Identification of modulated whole-brain dynamical models from nonstationary electrophysiological data
Addison Schwamb, Zongxi Yu, ShiNung Ching

TL;DR
This paper introduces a new method to model changing brain dynamics in individuals using electrophysiological data, validated with anesthesia effects.
Contribution
The novel contribution is extending the MINDy model to capture nonstationary brain dynamics through a modulatory component.
Findings
The modulated MINDy model accurately captures individualized and nonstationary brain dynamics.
The model provides biologically interpretable insights into propofol's effects on cortical networks.
The approach is reliable, scalable, and consistent with prior literature on neuromodulation.
Abstract
Objective. Understanding the mechanisms underlying brain dynamics is a long-held goal in neuroscience. However, these dynamics are both individualized and nonstationary, making modeling challenging. Here, we present a data-driven approach to modeling nonstationary dynamics based on principles of neuromodulation, at the level of individual subjects. Approach. Previously, we developed the mesoscale individualized neural dynamics (MINDy) modeling approach to capture individualized brain dynamics which do not change over time. Here, we extend the MINDy approach by adding a modulatory component which is multiplied by a set of baseline, stationary connectivity weights. We validate this model on both synthetic data and publicly available electroencephalography data in the context of anesthesia, a known modulator of neural dynamics. Main results. We find that our modulated MINDy approach is…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
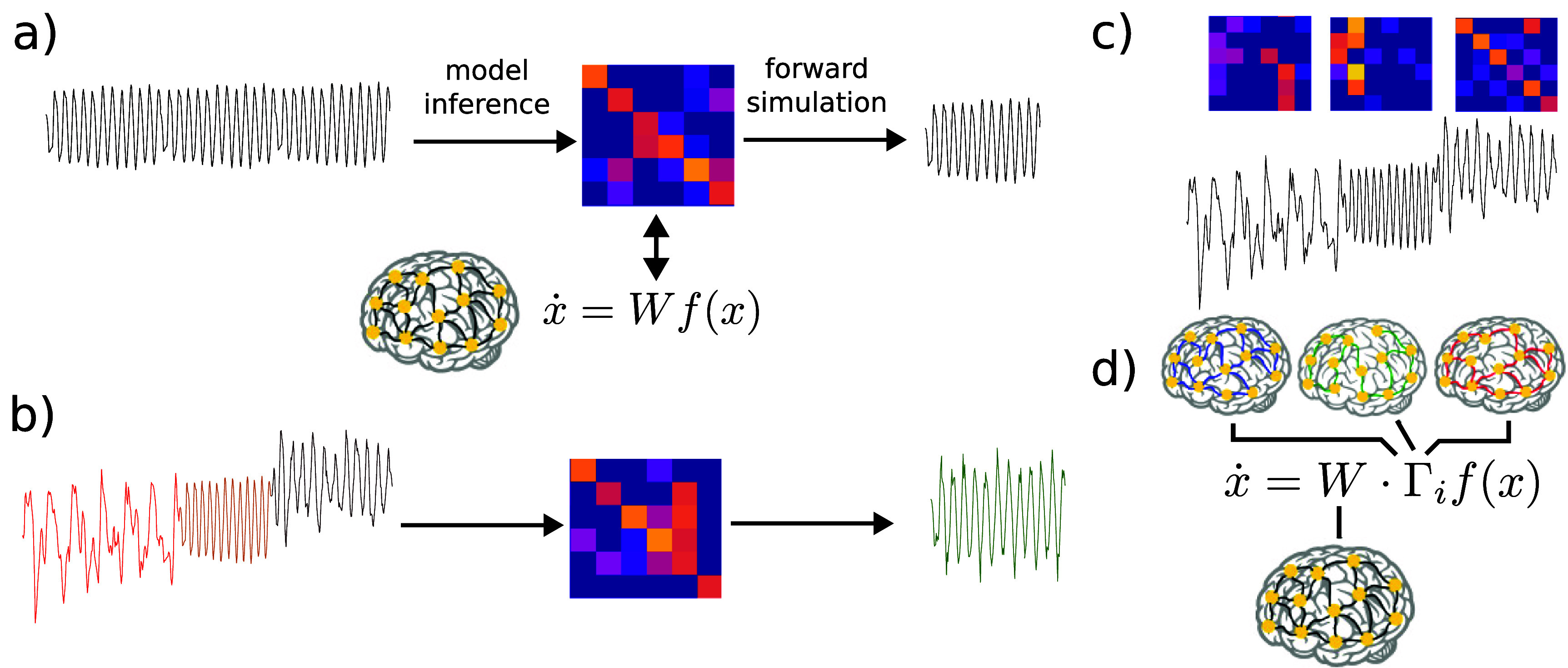 Figure 1
Figure 1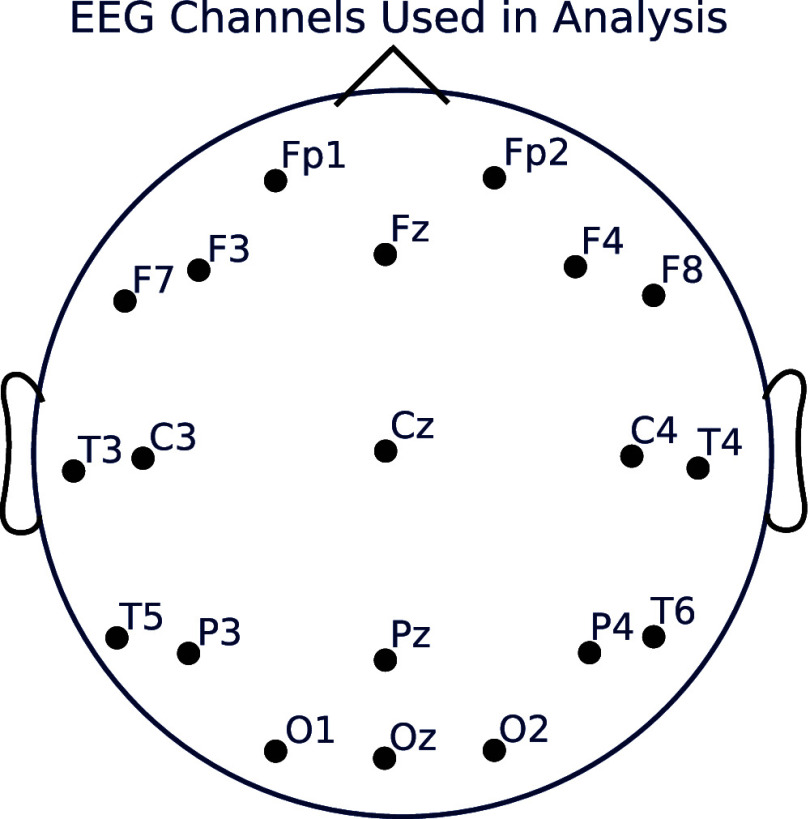 Figure 2
Figure 2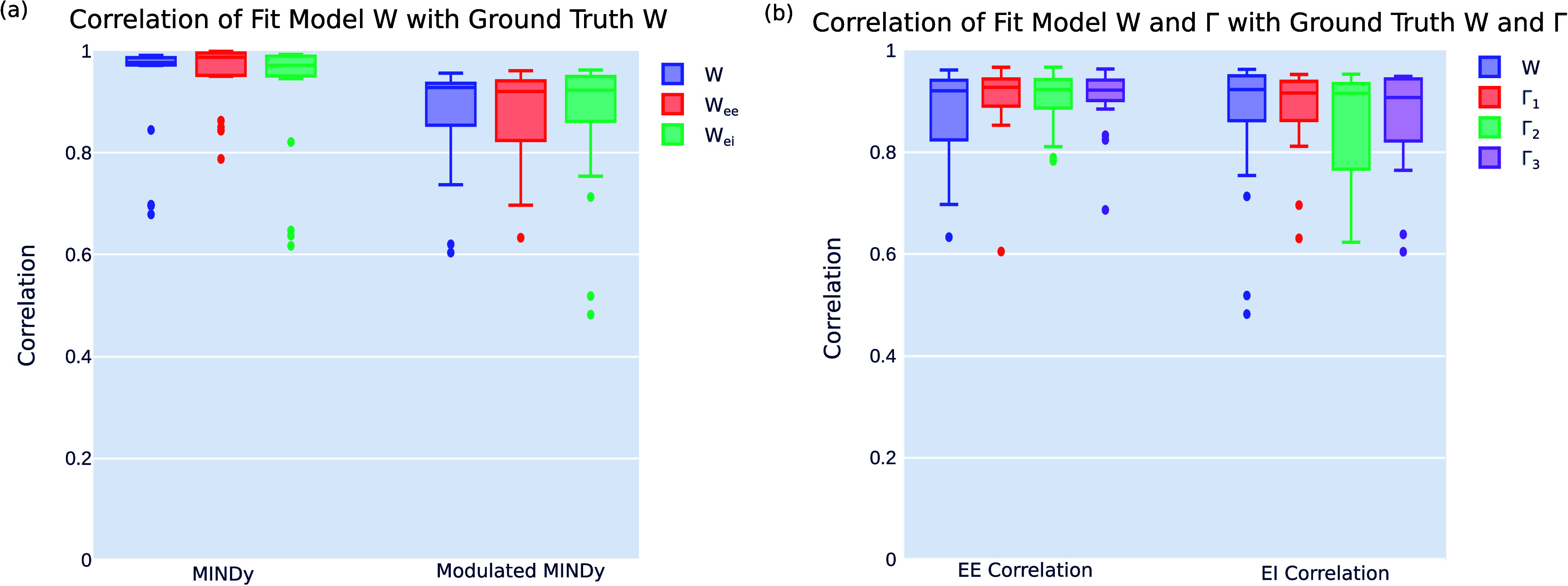 Figure 3
Figure 3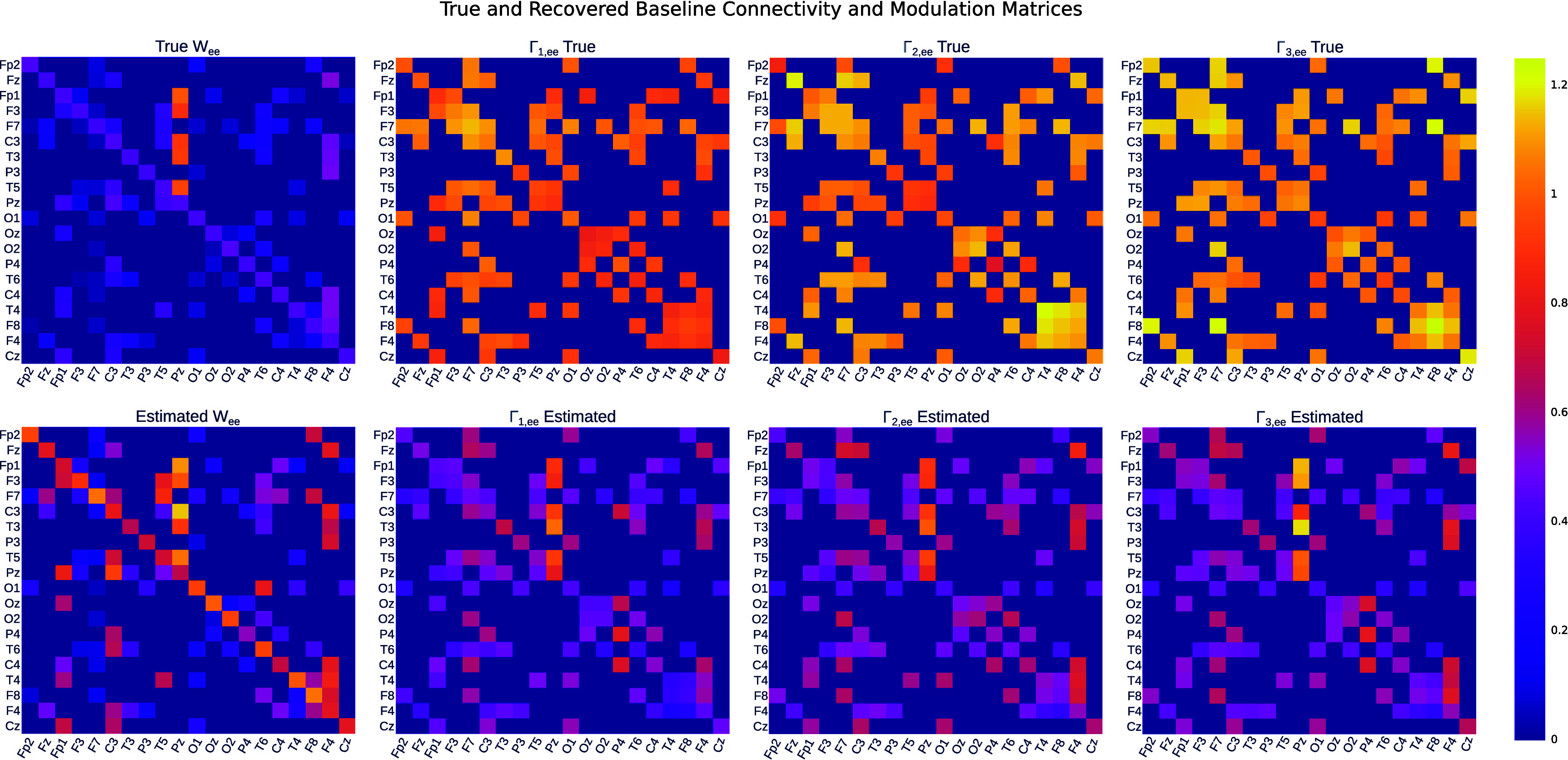 Figure 4
Figure 4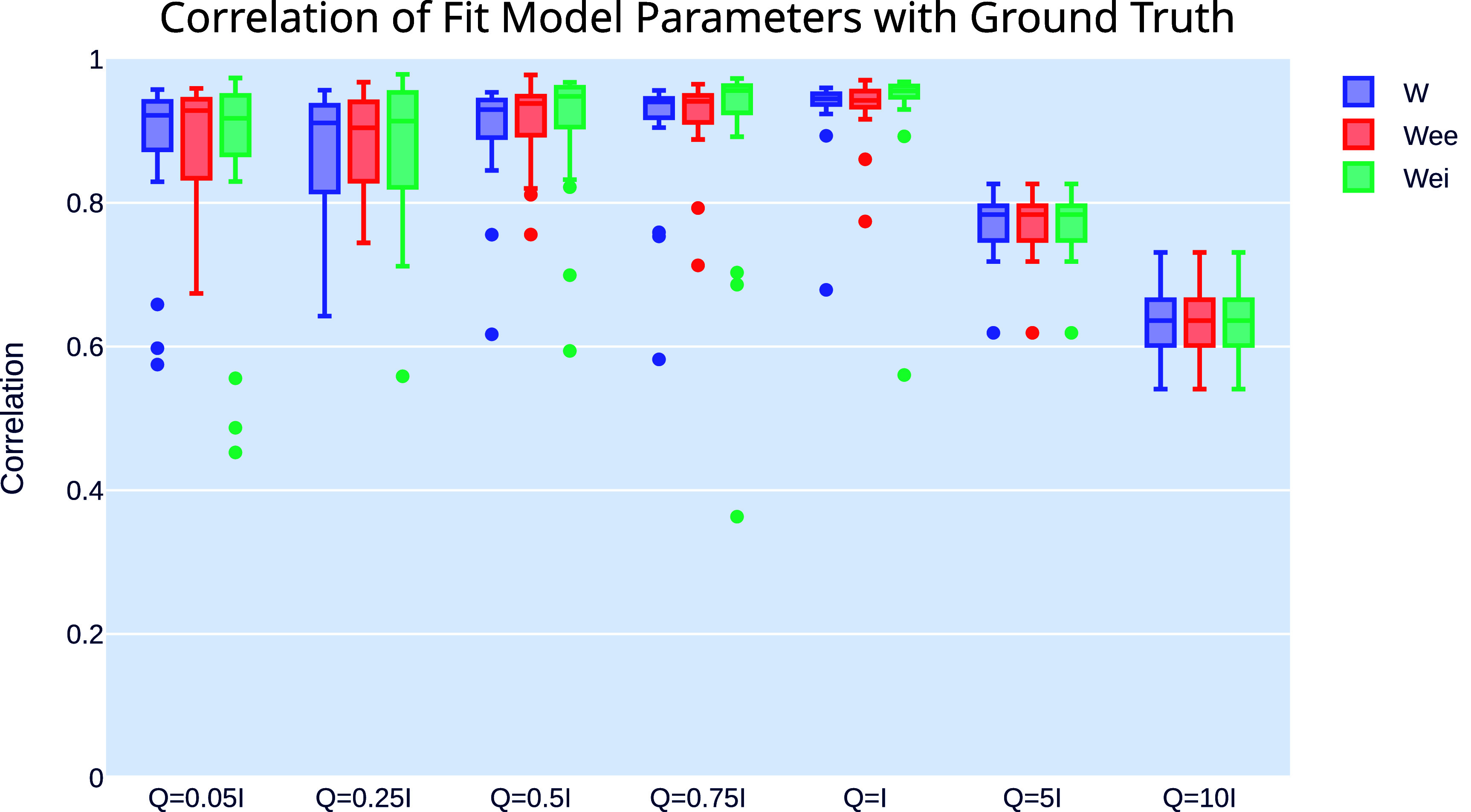 Figure 5
Figure 5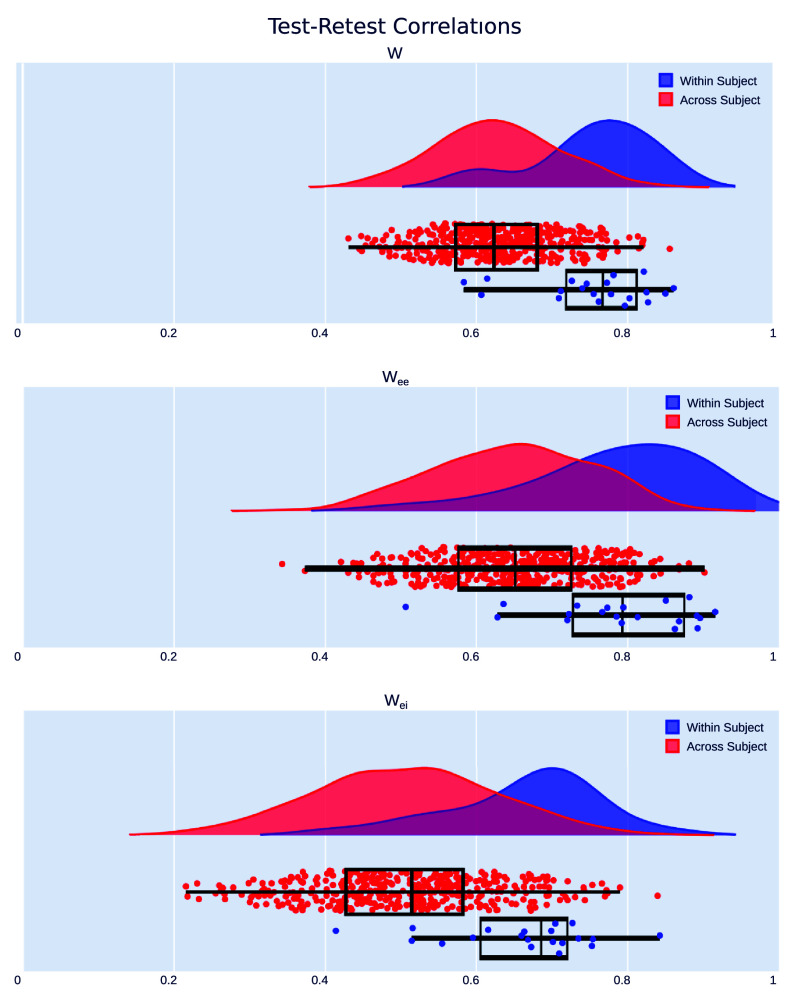 Figure 6
Figure 6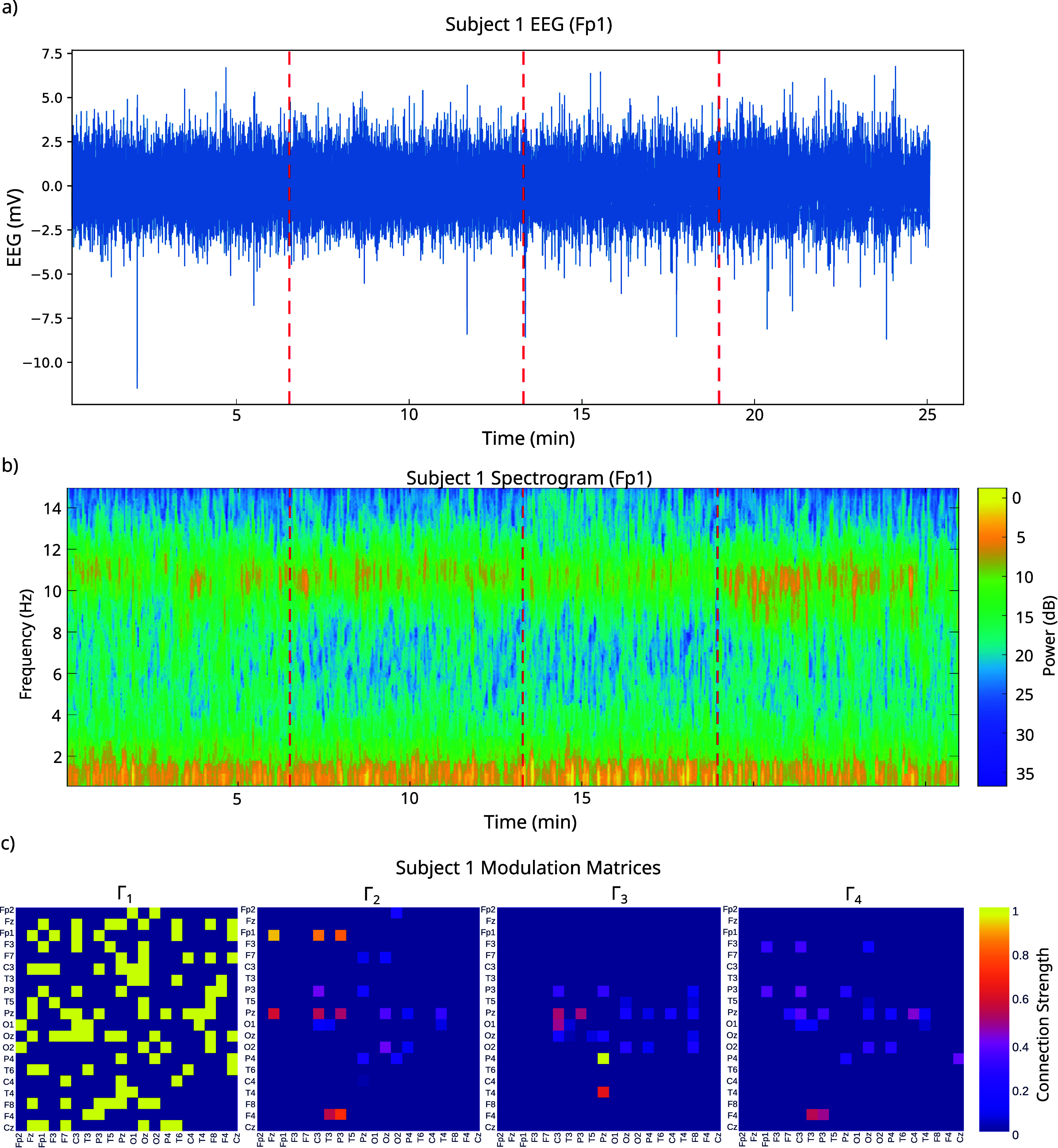 Figure 7
Figure 7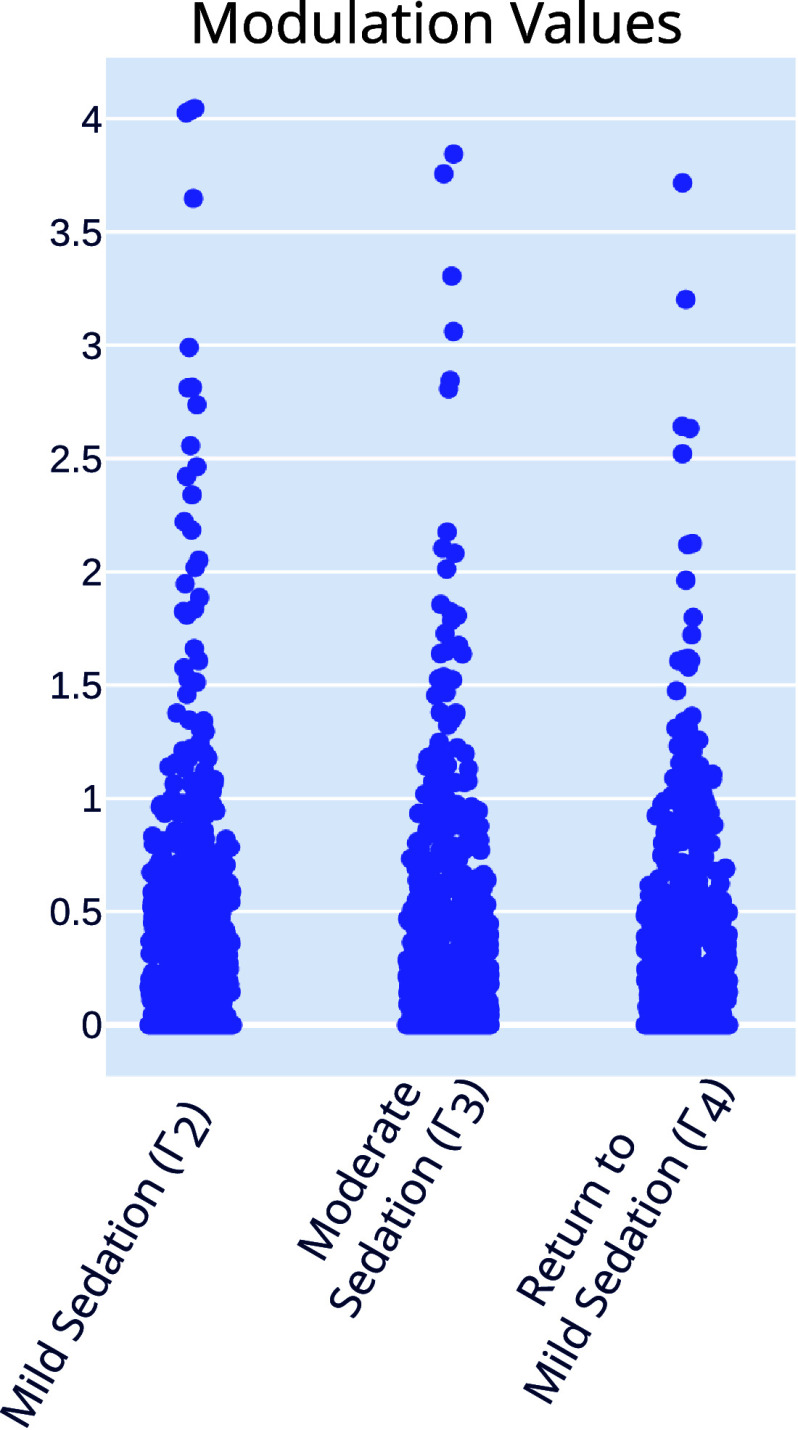 Figure 8
