Evaluation of GPT-4 Accuracy in the Interpretation of Medical Imaging: Potential Benefits, Limitations, and the Future
Nikoloz Papiashvili, Christina Abshilava, Mohammad H Malik, Tinatin Dzindzibadze, Emeli J Anderson, Sopio Gagua, Vladimir Guruli, Kaveesha Amarasinghe, Nana Gonjilashvili, Irma Tchokhonelidze

TL;DR
This study evaluates how well GPT-4 interprets medical images like X-rays and CT scans, finding it more accurate for some types of images and conditions than others.
Contribution
The study introduces a systematic evaluation of GPT-4's diagnostic accuracy in medical imaging across different modalities and disease types.
Findings
X-ray images were interpreted 2.21 times more accurately than CT scans.
Pelvic imaging accuracy was 6.25 times lower than abdominal imaging.
Neoplastic conditions were interpreted 2.7 times less accurately than bleeding conditions.
Abstract
Introduction The implementation of artificial intelligence (AI) in radiology as a medical decision support system has the potential to enhance diagnostic accuracy and improve patient outcomes. This retrospective study aimed to evaluate the diagnostic capabilities of GPT-4o in interpreting radiological imaging, specifically X-ray, CT, and MRI images, across various organ systems and disease types. Methods A total of 377 cases were collected and presented to GPT-4o with a standardized prompt and no clinical context. The responses were assessed by three independent raters using a five-point rating system. Results X-ray imaging exhibited a 2.21 times higher chance, on average, of being interpreted accurately compared to CT scans (odds ratio (OR): 2.21; 95% confidence interval (CI): 1.33 - 3.69), while pelvic imaging had a 6.25 times lower chance, on average, of being interpreted…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
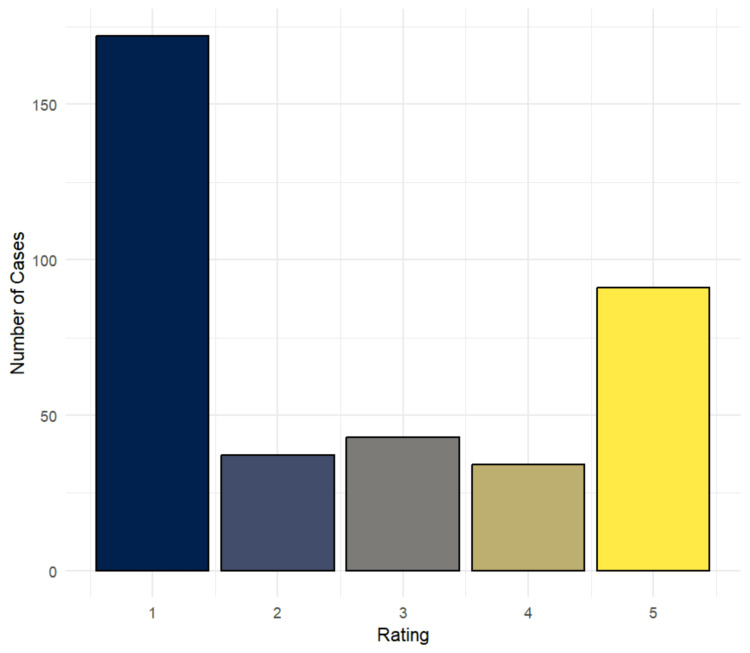 Figure 1
Figure 1 Figure 2
Figure 2| Characteristic | Total | CT | MRI | X-ray |
| N=377 | N=192 (n, %) | N=86 (n, %) | N=99 (n, %) | |
| System | ||||
| Abdomen | 111 | 83 (74.77%) | 4 (3.6%) | 24 (21.62%) |
| Chest | 80 | 48 (60%) | 1 (1.25%) | 31 (38.75%) |
| Extremities | 28 | 0 (0%) | 11 (39.29%) | 17 (60.71%) |
| Head | 88 | 41 (46.59%) | 45 (51.14%) | 2 (2.27%) |
| Pelvis | 31 | 16 (51.61%) | 13 (41.94%) | 2 (6.45%) |
| Spine | 20 | 3 (15%) | 12 (60%) | 5 (25%) |
| Other | 19 | 1 (5.26%) | 0 (0%) | 18 (94.74%) |
| Type | ||||
| Bleeding | 35 | 33 (94.29%) | 2 (5.71%) | 0 (0%) |
| Inflammatory | 62 | 31 (50%) | 10 (16.13%) | 21 (33.87%) |
| Neoplastic | 78 | 37 (47.44%) | 31 (39.74%) | 10 (12.82%) |
| Structural | 174 | 80 (45.98%) | 38 (21.84%) | 56 (32.18%) |
| Normal | 5 | 0 (0%) | 0 (0%) | 5 (100%) |
| Other | 23 | 11 (47.83%) | 5 (21.74%) | 7 (30.43%) |
| Characteristic | CT | MRI | X-ray | Chi-square value | p-value** |
| N=192 (n, %) | N=86 (n, %) | N=99 (n, %) | |||
| Median | 16.690 | 0.034 | |||
| 5 | 35 (18%) | 22 (26%) | 34 (34%) | ||
| 4 | 16 (8.3%) | 8 (9.3%) | 10 (10%) | ||
