EIM: An effective solution for improving multi-modal large language models
Yuting Bai, Tonghua Su, Zixing Bai, Hung Bui, Hung Bui, Hung Bui

TL;DR
This paper introduces EIM, a new method to improve multi-modal large language models without adding parameters or changing model structure.
Contribution
EIM offers a novel training process-based solution for enhancing multi-modal LLMs with minimal parameter increase.
Findings
EIM improves performance on COCO Caption with fewer parameters than larger models.
EIM achieves competitive results on ScienceQA and MME with 7B parameters versus 13B models.
EIM is applied to multiple models like ClipCap, LLaMA-Adapter, and LaVIN with consistent improvements.
Abstract
Enabling large language models (LLMs) to have multi-modal capabilities, such as vision-language learning, has become a current research hotspot and the next milestone in LLM development with the advent of models like GPT4. The basic structure of current multi-modal LLMs usually includes three parts: the image encoder for extracting visual features, the semantic space transformation network ST for aligning the multi-modal semantic spaces, and LLM for generating text. Current works on multi-modal LLMs primarily focus on enhancing performance by utilizing larger image encoders and LLMs, and designing more complex fine-tuning methods and STs, which results in an escalation of model parameters. In this paper, we propose EIM, a novel effective solution for improving the performance of multi-modal large language models from the perspective of training process which reduces the need to…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
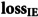 Fig 1
Fig 1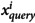 Fig 2
Fig 2 Fig 3
Fig 3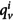 Fig 4
Fig 4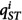 Fig 5
Fig 5 Fig 6
Fig 6 Fig 7
Fig 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMultimodal Machine Learning Applications · Domain Adaptation and Few-Shot Learning · Topic Modeling
Introduction
In recent years, with the increase in model parameter size, large language models (LLMs), such as the GPT series [1–4] and LLaMA series [5–8], continuously push the upper limit of natural language understanding. The next milestone of LLMs is usually considered to enable multi-modal capabilities. For instance, GPT4 [4] not only has excellent text comprehension ability but also supports multi-modal data such as images. The trend of enabling LLMs with multi-modal capabilities, such as image captioning and visual Q&A, has stimulated research and development in the field of multi-modal LLMs [9–26]-28].
CLIP [29] has become the de facto fundamental model in the current multi-modal field due to its excellent performance [30–40]. For instance, the combination of CLIP and diffusion models [41–44] can generate stunning images solely based on text instructions [45–47]. With the rapid development of LLMs [9, 48], how to combine CLIP and LLMs to support multi-modal tasks, such as visual language generation, has become a research hotspot [9–15, 17–20, 22–24, 26, 57, 58].
ClipCap [49] is the earliest case to consider combining CLIP and language models, which converts images into text through the three-segment structure: the image encoder CLIP for extracting visual features, the semantic space transformation network ST for aligning the multi-modal semantic spaces, and the language model GPT-2 [2] for generating text. With the development of LLMs [4, 6, 48, 50] and CLIP-like models [29, 51–56], the three-segment structural design similar to ClipCap that connects two different modal models through ST has shown strong versatility and has been widely used in recent multi-modal LLMs [11, 12, 14, 19, 22, 24]. For instance, LLaMA-Adapter [19] uses LLaMA [5] as the LLM, and PandaGPT [16] uses ImageBind [56] as the image encoder and Vicuna [7, 8] as the LLM. Following the three-segment structure, some recent works, like Emu3 [59], Show-o [60], InternVL3 [61], Janus-Pro [62], extend the multi-modal LLM ability from visual understanding to visual understanding and generation by introducing the additional image decoder. However, the training costs of this new structure are too expensive. Its biggest highlight, image generation, is a bit lackluster because it can only generate an image that is the same as the model’s input image, lacking practical application scenarios. Therefore, we only consider the three-segment structure in this paper. In summary, current research on multi-modal LLMs is still in its early stage and mainly focuses on using larger image encoders or LLMs to improve the performance.
We summarize the problems and shortcomings of current research in the field of multi-modal LLMs as below:
Current research on multi-modal LLMs primarily concentrates on enhancing performance by utilizing larger image encoders [29, 56] and LLMs [5, 7], designing more complex fine-tuning methods like MMA [22] and STs like Q-Former [23], as well as a huge number of high-quality image-text pairs for pre-training ST to align the semantic spaces between vision and language [10–13, 25, 28], which results in an escalation of model parameters and a surge in training costs.Although text features have been proven to help improve the performance of CLIP [31, 63–65], there is currently a lack of research cases in the field of multi-modal LLMs that utilize text features of CLIP. Some studies have even suggested that fine-tuning CLIP may be detrimental to downstream tasks training [36, 66–68].Current research on multi-modal LLMs usually only uses the auto-regressive training objective [11, 19, 22]. Optimizing multi-modal LLMs from the perspective of the training process is ignored and less explored.