Figure 8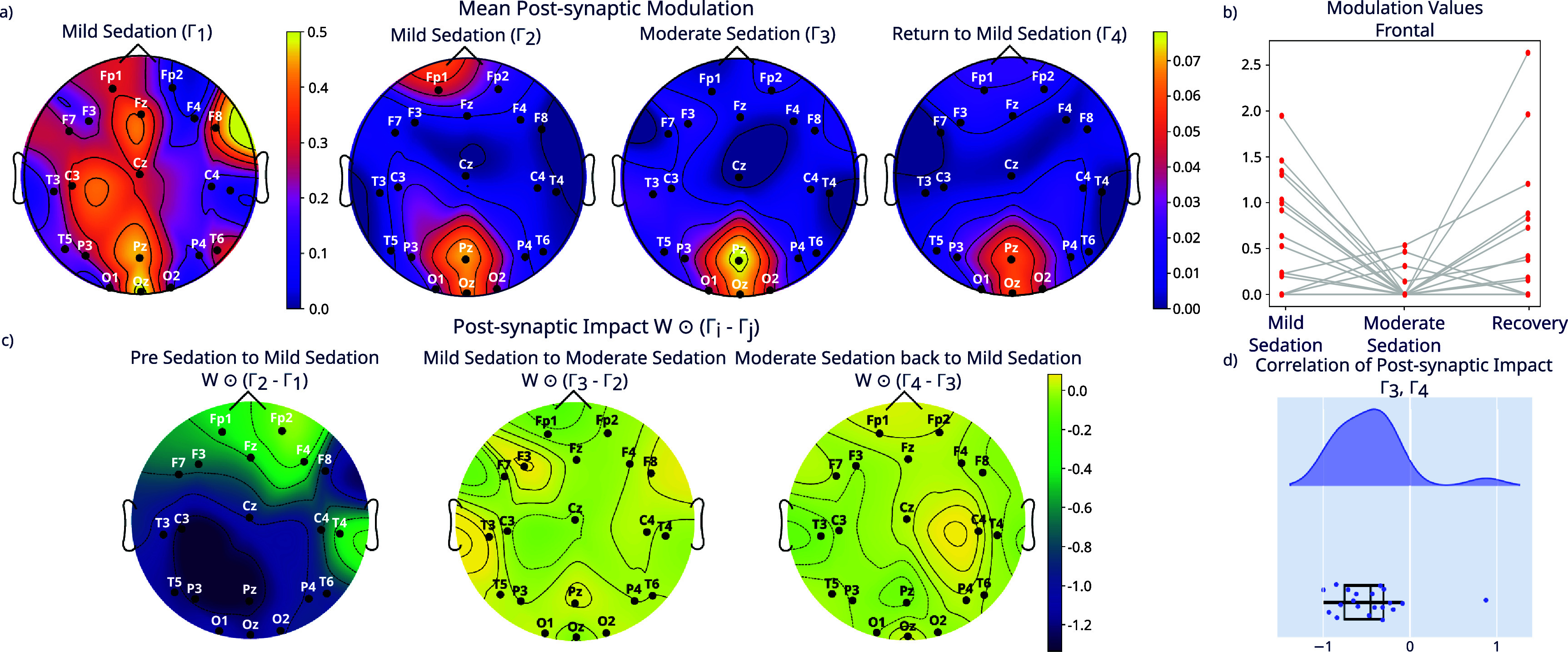 Figure 9
Figure 9| Parameter | Description | Initialization value |
|---|---|---|
|
| Sparse part of connectivity matrix |
|
|
| Low rank part of connectivity matrix |
|
|
| Excitatory nonlinearity slope | 2.5 |
|
| Inhibitory nonlinearity slope | 1 |
|
| Nonlinearity offset | 0 |
|
| Excitatory decay |
|
|
| Inhibitory decay |
|
|
| Baseline neural activity | 0 |
|
| Lead field for excitatory populations |
|
|
| Measurement noise covariance |
|
|
| Process noise covariance |
|
| nS | Number of modulation states | 3 |
|
| Mean of |
|
| Variance of |
| |
| Variance of |
| |
| Vector constructing |
| |
| Vector constructing |
| |
|
| HMM transition probability |
|
|
| Initial HMM state probability |
|
| Parameter, model | Correlation ( | Inter-quartile range (IQR) |
|---|---|---|
| 0.9771 | 0.9720–0.9866 | |
| 0.9280 | 0.8359–0.9362 | |
| 0.9873 | 0.9519–0.9957 | |
| 0.9202 | 0.8238–0.9408 | |
| 0.9715 | 0.9506–0.9895 | |
| 0.9227 | 0.8615–0.9495 | |
| 0.9160 | 0.8618–0.9385 | |
| 0.9228 | 0.8864–0.9421 | |
| 0.9215 | 0.9011–0.9411 | |
| 0.9160 | 0.8618–0.9385 | |
| 0.9152 | 0.7665–0.9343 | |
| 0.9071 | 0.8216–0.9435 |
| Parameter | Corr. (IQR), | Corr. (IQR), | Corr. (IQR), | Corr. (IQR), | Corr. (IQR), | Corr. (IQR), | Corr. (IQR), |
|---|---|---|---|---|---|---|---|
|
| 0.9217 (0.8736–0.9412) | 0.9112 (0.8152–0.9567) | 0.9297 (0.8907–0.9430) | 0.9403 (0.9184–0.9453) | 0.9447 (0.9368–0.9518) | 0.7836 (0.7476–0.7959) | 0.6361 (0.6013–0.6652) |
|
| |||||||
|
| 0.9283 (0.8342–0.9441) | 0.9044 (0.8301–0.9405) | 0.9382 (0.8942–0.9483) | 0.9412 (0.9119–0.9494) | 0.9425 (0.9329–0.9554) | 0.7836 (0.7476–0.7959) | 0.6361 (0.6013–0.6652) |
|
| |||||||
|
| 0.9175 (0.8668–0.9494) | 0.9137 (0.8215–0.9535) | 0.9481 (0.9054–0.9609) | 0.9562 (0.9252–0.9631) | 0.9559 (0.9468–0.9627) | 0.7836 (0.7476–0.7959) | 0.6361 (0.6013–0.6652) |
| Parameter | Within-subject correlation | Within-subject IQR | Across-subject correlation | Across-subject IQR | |
|---|---|---|---|---|---|
|
| 0.7670 | 0.7187–0.8118 | 0.6230 | 0.5722–0.6802 |
|
|
| 0.7930 | 0.7276–0.8746 | 0.6510 | 0.5760–0.7252 |
|
|
| 0.6855 | 0.6054–0.7202 | 0.5144 | 0.4275–0.5821 |