| 3 | 18 (9.4%) | 12 (14%) | 13 (13%) | ||
| 2 | 19 (9.9%) | 11 (13%) | 7 (7.1%) | ||
| 1 | 104 (54%) | 33 (38%) | 35 (35%) | ||
| Rating | 9.574 | 0.008 | |||
| Satisfactory | 51 (27%) | 30 (35%) | 44 (44%) | ||
| Poor | 141 (73%) | 56 (65%) | 55 (56%) |
| Characteristic | Abdomen | Chest | Extremities | Head | Other | Pelvis | Spine | Chi-square value | p-value |
| N=111* | N=80* | N=28* | N=88* | N=19* | N=31* | N=20* | |||
| Median | N/A | 0.001** | |||||||
| 5 | 21 (19%) | 13 (16%) | 9 (32%) | 29 (33%) | 11 (58%) | 2 (6.5%) | 6 (30%) | ||
| 4 | 13 (12%) | 8 (10%) | 2 (7.1%) | 6 (6.8%) | 3 (16%) | 0 (0%) | 2 (10%) | ||
| 3 | 8 (7.2%) | 8 (10%) | 4 (14%) | 14 (16%) | 1 (5.3%) | 5 (16%) | 3 (15%) | ||
| 2 | 8 (7.2%) | 9 (11%) | 2 (7.1%) | 11 (13%) | 0 (0%) | 5 (16%) | 2 (10%) | ||
| 1 | 61 (55%) | 42 (53%) | 11 (39%) | 28 (32%) | 4 (21%) | 19 (61%) | 7 (35%) | ||
| Rating | 28.733 | <0.001*** | |||||||
| Satisfactory | 34 (31%) | 21 (26%) | 11 (39%) | 35 (40%) | 14 (74%) | 2 (6.5%) | 8 (40%) | ||
| Poor | 77 (69%) | 59 (74%) | 17 (61%) | 53 (60%) | 5 (26%) | 29 (94%) | 12 (60%) |
| Characteristic | Bleeding | Inflammatory | Neoplastic | Normal | Structural | Other | p-value** |
| N=35* | N=62* | N=78* | N=5* | N=174* | N=23* | ||
| Median | 0.018 | ||||||
| 5 | 13 (37%) | 10 (16%) | 14 (18%) | 2 (40%) | 47 (27%) | 5 (22%) | |
| 4 | 4 (11%) | 10 (16%) | 6 (7.7%) | 1 (20%) | 9 (5.2%) | 4 (17%) | |
| 3 | 5 (14%) | 4 (6.5%) | 10 (13%) | 1 (20%) | 17 (9.8%) | 6 (26%) | |
| 2 | 4 (11%) | 10 (16%) | 7 (9.0%) | 0 (0%) | 15 (8.6%) | 1 (4.3%) | |
| 1 | 9 (26%) | 28 (45%) | 41 (53%) | 1 (20%) | 86 (49%) | 7 (30%) | |
| Rating | 0.2 | ||||||
| Satisfactory | 17 (49%) | 20 (32%) | 20 (26%) | 3 (60%) | 56 (32%) | 9 (39%) | |
| Poor | 18 (51%) | 42 (68%) | 58 (74%) | 2 (40%) | 118 (68%) | 14 (61%) |
| Variables | OR (95% CI) |
| Modality | |
| CT | - |
| MRI | 1.48 (0.85, 2.55) |
| X-ray* | 2.21 (1.33, 3.69) |
| System | |
| Abdomen | - |
| Chest | 0.81 (0.42, 1.52) |
| Extremities | 1.47 (0.61, 3.44) |
| Head | 1.50 (0.83, 2.70) |
| Pelvis* | 0.16 (0.02, 0.56) |
| Spine | 1.51 (0.55, 3.99) |
| Other* | 6.34 (2.23, 20.92) |
| Type | |
| Bleeding | - |
| Inflammatory | 0.50 (0.21, 1.18) |
| Neoplastic* | 0.37 (0.16, 0.84) |
| Structural | 0.50 (0.24, 1.05) |
| Normal | 1.59 (0.24, 13.20) |
| Other | 0.68 (0.23, 1.97) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRadiomics and Machine Learning in Medical Imaging · Artificial Intelligence in Healthcare and Education · Radiation Dose and Imaging
Introduction
The role of artificial intelligence (AI) in medicine has emerged as a significant area of research in recent years, and its capabilities have found applications in many aspects of healthcare. While both its text-based interpretation and image recognition skills are remarkable, the latter has been particularly impactful in areas such as diagnosing cancer on histopathology [1], differentiating between skin lesions [2], or assessing lung injury [3].
