Circuit mechanisms of GPe pauses account for adaptive exploration
Sang Wan Lee, Minryung Song, Shinwoo Kang, Minsu Abel Yang, Doo-Sup Choi

TL;DR
This paper explores how pauses in the globus pallidus (GPe) help the brain adapt during learning, using a computational model and real brain data.
Contribution
The study introduces a neurophysiologically grounded model linking GPe pauses to reinforcement learning through a GPe-STN circuit acting like a denoising autoencoder.
Findings
GPe pauses emerge from strong inhibition from GPe to STN, modulating downstream brain circuits.
GPe-STN activity increases after environmental changes, promoting adaptive exploration.
Extended training weakens GPe-STN projections, favoring habitual behavior over exploration.
Abstract
The external globus pallidus (GPe) has traditionally been viewed as a relay nucleus within the basal ganglia (BG), but accumulating evidence indicates a more dynamic role in reinforcement learning (RL). One key characteristic of GPe activity—transient pauses in high-frequency discharge (HFD) neurons—is preserved across species, yet its potential implications in RL remains unclear. Here, we developed a neurophysiologically grounded computational model to investigate the origin and role of GPe pauses in RL. Our model successfully replicated a range of empirical observations, including pause dynamics during learning and cue-related activity modulation. We demonstrated that the GPe-subthalamic nucleus (STN) circuit functions analogously to a denoising autoencoder, modulating baseline excitability in downstream BG circuits and that GPe pauses emerge as circuit-level consequences of strong,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
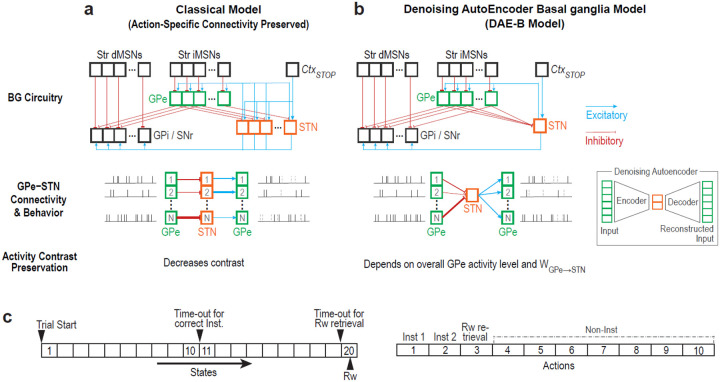 Figure 1
Figure 1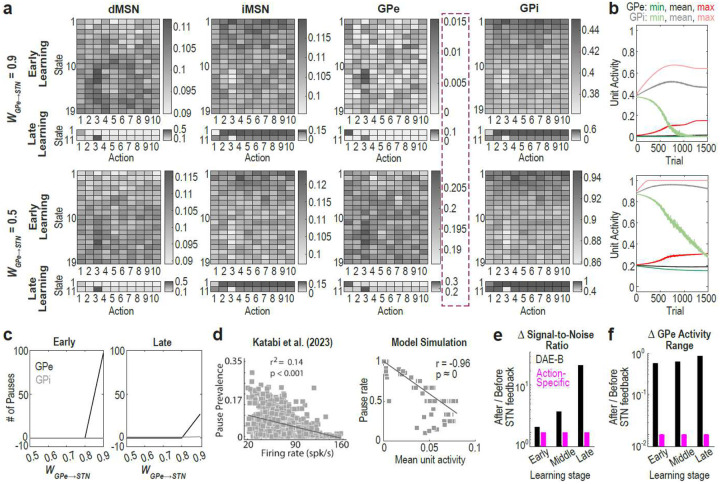 Figure 2
