Quantitative Assessment of Biological Dynamics with Aggregate Data
Stephen McCoy, Daniel McBride, D. Katie McCullough, Benjamin C. Calfee, Erik Zinser, David Talmy, Ioannis Sgouralis

TL;DR
This paper introduces a new method for estimating model parameters using aggregate data, improving accuracy in biological modeling.
Contribution
A novel Bayesian learning framework using modified Hamiltonian Monte Carlo and an elliptical slice sampler for parameter estimation.
Findings
The framework outperforms least-squares fitting in parameter estimation for ODE models.
It successfully uses real and synthetic data from microbial growth experiments.
Results show robust data assimilation and improved model accuracy.
Abstract
We develop and apply a learning framework for parameter estimation in initial value problems that are assessed only indirectly via aggregate data such as sample means and/or standard deviations. Our comprehensive framework follows Bayesian principles and consists of specialized Markov chain Monte Carlo computational schemes that rely on modified Hamiltonian Monte Carlo to align with constraints induced by summary statistics and a novel elliptical slice sampler adapted to the parameters of biological models. We benchmark our methods with synthetic data on microbial growth in batch culture and test them with real growth curve data from laboratory replication experiments on Prochlorococcus microbes. The results indicate that our learning framework can utilize experimental or historical data and lead to robust parameter estimation and data assimilation in ODE models that outperform…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
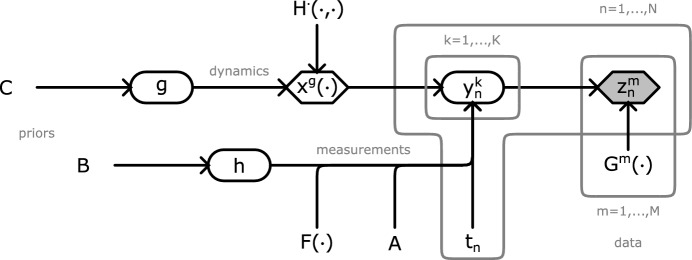 Figure 1
Figure 1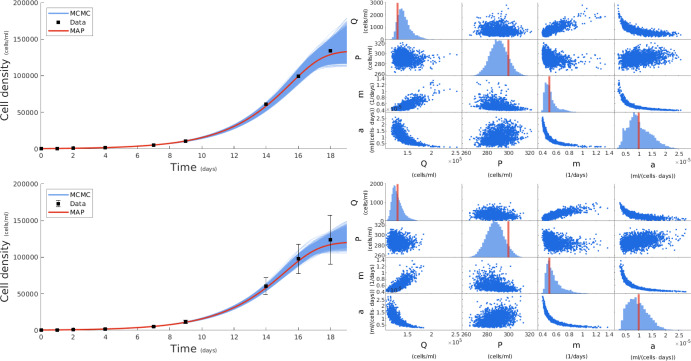 Figure 2
Figure 2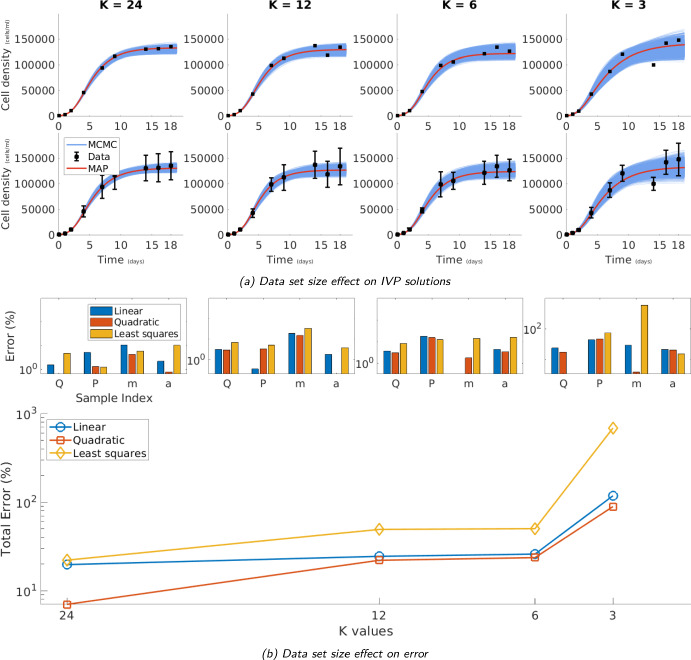 Figure 3
Figure 3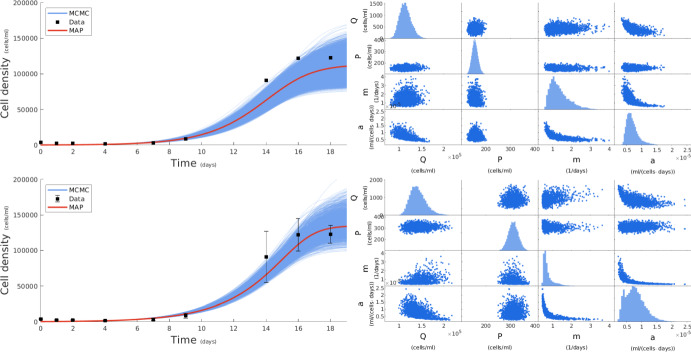 Figure 4
Figure 4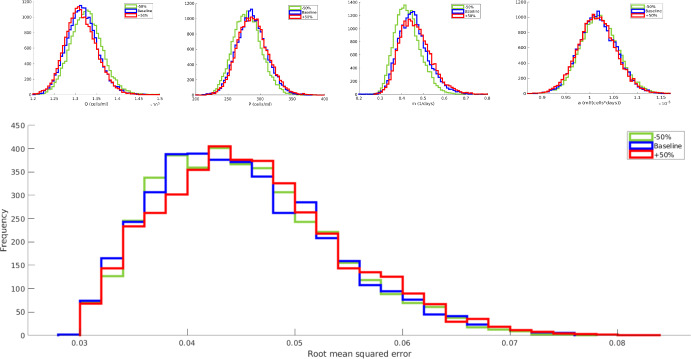 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9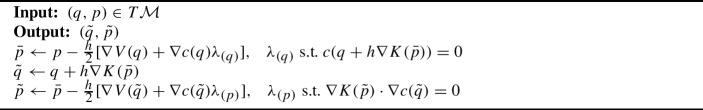 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMarkov Chains and Monte Carlo Methods · Gaussian Processes and Bayesian Inference · Protein Structure and Dynamics
Introduction
The practice of acquiring large sets of individual data points and combining them to obtain diverse summary statistics, which we refer to as data aggregation, is a commonly used technique in multiple domains, including economics, policy making, social sciences, health care and biological and ecological research (Jim et al. 2020; Venkataramani et al. 2020; Markham et al. 2023). In modern science and engineering, collecting and interpreting aggregate data appears occasionally more advantageous than analyzing raw data, particularly in scenarios involving high-level data analysis.
