Estimating metabolite networks subject to dietary preferences and lifestyle
Georgios Bartzis, Carel F. W. Peeters, Hae-Won Uh, Jeanine J. Houwing-Duistermaat, Fred A. van Eeuwijk

TL;DR
This study explores how diet and lifestyle influence metabolite networks over time, using genetic and self-reported data to identify shared patterns.
Contribution
A novel approach to estimate lifestyle effects on metabolites by modeling residual variation after accounting for diet and genetics.
Findings
Metabolite networks were built based on shared associations with diet and lifestyle.
Lifestyle effects were modeled as random intercepts in a mixed model framework.
Correcting for multiple variation sources revealed meaningful metabolite groupings.
Abstract
The metabolome is an intermediate between DNA variation and clinical phenotypes. Metabolomics have been widely used in biomedical studies for reflecting physiological changes in response to variation coming from various sources, such as diet, environment, time, and lifestyle. While lifestyle factors contribute a considerable part of the metabolic variation, current human studies lack information estimating lifestyle, mainly because it is not strictly defined. In this work, metabolite concentrations are measured at two time points (2007 and 2014). Additionally, SNP data together with self-reports on dietary behavior. By having measurements over time, as well as all main sources of metabolic variation (diet, genetics), both time-effects and lifestyle-effects can be estimated. Since lifestyle and time effects can be estimated under this setting, we are interested in identifying…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
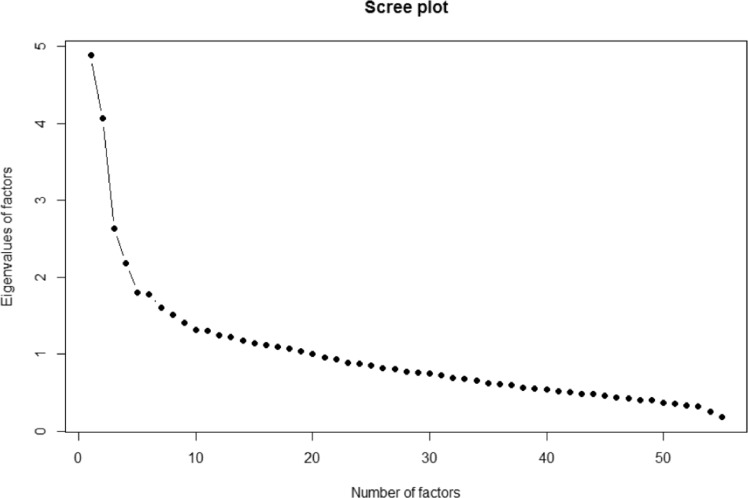 Figure 1
Figure 1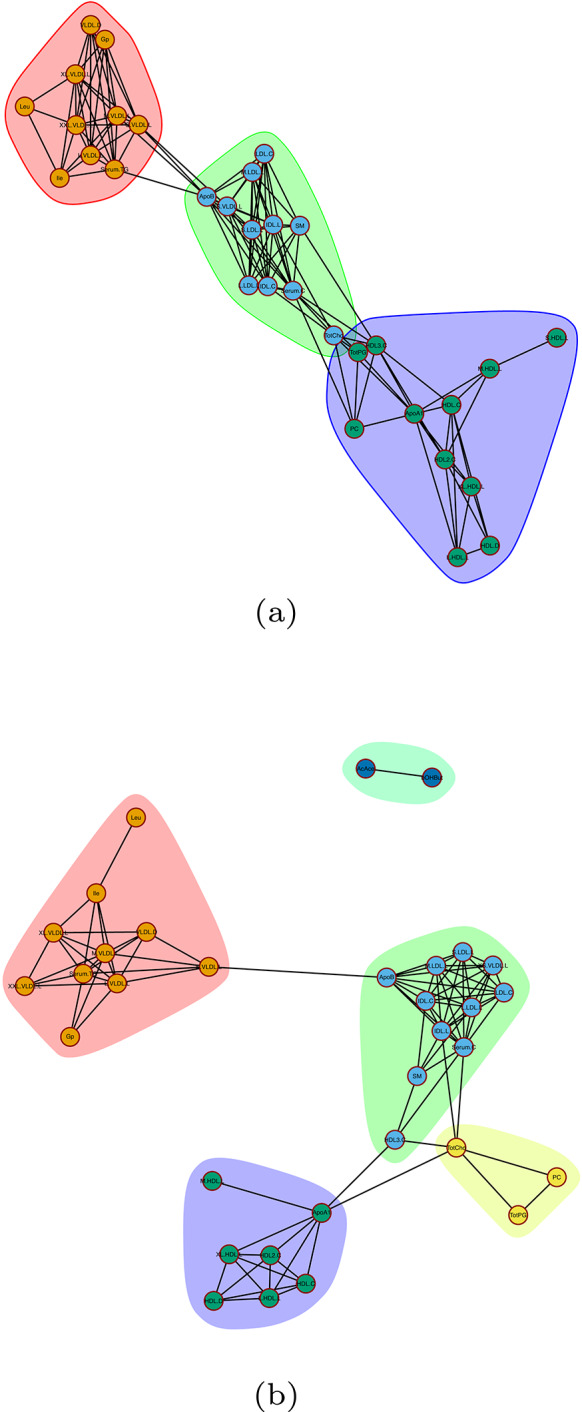 Figure 2
Figure 2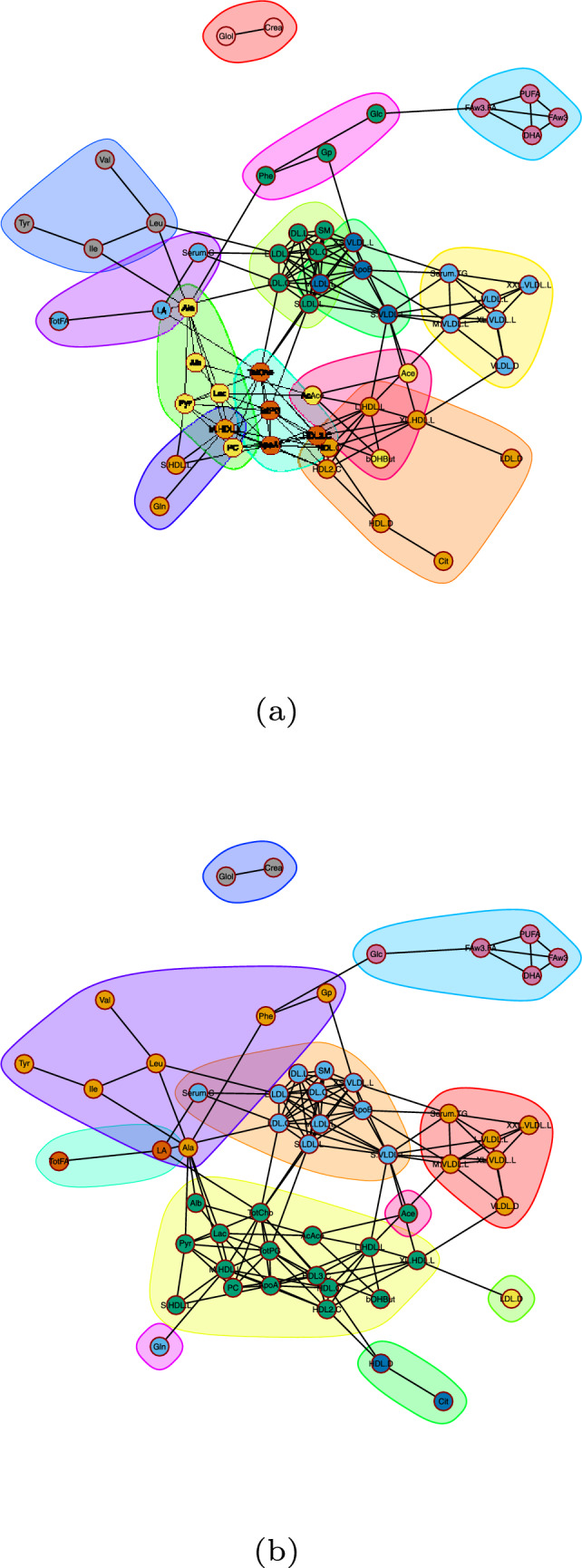 Figure 3
Figure 3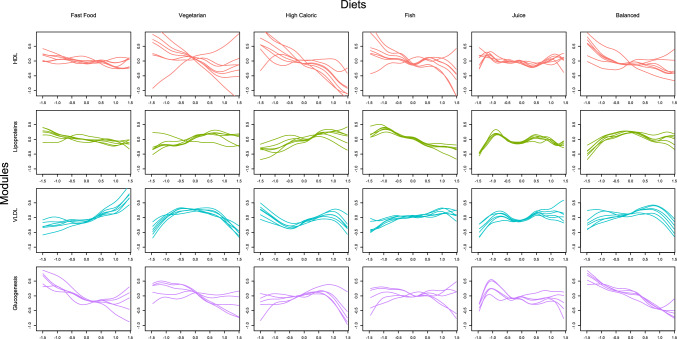 Figure 4
Figure 4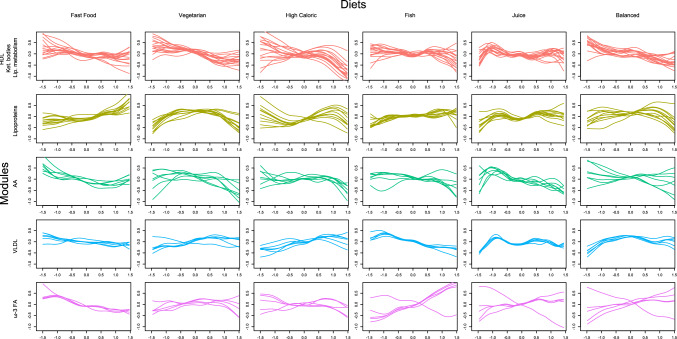 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetabolomics and Mass Spectrometry Studies · Nutritional Studies and Diet · Bioinformatics and Genomic Networks
Introduction
