Optimizing One-Sample Tests for Proportions in Single- and Two-Stage Oncology Trials
Alan David Hutson

TL;DR
This paper introduces a new statistical method to improve the efficiency and accuracy of early-stage cancer trials by reducing sample sizes and controlling errors better than traditional approaches.
Contribution
A novel convolution-based method combining binomial and normal distributions is proposed to enhance Type I error control and trial efficiency.
Findings
The convolution-based method achieves more precise Type I error control compared to traditional binomial tests.
The new two-stage design with early stopping for futility reduces sample sizes and trial costs.
Simulations show the proposed approach improves efficiency without compromising statistical rigor.
Abstract
Phase II oncology trials often use single-arm designs when randomized trials are too expensive or impractical, such as in rare diseases. These trials typically test whether a treatment’s success rate exceeds a specified benchmark. Standard statistical methods, like the exact binomial test or Simon’s two-stage design, are commonly used but tend to be conservative, often underestimating the actual probability of incorrectly rejecting a true null hypothesis (Type I error). To address this, a new method is proposed that blends the binomial distribution with simulated normal data to create an unbiased estimate of treatment success. This convolution-based method improves the precision of Type I error control and can lead to more efficient trial designs. It also introduces a new two-stage design that includes an early stopping point for futility, offering flexibility and reduced sample sizes…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
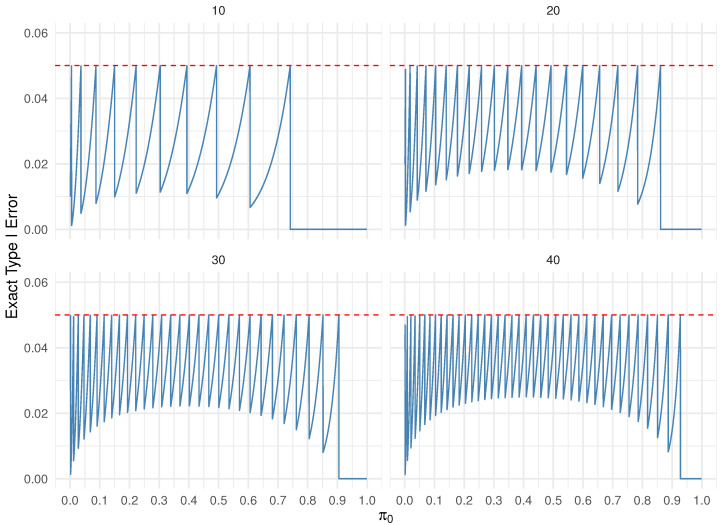 Figure 1
Figure 1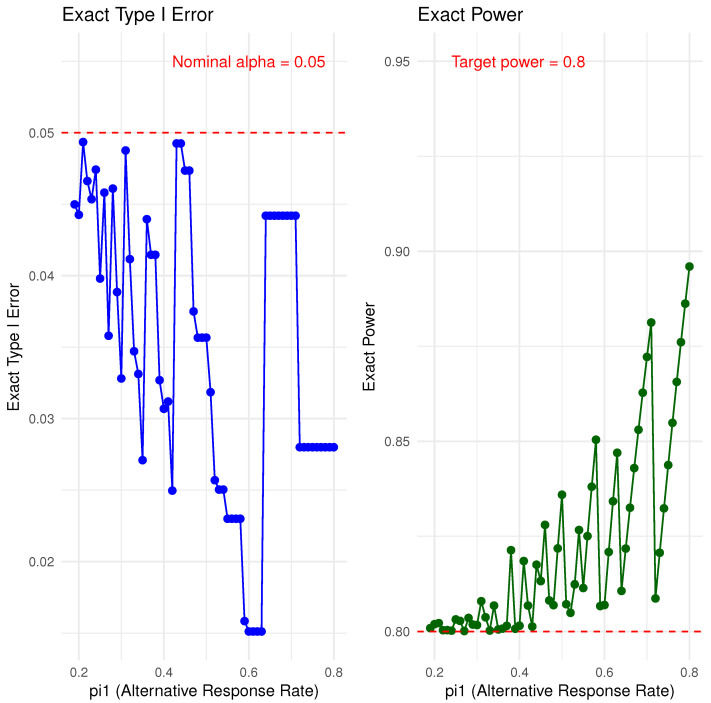 Figure 2
Figure 2- —NRG Oncology Statistical and Data Management Center
- —Immuno-Oncology Translational network (IOTN) Moonshot
- —Acquired Resistance to Therapy network (ARTNet)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods in Clinical Trials · Optimal Experimental Design Methods · Cancer Genomics and Diagnostics
1. Introduction
Common designs for phase II oncology trials typically focus on testing the hypothesis versus in a one-arm non-randomized setting. Although randomized trials are generally preferred, considerations such as cost, feasibility, and the rarity of certain cancer types often necessitate the use of single-arm designs. The estimated per-patient cost of conducting an oncology clinical trial was approximately 59,500, as reported by Batelle in 2013 [[1](#B1-cancers-17-02570)]. More recent studies, particularly those involving cellular therapies, report substantially higher costs, in some cases exceeding 500,000 per treatment cycle [2,3,4]. Consequently, there is a critical need to optimize both phase II and phase III randomized trial designs to shorten trial duration and reduce required sample sizes. These efforts not only address escalating costs but also aim to expedite the availability of effective therapies to cancer patients. The focus of this work is towards optimizing phase II one-arm oncology trials with a binary endpoint in terms of reduced sample size and increased efficiency.
