Harmonizing organ-at-risk structure names using open-source large language models
Adrian Thummerer, Matteo Maspero, Erik van der Bijl, Stefanie Corradini, Claus Belka, Guillaume Landry, Christopher Kurz

TL;DR
This paper shows that open-source large language models can accurately rename organs at risk in radiotherapy according to a standard guideline, with one model achieving nearly perfect accuracy.
Contribution
The study demonstrates the effectiveness of open-source large language models in harmonizing organ-at-risk nomenclature across multilingual and multi-institutional datasets.
Findings
DeepSeek R1 achieved 98.6% unique accuracy in renaming organs at risk.
Reasoning-enhanced models outperformed non-reasoning models in nomenclature harmonization.
Monte Carlo uncertainty estimation better detected prediction errors than prompt-based confidence.
Abstract
•Large language models can rename structures according to the AAPM TG-263 guideline.•Investigated four open source models using a multi-lingual, multi-center dataset.•DeepSeek R1 achieved the highest accuracy with 98.6% correctly renamed structures.•Monte Carlo uncertainty correlated with prediction errors (r = 0.7) Large language models can rename structures according to the AAPM TG-263 guideline. Investigated four open source models using a multi-lingual, multi-center dataset. DeepSeek R1 achieved the highest accuracy with 98.6% correctly renamed structures. Monte Carlo uncertainty correlated with prediction errors (r = 0.7) Standardized radiotherapy structure nomenclature is crucial for automation, inter-institutional collaborations, and large-scale deep learning studies in radiation oncology. Despite the availability of nomenclature guidelines (AAPM-TG-263), their…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
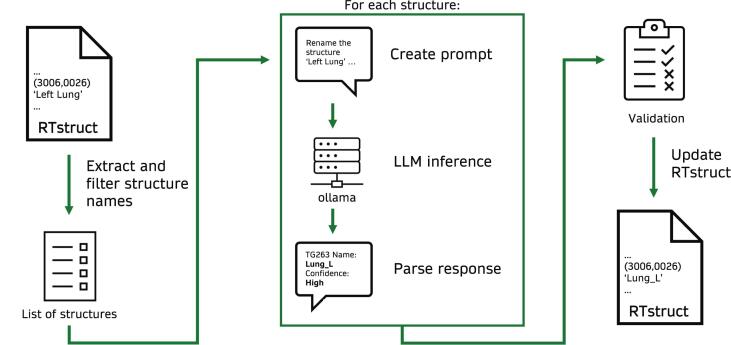 Figure 1
Figure 1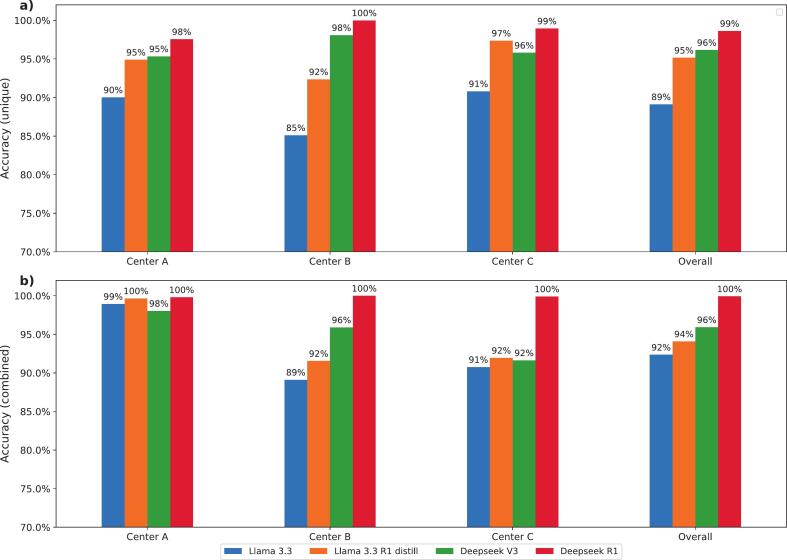 Figure 2
Figure 2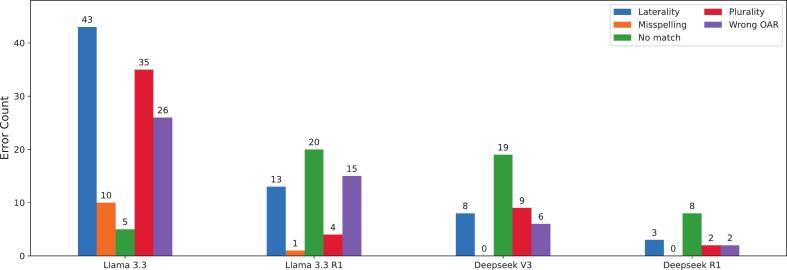 Figure 3
Figure 3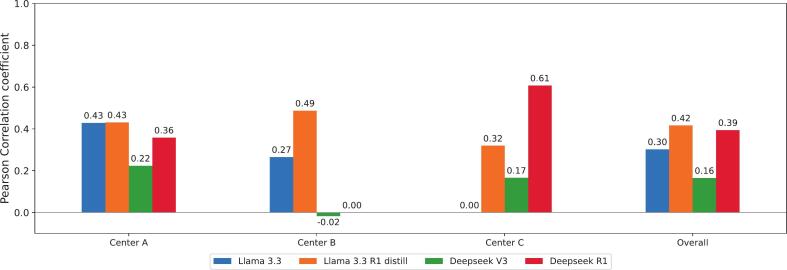 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBiomedical Text Mining and Ontologies · Topic Modeling · Machine Learning in Healthcare
Introduction
1
In radiation oncology, accurate delineation of target volumes and organs-at-risk (OARs) is critical for effective treatment planning, balancing precise dose delivery to targets while sparing healthy tissues. However, significant variability in naming conventions for radiotherapy structures persists within and between institutions and countries [1]. Recognizing the need for standardization of radiotherapy structure names, in 2018 the American Association of Physicists in Medicine (AAPM) established Task Group 263 (TG-263) to provide comprehensive guidelines for harmonizing nomenclature [2]. Despite this effort, adoption remains limited due to legacy datasets, institutional and vendor variability, perceived limited benefit, and resource constraints [3]. Overcoming these barriers is critical to fully leverage the advantages of standardized datasets, particularly for developing advanced artificial intelligence applications that rely on large, consistently labeled datasets.