The metabolome is the complete collection of metabolites, which are intermediates or end products of metabolic pathways associated with cells, tissues or organs (Nielsen and Jewett, 2007). The metabolome captures information from all functional levels of a cell (Nielsen, 2003). It has been used as a tool for biomarker detection, drug discovery and safety, diet strategies and genetic disease testing (Tebani et al., 2016) because it reflects the underlying biochemical activity. Since it dynamically interacts with other molecules and the environment (Beisken et al., 2015), it occupies a unique place in systems biology, where an organism is viewed as a complex web of interacting molecular entities (Nielsen and Jewett, 2007). Additionally, metabolites themselves, by being sensitive to variation coming from genetics, time, and environmental stimuli, are widely used for assessing any type of systematic change in biochemical activity (Tebani et al., 2016). The variability induced by these sources of variation, produces fluctuations in the metabolite concentrations that spread through enzymatic reactions and create correlation patterns (Morgenthal et al., 2006). Metabolic network analysis tools that recover these correlation patterns have been described in the literature by representing metabolites as nodes in a graph and their relationships as edges connecting the nodes (Morgenthal et al., 2006; Ursem et al., 2008; Weng et al., 2019; Watson et al., 2013; Floegel et al., 2014; Bartzis et al., 2017).
Objective and motivation
In this study, our interest is in recovering meaningful metabolite patterns using network analysis, while metabolite measurements are taken repeatedly on the same individuals over time. Previously, we incorporated information on the study design when metabolite networks were estimated (Bartzis et al., 2017). Extending this approach, here we work with repeated metabolite measurements. In this setting, metabolite concentrations of a subject are dependent (due to time) and this dependence should be taken into account when the data are analyzed. We use a linear mixed effects model for the metabolite concentrations, allowing us to estimate time-specific and subject-specific random effects. When time, diet, and genetics are included in the model, the subject-specific effects represent all remaining unmeasured shared sources of metabolic variation, i.e., lifestyle. Lifestyle can be defined as the collection of smaller environmental effects, like physical activity, sleeping patterns, interests, etc. Since it is thought of in an abstract way, it is usually not quantifiable and common approaches ignore it as a part of random variation.
