Sustainable open data ecosystems through data quality, governance, and infrastructure: Unlocking social, political and economic value
Ramya Chandrasekhar, Melanie Dulong de Rosnay, Sophie Weerts, Clarissa Valli Buttow, Enric Senabre Hidalgo, Arwid Lund, Mohsan Ali

TL;DR
This paper argues that open data needs better governance, quality, and infrastructure to ensure it benefits society and not just the economy.
Contribution
The paper provides actionable recommendations for sustainable open data ecosystems based on interdisciplinary research.
Findings
Open data availability alone does not ensure reuse or societal benefit.
Data skills, infrastructure, and regulatory guidance are essential for effective open data use.
Sustainability and social value must be prioritized alongside economic value in open data initiatives.
Abstract
Open data are crucial for scientific knowledge production, transparency and accountability, as well as innovation. The European Union has implemented various policies and regulatory frameworks for open government data and open scientific data, as well as for data sharing and re-use of non-government data. However, the mere availability of open data does not ensure its reuse and distributional benefit to society, and its production can meet sustainability challenges. Working with open data requires data skills, access to data infrastructures, and regulatory guidance to address privacy, confidentiality and intellectual property requirements. Further, critical scholarship has cautioned against the de facto valorisation of open data, and urges focus on the socio-technical and political aspects of production, dissemination and use of open data beyond mere economic value. This open letter is…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2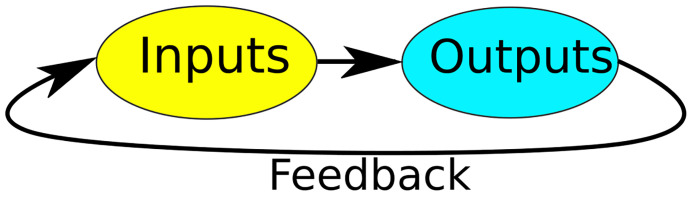 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9| ODECO Deliverable | Title | Date of Publication | URL |
|---|---|---|---|
| 2.1 | Open data user needs:
| 31-05-2023 |
|
| 2.2 | User needs from a
| 30-09-2023 |
|
| 2.3 | User needs from a
| 28-02-2024 |
|
| 3.1 | Closing the cycle:
| 29-11-2023 |
|
| 3.2 | Closing the cycle:
| 11-04-2024 |
|
| 3.3 | Closing the cycle:
| 03-05-2024 |
|
| 4.1 | Motivations of non-
| 28-06-2024 |
|
| 4.2 | An approach to steer
| 22-10-2024 |
|
| 4.3 | An approach to steer
| 30-09-2024 |
|
| 5.1 | Models of allocating roles,
| 28-11-2024 |
|
| 5.2 | Strategies to balance and
| 13-02-2025 |
|
| Data quality | ||
|---|---|---|
| 1. Discoverability
| 2. Metadata
| 3. Engagement and participation
|
| Wide data re-use | ||
| 4. Beyond open government data
| 5. Data literacy
| 6. Mind the gap(s)
|
| Infrastructures for open data | ||
| 7. Usability
| 8. Interoperability
| 9. Public administrations’ investments
|
- —Horizon 2020 Framework Programme
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Quality and Management · E-Government and Public Services · Privacy-Preserving Technologies in Data
Disclaimer
The views expressed in this article are those of the author(s). Publication in Open Research Europe does not imply endorsement of the European Commission.
Introduction
Open data is crucial for scientific knowledge production, transparency and accountability, as well as innovation ( Davies et al., 2019; Kitchin, 2014; Ruijer et al., 2017; Van Loenen et al., 2018; Zuiderwijk et al., 2014). Open data is typically understood to include datasets and creative content that are made freely available by creators or stewards, with little to no technical or legal restrictions on their reuse ( Open Knowledge Foundation, n.d.). Open data encompasses open government data, open access artefacts resulting from the open science movement, as well as open data generated and/or released by non-government actors such as citizens, non-profit organisations, and commercial actors.
Open data is often conceived of as an inherent public good funded by government that is both non-excludable and non-rivalrous, and therefore its access can be unrestricted (see for e.g., ( Jetzek et al., 2013; Open Data Charter, 2015). But, there are several barriers to both the production of open data as well as its downstream use ( Barry & Bannister, 2014; Conradie & Choenni, 2014; Janssen et al., 2012; Nikiforova et al., 2024; Toots et al., 2017; Zuiderwijk et al., 2012a). On the production side of open government data for instance, there are often opaque decisions made by public administrations on what types of information are selected to be released as open data, as well as inconsistent use of data standards and formats which limit interoperability, i.e. the seamless circulation of data between systems thanks to norms and protocols ( Denis & Goëta, 2014; Goëta & Davies, 2016). When it comes to production of non-government open data, it is difficult to incentivise non-government actors such as companies to voluntarily and freely release open datasets, while ensuring due protection of proprietary information as well as personal data, since those cannot be released without an open licence, which is key to ensure legal access and reuse ( Enders et al., 2021; Enders et al., 2022). Research programmes such as Horizon Europe have long experimented with mandates to stimulate the release of results as open data to benefit to others ( European Research Executive Agency, n.d.). On the use side, lack of public access to internet connectivity, computing infrastructure and the need for data skills mean that the distributional impact of open data is not equal ( Bezuidenhout et al., 2017; Lansana et al., 2020; Zuiderwijk & Janssen, 2014a). Further, the mere existence of ‘data heaps’ does not mean that its use is equal, nor always beneficial for society ( Gurstein, 2011). Intellectual property and personal data protection issues arise on both the production and the use side ( Dalla Corte, 2018; Giannopoulou, 2018; Scassa, 2019). There are also sustainability challenges with open data initiatives, particularly with regard to maintenance of open data resources and infrastructure ( Dodds & Wells, 2019) as also with regard to extractive use of open data by reusers who give little to value back to the ecosystem, similar to the free-rider problem in public goods ( Bezuidenhout & Chakauya, 2018; Sharma, 2022).
