Modeling Multivariate Distributions of Lipid Panel Biomarkers for Reference Interval Estimation and Comorbidity Analysis
Julian Velev, Luis Velázquez-Sosa, Jack Lebien, Heeralal Janwa, Abiel Roche-Lima

TL;DR
This paper introduces a new method to estimate reference intervals for lipid biomarkers using real-world data, accounting for age, sex, and comorbidities without needing healthy cohorts.
Contribution
A data-driven approach using Gaussian Mixture Models to derive age- and sex-stratified reference intervals from real-world lab data, incorporating comorbidity networks and selective mortality effects.
Findings
Reference intervals for lipid biomarkers were derived from real-world data, stratified by sex and age.
Selective survival explained apparent improvements in biomarker profiles after midlife.
Comorbidity networks revealed strong influences on biomarker ranges and interdependencies between conditions.
Abstract
Background/Objectives: Laboratory tests are a cornerstone of modern medicine, and their interpretation depends on reference intervals (RIs) that define expected values in healthy populations. Standard RIs are obtained in cohort studies that are costly and time-consuming and typically do not account for demographic factors such as age, sex, and ethnicity that strongly influence biomarker distributions. This study establishes a data-driven approach for deriving RIs directly from routinely collected laboratory results. Methods: Multidimensional joint distributions of lipid biomarkers were estimated from large-scale real-world laboratory data from the Puerto Rican population using a Gaussian Mixture Model (GMM). GMM and additional statistical analyses were used to enable separation of healthy and pathological subpopulations and exclude the influence of comorbidities all without the use of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
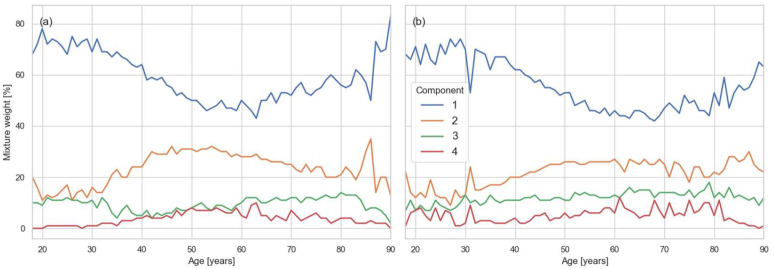 Figure 1
Figure 1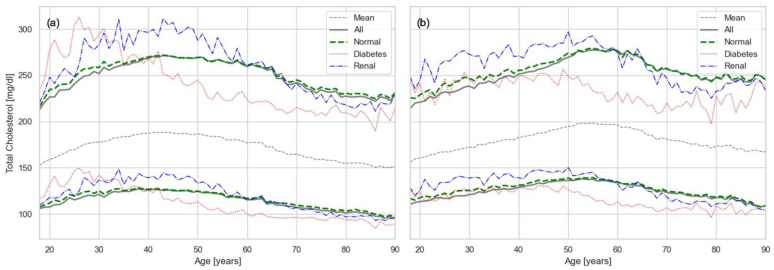 Figure 2
Figure 2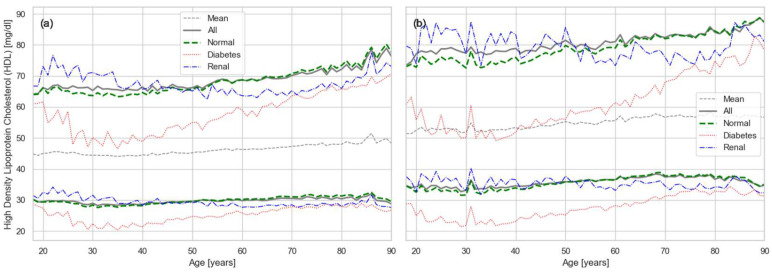 Figure 3
Figure 3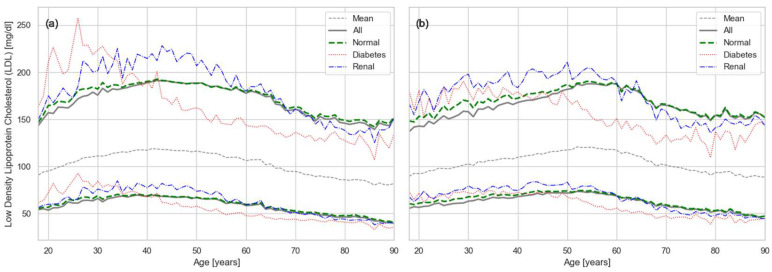 Figure 4
Figure 4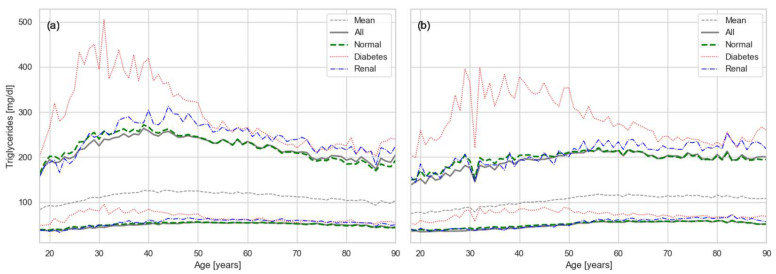 Figure 5
Figure 5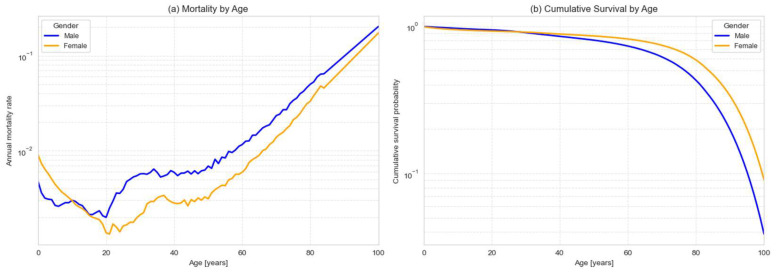 Figure 6
Figure 6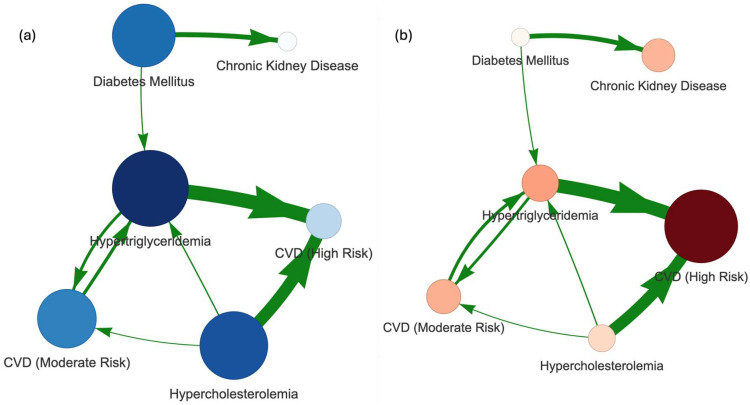 Figure 7
Figure 7- —Office of the Director, National Institutes of Health Common Fund
- —Center for Collaborative Research in Health Disparities (CCRHD)
- —National Institutes of Health
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetabolomics and Mass Spectrometry Studies · Health, Environment, Cognitive Aging
1. Introduction