In the field of radiology, this technology has the potential to streamline the diagnostic workflow, enhance accuracy, improve patient outcomes by eliminating the need for additional, unnecessary procedures, and highlighting lesions that might otherwise be missed by human error [4]. This impact has led to a focus on the field, further amplified by the shortage of qualified radiologists in underserved communities and the technology’s ability to enable faster decision-making in emergency settings.
While existing research has explored the applications of AI in interpreting a variety of diagnostic modalities, organ systems, and conditions, the results have shown considerable variability [5-7]. Additionally, the interpretation of these results is often subjective, as the development of standardized assessment guidelines has proven to be challenging [8]. For this reason, many studies have used ChatGPT, which has demonstrated noteworthy diagnostic capabilities of its own [9-11], as a benchmark for comparison, even though its overall accuracy in this context remains difficult to ascertain.
This retrospective study aimed to establish a defined level of accuracy for GPT-4o’s capabilities in interpreting radiological images. To achieve this, 377 cases were collected, encompassing X-ray, CT, and MRI images, stratified by organ system and disease type. These were individually presented to the AI without clinical context and its responses were assessed by three independent raters, allowing us to evaluate its diagnostic performance and identify areas showing potential for implementation, as well as those requiring further improvement.
Materials and methods
Data collection
Medical imagery was collected from Radiopaedia, an online peer-reviewed open-access radiology resource [12]. A target minimum of 300 cases was selected, considering the availability of applicable cases, as well as the sample sizes described by similar existing studies [5,13]. Our study included CT, MRI, and X-ray images of cases with a diagnostic certainty of “Certain” [14]. The cases were considered for inclusion randomly, but images with poor graphical quality and those with annotations, arrows, circles, or other edits were excluded. Due to technical limitations, only the thumbnail slice, which best depicts the findings and is selected by the case author during upload, was acquired from CT and MRI studies.
Each image was then reviewed by a consultant radiologist who either approved or rejected its inclusion based on whether the diagnosis could be suspected from the image alone, without clinical context. For all approved cases, we collected the file name, diagnosis, description, study modality, and downloaded the image. In the case of images lacking a description, one was provided by the consultant radiologist. Additionally, to ensure the proper attribution of all cases, the following details were collected separately: name of case contributor, radiopaedia identification number (rID), and digital object identifier (DOI) [15]. Case attributions for all cases can be found in the Appendix.
Data preparation
All images were checked to ensure they contained no identifying information. Duplicate cases were identified, with only one copy retained. All file names were replaced with numerical IDs to prevent the AI from obtaining additional information about the case. Each case was assigned a system category, which included abdomen, chest, extremities, head, pelvis, spine, and other, as well as one of the following type categories: bleeding, inflammatory, neoplastic, structural, normal, and other. The system category was selected based on the part of the body under study in the given image, while the type category was chosen based on the pathophysiology of the depicted condition. Bleeding conditions included hematomas, hemorrhagic stroke, and hemothorax, among others; inflammatory conditions included infectious diseases, autoimmune disorders, and inflammatory bowel disease; neoplastic conditions included benign or malignant tumors; structural conditions encompassed aneurysms, obstructions, hernias, fractures, tears, ulcers, congenital abnormalities, and more.
