Are Machine Learning methods effective in detecting undiagnosed atrial fibrillation in primary care settings using electronic health records? A systematic review
Mhd Diaa Chalati, Chetan Shirvankar, Genevieve Gore, Abhinav Sharma, Samira Abbasgholizadeh-Rahimi

TL;DR
This review evaluates how well machine learning models using electronic health records can detect undiagnosed atrial fibrillation in primary care, finding promise but also significant limitations.
Contribution
The study is the first systematic review to assess the effectiveness of EHR-based ML models for AF detection in primary care settings.
Findings
EHR-based ML models show potential for detecting undiagnosed AF, with AUROC ranging from 0.71 to 0.948.
Only 25% of studies underwent external validation, and 53% were at high risk of bias.
Combining ML with clinical tools improved discrimination compared to ML models alone.
Abstract
Atrial fibrillation (AF) increases the risk of stroke, heart failure and mortality. Current screening guidelines fail to detect AF effectively, and existing models have limited applicability in primary care. Electronic health records (EHRs) provide an opportunity to apply machine learning (ML) for automated AF detection; however, their performance relative to standard care remains unclear. We conducted a systematic review to evaluate the effectiveness, quality, and applicability of EHR-based ML models for detecting AF in primary care. The review is informed by Joanna Briggs Institute and Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) guidelines. We searched seven databases from inception to May 2023. Eligible studies involved adults in primary care where ML models using EHRs were compared to standard care. The primary outcome was the detection of undiagnosed…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
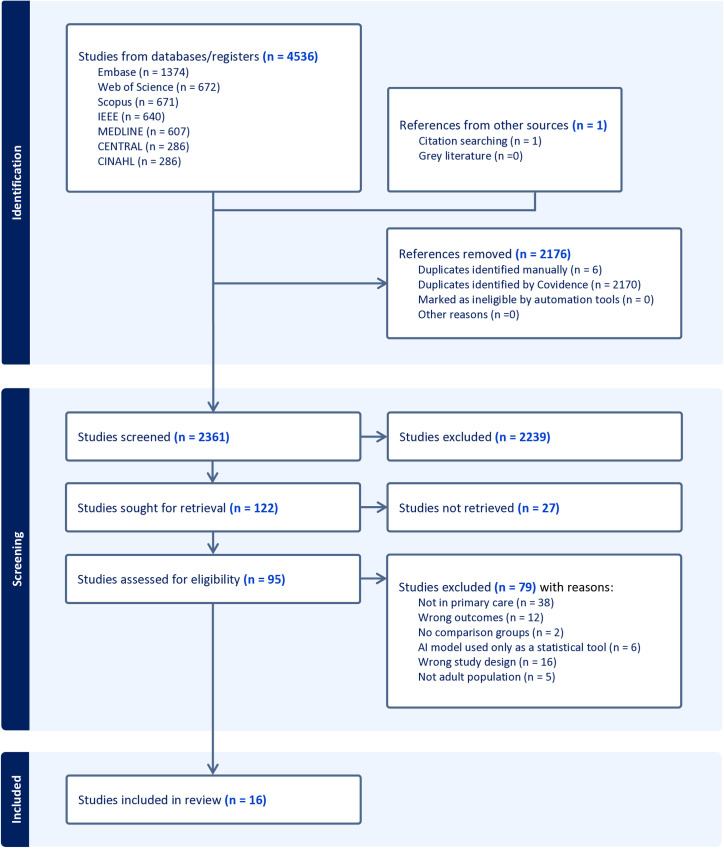 Fig 1
Fig 1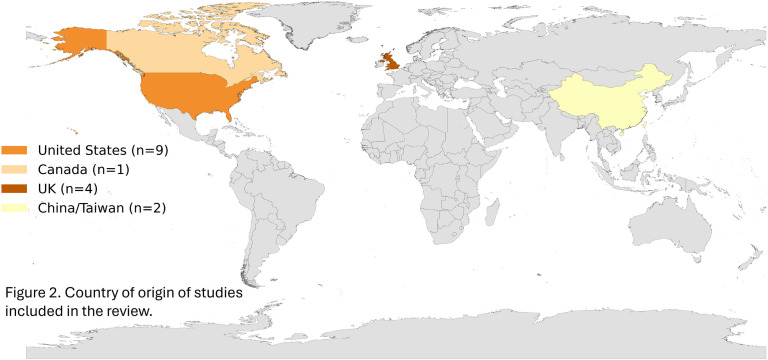 Fig 2
Fig 2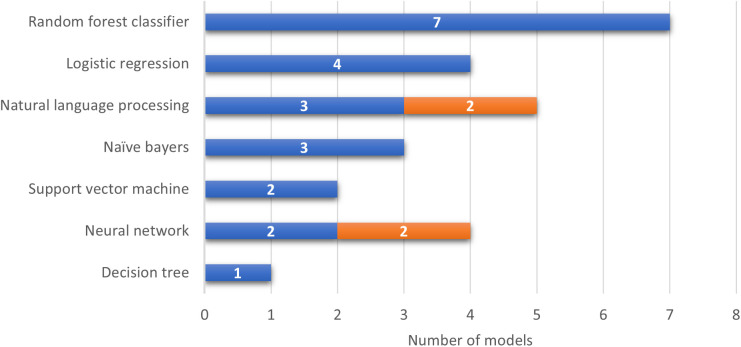 Fig 3
Fig 3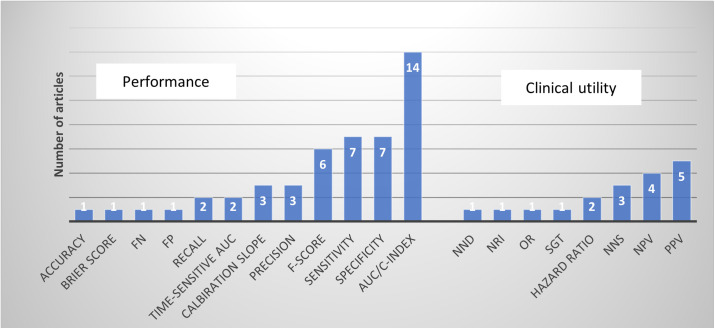 Fig 4
Fig 4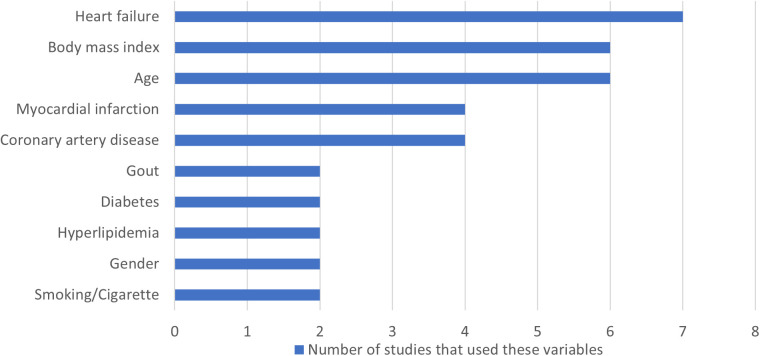 Fig 5
Fig 5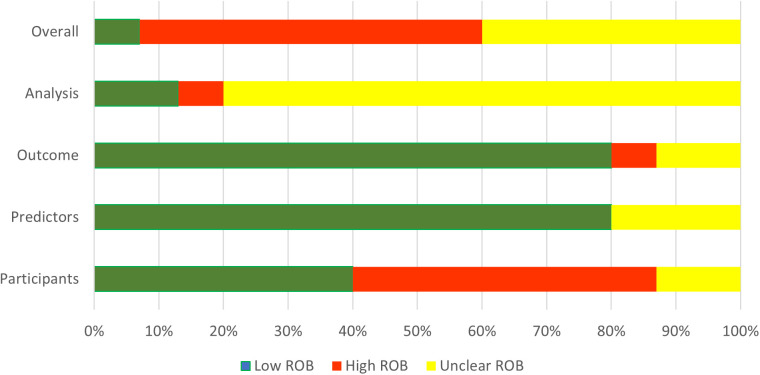 Fig 6
Fig 6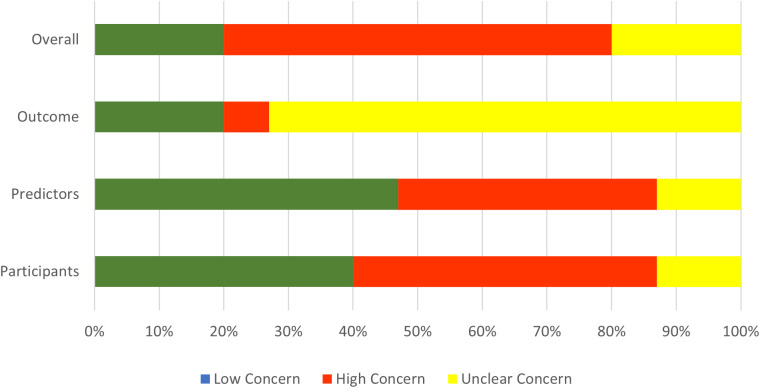 Fig 7
Fig 7- —The Canadian Institute for Health Research project grant
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAtrial Fibrillation Management and Outcomes · Acute Myocardial Infarction Research · Cardiac Arrhythmias and Treatments
Introduction
