SatHealth: A Multimodal Public Health Dataset with Satellite-based Environmental Factors
Yuanlong Wang, Pengqi Wang, Changchang Yin, Ping Zhang

TL;DR
SatHealth is a new dataset combining satellite and health data to improve AI models for public health by incorporating environmental factors.
Contribution
SatHealth introduces a novel multimodal dataset integrating environmental, satellite, and health data for public health AI research.
Findings
Environmental data significantly improves AI model performance in public health tasks.
SatHealth enables better temporal-spatial generalizability in disease risk prediction.
A web application and code pipeline support easy access and use of the dataset.
Abstract
Living environments play a vital role in the prevalence and progression of diseases, and understanding their impact on patient’s health status becomes increasingly crucial for developing AI models. However, due to the lack of long-term and fine-grained spatial and temporal data in public and population health studies, most existing studies fail to incorporate environmental data, limiting the models’ performance and real-world application. To address this shortage, we developed SatHealth, a novel dataset combining multimodal spatiotemporal data, including environmental data, satellite images, all-disease prevalences estimated from medical claims, and social determinants of health (SDoH) indicators. We conducted experiments under two use cases with SatHealth: regional public health modeling and personal disease risk prediction. Experimental results show that living environmental…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
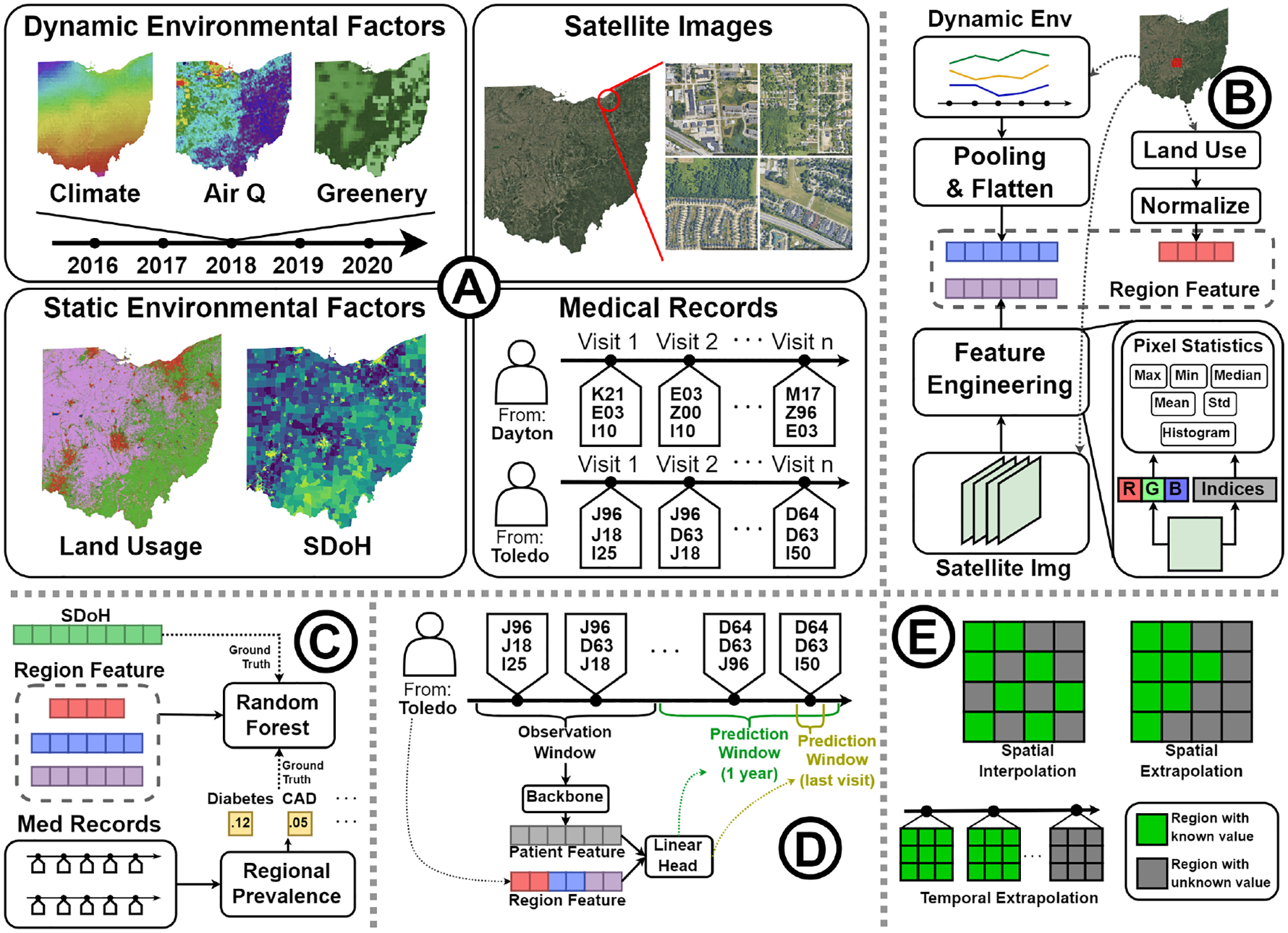 Figure 1
Figure 1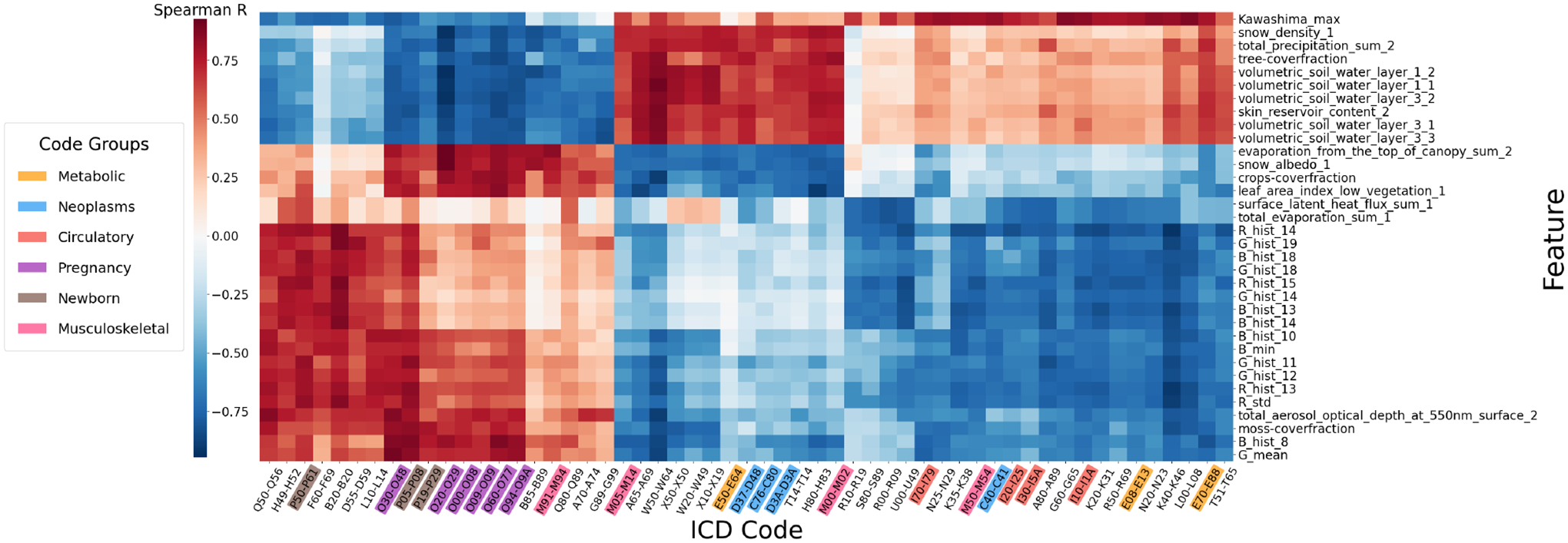 Figure 2
Figure 2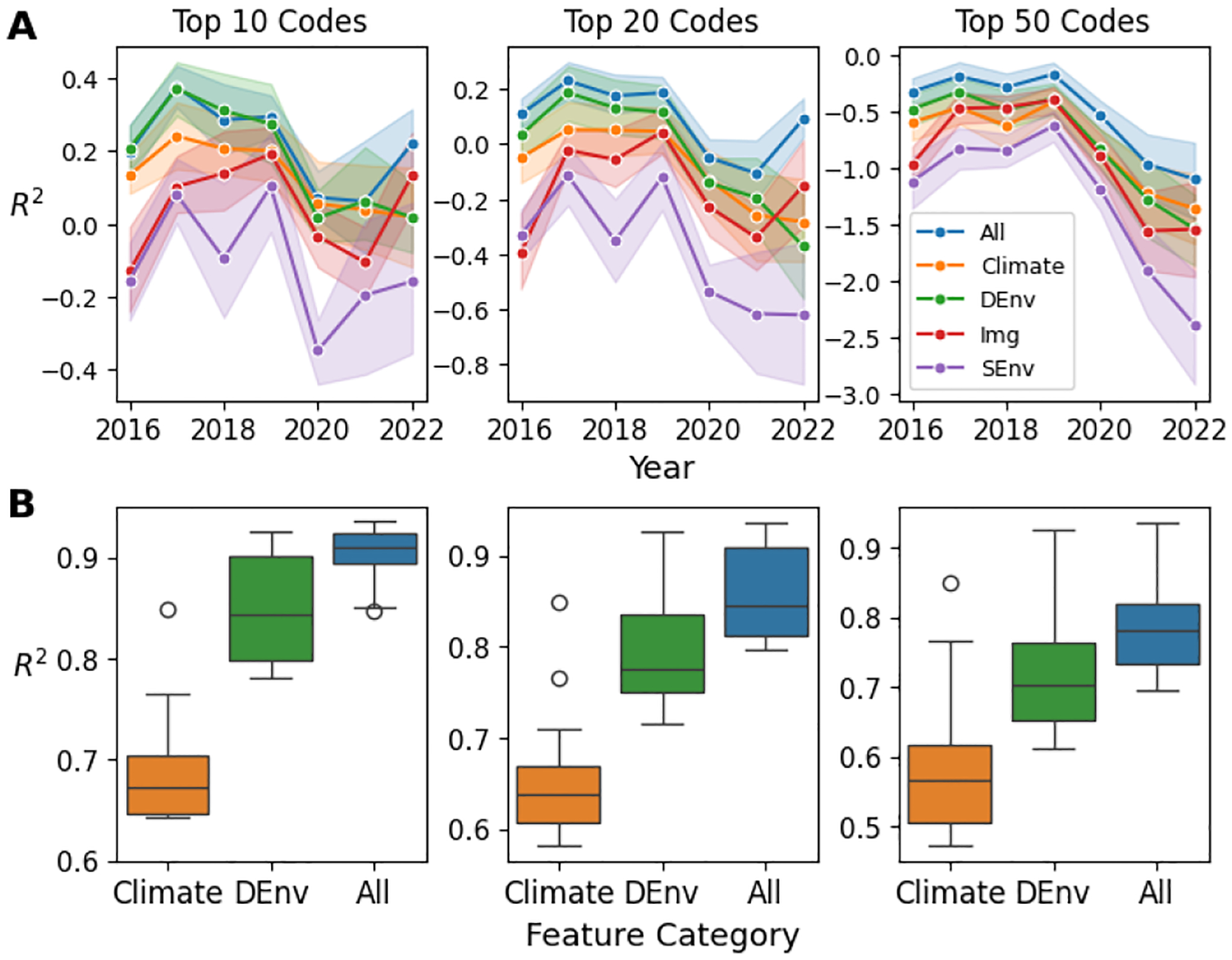 Figure 3
Figure 3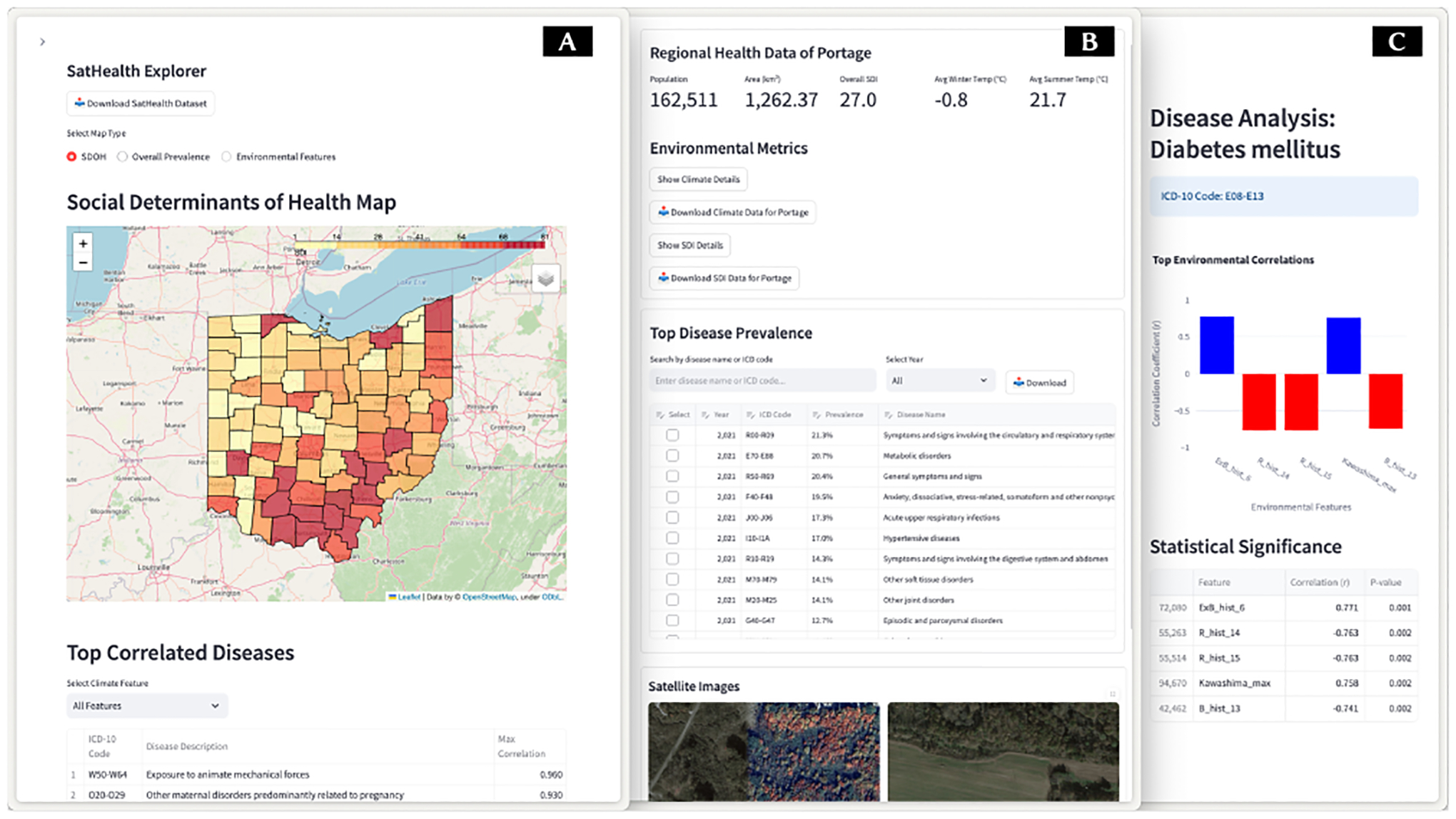 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData-Driven Disease Surveillance · Health disparities and outcomes · Health, Environment, Cognitive Aging
Introduction
1
The living environment (e.g., climate, green spaces, air quality, and socioeconomic factors) considerably impacts people’s physical [20, 25] and mental [67] health, and understanding such impact is an emerging topic [18, 32, 38]. Considerable efforts have been made to explore how these factors are associated with human health [36, 60, 63]. However, due to the complexity of aligning multi-source geospatial data with medical data, there are still limited handy medical datasets equipped with high spatiotemporal resolution, long-term coverage, and comprehensive environmental data. Therefore, existing studies either focus on specific diseases and environmental factors [14, 40] or take solely patients’ medical record histories without consideration of environmental factors [13, 69, 74, 75]. As a result, these models might be limited in their accuracy, comprehensiveness, and spatiotemporal robustness. Moreover, the benefit of information from the living environment in healthcare AI remains unexplored.
To fill the shortage, we propose a pipeline and develop SatHealth, a compound dataset featuring satellite-based environmental data, satellite imagery, prevalence of all diseases estimated from medical claims, and Social Determinants of Health (SDoH) indices. To the best of our knowledge, SatHealth is the first dataset in the US that combines regional environmental characteristics with a healthcare database. We requested over 400k aerial view satellite images from Google Maps [27], each image covers about a 500m wide square area. Furthermore, we use medical claims from the MarketScan [44] database to estimate the regional prevalence for all diseases. As for SDoH, we use the Social Deprivation Index (SDI) [33], which is a comprehensive score calculated from US census data from the American Community Survey (ACS) [9]. Moreover, we designed a multimodal fusion framework to seamlessly integrate heterogeneous multimodal environmental data sources and provide user-friendly regional environment embeddings, facilitating downstream analyses and follow-up studies.
We first validated and quantified the environmental-disease relationship by statistical testing, reflecting regional health status disparity. After that, we use the dataset for two clinical tasks: regional public health modeling (e.g., to predict regional SDI scores and disease prevalence based on environmental data) and personalized disease risk prediction (e.g., to enhance personal disease risk prediction with environmental data). The experimental results show that living environmental information can significantly improve AI models’ performance and spatiotemporal generalizability. Finally, we deployed a web-based application^1^ where users could explore and access SatHealth data with regional embedding vectors. Our regional embeddings can be plugged into any clinical AI with geospatial information, which paves the way for integrating environmental factors into clinical AI development.
