VLA-MP: A Vision-Language-Action Framework for Multimodal Perception and Physics-Constrained Action Generation in Autonomous Driving
Maoning Ge, Kento Ohtani, Yingjie Niu, Yuxiao Zhang, Kazuya Takeda

TL;DR
VLA-MP is a new framework for autonomous driving that combines vision, language, and physics to improve perception and action generation.
Contribution
Introduces VLA-MP, a unified framework with physics-informed action generation and language-conditioned perception for autonomous driving.
Findings
VLA-MP outperforms recent methods on the LangAuto benchmark with high driving scores and low infraction rates.
The framework successfully follows complex language instructions and adapts to dynamic environments.
Combining multimodal perception and physics-aware adapters improves safety and interpretability in autonomous driving.
Abstract
Autonomous driving in complex real-world environments requires robust perception, reasoning, and physically feasible planning, which remain challenging for current end-to-end approaches. This paper introduces VLA-MP, a unified vision-language-action framework that integrates multimodal Bird’s-Eye View (BEV) perception, vision-language alignment, and a GRU-bicycle dynamics cascade adapter for physics-informed action generation. The system constructs structured environmental representations from RGB images and LiDAR, aligns scene features with natural language instructions through a cross-modal projector and large language model, and converts high-level semantic hidden states outputs into executable and physically consistent trajectories. Experiments on the LMDrive dataset and CARLA simulator demonstrate that VLA-MP achieves high performance across the LangAuto benchmark series, with best…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
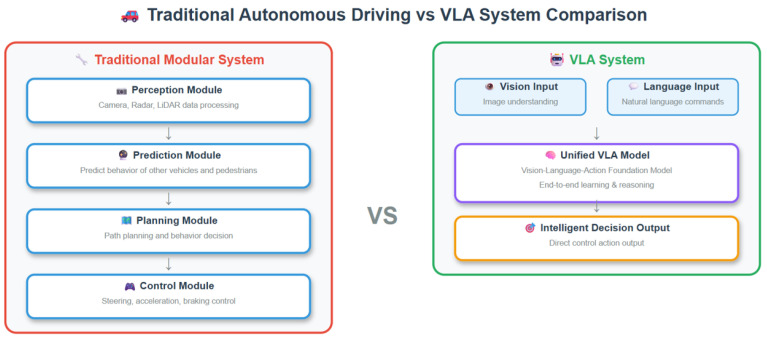 Figure 1
Figure 1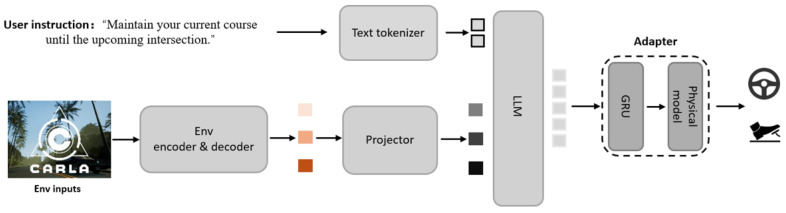 Figure 2
Figure 2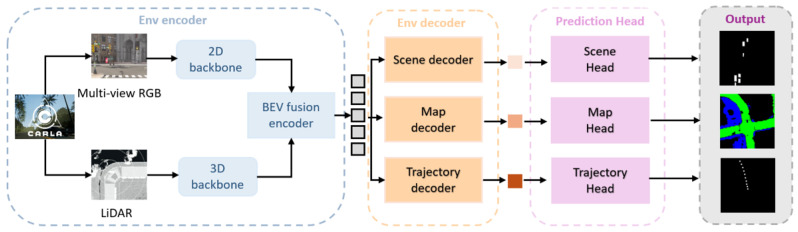 Figure 3
Figure 3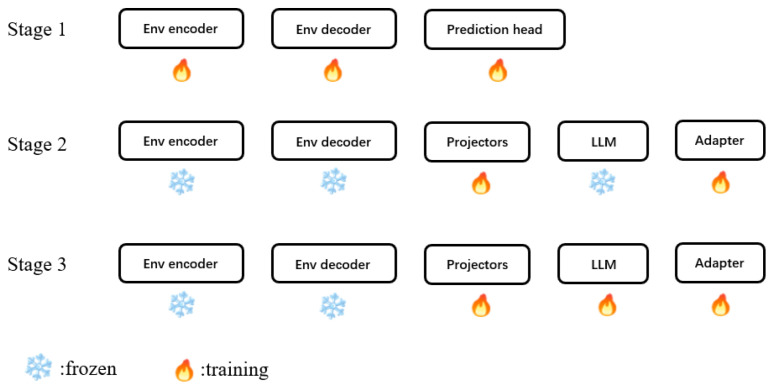 Figure 4
Figure 4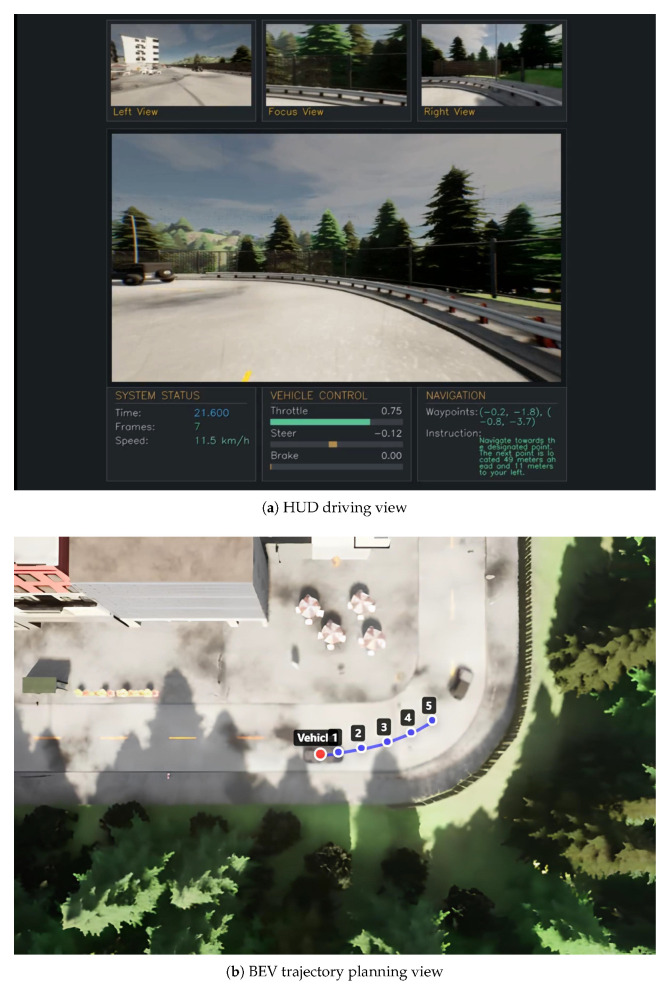 Figure 5
Figure 5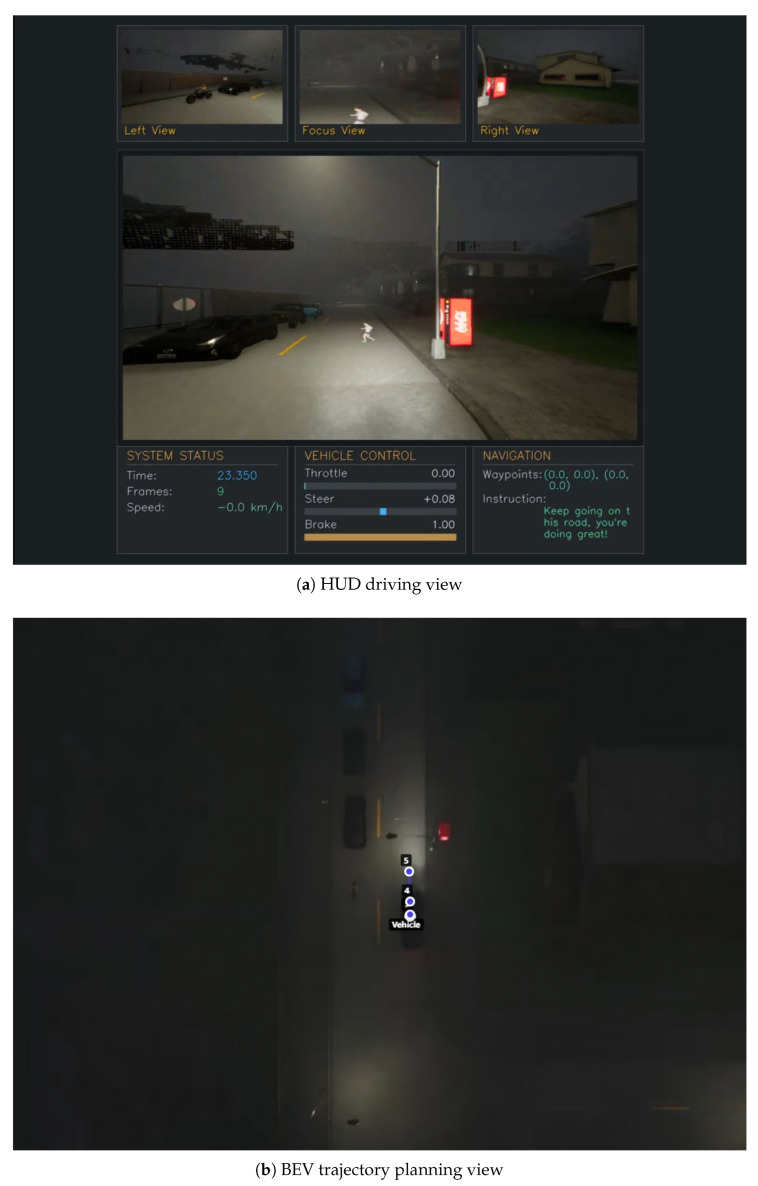 Figure 6
Figure 6 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Autonomous Vehicle Technology and Safety · Multimodal Machine Learning Applications