The ODECO (Towards a sustainable Open Data ECOsystem) consortium is a Marie Curie Action Innovative Training Networks gathering 15 early career researchers, 20 academics from 8 universities and research institutions, and 18 public and private partner organisations. ^ 1 ^ From 2021 to 2025, the members of ODECO conducted interdisciplinary research and participated in routine training activities on the topic of ‘sustainable open data ecosystems.’ ODECO responds to a specific research gap – how to maximise value generation from open data as well as ensure sustainability of open data initiatives, by adopting an ecosystemic perspective. The background paper for ODECO hypothesised four pillars necessary for value-creating and sustainable open data ecosystems – moving from producer-driven to user-driven, exclusive to inclusive, linear to circular, and best-effort to skill-based open data initiatives ( Van Loenen et al., 2021).
The project outputs of ODECO contain valuable insights on technical, social, economic, legal, governance and design aspects of open data ecosystems. In this open letter, we summarise key findings of ODECO as they relate to user needs and governance of open data ecosystems (including technical as well as non-technical strategies). We further synthesis and present 9 recommendations, which convey actions necessary to improve open data ecosystems, which can be undertaken and funded by policymakers and actors themselves. Similarly to MacFeely et al. (2025) data principles, we present these recommendations as the basis for a normative contribution on the governance and sustainability of open data. An early version of these recommendations was prepared for and presented at the final conference of the ODECO Consortium, held in Athens from May 14 to 16, 2025.
This open letter is structured in three parts. First, we discuss the state-of-the-art on open data research, initiatives and policy, with a focus on the European Union (EU). Second, we introduce the ODECO project, and outline the methodology by which we extracted practical recommendations for sustainable open data ecosystems from the ODECO project outputs. Finally, we present a set of 9 recommendations meant to support the future of open data, by imagining, building and maintaining open data ecosystems that are financially, socially and ecologically sustainable, equitable, and empower all stakeholders. Accordingly, these recommendations are relevant for researchers, data infrastructure builders, funders and policymakers interested in open data as well as data reuse and more broadly, data science, public policy and research policy.
Open Data policy and regulation in the EU
From open government data
While the word “data” itself is polysemic, “open data” is equally if not more polysemic in nature. The open data movement has been related to open government (where data held by public bodies is made publicly and freely accessible to ensure transparency and return on taxpayers’ money), open source (where datasets made available for access and reuse in repositories under permissive open licenses which emerged for free and open source software) and open science (where research is sought to be made publicly available and reproducible through open access databases, platforms and infrastructure). As a result, open data is a “malleable” concept that acquires different meanings in different contexts of democracy and governance ( Gray, 2014) and became a fundamental pillar for science and evidence-based and participatory policy.
Open data is commonly understood as digital creative or knowledge works and datasets made freely accessible for use and reuse, with little to no legal, economic or technical restrictions ( Open Knowledge Foundation, n.d.). Institutionalised approaches to open data emerge from open government as well as from open science.
Open government data was originally made available on request, by virtue of freedom of information laws, where users had to “pull” information out of public administrations ( Whittington et al., 2015). However, with the digitalisation of public sector information and the diffusion of the open source, open science, and open government movements, legal frameworks as well as institutionalised practices for publication and dissemination of open datasets and open content by public administrations became more widespread, supplementing the “pull” model with the “push” model (Id). Non-government actors also became active participants in open data initiatives, by voluntarily publishing non-government data as open datasets, offering services for other open data initiatives, as well as using open data for different purposes, with the metaphor of “spill” often used to describe the release of open data from such non-government actors (Id). Requiring the release of public sector information as open datasets combined with open licenses that invert the logic of copyright to enable wider use and reuse of such information constitute the foundational legal instruments for open data ( Giannopoulou, 2018), which were not without legal and institutional applicability challenges ( Dulong de Rosnay & Janssen, 2014). Further, the open science movement contributed technical standards for improving the provenance, findability and usability of open datasets. A crucial contribution is the FAIR principles – which propose four characteristics for scientific data – Findable, Accessible, Interoperable and Reusable ( Wilkinson et al., 2016).
