A Resource-Virtualized and Hardware-Aware Quantum Compilation Framework for Real Quantum Computing Processors
Hong-Ze Xu, Xu-Dan Chai, Meng-Jun Hu, Zheng-An Wang, Yu-Long Feng, Yu Chen, Xinpeng Zhang, Jingbo Wang, Wei-Feng Zhuang, Yu-Xin Jin, Yirong Jin, Haifeng Yu, Heng Fan, Dong E. Liu

TL;DR
This paper introduces QSteed, a quantum compilation framework that uses resource virtualization and hardware-aware techniques to efficiently compile programs for real quantum processors.
Contribution
The novel contribution is the integration of resource virtualization and hardware-aware compilation in a 4-layer abstraction model for quantum processors.
Findings
QSteed's virtualization model and compiler workflow were validated on the Quafu superconducting cluster.
The framework enables efficient compilation without requiring user code modifications.
The approach shows promise for scaling across various superconducting quantum platforms.
Abstract
As quantum computing systems continue to scale up and become more clustered, efficiently compiling user quantum programs into high-fidelity executable sequences on real hardware remains a key challenge for current quantum compilation systems. In this study, we introduce a system-software framework that integrates resource virtualization and hardware-aware compilation for real quantum computing processors, termed QSteed. QSteed virtualizes quantum processors through a 4-layer abstraction hierarchy comprising the real quantum processing unit (QPU), standard QPU (StdQPU), substructure of the QPU (SubQPU), and virtual QPU (VQPU). These abstractions, together with calibration data, device topology, and noise descriptors, are maintained in a dedicated database to enable unified and fine-grained management across superconducting quantum platforms. At run time, the modular compiler queries the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
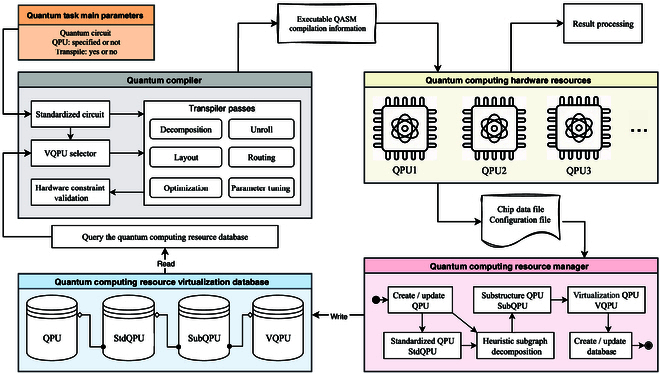 Fig. 1
Fig. 1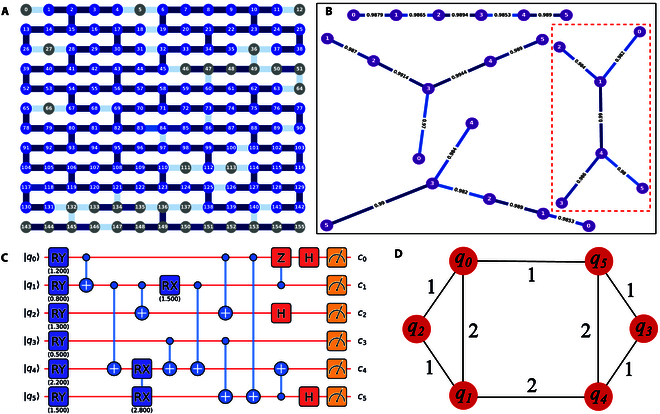 Fig. 2
Fig. 2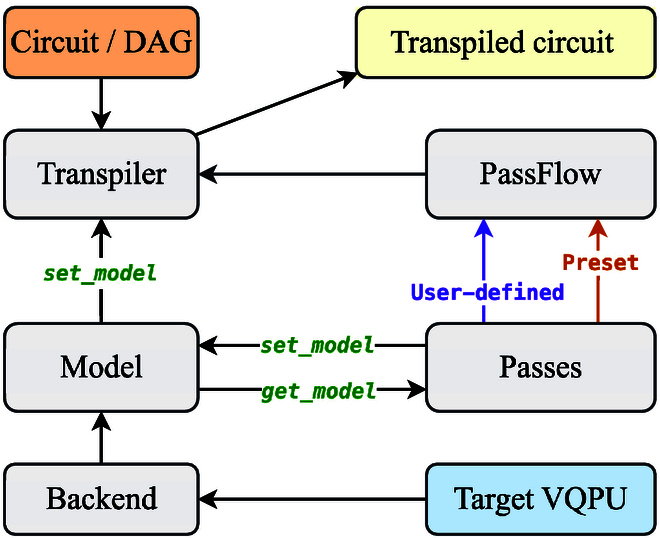 Fig. 3
Fig. 3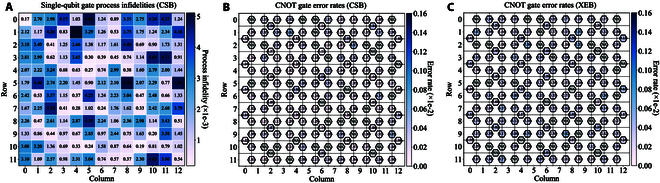 Fig. 4
Fig. 4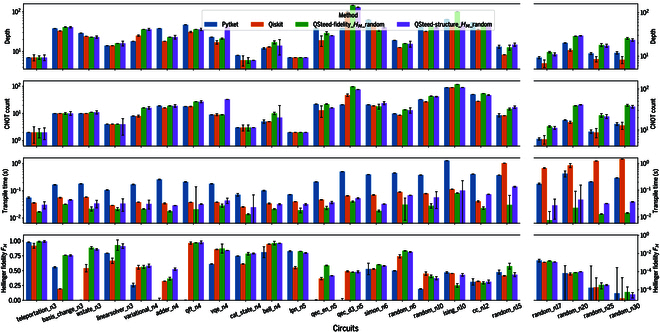 Fig. 5
Fig. 5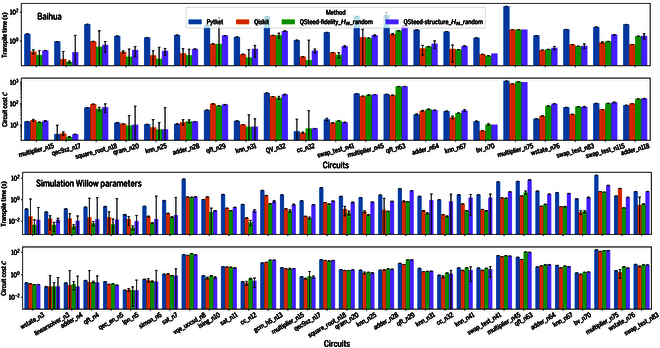 Fig. 6
Fig. 6- —Natural Science Foundation of Beijing Municipalityhttp://dx.doi.org/10.13039/501100004826
- —the National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsQuantum Computing Algorithms and Architecture · Cloud Computing and Resource Management · Parallel Computing and Optimization Techniques
Introduction
In recent years, various quantum computing platforms, including superconducting qubit [1–4], ion trap [5–7], neutral atoms [8–10], and photonic quantum devices [11,12], have achieved remarkable progress, with increasing qubit control fidelities and scalable architectures reaching dozens or even hundreds of qubits. Despite these advances, quantum computing devices remain scarce resources. The advent of quantum cloud platforms has alleviated this limitation by providing remote access to both public and private quantum hardware via cloud services. This paradigm shift substantially lowers the threshold for quantum experimentation and accelerates progress in domains such as quantum chemistry [13,14], machine learning [15–17], combinatorial optimization [18], and fundamental quantum physics [19,20]. However, deploying high-level quantum algorithms on real hardware remains challenging due to the mismatch between algorithmic abstractions and hardware operations. Bridging this gap depends on efficient quantum compilation, which serves as a critical layer for transforming quantum programs into hardware-executable instructions.
In the field of quantum compilation, several commercial-grade software frameworks have been developed, including IBM’s Qiskit [21], Google’s Cirq [22], Rigetti’s PyQuil [23], Quantinuum’s Pytket [24], and Origin Quantum’s QPanda [25]. These frameworks provide comprehensive toolchains that are tightly integrated with their respective hardware platforms. Concurrently, academic research has produced a number of specialized toolkits, such as Quartz [26] for circuit super-optimization and BQSKit [27] that incorporates advanced synthesis algorithms. Additionally, there are compilers tailored to specific quantum algorithms, such as Qcover [28] for the quantum approximate optimization algorithm (QAOA) [29]. Despite these advances, most existing frameworks still face challenges in handling hardware noise and adapting to