ColoPola: A polarimetric imaging dataset for colorectal cancer detection
Thi-Thu-Hien Pham, Quoc-Hoang-Quyen Vo, Thao-Vi Nguyen, The-Hiep Nguyen, Quoc-Hung Phan, Thanh-Hai Le

TL;DR
This paper introduces ColoPola, a new dataset of polarimetric images for colorectal cancer detection, and evaluates its effectiveness using various machine learning models.
Contribution
The paper introduces ColoPola, the first standardized polarimetric imaging dataset for colorectal cancer.
Findings
ColoPola contains 20,592 polarimetric images from 572 sample slices (288 healthy, 284 malignant).
EfficientNetV2 achieved the highest performance with F1 score of 0.965 and all metrics exceeding 0.95.
The dataset shows significant potential as a diagnostic tool for colorectal cancer in clinical practice.
Abstract
In recent years, polarimetric imaging has been developed for various biological applications, including tissue morphological characterization and cancer stage detection. However, to facilitate classification models based on the characteristics of polarization states, it is essential to develop a consistent and standardized dataset of polarimetric images. This study presents a dataset of colorectal cancer polarimetric images designated as ColoPola, which is intended to facilitate research efforts in the field. The dataset consists of 572 sample slices (288 healthy and 284 malignant). For each slice, 36 polarimetric images corresponding to different polarization states are provided. Thus, ColoPola contains 20,592 polarimetric images, of which 10,368 correspond to healthy samples and 10,224 to malignant samples. To the best of the authors’ knowledge, the dataset is the first of its kind…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
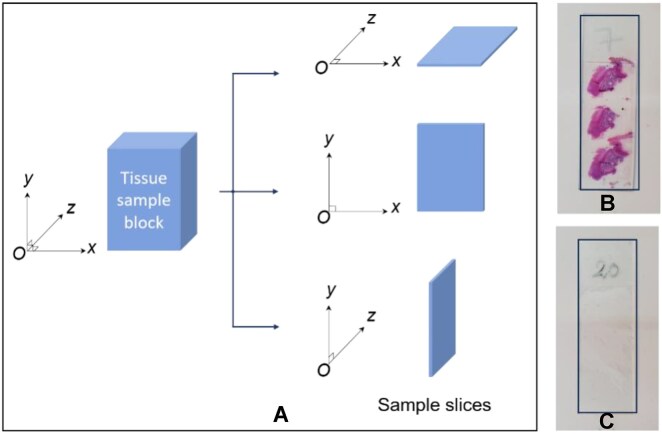 Figure 1
Figure 1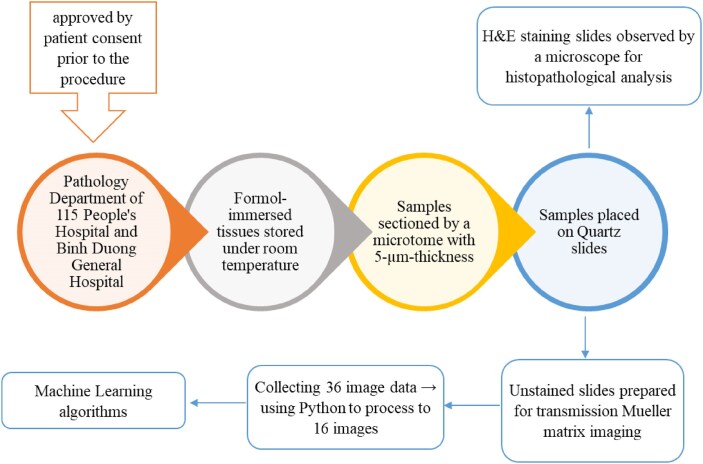 Figure 2
Figure 2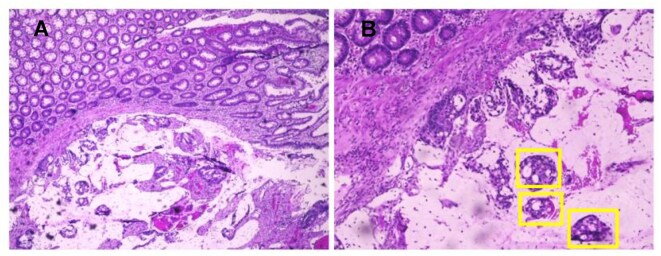 Figure 3
Figure 3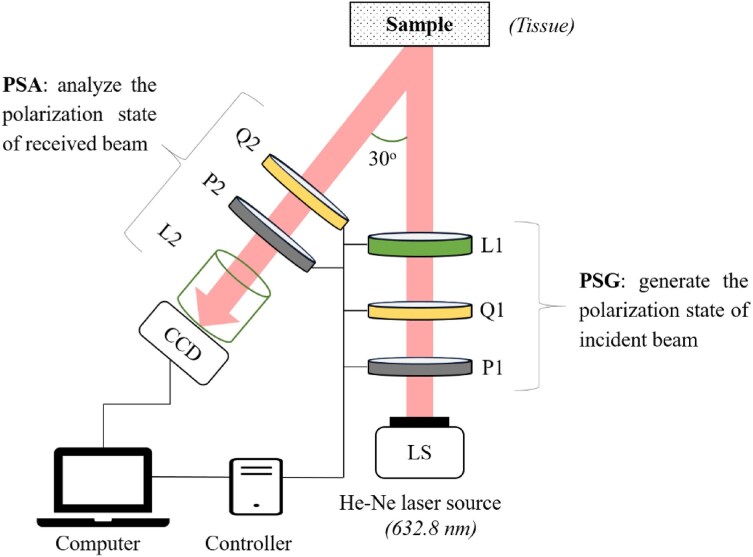 Figure 4
