Sharing a whole-/total-body [18F]FDG-PET/CT dataset with CT-derived segmentations: an ENHANCE.PET initiative
Daria Ferrara, Manuel Pires, Sebastian Gutschmayer, Josef Yu, Yasser G. Abdelhafez, Elisabetta Abenavoli, Ramsey D. Badawi, Abhijit J. Chaudhari, Moon S. Chen, Simon R. Cherry, Armin Frille, Barbara K. Geist, Stefan Gruenert, Marcus Hacker, Swen Hesse, Teresa Kerkhoff

TL;DR
A new dataset of PET/CT scans with detailed segmentations is shared to support research and deep learning in medical imaging.
Contribution
The novel contribution is a large, curated PET/CT dataset with CT-derived segmentations of 130 anatomical regions for research and AI training.
Findings
The dataset includes 1,597 PET/CT images with segmentations of 130 anatomical regions.
Segmentations cover diverse tissues like organs, muscles, and bones, verified by medical professionals.
The dataset is anonymized and in NIfTI format, suitable for deep learning and multi-modality analysis.
Abstract
We present a large whole-body and total-body curated dataset of dual-modality 2-deoxy-2-[18F]fluoro-D-glucose (FDG)-Positron Emission Tomography/Computed Tomography (PET/CT) studies, consisting of 1,597 PET/CT images and the corresponding CT-derived segmentations of 130 target regions. This multi-center dataset includes images from individuals without overt disease