Cardiovascular disease (CVD) remains the leading cause of death in the United States, responsible for roughly one in every five deaths, and has held this position since 1950 [1,2]. Among the spectrum of CVDs, coronary artery disease (CAD) is the most prevalent, claiming over 370,000 lives in 2022, and affecting approximately 5% of adults aged 20 and older [2,3]. Established risk factors include non-modifiable traits such as age, sex, race, and genetics, as well as modifiable lifestyle factors—notably hypertension, hyperlipidemia, diabetes, obesity, smoking, poor diet, and physical inactivity [4]. While genetic predisposition remains significant, the growing obesity epidemic and its metabolic consequences—like diabetes and dyslipidemia—have increasingly driven the rise in cardiac conditions, particularly in developed nations.
Because lipid abnormalities are central to the development and progression of cardiovascular disease, the lipid panel (LP) has become the main laboratory tool for monitoring cardiovascular health and assessing risk [5,6,7]. It includes total cholesterol (CHOL), triglycerides (TRIG), high-density lipoprotein cholesterol (HDL), low-density lipoprotein cholesterol (LDL), and very-low-density lipoprotein (VLDL). These biomarkers represent different classes of lipoproteins—complexes of lipids and proteins that transport cholesterol and triglycerides through the bloodstream. HDL is termed “good cholesterol” because it helps remove excess cholesterol from tissues and plaques, whereas LDL is labeled “bad cholesterol” since elevated levels promote atherosclerosis and increase CVD risk [8]. Triglycerides, the main form of stored fat, are linked to insulin resistance, metabolic syndrome, and higher CVD risk, particularly when HDL is low [9].
Comorbidities have a significant impact on biomarker levels, and understanding their influence is essential for correctly interpreting LP results. In this study, we focus on two highly prevalent conditions—diabetes mellitus (DM) and chronic kidney disease (CKD)—that strongly affect cardiovascular outcomes [7]. Diabetes is a major risk factor for atherosclerotic cardiovascular disease through its effects on insulin resistance, dyslipidemia, and systemic inflammation [10]. CKD is likewise accompanied by dyslipidemia, typically characterized by elevated triglycerides and reduced HDL concentrations [7,11]. Their two key diagnostic markers—glycated hemoglobin (A1C) for diabetes and serum creatinine (CREA) for renal function—are included in the comprehensive metabolic panel (CMP) [5]. Since LP and CMP are often ordered together in routine general health screening, ample data are available for assessing how comorbidities influence lipid biomarkers.