Commonly employed binary endpoints in phase II trials include objective response, complete response, and progression-free, event-free, or overall survival at fixed time points, such as 6 months or 1 year. A key feature of non-randomized, single-arm phase II trials is that, in many cancer indications, the standard-of-care population response rate is sufficiently well-characterized to serve as a comparator. If no promising signal is observed, further development, including progression to a randomized phase II or III trial, is typically not pursued.
In single-stage designs, the hypothesis about a rate or proportion, versus , is most often tested using an exact binomial test, where the Type I error rate . In contrast, one-arm two-stage designs commonly employ Simon’s two-stage design [5], using either the minimax or optimal design configurations. The minimax design minimizes the total sample size, while the optimal design minimizes the expected sample size under the null hypothesis, where with the constraints are that the Type I error rate and the Type II error rate . Both designs incorporate an interim futility analysis at a predetermined sample size to allow early termination for lack of efficacy. Historically, it is noteworthy that very similar sampling schemes were developed decades earlier in the field of quality control, referred to as double sampling plans [6], with Simon’s two-stage design representing a special case of these earlier methods [7].
The issue with both single-stage and two-stage designs is that the exact Type I error rate is often considerably lower than the desired Type I error rate and the desired power is often larger than the desired power value , due to the discreteness of the underlying binomial distribution under both the null and alternative hypotheses for a given design. This phenomenon is illustrated in the so-called saw-tooth plots in Figure 1, which display the exact Type I error across a range of potential null values for with sample sizes . As a result, these tests can be conservative in certain scenarios where the exact Type I error rate falls substantially below the target level .
One approach to mitigate this conservatism is to incorporate a continuity correction [8]; however, this does not eliminate the saw-tooth behavior in Type I error control. Similarly, the power function may also exhibit a saw-tooth pattern and can be non-monotonic [9]. For a fixed sample size n, there are n discrete values of corresponding to ( is infeasible), at which the Type I error equals , given by
where is the inverse regularized incomplete beta function.
Interestingly, Simon’s two-stage design can exhibit the same phenomenon, where the exact Type I error rate is often much lower than the derired Type I error rate . In this case, however, we cannot produce a saw-tooth plot as a function of alone, since Simon’s two-stage design also depends on the choice of the alternative response rate, denoted . In Figure 2, we present the exact Type I error rate and power for testing versus , with and varying from 0.19 to 0.8, while fixing and power = 0.80 for the minimax design. As increases, the required total sample size decreases, thus reducing the dimensionality of the sample space for design choices. In fact, for this example, there are very few instances where the exact Type I error rate approaches the nominal . For example, when , the exact Type I error rate is 0.027 with a final stage sample size of . Increasing to 0.36 raises the exact Type I error rate to 0.044, with a corresponding final stage sample size of . For smaller values of n, the exact Type I error rate can drop as low as 0.015. Similarly, as the sample size decreases with increasing , the exact power may deviate considerably from the target power.