and patients with different pathologies (lung cancer, lymphoma, and melanoma). Target regions were first automatically segmented from CT images using an in-house software, and subsequently verified and corrected by physicians-in-training. In total, the segmented regions encompass 130 volumes, including abdominal organs, muscles, bones, cardiac subregions, vessels, adipose tissue, and skeletal muscle around the third lumbar vertebra. PET/CT images and corresponding CT-derived segmentations are provided in anonymized NIfTI…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
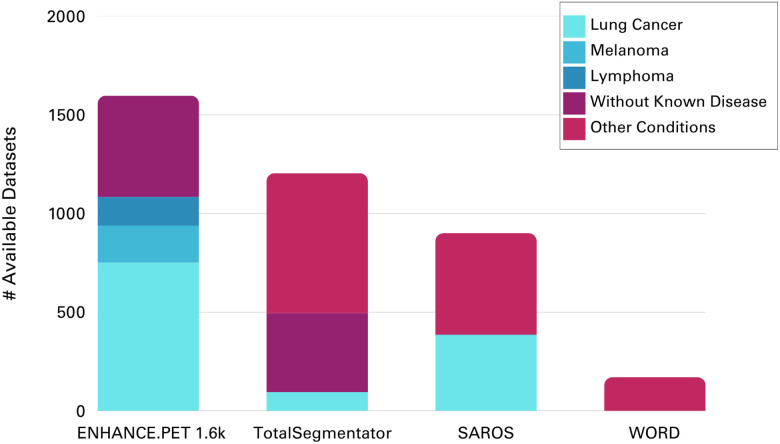 Figure 1
Figure 1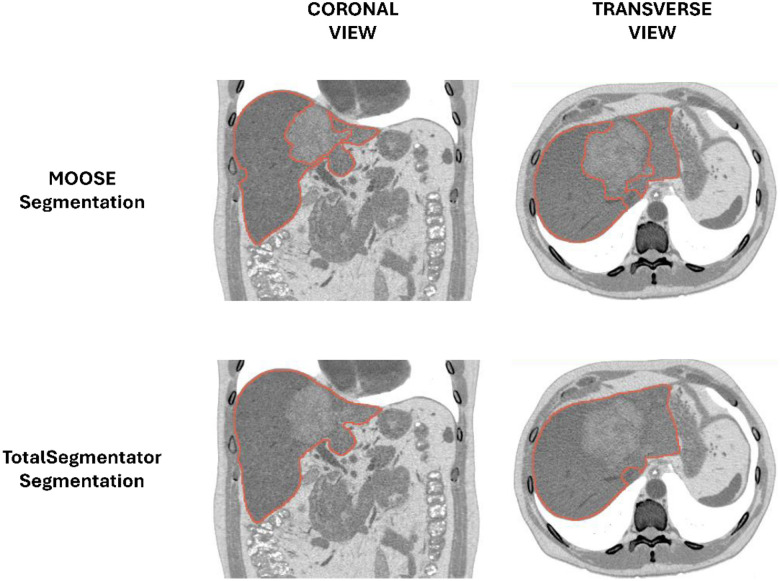 Figure 2
Figure 2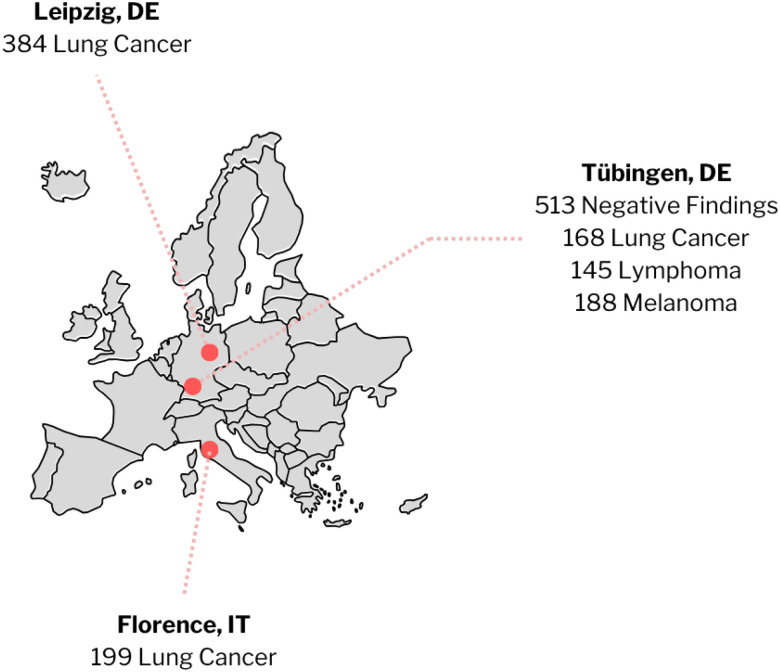 Figure 3
Figure 3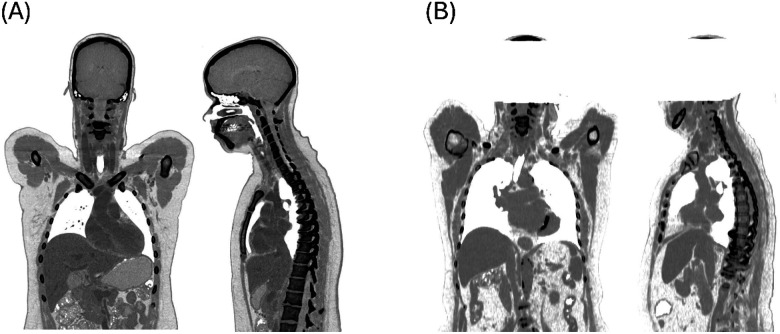 Figure 4
Figure 4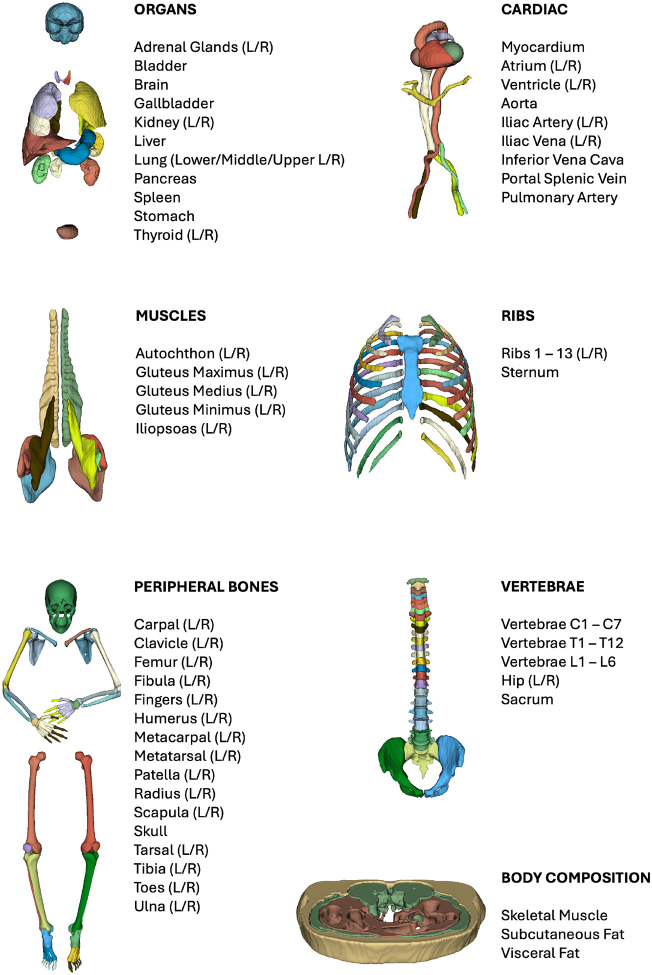 Figure 5
Figure 5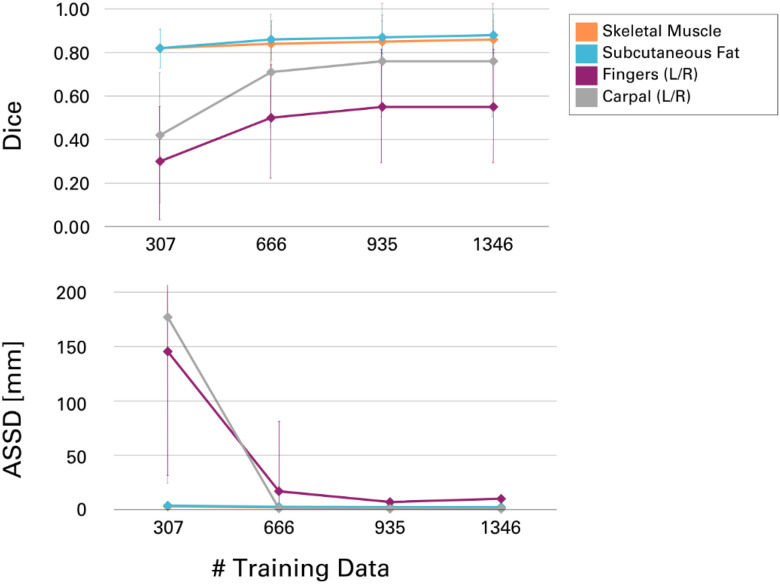 Figure 6
Figure 6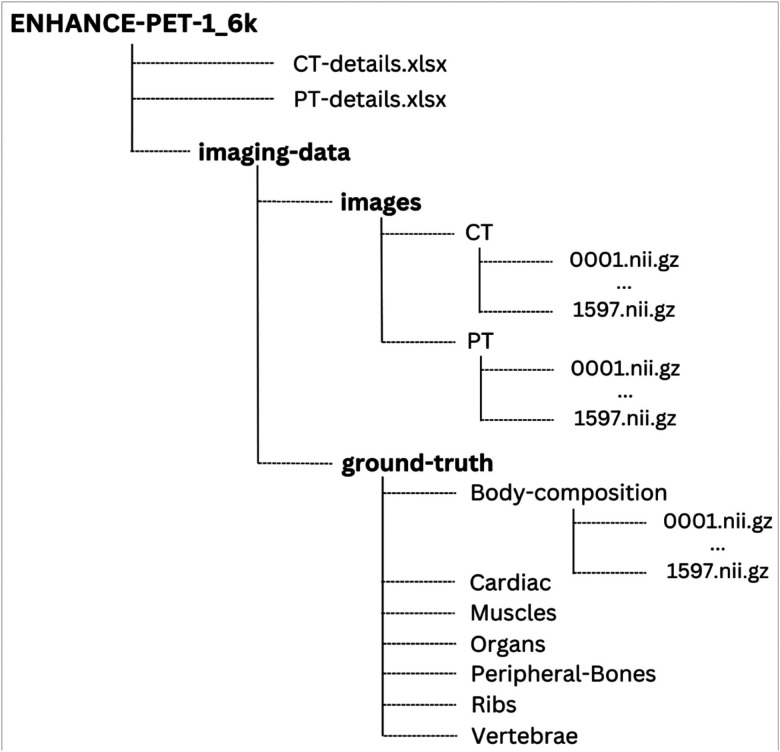 Figure 7
Figure 7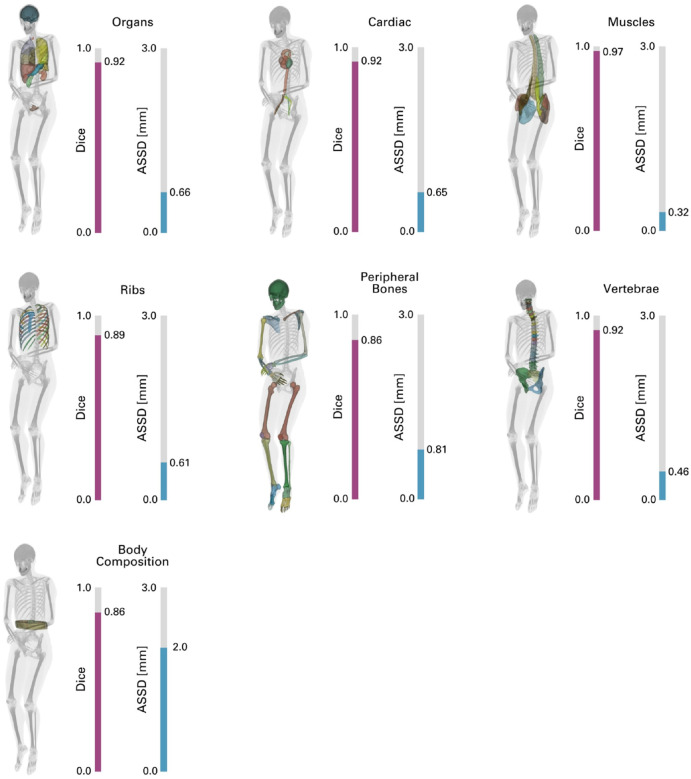 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedical Imaging Techniques and Applications · Radiomics and Machine Learning in Medical Imaging · Advanced X-ray and CT Imaging
Background & Summary
