ALERT: A benchmark Bengali dataset for identifying and categorizing religiously aggressive texts
Suhana Binta Rashid, Bibhas Roy Chowdhury Piyas, Sadia Rahman, Bijoy Roy Chowdhury Preenon

TL;DR
This paper introduces ALERT, a Bengali dataset for identifying religiously aggressive texts, aiming to improve detection tools in regional languages.
Contribution
The paper presents ALERT, a new benchmark Bengali dataset for classifying religiously aggressive content.
Findings
ALERT contains 4027 annotated Bengali instances across four aggression categories.
The dataset achieved a Cohen’s kappa score of 72%, indicating strong inter-annotator agreement.
Experiments with machine learning and transformer models showed promising classification results.
Abstract
The widespread proliferation of religiously aggressive contents on social media platforms poses significant threats to societal harmony and communal solidarity. It often incites religious animosity, provokes violence and disseminates life-threatening messages that intensifies societal divisions and undermines social harmony. Despite significant advancements in identifying such contents in high-resource languages like English, there exists a notable scarcity of resources for regional languages like Bengali which constrains the development of effective detection and prevention tools. To address this gap, we introduce ALERT (Analysis of Linguistic Extremism in Religious Texts), a newly developed Bengali dataset along with English translation which includes 4027 annotated instances classified into four categories: hate speech (995), vandalism (909), atrocity (1117), and no aggression…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
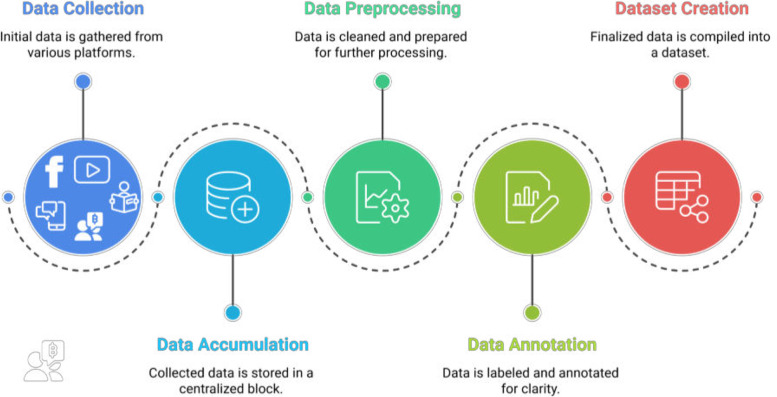 Figure 1
Figure 1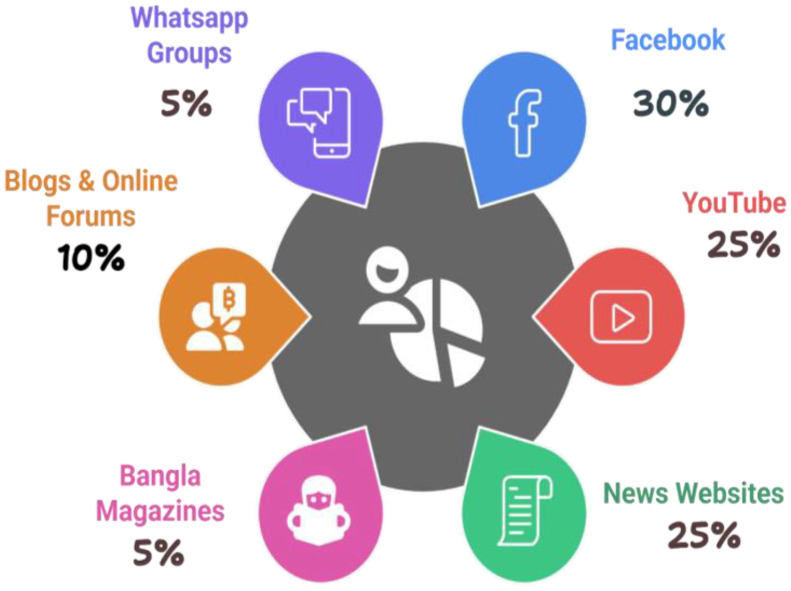 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4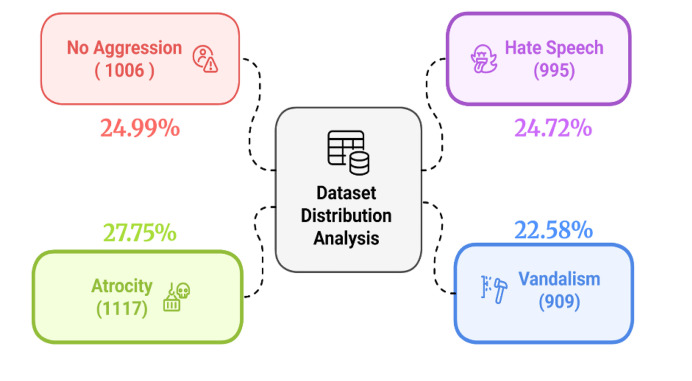 Figure 5
Figure 5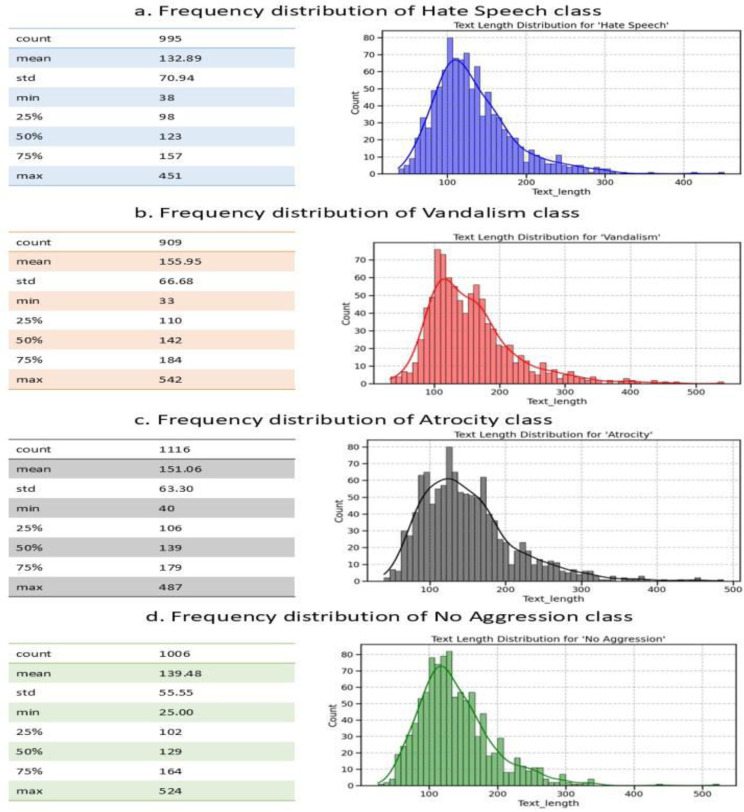 Figure 6
Figure 6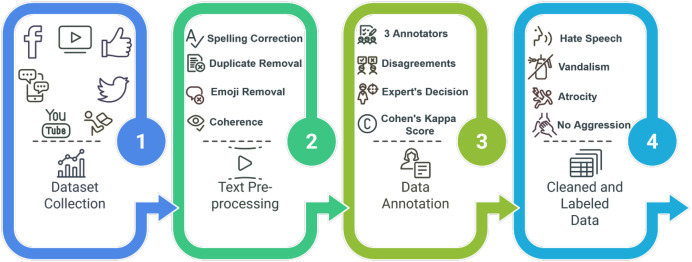 Figure 7
Figure 7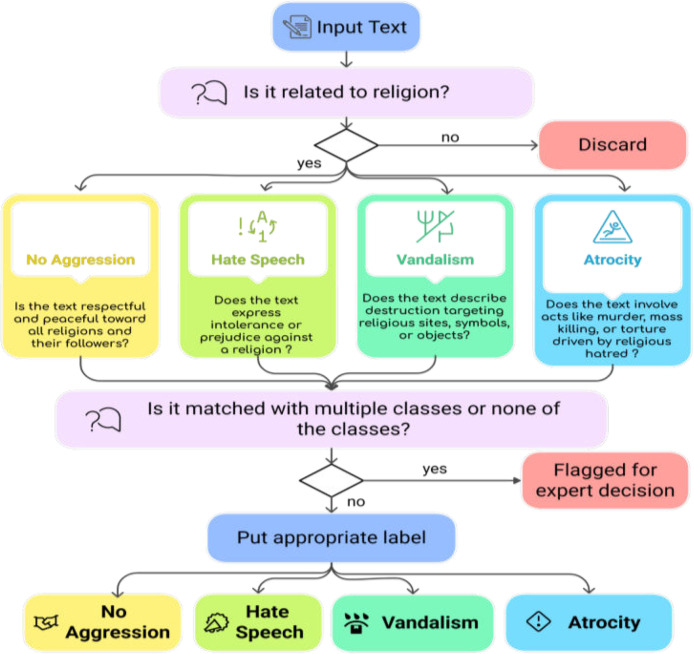 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHate Speech and Cyberbullying Detection
