
Baker and Jackson [24] suggested a similar model to Beath’s [15]but expressed the weight of the outlying studies in the mixture as a function of their variance. They also proposed a skewed marginal distribution which is a mixture of a normal and a lagged-normal distribution. The latter is the sum (or difference) of one or more exponential distributions and a normal distribution. This model further includes parameters for skewness and kurtosis. Accounting for covariates is also possible by expressing the proposed model in a regression form. The suggested model appeared to have better fit than the t-distribution model by Baker and Jackson [14], the skewed-t model by Lee and Thompson [13] and the normal one for non-normal data in real data applications.
Sangnawakij et al. [25] suggest a likelihood-based non-parametric mixture model for meta-analyses with rare events that can be used either with arm-based or contrast-based data. They employ a mixture algorithm that assigns study-arms or studies to a fixed number of components with the component parameters being estimated via Poisson regression. Mixture weights are defined as the proportion of studies in each component. The algorithm generates estimates from all possible data classifications to the mixture components. This model was first proposed by Böhning et al. [26] along with a bivariate extension, but without considering arm-based data.
Van Houwelingen et al. [27] introduced the use of another (EM) algorithm [56] that results in a discrete mixture distribution for the random effects. They also proposed a bivariate extension of this approach assuming random effects for both treatment and control arms in order to investigate their relationship with the overall mean of the mixture distribution.
Karabatsos et al. [28] propose a Bayesian infinite random-intercept mixture of regressions. This is, in practice, a discrete mixture model where the random intercept parameter is derived from a covariate-dependent infinite mixture distribution. This model allows for a wide range of distributions for the random effects, including unimodal symmetric, skewed, or multimodal distributions. The proposed model can identify which of the included covariates may be important predictors. Based on a meta-analysis of highly heterogeneous studies involving 24 covariates and multiple study reports, the authors suggested that the proposed non-parametric model describes better the distribution of the underlying treatment effects in comparison to various versions of normal fixed and random-effects models. It was also considered to fit better to the data based on goodness of fit measures. They applied their proposed model through a software [57] developed by Karabatsos [57].
A flexible finite mixture model of bivariate normal distributions is proposed by Schlattmann et al. [29] for DTA meta-analysis. The model uses a bivariate version of the model of Eq. (6) to model sensitivity and specificity simultaneously. This model was applied using the CAMAN [58] and mada [59] R packages developed by Schlattmanna et al. [29] and Doebler [59] respectively.
Dirichlet Process priors
A further possibility to model the random-effects distribution is through a class of semi-parametric priors, namely Dirichlet Process (DP) priors. The use of DP priors is the most flexible option among the identified alternative models and offers the opportunity to automatically identify the potential underlying clustering of the data: here relevant subgroups of studies. In practice, the DP is a generalization of the Dirichlet distribution with the property that, for any finite partition of the parameter space, the DP marginalizes to a Dirichlet distribution [60, 61]. In other words, the models based on DP priors treat the number of components as an additional unknown parameter to be estimated and assign to each study a probability to be included in each component.
Muthukumarana and Tiwari [30] suggested a simple DP model for meta-analysis described as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta_i\sim F$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F\sim\text{D}\text{P}\left(\alpha\:,{F}_{0}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{F}_{0}\sim\text{N}\left({\mu\:}_{b},{\tau\:}_{b}^{2}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{F}_{0}$$\end{document} is the base distribution that controls the mean of the process and can be any distribution; here a normal distribution with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{b}$$\end{document} and variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:{\tau\:}_{b}^{2}$$\end{document} is assumed. The concentration parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:\ge\:0$$\end{document} measures the variability of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F$$\end{document} around \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{F}_{0}$$\end{document} , with higher values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} suggesting that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F$$\end{document} is ‘closer’ to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{F}_{0}$$\end{document} . It can be given either a fixed value or a prior distribution and larger values (e.g. larger than the number of studies) give more weight to the base distribution.
A DP can be implemented using different approaches, such as the Chinese restaurant process [62, 63]the Polya urn scheme [64]or the stick and breaking process [65]. For example, the latter generates a set of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{j}\sim{F}_{0}$$\end{document} points (i.e. location parameters), and their corresponding weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{p}_{j}$$\end{document} which depend on the value of the concentration parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} .Then, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F={\sum\:}_{j=1}^{\infty\:}{p}_{j}{I}_{{x}_{j}}\left(x\right),$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{I}_{{x}_{j}}$$\end{document} is an indicator variable with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{I}_{{x}_{j}}\left({x}_{j}\right)=1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{I}_{{x}_{j}}\left(x\right)=0$$\end{document} otherwise. The weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{p}_{j}$$\end{document} are defined using a recursive scheme that repeatedly samples from the beta distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{B}\text{e}\text{t}\text{a}(1,\alpha\:)$$\end{document} . That is, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{p}_{j}={q}_{j}*\prod\:_{i=1}^{j-1}\left(1-{q}_{i}\right)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{q}_{j}\sim\text{B}\text{e}\text{t}\text{a}(1,\alpha\:)$$\end{document} . A truncation that allows obtaining a plausible approximation to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{F}$$\end{document} is usually applied to make the process faster; for instance, the number of studies in the meta-analysis was used here as a truncation point.
Based on a real data example, Muthukumarana and Tiwari [30] suggest that their proposed method provides narrower credible intervals for the study specific effects in comparison to the normal model. In their simulation study, under highly heterogeneous and non-normal scenarios, the DP model had a better fit to the data compared with the normal model.