Interpretation of these biomarkers depends on reference intervals (RIs), which define the expected range of values in healthy populations [12,13,14,15]. This term is preferred over “normal range” because it emphasizes comparison with a defined reference group rather than implying an absolute standard of health [14,16]. By convention, RIs correspond to the central 95% of the distribution in a healthy population [13]. Their use has been standardized by the International Federation of Clinical Chemistry (IFCC) and the Clinical and Laboratory Standards Institute (CLSI), which have issued detailed guidelines for their estimation and periodic updating [17].
Standard RIs are established through cohort studies, which require at least 120 healthy individuals for each analyte [17]. This approach is time-consuming and costly, making it difficult to update RIs regularly. As a result, many published intervals are outdated and lack stratification by sex, age, or ethnicity—factors known to strongly influence biomarker distributions [18,19,20,21,22,23]. These limitations can be addressed by indirect methods, which infer RIs from secondary use of data sources not originally collected for this purpose, such as clinical laboratory results [24,25,26].
Building on these advances, we have previously proposed indirect methods to estimate RIs from real-world clinical laboratory data originally collected for diagnostic purposes [27,28,29]. These approaches assume that each biomarker distribution consists of a dominant “healthy” component with pathological results superimposed [30]. Using Gaussian mixture models (GMM), we successfully separated these contributions and derived RIs for biomarkers related to CKD [27] and chronic liver disease (CLD) [29] in the Puerto Rican (PR) population.
In the present work, we extend these studies in two important ways. First, methodologically, we advance the GMM framework to multivariate data, using conditional probability distributions with comorbidity markers to better exclude pathological values without relying on diagnostic codes. This approach not only produces RIs that are more representative of the healthy population but also reveals how comorbidities systematically distort biomarker distributions. Second, epidemiologically, we leverage a very large dataset of laboratory results from the PR population to derive age- and sex-specific RIs at single-year resolution for key CVD-related biomarkers, providing the first large-scale characterization of this kind. In doing so, we also identify population-level patterns such as selective mortality, which help explain counterintuitive improvements in biomarker values at older ages, and we construct comorbidity implication networks to capture interdependencies among conditions and their impact on lipid biomarkers.
2. Materials and Methods
2.1. Data
In this study, data were obtained from the clinical results datalake of Abartys Health, a clinical laboratory data processor headquartered in San Juan, PR, which aggregates laboratory test results from hundreds of laboratories across the island. All data were de-identified by removing personally identifiable information (e.g., names, dates of birth, addresses); unique patients were assigned non-descriptive identifiers, with only age and sex retained as demographic information. In accordance with US CFR 46.104(d), analysis of de-identified results does not require patient consent. The study protocol was reviewed and approved by the University of Puerto Rico—Medical Sciences IRB (Ref. 2301072914).
After extracting the data for each measure, results are coarse-grained by month: multiple readings for the same individual within a given month are averaged. Most patients have only a single monthly reading, but a small subset—likely hospitalized patients—show multiple results. In such cases, coarse-graining helps reduce bias toward more severely ill individuals. Finally, the datasets for all measures are merged by patient ID and the corresponding year and month of testing.
The dataset covers LP results [5] from 2019 to 2024. Because LP and CMP are routinely prescribed as screening tests during medical visits, the resulting data for these biomarkers is extensive, as summarized in Table 1.
From 2019 to 2024, the dataset contains over 4.3 million LP results covering more than 1.3 million unique individuals, with a comparable number of records for the renal panel. About two million glycemic tests are available in the data. The sex distribution across these datasets is fairly consistent at approximately 42% male and 58% female. When restricted to lipid biomarkers tests performed within the same time window and alongside contemporary glycemic and renal tests, the joint dataset includes about 1.8 million results representing roughly 0.7 million individuals (Table 1). Additional details on the data collection and processing are given in the Supplementary Materials.
2.2. Methods
As described in our previous work, GMM was used to analyze the data distribution [27,29].
2.2.1. Transformation
The quantitative biomarkers considered in this study are strictly positive, as they represent concentrations, counts, or ratios. Their empirical distributions are typically either approximately normal or lognormal, depending on the underlying physiology. Many biomarkers are subject to homeostatic regulation, which constrains their values within a narrow physiological range around an equilibrium. Deviations from this equilibrium arise due to differences in body size, metabolic rate, and other natural variations. In such cases, a normal distribution provides an adequate description. Conversely, biomarkers such as those in the lipid panel often display multiplicative variability, leading to skewed distributions that are more appropriately modeled as lognormal. To accommodate this, we apply logarithmic transformations to skewed variables prior to further analysis, thereby stabilizing the variance and producing approximately symmetric distributions suitable for multivariate Gaussian modeling.
