TOSQ: Transparent Object Segmentation via Query-Based Dictionary Lookup with Transformers
Bin Ma, Ming Ma, Ruiguang Li, Jiawei Zheng, Deping Li

TL;DR
This paper introduces TOSQ, a new method for segmenting transparent objects using transformers and a query-based approach, achieving better performance than previous methods.
Contribution
The novel Query Parsing Module (QPM) formulates segmentation as a dictionary lookup problem using learnable class prototypes.
Findings
TOSQ achieves 76.63% mIoU and 95.34% Acc on the Trans10K-V2 dataset.
It shows significant improvements in challenging categories like windows and glass doors.
The model leverages transformer-based global modeling for transparent object segmentation.
Abstract
Sensing transparent objects has many applications in human daily life, including robot navigation and grasping. However, this task presents significant challenges due to the unpredictable nature of scenes that extend beyond/behind transparent objects, particularly the lack of fixed visual patterns and strong background interference. This paper aims to solve the transparent object segmentation problem by leveraging the intrinsic global modeling capabilities of transformer architectures. We design a Query Parsing Module (QPM) that innovatively formulates segmentation as a dictionary lookup problem, differing fundamentally from conventional pixel-wise mechanisms, e.g., via attention-based prototype matching, and a set of learnable class prototypes as query inputs. Based on QPM, we propose a high-performance transformer-based end-to-end segmentation model, Transparent Object Segmentation…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
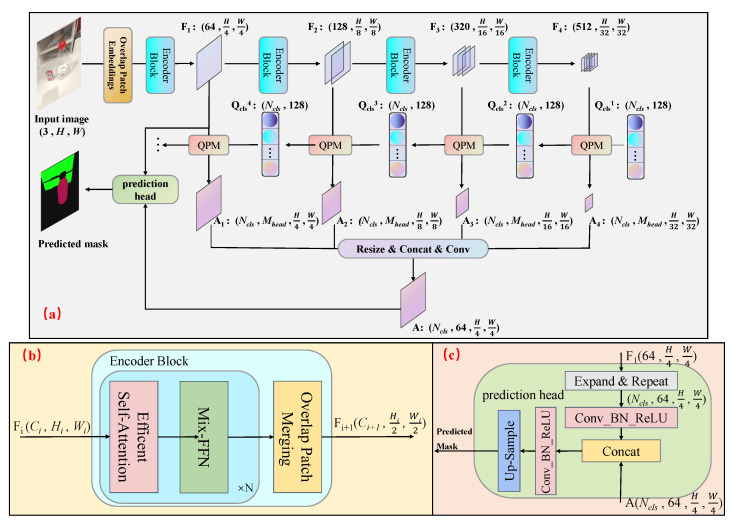 Figure 1
Figure 1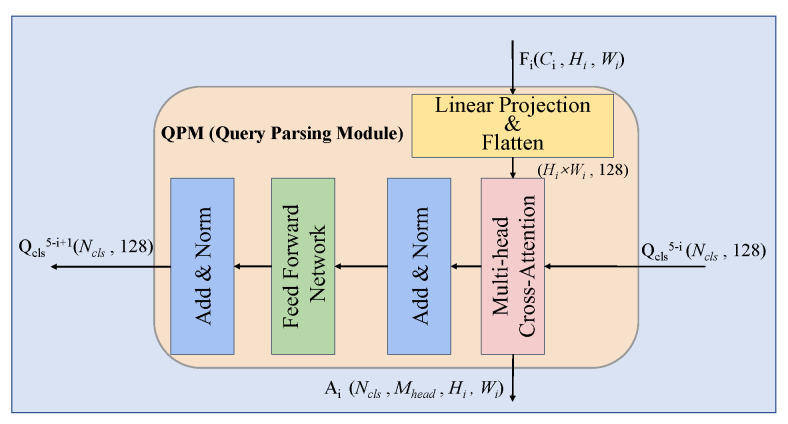 Figure 2
Figure 2 Figure 3
Figure 3- —investigation on the utilization of the “Smart Cloud” Maintenance Platform for the ATC of the Machining Center, Department of education of Hubei Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Advanced Image and Video Retrieval Techniques · Robotics and Sensor-Based Localization
1. Introduction
Transparent objects, such as car glass, glass cups, plastic bottles, glass doors, and glass walls, are prevalent in daily life but pose unique segmentation challenges due to their lack of contrast with backgrounds and complex optical properties. Effective transparent object segmentation is critical for applications like autonomous driving, augmented reality, and robot navigation in environments with glass partitions.
