The generalized Hausman test for detecting non‐normality in the latent variable distribution of the two‐parameter IRT model
Lucia Guastadisegni, Silvia Cagnone, Irini Moustaki, Vassilis Vasdekis

TL;DR
The paper introduces a new statistical test to detect non-normality in latent variable distributions used in binary data models.
Contribution
The generalized Hausman test is proposed as a novel method for detecting non-normality in latent variable distributions.
Findings
The generalized Hausman test outperforms other tests in detecting non-normality under most conditions.
Simulation results show the test's effectiveness compared to existing methods and goodness-of-fit statistics.
Information criteria results were contradictory in some cases, indicating a need for further study.
Abstract
This paper introduces the generalized Hausman test as a novel method for detecting the non‐normality of the latent variable distribution of the unidimensional latent trait model for binary data. The test utilizes the pairwise maximum likelihood estimator for the parameters of the latent trait model, which assumes normality of the latent variable, and the maximum likelihood estimator obtained under a semi‐non‐parametric framework, allowing for a more flexible distribution of the latent variable. The performance of the generalized Hausman test is evaluated through a simulation study and compared with other test statistics available in the literature for testing latent variable distribution fit and an overall goodness‐of‐fit test statistic. Additionally, three information criteria are used to select the best‐fitted model. The simulation results show that the generalized Hausman test…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
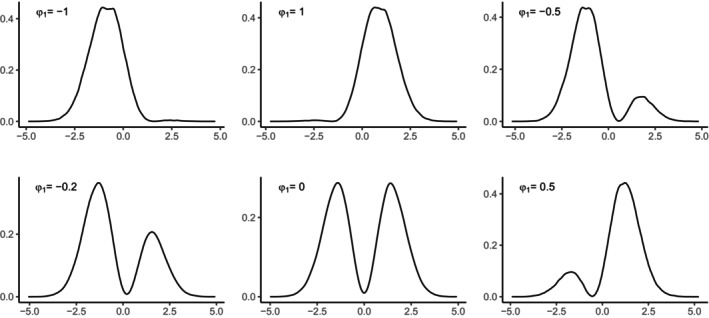 FIGURE 1
FIGURE 1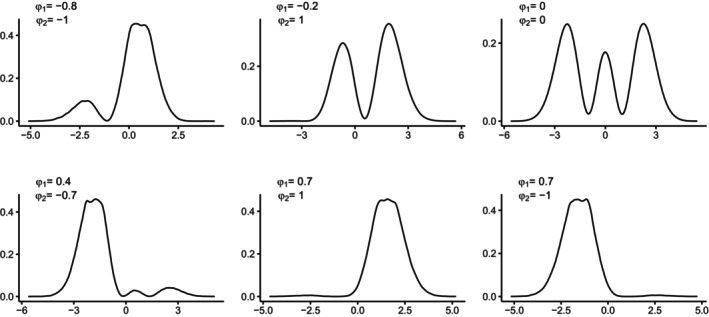 FIGURE 2
FIGURE 2| 10 | 500 |
| .066 |
|
| .002 | .012 | 0 | .006 |
| 1000 | .044 | .046 |
| .038 | .006 | .01 | 0 | .014 | |
| 5000 | .056 | .04 | .042 | .052 | .02 | .002 | 0 | .012 | |
| 20 | 500 |
| .036 |
| .056 | .008 | 0 | 0 | .01 |
| 1000 | .042 | .054 | .054 | .06 | .008 | .006 | 0 | .012 | |
| 5000 | .042 | .05 |
| .052 | .01 | .016 |
| .018 | |
| AIC (%) | BIC (%) | HQ (%) | ||
|---|---|---|---|---|
| 10 | 500 | 97 | 100 | 99.8 |
| 1000 | 93.2 | 100 | 98.8 | |
| 5000 | 90.6 | 100 | 96.6 | |
| 20 | 500 | 87.8 | 99.8 | 99.2 |
| 1000 | 78.4 | 100 | 94.6 | |
| 5000 | 54.4 | 97 | 78.4 |
| SC | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| B | 10 | 500 | .612 | .03 | .572 | .508 | .536 | .004 | .462 | .282 |
| 1000 | .868 | .028 | .792 | .866 | .796 | .006 | .558 | .672 | ||
| 5000 | 1 | .052 | .936 | 1 | 1 | .014 | .93 | 1 | ||
| 20 | 500 | .886 | .022 | .596 | .728 | .76 | .006 | .428 | .472 | |
| 1000 | .984 | .036 | .63 | .984 | .96 | .002 | .60 | .928 | ||
| 5000 | .996 | .034 | .678 | 1 | .996 | .004 | .666 | 1 | ||
| C | 10 | 500 | .924 | .01 | .912 | .992 | .852 | .002 | .8 | .976 |
| 1000 | .998 | .006 | .968 | 1 | .994 | 0 | .96 | 1 | ||
| 5000 | 1 | .028 | .972 | 1 | 1 | .004 | .972 | 1 | ||
| 20 | 500 | .988 | 0 | .782 | 1 | .95 | 0 | .72 | 1 | |
| 1000 | .996 | 0 | .822 | 1 | .994 | 0 | .756 | 1 | ||
| 5000 | .998 | .004 | .922 | 1 | .998 | 0 | .892 | 1 | ||
| SC | AIC (%) | BIC (%) | HQ (%) | ||
|---|---|---|---|---|---|
| B | 10 | 500 | 75.6 | 47.6 | 58.8 |
| 1000 | 85.2 | 55.4 | 78.8 | ||
| 5000 | 94 | 93 | 93.4 | ||
| 20 | 500 | 66.2 | 47 | 60.2 | |
| 1000 | 65.2 | 60 | 63 | ||
| 5000 | 70 | 65.4 | 67.6 | ||
| C | 10 | 500 | 95.6 | 80.6 | 91.8 |
| 1000 | 97 | 95.6 | 96.8 | ||
| 5000 | 97.6 | 97.2 | 97.2 | ||
| 20 | 500 | 85.8 | 73 | 79.4 | |
| 1000 | 87.6 | 75.4 | 82 | ||
| 5000 | 95 | 87.2 | 92 |
| SC | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D | 10 | 500 | .554 | .374 | .492 | .7 | .024 | .39 | .416 | .27 | .338 | .462 | .004 | .186 |
| 1000 | .764 | .588 | .722 | .956 | .028 | .742 | .636 | .264 | .608 | .85 | .008 | .504 | ||
| 20 | 500 | .786 | .358 | .89 | .972 | .026 | .69 | .576 | .196 | .762 | .876 | .008 | .484 | |
| 1000 | .962 | .38 | .992 | 1 | .02 | .972 | .924 | .348 | .972 | 1 | .002 | .898 | ||
| E | 10 | 500 | .588 | .43 | .562 | .818 | .028 | .548 | .458 | .334 | .404 | .62 | .01 | .282 |
| 1000 | .894 | .736 | .814 | .98 | .036 | .844 | .834 | .448 | .688 | .92 | .014 | .688 | ||
| 20 | 500 | .874 | .45 | .916 | .99 | .022 | .808 | .71 | .282 | .836 | .946 | .006 | .626 | |
| 1000 | .986 | .474 | 1 | 1 | .026 | .996 | .948 | .458 | .998 | 1 | .026 | .996 | ||
| SC | over | over | ||||||
|---|---|---|---|---|---|---|---|---|
| AIC (%) | BIC (%) | HQ (%) | AIC (%) | BIC (%) | HQ (%) | |||
| D | 10 | 500 | 58.4 | 28.4 | 39 | 87 | 26.2 | 60.4 |
| 1000 | 70.4 | 24.4 | 58.4 | 99 | 61.8 | 90 | ||
| 20 | 500 | 44.8 | 22 | 36.6 | 98.8 | 75.4 | 94 | |
| 1000 | 41.4 | 34.6 | 38 | 100 | 98.2 | 100 | ||
| E | 10 | 500 | 64.6 | 34.4 | 44.2 | 91.6 | 42.2 | 72.6 |
| 1000 | 81.2 | 44 | 73.2 | 99 | 76 | 95 | ||
| 20 | 500 | 51.2 | 31 | 45.2 | 99.6 | 84.4 | 97.8 | |
| 1000 | 49.6 | 45.6 | 47.4 | 100 | 99.6 | 100 | ||
| AIC | BIC | HQ | |
|---|---|---|---|
| 18,239.49 | 18,517.84 | 18,348.08 | |
| 18,199.7 | 18,482.39 | 18,309.98 |
| Test | Value | dof | ‐value |
|---|---|---|---|
| 675.53 | 464 | <.001 | |
| 41.79 | 1 | <.001 | |
| 40.775 | 6.80 | <.001 | |
| 172.8 | 30 | <.001 | |
| 7.59 | – | <.001/31 |
| Item | Question |
|---|---|
| 1 | In your neighbourhood, before you were 10 |
| do you remember seeing homeless people on the street? | |
| 2 | Prostitutes on street? |
| 3 | Gang members hanging out on the street? |
| 4 | Drug paraphernalia on the street? |
| 5 | People selling illegal drugs in public? |
| 6 | People using illegal drugs in public? |
| 7 | People drinking or drunk in public? |
| 8 | Physical violence in public? |
| 9 | Hearing the sound of gunshots? |
| 10 | In your grade school, did you see students fighting? |
| 11 | Students smoking? |
| 12 | Students cutting class? |
| 13 | Students cutting school? |
| 14 | Students verbally abusing teachers? |
| 15 | Did you see physical violence directed at teachers by students? |
| 16 | Vandalism of school or personal property? |
| 17 | Theft of school or personal property? |
| 18 | Students consuming alcohol? |
| 19 | Students taking illegal drugs? |