In this paper, we think the training process of multi-modal LLMs should be different from that of traditional autoregressive models due to the multi-modal input rather than uni-modal input. Besides, optimizing the training process can improve the model performance, reduce the need to introduce new parameters and modify the original model structure, be orthogonal to the mainstream solutions, and enable the utilization of text features of CLIP. Therefore, we propose an effective solution for improving multi-modal LLMs called EIM that enhances model performance from the perspective of the training process. Our approach involves utilizing the text features of CLIP and adding contrastive losses on CLIP, ST, and LLM. We conduct ablation studies on ClipCap and quantitatively analyze the effects in detail. Furthermore, we extend EIM to LLaMA-Adapter [19] and LaVIN [22] for validation. The experimental results confirm the effective performance improvement of EIM for multi-modal LLMs. Overall, our paper makes the following contributions:
We propose three contrastive losses to improve the performance from the perspective of the training process. The proposed losses are used for CLIP, ST, and LLM, respectively. And we further provide a solution that combines these losses to achieve stable performance improvement.We propose to enhance CLIP’s capability in multi-modal LLMs by introducing textual information. Although CLIP has the ability to extract both image and text features, as it undergoes image-text alignment during the pre-training stage, previous studies primarily focus on utilizing CLIP’s visual feature extraction capability while neglecting its text feature extraction capability. To address this limitation, the CLIP text encoder is introduced to encode the textual information and help to guide the CLIP fine-tuning during the training.Based on the above improvements, we propose EIM, a novel effective solution for improving the performance of multi-modal large language models from the perspective of the training process. We apply EIM on the model and achieve 1.75% performance improvement on the COCO Caption dataset when comparing to the experimental results of , which has 3.13 times the number of parameters of . Furthermore, we extend EIM to the representative multi-modal LLMs, such as LLaMA-Adapter and LaVIN, and evaluate on the ScienceQA dataset, achieving accuracy improvements of 2.76% and 2.05%, respectively. Finally, we apply EIM on LaVIN-7B-lite and evaluate on the MME benchmark, achieving comparable performance when compared to LaVIN-13B.
Related work
Due to the widely used three-segment structural design in current multi-modal LLMs, we will introduce the related multi-modal LLMs from the image encoder, ST, and LLM.
Image encoder.
PandaGPT [16] extracts visual features using ImageBind [56]. Compared to CLIP [29], ImageBind supports a wider variety of modal data. Similar to PandaGPT, ImageBind-LLM [28] also uses ImageBind to encode more modal data. The EVA-CLIP series [51–53], which achieve better performance through improving the training techniques of CLIP, are broadly introduced in models like BLIP-2 [23], InstructBLIP [24], MiniGPT-4 [12], Lynx [25], Ziya-Visual [17], and LLaVA-1.5 [10]. Unlike existing works, we improve the performance of CLIP by using contrastive learning, introducing textual information, removing CLIP’s output layer, and using the full visual features rather than replacing CLIP with larger image encoders like ImageBind and the EVA-CLIP series.
ST.
Most of the current multi-modal LLMs, such as LLaVA series [10, 11], LLaMA-Adapter [19, 20], Otter [15], MultiModal-GPT [18], MiniGPT-4 [13], VisualGLM-6B [69, 70], and InstructBLIP [24], use a large number of high-quality image-text pairs for pre-training ST to align the semantic spaces between vision and language, which results in a surge in training costs. Although LaVIN [22] reduces the training costs by Mixture-of-Modality Training without the pre-training stage, there is no alignment design for ST. Therefore, a novel contrastive loss for ST is proposed in this paper to reduce the training costs, and also take into account the alignment of ST and LLM.
LLM.
LLaVA [10, 11], LLaMA-Adapter [19, 20], and LaVIN [21, 22] use the LLaMA series [5–8] and use PETL (Parameter-Efficient Transfer Learning) [luo2023towards, [19–22, 71–79] to optimize the model. Unlike existing works, we introduce contrastive learning to help improve the performance of LLMs rather than solely relying on using PETL and replacing LLMs with larger ones.
Method
As shown in Fig 1, EIM includes the following improvement measures. Firstly, the CLIP text encoder CLIP.text is introduced to encode the textual information and help to guide the CLIP fine-tuning through lossIE during the training. Secondly, the contrastive loss lossST is proposed to align the visual and text semantics. Finally, the contrastive loss lossLM is proposed to help to guide the text generation.