Here, by having a repeated measures design together with information on diet and genetics, time and lifestyle effects can be estimated. By working in the network framework, our interest is in recovering meaningful metabolite patterns associated with specific dietary preferences and lifestyle. Additionally, working with the estimated time effects allows the recovery of metabolite sets that change similarly over time.
This work is motivated by the DILGOM (DIetary, Lifestyle, and Genetic determinants of Obesity and Metabolic syndrome) study. More information can be found in Inouye et al. (2010) and Kettunen et al. (2012). This Finnish population study investigates how nutrition, diet, lifestyle, psychosocial factors, environment, and genetics are linked to obesity and the metabolic syndrome.
Contribution
By using dietary preferences we have a better understanding of the extent to which the metabolic patterns are influenced by diet (Pallister et al., 2015). To date, several studies have assessed the interplay between diet and metabolism in the context of nutritional epidemiology (Guertin et al., 2014; Floegel et al., 2014; Pallister et al., 2015; Schmidt et al., 2015; Xu et al., 2010). A standard technique for quantifying dietary patterns is by making use of Food Frequency Questionnaires (FFQ) with Exploratory Factor Analysis (EFA) (Hu, 2002; Newby and Tucker, 2004). By exploring correlation patterns among food items, common underlying dietary factors are identified and a score summarizing dietary patterns is typically determined (Hu, 2002). Here, we use these scores for summarizing dietary information and studying the interplay between metabolites regarding dietary and lifestyle choices, as well as the interrelationship among the metabolites with regard to time.
Despite the extended use of network analysis in modeling metabolic pathways, to our knowledge, only a few other studies have investigated the link between diet and serum metabolites using network analysis (Watson et al., 2013; Floegel et al., 2014; Wang et al., 2018; Weng et al., 2019). This allows the determination of how habitual factors associate to metabolite classes (lipoproteins, amino acids, etc). In this work, we use lifestyle information and take into account the genetic contribution to metabolite concentrations. While studying the metabolome using network analysis, we address genetic variation by using Polygenic Risk Scores (PRS) (Dudbridge, 2013) for summarizing genetic information.
For network estimation, we use undirected networks, where the relationship between two connected nodes is symmetric. The estimation of metabolite connection patterns in this paper is based on the graphical LASSO (glasso) (Hastie et al., 2009; Friedman et al., 2008). Compared to methods that are based on the observed correlation structure (and therefore recovering edges based on indirect associations), glasso is based on partial correlation and recovers edges while avoiding spurious associations.
Overview
The rest of the paper is organized as follows. In Sect. 2 the motivating dataset is described. In Sect. 3, we propose an extension to the method of Bartzis et al. (2017) in the repeated measures setting for selecting information relevant to certain sources prior to network estimation. Additionally, we review existing methods for summarizing genetic and environmental variation. In Sect. 4, we demonstrate how to select specific variation parts in metabolite data, which deviates from standard approaches in nutritional epidemiology by addressing simultaneously metabolite variation induced by time, genetics, lifestyle, and diet. We conclude the article with a discussion in Sect. 5.
Data
In this section, we will describe the data used in this study coming from an epidemiological cohort, namely DILGOM, a subset of the FINRISK study (Inouye et al., 2010; Kettunen et al., 2012). In this study, metabolite data measured at two time points were available (2007 and 2014) together with information on food preferences (described by a Food Frequency Questionnaire; FFQ), genetic information (single nucleotide polymorphisms; SNPs), as well as age and biological gender (hereafter indicated as sex). Since only two time points (2007 and 2014) are included in our data, time was considered a binary factor. Similarly, sex was also a binary factor. Finally, we use the genetic information (SNP information) to calculate a genetic quantitative score per subject to capture the different genetic background of individuals. Our interest here is in studying metabolite patterns with regard to dietary and lifestyle choices. As part of the data cleaning process, we excluded subjects who were diagnosed with diabetes and had outlying fasting glucose levels (over 10mmol/l). In addition only subjects with complete information on age, sex and food preferences were further considered. After applying the exclusion criteria, 364 subjects (171 males and 193 females) aged between 25 and 74 years (median 51) at the first time point (2007) and 211 subjects (104 males and 107 females) aged between 32.11 and 81.23 years (median 59.1) at the second time point (2014) were considered for further analysis. For each time point (2007 and 2014), the continuous age values were transformed into a binary factor (one for individuals younger than 50 years old and two for individuals equal to or older than 50 years old). We opted for the age of 50 due to its alignment with (i) the recommended age for certain health screenings and check-ups for monitoring age-related health issues (Chen et al., 2019), and (ii) the average age of onset of menopause among women (Bromberger et al., 1997).
Food frequency questionnaire
A FFQ was given to the participants of the study in 2007 to record their eating and drinking patterns. The FFQ contained the eating frequency of 40 food items (e.g. pizza, meat, chocolate, etc.) in a scale from one (rarely) to eight (more than four times per day) and the daily drinking frequency of 15 beverages under a typical serving (e.g. cups of coffee, glasses of milk, etc.). The FFQ will be subjected to Exploratory Factor Analysis (EFA) to extract factors that correspond to interpretable diets.
SNP data
For computing the individual genetic effect on the subject-specific metabolite profiles, information on approximately 38 million genotyped and imputed SNPs was available for every individual. Since the metabolite variation explained by each SNP separately is rather small, PRS is used as described in Sect. 3.2.1.
Metabolite data
Metabolite data in both time points were measured by nuclear magnetic resonance and comprise absolute quantitative measurements on 228 serum metabolites (groups of lipoproteins, lipids, amino-acids, fatty acids and others). Metabolites that were expressed as percentages (78 metabolites) were removed and their concentration levels were retained. Additionally, we removed 83 lipid particle subfractions (due to high correlation) and only the total lipid concentrations per particle size were used. Furthermore, five more metabolites were removed since they were expressed either as fractions or they were highly correlated with retained metabolites. Finally, seven metabolites were eliminated for not having information on any possible association with any SNP (Kettunen et al., 2012); hence the data that were considered for analysis consisted of 55 metabolites.
