Personalized risk score for post‐COVID‐19 condition: Bayesian directed acyclic graphic approach
Sam Li‐Sheng Chen, Chen‐Yang Hsu, Tin‐Yu Lin, Amy Ming‐Fang Yen, Tony Hsiu‐Hsi Chen

TL;DR
This paper introduces a personalized risk score for post-COVID-19 condition using a Bayesian model, helping predict and manage long-term effects based on patient data.
Contribution
The novel use of a Bayesian DAG model to create a dynamic, adaptable risk score for post-COVID-19 condition.
Findings
The model incorporates 215 risk factor combinations from over 860,000 cases across 41 studies.
The risk score accurately predicts PCC probability across SARS-CoV-2 variants, though higher scores show slight deviations in BA.5 Omicron.
The model is adaptable to new subvariants and supports individualized care and resource allocation for high-risk groups.
Abstract
Post‐COVID‐19 condition (PCC) has gained traction currently in the post‐pandemic era. To address this, we utilized a Bayesian directed acyclic graphic (DAG) model to develop a personalized composite risk score (CRS) for PCC, based on the tabular data derived from a comprehensive meta‐analysis. Our risk assessment model incorporates 215 combinations of risk factors, including personal demographic and health‐related profiles, across 41 studies involving over 860,000 COVID‐19 cases. The CRS ranges from 0 to 500, categorizing patients into risk quartiles and estimating PCC probability across SARS‐CoV‐2 variants of concerns, including Wild/D614G/Alpha, Delta, and Omicron BA.1/BA.2. External validation demonstrated accurate predictions, though higher risk scores showed slight deviations, particularly in BA.5 Omicron subset. The risk assessment model is not only adaptable for incorporating new…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
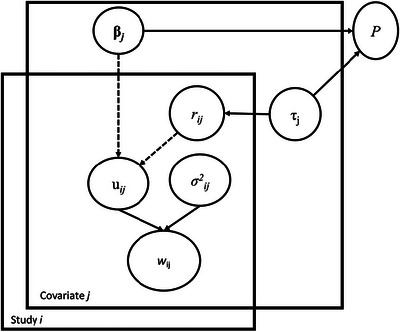 FIGURE 1
FIGURE 1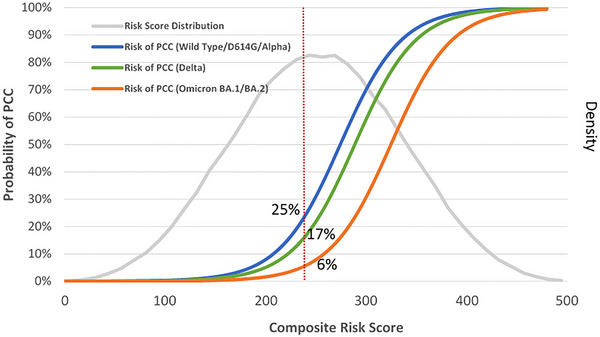 FIGURE 2
FIGURE 2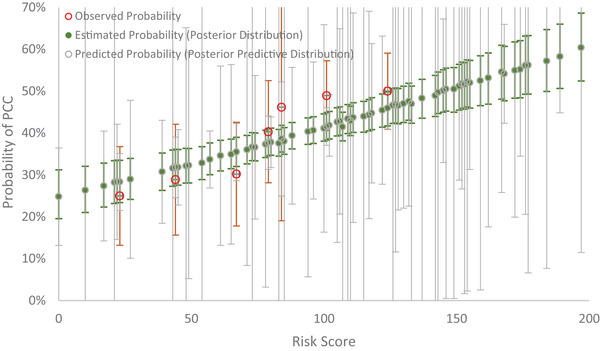 FIGURE 3
FIGURE 3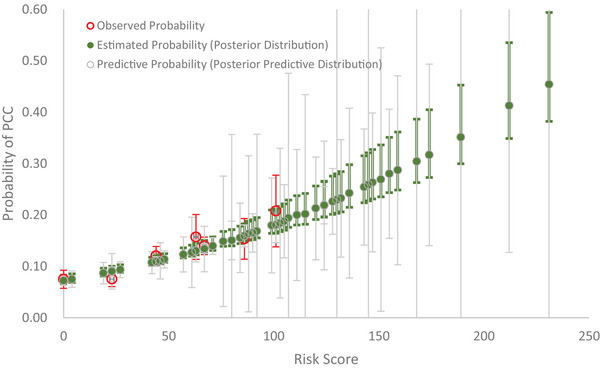 FIGURE 4
FIGURE 4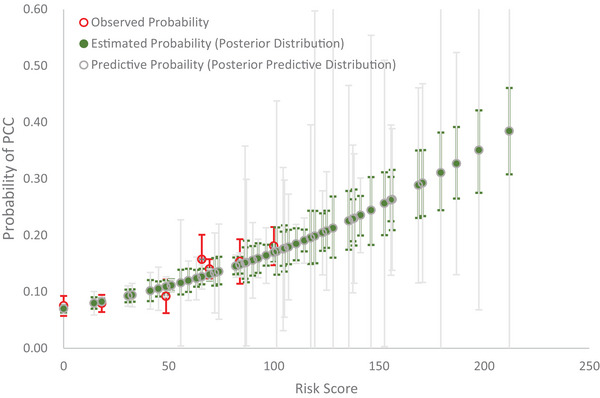 FIGURE 5
FIGURE 5| Decile (%) | Composite risk score | Risk of PCC | Quartile‐based risk groups |
|---|---|---|---|
| 90–100 | 350–500 | ≥90% |
Very high risk group (75th–100th) |
| 80–89 | 310–349 | 73%–89% | |
| 70–79 | 284–309 | 54%–72% | |
|
High risk group (50th–75th) | |||
| 60–69 | 263–283 | 37%–53% | |
| 50–59 | 241–262 | 23%–36% | |
| 40–49 | 220–240 | 13%–22% |
Moderate risk group (25th–50th) |
| 30–39 | 198–219 | 7%–12% | |
| 20–29 | 173–197 | 3%–6% | |
|
Low risk group (<25th) | |||
| 10–19 | 140–172 | 1%–2% | |
| <10 | <140 | <1% |
- —National Science and Technology Council, Taiwan
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsLong-Term Effects of COVID-19 · COVID-19 Clinical Research Studies · COVID-19 and healthcare impacts
INTRODUCTION
1