In this note, we illustrate how a straightforward convolution of a binomial random variable with a simulated normal random variable enables the construction of an unbiased estimator for the rate parameter , and facilitates inference for versus with precise Type I error control. This in turn can reduce sample size requirements for both one-stage and two-stage designs.
In Section 2, we define the convolution estimator, derive its density and distribution functions, outline key theoretical properties including its expectation and variance, and present a toy example to demonstrate the p-value calculation.
We then provide a detailed comparison of the new convolution-based test with the exact binomial test in terms of Type I error control and power. In Section 3, we introduce a new two-stage design with a futility stopping rule that also achieves precise Type I error control. A direct comparison between the convolution-based two-stage design and Simon’s two-stage design is presented.
In Section 4, we provide real-world examples of both one-stage and two-stage designs, demonstrating how the convolution-based approach can reduce the cost and duration of clinical trials based on published design parameters. We conclude with final remarks.
2. Convolution Estimator
Our approach for constructing a test of the hypothesis versus , with precise Type I error control, utilizes a convolution-based method, in which synthetic continuous noise is added to discrete binomial data. Specifically, let denote the binomial response over n subjects, where is the success probability. Let be an independent normal random variable with mean 0 and standard deviation h. We define the continuous variable and derive its probability density and cumulative distribution functions.
The probability density function (PDF) of Z, denoted , is obtained by convolving the binomial probability mass function of Y with the normal density of X. Since Y is discrete and X is continuous, this results in a finite mixture of normal densities:
Each component of the mixture is centered at , with mixing weights given by the binomial probabilities .
Similarly, the cumulative distribution function (CDF) of Z, denoted , is derived by conditioning on the values of Y:
where is the standard normal CDF defined as
To understand the properties of the test statistic, we compare the moments of Y and Z. The expectation and variance of Y are given by
Since Y and X are independent, the corresponding moments of follow directly:
Thus, the mean of Z remains identical to that of Y, while the variance of Z is increased by an additive term , capturing the additional variability introduced by the normal perturbation. Throughout this note, we fix the value of . Although this results in only a modest increase in the variance of Z we will demonstrate that this small adjustment is sufficient to produce tests with substantially improved power while maintaining the precise Type I error level.
To test against at significance level , we reject if , where the critical value c is chosen to satisfy
The solution for c is via numerical methods. Similarly, the p-value is given by
where z is the value of the observed convolution-based test statistic.
Under the alternative hypothesis , the corresponding CDF is
and the power of the test at is given by
2.1. Toy Example
We simulated the random variables and with , and computed . For each run, we calculated the convolution-based p-value and the exact binomial p-value testing
We see from Table 1 that the convolution-based p-values are consistently close to the exact binomial p-values, but tend to be slightly smaller due to the smoothing effect introduced by the normal perturbation X. The addition of this small normal noise transforms the discrete binomial distribution into a continuous mixture distribution, which leads to slightly different tail probabilities. For runs with larger observed binomial counts y, both the convolution and exact tests yield smaller p-values, indicating stronger evidence against the null hypothesis .
2.2. Convolution Approach and Exact Binomial Test Comparison
Table 2 presents a Type I error control and power comparison between the convolution-based test and the exact binomial test for a sample size of , across varying null hypotheses and corresponding alternatives . For each , a critical value c was determined so that the convolution-based test controls the Type I error exactly at level , as defined in Equation (3). The corresponding power was computed using Equation (5), noting that power equals the Type I error when . In contrast, the exact binomial rejection threshold k was chosen to ensure that the Type I error remained strictly below .