Each analyte have an invertible, monotone transform (e.g., or identity). The model is fit in the transformed space where are normally distributed. All conditioning values (and any bounds used elsewhere) are first mapped to Gaussian space via . After sampling or computing percentiles/ellipsoids in Gaussian space, results are mapped back analyte-wise by .
2.2.2. Joint Distribution
After log-transforming skewed biomarkers, the resulting data can be modeled using Gaussian mixtures. We assume that the observed population consists of a dominant distribution corresponding to physiologically healthy individuals, with pathological results appearing as secondary modes superimposed on this background. GMM provides a natural framework to disentangle these contributions and identify the principal component associated with health [31].
Formally, the probability distribution of an -dimensional biomarker vector Gaussian space (after any feature-wise transforms), modeled as a convex combination of multivariate Gaussian densities
where are non-negative mixture weights satisfying , and is the mean vector, and denote the positive definite covariance matrix of the -th Gaussian component, respectively.
To estimate these parameters from data, we employ a Bayesian Gaussian Mixture Model (BGMM), which performs variational inference rather than standard maximum likelihood estimation. A key advantage of BGMM is its adaptive treatment of the number of active mixture components: instead of fixing , a Dirichlet process prior allows redundant components to be suppressed, yielding a parsimonious representation. In practice, we implement this approach using the scikit-learn BGMM algorithm [32,33]. The healthy reference distribution is then defined as the principal Gaussian component, i.e., the mixture element with the largest weight , which captures the central tendency of the majority population.
2.2.3. Marginal and Conditional Distributions
Let be a -dimensional Gaussian random vector.
Marginals
For a subset of indices , the marginal distribution of the subvector is itself Gaussian, with parameters obtained by restricting the mean and covariance:
where and denote the sub-vector and sub-matrix of and , respectively.
In particular, for a single analyte , the univariate distribution is obtained as the marginal with . Marginals reduce the dimensionality of the distribution by integrating out irrelevant axes ( ) and thus summarize the variability of a subset of analytes. Although they discard explicit dependencies with the remaining variables, they implicitly reflect the influence of the full joint distribution and therefore provide more robust information than univariate fits.
Conditionals
For two disjoint index sets , the conditional distribution of given is also Gaussian:
where the partitioned mean and covariance are written as
and the conditional parameters are
Like marginals, conditional distributions reduce dimensionality by integrating out irrelevant coordinates. But first they restrict the distribution to a subset of axes under fixed values of another disjoint subset ( ).
3. Results
3.1. Joint Distribution
We applied the proposed methodology to the metabolic biomarker dataset described in Section 2.1. As an initial step, we constructed the joint distribution of all lipid panel biomarkers together with relevant comorbidity markers. To normalize the skewed distributions, logarithmic transformations were applied CHOL, TRIG, HDL, LDL, and VLDL, while A1C and CREA were left untransformed. Outliers were generally retained to preserve the natural variability of the population, with the exception of physiologically implausible values, which were excluded using predefined biomarker-specific thresholds. An overview of the data preparation, model fitting, and inference workflows is provided in the Supplementary Materials (Figures S1 and S2).
Subsequently, the BGMM was fitted to the full dataset, yielding the joint seven-dimensional distribution of all biomarkers, . The BGMM incorporates a Dirichlet process prior, which adaptively determines the effective number of active components. In this study, we specified a maximum of K = 7 Gaussian components, ensuring that several components could remain inactive if unsupported by the data.
The weights represent the relative proportion of the population assigned to each component. As shown in Figure 1, only two mixture components consistently carried substantial weight (>10%). The dominant component, corresponding to the healthy subpopulation, accounted for 40–80% of the distribution. Its weight was highest in younger age groups, where pathological conditions are less prevalent and the main distribution remains less distorted. The second major component captured pathological or outlier contributions, with its relative weight increasing in older age groups as comorbidities became more frequent. Together, these weights provide a quantitative view of how the balance between healthy and pathological subpopulations shifts across age and sex.
We optimized the model hyperparameters to bias the fit toward a dominant “central” Gaussian component representing the healthy population, while still allowing additional components to capture pathological or secondary subpopulations. The prior mean was estimated as the feature-wise median to reduce sensitivity to outliers, and the covariance prior was regularized with diagonal shrinkage to ensure stability and avoid ill-conditioning in higher dimensions. To encourage sparsity, the Dirichlet weight concentration prior was set to a very low value ( ), thereby limiting the number of active components. Conversely, the mean precision prior was set high (200.0) to constrain the component means more closely around the overall population mean.