It is of paramount importance to assess and predict an individual's risk of developing a post‐COVID‐19 condition (PCC). In spite of a number of studies addressing the possible risk factors associated with PCC that may be ex‐changeable with long‐COVID‐19 (Arjun et al., 2022; Sudre et al., 2021), evidence supporting such association studies has been individually reported by various SARS‐CoV‐2 variants in various countries and regions worldwide. Therefore, their external generalizability is rather limited and subject to the weakness of the small sample size. More importantly, each piece of information has not been synthesized in a systematic way. The recent meta‐analysis (Tsampasian et al., 2023) of integrating all kinds of association studies between risk factors and PCC not only revealed a panorama view of risk factors associated with PCC but also offered an opportunity for quantifying the potential of developing PCC on an individual level to streamline the stratification of a spectrum of risk groups in the underlying susceptible population with a constellation of factors in a systematic way. The tabular data provided from this study also creates a golden opportunity for building up a personalized risk assessment for PCC.
Meta‐analysis has been extensively used to synthesize data on a series of key interest parameters from multiple studies (Glass, 1976). The combined findings from the listed studies would be used to establish the summary of the effect size for each risk factor associated with the outcome of interest after pooling findings from various studies (Normand, 1999). However, a common challenge in many applications arises from the fact that different studies may include various sets of covariates that may or may not potentially overlap. Within a substantial consortium of epidemiological research, it is customary to assess certain crucial risk factors across all the investigations. However, it is inevitable that certain potentially significant covariates are only measured in a subset of the studies, rather than in all of them (Berkey et al., 1995; van Houwelingen et al., 2002). The meta‐regression analysis was adopted to accommodate a series of relevant covariates (Platt et al., 1999; St‐Pierre, 2001). Moreover, the biased estimation of parameters inherent from the heterogeneity across studies is supposed to be calibrated with the incorporation of the random effect across studies leveraging advanced meta‐analytics such as the generalized mixed model methodology. Although the mixed meta‐regression model extends beyond a basic synthesis of effect sizes and enables researchers to investigate the associations between study‐level variables (such as covariates) and the reported effect sizes in the included studies, it is still intractable to directly apply such a method to develop a series of composite risk scores (CRSs) synthesized from various studies, spanning over different periods with the common event‐based outcome but possibly with different underlying predictors varying with the time period, as seen in the current scenario of SASRS‐CoV‐2 variants and subvariants.