The overview of EIM.EIM is an effective solution for improving the performance of multi-modal large language models from the perspective of the training process. EIM includes using three contrastive losses: lossIE, lossST and lossLM, and introducing CLIP.text. lossIE is the contrastive loss for the Image Encoder CLIP.visual. lossST is the contrastive loss for the Semantic Space Transformation Network. lossLM is the contrastive loss for the LM. lossIE and lossLM should be used together with fine-tuning methods. There is no limitation on the CLIP and LM fine-tuning methods, which depend on the original model implementations. If the original multi-modal LLMs do not provide the fine-tuning methods for CLIP, we can skip using it or use the prompt-tuning method by default.
Following the previous contrastive learning works [49, 80–84], there is a queue to store key vectors for all samples, the positive sample refer to the input sample itself, and the negative samples refer to all other samples in the dataset. The details are shown in Fig 2. The contrastive loss aims to maximize the similarity between the query vector and the key vector , while minimizing the similarity between and all other , where .
The overview of contrastive learning.For xqueryi, the positive sample is the xkeyi, the negative samples are xkeyj, where j≠i. The larger the queue K, the richer the visual information and features it can represent. Then, when using queries for comparative learning, the more features of images can be learned. Therefore, previous works usually use all samples to build the queue K.
It is worth noting that in current multi-modal LLMs, the utilization of the output layer of CLIP is detrimental to downstream tasks training due to the differences between the pre-training task and downstream tasks, and the utilization of the partial visual features leads to the issue of losing information. Therefore, the CLIP image encoding capability is improved in this paper by modifying the usage of CLIP features, which includes removing CLIP’s output layer and using the full visual features. The CLIP’s output layer is a linear layer used to change the hidden dimension to the output dimension, ensuring that the output dimension of the CLIP.visual is consistent with that of the CLIP.text. The full visual features are the [CLS] token and the patch tokens extracted by CLIP.
Base structure
Fig 3 illustrates the basic structure of multi-modal LLMs, which includes three parts: the image encoder CLIP.visual for extracting visual features, ST for aligning the multi-modal semantic spaces, and LLM for generating text.
The overview of multi-modal LLMs.The structure of multi-modal LLMs contains three modules: the image encoder CLIP.visual for extracting visual features, ST for aligning the multi-modal semantic spaces, and LLM for generating text.
Current models usually use the auto-regressive training objective, which is called lossbase in this paper. Given the response , and the ST output features fST, the training objective lossbase is defined by:
Here, m represents the length of the response.
CLIP text encoder and contrastive loss for image encoder
Previous studies primarily focus on utilizing CLIP’s visual feature extraction capability while neglecting its text feature extraction capability. Therefore, as illustrated in Fig 4, CLIP.text is introduced to encode the textual information and help to guide the CLIP fine-tuning through lossIE during the training.
CLIP.text and lossIE.The semantics spaces of CLIP.text and CLIP.visual are aligned through lossIE. Kt is the pre-built queue, which contains all [EOS] token features extracted by CLIP.text from the image captions in the training dataset. qvi denotes the i-th image’s [CLS] token vector output by CLIP.visual. In addition, lossIE should be used together with fine-tuning methods. If the original multi-modal LLMs do not provide the fine-tuning methods for CLIP, we can skip using it or use the prompt-tuning method by default.
Given the pre-built queue which contains all [EOS] token features extracted by CLIP.text from the image captions in the training dataset, the i-th image’s [CLS] token vector output by CLIP.visual, lossIE is defined by:
Here, τ is the temperature coefficient, N is the number of image-text pairs in the training dataset.
Contrastive loss for ST
Most of current multi-modal LLMs use a large number of high-quality image-text pairs for pre-training ST to align the semantic spaces between vision and language, which results in a surge in training costs. Therefore, as illustrated in Fig 5, lossST is proposed to help align the multi-modal semantic spaces between vision and language with affordable training costs.
lossST, which is used to align the semantic spaces of images and texts by maximizing the similarity between the qSTi and the i-th vector of the queue Ke.Ke is the pre-built queue containing the average of the sentence token features, which are extracted by LMe from the instructions and responses in the training dataset. qSTi is the vector that averages the token features of the i-th image output by ST. LMe represents the LLM’s embedding layer. LMblock represents the hidden layers of LLM. LMproj is the output layer of LLM.
Given the pre-built queue which contains the average of the sentence token features that are extracted by LMe from the instructions and responses in the training dataset, which averages the i-th image’s token features output by ST, lossST is defined by:
Here, τ is the temperature coefficient, and N is the number of image-text pairs in the training dataset.