Prompt input and rating of responses
Each image was individually presented to GPT-4o, uploaded in .png or .jpg format, along with the following custom instructions: “You will be provided with an image depicting either an X-ray, CT scan, or MRI scan of the human body. Describe the findings shown in the image and name the most probable differential diagnoses based on the findings.” The description and differential diagnoses provided by GPT-4o were compared with the description and diagnosis of the case by three independent raters and scored using a five-point rating system. To ensure inter-rater reliability, the raters had no communication with one another and were not able to view others’ ratings.
The five-point rating system is as follows: 5=both the diagnosis and description of the image were accurate; 4=either the diagnosis or description of the image was accurate, but not both; 3=the diagnosis and description of the image were incorrect but another diagnosis was very similar; 2=the diagnosis and description of the image were incorrect but another diagnosis was possibly helpful in identifying the correct diagnosis; 1=the diagnosis and description of the image were incorrect and no diagnosis was possibly helpful in identifying the correct diagnosis. The median value of the three ratings was calculated for each case to be used during statistical analysis. In addition, a median score of 4 or 5 was defined as “Satisfactory”, while scores 1-3 were defined as “Poor”. This rating system was developed due to the lack of a standardized assessment guideline [8], with a similar approach as prior studies evaluating AI performance [9,10,13].
Statistical analysis
The analysis of the data was performed using R (version 4.3.1) (R Foundation, Vienna) [16]. A significance level of α=0.05 was assumed. The distributions of cases by modality, system, type, and rating are listed as frequencies and percentages. Pearson's chi-squared test and Fisher's exact test were used to evaluate the differences between ratings by modality, system, and type. Regression analysis was performed using a generalized linear model to assess the factors impacting the binary outcome (“Satisfactory” vs “Poor”). Adjusting for confounders was performed by stratifying the data during analysis. Fleiss’ κ (kappa) was calculated as a measure of inter-rater reliability between three independent raters.
Results
In total, 377 cases were included in the study. Among modalities, CT scans comprised 192 (50.93%) cases, followed by X-ray and MRI images with 99 (26.26%) and 86 (22.81%) cases, respectively. By system, the abdomen, head, and chest had the highest representation, with 111 (29.44%), 88 (23.34%), and 80 (21.22%) cases, respectively. From the type categories, structural, neoplastic, and inflammatory conditions had the highest amount of cases, with 174 (46.15%), 78 (20.69%), and 62 (16.45%) cases, respectively. The exact distribution of cases by these characteristics is presented in Table 1. Fleiss’ kappa, a measure of inter-rater reliability, was calculated to be 0.717.
The largest amount of cases received a median rating of 1 (n=172, 45.62%) or 5 (n=91, 24.14%) (Figure 1). When evaluating these results by modality, a statistically significant difference between the three categories was found for both the median score (p=0.034) and binary outcome (p=0.008). A detailed summary of these results is shown in Table 2. Additionally, when comparing cases by system, the difference was also found to be statistically significant for both the median score (p=0.001) and binary outcome (p<0.001). This distribution of cases is presented in Table 3. Stratification by type categories showed a statistically significant difference for the median score (p=0.018), but not for the binary outcome (p=0.2). An overview of these results can be found in Table 4.
Distribution of Median Ratings for Responses Given by GPT-4o Across all Cases
A regression analysis assessed the relationship between modality, system, and type on the binary outcome (Table 5). Of these factors, the following were shown to be statistically significant: X-ray images had a 2.21 times higher chance on average to lead to a rating of 4 or 5 compared to CT scans (OR: 2.21; 95% CI: 1.33-3.69); images of the pelvis had a 6.25 times lower chance on average of leading to a score of 4 or 5 compared to images of the abdomen (OR: 0.16; 95% CI: 0.02-0.56); images in the “other” category of systems had a 6.34 times higher chance on average to lead to a rating of 4 or 5 compared to images of the abdomen (OR: 6.34; 95% CI: 2.23-20.92); images of neoplastic conditions had a 2.7 times lower chance on average of leading to a score of 4 or 5 compared to bleeding conditions (OR: 0.37; 95% CI: 0.16-0.84). Examples of responses given by GPT-4o are shown in Figure 2.
Examples of Responses Generated by GPT-4o(A) Case depicting usual interstitial pneumonia, identified correctly. (B) Case depicting acute subdural hemorrhage, identified correctly. (C) Case depicting a C6-C7 fracture dislocation, misidentified as normal.