Specifications TableSubjectComputer ScienceSpecific subject areaMachine Learning, Natural Language Processing, Bengali Text Classification, Bengali Religious Aggression DetectionType of data*Text Files (xlsx-formatted)Data collectionOur developed dataset contains 4027 instances collected from multiple online platforms, such as Facebook, YouTube, news websites, Bangla blogs, online forums and group conversations. Each instance was classified into one of four categories: hate speech (995), vandalism (909), atrocity (1117), and no aggression (1006). Each of the instances in the dataset was annotated by any two annotators from the list of four with varied academic, religious, and racial backgrounds. Any conflict was resolved by a subject matter expert to guarantee consistency. To augment reliability, native Bengali speakers meticulously examined the dataset that made it a valuable asset to Bengali NLP research.Data source locationThe texts were gathered from a variety of online sources, such as Facebook, YouTube, news websites, Bangla blogs, online forums and group conversations.*Data accessibilityRepository name: Mendeley DataData identification number: 10.17632/f4xz5d4fzd.1Direct URL to data: https://data.mendeley.com/datasets/f4xz5d4fzd/1Related research articleNone
Value of the Data
1
- •This is the first publicly accessible dataset in the low-resource language Bengali that addresses various levels of religious aggression in texts, including hate speech, vandalism, atrocity, and no-aggression that aims to prevent the proliferation of religiously aggressive contents on social media.
- •The dataset was collected from prevalent online platforms like Facebook, YouTube, news websites, Bengali blogs, online forums, and group conversations that encapsulates real-world linguistic, cultural, religious, and emotional variations which made it rich and diverse in the context of religious hostility.
- •It aids the development of robust and context-aware models to identify religiously detrimental contents by utilising the complex patterns of religious aggression present in the dataset which can enhance digital safety through development of superior content moderation tools.
