One-Hot Multi-Level Leaky Integrate-and-Fire Spiking Neural Networks for Enhanced Accuracy-Latency Tradeoff
PIERRE ABILLAMA, CHANGWOO LEE, ANDREA BEJARANO-CARBO, QIRUI ZHANG, DENNIS SYLVESTER, DAVID BLAAUW, HUN-SEOK KIM

TL;DR
This paper introduces a new spiking neural network model that improves the balance between accuracy and energy efficiency by using a one-hot multi-level neuron design.
Contribution
The novel one-hot multi-level leaky integrate-and-fire neuron model expands the accuracy-energy tradeoff space in spiking neural networks.
Findings
One-hot M-LIF SNNs achieve 2% higher accuracy than conventional LIF SNNs on ImageNet.
The model reduces energy consumption by 20× compared to VGG16 ANNs on ImageNet.
M-LIF SNNs reduce latency by 3× on dynamic vision datasets with less than 1% accuracy loss.
Abstract
Spiking neural networks (SNNs) hold significant promise as energy-efficient alternatives to conventional artificial neural networks (ANNs). However, SNNs require computations across multiple timesteps, resulting in increased latency, heightened energy consumption, and additional memory access overhead. Techniques to reduce SNN latency down to a unit timestep have emerged to realize true superior energy efficiency over ANNs. Nonetheless, this latency reduction often comes at the expense of noticeable accuracy degradation. Therefore, achieving an optimal balance in the tradeoff between accuracy and energy consumption by adjusting the latency of multiple timesteps remains a significant challenge. This work leverages an additional dimension to enhance the accuracy-energy tradeoff space using a novel one-hot multi-level leaky integrate-and-fire (M-LIF) neuron model. The proposed one-hot…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
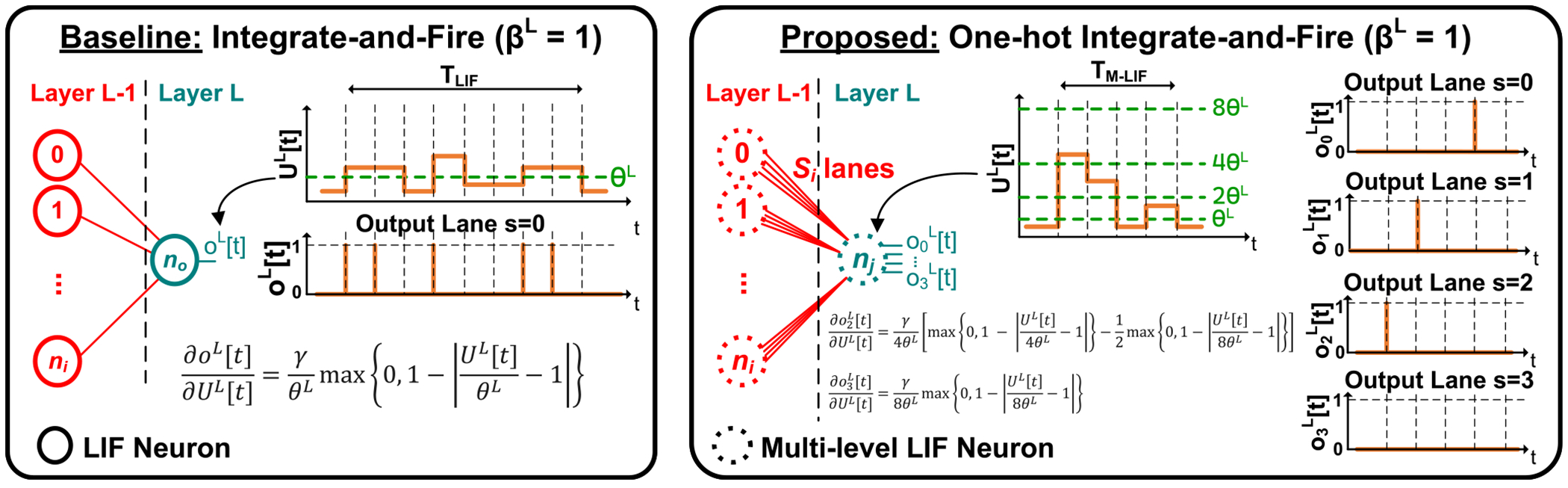 Figure 1
Figure 1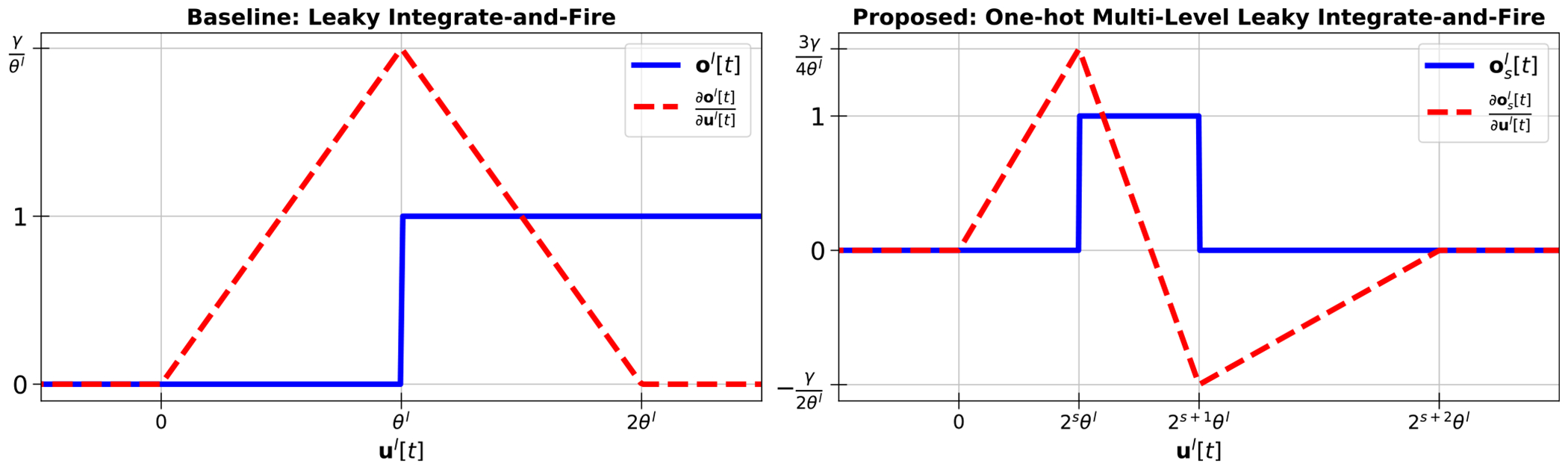 Figure 2
Figure 2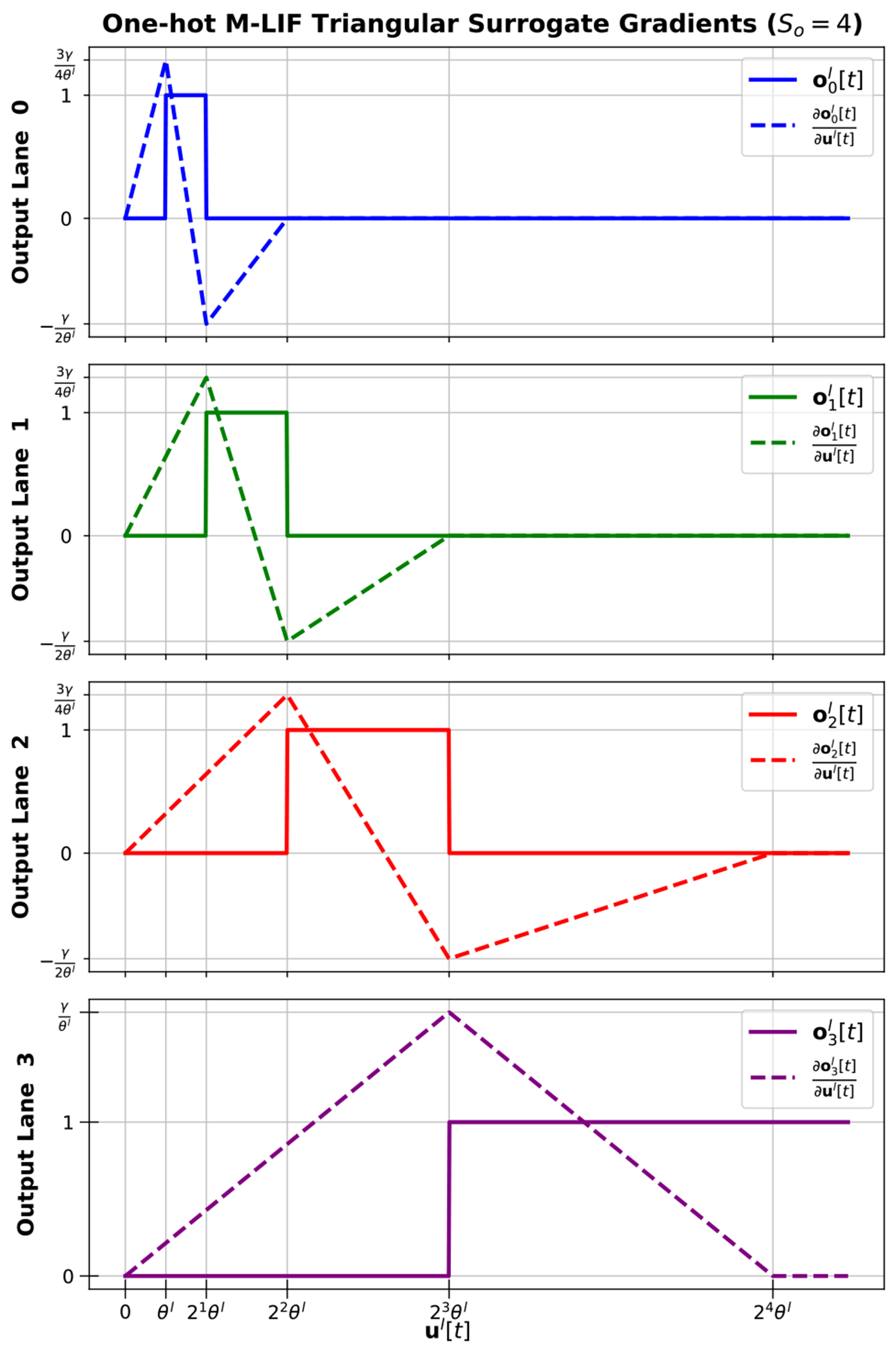 Figure 3
Figure 3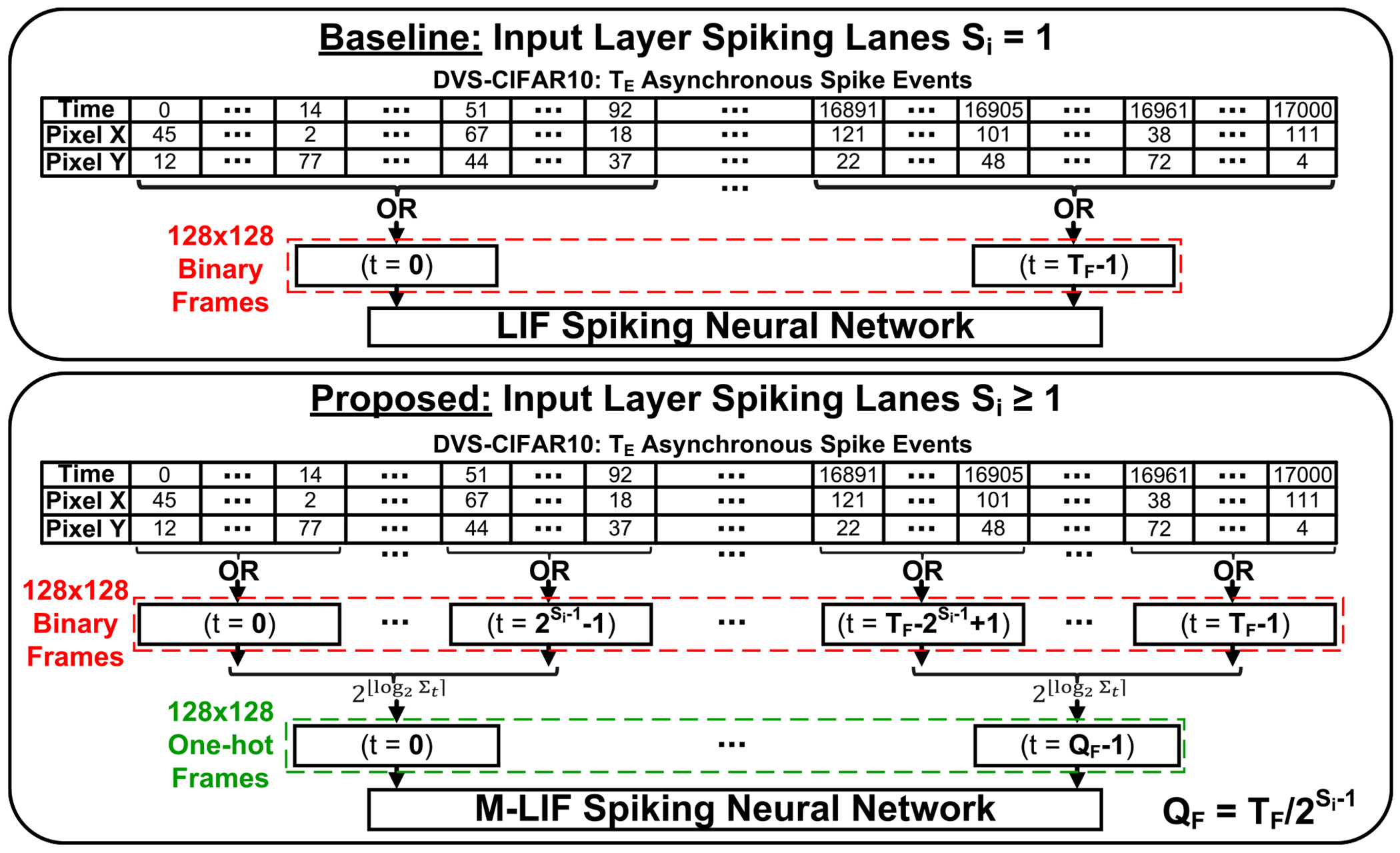 Figure 4
Figure 4 Figure 5
Figure 5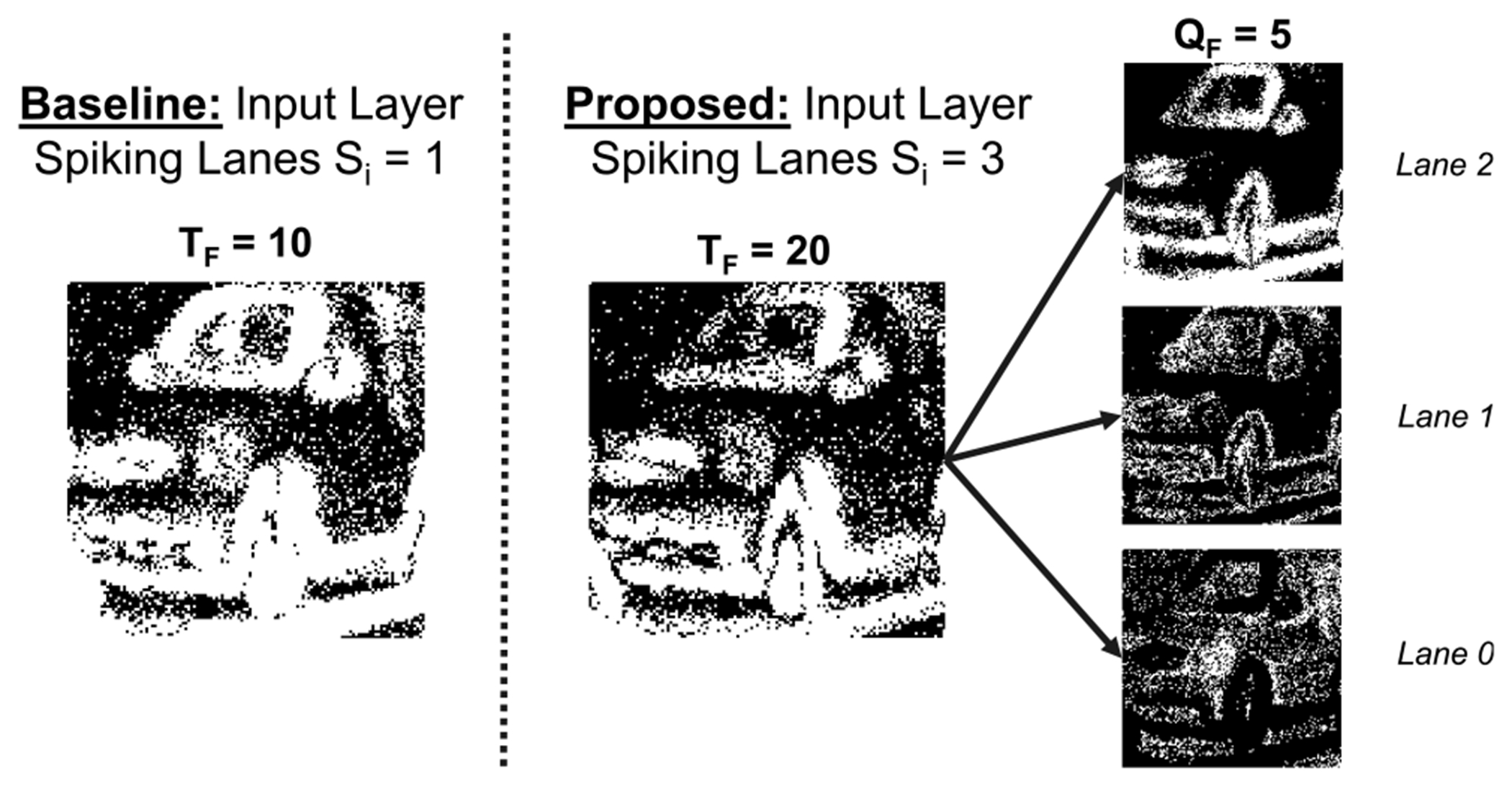 Figure 6
Figure 6 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Memory and Neural Computing · Advanced Neural Network Applications · CCD and CMOS Imaging Sensors
INTRODUCTION
I.
Neural networks have become a fundamental technique for solving many important problems such as image classification, object detection, and face recognition [1], [2]. As neural network accuracy improves, models become increasingly complex, making their energy-efficient deployment on the edge a significant challenge. In order to reduce the computational complexity of these tasks, spiking neural networks (SNNs) [3] were proposed as an alternative to traditional artificial neural networks (ANNs) [1], [4]. SNNs infer inputs across multiple timesteps while ANNs perform a one-shot inference, essentially over a single timestep. Neurons in SNNs differ from those in ANNs as they operate on sparse binary spike trains as opposed to non-binary ‘analog’ activations, resulting in the substitution of multiplications with energy-efficient additions [5].