Atrial fibrillation (AF) is the most prevalent arrhythmia encountered in family medicine, with estimates from the Canadian Cardiovascular Society indicating that up to a million Canadians experience either silent or paroxysmal AF [1]. Left untreated, AF substantially increases the risk of severe stroke—by three to five times [2], elevates mortality rates even after adjusting for other cardiovascular factors [3] and increases the risk of heart failure [4–6].
Despite the high prevalence and significant risks associated with AF, current primary care screening methods remain inadequate globally. For instance, in Canada, no unified guideline for AF screening exists, with the Canadian Cardiovascular Society’s recommendation limited to opportunistic screening for patients aged 65 and older, involving pulse palpation during annual check-ups [1]. Opportunistic screening often fails to detect silent AF due to its lack of systematic approach.
Traditionally, patients were flagged for AF screening based on age alone, with one study showing a number needed to treat (NNT) of 111 [7]. Himmelreich et al.‘s systematic review also identified the Cohorts for Heart and Aging Research in Genomic Epidemiology for Atrial Fibrillation (CHARGE-AF) model as the most successful for predicting incident AF over a five-year window. Despite widespread validation and readily available clinical metrics, CHARGE-AF has limitations such as primarily studied in three American cohorts which is limiting its applicability to non-white populations. Besides, it relies on static numerical values that require significant manual input from primary care physicians, adding to their workload. It also falls short in primary care when it comes to systematic and effective detection [8]. Consequently, it is estimated that 20% of AF cases are only diagnosed after a patient experiences their first stroke [9] leading to thousands of hospitalizations per year [10].
Given the high risks associated with untreated AF and the limitations of current screening methods, a more reliable, efficient, and integrated approach is urgently needed in primary care. Machine learning (ML) offers a promising solution by analyzing large volumes of patient data to identify AF risk patterns with greater accuracy. While wearable technologies are gaining greater acceptance in cardiovascular disease states such as heart failure [11,12], ML applications in AF detection are already showing potential. Notably wearables integrated with convolutional neural networks (CNNs) have demonstrated potential for AF monitoring [13], as well as for improving AF detection from ECGs [14]. However, these models often rely heavily on ECG-derived data and require active provider input, which limits their scalability in primary care.