Figure 2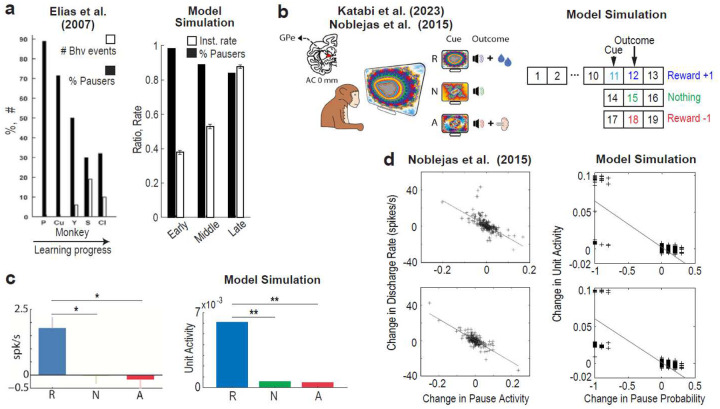 Figure 3
Figure 3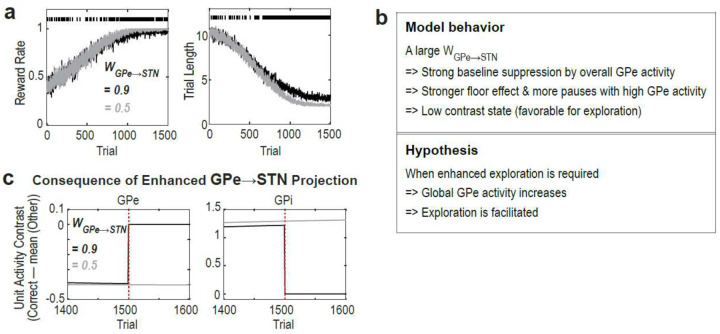 Figure 4
Figure 4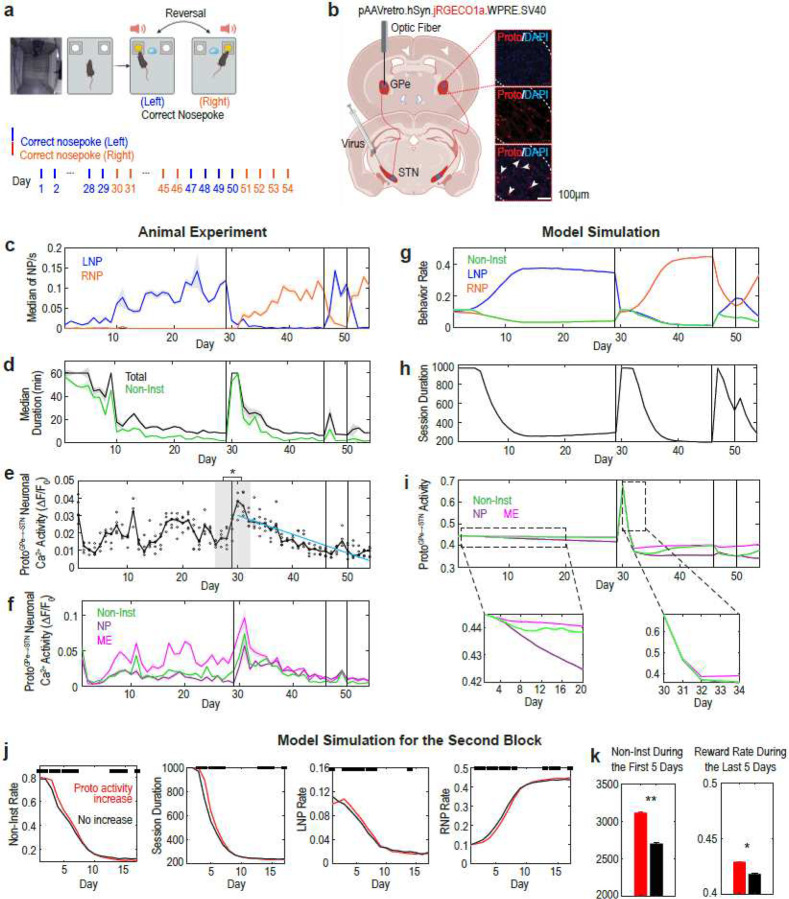 Figure 5
Figure 5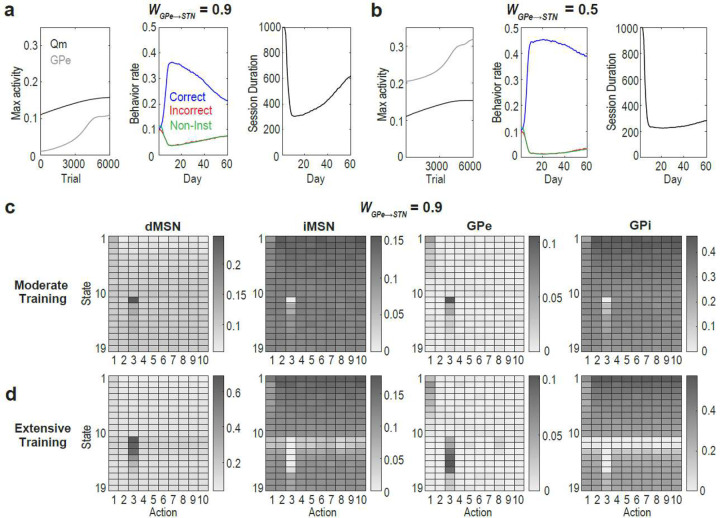 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSemiconductor materials and devices
Introduction
The external the globus pallidus (GPe) was once regarded as a simple relay nucleus within the basal ganglia (BG), leading reinforcement learning (RL) research to focus primarily on the striatum. However, more recent studies suggest that the GPe plays a broader role in RL^1–7^ through its modulatory influence on BG circuitry^8–10^. Notably, the GPe is anatomically positioned to modulate the baseline excitability of both itself and downstream BG output nuclei—namely, the internal globus pallidus (GPi) and substantia nigra pars reticulata (SNr)—primarily through its inhibitory projections to the subthalamic nucleus (STN)^11^.
Despite these advances, the relationship between physiological activity patterns of the GPe and RL remains poorly understood. A particularly elusive feature is the phenomenon of GPe pauses—brief cessation of spiking in high-frequency discharge (HFD) neurons^11–13^. While these neurons typically exhibit high firing rates (mean: ~ 55Hz)^13^, during pauses lasting a few hundred milliseconds, they temporarily cease firing. This pausing activity is a key distinction between the GPe and GPi^11^. Although both structures receive comparable input patterns, pauses are rare (~6%) in the GPi and SNr, but common (~56%) in the GPe^14^. Since their initial observation in 1971^13^, GPe pauses have been reported across multiple species, including humans^15^, non-human primates^14^, rodents^16^, and songbirds^17^. However, their underlying mechanisms and functional roles in RL remain unclear.