The effect of the GMM is twofold: first, it separates multimodal Gaussian structures, and second, it effectively absorbs outliers in the distribution tails by allocating a specific component to them. In one dimension, the healthy and pathological contributions overlap substantially, so pathological values primarily shift the mean and increase the weight of the tail rather than forming distinct modes. In contrast, in the seven-dimensional space, pathological values appear as separate modes that collapse onto each other in the one-dimensional projection. Our results indicate the presence of two to three such satellite modes, each carrying a substantial portion of the total weight (Figure 1). As population segments become less healthy, the weight of these satellite modes increases at the expense of the central distribution, reflecting the growing influence of pathological subgroups.
3.2. Marginal Distributions and Reference Intervals
One-dimensional marginal distributions, , for each analyte were obtained from the joint distribution , as described in the Methods. From each marginal distribution, it is possible to calculate the limits corresponding to any quantile . RIs were defined as the limits enclosing the central 95% of the distribution.
First, we estimated RIs for CHOL stratified by sex and age (Figure 2). The gray line represents the marginal distributions of CHOL as described in the Methods. During adolescence, CHOL RIs were similar in males and females. With increasing age, however, both the lower and upper limits rose, with a steeper slope in males. The values peaked around age 45 in males and 55 in females, after which both limits gradually declined. This decline is consistent with the effect of selective mortality, as discussed further in the Discussion.
The conditional distributions derived from the joint model provide deeper insight into the structure of RIs. In addition to the overall cohort RIs, we computed 95% intervals for sub-cohorts affected by comorbidities. In Figure 2, the red line corresponds to the diabetic sub-cohort (A1C = 9.0%) and the blue line to the renal disease sub-cohort (CREA = 2.0 mg/dL), where the values in of the diagnostic markers were chosen well in the unhealthy range. The presence of comorbidities markedly altered the lipid profile. Among younger adults with diabetes, the upper limit of CHOL was substantially elevated and the onset of selective mortality occurred earlier. Similarly, renal disease was associated with a pronounced increase in the upper limit of CHOL, although it did not seem to affect the selective mortality.
Conditional modeling also enabled the exclusion of comorbidity effects without requiring explicit diagnostic labels. By constraining analytes to healthy ranges (A1C = 5.7%, CREA = 1.0 mg/dL), the green line in Figure 2 captures the “true” RI for otherwise healthy adults. The near coincidence of the green (constrained) and gray (unconstrained) lines demonstrates that the BGMM successfully isolates the principal healthy distribution from pathological clusters. Nevertheless, along the comorbidity axes the distribution retains the imprint of disease effects, such that conditional probabilities in those directions still reveal how comorbidities distort lipid biomarkers. This illustrates that while the BGMM separates healthy and pathological populations, it also preserves meaningful covariance structure with comorbidity-related variables.
The RIs for the complementary cholesterol biomarkers, HDL and LDL, are shown in Figure 3 and Figure 4, respectively. HDL levels remained relatively stable across the cohort until middle age, after which a modest increase was observed, attributable to selective mortality (Figure 3). More striking, however, was the effect of comorbidities on HDL. In particular, diabetes caused a pronounced reduction in “good” cholesterol, underscoring its role as a strong contributor to cardiovascular risk [10].
The RIs for LDL (Figure 4) followed the same pattern as those for CHOL, since LDL values reported in clinical laboratories are typically not measured directly but calculated using the Friedewald formula: where VLDL is estimated as [34]. As a result, LDL behavior largely mirrored that of total cholesterol. However, the impact of comorbidities was amplified, because LDL incorporates both the elevation of total cholesterol and the reduction in high-density lipoprotein (HDL, “good” cholesterol).
The RIs for TRIG are shown in Figure 5. Their pattern resembled that of CHOL, with values rising until middle age and then declining due to selective mortality. The influence of comorbidities, however, was distinct. Diabetes exerted an even stronger effect on TRIG than on CHOL, consistent with the close metabolic relationship between triglycerides and glucose. Renal disease, in contrast, showed its strongest impact in older individuals, significantly increasing triglyceride levels in the elderly population probably due to less efficient filtration.
The uncertainty in RI estimation was quantified using bootstrapping. Specifically, 100 random subsamples were drawn, each comprising 50% of the dataset, and RI limits were recalculated for each iteration. The final RI limits were taken as the mean across bootstrap samples, and the associated error was estimated as the standard deviation. The resulting errors were consistently small—on the order of a fraction of a percent—indicating high robustness of the estimates. Comparable stability was observed in our previous studies [27,29].
4. Discussion
4.1. RI Interpretation
Internationally accepted RIs for lipid biomarkers are largely derived from U.S. and European populations [6,7]. These conventional RIs are typically reported as fixed thresholds and are not stratified by sex, age, or race, despite well-documented physiological differences across demographic groups. In contrast, our approach uses real-world clinical laboratory data to derive population-specific RIs, as demonstrated here for the PR population. The scale and richness of the dataset further allow stratification by age and sex, yielding intervals that more accurately capture biological variation within the population.