| 20 | Students carrying knives as weapons? |
| 21 | Students with guns? |
| AIC | BIC | HQ | |
|---|---|---|---|
| 21,309.32 | 21,422.12 | 21,349.36 | |
| 21,303.67 | 21,422.73 | 21,345.93 |
| Test | Value | dof | ‐value |
|---|---|---|---|
| 182.33 | 27 | 0 | |
| 7.66 | 1 | .006 | |
| 222.92 | 2.65 | 0 | |
| 11.8 | 7 | .106 |
| AIC | BIC | HQ | |
|---|---|---|---|
| 30,322.3 | 30,472.5 | 30,375.64 | |
| 30,219.13 | 30,375.59 | 30,274.69 |
| Test | Value | dof | ‐value |
|---|---|---|---|
| 979.39 | 54 | <.001 | |
| 105.17 | 1 | <.001 | |
| 127.69 | 2.53 | <.001 | |
| 68.4 | 10 | <.001 |
- —European Union‐NextGenerationEU, GRINS‐Growing Resilient, INclusive and Sustainable project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Advanced Statistical Methods and Models · Statistical Methods and Bayesian Inference
INTRODUCTION
1
This paper proposes a generalized Hausman‐type test for detecting deviation of the latent variable distribution from normality in the unidimensional latent trait model, also known as the two‐parameter model (2PL) in item response theory (IRT) (see e.g. van der Linden & Hambleton, 2013). The paper focuses on a mixture of normals and skew‐normal latent distributions.
Latent variable or trait models are used to study theoretical constructs, such as abilities, attitudes, quality of life or business confidence, which cannot be directly observed and measured. Latent variables are here continuous variables measured through correlated categorical indicators known as manifest variables or items (Bartholomew et al., 2011). This paper considers the two‐parameter latent trait model for binary manifest variables (2PL).
One of the standard assumptions of IRT models is that the latent variable(s) follows a normal distribution. However, assuming normality of the latent variable(s) when the actual distribution has a different shape can lead to biased parameter estimates, especially with binary outcomes (Ma & Genton, 2010). Furthermore, assuming an incorrect distribution of the latent variable can lead to erroneous conclusions when conducting hypothesis testing (Guastadisegni et al., 2022).
The need to accommodate more flexible latent variable distributions has been recognized in the literature. Montanari and Viroli (2010) introduced a skew‐normal latent variable in the classical factor analysis model, while Cagnone and Viroli (2012) presented a latent trait model where the factors are distributed as a finite mixture of multivariate Gaussians. Within the generalized linear latent variable model (GLLVM) framework (see e.g. Bartholomew et al., 2011; Skrondal & Rabe‐Hesketh, 2004), Ma and Genton (2010) proposed a semi‐parametric method, consistent for various types of manifest variables under different distributions of the latent variables, and Irincheeva et al. (2012) considered the semi‐non‐parametric (SNP) approach, introduced by Gallant and Nychka (1987). This approach allows for more flexible smooth densities of the latent variables. The SNP method has also been used in the unidimensional 2PL model by Woods and Lin (2009) and in the multidimensional 2PL model by Monroe (2014). For the 2PL model, Bock and Aitkin (1981) modelled the density of the latent variable using an empirical histogram instead of assuming a specific parametric form. They estimated the density together with the item parameters within an expectation‐maximization (E‐M) algorithm. The density of the latent variable was estimated directly at each quadrature point, rather than being derived from a predefined normal probability distribution. Woods and Thissen (2006) proposed a non‐parametric estimation of the latent variable while maintaining the logistic item response function (IRF). They modelled the latent variable through a Ramsey curve, which is a spline‐based density (Ramsay, 2000).
In the majority of cases, information criteria, such as the Akaike information criterion (AIC) (Akaike, 1974) or the Bayesian information criterion (BIC) (Schwarz, 1978), are used to choose between a model where the latent variables are normally distributed and a model where the latent variables have a more complex shape (Woods & Lin, 2009; Irincheeva et al., 2012; Monroe, 2014). With continuous manifest variables, Ma and Genton (2010) perform the Kolmogorov–Smirnov test on the continuous responses' distribution to evaluate the latent variable's normality.
When dealing with categorical responses, Li and Cai (2018) suggested employing summed score likelihood‐based statistics to test the fit of the latent variable distribution. They proposed two versions of the test: an unadjusted version, X¯2, and a moment‐adjusted version (Satorra & Saris, 1985). Similarly, Monroe (2021) introduced an alternative test statistic, denoted here by R(z), for detecting non‐normality in the latent variable distribution across the range of z. It is based on generalized residuals (Haberman & Sinharay, 2013), which compare the specified latent variable distribution to the sample average of latent variable posterior distributions, asymptotically distributed as standard normal. The paper also proposed a version to test the hypothesis that the distribution of the latent variable as a whole is correctly specified in the model denoted here as RB. A Bonferroni correction was applied to the critical value. The statistics proposed by Li and Cai (2018) and Monroe (2021) demonstrate high power when the latent variable is skewed or platykurtic and are insensitive to multidimensionality.
Hausman (1978) proposed a specification test to detect the failure of the orthogonality assumption in regression analysis. Due to its simplicity, the Hausman test can be applied in various contexts to detect different types of model misspecification. This test compares two different estimators that are consistent when the model is correctly specified, and one is also efficient. In the presence of model misspecification, only the inefficient estimator is consistent. The efficiency assumption simplifies the covariance matrix computation of the difference between the two estimators. However, this matrix can fail to be positive definite under model misspecification or in small sample sizes. Moreover, neither of the two estimators is considered fully efficient in some cases.