Several approaches have been proposed to automate structure renaming according to the TG-263 standard, including machine learning (ML) pipelines utilizing anatomical data [4], natural language processing (NLP) techniques analyzing clinician-assigned names [5] and automated tools and scripts, some integrated within treatment planning systems, to check and enforce compliance with TG-263 nomenclature [6,7].
Recent advancements in NLP, particularly in large language models (LLMs), present new possibilities for automating complex language-related tasks within the medical domain [[8], [9], [10]]. LLMs trained on extensive textual datasets have demonstrated remarkable capabilities in understanding and generating human-like text, making them also relevant for applications in radiation oncology [[11], [12], [13]]. A recent study by Holmes et al. has demonstrated the potential of LLMs for renaming radiotherapy structures in alignment with the TG-263 guideline [14], utilizing openAI’s proprietary GPT4 model for renaming OAR and target structures in prostate, head-and-neck and thoracic cancer patients, achieving high renaming accuracies up to 98.3 % [15], but limited to a single-institution dataset in English and center-specific prompts.
Our study evaluated open-source LLMs for radiotherapy structure renaming using a multilingual, multi-institutional dataset, comprising 34,177 radiotherapy structures from three European university medical centers. We focused specifically on open-source LLMs which can be deployed locally, thereby addressing critical privacy considerations within healthcare environments. Performance evaluation included comparison against manually assigned ground-truth labels, detailed error analysis, and uncertainty estimation, ensuring robust and reliable automated renaming workflows.
Materials and methods
2
The proposed LLM-based renaming workflow is illustrated in Fig. 1. Original structure names were extracted from DICOM RTstruct files and filtered to exclude non-TG-263 structures (see 2.1). For each structure, a prompt containing renaming instructions (see 2.2) was generated and used as input for the LLMs. Each LLM predicted a TG-263-conform structure name and an associated confidence score (see 2.6). All pipeline components were implemented in Python, including a graphical user interface to load, filter and review renamed structures (see Fig. S1 in supplementary materials). The source code is available at https://github.com/LMUK-RADONC-PHYS-RES/rt-rename.Fig. 1. Schematic overview of the envisioned renaming pipeline.