The PCC arising from a series of SARS‐CoV‐2 variants from wild type/D614G, Alpha, Delta, until Omicron in different time periods is a typical case. In addition to a systematic review and the conventional meta‐analysis method, a new statistical approach is therefore required to transcend various covariates from individual studies into a comprehensive risk assessment model in a synthetic manner to cover different periods of SARS‐CoV‐2 mutants. The development of Bayesian directed acyclic graphic (DAG) model is one of the useful approaches.
Based on the information provided from this comprehensive meta‐analysis of the Tsampasian et al. study, we sought to create a personalized risk score for assessing and forecasting the risk of developing PCC leveraging a Bayesian DAG model algorithm and validated the proposed risk score model with both real‐world data from Israeli and Japanese SARS‐CoV‐2.
METHODS
2
Data source
2.1
The risk score for PCC was calculated on the basis of the demographic characteristics and comorbidities in a meta‐analysis study (Tsampasian et al., 2023). It comprised 41 observational studies from the inception of COVID‐19 to December 5, 2022, including 860,783 adult patients with COVID19. An infected case with symptoms lasting longer than 3 months was considered PCC, consistent with the WHO definition in this study. The risk factors included female sex, advanced age (<40, 40–69, 70+), higher body mass index, smoking, preexisting conditions, prior hospitalization or ICU admission, and incomplete vaccination, giving 148 data records with 15 levels of risk factor.
Bayesian approach for a personalized risk score model for PCC
2.2
To incorporate covariates relevant to the estimated effect size, the integration of different studies applying a generalized linear mixed model (e.g., generalized random‐intercept model) with a Bayesian approach was developed. The incorporation of the random intercept can account for unobserved variations across studies. Under this framework, we proposed a Bayesian DAG model to assess the clinical weight (effect size) of each risk factor on the risk of PCC while simultaneously accounting for fourteen risk factors (see Figure 1). The Bayesian DAG model applied to meta‐analysis has been demonstrated by Smith et al. (1995) and has been extensively used as one of generalized linear mixed models in literature (Lian et al., 2019; Yen et al., 2006). Here, we take advantage of the Bayesian approach with the incorporation of prior distributions for sharing information on all related covariates across studies with each other to cope with the missing covariates of each study and its flexibility of generating samples of posterior distribution to re‐construct sufficient individual data as if they were primarily collected. In brief, with the mean value and variance fluctuating with each risk factor across studies, the risk of PCC was transformed with the log (odds ratio) of each study to obey a normal distribution. The Bayesian DAG model underpinning the generalized linear random intercept model using the logit link as a link function was first constructed to derive the posterior distribution formed by the prior distribution in conjunction with the likelihood function given the conditional independence (d‐separation) circumstances of all the involved parameters. A normal distribution was adopted for the prior distribution of each regression coefficient. For the variance parameter, the prior distribution of the inverse gamma distribution was adopted. The parameters of all regression coefficients of relevant covariates were trained by applying the Bayesian Markov Chain Monte Carlo (MCMC) method to generate samples that were leveraged to approximate the estimates of the marginal posterior distribution following the ergodic property of the stationary distribution of the Markov chain over a series of iterations. The initial values for parameters were assigned with reference to the results of maximum likelihood estimates. To stabilize and eliminate the effects from the initial values, the first numbers of burn‐in iterations were discarded. A Gibbs sampling algorithm was employed to derive samples of a stationary posterior distribution by which inferences on parameters were made. The detailed algorithms for applying the Bayesian DAG model to our scenario of PCC are elaborated as follows:
- The random variable Wij, namely the dependent variable of PCC, associated with the jth risk factor of the ith study is expressed by log(OR(oddsratio)ij), which obeys the normal distribution denoted as Normal(uij,σij2) where uij and σij2 represent the corresponding mean value and variance. Each W was abstracted from each study enrolled in the meta‐analysis of PCC (Tsampasian et al., 2023).
- The mean value of uij as a function of risk factors was modeled by linking uij with the estimated regression coefficients (βj) of each fifteen categories of risk factors plus the random effect that captures the variance dependent on risk factor across studies. The equation is expressed as follows:
- 3.Assign noninformative prior distributions to each hyperparameter, including τj and βj
- 4.The CRS is calculated using 2^15^combinations of risk factors.
where rij follow a normal distribution denoted as rij∼Normal(0,τij)
Bayesian directed acyclic graphic (DAG) model for estimating and predicting individual risk of post‐COVID‐19 condition (PCC).