Previous studies indicate a nuanced relationship between GPe pauses and behavior. While GPe pauses occur spontaneously during rest, they exhibit increased frequency during movement (e.g., reaching, grasping, lifting)^13^. Some pauses are temporally aligned with actions, though their timing relationships vary^13,14^. The proportion of frequently pausing GPe HFD neurons decreases as instrumental conditioning progresses^14^, and pause likelihood transiently decreases during the presentation of a rewarding cue^18^. A recent study also reported an association between GPe pauses and exploratory behavior^19^. Despite these diverse observations, no unifying framework coherently explains these diverse findings and their underlying circuit mechanisms.
In this study, we developed a novel BG model grounded in prior neurophysiological data to investigate the mechanisms and behavioral implications of GPe pauses in RL. Our model reproduces experimental results from three distinct studies, offering a unified explanation for seemingly disparate findings. We further show that while the circuit characteristics underlying GPe pauses can facilitate adaptive exploration, they may also interfere with the development of performance proficiency during extended training.
Results
A new computational hypothesis for the GPe-STN circuit as a denoising autoencoder
Our model is designed to fully accommodate the canonical basal ganglia circuitry (Fig. 1). Compared to the projections from the striatum to the GPe, the GPe-to-STN connections are more convergent: a single pallidal neuron receives input from less than 0.1% of striatal projection neurons, whereas a single STN neuron receives input from less than 2% of GPe neurons^12,20^. Given this high level of convergence, GPe-to-STN inhibition was modeled as the average activity of STN-projecting GPe neurons. As a result, unlike previous models^4,21^, our implementation does not preserve action-specific connectivity in the GPe-to-STN, STN-to-GPe, and STN-to-GPi pathways (Fig. 1b, top).
This connectivity pattern mirrors the structure of a denoising autoencoder^22,23^ (Fig. 1b inset), in which convergent input integration and divergent feedback promote abstraction and denoising, ensuring robust propagation of essential features such as contextual information. This architectural analogy suggests the key predictions regarding the function of the GPe-STN circuit.
First, the convergent GPe-to-STN projections allow STN neurons to encode the overall activity level of the GPe, thereby modulating the baseline excitability of pallidal neurons (Fig. 1b, bottom). The impact of the overall GPe activity on baseline modulation increases with the strength of . Consequently, when and/or overall GPe activity are excessively high, the contrast in activity among GPe units associated with different actions can diminish due to a floor effect. This provides a prediction that GPe pauses arise from this floor effect. Furthermore, within the GPe population, neurons with relatively lower activity levels would be more likely to exhibit pauses.
Second, the structural resemblance between denoising autoencoders and the GPe-STN circuit supports the extraction of important features via denoising, thereby preserving high contrast in activity across GPe units. In contrast, models featuring action-specific connectivity between the GPe and STN reduce this contrast, failing to account for the emergence of GPe pauses, which require a large activity difference between pausing and non-pausing neurons (Fig. 1ab, bottom).
To test these predictions, we implemented our model in strict accordance with neurophysiological constraints (see Methods for details). This model, which we term DAE-B (Denoising AutoEncoder-Basal ganglia), was trained to select the correct response—analogous to left- or right- lever presses, or saccadic movements directed toward a reward-predictive target in animal experiments--and then retrieve the reward as quickly as possible, using a discount factor of 0.9 and a cost of −0.2 per behavioral step (Fig. 1c, left). In practice, animals not only perform instrumental actions but also engage in a variety of non-instrumental, exploratory behaviors (Non-Inst), including rearing, roaming, sniffing, and gazing at task-irrelevant stimuli (Fig. 1c, right). To simulate this, the model incorporated three instrumental and seven arbitrary non-instrumental behaviors, which also enhanced its ability to account for animals’ exploratory actions.
Autoencoder-like computation of the GPe-STN circuit underlies GPe pauses
To test the first prediction—that GPe pauses arise from a floor effect caused by high overall GPe activity and large —we conducted two analyses: First, we examined whether a large induces a floor effect on GPe activity. Our findings indicate that when is large, GPe unit activity is generally low due to weakened excitatory input from the STN (Fig. 2ab) and exhibits frequent pauses (defined as activity level < 1%; Fig. 2c). As decreases, GPe activity increases and pauses become less frequent. Interestingly, GPi activity was consistently higher than GPe activity (Fig. 2ab), consistent with previous findings (mean firing rate of HFD neurons: 55 Hz in GPe and 63 Hz in GPi in primates)^13^. The significantly higher activity range of GPi compared to GPe may account for why pauses are frequent in the GPe but not in the GPi^13,14^—a key feature of pallidal pauses.
Next, we asked whether GPe units with relatively lower activity levels are more likely to exhibit pauses. Corroborating our hypothesis, a prior study showed that the tendency to pause increases as a neuron’s firing rate decreases^24^. This relationship was reproduced by the DAE-B model (Fig. 2d). This pattern persisted even when unit activity was corrected by calculating mean activity excluding pausing periods (Suppl. Fig. 7b), or when the model was trained on a different task design (Suppl. Fig. 7c).