To model spikes over time, SNNs employ various techniques, most notably the leaky integrate-and-fire (LIF) neuron model [6], [7]. Each neuron is characterized by two parameters: firing threshold and membrane leakage. During a timestep, a neuron either remains silent or produces a spike if the membrane potential exceeds its firing threshold. The membrane potential can shrink over time depending on the membrane leakage and is reset if a spike is produced. Using such models, many training methods have emerged and can be categorized into two main approaches: ANN-SNN conversion and direct training. ANN-SNN conversion methods [8], [9], [10] convert the weights of a pre-trained ANN to an iso-architecture SNN. However, these methods can require a large number of timesteps (on the order of 1000 in some cases [11]) to achieve comparable or better accuracy than ANNs. Note that multi-timestep inference results in more memory storage/accesses which can dominate the compute cost [12]. Therefore, the reliance on multi-timestep processing in ANN-to-SNN conversion has been a key factor hindering the practical deployment of SNNs in energy-constrained edge scenarios.
Direct training using surrogate gradient-based optimization and back-propagation through time (BPTT) [13], [14], [15] has enabled training SNNs with significantly fewer timesteps, occasionally reducing them to just a single timestep [16]. However, these SNNs still lag ANNs in terms of accuracy. For image classification on static datasets [1], [17], SNNs cannot bridge this accuracy gap with ANNs without increasing the number of timesteps, which in turn reduces energy efficiency. Moreover, single-timestep SNNs such as [16] require iterative temporal pruning to converge, rendering training more time-consuming. For image classification, multi-timestep SNNs traditionally outperform ANNs on dynamic vision sensor [18] data but suffer from a sharp accuracy degradation [19] with a reduced number of timesteps.
As conventional LIF models employ binary-valued neuron spike outputs, traditional SNNs are restricted to solely scaling the temporal dimension T (i.e., the number of timesteps) to achieve different accuracy-energy efficiency tradeoffs. Prior SNN works have explored the interaction between activation bit-width and timesteps using multi-spike [20], [21] and multi-threshold [22], [23] neurons to increase activation precision via uniform quantization. However, these approaches raise computational energy costs by disrupting the multiplication-free nature of traditional SNNs. To address these limitations and enhance the accuracy-energy tradeoff space, we extend the range of neuron spike outputs to include strictly powers of two by leveraging an additional dimension, S, and by using a novel one-hot multi-level leaky integrate-and-fire (M-LIF) neuron model as illustrated in Figure 1. The proposed one-hot M-LIF model has the following key properties: 1) it uses the S dimension to represent hidden layer outputs (inputs) as a set of S_o_ (S_i_) binary-weighted spike lanes, and 2) it limits the simultaneous firing behavior of those S_o_ (S_i_) spike lanes to only a single lane per timestep. These two properties of our one-hot M-LIF model enable new accuracy-energy tradeoff points for SNNs while still only requiring additions (without multiplications) like the conventional LIF model. Furthermore, the proposed one-hot M-LIF model can be easily integrated into prior existing training frameworks. For static datasets such as CIFAR and ImageNet, we demonstrate that one-hot M-LIF SNNs outperform conventional LIF SNN accuracy while achieving better or comparable energy efficiency on various architectures including the high-performance spike-driven transformer [15]. For dynamic vision datasets such as DVS-CIFAR10 [24], [25], we show that M-LIF SNNs using multi-level input layer encoding can achieve reduced timesteps (energy consumption) compared to conventional LIF SNNs for comparable or better accuracy. To summarize, the main contributions of this paper are:
- We propose a new direction to balance SNN energy efficiency and accuracy using a novel one-hot multi-level leaky-integrate-and-fire (M-LIF) neuron model.
- We enable a new tradeoff and show that one-hot M-LIF SNNs are more accurate than iso-architecture LIF SNNs while consuming comparable or lower energy with fewer timesteps.
- We demonstrate the benefit of one-hot M-LIF SNNs with dynamic vision sensor-based input compared to conventional SNNs. To the best of our knowledge, this is the first SNN work to achieve a top-1 accuracy of 82.5% on DVS-CIFAR10 using only 3 timesteps.
BACKGROUND AND RELATED WORKS
II.
LEAKY INTEGRATE-AND-FIRE MODEL
A.
A conventional spiking neural network (SNN) layer under the leaky integrate-and-fire (LIF) neuron model is described by
where is the weight matrix connecting layers and is a vector containing the membrane potential of output neurons, is the leakage factor, is an output vector of binary spikes, is the firing threshold, and represents the discrete timestep. The first term in Equation (1) corresponds to the membrane leakage allowing the potential to shrink (leak) over time, and the final term accounts for resetting the potential to a specific value when an output binary spike given by Equation (2) is generated. All neurons in an input/hidden layer typically share the same leakage factor and firing threshold values. As for the final layer, adopting the LIF model without any modifications can significantly impact the accuracy [13], [14]. Hence, the final output layer neurons only accumulate incoming inputs without any leakage and do not fire output spikes. Finally, the inference process is repeated for timesteps from to , and the output of the last layer is averaged to produce the final result. The output spiking behavior of traditional LIF neurons in Equation (2) is depicted in Figure 1 (left) where the output range of the membrane potential is subdivided using a single decision boundary defined by the threshold .
ANN-SNN CONVERSION
B.
ANN-SNN conversion methods [8], [9], [10], [11], [26], [27] convert the weights of a pre-trained ANN to an iso-architecture SNN. Specifically, these methods convert the output of a rectified linear unit neuron in an ANN into a sequence of binary spikes in the SNN over multiple timesteps. The primary challenge in this technique is determining the firing threshold in such a way that it balances the accuracy-latency tradeoff. In these methods, the firing thresholds are generally determined by profiling the pre-trained ANN and recording a certain percentile of layers’ input activation distributions. However, these heuristic techniques can lead to a sub-optimal choice of firing threshold and can also require a large number of timesteps to achieve comparable or better accuracy than ANNs, thus further aggravating the accuracy-latency tradeoff. This multi-timestep processing requirement is a challenge for widespread SNN deployment as it primarily introduces more memory storage and accesses which can be significantly higher than compute cost [12].