We started SatHealth development from Ohio as a concomitant of the Ohio O-SUDDEn program [23]. However, all satellite data we use have global coverage, and MarketScan patient-level medical claims have US coverage. Therefore, our framework’s environmental factor processing pipeline can be easily adapted to other areas. We also provide our code on GitHub^2^ so that users can create data and embeddings for different areas of interest. We will also gradually update SatHealth to cover the US in the future.
In summary, we summarize our contributions as follows:
- We construct SatHealth, the first publicly available dataset in the US consisting of environmental data, satellite imagery, regional SDoH, and all-disease prevalence for comprehensive environment-health analysis.
- We design an embedding pipeline to construct regional environment embeddings by fusing multimodal data from SatHealth.
- We show two use cases of SatHealth. The experimental results exhibit the benefit of environmental information in model accuracy and temporal-spatial generalizability.
- We deployed a web-based application to showcase and provide access to SatHealth and our embeddings. We also publish our code for data collection in other areas of interest.
Code and Docs: https://github.com/Wang-Yuanlong/SatHealth Web app and Dataset download: https://aimed-sathealth.net License: The dataset is released under the CC BY-SA 4.0 license.
Related Works
2
Environment-health Datasets
2.1
Environmental factors, such as built environment, air quality, and green space, are reported to be correlated with many diseases, such as heart diseases [14, 15], metabolic syndrome [37], and stroke [4]. Researchers construct datasets with earth observation (EO) and remote sensing data with various health outcomes to learn their health impacts. For example, Barboza et al. [7] and Temenos et al. [61] collected regional greenery indices like normalized difference vegetation index (NDVI) and percentage of green area (%GA), and studied their relationship with natural-cause mortality and COVID-19 cases. However, the greenery indices provide a limited expression of the living environment. Therefore, some datasets include satellite images to capture a more comprehensive neighborhood view. SatelliteBench [47] examines the dengue outbreak in 81 Colombian municipalities, collecting Sentinel-2 satellite images, climate, socioeconomic factors, and dengue cases to predict poverty, school access, and dengue outbreaks. Moreover, SustainBench [71] benchmarks prediction tasks of 4 public health indicators from surveys with satellite images and street view panorama. However, These datasets rely on public health surveys, which limit their target scope. Recently, MedSat [56] was developed in England by integrating sociodemographic features, satellite imagery, environmental variables, and prescription data. However, it is constrained by indirect prevalence estimation, leading to higher errors and limited disease scope. Finally, all these datasets suffered from a limited scope of target disease and none or moderate-resolution satellite images. Inspired by all these works, we developed SatHealth by combining SDoH, environmental variables, satellite images, and the MarketScan medical claim database. High-resolution satellite images from Google Maps provide a clear view of ground-level environments, while MarketScan provides prevalence estimates for thousands of diseases. Hence, SatHealth enables comprehensive environment-health analyses.
Health-related Target Modeling
2.2
Environment-health relationship modeling.
Numerous studies have been conducted to explore the impact of the environment on human health. The fundamental methods are community surveys and statistical tests. Wafula et al. [63] used surveys and mediation analysis to explore socioeconomic disparities in malaria prevalence in Malawi. Similarly, Keenan et al. [36] analyzed multidrug-resistant urinary tract infections (MDR UTIs) in East Africa using questionnaires and Bayesian profile regression to identify clusters of social and environmental determinants. By incorporating image modalities, Zhang et al. [76] explored the protective effects of shaded environments against adolescent myopia using commercial satellite maps and Spearman’s correlation analysis.
Machine learning methods are also widely adopted. For example, Araújo et al. [3] employed Sentinel-1 and Sentinel-2 data to investigate the relationship between green spaces and mental health, using spatial autocorrelation metrics like Moran’s I and regression models to quantify the impact of environmental features. Yin et al. [73] and Nazia et al. [49] applied Bayesian hierarchical models to study the dynamics of COVID-19 spread, incorporating environmental, social, and health data. Luo et al. [40] used mixed-effects models to analyze the association between air pollution and hypertension, revealing disparities in cardiovascular health risks. At the same time, Gibb et al. [26] employed Bayesian spatiotemporal modeling to investigate dengue emergence linked to climate change and urban infrastructure. Most recently, Chen et al. [14] investigated the correlation between built environment from street view and coronary artery disease prevalence using deep learning-based features. They also explored the correlation between satellite imagery and cardiometabolic diseases [15]. However, these works focus on some specific diseases without a broader understanding of the impact of the environment on diverse diseases.
Personalized disease risk prediction.
Predictive risk modeling predicts patients’ future disease status based on their historical medical records. Electronic health records (EHR) are generally used to provide patient medical history. As EHR data can be modeled naturally as sequential data, several deep-learning methods have been employed in previous studies for risk prediction. RETAIN [17] uses reverse time attention to capture health status from the most recent patient visits. Dipole [42] uses a bidirectional recurrent neural network to capture more complex time dependencies in EHR. In recent years, there are also transformer-based models [41, 70] and knowledge-enriched models [16, 43]. However, these models focus solely on personal patient status without utilizing information from patients’ living environments. We fill this gap by plugging our environmental embedding into patient representation according to their residence.
SatHealth Dataset
3
In this section, we introduce the SatHealth dataset by four components: SDoH, Environmental data, satellite imagery, and disease prevalence, as shown in Table 2. Besides data collection, we will introduce our embedding pipeline for environmental data and satellite images. We embed environmental data and satellite images across multiple geographic-level regions, including counties, ZIP Code Tabulation Areas (ZCTAs), census tracts, and Core Based Statistical Areas (CBSAs), ensuring comprehensive spatial granularity.
Social Determinants of Health
3.1
Social determinants of health (SDoH) refer to the environmental conditions in which people live, influencing a wide range of health outcomes and quality of life [52]. These include various socioeconomic factors, such as poverty, access to education, healthcare availability, the built environment, and community context.
Data Collection.