multi-backend cloud platforms. They generally follow a common paradigm: mapping logical circuits directly onto the entire physical device. However, in the noisy intermediate-scale quantum (NISQ) era, hardware noise on quantum processors (such as 2-qubit gate error rates) is nonuniformly distributed. Simply compiling and optimizing circuits by mapping them to the full chip neglects the intrinsic differences of hardware resources. In this context, developing compilation strategies that proactively avoid high-noise hardware resources emerges as an effective pathway to improving quantum program performance. Furthermore, deploying compilation software on multi-backend heterogeneous quantum cloud platforms and achieving unified resource management and hardware-aware compilation still requires further architectural innovation.
In this work, rather than concentrating on specific compilation optimization algorithms, we focus on an architectural-level innovation in compilation design. We introduce QSteed, a novel quantum compilation system designed for deployment on superconducting quantum computing platforms. QSteed embodies a distinct architectural paradigm built on resource virtualization and a select-then-compile workflow. In particular, it tightly integrates a modular compiler with a quantum resource virtualization layer, featuring several key characteristics: (a) The resource virtualization manager uses heuristic strategies to identify high-quality subregions of a quantum chip, which are then abstracted into a queryable database of virtual quantum processing units (VQPUs). This enables efficient and unified management of multiple quantum backends. (b) The quantum compiler first selects an optimal VQPU for a given input circuit based on structural similarity or fidelity metrics. It then performs efficient, hardware-aware transpilation on this smaller subregion to generate a high-fidelity executable circuit. (c) The system is packaged into 2 lightweight application programming interfaces (APIs), one for adding or updating quantum processors in the database and another for user task compilation, simplifying integration with existing superconducting quantum cloud toolchains.
We have deployed QSteed on a quantum cloud computing cluster based on superconducting qubit processors. Specifically, it has been integrated into the Quafu quantum cloud platform, which validates the effectiveness of its overall architecture. To assess QSteed’s compilation performance, we executed benchmark circuits with up to 30 qubits on Quafu’s Baihua processor and simulated larger circuits using calibration parameters from the Baihua chips. To further examine the robustness of the QSteed architecture, we performed the same simulations with parameter data from Google’s Willow processor. Experiments on real hardware and classical simulations show that, for the evaluated small- to medium-scale benchmark circuits, QSteed consistently outperforms leading toolchains such as Qiskit and Pytket in compilation speed while achieving comparable or higher circuit fidelity. Overall, QSteed provides efficient support for practical quantum cloud services. Conceptually, the architecture has the potential to be extended to other quantum computing platforms, but realizing such portability would require redesigning the VQPU database generation and qubit mapping strategies for each specific hardware architecture. At present, all implementations and experiments are based on superconducting qubit platforms.
Results
Overall system architecture design
As schematically depicted in Fig. 1, the QSteed system is designed with a layered architecture. Its core consists of 2 key functional modules: a quantum compiler and a quantum computing resource manager. Through a unified API interface, the system enables efficient and seamless hardware deployment. The operational workflow of the system is as follows:
QSteed system architecture. It consists primarily of 2 components: the quantum compiler and the quantum computing resource manager. The manager models the quantum chip at various abstraction levels, including QPU, StdQPU, SubQPU, and VQPU. These representations are stored in a quantum computing resource virtualization database, enabling unified management of quantum backend devices. The compiler queries the virtualization database to compile the user task onto the optimal physical qubits, returning the optimized executable QASM circuit along with relevant compilation information.