- •The dataset sets a benchmark for detecting religious aggression in Bengali texts that can enhance online safety and mitigate societal conflict. Moreover, it encourages linguists and language researchers to explore further research in this area.
Background
2
While recent research has explored various forms of aggression across multiple languages, a notable gap remains in datasets that specifically address the severity levels of religious aggression. Rashid et al. [1] introduced the Bangla Aggressive Dataset (BAD) from social media texts and annotated with both binary (aggressive/non-aggressive) and multiclass labels (religious, political, verbal and gendered). In a related area [2], proposed a multimodal dataset addressing misogynistic content in memes classified as misogynistic or non-misogynistic. Study [3] presented a dataset with annotated tweets in mixed Wolof-French for detecting abusive messages. Study [4] developed an English-language dataset for hate speech detection, while [5] contributed with the HS-BAN dataset for binary hate speech classification in Bengali. Das et al. [6] further expanded on hate categorization with a dataset curated from Bengali social media comments across seven categories of hate speech [7]. focused on cyberbullying detection in Bengali using data from various platforms. Addressing visual context [8], developed a multimodal dataset combining symbolic images with text and annotated into non-aggressive, medium, and highly aggressive classes. Lastly [9], introduced a dataset for political aggression in Bengali texts with binary and multiclass classification. Hence, there remains a gap in datasets to address religious aggression.
Data Description
3
Religion significantly influences societies, identities and social systems. Currently, social media platforms such as Facebook, YouTube, and Twitter serve as common platforms for discussion on religion that enable individuals to rapidly communicate their perspectives on worldwide incidents. With the increasing number of social media users, religious debates frequently arise. Conflicting perspectives can often lead to enmity, hatred, violence that damages the unity of society. This shows the necessity of monitoring online interactions to detect harmful activity and mitigate tensions among various groups.