Table 3 reports analogous results for a larger sample size of . As expected, power increases for both methods with larger n. Across both settings, the convolution-based test consistently achieves the nominal Type I error and provides greater power than the exact binomial test, particularly when the exact binomial test is overly conservative relative to Type I error control. This improved performance is attributed to the smoothing introduced by the normal perturbation, which results in a more refined and responsive rejection region. These findings underscore the practical utility of the convolution-based test in discrete-data settings, especially when measurement or process noise is present and sample sizes are limited. The only time the classic test and the convolution based test are equivalent are the n values for where Equation (1) is satisfied.
3. Two Stage Design
Similar to the one-stage test, we construct a two-stage test of the hypothesis versus , offering precise control of the Type I error rate and allowing for early stopping due to futility. Let the total sample size be . After the first subjects have completed their endpoint assessments, a futility stopping rule is applied.
As in the one-stage design, let denote the observed value of the convolution-based test statistic after the first subjects, and let be the corresponding statistic based on an independent second cohort of subjects. Under the null hypothesis , define the p-values as
where and follow a uniform distribution by the probability integral transform. The cumulative distribution function is defined in Equation (4).
Our approach uses a p-value threshold at the interim analysis and applies Stouffer’s weighted z-score method for the final efficacy analysis [10]. Define the transformed statistics:
where is the quantile function of the standard normal distribution.
The combined test statistic is given by the following:
where the weights are defined as and . With this weighting scheme, the statistic T follows a standard normal distribution under , i.e., .
The interim futility rule is to terminate the study early if , where the threshold may be specified by the user or selected to optimize statistical power or minimize the expected sample size,
If the study does not stop early for futility, the final p-value is computed as , where denotes the standard normal CDF. The null hypothesis is rejected if , where is adjusted to ensure that the overall Type I error rate is controlled at the nominal level .
To determine , let . The conditional probability of rejecting given that the futility boundary is not crossed is:
where is the standard normal density function. To ensure the overall Type I error rate is , we solve for c in the equation:
and define the adjusted significance level as , which satisfies . Once is determined numerically power can be calculated under via simulation. For a fixed n we can find combinations of and such that the overall and power is greater than or equal to the desired power. Practically speaking one can start at the n determined by the Simon two-stage design and reduce by increments of 1 until the power constraint is no longer satisfied. The search is over values of and , with . This will be illustrated in the next section.
Convolution Approach and Simon Two-Stage Design Comparison
There is no straightforward way to directly compare the convolution-based approach with Simon’s two-stage design. A key distinguishing feature is that the convolution-based method precisely controls the Type I error rate, whereas Simon’s two-stage design may be conservative in some scenarios, as illustrated earlier in Figure 2. In settings where the actual Type I error of Simon’s design falls well below the nominal level, the convolution-based method can achieve the same desired power with a smaller sample size, particularly when the difference between and is substantial.
To illustrate, we consider testing versus with and ranging from 0.3 to 0.6 in increments of 0.1. The results of various Simon two-stage designs are presented in Table 4, showing the corresponding total sample size, exact Type I error, power, expected sample size (EN_0_), and probability of early stopping.
Similarly, Table 5 displays results from the convolution-based two-stage designs across the same values of . For each design, we considered a range of values from 0.2 to 0.7 in steps of 0.01, and we report the total sample size n, stage-wise sample sizes and , , power, expected sample size (ESN), adjusted , for testing at the second stage, and the probability of early stopping, which is equal to . The designs in Table 5 represent a subset of possible scenarios to provide a concise summary.
The convolution-based approach demonstrates a clear advantage by achieving slightly smaller sample sizes across all settings. Moreover, it is not constrained by the range of early stopping probabilities observed in the Simon designs (approximately 0.549 to 0.810 in our example). Instead, the convolution-based method allows the user to specify any desired (and thus early stopping probability), offering greater flexibility to tailor the design to the specific goals and constraints of a given clinical trial.