Ranging from 0 to 500 as shown in Table 1.
- 5.The predicted value denoted as Z^ for each risk factor was generated by the aforementioned normal distribution denoted as Z^∼Normal(βj,τj)
- 6.Plot the normal distribution of CRS.
- 7.The risk of developing PCC by three periods dominated by Wild/D614G, Alpha/Delta, and Omicron is predicted by a logistic regression equation expressed by the Equation (1):
The intercept, α, was estimated as −9.056 for wild/D614G/Alpha, −9.532 for Delta, and −10.717 for Omicron. All these intercepts refer to the previous studies (Antonelli et al., 2022; Willan et al., 2023) across three corresponding periods of SARS‐CoV‐2 variants.
- 8.After discarding 10,000 burn‐in samples, another 10,000 samples with Gibbs sampling methodology were used to estimate the parameters of interest based on their posterior distributions. The MCMC simulation was carried out using WinBugs (Cambridge MRC). The risks of PCC for three eras of SARS‐CoV‐2 variants were plotted accompanied by the normal distribution of risk score. The predictive distribution (denoted by P in Figure 1) based on *β_j_
- and *τ_j_
- was also generated by using MCMC simulation for obtaining Bayesian predictive interval.
The languages of the Bayesian DAG algorithm are depicted as follows:
While m ≤ 183, do /m represents available data record/
Read data of each mean value and variance of the jth risk factor in the ith study for Wij following Normal(uij,σij2)
If m > 183 then break loop
While i≤ 47, do
While j ≤ 15, do
rij follows Normal(0,τij)
if j > 15 then break loop
if i > 47 then break loop
While j ≤ 15, do
βj follows Normal(0,0.000001)
Z^j follows Normal(βj,τj) /* Ẑ* j
- represents the predicted weight*/
ORj = exp(βj)
Predictive ORj= exp(Z^j)
τj follows Gamma (0.01, 0.01)
If j > 15 then break loop
A CRS was created by adding up all the estimated clinical weights given the 2^15^ combinations of each category of risk factor. The underlying susceptible population was stratified using the decile risk score. The risk of PCC given each risk score was therefore computed and predicted making allowance for the baseline risk varying with three eras of SARS‐CoV‐2 variants (Wild/D614G/Alpha, Delta, and Omicron BA.1/BA.2).
Model validation
2.3
To illustrate our proposed personalized risk score and extend its applications to assess the risk of developing PCC in different datasets, we utilized data obtained from two studies (Iba et al., 2024; Kuodi et al., 2022) for external validation. The study of Kuodi et al. included Israeli adults aged 18 and over who had been infected by COVID‐19 in the period between March 2020 and November 2021 before the Omicron subvariant. Information regarding age, sex, vaccine status, hospitalization, preexisting health conditions, and post‐COVID‐19 symptoms was collected through self‐reported questionnaires. Individuals who experienced any of the reported symptoms were categorized as having PCCs in our analysis. Individual data used for model validation are presented in Table A1. Another study used for external validation is pertaining to Japanese adults aged between 18 and 69 who had been infected by COVID‐19 during the BA.5 Omicron‐dominated period. Self‐reported information regarding age, sex, vaccine status, body mass index, preexisting health conditions, and PCC was collected through the questionnaire survey. Individual data generated from the study of Iba et al. for model validation are presented in Table A2. The goodness of fit for model validation between the observed probability and the predicted probability pursuant to posterior‐predictive distribution was performed with a Bayesian chi‐square test (Johnson, 2004).
The Bayesian X2 statistic R(θ^) following the notation of Johnson is expressed by Equation (2):
Oi represents the number of observations that fell into the ith bin. The number of bins, say I, are determined by the quantiles of risk score distribution, denoted as θ^. pi represents the predictive probability assigned in the interval i over the sample space n. Under the regular condition, the distribution of R(θ^) is assumed to converge to X2 with I − 1 degree of freedom as n → ∞ to have an asymptotic distribution of R(θ^).