The generalized version of the Hausman (GH) test, proposed by White (1982), is a more flexible and robust alternative to the original Hausman test. Indeed, the generalized version allows both estimators to be inefficient and obtained from two different models. Moreover, the covariance matrix of the difference between the two estimators is robust and always positive definite.
In the IRT context, as far as we know, the Hausman test has been used only by Ranger and Much (2020) to detect misspecification of the item characteristic functions and local dependencies among items. They highlight that this test performs well regarding Type I error rates for large sample sizes and power under most conditions. In generalized linear mixed models (GLMM) for clustered data, a robust version of the Hausman test, similar to the one by White (1982), has been proposed by Bartolucci et al. (2017) when a discrete distribution for the random effects is assumed. The test can also be used to detect the possible correlation between random effects and cluster‐specific covariates and detect endogeneity.
This work aims to extend the GH test to detect the non‐normality of the latent variable distribution in a unidimensional latent trait model for binary data. The estimators resulting from two different models are considered to build the test. The first model is a 2PL unidimensional IRT model that assumes the normality of the latent variable. In contrast, the second model is the unidimensional SNP‐IRT model, which assumes a more flexible distribution for the latent variable. The 2PL model is estimated using a pairwise maximum likelihood (PL) method (Katsikatsou et al., 2012), which is a composite likelihood method that uses information from bivariate‐order margins (Lindsay, 1988; Varin, 2008). The SNP‐IRT model is estimated using a maximum likelihood (ML) method. The choice of these estimators and models is motivated by the following reasons. First, both estimators are consistent when the latent variable is normally distributed. Moreover, the ML estimator for the SNP‐IRT model is also consistent under different distribution assumptions of the latent variable (Gallant & Tauchen, 1989; Irincheeva et al., 2012). These conditions on the consistency of the parameter estimators are required to correctly apply the GH test (White, 1982). Second, the PL and ML estimators yield different variances for the estimated parameters. This implies that under the normality of the latent variable distribution, the covariance matrix of the difference between the two estimators involved in the computation of the GH test differs from zero. The non‐zero covariance matrix avoids numerical instability in the calculation of the test.
The theoretical aspects of the models, estimators and matrices involved in the computation of the GH test are described in the following sections. Moreover, we carry out an extensive simulation study to evaluate the performance of the GH test in terms of both Type I error rates and empirical power. For the latter, we consider both a mixture of normals and skew‐normal distributions for the latent variable, with varying degrees of departure from the normal distribution. Additionally, we evaluate the asymptotic behaviour of the test in terms of both Type I error rates and power, using a very large sample size.
Furthermore, the performance of the GH test is compared with three available test statistics. Namely, the M2 is a statistic based on standardized univariate and bivariate residuals unaffected by sparseness (Maydeu‐Olivares & Joe, 2005). The likelihood ratio (LR) test for nested models and the X¯2 statistic proposed by Li and Cai (2018). The latter is available in FlexMIRT (Cai, 2017). We also study the performance of three model selection information criteria. Three applications to real data are also presented.
This article is organized as follows. In Section 2, we describe the 2PL model and SNP‐IRT models for binary data and the PL and ML estimation, respectively. Section 3 presents the GH test to detect the non‐normality of the latent variable distribution. In Section 4, we review the M2, the LR, the X¯2 and the RB test statistics, and in Section 5, the information criteria. Section 6 presents a Monte Carlo simulation study, and Section 7 presents the results from three real data analyses. Finally, in Section 8, some concluding remarks are presented and discussed.
THE 2PL AND SNP‐IRT MODEL FOR BINARY DATA
2
Consider n respondents answering p binary items. Let yij∈{0,1} for i=1,…,n and j=1,…,p be a binary random variable recording individual i's response to item j. We assume that the items measure a unidimensional construct modelled by a latent variable, z. The density function of this variable is expressed as h(z).
According to the two‐parameter model (2PL), the probability of a positive response for yij is modelled using a logistic model (measurement model) given by
where α0j is the item intercept and α1j the item slope (factor loading) and h(z)=ϕ(z), where ϕ(z) is the standard normal density.
An extension of the 2PL model is given by the SNP‐IRT model that assumes the same response probability as (1) but a SNP parametrization of the latent variable as follows:
where a0,…,aL are the real coefficients of the polynomial PL(zi) and L is the polynomial degree.
For h(z) to be a density, the coefficients a0,…,aL of PL(z) should be chosen such that ∫h(z)dz=1.
We follow the same parameterization as Woods and Lin (2009) and Irincheeva et al. (2012) to obtain a unique representation of the polynomial coefficients in Equation (2). The details of this parameterization can be found in Irincheeva et al. (2012) and are reported in the Data S1: Section S1.1.
Here, we consider L = 0, 1 and 2. When L=0, the distribution of the latent variable in (2) reduces to the standard normal one. When L=1, PL(z)=a0+a1z, where a0=sinφ1, a1=cosφ1, with −π/2<φ1≤π/2. The SNP parametrization with L=1 includes unimodal and bimodal distributions.
Figure 1 displays the SNP densities of z when L=1, for different values of the φ1 parameter.
SNP densities of z when L=1, for different values of the φ1 parameter.
When φ1 is negative and close to −1, the distribution is slightly right‐skewed, whereas when it is close to 1, it is slightly left‐skewed. When the values of φ1 are between −1 and 1, the distributions are bimodal. Even if not reported in the graph, when φ1=π2, the SNP distribution reduces to the standard normal.
When L=2, PL(z)=a0+a1z+a2z2, a0=sinφ1−12cosφ1cosφ2, a1=cosφ1sinφ2 and a2=12cosφ1cosφ2, with −π/2<φl≤π/2, l=1,2. The SNP parametrization with L=2 is more flexible than L=1 and encompasses unimodal, multimodal (including up to three modes) and skewed distributions. Figure 2 displays the SNP densities of z when L=2, for different values of the φ1 and φ2 parameters.
SNP densities of z when L=2, for different values of the φ1 and φ2 parameters.
When the value of φ1 is negative, and the value of φ2 is close to −1 or 1, the distributions are bimodal. When both parameters are close to 0, the distributions are trimodal. When the value of φ1 is positive and >0.5, and the value of φ2 is close to −1 or 1, the distributions are highly right‐skewed and left‐skewed, respectively. Even though it is not reported in Figure 2, when φ2=π2, the SNP densities reduce to those observed when L=1. Moreover, when both parameters are set to π2, the SNP densities return to the standard normal.
We indicate with SNP2 the 2PL model for L=2, with SNP1 the 2PL model for L=1 and with SNP0 the 2PL model for L=0.
PL estimation for the SNP0 model
2.1
To implement the GH test, the parameters of the SNP0 model are estimated with the PL. The pairwise log‐likelihood, based on the bivariate marginal densities f(yij,yik,θ), j,k=1,..p and k>j, is
plSNP0(y,θ) is maximized with respect to θ, where θ includes the item intercepts and slopes. Under correct model specification, the maximum PL estimator θ˜ converges in probability to the true parameter vector θ0′=(α00′,α01′) and
where A(θ)=Ey[−∂2plSNP0(y,θ)∂θ∂θ′], B=var[∂plSNP0(y,θ)∂θ] and A(θ)≠B(θ) (Lindsay, 1988, Varin, 2008). These matrices can be estimated by their observed versions evaluated at θ˜ as
and
ML estimator for the SNPL model
2.2
The parameter vector θ(1)′=(α0′,α1′,φ′)=(θ′,φ′) of the SNPL model, where L>0, is estimated using the ML method. The log‐likelihood of the data is
The integral in lSNPL(y,θ(1)) is approximated by using the Gauss–Hermite quadrature, as in Woods and Lin (2009). The degree of the polynomial L is fixed and is not estimated by ML. The log‐likelihood function is maximized with respect to the unknown vector of parameter θ(1) as follows:
When the model is correctly specified, this is the full ML method. Under model misspecification, the method becomes a quasi‐ML method (White, 1982). The two methods are computationally the same, but the estimators exhibit different theoretical properties, as will be clarified later in this section.