|
| Sum of squares | Degrees of freedom | |||
|---|---|---|---|---|
| Channel | 62.75 | 19 | 7.24 | b.m.p. |
| Sedation state | 89.70 | 2 | 98.33 | b.m.p. |
| Channel:Sedation state | 113.54 | 38 | 6.55 | b.m.p. |
| Residual | 519.97 | 1140 |
- —National Institute of Neurological Disorders and Stroke10.13039/100000065
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural dynamics and brain function · EEG and Brain-Computer Interfaces · Functional Brain Connectivity Studies
Introduction
An important and persistent challenge in the analysis of recorded mesoscale neural activity (i.e. commensurate with externally recorded fields and potentials) is the inference of latent neurophysiological mechanisms that underlie overt observations. Indeed, while there are myriad tools and methods to analyze brain electrophysiological recordings (e.g. power spectral density estimation [1, 2]), there are fewer that provide direct inference of circuit-level mechanisms (i.e. the interaction of excitatory and inhibitory neural subpopulations, from which said recordings originate). Identifying and understanding these mechanisms is a difficult task, however, as they are not directly observable via typical mesoscale recording modalities. For instance, electroencephalography (EEG) measures electrical potential non-invasively at the scalp, and hence does not provide direct access to neuronal sub-population-level activity [3]. Parametric dynamical systems modeling offers a methodological path to obviating this issue. Such models, via their mathematical formulation, embed mechanistic hypotheses or inductive biases regarding how neural activity and secondary observables such as EEG are generated. While dynamical systems modeling is potentially powerful in this context, there are several extant challenges that remain unsolved regarding the construction of such models from neural recordings.