In the EU, the first Directive encouraging public administrations and public institutions in members states to publish more open government datasets was released in 2003, and subsequently modified in 2013 to encourage the release of such datasets in machine-readable formats ( Valli Buttow & Weerts, 2022). In 2019, this legal framework was replaced with the Open Data Directive, which requires member states to make certain categories of public sector information open by default, on which only marginal fees can be levied for “reproduction, provision and dissemination of documents as well as for anonymisation of personal data and measures taken to protect commercially confidential information”. The Open Data Directive also introduced the concept of ‘high-value datasets’ - six thematic categories of datasets which are to be made freely available by public administrations on national open data portals and under open licenses, in machine-readable format, and accessible through both application programming interfaces (APIs) and bulk downloads. These six thematic categories are geospatial, earth observation and environment, meteorological, companies and company ownership, and mobility. Article 10 of the Open Data Directive also requires member states to support open access policies for publicly-funded research data, and the use of the FAIR principles for such data. Most recently in 2023, a new regulation known as the Data Governance Act was also implemented, which enables conditional access to public sector information which cannot be released openly, for instance due to personal data protection, commercial secrecy or statistical confidentiality.
In the EU, public policies and regulatory frameworks for open data are motivated by a desire to unlock primarily economic value from open data ( European Commission, 1989; European Commission et al., 2015; Publications Office of the European Union, 2020). But the value of open data is multi-faceted, and includes social as well as economic value ( López Reyes & Magnussen, 2022; Shaharudin et al., 2024; Zuiderwijk & Janssen, 2014b). This includes the creation of new open datasets (often by combining or adding to existing open datasets), identifying social issues of concern, creating new technological infrastructures for open data, offering educational and awareness activities related to open data, and new data-driven products and services ( Molina, 2022). Exclusive focus on economic value generation from open data can foreclose policy focus and allocation of resources for realising other types of value from open data, as well as development of additional infrastructures and capabilities for the realisation of such other types of value ( Broomfield, 2023; Davies, 2019).
To critical open data studies
Following Science and Technology Studies recognising technical artifacts are embedding values and are influenced by social factors, a growing body of critical scholarship calls attention to other aspects of open data, that challenge its neutrality. While open government often reduces the production of open data as merely the digital formatting and release of already existing public sector information, researchers of critical data studies and Science and Technology Studies reveal the “data work” that goes into the production and release of open government data, and the ways in which internal decisions about what data to release and in what format influence what types of value are generated from such open data ( Denis & Goëta, 2014; Goëta & Davies, 2016). And on the use side, there is also growing scholarship questioning the promise of universality of open data. There are various socio-technical barriers to the use of open data, ranging from data literacy skills to access, motivation and access to computational infrastructures ( Zuiderwijk et al., 2012b). Further, the focus on economic value generation has resulted in a disproportionate use of open data by market actors to create commercial solutions to societal problems, and to profit from openness while giving little to no value back to the maintenance or sustainability of open resources or nourishment of communities who contribute labour to such resources ( Bates, 2012; Lund & Zukerfeld, 2020; Tkacz, 2012). Open data initiatives and infrastructures also face many challenges ranging from lack of financial support to limited participation of non-government data holders, which impact their sustainability. But some open data initiatives also serve as useful examples of peer production (as in the case of citizen science initiatives) as well as knowledge commons (as in the case of Wikipedia and Science Commons), where open data are a form of digital commons – shared informational resources that community-maintained and are crucial for the realisation of digital rights (on digital commons, see Dulong de Rosnay & Stalder, 2020, on data commons and digital democracy, see Senabre Hidalgo et al., 2024).
Widespread machine reuse of openly licensed datasets and content for the purpose of AI training is also raising new problematics. Openly licensed creative works are often used to train proprietary generative AI models, by employing web crawling tactics. But many creative workers as well as researchers are opposed to such machine reuse, because of the lack of accountability as well as autonomy, privacy and economic risks of generative AI models. This is resulting in a move towards closure, either where more restrictive licenses are applied to such creative works or where website owners register strict opt-outs from commercial text and data mining which could result in a siloisation of the open web ( Chandrasekhar, 2025; Hardinges et al., 2025). On the other hand, machine reuse of open data has also resulted in the articulation of new expectations of attribution, reciprocity and sustainability by data creating communities and data stewards, to ensure sustainability of these communities and the open resources (Id). To make sense of these new developments however, there is a need to move beyond a binary approach to open data that assumes equal distributional impact of open data, and think more carefully about who creates open data , how, and who benefits ( Okorie & Marivate, 2024; Santoro et al., 2025).
Findings on open data users
The starting point of the ODECO project was to move away from a linear approach to open data, and articulate ecosystemic approaches. According to Zuiderwijk et al, “ an open data ecosystem is characterized by multiple interdependent socio-technical levels, dimensions, actors (including data providers, infomediaries and users), elements and components” ( Zuiderwijk et al., 2014). Jetzek further adds that such an open data ecosystem is “ circular in nature, building upon a complicated network of value that is generated by different participants that are creating valuable information as well as products and services” ( Jetzek, 2017). In the ODECO project background paper, van Loenen et al. go further, to argue that an open data ecosystem should be “ a cyclical, sustainable, demand-driven environment oriented around agents that are mutually interdependent in the creation and delivery of value from open data” ( Van Loenen et al., 2021).
Between May 2023 and March 2025, the ODECO project published 11 project reports, each exploring different aspects of open data ecosystems, as set out in Table 1 below.
The ODECO project focussed on 9 actors central to open data ecosystems: local government, regional/central government, non-specialist data users, journalists, students, non-profit organisations, companies, artificial users, and open data intermediaries. As an interdisciplinary research and training initiative, the ODECO project explored technical, legal, design, governance, social, economic and skill-based aspects of open data.