Regarding the identifiability of the model parameters with respect to the arbitrariness of the location and scale of the latent variable, we show in Section S1.4 of Data S1 that model parameters for the SNP1 model are locally identifiable without having to fix the location and scale of the latent variable or the elements of the loading matrix to specified values. This is not the case for most of the latent variable models with a parametric distribution for the latent variable. In the same way, for larger SNP models, one can show that high‐order moments of the observed variable contribute to the estimation of model parameters, thus providing at least locally identified model parameters. Irincheeva et al. (2012) also discusses the identifiability due to rotational indeterminacy.
After maximizing the log‐likelihood in (7), the algorithm converges to (α˙0′,α˙1′,φ^′) and the latent variable z has a density h(z|φ^,L) with an estimated mean E˜(Z) and variance V˜(Z) (see Section S1.2 of Data S1 for details). The estimators α˙0 and α˙1 are, in effect, calibrated with respect to the h(z|φ^,L) distribution. However, the estimates can be rescaled to compare with those of the 2PL with a standard normal latent variable distribution, as discussed in Section S1.3 of Data S1. The rescaled parameters are denoted as θ^(1)′=(α^0′,α^1′,φ^′).
The SNP densities can approximate various distributions, including a mixture of normals and skew distributions. However, as in almost all cases the SNP densities approximate the true latent variable distribution but do not exactly coincide with it, if the regularity conditions A2–A6 of White (1982) are satisfied, the obtained estimator is a Quasi‐ML estimator
where θ0(1)′=(α00′,α01′,φ∗′)=(θ0′,φ∗′). φ∗ is the value of φ that minimizes the Kullback–Leibler information criterion (White, 1982; Gallant & Tauchen, 1989; Irincheeva et al., 2012). If the true latent variable follows exactly an SNP_ L _ density, including the normal as a sub‐case, that is, when φl=π2, the vector φ∗ coincides with the true parameter value φ0, and the quasi‐ML method reduces to the full ML method. A(θ) and B(θ) are the expected Hessian and cross‐product matrices, respectively. Their observed versions can be computed with the Delta method (Cramér, 1946) and are defined similar to (5) and (6), where plSNP0(yi,θ) is replaced by lSNPL(yi,θ(1)).
THE GENERALIZED HAUSMAN TEST
3
In this section, we present the GH test, derived by White (1982), applied here to detect the non‐normality of the latent variable using the SNP‐IRT model.
As in the previous sections, let us denote by θ the sub‐vector of θ(1)′=(α0′,α1′,φ′) that includes the item intercepts α0 and slopes α1. θ has dimension 2p×1, where p is the number of items.
For the 2PL IRT model (SNP0), consider the maximum PL estimator θ˜SNP0.
Consider the ML estimator θ^SNPL(1)′=(θ^SNPL′,φ^′) of a SNP‐IRT model with L>0, where the sub‐vector of parameter φ^ has dimension L×1 and so θ^SNPL(1) has dimension (2p+L)×1.
Following White (1982), under normality of the latent variable
An estimator of S(θ0,θ0(1)) is given by
where the matrices Â(θ˜SNP0) and B^(θ˜SNP0), defined in Equations (5) and (6), have dimension 2p×2p and are evaluated at θ˜SNP0. Â(θ^SNPL(1)) and B^(θ^SNPL(1)) are the observed Hessian and cross‐product matrix of dimension (2p+L)×(2p+L) for the SNPL model, evaluated at θ^SNPL(1). The matrix Âθφ(θ^SNPL(1))−1 is obtained by deleting the last L rows from the matrix Â(θ^SNPL(1))−1 and has dimension 2p×(2p+L). The matrix R^(θ˜SNP0,θ^SNPL(1)) has dimension 2p×(2p+L) and can be computed as
where plSNP0(yi,θ) is the pairwise log‐likelihood for the individual i under the model SNP0 and lSNPL(yi,θ(1)) is the log‐likelihood for the individual i under the model SNPL. The matrix in (12) is evaluated at (θ˜SNP0,θ^SNPL(1)). We choose the maximum PL and the ML estimator for the two models to avoid that, under correct model specification, θ˜SNP0 and θ^SNPL converge to the same covariance matrix, producing a Ŝ(θ˜SNP0,θ^SNPL(1)) matrix in (11) with all entries close to 0.
Given the theoretical result in (10), the GH test is given by
Under normality of the latent variable, the GH test is asymptotically distributed as a χ2p2, with 2p degrees of freedom, that is, the number of parameters in θ.
We consider a simpler version of (13) that does not involve the inversion of the matrix Ŝ(θ˜SNP0,θ^SNPL(1)) giving
where I2p can be omitted from the above formula.
Following Yuan and Bentler (2010)
where d is the rank of S(θ0,θ0(1)) and λ1,…,λd are its non‐zero eigenvalues.
It is possible to approximate the distribution of GHT using the moment matching method (Welch, 1938; Yuan & Bentler, 2010) as follows:
The quantities a and b are defined as
and
As S(θ0,θ0(1)) can be consistently estimated by Ŝ(θ˜SNP0,θ^SNPL(1)) defined in (11), a and b can be consistently estimated substituting λ^1,…,λ^d in (17) and (18), where d is rank of Ŝ and λ^1,…,λ^d are its non‐zero eigenvalues. The approximation in (16) matches the first two moments of GHT with those of aχb2 (16).
Similar to the statistics derived by Monroe (2021) and Li and Cai (2018), the GHT test can be sensitive to the misspecification of either the latent variable distribution or the IRF. For this reason, correct IRFs for the items are assumed when testing the normality of the latent variable.
To study the sensitivity of the proposed GHT test to misspecification of the IRF, we run a small‐scale simulation and provide the results in Section S2.3 of Data S1.
AVAILABLE TEST STATISTICS FOR TESTING LATENT VARIABLE DISTRIBUTION FIT AND THE OVERALL FIT
4
In addition to the proposed test statistic, we review three test statistics for testing latent variable distribution fit and one for the overall goodness‐of‐fit of the model considered each time.
An LR test statistic for nested models can be used since the SNPL and SNP0 models are nested (Wilks, 1938). The SNPL model, when φ1=⋯=φL=π2, reduces to the SNP0 model (Irincheeva et al., 2012). For the computation of the LR test, the SNP0 model needs to be estimated using ML instead of pairwise likelihood to obtain a comparable value of the log‐likelihood function with that of the SNPL model.
Let us denote by φ′=(φ1,⋯,φL) and by c′=(π2,⋯,π2). The null and alternative hypotheses can be formulated as follows:
The test statistic is defined as
where lSNPL(y,θ^(1)) and lSNP0(y,θ^) are the log‐likelihood functions of the SNPL and SNP0 models, respectively, evaluated at their maximum values. Under H0, the LR test is asymptotically distributed as a χL2, where L is the degree of the polynomial. For a fixed sample size, the number of empty cells in a frequency table increases with the number of binary items. In this case, the distribution of the LR test statistic is not well approximated by the chi‐square distribution.