Ohlssen et al. [31] also suggest the use of a truncated DP ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{T}\text{D}\text{P})$$\end{document} by truncating at a maximum number of mass points \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N$$\end{document} . Hence, the prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F$$\end{document} in Eq. (7) now becomes
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F\sim\text{T}\text{D}\text{P}(\alpha\:,{F}_{o},N)$$\end{document}Here, in contrast to Muthukumarana and Tiwari [30] \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N$$\end{document} is closely related to the concentration parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} through \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N\approx\:1-\alpha\:{\text{log}}_{\text{e}}\epsilon\:$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\epsilon\:$$\end{document} representing the expected value of the probability assigned to the final point, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:E\left[{p}_{N}\right]$$\end{document} . In practice, using a very small value for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\epsilon\:$$\end{document} , such as 0.01, would give
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N\approx\:1+5\alpha\:$$\end{document}Several articles, though, use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N=n$$\end{document} [30, 34]. The above model assumes a discrete random-effects distribution by implementing a mixture of points (DPMp) but it can be extended to a continuous random-effects distribution by implementing a mixture of (normal) distributions instead (DPMd). Using a meta-analysis of routinely collected data as well as a simulation study with data generated from normal and mixture of binomial distributions, the authors suggest that the truncated DP models fit the data better than the normal one and correctly identify clusters among the underlying effects. Their simulations also imply that the estimated value for the concentration parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} is an indicator of whether the random-effects distribution is normal or not.
A modified version of the DPMd model suggested by Ohlssen et al. [31] is presented by Burr and Doss [11, 32]. Specifically, they introduce the “conditional DP” by replacing Eq. (7) with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F\sim{\text{D}\text{P}\text{M}\text{d}}^{{\mu\:}_{b}}\left(\alpha\:,{F}_{0}\right)$$\end{document} ; that is the conditional distribution for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F$$\end{document} given that the posterior median of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F$$\end{document} is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{b}$$\end{document} . This model might be preferable when the number of studies is small. It also has the advantage that the estimation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{b}$$\end{document} is not influenced materially by the presence of few outlying studies. Using these two models for an exemplar meta-analysis allowed to identify subgroup differences in one single analysis. The authors also developed an R package, called bspmma [41]in which the conditional and non-conditional DPM models have been implemented. Although the package runs the models fast, it only supports the normal distribution as base distribution ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{F}_{0}$$\end{document} ) and lacks flexibility in prior distributions.
Jo et al. [33] describe a flexible mixed effects meta-regression model to properly handle aggregate data for several subpopulations. They also employ a DPMd model for the random effects which can be alternatively written as an infinite mixture of truncated normal distributions.
Cao et al. [34] recently extended the truncated DPMp model described by Ohlssen et al. [31] for the estimation of reference intervals for a new individual or a new study [66]. The authors built their models using Nimble [67]an R package which, although it is not specific to meta-analysis, contains automated functions for the implementation of different DP processes such as the stick and breaking process or the Chinese restaurant process. More details can be found in the original article [34].
Another extension of the DP priors is proposed by Dunson et al. [35] who introduce the “Matrix Stick-Breaking Process” (MSBP) designed for individual participant data meta-analyses with several predictors per study. In practice, this model modifies the stick and breaking process to allow borrowing information across predictors and studies simultaneously. This is achieved by the incorporated increased probability of two studies being clustered together for a specific predictor given that those studies have already been clustered together for other predictors. Simulated examples indicated some superiority of MSBP compared to other DP models in terms of MSE only in cases with moderate or large number of coefficients.
Branscum and Hanson [36] introduce a Polya-tree mixture model for meta-analysis. Polya-tree priors can be seen as a generalization to DP priors [68–71]; they can be discrete or continuous with the latter resulting in less distinct cluster effects. The Polya-tree’s model structure resembles the “conditional DP” model described by Burr and Doss [11, 32] but the process weights depend on the tree partition of the space. In a simulation study comparing the proposed model and the normal model with data generated from a skewed bimodal distribution, the former resulted in posterior distributions closer to the distribution of the true effects. The Polya-tree mixture model has been implemented in the DPpackage [42] in R through the PTmeta function. However, the package only allows a base distribution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{b}=0$$\end{document} . The same package allows fitting the DPMp and DPMd models through the functions DPmeta and DPMmeta respectively.
Finally, Barrientos et al. [37] recently proposed a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{T}\text{D}\text{P}$$\end{document} for network meta-analysis aiming to identify treatment hierarchies or equalities. Two different base distributions are considered: a normal and a ‘spike and slab’; the latter is a two-component mixture distribution. The spike component could be either a disintegrated distribution at 0 or a continuous distribution centered at 0 with small variance while the slab component is a spread distribution typically also centered at 0. This model has been implemented in the R package CBnetworkMA [43].
Simulation study
We compared the normal model with some of the alternative models identified through our systematic review in a simulation study which we present following the recommendations by Morris et al. [72].
Data generating mechanism
We generated a range of meta-analysis datasets consisting of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} studies comparing an active with a control intervention for a dichotomous outcome. Based on empirical data [73]we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=14,\:26$$\end{document} to represent meta-analyses of moderate and large size respectively. We generated the underlying effects of the studies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{i}$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i=1,\dots\:,n$$\end{document} ) from a normal distribution, a skew-normal, or a mixture of two normal distributions: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(\mu\:,{\tau\:}^{2}\right)$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{S}\text{N}\left(\xi\:,\omega\:,a\right)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}_{1}\text{N}\left({\mu\:}_{1},{\tau\:}_{1}^{2}\:\right)+\:{w}_{2}\text{N}\left({\mu\:}_{2},{\tau\:}_{2}^{2}\:\right)$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}_{1}=0.3$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}_{2\:}=0.7$$\end{document} respectively. We considered scenarios with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:=0,\:0.5$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{1}=0,\:{\mu\:}_{2}=1$$\end{document} to represent the absence and the presence of a treatment effect. We also considered \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}=0.12,\:2.63$$\end{document} to reflect scenarios with moderate and high random-effects variance respectively based on the empirical distributions for log odds ratios provided by Turner et al. [74] for subjective outcomes and comparisons between a pharmacological intervention and a placebo/control. For the mixture of two normal distributions, we used \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{1}^{2}=0.12$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{2}^{2}=0.005,\:0.12,\:2.63$$\end{document} . The parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\xi\:,\omega\:,a$$\end{document} were derived from Eqs. (3), (4) and (5) assuming \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:=0.79.$$\end{document} .