4. Real World Examples
4.1. One-Stage Designs
4.1.1. Example 1
Our first example [11] is from a study of patients with concomitant advanced non-small cell lung cancer (NSCLC) and interstitial lung disease (ILD). This prospective, multicenter, single-arm phase 2 trial investigated the efficacy and safety of albumin-bound paclitaxel (nab-paclitaxel) in combination with carboplatin in patients with both advanced NSCLC and ILD. The primary endpoint was the overall response rate (ORR), testing versus , with , alternative , , and power = 0.80. Based on an exact binomial test, this required a sample size of . The actual study enrolled subjects between April 2014 and September 2017, corresponding to an average accrual rate of approximately 1.3 subjects per month.
Using the same design parameters, the convolution-based test would require subjects to achieve a power of 0.8117, or for a power of 0.7967, potentially reducing the trial duration by 4 to 5 months with the corresponding cost savings. The p-value was under both the exact binomial and convolution-based approaches. If a prorated response of 17 out of 31 positive responses were observed, the p-value using the convolution-based method would still be <0.001.
4.1.2. Example 2
Our next example study [12] enrolled metastatic prostate cancer patients with AR-V7-expressing circulating tumor cells into a prospective phase II trial. The primary endpoint was PSA response, with hypothesis testing conducted as versus , where , , , and target power = 0.80. The true Type I error rate for the exact binomial test was 0.0362. A positive outcome in the study was thus defined as ≥3 of 15 patients achieving a PSA response.
Using the same design parameters, the convolution-based test would require subjects to achieve a power of 0.824, or for a power of 0.793. In the actual trial, 2 out of 15 subjects achieved a PSA response, yielding a p-value of 0.14 using the exact binomial test. The convolution-based test yielded a p-value of 0.106. Although not statistically significant at the level, this result demonstrates the relative efficiency of the convolution-based approach.
4.2. Two-Stage Designs
4.2.1. Example 1
Our next example [13] is based on a study evaluating vinorelbine in advanced non-small cell lung cancer (NSCLC) patients aged 70 years or older. The study employed a multicenter, two-stage phase II design following Simon’s optimal method. The primary endpoint was objective response rate (ORR), with hypothesis testing structured as versus , where , , , , and target power = 0.80.
The final sample size under Simon’s design was with an interim futility analysis planned at subjects. The actual Type I error rate achieved was 0.048. Table 6 presents three example two-stage designs generated using the convolution-based estimator. Notably, if one is willing to delay the interim futility analysis beyond , the total required sample size can be reduced from to , offering a more efficient design compared to Simon’s optimal design alternative. Even maintaining the interim analysis at , the convolution-based approach can still reduce the total sample size to .
In the observed trial data, 5 of the initial 18 subjects achieved a positive ORR, with a total of 10 ORR responses observed out of 43 by the end of the study. Simon’s optimal design specified early stopping for futility if 3 or fewer ORR responses were observed in the first stage, and declared efficacy if 8 or more total responses were observed at the second stage.
For each convolution-based design in Table 6, we retrospectively aligned the observed data to the alternative designs to estimate what would have occurred under those configurations:
- For , : Assuming 7 out of 27 responses, the futility p-value was 0.011, below the stopping threshold . The final-stage p-value, assuming 8 out of 35 total responses, was 0.0158, significant at the adjusted level .
- For , : Assuming 6 out of 24 responses, the futility p-value was 0.002, below . The final-stage p-value based on 8 of 36 responses was 0.0162, also significant at .
- For , : Assuming 5 out of 18 responses, the futility p-value was 0.015, which is less than . The final p-value with 8 of 37 responses was 0.020, significant at .
This example again highlights the potential cost savings and efficiency gains achievable with the convolution-based approach compared to Simon’s two-stage design, while maintaining rigorous Type I error control and statistical power.
4.2.2. Example 2
Our next example [14] comes from a publication describing the LuDO-N trial, a phase II, open-label, multicenter, single-arm, two-stage clinical trial in children with high-risk neuroblastoma, utilizing an alternative administration schedule of Lutetium DOTATATE. The primary endpoint is the response rate, assessed by the Revised International Neuroblastoma Response Criteria one month after completion of therapy. Hypothesis testing is structured as versus , where , , , , and the target power is 0.80.