Although significant progress has been made in collecting a large amount of image data containing transparent objects [1,2,3], segmenting transparent objects from a single 2D RGB image remains a huge challenge. Industrial deployment of RGB imaging faces inherent constraints, including limited spectral sensitivity (visible band only), depth ambiguity in object stacking scenarios, vulnerability to specular interference under harsh lighting, and insufficient material discriminability among transparent substrates. Depth maps (RGB-D) [4,5], thermal maps (RGB-T) [6], and polarization maps (RGB-P) [7,8] are typically used by traditional methods to identify transparent objects in images. Using additional data can indeed help the model better understand the features of transparent objects and improve the accuracy of transparent object segmentation, but this data is often difficult to obtain.
In addition, transparent objects remain challenging due to their lack of fixed textures and strong dependency on background scenes. This motivates us to propose a dictionary-based formulation that explicitly models transparent attributes through learnable prototypes. To address the challenge of transparent object segmentation in single RGB images, we propose an efficient Query Parsing Module (QPM) and a high-performance transformer-based model, TOSQ. Our key contributions are:
(1) An end-to-end Transformer architecture for transparent objects. We propose TOSQ, a fully transformer-based model specifically designed for segmenting transparent objects in RGB images. By leveraging the intrinsic global modeling capability of Transformers, TOSQ effectively handles the ambiguous boundaries and variable appearances caused by light refraction/reflection.
(2) Novel dictionary-formulated segmentation paradigm. We design QPM to reformulate semantic segmentation as a dictionary look-up problem, where transparent objects are represented as compositions of learnable prototypes. A set of class-aware prototypes is introduced as dynamic query inputs, enabling the model to adaptively capture transparent object features (e.g., edge distortions, specular highlights) without manual feature engineering.
(3) State-of-the-art performance. Extensive experiments on the Trans10K-V2 dataset [2] demonstrate that TOSQ achieves state-of-the-art performance, with 76.63% mIoU and 95.34% accuracy, outperforming both convolutional-neural-network-based and transformer-based methods.
2. Related Work
Transparent object segmentation is an essential task in robot perception that classifies each pixel value of an image as transparent or non-transparent. This task enables autonomous robots to navigate in unknown environments, such as laboratories, markets, or factories, without colliding with glass walls or windows. Moreover, transparent object segmentation is a fundamental technique for other transparent object perception tasks, such as object pose estimation. In this section, we provide an overview of single-image transparent object segmentation methods developed over the past decade.
2.1. Hand-Crafted Feature-Based Methods
In early studies on transparent object segmentation, visual cues such as boundary features and strong highlights on the surface were mainly used to predict the regions of transparent objects [9,10]. McHenry et al. [9] presented a region-based segmentation method for detecting objects made of transparent materials such as glass. They combine two complementary measures of affinity between regions made of the same material and discrepancy between regions made of different ones into a single objective function and use the geodesic active contour framework to minimize this function over pixel labels. However, these methods only work well under the strong assumption that the background is similar on both sides of all glass edges.
2.2. CNN-Based Methods
In recent years, convolutional neural networks have seen extensive use by researchers for transparent object segmentation [11,12,13]. Chen et al. [14] introduced TOM-Net, a U-shaped method with consistent feature space dimensions in both encoder and decoder layers. Madessa et al. [15] employed Mask R-CNN to detect individual transparent objects. Mei et al. [16] proposed GDNet, which utilized a large-field contextual feature integration module and convolutional block attention module (CBAM) for feature fusion. Xu et al. [17] utilized dense connections between different atrous convolution blocks to restore detailed information for glass segmentation. Ref. [18] used multiple Discriminability Enhancement (DE) modules and Focus-and-Exploration-Based Fusion (FEBF) for coarse-to-fine glass segmentation. Xie et al. [3] introduced TransLab, a boundary-aware segmentation method that leverages boundaries to enhance segmentation performance. Cao et al. [19] proposed a boundary-aware segmentation method with an adaptive ASPP module capturing features of multiple receptive fields. However, edge supervision [3,19] may limit the generality of learning objects with various shapes. To address this, He et al. [20] introduced EBLNet, which utilizes an edge-aware point-based graph convolution network module for enhanced boundary prediction. Lin et al. [21] utilized a Rich Context Aggregation Module (RCAM) to extract multi-scale boundary features and a reflection-based refinement module for differentiating glass regions from non-glass regions. Finally, Lin et al. [22] proposed a method for glass surface detection by integrating contextual relationships of scenes with spatial information, differing from other works that focus on low-level feature extraction, such as boundary and reflections.