Figure 4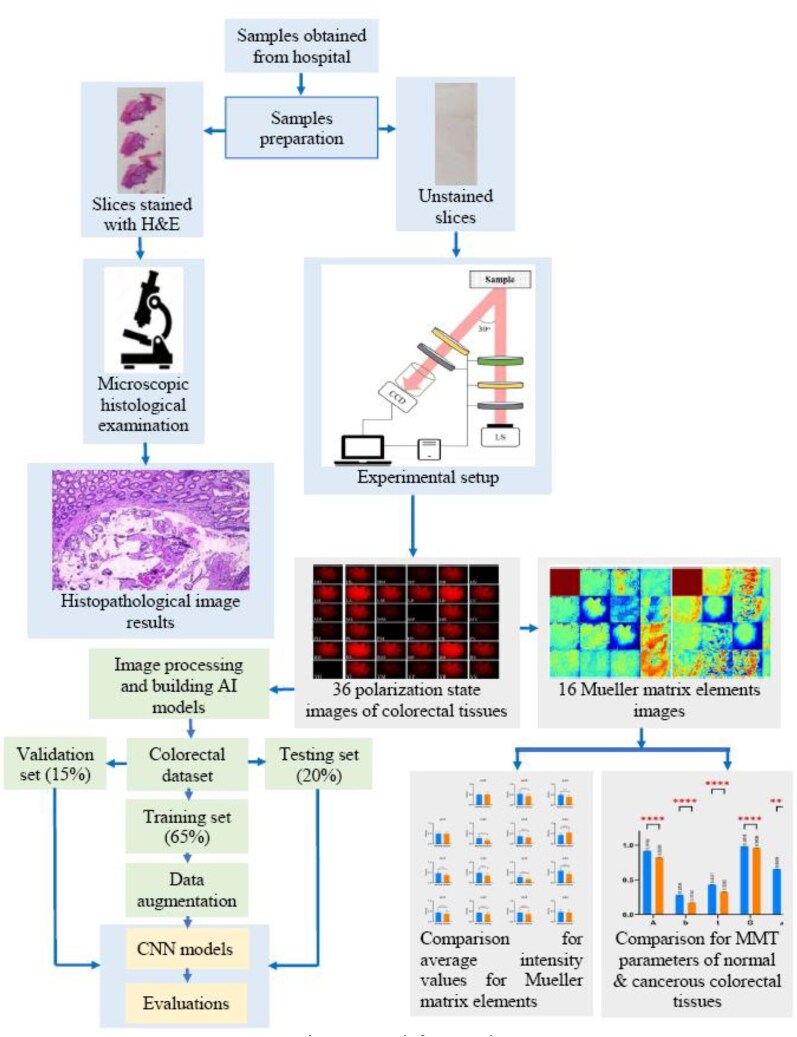 Figure 5
Figure 5 Figure 6
Figure 6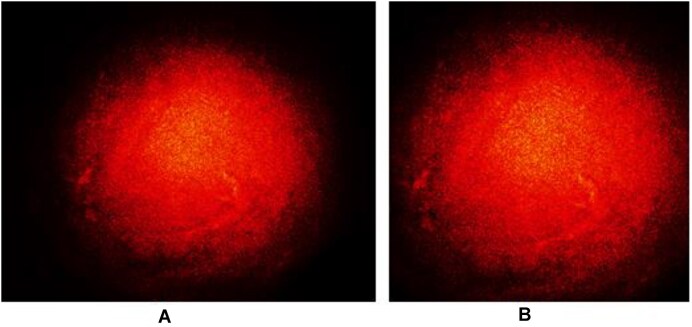 Figure 7
Figure 7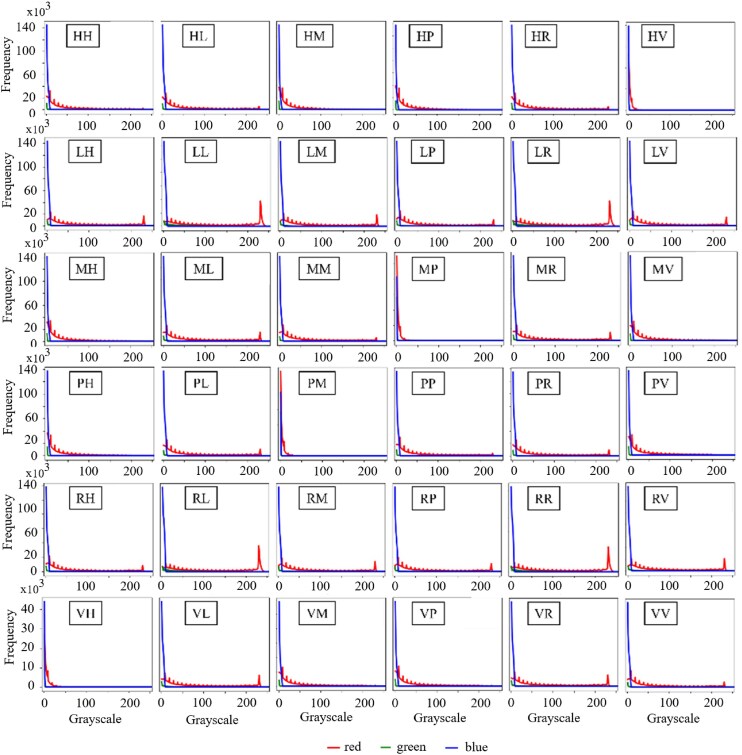 Figure 8
Figure 8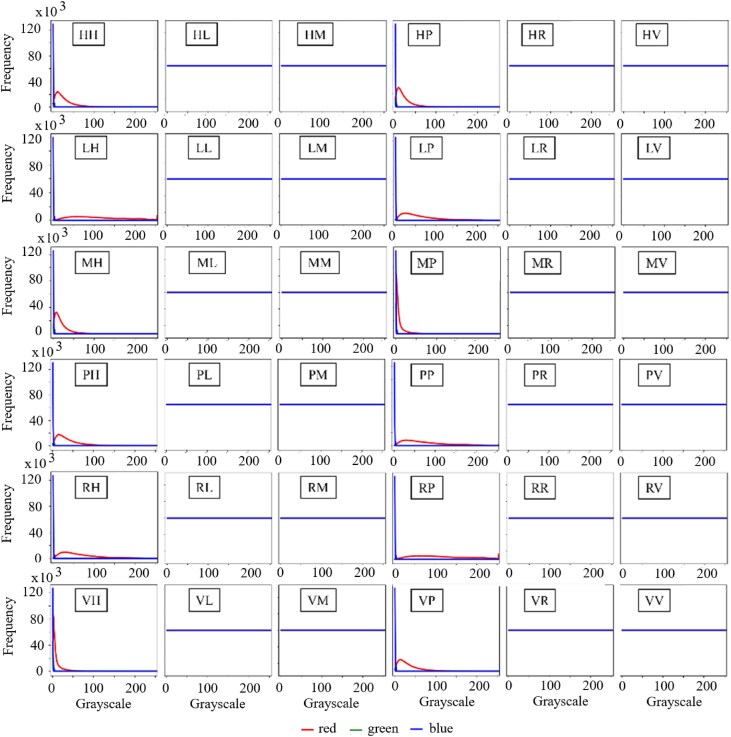 Figure 9
Figure 9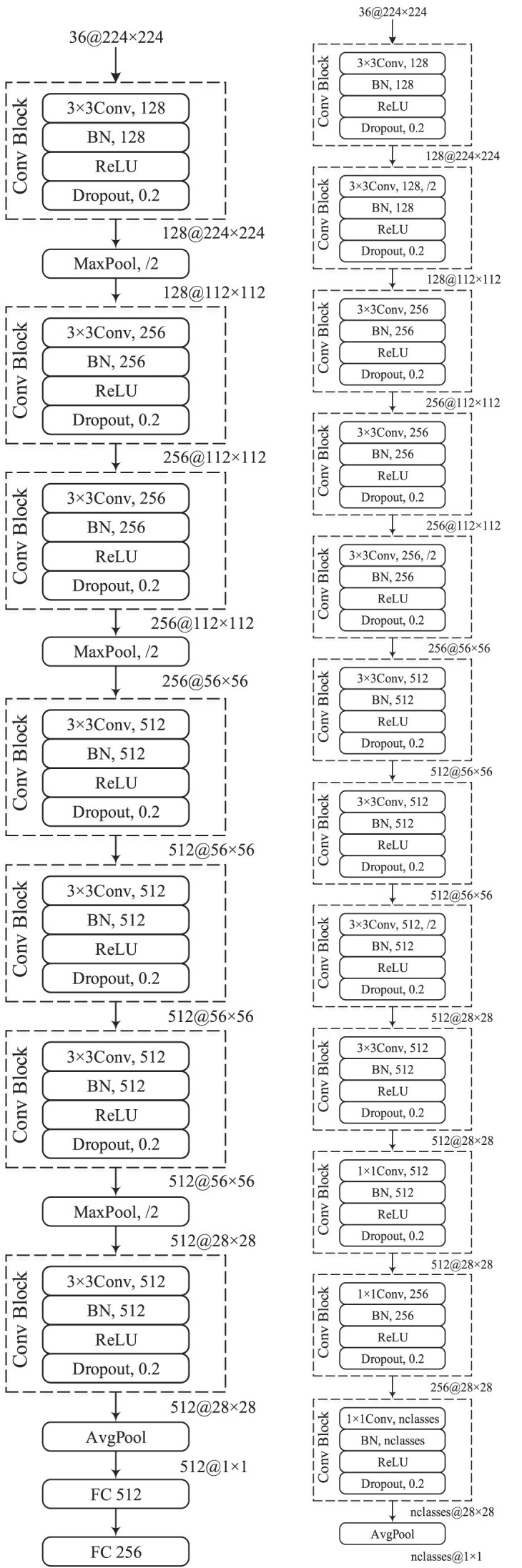 Figure 10
Figure 10 Figure 11
Figure 11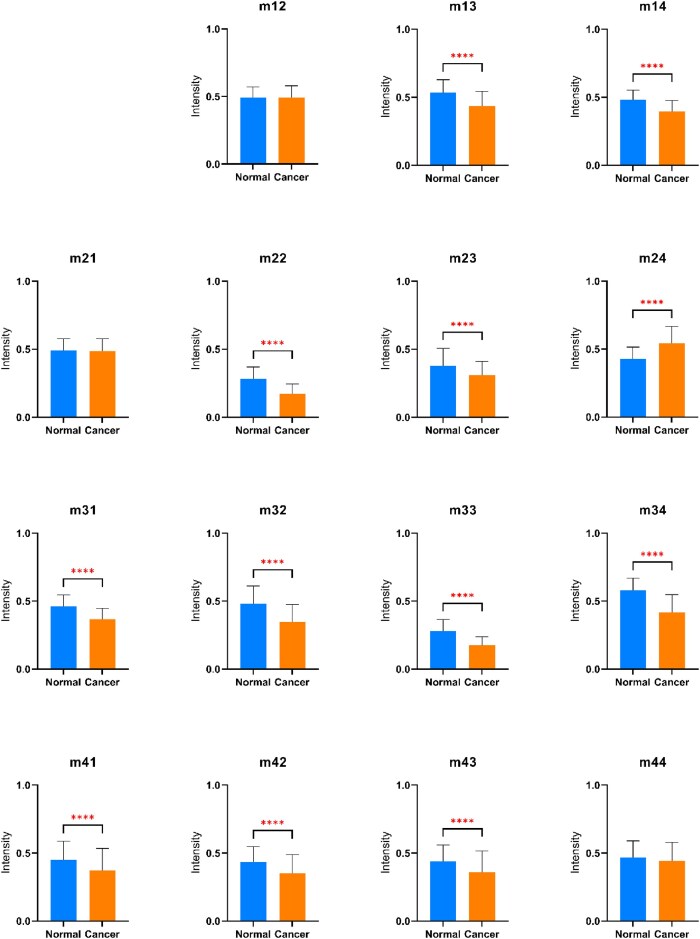 Figure 12
Figure 12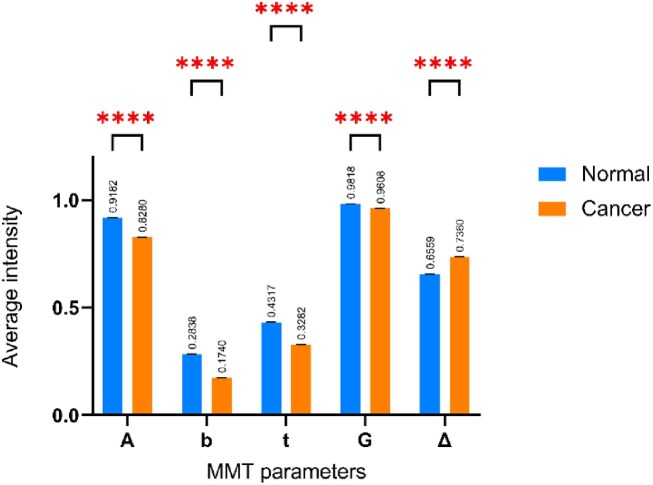 Figure 13
Figure 13 Figure 14
Figure 14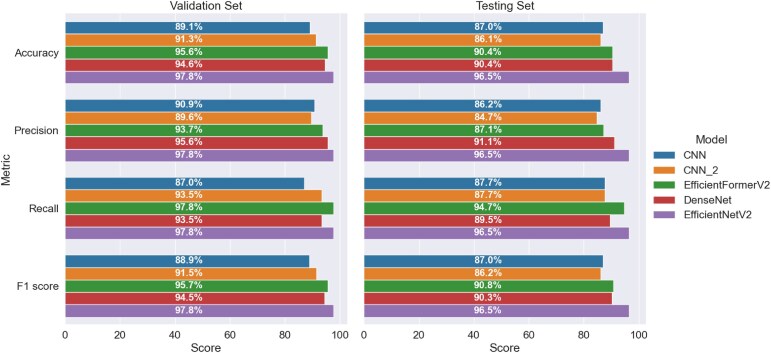 Figure 15
Figure 15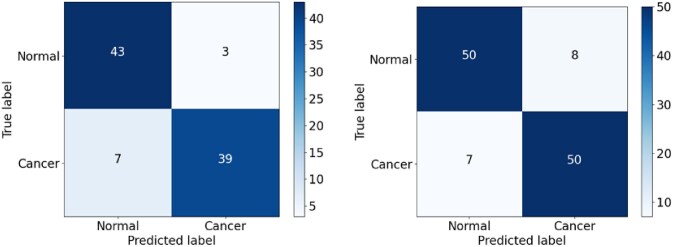 Figure 16
Figure 16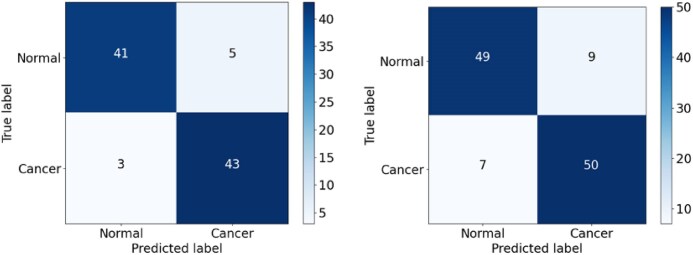 Figure 17
Figure 17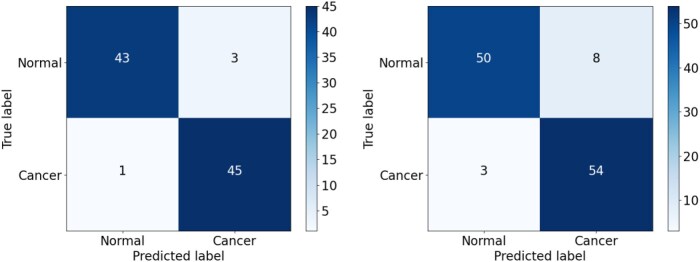 Figure 18
Figure 18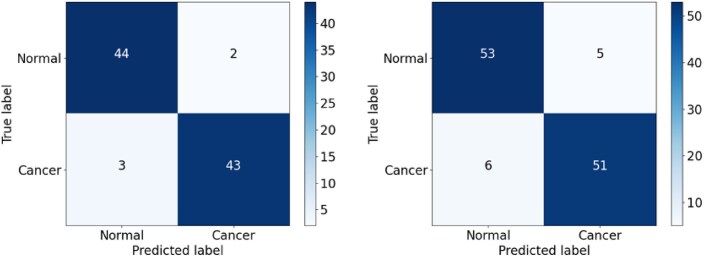 Figure 19
Figure 19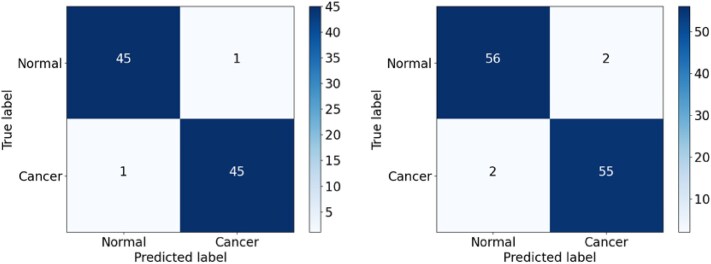 Figure 20
Figure 20| Type of sample | Specimen (sample slices) | Image | Training | Validation | Testing |
|---|---|---|---|---|---|
| Normal | 288 | 10,368 | 184 | 46 | 58 |
| Cancer | 284 | 10,224 | 181 | 46 | 57 |
|
|
|
|
|
|
|
| Parameter | Models from scratch | Pretrained models |
|---|---|---|
| Optimizer | AdamW [ | |
| Batch size | 16 | |
| Epoch | 200 | |
| Initial learning rate | 0.01 | 0.001 |
| Weight decay | 0.001 | |
| Loss | Binary cross entropy loss | |
| m11 | m12 | m13 | m14 | |
|---|---|---|---|---|
|
| 1 (normalization) | 0.4911 ± 0.0258 | 0.5327 ± 0.0043 | 0.4831 ± 0.0055 |
|
| 1 (normalization) | 0.4928 ± 0.0350 | 0.4361 ± 0.0166 | 0.3971 ± 0.0375 |
|
|
|
|
| |
|
| 0.4934 ± 0.0027 | 0.2845 ± 0.0087 | 0.3809 ± 0.0062 | 0.4291 ± 0.0043 |
|
| 0.4866 ± 0.0172 | 0.1732 ± 0.0572 | 0.3092 ± 0.0441 | 0.5429 ± 0.0163 |
|
|
|
|
| |
|
| 0.4618 ± 0.0037 | 0.4812 ± 0.0041 | 0.2818 ± 0.0088 | 0. 5786 ± 0.0047 |
|
| 0.3677 ± 0.0257 | 0.3461 ± 0.0149 | 0.1743 ± 0.0428 | 0.4181 ± 0.0839 |
|
|
|
|
| |
|
| 0.4521 ± 0.0057 | 0.4386 ± 0.0087 | 0.4411 ± 0.0113 | 0.4667 ± 0.0049 |
|
| 0.3716 ± 0.0512 | 0.3509 ± 0.0098 | 0.3612 ± 0.0135 | 0.4450 ± 0.0177 |