Then, we generated arm-level data from a discrete uniform distribution ranging from 50 to 500 assuming equal within-study sample sizes for the treatment ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{m}_{it}$$\end{document} ) and the control group ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{m}_{ic}$$\end{document} ). To generate the number of events in the control group, we used \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{c}_{i}\sim\text{B}\text{i}\text{n}\left({m}_{ic},{\rho\:}_{ic}\right)$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\rho\:}_{ic}\sim\text{U}(0.05,\:0.65)$$\end{document} and for the events of the treatment group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{t}_{i}\sim\text{B}\text{i}\text{n}\left({m}_{it},{\rho\:}_{it}\right)\:$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\rho\:}_{it}=\frac{{\rho\:}_{ic}{e}^{{\theta\:}_{i}}}{1-{\rho\:}_{ic}+{\rho\:}_{ic}{e}^{{\theta\:}_{i}}\:}$$\end{document} [75].Studies generated with zero events in both arms were excluded from the respective meta-analysis; two studies only from two different scenarios had to be excluded.
Overall, we assessed 22 scenarios and for each scenario we generated 1000 meta-analyses. A summary of all scenarios is available in Table 1. To evaluate the applicability of the alternative flexible models in meta-analyses with few studies, we conducted additional simulation scenarios with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=5$$\end{document} .
Table 1. Summary of the 22 scenarios considered in the simulation study
Evaluated models and software used
We evaluated 15 different models for which either an R package was available, or we were able to obtain relevant software code in R [76]JAGS [77]or STAN [78]: 11 were implemented in the Bayesian framework and 4 in the Frequentist framework (Table 2).
Table 2. Summary of the evaluated models in the simulation studyModel abbreviationFramework fittedWithin-study distributionRandom-effects distributionPrior distributions for key parametersDP truncation points ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{N}$$\end{document} )Mean of the random-effects distribution( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{\mu\:}$$\end{document} )Random-effects standard deviation( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{\tau\:}$$\end{document} )base mean ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{\mu\:}}_{\varvec{b}}$$\end{document} )base standard deviation( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{\tau\:}}_{\varvec{b}}$$\end{document} )concentration ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{\alpha\:}$$\end{document} )location( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{\xi\:}$$\end{document} )Scale( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{\omega\:}$$\end{document} )Shape( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{a}$$\end{document} )degrees of freedom ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{\nu\:}$$\end{document} )Binomial-Normal (HN)BayesianBinomialNormal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{H}\text{N}\left(\text{0,1}\right)$$\end{document} --------Binomial-Normal (Unif)BayesianBinomialNormal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0,10}\right)$$\end{document} --------Binomial-t(HN)BayesianBinomialt-distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{H}\text{N}\left(\text{0,1}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{E}\text{x}\text{p}\left(0.10\right)$$\end{document} -Binomial-t(Unif)BayesianBinomialt-distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0,10}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{E}\text{x}\text{p}\left(0.10\right)$$\end{document} -Binomial-SN(HN)BayesianBinomialSkew Normal----- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{H}\text{N}\left(\text{0,1}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(\text{0,25}\right)$$\end{document} --Binomial-SN(Unif)BayesianBinomialSkew Normal----- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0,10}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(\text{0,25}\right)$$\end{document} --Binomial-DP-26 (HN/Unif)BayesianBinomialDPMp-- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{H}\text{N}\left(\text{0,1}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0.3,5}\right)$$\end{document} ----26Binomial-DP-51 (HN/Unif)BayesianBinomialDPMp-- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{H}\text{N}\left(\text{0,1}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0.3,10}\right)$$\end{document} 51Binomial-DP-26 (Unif/Unif)BayesianBinomialDPMp-- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0,10}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0.3,5}\right)$$\end{document} ----26Binomial-DP-51(Unif/Unif)BayesianBinomialDPMp-- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0,10}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(0.3,10\right)$$\end{document} ----51Binomial-DP- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{n}$$\end{document} (Unif/Gamma)BayesianBinomialDPMp-- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0,10}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\Gamma\:}\left(\text{1,1}\right)$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} Binomial-normal(ML)FrequentistBinomialNormal----------Normal-Normal(REML)FrequentistNormalNormal----------Normal-tFrequentistNormalt-distribution----------Normal- Common-mean mixtureFrequentistNormalMixture of 2 normal distributions with common mean----------
For each Bayesian model we used a Binomial likelihood for the arm-level data and we applied one of the following four different random-effects distributions, each with different prior specifications for their parameters:
- normal with a non-informative normal prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} and for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} ;
- a half-normal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{H}\text{N}\left(\text{0,1}\right)$$\end{document} , or
- a uniform prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0,10}\right)$$\end{document} .
- t-distribution with a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left({\text{0,10}}^{4}\right)$$\end{document} prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} and an exponential prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{E}\text{x}\text{p}\left(0.10\right)$$\end{document} [12] for the degrees of freedom ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\nu\:$$\end{document} ) combined, as above, with (a) or (b) priors for the scale parameter ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\omega\:$$\end{document} ).
- skew-normal with a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document} prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\xi\:$$\end{document} and a normal prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(\text{0,25}\right)$$\end{document} for the shape parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a\:$$\end{document} combined again with (a) or (b) priors for the scale parameter ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\omega\:$$\end{document} ).
- a truncated DPMp (constructed using the stick and breaking process) with a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}\left(0,\:{10}^{4}\right)$$\end{document} prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{b}$$\end{document} combined with (a) or (b) priors for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{b}$$\end{document} as well as for the concentration parameter ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} );
- i.a uniform prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0.3,5}\right)$$\end{document} resulting from Eq. (8) in a truncation parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N=26$$\end{document} , using the prior’s maximum value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:=5$$\end{document} , or
- ii.a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0.3,10}\right)$$\end{document} prior resulting in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N=\:51$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:=10$$\end{document} . This allows for a larger number of potential clusters to be created and a better approximation to the full process [79]or
- iii.Gamma prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\Gamma\:}\left(\text{1,1}\right)$$\end{document} on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N=n$$\end{document} [30, 34].