Contrastive loss for LLM
Unlike existing works, as illustrated in Fig 6, the contrastive loss lossLM is proposed to help improve the performance of LLMs, rather than solely relying on using PETL and replacing LLMs with larger ones.
lossLM, which is used to align the semantic spaces of the tuning LLM and the original LLM by maximizing the similarity between the qLMi and the i-th vector of the queue Kb.Kb is the pre-built queue, which contains all [EOS] token features extracted by the original LLM’s LMblock from the instructions and responses in the training dataset. qLMi is the i-th text’s last token vector output by the tuning LLM’s LMblock. LMblock represents the hidden layers of LLM. LMproj is the output layer of LLM.
Given the pre-built queue which contains all [EOS] token features extracted by the original LLM’s LMblock from the instructions and responses in the training dataset, the i-th text’s last token vector output by the tuning LLM’s LMblock, lossLM is defined by:
Here, τ is the temperature coefficient, and N is the number of image-text pairs in the training dataset.
Segmented training
In experiments, we find that although the three contrastive losses lossIE, lossST, and lossLM can improve the performance of multi-modal LLMs when applied individually, using them simultaneously in one training stage may lead to training instability. To avoid the training instability, we use the segmented training to isolate the influence between different losses, thus enabling the stable performance improvements when using the combination of the three contrastive losses. In each stage, the training data is the training part of the dataset. Table 1 shows the details of segmented training.
Table 1: Segmented training.
Experiments
Following LLaMA-Adapter and LaVIN, we first apply EIM on ClipCap and evaluate the model on the traditional image captioning dataset COCO, then extend EIM to the representative multi-modal language models, such as LaVIN and LLaMA-Adapter, and evaluate the models on the first large scale multi-modal dataset ScienceQA, and finally apply EIM on LaVIN and evaluate the model on the first multi-modal LLM evaluation benchmark MME. We choose ClipCap because it still serves as the baseline in LLaMA-Adapter V2. We choose LaVIN and LLaMA-Adapter because they are representative works of the current multi-modal LLMs, with significant differences in fine-tuning methods and the ST structure, which can provide a more comprehensive test of our solution. LLaMA-Adapter does not use the fine-tuning method on CLIP, uses Transformer structure to design the ST, and uses the prompting method to fine-tune the LLM. In contrast, LaVIN uses the adapter to fine-tune CLIP, uses a lightweight MLP as ST, and uses the adapter MMA to fine-tune the LLM.
The COCO Caption dataset experimental results of , which is a model that applies EIM on the , show the 1.75% performance improvement when compared to those of , which has 3.13 times the number of parameters of . Furthermore, we extend EIM to the representative multi-modal LLMs, including LLaMA-Adapter and LaVIN, and evaluate on the ScienceQA dataset, achieving accuracy improvements of 2.76% and 2.05%, respectively, which confirms the effective performance improvement of EIM for multi-modal LLMs. Finally, we apply EIM on LaVIN-7B and evaluate on the MME benchmark, achieving comparable performance when compared to LaVIN-13B. The rest of this section is introduced in the order of the datasets and metrics, the implementation details, the experimental results of ClipCap on the COCO dataset, and the experimental results of two representative multi-modal LLMs on ScienceQA.
Datasets and metrics
COCO caption.
COCO Caption dataset [85] contains 0.6M training image caption data (120k images with 5 captions per image) over a wide range of distributions. We split the dataset according to the Karpathy [86] split. Similar to Oscar [87], we validate ClipCap over the COCO Caption dataset using the common metrics BLEU4 [88], METEOR [89], CIDEr [90], SPICE [91] and ROUGE_L [92], and the main reference metric is BLEU4.
ScienceQA.
ScienceQA [93] is the first large-scale multi-modal dataset designed for science question answering, covering multiple fields, including 3 subjects, 26 topics, 127 categories, and 379 skills. The dataset includes pure text and text-image examples, which are divided into three parts: train, validation, and test, with 12,726, 4,241, and 4,241 examples, respectively. Following LaVIN [22] and LLaMA-Adapter [19], we evaluate the models on the ScienceQA dataset using the average accuracy.
Alphaca-52k & LLaVA-158k & MME.
Alphaca-52k [94] contains 52k text-only instruction-following data generated by GPT-3.5 [95]. LLaVA-158k [11] is a large-scale image-text instruction dataset where the answer is automatically generated by GPT-4 [4]. Following LaVIN [22], we train the multi-modal chatbot model on Alphaca-52k & LLaVA-158k and evaluate the model on the first multi-modal LLM evaluation benchmark MME [96], which is free and widely used in 50+ recent multi-modal LLMs.
