Using Machine Learning to Create Prognostic Systems for Primary Prostate Cancer
Kevin Guan, Andy Guan, Anwar E. Ahmed, Andrew J. Waters, Shyh-Han Tan, Dechang Chen

TL;DR
This study uses machine learning to improve prostate cancer prognosis by creating a more accurate staging system than the current standard.
Contribution
The novel Ensemble Algorithm for Clustering Cancer Data (EACCD) outperforms the AJCC staging system in predicting patient outcomes.
Findings
The EACCD model with five variables achieved a C-index of 0.8293, outperforming the AJCC system.
Adding age and race improved the model's C-index to 0.8504, showing better prognostic accuracy.
EACCD effectively stratified patients into distinct groups with well-separated survival curves.
Abstract
Background: Cancer staging, guided by anatomical and clinicopathologic factors, is essential for determining treatment strategies and patient prognosis. The current gold standard for prostate cancer is the American Joint Committee on Cancer (AJCC) Tumor, Lymph Node, and Metastasis (TNM) Staging System 9th Version (2024). This system incorporates five prognostic variables: tumor (T), spread to lymph nodes (N), metastasis (M), prostate-specific antigen (PSA) levels (P), and Grade Group/Gleason score (G). While effective, further refinement of prognostic systems may improve prediction of patient outcomes and support more individualized treatment. Methods: We applied the Ensemble Algorithm for Clustering Cancer Data (EACCD), an unsupervised machine learning approach. EACCD involves three steps: calculating initial dissimilarities, performing ensemble learning, and conducting hierarchical…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
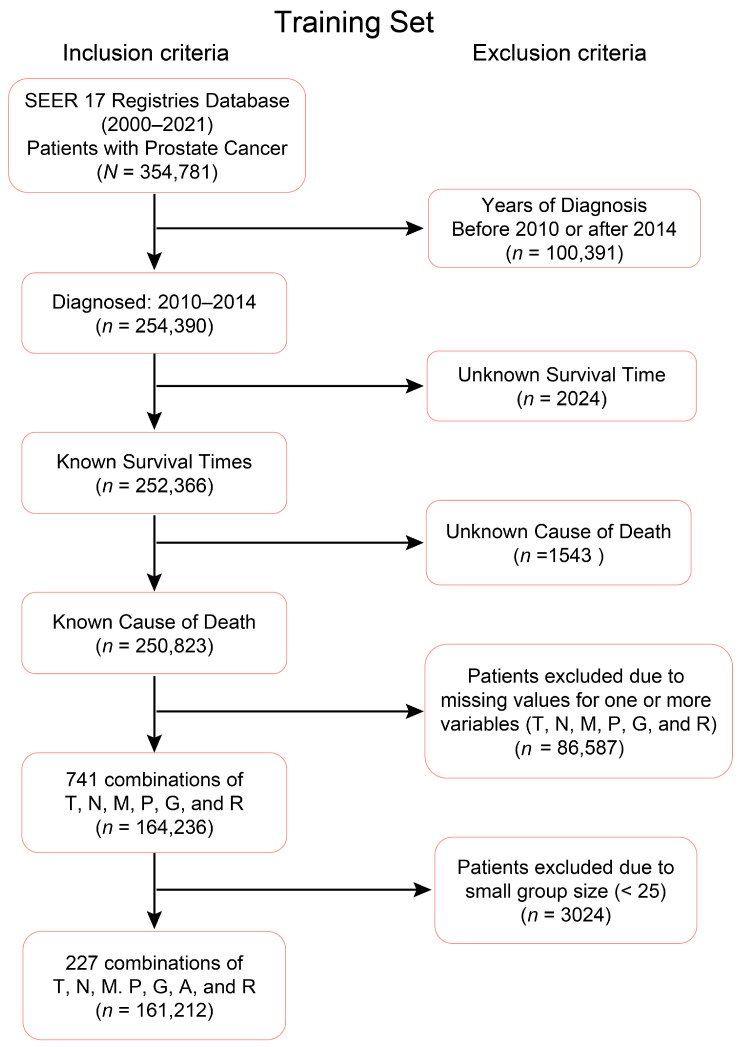 Figure 1