Under the Frequentist framework, we used one model with binomial likelihood on the arm-level data and normal random-effects distribution with a maximum likelihood (ML) estimator for variance and three models with normal approximation to the observed log-odds ratios of the studies with different random-effects distributions:
- normal with the restricted maximum likelihood (REML) estimator for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} .
- 2.t-distribution (normal-t model) with maximum likelihood (ML) estimator for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} and profile-likelihood confidence intervals [80].
- 3.mixture of two normal distributions with common mean and different variances (common-mean mixture) as described by Beath [15] again with ML estimator for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} .
We ran all simulations in the R statistical software version 4.2.2 (October 31, 2022) [76]. Bayesian models were built in JAGS [77] and Stan [78] through the rjags [81]R2jags [82] and cmdstanr [83] packages. For all analyses, we ran 2 chains with 50,000 iterations and a 10,000 burn-in period. The convergence of all Bayesian models was checked by extracting the ratio of between-chain to within-chain variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\widehat{R}$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\widehat{R}<1.05$$\end{document} suggesting convergence. Datasets that did not reach convergence were excluded from the simulation results but the respective model and scenario was included, given that at least 95% of the datasets converged. The Frequentist normal-normal and binomial-normal models were run using the metafor package [84]while the t-distribution and common-mean mixture models were run with the metaplus package [38].
Estimands and performance measures
The estimands of interest are the mean and standard deviation of the random-effects distribution and the shrinkage estimates of the studies measured on the log scale. The latter were only available for the eleven models fitted under the Bayesian framework and for the normal-normal(REML) model. For the common-mean mixture model, that provides two different standard deviation estimates (for outlying and for non-outlying studies), we used in our main results the standard deviation for outlying studies as a more conservative option. We also extracted and monitored the skewness coefficient from the skew-normal model and three additional parameters from the DP model: the concentration parameter as well as the mean and the variance of the base distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{F}_{0}$$\end{document} . The clustering assignment given by the DP was investigated in three meta-analyses from the simulation.
The performance of the models was investigated in terms of mean absolute bias defined as the mean absolute difference between the estimated and the true parameters of interest averaged over the simulated datasets in each scenario We further calculated the mean coverage defined as the percentage of the corresponding 95% confidence or credible intervals that included the true values of the parameters. The confidence interval for the coverage was calculated as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.95\:\pm\:1.96\sqrt{\frac{0.95\left(1-0.95\right)}{1000}}$$\end{document} . Additionally, the different models were compared in terms of the mean squared error (MSE). Moreover, for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} we also calculated the percent relative bias defined as the mean difference between the estimated and the true \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:\:$$\end{document} divided by the true \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} multiplied by 100 and the normalized MSE defined as the MSE divided by the square of the true \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:\tau\:.$$\end{document} Finally, whenever possible, we calculated the length of the prediction intervals [85] averaged over the simulated datasets in each scenario.
Simulation results
Mean of the random-effects distribution
Figure 2 shows the results in terms of average absolute bias for the mean of the random-effects distribution across all scenarios and models investigated. Supplementary Table 2 shows the 44 model-scenario pairs that we excluded due to lack of convergence of that model for a specific scenario (i.e., a model with at least 50 failures out of 1000 simulated datasets for a specific scenario). Overall, we found small differences in the average absolute bias between the different models for the estimated mean of the random-effects distribution. Irrespective of the true distribution of the random effects, the mean absolute bias of all models was relatively small for scenarios with moderate random-effects variance but substantially higher for scenarios with large random-effects variance. The mean absolute bias tended to be slightly smaller for scenarios with more studies. The normal-t and the common-mean mixture models tended to perform worse than the other models for scenarios with large random-effects variance. When data were generated from a skew-normal distribution with large variance and in some mixture scenarios the binomial-SN(HN) model seems to have the best and most stable performance along with the normal-normal(REML) and binomial-normal(ML) models. Under all scenarios considered, the DP models that reached convergence performed similarly to the normal models. This is possibly due to the use of a normal base distribution. Similar trends were observed in terms of the MSE, where the normal-normal(REML), the binomial-normal(ML) and the binomial-normal models with HN prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{b}\:$$\end{document} generally yielded lower MSE in scenarios with large random-effects variance (Supplementary Fig. 3). As expected, in scenarios with large random-effects variance all models produce on average very wide prediction intervals reflecting the large uncertainty regarding the treatment effect in future studies (Supplementary Fig. 4). The binomial-SN(HN) tends to provide the narrowest prediction intervals in most scenarios.
Fig. 2. Simulation results in terms of mean of absolute bias for the mean of the random-effects distribution. The names of the models are explained in Table 2. (NC = Non-convergence)
In terms of coverage probability, most of the models performed poorly in scenarios with large random-effects variance except the binomial-normal and binomial-DP models using a Uniform prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{b}$$\end{document} respectively that were close to the nominal level (Fig. 3). As expected, in four out of the six mixture scenarios where the shape of the true distribution was clearly bimodal (Scenarios 17, 18, 20, 21), the DP models that reached convergence had the best performance.
Fig. 3. Simulation results in terms of coverage probability for the mean of the random-effects distribution. The horizontal lines represent the upper and lower bounds of the 95% confidence interval for the nominal level. The names of the models are explained in Table 2. (NC = Non-convergence)
Random-effects standard deviation
In all investigated scenarios with moderate random-effects variance the mean absolute bias of all models regarding the estimation of the overall \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} was generally small with the common-mean mixture model being usually the most biased (Fig. 4). This is likely due to the choice of using the standard deviation from outlying studies, which inflates the estimate when only a few outliers are present, and does not properly reflect the random-effects standard deviation (Supplementary Table 3). The mean absolute bias was substantially higher in scenarios with large random-effects variance where the binomial models with a HN prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{b}$$\end{document} appeared to be the least biased especially for scenarios with 14 studies. Again, the binomial-SN(HN) model had the best performance in skew normal scenarios. Similar patterns are observed regarding the MSE of the different models (Supplementary Fig. 5(a)).