On the hardware management side, a backend operator registers a quantum processor via the Manager API. This process imports essential metadata, such as device topology, real-time calibration data, and native gate sets, into the resource manager. The manager then proactively virtualizes the physical hardware by constructing a 4-layer hierarchical model: QPU, standard QPU (StdQPU), substructure of the QPU (SubQPU), and VQPU. These models are stored in a relational database, establishing a precomputed and queryable resource pool for the compiler, which enables unified management across multiple superconducting backends.
On the quantum task processing side, a user task (containing information such as the quantum circuit and whether a backend is designated) is forwarded to the compiler through the Compiler API. The compiler adopts a select-then-compile workflow: First, the input circuit is standardized by rewriting it into a hardware-agnostic unified representation. Next, the compiler queries the resource database to select an optimal VQPU that best matches the circuit’s structural or fidelity requirements. Once the target VQPU has been determined, the compiler executes a hardware-aware transpilation process tailored to this optimal subregion, generates quantum assembly language (QASM) [30,31] code ready for the target hardware, and returns a detailed compilation report (e.g., compilation time, circuit depth, and gate counts). Finally, it performs hardware constraint verification on the output to ensure that the generated QASM code can run safely and directly on the selected quantum processor.
By deeply integrating the compilation process with resource management, QSteed provides unified orchestration of quantum resources and enables efficient task compilation and execution. Its virtualization and select-then-compile mechanism decouples hardware characteristics from user tasks, allowing quantum circuits to be dynamically mapped onto the most suitable physical qubits. Related use cases and implementation details are provided in Section S1.
It should be noted that throughout the system design, our primary focus is on 2-qubit gate noise. This emphasis is reflected in several core components, including the fidelity-first strategy in resource virtualization, the fidelity-first policy in VQPU selection, and the noise-aware routing algorithm. While decoherence noise is a consideration, it is only incorporated within the routing algorithm through the introduction of gate parallelism considerations.
Design of the quantum resource virtualization manager
Hierarchical abstraction of quantum processors
Our approach to quantum hardware management is conceptually inspired by classical virtualization. In classical computing, virtualization technologies such as virtual machines build an abstraction layer on top of reliable and homogeneous physical resources, thereby enabling efficient resource sharing and isolation. Similarly, our framework virtualizes quantum processors to mask the underlying physical complexity, manage resources more effectively, and provide a unified backend interface for upper-layer compilation services.
However, the analogy ends at this high-level concept, as the motivations and challenges of quantum virtualization are fundamentally different. Classical virtualization is designed to share stable and homogeneous resources, whereas in the NISQ era quantum virtualization must contend with noisy and heterogeneous resources. The central challenge is not simply partitioning a high-quality whole, but identifying and exploiting relatively high-quality subregions within a chip that is inherently imperfect and subject to time-varying noise. Unlike classical virtualization, which seeks to emulate a complete and stable runtime environment, our quantum virtualization constructs a lightweight hardware abstraction layer that is noise-aware and topology-constrained, specifically tailored to support resource management and compilation optimization. This distinction underpins the design of our framework.
As quantum chips scale up and their architectures become increasingly complex, managing quantum resources across multi-backend clusters is becoming progressively more challenging. To address this, we have developed a virtualization manager that abstracts quantum chips into a database representation, enabling efficient orchestration of large-scale quantum clusters. Within this framework, quantum chips are represented through 4 hierarchical abstraction levels: QPU, StdQPU, SubQPU, and VQPU.
QPU
The QPU serves as the foundational abstraction layer, providing a direct digital representation of a physical quantum processor’s characteristics. This “digital twin” encapsulates critical hardware parameters, including the chip’s architecture type, qubit connectivity topology, real-time calibration data (e.g., gate fidelities and coherence times), the supported native gate set, gate durations, a unique hardware identifier, and its current operational status. This layer grounds the entire virtualization stack in the precise state of the physical device.
StdQPU
Due to current limitations in micro-/nanofabrication processes, superconducting quantum chips inevitably have defects [32], rendering some qubits unusable and resulting in irregular chip structures. We therefore introduce StdQPU, an idealized StdQPU architecture designed to embed these defective chips. For instance, on superconducting platforms, StdQPU can be modeled as a 2-dimensional grid structure, into which most superconducting chips can be mapped. This abstraction facilitates the chip to be dynamically partitioned into multiple regions capable of hosting concurrent workloads, thereby laying the groundwork for QSteed’s future support of multi-program quantum execution [33]. Although the present study does not explore such multi-program scenarios in depth, we retain this layer of abstraction to preserve the completeness of the virtualization stack.
SubQPU
SubQPU represents high-quality substructures identified within a QPU. For a topology graph with N qubits and M coupling edges, enumerating all its substructures has an exponential complexity of . Consequently, we employ heuristic algorithms to identify valuable SubQPUs. To maximize the diversity of these substructures to suit different types of quantum circuits, we designed 3 complementary heuristic strategies.
Fidelity-first strategy: This strategy aims to identify n-qubit coupled substructures with high average fidelity, which is crucial for noise-sensitive quantum applications. Specifically, for n = 1 and n = 2, we construct the optimal substructures by sorting nodes or edges based on their respective single- or 2-qubit gate fidelities. For , we heuristically construct an n-qubit substructure, subG, by initializing it with the highest-fidelity edge and iteratively adding adjacent qubits sorted by 2-qubit gate fidelity until the substructure reaches size n.
Degree-first strategy: This strategy prioritizes node degree to identify substructures composed of highly connected qubits, which is beneficial for algorithms requiring a high degree of entanglement. Its implementation is similar to the fidelity-first strategy, with the key difference being that during the construction of the substructure subG, adjacent qubits sorted by node degree are iteratively added.