RESULTS
3
The personalized risk score for PCC
3.1
The self‐assessed personalized risk score for developing PCC based on Equation (1) is constructed as follows:
CRS =
Note that the clinical weights refer to the estimates of Bayesian posterior odds ratios. The score ranged from 0 to 500 with the corresponding normal distribution as shown in Figure 2 (lower panel). We divided the patient population into four quartile‐based risk groups.
Composite risk score distribution and the posterior probability of post‐COVID‐19 condition (PCC).
Table 1 shows the CRS and the risk of PCC in deciles from <1% for the lowest decile to ≥90% for the 90th highest decile. The score ranged from 0 to 500, yielding the normal distribution as shown in Figure 2 (lower panel). The 90th highest risk patients were 90 times the risk for PCC compared with the 10th lowest‐risk patients.
The risk of having PCC was around 23% for the average‐risk group (50th) during the entire period. The corresponding figures were 25% for Wild/D614G/Alpha, 17% for Delta, and 6% for Omicron.
External validation of PCC
3.2
The Israel study before omicron
3.2.1
The prevalence of PCC in Israel before Omicron was 40% (397/951). In this external data, infected cases with incomplete vaccines, asthma, chronic kidney disease, chronic obstructive pulmonary disease, diabetes, or immunosuppression were more likely to develop PCC. Among the total of 15 predictors, 9 risk factors in this dataset could be applied to the predictive model. After applying the clinical weights into individual variables, the average risk score was 90 in this dataset. The observed probability, the estimated probability with the posterior distribution (green color), and the predictive probability with the posterior‐predictive distribution (gray color) by risk score are delineated in Figure 3. Note that the 95% credible intervals of the predicted probability were wider than the estimated probability because the former has integrated out all relevant parameters according to posterior‐predictive distribution following the Johnson (2004) study. The goodness‐of‐fit test shows a lack of statistical discrepancy between the observed and the predictive probabilities following Equation (2) (X2=3.27, df = 6, p = 0.7734).
Observed, estimated, and predictive probability of post‐COVID‐19 condition (PCC) by risk score using Israel data.
Japanese Omicron BA.5 study
3.2.2
The prevalence of PCC in Japanese external data for Omicron BA.5 was 11.8% (992/8392). Six risk factors including age, sex, body mass index, vaccine status, severity of COVID‐19, and underlying medical conditions in this dataset were applied to the predictive model. Figure 4 shows the observed probability, the estimated probability with the posterior distribution (green color), and the predictive probability with the posterior‐predictive distribution (gray color) by risk score. The result of the goodness‐of‐fit test shows a lack of statistical discrepancy between the observed and the predictive probabilities following Equation (2) (X2=7.16, p = 0.3059).
Observed, estimated, and predictive probability of post‐COVID‐19 condition (PCC) by risk score using Japan data.
The model fitting was further improved if we incorporated the covariates with informative prior coefficients (sex∼Normal(0.44,0.0026), age∼Normal(0.23,0.0113), BMI∼Normal(0.19,0.0028), severeCOVID19∼Normal(0.88,0.0253), novaccine∼Normal(0.57,0.0315), and underlyingmedicalconditions∼Normal(0.4,0.0043)) into the predictive model. With all these informative priors, Figure 5 shows an even better model prediction with a smaller Bayesian statistic of goodness‐of‐fit (X2=5.16, p = 0.5236).
Observed, estimated, and predictive probability of post‐COVID‐19 condition (PCC) by risk score with prior information using Japan data.
DISCUSSION
4
Before the advent of the meta‐analysis, it was very difficult to assess and predict an individual risk for developing PCC partly because each risk factor had been individually reported with small sample size and partly because the results of previous studies are heterogeneous as they have spanned across various SARS‐CoV‐2 variants and regions worldwide. Taking advantage of information derived from a comprehensive meta‐analysis, we proposed a personalized risk assessment model for the risk of PCC using the Bayesian DAG method.
The merits of applying the Bayesian DAG approach to data from the recent well‐conducted meta‐analysis are threefold. First, it is easy to derive a self‐assessed personalized risk score for PCC for each individual given his/her own risk factors. Second, the posterior distribution can be used to estimate an individual's risk for PCC given the currently observed data whereas the predictive distribution can forecast an individual's risk for PCC while the new data provided. Both tackle the uncertainty of an individual's risk for PCC with the 95% posterior and predictive credible intervals. Third, the proposed Bayesian approach is very flexible in accommodating the incorporation of new evidence on PCC in the era of new SARS‐CoV‐2 subvariants such as XBB.1.15 or JN.1 as externally validated in Japanese Omicron BA.5. Finally, the proposed personalized risk score is useful for facilitating optimal individualized medical care for patients with PCC as well as prioritizing the risk groups for early PCC diagnosis using COVID‐19 related biomarker screening (Galán et al., 2022; Lai et al., 2023).