This work incorporates the Social Deprivation Index (SDI) [33] as the regional socioeconomic indicator. The SDI^3^ is a centile score comprised of seven demographic components derived from the American Community Survey (ACS): (1) the percentage of the population living below 100% of the Federal Poverty Level (FPL); (2) the percentage of individuals aged 25 years or older with less than 12 years of education; (3) the percentage of non-employed individuals aged 16–64; (4) the percentage of single-parent families with dependents under 18; (5) the percentage of households without access to a vehicle; (6) the percentage of households residing in renter-occupied units; and (7) the percentage of households living in crowded conditions.
Environmental Data
3.2
Environmental data contains four categories: climate, air quality, greenery, and land cover. We collect them from multiple satellite products.
Data Collection.
We obtained environmental variables for our dataset on Google Earth Engine (GEE) [28] following [56]. Climate variables include temperatures, humidity, solar radiation, snow cover, and wind components from ERA5-ECMWF product [48]. For air quality, we collect nitrogen dioxide (NO2) from Sentinel-5P Near Real-Time NO2 [34], total aerosols and PM2.5 from Copernicus Atmosphere Monitoring Service (CAMS) [24], and ozone from Total Ozone Mapping Spectrometer (TOMS) and Ozone Monitoring Instrument (OMI) Merged Ozone Data [2]. Greenary variables include Normalized Difference Vegetation Index (NDVI) derived from Sentinel-2 MultiSpectral Instrument (MSI) [1] and high/low vegetation greenery indices from ERA5-ECMWF. Land cover variables are area cover fractions of different land types (e.g., forest, water, urban) sourced from Copernicus Dynamic Land Cover products [58]. We collected all the available data in Ohio from 2016 to 2022.
Spatiotemporal Alignment.
Data from various satellite products have different spatial resolutions and temporal frequencies, so we align them to ensure consistency in both spatial and temporal granularity. Given a specific timestamp and an environment variable, we collect the values in various areas and obtain a heatmap, with each pixel denoting the value in a square area. We perform spatial reduction to a specific region (e.g., counties) by taking the average of all pixels within the region. After the reduction for every variable, we obtain an environmental vector for each specific region. We further align variables temporally by downsampling all vector series to the same monthly frequency. As land cover fractions are relatively stable, they are averaged across all timestamps to become a static variable.
Feature Embedding.
After the alignment process, each region has environment data as a multivariate time series. To embed the time series, we average the monthly vectors according to meteorological seasons and concatenate seasonal vectors to create annual regional embedding.
Satellite Images
3.3
In addition to environmental variables, satellite images offer additional visual insights into specific regions. By incorporating satellite imagery from Google Maps, we provide an implicit indicator of regional development, environmental characteristics, and land-use patterns. Compared to satellite products like Landsat 8 (30-meter resolution) and Sentinel-2 (10 to 60 meters depending on the spectral band), Google Maps provides significantly higher-resolution imagery, often better than 1 meter in many urban areas, and largely cloud-free visuals.
Data Collection.
We request aerial images from the Google Static Maps Application Programming Interface (API) [27]. A grid of spatial points with 500-meter spacing is created, and satellite image patches are retrieved at zoom level 17 with grid points. With the point-grid-based construction, we can establish the visual feature of an arbitrary region by aggregating satellite images within that region. This approach ensures complete coverage of Ohio, resulting in 432,918 images with a resolution of 1280×1280 pixels each, corresponding to a square area approximately 500 meters wide.
Feature Embedding.
We establish visual features by calculating several indices commonly used in remote sensing [10, 22, 29, 77] and computing their pixel-level statistics. For a given RGB aerial image, nine indices are calculated for each pixel based on RGB values, effectively creating new derived channels. These channels form a compound image with 12 channels alongside the original RGB channels. After that, to extract meaningful features from the compound images, we compute pixel-level statistics for each channel, including the mean, standard deviation, median, maximum, minimum, and 20-bin histogram features. This process produces feature vectors of size 300 for each satellite image. Note that images from Google Maps do not have timestamps, so the satellite image feature is static.
Disease Prevalence
3.4
We use regional disease prevalence as an indicator of the population health status of an area.
Data Collection.
We estimate disease prevalence using MarketScan [44], a real-world medical claims database. Specifically, we analyze patient encounters from the MarketScan Commercial Claims and Encounters (CCAE) database from 2016 to 2022. Each patient encounter includes a set of International Classification of Diseases (ICD-10) [12] diagnoses codes and the patient’s residency. Patient residency in MarketScan is identified by Metropolitan Statistical Areas (MSAs), a subset of CBSAs. This enables us to estimate the prevalence of each ICD-10 code for MSAs in a given year by calculating the percentage of patients associated with the code among all patients recorded in that year.
Data Processing.
The ICD-10 codes are organized hierarchically, allowing for a multi-level investigation of disease prevalence. For instance, the code “I10” represents essential hypertension, its parent node “I10-I1A” represents a broader group of hypertensive diseases, and the top-level code “I00-I99” encompasses circulatory system diseases. This hierarchical structure allows us to explore the prevalence of both broad disease categories and specific conditions. To capture both the overall trends and finer details, we calculated disease prevalence at the top three levels of ICD-10 codes using their first three digits, enabling a comprehensive understanding of disease patterns and correlations.
Dataset Use Cases
4
In this section, we first conduct a comprehensive analysis to examine the correlation between environmental data and human health status. We then demonstrate potential use cases of SatHealth through two kinds of tasks: regional public health modeling and personalized disease risk prediction. For regional public health modeling, we use regional environmental embeddings to predict the SDI score and disease prevalences, which display the power of multimodal data in modeling regional health status. For personalized disease risk prediction, we plug the environmental factors into patient representations produced by EHR risk prediction backbones according to patient residency, which shows the benefits of environmental information in predicting personal disease risks.
Basic Correlation Analysis
4.1
We first perform a statistical analysis to analyze the correlation between the living environment and regional disease prevalence. Note that this is an illustration of the dataset characteristics instead of a rigorous public health analysis.
Regional Disparity.
4.1.1
We start by exploring the disparity in health status between regions in Ohio. For illustration, we define Columbus, Cleveland, and Cincinnati as urban areas and compare the disease occurrence with other areas in Ohio. Specifically, we calculate urban-to-rural odds ratios (OR) and their confidence intervals (CI) to show the difference in disease occurrence between the urban (Columbus, Cleveland, and Cincinnati) and other areas.