2.3. Transformer-Based Methods
In recent years, Transformer has been successfully applied in both high-level vision and low-level vision, including transparent object segmentation [23,24]. Xie et al. [2] developed a transformer-based network (Trans2Seg) for transparent object segmentation with a transformer encoder–decoder architecture. The transformer encoder in Trans2Seg offers a crucial global receptive field for transparent objects segmentation. Meanwhile, the transformer decoder adopts a dictionary look-up approach with a series of learnable queries, where each query represents a distinct object category. Zhang et al. [25] propose Trans4Trans, an architecture utilizing a transformer-based encoder and decoder, featuring a dual-head design to address transparent object segmentation, and incorporating a Transformer Parsing Module to integrate multi-scale representations. Trans2Seg and our proposed method share similar components in the pipeline, including Transformer encoder and decoder, and a set of learnable class prototypes as the query. The biggest difference is the learnable class prototype interaction with the feature map. Trans2Seg uses a CNN-Transformer hybrid backbone network as an encoder to generate feature maps with a single resolution and interacts with each class prototype using the feature maps generated by the last encoder module. Our proposed method adopts a pure transformer architecture encoder to generate multi-level feature maps with resolution differences, and each class prototype interacts with the hierarchical feature maps output by each encoder module.
3. Our Method
This section introduces the TOSQ model, which draws upon and refines the ideas of transparent object semantic segmentation methods. As shown in Figure 1, the TOSQ model is based on the transformer architecture model. The TOSQ model includes a multi-scale hierarchical Transformer encoder, a decoder composed of several query parsing modules QPM (Query Parsing Module), and a lightweight small prediction head. Given an image with size , we first divide it into patches and use these patches as input to the hierarchical Transformer encoder to get multi-level features with resolution of the original image. Then, the QPM module in the decoder combines the multi-level feature maps with a set of learnable class prototypes. These class prototypes have a size of , where is the number of categories. This combination generates a new set of size-invariant but parsed class prototypes. The attention feature map of the input class prototype to the input feature map has a size of , Here, is the number of attention heads in the multi-head cross-attention layer of the QPM module. The dimensions and represent the height and width of the feature map output by the encoder module, respectively. Specifically, and correspond to the resolutions , , and for the respective encoder outputs, ensuring consistency with Figure 1. Finally, the attention feature maps output by the QPM modules are fused, and the fused attention feature maps are fed into a lightweight prediction head to obtain the final prediction result. In the remainder of this section, we detail the proposed encoder and decoder designs.
3.1. Encoder
To obtain high-resolution weak semantic information feature maps to preserve the detailed information of object boundaries in the image and low-resolution strong semantic information feature maps to obtain the semantic category features of objects in the image, we adopt the MiT (Mix Transformer encoders) in the Segformer model [26] as the image feature encoder. The design of MiT is somewhat inspired by the ViT (Vision Transformer) [27] model and has been customized and optimized for semantic segmentation. Unlike ViT, which can only generate single-resolution feature maps, given an input image, MiT will generate multi-level features like convolutional neural networks. After each encoder module, the image resolution will be downsampled by a quarter, and the channel dimension will increase to maintain more information. The structure of each MiT encoder module is shown in Figure 1b. MiT, which can provide both high-resolution coarse-grained features and low-resolution fine-grained features, can effectively improve the performance of semantic segmentation. To achieve a balance between accuracy and speed, the TOSQ model proposed in this paper selects MiT-B2 as the encoder. The four encoder modules have 3, 4, 6, and 3 repetitions, respectively. The customized and efficient multi-head self-attention layer has 1, 2, 5, and 8 heads, respectively. In the original formulation, the query Q, key K, and value V matrices all share the dimension , where denotes the flattened spatial length, is the dimension of each head. Self-attention is then computed as
where the inner product measures the pairwise similarity between queries and keys, and the resulting weights are applied to the values V.