Fig. 4. Simulation results in terms of mean of absolute bias for the random-effects standard deviation. The names of the models are explained in Table 2. (NC = Non-convergence)
However, when considering the percent relative bias of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} , the DP models that converged consistently exhibited the lowest bias across scenarios, particularly under high random-effects variance (Fig. 5). The frequentist t and common-mean mixture were among the most biased models, especially with non-normal data. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}$$\end{document} was 0.12, models with HN prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{b}$$\end{document} slightly overestimated the random-effects standard deviation. For larger \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}$$\end{document} , models with HN prior underestimate the true \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} to a similar extent as models with Uniform prior which tend to overestimate it. Using the normalized MSE of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} the differences between models were small across all scenarios except for the common mean-mixture which had the highest normalized MSE (Supplementary Fig. 5 (b)).
In terms of coverage probability (Supplementary Fig. 6), we could only compare the eleven models fitted in the Bayesian framework and the normal-normal(REML) model. In all normal and skew-normal scenarios, the normal models and the binomial-DP models using a Uniform prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{b}$$\end{document} outperformed the others.
Fig. 5. Simulation results in terms of percent relative bias for the random-effects standard deviation. The names of the models are explained in Table 2. (NC = Non-convergence)
Underlying effects of the studies
In the presence of a biased mean of the random-effects distribution and/or large heterogeneity, looking at the study-specific effects can give better insight in the underlying distribution of the data and, overall, in the available evidence [86]. Figure 6 presents the mean absolute bias of the study-specific effects averaged within and across meta-analyses for each scenario. In the two mixture scenarios with two clearly distinct distributions (scenarios 17 and 20), the DP models which reached convergence, estimated the study-specific effects with the smallest bias on average but they are equally or more biased than the other models in all other scenarios. Differences between the other models are small. Again, the average absolute bias of all models is higher for scenarios with large random-effects variance.
Fig. 6. Simulation results in terms of mean absolute bias for the study-specific treatment effects averaged within meta-analyses and across meta-analyses. The names of the models are explained in Table 2. (NC = Non-convergence)
Additional results from our simulation study are available in the Supplementary material (Sect. 1, Supplementary Table 4, and Supplementary Table 5).
Similar patterns with the main simulation were observed among the evaluated models in scenarios with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=5$$\end{document} (Supplementary Fig. 7, Supplementary Fig. 8 and Supplementary Fig. 9*)*. However, none of the DP models reached convergence with moderate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}$$\end{document} , suggesting that these models may not be suitable in these cases.
Selected simulated datasets
To investigate further aspects of the alternative models and their ability to give further insight in the underlying structure of the data and the underlying effects of the studies, we extracted three datasets from our simulation generated from a normal (scenario 6), a skew-normal (scenario 13), and a mixture (scenario 20) distribution, that were the most representative of each case. At each of these datasets we applied all models used in the simulation (Supplementary Table 6), but we discuss in detail the four Bayesian models with the best performance in terms of coverage probability and mean absolute bias for the mean of the random-effects distribution, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} . These are:
- the binomial-normal(Unif), the binomial-t(Unif), the binomial-SN(Unif) and the binomial-DP-n(Unif/Gamma) for scenario 6.
- the binomial-normal(HN), the binomial-t(Unif), the binomial-SN(Unif) and binomial-DP-26(HN/Unif) for scenario 13.
- the binomial-normal(HN), the binomial-t(HN), the binomial-SN(HN) and the binomial-DP-51(HN/Unif) for scenario 20.
Overall, all models gave similar estimates for the study-specific estimates and the mean of the random-effects distribution estimate for all three datasets (Supplementary Fig. 10, Supplementary Fig. 11 and Supplementary Fig. 12). The DP models tended to give more precise estimates for the effects of some studies, which in some cases resulted in 95% credible intervals not including the study-specific true values. They also tended to produce estimates of study-specific effects closer to the mean of the cluster they belong which is expected as highlighted by Burr and Doss [11, 32].
For the dataset generated from the normal distribution, all models yielded similar estimates of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} . The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}$$\end{document} was underestimated by all models with the binomial-t(Unif) and binomial-SN(Unif) models providing the closest estimation to the true value and the latter exhibiting the narrowest credible interval. The binomial-SN(Unif) model produced the narrowest prediction interval. The DP model here struggled to identify potential clusters and suggested a minimum of 4 to 8 clusters. This is in line with the estimate of 3.99 for the concentration parameter, which is large enough to support a normal random-effects distribution given that the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\Gamma\:}\left(\text{1,1}\right)$$\end{document} prior used is rather restricted around zero and one. For all models, despite the high probability of a positive mean of the random-effects distribution, the probability of a new study with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{i}<0$$\end{document} is around 0.45. This aligns with the clusters’ probabilities generated by the DP model, indicating that a new study has nearly equal chances of being assigned to either the first or the second cluster, with corresponding means of −0.70 and 0.28, respectively (Supplementary Fig. 10). Supplementary Fig. 14 shows that all models have a good overlap between the distribution of the true effects and the posterior distribution of the random effects.