In recent years, the field of biomedical engineering and medical physics has witnessed an increase in the complexity of data^1^, driven by rapid advancements in imaging technologies. Traditional data analysis methods have become increasingly inadequate to analyse these large data sets to meet the demand for greater diagnostic precision, and the shift toward personalized treatment strategies^2,3^. To support personalised medicine, more efficient, automated approaches capable of processing and interpreting large-scale datasets are needed. Artificial intelligence (AI) and machine learning (ML) have emerged as powerful tools in this context, offering the ability to identify complex patterns and insights that may not be apparent through conventional methods. However, the effectiveness of AI, particularly of deep learning, is heavily dependent on the availability of large, high-quality and heterogeneous datasets, thus requiring extensive training on vast amounts of data to achieve generalizability and robustness^4^.
Combined positron emission tomography (PET) and computed tomography (CT) integrates both anatomical and functional imaging capabilities, making it indispensable for diagnosing, staging, and monitoring diseases, such as oncological disorders^5–7^. Despite the clinical importance of PET/CT datasets, open sourcing of imaging data is hindered by strict regulations, and analyses are often conducted in-house^8^ on limited data. At present, very few nuclear medicine datasets with annotated lesions are publicly available: only 1,014 PET/CT lung cancer, lymphoma, melanoma, and healthy control cases from the AutoPET challenge^9^, and another 845 head and neck cancer cases through the HECKTOR challenge^10^. In contrast, Ma et al^11^ identified over one million open-source non-nuclear medicine datasets, most of which originating from radiology and not segmented, including more than 350,000 from CT scans alone. This restricts the development and validation of computational methods for functional imaging, such as image and tumor segmentation, volumetric analysis (e.g., for body composition assessment^12^), and radiomics.
Recent advancements in PET/CT technology, particularly the shift from single-organ imaging^13^ to total-body PET/CT systems^14,15^, allow for simultaneous imaging of multiple organs, fueling multi-organ analyses^16^ and the exploration of systemic metabolic abnormalities^17,18^. However, the development of reliable AI methods for automated analysis of these complex datasets requires access to comprehensive open-source resources, including both images and high-quality segmentations of anatomical structures, which are critical for applications such as diagnosis, treatment planning^19^, volumetric analysis, and patient-specific dosimetry^20,21^.