First, neural activity patterns vary between individuals, indicating that the underlying mechanisms also vary on an individual level. For example, the posterior dominant rhythm is a classic example of neural dynamics, which manifests as a strong alpha-band (i.e. 10–14 Hz) oscillation localized to the posterior of the scalp in EEG recordings (i.e. overlaying occipital cortex). While the general characteristics of the posterior dominant rhythm (its frequency and spatial location) are consistent across individuals [4], the exact frequency and power of the posterior dominant rhythm is specific to individuals [5]. To address this challenge of individuality, work has been done to create data-driven models based on single-subject data [6, 7], providing individualized neural dynamics models which can be used to infer mechanisms underlying a person’s brain activity [8–10]. This approach is schematized in figure 1(a).
Approaches to fitting individualized models from data. (a) In a stationary setting, a single set of (time-invariant) model parameters (here, a connectivity/weight matrix) is fit to data, yielding a corresponding stationary prediction/forward simulation. (b) When data is non-stationary, fitting a single stationary model will in general lead to erroneous or averaged modeled dynamics. (c) A typical way to address non-stationary data is to fit separate models (e.g. distinct weight matrices) to the distinct non-stationary regimes. (d) In the proposed approach, we seek to fit non-stationary models that decompose parameters into a baseline connectivity and regime-specific modulatory matrices.
In addition to varying between individuals, neural dynamics are also highly non-stationary, i.e. they vary temporally based on many factors such as modulation of neurophysiologic states (e.g. sleep vs. wake [11], rest vs. task [12, 13], and healthy activity vs. pathology [14]). Therefore, an individual dynamical systems model of the kind mentioned above can typically only offer insights for a specific physiological regime, and/or for a relatively narrow epoch of time during which dynamics are stationary [15]. There is an unmet need for data-driven modeling methods that can capture non-stationarity in dynamics associated with multiple neurophysiologic states. If an approach is taken that does not account for this nonstationarity, the model which is returned will be a poor fit for any of the regimes present in the data (figure 1(b)).