Random selection strategy: By introducing randomness, this strategy explores substructures with different topologies to enrich the database. In each step of the iteration, a neighboring qubit is randomly added to subG.
VQPU
To unify the description of quantum resources, each SubQPU is further abstracted into a VQPU, the final compiler-facing representation. The VQPU omits certain physical details of the quantum chip, retaining only the essential information needed for compilation. This includes the mapping from virtual qubits (numbered starting from 0) to physical qubits, the noisy topological structure, the native gate set, and the identifier of the parent QPU. This abstraction supplies the compiler with a clean, standardized interface. Figure 2B shows 6-qubit VQPU configuration extracted from the Baihua chip.
(A) Schematic of the Baihua quantum chip, with blue regions representing 122 connected qubits. (B) The 6-qubit VQPU structure within the Baihua quantum chip, where the red box highlights the target VQPU (the mapping from virtual qubits v to physical qubits q is v0,1,2,3,4,5→q61,62,63,74,75,76) with the structure most similar to the circuit in (C). (C) Quantum circuit. (D) Weighted graph representation of the quantum circuit, where the nodes represent qubits, the edges represent 2-qubit gates, and the edge weights represent the number of 2-qubit gates.
Complexity analysis of virtualization strategy
The time complexity of quantum hardware virtualization is primarily composed of 2 components. The first corresponds to identifying the optimal substructures of the chip, as described in Algorithm 1. The second pertains to the deletion and insertion costs incurred during database updates.
For a quantum processor with qubits and coupling edges, the time complexity of Algorithm 1 is dominated by the main loop structure. After an initial sorting of nodes and edges, which takes , the algorithm iterates through each of the edges to construct substructures of size (from 3 to ). The core of this process is an iterative growth step, where new qubits are added to the substructure. By employing a priority queue to efficiently select the best neighboring qubit at each step, the inner loop has a complexity of approximately . Consequently, the total time complexity of the algorithm is approximately . For sparsely coupled superconducting chips, we have , and the complexity simplifies to . A more detailed derivation can be found in Section S2.1. In addition, we performed numerical simulations on representative superconducting chip topologies, including the square-lattice topology adopted by Google and USTC’s Zuchongzhi processor, the heavy-hexagonal topology promoted by IBM, as well as the hexagonal topology. The numerical results (see Figs. S2 to S5) show that for chips with up to 200 qubits, our algorithm can complete the identification of optimal subregions within a few minutes, and the fitted scaling is consistent with . This demonstrates that the approach is fully practical for current NISQ devices.
The update time of the database depends on the specific implementation and architecture adopted. In our current implementation, a MySQL database is used, where record deletion and insertion are carried out in a serial manner. Numerical results (see Figs. S3 to S5) indicate that the associated complexity scales as . Possible directions for future improvement may include adopting primary-key-based differential deletion and batch insertion strategies, as well as redesigning the database architecture or considering migration to more efficient systems such as MongoDB or Redis.
Design of a modular hardware-aware quantum compiler
Standardized circuit
Before executing the core matching and compilation workflow, QSteed first normalizes user-submitted quantum circuits via a standardized preprocessing module. By correcting common formatting issues, such as invalid measurements, missing classical registers, and redundant qubits, this module effectively ensures that subsequent processes execute reliably. Its primary functions include the following.
Measurement and classical-register correction: Quantum programs require classical registers to store measurement results. This module automatically analyzes the QASM code, appends any omitted measurement instructions, and provisions the requisite classical registers, thereby averting runtime errors attributable to user oversight.
Redundant qubit cleaning: By analyzing the QASM code, this module identifies and removes qubits that do not participate in any effective quantum operations within the circuit. This step reduces unnecessary computational overhead in later compilation phases, conserves scarce qubit resources on NISQ devices, mitigates potential qubit interference, and ultimately helps improve circuit fidelity.
VQPU selector
Benefiting from the construction of the VQPU database, we no longer need to consider the low-level particulars of the entire quantum chips. Instead, we can focus on matching a suitable VQPU for each quantum circuit. The VQPU selection module begins by filtering all candidate VQPUs from the database that meet the circuit’s qubit count requirement. Subsequently, one of the following strategies is employed to determine the final VQPU.
Fidelity-first strategy: This strategy selects the VQPU with the highest overall fidelity, defined as the product of all 2-qubit gate fidelities within the VQPU. Since the VQPU database is presorted by this metric during its construction, this strategy ensures rapid identification of the optimal VQPU for the task.
Structure-first strategy: This strategy aims to reduce the overhead of SWAP gates generated during the subsequent qubit mapping process by identifying the VQPU that most closely resembles the circuit topology. This is a subgraph isomorphism problem within the field of quantum compilation [34–36]. In QSteed, we employ the following practical implementation: We represent both the quantum circuit and the VQPU as weighted graphs. In the circuit graph, vertices correspond to logical qubits, and edges correspond to 2-qubit gates (multi-qubit gates are expanded into a fully connected subgraph), where edge weights signify the number of 2-qubit gates. For example, the quantum circuit in Fig. 2C can be represented as the weighted graph shown in Fig. 2D. Similarly, in the VQPU graph, vertices denote physical qubits, edges represent direct coupling pairs, and edge weights indicate the fidelity of 2-qubit gates. For structural comparison, we first normalize the edge weights in both graphs to the range [0,1]. Then, we query whether there exists a graph isomorphic to the circuit diagram among the candidate VQPUs (ignoring edge weights). If such an isomorphic match is found, that VQPU is selected, enabling perfect mapping of the quantum circuit onto the hardware without requiring additional SWAP gates. When no isomorphic match exists, we quantify graph similarity with the Weisfeiler–Lehman subtree kernel [37] and select the VQPU that yields the highest similarity score. In cases where multiple VQPUs have the same score, we break ties by choosing the VQPU with the highest overall fidelity. Detailed algorithmic descriptions appear in Section S2.