Dataset
2.1
We utilized a fully anonymized dataset curated for the SynthRAD2025 deep learning challenge [16], containing structure information from 1,684 radiotherapy patients treated for head-and-neck, thoracic or abdominal cancer at three European medical centers: University Medical Center Utrecht, Radboud University Medical Center Nijmegen (both in the Netherlands), and LMU Klinikum Munich (Germany). These institutions did not adopt the TG-263 nomenclature, resulting in center-specific structure names in English, Dutch, or German. Our analysis focused explicitly on organs-at-risk (OAR). We manually excluded target structures, auxiliary planning structures (e.g., couch, immobilization masks, etc.) and OARs not part of the TG-263 guideline. Ground-truth labels were assigned manually for each structure by staff from the respective institutions, yielding a total dataset of 34,177 structures. Additionally, a refined list of 1,094 structures was generated by removing duplicates, facilitating more efficient inference, since duplicate structures were not renamed repeatedly. Evaluations were conducted on both the complete and unique datasets.
Prompt
2.2
The input prompt was iteratively developed using a small dataset comprising one patient from each center and included: (1) general instructions outlining the renaming task; (2) rules about possible languages (English, German, Dutch), abbreviations, anatomical locality indicators (e.g left, right, superior, inferior) and instructions to reply with “no match” if no suitable structure name was found; (3) instructions for output formatting and confidence level output (low, medium or high); (4) a few-shot prompting strategy with examples of both input and expected output, as this approach has been shown to enhance LLMs’ task comprehension and adherence to format [17,18]; (5) a list of all standardized TG-263 structure names [2] and the input structure name to be processed. Each prompt contained only a single input structure name per renaming task. The final prompt is provided in supplementary materials (Fig. S2).
Models
2.3
This study evaluated four open-source LLMs: Llama 3.3, Llama 3.3 R1, DeepSeek V3, and DeepSeek R1.
Llama 3.3 70B is a pre-trained and instruction-tuned LLM from Meta AI, comprising 70 billion parameters [19]. This multilingual model officially supports eight languages, including English and German (but not Dutch) and features a context window of up to 128 k tokens. Tokens are a unit of text, such as a word, sub-word or character, that the LLM processes as a single input element during training and inference [20]. Due to GPU memory limitations (NVIDIA A6000, 48 GB), a 4-bit quantized model (Q4_K_M) was used for inference. A deterministic output was ensured by setting the temperature parameter to 0 for all LLMs.
DeepSeek V3 is a pre-trained, instruction-tuned Mixture-of-Experts (MoE) LLM developed by DeepSeek-AI [21]. It comprises 671 billion parameters, with 37 billion activated per token, making it significantly larger than the Llama 3.3 70B model. Due to its size, inference of the V3 model was performed on a cloud platform with unspecified hardware using an unquantized model. Deepseek V3 also features a 128 k token context window.
DeepSeek R1 is a reasoning-specialized LLM from Deepseek AI, explicitly trained for logical reasoning using the chain-of-thought (CoT) methodology. It employs the same MoE architecture as DeepSeek V3, with 671 billion total parameters and 37 billion active per token, and a 128 k token context window [22]. The CoT approach generates more tokens during inference, increasing inference time and computational cost. Inference was performed on the same cloud platform as for DeepSeek V3.
Llama 3.3 70B R1 is a distilled variant of the original Llama 3.3 70B model, fine-tuned on outputs from the larger DeepSeek R1 671B model [22]. This distillation enhances the reasoning capabilities of the smaller Llama 3.3 70B model, especially in complex reasoning tasks involving CoT [22]. Like its base model, Llama 3.3 70B R1 supports the same context window of 128 k tokens, and we used a 4-bit quantized model (Q4_K_M) on a NVIDIA A6000 GPU.