To lower the quadratic complexity, MiT introduces a sequence-reduction factor R. The key tensor K is first reshaped to dimensions , then projected back to C channels via a linear layer:
thereby reducing the self-attention complexity from to . Therefore, the new K has dimensions . As a result, the complexity of the self-attention mechanism is reduced from to . In MiT-B2, the sequence scaling factors R for the four encoder modules are 8, 4, 2, and 1, respectively.
3.2. Decoder
The proposed TOSQ model employs a novel decoder architecture consisting of four sequential QPMs. Each QPM performs an adaptive fusion between the feature maps from corresponding encoder stages and a set of learnable class prototypes, generating two outputs: (1) refined class prototypes for subsequent modules, and (2) attention feature maps preserving the spatial dimensions of the input features.
The decoding process fundamentally reformulates semantic segmentation as a dynamic dictionary query problem. In this framework, the class prototypes, representing meta-features of target categories, serve as learnable queries. Encoder-derived feature maps are projected to aligned dimensions as keys and values. A multi-head cross-attention mechanism then establishes correspondence between queries (prototypes) and keys (image features).
The attention feature maps produced at each stage encode the spatial distribution of prototype matches, which are progressively aggregated to form the final segmentation mask. Simultaneously, the cross-attention operation outputs updated prototypes that incorporate image-specific adaptations. This iterative refinement enables context-aware prototype evolution across QPM stages, hierarchical feature integration from local patterns to global semantics, and adaptive adjustment to varying transparent object characteristics.
The complete architecture effectively transforms transparent object segmentation into a multi-scale dictionary lookup process, where prototypes dynamically adapt to input-specific visual patterns through successive refinement stages.
In detail, due to the significant influence of the external environment on the texture of different types of transparent objects, the details between classes are very similar and can only be distinguished by shape based on the environment. Therefore, explicitly incorporating category information into the model can help the model correctly distinguish the types of transparent objects. Therefore, we design a set of parameter learnable class prototypes as one of the inputs for the decoder in the TOSQ model, with a size of , where is the number of categories in the dataset, and is the hidden dimension of each class tensor. Due to limited computing resources and a trade-off between speed and accuracy, the hidden dimension selection for each class of the learnable class prototype in the SQT model proposed in this paper is 128.
The internal details of the QPM module are shown in Figure 2. The feature map output from the i-th encoder module is first subjected to a layer of linear transformation, aligning the size of the channel dimension with the size of the hidden dimension of the class prototype . In order to enable cross attention between the feature map and the class prototype , after dimension alignment, the new feature map is flattened to a size of and becomes . Next, in order to model and refine the interior of each class prototype tensor, the operation results of the multi-head cross-attention layer are input into a feedforward linear layer FFN after residual connection and layer normalization. This layer contains two fully connected layers, the first fully connected layer magnifies the input hidden dimension by four times, and the second fully connected layer scales the hidden dimension back. Finally, after residual connections and layer normalization, the output from FFN yields a new class prototype that has been parsed by the QPM module and feature maps.
After the input image is processed by the encoder and decoder, a series of feature maps and attention feature maps are obtained. To obtain the final prediction mask, this paper also designs a small, lightweight prediction head, whose internal architecture is shown in Figure 1c. To provide more detailed boundary contours of transparent objects in the final prediction result, the input of this small prediction head includes not only the output result A of the query parsing module QPM but also the high-resolution low semantic information feature map output by the first encoder module in the encoder. The feature map output by the first encoder module has not undergone much deep modeling, and the resolution is also high, retaining a lot of detailed information about the target category. Participating in the calculation of the prediction mask together can help obtain more accurate prediction mask contours, which can effectively improve the accuracy of semantic segmentation results. Before concatenating feature map and attention feature map A, it is necessary to align their dimensions. The feature map output from the decoder module will first be expanded in the first dimension within the prediction head, meaning its dimension size will increase from and be extended to ; then, the first dimension is repeated times, and the dimension size becomes . Then, it sends the physically aligned feature map into a convolution kernel with a convolutional layer for semantic space modeling and alignment after the batchnormalization [28] and ReLU activation function [29]. Then, the result of concatenating feature map with attention feature map A is also sent to a Conv-BN-ReLU module and then upsampled to obtain the final prediction mask.