We then tested the second prediction—that action-specific connectivity disrupts denoising and impairs contrast preservation. We found that the DAE-B model significantly enhanced signal-to-noise ratio (Fig. 2e) and better preserved the range of GPe unit activity following STN feedback (Fig. 2f; Suppl. Fig. 8c). In the model with action-specific connectivity, GPe units with stronger activity received weaker excitatory input from the STN, and vice versa (Fig. 1a bottom). This feedback dampens discriminability among action-encoding GPe neurons, causing pauses to occur in an all-or-none fashion depending on the size of (Suppl. Fig. 8ab). This contradicts experimental findings demonstrating substantial activity contrasts in GPe neurons during pausing (0 Hz) versus non-pausing (~20–160 Hz) periods^24^.
Taken together, the absence of action-specific connectivity between the GPe and STN, enables the circuit to function analogously to a denoising autoencoder, thereby accounting for GPe pause patterns. This architecture is well-suited to extract essential features (e.g., contextual information) and to modulate GPe baseline activity based on those features, while largely preserving activity contrast across GPe neurons. When is large, the baseline is lowered, resulting in a strong floor effect and frequent pauses.
The proposed GPe pause mechanism generalizes to various learning contexts
We then examined whether the DAE-B model could extend to RL contexts by replicating previous experimental findings on GPe neuronal activity and pauses during RL. First, we tested whether the DAE-B model reproduces the inverse relationship between learning progress and the proportion of frequently-pausing GPe neurons, as reported by Elias et al. (2007)^14^. The authors found that, as monkeys became more engaged in instrumental learning tasks—generating more instrumental responses—the proportion of GPe neurons displaying frequent pauses decreased (Fig. 3a left). The DAE-B model successfully reproduced this finding (Fig. 3a right). In the early stages of learning, correct instrumental responses are infrequent, leading to long trial durations, while pauses are widespread (Fig. 2a top; 2c left). As learning progressed, inhibition from indirect pathway medium spiny neurons (iMSNs) to GPe units associated with correct instrumental behaviors decreased, leading to fewer pauses in those GPe units (Fig. 2a top; 2c right). Furthermore, learning enabled the model to execute correct actions more efficiently, shortening trial durations. The combined effect of these changes led to a reduction in frequently pausing units over the course of learning (Fig. 3a right).
Next, we investigated whether the DAE-B model replicates findings from a different task design, in which three distinct cues predicted liquid food, no outcome, and an air-puff, respectively (Fig 3b left)^18,24^. To adapt the task for the model, rewards of 1, 0, and −1 were delivered after the reward, neutral, and aversive cues, respectively (Fig. 3b right). The model had two instrumental behavior options (licking and blinking) and eight non-instrumental behavior options, and was trained to select the appropriate action at the appropriate timing. In the experiment, monkeys tended to lick shortly after the reward cue onset but blinked at the time of air-puff delivery, likely due to the longer latency of the former (Suppl. Fig. 9a). To accommodate this behavioral asymmetry, a half-sized reward was also given when the model selected licking during the reward cue.
Using this RL task, we examined whether the DAE-B model replicates previous experimental findings in two domains: GPe neuronal activity and GPe pausing activity. Katabi et al. (2023)^24^ reported that GPe HFD neurons exhibited significantly higher firing rates during the reward cue compared to neutral or aversive cues (Fig. 3b left). After training with a large , the DAE-B model successfully learned the task (Suppl. Fig. 9b), and replicated this pattern (Fig. 3c right). As the model learned the task, iMSN activity for licking weakened, which was reflected in GPe activity.
We then tested whether the DAE-B model replicates GPe pausing activity during this RL task. Using a similar task design, Noblejas et al. (2015)^18^ demonstrated a negative correlation between changes in firing rates and changes in pause likelihood during both cue presentation (Fig. 3d left top) and outcome delivery (Fig. 3d left bottom). Since a reduction in firing rate increases the phase likelihood (Fig. 2d), this pattern was reproduced in all stages of learning—early, middle, late—in the DAE-B model simulation (Fig. 3d right; Suppl. Fig. 10). With learning, GPe unit activity became increasingly differentiated between correct and incorrect actions, and by the late stage, units associated with correct actions formed distinct clusters in the plot. Notably, the negative correlation remained significant even when units with activity changes greater than 0.05 were excluded.
In sum, the consistency between prior empirical findings and the DAE-B model supports the biological plausibility of the proposed mechanism underlying GPe pauses in RL settings. Our model provides a unified account of disparate findings on GPe pauses within an RL framework.
GPe-to-STN projection strengthens upon sudden environmental changes
Since the DAE-B model learned the task slightly better with a small than with a large one (Fig 4a), we questioned the potential advantage of a large in RL. In the DAE-B model (Fig. 4b), the global level of GPe activity inhibits baseline GPe activity at the next time step via recurrent GPe–STN interactions, with the strength of this modulation scaling with . Thus, when is large, a significant rise in overall GPe activity induces a low- contrast state through a strong floor effect. Simulations with the DAE-B model further demonstrated that, under a large , enhancing GPe-to-STN projection by 1.5 times abolished the activity contrast between correct versus incorrect behaviors in both the GPe and GPi (Fig. 4c)—a condition favorable for exploring actions with low values. This effect was not observed when was small.