A key observation from our results (Figure 2, Figure 3, Figure 4 and Figure 5) is the strong effect of age on lipid biomarker distributions. Applying a single RI across all ages fails to account for the normal, progressive decline in organ function, effectively treating age as a pathological state. In reality, most metabolic biomarkers—including those beyond the lipid panel—shift inexorably toward less favorable values with age [27,29]. Sex differences are also evident, driven by factors such as body size and hormone-related physiology. Thus, the conventional RIs used in current practice represent little more than population-wide averages, obscuring the biologically meaningful variation attributable to age and sex.
Our results for CHOL indicate that the upper RI limit in the PR population exceeds the widely recommended threshold of 200 mg/dL, even among young adults (Figure 2). Values rise quickly beyond the high-risk cutoff of 240 mg/dL, suggesting an accelerated trajectory toward dyslipidemia. A similar trend is observed for LDL, which largely mirrors total cholesterol, with upper limits exceeding the recommended threshold of 100 mg/dL (Figure 4). Triglycerides show the same pattern (Figure 5), with values generally above the established cutoff of 150 mg/dL. HDL levels are consistent with this unfavorable profile: the lower limit in our results falls below the conventional threshold of 40 mg/dL.
Together, these patterns suggest a population-wide shift toward higher cardiometabolic risk, likely influenced by dietary habits rich in fried foods and by the high prevalence of obesity, which increasingly affects younger age groups. Alternatively, this may suggest that the currently recommended cutoffs underestimate the physiological lipid ranges for the PR population—or perhaps for broader populations as well. It could also be that existing RIs for CHOL and LDL are set conservatively low, in part to encourage pharmacological intervention with statins. This interpretation aligns with recent evidence questioning whether elevated LDL levels are consistently associated with increased all-cause mortality [35].
It can also be argued that the distribution mean, rather than the conventional RI upper limit, is a more informative indicator of population health. The standard 95% interval is directly defined by the mean and standard deviation, , and narrower published RIs may simply reflect the limited diversity of the clinical trial cohorts from which they were derived. In contrast, our dataset captures the full PR population, providing a more representative picture. This underscores a broader issue with the way RIs and their associated abnormal flags are applied in practice: RIs define only hard cutoffs and do not convey how values are distributed within those limits. As a result, the laboratory abnormal flag is binary—indicating only whether a value lies inside or outside the interval. By modeling the full distribution, we can assign each individual measurement a percentile, offering a continuous measure of risk rather than a simple threshold. We have previously proposed this percentile-based framework as a more nuanced and clinically meaningful approach [27,29].
Finally, it is also important to emphasize the substantial sex differences in lipid profiles that are obscured by generalized recommendations. Females consistently exhibit lower CHOL and LDL levels, substantially higher HDL, and markedly lower TRIG compared to males—differences that are largely attributable to biological factors such as hormonal regulation and body composition. At the same time, the more rapid deterioration of lipid biomarkers observed in males likely reflects behavioral and lifestyle influences, compounding the biological baseline differences between the sexes.
4.2. Selective Mortality
The gradual rise in CHOL and LDL, coupled with a decline in HDL during early and mid-adulthood, aligns with the expected pattern of metabolic aging and physiological decline. This is consistent with the gradual loss of organ function due to normal wear and tear with age. Similar trajectories were seen in our earlier studies of CKD, where creatinine and urea levels increase steadily with age [27], and of CLD, where platelet counts and albumin concentrations progressively decrease [29].
However, lipid biomarkers display an unexpected pattern after midlife: CHOL and LDL values decline, while HDL rises. Although this could appear to reflect improved cardiovascular health, the paradox is better explained by selective mortality. Younger adults are resilient enough to survive despite adverse biomarker profiles, so their gradual health decline is visible in worsening trends. Beyond midlife, however, physiological reserves diminish, and the body can no longer compensate for chronic dysfunction. As a result, the least healthy individuals are more likely to die earlier, shifting the observed population distribution toward healthier values. The apparent improvement in biomarker profiles therefore reflects differential mortality rather than true physiological recovery. This interpretation is consistent with prior epidemiological studies reporting U-shaped cholesterol–mortality associations, where low cholesterol values in older adults were inversely associated with all-cause mortality and partly attributed to selective survival effects [36,37]. Nevertheless, similar reductions have also been observed longitudinally within individuals, suggesting that additional metabolic factors contribute [38].