Figure 1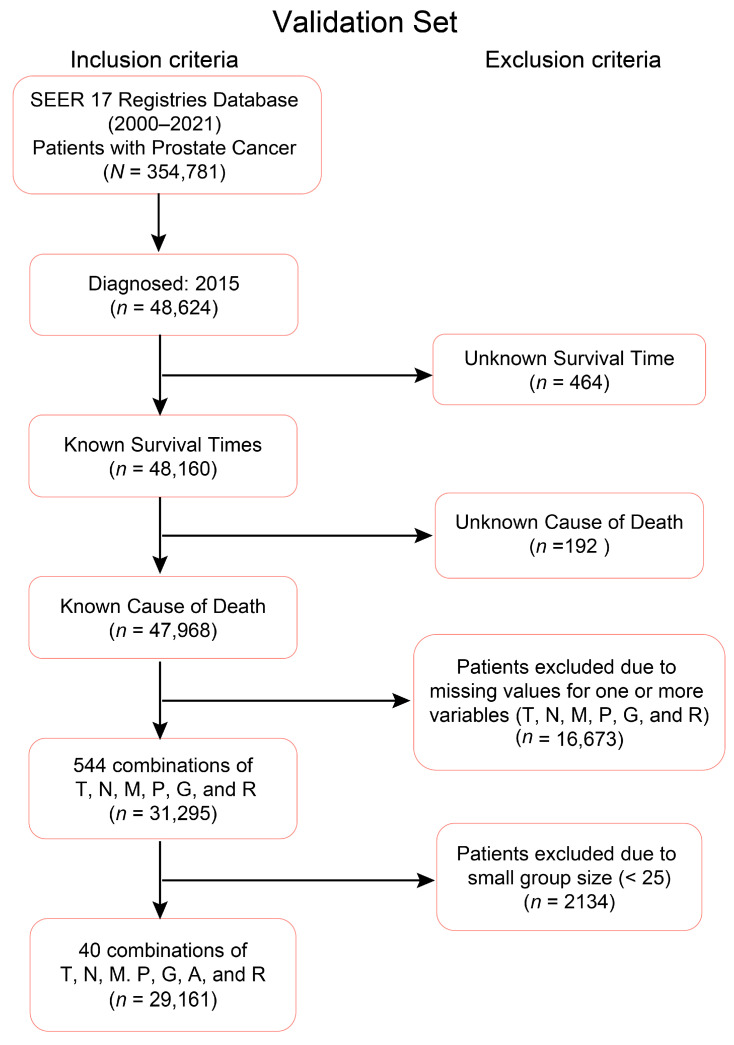 Figure 2
Figure 2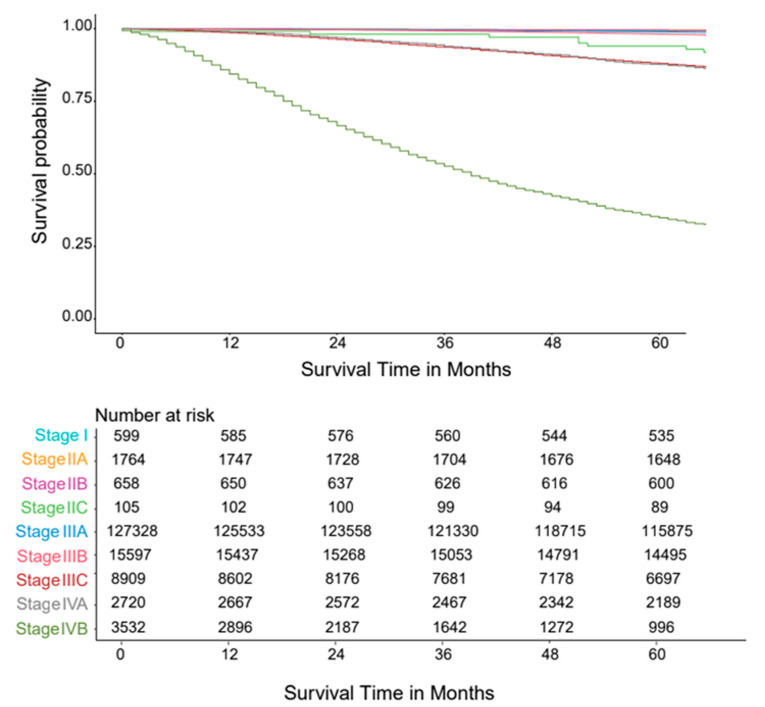 Figure 3
Figure 3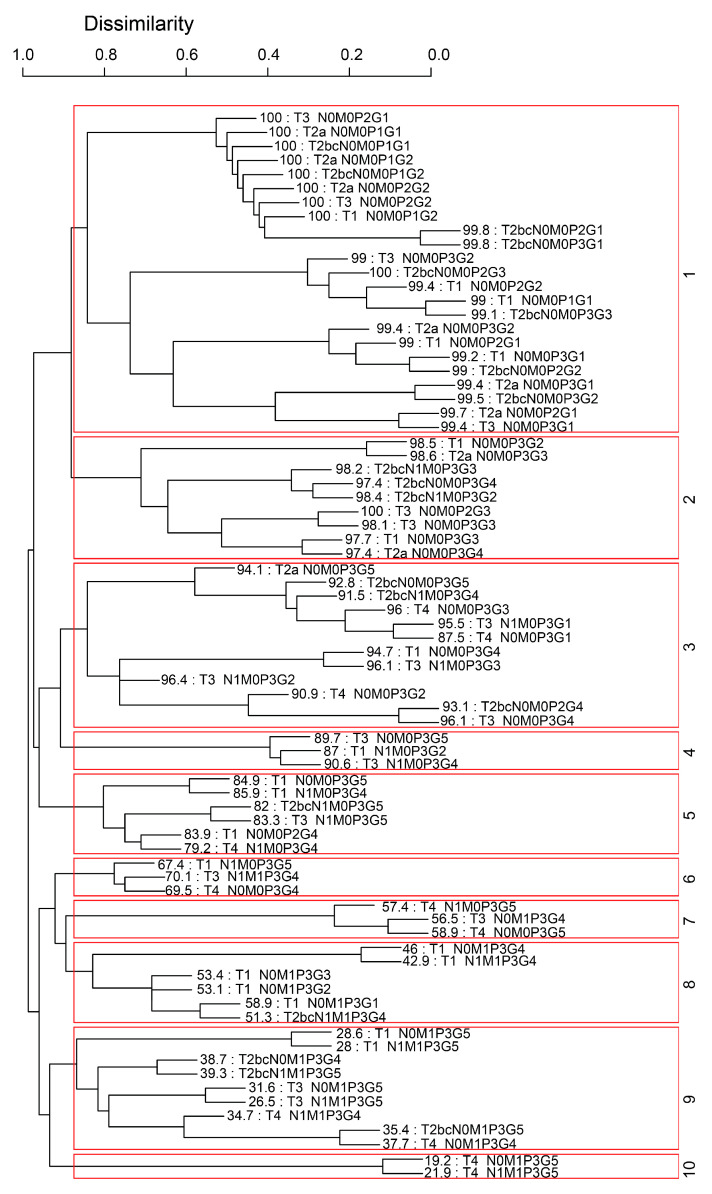 Figure 4
Figure 4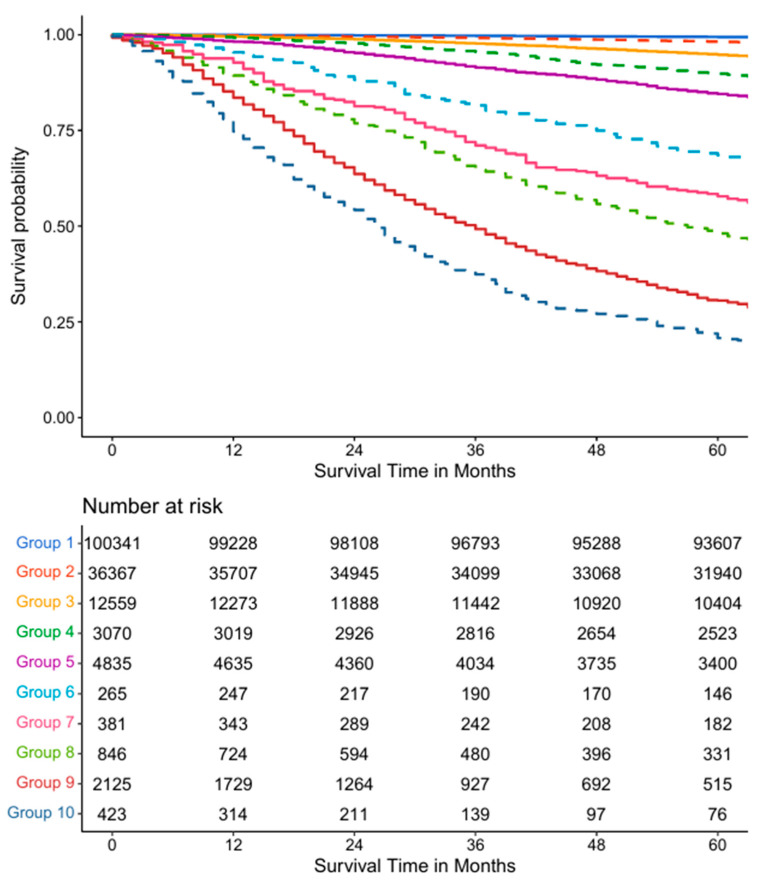 Figure 5
Figure 5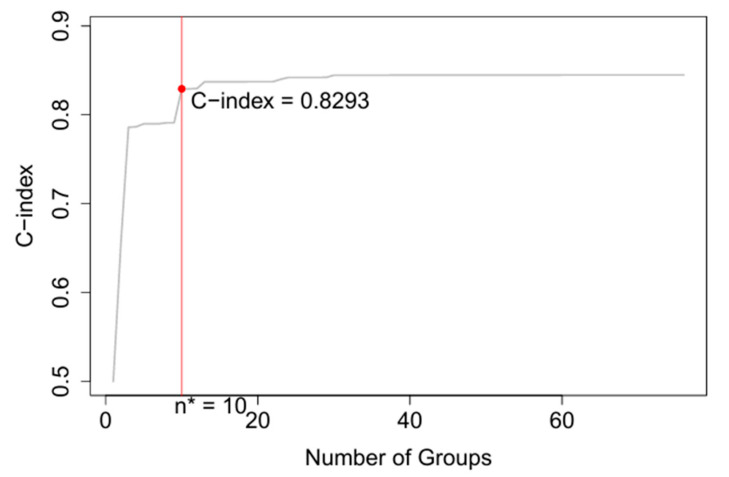 Figure 6
Figure 6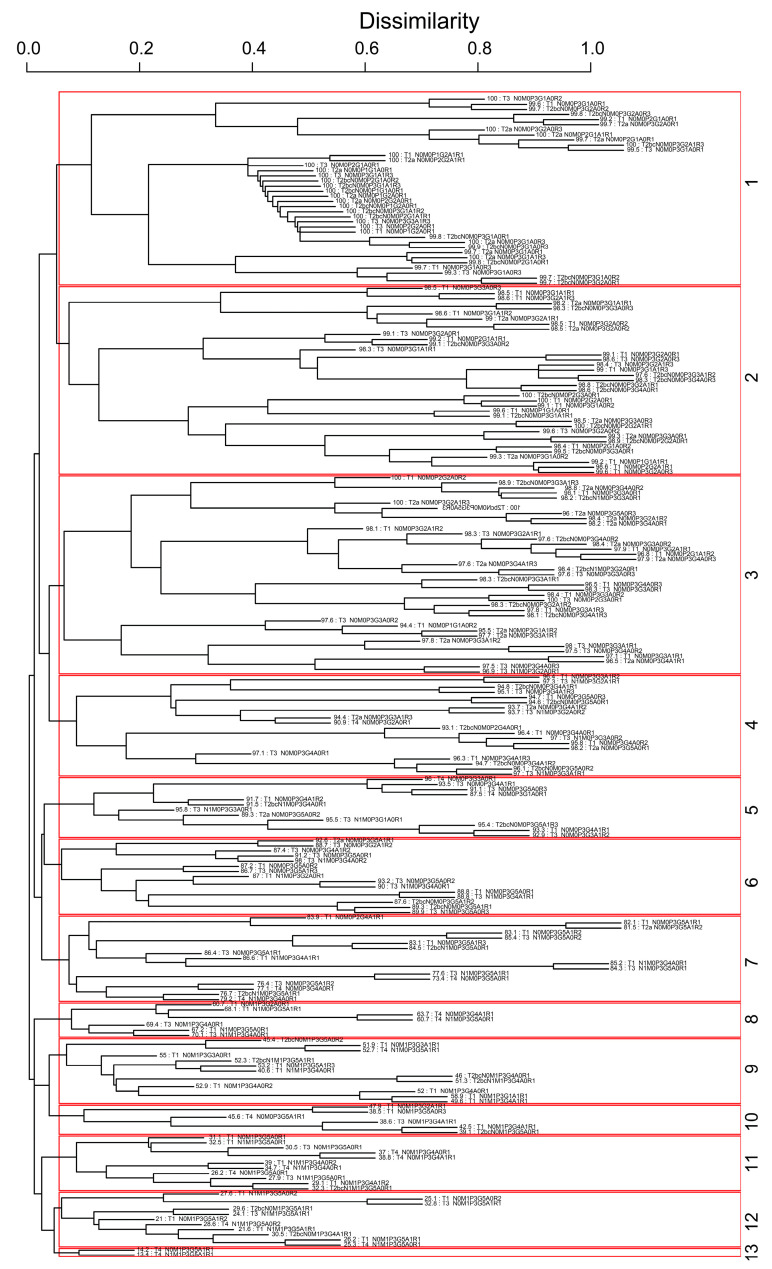 Figure 7
Figure 7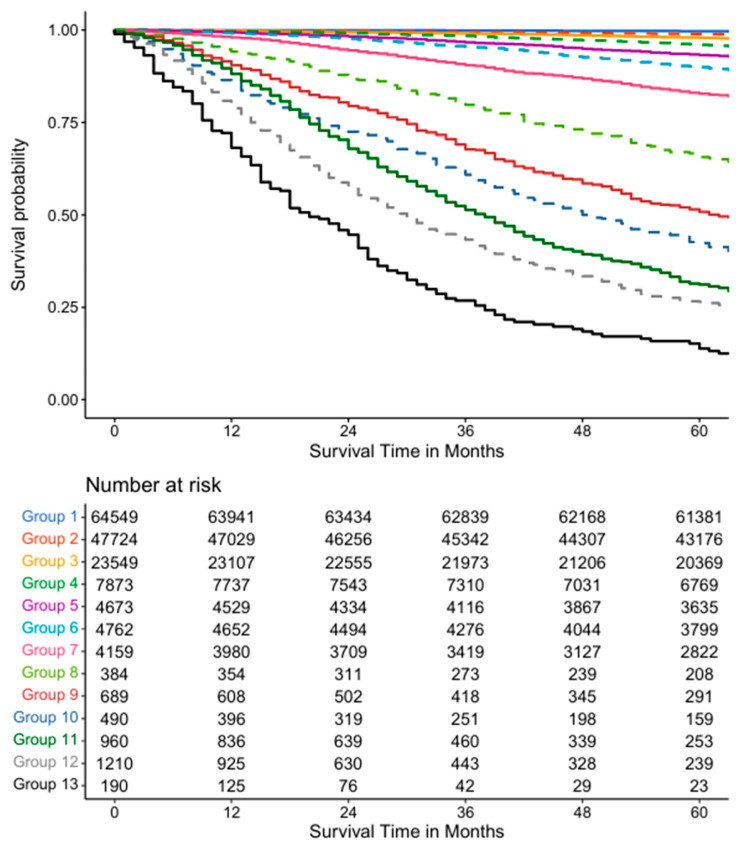 Figure 8
Figure 8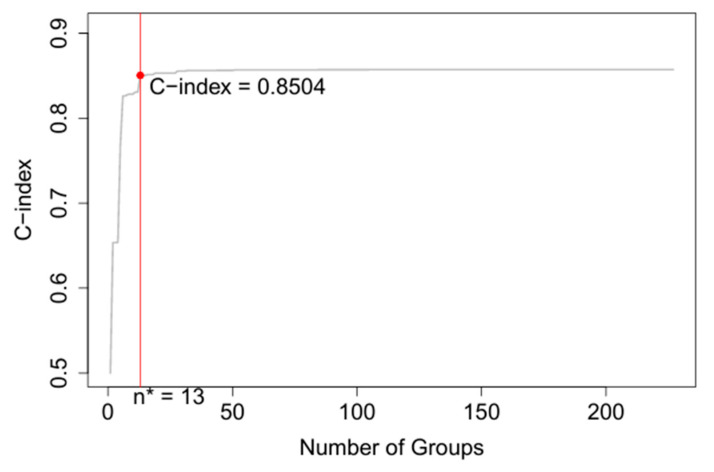 Figure 9
Figure 9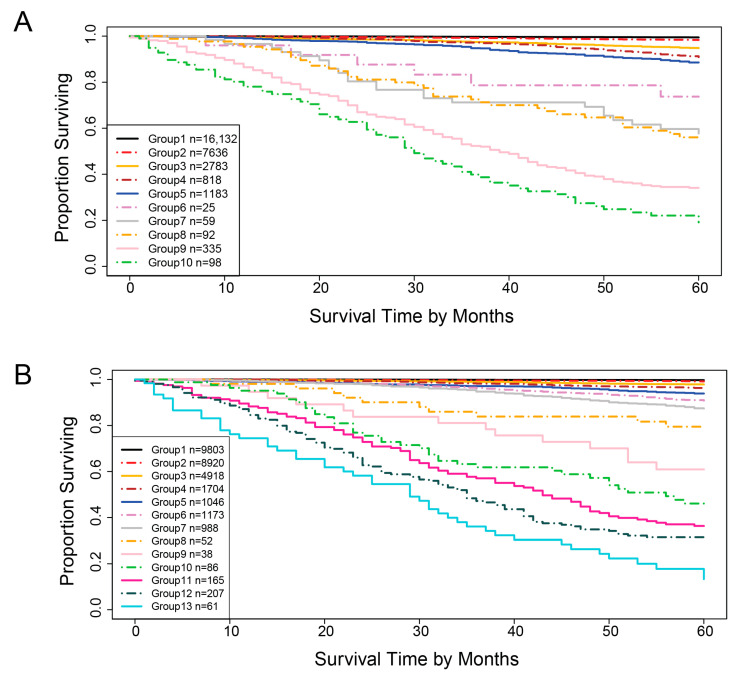 Figure 10
Figure 10- —Murtha Cancer Center Program (MCCRP)
- —MCCRP, Center for Prostate Disease Research (CPDR)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsProstate Cancer Diagnosis and Treatment · Prostate Cancer Treatment and Research · AI in cancer detection
1. Introduction
Prostate cancer is the most prevalent cancer among American men, with an estimated 299,010 new diagnoses and 35,250 deaths in 2024 [1]. Men of African ancestry are disproportionately affected, with higher rates of both diagnosis and mortality compared to men of European ancestry [1]. The widespread use of prostate-specific antigen (PSA) testing and advances in treatment has helped to reduce prostate cancer mortality by half since its peak in 1993 [2,3,4]. However, the potential for false positives has led to debates over PSA testing [5]. Meanwhile, the US Preventive Services Task Force (USPSTF) recommendations against screening in certain age groups have contributed to an increase in both localized and distant-stage diseases [6,7]. Accurately staging the disease is crucial for effective treatment and improved survival, as the 5-year survival rate drops significantly from 100% for localized cancer to 33% for distant stage patients [1,8].