Discussion
The diagnostic capabilities of GPT-4o in radiology have been assessed in several specific applications, but few studies have quantitatively evaluated its performance across multiple imaging modalities and systems [7,17]. This study fills this gap by evaluating GPT-4o’s performance with a diverse dataset, identifying strengths, pitfalls, and avenues requiring further improvement. Our results highlighted factors significantly affecting diagnostic accuracy, such as pelvic, neoplastic, and X-ray images. They also provide insight into the limitations affecting the overall accuracy of this technology and areas of interest for future development.
Several noteworthy findings emerged from the results. Statistically significant differences were observed in the scores of responses categorized by modality, system, and type. To assess these findings in more detail, regression analysis was performed, which showing that, on average, GPT-4o produced more favorable outcomes when working with X-ray images (OR: 2.21, 95% CI: 1.33-3.69). A similar finding was observed with the "other" category of systems (OR: 6.34; 95% CI: 2.23-20.92). The opposite result was seen with imaging of the pelvis (OR: 0.16; 95% CI: 0.02-0.56) and neoplastic conditions (OR: 0.37; 95% CI: 0.16-0.84), indicating that GPT-4o struggles considerably when evaluating these kinds of images. Additionally, inter-rater reliability was assessed, yielding a Fleiss' kappa of 0.717, indicating substantial agreement between the three independent raters.
Among X-ray images, 44% of cases achieved a "Satisfactory" rating, comparable to the 40.50% and 47% with an "Acceptable" rating in a study involving chest X-rays by Lee et al. [9]. Additionally, the increased success rate with this modality over CT scans could be attributed to the greater availability of X-ray images, which were likely more commonly presented to the AI, enabling improvement over time. Despite generally better performance with X-rays, it should be noted that almost all cases with bleeding conditions were CT scans. GPT-4o achieved a satisfactory rating in 49% of these cases, a higher percentage than most other case types. Furthermore, regression analysis indicated worse outcomes for most condition types, even though not all results reached statistical significance.
Regarding pelvic imaging, GPT-4o would often admit to being unable to identify whether the image depicted female or male pelvic anatomy, suggesting separate differential diagnoses based on either option. Other times, it would mistake an enlarged prostate or a distended bladder for the uterus, completely missing the diagnosis. These findings underline the critical need for further training in the interpretation of pelvic imaging, specifically in differentiating between normal male and female pelvic anatomy, before abnormal imaging can be introduced. Responses from the "other" category of systems achieved a satisfactory rating in 74% of cases, substantiated by the findings in regression analysis (OR: 6.34; 95% CI: 2.23-20.92). Although this group of cases consisted of a variety of conditions, a significant number of esophageal X-rays were included, suggesting the need for a more detailed evaluation of this subset of cases.
The overall distribution of median ratings demonstrates a bimodal distribution, indicating that most cases were interpreted either completely incorrectly or entirely without error, with only a small percentage of responses being partially accurate. This finding suggests that the AI adopts an "all or nothing" approach, expertly recognizing anything it has seen before but being practically unable to work with anything it has not visually encountered, despite having access to theoretical knowledge on these conditions. Another important factor negatively impacting accuracy was hallucinations, which are a commonly encountered, well-documented limitation of ChatGPT, representing false or misleading statements provided by an AI, presented as fact [9,17,18]. As diagnostic validity is of the utmost importance in radiology, the presence of this phenomenon underscores the importance of eliminating errors like these before the AI model can be reliably implemented in clinical settings.
Moreover, the study purposefully withheld key information, such as text-based descriptions and clinical history, which are typically available to human radiologists. This was done to eliminate potential confounding factors, both of which have been shown to significantly influence the responses provided by the AI. A study by Wu et al. found that the accuracy of responses significantly improved with the inclusion of clinical history alongside the image, relying heavily on details like the patient's past medical history [17]. Buckley et al. evaluated this phenomenon further by adding misleading text to medical images, such as a suggestion from a fictional colleague [19]. Their results showed that the AI would prioritize text-based information over the findings seen in the image, missing diagnoses even when the image alone would otherwise have been accurately interpreted.
While the precise mechanisms behind the AI’s decision-making process remain unclear even to the most seasoned researchers, these findings offer valuable insight into certain characteristics. The bimodal distribution of median ratings strongly suggests that the model relies primarily on comparing the prompted image to one it has encountered prior, rather than analyzing the various components of the image in detail. This could also explain the recurring hallucinations, which are likely a result of the model making incorrect comparisons. Furthermore, since the model is able to process text-based data with greater accuracy [20], it relies too heavily on clinical history and case descriptions, when they are available.