As Table 3 shows, the urban areas present a significantly higher prevalence of neonatal conditions and pregnancy-related codes. Specifically, the conditions originating in the perinatal period (P00-P96) have an odds ratio of 1.479 (95% CI: 1.418–1.542), and codes for pregnancy, childbirth, and the puerperium (O00-O9A) are also more frequent in urban areas (OR: 1.16, 95% CI: 1.131–1.190). This disparity could have originated from the higher in-hospital ratio of births [65] and limited access to maternity and prenatal care [21, 66, 72].
Moreover, rural areas have more mortality cases with ill-defined and unknown causes (ICD-10: R99, OR: 0.311, 95% CI: 0.227–0.427). This kind of coding is less informative and reflects a relatively lower data quality from the rural healthcare system [46, 68]. Besides, as the US Centers for Disease Control and Prevention (CDC) reported [11], rural residents tend to be older and sicker, and they have higher rates of cigarette smoking, high blood pressure, and obesity. Correspondingly, we observed higher prevalences of circulatory system diseases (I00-I99) as well as Endocrine, nutritional, and metabolic diseases (E00-E89). Specifically, rural areas have higher prevalences for chronic rheumatic heart diseases (OR: 0.631, 95% CI: 0.584–0.681), hypertensive diseases (OR: 0.743, 95% CI: 0.735–0.752), obesity (OR: 0.773, 95% CI: 0.761–0.785), and diabetes (OR: 0.792, 95% CI: 0.778–0.806). We show these results in Tabel 3, and more comprehensive results can be found in supplementary C. These findings help us in discovering health inequalities and support policy making [39, 71]. Furthermore, such observations and findings from public health data can help policy development, such as encouraging network development and telemedicine, and improving the rules for Medicare payments to providers [19, 55].
Factor Correlations.
4.1.2
In addition to the odds ratio, we calculate Spearman’s rank correlation coefficient to investigate the correlation between environmental factors and multi-level ICD code prevalence across spatial regions. We show the pairwise correlations between level-2 ICD codes and environmental features in Figure 2. Note that this figure only shows subsets of ICD codes and features with significant correlations. Additionally, we use color shading on ICD codes to differentiate between disease categories. More detailed results on a broader set of ICD codes are shown in the supplementary results.
We observed several outstanding color blocks in Figure 2, showing groups of diseases with distinct correlations with specific feature subsets. Firstly, a group of newborn or pregnancy-related conditions (O and P codes) with a purple or brown background lies on the left-hand side, with a significant negative correlation with tree cover fraction and volumetric soil water. Such correlation can be a reflection of the higher prevalence of newborn or pregnancy-related conditions in urban areas we found previously, as urban soil tends to be compact with lower water content [51]. In contrast, several neoplasm conditions show the opposite correlation pattern, which reflects a higher prevalence of tumors in rural areas [57]. Moreover, the correlation between neoplasms and soil water may also be explained by the higher mobility of chemical pollutants with higher precipitation and moisturized soil [8].
Moreover, some circulatory system diseases in orange color on the right-hand side, such as hypertensive diseases (I10-I1A) and heart diseases (I30-I5A). A similar pattern also applies to diabetes mellitus (E08-E13) and metabolic disorders (E70-E88). These diseases correlate positively with the Kawashima index [35] and negatively with many satellite image features. As the Kawashima index is negatively correlated to chlorophyll content [59], and image features also provide information about pixel color distribution, these correlations could be explained by the discovered benefit of green space on cardiovascular disease and diabetes [4, 5].
These results highlight the significant impact of the living environment on human health, consistent with existing studies [36, 60, 63]. They also demonstrate the potential of SatHealth to enhance AI models for health-related tasks (e.g., regional public health modeling and personalized disease risk prediction).
Regional Public Health Modeling
4.2
Regional public health modeling aims to predict health outcomes for the community or regional population. It helps identify health disparities and guide targeted interventions to improve public health outcomes and resource allocation [39, 71]. In this subsection, we use the created regional environment embeddings to predict regional SDI and disease prevalence to reveal the relationship between living environment and population health status.
We divide the environmental features into two subsets according to data structure: (1) Dynamic environmental factors (DEnv) refers to environmental factors that change over time, including climate, air quality, and greenery variables; (2) Static environmental factors refers to environmental factors that are stable over time, which include Land Cover (LC) and Satellite images (Img). For baselines, we train random forest regressors respectively on the feature subsets to show their fundamental functional relevance. After that, we combine all modalities (All) and display how this helps in regional health status modeling.
SDoH Regression.
4.2.1
The upper part of Table 4 presents the performance of the Social Deprivation Index (SDI) prediction. The performance metrics include Mean Absolute Error (MAE), Mean Squared Error (MSE), and R^2^, providing a comprehensive assessment of model accuracy and explanatory power. It is worth pointing out that we normalize the prevalence target by z-score normalization such that they have a standardized deviation of 1.
Overall SDI.
When predicting overall SDI, the dynamic features (DEnv) achieve the best performance, yielding the lowest MAE and highest R^2^. Besides, the combined feature (All) performs slightly worse but is comparable to DEnv, suggesting that DEnv variables predominantly drive the prediction. In contrast, land cover and image embeddings show suboptimal performance, likely because they capture only ground-level views, making it challenging to predict a comprehensive socioeconomic score.
Population Characteristics include poverty, education, and employment status. In this category, the best-performing features vary, suggesting different dependencies of SDoH on environmental factors. Specifically, the poverty ratio is better predicted by image features, likely due to their ability to capture urban-rural disparities, such as housing conditions. Education status relies more on dynamic features (i.e., climate, greenery, air quality). Employment benefits most from multimodal fusion as a combination of economic, infrastructure, and environmental factors influences it.
Household Characteristics refer to household-level factors, including single-parent family percentage, housing tenure (rent or owner-occupied), vehicle ownership, and household crowdedness. The combined feature outperforms all other features in predicting household characteristics except for the single-parent family ratio. This superiority indicates that integrating multimodal features provides a more comprehensive understanding of housing-related metrics. The combined features perform poorly in predicting the single-parent family ratio, likely because dynamic features (DEnv) tend to be independent of family structure. However, it is worth noting that none of these features are effective predictors for crowding prediction, with the best R^2^ score around 0.06.