This study introduces the ALERT(Analysis of Linguistic Extremism in Religious Text) dataset, a Bengali corpus focused on religiously aggressive texts. We put together a diverse dataset that reflects different levels of religious aggression, each showing its own unique language patterns. To make things clear, we carefully defined each category to facilitate accurate understanding and annotation.
- 1.Hate Speech: Text that expresses intolerance, prejudice, hostility, or discriminatory attitudes against a religion, its symbols, practices, or followers. This includes derogatory remarks, stereotyping, incitement of animosity, or any language promoting religious bias.
- 2.Vandalism: Text describing acts of intentional damage, destruction, defacement, or desecration of religious property, sites, symbols, or objects motivated by religious hostility or hatred. This includes attacks on temples, mosques, churches, statues, scriptures, or other religious artifacts.
- 3.Atrocity: Text describing severe and cruel acts of violence or oppression motivated by religious hatred or targeting religious groups. Examples include murder, torture, mass killings, death, or other forms of large-scale violent persecution explicitly linked to religious motives.
- 4.Non-Aggressive: Text that is respectful, peaceful, and promotes harmony toward all religions, their symbols, practices, and followers. It contains no hostility, intolerance, prejudice, or derogatory language related to any religion or religious group.
We created the ALERT dataset using established data development methods presented in Fig. 1.Fig. 1. Data collection to dataset creation workflow.Fig 1
In this section, we discuss data acquisition, the annotation procedure, calculation of annotation agreement, and dataset analysis to provide deeper insights into our developed 'ALERT' dataset.
Dataset acquisition
3.1
The dataset employed in this research was gathered from several online platforms, including Facebook, YouTube, news websites, blogs and online news websites. We excluded Twitter due to its limited availability of Bengali content. Recent social media data indicate that 30.4 % of social media users in Bangladesh actively use Facebook, whereas 19.3 % connected with YouTube. Thus, a significant portion of the dataset samples was obtained from these two platforms, as they have the highest concentration of Bengali social media users. A focused methodology was employed to identify religiously aggressive contents by paying special attention on social media posts, comments, and replies. Verified social media accounts associated with religious scholars, their supporters, and opposing groups were closely monitored due to their influential role in shaping public opinion. Furthermore, notable occurrences of assaults on religious minorities and disputed events during religious festivals were meticulously examined to identify aggressive content. Content for non-aggressive text data was sourced from Facebook and YouTube posts and comments, in addition to news websites, blogs and discussion forums. This included materials shared by religious institutions, scholars and community groups from both majority and minority communities. Only conversation threads with at least 200 reactions were considered relevant and engaging. Fig. 2 illustrates the sources of data, while Table 1 presents the overall status of the data collection sources.Fig. 2. Data collection sources.Fig 2. Table 1Statistical information about the data collection source.Table 1. NameFacebookOnline News PortalYouTubeBangla MagazinesOnline BlogsWhatsApp GroupAffiliationSocial MediaNews PlatformVideo PlatformDigital PublicationDigital contentMessaging PlatformPopularity2.8 B1.5 M2. 3 B200,000500,000Varies (depends on group size)Activity50–100 posts/day20–30 posts/day500 videos/day3–5 posts/day10–15 posts/dayFrequent (varies per group)
Dataset visualization
3.2
To visualize a text dataset, word cloud is crucial for highlighting the most frequent words in each class that can offer valuable insights into the linguistic patterns within the dataset. Additionally, identifying the top words that significantly contribute to classifying an instance can serve as an effective metric for data visualization. Fig. 3, Fig. 4 illustrate word clouds representing the 200 most frequent words from each class in the Bengali and English-translated datasets respectively, while Table 2 presents the most significant words from each of the classes.Fig. 3. Word clouds for different Aggression classes using Bengali dataset.Fig 3. Fig. 4Word clouds for different aggression classes using the English-translated dataset.Fig 4. Table 2Top words with English meanings for each class.Table 2
A few instances from the ALERT dataset with their final annotations are presented in Table 3.Table 3. Sample text entries with their respective categories in ALERT dataset.Table 3
Dataset analysis
3.3
Fig. 5 presents the dataset distribution that shows the number of instances in each class along with their corresponding percentages within the overall dataset. A detailed statistical analysis of the dataset shown in Table 4 that reveals key insights for model development. The lexical analysis shows clear variations in word count and diversity across categories. Atrocity has the highest total word count (26,111) and highest average text length (23.38), while Hate speech has the lowest. No aggression is typically found in medium-length texts, suggesting that religiously provocative content tends to be either too short or too long. On the other hand, atrocity texts are generally more detailed, as they often convey statistical information such as the number of deaths and losses. These findings indicate that the volume of text individuals write may fluctuate based on the nature of hostility in the communication.Fig. 5. Analysis of dataset distribution with sample counts.Fig 5. Table 4Summary of text statistics across different classes.Table 4. Class NameTotal wordsMTL (words)ANW (per text)Unique wordsANUW (per text)Hate Speech20,6296620.73638519.74Vandalism21,1508523.27605822.14Atrocity26,1117323.38542222.49No Aggression22,1508822.02664420.66MTL = Maximum Text Length, ANW = Average Number of Words per Text, ANUW = Average Number of Unique Words per Text.