Specifically, in the life and biological sciences aggregate data is often generated in replication experiments where the experiment’s actual raw measurements are used to generate summary statistics, such as averages and standard errors, that are maintained, curated, and made openly available while the original raw measurements are either discarded or access to them is kept restricted. This practice has the obvious advantages of conserving storage space when processing large data sets such as time-lapse and image data (Lee et al. 2017), obscuring the actual source of the data for security and privacy or competitive purposes (Wilson et al. 2021; Haibe-Kains et al. 2020), reducing noise (Xiangyu et al. 2020; Díaz et al. 2017; Sgouralis et al. 2016; Ioannis and Layton 2015; Sgouralis and Layton 2013), and aiding comparison between different experiments or protocols that are probing the same system but employing different modalities (Xia et al. 2022; Sgouralis and Pressé 2017; Sgouralis and Layton 2013; Ioannis and Layton 2014). However, such practices can cause problems; for example, many Covid-19 data related to maternal and neonatal outcomes are restricted to only summary statistics, leaving clinicians and patients to operate on partial information (Smith et al. 2020).
An additional challenge, perhaps more significant, of working with aggregate data is the loss of information that occurs when it is generated (Orcutt et al. 1968) and also the loss of reference to the underlying specific biological processes (Ronan et al. 2016; Raue et al. 2013). For example, similar to averaging, the integration of signals that occurs during the acquisition of single-molecule fluorescence data obscures fast dynamics without allowing for the precise estimation of detailed kinetics (Kilic et al. 2021, 2021b, 2021, 2021a; Mattamira et al. 2025). In addition, biological specimens often exhibit heterogeneity, and aggregating data without accounting for heterogeneity may produce skewed results (Sgouralis et al. 2016, 2017). Accurate quantitative analysis requires careful experimental design and data processing to avoid masking subtle differences between individual specimens. Under these conditions, reproducibility is particularly challenging, as variability in biological systems can make replicated findings difficult due to small differences that remain uncharacterized prior to data acquisition.
Data aggregation also poses serious challenges with rigorous data analysis or assimilation techniques (Law et al. 2015). Specifically, within data assimilation, the goal is to develop mathematical frameworks that process the information available in empirical form and obtain quantitative predictions (Williamson et al. 2002). However, predictions following the assimilation of aggregated data are limited by lost information or distortions caused by aggregation (Heesche and Asmild 2022; Clark and Avery 1976). In order to counteract such artifacts, elaborate frameworks that combine domain knowledge and physical constraints in the form of specialized models are often required. Such approaches naturally lend themselves to Bayesian assimilation methodologies (Reich and Cotter 2015).
Bayesian data assimilation methods have seen an increase in popularity, particularly in parameter estimation applications for dynamical problems modeled with initial value problems (IVP) (Huang et al. 2020; Hinson et al. 2023; Linden et al. 2022). A major advantage is that they offer uncertainty quantification, as the standard practice is to learn an entire distribution of plausible values for every variable of interest rather than point estimators. Another advantage is that they can restrict the parameters under estimation to only meaningful values; for instance, a rate parameter or an initial population can be assigned a prior distribution with only positive support, or prior distributions can be defined on only the intervals that remain meaningful in the spatiotemporal scales of the underlying problem. Furthermore, they apply equally to both identifiable and nonidentifiable cases, the distinction of which is a common modeling challenge in mathematical biology (Maiwald et al. 2016; Wieland et al. 2021). Finally, they offer modeling flexibility and realism that comes from explicitly accounting for different sources of noise and the complexity characteristic of the systems being studied (Pressé and Sgouralis 2023).
Nevertheless, Bayesian data assimilation is not without drawbacks, especially for IVPs (Rodriguez-Fernandez et al. 2006; Schober et al. 2014). To start, one needs to construct and characterize, often via intensive computational sampling procedures, the relevant posterior distribution. In particular, in the parameter estimation problem of models with ordinary differential equations (ODE), this typically involves numerically integrating the ODE for each new configuration of parameters for each posterior sample (Murphy et al. 2024; Roda 2020; Almutiry et al. 2021). Given that the required posterior sample sizes are typically large, sampling strategies become computationally costly and require efficient computational algorithms that are a topic of ongoing research. In addition, biological dynamics are typically contaminated with multiplicative noise (Campbell 1995a, b; Hinson et al. 2023), which poses additional challenges to common algorithms that assume additive noise (Tronarp et al. 2019; Attila and Banga 2015), such as sudden divergence of Kalman filters (Pressé and Sgouralis 2023; Briers et al. 2010) or degeneracy of particle filters (Djuric et al. 2003). Furthermore, the predictions provided in Bayesian data assimilation depends critically on the dynamical model used, its fidelity to the modeled system, and the quality of the data supplied.
A particular challenge when training a dynamical model with aggregated data is that, to properly model the data points that give rise to the supplied summary statistics, we have to mathematically reproduce the collapsing of unavailable raw measurements down to the available values. In the statistical representation of the resulting model, this translates into fitting the model parameters with singular distributions, that is, probability distributions supported only on subspaces of lower dimension than the model’s full parameter space. Parameter estimation is a routine topic in the Bayesian literature focused on simple models with nonsingular distributions (Sivia and Skilling 2006; Pressé and Sgouralis 2023); however, parameter estimation with singular distributions under complex statistical models necessary to tackle real-world scenarios remains an open challenge.