This has led to a growing interest in using ML with electronic health records (EHRs), which contain readily available patient information crucial for AF risk assessment. EHR-based ML models could analyze comprehensive data, including demographics, comorbidities, and health history, to provide an automated and effective screening tool. While evidence on this approach is expanding, it remains unclear how these EHR-based models perform compared to standard care. Many studies lack direct comparisons, and questions remain about the generalizability of ML models in primary care due to variability in validation methods and dataset limitations. A systematic synthesis of current evidence is therefore necessary to assess the benefits and limitations of ML-based tools for AF screening using EHR.
The primary aim of this systematic review is to evaluate the effectiveness of ML models in detecting undiagnosed AF in primary care settings using EHR data compared to standard screening practices. Additionally, this review seeks to assess the quality of these models by examining their validation methods and risk of bias, and to explore the clinical relevance of ML models by analyzing their impact on patients, healthcare providers, and healthcare systems. This will provide a comprehensive evaluation of ML-based AF detection tools using EHR, supporting primary care providers in making informed decisions about integrating these technologies into routine practice. Enhanced EHR-based ML screening could enable early AF detection, reducing strokes and hospitalizations. For clarity, key machine learning terms used this review are defined in Table 1.
Table 1: Glossary of machine learning terms used in this review.
Methods
The protocol for this systematic review was informed by the Joanna-Briggs Institute (JBI) guidelines [15] and registered on the International Prospective Register of Systematic Reviews (PROSPERO; ID: CRD42023390603) found in S1 Protocol. The PICOS (population, intervention, comparator, outcome) framework [16] was used to develop the inclusion and exclusion criteria for suitable studies. This systematic review followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) checklist [17].
Search strategy
An information specialist/librarian (GC) developed the search strategy and conducted a comprehensive search of electronic databases from the date of inception to May 2023. The search strategy was applied to Ovid-MEDLINE and translated to other databases (Ovid-MEDLINE, Embase, CINAHL, Cochrane CENTRAL, Web of Science, IEEE Xplore, Scopus) after validation and revision with the team. The relevant search strategy can be found in S1 Appendix.
Eligibility criteria
We included peer-reviewed publications in English using the PICOS framework. Population: Studies involving adult populations (aged >18 years) were included. Intervention: Oly studies that developed and/or applied ML methods using data from EHRs or primary care databases to detect new cases of AF within a primary care context were included. Accepted ML methods included algorithms such as decision trees, neural networks, support vector machines, Bayesian networks, and other models specifically designed for AF detection. Studies that utilized ML models developed exclusively with variables from ECGs, imaging data, or wearable devices without being integrated into EHR were excluded. However, studies that incorporated these models as clinical variables within EHR-based ML models or used them as part of a combined model with validated clinical risk scores for application in a primary care setting, were included. Comparison: Standard care practices or validated clinical risk scores for AF.
Outcome: The primary outcome of interest was the incidence of new AF diagnoses following the application of ML methods. Secondary outcomes included those related to patients (e.g., clinical outcomes, functional improvements, quality of life, patient satisfaction, and patient knowledge), healthcare providers (e.g., performance measures, provider satisfaction, skill enhancement, and patient-provider relationship quality), and healthcare systems (e.g., access to care, cost-efficiency, safety metrics, equity, healthcare utilization, and population health indicators). Settings: Eligible studies were conducted within primary care or outpatient settings where patients were managed by healthcare providers, such as general practitioners, family physicians, nurse practitioners, physician assistants, general internists, and geriatric primary care providers. Studies focused solely on pediatric populations, emergency rooms, or inpatient settings or those without a clear focus on primary care were excluded.
Articles screening and selection process
Two independent reviewers (DC & CS) screened all the articles’ titles and abstracts using the predetermined eligibility criteria. After excluding irrelevant articles and duplicates, selected articles were moved to full-text review to further assess their relevance. Reviewers conducted their assessments independently, with decisions blinded from one another. Any disagreements were resolved by consulting a third reviewer (SAR). Covidence software was used to facilitate the screening and selection process.
Data extraction
We used the Checklist for Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modeling Studies (CHARMS) for data extraction (Moons et al., 2014). The CHARMS checklist is structured to systematically extract data from primary studies reporting on prediction models as well as to assess potential sources of bias in ML method selection. Key categories extracted included study information (e.g., data source), participant details (e.g., population characteristics), outcomes (e.g., outcome type and blinding of assessment), candidate predictors (e.g., predictor type), model development (e.g., sample size, handling of missing data, and predictor selection), model performance (e.g., calibration, classification measures), and model evaluation (e.g., internal vs. external validation).
In addition to these criteria, we captured further details on study design, such as the clinical question, ML method, control groups, intended use of results, validation processes, and clinical outcomes (e.g., patient-related, provider-related, and healthcare system-related). For each study, we also documented the final variables used to develop the ML models.
We customized and tested the data extraction framework on several initial articles to ensure comprehensiveness and consistency. We specifically reported on the highest-performing AI systems in AF detection, whether their performance was achieved by an ML model alone or in combination with other tools, and compared it against control groups. In this context, we identified model discrimination—the ability to accurately distinguish between individuals with and without AF—as a key metric to measure the performance of ML models. Significance was defined as by a P value < 0.05 or non-overlapping confidence intervals as reported in each article.
Quality assessment
We used the Prediction Model Risk of Bias Assessment Tool (PROBAST) for quality assessment [18]. Data extracted via CHARMS was appraised with PROBAST, which evaluates risk of bias and applicability in prognostic model studies across four domains: participants (e.g., selection bias), model predictors (e.g., bias from inconsistencies in predictor definitions and selection), outcome (e.g., bias due to outcome misclassification), and analysis (e.g., bias from inappropriate statistical methods in model development). To streamline this process, we implemented the ready-to-use template by Fernandez-Felix et al., 2023 [19]. Additionally, we applied the Consolidated Standards of Reporting Trials–Artificial Intelligence (CONSORT-AI) guidelines to assess the quality of clinical trials involving AI, ensuring comprehensive adherence to reporting standards [20].