The current standard for prostate cancer staging is the American Joint Committee on Cancer (AJCC) Tumor, Lymph Node, and Metastasis (TNM) Staging System [9,10]. This system relies on five key clinical–pathologic factors: the tumor size and extent (T), spread to lymph nodes (N), presence of metastasis (M), PSA levels (P), and Grade Group (G) [9,11]. The AJCC TNM system classifies prostate cancer into four stages [9]. Stage I is a non-palpable tumor that is undetectable by digital rectal exam (DRE) or imaging. In Stage II, the tumor is larger and detectable within the prostate by DRE or imaging. Stage III tumors have spread to nearby tissues such as seminal vesicles, while Stage IV indicates the tumor has metastasized to distant parts of the body, such as lymph nodes or bones. Localized prostate cancer (stages I, II, and IIIA) and regional prostate cancer metastasized to lymph nodes (stages IIIB and IVA) have an almost 99% five year survival rate, and distant prostate cancer (stage IVB) and unknown or unstaged prostate cancer have a five year relative survival rate of 34% and 92%, respectively [8]. Though staging is important to guide treatment modalities, the AJCC TNM System has significant limitations. It omits potentially important variables and has shown limited accuracy in predicting progression and recurrence. As demonstrated by the current AJCC standards, there is illogical staging of localized prostate cancer as stage IIIA along with the other localized prostate cancer stages I and II. The stage IIIA discrepancy is further highlighted as stage IIIA is treated as localized prostate cancer in contrast to stage IIIB, as regional prostate cancer. Other studies demonstrate the difficulty in distinguishing survival outcomes between stage III and stage IV patients [12]. Attempts to revise or improve the AJCC staging have been limited. For example, Sun et al. [12] proposed a modified staging system based on a nomogram that integrates T, N, and M stages, primary and secondary Gleason pattern scores, and PSA levels. However, nomograms rely on the proportional hazards assumption, which is often violated in real-world datasets, limiting their prognostic accuracy. In addition, there are no standardized guidelines for translating nomogram scores into discrete risk groups, reducing their practical utility.
To overcome these limitations, we applied the Ensemble Algorithm for Clustering Cancer Data (EACCD) [13,14] to develop a more accurate prognostic system. This machine learning algorithm has been successfully used to cluster survival data to identify highly accurate prognostic groups from survival data for other cancers, including breast [15,16], colorectal [17], and lung cancer [18], as well as in ovarian [19] and endometrial cancers [20], Hodgkin and Non-Hodgkin lymphoma [21], and melanomas [22]. By using EACCD on population-level SEER data, we aim to enhance prostate cancer staging and provide a more accurate tool for predicting patient outcomes. We first constructed models using the five standard AJCC variables and then extended them by incorporating age and race, two well-established prognostic factors not currently included in the AJCC system. We subsequently evaluated the performance of the EACCD models using the validation dataset.
This paper is organized as follows: Section 2 describes the methods, Section 3 presents the results, and Section 4 provides the conclusions.
2. Methods
2.1. Clinical–Pathologic Datasets
Prostate cancer data as identified by the International Classification of Disease for Oncology (Third Edition) [ICD-O-3] histology code (C61.9) were extracted from de-identified data on patient demographics from the National Institutes of Health (NIH) National Cancer Institute (NCI) Surveillance, Epidemiology, and End Results Program (SEER) database. A total of 254,390 out of the total 354,781 prostate patients diagnosed between 2010 and 2015 were retrieved from 17 datasets from the SEER 17 Registries Database 2023 version [23]. SEER cases before 2010 were excluded to reflect the same revision criteria as AJCC’s TNM Staging Editions used to diagnose prostate cancers on or after 1 January 2020, with the adoption of the PSA and Grade Group. Cases after 2015 were also excluded because 2015 was the last year that allowed a follow up year of at least five years. For the study data, survival time measured in months were included in the prostate-specific survival analysis.