To overcome this challenge, several approaches to time- or state-dependent dynamical systems models for neural activity have been suggested. In essence, these models embed a mechanism to modify the model parameters in a manner that captures categorical changes in neural dynamics (e.g. sleep vs. wake). For instance, the switching linear dynamical system framework [16, 17] embeds multiple linear dynamical systems, of which a single model is ‘active’ at any given time [18–20], as shown in figure 1(c). Switches between models are often enacted through a latent model, such as a hidden Markov model (HMM) [21] that provides the dynamics behind switches [22, 23]. Through such a mechanism, a model can embed a number of distinct dynamical regimes. A similar approach is taken in [24, 25], but here the researchers use a recurrent neural network (RNN) model, rather than a linear dynamical system. They construct a discrete number of RNNs (each with a different recurrent weight matrix), thus implementing a different set of dynamics for each RNN.
It is important to note that modeling non-stationarity can be understood as a problem with two phases: (i) modeling when dynamical regimes change and (ii) modeling what in the latent dynamics has changed. Our proposed approach tackles the latter phase. Specifically, we infer the changes in latent dynamics as changes in mesoscale neuromodulation (figure 1(d)), rather than comparing distinct dynamic regimes (figure 1(c)). In this paper, we take a similar approach to [24, 25], beginning with a biologically interpretable RNN model describing population-level neural activity. However, in contrast to the approach of having a discrete set of recurrent weight matrices, we implement a modulation architecture (figure 1(d)). To our knowledge, data-driven inference of neuromodulatory effects on mesoscale dynamics has not been previously pursued in this way.
Our model consists of a single weight matrix common to all dynamical regimes, which is then multiplied element-wise by one of a discrete number of modulatory matrices corresponding to different dynamical regimes. Such an assumption is based, schematically, on the actions of neuromodulators on neural circuits that modulate synaptic efficacy. We assume that such modulation occurs on a slower timescale than the timescale of neural activity. By using this modulation structure, we are able to separate the aspects of an individual’s dynamics which are common across time and neurophysiologic state from those which are variable. Additionally, we impose specific excitatory and inhibitory sub-structures on our parameters, in order to preserve the biological interpretability of our fitted models. All model parameters are estimated directly from data in an individualized manner.
Below, we develop and present the proposed methodology. We first introduce our modulated RNN architecture, building from our prior data-driven modeling approach of mesoscale individualized neural dynamics (MINDy) [9, 10] to enact the aforementioned modulation architecture. We then validate this on simulated data, to test the accuracy and reliability of our model in recovering known ground truth parameters. We then test our model on the ability to infer distinct neural mechanisms associated with levels of general anesthesia, a pharmacological modulation of neural circuits. These data allow us to further validate the reliability and individuality of our fitted models. We then reconcile the inferred models and mechanisms with prior observations regarding the modulatory effects of anesthesia on cortical networks.
Methods
Model formation
2.1.
Our model is adapted from our prior whole-brain dynamical systems framework in [9, 10]. The base (i.e. unmodulated) dynamics are governed by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{equation*} \boldsymbol{x}_{t+1} - \boldsymbol{x}_t = \boldsymbol{W}\,\,\tanh\left(\boldsymbol{Sx} + \boldsymbol{V}\right) + \boldsymbol{Dx} + \boldsymbol{C} + \epsilon_t\end{equation*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{equation*} \boldsymbol{y}_t = \boldsymbol{Hx}_t + \nu_t,\end{equation*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{x}t \in \mathbb{R}^n\end{document} represents the neural activity of n neural populations at time t, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol{W}, \boldsymbol{S}, \boldsymbol{V}, \boldsymbol{D}, \boldsymbol{C}}\end{document} are the tunable model parameters. Here, W is the connectivity matrix, D is a diagonal matrix representing the decay (leak) in neural activity for each population, S and V parameterize the slope and offset of the sigmoidal activation function, and C represents a baseline bias of each neural population. H is the lead field model which translates the population-level neural activity into the measured data, and εt_ and νt represent the process noise and measurement noise, respectively.
Note that this model is mathematically comparable to a vanilla RNN, but arranged and constrained to reflect biologically interpretable relationships between excitatory and inhibitory neural populations. By assigning neural populations to spatial locations in the brain and constraining the parameters to specific valence (i.e. positive/excitatory, negative/inhibitory), we can examine changes in these parameters associated with physiological changes. Specifically, we enforce excitatory and inhibitory substructures onto the neural population activity vector xt and the connectivity matrix W like so:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{equation*} \boldsymbol{x}_t = \begin{bmatrix} \boldsymbol{x}_{t,\mathrm{exc}} \\ \boldsymbol{x}_{t,\mathrm{inh}}\end{bmatrix}, \; \boldsymbol{W} = \begin{bmatrix} \boldsymbol{W}_\textrm{ee} & \boldsymbol{W}_\textrm{ie} \\ \boldsymbol{W}_\textrm{ei} & \boldsymbol{W}_\textrm{ii}\end{bmatrix}.\end{equation*}\end{document}Entries in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ee}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ei}\end{document} are constrained to be positive or 0, as they represent the connections from excitatory neural populations. Additionally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ee}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ei}\end{document} are full submatrices. Conversely, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ie}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ii}\end{document} have entries which are negative or 0, as they represent the connections from inhibitory neural populations. Since inhibitory neurons only have local connections [26], these submatrices are constrained to be diagonal.
We adapted and generalized this model by adding neuromodulation via matrices \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i = 1,\dots ,m\end{document} multiplied element-wise by the connectivity matrix W:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \boldsymbol{x}_{t+1} - \boldsymbol{x}_t = \left(\boldsymbol{W} \odot \boldsymbol{\Gamma}_i\right)\tanh\left(\boldsymbol{Sx} + \boldsymbol{V}\right) + \boldsymbol{Dx} + \boldsymbol{C} + \epsilon.\end{align*}\end{document}Here, m represents the number of modulatory states to be modeled. This modulation structure is schematized in figure 1(d). To preserve the signed connectivity structure of W, entries in each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} matrix are constrained to be positive or 0. This enables a modulation which scales entries in W by varying amounts, without affecting the base structure of the connectivity.
The specification of H is made to reflect the specifics of the data modality being used for model construction. In our case, because we are using cortical data (EEG), we account for prevailing hypotheses regarding the contributions of different cell types to surface-level potentials. In this context, it is generally believed that inhibitory neurons are not close enough to the surface of the cortex, nor do they possess the spatial organization, to generate fields detectable via EEG [27]. Therefore, we construct our lead field matrix H to have zeros in the submatrix multiplied by the inhibitory component of x:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{equation*} \boldsymbol{H} = \begin{bmatrix} \boldsymbol{H}_\textrm{exc} & \mathbf{0}\end{bmatrix} .\end{equation*}\end{document}Model fitting procedure
2.2.
Because H is not invertible, we now face what is sometimes termed a dual inference problem: i) estimate xt and ii) estimate the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol{W}, \boldsymbol{\Gamma}, \boldsymbol{D}, \boldsymbol{S}, \boldsymbol{V}, \boldsymbol{C}}\end{document} , from the observable (i.e. EEG) data.
To address this, we adopt the iterative estimation approach detailed in [10, 28]: first we apply a Kalman filter [29, 30] to a small window of data in order to estimate the state. We then evolve the model forward from the (estimated) state to generate a forward prediction. We then backpropagate the error through both the free simulation steps and the Kalman filtering steps, calculating the error gradient for each parameter at each step. In addition to calculating the parameter error gradients (i.e. error gradients of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol{W}, \boldsymbol{\Gamma}, \boldsymbol{D}, \boldsymbol{C}, \boldsymbol{S}, \boldsymbol{V}}\end{document} ), we also calculate the error gradients of the estimated covariances of the noise terms ε and ν. These noise covariances are necessary for the Kalman filter to estimate the current state xt, and are optimized alongside the model parameters. By backpropagating the error in this manner and fitting both the parameters and the noise covariances, we fit a model which produces the most accurate state estimator which can best predict future measurements.
After backpropagation through the free simulation and Kalman filtering steps, we then update the model parameters and the estimates of the noise covariances. Then, the process is repeated with a new small window in the epoch of fitting data. This process of Kalman filtering, free simulation and backpropagation is repeated with new data windows until the Kalman and free simulation errors converge. Multiple windows of the data epoch are used so that the model captures the general dynamics and statistical properties of the entire epoch, to avoid overfitting to a few timesteps of data. These windows are selected at random to avoid biasing the fit toward any one period within the epoch (e.g. the beginning or end of the epoch).
In the unmodulated MINDy model, the parameters do not vary temporally, so all parameters are updated in all steps of the model. In the expanded modulated MINDy model proposed here, only one of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} matrices is used at each timepoint. To account for this, we select the appropriate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} at each time t using the modulation labels and use that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} for model evolution and gradient calculation.
To aid in the tractability of the problem, we implement several constraints on W and Γ. We constrain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\mathrm{ee}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\mathrm{ei}\end{document} to have 75% of their non-diagonal connections be zero, enforcing a prior level of sparsity in connections. We also constrain each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} to be rank 1, i.e. the outer product of two n-dimensional vectors. This assumption is motivated by the premise that neuromodulators act in a spatially diffuse manner [31]. Because each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} is multiplied element-wise by W, the excitatory submatrices of each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} also effectively have 75% of their elements set equal to 0.
To fit the model parameters, we use NADAM [32], implemented with PyTorch’s Autograd engines [33]. This improves fitting efficiency and scalability relative to our prior work, by allowing GPU acceleration, which can be especially beneficial for processing large-scale EEG recordings. Notably, this significantly reduces the number of iterations needed for the convergence of the backpropagated Kalman filter approach. With Autograd, both the covariance update and local linearization process are included in the backward operation.
Simulation and actual data
2.3.
Synthetic data
2.3.1.