In this study, we develop a novel comprehensive statistical learning framework that addresses these challenges. Our framework exploits the iterative and adaptive nature of Bayesian estimation methods and draws parallels with modern machine learning procedures. Our framework allows for parameter estimation in IVPs of ODE models and also allows modeling of the latent raw measurements that gave rise to the summary statistics forming our dataset. To perform parameter estimation on our statistical model, we apply computational methods that can sample from distributions restricted to particular subsets of the parameter space determined by data aggregation. To this end, we develop a novel extension of the Hamiltonian Monte Carlo (HMC) sampling algorithm that allows for navigating highly dimensional parameter spaces while accounting for parameter constraints. In addition, we develop a novel slice sampling scheme that allows for the IVP parameter’s positive support to be exploited efficiently by means of the elliptical slice sampling (ESS) algorithm.
The rest of this study is structured as follows. In Methods, we begin by describing the data format under consideration, the IVP we aim to address, and the Bayesian framework that we use for its parameter estimation. First, we present our framework in general form, followed by its application to the analysis of growth curve data. In Results, we demonstrate how our framework performs and compares it with standard estimation approaches, such as least squares fitting, with in silico and in vivo data of microbial growth curves from batch culture laboratory experiments commonly conducted in microbiology research. Lastly, in Discussion, we provide an overview of our methods and elaborate on its perspectives for future applications.
Methods
In this section, we first present a general description of our framework that emphasizes modeling and computational aspects. Subsequently, we present a specialized application to microbial growth curve data acquired in replication experiments.
Statistical Learning
Learning Scheme
Our framework considers the analysis of aggregated data that we denote by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{1:N}^{1:M}$$\end{document} . Specifically, we denote individual data points with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_n^m$$\end{document} and use superscripts \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m=1,\dots ,M$$\end{document} to refer to different summary statistics that may be available and subscripts \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=1,\dots ,N$$\end{document} to refer to assessments made at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_n$$\end{document} . For example, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_2^1$$\end{document} indicates our 1^st^ summary statistic obtained at the 2^nd^ time assessment.
Our data stem from collapsing batches of raw measurements made at the same time, which we represent by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} z_n^m&=G^m\left( y_n^{1:K}\right) . \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_n^k$$\end{document} denotes individual raw measurements, made at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_n$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=1,\dots ,K$$\end{document} indexes the batch of measurements. The functions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G^m(\cdot )$$\end{document} model the corresponding batch statistics. For instance, the common sample mean and standard deviation correspond to the functions
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} G^1\left( y^{1:K}\right)&=\frac{1}{K}\sum _{k=1}^{K} y^{k}, \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} G^2\left( y^{1:K}\right)&=\sqrt{\frac{1}{K-1}\sum _{k=1}^{K} \left( y^k-\frac{1}{K}\sum _{k'=1}^{K} y^{k'} \right) ^2}. \end{aligned}$$\end{document}In this study, we focus on the cases where only \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{1:N}^{1:M}$$\end{document} are available, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:N}^{1:K}$$\end{document} are not. For this reason, we explicitly model the missing measurements using a likelihood that represents biological or measurement noise. Our likelihood, which we cast in the form
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_{n}^{k}|g,h\sim \mathbb {A}\left( F\left( x^g(t_n)\right) ,h\right) , \end{aligned}$$\end{document}is a probability distribution that models the generation of independent measurements. Although we do not consider it in this study, our eq. (4) could be modified to model also measurements that depend on each other without limiting the applicability of the methods we develop below.
In the likelihood of eq. (4), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F(\cdot )$$\end{document} is a problem-specific observation function that links measurements with the dynamical variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^g(\cdot )$$\end{document} of an underlying ordinary differential equation (ODE) that models the dynamics of interest. Often, this is simply a projection that reduces the full dynamical state of the system of interest to a single component. The parameter h allows for tunable noise characteristics, such as noise spread, which can better reflect the inherent statistics of the measurements.
To model the dynamics of our system, we consider a generic initial value problem (IVP) for an ODE of the from
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{dx}{dt}&=H^g(t,x) . \end{aligned}$$\end{document}The dynamics function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H^g(\cdot ,\cdot )$$\end{document} is also problem specific and depends on unknown parameters gathered in g. Together, with the appropriate initial conditions that may also depend on unknown parameters gathered in g, our IVP leads to a solution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^g(t)$$\end{document} which, at any time t, describes the dynamical state of the system of interest.
Our framework contains unknown measurements \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:N}^{1:K}$$\end{document} whose statistical properties are fully described by the likelihood in eq. (4) and also unknown parameters g and h. The latter is associated with the noise of the system, while the former is associated with the dynamics. Following the Bayesian paradigm (Pressé and Sgouralis 2023), we assign independent priors to them
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h&\sim \mathbb {B}, \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} g&\sim \mathbb {C}, \end{aligned}$$\end{document}which, in addition to completing our statistical framework, allow the specification of meaningful bounds for their values through their support.Fig. 1. Graphical representation of the statistical learning framework in this study. Following the common convention (Pressé and Sgouralis 2023; Christopher 2006), random quantities are shown with circles, deterministic quantities are shown with diamonds, and quantities with known values are shaded. In addition, arrows indicate dependencies among the various quantities of interest, plates indicate repetition over the marked index, and hyperparameters are left free
Given a data set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{1:N}^{1:M}$$\end{document} , assessment times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{1:N}$$\end{document} , statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G^{1:M}(\cdot )$$\end{document} , and batch size K, our learning framework consists of problem-specific choices for the noise distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {A}(\cdot ,\cdot )$$\end{document} , noise parameter h, observable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F(\cdot )$$\end{document} , dynamical variables g, dynamics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H^\cdot (\cdot ,\cdot )$$\end{document} , and prior distributions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {B},\mathbb {C}$$\end{document} . A graphical summary is shown in fig. 1 and a complete statistical summary is given in appendix A .