DIRECT TRAINING
C.
An alternate approach to training SNNs is to use gradient-based techniques, such as back-propagation, either from scratch or from a pre-trained iso-architecture ANN [13], [14], [16], [28]. These approaches relate the temporal dimension of SNNs to that of recurrent neural networks, and perform back-propagation through time (BPTT) to learn weights across multiple timesteps.
The cross-entropy loss and gradients are calculated by
where is the index of the final layer, denotes the softmax function, and is the one-hot encoded vector of the true label. The term in Equations (3) and (4) is the discontinuous gradient that is typically replaced by differentiable surrogate gradients. Prior works have explored the use of various surrogate gradient shapes such as triangular [13], [29], or the derivative of the sigmoid function [15] which are given below in Equations (5) and (6), respectively, where and are constants used to scale the shapes of the gradients. The triangular surrogate gradient in Equation (5) used for the output spike of the traditional LIF model is depicted in Figure 2 (left) for the single activation channel case where is shown to scale the peak value of the gradient at .
Compared to ANN-SNN conversion techniques, direct training approaches typically achieve a better accuracy-latency tradeoff (higher accuracy using fewer timesteps overall) at the cost of more compute- and memory-intensive training [30]. To achieve competitive accuracy, most employ direct input encoding [31] and utilize the first layer as a spike generator by directly feeding pixel values as inputs to the network. Through gradient-based learning, many recent works have sought to optimize different aspects of this training methodology such as loss function definition [14], initialization and parameterization [13], [16], and extension to advanced network architectures such as spike-driven transformers [15]. Notably, the authors in [16] propose temporal pruning to gradually reduce the number of timesteps to successfully train SNNs with as little as a single timestep, despite a noticeable accuracy degradation (up to 4%). All these works differ from ours as they are restricted to solely scaling the temporal dimension T in order to achieve different accuracy-latency tradeoffs given a fixed neural network architecture. To address this limitation, our approach leverages the S dimension using our one-hot multi-level LIF (M-LIF) neuron model to improve the accuracy-latency tradeoff space.
QUANTIZED-ACTIVATION ANNS
D.
As the number of timesteps converges to one, conventional SNNs become closely related to binary activated artificial neural networks (BNNs) [32], [33] as both use binary activations to perform an inference over a single timestep. The authors in [16] discuss that they are in fact distinct. While SNNs quantize outputs to spikes (i.e. {0, 1}), BNNs quantize outputs to be ±1. Unlike BNNs which use non-linear activation functions where the firing threshold is zero, the firing threshold is learnable in SNNs. The authors in [16] observe that this allows SNNs to outperform BNNs in terms of accuracy and scale better to larger datasets such as ImageNet. Moreover, LIF enables SNNs to extend the same network for sequential processing unlike BNNs. Similarly, our one-hot M-LIF SNNs become closely related to log-quantized-activation ANNs (LQ-ANNs) [34], [35] as timesteps converge to one, but remain distinct for analogous reasons. A discussion regarding similarities and differences is provided in Section III-B.
QUANTIZED-ACTIVATION SNNS
E.
Prior SNN works have explored the interaction between activation bit-width and timesteps [20], [21], [22], [23], [36], [37]. Our work’s major distinction is that the one-hot M-LIF neuron model constrains outputs of neurons to be powers-of-two while enabling better accuracy with low spike rates in the low-latency (unit-timestep) regime.
Multi-threshold SNNs [22], [23] apply multiple thresholds to each membrane potential after integration, either in parallel or sequentially, and sum resulting spikes together to produce an output activation. As a result, multi-threshold neurons lead to a uniformly quantized output whose output range depends on the number of thresholds used. Our one-hot M-LIF neuron on the other hand uses dual-sided thresholding as shown later in Equation (8) to only produce a single spike on one of S_o_ weighted output spike lanes. As a result, we restrict outputs to be strictly powers-of-two, a constraint which is accounted for during training. This enables efficient FP32 weight exponent updates via a single INT8 addition as discussed in Section IV, unlike the multiplication demands of uniformly quantized outputs. In [22], [23], the surrogate gradient of a traditional LIF neuron (e.g., Equations (5) or (6)) is applied to each spike lane while in our approach, the surrogate gradient of the traditional LIF neuron was adapted to handle dual-sided thresholding per spike lane. Finally, unlike [22], [23] which perform evaluations solely on convolutional neural network (CNN) architectures, our evaluations span both CNNs and the more complex, high-performing spike-driven transformer architecture.
Burst-spike neuron models [36], [37] work by increasing the spike rate, in other words the number of spikes issued within a single timestep. This is unlike our approach which emits at most a single spike per timestep independent of the number of spike lanes used per neuron. Moreover, evaluations for burst-spike neuron models show that resulting SNNs do not scale down to unit-timestep processing. For example, [37] reports results for at least T ≥ 32 timesteps with a 14.2% and 18.2% accuracy drop at T = 16 for VGG16 and ResNet-20 on CIFAR100, respectively. The work in [36] reports an accuracy of 70.61% for VGG16 on ImageNet with T = 8 (vs. 71.05% with T = 1 for our one-hot M-LIF VGG16 SNN using T = 1 and S = 3) and lacks comprehensive reporting of energy estimation analyses for all experimental results. Memory energy models for SNNs such as in [38] indicate that memory access energy of spikes and membrane potentials scales linearly with the number of timesteps, with single memory access costs often being 10× higher than single compute energy costs as discussed in [12] for a 45nm CMOS technology. Unlike burst-spike neuron models that require multi-timestep processing, our model achieves high accuracy with unit-timestep processing as reported later in Table 1 of our manuscript along with comparisons against existing state-of-the-art unit-timestep SNNs [16], [38].
PROPOSED ONE-HOT MULTI-LEVEL LIF-BASED SNNS
III.
MULTI-LEVEL LIF MODEL
A.