Methods
Often, one might be interested in metabolite variation from a specific source, such as, for example, diet (Bartzis et al., 2017). By estimating networks based on this source of variation, metabolites that associate to that source of variation in the same way, will share an edge. For estimating networks that contain information on parts relevant to this source of variation, we take two steps: 1) we identify an appropriate model for the responses (metabolites here) and 2) we select the part of the responses that we are interested in to extract a network. A network consists of a set of p nodes (metabolites) connected by a set of edges (relationships between metabolites) and is represented by a symmetric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\times p$$\end{document} matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf {A}}$$\end{document} (adjacency matrix) of ones and zeroes depending on whether the corresponding metabolites are connected. In addition, an intensity matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf {W}}$$\end{document} can be considered where the elements represent the intensity of the connection between the nodes (essentially a weighted version of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf {A}}$$\end{document} ). In this paper, we consider as intensity the stability of the estimated edges (i.e., the probability of an edge being true, as calculated by the network estimation method in 3.3). The number of neighbors of a node i which is the sum of row or column i of matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{A}$$\end{document} , is called degree. By taking into account both the degree and the intensity of the edges, the strength of node i ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_i$$\end{document} ) can be calculated as the sum of row or column i of matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} . Following the estimation of the intensity and adjacency matrices, groups of closely interconnected metabolites are usually identified using a clustering algorithm where the similarity measure is based on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} (as described in Sect. 3.3.1).
Estimating subject-specific metabolite effects
At the first step, since we work in the repeated measures framework, the correlation between the measurements is modeled using linear mixed effect models with random intercepts, representing the shared unobserved factors.
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{Y}^{(p)}$$\end{document} be the vector of concentrations of the pth metabolite over two timepoints. Further, assume that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{T}$$\end{document} is the covariable denoting the discrete point in time where the metabolite concentrations were measured for each individual. Finally, we can have m other covariables, e.g. genetics, dietary preferences, age, and sex.
For the pth metabolite we model the within subject correlation by using subject-specific effects from a random-intercepts linear mixed model. For identifying the part of the metabolite concentrations associated to dietary and lifestyle choices we then fit the following model:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{Y}^{(p)}=\beta _{0}^{(p)}+&\beta _{1}^{(p)}\textbf{Age}+\beta _{2}^{(p)}\textbf{Sex}+\beta _{3}^{(p)}\textbf{T}+\beta _{4}^{(p)}\textbf{F} +\nonumber \\&\beta _{5}^{(p)}\textbf{G}+\beta _{6}^{(p)}\textbf{Age}\circ \textbf{Sex}+\beta _{7}^{(p)}\textbf{Age}\circ \textbf{T}+\nonumber \\&\beta _{8}^{(p)}\textbf{Age}\circ \textbf{F}+\beta _{9}^{(p)}\textbf{Age}\circ \textbf{G}+\beta _{10}^{(p)}\textbf{Sex}\circ \textbf{T}+\nonumber \\&\beta _{11}^{(p)}\textbf{Sex}\circ \textbf{F}+\beta _{12}^{(p)}\textbf{Sex}\circ \textbf{G}+\beta _{13}^{(p)}\textbf{T}\circ \textbf{F}+\nonumber \\&\beta _{14}^{(p)}\textbf{T}\circ \textbf{G}+\beta _{15}^{(p)}\textbf{F}\circ \textbf{G}+\textbf{u}^{(p)}+\varvec{\varepsilon }^{(p)}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varepsilon }^{(p)} \sim \mathcal{N}\big(0, \sigma^2_{(p)}\big)$$\end{document} is the random noise, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\circ $$\end{document} is the Hadamard product. In model 1, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}^{(p)} \sim \mathcal{N}\big(0, \sigma^2_{u(p)}\big)$$\end{document} are the subject-specific effects representing all unmeasured shared factors. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G}$$\end{document} , represents the genetics, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}$$\end{document} the dietary patterns. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{Age}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{Sex}$$\end{document} are the vectors containing the age and sex of the subjects, respectively. Note that the subject-specific effects ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}^{(p)}$$\end{document} ) are conditioned on multiple terms, i.e., age, sex, time, genetics, diet, and their interactions. Therefore, this source of metabolic variation is not associated with them, thus is a variable accounting for individual metabolic differences, hence lifestyle. In principle, lifestyle is hard to estimate since it depends on many factors that are not available to us. Here, by having measurements over time we were able to estimate it as the random intercepts of the linear mixed effects model conditioned on all other sources of variation. Finally, the time interval between the repeated measures is the same for all subjects.
The relevant metabolite part related only to dietary and lifestyle choices in the linear mixed model 1 that will be used for estimating metabolite networks is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \tilde{\textbf{Y}}_L^{(p)}= & \hat{\beta }_{4}^{(p)}\textbf{F}+\hat{\beta }_{8}^{(p)}\textbf{Age}\circ \textbf{F}+\hat{\beta }_{11}^{(p)}\textbf{Sex}\circ \textbf{F}+\nonumber \\ &\hat{\beta }_{13}^{(p)}\textbf{T}\circ \textbf{F} +\hat{\beta }_{15}^{(p)}\textbf{F}\circ \textbf{G}+\hat{\textbf{u}}^{(p)}. \end{aligned}$$\end{document}The quantification of the dietary (F) and genetic (G) parts for inclusion in model 1, using EFA and PRS, is described in Sect. 3.2.
Identifying diets with exploratory factor analysis
Different diet patterns strongly influence disease risks and have an effect on health. Many studies have examined the associations between intakes of individual foods (Hu et al., 1999) and health or lifestyle. However the intake of one food or nutrient is often correlated with the intake of another (Randall et al., 1992; Hu et al., 1999). Therefore, dietary patterns can be identified by using the correlation among the foods, typically by using EFA (Slattery et al., 1998; Hu et al., 1999, 2000; Williams et al., 2000).