Quantum circuit transpiler
Once the target VQPU has been identified, the quantum circuit transpiler is responsible for compiling the logical circuit into a physical circuit that can be executed on that VQPU. The key challenge of this process is to satisfy the hardware’s topological constraints while performing gate-level optimizations to enhance the fidelity of the final circuit. To facilitate flexible and efficient compilation, the transpiler of QSteed adopts a modular pipeline architecture and employs directed acyclic graph (DAG) as the intermediate representation of circuits, which aligns with the design philosophy of mainstream frameworks such as Qiskit [21] and Pytket [24]. This design offers a high degree of flexibility and extensibility, enabling researchers to conveniently test new compilation algorithms.
Our transpiler is specifically composed of several key components: Transpiler, Pass, PassFlow, Model, and Backend, as depicted in Fig. 3. The Transpiler serves as the main entry point, responsible for selecting a particular PassFlow to execute the transpilation process according to a preset optimization level. Users also have the option to customize their own PassFlow. A PassFlow is an ordered sequence of various Pass instances, each responsible for a specific task such as gate decomposition, qubit mapping, circuit optimization, and variational circuit parameter tuning. Users can create a custom Pass by inheriting from the BasePass class to implement specific functionalities. Throughout transpilation, a shared Model object maintains all state information, including the current qubit layout and the Backend description derived from the selected VQPU. Each Pass obtains this state via get_model, performs its transformation, and writes back the updated state using set_model. This disciplined data flow keeps the Model synchronized across the pipeline, ensuring that every subsequent pass operates on the latest information.
The quantum circuit transpilation and optimization workflow adopts a modular design, consisting of core components: Transpiler, Pass, PassFlow, Model, and Backend. The target VQPU is first modeled as a Backend object and then abstracted into a Model object. During the transpilation process, the Model object stores and passes the parameter data required for transpilation. The transpiler selects a predefined or user-defined PassFlow based on the optimization level to execute the transpilation process. A PassFlow is composed of a sequence of functional components, each responsible for a specific transpilation task. The transpilation process is primarily performed on the directed acyclic graph (DAG) representation of the quantum circuit. Upon completion, the transpiled quantum circuit is output.
Among all transpilation steps, qubit mapping is often the most critical, directly determining the final circuit’s depth and fidelity. This process dynamically assigns logical qubits to physical qubits and is typically divided into 2 key stages, layout and routing. Layout establishes the initial mapping of logical qubits to physical qubits, while routing ensures that all 2-qubit gate operations adhere to the hardware’s connectivity constraints by inserting SWAP gates. Accordingly, the remainder of this subsection focuses on the qubit mapping process; the other transpilation steps follow standardized methodologies detailed in Section S3.
Numerous qubit mapping algorithms have been developed [38,39], among which the SABRE algorithm [40] is widely adopted in mainstream compilation frameworks like Qiskit due to its recognized efficiency and scalability. However, this algorithm still has certain limitations, such as its trivial initial layout and its insensitivity to hardware noise. Currently, various optimization algorithms specifically targeting initial layout [35,41,42], as well as routing algorithms that consider hardware noise [43–45], have been proposed. The qubit mapping algorithm implemented in QSteed introduces the following improvements over the original SABRE algorithm.
Structure-aware initial layout: Let the quantum circuit’s weighted graph be and the graph of the optimal VQPU determined by the VQPU selector be . We apply 2 layout initialization methods: (a) Degree initialization: Nodes in and are sorted by degree, and logical qubits are mapped one-to-one onto virtual qubits based on the sorted order. For instance, if the sorted orders are for and for , the initial layout is . (b) Weight initialization: If node degrees are identical, sorting is performed based on edge weights, and nodes are then mapped one-to-one.
Noise-aware routing: The original SABRE algorithm employs the nearest neighbor cost function, defined by the distance matrix , which represents the shortest path between physical qubits and . However, for NISQ hardware with nonuniform 2-qubit gate fidelities, this approach may fail to maximize the overall circuit fidelity. To improve this, we replace the distance matrix with a fidelity matrix , where each entry identifies the path with the highest cumulative fidelity, calculated as the product of all 2-qubit gate fidelities along the path. We then define an improved, noise-aware heuristic cost function ,
where represents the front layer of gates in the quantum circuit, denotes the extended layer of gates, and represents the mapping from logical qubits to physical qubits . The parameter is a weight factor, and characterizes the parallelism of the compiled circuit. Detailed explanations of these parameters can be found in [40].
However, solely pursuing the highest-fidelity path may lead to an increased number of SWAP operations, which in turn deepens the circuit and exacerbates decoherence. Therefore, we further design a hybrid heuristic that integrates both distance-based and fidelity-based cost functions. Specifically, at each step of the routing process, given the set of candidate SWAPs , we first compute the distance-based cost (replacing in Eq. (1) with the distance matrix ) for each SWAP and retain only those with the minimum value. If multiple candidates remain, we evaluate the fidelity-based cost within this subset and select the SWAP with the highest score. If a tie still exists, one SWAP is selected at random from the remaining candidates as the final result, denoted by . This method is formally defined as:
Hardware constraint validation
Before dispatching the compiled QASM code to the target backend, QSteed performs a series of final hardware compatibility checks. This step does not constitute formal program verification in the strict academic sense [46–48]; rather, it is a pragmatic pre-execution safeguard commonly embedded in production-grade compilation frameworks. Its purpose is to intercept tasks that are destined to fail because they violate the physical limitations of the hardware, thereby averting futile consumption of real quantum resources. Specifically, QSteed’s hardware constraint validation module includes the following.
Two-qubit coupling constraints: Verifies that every 2-qubit gate in the circuit respects the qubit coupling graph of the target processor, thereby ensuring topological compatibility with the designated device.
Gate count and circuit depth limits: Checks that the total number of gates and the circuit depth remain below the backend’s execution thresholds, preventing invalid tasks with excessively low fidelity.