Accuracy
2.4
Renaming accuracy was evaluated by comparing LLM predictions to manually assigned TG-263 labels. The evaluation was structured as a classification task, with each structure instance assigned a single correct label. Two accuracy metrics were calculated: (1) unique match accuracy, the proportion of exact matches between LLM-predicted and ground-truth labels across 1094 distinct structure names; and (2) overall accuracy, calculated on the full dataset of 34,177 structure names including all instances and duplicates. Accuracy was reported per center and for the combined dataset.
Failure analysis
2.5
Misassignments were manually classified into five categories: (1) Wrong OAR (incorrect organ-at-risk identified); (2) Laterality (correct OAR, incorrect spatial designation, e.g., left vs. right, superior vs. inferior); (3) Plurality (correct OAR, singular/plural form errors); (4) Misspelling (correct OAR, misspelling of TG-263 name); and (5) No match (no suitable TG-263 name found). Error frequencies were computed per LLM for the unique dataset, with representative examples provided in the results section.
Prompt-based confidence estimation
2.6
The input prompt contained instructions for a confidence rating (low, medium, or high) next to the predicted structure names. To assess the usability of these self-reported confidence ratings as indicators of naming errors, we calculated a binary Pearson correlation coefficient, between low confidence ratings (low or medium = 1, high = 0) and structure naming errors (false = 1, correct = 0) for the unique dataset. This quantified the usefulness of self-reported confidence for flagging errors.
Monte Carlo sampling for uncertainty estimation
2.7
A temperature value of 0 enforces deterministic behavior by consistently selecting the most probable token at each step, yielding identical outputs for repeated inferences. In contrast, higher temperature values introduce stochastic behavior by allowing less probable tokens to be selected, enabling more diverse responses. We used a Monte Carlo sampling approach to assess the uncertainty associated with structure name predictions. Monte Carlo sampling and uncertainty estimation is a framework for quantifying uncertainty through repeated randomized simulations and has been widely applied in radiotherapy for tasks such as image synthesis or auto-segmentation [[23], [24], [25]]. We performed ten repeated inferences for each input structure using a temperature of 1 in combination with top-p sampling (0.95). This sampling strategy samples from the smallest set of tokens whose cumulative probability exceeds 95 %. Due to computational demands of repeated inferences, we limited the analysis to a randomly selected subset of 30 structures per model, comprising 15 correctly and 15 incorrectly labeled cases under deterministic conditions.
For each structure, we calculated the Shannon entropy of the distribution of predicted labels, defined as:
where denotes the relative frequency of the -th unique predicted structure across the distinct predicted structures. Entropy is a quantitative measure of uncertainty and output variability in this context. We calculated the binary Pearson correlation coefficient to quantify the correlation between wrong structure name assignments (wrong = 1, correct = 0) and non-zero entropy. Additionally, we calculated the sensitivity (true positive rate) and specificity (true negative rate) for using entropy as a binary classifier of prediction errors, where a positive event was defined as an incorrect structure name assignment with corresponding non-zero entropy.
Results
3
Accuracy
3.1
Deepseek R1, which incorporates reasoning capabilities, consistently achieved the highest accuracy on the unique dataset (Fig. 2a), with center-specific accuracies ranging from 97.6 % to 100 %. In contrast, the Llama 3.3 model, lacking reasoning functionality, showed the lowest accuracy with values ranging from 85.1 % to 90.8 %. The results revealed variability across centers on the complete dataset (Fig. 2b). For Center A, all four models showed improved accuracy relative to their performance on the unique dataset, ranging from 98.0 % (DeepSeek V3) to 99.9 % (DeepSeek R1). Contrarily, for Center B, accuracy declined for DeepSeek V3 and Llama 3.3 R1, while Llama 3.3 improved and DeepSeek R1 remained constant with a perfect 100 % accuracy. A declined accuracy indicates that failed structures had a high frequency in the overall dataset. Results from Center C also showed mixed outcomes, with Llama 3.3 and DeepSeek R1 slightly improving the accuracy, while Llama 3.3 R1 and DeepSeek V3 experienced slight reductions in accuracy.Fig. 2. Renaming accuracy of Llama 3.3, Llama 3.3 R1 distill, Deepseek V3 and Deepseek R1 for datasets from center A, B and C calculated for the unique (a, upper) and combined datasets (b, lower).