These findings led to a new hypothesis: (1) in situations requiring enhanced exploration—such as sudden environmental changes—GPe-to-STN projection strength would increase, and (2) this increase would promote exploration by disrupting established action preferences.
To test the first part of this hypothesis, we conducted an experiment in which mice were trained to nose-poke (NP) the correct hole and enter the magazine (ME) to retrieve a reward (Fig. 5a, top)^25^. After training, the correct NP hole was reversed to the other side (from left to right) without notice and reversed twice more thereafter (Fig. 5a, bottom). The activity of GPe prototypic neurons projecting to the STN ( ; Proto from prototypic neurons, which are putative HFD neurons in rodents) was recorded throughout the experiment (Fig. 5b).
Mice successfully learned the task (Fig. 5c), and exploratory, non-instrumental (Non-Inst) behaviors increased following reversals (Fig. 5d). Non-Inst behaviors were defined as any behavior during the session, excluding intervals from −1 to 1 s around NP, the period between magazine entrance and exit, −1 to 0 s before magazine entrance, and 0 to 1 s after magazine exit.
The results confirmed our hypothesis. The activity significantly increased immediately after the first reversal compared to before the reversal (shaded area in Fig. 5e) and then gradually decreased (blue line in Fig. 5e; repeated-measures correlation r = −0.83, p = 5.44×10^−31^). This result is also consistent with previous findings in monkeys^5^, where firing rates of GPe HFD neurons peaked when monkeys had to explore different choices following an unexpected rule change, but gradually decreased over consecutive trials as the newly correct choices became routine.
Enhancing GPe-to-STN projection promotes exploration
After showing that the GPe-to-STN projections get stronger in response to sudden environmental changes, we next examined the second part of our hypothesis—that enhanced GPe-to-STN projections promote exploration. To simulate the observed increase in activity after reversal, we artificially doubled its activity following the reversal and then set it to gradually decrease (see Methods). Under this implementation, and with a large , relative differences in GPe activity across actions were flattened, resulting in prevalent pauses (Suppl. Fig. 11). The model successfully replicated the experimental results (Fig. 5g–i), including the relative activity difference of during nose-poke (NP), magazine entrance (ME) and Non-Inst behaviors (Fig. 5i).
To evaluate the effect of increased activity on exploration, we compared model behaviors with and without this manipulation (Fig. 5jk). When activity was elevated, exploratory Non-Inst behavior increased following the first reversal. Despite this heightened exploration, task performance also improved: by the end of the second block, previously correct responses (LNP) decreased more, while currently correct responses (RNP) increased more. These results indicate that, when is large, increased activity facilitates RL by promoting exploration.
Our animal data also support this conclusion. After the second and third reversals—when mice adapted more quickly and showed smaller increases in exploratory Non-Inst behaviors compared to the first reversal (Suppl. Fig. 12)— activity did not significantly increase (Fig. 3ef). It is likely that other circuits, such as the hippocampus, contributed to faster adaptation following the second and third reversals, reducing the need for activity modulation^26–29^.
Taken together, our experimental and simulation results suggest that overall activity increases in response to exploratory demands, thereby enabling adaptive exploration when is large.
Model provides circuit-level account for habitual vs. goal-directed control
We also explored the potential disadvantages of a large . We found that when is large, maximum Qm activity exceeds that of GPe, with the gap increasing with extensive training (Fig. 6a left). This mismatch suggests that learning in Qm cannot be fully accommodated by the GPe, ultimately leading to performance deterioration with extensive training (Fig. 6a middle, right; Fig. 6cd). In contrast, when is small, maximum Qm activity remained below that of the GPe, and performance deterioration is less pronounced (Fig. 6b). These results suggest that proficiency acquired through extended training (e.g., habit formation) may rely on a distinct circuit characterized by a smaller .
Like the striatum, the GPe and STN are anatomically and functionally divided into limbic, associative, and sensorimotor subregions, with topographic connectivity largely preserved across these territories^30–33^. It is widely accepted that the associative and sensorimotor domains of the BG support goal-directed and habitual behavior, respectively^34–40^. However, it remains unclear why and how the circuit properties of these regions differ to support these distinct roles. The DAE-B model proposes a testable hypothesis: may be smaller in the sensorimotor territory than in the associative territory. A large in the associative regions would support adaptive exploration and generate GPe pauses, whereas a smaller in the sensorimotor territory may facilitate development and maintenance of proficient, habitual performance.
Discussion
Building on prior neurophysiological findings, we developed the DAE-B model that provides a unified account of the mechanisms underlying GPe pauses and reconciles disparate experimental findings. Our simulation results demonstrate that GPe pauses emerge from the absence of action-specific connectivity between the GPe and STN, combined with a large . Furthermore, using animal experiments and model simulations, we show that this circuit structure enables transient reduction in discriminability among GPe action encodings during adaptive increases in global GPe activity, thereby promoting exploration. We also propose a novel, testable hypothesis that may be smaller in the sensorimotor territory than in the associative territory in order to support the development and maintenance of proficient performance with extended training. If supported, this hypothesis would suggest a computational basis for the division of labor between associative and sensorimotor domains of the BG.