Non-empty circuit check: Confirms that the circuit contains at least one quantum operation, averting the submission of empty jobs that would waste quantum resources and trigger runtime errors.
Experiments and simulations
We first conducted real-device experiments using the Quafu superconducting quantum computing cloud platform, selecting the Baihua quantum processor (as shown in Fig. 2A) as the target backend. Through the cloud platform, we accessed the most recent calibration data of the chip, including qubit coupling topology as well as single- and 2-qubit gate fidelities. The median values of key performance parameters for the Baihua chip are a single-qubit error rate of 7.6 × 10^–4^, a 2-qubit error rate of 2 × 10^–2^, a relaxation time of 71.608 μs, and a dephasing time of 23.724 μs (these values may vary after recalibration of the chip). To ensure the reliability of the calibration data provided by the platform, we employed the ErrorGnoMark [49] software for benchmarking, which is designed to provide a comprehensive diagnostic of quantum chips. Specifically, we assessed single-qubit gate and CNOT gate infidelities using cross-entropy benchmarking (XEB) [1] and channel spectrum benchmarking (CSB) [50], thereby establishing a reliable hardware noise baseline for the subsequent experiments. Although CSB can characterize process infidelity, statistical infidelity, and rotation angle errors, our compilation study concerns only gate fidelity, so we report process infidelity exclusively. Gate benchmarking results are summarized in Fig. 4. Specifically, Fig. 4A illustrates single-qubit process infidelities obtained through CSB, which approximate average gate infidelities. CNOT process infidelities, also derived from CSB, are reported in Fig. 4B. Figure 4C details average CNOT error rates from XEB, reflecting the difference between measured and ideal output distributions. A theoretical expectation of consistency exists for the data presented in Fig. 4B and C. The observed discrepancies may be attributable to noise instability.
Benchmarking results of the Baihua quantum chip. (A) Single-qubit process infidelities from CSB. (B) CNOT gate error rates from CSB. (C) CNOT gate error rates from XEB. NA means that the error rate is too high or gates are unavailable.
To ensure fairness in performance comparisons among different compilers under realistic noise conditions, all frameworks were evaluated using the same calibration data obtained from the Baihua chip. Subsequently, all benchmarking runs for QSteed, Qiskit, and Pytket were executed within a single continuous time block, ensuring that they operated under the same physical hardware state and thereby minimizing the impact of calibration drift. In addition, to avoid the influence of short-term chip fluctuations, each data point for algorithm-specific circuits is reported as the median of 5 consecutive runs, while results for random circuits are averaged over approximately 50 runs, providing statistically robust performance metrics. The compilation results are presented in Fig. 5. Across most evaluated benchmarks, QSteed achieves shorter compilation times while maintaining comparable or higher Hellinger fidelity. This advantage stems from its prebuilt VQPU database, which restricts optimization to an appropriate VQPU rather than the entire chip. In contrast, Qiskit and Pytket take the entire chip as input, which prolongs their compilation time. Moreover, although QSteed does not lead to shallower circuits or fewer gates, its noise- and topology-aware VQPU selection strategy, coupled with a noise-aware qubit mapping pass, systematically yields higher Hellinger fidelity than either Qiskit or Pytket, with most of the fidelity gains attributable to the former. Notably, the fidelity-first strategy compiles more quickly because it simply selects the VQPU with the highest aggregate fidelity, whereas the structure-first strategy incurs additional overhead to compute graph-similarity scores in order to identify the best-matching VQPU. However, when a circuit is exactly isomorphic to a candidate VQPU, such as the linear ising-n10 circuit, the structure-first strategy achieves higher Hellinger fidelity. Detailed results for QSteed under other compilation strategies are provided in Fig. S6.
Performance comparison of different quantum compilers on the Baihua quantum processor. The results for each benchmark circuit represent the median of 5 runs, while the results for random types are averaged over more than 50 runs of randomly generated circuits. Error bars indicate the standard error of the mean. The vertical axes, from top to bottom, represent the compiled circuit depth, the number of CNOT gates, the transpilation time, and the Hellinger fidelity FH (higher is better). Except for the random circuits, the circuit names (trailing number denotes qubits) on the horizontal axis are derived from the QASMBench benchmarking suite [56].
For larger-scale quantum circuits, direct execution on physical hardware becomes unreliable due to the cumulative impact of hardware noise, and simulation for obtaining ideal results presents significant computational demands. Therefore, we use the circuit cost function, , as a proxy for the expected circuit fidelity to evaluate compilation performance for larger circuits. The upper panel of Fig. 6 shows benchmarking results for circuits scaling from a dozen to over a hundred of qubits. Based on characterization data from the Baihua quantum processor, parameters in Eq. (5) were set to and . The analysis demonstrates that for moderate-scale circuits (up to ≈50 qubits), QSteed employing the fidelity-first strategy offers the shortest compilation times while maintaining circuit cost comparable to, or lower than, that of Qiskit and Pytket. However, as circuit size increases, QSteed’s compilation speed advantage over Qiskit gradually wanes. This is primarily because Qiskit has migrated its performance-critical kernels to Rust, wrapped by a Python interface, whereas QSteed has so far refactored only the DAG and qubit mapping modules in C++. Secondly, particularly when the circuit’s qubit count approaches the chip’s full capacity, searching for an optimal mapping over the entire processor becomes essentially as costly as searching within the VQPU subspace. Moreover, for large-scale circuits, Qiskit generally achieves lower . This is primarily attributed to its deeper optimization passes, such as those utilizing commutation relations and advanced circuit synthesis, while the current QSteed only employs optimizations like gate elimination and merging.