| Statistical values | CNN vs. CNN_2 | CNN vs. DenseNet | CNN vs. EfficientNetV2 | CNN_2 vs. DenseNet | CNN_2 vs. EfficientNetV2 | DenseNet vs. EfficientNetV2 |
|---|---|---|---|---|---|---|
|
| 5 | 4 | 8 | 5 | 9 | 6 |
|
| 4 | 6 | 9 | 8 | 11 | 5 |
|
| 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 |
|
| 0 | 0.1 | 0 | 0.308 | 0.05 | 0 |
|
| 1 | 0.752 | 1 | 0.579 | 0.823 | 1 |
|
| 1 | 0.754 | 1 | 0.581 | 0.824 | 1 |
|
| No | No | No | No | No | No |
|
|
|
|
|
| ||
|
| 5 | 6 | 7 | 9 | ||
|
| 1 | 3 | 1 | 4 | ||
|
| 0.05 | 0.05 | 0.05 | 0.05 | ||
|
| 1.5 | 0.444 | 3.125 | 1.231 | ||
|
| 0.221 | 0.505 | 0.077 | 0.267 | ||
|
| 0.219 | 0.508 | 0.070 | 0.267 | ||
|
| No | No | No | No |
- —VNU-HCM10.13039/501100010712
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsOptical Polarization and Ellipsometry · Soil and Environmental Studies
Introduction
Colorectal cancer (CRC) is one of the most common malignancies worldwide and is a leading cause of cancer-related death in both men and women. GLOBOCAN estimated that CRC was the third most common cancer type globally in 2020, accounting for approximately 10% of all cancer cases (including 1.9 million new cancer cases and over 915,000 deaths) [1]. Hence, there is a requirement for effective diagnostic methods capable of detecting CRC at the earliest stage possible. Colorectal cancer usually originates in the colon or rectum and is classified as colon or rectal cancer accordingly. Most CRCs start as a growth on the inner layer of the colon or rectum. These growths, known as polyps, may become cancerous over time (usually 10–15 years); however, not all polyps do [2]. The tumor stage at the time of treatment is the most significant predictor of survival. However, CRC identification in symptomatic individuals is challenging because some of the symptoms of colorectal cancer can be nonspecific and may overlap with those of other gastrointestinal conditions.