In the field of CT imaging alone, few open-source datasets include corresponding anatomical segmentations. Rister et al.^22^ presented a dataset of 140 abdominal, neck-to-pelvis, and whole-body CT images from patients with liver cancer, segmented into six organ regions. The WORD dataset^23^ comprises 170 abdominal CT images, primarily from prostate, cervical, or rectal cancer cases, along with the segmentations of 16 abdominal organs. These studies, however, are limited in the number of available CT images and segmented regions, and they do not extensively cover different pathologies. More recently, Koitka et al. introduced the Sparsely Annotated Region and Organ Segmentation (SAROS) dataset^24^, which consists of 900 abdominal, thoracic, or whole-body CT images from various pathologies. This work focused on 13 semantic body regions and six body parts, including annotations for every fifth image slice. Similar scope and scale were achieved in the AbdomenCT-1k study^25^, which focused on the liver, kidneys, spleen, and pancreas segmentations, and the comprehensive TotalSegmentator dataset^26^, with CT images of the abdomen, pelvis, or thorax segmented into a total of 104 regions of interest.
However, these datasets are limited in scope, often focusing on specific body regions rather than total-body imaging. It is understood that CT images alone are sufficient for many applications, such as volumetric analysis for body composition^12^ or the delineation of organs at risk in radiotherapy treatment planning^27^. In other applications, however, the functional information from PET imaging is essential as it provides complementary insights into disease mechanisms that CT alone cannot offer. For example, in pathological settings, [18F]FDG-uptake can help track disease progression by detecting systemic changes in metabolism, such as those seen in patients with infections^28,29^, chronic inflammation^30^, metabolic syndrome^31^ or cancer-associated cachexia^32–34^. In studies involving healthy cohorts, longitudinal [18F]FDG PET/CT imaging allows for monitoring metabolic activity in participants and how it changes with aging or other factors^35–37^. Also, a more complete understanding of normal physiological metabolism would help identify deviations that may signal early stages of disease^18^. While the aforementioned AutoPET^9^ and HECKTOR^10^ challenges provide large PET/CT datasets, they focus on segmentations of pathological tissues but ignore healthy anatomical regions.
In the present study, we address the limited availability of open source PET/CT images with segmented tissues as part of our ENHANCE.PET^38^ initiative, which aims to facilitate the sharing of open-source tools and datasets to support research within the PET community. We curated a large [18F]FDG PET/CT dataset with anatomical segmentations fully verified by human readers. This dataset includes 1,597 whole-body and total-body PET/CT scans, along with corresponding CT-derived segmentations of 130 non-pathological tissues per scan. The initial segmentations were generated using our in-house tool, MOOSE^39^, for automatic CT segmentation and were manually verified and corrected using 3D Slicer^40^, a software platform for image analysis. The data include contributions from the LuCaPET consortium (grant number ERAPerMed_324, “Clinical decision support for predicting cachexia in cancer patients using hybrid PET/CT imaging”) and from the AutoPET Challenge^9^, whose images and lesion segmentations were already available as open-source on The Cancer Imaging Archive^41^. Focused mainly on the oncological cases of lung cancer, melanoma, and lymphoma (Fig. 1), the ENHANCE.PET 1.6k dataset also includes participants without known disease. The dataset is provided in anonymized NIfTI format to ensure patient privacy, along with demographic details and CT and PET acquisition parameters as non-imaging metadata.
Compared to other publicly available datasets, ENHANCE.PET 1.6k uniquely focuses on the segmentations of organ volumes while avoiding pathological tissues (e.g., tumors, Fig. 2). This dataset is particularly suited for training models aimed at automatic image segmentation and identification of healthy tissues. We believe that the open availability of this dataset will advance the differential understanding of healthy and pathological tissues in computational medicine. This comprehensive resource is now available to facilitate future research and advanced data analysis in whole-body PET/CT imaging. We anticipate that applications such as developing and validating deep learning algorithms for automated data analysis and studies on disease-related systemic abnormalities will greatly benefit from this high-quality data collection.
Methods
Data collection
The ENHANCE.PET 1.6k dataset was acquired in accordance with the guidelines set forth in the Declaration of Helsinki. Images were acquired between 1999 and 2022 from various institutions and studies, summarized in Fig. 3: the open-source dataset AutoPET^9^, the University Hospital Leipzig in Germany (IRB: 259/18-ek) and the Azienda Ospedaliero Universitaria Careggi in Italy (IRB: 21306_oss) as part of the LuCaPET consortium.
Participant demographics across the different clinical conditions are summarized in Table 1.