To enable the validation of our fitting procedure, we created synthetic data with known parameters. To create this synthetic data, we established models with a combination of fixed and random parameters. The fixed values and distributions for the model parameters are listed in table 1. It should be noted that our W submatrices were constructed as a linear combination of a sparse and low-rank matrix via:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{equation*} \boldsymbol{W}_\textrm{ee} = \boldsymbol{W}_\textrm{s} + \boldsymbol{W}_\textrm{l1}\boldsymbol{W}_\textrm{l2}^{\top} + \boldsymbol{W}_\textrm{diag},\end{equation*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{s} \in \mathbb{R}^{n\times n}\end{document} is a sparse matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{l1}, \boldsymbol{W}\textrm{l2} \in \mathbb{R}^{n \times n/4}\end{document} are low rank matrices, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{diag} \in \mathbb{R}^n\end{document} is a vector specifying the diagonal self-connection weights. Note that equation (6) specifies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ee}\end{document} , but both \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ee}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ei}\end{document} were constructed in this way. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ie}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}_\textrm{ii}\end{document} were constructed as diagonal matrices with diagonal values directly sampled from their distributions.
We initialized each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}i\end{document} matrix as the outer product of a vector drawn from a unique distribution. To construct each unique distribution, we first randomly generate its mean, µi, from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathcal{N}(1,0.1)\end{document} . We then generate a random binary digit indicating whether we should use a uniform distribution, or a normal distribution. Then, we generate a variance σi_ for the distribution. If we are using a uniform distribution, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sigma_i \sim \mathcal{N}(0.4,0.1)\end{document} , and if we are using a normal distribution, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sigma_i \sim \mathcal{N}(0.05,0.01)\end{document} . Then, we generate a vector, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\Gamma}{i,k}\end{document} , from the constructed distribution: if uniform, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\Gamma}{i,k} \sim \mathcal{U}(\mu_i-(\sigma_i/2), \mu_i+(\sigma_i/2))\end{document} ; if normal, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\Gamma}{i,k} \sim \mathcal{N}(\mu_i,\sigma_i)\end{document} . Then, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\Gamma}i = {\Gamma}{i,k}{\Gamma}{i,k}^\top\end{document} .
We chose the distributions for µi and σi such that there could be variation in the distributions of Γi, while also maintaining values close to 1. If the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\Gamma}\end{document} are very large or very small, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\Gamma}\end{document} will overwhelm W in the effective neural connectivity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W} \odot {\Gamma}_i\end{document} . In other words, our assumed modulation does not re-scale synaptic weights by large amounts.
To generate state changes in our synthetic data, we initialized a HMM with transition probability matrix A and initial state probability π. At each timestep, we calculated the probability of the next state based on A and then randomly selected the state index weighted by the calculated probability.
Once we had generated our random models, we forward simulated them for 20 000 timesteps (equivalent to 80 s of 250 Hz EEG) to create synthetic data. When fitting on this synthetic data, the true lead field matrix and noise covariances (H, Q, and R) were used to initialize the models, but the other model parameters were initialized randomly and compared to the true values after fitting, to test parameter recovery when ground truth is known. Since the true value of W is known, however, we create a mask zeroing out the same entries in the fit W, to avoid zeroing out connections which are actually present in the synthetic models.
EEG data
2.3.2.
For our second experiment, we used EEG data of 20 subjects dosed with propofol published in [34] and available online [35]. In this data, subjects were recorded at four levels of sedation: (i) resting baseline with no anesthesia, (ii) mild sedation (defined as 0.6 µg ml^−1^ target blood plasma concentration), (iii) moderate sedation (1.2 µg ml^−1^ target blood plasma concentration), and iv) return to mild sedation. Each sedation level had approximately 7 min of data, recorded at 250 Hz after 10 min of allowing the blood plasma level to reach a steady state and was saved as a separate EEG file. This data is highly compatible for our purposes because the four pharmacological regimes above can be used as labels for constructing and validating our modulated model.
We filtered the data between 0.5 and 15 Hz, subtracted the median of each channel, and divided by the mean absolute deviation of each channel. We combined all four sedation state recordings into a single array for each subject, and added a sedation state index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i \in {1, 2, 3, 4}\end{document} for each timepoint of the array. We also used a subset of the recorded channels in [34], using only 20 channels, shown in figure 2. These channels make up the 10–20 system, a standard montage commonly used in EEG analysis—the remaining 108 channels are at less frequently used locations on the scalp.
EEG channels used in analysis of propofol dosage EEG data.
The data can be modeled with all 128 channels if desired, however the parameter search space will be significantly larger than with 20 channels and as a result the computational time will be longer and the quality of the fit may degrade. Because clinical EEG uses lower density montages (typically in the range of 18–25 channels), we conducted our analysis with a montage of channels in this range.
Any channel montage will suffice for the model, provided the montage yields enough spatial information for the analysis in question. If the activity under investigation is frontal in nature, for example, then a simple 4-channel frontal montage may suffice. For whole-brain analyses, the montage should have a good distribution across the surface of the scalp. Analyses that require very granular spatial information will need a higher number of channels to be modeled than those requiring only approximate spatial information. In clinical settings, it is likely that the montage used will be limited by the channel setup for EEG used in the clinic. For basic scientific investigations, there may be more freedom to choose a montage based on the specific needs of the analysis.
Our modeling methodology does not depend on the sampling frequency of the data used; however it can only encode frequency information that is present in the data. Therefore it is required that any frequencies under analysis be no greater than half the sampling rate of the data, according to the Nyquist sampling criterion [36].
Our H matrix was constructed as in equation (5), with
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{equation*} \boldsymbol{H}_\textrm{exc} = \mathbf{I} - 0.05\mathbf{11}^\top,\end{equation*}\end{document}where I denotes the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 20\times 20\end{document} identity matrix and 1 denotes the 20-dimensional vector of all ones. We constructed R and Q as diagonal matrices, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{R} = 1.2,\mathbf{I}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{Q} = 0.25,\mathbf{I}\end{document} . The other model parameters were initialized randomly, as in experiment 1. In this experiment, we do not have a ground truth of the 75% of non-diagonal connections in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ee}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ei}\end{document} submatrices which are zero as we did in the synthetic data case. To continue enforcing this constraint, we selected a random 75% of non-diagonal connections in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ee}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ei}\end{document} , and set these to 0 for all subjects. Finally, because we wanted to explore modulations relative to baseline (prior to propofol dosing), we enforce \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_1 = \mathbf{11}^\top\end{document} , i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W} \odot \boldsymbol{\Gamma}_1 = \boldsymbol{W}\end{document} . The other Γ matrices ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i \in {2,3,4}\end{document} ) are fit as all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} in the synthetic data experiment.
Results
Modulated MINDy recovers ground truth connections and modulations
3.1.
Our first experiment tested whether modulated MINDy could accurately recover the connectivity and modulation matrices in models with known ground-truth parameters. To benchmark this, we compared the accuracy of parameter inferences for the modulated MINDy architecture in the presence of multiple non-stationary regimes to the performance of the unmodulated MINDy architecture (previously validated in [10]) on data in which there is only a single, stationary regime. That is, for the unmodulated MINDy results, we fit unmodulated MINDy models to single-regime synthetic data generated by using the simulated data setup specified in [10].
As shown in figure 3(a), we achieve ground truth correlations of nearly the same level as in the unmodulated MINDy problem. The unmodulated MINDy models achieve a median correlation coefficient of r = 0.9771 (IQR: 0.9720–0.9866) for the full W correlation, whereas the modulated MINDy models yield a correlation coefficient of r = 0.9280 (IQR: 0.8539–0.9362). The EE and EI submatrices had similar correlations: MINDy EE, r = 0.9873 (IQR: 0.9519–0.9957); Modulated MINDy EE, r = 0.9202 (IQR: 0.8238–0.9408); MINDy EI, r = 0.9715 (IQR: 0.9506–0.9895), Modulated MINDy EI, r = 0.9227 (IQR: 0.8615–0.9495). Since we are fitting not only one connectivity matrix but also several Γ matrices, a slight decrease in fit quality is expected relative to the unmodulated problem, due to the increase in the connectivity parameter search space from n × n (MINDy) to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n \times n \times m\end{document} (modulated MINDy).
Modulated MINDy returns models with high ground truth correlations. (a) Ground truth correlations for the full connectivity, excitatory–excitatory connections, and excitatory–inhibitory connections for both unmodulated and modulated MINDy problems. (b) Ground truth correlations for the connectivity matrix (W) and the connectivity modulation matrices (Γ) in the modulated MINDy problem.
Additionally, we achieved similarly high ground truth correlations for the EE and EI components of the modulation matrices Γ: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_1\end{document} r = 0.9269 (IQR: 0.8902–0.9434) EE, r = 0.9160 (IQR: 0.8618–0.9385) EI; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_2\end{document} r = 0.9228 (IQR: 0.8864–0.9421) EE, r = 0.9152 (IQR: 0.7665–0.9343) EI; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_3\end{document} r = 0.9215 (IQR: 0.9011–0.9411) EE, r = 0.9071 (IQR: 0.8216–0.9435) EI, as shown in figure 3(b). These results indicate that we can accurately recover both the true base connectivity and the true modulations of that connectivity, and are summarized in table 2.
Figure 4 provides examples of individual connection and modulation matrices and their recovered estimates via modulated MINDy (i.e. the proposed method). As shown, the spatial patterns of high- and low-amplitude connections in the true matrices are replicated in the estimated matrices. The estimated W tends to have a slightly higher amplitude than the true W, and the estimated Γ tends to have a slightly lower amplitude than the true Γ. This is to be expected, since we only regularized the structure of W and Γ, and did not regularize their amplitude. In summary, we can conclude that the modulated MINDy model can estimate the connectivity and modulation parameters to within a potential scaling factor of the true value.