Once such choices are made, our framework leads to a posterior probability distribution which, via Bayes’ rule (Gelman 1995; Lee 1989), is formally characterized by a probability density that takes the form
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {P}\left( h,g,y_{1:N}^{1:K}|z_{1:N}^{1:M}\right)&\propto \mathcal {P}\left( z_{1:N}^{1:M}|y_{1:N}^{1:K}\right) \mathcal {P}\left( y_{1:N}^{1:K}|g,h\right) \mathcal {P}\left( h\right) \mathcal {P}\left( g\right) . \end{aligned}$$\end{document}According to our model’s statistical representation, this density specializes to
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {P}\left( h,g,y_{1:N}^{1:K}|z_{1:N}^{1:M}\right)&\propto \left[ \prod _{n=1}^N\left( \prod _{m=1}^M\delta _{G^m\left( y_n^{1:K}\right) }\left( z_n^m\right) \right) \left( \prod _{k=1}^KA\left( y_n^k|g,h\right) \right) \right] B\left( h\right) C\left( g\right) . \end{aligned}$$\end{document}Here, the factors that contain Dirac deltas \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{G^m\left( \cdot \right) }\left( \cdot \right) $$\end{document} arise due to eq. (1), which dictates the precise agreement between our model measurements and the corresponding batch statistics, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A(\cdot |\cdot ,\cdot ),B(\cdot ),C(\cdot )$$\end{document} are the probability functions associated with the distributions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {A}(\cdot ,\cdot ),\mathbb {B},\mathbb {C}$$\end{document} in eqs. (4),(6) and (7), respectively.
Markov Chain Monte Carlo
Due to the IVP, which most often remains analytically intractable, we generally cannot obtain a closed-form expression to the posterior of eq. (8). For this reason, to characterize eq. (8), we develop a specialized Markov chain Monte Carlo (MCMC) sampling scheme that generates pseudorandom samples (Liu 2001; Christian 1999; Metropolis et al. 1953) of the unknowns of the model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h,g,y_{1:N}^{1:K}$$\end{document} .
Due to the natural grouping of our unknowns, we use a Gibbs sampler that iterates the following two steps:
- update parameters by sampling from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}\left( h,g|y_{1:N}^{1:K},z_{1:N}^{1:M}\right) $$\end{document} ,
- update measurements by sampling from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}\left( h,y_{1:N}^{1:K}|g,z_{1:N}^{1:M}\right) $$\end{document} . Because of data aggregation, sampling of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h,y_{1:N}^{1:K}$$\end{document} in the second Gibbs step incorporates an implicit constraint, namely, that the sampled \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:N}^{1:K}$$\end{document} must agree with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{1:N}$$\end{document} .
To initialize our sampler, we directly generate h and g from the priors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {B}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {C}$$\end{document} , respectively. Next, we generate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_n^k\mid g,h,$$\end{document} from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {A}$$\end{document} , and then apply root-finding on the generated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:N}^{1:M}$$\end{document} to ensure that the constraints of eq. (1) are satisfied. In all cases, we combine our sampler with appropriate numerical integrators, such as adaptive Runge-Kutta or other specialized schemes, to solve the IVP according to the specifics of the problem at hand (Quarteroni et al. 2006; Stoer et al. 1980; Atkinson 1991; Shampine and Reichelt 1997).
In the special case where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {A}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {B}$$\end{document} are conditionally conjugate (Gelman 1995), our Gibbs updates can be implemented via ancestral sampling (Christopher 2006; Liu 2001; Gelman 1995; Pressé and Sgouralis 2023) based on the respective factorizations
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {P}\left( h,g|y_{1:N}^{1:K},z_{1:N}^{1:M}\right)&=\mathcal {P}\left( h|g,y_{1:N}^{1:K}\right) \mathcal {P}\left( g|y_{1:N}^{1:K}\right) ,\\ \mathcal {P}\left( h,y_{1:N}^{1:K}|g,z_{1:N}^{1:M}\right)&=\mathcal {P}\left( h|g,y_{1:N}^{1:K}\right) \mathcal {P}\left( y_{1:N}^{1:K}|g,z_{1:N}^{1:M}\right) , \end{aligned}$$\end{document}both of which allow direct generation of h via \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}\left( h|g,y_{1:N}^{1:K}\right) $$\end{document} . For both the parameters and the measurements, our updates are derived from specialized samplers adapted to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}\left( g|y_{1:N}^{1:K}\right) $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}\left( y_{1:N}^{1:K}|g,z_{1:N}^{1:M}\right) $$\end{document} as described below.
mESS for parameter sampling
The first Gibbs update requires the generation of g given measurements \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y^{1:K}_{1:N}$$\end{document} from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}\left( g|y_{1:N}^{1:K}\right) $$\end{document} , which we achieve using a novel multiplicative elliptical slice sampler (mESS), which naturally aligns with distributions restricted to positive support, as often found in dynamical systems of biological processes. See appendix C.1 for a detailed explanation of the sampler. Our approach retains the core benefits of elliptical slice sampling, such as parameter updates without tuning and efficient exploration of complex posterior landscapes, while offering a targeted enhancement for distributions with strictly positive values and non-Gaussian characteristics (Pressé and Sgouralis 2023; Murray et al. 2010).
cHMC for measurement sampling
In our second Gibbs update, we generate samples of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:N}^{1:K}$$\end{document} given known parameters g from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}\left( y_{1:N}^{1:K}|g,z_{1:N}^{1:M}\right) $$\end{document} that satisfy the constraints \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_n^m = G^m(y_n^{1:K})$$\end{document} of eq. (1). For this, we apply a novel constrained Hamiltonian Monte Carlo (cHMC) sampler specialized for handling the constraints. Our method is fully detailed in appendix C.3. As we explain in appendix C.2, standard HMC is suitable for sampling smooth high-dimensional distributions with full support (Liu 2001; Brooks et al. 2011; Betancourt 2017); however, satisfying the constraints requires modifications as described in appendix C.3. Our novel cHMC sampler takes advantage of the RATTLE numerical integrator (Andersen 1983; Brubaker et al. 2012; Hairer and Lubich 2006) in the HMC integration loop to ensure that the generated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:N}^{1:K}$$\end{document} satisfy the constraints while remaining statistically correct, i.e. ensuring that our MCMC chain converges to the target distribution of eq. (8). Our method maintains HMC’s efficient sampling of high-dimensional distributions (Liu 2001; Brooks et al. 2011; Betancourt 2017) arising due to multiple time points (i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N\gg 1$$\end{document} ) and large batch-sizes (i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K\gg 1$$\end{document} ) per time point, while permitting navigation on the support of singular distributions arising due to the constraints.