ODECO Findings on users’ needs, contributions and motivations
In the first project report, the ODECO consortium identified a list of user needs, as relating to the 9 actors that constitute the core stakeholders of open data ecosystems ( Di Staso et al., 2023). This project report identified 9 buckets of user needs: availability, accessibility, and findability of open data; improved data quality; reliable data infrastructures; adequate funding; literacy; data ethics; licensing and privacy regulations; governance principles; and communication and coordination frameworks. These users’ needs were identified as being crucial to the transition from linear producer-driven models of open data, to circular user-driven models of open data, by recognising the centrality of various actors to open data initiatives as well as recognising the multiple roles discharged by these actors.
In the next two project reports, the ODECO consortium identified certain technical and governance aspects of these open data user needs ( Aziz et al., 2023; Cazacu et al., 2024). From a technical perspective, the ODECO consortium focussed on everyday user stories of different types of users navigating open data portals, and proposed strategies for addressing these user needs through implementation of the FAIR principles ( Aziz et al., 2023). From a governance perspective, some members of the ODECO consortium proposed commons-based principles to ensure open access as well as sustainability of open data initiatives ( Cazacu et al., 2024). In particular, governance of open data ecosystems should entail focus on creating communities of practice as well as communities of shared purpose, as well as encouraging shared decision-making by the different actor groups.
In the next 3 project reports, the ODECO consortium focussed on open government data, exploring different types of values generated from open government data and contributions by users back to open data ecosystems ( Ktistakis et al., 2023), as well as technical and governance aspects of open government data ( Magnussen et al., 2024; Polini et al., 2024).
The ODECO consortium identified various types of contributions made by users of open government data – which ranges from creation of more open datasets, as well as other non-data contributions such as technological infrastructures for data storage and analysis, data flow automations, educational services, consultancy services, organisational services, communication products, and collaboration spaces ( Ktistakis et al., 2023). Based on these diverse contributions, the ODECO consortium identified different types of value created by users of open government data – which includes knowledge enrichment, informed decision-making by citizens, collaboration between multiple actors for a shared purpose, transparency and accountability of public administrations, and improve internal efficiency of a user (Id).
Having identified these different types of user contributions, the ODECO consortium also identified motivations for users to engage in such contributions, which must be accounted for in governance frameworks for sustainable open data ecosystems ( Magnussen et al., 2024). Most users contribute to open data ecosystems due to a mix of intrinsic and extrinsic motivations (Id). Extrinsic motivations often arise from legal obligations or profit-driven motivations. Further, local governments are motivated to contribute open datasets as well as other non-data contributions to improve their communities – by improving community-participation in decision-making as well as co-created innovation (Id).
Thereafter, the ODECO consortium focussed on open data portals as one of the most important mediums by which public administrations make open government data available, and proposed design and technical strategies to account for user needs in the functioning of open data portals ( Polini et al., 2024). The ODECO consortium proposed a design pipeline by which user feedback can be obtained and integrated into open datasets (Id). The ODECO consortium also proposed additional features that should be included in open data portals – such as hackathons and competitions to incentivise use of open data, categorisation of open datasets based on temporally-relevant thematic categories (such as open datasets relating to the climate crises, and open datasets relating to the covid-19 pandemic), and suggestions for data analysis tools and/or integration of these tools into the open data portals (Id). Artificial Intelligence (AI) can also be relied on, particularly for real-time data searching, data discovery, and metadata generation (Id).
ODECO findings on contributions by non-government actors to open data ecosystems
The ODECO consortium also produced 3 reports on non-government open data, focussing in particular on motivations and challenges for non-government actors to contribute their data as open data. The non-government actors include companies as well as other data holders such as journalists, non-profit organisations and non-technical individuals. The ODECO consortium identified several motivations, ranging from the desire to create and support communities of practice, the desire to support organisational networks through sharing and reuse of data, create private value, create social impact, improve the contributor’s internal skills or data processes, for personal enjoyment, and because of a sense of belonging in an open data community ( Re et al., 2024). The barriers to open data contributions by non-government actors are lack of data skills and literacy, lack of governance mechanisms, lack of awareness about the value of open data, lack of technical tools, misaligned goals and interests, and lack of resources (Id).
The ODECO consortium also identified technical strategies, to increase contributions of open data by non-government data holders. In particular, the ODECO consortium identified three challenges for which technical solutions may be appropriate – at the data creation stage to improve dataset and metadata quality and interoperability, at the data sharing stage to improve privacy and licensing challenges, and at the feedback stage to create a vibrant community involving both data holders and data users ( Alexopoulos et al., 2024). Further, an ideathon (as described in Alexopoulos et al., 2024) was conducted at a training week organised by the ODECO consortium in September 2024, where participants create prototypes of technical solutions that could respond to these challenges, such as the use of AI for metadata generation, workflow management to improve adherence to interoperability standards, and questionnaire-based tools for identification and selection of appropriate licenses.
ODECO findings on collaboration and redistribution
The ODECO consortium also studied models of collaboration between various open data actors, to collectively generate value from open data ( Chandrasekhar et al., 2024). By analysing four-case studies of collaboration between 2 or more open data actors, the ODECO consortium identified key institutional factors relevant for such collaborations – which include partnerships between government and non-government actors for open data initiatives, coordinating roles discharged by public administrations to regularly involve non-government actors in open data initiatives, the creation and maintenance of strong interorganisational culture around open data, and investment in secure public data infrastructures for data storage, sharing and analysis (Id).