Li and Cai (2018) proposed a Pearson‐type statistic based on summed scores given by:
where n is the sample size, S=1+p represents the possible summed scores with p binary items, ranging from 0 to S−1. p¯s and π¯s denote the observed summed score proportions and the corresponding model‐implied summed score probabilities computed under an IRT model, respectively, for s=0,⋯,S−1.
Li and Cai (2018) conjectured that under a wide variety of conditions, the tail‐area probabilities of X¯2 can be well approximated by a χ2 distribution with S−1−2 degrees of freedom under the null hypothesis that the latent variable distribution is correctly specified in the IRT model. The authors also proposed a moment‐adjusted version of this test.
Monroe (2021) proposed a test statistic based on posterior residuals written as:
where θ^ denotes the ML estimates of the free parameters of the IRT model, f¯(z|y,θ^)=n−1∑i=1nf(z|yi,θ^) denotes the sample average of the posterior distribution, d(z;θ^) is the ML estimate of the distribution of the latent variable and s(z) is the corresponding standard error estimate. If d(z;θ) is assumed to be standard normal, then R(z) compares the posterior average, f¯(z|y,θ^), with the standard normal distribution. A version of this test statistic for overall latent variable distribution fit, denoted by RB, is defined as the maximum absolute of R(z) and compared to a Bonferroni‐corrected critical value.
We also review one more test statistic for the overall fit of the SNP0 model proposed by Maydeu‐Olivares and Joe (2005). Although not developed for testing latent distribution fit, it provides an overall goodness‐of‐fit test statistic that can work well under sparseness. Maydeu‐Olivares and Joe (2005) propose a family of test statistics Mr, based on the residuals up to order r. The most popular statistic is M2, which uses the univariate and bivariate marginal information. As data sparseness increases, the empirical Type I error rates of the M2 test remain accurate (Maydeu‐Olivares & Joe, 2005, 2006). Under the null hypothesis, we test that the SNP0 model holds. The hypotheses H0 and H1 can be formalized as follows:
where θ, as usual, includes the item intercepts and slopes and π(θ) indicates the response patterns probabilities.
The test statistic M2 is (Maydeu‐Olivares & Joe, 2005):
The vector e^ includes the univariate and bivariate residuals while the matrix U^2 depends on a transformation matrix and the Jacobian matrix of the cell probabilities with respect to the items intercept and slope parameter (more details can be found in (Maydeu‐Olivares & Joe, 2005, 2006). Under H0, the statistic M2 is asymptotically distributed as a χm2, with degrees of freedom m=p(p+1)2−2p, that is the number of univariate and bivariate residuals minus the number of estimated parameters of the SNP0 model.
In the simulations, we evaluate the performance of the LR, X¯2 and M2 test statistics under normality and non‐normality of the latent variable distribution. However, RB is not available in commercial software and has therefore been reported only in the real data application in Section 7.1, where it was previously computed.
MODEL SELECTION CRITERIA
5
The AIC, the BIC and the Hannan–Quinn criterion (HQ) can be used to choose the degree of the polynomial L of the SNP‐IRT model (Davidian & Gallant, 1993; Woods & Lin, 2009; Irincheeva et al., 2012; Monroe, 2014).
The AIC is (Akaike, 1974):
where l(y,θ^(1)) is the maximum value of the log‐likelihood function of the SNPL model and k is the number of free mode parameters.
The BIC is (Schwarz, 1978):
where n is the sample size.
The HQ is (Hannan & Quinn, 1979):
Usually, L=1 or L=2 is enough to detect a departure from normality and approximate different latent variable distribution shapes. Selecting a higher order of the polynomial could result in overfitting (Irincheeva, 2011).
When L=0, θ^(1) equals θ^ in the aforementioned formulas.
SIMULATION STUDY
6
Design
6.1
In this section, we study the performance of the GHT test to assess the non‐normality of the latent variable distribution, and we compare its performance with the LR, X¯2 and M2 test statistics. Moreover, the BIC, AIC and HQ criteria were computed for all simulation scenarios.
We have considered five scenarios (SC) corresponding to five distribution assumptions for the latent variable z in the data‐generating models. The unidimensional latent trait model is
Item intercepts, α0j, have been randomly chosen from the interval [−.8; 1.12] while the item slopes, α1j, from the interval [.5; 1.5]. To study the Type I error rates of the above four test statistics, we have considered the following scenario:
- A z∼N(0,1).
For the power, we have considered the following cases of two bimodal distributions and two skewed distributions:
-
B z∼.7N(−1,.7)+.3N(1,.8), where z has an overall mean of −.40 and a variance of 1.38.
-
C z∼.1N(−2,.25)+.9N(2,1), where z has an overall mean of 1.6 and a variance of 2.37.
-
D Z∼SN(μ=−2.5,σ=2,λ=5),where z has a mean of −.93 and a variance of 1.55.
-
E Z∼SN(μ=−2.5,σ=2,λ=10),where z has a mean of −.91 and a variance of 1.47.
The degree of deviation from the normal distribution is greater in scenario C than in scenario B, and similarly, the skew‐normal distribution in scenario E exhibits a greater deviation from the normal distribution than the one in scenario D.
In the simulations, two versions of the GHT test were considered. The first version, named GHT1, is based on the SNP0 and SNP1 models. The SNP1 model was chosen because it can approximate bimodal distributions well, present in scenarios B and C.
The SNP1 model has been optimized in R using the ‘nlminb’ function, which maximizes directly through the analytically computed gradient and Hessian matrix. In the case of the SNP1 model, the initial values for the parameters α0j and α1j used in the optimization process are the ML parameter estimates obtained with the SNP0 model. For the φ1 parameter, we have sampled 10 initial values from a sequence of values equally spaced by .1 within the domain of φ1 which is the interval [−π2;π2]. From the estimated SNP1 models in each data replication, we selected the one corresponding to the maximum value of the quasi‐log‐likelihood function. The GHT1 test has been evaluated under all scenarios to assess its performance.
In scenarios D and E, a second version of GHT called GHT2 has been considered in addition to GHT1. GHT2 is based on the SNP0 and SNP2 models, suitable for capturing highly skewed cases when L=2, as shown in Figure 2. The SNP2 model optimization uses the direct maximization function ‘nlminb’ in R. However, it is susceptible to the initial values chosen. To overcome this, the true parameter values have been used as initial values for the α0j and α1j parameters, and the initial values for the φ1 and φ2 parameters have been set to 0.7 and 1, respectively, corresponding to a skew‐normal case. To compute the GHT1 and GHT2 test statistics, the SNP0 model has been estimated using the maximum PL method through the R function ‘optim’. The Hessian, cross‐product matrices and the matrix in formula (12) involved in the GHT1 and GHT2 tests have been computed numerically with the ‘NumDeriv’ R package.
To compute the values of the information criteria and the LR test, the SNP0 model has been estimated using ML in R via the ‘optim’ function. For the M2 test, we also used ML estimation. We estimated the 2PL model with the expectation‐maximization (E‐M) algorithm with the ‘mirt’ function in R. Then, we applied the ‘M2’ function to calculate the test statistic.
We used flexMIRT (Cai, 2017) to compute X¯2.
The Type I error rates and power of the GHT1,GHT2, LR, X¯2 and M2 have been computed using the following formula: p^=∑l=1NvI(Tl≥c)Nv. Here, Nv represents the number of valid replications out of the total, I denotes an indicator function and Tl is the test statistic value evaluated in the l‐th replication. The critical value c corresponds to the theoretical asymptotic value, specifically the (1−α)th percentile of the âχb^2 distribution for the GHT test. The values â and b^ are computed as in (17) and (18). For the M2 test, the critical value is associated with the χm2 distribution, where m is equal to p(p+1)2−2p. For X¯2, the critical value is associated with the χS−1−22 distribution.