Colonoscopy and biopsy, together with stool-based diagnostics and visual structural examinations, are considered the “gold standard” for CRC assessment [3]. However, owing to limited endoscopic resources, the high demand for colonoscopies can lead to prolonged waiting periods, potentially delaying the detection of CRC. Thus, computed tomography (CT) colonography is often preferred, especially for seniors with specific symptoms such as stomach pain or weight loss [4, 5]. However, CT colonography not only is expensive but also raises important concerns regarding radiation exposure, particularly if follow-up testing is required. Many CRC screening methods are available, including stool DNA testing, colonoscopy with biopsy, ultrasound, X-ray, CT, and magnetic resonance imaging (MRI) scanning [6]. Although these methods have reasonable accuracy, they are prone to lost time, false-positive test results, and a high price tag relative to typical patient incomes. Stool DNA testing, in particular, may result in false-positive results, missed polyps and cancers, and the need for 3-yearly colonoscopy in the event of abnormalities [7, 8]. Furthermore, while colonoscopy can usually visualize the whole colon and a biopsy can be performed to remove polyps if necessary, it may miss tiny polyps, require anesthesia, amd cause mild bleeding, bowel tears, or infection, which may be disruptive to the patient’s daily routine. In addition, long-term exposure to X-ray radiation has adverse effects on human health [9, 10]. Therefore, there is an important need for noninvasive in situ techniques capable of detecting CRCs with high accuracy and low cost.
Polarimetry is an effective method for evaluating the microstructure of biological materials and has found widespread use in biomedical sensing [11, 12]. Polarized light has long been used to aid in the imaging of turbid materials. For example, Hossain et al. [13] used terahertz-band polarimetric imaging for capturing the anisotropic features in a sample by discriminating edges based on the polarization. Mann et al. [14] investigated the birefringence mapping of biological tissues by incorporating the conventional polarization microscope and transport of intensity equation phase retrieval algorithm. Yin and Gao [15] combined widefield Mueller matrix and optical coherence tomography for capturing polarization imaging of biological samples. The results indicated that the depolarization power of malignant samples was a reliable predictor of the cancer growth stage and histological variety. Thus, several Mueller matrix transformation (MMT) parameters were also proposed to provide additional quantitative information on the structural and optical properties of the sample.
As artificial intelligence (AI) technology has advanced in recent years, it has been increasingly applied for the detection and diagnosis of many cancers, including CRC [16–21]. Chen et al. [16] used a deep neural network (DNN) to analyze narrowband images of diminutive colorectal polyps in a dataset of 1,476 images of neoplastic polyps and 681 images of hyperplastic polyps. The network achieved a classification accuracy of 90.1% and a sensitivity of 96.3%. Thakur et al. [17] conducted a systematic review of the use of machine learning models in the analysis of CRC pathology images. The results showed that deep learning models such as DCAN, CNN, U-Net, and FCN achieved a good segmentation performance when applied to gland segmentation in the Warwick-Qu and CRAG datasets for both benign and malignant tissue samples. Iizuka et al. [18] evaluated the performance of several deep learning models when applied to tumor classification, microenvironment analysis, and prognosis prediction tasks for CRC images. It was shown that convolutional neural networks (CNNs) and recurrent neural networks (RNNs) trained on biopsy histopathology whole-slide images of the stomach and colon achieved area under the receiver operating characteristic curves (AUCs) of up to 0.96 for colonic adenocarcinomas. Xu et al. [19] compiled a dataset of 85 normal colorectal tissue slides and 222 colorectal cancer tissue slides from hematoxylin and eosin (H&E)–stained tissue sections. An InceptionV3 model was trained using a transfer learning technique and was used to segment the tumor regions in the images. The proposed model achieved an average accuracy of 0.936 and a Dice score of 0.885 for cancerous slices. Yu et al. [20] proposed a semi-supervised learning (SSL) algorithm based on a mean teacher architecture and evaluated the model on 13,111 histological CRC images acquired from 8,803 subjects. The results showed that the proposed method achieved an AUC performance similar to that of a supervised learning (SL) method while requiring significantly less labeled data. Tharwat et al. [21] reviewed the effectiveness of various machine learning (ML) and deep learning (DL) techniques in performing the early-stage detection of CRC. The strengths and limitations of the different methods were identified, and opportunities for future research on the automatic diagnosis of colon cancer were proposed.
Overall, the above studies [15–21] confirm the feasibility of combining polarimetry and AI frameworks to perform automatic diagnosis and classification of CRCs. However, to the best of the authors’ knowledge, polarized images of CRC tissues have not yet been published in the image-processing community. To address this gap, this study introduces a dataset of CRC polarimetric images, designated as ColoPola, which comprises optical images of normal and colorectal cancer tissue samples acquired using a Mueller matrix polarimetry technique. The ColoPola dataset not only fills a critical gap in available biomedical imaging data but also sets a new standard for the early detection of CRC, offering a potential reduction in the reliance on invasive procedures and improving the prognosis for patients through earlier intervention. The practical utility of the dataset is assessed using 5 ML models (CNN, CNN_2, EfficientFormerV2, DenseNet, and EfficientNetV2). A novel data input is generated in which the red channels of the 36 polarimetric color images are concatenated for each sample. The experimental results confirm that ColoPola has considerable promise as a noninvasive, optical imaging–based diagnostic tool for colorectal cancer in clinical settings.
Sample Preparation
In total, 572 slices of healthy and colorectal cancer tissue were acquired from the pathology departments of Binh Duong Provincial General Hospital in Binh Duong Province and the 115 People’s Hospital in Ho Chi Minh City, both located in Vietnam. The slices were provided with patient consent, and all the treatments and experiments were performed following relevant guidelines and regulations. All personal information about these samples was concealed, and the sample was then classified by histopathologists. The formol-immersed tissues were kept at room temperature and analyzed within 72 hours of receipt. The tissue samples were sectioned with a microtome at a thickness of 5 µm and placed on 5-mm-thick quartz slides for subsequent analysis. As illustrated in Fig. 1A, each tissue sample was sliced along the xOz, xOy, and yOz planes to ensure that all structures within the sample were clearly visible during the polarization imaging process. Figure 1B, C shows a typical stained slide used for histopathological analysis through a microscope and an unstained slide used for measurement by the polarized light system.