The proposed design follows Simon’s Two-Stage Minimax design. Recruitment is expected to be completed within 3–5 years. Based on the specified parameters, the Simon design requires a total sample size of , with a first-stage futility analysis at , yielding a true Type I error rate of 0.0874.
In contrast, an alternative convolution-based design would require a total of subjects, with in the first stage, using a futility threshold of and a final adjusted significance level of . If the projected recruitment rate is 24 subjects over 5 years (approximately 4.8 subjects per year), the convolution-based design would reduce the total accrual period by roughly one year.
5. Conclusions
The convolution-based approach presented in this work offers a flexible and efficient alternative to traditional exact methods for designing and analyzing single-arm phase II oncology trials with binary endpoints. By convolving the binomial distribution with a simulated normal random variable, this method produces an unbiased estimator for the response rate and achieves precise Type I error control. This leads to reduced sample size requirements in both one-stage and two-stage designs, while maintaining desirable operating characteristics.
A significant advantage of the convolution framework is its adaptability. It can be easily modified to incorporate an interim analysis for either futility or combined efficacy and futility, allowing for early decision-making and further optimization of trial resources. Moreover, the convolution-based method provides a smooth and continuous approximation to the binomial tail distribution, making it especially valuable in scenarios where measurement error or process variability exists, and a continuous p-value function is preferred.
Overall, this approach enhances the efficiency of early-phase oncology clinical trial design and provides a theoretically sound and practically implementable alternative to exact binomial and Simon’s two-stage methods. It holds particular promise for high-cost therapeutic areas, such as oncology and cellular therapies, where efficient trial execution is critical.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Prepared by Battelle Technology Partnership Practice Biopharmaceutical Industry-Sponsored Clinical Trials: Impact on State Economies Prepared for Pharmaceutical Research and Manufacturers of America (Ph RMA).2015 Available online: http://orclinicalresearch.com/wp-content/uploads/2018/12/battelle-2015-study.pdf(accessed on 8 July 2025)
- 2Leighl N.B. Nirmalakumar S. Ezeife D.A. Gyawali B. An Arm and a Leg: The Rising Cost of Cancer Drugs and Impact on Access Am. Soc. Clin. Oncol. Educ. Book. Am. Soc. Clin. Oncol. Annu. Meet.202141 e 1e 1210.1200/EDBK_10002833956494 · doi ↗ · pubmed ↗
- 3Kapinos K.A. Hu E. Trivedi J. Geethakumari P.R. Kansagra A. Cost-Effectiveness Analysis of CAR T-Cell Therapies vs. Antibody Drug Conjugates for Patients with Advanced Multiple Myeloma Cancer Control 2023301810.1177/1073274822114294536651055 PMC 9869188 · doi ↗ · pubmed ↗
- 4Hoover A. Reimche P. Watson D. Tanner L. Gilchrist L. Finch M. Messinger Y.H. Turcotte L.M. Healthcare cost and utilization for chimeric antigen receptor (CAR) T-cell therapy in the treatment of pediatric acute lymphoblastic leukemia: A commercial insurance claims database analysis Cancer Rep.2024 Epub ahead of print 10.1002/cnr 2.198038217445 PMC 10884615 · doi ↗ · pubmed ↗
- 5Simon R. Optimal two-stage designs for phase II clinical trials Control. Clin. Trials 19891011010.1016/0197-2456(89)90015-92702835 · doi ↗ · pubmed ↗
- 6Hamaker H.C. van Strik R. The Efficiency of Double Sampling for Attributes J. Am. Stat. Assoc.19555083084910.1080/01621459.1955.10501969 · doi ↗
- 7Duncan A.J. Quality Control and Industrial Statistics Irwin Homewood, IL, USA 1986
- 8Hutson A.D. Modifying the Exact Test for a Binomial Proportion and Comparisons with Other Approaches J. Appl. Stat.20063367969010.1080/02664760600708723 · doi ↗