To compare the performance of two models, SNP1 and SNP0, we use the LR test. As SNP1 has an additional parameter compared to SNP0, we use c as the theoretical asymptotic critical value corresponding to the (1−α)th percentile of the χ12 distribution. This specific test is called LR1. To compare SNP0 with SNP2, we use the LR test with two degrees of freedom, denoted as LR2. A confidence interval (CI) of each rate p^ is computed as p^±z(1−α2)α(1−α)Nv.
Next, the percentages of times the AIC, BIC and HQ criteria select the SNP1 over SNP0 have been computed as P^=∑l=1NvI(ICSNP1<ICSNP0)Nv100, where IC indicates the AIC, BIC and HQ criteria. Similarly, we computed percentages for selecting the SNP2 model over the SNP0 model using information criteria.
We have conducted simulations for scenarios A, B and C with the following conditions: number of items (p=10,20), sample size (n=500,1000,5000), test statistics (GHT1, LR1, X¯2, M2) and information criteria (AIC, BIC, HQ). For scenarios D and E, the simulation conditions are the number of items (p=10,20), sample size (n=500,1000), test statistics (GHT1,GHT2, LR1, LR2, X¯2, M2) and information criteria (AIC, BIC, HQ). We have considered two nominal levels of α, α=.05,.01 and R=500 replications for all scenarios.
Preliminary results from Guastadisegni et al. (2023) indicate that the GHT1 test performs well under scenarios A and C, particularly for large sample sizes, with reasonable rates of Type I error and power.
Additional results that include the bias for the parameter estimates of the model SNP0, SNP1 and SNP2 have been reported in Section S2.1 of Data S1. When the mean of the true latent variable differs from 0, and the variance differs from 1, as in scenarios B, C, D and E, to compute the parameter bias, the true α00 and α01 parameters have been rescaled accordingly to formulas (S12) and (S13) in Section S1.3 of Data S1, replacing α˙0j with the true intercept, α˙1j with the true slope, E˜(Z) and V˜(Z) with the mean and the variance of the true latent variable. In this way, the parameter bias is due only to the misspecification of the shape of the latent variable and not to the misspecification of the moments. A similar procedure to compute parameter bias has been adopted by Irincheeva (2011).
Results
6.2
Table 1 reports the Type I error rates of the GHT1, LR1, X¯2 and M2 for scenario A.
The GHT1 and X¯2 tests exhibit good Type I error rates under most conditions. However, GHT1 is more conservative than expected, but only when the sample size is small, and there are 10 or 20 items with α=.05. The X¯2 test has lower than expected Type I error rates with a small sample size, 10 items and α=.05. M2 performs well regarding Type I error rates for both values of α, number of items and sample sizes. The LR1 test performs the worst of the four tests. When there are 10 items and the sample size is 500 or 1000, or when there are 20 items, the sample size is 500, and α=.05 rejects more than it should. Moreover, for every level of α considered, it has seriously inflated Type I error rates with 20 items and n=5000.
Table 2 shows the percentages of times AIC, BIC and HQ select SNP0 over SNP1 for scenario A.
Among the three information criteria considered, the AIC has the worst performance. This is particularly noticeable with 20 items and all sample sizes, where it selects the SNP0 model from 54% to 88% of times. On the contrary, the BIC performs the best, selecting the SNP0 model almost every time under all conditions. The HQ performs moderately well in selecting the SNP0 model, with its performance lying between that of the AIC and BIC criteria.
Table 3 presents the empirical power of the GHT1, LR1, X¯2 and M2 for scenarios B and C.
Regarding the four tests and both levels of α considered, it was found that GHT1 consistently exhibits higher power than the other tests under scenario B for small sample sizes. Under scenario C, and generally as the sample size increases, GHT1 and X¯2 tend to have very similar power, which is consistently higher than LR1. Overall, the power of the GHT1, LR1 and X¯2 tests increases as both the sample size and the number of items increase, and as the true latent variable distribution significantly diverges from the normal distribution. On the contrary, the M2 test has very little or no power to detect non‐normality of the latent variable distribution under both scenarios considered.
Table 4 shows the percentages of times AIC, BIC and HQ select SNP1 over SNP0 for scenarios B and C.
In all cases, AIC performs best when the sample size is 500 or 1000, with the highest percentage of selecting the SNP1 model. On the contrary, BIC has the poorest performance with sample size of 500 or 1000, especially when it comes to selecting the SNP1 model under scenario B and a sample size of 500, where it only selects it around 47% of the time. HQ performs better than BIC but not as well as AIC in selecting the SNP1 model under all scenarios for small sample sizes.
Table 5 reports the empirical power of the GHT1, LR1, GHT2, LR2, M2 and X¯2 for scenarios D and E.
Under scenarios D and E, GHT1 and GHT2 generally exhibit very similar power across all conditions. For small sample sizes, the power of these tests is consistently higher than that of X¯2. For large sample sizes, GHT1, GHT2 and X¯2 demonstrate similar power, and it increases as the skew‐normal distribution becomes more extreme. LR1 has low power under all conditions, while LR2 exhibits the highest power among all scenarios. Although increasing the degree of the polynomial can enhance the LR test performance, the SNP2 method requires accurate initial values for the parameters to yield good results, making it challenging to use in practice. As observed in scenarios B and C, the M2 test has very low or no power in detecting misspecifications of the latent variable distribution.
Table 6 shows the percentages of times AIC, BIC and HQ select SNP1 over SNP0 and SNP2 over SNP0 for scenarios D and E.
In both scenarios and with different sample sizes, none of the criteria were effective in choosing between SNP1 and SNP0. However, because the true latent variables are skewed and SNP2 better approximates this type of distribution, all the information criteria performed better when selecting between SNP0 and SNP2. Among the criteria, AIC showed the best performance, while BIC performed the worst. Overall, based on the results in Tables 2, 4 and 6, it was not possible to determine which criterion performed the best under normality and non‐normality of the latent variable.
To assess the performance of the GHT test in the presence of misspecification of the IRF, an additional scenario, referred to as F, was examined. Details of the simulation conditions and results are in Section S2.3 of Data S1. The results indicate that GHT1 has lower power than X¯2. This suggests that if the GHT1 test rejects the null hypothesis, it is more likely due to misspecification in the latent variable distribution rather than in the IRF specification.
REAL DATA APPLICATIONS
7
Grade 12 science assessment test
7.1
The Grade 12 science assessment test (SAT12) dataset can be found in the TESTFACT manual (Wood et al., 2003) and is also included in the R package mirt (Chalmers, 2012). It comprises 32 binary‐scored items measuring chemistry, biology and physics knowledge. Previous analysis by Monroe (2021) revealed that the 2PL model provided a poor fit, as indicated by the significant values of RB and X¯2. To further analyse this dataset, the SNP0 and SNP1 models were fitted to the same dataset used by Monroe (2021), which included 572 complete cases.
Section S3.1 of Data S1 reports estimates for the SNP0 and SNP1 models. These estimates show some differences, but they are not too large. To choose between the classic 2PL model and a more complex one, we first assessed the fit of the SNP0 model. As the data are sparse, with all 570 observed response patterns having expected frequencies <5, we examined residuals calculated from marginal frequencies. We have used the rule that residuals >4 indicate a bad fit of the correspondent pair or triplets of items (Bartholomew et al., 2011). Although the results are not presented in the tables, the SNP0 model exhibits a poor fit for specific pairs and triplets of items. We computed information criteria to assess whether the SNP1 model would better fit.