Application to Prochlorococcus Growth Curve Data
In this section, we specialize our statistical learning framework in a case study of interest in microbiology and marine biology. In our study, the aggregated data stem from batch growth experiments of the marine cyanobacteria Prochlorococcus (Pro). Pro is the most abundant photosynthetic phytoplankton in the ocean (Partensky et al. 1999) and is studied in situ for genetic and physical connections to their bio-geographical significance (Flombaum et al. 2013; Berube et al. 2015). These photosynthetic organisms play a vital role in the regulation of ocean food chains and climate (Biller et al. 2015; Partensky et al. 1999). Laboratory growth experiments take the form of replicate time series data, where multiple sets of triplicate test tubes of Pro are monitored for cell density as they grow in batch culture. Data aggregation is applied to the runs to produce sample averages and standard deviations.
Our growth curves depend on two pivotal quantities: the maximum growth rate, typically reported in units of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1/\text { days}$$\end{document} , and the nutrient affinity, typically reported in units \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text { ml} / (\text { cells}\cdot \text { days})$$\end{document} , of the Pro cells which we denote with m and a, respectively. These parameters, as well as the initial nutrient and Pro cell densities of batch culture experiments, which we denote with Q and P, determine the overall dynamics of the cell and nutrient density.
To model the dynamics in eq. (5) we introduce an IVP that consists of
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{dq}{dt}&= -\frac{q}{q+m/a}mp&q(t_{0})&= Q \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{dp}{dt}&= +\frac{q}{q+m/a}mp&p(t_{0})&= P \end{aligned}$$\end{document}for a fixed initial time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ t_{0} $$\end{document} that coincides with the onset of the experiment. Our dynamical state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x=(q,p)$$\end{document} consists of the density of nutrients q and the density of cells p, both reported in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text { cells/ml}$$\end{document} . Our eq. (9) and (10) depend on the unknown parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g = (Q,P,m,a)$$\end{document} . Given g, we denote the solution of our IVP with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^g(t)=(q^g(t),p^g(t))$$\end{document} .
In a typical experiment that monitors the growth curve, the measurements probe only the cell density. Accordingly, our measurement function in eq. (4) reduces to a projection
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} F(q,p)=p. \end{aligned}$$\end{document}Theoretical and empirical studies on microbial growth (Campbell 1995a, b; Hinson et al. 2023) indicate the presence of multiplicative noise in the measurements. Accordingly, for the likelihood \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {A}(\cdot ,\cdot )$$\end{document} we choose the LogNormal distribution
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_{n}^{k}|g,h \sim \text {LogNormal}\left( p^g(t_n),h\right) , \end{aligned}$$\end{document}with an unknown scale parameter h. For the definition, see appendix B. Following Section 2.1.1, we denote by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_n^k$$\end{document} the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^\text {th}$$\end{document} measurement made at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_n$$\end{document} during the experiment and assume the statistics in eqs. (2) and (3) to form the reported batch mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z^1_n$$\end{document} and standard deviation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z^2_n$$\end{document} of each time point.
Finally, for eq. (6), we apply a prior on the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g = (Q,P,m,a)$$\end{document} of our IVP that allows only for strictly positive values as defined by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Q&\sim \text {Gamma}\left( \phi _Q,\psi _Q/\phi _Q\right) , \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P&\sim \text {Gamma}\left( \phi _P,\psi _P/\phi _P\right) , \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} m&\sim \text {Gamma}\left( \phi _m,\psi _m/\phi _m\right) , \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} a&\sim \text {Gamma}\left( \phi _a,\psi _a/\phi _a\right) , \end{aligned}$$\end{document}and, for eq. (7), we also apply a Gamma prior
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h \sim \text {Gamma}\left( \phi _h, \psi _h/\phi _h \right) , \end{aligned}$$\end{document}which is conditionally conjugate to the likelihood in eq. (12). Here, we use the parameterization of the Gamma distribution, shown in appendix B, which allows the specification of shape and expectation hyperparameters via \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi _Q,\phi _P,\phi _m,\phi _a,\phi _h$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\psi _Q,\psi _P,\psi _m,\psi _a,\psi _h$$\end{document} , respectively.
Our framework leads to the derivation of a formal posterior density
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \mathcal {P}\left( Q,P,m,a,y_{1:N}^{1:K}|z_{1:N}^{1:M}\right) \nonumber \\ & \quad \propto \mathcal {P}(Q)\mathcal {P}(P)\mathcal {P}(m)\mathcal {P}(a)\int _0^\infty dh\, \mathcal {P}\left( z_{1:N}^{1:M},h|Q,P,m,a,y_{1:N}^{1:K}\right) . \end{aligned}$$\end{document}Here, we marginalize the noise parameter h since its value is of little biological interest. By this marginalization, we avoid the ancestral sampling steps in our MCMC scheme of section 2.1.2, but still apply mESS to update Q, P, m, a and cHMC to update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:N}^{1:M}$$\end{document} as previously described.
Data Acquisition
The in vivo data shown in Results are obtained with the following methodology. Axenic cultures of Prochlorococcus strain MIT9215 cyanobacteria were maintained in an artificial seawater medium, AMP-MN (Calfee et al. 2022), a derivative of AMP-A medium (Jeffrey et al. 2011; Moore et al. 2007) without any nitrogen amendment. Purity tests to determine the axenicity of cyanobacteria stocks and experimental cultures were performed routinely as previously described in Jeffrey et al. (2008). All experiments were carried out at 24 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^\circ $$\end{document} C in Percival I36VLX incubators (Percival, Boone, IA) with modified controllers that allowed a gradual increase and decrease of cool white light to simulate sunrise and sunset with a peak midday light intensity of 150 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu $$\end{document} mol quanta m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{-2}$$\end{document} s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{-1}$$\end{document} on a 14 hr:10 hr light:dark cycle (Zinser et al. 2009). The abundance of cyanobacteria was quantified by flow cytometry using a Guava EasyCyte 8HT flow cytometer (Millipore, Burlington, MA) with populations of Prochlorococcus determined by their red fluorescence (Jeffrey et al. 2008; Cavender-Bares et al. 1998). Raw measurements were obtained in batches of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=24$$\end{document} for a total of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=9$$\end{document} time points spread over the duration of the experiment.