Our results suggest that the GPe is not merely a relay nucleus within the BG but may function as both a denoising autoencoder and a baseline modulator. Medium spiny neurons in the striatum typically exhibit low firing rates (0.1–10.8 Hz; mean 3.3 Hz)^41,42^. This narrow discharge range constrains both the dynamic range of representable action values and the discriminability among actions. In contrast, pallidal neurons fire at much higher rates, with a broader range (20.3–156.7 Hz; mean 71.1 Hz; somewhat lower in rodents)^24,43^ enabling a wider and more separable action encoding. This distinction necessitates that action values learned in the striatum be amplified in the GPe while suppressing noise. The connectivity pattern between the GPe and STN, which resembles a denoising autoencoder, may support this function while also modulating the baseline excitability of pallidal neurons in a context-dependent manner.
Although we and a previous study^5^ observed that activity increased after sudden environmental changes, the underlying mechanism remains unclear. A prior study reported a correlation between arousal (measured via pupil dilation) and GPe pause occurrences, suggesting that arousal-related regions may be involved^19^. One possibility is enhanced cortical input to the STN during reversal, increasing excitatory drive to GPe neurons^44^. Another possibility is involvement of the corticotropin-releasing factor (CRF) system: CRF neurons in the PVN (Paraventricular nucleus), CeA (central amygdala), and BNST (bed nucleus of the stria terminalis) project to the GPe, where CRFR1 is highly expressed in prototypic but not arkypallidal neurons^45^. CRFR1 activation excites these neurons and, unlike its anxiogenic effects elsewhere, has been shown to promote exploration (e.g., increased distance traveled, speed, and center time)^46,47^. Future studies are warranted to elucidate the mechanisms underlying context-sensitive global modulation of activity. It also remains to be tested whether a general increase in activity actually leads to more pauses.
In addition to prototypic neurons (putative HFD neurons in rodents), the GPe contains arkypallidal neurons (putative low-frequency discharge [LFD] neurons in rodents). These neurons differ markedly from prototypic neurons in both connectivity and activity patterns^48–51^, and they do not typically exhibit pauses^24^. Because our primary interest was the circuit mechanisms underlying GPe pauses, we did not include arkypallidal neurons in the DAE-B model to avoid unnecessary complexity. For similar reasons, we also omitted lateral inhibition among prototypic neurons, as their functional roles and connectivity patterns remain less well characterized and are still under active investigation^48,51–53^. Nevertheless, we cannot exclude the potential contributions of arkypallidal neurons and lateral inhibition to the generation of GPe pauses, and future studies are needed to explore these possibilities.
Previous studies have reported that pauses are not temporally locked to movements^13,14^, whereas our simulation showed pauses coinciding every behavior (Suppl Fig. 13). In the DAE-B model, this occurred because executing any behavior requires stronger suppression of other behaviors, increasing the likelihood of pauses in GPe units associated with those actions. Many experimental and model studies have primarily focused on a limited set of instrumental actions despite the wide diversity of the behavioral repertoire—including saccades^19^—which may have led to an underestimation of pauses that are time-locked to non-instrumental movements. The present study demonstrates that animals spend a substantial amount of time engaged in non-instrumental behaviors. Importantly, a reduction in these behaviors—reflected in the gradual decrease of session duration as learning progresses and the minimal increase in Non-Inst behaviors after the second and third reversals—marks learning progress. Therefore, more closely analyzing non-instrumental behaviors^54^ and incorporating a broad range of non-instrumental behaviors into computational models may deepen our understanding of the exploration-exploitation tradeoff in animals.
Associative and habitual behaviors depend on distinct computations and are mediated by anatomically segregated loops within the basal ganglia (BG)^34,55^. Yet, many computational models treat the BG as a functionally uniform structure and attribute habit formation primarily to Hebbian plasticity in the cortex^56,57^, overlooking extensive evidence implicating the sensorimotor loop^36,37,40,58,59^. Consequently, apart from anatomical connectivity^30,31,33,60^, the circuit-level distinctions supporting domain-specific functions remain poorly understood. The DAE-B model offers a neurophysiological hypothesis that the synaptic strength of GPe-to-STN inhibition differentiates associative and sensorimotor territories. A larger in associative regions may support flexibility and adaptive exploration via baseline modulation, while a smaller in sensorimotor regions may stabilize behavior and facilitate habitual performance. This framework links domain-specific computational demands to distinct circuit configurations, offering a mechanistic account of the division of labor across BG subregions.
This study provides a circuit-level framework for understanding the emergence and functional significance of GPe pauses in RL. We show that the GPe–STN circuit, by operating analogously to a denoising autoencoder, enhances exploration in an adaptive manner. Our results call for further investigation into how distinct BG subdomains differentially support behavioral flexibility and proficiency.