Modulated MINDy returns connectivity and modulation matrices accurate to a potential scaling factor. True (top row) and estimated (bottom row) W and Γ matrices from a single subject.
This scaling factor arises from the decomposition of the connectivity into two matrices, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W} \odot \boldsymbol{\Gamma}_i\end{document} . Since there are an infinite number of ways to factor a number into the product of two other numbers, we cannot assure that the elements of the estimated W and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} are not off by a constant from the ‘true’ values, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{\boldsymbol{W}} = \gamma\boldsymbol{W}\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{\boldsymbol{\Gamma}}_i = (1/\gamma)\boldsymbol{\Gamma}_i\end{document} , where γ represents the scaling factor. To reduce the impact of this, we constrain the parameter search space by enforcing a low-rank constraint onto \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} . However, this does not entirely resolve the issue, and it is an important limitation to consider when analyzing the models returned by modulated MINDy. For many use cases, this ambiguity is irrelevant. For example in this analysis, we analyze parameter values in comparison to one another, i.e. by comparing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_j\end{document} , in which case the scaling factor cancels out.
Modulated MINDy is robust to noise
3.2.
To test modulated MINDy’s robustness to noise, we repeated our ground truth recover experiment with varying levels of noise covariance in our generated data ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Q = [0.05\mathbf{I}, 0.25\mathbf{I}, 0.5\mathbf{I} 0.75\mathbf{I}, \mathbf{I}, 5\mathbf{I}, 10\mathbf{I}]\end{document} . We found that modulated MINDy accurately inferred the ground truth parameters for levels of noise up to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{Q} = \mathbf{I}\end{document} , and then the performance declined (figure 5, table 3).
Modulated MINDy is robust to noise. Correlation of inferred W (blue), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}Wee (red), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}Wei (green) with ground truth values, for differing noise covariances.
Modulated MINDy is reliable and individualized
3.3.
In our second experiment, we tested modulated MINDy on actual EEG data to understand how it functioned on a population of individuals. We split each subject’s data in half temporally within each sedation level, in order to perform a test–retest reliability analysis.
We observed that models were reliable, showing high correlations within a single subject (W: r = 0.7670 (IQR: 0.7187–0.8118); \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ee}\end{document} : r = 0.7930 (IQR: 0.7276–0.8746); \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ei}\end{document} : r = 0.6855 (IQR: 0.6054–0.7202; figure 6). Additionally, correlations across subjects were significantly lower (W: r = 0.6230 (IQR: 0.5722–0.6802), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p = 1.97\mathrm{e}^{-11}\end{document} ; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ee}\end{document} : r = 0.6510 (IQR: 0.5760–0.7252), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p = 1.04\mathrm{e}^{-8}\end{document} ; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W}\textrm{ei}\end{document} : r = 0.5144 (IQR: 0.4275–0.5821), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p = 1.61\mathrm{e}^{-8}\end{document} ), indicating that models are individualized, a requisite condition for capturing dynamics and mechanisms which vary across individuals. These results are summarized in table 4.
Modulated MINDy is reliable and individualized. Test–retest correlations on split-half data are significantly higher within subject than across subject in the full W connectivity matrix, as well as the EE and EI submatrices.
Models identify consistent modulation associated with pharmacology
3.4.
Having established validity in ground-truth settings, we proceeded to apply the method to labeled EEG data from stages of propofol anesthesia. Specifically, for each of 20 individuals, we inferred a base connectivity matrix for the pre-sedation regime, as well as modulation matrices for the regimes of mild anesthesia, moderate anesthesia and return to mild anesthesia. To test our method’s ability to provide insight into the observed changes into dynamics, we analyzed the modulation (Γ) matrices at each sedation level compared to baseline. An exemplar subject is shown in figure 7.
Modulated MINDy detects changes not obvious by eye. EEG timeseries data (a), power spectrogram (b) and Γ matrices for an exemplar subject. Dashed red lines indicate times when the anesthesia state changes.
Of note, modulated MINDy is detecting changes that are not clear to the naked eye in either the raw EEG or the power spectrogram (figure 7). This indicates that modulated MINDy is picking up on true latent dynamics which cannot be observed directly from the data. By capturing these latent dynamics, modulated MINDy is capable of providing greater insight into the mechanisms that generate changes in neural state, in this case, changes in consciousness.
We performed a two-way ANOVA on the post-synaptic modulation of excitatory connections to analyze the effects of channel location and sedation state. We excluded the pre-sedation state from this analysis since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_1 = \mathbf{11}^\top\end{document} and so there will not be any variance across subjects or spatial location in that sedation state. The ANOVA indicated that channel location and sedation state both significantly affected post-synaptic modulation of excitatory connections, as did their interaction (ANOVA values given in table 5).
In analyzing the models at the population level, we observed first that the vast majority of the values within the matrices fall within the range \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} [0, 1)\end{document} , though a small percentage ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_2\end{document} : 0.169%, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_3\end{document} : 0.150%, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_4\end{document} : 0.128%) are greater than 1 (figure 8). Since these values are multiplying the base connection weights W, a fractional value in Γ indicates a relative decrease of connection strength, or a relative increase in inhibition. In the population average, all values are fractional. This pattern of the modulations increasing inhibition is consistent with the widespread inhibitory effects of propofol [37, 38].
Modulated MINDy identifies inhibitory modulation during sedation. Distributions of all modulation values in each sedation state.
Importantly, we went beyond these bulk inferences and also analyzed the spatiotemporal changes associated with each modulation regime. We found that in the population mean, the modulation values which were highest (i.e. smallest relative inhibition) were typically connections to populations underlying posterior channels, particularly in the moderate sedation state (figure 9(a)). This is compatible with prior characterizations of the effect of propofol on attenuating the posterior regions of the scalp [39, 40]. Also note the substantial decrease in post-synaptic modulation value from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_1\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_2\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}3\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}4\end{document} , further indicating propofol’s general inhibitory effects. We also noted that each modulation state introduced specific spatial changes to the effective connectivity. Note that in this paper we use the term ‘effective connectivity’ differently from how it is used in connectomics papers, e.g. [41, 42]. That field uses ‘effective connectivity’ as a technical term, analogous to functional connectivity or structural connectivity. We use ‘effective connectivity’ to refer to the constant connectivity W multiplied by the current modulation Γi. In other words, ‘effective connectivity’ in this paper refers to the modulated connectivity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W} \odot {\Gamma}_i\end{document} . To quantify the spatial changes of the effective connectivity in each modulatory state, we define a measure of the modulation’s impact, defined as the difference between two temporally adjacent modulations matrices scaled by W, e.g. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W} \odot (\boldsymbol{\Gamma}_2 - \boldsymbol{\Gamma}_1)\end{document} . Thus, we account for both the magnitude differences in Γ as well as the base magnitude of the connection weights which are being modulated. A positive impact indicates a strengthened connection, and a negative impact indicates a weakened connection.
Modulated MINDy identifies inhibitory, spatially focused modulation during sedation. (a) Mean post-synaptic modulation in population mean of modulation matrices in sedation states. (b) Post-synaptic modulation impact (difference between two temporally adjacent modulation matrices, scaled by W) across transitions between sedation states (population mean). (c) Distributions of EE modulation values in frontal channels. (d) Correlation between moderate sedation post-synaptic impact and return to mild sedation post-synaptic impact.
As the subjects move from pre-sedation to mild sedation, there is a widespread weakening of connections across the whole brain, but again particularly in the posterior areas (figure 9(c), panel 1). As the subjects progress from mild to moderate sedation and from moderate sedation to the return to mild, the changes are of smaller, less significant magnitude (figure 9(c)). The change from mild to moderate sedation is characterized by a further weakening of the frontal connections (figure 9(b)). This general observation is consistent with the observation of anteriorization of neural activity in the time before loss of consciousness [39, 40, 43], in which the loss of posterior EEG power is accompanied by a potentiation of activity in frontal regions (note the posterior–anterior dichotomy in inferrered modulatory impact, especially from baseline to mild sedation, panel 1 of figure 9(c). Anteriorization has been modeled as a differential effect of inhibition along the posterior–anterior axis [44, 45]. Interestingly, as the subjects transition from moderate sedation back to mild sedation, there is a reversal of the effects seen in the transition from mild sedation to moderate sedation (figure 9(c)), highlighted by the negative correlations between the impact of moderate sedation and the impact of the return to mild sedation (figure 9(d)). This indicates a gradual decrease in EE connection strength as the subjects are dosed with anesthesia, followed by a return to a state similar to the mild sedation in the return to mild phase.
Overall, these results indicate that the methodology is identifying modulatory effects that are consistent with what we would expect from prior detailed studies on the mesoscale effects of propofol anesthesia, thus supporting the validity of the proposed approach.
Importantly, this modeling methodology identifies changes in electrophysiological dynamics that may or may not be observable by eye. Currently, identifying changes in electrophysiological dynamics, even when the times state changes occur are labeled, requires electrophysiologists examining long EEG recordings by hand. This process is time-consuming, and algorithms to categorize changes in neural activity can reduce reliance on it. Additionally, modeling methodologies such as this one can produce mechanistic insights into the underlying circuit dynamics that cannot be identified by simple descriptive analyses or observed by eye.
Discussion
Data-driven inference of modulation for understanding non-stationary brain dynamics
4.1.