Tables S1 and S2 in the supplementary materials present the corresponding fractions of correctly renamed structures. To further explore model performance across anatomical regions, we conducted a sub-analysis grouped by anatomical region: head-and-neck, thorax, and abdomen. Results are presented in Fig. S3 in the supplementary materials. All four LLMs achieved their highest accuracy on abdominal structures and their lowest on thoracic structures. Fig. S4 in the supplementary materials presents some exemplary outputs from the Llama 3.3 R1 and DeepSeek R1 reasoning models, illustrating the CoT reasoning process.
Inference times for locally deployed models averaged 1.2 s for Llama 3.3 and 25.1 s for Llama 3.3 R1 using a single NVIDIA A6000 GPU with 48 GB VRAM. Average inference times on the cloud-hosted inference platform were 1.5 s for DeepSeek V3 and 35.6 s for DeepSeek R1.
Error types
3.2
Table 1 presents representative examples of each error type. For the Llama 3.3 model, laterality, plurality, and wrong OAR errors were recurring most often, while “no match” errors were rare, indicating an overly confident model (Fig. 3). In contrast, the “no match” error was the most frequently observed error type for the Llama 3.3 R1, Deepseek V3, and Deepseek R1 models. Misspelling errors were also mainly observed in the Llama 3.3 model.Table 1. Examples of the error types observed in the renamed structure names.Error typeModelInput structureLLM predictionGTCommentsLocalityLlama 3.3CervMyelumSpinalCordSpinalCord_CervCorrectly identified “SpinalCord” but failed to capture the regional specification “Cerv”.PluralityLlama 3.3 R1Niere bdsKidneyKidneysCorrectly translated “Niere” (kidney in German), but failed to interpret “bds” (bilateral).Wrong OARDeepseek V3PharynxConstPharynxMusc_ConstrictMisinterpreted “PharynxConst” as general pharynx rather than pharyngeal constrictor muscles.No matchDeepseek R1SfincterNo matchSphincter_AnalFailed to identify and match “Sfincter” with the correct anatomical term.MisspellingLlama 3.3Traenendruese li.Lacrimal_Gland_LGlnd_Lacrimal_LCorrectly identified the OAR but did not adhere to the required TG-263 spelling.Fig. 3. Distribution of error types for each LLM based on misclassified structure names.
Prompt-based uncertainty estimation
3.3
Only a moderate positive correlation was observed between confidence levels (low or medium) and prediction errors. Fig. 4 presents the corresponding Pearson correlation coefficients. For the combined dataset, the reasoning models Llama 3.3 R1 and DeepSeek R1 exhibited the strongest correlation between reduced confidence and incorrect predictions, with correlation coefficients of 0.42 and 0.39, respectively. The non-reasoning Llama 3.3 and Deepseek V3 models showed noticeably lower correlation coefficients of 0.30 and 0.16 respectively.Fig. 4. Pearson correlation coefficient calculated between low confidence (low or medium) and incorrect structure assignment for the four investigated LLMs grouped by centers.
Monte Carlo sampling for uncertainty estimation
3.4
Deepseek R1 achieved the highest correlation coefficient (0.70) between non-zero entropy and structure renaming failures, suggesting that entropy can be a useful metric to flag potentially wrong structure name assignments (Table 2). This model also demonstrated the highest sensitivity (0.73) and perfect specificity (1.0). Similar to the analysis of prompt-based confidence levels, reasoning models (Deepseek R1 and Llama 3.3 R1) showed a higher correlation between entropy and errors than non-reasoning models (Deepseek V3 and Llama 3.3).Table 2. Performance metrics reported as Pearson correlation coefficient, sensitivity (true positive rate = TPR) and specificity (true negative rate = TNR) for entropy-based uncertainty estimation derived from Monte Carlo sampling.ModelCorrelation coefficientSensitivity (TPR)Specificity (TNR)Llama 3.30.180.071Llama 3.3 R10.570.670.87Deepseek V30.360.640.36Deepseek R10.700.731
Discussion
4
This study systematically evaluated open-source large language models (LLMs) for harmonizing radiotherapy OAR structure nomenclature according to the AAPM TG-263 guideline across a multilingual, multi-institutional dataset. To our knowledge, this is the first comprehensive assessment of open-source LLMs in this context, addressing generalizability across institutions and languages and data privacy concerns. Our results demonstrated that open-source LLMs can effectively standardize structure names, with DeepSeek R1 achieving the highest accuracy (99 %).