Disease Prevalence Regression.
4.2.2
There are thousands of diseases, but only a small subset correlates significantly with environmental features. Therefore, we focus on diseases reported to correlate with environmental factors [4, 5]: neoplasms (C00-D49), endocrine, nutritional, and metabolic diseases (E00-E89), and circulatory system diseases (I00-I99). Moreover, we explored several subcategories, including diabetes (E08-E13), metabolic disorders (E70-E88), hypertensive diseases (I10-I1A), and ischemic heart diseases (I20-I25).
Overall Comparison.
We show the regression performance of predicting the prevalence of the diseases in the lower part of Table 4. For most diseases (e.g., Neoplasms and Metabolic diseases), combining all modalities (All) achieves the best prediction performance, demonstrating the essential role of multimodal environmental factors in modeling the regional prevalence of these diseases.
Neoplasms.
Neoplasms (C00-D49) include all kinds of tumors, including both malignant and benign. Table 4 shows that dynamic features (DEnv) have better prediction performance than land cover and satellite, as these features contain carcinogens potentially related to some specific cancer, such as solar radiation [4] and air pollutants [64]. Moreover, by combining all features, the regression model gains 0.086 improvement in R^2^, the highest improvement among the explored diseases. Such improvement demonstrates that the three feature sets are complementary when modeling neoplasm prevalence.
Metabolic diseases.
As for endocrine, nutritional, and metabolic diseases (E00-E89), land cover (LC) and satellite image (Img) features perform consistently better than dynamic factors (DEnv). Especially for metabolic disorders (E70-E88), the R^2^ score on dynamic factors is 0.064 lower than the other two features. This is intuitively reasonable as these diseases are more related to our lifestyle [37, 54], and the effect of air quality or climate tends to be long-term and maybe implicit [78].
Circulatory system diseases.
Finally, it can be seen that the three feature modalities gain high but similar performance for circulatory system diseases (I00-I99), and the improvement of combined features is not significant. This could be due to each feature modality’s relatively high performance, making it hard to improve further. On the other hand, land cover (LC) and satellite features (Img) have higher performances than dynamic factors (DEnv) for ischemic heart diseases (I20-I25), possibly due to the reported correlation between green space and ischemic heart diseases [5].
Personalized Disease Risk Prediction
4.3
In this subsection, we use living environmental data to help predict patient-level disease risks. Specifically, we focus on the next visit prediction and 1-year predictive modeling tasks. We use the patient visit history data from the MarketScan database [13] to conduct experiments. We build models to predict the level-2 ICD codes within a patient visit with all previous visits from the patient. We define the multi-label ground truth in two ways: Next visit setting takes one visit as the ground truth and use all previous visits as input no matter how long it is from the target visit to its previous visit, while 1-Year Predictive Modeling takes all codes within the next one year of the patient’s last known visit. In addition to the visit history, we concatenate the embedding of the patient’s living environment to the patient representation produced by the visit encoder network to enhance the backbone model. The embedding of the patient’s living environment is created by data within the patient’s residence area in the year of the patient’s last known visit.
We implemented several backbone networks for comparison. They are well-known architectures handling sequences, including LSTM [31] and Transformer [62], and models designed for medical data such as RETAIN [17] and Dipole [42]. This task can be formulated as a multi-label problem, so we use the macro average AUROC score (mAUC) across all diseases as the basic evaluation metric. Additionally, we use the macro average AUROC score of the top 10 performed diseases (mAUC-t10). Furthermore, as this model predicts the disease risk for each patient, we calculate the recall at k (Recall@k) metric to evaluate the model’s capability of producing correct disease warnings for patients.
We put the experimental results in Table 5. We highlight the best performance among the two variations in bold for each backbone model. Using environmental information boosts model performance in most cases, especially for the recall, indicating that the patient’s living environment may help us identify their disease risks. Moreover, for the next visit prediction task, models with environmental information tend to have much higher mAUC scores for top-performed diseases, which shows the capability of environmental data in differentiating patients with various disease risks.
Spatiotemporal Generalizability Analysis
4.4
The living environment varies in different areas and is subject to change over time. Therefore, users must be careful about spatiotemporal distribution shifts when applying models trained on SatHealth to other regions or conducting long-term forecasting. To find out how this affects the model performance with SatHealth, we conducted experiments on three cases of spatiotemporal generalization on regional public health modeling. Moreover, we designed a spatiotemporal-enhanced regression strategy to improve model robustness. In this subsection, we show the experimental performance of the enhanced model in the three generalization scenarios: spatial interpolation (e.g., missing value imputation [6]), spatial extrapolation (e.g., distant region generalization [45, 53]), and temporal forecasting [30, 50]. We provide more experimental details in the supplementary Section C.
We start by evaluating the generalizability of basic regression models without spatiotemporal enhancements. Using R^2^ scores, we show the top 10, 20, and 50 performing diseases. Figure 3 compares model performance across input modalities for (A) spatial interpolation and (B) temporal forecasting. LC and Img models are excluded from temporal forecasting due to their time independence. A model trained solely on climate variables is also included for comparison. For spatial interpolation, we stratify results by year. As shown in Figure 3B, Combined features show higher stability to temporal shift, likely due to reduced feature variance over time. Additionally, the combined features improve spatial generalization. Dynamic features, including climate, greenery, and air quality, exhibit stronger spatial robustness, possibly due to their pronounced spatial clustering effect.
Next, we show how spatiotemporal information can improve model generalizability. We train boosting models as described in Section C. Models with neighborhood information are annotated with “+S”, and models with history information are annotated with “+T”. We compared the combined feature model (All) with the Dynamic feature model (DEnv) under three generalization cases, and the result is shown in Table 6. We calculate the average for SDoH variables and the top-10 performing ICD codes. It can be seen that incorporating spatiotemporal information can be beneficial to model robustness, as the “+T+S” models are either the best or the second best for all cases. Although not the best, the “All+T+S” model is comparable to the best, providing a general solution that works under all cases. Moreover, the combined feature models tend to perform better than the DEnv models, further showing the multimodal models’ benefits. Finally, we find that our model performs poorly when predicting SDoH under spatial extrapolation, which may indicate a high spatial disparity between regions, making the spatial generalization of the SDoH model challenging.