MME includes two major categories: perception and cognition. The former, with 10 subtasks, refers to recognizing specific objects in images, while the latter, with 4 subtasks, is more challenging for deducing complex answers from visual information. MME manually designs the annotations of instruction-answer pairs to avoid data leakage that may arise from the direct use of public datasets for evaluation. For each test image, MME adopts an instruction of a question and a description “Please answer yes or no", which prompts LLMs to answer “yes" or “no". The full score of MME is 2800.
Implementation details
The performance of EIM applied to ClipCap is evaluated on the COCO Caption dataset with a single RTX-3090 graphics card. Following the settings in ClipCap, the epochs, batch size, and learning rate are set to 10, 40 and 2E-5, respectively. In order to apply EIM to ClipCap, we make modifications to ST due to the use of the full visual features instead of a single visual feature, and use the segmented training to ensure the stability of the training process. The segmented training sequence is lossST, lossLM, and . To reduce the training costs and ensure the fair comparison of experiments, only the stage trains the entire model. In the lossST stage, only the ST is trained through the training objective lossST. In the lossLM stage, only the LLM is trained through the training objective lossLM.
The performance of EIM applied to the representative models is evaluated on the ScienceQA dataset with four A100 graphics cards. Following the settings in LaVIN and LLaMA-Adapter, the epochs, batch size, and learning rate are 20, 32, and 9E-3, respectively. Due to the adapter and prompt methods used in LaVIN and LLaMA-Adapter, which harm the training stability, a new training stage Adapter, which fine-tunes the multi-modal LLMs solely by lossbase, is added after the lossLM stage. Therefore, the segmented training sequence is lossST, lossLM, Adapter, and .
We also apply EIM to LaVIN-7B-lite, train the chatbot model on four RTX-3090 graphics cards, and evaluate on the MME benchmark. Following LaVIN, the training settings are the same, except that the training epochs are 15 in the original LaVIN and 10 in ours.
Following the previous works [80, 84], the temperature coefficient τ is set as 0.07. It is worth noting that in our solution, lossIE uses the image caption, lossST uses the instruction and response, and lossLM uses the instruction and response. These losses are not applied in the inference stage, so there will be no additional restrictions on model deployment and application scenarios. In practice, the instruction is empty, and the response is caption in COCO Caption dataset. In the ScienceQA dataset, the instruction includes question, context, and options, and the response includes answer, lecture, and solution. We think that both visual question answering and image captioning can be seen as tasks for generating a response when given an image and an instruction as input, and the combination of the instruction and response can describe the image from another perspective. Specially, we observe that the solution in ScienceQA contains a lot of image related information. Therefore, if the proposed loss is effective on image captioning datasets like COCO Caption, it should also be effective on visual question answering datasets like ScienceQA.
Experimental results on COCO
We choose the ClipCap as the baseline model and conduct experiments to quickly validate the feasibility of our ideas. ClipCap uses the CLIP VIT-B/32 as the visual encoder and uses GPT-2 as the language model. The ST in ClipCap is an MLP with a hidden layer and is used to translate a single visual token with 512 dimensions to 10 tokens with 768 dimensions. ClipCap does not provide the fine-tuning methods on CLIP and fully fine-tunes GPT-2.
From Table 2, is the model that applies EIM on , which achieves the 2.7% performance improvement in BLEU4 when compared to . Furthermore, achieves the 1.75% performance improvement with only 31.99% total parameters when compared to . In practice, the parameter size of is smaller than that of because of a certain structure change of ST due to the usage of full visual features instead of using a single visual feature in original and removing the CLIP’s output layer. In the original ClipCap, the input dimension of ST is 512, the hidden dimension of ST is 3840, and the output dimension of ST is 7680. Because this ST is responsible for converting one token into multiple tokens, if we use the full visual features, the input dimension, hidden dimension and output dimension will be changed to 197376, 98688, and 197376, respectively. It is too large and has 39B parameters. So, we changed the ClipCap ST structure to a simple FFN, with the input dimension of 768, the hidden dimension of 3072, and the output dimension of 768. The ST parameters are reduced from the original 31.47M to 4.72M. While the prompting method introduces 26.07M parameters, the number of trainable parameters is reduced by 0.68M. Finally, the total parameters is reduced by 1.08M, which is the sum of the reduced trainable parameters 0.68M and the removed CLIP’s output layer parameters 0.4M. What’s more, we do not need to modify the ST to the extent of ClipCap in current representative models such as LaVIN, LLaMA-Adapter. For instance, we just modify the input dimension of ST from 768 to 1024 in LLaMA-Adapter and do not need to modify the ST in LaVIN.