EFA is a latent variable model attempting to explain complex relationships between observed variables by using an unobserved structure (Rencher, 2003). The dimension of the latent vector is lower than the dimension of the observable variables. In EFA, we have a set of observed variables (e.g. food preferences) generated by a number of unobserved latent variables (e.g. diets). The idea is to identify and summarize the unobserved variables that explain the dependence between the observed variables.
For p observed variables, and m unobserved factors, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{o}$$\end{document} be the observed centered eating frequencies, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{o}=(\textbf{o}_1,\textbf{o}_2,\ldots,\textbf{o}_p)^\top $$\end{document} . For notational simplicity, we leave out the notation for observations. Also let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{f}=(\textbf{f}_1,\textbf{f}_2,\ldots,\textbf{f}_m)^\top $$\end{document} be the unobserved diets. Factor analysis is expressing each food frequency as a linear combination of the diets, i.e.,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{o} = \textbf{L}\textbf{f}+\varvec{\epsilon }, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{L}$$\end{document} is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\times m$$\end{document} loadings matrix measuring the dependence of observed variables on factors, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\epsilon }=(\varvec{\epsilon }_1,\varvec{\epsilon }_2,\ldots,\varvec{\epsilon }_p)^\top $$\end{document} is the random error distributed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}(\textbf{0},\mathbf {\Psi })$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Psi }$$\end{document} being diagonal, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{f} \sim \mathcal {N}(\textbf{0},\mathbf {\Phi })$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{Cor}(\textbf{f}, \varvec{\epsilon }) = \textbf{0} $$\end{document} . Factor analysis is expressing the covariance of the observed variables ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{Cov}(\textbf{o})=\mathbf {\Sigma }$$\end{document} ) in terms of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{L}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Phi }$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Psi }$$\end{document} , i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Sigma }=\mathbf {L\Phi L}^\top +\mathbf {\Psi }$$\end{document} . The number of latent factors can be chosen based on the factor interpretability. In order to do so, we need to carefully examine the loading matrix for different selections of number of factors in combination with usage of the scree plot (Cattell, 1966). A typical practice for making the results more interpretable is by employing factor rotation, where the estimated loading matrix is generally transformed by multiplying it by an orthogonal or non orthogonal matrix. Factor analysis was conducted using the principal axis factoring (PA) method, followed by “oblimin" rotation to allow for correlated factors. The analysis was performed using the psych package for R (Revelle, 2021).
The latent diets \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}$$\end{document} can be quantified by using the “ten Berge" factor scores (Ten Berge et al., 1999). In that way, the correlation of the dietary patterns is preserved when the sample factor score correlations are computed.
Polygenic risk scores (PRS)
A popular practice for uncovering the genetic variants that influence metabolite concentrations are the metabolite-based genome-wide association studies, i.e., mGWAS (Raffler et al., 2015). It has been shown that in GWAS, common single nucleotide polymorphisms (SNPs) exhibit significant roles in determining phenotypic variation (Chatterjee et al., 2016). Although separate SNPs typically explain only a moderate proportion, a combination of them can explain a substantial part of the phenotypic variation (Chatterjee et al., 2016; Dudbridge, 2013). Therefore, polygenic risk scores (PRS) are widely used for summarizing genetic effects \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G}$$\end{document} from a set of markers associated to a phenotype of interest.
Typically, for estimating a PRS (denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G}$$\end{document} here) for a phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{Y}$$\end{document} (e.g. the concentration levels of a metabolite), we have a set of l SNPs ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{S}=(\textbf{S}_{1},\ldots,\textbf{S}_{l})^{\top }\in \{0,1,2\}^{l}$$\end{document} ). For each of the markers, the effect size ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\eta }$$\end{document} ) is determined, e.g. by the estimated coefficients from a linear regression of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{Y}$$\end{document} on each of the l SNPs.
For computing the PRS ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G}$$\end{document} ), a subset of the top \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{l}$$\end{document} associated SNPs is used (Euesden et al., 2015). Then, the linear combination of the top SNPs weighted by their corresponding effect sizes is calculated. For subject i the PRS is computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{G}_{i}=\sum ^{\tilde{l}}_{j=1} \mathbf {\eta }_{j}\textbf{S}_{ij}. \end{aligned}$$\end{document}Note that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G}$$\end{document} contains genetic information related to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{Y}$$\end{document} and can be used for further analysis.
Network estimation using glasso
In this paper, for network estimation we use glasso (Hastie et al., 2009; Friedman et al., 2008), which is based on partial-correlations using conditional independence and recovers conditional associations between the nodes.
In glasso, it is assumed that the metabolite concentrations follow a multivariate Gaussian distribution with mean vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu }$$\end{document} and variance-covariance matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Sigma }$$\end{document} . The network is estimated as the non-zero entries of the precision matrix ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Theta }=\mathbf {\Sigma }^{-1}$$\end{document} ). For estimating the precision matrix, typically a penalized log-likelihood approach is used which produces a sparse estimate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf{\Theta}$$\end{document} . The penalized version of the log-likelihood that is maximized (Hastie et al., 2009; Friedman et al., 2008) uses a LASSO penalty as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \ell _\lambda (\varvec{\Theta })\propto \log|\varvec{\Theta }|-\text {tr}(\varvec{K}\varvec{\Theta })-\lambda||\varvec{\Theta }||_1, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{K}$$\end{document} is the sample covariance matrix of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{Y}}_L$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} is a non-negative tuning parameter controlling the sparsity of the estimated precision matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\mathbf {\Theta }}$$\end{document} . Here we use the stability approach for regularization selection (StARS) (Liu et al., 2010) for obtaining the regularization parameter making the network sparse and replicable under random sampling. In StARS multiple overlapping subsamples of the data are selected and sparse networks are estimated for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} values in a grid. For the optimal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , the stability of an edge can be calculated as the observed relative frequency of it being estimated over the subsamples.