Finally, the ODECO consortium also proposed some strategies to redistribute value in open data ecosystems, to ensure that both financial and social value can be generated from open data ( Cazacu et al., 2025a). In terms of financial value, strategies proposed to mitigate the imbalanced distribution of financial value include tax incentives for open data contributions, the provision of shared infrastructures, and enabling value-added services by government agencies to offset costs. These initiatives point toward the need for redistributive mechanisms that counterbalance the financial dominance of well-resourced actors and foster a more equitable ecosystem. In terms of social value, institutionalising both the FAIR principles for data quality as well as other principles for addressing power inequalities are important, as well as the use of legal frameworks to enable more open sharing of data that is of public interest but are currently enclosed by private service providers, such as mobility data. Specifically, researchers from the indigenous data sovereignty movement have criticised the FAIR principles for focussing exclusively on techno-legal aspects of data quality, and ignoring the social, historical and material contexts within which open data is produced and used. This has resulted in the articulation of the CARE principles as a companion to the FAIR principles for open data and open science, where the focus is also on Collective Benefit, Authority to Control, Responsibility and Ethics ( Carroll et al., 2020; Carroll et al., 2021).
Extracting recommendations for enabling and improving open data ecosystems in the long term
From the ODECO project reports described above, we propose a synthesis of recommendations for enabling and improving open data ecosystems. We conducted a narrative review ( Greenhalgh et al., 2018) of the ODECO project reports described above, to identify all recommendations, suggestions and proposals contained in these reports. We then organised these into 9 thematic categories, as illustrated in Table 2 below, and further clustered them under 3 topics applicable to different stages of open data ecosystems lifecycle, data production and access, data reuse, and the long-term perspective with required infrastructural investment. Each recommendation is also supplemented with a logo. In doing so, we illustrate the diversity of policy and infrastructural actions required to create and sustain open data ecosystems, beyond purely technical or techno-optimistic solutions, and pay attention to the socio-technical and political aspects of open data production and use as well as to all facets of the necessary investments and strategies.
In the section below, we expand on each of these recommendations for sustainable open data ecosystems. These recommendations can be broadly categorised into three buckets – data quality, wide data re-use, and infrastructures for open data. These buckets represent the overall problem sought to be addressed. Each recommendation within these buckets outlines the different solutions (technical, governance, policymaking) proposed in the surveyed ODECO project reports.
Data quality
Despite global uptake of principles such as the FAIR principles, findability and interoperability of open datasets as well as data elements within these datasets remains weak. Accordingly, the ODECO project put forth three recommendations to improve data quality in open data initiatives – to boost discoverability, improve metadata, and focus on ongoing engagement and participation.
** 1. Discoverability **
Open data initiatives should create multiple access modalities, including open data portals, open APIs and direct downloads ( Ali et al., 2022). Policymakers should also encourage the adoption of technical openness in data publication by advocating for machine-readable formats ( Dulong de Rosnay, 2008). To enhance the accessibility of open data for non-technical users as well users in low-resource settings, governments and open data researchers should also support the development and distribution of low-code tools, as well as low-tech and mid-tech data analysis systems ( Kostakis et al., 2023; Philippe, 2020). Figure 1 serves as a logo for this recommendation on discoverability.
Photo by Dyon Joël, representing a logo for discoverability.Dedicated to the public domain. Source: https://commons.wikimedia.org/wiki/File:Toutes_directions.JPG.
{kind=link}
** 2. Metadata **
Enhancing metadata quality boosts data discoverability ( Chokki et al., 2022; Nogueras-Iso et al., 2021). Policymakers should continue to advocate for metadata standards, ensuring datasets include comprehensive descriptions, provenance, and structured classifications ( Brewster et al., 2020; Maratsi et al., 2024b). To this extent, emerging technologies such as artificial intelligence can be leveraged to generate core metadata automatically, thereby reducing the burden on open data providers ( Ahmed, 2023). Figure 2 serves as a logo for this recommendation on metadata.
Image by cea, representing a logo for metadata.Licensed under CC BY 2.0. Source: https://commons.wikimedia.org/wiki/File:Metadata_is_a_love_note_to_the_future_(8071729256)_(cropped).jpg.
_(cropped).jpg){kind=link}
** 3. Ongoing engagement and participation **
Open data initiatives should be attuned to stakeholders’ needs through feedback loops, as illustrated in Figure 3. A priori, open data initiatives should undertake ecosystem mapping to identify different stakeholders and their needs ( Nthubu et al., 2022). They may do so using tools from the discipline of design thinking ( Sanders & Stappers, 2008) and theoretical principles from the discipline of information visualisation and communication ( Bohman, 2015). This can engender both technical data openness as well as social equity in open data initiatives. On an ongoing basis, open data initiatives should create robust feedback loops ( Alexopoulos et al., 2014; Bisztray et al., 2021; Herrera-Murillo et al., 2022; Nikiforova, 2020). This can include digital design strategies to create participative interfaces as in the case of the French open data portal, which contains a discussion section under each dataset where users can flag errors and propose edits to the datasets. Open data initiatives could also adopt participative design strategies, to create spaces for community discussion and deliberation on data re-use ( Verhulst et al., 2024). Other examples include open data game jams i.e. the use of serious games to enable collectivisation around open data ( Di Staso et al., 2024), data physicalisation i.e. the use of physical artefacts to represent data and visualise data and value flows ( Cazacu et al., 2025b), data sprints ( Venturini et al., 2018) and game-based classroom learning pedagogies ( Vargas et al., 2024b). A posteriori, open data initiatives should also undertake evaluations. This can include automated validation tools, periodic audits, quality dashboards, automated interoperability assessment frameworks, and collaborative stakeholder engagement to maintain high data quality standards and to assess whether open data initiatives are discharging their original stated objectives ( Alexopoulos et al., 2024).