Results
In this section, we show how our framework performs on estimating the parameters of IVPs. To demonstrate its effectiveness in revealing the correct parameter values, we first validate our model on synthetic data, mimicking the characteristics of real data, that are generated with prescribed parameter values. Our in silico experiments are conducted by simulating the model of section 2.2. Subsequently, we demonstrate that our methods maintain their performance on real laboratory data. Our in vivo experiments are conducted as described in section 2.3. We also compare against naive parameter estimation methods based on least-squares fitting.
In Silico Growth Curve Data
To generate the synthetic data, we employ the IVP in eqs. (9) and (10)modeling Pro growth with the values of the ground truth parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(Q,P,m,a) = (130\,000,300,0.5,0.000\,01)$$\end{document} which we chose in agreement with the in vivo data of the next section. Then, we generate cell density measurements \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:N}^{1:K}$$\end{document} according to eq. (12) and derive summary statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{1:N}^{1:M}$$\end{document} calculated by eqs. (2) and (3). Our data are shown in fig. 2 with the upper panels corresponding to a scenario in which only batch means are maintained and the lower panels to a scenario in which both batch means and standard deviations are maintained after aggregation. We then employ our statistical learning framework to generate samples of the posterior distribution considering only sample means \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}(Q,P,m,a|z_{1:N}^1)$$\end{document} or sample means and standard deviations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}(Q,P,m,a|z_{1:N}^{1:2})$$\end{document} . Fig. 2. Fitting in silico data with our statistical learning framework. The first row shows our results for a mean only constraint, and the second row shows our results for a mean and standard deviation constraint. Left: We use our MCMC parameter values to generate IVP solutions which are plotted as the blue curves, we then use the MAP estimate to generate the red curve and compare to the data points shown in black. Right: in the off-diagonal panels, we show MCMC scatter plots of pairwise parameter comparisons and, in the diagonal, we show MCMC histograms of each parameter and overlay the ground truth values with vertical red lines. Our results recover well the parameter truth parameters values and producing well-fitting IVP solutions (Color figure online)
To allow for comparison with ground truth, for each case, we approximate the maximum a posterior estimate (MAP) of our parameters by selecting the MCMC sample with the highest posterior probability density (van der Meer et al. 2011) which can be evaluated through eq. (18). These estimates represent our framework’s best choices for parameter values in each case and are indicated by solid lines in fig. 2. Their specific values are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{Q},\hat{P},\hat{m},\hat{a}) = (134\,000,290,0.491,0.000\,0104)$$\end{document} for the first case considering only batch means and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{Q},\hat{P},\hat{m},\hat{a}) = (121\,000,291,0.509,0.000\,0107)$$\end{document} for the second case considering both batch means and standard deviations. Both estimators are in good agreement with the ground truth.
For the two groups of panels in the left column of fig. 2, we also show a collection of sample trajectories. These are randomly selected MCMC samples that correspond to the solutions of eqs. (9) and (10). For both cases, we obtain a spread of trajectories around the MAP solution that indicates uncertainty coming from the noise in the measurements and missing information due to data aggregation. The uncertainty in the upper left panel is higher than that in the lower left panel, as indicated by the wider spread of the sampler trajectories around MAP. This is expected behavior because we assimilate the same information (i.e. batch means) plus additional information (i.e. batch standard deviations) in the second case.
The right panels in fig. 2 show MCMC samples of the parameters. Specifically, along the diagonals, we show the MCMC approximations (histograms) of the marginal posteriors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}(Q|z_{1:N}^{1:M}),\mathcal {P}(P|z_{1:N}^{1:M}),\mathcal {P}(m|z_{1:N}^{1:M}),\mathcal {P}(a|z_{1:N}^{1:M})$$\end{document} along with the MAP estimates as vertical lines. Again, although there is general agreement with the ground truth, there is more uncertainty in the case of only the batch means than in the case of both batch means and standard deviations, as indicated by wider histograms. In the off-diagonal panels, we show MCMC approximations (scatter plots) of each pairing of the sample parameters. In both cases, our framework reveals preferences between combinations of parameters, indicating that, to comply with the supplied data, the trajectories of the underlying IVP require specific configurations of parameter values. For instance, the pair (m, a) has the highest correlation among all pairs. This is expected behavior, as our dynamical model, see eqs. (9) and (10), depends only on the ratio m/a and not separately on a; therefore, the value of a can be estimated only relative to the value of m, as seen.
In addition to showing that our framework successfully recovers the values of the ground truth parameters with quantified uncertainty, in fig. 3 we demonstrate the performance of our methods when challenged with scenarios involving more demanding data. To this end, we apply our learning framework in the same two cases (only batch means and both batch means and standard deviations) now considering scenarios of decreasing batch size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=24,12,6,3$$\end{document} . In this way, we simulate a series of aggregate data generated in experiments of successively fewer raw measurements. Although fewer raw measurements result in increasingly noisier aggregate data, as seen in fig. 3 (upper two rows), our framework’s estimates remain in good agreement with the ground truth. This indicates our framework’s robustness to increased noise.
Least squares estimation (LS) is one of the most widely used methods in data analysis due to its simplicity, efficiency, and ability to provide parameter estimates under minimal modeling assumptions. LS serves as a foundational tool for practical applications and is nowadays available to data practitioners through numerous off-the-shelf software implementations. A head-to-head comparison of our framework with naive procedures mediated by LS, see appendix D, indicates superior performance. In particular, in fig. 3 (bottom two rows) and table 1 we quantify the percentage error in our MAP estimates and those resulting from LS for each parameter. For clarity, our error metrics are given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \% \text {Error}= \left| \frac{ X^{\text { estimate}}}{X^{\text { ground}}} - 1\right| \times 100\%, \end{aligned}$$\end{document}where X stands for any of Q, P, m, a. As seen, while the error for all three methods generally increases as the batch size K decreases, and therefore the noise that persists in the aggregated data increases, LS consistently produces the least accurate estimates. In contrast, our framework consistently produces the most accurate ones. This indicates that, in addition to recovering the ground truth more accurately, our learning framework is also more robust when faced with excessively noisy data than existing practices.