Module identification
A network usually consists of a set of modules that have closely interconnected metabolites. A typical way of identifying them is by using the two-step dynamic hybrid algorithm (Langfelder et al., 2008) on the metabolite dendrogram resulting by using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} as the similarity matrix. An alternative way for module identification is by using the Girvan–Newman algorithm (Newman & Girvan, 2004) based on edge-betweenness implemented in the rags2ridges R-package (Peeters et al., 2022). Using different module identification algorithms allows us to get a better understanding of the network’s modular structure and possibly identify sets of nodes that consistently emerge. In this study, we base \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} on StARS. We first recover the adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf {A}}$$\end{document} for the estimated optimal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} resulting to a stable network under random subsampling. The symmetric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf {A}}$$\end{document} matrix contains 1s and 0s depending on whether the corresponding nodes are connected for the optimal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} value. The non-zero entries (edges) are then weighted by the relative estimated frequency of the edge being present over all subsamples used. Subsequently, the matrix containing the relative estimated frequency of the stable estimated edges is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} and can be used for module identification.
Network characterization
We now consider three measures to describe a network or a module, namely density, centralization and heterogeneity (Dong and Horvath, 2007). For a square symmetric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\times p$$\end{document} matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} , let s be the strength of a node (row sum of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} ) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{s}$$\end{document} s. The quantities in Table 1 are then computed for network or module characterization. For density, a value close to one indicates high interconnectedness between the nodes in the network/module. High values in Centralization, denote a star shaped network, i.e., the network contains one highly connected node. Finally, the heterogeneity indicates the amount of edge diversity in the network/module.Table 1. Measures that can be used for describing a network or part of a networkQuantityFormulaHigh values denote that..RangeDensity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{i}\sum _{j}\dfrac{M_{ij}}{p(p-1)}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} is highly interconnected \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left[ -1,1\right] $$\end{document} Centralization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\dfrac{1}{p}\left( \text{ max }(s)-\bar{s} \right) $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} contains hub node(s) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left[ -1,1\right] $$\end{document} Heterogeneity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\dfrac{\sqrt{\textsf {var}(s)}}{\bar{s}}$$\end{document} the values in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} are diverse \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left[ 0, \infty \right) $$\end{document}
Application to data
In this section, we will use the methods of Sect. 3 for analyzing, visualizing, and evaluating the conditional correlation structure of the metabolite data subject to: i) dietary and lifestyle variation, ii) time variation, while addressing for individuals genetic background. Prior to that, we need to estimate dietary ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}$$\end{document} ) and genetic information ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G}$$\end{document} ) for adding them together with age, sex, and time in model 1, while lifestyle is estimated by the empirical Bayes estimates of the random intercepts of this model.
The FFQ data were used for identifying latent dietary patterns emerging from the complex relationships between the 55 observed eating/drinking items. To estimate dietary information we used EFA. The loading matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{L}$$\end{document} was estimated and can be seen in Table 2. The visual inspection of the scree plot (Fig. 1) revealed that the number of possible latent diets that could be recovered from the data were five to six. Here, we chose six diets. For the rest of the paper we refer to these six diets as: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {F}_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {F}_2$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {F}_3$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {F}_4$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {F}_5$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {F}_6$$\end{document} .Fig. 1. Scree plot for selecting number of dietary profiles
The dietary patterns were determined after closely examining the factor loadings: a) fast food (F1), b) vegetarian (F2), c) high caloric (F3), d) fish (F4), e) juice (F5), and f) balanced (F6) respectively. Finally, we assumed that individuals do not change dietary patterns in a 7-year period time. That means the dietary scores are the same in the two time points.
For estimating the individuals genetic background, we first selected 48 SNPs based on a mGWAS study (Kettunen et al., 2012) on 8,330 Finnish individuals (DILGOM was part of the study) and Linkage Disequilibrium pruning for dealing with correlation between SNPs. In Eq. 4, the PRS ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G}_i$$\end{document} ) was computed for every available metabolite with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\eta }$$\end{document} obtained from the supplementary material of Kettunen et al. (2012).
Metabolite networks for separate timepoints
In order to analyze the data, we first estimated metabolite networks with regard to the different time points, i.e., 2007 and 2014. The estimated metabolite networks can be seen in Fig. 2. For those networks, the metabolites were corrected for age and sex differences by keeping the residuals of a linear model with each metabolite as response and Age, Sex, and their interaction as predictor variables.Fig. 2. Estimated metabolite networks and cluster identification using the Girvan–Newman algorithm when age and sex have been accounted for. The metabolite networks concern different time points a 2007, b 2014
In the case of the network concerning the metabolite measurements in 2007, three modules have been identified using the Girvan–Newman algorithm. The first mainly consisted of VLDLs, the second of Lipoproteins, while the last one had mainly high density lipoproteins. For the metabolite network when using the 2014 measurements, four modules were identified using the Girvan–Newman algorithm. Those modules had high overlap with the ones from the 2007 network.
As the data concern metabolite measurements of the same individuals over different time points, the intra-subject correlation is not utilized when networks are estimated separately. Additionally, repeated measures allow us to estimate time effects and study interactions between time, genetics, and dietary patterns. By utilizing a detailed mixed model which suitably models the repeated measure data, random intercepts are estimated and can be interpreted as the residual metabolic variation not attributed to dietary, demographic or genetic information, i.e., lifestyle. The estimated lifestyle information can further be used together with dietary information to estimate metabolite networks subject to those two sources of metabolic variation.
Metabolite networks subject to dietary patterns and lifestyle
For estimating networks of metabolites with respect to dietary and lifestyle information, model 1 was first fitted on the data. Then, for the pth metabolite, the values \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{Y}}_L^{(p)}$$\end{document} (Model 2) were used for network estimation. To estimate a metabolite network using glasso, we first selected the tuning parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} controlling the network sparsity in glasso ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda = 0.533$$\end{document} ).
Using the two-step dynamic hybrid algorithm, 12 modules were identified (VLDL1, VLDL2, lipid metabolism, lipoproteins, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega $$\end{document} -3 FA, carbohydrate metabolism, glycogenesis, AA, ketone bodies, BCAAs, HDL; Fig. 3a). In Table 3, the clusters of interconnected metabolites were characterized by using our descriptive measures (density, centralization and heterogeneity) for clusters that contain five or more metabolites. The complete network displays a small value in terms of density (0.10) and high value for heterogeneity (0.64) compared to the identified modules (high densities and low heterogeneity). This implies a good module separation (high density within modules compared to low for nodes in different modules).