For the dataset generated from the skew-normal distribution, the point estimates from all models except for the binomial-t(Unif), were similar for the mean of the random-effects distribution and closer to the true mean than those from the dataset assuming normal random effects and with larger probabilities for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:<0$$\end{document} (Supplementary Fig. 11). The point estimate from the binomial-t(Unif) model, exhibited the largest difference from the true \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} while its credible interval included the true mean value of zero but only marginally. As expected, the binomial-SN(Unif) model provides the closest estimate to the true mean, also producing the narrowest prediction interval. Additionally, the estimated mean skewness coefficient from this model is 0.85 which is close to the true skewness coefficient of 0.79. The DP model suggests the presence of three clusters with only study 22 occupying the third cluster; this implies that this study is a potential outlier contributing to the skewness of the data (Supplementary Fig. 13 (b)). Also, the concentration parameter was estimated as 2.78 supporting the presence of a non-normal random effects’ distribution. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Pr\left({\mu\:}_{new}<0\right)$$\end{document} ranges from 61 to 66% using the parametric models indicating that most likely a new study would fall below the null effect. This is also supported by the DP model, where the first cluster has the larger number of studies and a corresponding negative mean of −0.30 (Supplementary Fig. 11). The DP model produces a highly peaked posterior distribution, which leads to a seemingly poor overlap with the distribution of the true effects (Supplementary Fig. 15). However, this is possibly due to the use of a discrete distribution for the random effects rather than a continuous one.
Similar estimates between the models were also obtained for the dataset generated from the mixture distribution regarding the mean and the variance of the random-effects distribution with the skew normal and the DP models estimating accurately the true \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} and only the binomial-t(HN) model resulting in a slightly higher estimate (Supplementary Fig. 12). All models gave zero probability of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:<0$$\end{document} , while the prediction interval from the binomial-SN(HN) model was the narrowest. The DP model identified three clusters with the first and the second cluster being very close. The first cluster is mainly formed due to study 6 which, though, can also be assigned to the second cluster with the same probability. Study 16 is assigned to the third cluster, but it can also be assigned to the second one with the same probability. Clusters 2 and 3 have means − 0.06 and 0.99, namely very close to the true means of the two distributions in the mixture. The concentration parameter was estimated 3.90 which is small enough (given the prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{U}\left(\text{0.3,10}\right)$$\end{document} ) to support the presence of a non-normal distribution. The probability of a new study falling into the third cluster is the highest compared to the other two clusters, indicating that the effect of a new study is likely to be above 0 and closer to the third cluster’s mean of 0.99 (Supplementary Table 7). This conclusion is also supported by the parametric models since the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:Pr\left({\mu\:}_{new}<0\right)$$\end{document} is around 0.10. Finally, as expected, the posterior distribution of the random effects from the DP model has the best overlap with the distribution of the true study effects for this dataset (Supplementary Fig. 16).
Discussion
In the present article, we identified and compared several meta-analysis models that relax the random-effects normality assumption which is typically used in published meta-analyses. We first performed a methodological systematic review to search for alternative random-effects models suggested in the literature and then conducted a simulation study to investigate their performance under different scenarios. We found 27 eligible articles suggesting 24 different random-effects distributions: based on long-tail or skewed extensions of the normal and t-distribution, on the beta distribution, on mixtures of two or more distributions, and on variations of DP priors. In our simulation, we generated meta-analyses with binary data and we considered 22 scenarios varying the true distribution, the level of the random-effects variance, the true mean of the random-effects distribution, and the number of studies. We compared 11 of the identified alternative models between them as well as with 4 versions of the normal model.
Our findings highlight the limited ability of all evaluated models to accurately estimate the mean of the random-effects distribution as the true random-effects variance increases. This has important implications for applications of meta-analysis since, to date, the focus in the literature is most often on the mean of the random effects distribution and its confidence interval even when the results of the studies differ substantially. In such cases, exploring the factors that may cause random-effects variance is of great importance. Mixture and semi-parametric models can give insight on the underlying clustering of the studies and assist to form homogenous subgroups that may share common characteristics.
Overall, our simulation results suggest that using a HN prior for standard deviation parameters tended to improve the performance of the Bayesian models in terms of mean absolute bias and MSE across all scenarios, while the use of Uniform prior resulted in coverage probabilities closer to the nominal level. These are probably the most common choices of prior distributions for the random-effects standard deviation in Bayesian meta-analyses. However, investigators should make sure that the prior distributions accurately reflect prior information, or they are specified conservatively. We found minor differences among the evaluated models in the mean absolute bias of the estimated mean of the random-effects distribution which was materially increased for scenarios with large random-effects variance. These findings imply that in meta-analyses with small to moderate random-effects variance the mean of the random-effects distribution from any model, including the normal models, may provide a sufficiently accurate summary of the studies at hand, whereas in meta-analyses with large random-effects variance focusing only on the estimated mean of the random-effects distribution may lead to meaningless and/or spurious conclusions.
Similar results were obtained for the mean absolute bias of the random-effects standard deviation. However, the respective percent relative bias was not significantly affected by the value of the true \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}$$\end{document} . We did not find important differences between the different Bayesian models in the average absolute bias of the estimated study-specific effects in scenarios with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{2}=0.12$$\end{document} . In scenarios with large random-effects variance, though, and when the true distribution was closer to normal or skew normal the DP models performed worse than the other models, whereas when the true distribution was clearly bimodal the DP models performed substantially better. Hence, the use of such complex models seems mostly beneficial when the presence of a bimodal or multimodal distribution is suspected.
In the three selected simulated datasets, we obtained similar patterns as in the full simulation study for the mean absolute bias of the mean of the random-effects distribution. For the skew-normal dataset, the skew normal model provided the closest estimate to the random-effects variance, while the DP model correctly identified three clusters. For the mixture dataset, both the skew normal and the DP models performed similarly well with the latter accurately identifying two to three clusters. In all three datasets, the use of additional parameters and statistics, such as the concertation parameter, the prediction intervals, and the probability for the presence of an effect helped us to understand better the structure of the data and the variation of the study effects.