Applicability
Alongside the applicability assessment section in PROBAST, we used the Minimum Information about Clinical Artificial Intelligence Modeling (MI-CLAIM) checklist [21] to evaluate the clinical relevance of ML models. MI-CLAIM facilitates the evaluation of the clinical impact and the reproducibility of AI models in clinical AI studies and includes six key areas: study design, data partitioning for model training and testing, data optimization, performance evaluation, model examination, and code sharing. This comprehensive approach ensured the systematic extraction of relevant data for our review. Integrating MI-CLAIM into the data extraction process enabled us to address critical aspects of validity, fairness, and replicability, contributing to a robust and nuanced evaluation of AI’s role in AF screening.
Data synthesis and analysis
Given the heterogeneity among studies and the diversity in performance metrics reported, a meta-analysis was not feasible; instead, we conducted a narrative and descriptive synthesis. This involved using textual descriptions of each study, grouping and clustering by relevant characteristics, and tabulating key effectiveness measures, with a particular focus on model performance metrics such as sensitivity, specificity, positive predictive value, accuracy, ROC-AUC, PRC-AUC, and F1 score. We also explored sources of variation across studies, including differences in study design, methodology, populations, interventions, control groups, and outcomes. Bias assessment was reported in accordance with PROBAST, utilizing the template developed by Fernandez-Felix et al., 2023 [19].
Results
Study selection
Fig 1 shows the PRISMA flow diagram for the study selection process in this review. Our initial search across seven databases yielded 4,536 references, with one additional study manually included through citation tracking due to its relevance to our inclusion criteria. After removing duplicates, 2361 unique records remained for title and abstract screening. Following the first round of screening, 122 studies were selected for full-text review. Ultimately, 16 articles met the eligibility criteria and were included for data extraction. Fig 1 provides a breakdown of exclusion reasons. S1 Checklist shows PRISMA checklist.
PRISMA flow diagram.Summary of study selection process for inclusion in the systematic review. Abbreviations: PRISMA, preferred reporting items for systematic reviews and meta-analyses.
Study characteristics
Studies location/context: Of the 16 articles, the majority were conducted in the United States (n = 9), followed by the United Kingdom (n = 4), Canada (n = 1), and China/Taiwan (n = 2). Twelve studies developed ML methods using outpatient databases, while four studies [22–25] utilized databases integrating both inpatient and outpatient data. Most articles (n = 15, 94%) were published between 2019 and 2022. A visual map of study locations is provided in Fig 2. Table 2 provides an overview of the characteristics of studies included in this review including detailed comparisons of datasets and model characteristics.
Table 2: Studies Characteristics.
Geographic distribution of included studies.Map displaying the countries where included studies were conducted. Source shapefile: Map created in Python using shapefile data from the geo-countries dataset, which is derived from Natural Earth and licensed under the Open Data Commons Public Domain Dedication and License (PDDL).
Data source: Among the 16 articles reviewed, 12 (92%) developed models exclusively using readily available EHR data. The rest of the studies included additional data modalities integrated with EHR data. For example, Christopoulos et al [30] developed a model that combined ECG data with EHR-based tools, which was later validated and tested on a larger sample by Khurshid et al. [32]. Similarly, two studies [34,35] incorporated imaging data alongside EHR data for their model development. Although these additional data sources were utilized, they were integrated with EHR data, meeting the inclusion criteria for this review. Study Designs: Most articles (n = 14, 87%) adopted retrospective cohort study designs. The remaining studies included a prospective cohort study design [35], and a prospective randomized clinical trial [36]. Intervention (ML Models characteristics): Among the 16 articles reviewed, a total of 13 unique models were identified. Notably, one model was externally validated and later tested in a clinical trial, as reported across two separate articles, and two studies [30,32] utilized the same model. Of these 13 models, the majority were supervised models (n = 11, 85%) and primarily relied on structured data (n = 13, 100%). Random forest classifiers were the most commonly used algorithm (n = 7, 54%). Additionally, deep learning models (n = 4, 31%) were employed, including time-varying neural networks [28], single-layer shallow neural networks [23], and convolutional neural networks (CNNs). The CNN-based AI-ECG model, originally developed by Attia et al. [38], was later implemented by Khurshid et al [32] and Christopoulos et al [30]. Fig 3 illustrates the ML models evaluated in each article (not the final model). Clinical comparator: The most frequently used control for comparison was the CHARGE-AF score (n = 6, 38%) followed by logistic regression models (n = 3, 19%) and clinician assessment (n = 3, 19%). Other control scores included C2HEST/CHADS, AS5F/CHseless, and the Charlson Comorbidity Index.
Distribution of machine learning models across included articles.Bar graph showing the frequency of different ML model types used among the included studies. Abbreviations: ML, machine learning; RF, random forest; SVM, support vector machine; LR, logistic regression; ANN, artificial neural network.
Taxonomy
We propose a taxonomy (Table 3) to categorize the models based on three key dimensions: ML type, validation approach, and data type. Rather than listing all models tested in each study, we included only the best-performing machine learning models—based on discrimination performance. The taxonomy highlights the frequent use of random forest models, the limited use of external validation, and the inclusion of imaging or ECG data input alongside structured EHRs in a few models.
Table 3: A taxonomy of the types of ML models highlighting the best performing AI model within each study.
Outcomes
Study outcomes primarily reported AF incidence or prevalence over periods ranging from 6 months to 5 years. Table 4 categorizes outcomes into patient-related, provider-related, and healthcare system-related outcomes.
Table 4: Performance metrics of AI systems compared to controls and clinical outcomes.