Performance was comparable to Holmes et al., who used a proprietary model with center-specific prompts and a single center dataset and achieved an accuracy of 97 % (including target volumes) [14]. The strong performance of DeepSeek R1 and the distilled Llama 3.3 R1 highlights the benefit of explicit reasoning capabilities, particularly in ambiguous or abbreviated structure names. Despite identical architecture, Llama 3.3 R1 outperformed the non-reasoning Llama 3.3 noticeably (95 % vs. 89 %). However, with a considerably longer inference time (1.2 s vs. 25.1 s), which could be further optimized by using a different LLM engine, batched inference, or higher-tier GPUs.
Analysis of error types revealed noticeable performance differences between the models, primarily linked to their size and reasoning capabilities. The smallest model (Llama 3.3) struggled mostly with “post-processing” tasks like assigning location identifiers, laterality, plurality, or interpreting abbreviations. In contrast, larger (DeepSeek V3) and reasoning enabled models (DeepSeek R1 and Llama 3.3 R1) were more robust, frequently opting for “no match” in ambiguous cases. This conservative approach is clinically advantageous, as false positives pose greater risk than unassigned labels flagged for review. Holmes et al. similarly noted that most errors in their study arose from minor spelling and capitalization errors [14]. However no detailed error analysis was performed in their study. We observed no clear correlation between structure name language and error type. In reasoning-capable LLMs, the CoT outputs could be particularly helpful for understanding why the model fails on an individual structure level.
Unlike previous studies [4,6,7,14], we also explored strategies for error prediction and quality assurance. Prompt-based confidence scores showed limited effectiveness in identifying uncertain cases, indicating that they are unsuitable for flagging uncertain cases for manual review in automated workflows. However, we observed that both reasoning models showed a higher correlation than the non-reasoning models, suggesting that the additional tokens generated in reasoning models can assist with confidence prediction. Monte Carlo sampling entropy demonstrated higher predictive correlation but significantly increased inference times, especially limiting real-time clinical application. For offline data processing, the observed inference times (1–35 s) remain acceptable, with expected hardware advancements further reducing limitations.
The proposed automatic renaming workflow directly addresses one of the primary roadblocks to TG-263 adoption: the perceived effort required to update institutional templates and legacy datasets [3]. By providing a reliable method for harmonizing existing structure sets and templates, our tool can substantially lower the barrier for clinical sites to implement standardized nomenclature and thereby facilitate the creation of large, consistently labeled datasets accelerating multi-institutional research and the development of advanced AI applications. The pipeline is also highly flexible and can be easily adapted by incorporating additional LLMs, custom prompts, or updated guidelines, such as those currently in preparation for TG-263.
However, standardizing nomenclature alone does not resolve the broader challenge of collecting and curating large multi-institutional datasets. Our work complements frameworks like that described by Refsgaard et al. for collecting and curating large scale datasets (e.g. a national dataset of over 7000 breast cancer patients) [26].
Previous efforts to automate TG-263 nomenclature standardization have evolved from machine learning methodologies that rely solely on image-based features, to multi-view approaches that integrate both image and text data for improved performance [4,5]. Our study demonstrates that due to rapid advancements in natural language processing, modern LLMs are powerful enough to make accurate, text-only structure renaming feasible, even on a complex multi-lingual and multi-institutional dataset. However, to address the challenging cases where text-based context alone may be insufficient, future work could explore advanced vision-language models (VLMs) [27].
There are several limitations in our study. Although our dataset was large and institutionally diverse, it included only three centers from two European countries. Future studies should investigate generalizability across additional languages and naming conventions. Additionally, our study solely focused on OARs. As shown by the recent TG-263 survey [3], implementing the structure naming guideline for target volumes and planning structures (e.g., PTVs, PRVs) presents additional challenges due to their higher intra-institutional variability and center-specific clinical protocols. Lastly, although our prompt was carefully designed and few-shot examples were used, prompt engineering remains a critical component that can influence model performance, and further optimization specific to each model could lead to better outcomes for specific models. Due to limited availability of GPUs in our institution, only the smaller Llama 3.3 and Llama 3.3 R1 models could be deployed locally on our own hardware, while the larger Deepseek models were hosted on a cloud platform. However, given sufficient hardware, DeepSeek models could also be deployed locally.