Future research should focus on methods to combat these pitfalls. One possibility may be to instruct the AI to analyze the image in sections, with each part contributing to a consolidated list of potential diagnoses. This approach has shown particular success in the field of pathology [1]. Additionally, text-based data could be incorporated as a secondary source of information, supporting or challenging certain diagnoses that the model has already considered.
Multiple limitations were encountered during this study, which should be considered during the interpretation of results. The inability to provide more than one slice for each case was an important technical limitation, as it would particularly impact the interpretation of MRI and CT scans, omitting valuable information that AI might have derived from additional slices. This provides a potential explanation for the results observed in the regression analysis regarding X-ray images. Furthermore, the dataset was not evenly distributed, with 192 cases being CT scans and only 86 and 99 cases representing MRI and X-ray images, respectively. Some medical conditions were represented multiple times, while others appeared only once. These factors could be considered a type of selection bias, caused by technical limitations and lack of availability of a more diverse dataset. Future work should focus on the development of an extensive and diverse dataset, as this is essential for enhancing the model's accuracy and generalizability.
Another concern encountered in many AI studies stems from the lack of an objective, standardized assessment guidelines, with each study developing a unique approach to evaluating responses. In our case, we opted for the five-point rating system, following the approach of prior research in the field. However, in order to avoid this measurement bias, future work should prioritize the development of clear, standardized evaluation criteria to ensure consistency and comparability across studies.
Conclusions
The objective of the study was to evaluate the diagnostic capabilities of GPT-4o in radiological imaging, taking into account the factors influencing accuracy, limitations, and potential areas for improvement. The results demonstrated higher accuracy with X-ray images, while pelvic imaging and neoplastic conditions posed notable challenges. A bimodal distribution in the quality of responses suggests that the AI relies heavily on prior encounters with similar images, limiting generalizability. Furthermore, hallucination was identified as a significant concern for the safe integration of GPT-4o into medical settings, highlighting the need for strategies to mitigate this issue.
Avenues for future research should include the creation of standardized assessment guidelines, the development of an extensive dataset, and the implementation of a systematic approach to image analysis. In addition, exploring methods to incorporate text-based data by having it complement rather than override the image will be essential in improving the model’s overall diagnostic capabilities.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1A pathology foundation model for cancer diagnosis and prognosis prediction Nature Wang X Zhao J Marostica E 97097863420243923216410.1038/s 41586-024-07894-z PMC 12186853 · doi ↗ · pubmed ↗
- 2What is AI? Applications of artificial intelligence to dermatology Br J Dermatol Du-Harpur X Watt FM Luscombe NM Lynch MD 42343018320203196040710.1111/bjd.18880 PMC 7497072 · doi ↗ · pubmed ↗
- 3Deep learning for rapid and reproducible histology scoring of lung injury in a porcine modelbio Rxiv Silva IAN Rashed SK Hedlund L 2023
- 4Chat GPT in radiology: the advantages and limitations of artificial intelligence for medical imaging diagnosis Cureus Srivastav S Chandrakar R Gupta S 015202310.7759/cureus.41435 PMC 1040412037546142 · doi ↗ · pubmed ↗
- 5Artificial Intelligence based detection of pneumoperitoneum on CT scans in patients presenting with acute abdominal pain: A clinical diagnostic test accuracy study Eur J Radiol Brejnebøl MW Nielsen YW Taubmann O Eibenberger E Müller FC 11021615020223525970910.1016/j.ejrad.2022.110216 · doi ↗ · pubmed ↗
- 6Deep neural networks for automatic detection of osteoporotic vertebral fractures on CT scans Comput Biol Med Tomita N Cheung YY Hassanpour S 8159820182975845510.1016/j.compbiomed.2018.05.011 · doi ↗ · pubmed ↗
- 7GPT-4 and medical image analysis: strengths, weaknesses and future directions J Med Artif Intell Waisberg E Ong J Masalkhi M Zaman N Sarker P Lee AG Tavakkoli A 2962023
- 8Possibilities and challenges for artificial intelligence and machine learning in perioperative care BJA Educ van der Meijden SL Arbous MS Geerts BF 2882942320233746523510.1016/j.bjae.2023.04.003PMC 10350557 · doi ↗ · pubmed ↗