Methods
DAE-B Model Simulations (Fig. 1–6 except for Fig. 5a–f)
Denoising AutoEncoder-Basal ganglia (DAE-B) Model structure
STN activity
The STN receives excitatory inputs from cortical areas, while afferents from the GPe constitute its main source of inhibitory input^61^. During sudden needs for rapid action cancellation, additional inputs from the cortex to the STN via the hyperdirect pathway halt behaviors^62,63^. Reflecting these, STN activity was defined as:
where , the baseline STN activity, was set to 0.5, and (representing cortical stop signal input) was fixed at 0.
At each state, STN activity is initially computed with . This preliminary value is used to compute GPe activity (Eq. 3), which in turn is fed into the STN calculation (Eqs. 1–2). The updated STN value is then used to recompute GPe activity (Eq. 3), which is subsequently passed downstream.
GPe-to-STN inhibition
The primary excitatory input to both the GPe and GPi is originated from the STN^11^. In turn, GPe prototypic neurons (putative HFD neurons in rodents) send inhibitory projections to the STN ( ). Considering the convergent projection patterns from the GPe to the STN^12,20^, GPe-to-STN inhibition was defined as mean activity of , given by:
where represents the activity of iMSNs in the striatum and denotes the synaptic strength from GPe to STN.
GPe and GPi/SNr activity
Activity of GPe and GPi/SNr neurons was defined as:
represents the activity of dMSNs. To amplify learning in Qm, was set to 2, although other values such as 1 or 3 also performed well (Suppl. Fig. 1–4). The hyperdirect pathway enables rapid inhibition of pre-planned movements by transmitting excitatory cortical input directly to the subthalamic nucleus (STN), which then activates inhibitory output nuclei such as the GPi/SNr to suppress motor execution^62,63^. Reflecting this, was calibrated to cancel all behavioral output when and fixed at 4 ( ). All other weights were fixed at 1.
Range of WGPe→STN
The activity of each unit was bounded within [0, 1]. To ensure that GPe-to-STN inhibition generally remained within this range, the following inequality was required:
favoring non-small values of . Approximating , The GPe activity after STN feedback can be expressed as:
To ensure GPe activity remains within bounds and Eq. 5 holds, the following condition must be satisfied:
Furthermore, Eq. 6 implies:
To allow a wide range for , a large and a non-negligible value of are preferred. For simplicity and in consideration of the hyperdirect pathway, was fixed at 1.1, while was systematically varied. However, the model displays a similar performance pattern with other values, such as and (Suppl. Fig. 5–6).
DAE-B Model learning
Value learning
and were updated to according to the following rules:
(learning rate) was fixed at 0.001. The eligibility trace (el) decayed with a factor of 0.9. The prediction error ( ) was defined as:
following the convention of SARSA learning. was defined as , simulating thalamic output. Effort (cost of behavior) was fixed at −0.2. The discount factor ( ) was set to 0.9. and units were initialized to ~0.1 to account for the low baseline activity of MSNs^64^. Actions were selected using a softmax function with a temperature of 0.1, except in Fig. 3b–d, which simulated a different task and used a temperature of 0.05.
Reversal
After reversal, activity was initially doubled and then gradually decreased according to the following rule:
where is the number of time steps since reversal and was fixed at 0.0005.
Simulating animal experimental data (Fig. 5j–k)
Mimicking our animal experiment (see below), a session was defined as a set of consecutive trials in which either the cumulative length (excluding the final trial) remained below a threshold (set to 1000), or the number of rewards obtained was equal to or less than (fixed at 100). Next session began with the values of and from the end of the last trial of the previous session.
Animal Experiment (Fig. 5a–f)25
Animals
All procedures were approved by the Mayo Clinic Institutional Animal Care and Use Committee. GFAP-Cre (JAX #024098) × DIO-GCaMP6s (JAX #028866) bi-transgenic mice (8–10 weeks old; 5 males) were used. Mice were housed under a 12 h light/dark cycle (lights on at 07:00) and food-restricted to 85% of their initial body weight during behavioral experiments.
Instrumental task
Behavioral testing was conducted in operant chambers equipped with an active nose port, an inactive port, a magazine, house light, speaker, and cue lights. Each rewarded nose-poke in the active port triggered auditory and visual cues, followed by delivery of a 20% (w/v) sucrose solution via syringe pump. Inactive nose-pokes had no programmed consequences.
Mice were first trained to retrieve 60 rewards from the magazine (days 1–3). This was followed by a fixed-ratio 1 (FR1) schedule with a 60-minute session limit. Sessions ended early if 60 rewards were earned. To facilitate learning, 10 μL of sucrose was placed as bait in the active port during initial FR1 sessions and removed once response latencies stabilized (<2 s across two consecutive sessions).
Stereotaxic surgery and virus injection
Under 1.5% isoflurane in oxygen anesthesia, mice were secured in a stereotaxic frame and received bilateral injections (7 × 10^12^ GC/mL; Addgene #100854) of pAAVretro.Syn.NES-jRGECO1a.WPRE.SV40 into the STN at the following coordinates (from dura, relative to bregma): AP −2.14 mm, ML ±1.65 mm, DV −3.90 mm. Experiments were conducted 4–5 weeks post-injection.