Table 2: The experimental results (%) of applying EIM to ClipCap on the COCO Caption dataset.
Ablation study.
To demonstrate the reliability of EIM in detail, ablation experiments are conducted. As shown in Table 3, when using lossST and lossLM, the performance is increased by 0.8% and 0.6% respectively. When using lossIE, the performance is improved by 1.6% with the increased parameters from the default prompt network. In contrast, if the original model provides a fine-tuning method on CLIP, lossIE can be directly used without increasing parameters. We also present the case studies in Fig 7, which show that generates more accurate and detailed captions than .
Case study of applying EIM to ClipCapsmall on the COCO Caption dataset.We show the caption generated by ClipCapsmall, the caption generated by ClipCapeim, and the ground truth. ClipCapeim generates more accurate and detailed captions than ClipCapsmall. Incorrect text is highlighted in red.
Table 3: Ablation study (%).
Segmented training.
The experimental results of the segmented training are detailed in Table 4. The results show that when removing the CLIP’s output layer and using the full visual features on , the performance is improved by 1.7%. After introducing the lossST stage, the performance is improved by 1.9%. After introducing the lossLM stage, the performance is improved by 2.3%. After introducing the stage, the performance is improved by 2.7%.
Table 4: Segmented training (%).
Why use segmented training?
We have tried to combine different losses, but the performance is unstable. As shown in Table 5, when we use lossbase, lossST, lossLM, and lossIE together in one training stage, the performance is 33.0%. When we use segmented training, the performance is improved to 33.9% with a 0.9% improvement. As shown in Table 6, when we use both lossST and lossLM simultaneously, the performace is 32. The result is lower than our expectation. We speculate that this is due to the inconsistent optimization goals among the different losses. lossIE is designed to help the visual encoder to adapt to downstream tasks, lossST is designed to help ST align the image and text, and lossLM is designed to preserve the performance of LLM. Therefore, we completely eliminate the interference between these three losses through gradient truncation and segmented training to achieve stable performance improvement.
Table 5: Experimental results (%) of applying lossST, lossLM, and lossIE in one training stage and segmented training.
Table 6: Experimental results (%) with the combination of lossST and lossLM.
We refer to the common training approach of multi-modal LLMs, that is firstly pre-training the ST and then fine-tuning the LLM. lossIE is placed in the last as a supplement because models like LLaMA-Adpater do not fine-tune the CLIP. We also conduct experiments to ensure the order of these losses. As shown in Table 7, we conduct experiments to verify whether the pre-training order of lossST and lossLM is reasonable. We also verify whether lossIE, as a supplement, should be placed at the beginning or at the end of the training sequence, and the results are shown in Table 8. In practice, we think lossIE should be used together with lossbase to prevent the excessively fine-tuning of CLIP. We can only provide such a stable version right now. We will try to integrate these losses in future work.
Table 7: Experimental results (%) under different orders of lossST and lossLM.
Table 8: Experimental results (%) of lossIE at both ends of the sequence.
Modifying the usage of CLIP features.
In this paper, modifying the usage of CLIP features includes removing CLIP’s output layer and using the full visual features. According to Table 9, when removing the CLIP’s output layer or using the full visual features alone, the performance is 31.6% and 31.8%, respectively. However, when both are used simultaneously, the performance is improved to 32.9%. We speculate that the visual features after removing the output layer contain more information, which benefits the use of the full visual features. Our findings indirectly confirm the speculation that the use of the output layer of CLIP is detrimental to downstream task training due to the differences between the pre-training task and downstream tasks.
Table 9: Experimental results (%) of modifying the usage of CLIP features.
Comparison of training efficiency.
According to Table 2, EIM can improve the performance with fewer parameters, which means that there will be no additional hardware overhead. However, due to the segmented training method used in this paper, the training time will be increased compared to . One epoch training time for , , and is 23 minutes, 75 minutes, and 51 minutes, respectively. The training time for the three stages of segmented training is 0.9 minutes, 6.4 minutes, and 43.7 minutes, respectively. The increase in training time mainly comes from the stage due to differences in CLIP usage. In , lossIE necessitates the use of CLIP during the training phase. In contrast, ClipCap uses pre-extracted visual features from CLIP instead of using CLIP during the training phase. This is confirmed in subsequent LLaMA-Adapter and LaVIN model experiments. LLaMA-Adapter and LaVIN use CLIP during the training phase instead of pre-extracted visual features, which does not increase training time during the training phase.