Our goal is to reduce the number of timesteps during SNN inference while improving accuracy and maintaining the low-spike rates of traditional SNNs. By reducing the timesteps while maintaining low spike rates, we can consequently decrease the energy overhead associated with multi-timestep processing. To do so, our multi-level leaky integrate-and-fire (M-LIF) neuron model still uses a single membrane potential per output neuron while extending the range of neuron outputs to more than just binary representations. It employs a new dimension to represent hidden layer outputs (inputs) as a set of binary-weighted spike lanes. We denote to be the output vector of binary spike lane in layer at timestep . Each spike lane is weighted by resulting in a non-binary output range for the neuron output . As a result, Equation (1) needs to be modified to combine weighted spike lanes prior to updating the membrane potential as follows
We also define as the maximum number of simultaneously firing output spike lanes in any given timestep. With all spike lanes sharing the same firing threshold and membrane potential, it is non-trivial to devise a firing mechanism with concurrent firing lanes. Section III-B discusses the practical one-hot case we propose for SNNs where .
ONE-HOT MULTI-LEVEL LIF MODEL
B.
In the one-hot M-LIF model, and only one of the output spike lanes fires in any given timestep. The threshold mechanism is given by
Figure 1 depicts the difference between the conventional LIF model (left) and our proposed one-hot ( ) M-LIF model (right) given . Instead of having only one output (input) spiking signal, an M-LIF neuron has multiple ( ) binary-weighted output (input) spike lanes. With the one-hot constraint, only a single spike lane fires at any given timestep. In the example illustrated in Figure 1 (right), the membrane potential can increase by one of possible levels in from one timestep to the next, as opposed to the single level in the conventional LIF model. The output spike lanes are one-hot, meaning that the output range is also subdivided into non-overlapping decision boundaries using the binary weight of each spiking lane as shown in Equation (9). Therefore, for a single activation channel case, we have .
Note that by setting (i.e., single lane), Equations (7) and (8) simplify to Equations (1) and (2). Therefore, binary spiking SNNs can be considered as a special case of the proposed one-hot M-LIF scheme.
SURROGATE GRADIENT FOR BACK-PROPAGATION TRAINING
Given the update to in Equation (8), the surrogate gradient is extended from the LIF case to the proposed one-hot M-LIF neurons. For example, Figure 2 illustrates the differences in an updated triangular surrogate gradient for the single activation channel case when . Each spike lane is now a window function of as opposed to a step function. This is equivalent to the difference of two step functions, the first of which is evaluated at the spike lane’s threshold, and the second of which is evaluate at the next spike lane’s threshold. As a result, the surrogate gradient becomes the difference of two triangular sub-gradients, one for each of the rising and falling window edges, as shown in Equation (10). An example illustrating Equation (10) for is provided in Figure 3. An additional example for the derivative of the sigmoid function is included in Appendix A.
DISCUSSION
As (i.e., unit timestep inference), Equations (7) and (8) can be rewritten as
where
From this, an observable parallel can be drawn between our one-hot M-LIF SNNs with unit timestep ( ) and log quantized-activation ANNs (LQ-ANNs) [39], [40]. While one-hot M-LIF-based SNNs are trained in a single phase, LQ-ANN training is performed in two phases per epoch. First, using the entire training dataset and full precision inference, a percentile value of each layer’s input activation distribution is recorded. Second, a straight-through estimator is typically applied to approximate the gradient with respect to quantized activations. Using bits and assuming a ReLU activation function, the neuron output in an LQ-ANN is given by Equation (12). While both one-hot M-LIF SNNs with unit timestep ( ) and LQ-ANNs share commonalities, they remain slightly distinct. As highlighted by Equations (11) and (12), they namely differ in their choices of firing threshold and their final output value ranges. They also differ in their training methods and abilities to extend to sequential processing (i.e., ).
ENERGY CONSUMPTION ESTIMATION
IV.
We evaluate the inference energy of our approach based on the approach in [15] and [16]. In conventional SNNs, 32-bit floating-point (FP32) additions replace the FP32 multiply-and-accumulates (MACs) of ANNs except in the first layer which uses direct encoded inputs. For one-hot M-LIF SNNs (ω = 1), inputs (outputs) are restricted to powers of 2, and multiplying by a power of 2 corresponds to adjusting the 8-bit integer (INT8) exponent of the FP32 multiplicand (see Appendix B). Therefore, scaling the intermediate FP32 membrane potential by 2*^s^* during integration in Equation (7) corresponds to increasing or decreasing its exponent in the INT8 format. According to [12], an INT8 addition consumes 30× less energy than a FP32 addition, hence the overhead of scaling in M-LIF SNNs is negligible and FP32 additions dominate the energy consumption of one-hot M-LIF SNNs. It is important to note that due to the one-hot constraint, the overall spiking rate (and consequently, the number of additions) per layer per timestep in one-hot M-LIF SNNs is not necessarily higher than that of conventional SNNs, even though one-hot M-LIF SNNs have multiple spiking lanes per neuron. This gives one-hot M-LIF SNNs the opportunity to learn more within a single timestep without increasing the computational complexity and energy compared to conventional SNNs.
It is also known that memory access energy can be significantly higher than compute energy [12], [41] and that a proportion of the number of memory accesses scales linearly with the number of timesteps in SNNs [16], [38]. However, estimating memory energy improvements would depend on hardware architecture and system configuration. Therefore, as noted in [16], we are restricting our attention to the computational energy benefits, δ defined in Equation (13) [16], of one-hot M-LIF SNNs and conventional SNNs over ANNs. As a result, we consider δ to be an optimistic energy gain estimate when T > 1. Note that when T = 1, memory requirements are identical for both SNNs and full-precision ANNs. When an iso-architecture ANN does not exist as in the case of spike-driven transformers [15] due to unique mechanisms such as spike-driven attention, we compare directly using the computational energy E.
As depicted in Figure 1, the one-hot M-LIF neuron model does not introduce any additional neurons to the existing set of neurons in iso-architecture SNNs and ANNs. As a result, ANNs and unit-timestep SNNs (both one-hot M-LIF and traditional LIF) have the same computational complexity. The computational complexity of multi-timestep SNNs, both one-hot M-LIF and traditional LIF, scales linearly with the number of timesteps as the inference process is repeated for T timesteps. Note however, that multi-timestep and unit-timestep SNNs, both one-hot M-LIF and traditional LIF, exhibit high activation sparsity per layer at each timestep enabling linear reduction in computational complexity. In Equation (13), the computational complexities #ANN_ops,l_ and #SNN_ops,l_ of layers in ANNs and SNNs are given in Equations (14) and (15) for convolution layers and in Equations (16) and (17) for linear layers, respectively. Based on [12], we set the relative MAC and addition energy to 4.6pJ and 0.9pJ, respectively. , and denote the number of input channels, number of output channels, kernel size, feature map height, and feature map width, respectively. These computational complexities are employed along with Equation 13 calculate the computational energy expenditure reported in Tables 1, 2, and 4 throughout Section V. Finally, note that in one-hot M-LIF SNNs, only a single spike lane fires per timestep as explained in Section III-B. The spiking activity is already accounted for in the term . Therefore, the computational complexity does not explicitly depend on the number of spike lanes per timestep.