Imaging Protocols
Three different PET/CT systems were used for image acquisition at the participating medical centres: Siemens Biograph mCT (N = 1398), Philips Gemini TF (N = 179), and GE Healthcare Discovery MI (N = 20). At all three sites, diagnostic CT scans were acquired with X-ray tube voltages between 100 kVp and 140 kVp, and CT data were reconstructed with a slice thickness between 1 mm and 5 mm. Details on the CT reconstruction parameters are provided in Table 2.
Participants were asked to fast for 6 hours before the examinations and were scanned in the supine position, with arms up. Each subject underwent a static PET acquisition following an intravenous injection of [18F]FDG (314 ± 48 MBq). Uptake times varied across the three sites, with an average of (68 ± 21) minutes post-injection. PET images were reconstructed with attenuation and scatter corrections applied using the corresponding CT data.
Details on the CT and PET acquisition parameters are reported for each participant as non-imaging parameters in the available spreadsheet files. The download link is provided in the Data Records section.
Segmentations and Data Processing
PET/CT images were retrieved in anonymized DICOM format from the participants and centralized at the Medical University of Vienna. The metadata were used to extract relevant information about the CT and PET acquisition protocols as well as essential demographic details of the participants. For subsequent analysis and segmentation, all data were converted to NIfTI format using the dcm2niix DICOM to NIfTI converter^42^. To ensure that participants could not be visually identified from their CT images^43–45^, both the PET and CT images from the Azienda Ospedaliero Universitaria Careggi and the University Hospital Leipzig were edited: in the PET images, voxels between the upper part of the skull segmentation and the bottom of the brain, within a cylinder of 16 voxels in the z-direction, were set to zero (Fig. 4B). Similarly, the corresponding CT region was set to −1000 Hounsfield Units to simulate air. The images from the AutoPET challenge were left unedited as per their version available online.
To maximize efficiency and accelerate the workflow, the processing of the entire ENHANCE.PET 1.6k dataset was done serially: automatic segmentation of the CT images, manual refinement of the derived labels, and retraining of the original segmentation models, according to the following scheme. Our in-house developed software, MOOSE^39^, was first used for the automatic segmentation of 384 lung cancer images from the University Hospital Leipzig. The resulting segmentations were manually refined by 10 medical students using the 3D Slicer image analysis software^40^. For each dataset, a student was randomly assigned to verify and correct the segmentations, addressing possible systematic errors such as inaccuracies at anatomical borders of target regions, mislabelling between left and right regions, or misclassification of regions with similar intensities on CT. A second student was then tasked with reviewing the first student’s work and correcting any remaining mistakes. Once both students agreed on the final version of the dataset, it was reviewed by a radiology resident and a nuclear medicine resident. The PET images overlapped with the corresponding CT were used to exclude tumor volumes from the segmentation of various abdominal organs.
These preliminary segmentations were divided into seven different classes, as shown in Fig. 5: organs, cardiac, muscles, ribs, peripheral bones, vertebrae, and body composition around the L3 vertebra area. These masks were then used to retrain our models using nnU-Net^46^. Details on the retraining process are provided in the Technical Validation section.
The newly trained models were subsequently used for the segmentation of the second dataset, originating from Azienda Ospedaliero Universitaria Careggi, and again underwent manual refinement and quality control described above. The same workflow of automatic segmentation, manual refinement, and model retraining was then applied to the remaining images from the AutoPET^9^ open-source dataset. In the case of the AutoPET data, since the corresponding lesion segmentations were available online, they were taken as ground truth and directly subtracted from the organ segmentations without the need for manual correction.
To maximize data variability and ensure robust performance across different scanning conditions, we included in our training dataset 86 additional total-body CT images (30F/56M, 53 ± 15 years, 87 ± 19 kg, 172 ± 9 cm) from the University of California Davis, California (USA), acquired on a United Imaging uEXPLORER PET/CT system. The segmentations were generated using the same workflow as for the other datasets. Their inclusion helped account for different acquisition protocols (arms-down positioning) and provided broader representation of physiological variations, as they covered various inflammatory and pathological conditions, such as head and neck cancer (N = 5), arthritis (N = 43), genito-urinary cancer (N = 9), and healthy controls (N = 29). While these cases cannot currently be shared due to privacy restrictions, we are working to make them publicly available in the future.