In conclusion, this work presents a novel, open-source LLM-based framework for harmonizing radiotherapy structure nomenclature, achieving a high accuracy across a multilingual and multi-institutional dataset. This can help with the clinical implementation of structure naming guidelines and generate large-scale, high-quality datasets for research and development in radiation oncology.
CRediT authorship contribution statement
Adrian Thummerer: Conceptualization, Methodology, Software, Formal analysis, Investigation, Data curation, Writing – original draft, Visualization. Matteo Maspero: Conceptualization, Methodology, Resources, Data curation, Writing – review & editing. Erik van der Bijl: Conceptualization, Methodology, Resources, Data curation, Writing – review & editing. Stefanie Corradini: Resources, Data curation, Writing – review & editing, Funding acquisition. Claus Belka: Resources, Data curation, Writing – review & editing, Funding acquisition. Guillaume Landry: Conceptualization, Methodology, Validation, Resources, Data curation, Writing – review & editing, Project administration, Funding acquisition. Christopher Kurz: Conceptualization, Methodology, Validation, Resources, Data curation, Writing – review & editing, Project administration, Funding acquisition.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper. The author Guillaume Landry is an Editorial Board Member for this journal and was not involved in the editorial review or the decision to publish this article.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Santanam L.Hurkmans C.Mutic S.Vliet-Vroegindeweij C.V.Brame S.Straube W.Standardizing naming conventions in radiation oncology Int J Radiat Oncol Biol Phys 8320121344134910.1016/j.ijrobp.2011.09.05422245204 PMC 4306340 · doi ↗ · pubmed ↗
- 2Mayo C.S.Moran J.M.Bosch W.Xiao Y.Mc Nutt T.Popple R.American Association of Physicists in Medicine Task Group 263: standardizing nomenclatures in radiation oncology Int J Radiat Oncol Biol Phys 10020181057106610.1016/J.IJROBP.2017.12.01329485047 PMC 7437157 · doi ↗ · pubmed ↗
- 3Covington E.L.Suresh K.Anderson B.M.Barker M.Dess K.Price J.G.Perceptions on and roadblocks to implementation of standardized nomenclature in radiation oncology: a survey from TG-263U 1J Appl Clin Med Phys 252024 e 1435910.1002/ACM 2.14359 PMC 1116350938689502 · doi ↗ · pubmed ↗
- 4Sleeman W.C.Nalluri J.Syed K.Ghosh P.Krawczyk B.Hagan M.A Machine Learning method for relabeling arbitrary DICOM structure sets to TG-263 defined labels J Biomed Inform 109202010352710.1016/J.JBI.2020.10352732777484 · doi ↗ · pubmed ↗
- 5Syed K.Sleeman W.C.Hagan M.Palta J.Kapoor R.Ghosh P.Multi-view data integration methods for radiotherapy structure name standardization Cancers 132021179610.3390/CANCERS 1308179633918716 PMC 8070367 · doi ↗ · pubmed ↗
- 6Anderson B.M.Padilla L.Ryckman J.M.Covington E.Hong D.S.Woods K.Open RT structures: a solution for TG-263 accessibility Int J Radiat Oncol Biol Phys 118202485986310.1016/j.ijrobp.2023.09.04137778423 · doi ↗ · pubmed ↗
- 7Schuler T.Kipritidis J.Eade T.Hruby G.Kneebone A.Perez M.Big data readiness in radiation oncology: an efficient approach for relabeling radiation therapy structures with their TG-263 standard name in real-world data sets Adv Radiat Oncol 4201919120010.1016/J.ADRO.2018.09.01330706028 PMC 6349627 · doi ↗ · pubmed ↗
- 8Shool S.Adimi S.Amleshi R.S.Bitaraf E.Golpira R.Tara M.A systematic review of large language model (LLM) evaluations in clinical medicine BMC Med Inf Decis Making 25202511110.1186/S 12911-025-02954-4PMC 1188979640055694 · doi ↗ · pubmed ↗