The magnitude of selective mortality also varies across conditions. Some chronic dysfunctions, such as CKD, can often be tolerated until later in life and therefore do not substantially alter the overall trajectory of the lipid curves. In contrast, conditions that contribute more directly to early mortality, such as diabetes and cardiovascular disease, shift the onset of selective mortality to earlier ages. This difference is evident in our results (Figure 2, Figure 3, Figure 4 and Figure 5), where CKD does not substantially change the lipid curves, while DM produces a marked shift toward earlier onset of selective mortality.
For comparison, mortality rates for the PR population were estimated using U.S. Census data for the period 2020–2024, stratified by sex [39]. For each year, we calculated the fraction of individuals of age who survived to age in the following year and then averaged these survival rates across years to reduce variability. The annual mortality rate, defined as ( ), is shown by age and sex in Figure 6a. Mortality remained relatively stable through early and middle adulthood, though subject to fluctuations likely attributable to migration and other demographic factors. Beginning in midlife, however, mortality rose exponentially, consistent with the Gompertz law, a well-documented demographic pattern of age-dependent mortality rise [40].
The corresponding cumulative survival function, , representing the fraction of the population surviving to age , is shown in Figure 6b. Consistent with the RI curves, survival declines approximately exponentially at advanced ages, with males consistently exhibiting lower survival than females across the entire age range.
Although the survival function aggregates all causes of mortality and cannot be stratified by specific causes using the available census data, it nevertheless explains the patterns observed in the lipid panel RIs. Because male mortality is higher, individuals with adverse lipid profiles are removed from the cohort earlier, producing the earlier decline in elevated CHOL and LDL values in men. Similarly, sub-cohorts affected by specific chronic conditions would be expected to have steeper survival curves than the population average, leading to an earlier onset of mortality and corresponding shifts in their biomarker distributions.
4.3. Implication Network
To better understand how comorbidities influence lipid panel biomarkers, we constructed a comorbidity implication network. For this purpose, a set of diagnostic criteria was developed, as summarized in Table 2, and then joined biomarker data by patient ID and date to apply these rules. This framework allowed us to model disease co-occurrence and explore how multiple conditions interact within individuals. This methodology aligns with contemporary network medicine approaches—where diseases are represented as nodes and statistically derived associations as edges—to uncover patterns of comorbidity and aid in identifying preconditions and complications within patient trajectories [41,42].
After assigning diagnoses, we calculated the conditional probability that an individual has condition given the presence of condition
where is the number of individuals with both and , and is the number of individuals with . Together with the complementary probability , these values were used to construct the implication matrix, defined as . This matrix serves as the foundation for the comorbidity implication network, where directed edges capture the strength and asymmetry of conditional relationships between diseases. Additional details on the construction of the implication matrix, together with its heatmap representation, are provided in Figure S3.
We then constructed a comorbidity network defined as a directed graph, using the implication matrix as the adjacency matrix. The resulting network, illustrated in Figure 7, was analyzed with the Hyperlink-Induced Topic Search (HITS) algorithm to identify hub and authority nodes [43]. Conditions with high hub scores act as precursors, pointing toward multiple downstream comorbidities and serving as initiators of disease cascades. In contrast, conditions with high authority scores function as endpoints, receiving links from many hubs and representing common complications or outcomes of diverse pathological pathways.
The network provides a qualitative view of the relationships among comorbidities. As expected, both hypercholesterolemia and hypertriglyceridemia showed strong implications for CVD, reflected in both edge strengths and high hub scores (Figure 7a). Diabetes also emerged as an important precondition. Conversely, CVD appeared as the most common complication of hyperlipidemia (Figure 7b), while CKD was more closely associated as a complication of diabetes. The strong linkage between hyperlipidemia and CVD is partly tautological, since CVD risk is clinically estimated using cholesterol ratios (Table 2). Nevertheless, the network highlights important nuances: elevated triglycerides were more strongly associated with moderate CVD risk, whereas high cholesterol was more indicative of severe CVD risk. Furthermore, high cholesterol also appeared as a possible precondition for elevated triglycerides.
Even more importantly, the network helps to elucidate how comorbidities directly affect lipid biomarkers. For instance, diabetes appears as a precondition for elevated triglycerides. Impaired glucose metabolism in diabetes promotes hepatic triglyceride synthesis and reduces lipid clearance, leading to hypertriglyceridemia. This, in turn, amplifies cardiovascular risk by contributing to atherogenic dyslipidemia, characterized by high triglycerides, low HDL, and elevated small dense LDL particles.
4.4. Limitations and Future Work
4.4.1. Ground Truth and Laboratory Data Limitations
The principal issue with underrepresented populations, such as PR, is that there are no cohort studies of population that could provide independent validation of the derived RIs. Moreover, chemical laboratory data represents only one side of the health profile of the individual. It lacks important invocators such as vital signs (height, weight, blood pressure, etc.) and other relevant information about the patients’ condition such as pregnancy, postpartum, or perimenopause. Better analyses would require linkage with electronic health records (EHRs) to enrich the laboratory data.