In Table 5, the Jaccard similarity analysis reveals the highest similarity (0.23) between the Vandalism and Atrocity categories, while the lowest similarity (0.16) is found between No Aggression and Vandalism.Table 5. Jaccard similarity value for each class.Table 5. Class NameHate SpeechVandalismAtrocityNo-AggressionHate Speech-0.190.180.21Vandalism--0.230.16Atrocity---0.17No Aggression----
Fig. 6 shows the frequency distribution of text lengths across the four classes in the dataset. The Hate Speech class includes 995 instances with an average length of 132.89 characters where most of the texts fall between 98 and 157 characters, with a maximum of 451. The Vandalism class, consisting of 909 samples, has the highest average length at 155.95 characters and displays a broader distribution with lengths ranging from 33 to 542 characters. The Atrocity class is the largest, with 1116 instances and an average length of 151.06 characters, reaching up to 451 characters. In contrast, the No Aggression class contains 1006 samples and shows the shortest mean length of 139.48 characters along with the lowest standard deviation 55.55 which indicates more consistent and tightly clustered text lengths compared to the other categories.Fig. 6. Text length distribution for Hate Speech, Vandalism, Atrocity and No Aggression classes.Fig 6
While recent research has explored various forms of aggression across multiple languages, to the best of our knowledge, no existing dataset specifically addresses the varying severity levels of religious aggression. However, in the broader domain of aggression detection and related areas including political aggression, misogynistic aggression, hate speech and toxic content, numerous datasets have been developed over the years. Table 6 presents a comparative analysis of these existing datasets with ours to highlight both the contextual similarities and differences between our developed dataset and prior work.Table 6. Comparison with existing work.Table 6. RefDataset NameContextLabel TypeLanguageVolumeYear[1]BADAggression DetectionBinary and MulticlassBangla14,1582022[2]–Misogynistic content detectionBinaryEnglish8002022[3]AWOFROAbusive text detectionBinaryWolof & French35002025[4]–Hate Speech DetectionBinaryEnglish451,7092023[5]HS-BANHate Speech DetectionBinaryBangla50,0002021[6]–Hate Speech DetectionMulticlassBangla56002021[7]–Cyberbullying DetectionMulticlassBangla12,2822024[8]MMHS150KAggression DetectionMulticlassBangla74252021[9]–Political Aggression DetectionBinary & MulticlassBangla30562023ProposedALERTReligious Aggression DetectionMulticlassBangla4027–
Experimental Design, Materials and Methods
4
This section describes the overall experimental design, including the methods used for data collection, preprocessing and annotation in the development of the dataset. Fig. 7 presents the structured workflow of the dataset generation process, showing each stage from initial data collection to the final labeling phase.Fig. 7. Workflow diagram of dataset generation process.Fig 7
Preprocessing
4.1
Raw datasets frequently contain inconsistencies that may hinder effective model training. To guarantee the quality and reliability of the ALERT dataset, multiple preprocessing steps were implemented following data collection. This included spelling correction, emoji removal, redundancy removal and the assurance of sentence coherence. English words and unnecessary symbols were removed from dataset to reduce data complexity. English words that do not relate to religious aggression and only introduce noise were removed, while words directly connected to religious aggression were kept in the dataset. Additionally, some words were anonymized to mitigate sensitivity and maintain the dataset's integrity. To maintain coherence, we organized the words logically and used consistent terminology throughout the text.