EXPERIMENTS AND RESULTS
V.
We validate our one-hot M-LIF model and compare the performance and inference energy of our one-hot M-LIF SNNs with existing SNN works on both static and dynamic image classification tasks. Our proposed neuron model can be integrated into existing SNN training methodologies. We compare against the hybrid training methods [13], [16] for static tasks (Section V-A) and the temporal efficient training method [14] for dynamic vision tasks (Section V-B). We also evaluate the impact of one-hot M-LIF on more complex SNN-based high performance models such as the spike-driven transformer [15]. As in prior works, we employ direct input encoding for static tasks such that the input layer is fed with full-precision pixels. We also fix all layers to use the same number of (input) output spike lanes, S, as this reduces the number of hyperparameters. While certain hyperparameter, dataset, network architecture are highlighted in the following section, a detailed account of experimental settings such as optimizers, learning rates and schedules, number of epochs, number, and type of layers in different networks, is provided in Appendix C. The source code is available at: https://github.com/pabillam/one-hot-mlif-snn.
STATIC IMAGE CLASSIFICATION
A.
IMPLEMENTATION DETAILS
We apply hybrid direct training as described in [13] and [16] to evaluate the accuracy of our approach on CIFAR10, CIFAR100, and ImageNet using VGG16 and ResNet20. We train an ANN with batch-norm [42] and subsequently fuse the batch-norm parameters with the weights of the corresponding layer. We then copy the weights of the pre-trained ANN to an iso-architecture one-hot M-LIF SNN and use the 90-th percentile of the input activation distribution as each layer’s threshold θ^l^. The SNN is then trained using BPTT but without temporal pruning. For spike-driven transformer, we evaluate our approach on CIFAR10, CIFAR100, and ImageNet using Transformer-2-512 and Transformer-8-512 by replacing all LIF neurons with one-hot M-LIF neurons while using the same training methodology as in [15]. Note that Transformer-L-D represents a model with L encoder blocks and D channels. These networks are trained from scratch using BPTT without any pre-trained ANN initialization or batch norm fusion. Supplemental network architecture details and hyperparameters are discussed in Appendix C.
COMPARISON WITH SNNS
Table 1 compares the accuracy and inference energy of one-hot M-LIF SNNs with iso-architecture conventional SNNs. While our approach offers comparable or slightly lower energy benefits across most benchmarks, it consistently matches or exceeds conventional SNNs in accuracy. The one-hot constraint ensures energy usage comparable to conventional SNNs in the worst-case (all neurons fire at each timestep) despite each M-LIF neuron having multiple spiking lanes, discovering new accuracy-energy tradeoff points. Prior work achieved 69% accuracy with a unit timestep on ImageNet using VGG16, while we reached 71.05% with S = 3 spike lanes. For spike-driven transformers, M-LIF SNNs boost accuracy by up to 3% on ImageNet compared to LIF counterparts, consuming slightly more energy for a given T but achieving better tradeoffs. This is the case of (T = 1, S = 3) one-hot M-LIF spike-driven transformer, which achieves comparable or better accuracy to (T = 4) LIF on CIFAR100 and ImageNet with 4× less memory access energy (which can dominate overall energy as discussed in Section IV and in Appendix E) due to multi-timestep processing.
COMPARISON WITH LQ-ANNS
As discussed in Section III-B, LQ-ANNs and unit timestep (T = 1) M-LIF SNNs remain distinct while both perform inference using a single timestep. Here, we compare the accuracy and inference energy of b-bit LQ-ANNs and M-LIF-based SNNs using S spike lanes as shown in Table 2. We observe that M-LIF SNNs perform on par or better than LQ-ANNs in terms of accuracy and inference energy. For CIFAR10, we observe similar accuracy and energy benefits to LQ-ANNs. On the other hand, for CIFAR100, we note that one-hot M-LIF SNNs are up to 54% more energy efficient than LQ-ANNs with comparable accuracy. Finally, our approach scales much better on a large challenging dataset such as ImageNet yielding > 3% accuracy improvement. This gain can be primarily attributed to threshold parameter learning for SNNs.
COMPARISON WITH QUANTIZED-ACTIVATION SNNS
As discussed in Section II-E, prior works have explored the interplay between activation bit-width and timesteps in order to improve SNN accuracy. In this section, we perform a quantitative comparison provided in Table 3 with reported accuracies and energy estimates (when available) of burst-spike and multi-threshold methods on all evaluated static image classification datasets. Compared to burst-spike SNNs [36], [37], our one-hot M-LIF SNNs significantly reduce the number of timesteps (8 – 32×) while achieving better accuracy (up to > 4%) on more challenging datasets such as ImageNet. Compared to multi-threshold SNNs [22], [23] our one-hot M-LIF SNNs achieve better accuracy (up to > 4%) while significantly reducing computational energy. This is due to the introduction of uniform activation quantization in multi-threshold SNNs which breaks the multiplication-free property of SNNs.
DYNAMIC IMAGE CLASSIFICATION
B.
IMPLEMENTATION DETAILS
For the dynamic image classification task where SNN accuracy is generally superior than that of ANNs, we apply temporal efficient training similar to [14] using our one-hot M-LIF neuron. Here, we train from scratch using BPTT without any pre-trained ANN initialization or batch norm fusion. We perform experiments on DVS-CIFAR10 [24] (converted from CIFAR10) which is one of the most challenging mainstream dynamic vision datasets. It has 10k images with size 128×128. Following prior works, we reduce the spatial resolution to 48 × 48, and split the dataset into 9k training and 1k test images [43]. We also apply data augmentation techniques such as random horizontal flip and random roll within 5 pixels [44]. For all experiments, we use the VGGSNN architecture [14] using 300 epochs, the Adam optimizer with learning rate λ = 0.001 and a cosine annealing scheduler with 0 decay. Details regarding the VGGSNN architecture [14] along with firing thresholds, membrane leakage, and surrogate gradient settings are included in Appendix C.