Patient-Related Outcomes: Most studies (n = 11, 69%) reported improved clinical outcomes, including early diagnosis and identification of high-risk individuals, along with the identification of new predictors and risk factors. Other patient-related outcomes were not addressed. Provider-Related Outcomes: Improvements in provider performance measures, particularly diagnostic accuracy, sensitivity, and precision, were reported in four studies. Additional provider-related outcomes included the persistence of model performance over time (n = 2), robust performance across different genders and ethnicities (n = 1), and enhanced detection using free-text data (n = 1). System-Related Outcomes: Enhanced healthcare utilization was noted in three studies, as evidenced by improved numbers needed to screen (NNS) or detect (NND), leading to more efficient AF screening in primary care. One study [26] conducted a cost analysis, estimating $13 billion in potential savings in the USA by preventing strokes with nationwide model implementation. Other system-related findings included scalability to other EHR systems using harmonized data (n = 1) and potential applications of ML in wearable devices (n = 1). Additional system-related outcomes were not reported.
AI models performance metrics
Performance measures were reported with considerable variability across the articles. Most studies evaluated their models’ performance using the Area Under the Curve (AUC) or Concordance Index (C-index) (n = 14, 87.5%) and the F-score (n = 7, 44%) to assess model discrimination as an indicator of performance. Fig 4 illustrates the distribution of the various metrics used across the studies.
Distribution of performance metrics reported.Graph showing the variety and frequency of evaluation metrics used to assess machine learning models. Abbreviations: FN, false negatives; FP, false positives; AUC, area under the curve; C-index, concordance index; NND, number needed to detect; NRI, net reclassification improvement; OR, odds ratio; NNS, number needed to screen; NPV, negative predictive value; PPV, positive predictive value.
AI models performance comparison
Since AUC was the most frequently reported performance metric, we compared the AUC of each evaluated ML model to its respective control and summarized the results in Table 4, highlighting the highest-performing AI systems—either as standalone tools or combined with clinical tools—based on the highest reported AUC within each article. Table 4 also reports statistical significance (defined as p-value < 0.05 or non-overlapping confidence intervals) and includes performance results from models that underwent external validation. It is important to note that the performance metrics reflect results obtained within each study’s own dataset and therefore cannot be directly compared across studies. This limitation is one of the key reasons a meta-analysis was not feasible.
The AUC values for ML models ranged from 0.71 to 0.948. Eight studies (50%) demonstrated statistically significant superior performance compared to control groups, indicating effective discrimination between AF cases and non-AF cases. Among these, the random forest algorithm by [37] achieved the highest reported AUC (0.948) and F1 score (0.969). Other high-performing models included neural networks [28,36], random forest classifiers [29,35], logistic regression and naive Bayes classifiers [34] as well as natural language processing combined with other structured data [26,33]. Conversely, five studies (32%) reported no difference in performance between their ML models and control groups [22–24,30,32] indicating similar discrimination between AF and non-AF cases. However, when three of these models (19%) were combined with other clinical tools, ML methods, or structured data, a statistically significant improvement in AUC/C-index was observed compared to controls [22,24,32], except for Christopoulos et al [30] where no significant improvement was observed. The rest of studies (3 studies, 19%) did not report P values with control groups [25,27,31]; however, Shah et al [25] reported a relatively high AUC of 0.80 in external validation.
In Hill et al.[36], a UK-based prospective randomized controlled multicentric trial, the model showed no significant difference in new AF diagnoses in the full analysis population (OR = 1.15 [0.77–1.73], P = 0.486). However, in the per-protocol analysis, which includes only participants who adhered strictly to the study protocol (e.g., completed all required interventions and follow-ups as planned), the model significantly outperformed routine care (OR = 3.07 [1.57–5.81], P = 0.001). Despite COVID-19 disruptions, the trial found the ML algorithm effective in identifying high-risk patients, diagnosing AF in 5.3% of high-risk versus 0.6% of low-risk participants. The NNS was 12, much better than the NNS of 70 for opportunistic screening.
Variables/model predictors
S2 Table summarizes the key variables and predictors used in the ML models for AF detection in this review. These variables are categorized into demographics, clinical findings, lab/imaging features, diagnoses, procedures, and miscellaneous factors. Due to the heterogeneity in how each variable’s impact was assessed and reported across studies, direct comparison of variable strength was not feasible. Instead, we counted the frequency with which each variable appeared across studies, as shown in the supplemental material. This count represents the number of times a specific variable was included as a predictor in the ML models reviewed. To perform this count, we reviewed the methods and feature selection sections of each study and noted variables explicitly identified as predictors in their models. Fig 5 highlights variables that were reported in more than one study, suggesting their potential significance in AF detection as commonly used predictors.
Frequently reported predictor variables.Visualization of the most common clinical and demographic variables used as predictors in the machine learning models.
In the demographics category, age, gender, and smoking emerged as the most frequently cited variables. For clinical findings, body mass index—both static measurements and changes over time—was prominent, along with signs of heart failure such as edema. Imaging-based variables frequently mentioned included anatomical metrics like left atrial diameter, right ventricular end-diastolic volume, diastolic flow, and left ventricular hypertrophy, which are all potentially linked to cardiac strain or heart failure. Other notable predictors were reduced exercise capacity and left ventricular late gadolinium enhancement, indicative of replacement fibrosis. Lower chronotropic response, abnormal blood pressure responses during exercise, and lower diastolic blood pressure at peak exercise were also associated with increased AF risk, as reported by Bhattacharya et al.[34].
Lab-based variables included hyperlipidemia and renal function tests. In the diagnoses category, cardiovascular conditions were most prevalent predictors, with heart failure as the most reported variable, notably with time-varying heart failure within the last 91 days, as reported by Hill (2019) [28]. Hypertension was frequently reported, including arterial, pulmonary, and venous forms, along with systolic and diastolic blood pressure records.