Table 7 reports the AIC, BIC and HQ criteria for the SNP0 and SNP1 models. Based on the information criteria selected, the SNP1 model is preferred, indicating the non‐normality of the latent variable.
Table 8 reports the value of the M2, LR1, GHT1, X¯2 and RB, the degrees of freedom (dof) and the associated p‐values.
The values of RB and X¯2 were obtained from Monroe (2021). The RB indicates that the latent variable is not normally distributed. The test M2 rejects the null hypothesis that SNP0 fits the data well. The LR1 suggests a better fit for the SNP1 model. Both GHT1 and X¯2 reject the null hypothesis that the latent variable is normally distributed. As some of the parameter estimates are more extreme than those considered in the simulation study in Section 6, the reliability of the test results was evaluated through a simulation study that mimics the real dataset, as explained in Section S3.1 of Data S1. The findings indicate that all tests perform well in terms of Type I error rates and power, except for the M2 test, which shows very low or no power in identifying non‐normality in the latent variable distributions.
This data analysis did not consider the GHT2 and LR2 tests as we already rejected the null hypothesis when considering only L=1.
The NLSF dataset
7.2
This study is based on data collected from the National Longitudinal Survey of Freshmen (NLSF), which is a project funded by the Mellon Foundation and the Atlantic Philanthropies (available at http://oprdata.princeton.edu/archive/restricted), designed by Douglas S. Massey and Camille Z. Charles. The NLSF aims to collect data to explain the underachievement of minority groups in higher education. The data were collected from 1999 to 2003 in four waves to capture emergent psychological processes, measuring the degree of social integration and intellectual engagement. The survey included equal‐sized samples of first‐year white, black, Asian and Latino students entering selective colleges and universities. For this study, we have analysed only a part of the questionnaire that refers to 1999. Specifically, we have selected 21 binary items, whose descriptions are reported in Table 9. The first 9 items measure violence in the neighbourhood, while the remaining 12 measure violence in the school.
The initial set of observations contained 3924 responses, with possible answers being ‘no’, ‘yes’, ‘don't know’ and ‘refused’. Responses including ‘don't know’ or ‘refused’ were excluded from the analysis. In addition, ‘no’ responses were coded as 0 and ‘yes’ responses as 1. The final dataset used for analysis contained 3860 responses.
A subset of 400 observations, along with the items listed in Table 9, was analysed by Cagnone and Viroli (2012), who fitted a latent trait model to the data, with latent variables distributed as a finite mixture of multivariate Gaussians, to achieve both dimension reduction and clustering simultaneously. Cagnone and Viroli (2012) found a good fit for the model with 2 factors distributed as a mixture of Gaussians, with the first 9 items listed in Table 9 loading highly on one factor, and the remaining 12 on the other factor.
In this work, we analyse the two item batteries separately. The results are reported in the following subsections.
American students exposure to neighbourhood violence
7.2.1
This section presents the analysis results of the nine items that measure neighbourhood violence.
Despite the SNP0 and SNP1 methods being on the same scale, we observe different parameter estimates with very extreme values, as reported in Section S3.2.1 of Data S1.
We evaluated the fit of the SNP0 model, considering the data's sparsity.
Specifically, 174 of the 231 observed response patterns have expected frequencies of <5. Residuals calculated from marginal frequencies were examined, revealing that the SNP0 model does not fit well for some pairs and triplets of items.
Table 10 reports the values of the AIC, BIC and HQ criteria for the SNP0 and SNP1 models.
The information criteria give conflicting results. Indeed, AIC and HQ select the SNP1 model, while BIC the SNP0 model.
Table 11 reports the value of the M2, LR1, GHT1 and X¯2 test statistics, the degrees of freedom (dof) and the associated p‐values.
TABLE 11: NLSF data, nine items: M2, LR1 GHT1, X¯2 test statistics and associated degrees of freedom and p‐values.
The test results show contradictions. Specifically, the M2 test indicates that the SNP0 model does not fit the data well. For the LR1 and GHT1 tests, the null hypothesis – that the latent variable is normally distributed – is rejected. In contrast, the X¯2 test does not reject the null hypothesis of normality for the latent variable. To further investigate these contradictory results, a simulation study was conducted with nine items. The study used the SNP0 estimates (intercepts and slopes) as the true values for generating data. These estimates deviate significantly from the true parameter values used in the simulation presented in Section 7. The simulation results, presented in Section S3.2.1 of Data S1, indicate that all tests, except for LR1, perform well regarding Type I error rates and when the latent variable is generated from a mixture of normals. Limitations arise under skew‐normal scenarios. Specifically, the X¯2 and M2 tests exhibit almost no power. While the GHT1 test shows slightly better performance than X¯2, its power remains low. Moreover, the SNP1 method encountered convergence issues in nearly 20% of the replications. The results of the LR1 test are unreliable due to significantly inflated false positive rates. Upon examining the results in Table 11 and those in Data S1, we conjecture that the situation observed in the real data is similar to scenarios D and E, where the GHT1 test demonstrates somewhat higher power than the X¯2 test. Nevertheless, we cannot trust the test results as the overall power is very low. Additionally, this dataset presents a specific challenge not encountered in the other data analysed or in the other simulation studies presented in the paper and Data S1: approximately 33% of the loadings for the SNP0 model, which are used as data‐generating values in the simulation study, are large, exceeding a value of 3. This factor could contribute to instability in the results and impact the estimation process of the SNP1 model. While the application results remain unresolved, they could serve as a starting point for further investigation, as discussed in Section 8.4.
American students exposure to school violence
7.2.2
This section presents the analysis results on the 12 items that measure school violence. Also, in this battery of items, it has been observed that the parameter estimates reported in Section S3.2.2 of Data S1 are different despite the methods being on the same scale, and they exhibit extreme values. To choose the best model for the data, we first evaluated the fit of the SNP0 model.
The data are sparse, with 227 out of the 302 observed response patterns having expected frequencies <5. Inspection of the bivariate and trivariate residuals showed that the SNP0 model does not fit well.
Table 12 reports the values of the AIC, BIC and HQ criteria for the SNP0 and SNP1 models.
All three information criteria indicate that the SNP1 model fits better than the SNP0 model.
Table 13 reports the value of the M2, LR1, GHT1 and X¯2 test statistics, the degrees of freedom (dof) and their associated p‐values.
Based on the M2 test results, the SNP0 model does not fit the data well. However, it is essential to note that the M2 test does not identify the specific reason for this poor fit. On the contrary, the LR1, GHT1 and X¯2 tests reject the null hypothesis that the latent variable is normally distributed. For this particular set of items, the test statistics and information criteria yield consistent results. This is evident from an additional simulation study we conducted, which mimics the parameter estimates from the SNP0 model fitted to the 12 items. The results can be found in Section S3.2.2 of Data S1. In summary, the performance of the test statistics varies significantly based on the scenario being considered. None of the test statistics exhibit inflated false positive rates, and all tests demonstrate high power when the latent variable is generated from an extreme mixture of normals, including the M2 test. The power is notably low only when the latent variable is generated from a skew‐normal distribution, irrespective of the level of skewness.
DISCUSSION
8
In the following subsections, we provide a summary of the work done in this paper, present the main findings with a focus on comparisons between the proposed tests and others, discuss the limitations of the GHT test and outline directions for future work.