Diagram by SilverStar, representing a logo for ongoing engagement and participation.Licensed under CC BY-SA 3.0. Source: https://commons.wikimedia.org/wiki/File:Feedback-loop-general.svg.
{kind=link}
Wide data re-use
The ODECO project also proposed recommendations to ensure wide data re-use. The GovLab identified four phases in the political journey of the open data movement ( Chafetz et al., 2024; Verhulst et al., 2020). In the first phase, citizens could obtain conditional access to public sector information on request, pursuant to “freedom of information” regulations ( Birkinshaw, 2006). The second phase sought to make government datasets ‘open by default’ by law. This focus on ‘open by default’ has had a significant impact on open government. For instance, the EU Data Portal (the open government data portal at the EU-level) now hosts more than 1.5 million open datasets. The third wave of open data was focussed on the issue of impactful re-use, focussing on incentives, barriers are infrastructures for data re-use. In this regard, the third wave illustrated the need to move beyond the creation of ‘data heaps’ in the public domain, and to think more critically about the conditions in which data is created, used and re-used. The (more speculative) fourth wave of data investigates how to make open data ‘AI-ready’, by focusing more on issues of data provenance and AI-related re-use.
The open data movement is currently between the third and fourth wave. On the one hand, large amounts of data that is in the public interest, such as mobility data, are generated and enclosed by non-government actors such as companies. This data should be made publicly accessible and reusable. On the other hand, the mere existence of open datasets on open data portals does not automatically ensure value generation from such open data. Accordingly, the ODECO project proposed recommendations relating to non-government open data, data literacy and data gaps.
** 4. Beyond Open Government Data **
In addition to open government data, non-government stakeholders are also an important category of data holders. Policymakers should advocate for legal frameworks that require both government and non-government data holders to release open datasets as well as enable wider reuse of data, especially for public interest purposes such as research or prevention of emergencies, and to ensure that data does not only serve the private interest (see for e.g., Bietti, 2025). Figure 4 serves as a logo for this recommendation on legal frameworks.
Photo of the Code of Hammurabi Curved Stone of 282 laws by rideaology, logo to represent non-government open data.Licensed under CC-BY 2.0. Source: https://commons.wikimedia.org/wiki/File:Code_of_Hammurabi_54.jpg.
{kind=link}
Public procurement contracts can also be leveraged to obtain more open datasets from commercial data holders. For example, the City of Barcelona included “data sovereignty clauses” in public procurement contracts with vendors contracted to provide services to the city, which required such vendors to share all data generated in the course of providing the contracted service in an open machine-readable format with the public administration, so that this data can be released as open government data ( Avila & Weress, 2023). Public procurement contracts can also be used to improve open data supply chains, as in the case of the Netherlands, where public procurement yielded innovation in the data management systems of regional water authorities to ensure standardised stream of open data collected by these authorities and passed on to the Dutch national spatial data infrastructure ( Smart City Innovation, 2021, pp. 41–42).
Standard licenses have also been central to open data ecosystems. Non-government data holders (particularly commercial actors) should also be incentivized to use open data licenses. The open science movement has resulted in open sharing of research artefacts, and holds valuable strategies for other types of non-government data as well ( Burgelman et al., 2019; Ramachandran et al., 2021). Where the data in question does not relate to any personal or sensitive information, broad licenses should be used that impose little to no restriction on reuse (for e.g., in the form of attribution and sharealike) should be used for government as well as non-government data when possible ( The Open Data Handbook, n.d.). Communities contribute to open datasets, but in many cases, commercial re-users offer little to no value back to the maintenance of these datasets or to the preservation of open data ecosystems ( Bates, 2012; Lund & Zukerfeld, 2020). In such cases, open licenses that impose stronger copyleft obligations on re-users can also serve as helpful strategies to respond to the current political economy of data re-use, while preserving a culture of openness ( Okorie & Marivate, 2024; Stallman, 2015).
Other incentives can also be used to obtain open data from non-government data holders. Non-government data holders, such as commercial actors, may be reluctant to share data openly even if this data is of public interest, because of their business interests backed by trade secret and confidentiality agreements, and a lack of clear incentives ( Herala et al., 2016; Kitchin, 2014, p. 86; Scassa, 2022) . Governments may consider offering financial incentives (such as tax credits) to companies ( Crompvoets et al., 2024). Such financial incentives could also boost participation of non-profit and non-commercial actors to the production of open data. Non-government stakeholders can also be tasked with providing additional services to open data initiatives, such as open data trainings, visualisations and data stories, and capacity building tools such as data literacy initiatives ( Enaholo, 2017; Shaharudin et al., 2023). In general, government and non-government stakeholders should invest in capacity-building initiatives that can enable non-government data holders as well as non-specialised users to share more open data. Finally, continued advocacy on open data – by making citizens aware of open data, valourising the use of open data, and suggesting measures to improve the use of open data - to create a culture where such data holders are motivated to release their data as open data ( Chattapadhyay, 2014).