4. Experiments
4.1. Details
We used the mmsegmentation open source code framework [30] based on Pytorch to implement the TOSQ model and conducted experiments on the Trans10Kv2 dataset [2], as shown in Figure 3. The Trans10Kv2 dataset contains a total of 10,428 images, including 11 transparent object categories: shelves, jars, freezers, windows, glass doors, glasses, cups, glass walls, glass bowls, water bottles, and boxes. Among them, 5000 images are used as the training set, 1000 images are used as the validation set, and 4428 images are used as the test set. In addition, the TOSQ model experiment proposed in this article uses an Adam optimizer with an epsilon parameter of and weight decay coefficient of . The sample size for each batch is 8, the total batch iteration is 160 lk, and the experiment is conducted using 1 NVDIA Geforce RTX 3090 (NVIDIA Corporation, Santa Clara, CA, USA). The learning rate is set to and is attenuated using a Poly strategy with parameter of 0.9. In order to ensure stable convergence of the model, a learning rate warm-up was also used, allowing the learning rate to linearly increase from the initial learning rate of one millionth to the present value within 1.6 k iteration steps, and then attenuated. Although the TOSQ model does not require scaling the image to a fixed size due to position encoding, in order to fairly compare with models such as Trans2Seg [2] and Trans4Trans [25], the image is randomly scaled and randomly cropped to a resolution of during training. During testing, the image is uniformly scaled to a resolution of , and the aspect ratio of the image is maintained during scaling. The remaining portion is filled with 0, and the filled portion is not included in the loss calculation and prediction.
Performance was evaluated using three standard semantic segmentation metrics: Pixel Accuracy (Acc), Mean IoU (mIoU), and Category IoU.
4.2. Comparisons with State-of-the-Art Models
As shown in Table 1, TOSQ achieves state-of-the-art performance on the Trans10K-V2 benchmark with 76.63% mIoU and 95.34% accuracy, outperforming previous transformer-based methods like Trans4Trans by +1.49% mIoU and +0.33% accuracy while maintaining similar computational efficiency.
The performance gains are particularly pronounced in challenging categories where transparent objects exhibit visual ambiguity. (1) Structural elements: windows (+23.59% mIoU) and glass doors (+11.22%); (2) thin-walled containers: glass bowls (+10.05%), cups (+2.48%), and cans (+7.48%). This advancement stems from two key innovations in our architecture. First, the QPM enables dynamic feature adaptation through prototype-based dictionary lookup. Second, learnable class prototypes explicitly encode category-specific priors for long-range context modeling (critical for large transparent surfaces) and fine-grained semantic discrimination (essential for similar categories).
The consistent improvements across all metrics validate TOSQ’s effectiveness in handling the unique challenges of transparent object segmentation, particularly in scenarios requiring optical distortion compensation, inter-class similarity resolution, and structural detail preservation.
4.3. Ablation Study
4.3.1. Ablation Study on Encoder
Since one of our critical designs lies in a hierarchical Transformer encoder, we now analyze the effect of the encoder block of TOSQ, as shown in Table 2. It can be seen that as the number of encoder blocks increases and the model parameters increase, the Acc and mIoU of transparent objects show a significant increase. Especially when the number of encoder blocks increases from three to four, Acc increases from 85.86% to 95.34%, and mIoU increases from 38.90% to 76.63%. This indicates that advanced semantic information is crucial for transparent object segmentation.
4.3.2. Ablation Study on the Class Prototypes
The learnable class prototype serves as a cornerstone of TOSQ’s architecture. To investigate its design impact, we conduct systematic experiments evaluating how the prototype dimension (D) affects segmentation performance (Table 3). Through experiments, expanding the hidden dimension from D = 128 to D = 256 yields consistent metric improvements: Acc increases from 95.34% to 95.53%, and mIoU increases from 76.63% to 77.47%. This performance gain demonstrates: the prototypes’ capacity to encode richer feature representations at higher dimensions and the effectiveness of dimension scaling for both global and class-wise metrics. However, considering computational trade-off between speed and accuracy, the hidden dimension selection for each class of the learnable class prototype in the TOSQ model is set to 128.