Sample slices. (A) Different slice planes from the tissue sample block. (B) Slice stained with H&E for histological examination. (C) Unstained slice for Mueller matrix imaging measurement.
Figure 2 shows the sample preparation procedure used in this study. The slices cut in the 3 directions were mounted on quartz slides for observation and measurement purposes. The stained samples were observed using a microscope to perform conventional histopathological analyses. The unstained samples were placed in a self-built transmission Mueller matrix polarimetry system, where 36 images were obtained by a CCD camera for each sample under different polarization conditions. For both types of samples (stained and unstained), the measurement process was performed at least 3 times for each slice to ensure the reliability of the observation/measurement results.
Sample preparation and basic experimental procedure.
Histopathological analysis
To serve as a benchmark for the classification results obtained from the Mueller matrix imaging system and deep learning models, the stained H&E samples were carefully annotated by an experienced histopathologist. Figure 3 presents 2 images showing the typical histopathological features of rectal cancer [22]. Both images show the disappearance of the normal glandular architecture typical of rectal cancer tissue, together with significant nuclear atypia with protruding nucleoli and a high nucleus-to-cytoplasm ratio. Both tissues also show high-grade mucinous adenocarcinomas and malignant epithelial cells in clumps and layers in pools of extracellular mucin.
H&E-stained rectal cancer tissues: (A) magnification 40× and (B) magnification 100×.
Construction of the ColoPola Dataset
Mueller matrix transformation
The Mueller matrix M_Sample_ used to define the polarization characteristics of biomedical samples has the form of a 4 × 4 matrix, in which the elements are obtained using different combinations of polarized light produced by the generator and analyzer modules in the polarimetry system. The matrix has the form [23]
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \begin{array}{@{}l@{}} {{M}_{\textit{Sample}}} = \left[ {\begin{array}{@{}*{4}{c}@{}} {{{m}_{11}}}&{{{m}_{12}}}&{{{m}_{13}}}&{{{m}_{14}}}\\ {{{m}_{21}}}&{{{m}_{22}}}&{{{m}_{23}}}&{{{m}_{24}}}\\ {{{m}_{31}}}&{{{m}_{32}}}&{{{m}_{33}}}&{{{m}_{34}}}\\ {{{m}_{41}}}&{{{m}_{42}}}&{{{m}_{43}}}&{{{m}_{44}}} \end{array}} \right]\\ = \left[ {\begin{array}{@{}*{4}{c}@{}} {HH + HV + VH + VV}&{HH + HV - VH - VV}&{PH + PV - MH - MV}&{RH + RV - LH - LV}\\ {HH - HV + VH - VV}&{HH - HV - VH + VV}&{PH - PV - MH + MV}&{RH - RV - LH + LV}\\ {HP - HM + VP - VM}&{HP - HM - VP + VM}&{PP - PM - MH + MM}&{RP - RM - LP + LM}\\ {HR - HL + VR - VL}&{HR - HL - VR + VL}&{PR - PL - MR + ML}&{RR - RL - LR + LL} \end{array}} \right] \end{array}\\ \end{eqnarray*}\end{document}where 6 different polarization states of the incident light and analyzed light are generated for measurement purposes: horizontal linear (H), vertical linear (V), 45-degree linear (P), 135-degree linear (M), right circular (R), and left circular (L). From these 6 polarization states, a total of 36 images are obtained by the CCD placed after the analyzer module sample: HH, HV, HP, HM, HR, HL, VH, VV, VP, VM, VR, VL, PH, PV, PP, PM, PR, PL, MH, MV, MP, MM, MR, ML, RH, RV, RP, RM, RR, RL, LH, LV, LP, LM, LR, and LL. Note that the first letter of each notation describes the polarization state generated by the polarization state generator (PSG) in the polarimetry system, while the second letter describes the polarization state generated by the polarization state analyzer (PSA). Having obtained the 36 images, the Mueller matrix image for the sample is computed as shown in Eq. (1). For example, element m_11_ is obtained by superimposing (HH), (VV), (HV), and (VH) as m_11_ = HH + HV + VH + VV. Similarity, 36 data images can thus be converted into 16 Mueller matrix images for the remaining matrix elements. In the present study, the matrix elements were constructed using a self-written program coded in Python to merge the individual polarized photos as required. The details on converting from 36 polarization state images to 16 elements of the Mueller matrix images are publicly available, as described in [24].
The microstructural properties of the tissue samples can be determined using the MMT parameters described detail in [25–30]. Accordingly, the anisotropy (A), the depolarization power factor (b), the magnitude of the anisotropy attribute (t), the degree of anisotropy or isotropy (G), and the depolarization power (Δ) are defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} A = \frac{{2\left( {{{m}_{22}} + {{m}_{33}}} \right)\sqrt {{{{\left( {{{m}_{22}} - {{m}_{33}}} \right)}}^2} + {{{\left( {{{m}_{22}} + {{m}_{33}}} \right)}}^2}} }}{{{{{\left( {{{m}_{22}} + {{m}_{33}}} \right)}}^2} + {{{\left( {{{m}_{22}} - {{m}_{33}}} \right)}}^2} + {{{\left( {{{m}_{23}} + {{m}_{32}}} \right)}}^2}}}, \in \left[ {0,1} \right] \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} b = \frac{{{{m}_{22}} + {{m}_{33}}}}{2} \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} t = \frac{{\sqrt {{{{\left( {{{m}_{22}} - {{m}_{33}}} \right)}}^2} + {{{\left( {{{m}_{23}} + {{m}_{32}}} \right)}}^2}} }}{2} \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} G = \sqrt {1 - \frac{{2{{{({{m}_{22}}{{m}_{33}} - {{m}_{22}}{{m}_{33}})}}^2}}}{{2{{{({{m}^2}_{23} + {{m}^2}_{22} + {{m}^2}_{33} + {{m}^2}_{32})}}^2}}}} \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \Delta = 1 - \frac{{\left| {{{m}_{22}}} \right| + \left| {{{m}_{33}}} \right| + \left| {{{m}_{44}}} \right|}}{3},0 \le \Delta \le 1 \end{eqnarray*}\end{document}Image acquisition system
Figure 4 illustrates the experimental polarimetry system used to obtain the MMT parameters of the healthy and cancerous tissue samples. As shown, the polarization system comprised a PSG block for generating polarized images and a PSA block for analyzing these images. In particular, the PSG block was used to produce incident lights with particular states of polarization, while the PSA block was used to adjust the polarization state of the beam scattered by the sample. The PSG block consisted of a frequency-stable He-Ne laser (HNLS008R; Thorlabs) with a central wavelength of 633 nm, a linear polarizer P1 (GTH5M; Thorlabs) to generate 4 linear polarization states (i.e., 0° [denoted as H], 45° [denoted as P], 90° [denoted as V], and 135° [denoted as M]), a quarter-wave plate Q1 (QWP0-63304-4-R10; CVI) to produce left-handed circular polarization light (denoted as L) and right-handed circular polarization light (denoted as R), a convex lens L1 (LSSB04-A; Thorlabs), and a concave lens L2 (LSSB04-A; Thorlabs). The PSA block consisted of a linear polarizer P2 (GTH5M; Thorlabs), a quarter-wave plate Q2 (QWP0-63304-4-R10; CVI), and a CCD camera (CCD, DCU224C; Thorlabs) fitted with a zoom lens and connected to a computer. Elements P2 and Q2 in the analyzer performed the same functions as P1 and Q1 in the generator. The polarizers P1 and P2 and quarter-wave plates Q1 and Q2 were mounted on rotation motorized stages (SGSP-60YAW-0B; Sigma Koki) to generate the 36 polarization states required to construct the Mueller matrix for each sample. In the experiments, the linear polarization states of the PSG block were produced by rotating the polarizer (P1), and the circular polarization states were generated by rotating Q1 to the right- and left-hand circular polarization states, respectively. The same procedure was adopted to generate the required polarization states for the PSA block.
Schematic of the experimental setup.