Furthermore, a comparison between the batch means only scenario and the scenario incorporating both batch means and standard deviations, afforded by our framework, indicates that the best estimates are consistently obtained with the latter. Again, this is not surprising, since the latter scenario assimilates the largest amount of data.Fig. 3. Batch size robustness of our methods. We show the effect of reducing the batch size K from 24 to 3 going from left to right across all figures. In the upper two rows, we show the solutions of our IVP eqs. (9) and (10) for the constraints on the batch means (top) and the constraints on the batch means and standard deviations (bottom) as K is decreased. In the bottom two rows, we show the percentage error between the mean only constraint MAP predictions (blue), mean and standard deviation constraint MAP prediction (red), and a LS prediction (yellow) for the parameter values (Q, P, m, a) compared to their ground truth. This is shown in the upper panels as their individual errors in the form of a bar chart and in the bottom panel as a line plot of the total error (sum of individual errors) for each batch size. As we reduce the number of samples per time point down from a collection of experiments \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=24$$\end{document} , to one experiment \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=3$$\end{document} we see LS breaks down whereas our framework copes better with the decrease in the signal to noise content of the resulting data. See table 1 for the precise values used in the comparison (Color figure online)Table 1. Quantitative validation against ground truth. The comparison shows that our model outperforms LS estimation, particularly as batch size K size decreases.GroundOnly batch meansBoth batch means andLeast squaresUnitstruthstandard deviations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=24$$\end{document} Estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorEstimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorEstimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorQ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cells}/\text {ml}$$\end{document} 1300001320001.5451310000.6301360004.761P \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cells}/\text {ml}$$\end{document} 3002845.1732961.3113041.216m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1/\text {days}$$\end{document} 0.50.44610.8280.4784.3000.5295.811a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ml} /(\text {cells} \cdot \text {days})$$\end{document} 0.00001.00001022.187.0000100780.780.0000089610.372 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=12$$\end{document} Estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorEstimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorEstimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorQ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cells}/\text {ml}$$\end{document} 1300001340003.1961340002.9851390007.069P \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cells}/\text {ml}$$\end{document} 3003010.3503103.4283165.202m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1/\text {days}$$\end{document} 0.50.40519.0740.42315.4620.33533.054a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ml} /(\text {cells} \cdot \text {days})$$\end{document} 0.00001.00001011.838.00001000.198.00001033.898 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=6$$\end{document} Estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorEstimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorEstimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorQ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cells}/\text {ml}$$\end{document} 1300001350003.6991340003.0411190008.119P \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cells}/\text {ml}$$\end{document} 30035317.52634715.54126312.440m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1/\text {days}$$\end{document} 0.50.5020.3130.4911.7500.56913.892a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ml} /(\text {cells} \cdot \text {days})$$\end{document} 0.00001.000009554.406.000009663.333.000011515.797 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=3$$\end{document} Estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorEstimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorEstimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\%$$\end{document} ErrorQ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cells}/\text {ml}$$\end{document} 13000016100023.73715300017.4151260003.318P \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cells}/\text {ml}$$\end{document} 30043244.11944247.3858272.596m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1/\text {days}$$\end{document} 0.50.35429.1200.4813.8623.475595.081a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ml} /(\text {cells} \cdot \text {days})$$\end{document} 0.00001.0000078821.138.0000079520.484.000011515.305
In Vivo Growth Curve Data
Having demonstrated our framework’s ability to accurately recover ground truth parameter values with synthetic data, we now demonstrate its application on real laboratory data. Here, our summary statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{1:N}^{1:M}$$\end{document} are obtained directly from the batch growth Pro data acquired in the experiments of section 2.3. Our data are shown in fig. 4 and, as previously, we distinguish a case that considers only batch means (upper panels) and one that considers both batch means and standard deviations (lower panels). For the two cases, our MAP estimators are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{Q},\hat{P},\hat{m},\hat{a}) = (113\,000,153,1.114,0.000\,0699)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{Q},\hat{P},\hat{m},\hat{a}) = (134\,000,319,0.567,0.000\,0964)$$\end{document} , respectively. These represent growth rate estimates in line with the empirical literature (c.f. Figure 2 of Martiny et al. (2016), Figure S5 of Johnson et al. (2006)). In addition to MAP estimates, our framework fully quantifies uncertainty in this case in either trajectories or parameter values. As anticipated, similar to the synthetic cases of section 3.1, our learning framework also performs well with real experimental data.Fig. 4. Fitting in vivo data with our statistical learning framework. The first row shows our results for a mean only constraint, and the second row shows our results for a mean and standard deviation constraint. Left: We use our MCMC parameter values to generate IVP solutions which are plotted as the blue curves, we then use the MAP estimate to generate the red curve and compare to the data points shown in black. Right: in the off-diagonal panels, we show MCMC scatter plots of pairwise parameter comparisons and, in the diagonal, we show MCMC histograms of each parameter. Our results generate parameter values in line with expectations based on the literature. We also note the ridge like structure of the (m, a) joint distribution indicating a non-identifiability as moves along one domain are highly correlated with the other to maintain a fixed value for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{m}{a}$$\end{document} in the IVP (Color figure online)
Sensitivity Analysis
Because our Bayesian framework depends on prior probability distributions, which may influence our posterior estimates, for all analyses shown we choose weakly informative priors for the parameters (Gelman 1995). We achieve these using in all simulations default values for the shape hyperparameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi _Q=\phi _P=\phi _m=\phi _a=2$$\end{document} in eqs. (13) to (16). However, the expectation hyperparameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\psi _Q,\psi _P,\psi _m,\psi _a$$\end{document} may still have a substantial effect. For this reason, to quantify our prior’s influence on the resulting estimates, we conduct a sensitivity analysis taking into account large changes in their values.
Specifically, we vary the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\psi _Q,\psi _P,\psi _m,\psi _a$$\end{document} within \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm 50\%$$\end{document} of their baseline values used in our earlier simulations and derive the resulting marginal posteriors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}(Q|z_{1:N}^{1:M}),\mathcal {P}(P|z_{1:N}^{1:M}),\mathcal {P}(m|z_{1:N}^{1:M}),\mathcal {P}(a|z_{1:N}^{1:M})$$\end{document} . As shown in fig. 5 (top panels), our hyperparameter changes are not transmitted to the resulting posteriors, indicating that the associated point estimates are robust, as expected, to the choice of the priors.