Results on ScienceQA
We choose LaVIN and LLaMA-Adapter because they are representative works of the current multi-modal LLMs, with significant differences in fine-tuning methods and the ST structure, which can provide a more comprehensive test of our solution. LLaMA-Adapter uses the CLIP VIT-L/14 as the visual encoder, uses the Transformer structure to design the ST, and uses the LLaMA as the LLM. In terms of fine-tuning methods, LLaMA-Adapter does not fine-tune CLIP and fine-tunes the LLM through the prompting method. In contrast, LaVIN uses the CLIP VIT-L/14 as the visual encoder, uses a lightweight MLP as ST, and uses the LLaMA as the LLM. In terms of fine-tuning methods, LaVIN uses the adapter to fine-tune CLIP and LLM.
As shown in Tables 10 and 11, we extend EIM to the representative multi-modal LLMs, including LLaMA-Adapter and LaVIN, and evaluate on the ScienceQA dataset, achieving accuracy improvements of 2.76% and 2.05%, respectively, which confirms the effective performance improvement of EIM for multi-modal LLMs. It should be noted that because LaVIN takes the output features of ST as the input of the LLM and there is a maximum input length limitation in LaVIN’s LLM setting, we choose 50 visual token vectors instead of using the full visual features. In contrast, LLaMA-Adapter uses the full visual features.
Table 10: The experimental results (%) of applying EIM to LLaMA-Adapter on the ScienceQA dataset.
Table 11: The experimental results (%) of applying EIM to LaVIN on the ScienceQA dataset.
Results on LLaMA-adapter.
Table 10 shows the experimental results of applying EIM on LLaMA-Adapter. From the table, it can be seen that the performance improved by 2.76%. However, due to the default prompt tuning method, the number of trainable parameters is increased by nearly 55M. Therefore, we also provide the experimental results for only the first three stages of training, which can improve performance by 2.43% without increasing the number of parameters. It is worth noting that when we apply lossST and lossLM, the performance of all tasks has significantly increased except for LAN and NO. After lossIE is applied, the performance of LAN and NO tasks is increased by 1.01% and 1.12%, respectively, which indicates that lossIE and the other two losses are complementary. Besides, the G7-12 task is increased from 86.82% to 87.74%, which indicates that lossIE can further improve the complex reasoning ability. However, we also notice that there is a little performance decrease on IMG and SOC tasks which rely more on the image understanding ability. We think this is because the ScienceQA dataset contains text-only samples which are better not to be used in lossIE.
Results on LaVIN.
From Table 11, LaVIN-7B- and LaVIN-7B- can achieve optimal or suboptimal performance on almost all tasks even when compared to the best model LaVIN-13B. LaVIN-7B- achieves the 2.05% performance improvement. It does not increase the number of model parameters and trainable parameters when compared to LaVIN-7B-lite(llama) because that LaVIN provides the Adapter to fine-tune the CLIP. Furthermore, LaVIN-7B- achieves the 1.18% performance improvement with only 7B total parameters when compared to the 13B parameters model LaVIN-13B-lite(llama). In addition, we also provide the experimental results of LaVIN-7B- that applies EIM on LaVIN-7B-lite(llama) with the LLM adapter network trained in the Adapter stage, which can improve the performance by 1.65%. Compared to the 13B model LaVIN-13B-lite(llama), LaVIN-7B- can also achieve the 0.78% performance improvement. The improvement of EIM on LaVIN is weaker than that applied to ClipCap and LLaMA-Adapter. We speculate this is mainly due to the fact that we only use the 20% visual features instead of using the full visual features.
Comparison of training efficiency.
The training time of one epoch is increased by 8 minutes after applying EIM to LLaMA-Adapter, with 20 seconds from the lossST stage, 1 minute from the lossLM stage and nearly 7 minutes from the Adapter stage. After applying EIM to LaVIN, the training time of one epoch is increased by 8.5 minutes, with 27 seconds, 1.05 minutes, and 7 minutes from the lossST stage, the lossLM stage, and the Adapter stage, respectively. Introducing lossIE in the stage does not increase the training time in both experiments, which confirm the analysis that the increase time in the ClipCap stage is due to the different use of CLIP. Although the training time on both experiments is increased by nearly 120%, primarily due to the Adapter stage, we believe that this is acceptable when compared to the performance improvements.
Experimental results on MME
In this paper, we apply EIM on LaVIN-7B-lite, follow the original LaVIN model [22] to train the chatbot model on Alphaca-52k & LLaVA-158k datasets, and evaluate on the first multi-modal LLM evaluation benchmark MME [96].