The proposed personalized risk‐score model was also applied to the external datasets from Israel and Japan. The predicted probability of PCC using both Israel and Japan data was well comparable with the one derived from our risk assessment model. As our predictive model was developed based on data before BA.2 Omicron, the risk factors for PCC might have some differences for BA.5 Omicron. It could be argued that the calibration between the observed and predicted probabilities in external data from Japan may be limited to the availability of predictors and the unexplained variation due to the emergence of new variant concerns, such as Omicron BA.5. To improve this weakness, we incorporated the informative prior coefficients to demonstrate the improvement in the calibration between observed and predicted probabilities (X2 reduced from 7.16 to 5.16). Thus, we believe that while the healthcare of long COVID has been neglected, particularly in low‐ and middle‐income countries (Ledford, 2024), our Bayesian risk assessment model may aid health decision‐makers in identifying the high‐risk group and allocating the medical resources for long COVID care.
Using Bayesian DAG random‐effect model has several advantages. Random‐effect analysis accounts for the heterogeneity across studies derived from measured and unobserved factors that are consistent within each study but vary across studies. Leveraging these random effect reduced the random error and enhanced the accuracy of the model. Second, it can also improve the robustness of estimates by combining information across studies, even with limited data in some studies. To elucidate these effects, we examined the effects of risk factors on PCC using the same data with the random‐effect model compared with the fixed‐effect model. The resultant factor coefficients are shown in Table B1. The differences in deviance information criterion (DIC) test across a series of random‐effect modes and the corresponding estimated random effects (τj) incorporating with one‐by‐one covariates are presented in Table B2. The results regarding the effect size of random effects seems robust across forward model selection process. This may suggest that the heterogeneity across studies was consistent once the random effect was considered and relevant significant covariates were captured in the model. However, the fixed‐effect model yielded a DIC (deviance information criterion) of 1173.3, which was higher than the DIC of −14.350 produced by the random‐effect model. These findings have justified the necessity of incorporating the random effect for making allowance for the heterogeneity across studies. Our random‐effect model is robust to the forward model selection varying with different covariates.
As DIC values, when comparing multiple models, provide a relative measure rather than the absolute value a smaller DIC indicates the better model fit. Since the number of studies contributing to each factor varies, we utilized the forward random‐effect model selection, starting from 7 factors and increasing up to 15 factors. The DIC values changed from −10.309 to −30.252 throughout this process. The forward one‐by‐one addition of covariates highlights how each factor contributes to explaining the variability in the outcome (Table B3). Most covariates, except for ischemic heart disease, significantly improved the model. Although the DIC shows slight differences in random‐effect models with different factor loadings, the estimated coefficients for each covariate were still robust.
In the fixed‐effect model, the observed probabilities in the Israel data appear more clustered into two groups (lower and higher risk scores) (Figure C1). The goodness‐of‐fit test revealed a moderate fit compared to the alignment between observed and predicted probabilities in the random‐effect model. An even poorer model fit (X2=38.19, df = 6, p < 0.0001) was observed when the predictive model was built based on the estimates from the fixed‐effect model (Figure C2).
However, the external validation of the Bayesian DAG random‐effect model revealed slight discrepancies between observed and predicted probabilities, particularly at higher risk scores, in both Israeli and Japanese datasets. Beyond the potential influence of evolving viral strains, real‐world data for high‐risk groups typically involve smaller sample sizes, resulting in greater variation and increasing susceptibility to bias, making accurate prediction challenging due to insufficient data.
We attempted to address this issue by applying Bayesian priors derived from meta‐analysis to Japanese data; however, the use of priors still carries one limitation that the unobserved heterogeneity beyond the explanation from covariates inherent from the random effect in the meta‐analysis has been not introduced to priors. For example, we acknowledge that assumptions embedded in prior distributions may not fully capture the rapidly evolving dynamics of COVID‐19 variants and the availability of diverse datasets. This section examines how prior selection influences model performance and suggests that incorporating recent data with adaptable priors could improve predictive accuracy.