Following the AJCC staging system, this study included five primary variables: Tumor (T), Lymph Node (N), Metastasis (M), PSA (P), and Grade Group (G). Additionally, two other variables—Age (A) and Race (R)—were included due to their established prognostic influence [24,25,26,27]. A detailed description of these seven variables is provided in Table 1. The original AJCC staging system is outlined in Table 2, compiled from information in the literature [9,10].
Other variables used in clinical prognosis such as androgen deprivation therapy, neoadjuvant androgen deprivation therapy, and genetic predisposition to prostate cancer from family lineage were not collected in the SEER database. Therefore, they could not be included in the EACCD calculations.
Cases diagnosed between 2010 and 2014 were used to create the training dataset, while cases diagnosed in 2015 served as the validation set. The inclusion and exclusion criteria outlined in Figure 1 and Figure 2 were applied to filter the training and validation datasets, respectively. The final training and validation datasets contain known values corresponding to the prognostic variables of interest. Any missing or unknown values were not imputed, and therefore excluded. Only patients with known Survival Time and Cause of Death were included because these variables are essential for reliable survival analysis; without them, it is not possible to calculate time-to-event outcomes or to distinguish prostate cancer–specific mortality. In the datasets, these exclusions represented a small fraction of the overall cohort (e.g., 464 patients, 1.6% of the total), and their removal ensured that survival endpoints were well-defined for all included cases. Any combination during the data processing step that had less than 25 patients was also excluded due to the low statistical power associated with lower representation. In this context, a “combination” refers to a subset of patients corresponding to specific levels of the selected factors, such as T4N1M1, which represents patients with T = T4, N = N1, and M = M1. A threshold of 25 was used to optimize the robustness of the statistical techniques, though any reasonable cutoff could be applied. Importantly, after applying these exclusion principles, the demographic and clinical–pathologic distribution of the final dataset remained consistent with the broader SEER prostate cancer population, suggesting no systematic bias was introduced. Thus, the final dataset structure was robust, reproducible, and appropriate for developing and validating prognostic models. The sample characteristics distribution of the variables in the training and validation datasets are outlined in Table 3 and Table 4, respectively. The EACCD algorithm was utilized on the training data to develop prognostic models, which were subsequently validated using the validation dataset.
2.2. EACCD
The Ensemble Algorithm for Clustering Cancer Data (EACCD) is a machine learning technique introduced by Chen et al. [13,16], designed to partition cancer survival data based on combinations of factors. Given a collection of combinations and nonnegative weights with , the EACCD consists of the following three main steps (see Section Experiments in [14]):
- Define the initial dissimilarity for any pair and .
- For each with , apply the two-phase Partitioning Around Medoids and the initial dissimilarities in Step 1 to partition combinations into clusters. is defined as 1 if and are not assigned into the same cluster, otherwise was defined as 0. Then the learned dissimilarity is defined as follows: .
- Perform hierarchical clustering to cluster the combinations by using .
Each of these steps can employ different approaches. In the present study, the initial dissimilarity between and is defined as the survival difference between them, estimated using the effect size derived from the Gehan–Wilcoxon test statistic [14,28]. The ensemble learning process utilizes weights for . For hierarchical clustering, the minimax linkage method [29] is selected.
The EACCD algorithm generates a dendrogram showcasing all the possible combinations in terms of survival. Dendrograms enable researchers and physicians to understand the rationale behind the grouping of patients. Combinations can be partitioned by horizontally cutting the dendrogram to the specific level of dissimilarity. Harrell’s C-index (also known as the concordance index) [30] is then computed from the available (prognostic) groups of combinations to highlight the statistical predictive accuracy. Generally, the curve for the C-index plotted against the number of groups increases for a relatively small number of groups before plateauing as more groups are generated. The optimal n* of prognostic groups is obtained from the “knee” point of the C-index curve.
We conclude this subsection with the following note: When we focus on patient features and survival times (numerical data), EACCD serves as an outcome-guided clustering method, that is, a form of supervised clustering where the supervision is provided by the outcome of interest. In contrast, when we focus on the survival curves of combinations (curves treated as geometric objects rather than raw numbers), EACCD functions as a fully unsupervised learning method, clustering these unlabeled curves based solely on their shapes.
2.3. Prognostic Systems
The proposed EACCD was trained on SEER 2010–2014 data to obtain n* prognostic groups. Survival curves for these groups were then plotted with Kaplan–Meier estimates to visually examine the survival differences among the different prognostic groups. The final prognostic system, named the EACCD prognostic system, consists of the dendrogram, group assignment, C-index, and survival curves.
As more variables are included, the number of possible combinations of values of variables increases, making it more difficult to visually examine the dendrogram. To address this, the dendrogram and corresponding group assignments can be summarized in tables (see the Results section below). In the EACCD system, risk stratification can be evaluated by visually examining the survival curves of the prognostic groups, while the accuracy of survival prediction is measured using the C-index. Overall, the EACCD system has been shown to provide effective patient risk stratification and high predictive accuracy.
The use of the EACCD system is straightforward. First, a patient’s values for the relevant variables are determined. Next, the patient is assigned to a prognostic group based on these values. Finally, the system’s survival curve associated with that group is used to help doctors and the patient understand the prognosis and guide treatment decisions.
2.4. Software
All statistical analyses as well as their respective visualizations were conducted in R (Version 4.2.2) using the following libraries: survival (Version 3.4-0), cluster (Version 2.1.4), protoclust (Version 1.6.4), factoextra (Version 1.0.7), and compareC (Version 1.3.2).