Figure 5 illustrates the overall framework of the data collection and analysis tasks performed in this study. As described in Sample Preparation section, some of the sliced samples were stained with H&E and observed under a microscope for reference purposes. Meanwhile, the unstained samples were measured using the experimental polarimetry system. The 36 polarization state images captured by the measurement system for each sample were used to construct a colorectal cancer polarimetric (ColoPola) dataset. The polarization images in the ColoPola dataset were used in 2 ways: (i) to construct Mueller matrix images of the cancerous and healthy tissue samples and analyze the properties (average intensity, polarization parameters, and frequency distribution histograms [FDHs]) of the 16 elements in each sample class and (ii) to serve as the inputs for AI models designed to classify the samples as either healthy or cancerous colorectal tissue.
Research framework.
ColoPola dataset
Figure 6 shows the 36 images of a typical healthy tissue sample and a typical malignant CRC sample, respectively, where these images were acquired using 6 input polarization states and 6 output polarization states, as described in Mueller matrix transformation section. The ColoPola dataset consists of 572 tissue slices, of which 284 are cancer samples and 288 are normal (healthy) samples. For each slice, 36 polarimetric images are prepared. Thus, the dataset contains 20,592 images (10,224 malignant and 10,368 malignant). Each image has a size of 1,280 × 1,024 pixels and is stored in the TIFF file format. The dataset is available for downloading in 6 Roshal archive (RAR) files, 3 with polarimetric images of standard samples (12.2 GB total) and 3 with polarimetric images of colorectal cancer samples (15.3 GB total). A single Python script, colorectalcancer_main_ver1.py, is utilized to convert 36 polarimetric images into 16 Mueller matrix images (see Fig. 2). Moreover, a README file (README.md) provides additional information about sample name (name id), alongside 2 text files (train.txt and test.txt) that contain the list of samples in training and validation sets (457 samples) and the testing set (115 samples) [31].
Thirty-six images of (A) normal and (B) malignant colorectal samples.
For the AI classification task, the ColoPola dataset was divided into 3 sets for training, validation, and testing purposes, respectively, in a ratio of approximately 65:15:20. The size and composition of each set are listed in Table 1. The training set contained 365 slices (184 normal slices and 181 cancer slices). The validation set contained 92 slices (46 normal and 46 cancerous), and the testing set contained 115 slices (58 normal and 57 cancerous). It should be noted that the samples in the ColoPola dataset were uniformly distributed between the normal and cancer classes (288:284 samples) and were randomly assigned to the training, validation, and testing sets.
Data Processing and Deep Learning Models
Data processing
The images captured by the CCD camera had a size of 1,280 × 1,024 pixels (Fig. 7). To reduce the computational cost while preserving sufficient polarimetric information for classification purposes, the images were cropped using a kernel of size 900 × 900 pixels, located at the center of the original image [32]. The images were then saved in the ColoPola dataset in a PNG format.
Input images (A) before and (B) after cropping.
As described above, the ColoPola dataset contained 36 polarimetric images for each cancerous and healthy sample. Each image consisted of 3 basic channels: red, green, and blue. Figure 8 shows the distribution of the intensity values of the 36 color images associated with a typical healthy sample. The intensity values of the green channel are all almost equal to zero, and most of the pixels in the blue channel have intensity values in the interval [0, 4]. In contrast, the intensity values of the red channel vary over the full interval of [0, 255] in most of the 36 images. Figure 9 shows the frequency distributions of the 3 color channels for a typical malignant sample. As shown, the color channel information is available for the first column (HH, LH, MH, PH, RH, and VH) and fourth column (HP, LP, MP, PP, RP, and VP) of the images. However, for the rest images, no color channel information is available. These images yield no useful information for model training and may introduce errors. Each channel might provide sufficient information for the analysis. However, based on the results obtained from Figs. 8 and 9, it is indicated that the blue and green channels can be ignored and do not affect the results. In addition, using a single red channel as the primary input data reduces the time-consuming and costly analysis. Thus, to ensure consistent learning performance across the 2 classes (healthy and malignant), the red channel was chosen as the primary input data for each image in the dataset. Accordingly, the size of the input data was set as 900 × 900 × 36, corresponding to the width, height, and red channel value of 36 polarimetric images, respectively. Note, however, that in accordance with the normal input size for most common DL models, the input images were rescaled to a size of 224 × 224 × 36 before processing.
Histograms of RGB intensity values for normal tissue samples.
Histograms of RGB intensity values for malignant tissue samples.
Deep learning models
The normal and cancerous tissue samples were classified using 5 deep learning models, including 3 models built from scratch (i.e., CNN, CNN_2, and EfficientFormerV2) and 2 pretrained models (i.e., DenseNet-121 and EfficientNetV2-M). It is noted that the pretrained models utilized weights that were trained on the ImageNet-1K dataset, as detailed in this study’s GitHub repository. Figure 10 shows the architecture of the CNN and CNN_2 models. Both models utilize convolutional blocks consisting of a convolutional layer (Conv) with a kernel size of 3, batch normalization (BN) [33], rectified linear unit (ReLU), and dropout [34] with a probability of 0.2 (after numerous trial-and-error steps). The CNN model has an architecture similar to that of VGG [35] but is smaller. Furthermore, it uses only 1 convolutional layer before applying an activation function (AvgPool) and then 2 fully connected (FC) layers to reduce the number of features from 512 to 256. In the CNN_2 model, a convolutional block with a stride of 2 is used instead of the max pooling layer (MaxPool) to reduce the data dimensions [36]. In addition, a convolutional block with a kernel size of 1 × 1 is used to replace the FC layers in the CNN model for the same purpose. Meanwhile, the EfficientFormerV2-S0 model [37] was chosen and trained from scratch, similar to the CNN and CNN_2 models. The EfficientFormerV2 architecture was introduced as a vision transformer to maintain a small size with low latency and high parameter efficiency. The EfficientFormerV2 network was applied to various advanced techniques (i.e., token mixer, improved multihead self-attention, stride attention, and attention on downsampling) for improvements and then utilized a fine-grained joint search method to find the optimal model size and speed. This network outperformed the previous EfficientFormer [38] with similar latency and parameters on several experiments.
CNN and CNN_2 architectures.
Two pretrained DL models, DenseNet-121 [39] and EfficientNetV2-M [40], were selected and fine-tuned for the ColoPola dataset. The DenseNet architecture uses the concept of residual connections, in which all the previous features are concatenated iteratively. By fine-tuning the model in each layer based on all the preceding feature maps, DenseNet can learn the parameters more efficiently. Meanwhile, EfficientNetV2 is optimized to increase the training speed and parameter efficiency. Similar to EfficientNet [41], the EfficientNetV2 model includes several new convolutional blocks (such as Fused-MBConv) that replace the depth-wise 3 × 3 Conv and expansion 1 × 1 Conv in EfficientNet with a normal 3 × 3 Conv after using the neural architecture search. Moreover, progressive learning with adaptive regularization is applied to gradually increase image size and the regularizations at a specific stage. By doing so, EfficientNetV2 achieves both a faster speed and a smaller size than EfficientNet.
The inputs of the DenseNet-121 and EfficientNetV2-M models both have 3 channels (i.e., the red, green, and blue color values of the images). However, the inputs of the present study have 36 channels (i.e., 36 polarimetric images of each sample). Therefore, the number of input channels of the first convolutional layer in both models was increased from 3 to 36, where the weights of the first 3 channels were unchanged while those of the remaining 33 channels were initialized using the He technique [42].
Table 2 shows the hyperparameters used to train the 5 models. As shown, most of the hyperparameters were the same for all 5 models. However, different initial learning rates were applied to the models built from scratch (CNN, CNN_2, and EfficientFormerV2-S0) and the pretrained models (DenseNet-121 and EfficientNetV2-M). In particular, CNN and CNN_2 were trained with a higher learning rate to accelerate the model update in the first few epochs. For all 5 models, learning rate scheduling (ReduceLROnPlateau scheduler) was applied when the metrics ceased to improve in successive iterations during the latter stages of the training process. Moreover, the early stopping technique [43] was utilized to mitigate overfitting by monitoring the validation loss. All of the models were implemented on a desktop computer using the PyTorch library with an Intel i7-12700 CPU, 32 GB RAM, and a GeForce RTX 4070 GPU.