** 5. Data literacy **
Users of open data – ranging from NGOs, journalists, non-specialist users and open data intermediaries – require a broad level of skills to generate value from open data. Not all users possess the same data literacy ( Van Audenhove et al., 2020). Governments should therefore invest in building data literacy and digital equity ( Lohr, 2025). In this regard, the education sector can be leveraged to improve data literacy across populations, as illustrated by Vargas et al. in elementary schools in Denmark ( Vargas et al., 2024a). Accordingly, Figure 5 serves as the logo for this recommendation on data literacy. Further, government actors themselves require regular trainings and guidance on certain aspects of open data, such as interoperability ( Overton & Kleinschmit, 2022). Data science trainings for governmental and non-government actors, as well as simple and accessible step-by-step guides can be useful, such as open access courses for Open Data Editor (a open source tool for data validation), the Third Wave of Open Data Toolkit (a resource for realising value from open data) and the 100 Questions Initiative (a resource for designing critical data literacy programmes). Design strategies to improve data literacy, through the use of open data game jams (i.e. the use of serious games to enable collectivisation around open data) and data physicalisation (i.e. the use of physical artefacts to represent data and visualise data and value flows), can also be useful.
Photo by Aussie-mobs, titled “Palestine - Little folks studying at the village school in Ramah, Palestine”, as a logo representing data literacy.Dedicated to the public domain. Source: https://www.flickr.com/photos/hwmobs/8169084168/.
** 6. Mind the gap(s) **
The generation of open data with its underlying choices is not a neutral activity. The existence of more open datasets, released by both government and non-government actors, can enable more uses of open data, data-driven policymaking and realisation of more value from open data. At the same time, the volume of open datasets does not always mean that these datasets are representative of the diversity of human experiences and social phenomena, as illustrated in Figure 6. The generation of open data comes with problems of missing data, particularly with regard to data about vulnerable or historically marginalised groups ( Jarke, 2019; Santoro, 2024). Here, an ‘open data justice’ approach can be useful, to assess the extent to which open data initiatives are representative of various realities and the extent to which they allow for participation by a diverse range of stakeholders Johnson, 2014). Participative processes for the generation and use of open data are also necessary, with due regard for accessibility. Open data initiatives should continuously acknowledge and account for the power dynamics in the generation and reuse of data, especially with data-driven decision-making ( Robinson & Scassa, 2022).
Photo of "Mind the gap" by London Student Feminists, as an icon to represent the politics of open data production.Licensed under CC-BY SA 3.0. Source: https://commons.wikimedia.org/wiki/File:Mind_the_gap1.jpg.
{kind=link}
Infrastructures for open data
Finally, as part of an ecosystemic approach to open data, the ODECO project reports also discuss different infrastructures necessary for production, use and value generation from open data. In this regard, the ODECO project reports contain recommendations on usability, interoperability and public data infrastructures.
** 7. Usability **
Open data portals maintained by institutions as well as by different governments across regional, national and local levels, are important modalities for access to open datasets. Open data portals should conduct routine evaluations of user experience, and adopt iterative interface design practices based on user feedback ( Polini et al., 2024). Features such as screen reader compatibility, high-contrast visuals, and accessible navigation cater to diverse user needs, including those with disabilities, as detailed in the EU Data Portal’s Data Visualisation Guide and as practiced and recommended by Spain’s open data portal. Responsible use of artificial intelligence and collective intelligence technologies can also improve the functionalities of open data portals ( Ahmed, 2023). Figure 7 serves as a logo for this recommendation on usability.
Photo of abacus kit by Manju Thilagavathi, as a logo to represent usability.Dedicated to the public domain. Source: https://commons.wikimedia.org/wiki/File:Abacus_Kit.jpg.
{kind=link}
** 8. Interoperability **
Maintainers of open data portals should participate in and adopt interoperability standards, to extend the reach of these portals to everyday information search scenarios on other platforms. Governments and organizations should establish mandatory compliance with widely accepted interoperability standards such as DCAT, FOAF, and the vocabularies maintained by Schema.org. Further, semantic interoperability, i.e. the ability to share data in a way that ensures mutual understanding and clarity of the meaning of that data, is a core component of the open web and to ensure interoperability between different open data portals/repositories/systems ( Berners-Lee, 2006). Governments and organisations should prioritize the adoption of semantic interoperability principles such as the 5-star Linked Open Data rating developed by Berners-Lee. To enable release of machine-readable data under open licenses, in non-proprietary formats, using open standards, and linked vocabularies, as well as vocabularies and indicators, to strengthen semantic interoperability ( Maratsi et al., 2024a). At the European level, adopting established classification frameworks, such as those used by the European Data Portal as well as European Interoperability Framework to be created pursuant to new regulations such as the Interoperable Europe Act for cross-border interoperability of European digital public services, also facilitates interoperability and alignment with broader data ecosystems ( Pflücke, 2024). Figure 8 serves as a logo for this recommendation on interoperability.