At each stage of retraining, the size of the training data increased, improving model performance. This iterative process allowed for efficient verification and faster corrections by the medical students without compromising precision, especially in regions where systematic errors had been identified and were hindering the manual correction process. Segmentation of the fingers and hand bones showed the most significant improvement as the training dataset grew (Fig. 6). In the first round of training, several instances of left-right misclassification were identified, especially when the hands were crossed over the abdomen or above the head. However, this issue progressively improved with each retraining step. Another improvement achieved through more extensive training data was the automatic inclusion of the quadratus lumborum muscle in the “skeletal muscle” label for body composition, which had previously been missing and required manual correction (Fig. 6).
Data Records
The PET/CT images and corresponding segmentations from Azienda Ospedaliero Universitaria Careggi, University Hospital Leipzig, and the AutoPET^9^ dataset are stored on Amazon Web Services (AWS, https://aws.amazon.com/) and can be downloaded either directly following MOOSE^39^ installation via command line, as described in the Code Availability section, or at the following link:
https://enhance-pet.s3.eu-central-1.amazonaws.com/enhance-pet-1_6k/enhance-pet-1_6k.zip
The imaging data are stored in three separate folders containing the CT images, PET images, and ground truth segmentations, respectively. Within the segmentations folder, there are seven subfolders corresponding to different segmentation classes: “Body-Composition,” “Cardiac,” “Muscles,” “Organs,” “Peripheral Bones,” “Ribs,” and “Vertebrae.” Each folder contains NIfTI data files, named sequentially from 0001.nii.gz to 1597.nii.gz. The directory structure of the ENHANCE.PET 1.6k dataset is shown in Fig. 7.
A JSON file containing the complete list of segmentations and their corresponding intensities within the multi-class files is available for download at the following link:
https://enhance-pet.s3.eu-central-1.amazonaws.com/enhance-pet-1_6k/labels.json
In addition to the imaging data, non-imaging information is provided in two spreadsheet files. The CT-details.xlsx file contains details on the CT acquisition parameters (e.g., PET/CT system manufacturer and model, kVp, filter type, convolutional kernel, axial pixel size, slice thickness, and focal spot size) for each participant. The PT-details.xlsx file provides the corresponding demographic information (e.g., clinical indication, sex, age, weight, height) as well as PET acquisition parameters (e.g., injected activity, acquisition date and time, radioactivity injection details, image units, slope, intercept, system model and manufacturer).
Technical Validation
We used the ENHANCE.PET 1.6k dataset with the additional 86-image contribution from the University of California, Davis to develop a deep learning-based method for the automatic segmentation of CT scans: 80% of the images and corresponding labels were sampled from the total with a stratified sampling, thus ensuring that the original proportion of data by medical facility and clinical condition remained unchanged. The 1346 selected imaging data served as a training dataset for multiple segmentation models targeting different anatomical regions, including bones of the limbs and skull, thoracic cage bones, vertebrae and sacrum, major abdominal organs, lower back muscles, cardiac tissues, and body composition around the L3 vertebra. A detailed list of regions segmented by each model is shown in Fig. 5.
Prior to training, all images and labels were resampled with SimpleITK (https://simpleitk.org/about.html) from the original resolution to a voxel spacing of 1.5 × 1.5 × 1.5 mm using B-spline interpolation. This provided a resolution high enough to segment fine structures on the CT images, while considering the computational burden of training. The models were trained using nnU-Net^46^, a state-of-the-art self-configuring framework based on the U-Net architecture for semantic segmentation. The training process was performed over 2000 epochs.
To assess the model performance, we tested all segmentation models on the remaining 20% of the ENHANCE.PET 1.6k. Segmentation accuracy was evaluated using the Dice Similarity Coefficient (DSC) to quantify the overlap between predicted segmentations and the reference labels and with the Average Symmetric Surface Distance (ASSD)^47^ to estimate the average distance between surface voxels of the reference labels and the automated segmentation. The averaged results for the generated models are shown in Fig. 8, and the metrics for each label are reported in Table 4.