Of course, our study is not free of limitations. First, we did not compare all the identified alternative models in our simulation; nevertheless, to our knowledge, this is the most extensive simulation study evaluating several meta-analysis models assuming different random-effects distributions on a wide range of scenarios. Our results are in agreement with previous smaller simulation studies [13, 14, 30, 31]but most of these studies did not consider the level of random-effects variance as a characteristic affecting the performance of the models. Using scenarios with more studies might have improved the performance of some of the models and particularly the DP models where the underlying distribution is treated as a random variable. We selected the number of studies, though, based on empirical data of potentially heterogeneous meta-analyses from different medical fields involving observational studies, to generate meta-analyses often encountered in the literature. Future simulation studies may also consider meta-analyses with very few or a lot of studies encountered in certain situations (e.g. meta-analyses including RCTs only, meta-analyses in social science). We should acknowledge, that some of the models considered here might not be applicable or useful in the presence of very few studies. Our additional scenarios with five studies suggested that even when a non/semi-parametric method is theoretically preferable, it is often not superior to an appropriate parametric approach when the sample size is small. In such meta-analyses, the use of a normal random-effects distribution would be reasonable. Including studies with rare events could be also something interesting to explore in future work.
In addition, we only used a fixed skewness coefficient ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:=0.79$$\end{document} ) which might have not resulted in many highly skewed datasets. Varying the skewness coefficient in the data generating process could also potentially provide more insights into the performance of the skew normal models. Moreover, the performance of the t-models cannot be fully assessed in the present study due to the fact that we did not generate data from a t-distribution. Our results imply, though, that the t-models used here are not flexible enough to be used for datasets with different underlying distributions. The DP models with a Uniform prior on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{b}$$\end{document} failed to reach convergence for most scenarios with moderate random-effects variance. This might be due to the relatively small number of studies that we used in the data generation. Using non-normal distributions for the base distribution of the DP models and the DPMd approach would be interesting directions for future research. Finally, for the common-mean mixture model, using the standard deviation of outlying studies in the simulation results might have influenced its performance since this model appeared the most biased under all scenarios.
Conclusions
Our systematic review revealed that several alternative flexible meta-analyses models have been suggested in the literature. Despite the potential advantages these models may have, they are typically not used in clinical applications. Overall, we found small differences in the performance measures of our simulation between the models we compared. The normal-normal(REML) model, which is the most commonly used model in clinical applications, did not appear to be inferior to the other more sophisticated and complex models for most scenarios. Our results imply that when substantial heterogeneity among studies is suspected or outlying studies are present, making inferences solely based on the mean of the random-effects distribution in meta-analysis could be misleading since its estimate may be highly inaccurate. In such cases, identifying the factors that differentiate the studies and looking at the prediction intervals are more informative than the estimated mean of the random-effects distribution. We encourage meta-analysts to always examine carefully the plausibility of the random effects’ distribution normality assumption and the extent of variability between studies before undertaking their analysis. When considering more flexible models, particularly in the presence of few studies, there is always a risk of overfitting without necessarily having a real gain in terms of coverage or precision. Hence, investigators could have the conventional normal model as their starting point and consider the use of alternative models in view of seemingly non-normal data. Sensitivity analysis using different models may give some insight into the underlying structure of the data and help understanding factors causing random-effects variance.
Supplementary Information
Supplementary Material 1: Supplementary Table 1. Characteristics of all the eligible articles identified through the systematic review Supplementary Table 2. Bayesian models and scenarios included (✔) or excluded (✘) from the simulation study due to lack of convergence in more than 5% of the datasets Supplementary Table 3. Summary of performance metrics for the common-mean mixture model, reporting results separately for outlying and non-outlying studies. The metrics include mean absolute bias, percent relative bias, mean squared error (MSE), and normalized MSE, for both standard deviation components of the model Supplementary Table 4. Mean absolute bias of the estimated skewness coefficient ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:$$\end{document} ) from the skew-normal model in scenarios where data were generated from a skew-normal distribution Supplementary Table 5. Estimated means with credible intervals of the concentration parameter ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} ) from the five DP models for the different simulation scenarios Supplementary Table 6. Mean and variance of the random-effects distribution estimates along with their 95% Confidence*/*Credible Intervals for each selected simulated dataset using all models evaluated in the simulation study. The 95% prediction intervals are also presented Supplementary Table 7. Cluster probabilities for each selected simulated dataset using the respective DP model. Supplementary Fig. 1 Flow chart of the article selection process. Supplementary Fig. 2. Density plot of the skew normal distribution with location parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\xi\:$$\end{document} = 0, scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\omega\:$$\end{document} = 1 and various shape parameters ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a$$\end{document} )/skewness coefficients ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:$$\end{document} ). Supplementary Fig. 3. Simulation results in terms of mean square error (MSE) for the mean of the random-effects distribution. The names of the models are explained in Table 2. (NC = Non-convergence). Supplementary Fig. 4. Simulation results in terms of the mean length of the prediction intervals. The names of the models are explained in Table 2. Supplementary Fig. 5. Simulation results in terms of mean square error (MSE) (a) and normalized mean square error (MSE) (b) for the random-effects standard deviation. The names of the models are explained in Table 2. (NC = Non-convergence). Supplementary Fig. 6. Simulation results in terms of coverage probability for the random-effects standard deviation. The horizontal lines represent the upper and lower bounds of