3. Results
In this section, we begin by presenting the AJCC 9th edition staging system and the EACCD system, both of which are based on five key variables: tumor, lymph nodes, metastasis, PSA, and Grade Group. Then an extended version of the EACCD system, which includes two additional variables race and age, was introduced. Finally, the validation results were shown to demonstrate reproducibility. For simplicity, the various AJCC prognostic stages are referred to as stages, while the corresponding EACCD outputs are referred to as groups.
3.1. Five Variable AJCC System
The original stages from the AJCC TNM System 9th Version consisting of four principal stages (I, II, III, and IV) from the five variables of Tumor (T), Metastasis (M), Lymph Nodes (N), PSA(P), and Grade Group (G) were included for comparisons to the groupings produced by the EACCD algorithm. Depending on the anatomic extent of the disease, PSA levels, and Grade Group, the AJCC TNM Prostate Staging System can be further divided into nine prognostic substages (I, IIA, IIB, IIC, IIIA, IIIB, IIIC, IVA, and IVB) as described in Table 2. Survival curves provide visual comparisons of the substages over time within the data. By applying the AJCC 9th Version Staging System to the training dataset, the survival curves shown in Figure 3 were generated. These curves reveal weak separations between stages. For instance, the curve for Stage I closely resembles that of Stage IIA, and the curve for Stage IIC is close to that of Stage IIIA. The C-index for the AJCC 9th Version was calculated to be 0.7676 (95% CI: 0.7622–0.7731).
3.2. Five Variable EACCD System
Using the same training data and the same five variables—T, N, M, P, and G—as in the AJCC system, the EACCD algorithm clustered 227 unique combinations of patients into 10 distinct groups in Figure 4. To aid readability, Supplementary Table S1 lists the specific combinations for each of the 10 groups in Figure 4. In addition, Supplementary Table S2 shows the number of events (deaths) in each of the 10 groups. The survival curves for these 10 groups were plotted in Figure 5. Note that the separation between any two adjacent curves is statistically significant (log-rank test p < 0.05). Comparing Figure 5 with Figure 3 shows that EACCD distinguishes and stratifies prostate cancer patients much more effectively than the AJCC system. Furthermore, the C-index for EACCD on the training set is 0.8293 (95% CI: 0.8245–0.8341) as demonstrated in Figure 6, which is higher than the AJCC C-index of 0.7676 (95% CI: 0.7622–0.7731).
3.3. Seven Variable EACCD System
The inclusion of two additional variables, age and race, in the EACCD algorithm results in the dendrogram shown in Figure 7. To improve readability, Supplementary Table S3 lists the specific combinations corresponding to each of the 13 groups in Figure 7. Supplementary Table S4 further provides the number of events (deaths) within each group. The survival curves for the 13 resulting groups are shown in Figure 8. These curves are clearly separated (log-rank test p < 0.05 for any two adjacent curve comparisons), similar to those of the EACCD five-variable system in Figure 5. The C-index for this extended model is 0.8504 (95% CI: 0.8461–0.8547) as shown in Figure 9, which is higher than the AJCC C-index of 0.7676 (95% CI: 0.7622–0.7731) and the C-index of 0.8293 (95% CI: 0.8245–0.8341) from the EACCD five-variable model.
3.4. Validation
In Section 3.2 and Section 3.3, we developed the EACCD systems using five and seven variables with the training data. Both the five- and seven-variable EACCD systems outperformed the AJCC 9th Edition, providing clearer separation of survival groups and higher predictive accuracy. In this subsection, we present the results of evaluating these systems using the validation dataset. The validation process was as follows: we first applied the assignment rules of the systems to the validation dataset to group (“stage”) the patients. Next, we computed the C-indices and plotted survival curves based on these groups. Finally, we compared the C-indices and survival curves from the validation dataset with those from the training dataset in Section 3.2 and Section 3.3. Consistency of C-indices and survival curves between training and validation data indicates the reliability of the EACCD systems.
Table 5 compares the C-indices between the training and validation datasets in the five variable system and seven variable system. The five-variable EACCD system has a C-index of 0.8293 (95% CI: 0.8245–0.8341) in the training data and 0.8437 (95% CI: 0.8308–0.8566) in the validation data, while the seven-variable EACCD system has a C-index of 0.8504 (95% CI: 0.8461–0.8547) in the training data and 0.8585 (95% CI: 0.8468–0.8703) in the validation data. This indicates that the survival prediction performance of each EACCD system is consistent across both the training and validation datasets.
Figure 10 shows the survival curves of the groups in the validation dataset. For the five-variable system, 10 survival curves corresponding to 10 groups are obtained. The separation between adjacent curves is significant (log-rank test p < 0.05) except for group 5 vs. group 4, group 7 vs. group 6, and group 8 vs. group 7. In these cases, the hazard ratios still point in the expected direction, providing objective evidence of group separation. Thus, applying the EACCD TNM system to the validation data yields 10 groups with clearly separated survival curves. Similarly, applying the EACCD TNMA system to the validation data results in 13 groups with separated survival curves. Here, the separation is significant for all adjacent pairs except group 10 vs. group 9, group 11 vs. group 10, and group 12 vs. group 11. Again, the hazard ratios for these comparisons remain consistent with the intended risk ordering. Together, these results indicate that the risk stratification performance of both systems is consistent across the training and validation datasets.
The above validation results suggest that EACCD performance is reproducible on future data. This further supports the robustness of the system for clinical application.
4. Discussion
There appear to be very few studies in the literature focused on developing methods to improve prostate cancer staging. A recent study by Sun et al. [12] modified the AJCC staging system using nomogram scores derived from multivariate Cox survival modeling. Sun et al. used a filtered dataset of 16,803 patients and achieved a C-index of 0.789 (95% CI: 0.777–0.801) compared to the calculated C-index 0.762 (95% CI: 0.748–0.776) on their dataset using the gold standard AJCC model [12]. In contrast, our EACCD model was trained on a larger and more recent dataset of 161,212 patients and produced C-indices of 0.8293 (95% CI: 0.8245–0.8341) and 0.8504 (95% CI: 0.8461–0.8547) for the five- and seven-factor prognostic systems, respectively.