Using the Girvan–Newman algorithm, eight modules were identified (VLDL, lipoproteins, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega $$\end{document} -3 FA, HDL/ketone bodies/lipid metabolism, AA; Fig. 3b). In Table 4, the clusters of interconnected metabolites were again characterized by density, centralization and heterogeneity. As in the two-step dynamic hybrid algorithm, here the complete network displays again a small value in terms of density (0.10) and high value in heterogeneity (0.64). Contrarily to the networks for the separate time points, the identified modules had high densities and low heterogeneity pointing again to good module separation.Fig. 3. Estimated metabolite networks with respect to dietary and lifestyle variation when cluster identification is performed using the a two-step dynamic hybrid algorithm b Girvan–Newman algorithm
Comparison between networks for separate time points and networks subject to dietary patterns and lifestyle
Compared to the case of separate networks per time point, here we estimate different parts of metabolic variation before we reconstruct metabolic networks. This resulted in better separated networks, i.e., higher number of modules. The estimated modules can be better identified as the different metabolic classes, i.e., amino acids, VLDLs, HDLs, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega $$\end{document} -3 fatty acids, etc.
For the estimated modules using the two-step hybrid algorithm, the HDL module (Cit, HDL.C, HDL.D, HDL2.C, L.HDL.L, LDL.D, XL.HDL.L), the lipoproteins module (IDL.C, IDL.L, L.LDL.L, LDL.C, S.LDL.L, SM), and one of the VLDL modules (L.VLDL.L, M.VLDL.L, Serum.TG, VLDL.D, XL.VLDL.L, XXL.VLDL.L) had the highest amount of metabolites (7, 6, and 6 respectively). By inspecting the metabolite profiles (Fig. 4), it can be observed that the metabolic profiles for the HDL module were not as homogeneous as for the other modules (density was estimated at 0.46). Conversely the profiles for the lipoproteins and VLDL modules were much more homogeneous, seen also by their density (0.96 and 0.86, respectively).Fig. 4. Metabolite profile plots when the metabolite clusters have been identified using the dynamic cut tree algorithm. The relationship of the concentration levels of every metabolite (y-axis) to each diet (factor scores on the x-axis) is depicted using a spline. All metabolites belonging in the same module have the similar relationships to the diets
Interestingly, using the Girvan–Newman algorithm for module identification, the lipid metabolism module was clustered together with the ketone bodies and the high-density lipoproteins resulting in 16 metabolites within the cluster. The lipoproteins module in this case contained 11 metabolites and had again high density (0.76).
The VLDL and HDL modules appeared to have on average opposite associations to every diet. The negative association might stem from HDL transporting very-low-density lipoprotein to the liver, where they are broken down. Mainly, by following a fast-food, a vegetarian, or a high-caloric diet, a negative association to HDL was observed in our data (Figs. 4 and 5).Fig. 5. Metabolite profile plots when the metabolite clusters have been identified using the Girvan–Newman algorithm. The relationship of the concentration levels of every metabolite (y-axis) to each diet (factor scores on the x-axis) is depicted using a spline. All metabolites belonging in the same module have the similar relationships to the diets
Discussion
In this work, our interest was on recovering metabolite networks under a repeated measures setting. By having information on various sources of variation (age, sex, time, genetic background, dietary preferences), lifestyle was able to be estimated as the random effects of a linear mixed effects model with the metabolite concentrations as response variable. By estimating time effects and quantifying lifestyle, metabolite networks were estimated with regard to lifestyle and dietary preferences while addressing for individual’s genetic differences. For network estimation, we considered the glasso method which is based on conditional independence. The network estimation method was applied to human metabolite data and interconnected modules having the same relationship to diets and lifestyle were identified using two methods: i) the two-step dynamic hybrid algorithm, and ii) the Girvan–Newman algorithm. Obtained networks and modules were described in terms of density, centralization, and heterogeneity.
As the data were collected at two time-points (2007 and 2014), we estimated metabolite networks for the separate time-points, as a benchmark, for comparing to the more elaborate model which utilizes information on time, genetics, and dietary patterns. We observed that the separate networks had fewer, more dense modules. Contrarily, a network accounting for different sources of variation resulted in more modules that were also more homogenous in terms of constituent metabolites. When information related to dietary preferences and lifestyle was retained in metabolite networks, several groups of biologically associated metabolites were clustered together.
By working on the repeated measures setting, networks subject to time variation can also be estimated. Identified modules will contain metabolites that change similarly over time. In order to perform such analysis, the metabolite part related to time variation that can be used for network estimation is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \tilde{\textbf{Y}}_T^{(p)}= & \hat{\beta }_{3}^{(p)}\textbf{T}+\hat{\beta }_{7}^{(p)}\textbf{Age}\circ \textbf{T}+\hat{\beta }_{10}^{(p)}\textbf{Sex}\circ \textbf{T}+\hat{\beta }_{13}^{(p)}\textbf{T}\circ \textbf{F} +\nonumber \\ &\hat{\beta }_{14}^{(p)}\textbf{T}\circ \textbf{G}. \end{aligned}$$\end{document}Although, several studies have examined the interplay between diet and metabolism, to our knowledge, this is the first attempt studying metabolite patterns in the network framework while simultaneously modeling diet ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}$$\end{document} ), lifestyle ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}$$\end{document} ), and genetics ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G}$$\end{document} ), when concentrations are measured over time. Under this design, metabolite measurements are dependent and this dependence should be taken into account when the data are analyzed. By using linear mixed effects models, we were able to decompose and select the part of metabolic variation relevant to specific covariables, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}$$\end{document} . Established relationships were identified and metabolites were separated by their different biochemical classes.