In addition, a quantitative comparison of the estimated MAP trajectories \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p^{\hat{g}}(\cdot )$$\end{document} via the relative root-mean-square error
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {RMSE}= \sqrt{\frac{1}{N}\sum _{n}\left( \frac{p^{\hat{g}}(t_n)}{z_{n}} -1 \right) ^2}, \end{aligned}$$\end{document}also shown on fig. 5 (bottom panel), illustrates that hyperparameter changes are not transmitted to the trajectories as well. This indicates that the dynamics recovered by our framework are informed by the supplied data rather than by the hyperparameters.Fig. 5. Sensitivity analysis of our posterior estimates of the hyperparameters. To evaluate the sensitivity, we change the values of the hyperparameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\psi _Q,\psi _P,\psi _m,\psi _a$$\end{document} from a baseline (blue) to an increase (red) of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$50\%$$\end{document} and a decrease (green) of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$50\%$$\end{document} . In the upper panels, we show marginal posteriors for each parameter across the three cases. In the lower panel, we show the root mean squared error (RMSE) when we compare our MCMC trajectories from the three different cases with the data. Across all panels, we see a significant overlap of the three cases, indicating that our methods are insensitive to changes in the hyperparameter values (Color figure online)
Discussion
In this study, we present a unified statistical learning approach to the estimation of the parameters of IVPs probed with aggregated data. Our framework reproduces the missing measurements and explicitly accounts for data aggregation, this way allowing for high modeling fidelity and improved estimation. For our learning tasks, we derived and applied specialized MCMC methods, such as cHMC and mESS, that include a modified HMC sampler to handle summary statistics constraints in the data we model, as well as a modified elliptical slice sampler to navigate parameter sampling (Betancourt 2017; Neal 2012; Murray et al. 2010; Cabezas and Nemeth 2023). Developed within a fully Bayesian methodology, our framework can be readily used to provide point estimates of the parameters of interest as well as uncertainty quantification.
Our study focuses on the analysis of biological data derived from replication measurements as commonly used in biological research. We demonstrated that our methods successfully analyze data from laboratory batch growth experiments conducted on Prochlorococcus cultures and a specialized dynamical system representing the underlying behavior. Nevertheless, the generality of our method allows for applications involving diverse data sets or dynamical models beyond those tested in this study.
Due to its robustness, our methods can contribute to principled learning and assimilation efforts in IVPs where the underlying measurements are hidden, missing, or distorted by non-Gaussian non-additive noise and aggregation. These features are critical for extracting reliable insights from historical data sets or data sets that are confidential or obfuscated, and only down-sampled data or summary statistics are available. Using our advanced learning approach, our methods provide modelers and practitioners with enhanced tools to decipher incomplete data, ensuring the validity of their analysis despite the lack of pre-aggregated information. Our approach not only strengthens the accuracy of the inference that can be drawn, but also facilitates broader applications in the biological and life sciences (Taylor et al. 2022; Jiang et al. 2018; Mante et al. 2019).
Our novel framework leverages the Bayesian paradigm to unify all aspects of modeling biological dynamics under uncertainty within a single posterior distribution (Pressé and Sgouralis 2023). Our comprehensive approach allows simultaneous parameter estimation, recovery of lost information, and interpretation in physical terms; however, its improved performance comes with its drawbacks. In particular, our framework entails a complex statistical learning approach that requires an extensive mathematical background and advanced computational procedures that pose a barrier to practitioners. To help a wider adoption of the developed methods, we provide a prototype computational implementation in McCoy et al. (2025). Our implementation is developed in the Matlab programming language (The MathWorks 2022) and solves the synthetic Prochlorococcus scenarios of sections 2.2 and 3.1.
Nevertheless, a successful implementation of our framework cannot avoid costly algorithmic steps, such as the numerical integration of the underlying ODE, or, similar to all methods based on MCMC, repetitive generation of random variates leading to generally long runs even under the efficient sampling schemes developed herewith. Characteristically, the generation of the results in each analysis of this study with our prototype implementation requires runs of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx 5$$\end{document} min, on a typical single-core laptop computer (Apple MacBook Pro, 2022 model). This time is contrasted with least squares fitting that is completed within \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx 1$$\end{document} min. Reducing such a high computational time is the focus of future research that may consider specialized algorithmic solutions within problem-specific domains.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Atkinson K (1991) An introduction to numerical analysis. John wiley & sons,
- 2Betancourt M (2017) A conceptual introduction to Hamiltonian Monte Carlo. ar Xiv preprint ar Xiv:1701.02434
- 3Brooks S, Gelman A, Jones G, Meng XL (2011) editors. Handbook of Markov Chain Monte Carlo. CRC Press,
- 4Brubaker M, Salzmann M, Urtasun R (2012) A family of MCMC methods on implicitly defined manifolds. In Artificial intelligence and statistics, pages 161–172. PMLR
- 5Cabezas A, Nemeth C (2023) Transport elliptical slice sampling. In International Conference on Artificial Intelligence and Statistics, pages 3664–3676. PMLR,
- 6Díaz GJ, Brunet CP, Navazo ÁI, Vázquez APP (2017)Downsampling methods for medical datasets. In Proceedings of the International conferences Computer Graphics, Visualization, Computer Vision and Image Processing 2017 and Big Data Analytics, Data Mining and Computational Intelligence 2017: Lisbon, Portugal, July 21-23, 2017, pages 12–20. IADIS Press,
- 7Goldstein H, Poole C, Safko J (1980) Classical Mechanics. Addison-Wesley,
- 8Haibe-Kains B, Adam GA, Hosny A, Khodakarami F (2020) Massive Analysis Quality Control (MAQC) Society Board of Directors Shraddha Thakkar 35 Kusko Rebecca 36 Sansone Susanna-Assunta 37 Tong Weida 35 Wolfinger Russ D. 38 Mason Christopher E. 39 Jones Wendell 40 Dopazo Joaquin 41 Furlanello Cesare 42, Levi Waldron, Bo Wang, Chris Mc Intosh, Anna Goldenberg, Anshul Kundaje, et al. Transparency and reproducibility in artificial intelligence. Nature, 586(7829):E 14–E 16,