The strength of unsupervised clustering algorithms lies in their ability to autonomously identify novel subgroups within complex and high-dimensional datasets. Traditional supervised methods, while effective for specific tasks like predicting biochemical recurrence, as seen in studies by Tan et al. [31] and Ekşi et al. [32], are ultimately designed to reinforce existing knowledge. Semwal et al. trained multiple supervised models to predict pathological stages using an XGBoost model that outperformed existing clinical methods [33]. Martelin et al. also used a gradient boost model that included PSA and personal variables to improve the model’s accuracy [34]. Nayan et al. employed an XGB algorithm to predict 5-year survival, highlighting the need to consider race in ML models to address healthcare disparities [35]. Finally, Fonseca et al. developed an XGB-based tool to predict whether there was enough circulating tumor DNA for informative genotyping in metastatic cases, further demonstrating the potential of machine learning to optimize biomarker use and refine risk stratification [36].
Our EACCD approach, which utilizes unsupervised clustering at its core, allowed us to identify new patient subgroups that were not evident in the current staging system. This is a crucial step toward creating more precise and personalized prognostic systems. Unsupervised learning approaches, with their ability to uncover hidden structures and inherent data patterns, provide a powerful tool for deepening our understanding of prostate cancer heterogeneity. They present an improvement beyond traditional approaches that rely on clinical pathologic features such as Gleason score, which often fail to capture the full picture of disease heterogeneity [37]. These approaches have been applied on diverse data types, including genomic and proteomic profiles, to discover new molecular subtypes with distinct clinical outcomes [38]. Increasingly, more studies employ integrated multi-modal systems that combine data from multiple sources such as digital pathology and clinical records to create highly accurate patient specific models [39]. These unsupervised clustering approaches provide more accurate and reliable prognostic information that is independent of existing risk classifications, therefore aiding in identifying at-risk patients who might otherwise be miscategorized. They will also improve as more data becomes available, supporting their value as a risk stratification tool to optimize for follow-up and reduce over-treatment.
The development of the EACCD prognostic system marks a promising step toward advancing personalized medicine in prostate cancer. Moving beyond the traditional and subjective committee-based decision-making, our EACCD method provides an algorithmic and data-driven framework. The EACCD system can be continually updated with new prognostic factors as they are discovered, such as circulating tumor DNA (ctDNA) and other clinical variables like lactate dehydrogenase [36]. This adaptability ensures its long-term relevance and accuracy. The potential for developing a clinical decision support tool that leverages EACCD to provide real-time prognostic groups for patients could significantly enhance clinical decision-making, optimize treatment strategies, and ultimately improve health outcomes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Siegel R.L. Giaquinto A.N. Jemal A. Cancer statistics, 2024 CA Cancer J. Clin.202474124910.3322/caac.2182038230766 · doi ↗ · pubmed ↗
- 2Etzioni R. Tsodikov A. Mariotto A. Szabo A. Falcon S. Wegelin J. Di Tommaso D. Karnofski K. Gulati R. Penson D.F. Quantifying the role of PSA screening in the US prostate cancer mortality decline Cancer Causes Control 20081917518110.1007/s 10552-007-9083-818027095 PMC 3064270 · doi ↗ · pubmed ↗
- 3Tsodikov A. Gulati R. Etzioni R. Reconciling the Effects of Screening on Prostate Cancer Mortality in the ERSPC and PLCO Trials Ann. Intern. Med.201816860860910.7326/L 17-073829677262 · doi ↗ · pubmed ↗
- 4Matsukawa A. Yanagisawa T. Bekku K. Kardoust Parizi M. Laukhtina E. Klemm J. Chiujdea S. Mori K. Kimura S. Fazekas T. Comparing the Performance of Digital Rectal Examination and Prostate-specific Antigen as a Screening Test for Prostate Cancer: A Systematic Review and Meta-analysis Eur. Urol. Oncol.2024769770410.1016/j.euo.2023.12.00538182488 · doi ↗ · pubmed ↗
- 5Borregales L.D. De Meo G. Gu X. Cheng E. Dudley V. Schaeffer E.M. Nagar H. Carlsson S. Vickers A. Hu J.C. Grade Migration of Prostate Cancer in the United States During the Last Decade J. Natl. Cancer Inst.20221141012101910.1093/jnci/djac 06635348709 PMC 9275764 · doi ↗ · pubmed ↗
- 6Jemal A. Fedewa S.A. Ma J. Siegel R. Lin C.C. Brawley O. Ward E.M. Prostate Cancer Incidence and PSA Testing Patterns in Relation to USPSTF Screening Recommendations JAMA 20153142054206110.1001/jama.2015.1490526575061 · doi ↗ · pubmed ↗
- 7Moyer V.A. U.S. Preventive Services Task Force Screening for prostate cancer: U.S. Preventive Services Task Force recommendation statement Ann. Intern. Med.201215712013410.7326/0003-4819-157-2-201207170-0045922801674 · doi ↗ · pubmed ↗
- 8Siegel D.A. O’Neil M.E. Richards T.B. Dowling N.F. Weir H.K. Prostate Cancer Incidence and Survival, by Stage and Race/Ethnicity—United States, 2001–2017 MMWR Morb. Mortal. Wkly. Rep.2020691473148010.15585/mmwr.mm 6941 a 133056955 PMC 7561091 · doi ↗ · pubmed ↗