In vivo calcium imaging (fiber photometry)
Fiber photometry was used to monitor in vivo calcium dynamics. An optic cannula (200/240 μm diameter, 200 μm core) was implanted in the GPe (AP −0.46 mm, ML +2.0 mm, DV −3.0 mm). The cannula was connected to a patch cord delivering 60 μW light at the fiber tip.
Signals were recorded using a multi-wavelength photometry system (v1.2.0.14, Plexon) with time-division multiplexing. Excitation wavelengths included 410 nm (isosbestic control), 465 nm (GCaMP6s), and 560 nm (jRGECO1a). The 410 nm signal was linearly fitted to both 465 nm and 560 nm signals to correct for motion artifacts and bleaching. ΔF/F was calculated as (signal – fitted 410 nm)/fitted 410 nm for both astrocytic and neuronal indicators.
Immunofluorescence
Brains were fixed in 4% paraformaldehyde and cryoprotected in 30% sucrose at 4°C. Coronal sections (40 μm) were cut, mounted on gelatin-coated slides, and coverslipped with VECTASHIELD containing DAPI (Vector Laboratories). Confocal images were acquired using an LSM 700 microscope (Zeiss) with 10× and 63× objectives.
Statistical analyses
To generate Fig. 2d (right), GPe activity for each of the 10 action options was collected during the trial of interest: 100 for the early stage, 600 for the middle stage, and 1500 for the late stage. The average unit activity across the trial for each action was taken as the mean unit activity. Pause rate for each action was calculated by dividing the number of states where unit activity was less than 0.01 by the trial length (i.e. the total number of states in that trial). Thus, each simulation yielded 10 pairs of pause rate and mean unit activity. We ran 100 simulations for Fig. 2d and each panel in Suppl. Fig. 7.
To compute the signal-to-noise ratio in Fig. 2e, we ran 100 simulations. Signal was defined as the difference between the activity for the correct response and the mean activity for other responses at state 1. This signal was computed for each simulation, and the square of these values was averaged across 100 simulations to obtain the signal power. Noise power was defined as the mean of the variances computed for each of the 10 action options across 100 simulations.
Fig. 5cd show the raw behavioral data without further preprocessing such as per animal normalization. For Fig. 5ef, the average Ca^2+^ activity (ΔF/F_0_) was computed for each session and each animal, and then averaged across animals. In Fig. 3e, the entire session data were used. In Fig. 3f, data were extracted from specific epochs: 0–1 s after NP for NP, 0–1 s after ME for ME, and −2 to −1 s before NP for Non-Inst.
Supplementary Material
Supplementary Files
This is a list of supplementary files associated with this preprint. Click to download.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kang S. Astrocyte activities in the external globus pallidus regulate action-selection strategies in reward-seeking behaviors. Sci Adv 9, (2023).10.1126/sciadv.adh 9239 PMC 1027559737327345 · doi ↗ · pubmed ↗
- 2Baker M. External globus pallidus input to the dorsal striatum regulates habitual seeking behavior in male mice. Nat Commun 14, (2023).10.1038/s 41467-023-39545-8PMC 1033852637438336 · doi ↗ · pubmed ↗
- 3Farries M. A., Faust T. W., Mohebi A. & Berke J. D. Selective encoding of reward predictions and prediction errors by globus pallidus subpopulations. Current Biology 33, 4124–4135.e 5 (2023).37703876 10.1016/j.cub.2023.08.042PMC 10591972 · doi ↗ · pubmed ↗
- 4Bogacz R., Martin Moraud E., Abdi A., Magill P. J. & Baufreton J. Properties of Neurons in External Globus Pallidus Can Support Optimal Action Selection. P Lo S Comput Biol 12, e 1005004 (2016).27389780 10.1371/journal.pcbi.1005004 PMC 4936724 · doi ↗ · pubmed ↗
- 5Schechtman E., Noblejas M. I., Mizrahi A. D., Dauber O. & Bergman H. Pallidal spiking activity reflects learning dynamics and predicts performance. Proc Natl Acad Sci U S A 113, E 6281–E 6289 (2016).27671661 10.1073/pnas.1612392113 PMC 5068334 · doi ↗ · pubmed ↗
- 6Lilascharoen V. Divergent pallidal pathways underlying distinct Parkinsonian behavioral deficits. Nature Neuroscience 2021 24:4 24, 504–515 (2021).33723433 10.1038/s 41593-021-00810-y PMC 8907079 · doi ↗ · pubmed ↗
- 7Ging-Jehli N. R. Basal ganglia components have distinct computational roles in decision-making dynamics under conflict and uncertainty. P Lo S Biol 23, e 3002978 (2025).39847590 10.1371/journal.pbio.3002978 PMC 11756759 · doi ↗ · pubmed ↗
- 8Dong J., Hawes S., Wu J., Le W. & Cai H. Connectivity and Functionality of the Globus Pallidus Externa Under Normal Conditions and Parkinson’s Disease. Front Neural Circuits 15, 645287 (2021).33737869 10.3389/fncir.2021.645287 PMC 7960779 · doi ↗ · pubmed ↗