Data annotation
4.2
Each data instance was subsequently annotated by two annotators chosen from a pool of four based on their availability and workload distribution, with disagreements resolved by a domain expert. To mitigate bias, annotators were selected from diverse academic, gender, religious, and ethnic backgrounds. To mitigate inconsistencies during the annotation process, all annotators were provided with annotation guidelines, as shown in Fig. 3, to label instances based on specific questions. Additionally, before starting the annotation, each annotator was given a set of example instances along with explanations behind the labels which helped make the process smoother. Fig. 8 illustrates the structured workflow of the dataset generation process demonstrating each stage from initial data collection to the final labelling phase.Fig. 8. Dataset annotation criteria.Fig 8
Annotation procedure
4.3
To address potential biases, annotators with diverse academic, cultural, racial and religious backgrounds were selected. The manual annotation was performed by five native Bengali speakers and their details summarized in Table 7.Table 7. Information of annotators.Table 7. Academic LevelArea of StudyResearch ExperienceAgeGenderReligionTargeted by ORAAn-1UndergraduateNLP223FemaleIslamYesAn-2GraduateNLP225MaleIslamNoAn-3GraduateNLP2.525FemaleHinduYesAn-4Graduate RANLP327MaleHinduYesExpertAssistant ProfessorNLP, Cybersecurity933MaleIslamNoAn = Annotator, ORA = Online Religious Aggression.
To ensure accurate annotation, it is essential to establish explicit annotation criteria as individuals' ways of thinking may differ. Annotators must consider specific guiding questions to correctly assign a class to each instance. Without well-defined criteria, ambiguity and inconsistency may arise that can lead to unreliable results. A well-defined annotation criterion that we followed is illustrated in Fig. 8.
In this dataset each of the instances was annotated by any two annotators selected from a list of four, with conflicts resolved through domain expert judgement. Instances with unclear messages or overlaps are assigned for additional discussion with domain expert. Algorithm 1 shows the overall annotation guidelines to prepare the dataset.Algorithm 1Step-by-step process for data annotation.Algorithm 1Input: Set of texts without labelsOutput: Annotated Religious aggression text 1. T ← {t_1_, t_2_, …, t_n_} (set of accumulated texts) 2. RA ← [] (Religious aggression text dataset) 3. D_disagree ← [] (Separate list for texts with annotator disagreement) 4. for t_i_ ∈ T do 5. l_1_ ← Annotator 1 assigns label to t_i_ 6. l_2_ ← Annotator 2 assigns label to t_i_ 7. if l_1_ == flag and l_2_ == flag then 8. Discard text 9. else if l_1_ == l_2_ then 10. RA.append(t_i_, l_1_) 11. else 12. D_disagree.append(t_i_) 13. end if 14. i ← i + 1 15. end for 16. for d_j_ ∈ D_disagree do 17. 1. Expert discuss with annotators: 18. 2. Either add d_j_ to 'RA' with final annotation or discard it; 19. j ← j + 1 20. end for
Calculation of annotators agreement
4.4
- a)The 'ALERT' dataset was analysed and annotated by two independent annotators and any disagreements between them during the annotation process were resolved by a domain expert. To assess the level of agreement, we calculated Cohen’s kappa coefficient, as outlined in Eq. (1).
- b)Here, P_o_ denotes the actual level of agreement observed among annotators, whereas P_e_ indicates the expected agreement that might occur by chance. Table 8 presents the kappa scores, with the highest agreement (0.82) for the Atrocity category and the lowest (0.61) for Hate Speech. Overall, the average kappa score of 0.72 reflects strong consistency between annotators.Table 8. Cohen's Kappa value for each class.Table 8. Class NameKappa ScoreMean ScoreHate Speech0.610.72Vandalism0.76Atrocity0.82No Aggression0.71
Examples of annotation agreements and disagreements
4.5
- a)Table 9 presents few instances where two annotators provided differing opinions, which were further discussed with a domain expert to resolve the conflicts and finalize the annotations.Table 9. Example texts with annotator disagreements and expert remarks.Table 9
Ablation study
4.6
To ensure that the preprocessing decisions applied during dataset construction were well-justified rather than arbitrary, we conducted a small ablation analysis. Specifically, we examined the impact of modifying certain preprocessing steps on the dataset’s characteristics. Key operations included the removal of emojis, special characters, English tokens as well as the anonymization of user mentions and named entities. We observed that removing unnecessary English tokens reduced the proportion of code-mixed text, while the removal of emojis and special characters lowered noise and reduced the overall vocabulary size. Anonymization, in turn, sharply decreased the occurrence of identifiable names, ensuring privacy protection. Alongside descriptive statistics, we also trained a lightweight baseline model on both the raw and pre-processed datasets to illustrate the effects of these steps. The results confirmed that removing unnecessary characters, emojis, and English words produced a cleaner dataset, while anonymization effectively safeguarded data privacy with negligible impact on dataset utility.