Web Application Deployment
5
To improve the utility of our dataset, we designed a web-based application to explore and access SatHealth. The system design is shown in Figure 4.
The default page (Figure 4A) is the satellite map of Ohio, with the overall SDI score for each county shown in the heatmap. Users can select different variables to be displayed in the heatmap, including SDI, environmental variables, and disease prevalence of the user-selected ICD code. For time-dependent variables, there’s a slide bar for users to define the time range of the data shown. Moreover, diseases with a high correlation to environmental features are shown below the map; users can also select specific environmental features to check their correlation to the map. We also provide the button to download the whole dataset at the top of this page. More information about data access can be found in Section A.4.
Once users click on one of the regions in the map, its basic information will be shown in a new column on the right-hand side (Figure 4B). There will be three sub-panels in this sidebar. On the top, basic metrics, including population and total area of the region, are shown, together with the overall SDI score and seasonal average temperature. When users click the “Show Details” button, a drop-down list will appear to display more variables. Buttons are also provided to download the SatHealth subset in the selected region. In the middle, there’s a list of the most prevalent diseases in the selected region; users can also search for ICD codes to see their prevalence. At the bottom of this sidebar, random satellite images in the selected region will be displayed.
Users can check the selection box in the disease list. The right-hand side column will be updated (Figure 4C) to show a bar chart of the correlation score of the selected disease with the top 5 correlated environmental features in a bar chart. The correlation score and corresponding p-value will also be displayed below the bar chart. Users can search for a specific variable to check its correlation to the current disease.
Limitations and Future Work
6
Our work still has several limitations. First, SatHealth is currently restricted to Ohio due to budget constraints, but we will gradually expand our dataset to include more states, toward full US coverage. Furthermore, although environmental data showed effectiveness in our experiment, our embedding method of such multimodal data is relatively straightforward using feature engineering. We will explore more complicated deep-learning strategies to unlock the power of multimodal environmental data. Finally, the individual residences in our dataset are coarse due to privacy issues, making the living environment less representative. Despite these limitations, we believe SatHealth still provides a solid foundation and a good starting point for research on the interplay between the living environment and human health.
Conclusion
7
In this study, we developed SatHealth, a multimodal public dataset in Ohio consisting of environmental variables, satellite images, SDoH, and regional disease prevalence. To the best of our knowledge, SatHealth is the first dataset in the US that combines regional environmental characteristics with a healthcare database. We designed an embedding pipeline to fuse multimodal environmental data and produce regional living environment representations. Using the representation, we conduct experiments on two tasks: regional public health modeling and personalized disease risk prediction. The experimental results show that multimodal environmental information helps boost model performance in these problems. We also find that leveraging spatiotemporal information helps improve model robustness. Finally, we deployed a web application for users to explore and download our dataset.
Supplementary Material
1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1European Space Agency. 2024. Sentinel-2. https://sentiwiki.copernicus.eu/web/sentinel-2
- 2Ahmad Suraiya P, Torres Omar, Bhartia Pawan K, Leptoukh Gregory, and Kempler SJ. 2006. Aerosol index from TOMS and OMI measurements. In Proc. of the 86th AMS annual meeting.
- 3Araújo Leonardo D., Zanotta Daniel C., Ray Nicolas, and Veronez Maurício R.. 2024. Earth observation data uncover green spaces’ role in mental health. Scientific Reports 14, 1 (Sept. 2024), 20933. doi:10.1038/s 41598-024-72008-8 Publisher: Nature Publishing Group.39251711 PMC 11384788 · doi ↗ · pubmed ↗
- 4Asri Aji Kusumaning, Yu Chia-Pin, Pan Wen-Chi, Guo Yue Leon, Su Huey-Jen, Lung Shih-Chun Candice, Wu Chih-Da, and Spengler John D. 2020. Global greenness in relation to reducing the burden of cardiovascular diseases: ischemic heart disease and stroke. Environmental Research Letters 15, 12 (Dec. 2020), 124003. doi:10.1088/1748-9326/abbbaf · doi ↗
- 5Astell-Burt Thomas and Feng Xiaoqi. 2019. Urban green space, tree canopy, and prevention of heart disease, hypertension, and diabetes: a longitudinal study. The Lancet Planetary Health 3 (Sept. 2019), S 16. doi:10.1016/S 2542-5196(19)30159-7 Publisher: Elsevier. · doi ↗
- 6Baker Jannah, White Nicole, and Mengersen Kerrie. 2014. Missing in space: an evaluation of imputation methods for missing data in spatial analysis of risk factors for type II diabetes. International Journal of Health Geographics 13, 1 (Nov. 2014), 47. doi:10.1186/1476-072X-13-4725410053 PMC 4287494 · doi ↗ · pubmed ↗
- 7Barboza Evelise Pereira, Cirach Marta, Khomenko Sasha, Iungman Tamara, Mueller Natalie, Barrera-Gómez Jose, Rojas-Rueda David, Kondo Michelle, and Nieuwenhuijsen Mark. 2021. Green space and mortality in European cities: a health impact assessment study. The Lancet Planetary Health 5, 10 (Oct. 2021), e 718–e 730. doi:10.1016/S 2542-5196(21)00229–134627476 · doi ↗ · pubmed ↗
- 8Biswas Bhabananda, Qi Fangjie, Biswas Jayanta Kumar, Wijayawardena Ayanka, Khan Muhammad Atikul Islam, and Naidu Ravi. 2018. The Fate of Chemical Pollutants with Soil Properties and Processes in the Climate Change Paradigm—A Review. Soil Systems 2, 3 (Sept. 2018), 51. doi:10.3390/soilsystems 2030051 Number: 3 Publisher: Multidisciplinary Digital Publishing Institute. · doi ↗