Brain dynamics are fundamentally nonstationary, changing as individuals switch between varying tasks, cycle between sleep and wake states, or as pathologies within the brain improve or worsen. Such non-stationarity is mediated, at least in part, by processes of neuromodulation that potentiate or attenuate synaptic connections within and between brain areas. Our goal in this paper was to develop a data-driven, parametric modeling framework for identifying such modulation at whole-brain scales.
Our specific approach was to formulate modulation within a physiologically interpretable RNN construct, where a baseline set of synaptic weights—common to all non-stationary regimes—is scaled by regime-specific modulation. Within this framework are several nontrivial technical challenges. Specifically, because our model is formulated at the level of latent (unobserved) neural populations, we faced the dual-estimation problem of fitting model parameters and estimating state variables at the same time. Compounding this is the need to fit not one connection matrix, but rather a family of such matrices. Since the base connection weights W are multiplied by the modulations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i = 1,2,\dots ,m)\end{document} , this is a fundamentally ill-posed problem. However, we showed that by imposing appropriate priors on the construction of both W and Γ, the problem can be made tractable, leading to interpretable results.
At a mathematical level, our modeling setup involves, in essence, a matrix factorization problem: there are a number of distinct effective connectivity matrices ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W} \odot \boldsymbol{\Gamma}_i\end{document} ), which are then factorized into a component common across all regimes (W), and a modulatory component which varies discretely based on regime ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Gamma}_i\end{document} ). While there are algorithms for the decomposition of a matrix into the Hadamard product of two matrices [46, 47], these algorithms solve a problem which is constructed differently from ours. The algorithms in [46, 47] decompose a given matrix into two or more low-rank matrices. In our problem, we are principally concerned with finding finding a decomposition with a component matrix common to all given matrices, as motivated by our specific domain application context. Importantly, we allow our common component (W) to be full-rank, rather than decomposing into two low-rank matrices.
As noted, data-driven decomposition of neuromodulatory effects on mesoscale dynamical models has not been widely studied in the computational neural modeling community. Several authors have, however, done work with a similar motivation for taking a neuromodulation approach to modeling. Li et al [23] developed a statistical generalized linear model (GLM) construct that embodies a modulatory nonstationary architecture for neuronal-level modeling. They specifically imposed a level of similarity between switched models by incorporating a Gaussian prior onto the weight matrices of their GLMs. They further incorporated a decomposition of connection strength from connection direction—decomposing their weight matrices into a direction component in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {-1,0,1}\end{document} , and a strength component in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbb{R}_{> 0}\end{document} . Having done this decomposition, they also impose a Gumbel–Softmax prior on the direction component, minimizing the number of connections that switch direction with different regimes. In contrast, working at the meso-scale, we enforce a direction mask onto our effective connectivity matrices which does not change over time, and decompose the strength of each matrix into a common component W and a switched component Γ.
There are certainly many biophysical models that have engaged neuromodulation from a bottom-up perspective, especially at neuronal and small-circuit scales, e.g. [48–51], which can generate inferences and predictions at the meso- and macro-scale [52, 53]. We view our contribution here as a methodological enabling of such approaches in the sense that our framework takes mesoscale data and performs an inference problem to arrive at a mesoscale model of neural modulation.
Modulated MINDy provides individualized inference of modulated whole-brain dynamics
4.2.
Our developed approach represents a generalization of our mesoscopic individualized neural dynamics (MINDy) framework [9, 10]. Specifically, rather than identifying a single dynamical regime, the generalized framework proposed here allows for spatially relevant representations of both the base connectivity common to all regimes as well as modulation that may vary with time and brain state. In this sense, this modulated model architecture is also multi-timescale, as the population activity state x changes on a much faster timescale than the selection index i. Importantly, our model architecture is biologically interpretable, providing insight into excitatory–inhibitory dynamics not provided by vanilla RNN architectures. Modulated MINDy accurately estimates known latent dynamics from synthetic data, and infers reliable and individualized models when tested on human data. Modulated MINDy is also scalable, requiring only ∼10 min to fit 30 min of 20-channel EEG data with 3 modulation matrices.
Modulated MINDy as a tool to infer interpretable neuromodulation
4.3.
As a proof of concept, we tested modulated MINDy on open-source, labeled EEG recordings of subjects receiving the general anesthetic drug propofol. We found that our models had modulation structures consistent with prior literature on propofol sedation, including promoting inhibition along the posterior–anterior spatial axis. Thus, modulated MINDy provides spatiotemporal models which are not only accurate and reliable, but can be interpreted to gain mechanistic insight into an individual’s brain dynamics and how they are modulated over time or as a function of exogenous factors or inputs. We emphasize that our applicative example in anesthesia was not intended to make a specific scientific point about propofol per se, but rather as a methodological validity test.
In this validity test, we did not explicitly model GABA_A_ and GABA_B_ receptors separately, but modeled inhibitory populations as a single type type compared to excitatory populations, regardless of their subtype. To model GABA_A_ and GABA_B_ separately, this model can be extended to include two inhibitory populations, one corresponding to GABA_A_ and one corresponding to GABA_B_. (See for example, [28], which used MINDy to model two excitatory and two inhibitory populations per EEG channel, though the inhbitory populations did not explicitly correspond to different GABA types.)
We envision a number of applicative contexts for the proposed method, for both basic scientific and clinical questions. Modulated MINDy can be used in a task context, to infer modulations unique to specific cognitive functions. It could be used, as in this proof of concept, to characterize the spatiotemporal effects of an exogenous intervention, either pharmacological or otherwise. Additionally, it could be used in clinical contexts, to associate different modulation patterns with various states of pathology, e.g. seizures, coma, or ischemia. A key aspect of modulated MINDy is that it infers individual changes in brain dynamics from EEG recordings. This enables comparison of the patients based on characteristics of their brain dynamics, rather than by external measures such as propofol concentration. Since pharmacodynamics are highly individualized, comparison at this level could yield interesting results related to the mechanisms of propofol onto individual brains. Ultimately, modulated MINDy is a modeling tool to infer changes that underlie non-stationary brain recordings, where the non-stationary regimes are labeled in the data.
Limitations
4.4.
We note a few important limitations of the proposed approach. Most notably, as outlined in our introduction, our approach tackles the problem of inferring what is modulated within network dynamics, and not the companion problem of inferring when such modulation has occurred. In other words, we require here known demarcation or labeling of nonstationary regimes. Future work will engage the challenge of inferring both modulation and regime engagement, simultaneously. Our model itself is formulated at the mesoscale, with clear abstraction of cellular and sub-cellular dynamics. These assumptions could in principle be generalized, though that would lead to increasingly computational complexity regarding the ensuing inference problem. Additionally, the nature of the Hadamard decomposition results in the inferred W and Γ parameters being subject to a potential scaling factor, as discussed in 3.1. This means that any direct analysis of parameter values should be applied with caution. This scaling factor is irrelevant, however, for analyses comparing parameters (as in this paper), analyses of the product \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{W} \odot \boldsymbol{\Gamma}_i\end{document} , or analyses of the overall dynamics of the model.
Conclusion
4.5.
In conclusion, we have presented modulated MINDy, a framework for fitting multiscale, modulated, mesoscale models of brain dynamics to individual data, and have validated it on both ground truth synthetic and actual human EEG data. In the future, we plan to extend this model by enabling modulated inference on data where the modulatory states are unlabeled, i.e. where there is a need to infer also the points at which the non-stationary regimes within the data change. We anticipate that modulated MINDy’s ability to give mechanistic inference will make it a powerful tool for analysis in many neuroscientific and clinical contexts.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Babadi B Emery N B 2014 A review of multitaper spectral analysis IEEE Trans. Biomed. Eng.611555641555–6410.1109/TBME.2014.231199624759284 · doi ↗ · pubmed ↗
- 2Liu S Wang J Shanshan Li Cai L 2023 Epileptic seizure detection and prediction in EE Gs using power spectra density parameterization IEEE Trans. Neural Syst. Rehabil. Eng.313884943884–9410.1109/TNSRE.2023.331709337725738 · doi ↗ · pubmed ↗
- 3Blinowska K Durka P 2006 Electroencephalography (EEG)Wiley Encyclopedia of Biomedical Engineeringvol 10p 9780471740360
- 4Louis E K S Frey L C Britton J W Hopp J L Korb P Koubeissi M Z Lievens W E Pestana-Knight E M 2016 The normal EEG Electroencephalography (EEG): an introductory text and atlas of normal and abnormal findings in adults, children and infants [internet]American Epilepsy Society 27748095 · pubmed ↗
- 5Marcuse L V Schneider M Mortati K A Donnelly K M Arnedo V Grant A C 2008 Quantitative analysis of the EEG posterior-dominant rhythm in healthy adolescents Clin. Neurophysiol.1191778811778–8110.1016/j.clinph.2008.02.02318486545 · doi ↗ · pubmed ↗
- 6Sanzleon P Stuart A K Woodman M M Domide L Mersmann J Anthony R M Jirsa V 2013 The virtual brain: a simulator of primate brain network dynamics Front. Neuroinform.71010.3389/fninf.2013.0001023781198 PMC 3678125 · doi ↗ · pubmed ↗
- 7Schirner M Rothmeier S Jirsa V K Mcintosh A R Ritter P 2015 An automated pipeline for constructing personalized virtual brains from multimodal neuroimaging data Neuro Image 11734357343–5710.1016/j.neuroimage.2015.03.05525837600 · doi ↗ · pubmed ↗
- 8Breakspear M 2017 Dynamic models of large-scale brain activity Nat. Neurosci.2034052340–5210.1038/nn.449728230845 · doi ↗ · pubmed ↗