Limitations
The ALERT dataset offers valuable insights though it is not without certain limitations. The dataset can be enhanced by incorporating a broader range of aggression types. Also, more complex forms of expressions like mixed aggression and paradoxical sentiments can be incorporated to ensure the robustness of the dataset. Moreover, the use of mixed-code language, such as Bengali-English and language switching, is increasingly common in everyday conversation. The enhanced version of the dataset will account for this by incorporating more such sentences.
Ethics Statement
The ALERT dataset has been developed on ethical data collection principles. All content was cautiously obtained from publicly accessible sources, including blogs, Facebook pages, news websites and blogs. To mitigate the possibility of copyright infringement, strict selection procedures were carried out to guarantee the inclusion of only copyright-free material. The dataset adheres to responsible use principles, emphasising the safeguarding of individual rights and the prevention of harm. Given the sensitive nature of the topic, significant care was taken to avoid targeting or harming any particular country, religion, or community. To ensure fairness and neutrality, the dataset was independently reviewed by a group of volunteers who assessed the content for potential bias or harm. Our primary goal is to support the development of content moderation tools aimed at reducing religious aggression online. This work is not intended to criticize or demean any religion or belief system. Data obtained from Facebook sites adhered to Facebook's content restrictions, negating the necessity for further authorisation. We would also like to express our sincere gratitude to the volunteers who reviewed the dataset to help mitigate potential bias, harm, and inconsistencies.
Credit Author Statement
Suhana Binta Rashid: Conceptualization, Data curation, Methodology, Software, Writing – original draft, Visualization. Bibhas Roy Chowdhury Piyas: Conceptualization, Data curation, Methodology, Software, Visualization, Writing – review & editing. Sadia Rahman: Data curation, Investigation, Validation, Writing – review & editing. Bijoy Roy Chowdhury Preenon: Data curation, Validation, Writing – review & editing.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Rashid M.M.O.Tox Lex_bn: a curated dataset of bangla toxic language derived from Facebook comment Data Br.43202210841610.1016/j.dib.2022.108416 PMC 925654335811647 · doi ↗ · pubmed ↗
- 2Gasparini F.Benchmark dataset of memes with text transcriptions for automatic detection of multi-modal misogynistic content Data Br.44202210852610.1016/j.dib.2022.108526 PMC 947136636117643 · doi ↗ · pubmed ↗
- 3Ndao I.Annotated tweet data of mixed Wolof-French for detecting obnoxious messages Data Br.60202511150010.1016/j.dib.2025.111500 PMC 1200282440242030 · doi ↗ · pubmed ↗
- 4Mody D.Huang Y.Alves De Oliveira T.E.A curated dataset for hate speech detection on social media text Data Br.46202310883210.1016/j.dib.2022.108832 PMC 980781536605500 · doi ↗ · pubmed ↗
- 5N. Romim, et al. ``HS-BAN: a benchmark dataset of social media comments for hate speech detection in bangla.'' ar Xiv preprint ar Xiv:2112.01902 (2021).
- 6Das A.K.Bangla hate speech detection on social media using attention-based recurrent neural network J. Intell. Syst.30.12021578591
- 7S.S. Nath, K. Razuan and Mahdi H. Miraz. ``Deep learning based cyberbullying detection in bangla language.'' ar Xiv preprint ar Xiv:2401.06787 (2024).
- 8Kumari K.Multi-modal aggression identification using convolutional neural network and binary particle swarm optimization Future Gener. Comput. Syst.1182021187197