In terms of lab-based variables, hyperlipidemia and renal function tests were commonly mentioned. The diagnoses category predominantly featured cardiovascular conditions, with heart failure being the most frequently reported predictor—particularly time-varying heart failure within the last 91 days, as noted by Hill (2019) [28]. Hypertension was another frequently reported variable, encompassing arterial, pulmonary, and venous forms, along with systolic and diastolic blood pressure measurements. Myocardial infarction, coronary artery disease, and peripheral artery disease were also frequently reported variables. Other cardiovascular-related diagnoses as variables for prediction included chronic obstructive pulmonary disease (COPD), rheumatologic diseases, valvular issues (particularly mitral valve), and sleep disorders. Cardiovascular procedures such as ablation and angiography were also frequently mentioned.
Additional commonly reported variables included gout, diabetes, and various medications. Notably, diuretics (likely related to hypertension or heart failure), oral anticoagulants (non-AF related), antinausea drugs, and analgesics—including potent opioids—were also frequently mentioned as predictor variable.
Critical appraisal
Assessment of bias.
Out of the 16 articles included in this review, 15 were assessed using the PROBAST tool, while one clinical trial was excluded as it did not meet the criteria for PROBAST evaluation. Among the 15 studies, the overall risk of bias was high in 8 studies (53%), primarily due to issues with participant selection methods. Only one study (7%) was rated as having a low risk of bias. The remaining six studies (40%) were deemed to have an unclear risk of bias, largely due to insufficient information about how the analysis was conducted, particularly the handling of missing data. Notably, 12 studies (80%) exhibited an unclear risk of bias in the analysis domain. Additional sources of unclear risk of bias were identified in specific domains, including 2 studies (13%) with unclear risk related to participant selection, 3 studies (20%) with unclear bias in predictors, and 2 studies (13%) with unclear risk in the outcome domain. Fig 6 summarizes overall risk of bias across articles. S1 Table summarizes the individual results of the critical appraisal in each article.
Risk of bias across studies.Summary of the risk of bias assessment for included studies using the PROBAST tool. Abbreviations: PROBAST, prediction model risk of bias assessment tool.
Model validation and data processing.
S1 Table details the validation approaches and methods of feature selection used in model development. Among the 16 studies, four models underwent both internal and external validation (25%), while the remaining articles conducted only internal validation. Notably, one article did not perform any validation, as their primary aim was to compare population characteristics rather than assess performance metrics. The most common method of internal validation was a random split of training and test sets (n = 9, 56%), while the most common method for external validation was geographical splitting (n = 5, 31%). Calibration was not assessed in 12 studies (75%), and missing data were not properly handled in 8 studies (50%). The number of potential variables/features for model development varied significantly, ranging from 13 to 26,000. However, the number of final variables was relatively consistent across articles generally ranging from 13 to 19. The selection method for candidate predictors was primarily based on prior knowledge (n = 7, 44%). However, the approach for selecting final predictors was frequently unspecified in six studies (38%), with the Least Absolute Shrinkage and Selection Operator (LASSO) used in two studies (13%).
Applicability and reproducibility.
Among the 15 studies evaluated using PROBAST, the majority of studies (n = 9 studies, 60%) were rated as having high concern for overall applicability to clinical practice in primary care. These concerns were mainly due to the irrelevance of the setting and participant selection (n = 7 studies, 47%) and the lack of applicability of certain predictors in primary care (n = 6 studies, 40%). One study (7%) also showed applicability concerns due to issues with outcome definitions. Additionally, 11 studies (73%) had unclear applicability due to insufficient reporting on patient-, provider-, or system-related outcomes. Fig 7 shows overall applicability assessment.
Concerns regarding applicability.Assessment of concerns related to the applicability of included studies using the PROBAST framework. Abbreviations: PROBAST, prediction model risk of bias assessment tool.
MI-CLAIM checklist assessment.
Part 1 (Study Design): All the 16 studies (100%) clearly stated the research question and clinical problem. Nearly all (n = 15, 94%) described cohort characteristics, and representativeness to clinical settings reflecting a good adherence to study design standards.
Part 2 (Data and Optimization): Most studies (n = 15, 94%) detailed data origin and format, and (n = 13, 81%) provided details on the models evaluated. However, only 56%(n = 9) reported on training-test set independence, while data transformations are rarely addressed (n = 3, 19%), indicating gaps in data handling transparency.
Part 3 (Model Performance): Most articles (n = 15, 94%) presented baseline-to-model performance comparisons and 88% (n = 14) specifying algorithm performance metrics. Clinical utility metrics are noted in 69% (n = 11) with minor gaps in clarity. Overall, model performance documentation is comprehensive, particularly for baseline comparisons.
Part 4 (Percentage of Model Code Sharing): Overall, model code sharing is limited. Only 7% of studies (n = 1) fully shared their models’ codes, while most studies (n = 10, 62%) restrict access or do not share their code as shown in S1 Fig. Summary of MI-CLAIM checklist is shown in S1 Fig.
Cross-mapping of model effectiveness and applicability.
To visualize how often models achieved in terms of predictive performance and clinical applicability, we developed a matrix mapping these two dimensions (Table 5). The majority of studies (n = 7, 44%) fell into the moderate effectiveness/ high or unclear applicability quadrant, indicating limited readiness for clinical use, while only three models (19%) demonstrated both high effectiveness and low applicability concern. These findings underscore the need to improve the predictive performance of future models while using primary care-based metrics.
Table 5: Matrix mapping study-level performance against PROBAST-rated applicability: number (percentage).
Discussion
We conducted a systematic review to assess the effectiveness of ML methods in detecting new cases of AF using EHR in primary care settings. Additionally, we evaluated the quality and practical applicability of these models. The key findings from our review are summarized below.