All models achieved high accuracy, with mean DSC values exceeding 0.85 across most regions and mean ASSD values below 3 mm in all regions. The “Muscles” model achieved the highest overlap and the lowest prediction error, with an average DSC of 0.97 ± 0.02 and an ASSD of 0.3 ± 0.2 mm (Fig. 8). Cardiac, organ, and vertebrae models also achieved high average DSC values, exceeding 0.90. The peripheral bones model had the lowest performance, with an average DSC of 0.86 ± 0.27 and the highest variation in ASSD, at 0.8 ± 7.2 mm. The lower performance in these regions is likely due to their small size and thin anatomical structures: the digits of the hand had the most significant negative impact on model performance, with some cases of left/right misclassification identified (especially when patients underwent imaging with their hands crossed over the abdomen), resulting in an average DSC of 0.55 ± 0.39 and an ASSD of 10 ± 37 mm (Table 4). Similarly, the segmentation of the metacarpals yielded a DSC of 0.71 ± 0.33 and an ASSD of 5 ± 23 mm. Other regions with lower overlap included the portal and splenic veins (DSC: 0.82 ± 0.18) and the adrenal glands (DSC: 0.82 ± 0.12), most likely due to their low contrast resolution in CT imaging of the test dataset, which makes delineation more challenging. The ribs and body composition models also showed higher variation in ASSD, at 0.6 ± 2.1 mm and 2.0 ± 1.7 mm, respectively.
The ENHANCE.PET 1.6k dataset proved to be satisfactory for training models for automated CT image segmentation. This dataset has the potential to contribute significantly to further advancements in deep learning-based algorithms, including attempts to improve segmentation models performance or the addition of new volumes of interest not covered in the present study. The dual availability of both CT and PET images, together with the inclusion of segmentations for multiple anatomical regions, makes the ENHANCE.PET 1.6k dataset particularly valuable for research focused on diseases that affect multiple organs or systems, such as metabolic disorders or systemic inflammatory diseases^48,49^, or for studies on normal glucose metabolism in healthy tissues. As a limitation, since the segmentations were derived from the CT images, the alignment with the corresponding PET images may be compromised in cases of significant patient motion, which was not systematically assessed in this study.
We hope that this open-source dataset will accelerate developments in medical imaging, ultimately contributing to the advancement of personalized medicine and more effective clinical decision-making.
Usage Notes
The contributions of the Azienda Ospedaliero-Universitaria Careggi and the University Hospital Leipzig to the ENHANCE.PET 1.6k dataset are licensed under the Creative Commons Attribution 4.0 International License (CC BY 4.0). Data from the AutoPET^9^ Challenge are licensed under the Creative Commons Attribution-NonCommercial 4.0 International License (CC BY-NC 4.0). All imaging data are presented in NIfTI format, ensuring participants’ privacy while allowing for easy use in further analysis. This format can be opened with most visualization software, including 3D Slicer (https://www.slicer.org/) and ITK-SNAP (http://www.itksnap.org/pmwiki/pmwiki.php). DICOM to NIfTI conversion was performed using dcm2nii^42^, and all image processing was conducted using Python.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhang S, Metaxas D (2016) Large-Scale medical image analytics: Recent methodologies, applications and Future directions. Med Image Anal 33:98–10127503077 10.1016/j.media.2016.06.010 · doi ↗ · pubmed ↗
- 2Pinto-Coelho L (2023) How artificial intelligence is shaping medical imaging technology: A survey of innovations and applications. Bioeng (Basel) 1010.3390/bioengineering 10121435 PMC 1074068638136026 · doi ↗ · pubmed ↗
- 3Khalifa M, Albadawy M (2024) AI in diagnostic imaging: Revolutionising accuracy and efficiency. Comput Methods Programs Biomed Update 5:100146
- 4Shen C (2020) An introduction to deep learning in medical physics: advantages, potential, and challenges. Phys Med Biol 65:05TR 0110.1088/1361-6560/ab 6f 51PMC 710150931972556 · doi ↗ · pubmed ↗
- 5Beyer T (2000) A combined PET/CT scanner for clinical oncology. J Nucl Med 41:1369–137910945530 · pubmed ↗
- 6Townsend DW (2008) Dual-modality imaging: combining anatomy and function. J Nucl Med 49:938–95518483101 10.2967/jnumed.108.051276 · doi ↗ · pubmed ↗
- 7Wechalekar K, Sharma B, Cook G (2005) PET/CT in oncology—a major advance. Clin Radiol 60:1143–115516223611 10.1016/j.crad.2005.05.018 · doi ↗ · pubmed ↗
- 8Larson DB, Magnus DC, Lungren MP, Shah NH, Langlotz CP (2020) Ethics of using and sharing clinical imaging data for artificial intelligence: A proposed framework. Radiology 295:675–68232208097 10.1148/radiol.2020192536 · doi ↗ · pubmed ↗