For each model, 572 samples were input into the learning algorithm, where 457 samples were used for training and validation purposes (i.e., 80% of the dataset) and 115 samples were retained for testing (i.e., 20% of the dataset). To increase the amount of training data, an augmentation technique (e.g., random rotation, contrast-limited adaptive histogram equalization, blur) was applied before the training process (see Fig. 5) [44].
Performance metrics
The performance of the 5 classifiers in the training, validation, and testing stages was evaluated using 4 metrics—namely, the accuracy, precision, recall, and F1 score—defined respectively as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} {\mathrm{Accuracy}} = \frac{{TN + TP}}{{TN + FP + TP + FN}} \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} {\mathrm{Precision}} = \frac{{TP}}{{TP + FP}} \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} {\mathrm{Recall}} = \frac{{TP}}{{TP + FN}} \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} {\mathrm{F1\textit{score}}} = 2 \times \frac{{{\mathrm{Precision}} \times {\mathrm{Recall}}}}{{{\mathrm{Precision + Recall}}}} \end{eqnarray*}\end{document}where TP, TN, FP, and FN denote true positive, true negative, false positive, and false negative, respectively. The accuracy metric is simply the ratio of the correctly predicted observations to the total number of observations and is thus the most intuitive performance measure. The precision metric evaluates the proportion of positive class predictions that truly belong to the positive class, while the recall metric evaluates the number of positive class predictions as a proportion of the total number of positive examples in the dataset. Finally, the F1 score provides a weighted average of the precision and recall metrics in a single measure.
Results and Discussion
Construction of Mueller matrix images using the ColoPola dataset
Mueller matrix images and intensity values
To demonstrate the utility of the ColoPola dataset, this section describes 2 Mueller matrix images (1 for a healthy tissue sample and 1 for a malignant sample) constructed using the polarization images in the dataset and Eq. (1). A preliminary investigation revealed that the standard deviations of the element intensities in each sample class (healthy and malignant) were statistically insignificant. Thus, it was inferred that any sample could be used to represent the entire class. For both matrices in Fig. 11, the matrix elements are normalized by m_11_. Furthermore, the intensity of the Mueller matrix elements has a value in the range of [−1, 1], corresponding to a color change from blue to red. It is seen that the matrices corresponding to the healthy and malignant samples are qualitatively different. For example, the matrix of the normal colorectal tissue sample is predominantly green, corresponding to a neutral intensity, and the color boundaries between adjacent images are relatively indistinct. By contrast, for the cancerous sample, most of the images are readily distinguishable from their neighbors, and the matrix contains a greater distribution of red and blue pixels, indicating the presence of regions of extreme intensity variation. Overall, the results confirm the feasibility of using the polarization images in the ColoPola dataset to qualitatively distinguish between healthy and cancerous colorectal tissue samples.
Mueller matrix images of (A) normal colorectal tissue and (B) cancerous colorectal tissue.
Table 3 lists the intensity values of the Mueller matrix elements for the healthy and malignant colorectal tissues. Both classes show diagonal symmetry, in which elements m22 and m33 have similar values of 0.2845 and 0.2818, respectively, for the healthy tissue and 0.1732 and 0.1743, respectively, for the malignant tissue. In general, the intensity values of the elements in the cancerous sample are much lower than those in the cancerous sample and show a greater variation across the matrix elements. Thus, it is inferred that the cancerous sample is anisotropic, implying that it has a more complex microstructure.
Figure 12 shows the t-test results for the intensity differences between the elements of the normal and cancerous colorectal tissues. The element intensities of the healthy samples differ from those of the cancerous samples, with a significance level of P < 0.0001 for almost all the elements, including m13, m_14_, m_22_, m_23_, m_24_, m_31_, m_32_, m_33_, m_34_, m_41_, m_42_, and m_43_. In other words, the matrix elements of the 2 tissue classes are statistically different, and hence the polarimetric images provide valid inputs for AI models designed to distinguish between them.
*Average intensity of Mueller matrix elements in normal and cancerous colorectal tissues. The t-tests with statistically significant levels of P < 0.0001 (marked by ***) are used to examine differences in MMT parameters.
Mueller matrix transformation parameters
One of the main obstacles to the practical application of the Mueller matrix is the lack of obvious physical meaning for each component. In particular, each element may be significantly affected by different structural traits, which causes the appearance of the Mueller matrix to be very different for different dispersion media. Thus, the concept of MMT parameters has been introduced to provide a more quantitative approach for measuring the polarization variables of the Mueller matrix components associated with specific microstructures or optical characteristics of the medium, such as the subwavelength scatterer density values and widths, or fiber orientation and alignment [25]. In the present study, polarization images were produced using each of the MMT parameters, and the corresponding Mueller matrix was then constructed pixel-by-pixel using Python code to integrate the MMT images. Figure 13 shows the MMT parameter values obtained from Eqs. (2) to (6) for healthy and malignant colorectal tissues, respectively. Both samples have values of A and G close to 1, which indicates significant anisotropy [25]. The values of b and t for the cancerous tissue are also slightly lower than those for the healthy sample. However, the depolarization power, ∆, and parameter b have an inverse relationship, as discussed by He et al. [25]. Hence, the depolarization power of the malignant sample is higher than that of the benign sample. According to Sun et al. [28], a higher value of ∆ indicates a greater anisotropy. Thus, the results presented in Fig. 13 confirm the finding in Fig. 11 that the cancerous tissue sample is more anisotropic than the healthy sample and has a more complex microstructure.
MMT parameters in normal and cancerous colorectal tissues. The asterisks (**) represent the P values <.0001, as determined by the paired t-test.
Frequency distribution histograms (FDHs)
Figure 14 shows the FDHs of the intensity of the 15 normalized elements in the Mueller matrix images of the healthy and cancerous colorectal tissue samples. Although the 2 curves in each figure overlap, in most cases, the peaks of the curves are distinct. Consequently, the intensity feature of the images provides a viable means of differentiating between the 2 sample classes. However, for each element, the AUCs of the healthy and malignant samples differ, and thus an appropriate setting of the machine learning hyperparameters is essential to determine the elements required to most reliably classify the 2 groups of data.
FDHs of 15 Mueller matrix elements in normal and colorectal cancer tissues.
AI models for classification of colorectal cancer based on the ColoPola dataset
Figure 15 shows the classification performance of the 5 DL models when applied to the validation and testing sets. The EfficientNetV2 model achieved the highest F1 score of the 5 models on both datasets (F1 = 0.978 for the validation set and 0.965 for the testing set) and showed a difference of less than 1.5% between the 2 datasets for all 4 metrics. The DenseNet model also showed a good performance, with all the metrics having a value higher than 90% for both sets, except for the recall metric for the testing set (0.895). Meanwhile, the EfficientFormerV2 showed a similar performance with DenseNet on the F1 score, but EfficientFormerV2 had higher recall (0.978 and 0.947) and lower precision scores (0.937 and 0.871) on both datasets than the DenseNet. The CNN and CNN_2 models achieved a relatively lower performance, with precision values of 0.862 and 0.847, respectively, for the testing set. Similar to the EfficientFormerV2, the CNN_2 model exhibited a large difference of approximately 6% between the precision scores for the validation set and testing set, respectively.
Performance metrics of 5 models onthe validation set and testing set.
As shown in Fig. 16, the CNN model showed a relatively high false-positive rate (FPR) when classifying the malignant (positive) cancer class, with 3 FP samples in the validation set and 8 in the testing set. More worryingly, the CNN model also had a high false-negative rate (FNR) for the normal (negative) class, with 7 FN samples in both datasets. The CNN_2 model exhibited a slightly poorer classification performance, with FP values of 5 and 9 and FN values of 3 and 7 in the validation and testing sets, respectively (Fig. 17). Similar to both CNN and CNN_2, the EfficientFormerV2 model had the high FPR, especially on the testing set, with FP values of 8 (Fig. 18). Overall, the CNN model had the lowest recall owing to the high FNR for the 2 datasets, while the CNN_2 model had the lowest precision score owing to the high FPR of the 2 datasets. In addition, EfficientFormerV2 had the largest difference of precision score between validation and testing sets because of the difference in FP values on these datasets (see Fig. 15).
Confusion matrix for the CNN model on the validation and testing sets.
Confusion matrix for the CNN_2 model on the validation and testing sets.
Confusion matrix for the EfficientFormerV2 model on the validation and testing sets.