ML methods are effective in detecting AF using EHR in primary care
For a thorough evaluation of predictive models’ performance, two key metrics—calibration and discrimination—are essential. Calibration assesses how well predicted probabilities align with observed outcomes, while discrimination, often measured by AUC or C-index, reflects a model’s ability to differentiate between high- and low-risk individuals [39]. Both metrics range from 0 to 1, with higher values (closer to 1.0) indicating better performance. C-index above 0.75 suggests strong discrimination [39]. However, for utility in clinical practice, discrimination above 0.9 is required for regulatory considerations [40,41]. In this review, 81% of studies (n = 13) reported an AUC above 0.75, demonstrating strong discrimination. However, the lack of reported calibration metrics limits a comprehensive assessment of model accuracy. A meta-analysis was not feasible due to high risk of bias in many studies and substantial heterogeneity in both performance metrics and the datasets used to develop ML models. As a result, cross-study comparisons were inappropriate. Instead, we evaluated model performance relative to control groups within each study.
When compared to the performance (discrimination) of control groups, half of the models (50%, n = 8) in this review outperformed the controls with supervised models accounting for 63% (n = 5) of these superior models. In contrast, models based on unsupervised learning methods or deep learning models showed only moderate performance. Notably, combining machine learning models (both supervised and unsupervised) with clinical tools, such as CHARGE-AF or ICD codes for AF, significantly improved model performance (discrimination). This indicates that optimal results are achieved when predictive models are used in conjunction with established clinical tools.
These findings underscore the considerable potential of ML models for AF screening in primary care. Compared to traditional models like CHADS2 (C-index 0.674) and CHARGE-AF (C-index 0.71) [7] or in head-to-head comparisons with control groups, ML models in this review demonstrated superior diagnostic performance, improving the identification of high-risk patients and contributing to better clinical outcomes. For the healthcare system, ML models in this review significantly reduced the NNS to 12, as shown in the prospective clinical trial in this review, Hill et al.’s [36], compared to 70 with conventional methods [7]. At a population level, applying such models could improve resource utilization and reduce the burden on primary care. Hill et al. [42] further demonstrated this, in another article, through cost-effectiveness analyses, showing substantial health benefits with an incremental gain of 80,669 QALYs, linked to fewer AF-related complications.
Most current ML models have high risk of bias
Our analysis revealed a spectrum of bias risks ranging from uncertain to high across most studies, primarily driven by participant selection, model overfitting, and lack of external validation. Specifically, selection bias emerged as a significant concern in 56% (n = 9) of the included studies, often due to single-center data, non-random participant selection, or exclusion of participants with incomplete data. Notably, only 25% (n = 4) of the studies conducted external validation, a critical step in mitigating the risk of overfitting and enhancing model generalizability. This observation aligns with previous findings on the prevalence of this issue in similar research contexts [43,44]. Another common source of bias was inadequate reporting on handling missing data. Only five studies (31%) reported their approach to missing data, while three studies (19%) included only participants with complete data. This oversight is a common issue in ML predictive model development. As Nijman et al. [45] noted, most ML models developed between 2018 and 2019 lacked adequate strategies for handling missing data, which can introduce significant non-reporting bias and undermine model reliability.
Most current ML models show limited applicability in primary care
While ML models show promise for AF screening, concerns remain regarding their applicability in primary care. Most studies used retrospective cohort designs, which can introduce selection and recall bias. Although primary care data were utilized, the inclusion of inpatient records, imaging, and laboratory results—often not readily accessible in primary care—further limits models’ practical applicability. We emphasize the need for using representative datasets to the intended clinical context when developing ML models inline with previous research. To enhance clinical relevance, ML models should be developed using datasets that accurately reflect the target care setting, as emphasized in prior research [46]. Furthermore, the predominance of North American datasets restricts generalizability to other populations.
Furthermore, important clinical metrics such as positive predictive value and number needed to screen were inconsistently reported, limiting understanding of these models’ practical relevance in primary care. Nevertheless, studies that included these metrics demonstrated notable improvements in screening efficiency as discussed above. Reproducibility also remains a challenge, as limited sharing of model codes restricts broader validation and real-world implementation.
ML models were able to identify novel predictors for AF in primary care
Our review shows that ML models effectively identified both traditional and novel AF risk factors. Classic predictors, including age, gender, smoking, hypertension, type 2 diabetes, and myocardial infarction, were consistent with established tools like CHARGE-AF [1,47]. Unlike traditional models that rely on static numerical values, some ML models integrated dynamic predictors, enabling the identification of non-linear relationships. For example, one model in this review [28] highlighted that recent heart failure episodes (within the last three months), changes in BMI, and recent, frequent blood pressure measurements emerged as stronger predictors of AF risk compared to a single heart failure diagnosis or isolated BP readings. These dynamic variables offer potential targets for AF screening in primary care, potentially improving screening accuracy.
Beyond traditional risk factors, our review identified imaging markers linked to heart failure or diastolic dysfunction, such as left atrial diameter, left ventricular hypertrophy, and fibrosis, consistent with existing literature [48,49]. Features like exercise intolerance and reduced chronotropic response, associated with cardiovascular stress reactivity, were identified by our review as predictors of AF aligning with prior research [50]. Additionally, clinical conditions such as valvular disease, chronic inflammatory conditions (e.g., rheumatologic diseases, kidney disease), and COPD were identified by our review as predictors associated with AF, consistent with broader research [51,52].
Notably, our review found that cancer and cancer-related medications, such as antiemetics and potent opioids, emerged as significant AF predictors, AF’s increased incidence during chemotherapy. This observation aligns with existing literature, which report a peak in AF incidence within 90 days post-cancer diagnosis, likely due to inflammation and oxidative stress [53]. These findings underscore an opportunity to target high-risk cancer patients for AF screening in primary care.
Finally, our review identified gout as a novel AF risk factor in the reviewed studies. This finding aligns with external research, such as the meta-analysis by Deng et al.[54], which demonstrated that gout increases AF risk by 33%, highlighting hyperuricemia’s role in AF pathogenesis. These results suggest a new opportunity to target patients with gout for AF screening in primary care.