4.4. Cross-Dataset Generalization on Cityscapes
To evaluate the generalization capability of TOSQ beyond transparent objects, we further tested it on the Cityscapes urban-scene dataset. All models (TOSQ and Trans4Trans) were evaluated under identical experimental protocols: both used a input resolution, a MIT-B2 backbone pre-trained on ImageNet, and were trained for 160 k iterations with a batch size of 2 (training) and 1 (testing). Optimization was performed using Adam ( , weight decay ) with a learning rate of , which was decayed using a polynomial schedule (power = 0.9).
Table 4 shows that TOSQ achieves higher mIoU (+3.0%) and Pixel Accuracy (+1.0%) than Trans4Trans, demonstrating its robustness to domain shifts (transparent objects → urban scenes). Notably, TOSQ excels in fine-grained categories such as traffic signs (+6.5%), vegetation (+0.3%), and person (+0.9%), validating the effectiveness of its learnable class prototypes for semantic discrimination.
5. Conclusions
In this paper, we introduce a novel approach to the semantic segmentation of transparent objects by leveraging a Transformer-based model, TOSQ, which incorporates the innovative QPMs. The TOSQ model’s encoder, built upon the MiT backbone, provides a global receptive field and generates hierarchical multi-resolution feature maps, significantly enhancing the model’s performance in transparent object segmentation. The decoder, composed of multiple QPMs, reformulates the segmentation task as a dictionary query problem using learnable class prototypes, effectively improving the model’s ability to distinguish between similar categories. Experimental results on the Trans10K-V2 dataset demonstrate that TOSQ achieves state-of-the-art performance, with 76.63% mIoU and 95.34% accuracy, outperforming both convolutional neural network-based and other transformer-based methods. Furthermore, TOSQ achieves these results with a computational efficiency of only 41.48 GFLOPs, highlighting its effectiveness and efficiency for real-world applications. TOSQ’s RGB-only design struggles with variable lighting, transparent/specular surfaces, and industrial safety requirements (≤0.1% error, ≥30 FPS). Future work should integrate multimodal inputs (e.g., polarization, LiDAR) and uncertainty estimation, validated on industrial datasets (e.g., MVTec AD).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Xu Y. Nagahara H. Shimada A. Taniguchi R. Transcut: Transparent object segmentation from a light-field image Proceedings of the IEEE International Conference on Computer Vision Santiago, Chile 7–13 December 201534423450
- 2Xie E. Wang W. Wang W. Sun P. Xu H. Liang D. Luo P. Segmenting transparent object in the wild with transformerar Xiv 20212101.08461
- 3Xie E. Wang W. Wang W. Ding M. Shen C. Luo P. Segmenting transparent objects in the wild Proceedings of the Computer Vision—ECCV 2020: 16th European Conference Glasgow, UK 23–28 August 2020 Springer Cham, Switzerland 2020696711
- 4Lin J. Yeung Y.H. Lau R.W. Depth-aware glass surface detection with cross-modal context miningar Xiv 20222206.11250
- 5Ummadisingu A. Choi J. Yamane K. Masuda S. Fukaya N. Takahashi K. Said-nerf: Segmentation-aided nerf for depth completion of transparent objects Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)Abu Dhabi, United Arab Emirates 14–18 October 202475357542
- 6Huo D. Wang J. Qian Y. Yang Y.H. Glass segmentation with RGB-thermal image pairs IEEE Trans. Image Process.2023321911192610.1109/TIP.2023.325676237030759 · doi ↗ · pubmed ↗
- 7Mei H. Dong B. Dong W. Yang J. Baek S.H. Heide F. Peers P. Wei X. Yang X. Glass segmentation using intensity and spectral polarization cues Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition New Orleans, LA, USA 18–24 June 20221262212631
- 8Yu R. Ren W. Zhao M. Wang J. Wu D. Xie Y. Transparent objects segmentation based on polarization imaging and deep learning Opt. Commun.202455513024610.1016/j.optcom.2023.130246 · doi ↗