As shown in Tables 12 and 13, our model LaVIN-7B- can achieve comparable performance in Perception and Cognition tasks when compared to LaVIN-13B. It can be seen that LaVIN-7B- can achieve significantly better performance in Celebrity, Scene, Landmark, Artwork, and Text Translation tasks, and comparable performance in Position, Color, Poster, Commonsense Reasoning, and Code Reasoning tasks. This shows that our solution EIM can improve the model performance from the image understanding and complex reasoning abilities and preserve the knowledge of LLM. For instance, when compared to LaVIN-13B, LaVIN-7B- can archive 32.36, 7.25, and 4.5 improvements in Celebrity, Landmark, and Artwork tasks, which rely more on image understanding ability and the knowledge of LLM. And LaVIN-7B- can achieve 14.5 improvement in the Scene task which relies more on the image understanding ability. Besides, LaVIN-7B- can achieve 10 improvements in the Text Translation task which relies more on complex reasoning ability. However, the performance of LaVIN-7B- on Existence, Count, and OCR tasks is lower than that of LaVIN-13B. We speculate this is due to the fact that we only use 20% visual features in LaVIN-7B- rather than using full visual features. This will reduce the model performance in Existence, Count, and OCR tasks which partial visual features have a significant impact on results. So, we think we can introduce more partial visual features in future works to improve the performance of LaVIN-7B- on tasks like OCR, Count and Existence that are sensitive to local image details. This will also benefit tasks like Position which require the local image details to better understand the image.
Table 12: Perception performance comparison on MME benchmark.
Table 13: Cognition performance comparison on MME benchmark.
Conclusion
In this paper, we propose a novel effective solution, EIM, for improving the performance of multi-modal large language models from the perspective of the training process. EIM contains three losses: lossIE, lossST, and lossLM. The three losses are proposed for CLIP, ST, and LLM, respectively. lossIE is designed to help the visual encoder to adapt to downstream tasks, lossST is designed to help ST align the image and text, and lossLM is designed to preserve the performance of LLM. These losses can be used separately, and we further provide a stable solution with segmented training to combine these losses. Especially if the original model, like LLaMA-Adapter, does not fine-tune the CLIP, we can omit lossIE to achieve 2.43% improvement or use lossIE to achieve further 2.76% improvement with certain new trainable parameters introduced as needed.
To validate EIM, we first apply it to and conduct experiments on the COCO Caption dataset. The experimental results show that we can achieve the 1.75% performance improvement with only 31.99% total parameters when compared to those of . Secondly, we extend EIM to the multi-modal LLMs, such as LLaMA-Adapter and LaVIN, and evaluate them on the ScienceQA dataset. Finally, we also conduct multi-modal chatbot experiments with the EIM-enhanced LaVIN and evaluate it on the MME benchmark. The experimental results on the ScienceQA dataset and MME benchmark show that EIM can achieve competitive performance with 7B model parameters when compared to the 13B multi-modal LLMs, which confirms the effective performance improvement of EIM for multi-modal LLMs. However, the segmented training, which is used to ensure the stability of the training process, inevitably leads to the increase of the training time and may limit the performance. We will make improvements in future work.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems. 2020;33:1877–901.
- 2Achiam J, Adler S, Agarwal S, Ahmad L, Akkaya I, Aleman FL. Gpt-4 technical report. ar Xiv preprint 2023. doi: ar Xiv:230308774
- 3Touvron H, Lavril T, Izacard G, Martinet X, Lachaux MA, Lacroix T. Llama: Open and efficient foundation language models. ar Xiv preprint 2023. https://arxiv.org/abs/2302.13971
- 4Touvron H, Martin L, Stone K, Albert P, Almahairi A, Babaei Y. Llama 2: open foundation and fine-tuned chat models. ar Xiv preprint 2023. https://arxiv.org/abs/2307.09288
- 5Chiang WL, Li Z, Lin Z, Sheng Y, Wu Z, Zhang H. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. Vicuna. 2023;2(3):6.
- 6Zheng L, Chiang WL, Sheng Y, Zhuang S, Wu Z, Zhuang Y, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems. 2023;36:46595–623.
- 7Yin S, Fu C, Zhao S, Li K, Sun X, Xu T. A survey on multimodal large language models. ar Xiv preprint 2023. https://arxiv.org/abs/2306.1354910.1093/nsr/nwae 403PMC 1164512939679213 · doi ↗ · pubmed ↗
- 8Liu H, Li C, Wu Q, Lee YJ. Visual instruction tuning. Advances in neural information processing systems. 2023;36:34892–916.PMC 1186773240017809 · pubmed ↗