Future directions
To enhance the effectiveness and applicability of ML methods in AF screening, future research should prioritize several key areas. First, consistent and transparent reporting of calibration metrics—such as calibration plots or Brier scores—is essential to determine whether predicted probabilities accurately reflect real-world outcomes. This is particularly important in clinical settings, where accurate risk estimates guide decisions about screening and treatment. Second, addressing and reporting missing data is important for improving model robustness. Third, external validation across diverse but primary care-based datasets is necessary to mitigate overfitting and improve generalizability. Fourth, prospective cohort designs are recommended to reduce selection and recall bias. Fifth, developing models that prioritize clinically accessible predictors over ECG or imaging variables, will enable seamless integration into routine primary care workflows without adding to the burden on healthcare providers. Sixth, using clinically meaningful metrics—such as positive predictive value and number needed to screen—along with standardized performance measures, will enhance the practical relevance of findings for primary care settings and facilitate cross-study comparisons. Finally, ensuring reproducibility through the sharing of code and methodologies is an important practice to replicate and test models on different contexts.
Strengths
This review provides a comprehensive analysis of the effectiveness of EHR-based ML models for AF detection in primary care, alongside a rigorous evaluation of bias sources and applicability limitations. It offers valuable insights for primary care providers to critically assess these tools, which have the potential to surpass current standard practices, and presents actionable recommendations to address existing gaps and support their practical integration into primary care workflows.
Limitations
This study has several limitations. Our search strategy excluded ML methods that rely on ECG, imaging, laboratory tests, and wearable devices, which may have narrowed the scope of our analysis. A meta-analysis was not possible due to substantial variations in performance metrics and follow-up durations, limiting cross-study comparisons. Furthermore, the predominance of retrospective single-center cohort designs and North American data registries also restricted the generalizability of our findings. Regarding missing data, we recorded unreported items as “not reported” or “unclear” in our extraction sheet. Due to the extent and variability of missing data, we did not impute values or contact study authors but instead chose to retain these studies and highlight the issue as a gap and a limitation in the current literature.
Conclusions
In conclusion, this study highlights the promise of machine learning models in leveraging electronic health records for early atrial fibrillation detection in primary care. These models demonstrate strong potential for scalable and efficient screening by utilizing real-world data. However, addressing challenges such as limited generalizability, lack of external validation, and insufficient clinically relevant metrics is essential to enhance their applicability. By overcoming these barriers, these models can transform AF screening and significantly improve patient outcomes in primary care.
Supporting information
S1 AppendixSearch Strategy.(DOCX)
S1 FigSummary of MICLAIM checklist.(DOCX)
S1 TableData extraction (CHARMS) and risk of bias evaluations (PROBAST) for each study.(XLSX)
S2 TableSummary of atrial fibrillation predictors included across the reviewed ML models.(DOCX)
S1 ProtocolFull registered protocol for the review (PROSPERO CRD42023390603).(PDF)
S1 ChecklistCompleted PRISMA 2020 checklist for systematic reviews.(DOCX)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Andrade JG, Aguilar M, Atzema C, Bell A, Cairns JA, Cheung CC, et al. The 2020 Canadian Cardiovascular Society/Canadian Heart Rhythm Society Comprehensive Guidelines for the Management of Atrial Fibrillation. Can J Cardiol. 2020;36(12):1847–948. doi: 10.1016/j.cjca.2020.09.001 33191198 · doi ↗ · pubmed ↗
- 2Healey JS, Connolly SJ, Gold MR, Israel CW, Van Gelder IC, Capucci A, et al. Subclinical atrial fibrillation and the risk of stroke. N Engl J Med. 2012;366(2):120–9. doi: 10.1056/NEJ Moa 1105575 22236222 · doi ↗ · pubmed ↗
- 3John RM, Michaud GF, Stevenson WG. Atrial fibrillation hospitalization, mortality, and therapy. Eur Heart J. 2018;39(44):3958–60. doi: 10.1093/eurheartj/ehy 622 30329031 · doi ↗ · pubmed ↗
- 4Lee E, Choi E-K, Han K-D, Lee H, Choe W-S, Lee S-R, et al. Mortality and causes of death in patients with atrial fibrillation: A nationwide population-based study. P Lo S One. 2018;13(12):e 0209687. doi: 10.1371/journal.pone.0209687 30586468 PMC 6306259 · doi ↗ · pubmed ↗
- 5Elharram M, Ferreira JP, Huynh T, Ni J, Giannetti N, Verma S, et al. Prediction of heart failure outcomes in patients with type 2 diabetes mellitus: Validation of the Thrombolysis in Myocardial Infarction Risk Score for Heart Failure in Diabetes (TRS-HFDM ) in patients in the ACCORD trial. Diabetes Obes Metab. 2021;23(3):782–90. doi: 10.1111/dom.14283 33269511 · doi ↗ · pubmed ↗
- 6Razaghizad A, Oulousian E, Randhawa VK, Ferreira JP, Brophy JM, Greene SJ, et al. Clinical Prediction Models for Heart Failure Hospitalization in Type 2 Diabetes: A Systematic Review and Meta-Analysis. J Am Heart Assoc. 2022;11(10):e 024833. doi: 10.1161/JAHA.121.024833 35574959 PMC 9238543 · doi ↗ · pubmed ↗
- 7Himmelreich JCL, Veelers L, Lucassen WAM, Schnabel RB, Rienstra M, van Weert HCPM, et al. Prediction models for atrial fibrillation applicable in the community: a systematic review and meta-analysis. Europace. 2020;22(5):684–94. doi: 10.1093/europace/euaa 005 32011689 PMC 7526764 · doi ↗ · pubmed ↗
- 8Alonso A, Krijthe BP, Aspelund T, Stepas KA, Pencina MJ, Moser CB, et al. Simple risk model predicts incidence of atrial fibrillation in a racially and geographically diverse population: the CHARGE-AF consortium. J Am Heart Assoc. 2013;2(2):e 000102. doi: 10.1161/JAHA.112.000102 23537808 PMC 3647274 · doi ↗ · pubmed ↗