Summary of work
8.1
We have expanded the utilization of the GH test to detect the non‐normality of the latent variable distribution in a unidimensional IRT model for binary data. The GH test has been derived through the comparison of the PL estimator of the 2PL model for binary data with the ML estimator of the SNP‐IRT model, which allows for a more flexible shape of the latent variable distribution. We have used a simpler version of the GH test, referred to as the GHT test, which does not require the inversion of the covariance matrix. Its approximated distribution has been derived using the moment matching method. Two versions of GHT have been considered. The first version is the GHT1 test, based on the SNP1. Through the simulation study in Section 6, as well as through three real data applications and the simulation studies based on these real applications reported in Data S1, we have compared the performance of the GHT1 test with the M2, LR1 and X¯2 test statistics and computed three information criteria, such as AIC, BIC and HQ. We also evaluated the sensitivity of the tests mentioned above to misspecifications of the item response function, with results reported in Data S1. As the SNP density when L=1 can only capture bimodal and slightly skew‐normal distributions, we have used the SNP density with L=2 because this parameterization enables the representation of highly skew‐normal distributions for specific combinations of parameter values. Therefore, we employed the second version of GHT based on the SNP0 model, namely GHT2, and the LR2 test only in the context of skew‐normal scenarios in the main simulation study of Section 6 and in the study based on the SAT12 dataset to evaluate the performance of these tests with many items.
Main findings
8.2
In the main simulation study discussed in Section 6, we used a standard range of values (without extreme values) to generate the intercepts and slopes of the items. The results showed that the GHT1 test performs well in terms of Type I error rates under most conditions. Furthermore, it demonstrates the highest power for detecting non‐normality in the latent variable distribution across various scenarios, particularly with small sample sizes. Specifically, GHT1 outperforms X¯2 in terms of power for small sample sizes in the majority of cases, while both tests exhibit similar power when sample sizes are large. The GHT1 test consistently exhibits higher power than the LR1 test, which can produce inflated or deflated Type I error rates under specific conditions. Additionally, Irincheeva (2011) noted some limitations in using the LR test within the framework of SNP models. Furthermore, the GHT1 test outperforms the M2 test in terms of power. While the M2 performs well regarding Type I error rates, it shows very low or no power to detect non‐normality in the latent variable distribution. The only exception to this occurs in extreme mixture of normal distributions, as shown in simulation studies utilizing the NLSF dataset (with 9 and 12 items) reported in Data S1. In this scenario, the M2 test shows high power to detect this misspecification. Similar findings regarding the low power of the M2 test to identify non‐normality in the latent variable distribution have also been reported by Li and Cai (2018), Paek et al. (2019) and Monroe (2021). As pointed out by Li and Cai (2018), this phenomenon can be attributed to the fact that M2 relies on the first‐ and second‐order margins of the underlying contingency table. To identify any misfit in the latent variable distribution, it may be necessary to incorporate information from higher‐order margins.
The GHT1 test proves to be more effective than the information criteria in this context, as none of the criteria consistently outperforms the others. The simulations indicate that it is challenging to determine which information criterion performs best, whether the latent variable is normally or non‐normally distributed. The AIC often selects more complex models in the highest percentage of cases, regardless of the distribution of the latent variable. This tendency to favour models with more parameters can result in overfitting. On the contrary, the BIC performs best when the latent variable follows a normal distribution. This is because BIC applies a stronger penalty for the number of parameters compared to the AIC, making it more suitable for selecting parsimonious models. However, BIC performs poorly under non‐normal distributions for small sample sizes, as it tends to select models that are too simple and fail to capture the complexity of the data. The performance of the HQ criterion lies between that of AIC and BIC.
From the additional simulation studies reported in Data S1, we found that the GHT1 test is less sensitive to misspecifications in the item response function compared to X¯2, particularly with a small number of items and small sample sizes. Therefore, if the GHT1 test results in a rejection, it is more likely that the misspecification is related to the latent variable distribution rather than the item response functions.
The simulation study based on the SAT12 dataset demonstrated that the performance of both the GHT1 and GHT2 tests remains stable, even when the number of items increases and certain item parameter values become more extreme. Overall, the results for all tests and information criteria are consistent with those observed in the main simulation study discussed in Section 6. Finally, the GHT1 and GHT2 tests show similar performance under skew‐normal scenarios.
Limitations of the proposed test
8.3
We identified two limitations in the GHT1 and GHT2 tests discussed in this work mainly in the case of examples with large slopes. For the GHT1 test, issues arose particularly during the simulation studies based on the NLSF dataset mentioned in Data S1. Specifically, when data were generated with extreme values for item slopes under skew‐normal scenarios, the power of the GHT1 test was notably low. Additionally, in simulations involving nine items, the SNP1 model, which the test relies on, encountered convergence problems. It is also important to note that neither X¯2 nor the information criteria performed well under the skew‐normal scenarios in the simulations based on the NLSF dataset, especially with nine items. Furthermore, both LR1 and M2 exhibited limitations in these particular simulation studies. The second limitation is on the GHT2 test that requires estimation of the SNP2 model, which poses a challenge as accurate initial values are necessary for the optimization process to attain a reliable approximation of the true latent variable and minimize bias in parameter estimates compared to SNP0. Also the LR2 test, which shows high power under the skew‐normal scenarios in the simulation studies, is affected by the same problem. As a result, applying the SNP2 model and the tests based on it in real data analysis becomes impractical due to these demanding requirements.
Future research
8.4
Further studies could address the issue of initial values in SNP estimation when L>1, enhancing its applicability in practical contexts. The performance of the GH test, when implemented with higher‐order polynomials, could also be assessed through simulations and real data analysis. Increasing the degree of the polynomial allows for greater flexibility in modelling the shape of the latent variable distribution, which can improve both information criteria and test performance.
The limitations identified from the NLSF data application, particularly concerning the nine items, may serve as a foundation for further investigation. The GH test could be applied using other estimation methods and models different from SNP to improve performance, especially in situations where slope parameter values are more extreme.
Additionally, evaluating the performance of the GH test in the IRT context could involve examining other types of model violations, such as local dependence or violations of the item characteristic function. In these cases, it is important to consider other estimation methods that provide consistent estimates under model misspecification for the application of the test.
AUTHOR CONTRIBUTIONS
Lucia Guastadisegni: software; writing – original draft; methodology; data curation; visualization. Silvia Cagnone: methodology; writing – review and editing; formal analysis; supervision; conceptualization; data curation. Irini Moustaki: methodology; conceptualization; writing – review and editing; supervision; formal analysis; writing – original draft; validation. Vassilis Vasdekis: conceptualization; methodology; writing – review and editing; supervision; formal analysis.
CONFLICT OF INTEREST STATEMENT
The authors declare no potential conflicts of interest with respect to the research, authorship and/orpublication of this article.
Supporting information
Data S1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control, 19(6), 716–723.
- 2Bartholomew, D. J. , Knott, M. , & Moustaki, I. (2011). Latent variable models and factor analysis: A unified approach (3rd ed.). Wiley.
- 3Bartolucci, F. , Bacci, S. , & Pigini, C. (2017). Misspecification test for random effects in generalized linear finite‐mixture models for clustered binary and ordered data. Econometrics and Statistics, 3, 112–131.
- 4Bock, R. D. , & Aitkin, M. (1981). Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. Psychometrika, 46(4), 443–459.
- 5Cagnone, S. , & Viroli, C. (2012). A factor mixture analysis model for multivariate binary data. Statistical Modelling, 12(3), 257–277.
- 6Cai, L. (2017). flex MIRT® version 3.65: Flexible multilevel multidimensional item analysis and test scoring [computer software]. Vector Psychometric Group.
- 7Chalmers, R. P. (2012). Mirt: A multidimensional item response theory package for the r environment. Journal of Statistical Software, 48, 1–29.
- 8Cramér, H. (1946). Mathematical methods of statistics. Princeton University Press.