Icon that symbolises interoperability, by Julian Kücklich.Dedicated to the public domain. Source: https://commons.wikimedia.org/wiki/File:Interoperability_2.png.
{kind=link}
** 9. Public administrations’ investments **
Public administrations should adopt a more active approach towards open data initiatives. Many public administrations and their open data initiatives as well as data sharing initiatives have dependencies on non-EU commercial actors, such as the French Health Data Hub’s reliance on Microsoft’s Azure cloud infrastructure ( Vitard, 2025). As a result, there should be more public funding and investment in shared open infrastructures (including digital public infrastructures such as open platforms, as well as open source tools and technologies), that limit infrastructural dependencies on commercial actors in order to foster European digital sovereignty, i.e. financial and geopolitical independence from non-EU technologies ( Gates et al., 2025; Open Future, n.d.). Public administrations should also build and maintain infrastructures that enable open access to scientific information as well as enable easy publication of more open data, information and knowledge, such as France’s OpenEdition – a set of four platforms for publishing and accessing scientific resources relating to social and human sciences. At the EU-level, publicly-funded infrastructures such as the European Open Science Cloud, seek to create standards for data circulation, enable various government and non-government actors to share more data as well as resources for data work such as storage and computing capabilities, as well as make tools for data analysis and visualisation publicly available ( Wilk, 2024). Figure 9 serves as a logo for this recommendation on public administrations’ investments.
Photo of a PeruRail Train by David Gubler, as a logo representating investments by public administrations.Licensed under CC-BY SA 4.0. Source: https://commons.wikimedia.org/wiki/File:PeruRail_EMD_GT42AC_812_at_Km_99.jpg.
{kind=link}
Public administrations should coordinate civic projects involving themselves and other actors such as academic universities, civil society organisations, and commercial data holders. This can result in the formation of communities through open data, as well as collaborations between these actors to generate value from data, in the form of public-private or public-commons partnerships. For instance, the Glasgow Centre for Population Health coordinates civic projects involving local administrations, academic universities and civil society organisations. This led to the creation of Understanding Glasgow, a website that hosts visualisations on health and life circumstances, encompassing visualisations on poverty, transport services, population and culture to name a few.
Conclusions
This open letter has summarised key contributions of the ODECO consortium for sustainable open data ecosystems, and provided a synthesis 9 practical recommendations along with logos illustrating each recommendation, to ensure open data quality, productive use of open data, and sustainability of open data initiatives, enabling institutions and policy-makers with the means to improve their open data policy and actions in the short (production and access), medium (reuse) and long term (investments).
Open data is important particularly for data-driven innovation, transparency and accountability of public administrations, as well as data-driven decision-making where public interest data held by non-government data holders are also released as open data. The positive impact of open data cannot be assumed automatically, simply by creating open data portals. There are many gaps to the full realisation of both economic and social value from open data, which the ODECO consortium has tried to address through its recommendations for sustainable open data ecosystems.
Further, support for open data does not automatically mean support for the further datafication of society ( Baack, 2015). In fact, open data initiatives as in the city of Montreal illustrate the ways in which public administrations are more attuned to the public interest as a result of which, open data initiatives improve the internal functioning of public administrations ( Millerand & Meunier, 2025). By focussing on user needs and ecosystems sustainability, the ODECO consortium has sought to valourise open data carefully, to ensure that open data is not simply produced for the sake of it, but is more purpose and value-driven. This can aid in achieving the original goals of freedom, transparency and accountability of the open movement, as well as supporting evidence-based policy decisions and new goals such as digital sovereignty of liberal democracies
Ethics and consent
Ethical approval and consent were not required
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ahmed U : Reimagining open data ecosystems: a practical approach using AI, CI, and knowledge graphs. BIR Workshops.2023;235–249. Reference Source
- 2Alexopoulos C Maratsi MI Ali M : D 4.2 An approach to steer the behaviour of non-government data holders towards open data through a technical strategy.ODECO,2024. Reference Source
- 3Alexopoulos C Zuiderwijk A Charapabidis Y : Designing a second generation of open data platforms: integrating open data and social media.In: M. Janssen, H. J. Scholl, M. A. Wimmer, &z F. Bannister (Eds.), Electronic Government.Springer,2014;230–241. 10.1007/978-3-662-44426-9_19 · doi ↗
- 4Ali M Alexopoulos C Charalabidis Y : A comprehensive review of open data platforms, prevalent technologies, and functionalities. Proceedings of the 15th International Conference on Theory and Practice of Electronic Governance.2022;203–214. 10.1145/3560107.3560142 · doi ↗
- 5Avila R Weress G : Citynetics in the South: a blueprint for a city data commons.Unskewing the Data Value Chain. I Tfor Change,2023. Reference Source
- 6Aziz A Murillo DJH Ali M : D 2.2 User needs from a technical perspective.ODECO,2023. Reference Source
- 7Baack S : Datafication and empowerment: how the open data movement re-articulates notions of democracy, participation, and journalism. Big Data Soc. 2015;2(2): 2053951715594634. 10.1177/2053951715594634 · doi ↗
- 8Barry E Bannister F : Barriers to open data release: a view from the top. Inform Polity. 2014;19(1–2):129–152. 10.3233/IP-140327 · doi ↗