the 95% confidence interval for the nominal level. The names of the models are explained in Table 2. (NC = Non-convergence). Supplementary Fig. 7. Simulation results for small meta-analyses (with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=5$$\end{document} studies) in terms of mean of absolute bias (a) coverage probability (b) and mean length of the prediction intervals (c) for the mean of the random-effects distribution. Different \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:,{\mu\:}_{1},{\mu\:}_{2},{\tau\:}^{2},{\tau\:}_{1}^{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{2}^{2}$$\end{document} values represent the true mean(s) and true variance(s) of the different random-effects distributions used for the data generating process. The horizontal lines represent the upper and lower bounds of the 95% confidence interval for the nominal level. The names of the models are explained in Table 2. (NC=Non-convergence). Supplementary Fig. 8. Simulation results for small meta-analyses (with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=5$$\end{document} studies) in terms of mean of absolute bias (a) percent relative bias (b) and coverage probability (c) for the random-effects standard deviation. Different \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:,{\mu\:}_{1},{\mu\:}_{2},{\tau\:}^{2},{\tau\:}_{1}^{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{2}^{2}$$\end{document} values represent the true mean(s) and true variance(s) of the different random-effects distributions used for the data generating process. The horizontal lines represent the upper and lower bounds of the 95% confidence interval for the nominal level. The names of the models are explained in Table 2. (NC=Non-convergence). Supplementary Fig. 9. Simulation results for small meta-analyses (with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=5$$\end{document} studies) in terms of mean absolute bias for the study-specific treatment effects averaged within meta-analyses and across meta-analyses. Different \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:,{\mu\:}_{1},{\mu\:}_{2},{\tau\:}^{2},{\tau\:}_{1}^{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}_{2}^{2}$$\end{document} values represent the true mean(s) and true variance(s) of the different random-effects distributions used for the data generating process. The names of the models are explained in Table 2. (NC=Non-convergence). Supplementary Fig. 10. The estimated study-specific effects for the selected simulated dataset from Scenario 6, with a true mean of 0 and a true random-effects variance of 2.63, are shown using the binomial-Normal(Unif) (panel a), the binomial-t(Unif) (panel b), the binomial-SN(Unif) (panel c), and the binomial-DP-n(Unif/Gamma) (panel d) models. The diamonds represent the estimated mean of the random-effects distribution from each model. The probabilities of the mean of the random-effects distribution or a new study (μ_new) to be less than 0 are also presented. In all panels the extra column to the right presents the study-specific true effects. In panel (d), the two extra columns to the right give the cluster assignment and the probability for each study of belonging to the respective cluster. The dashed vertical lines represent the means of the identified clusters. Red studies are those belonging to the dominant cluster and the black ones those belonging to the other clusters. Supplementary Fig. 11. The estimated study-specific effects for the selected simulated dataset from Scenario 13, with a true mean of 0 and a true random-effects variance of 0.12, are shown using the binomial-Normal(HN) (panel a), the binomial-t(Unif) (panel b), the binomial-SN(Unif) (panel c), and the binomial-DP-26(HN/Unif) (panel d) models. The diamonds represent the estimated mean of the random-effects distribution from each model. The probabilities of the mean of the random-effects distribution or a new study (μ_new) to be less than 0 are also presented. In all panels the extra column to the right presents the study-specific true effects. In panel (d), the two extra columns to the right give the cluster assignment and the probability for each study of belonging to the respective cluster. The dashed vertical lines represent the means of the identified clusters. Black, red and blue studies are those belonging to the first, second and third cluster respectively. Supplementary Fig. 12. The estimated study-specific effects for the selected simulated dataset from Scenario 20, with a true mean of 0.70 and a true random-effects variance of 0.25, are shown using the binomial-Normal(HN) (panel a), the binomial-t(HN) (panel b), the binomial-SN(HN) (panel c), and the binomial-DP-51(HN/Unif) (panel d) models. The diamonds represent the estimated mean of the random-effects distribution from each model. The probabilities of the mean of the random-effects distribution or a new study (μ_new) to be less than 0 are also presented. In all panels the extra column to the right presents the study-specific true effects. In panel (d), the two extra columns to the right give the cluster assignment and the probability for each study of belonging to the respective cluster. The dashed vertical lines represent the means of the identified clusters. Blue, red and black studies are those belonging to the first, second and third cluster respectively. Supplementary Fig. 13. Distribution of the 26 true study-specific effects of the selected simulated dataset from Scenario 6 (panel (a), Scenario 13 (panel (b), and Scenario 20 (panel (c). Supplementary Fig. 14. Overlap between the distribution of the 26 true study-specific effects (Scenario 6) and the posterior distribution of the random effects from each Bayesian model used. Supplementary Fig. 15. Overlap between the distribution of the 26 true-study-specific effects (Scenario 13) and the posterior distribution of the random effects from each Bayesian model used. Supplementary fig. 16. Overlap between the distribution of the 26 true-study-specific effects (Scenario 20) and the posterior distribution of the random effects from each Bayesian model used.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Deeks JJ, Higgins JPT, Altman DG et al. Chapter 10: Analysing data and undertaking meta-analyses. In: Higgins JPT, Thomas J, Chandler J, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.4. Cochrane. 2024. www.training.cochrane.org/handbook
- 2Bodnar O, Bodnar T, Thorsén E. Bayes Mult Meta: Bayesian Multivariate Meta-Analysis. 2022. R package version 0.1.1.https://CRAN.R-project.org/package=Bayes Mult Meta. Accessed 17 Sept 2024.
- 3Hong C, Luo C, Tong G et al. xmeta: A Toolbox for Multivariate Meta-Analysis. 2023. R package version 1.3.2. https://CRAN.R-project.org/package=xmeta. Accessed 17 Sept 2024.
- 4Page G, C Bnetwork MA. Contrast-Based Bayesian Network Meta Analysis. 2024. R package version 0.1.0. https://CRAN.R-project.org/package=C Bnetwork MA. Accessed 17 Sept 2024.
- 5Stan Development team. Rstan: the R interface to stan. 2024. R package version 2.32.6. http://mc-stan.org/. Accessed 19 Jul 2024.
- 6Schlattmann P, Hoehne JCAMAN. Finite Mixture Models and Meta-Analysis Tools - Based on C.A.MAN. 2023. R package version 0.78. http://CRAN.R-project.org/package=CAMAN. Accessed 17 Sept 2024.
- 7Doebler P. Meta-Analysis of Diagnostic Accuracy with mada. 2022. R package version 0.5.11. http://CRAN.R-project.org/package=mada. Accessed 17 Sept 2024.
- 8Core Team R, Vienna. Austria: R Foundation for Statistical Computing. 2022. https://www.R-project.org/.