However, some limitation should be noted. First, we assumed the individual dietary scores, as estimated by the EFA, to be the same between the two time points. Overall dietary patterns tend to be relatively stable over time, while it is suggested that in repeated measures studies, dietary information is to be reevaluated after at least seven years (Weismayer et al. 2006). Second the FFQ contains self-reported data, which may have limitations such as recall bias and social desirability bias. Despite the limitations, FFQs are still valuable tools for assessing dietary intake in large-scale epidemiological studies.
Zooming into variation of specific covariables allows us to interpret and infer different metabolite aspects. Using this framework while working on the metabolome, more can be done. For example, by identifying clusters of metabolites responding similarly to specific dietary patterns, network analysis can help detect diet-responsive biomarkers. This can be valuable for evaluating metabolic health and/or risk for chronic conditions. Additionally, in metabolite identification and characterization, when an unidentified metabolite is included in the network, its properties regarding different aspects can be deduced by carefully examining the edges connected to the metabolite, with respect to different variation sources. Working in the same framework for the reconstruction of metabolite networks in humans and plants (Bartzis et al., 2017), in the future we plan to use information from the graphical structure of lower leveled omic sources (gene or marker level) besides accounting for the study design. This will allow us to use an extra level of information for reconstructing metabolite networks.Table 2. Loadings matrixFood itemFast Food (F1)Vegetarian (F2)High Caloric (F3)Fish (F4)Juice (F5)Balanced (F6)Chocolate0.60Other candies0.55Sweet biscuits0.52****0.29Other sweet pastry0.45Salty snacks0.44 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.30Ice cream puddings0.43Cereals or muesli0.37−0.29Store bought ready meal0.37Pizza0.32−0.28Flavoured yoghurt0.31Yeast bread.graham breadCola light/dayChocolate milk/dayFruits0.55Fresh or frozen berries0.53Porridge0.49Sweet coffee bread or pies0.31****0.43Low fat cheese0.36****0.28Burgers0.29−0.34Rye bread & rye crisp0.31Non-flavoured yoghurt0.31Cooked vegetables0.30Sour milk/day0.28Vegetarian food0.26Energy drink/daySausages** 0.62Cutlets0**.59Meat0.43****0.33Cooked or smashed potatoes0.40****0.42Roasted potatoes or french fries0.42Salty pies and pastry0.30****0.36White bread0.29Eggs0.29Coffee/day0.26Milk/dayOther cheeseCoffee/day0.26Tap water/daySoft drink/dayLow alcohol /dayFish and other fish food combined0.91Salmon & rainbow trout0.64Other fish0.58Herring0.48Tea/dayBottled water/dayFruit and berry juices0.76Poultry meat0.60Cold cuts0.30****0.44Pasta or rice0.26****0.36Fresh salad. Fresh vegetables0.29****0.32Salad dressing or oilLow calorie soft drink/dayWell water/day Measures the dependence of observed variables on factors. Loadings with absolute value above 0.25 have been indicated Table 3. Characterization of the modules when the Girvan–Newman algorithm is usedModuleDensityCentralizationHeterogeneityNr of nodesHDL ^a^0.460.180.507Lipoproteins^b^0.960.030.046VLDL2^c^0.860.120.196gluconeogenesis ^d^0.630.280.375Complete Network0.100.110.6454Only modules with five or more metabolites have been reported^a^ Cit, HDL.C, HDL.D, HDL2.C, L.HDL.L, LDL.D, XL.HDL.L^b^ IDL.C, IDL.L, L.LDL.L, LDL.C, S.LDL.L, SM^c^ L.VLDL.L, M.VLDL.L, Serum.TG, VLDL.D, XL.VLDL.L, XXL.VLDL.L^d^ Ala, Alb, Lac, PC, PyrTable 4Characterization of networks and modules subject to dietary patterns and lifestyle, when the Girvan–Newman algorithm is usedModuleDensityCentralizationHeterogeneityNr of nodesHDL/Ket. bodies/Lip. metabolism ^a^0.370.230.4316Lipoproteins^b^0.760.200.2911AA ^c^0.300.160.487VLDL ^d^0.860.120.196 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega $$\end{document} -3 FA ^e^0.670.230.395Complete Network0.100.110.6454Only modules with five or more metabolites have been reported^a^ AcAce, Alb, ApoA1, bOHBut, HDL.C, HDL2.C, HDL3.C, L.HDL.L, Lac, M.HDL.L, PC, Pyr, S.HDL.L, TotCho, TotPG, XL.HDL.L^b^ ApoB, IDL.C, IDL.L, L.LDL.L, LDL.C, M.LDL.L, S.LDL.L, S.VLDL.L, Serum.C, SM, XS.VLDL.L^c^ Ala, Gp, Ile, Leu, Phe, Tyr, Val^d^ L.VLDL.L, M.VLDL.L, Serum.TG, VLDL.D, XL.VLDL.L, XXL.VLDL.L^e^ DHA, FAw3, FAw3.FA, Glc, PUFA
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Guertin, K.A., Moore, S.C., Sampson, J.N., Huang, W.-Y., Xiao, Q., Stolzenberg-Solomon, R.Z., Sinha, R., & Cross, A.J. (2014). Metabolomics in nutritional epidemiology: Identifying metabolites associated with diet and quantifying their potential to uncover diet-disease relations in populations. The American Journal of Clinical Nutrition, 078758.10.3945/ajcn.113.078758 PMC 414409924740205 · doi ↗ · pubmed ↗
- 2Randall, E., Marshall, J.R., Brasure, J., & Graham, S. (1992). Dietary patterns and colon cancer in western New York.10.1080/016355892095142271296200 · doi ↗ · pubmed ↗
- 3Rencher, A.C. (2003). Methods of multivariate analysis 492.
- 4Revelle, W. (2021). Psych: Procedures for Psychological, Psychometric, and Personality Research. Northwestern University, Evanston, Illinois. Northwestern University. R package version 2.1.9. https://CRAN.R-project.org/package=psych.
- 5Liu, H., Roeder, K., Wasserman, L. (2010). Stability approach to regularization selection (stars) for high dimensional graphical models. In: Advances in Neural Information Processing Systems, pp. 1432–1440.PMC 413872425152607 · pubmed ↗