MULTI-LEVEL INPUT LAYER ENCODING
For DVS-CIFAR10, direct input encoding is not applicable as the dataset consists of events recorded using a dynamic vision sensor. The adopted methodology described in [43] to prepare the data for SNN training is to split and convert the stream of events into binary frames as depicted in Figure 4 (top). In [14], a VGGSNN is trained with and a top-1 accuracy of . However, M-LIF SNNs are not limited to single spike lanes at the input layer. Therefore, we allow and incorporate an additional data preparation step to perform multi-level input layer encoding as depicted in Figure 4 (bottom). After obtaining the binary frames, we combine every consecutive frames into a one-hot frame resulting in frames of one-hot spike lanes. This enables M-LIF SNNs to limit accuracy degradation after reducing below the number of timesteps .
COMPARISON WITH SNNS
We compare against existing works on DVS-CIFAR10 in Table 4. The compute energy is calculated using , where is defined in Section IV and 0.9 pJ is the energy of addition [12]. We achieve an accuracy of using 10 timesteps and 4 spike lanes per neuron. This is also the first SNN work to achieve accuracy on DVS-CIFAR10 using 3 timesteps and 4 spike lanes compared to the best prior work [19] which can only achieve using 4.5 timesteps and using 2.5 timesteps. These improvements in accuracy stem primarily from introducing the dimension. By reducing , not only do we improve the computational energy by , we also reduce membrane potential and spike memory access energy which scales linearly with timesteps and can be significantly higher than compute energy [16]. Table 4 also shows the impact of scaling and on accuracy. By increasing for a fixed , we are able to recover accuracy degradation unlike prior works which are limited by solely scaling . By increasing and , we can scale the accuracy to even higher than conventional SNNs.
FUTURE DIRECTIONS
VI.
In this work, we introduce and evaluate a novel algorithmic optimization to existing SNNs, namely the one-hot M-LIF neuron model. We distinguish this approach from other multi-threshold and burst-spike SNNs as well as unit-timestep SNNs and log-quantized ANNs, and demonstrate that one-hot M-LIF SNNs provide a better accuracy tradeoff in low-latency (unit-timestep) regimes on a wide range of network architectures for both static and dynamic image classification tasks. However, several areas remain unexplored.
Expanding experiments beyond image-based datasets (CIFAR10, CIFAR100, ImageNet, DVS-CIFAR10) to include speech and text tasks, such as in [51] and [52], would enhance generalizability. Robustness to noise and data distribution shifts is another critical aspect for real-world deployment. Integrating techniques from works solely focused on training robust SNNs such as [53] and [54] into one-hot M-LIF SNN training could address this gap. Many prior works have also investigated the topic of hardware architectures and dataflow optimizations for existing SNN algorithms on ASIC or FPGA platforms [55], [56], [57], [58]. For example, [55] discusses the feasibility of leveraging systolic arrays to perform SNN inference using a small number of timesteps. The one-hot M-LIF neuron model was designed to be adaptable to many existing SNN hardware accelerator architectures. Our work highlights the potential advantages of one-hot M-LIF SNNs over traditional SNNs through energy modeling. Future work could investigate the complete implementation and execution of one-hot M-LIF SNNs on ASIC or FPGA which would then further validate its hardware advantages. This aspect is also critical for practical deployment of one-hot M-LIF SNNs in low-power and real-time scenarios such as in edge computing, autonomous driving, and IoT systems.
CONCLUSION
VII.
SNNs hold promise as an energy-efficient alternative to traditional ANNs. However, achieving an optimal balance in the accuracy-energy tradeoff by adjusting latency remains a significant challenge for widespread deployment. To that end, we introduce the dimension of spike lanes to conventional SNNs using a novel M-LIF neuron model without latency and computational complexity overhead. The proposed model represents the inputs and outputs of hidden layers as a set of one-hot binary-weighted spike lanes. Using our one-hot M-LIF neuron model, we are able to find new and better tradeoff points for both static and dynamic vision tasks. In particular, our one-hot M-LIF-based SNNs achieve a top-1 accuracy of 71.05% on ImageNet using VGG16 and enhance the computational efficiency by 20×. One-hot M-LIF neurons also improve the accuracy-latency tradeoff for advanced network architectures such as spike-driven transformers (> 3% higher accuracy and 4× fewer timesteps on ImageNet). For dynamic vision tasks, such as image classification using dynamic vision sensor data, our one-hot M-LIF SNNs retain higher accuracy (82.5%) when scaling down to fewer timesteps (3) on CIFAR10-DVS thus providing better energy efficiency.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Krizhevsky A, Sutskever I, and Hinton GE, “Image Net classification with deep convolutional neural networks,” in Proc. Adv. Neural Inf. Process. Syst, vol. 60, Pereira F, Burges C, Bottou L, and Weinberger K, Eds., May 2017, pp. 84–90. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2012/file/c 399862 d 3b 9d 6b 76c 8436 e 924a 68c 45b-Paper.pdf
- 2Redmon J, Divvala S, Girshick R, and Farhadi A, “You only look once: Unified, real-time object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 779–788.
- 3Maass W, “Networks of spiking neurons: The third generation of neural network models,” Neural Netw., vol. 10, no. 9, pp. 1659–1671, Dec. 1997.
- 4Simonyan K and Zisserman A, “Very deep convolutional networks for large-scale image recognition,” 2014, ar Xiv:1409.1556.
- 5Han B, Sengupta A, and Roy K, “On the energy benefits of spiking deep neural networks: A case study,” in Proc. Int. Joint Conf. Neural Netw. (IJCNN), Jul. 2016, pp. 971–976.
- 6Hunsberger E and Eliasmith C, “Spiking deep networks with LIF neurons,” 2015, ar Xiv:1510.08829.
- 7Burkitt AN, “A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input,” Biol. Cybern, vol. 95, no. 1, pp. 1–19, Jul. 2006.16622699 10.1007/s 00422-006-0068-6 · doi ↗ · pubmed ↗
- 8Rueckauer B, Lungu I-A, Hu Y, Pfeiffer M, and Liu S-C, “Conversion of continuous-valued deep networks to efficient event-driven networks for image classification,” Frontiers Neurosci, vol. 11, p. 682, Dec. 2017.