The DenseNet erroneously classified 3 cancer samples as normal in the validation dataset and 6 cancer samples as normal in the testing dataset (Fig. 19). In contrast, EfficientNetV2 misclassified only 1 cancer sample in the validation set and 2 in the testing dataset (Fig. 20). Overall, therefore, EfficientNetV2 outperformed DenseNet for all 4 performance metrics, as shown in Fig. 15.
Confusion matrix for the DenseNet model on the validation and testing sets.
Confusion matrix for the EfficientNetV2 model on the validation and testing sets.
Two statistical tests (McNemar’s and 2-sided binomial) [46] were applied to further compare the binary classification performance of the 5 trained models when applied to the testing set. The models were compared through side-by-side comparisons under the null hypothesis that the 2 models should show no significant difference in their classification ability. That is, the number of samples classified as normal by model A but classified as cancer by model B (n_01_) should be equal to the number of examples classified as cancer by model A but classified as normal by model B (n_10_). The evaluation results are presented in Table 4, where the significance level (α) was set at 0.05 for both statistical tests. In McNemar’s test, the P value was calculated based on the chi-square (χ^2^) distribution with continuity correction and 1 degree of freedom. However, some of the paired models (CNN vs. CNN_2, CNN vs. EfficientFormerV2, DenseNet vs. EfficientFormerV2) had very few examples (n_01_ + n_10_ ≤ 10), and hence a 2-sided binomial test was required to properly identify any difference between them. The binomial test for such models was calculated with a probability of 0.5, indicating an assumption that there was a 50% chance of the model’s output being true or false. The sig entries at the foot of the table indicate a significant difference (Yes) if the P value is less than α or no difference (No) if the P value is greater than α. Overall, the results presented in the table show no significant difference in the performance of the 5 trained models on the testing set. In other words, the null hypothesis cannot be rejected, and hence all 5 models can be used with the ColoPola dataset to detect colorectal cancer.
In the present study, the input data had a size of 224 × 224 and 36 channels, as described in Data processing section. Based on preliminary experiments, the first convolutional layers in the CNN and CNN_2 models were designed to extract 128 output features in order to achieve a balance between the amount of usable information obtained and the computational complexity. The original EfficientFormerV2, DenseNet, and EfficientNetV2 models are designed to classify color images using the red, green, and blue channel values as the input data. In order to ensure consistent learning performance across the healthy and malignant classes, the red channel was chosen as the primary input data for each image in the dataset. Using a single red channel as the primary input data reduces the time-consuming and costly analysis compared to method proposed in [47, 48]. Moreover, the default values of the number of output features in the first convolutional layers of the 3 models are 16, 64, and 24, respectively. Thus, when processing a 36-channel input, insufficient information may be extracted from the first convolutional layer for transfer to the next layers, particularly in the case of the EfficientFormerV2 and EfficientNetV2 models. However, both the DenseNet and EfficientNetV2 models are much deeper and more sophisticated than the CNN and CNN_2 models. Meanwhile, EfficientFormerV2 has a different strategy when combining the extracted features from convolution and vision transformer networks to obtain the useful information, despite training from scratch. Consequently, they outperform both models despite this potential limitation (see Fig. 15). The performance improvement is particularly evident for the EfficientNetV2 model, owing to its use of various techniques (e.g., new convolutional blocks; a combination of optimized scaling on width, height, and resolution; and a progressive learning technique) to optimize the training speed and parameter efficiency compared to the method proposed in [49, 50, 51], or combining both data types [52]. However, the input data in the present study are large (i.e., 36 channels). In other words, each input requires the preprocessing of 36 polarimetric images, followed by the concatenation of the red channels of these images. This is a time-consuming task, which can require a high-performance computing system for large datasets. Moreover, when applying the transfer learning technique, it is necessary to modify the first layer of the pretrained models to accommodate the new input format.
One limitation of this study is that the dataset was derived exclusively from 2 hospitals in Vietnam, which may limit the generalizability of the findings to broader and more diverse populations. Additionally, the distribution of cancer stages within the dataset was constrained by the availability of patients during the data collection period. Moving forward, we plan to expand the dataset to collect more data in different geographic and ethnic regions for multicenter and multiethnic datasets, as well as widen the range of cancer stages based on hospital diagnostic records and evaluations from clinical specialists.
Conclusion
This study has presented a dataset of colorectal cancer polarimetric images, designated as ColoPola, containing 10,368 instances of healthy colorectal tissue and 10,224 instances of colorectal cancer tissue corresponding to 572 tumor slices (36 polarization images per slice). The observation results have shown that the Mueller matrix images of both classes have diagonal symmetry. However, in cancerous tissues, the diagonal components are generally lower than those in healthy tissues, indicating that the cancerous samples have a more complex microstructure. The difference in the degree of anisotropy between the 2 sample classes has been confirmed through a comparison of the MMT parameters, which showed that the ∆ value of the cancerous samples is higher than that of the healthy samples. Notably, a significant difference has been found between all the MMT parameter values for the 2 classes. In other words, the MMT parameters provide a viable means of distinguishing between the healthy and malignant CRC samples.
The utility of the ColaPola dataset for classification purposes has been evaluated using 5 DL models, including 3 models trained from scratch (CNN, CNN_2, and EfficientFormerV2) and 2 pretrained models (DenseNet and EfficientNetV2). For each model, the input data had a size of 224 × 224 × 36, where the latter dimension corresponds to the red channel values of the 36 polarimetric images associated with each tumor slice. The results showed that EfficientFormerV2, DenseNet, and EfficientNetV2 both achieved an F1 score of more than 90% on the testing set. By contrast, the CNN and CNN_2 models achieved lower F1 scores of 87% and 86.2%, respectively. The superior performance of the pretrained models can be attributed to their deeper structures and more sophisticated operations. Overall, the results suggest that the ColoPola dataset serves as a useful resource for further research into the identification of CRC malignant tissue using statistical methods based on the MMT parameters or machine learning methods based on the red channel values of the polarimetric images.
Supplementary Material
giaf120_Authors_Response_To_Reviewer_Comments_Original_Submission
giaf120_GIGA-D-25-00173_Original_Submission
giaf120_GIGA-D-25-00173_Revision_1
giaf120_Reviewer_1_Report_Original_SubmissionRuitian Gao -- 6/29/2025
giaf120_Reviewer_1_Report_Revision_1Ruitian Gao -- 9/3/2025
giaf120_Reviewer_2_Report_Original_SubmissionXiaobo Li -- 7/3/2025
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sung H, Ferlay J, Siegel RL, et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2021;71(3):209–49. 10.3322/caac.21660.33538338 · doi ↗ · pubmed ↗
- 2Sninsky JA, Shore BM, Lupu GV, et al. Risk factors for colorectal polyps and cancer. Gastrointest Endosc Clin N Am. 2022;32(2):195–213. 10.1016/j.giec.2021.12.008.35361331 · doi ↗ · pubmed ↗
- 3Bond JH . Colorectal cancer screening: the potential role of virtual colonoscopy. J Gastroenterol. 2002;37(Suppl 13):92–96. 10.1007/BF 02990108.12109675 · doi ↗ · pubmed ↗
- 4Akhtar R, Lee M, Itzkowitz SH. Colonoscopy versus computed tomography colonography for colorectal cancer screening. Mt Sinai J Med. 2010;77(2):214–24. 10.1002/msj.20175.20309919 · doi ↗ · pubmed ↗
- 5Bretthauer M, Holme O, Garborg K. Computed tomography colonography vs. colonoscopy for colorectal cancer screening: close call, but not closed case. Endoscopy. 2013;45(3):159–60. 10.1055/s-0032-1326208.23446666 · doi ↗ · pubmed ↗
- 6Le NT, Dao HV. Colorectal cancer in Viet Nam. Intech Open 2020. 10.5772/intechopen.93730. Accessed 20 October 2024. · doi ↗
- 7Winawer SJ, Zauber AG, Ho MN, et al. Prevention of colorectal cancer by colonoscopic polypectomy. N Engl J Med. 1993;329:1977–81. 10.1056/NEJM 199312303292701.8247072 · doi ↗ · pubmed ↗
- 8Ahlquist DA . Stool-based tests vs screening colonoscopy for the detection of colorectal cancer. Gastroenterol Hepatol (N Y). 2019;15(8):437–40. https://pubmed.ncbi.nlm.nih.gov/31592245/.31592245 PMC 6771036 · pubmed ↗