Simulation results. For large-scale quantum circuits, the sampling results obtained from NISQ devices are unreliable, and obtaining ideal results from simulators is also challenging, which hinders the calculation of the Hellinger fidelity FH. Therefore, we numerically simulate the circuit cost function C for each compiled circuit based on the qubit fidelity information of the Baihua quantum processor. To further evaluate the robustness of our compilation framework, we also compute C based on the Willow quantum processor parameters reported in [4]. The upper and lower panels respectively present the performance comparison of various quantum compilers on the Baihua processor and comparison of the simulation results based on data of Willow processor. For each benchmark circuit, results represent the median over 5 runs. Error bars indicate the standard error of the mean. Lower values of transpilation time and the circuit cost function C indicate better compilation performance. The circuit names (trailing number denotes qubits) along the horizontal axis are taken from the QASMBench benchmarking suite [56].
To validate QSteed’s robustness across diverse processor architectures, we conducted the same simulations on Google’s 105-qubit superconducting Willow processor, which features a 2D grid topology (using the 97-qubit data available in [4]). Employing chip parameters from [4], the constants in Eq. (5) were set to and K = 0.995. The lower panel of Fig. 6 shows the results. On Willow, we observed similar trends to those on Baihua: QSteed demonstrated an advantage in compilation speed while achieving comparable or superior circuit cost for small- to medium-scale circuits.
These results indicate that QSteed’s virtualization mechanism and select-then-compile workflow are robust. Moreover, the consistent benefits observed on 2 distinct superconducting processor structures indicate that the framework’s advantages are not confined to a single hardware topology, although validating its applicability across other quantum hardware platforms remains future work.
Discussion
In this work, we have designed and implemented QSteed, a novel compilation architecture that abstracts complex quantum hardware into a database of high-quality VQPUs. The data associated with these VQPUs are updated upon hardware recalibration. This abstraction obviates the need for the compiler to directly interface with the entire complex hardware backend. Instead, it maps user tasks to the optimal VQPU within the database, thereby enabling an efficient select-then-compile workflow. Experimental and simulation results demonstrate that the QSteed compiler consistently outperforms mainstream compilers such as Qiskit and Pytket on most benchmark circuits, showing strong practicality.
We also acknowledge that QSteed faces scalability challenges when considering future fault-tolerant quantum computers that may comprise thousands or even millions of qubits. At such scales, even the offline precomputation of the quantum resource virtualization database could become a bottleneck, suggesting that it may be necessary for more scalable or parallelizable heuristics for optimal VQPU identification. Potential directions include restricting the search depth, exploiting regularities in chip topologies for optimization, and parallelizing the search from multiple starting points.
Another limitation concerns calibration drift. Although the VQPU database stays dynamically synchronized with calibration data, if the backend hardware is not recalibrated in a timely manner, our current system architecture cannot detect parameter drift. This is a general issue that cannot be fully resolved at the compilation or virtualization level alone, but requires coordination with hardware benchmarking and automated calibration systems. In future work, we plan to integrate our system architecture with such benchmarking and calibration mechanisms to mitigate this limitation.
In addition, although our implementation and validation have primarily targeted superconducting processors, the architectural paradigm of QSteed holds potential for broader applicability. However, extending QSteed to other quantum hardware platforms requires addressing 2 key challenges:
First, applying QSteed’s resource virtualization mechanism to other hardware platforms necessitates the identification of high-quality subregions within the specific hardware architecture and the corresponding construction of a VQPU database. Below, we explore possible adaptation pathways for several leading platforms: For one-dimensional linear ion trap, although they are logically fully connected, the fidelity of 2-qubit gates varies substantially with ion position [5]. Therefore, a fidelity-first strategy could still be envisioned to identify and extract SubQPUs composed of ions linked by high-fidelity connections. For modular quantum charge-coupled device (QCCD) architectures, which consist of multiple traps where ions are fully connected within each trap but have limited connectivity between traps [51], we can foresee that a degree-first strategy would be an effective heuristic for finding the most highly connected physical regions to serve as SubQPUs. For zoned architecture neutral atom devices, the hardware is divided into entanglement, storage, and readout zones based on the laser-addressable range [8,10]. To execute a 2-qubit gate, relevant atoms must be moved from a storage zone to an entanglement zone and returned afterward. Since atom transport error is proportional to the distance moved, it would be necessary to design a completely new heuristic, such as a distance-first strategy. This strategy, as its name suggests, would iteratively select atoms with the shortest required movement distance when constructing substructures. All generated SubQPUs could still be abstracted as VQPUs and stored in the same database.
Second, enabling the select-then-compile workflow requires designing corresponding VQPU selection strategies for different hardware platforms. For linear ion trap and QCCD architectures, fidelity-first and structure-first strategies may still prove effective, but their efficacy must be further validated on the specific hardware. For zoned architecture neutral atom devices, one could prioritize VQPUs that are sorted according to the distance-first strategy. Once a target VQPU is determined, the subsequent prerequisite is to design a hardware-specific transpilation process. Although the transpiler’s modular pipeline architecture is conceptually general, the qubit mapping step must be tailored to the specific hardware. Unlike superconducting processors with fixed and limited connectivity, trapped-ion systems offer logical all-to-all connectivity; however, in scalable QCCD structures, interactions between multiple traps rely on physical ion shuttling, which makes minimizing this slow and error-prone movement the primary focus of the mapping strategy [52]. For neutral-atom arrays, which achieve dynamically reconfigurable connectivity via optical tweezers, the qubit mapping objective is to efficiently utilize atom movement and maximize parallelism [53,54].
Looking forward, the architectural principles embodied by QSteed, namely, resource virtualization and the select-then-compile paradigm, offer a promising path toward scalable, hardware-aware quantum compilation across heterogeneous physical platforms. This abstraction layer not only facilitates compiler portability but also creates opportunities for a unified compilation workflow in heterogeneous quantum clusters, a critical step toward the broader practical deployment of quantum computing systems.