4.4.2. Data Standardization and Harmonization
Although Abartys Health’s core business involves collecting, cleaning, and standardizing laboratory data across PR, challenges remain due to the lack of standardized and adherence to exchange formats in raw clinical data. Common issues that cannot be easily corrected include—incorrect or ambiguous coding of tests (that cannot distinguish between several closely related tests); lack of detailed metadata on analytical principles, reagents, and platforms that hamper data harmonization; lack of units or incorrect units, etc.
4.4.3. Future Work
The application by this methodology is by no means specific to the PR population. It is fully generalizable provided that routine laboratory test results with demographic information (sex and age) are available. The additional features (e.g., ethnicity) can be easily incorporated to further stratify the RIs. In this case, the PR population serves not only as illustration but also provides valuable epidemiological information of an underrepresented population.
Furthermore, while here we only consider two comorbidities, this is not a limitation of the methodology. This is done to introduce and illustrate the idea of comorbidity networks in a simple form while capturing two of the major comorbidities—DM and CKD—that are highly prevalent in the population. Comorbidity networks construction from laboratory data is only limited by the possibility of diagnosing condition entirely based on laboratory data. There must be sufficient data for the principal biomarkers and the comorbidities available within the same time window.
5. Conclusions
This study demonstrates that Gaussian mixture modeling provides a robust framework for disentangling healthy from pathological distributions in large-scale, real-world laboratory data. By leveraging conditional probability, we were able to estimate definitive RIs for healthy cohorts without relying on diagnostic labels. Conditional modeling further revealed how comorbidities such as diabetes and renal disease systematically alter lipid distributions, while comorbidity implication networks clarified dependencies between conditions and highlighted key precursors and complications.
Unlike traditional RIs, which are reported only as fixed limits, our approach models the entire distribution of biomarker values in the population. This enables each individual result to be placed on a continuous percentile scale of risk, rather than being reduced to a binary abnormal flag. Such distribution-aware reporting provides a more nuanced basis for clinical decision-making.
Finally, our analysis highlights that the narrower RIs in published guidelines likely reflect the limited diversity of the clinical trial cohorts from which they were derived. In contrast, our framework captures the biological and demographic variability of the PR population, underscoring the need for population-specific standards derived from representative real-world data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Tsao C.W. Aday A.W. Almarzooq Z.I. Anderson C.A.M. Arora P. Avery C.L. Baker-Smith C.M. Beaton A.Z. Boehme A.K. Buxton A.E. Heart Disease and Stroke Statistics—2023 Update: A Report from the American Heart Association Circulation 2023147810.1161/CIR.000000000000112336695182 PMC 12135016 · doi ↗ · pubmed ↗
- 2Centers for Disease Control and Prevention (CDC) Heart Disease Facts Available online: https://www.cdc.gov/heart-disease/data-research/facts-stats/(accessed on 23 August 2025)
- 3Centers for Disease Control and Prevention (CDC) Heart Disease Deaths Available online: https://www.cdc.gov/nchs/hus/topics/heart-disease-deaths.htm(accessed on 23 August 2025)
- 4Martin S.S. Aday A.W. Almarzooq Z.I. Anderson C.A.M. Arora P. Avery C.L. Baker-Smith C.M. Barone Gibbs B. Beaton A.Z. Boehme A.K. 2024 Heart Disease and Stroke Statistics: A Report of US and Global Data from the American Heart Association Circulation 2024149810.1161/CIR.000000000000120938264914 PMC 12146881 · doi ↗ · pubmed ↗
- 5Van Leeuwen A.M. Bladh M.L. Davis’s Comprehensive Manual of Laboratory and Diagnostic Tests with Nursing Implications 9th ed.F.A. Davis Company Philadelphia, PA, USA 20219781719640589
- 6Arrobas Velilla T. Guijarro C. Ruiz R.C. Piñero M.R. Valderrama Marcos J.F. Pérez Pérez A. Botana López A.M. López A.M. García Donaire J.A. Obaya J.C. Consensus Document for Lipid Profile Testing and Reporting in Spanish Clinical Laboratories: What Parameters Should a Basic Lipid Profile Include?Adv. Lab. Med. Av. Med. Lab.2023413814610.1515/almed-2023-004738075943 PMC 10701497 · doi ↗ · pubmed ↗
- 7Davidson M.H. Altenburg M. Dyslipidemia Available online: https://www.merckmanuals.com/professional/endocrine-and-metabolic-disorders/lipid-disorders/dyslipidemia(accessed on 23 August 2025)
- 8Ouimet M. Barrett T.J. Fisher E.A. HDL and Reverse Cholesterol Transport Circ. Res.20191241505151810.1161/CIRCRESAHA.119.31261731071007 PMC 6813799 · doi ↗ · pubmed ↗