While the random‐effect models offer better accuracy than the fixed‐effect models as discussed above, applying the random‐effect model to predicting the risk of PCC for the broader population is of great interest by providing sensitivity analysis based on Tables B1 and B2 for the comparisons between the fixed‐effect models and the random effects. However, although the random‐effect model can throw light on the heterogeneity across studies as demonstrated in Table B2 to give a cue to providing the rationales for uncovering those unexplained heterogeneity, they are still limited to offer new insights into how other specific factors such as the rapid evolution of SARS‐CoV‐2 variants, the measurements of PCC, the repeated infection in the same individual, and the underlying features of healthcare delivery system improve the better accuracy for prediction. Accordingly, the potential limitations of the current model based on meta‐analysis data while applying to external populations should be improved by uncovering new information as related to the heterogeneity across studies as shown in these random‐effect models. Continuous model validation and recalibration using updated datasets like our extension from Israel to Japan are necessary to ensure robustness and generalizability across diverse settings in the world.
In conclusion, given the 148 data records with 15 levels of risk factor from meta‐analysis, we developed a personalized risk assessment model by Bayesian DAG approach for estimating and forecasting the risk of developing PCC. The feasibility of its application to risk stratification would be useful for facilitating optimal individualized medical care for PCC patients.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Antonelli, M. , Pujol, J. C. , Spector, T. D. , Ourselin, S. , & Steves, C. J. (2022). Risk of long COVID associated with delta versus omicron variants of SARS‐Co V‐2. Lancet (London, England), 399(10343), 2263–2264.35717982 10.1016/S 0140-6736(22)00941-2PMC 9212672 · doi ↗ · pubmed ↗
- 2Arjun, M. C. , Singh, A. K. , Pal, D. , Das, K. , G, A. , Venkateshan, M. , Mishra, B. , Patro, B. K. , Mohapatra, P. R. , & Subba, S. H. (2022). Characteristics and predictors of long COVID among diagnosed cases of COVID‐19. P Lo S ONE, 17(12), Article e 0278825.36538532 10.1371/journal.pone.0278825 PMC 9767341 · doi ↗ · pubmed ↗
- 3Berkey, C. S. , Hoaglin, D. C. , Mosteller, F. , & Colditz, G. A. (1995). A random‐effects regression model for meta‐analysis. Statistics in Medicine, 14(4), 395–411.7746979 10.1002/sim.4780140406 · doi ↗ · pubmed ↗
- 4Galán, M. , Vigón, L. , Fuertes, D. , Murciano‐Antón, M. A. , Casado‐Fernández, G. , Domínguez‐Mateos, S. , Mateos, E. , Ramos‐Martín, F. , Planelles, V. , Torres, M. , Rodríguez‐Mora, S. , López‐Huertas, M. R. , & Coiras, M. (2022). Persistent overactive cytotoxic immune response in a Spanish cohort of individuals with long‐COVID: Identification of diagnostic biomarkers. Frontiers in Immunology, 13, Article 848886.35401523 10.3389/fimmu.2022.848886 PMC 8990790 · doi ↗ · pubmed ↗
- 5Glass, G. V. (1976). Primary, secondary, and meta‐analysis of research. Educational Researcher, 5(10), 3–8.
- 6Iba, A. , Hosozawa, M. , Hori, M. , Muto, Y. , Muraki, I. , Masuda, R. , Tamia, N. , & Iso, H. (2024). Prevalence of and risk factors for post‐COVID‐19 condition during Omicron BA.5‐dominant wave, Japan. Emerging Infectious Diseases, 30(7), 1380–1389.38916571 10.3201/eid 3007.231723 PMC 11210664 · doi ↗ · pubmed ↗
- 7Johnson, V. E. (2004). A Bayesian χ2 test for goodness‐of‐fit. Annals of Statistics, 32(6), 2361–2384.
- 8Kuodi, P. , Gorelik, Y. , Zayyad, H. , Wertheim, O. , Wiegler, K. B. , Abu Jabal, K. , Dror, A. A. , Nazzal, S. , Glikman, D. , & Edelstein, M. (2022). Association between BNT 162b 2 vaccination and reported incidence of post‐COVID‐19 symptoms: Cross‐sectional study 2020–21, Israel. NPJ Vaccines, 7(1), Article 101.36028498 10.1038/s 41541-022-00526-5PMC 9411827 · doi ↗ · pubmed ↗