Methods
We compared QSteed with the most widely used quantum compilation software, including Qiskit (v1.2.4) [21] and Pytket (v1.33.1) [24]. In the Qiskit and Pytket compilation frameworks, the entire quantum chip is required as the input for the compiler, whereas the QSteed compilation framework selects an appropriate VQPU from the resource virtualization database before performing the transpilation. To represent their best-effort performance, we configure Qiskit to its highest optimization level (optimization_level = 3), and Pytket follows the compilation flow adopted in MQTbench [55]. QSteed employs different compilation strategies, denoted as QSteed-xyz, where x, y, and z represent the VQPU selection strategy, the routing heuristic, and the initial layout method, respectively.
We selected algorithmic circuits from the QASMBench suite [56] and generated random circuits using gates like CNOT, RZZ, and RX to form our benchmark set. Each algorithmic benchmark was compiled and executed 5 times, with the median value taken as the performance metric. For random benchmarks, the metric was computed as the average over more than 50 circuit instances. Specifically, we adopted the following evaluation metrics.
Compilation time: For compilers designed for hardware deployment, shorter compilation times effectively reduce user waiting times and improve hardware utilization.
Circuit depth: Due to the limited coherence time of qubits in NISQ devices, shallower circuits tend to produce more reliable computational results.
Gate count: Different quantum processors may employ different native gate sets. Here, we uniformly assume the native gate set is {CNOT, RX, RY, RZ}, and we primarily focus on the number of CNOT gates after compilation, as their error rates are typically an order of magnitude higher than those of single-qubit gates.
Hellinger fidelity: We use the Hellinger fidelity, , to quantify the actual fidelity of a compiled circuit. It is defined from the Hellinger distance as [57]:
where and are the experimental and ideal probability distributions, respectively. This metric intuitively quantifies the deviation between experimental and ideal outcomes. All ideal results in this work are obtained using the Qiskit simulator (for circuits with up to 15 qubits) [21] or the NVIDIA CUDA-Q simulator (for circuits with more than 15 qubits).
Circuit cost function: Due to the performance limitations of NISQ hardware, obtaining reliable results for large-scale circuits through hardware sampling becomes extremely challenging. Under such conditions, we adopt a circuit cost function [58] as a proxy to evaluate compiler performance. To this end, we assume a simplified noise model: Markovian gate errors without temporal correlations, no crosstalk between parallel operations, decoherence errors approximated as an exponential function of the circuit depth, and the neglect of measurement errors as well as other hardware-specific imperfections. Under these assumptions, the effective fidelity of the circuit can be approximately defined as:
where denotes circuit depth, is a factor that penalizes deep circuits, and / represent single/2-qubit gate fidelitie. This metric is similar to the cost function proposed by IBM Quantum in [59]. To avoid vanishingly small values arising from multiplicative products, we further take the negative logarithm, leading to the circuit cost function [58]:
In this work, the fidelity of single-qubit gates is set to the average value, while the fidelity of 2-qubit gates is based on their individual values. Theoretically, is strictly negatively correlated with the effective fidelity, which itself serves as a reasonable approximation to the true hardware fidelity under the simplified noise model, capturing the dominant contributions from gate errors and decoherence. Empirical evidence from Fig. S7 shows that for circuits up to 30 qubits, the circuit cost exhibits a clear negative correlation with the Hellinger fidelity (Spearman rank correlation ), demonstrating that circuits with higher generally have lower . Accordingly, we adopt this metric as a proxy for the expected circuit fidelity in our simulation experiments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arute F, Arya K, Babbush R, Bacon D, Bardin JC, Barends R, Biswas R, Boixo S, Brandao FGSL, Buell DA, et al. Quantum supremacy using a programmable superconducting processor. Nature. 2019;574(7779):505–510.31645734 10.1038/s 41586-019-1666-5 · doi ↗ · pubmed ↗
- 2Gong M, Wang S, Zha C, Chen MC, Huang HL, Wu Y, Zhu Q, Zhao Y, Li S, Guo S, et al. Quantum walks on a programmable two-dimensional 62-qubit superconducting processor. Science. 2021;372(6545):948–952.33958483 10.1126/science.abg 7812 · doi ↗ · pubmed ↗
- 3Zhang X, Jiang W, Deng J, Wang K, Chen J, Zhang P, Ren W, Dong H, Xu S, Gao Y, et al. Digital quantum simulation of Floquet symmetry-protected topological phases. Nature. 2022;607(7919):468–473.35859194 10.1038/s 41586-022-04854-3PMC 9300455 · doi ↗ · pubmed ↗
- 4Google Quantum AI and Collaborators. Quantum error correction below the surface code threshold. Nature. 2024;638:920–926.39653125 10.1038/s 41586-024-08449-y PMC 11864966 · doi ↗ · pubmed ↗
- 5Wright K, Beck KM, Debnath S, Amini JM, Nam Y, Grzesiak N, Chen J-S, Pisenti NC, Chmielewski M, Collins C, et al. Benchmarking an 11-qubit quantum computer. Nat Commun. 2019;10(1):5464.31784527 10.1038/s 41467-019-13534-2PMC 6884641 · doi ↗ · pubmed ↗
- 6Pogorelov I, Feldker T, Marciniak CD, Postler L, Jacob G, Krieglsteiner O, Podlesnic V, Meth M, Negnevitsky V, Stadler M, et al. Compact ion-trap quantum computing demonstrator. PRX Quant. 2021;2(2): Article 020343.
- 7Hou Y-H, Yi Y-J, Wu Y-K, Chen Y-Y, Zhang L, Wang Y, Xu Y-L, Zhang C, Mei Q-X, Yang H-X, et al. Individually addressed entangling gates in a two-dimensional ion crystal. Nat Commun. 2024;15(1):9710.39521764 10.1038/s 41467-024-53405-z PMC 11550402 · doi ↗ · pubmed ↗
- 8Bluvstein D, Levine H, Semeghini G, Wang TT, Ebadi S, Kalinowski M, Keesling A, Maskara N, Pichler H, Greiner M, et al. A quantum processor based on coherent transport of entangled atom arrays. Nature. 2022;604(7906):451–456.35444318 10.1038/s 41586-022-04592-6PMC 9021024 · doi ↗ · pubmed ↗