Varying image assessment of pecking injuries in Turkeys while performing repetitions
Nina Volkmann, Lars Schmarje, Reinhard Koch, Nicole Kemper

TL;DR
This study examines how different observers assess pecking injuries in turkey hens from images, finding that experience affects classification patterns over time.
Contribution
The study reveals how observer experience influences classification trends of pecking injuries in turkeys during repeated image assessments.
Findings
Inexperienced observers classified more images as skin injuries compared to experienced ones.
All observers increasingly classified more images as 'no injury' over time.
Experienced observers showed a larger increase in 'no injury' classifications compared to less experienced ones.
Abstract
This study investigated variations in assessing potential pecking injuries in turkey hens when annotating image excerpts. Three observers (OBS1, OBS2, OBS3) with different levels of previous knowledge - one with experience in pecking injuries in turkeys and two computer science students - rated a total of 24,912 image excerpts. The image excerpts were evaluated in work packages (2,076 images each) and were classified by the observers as either head injury (HI), skin injury in the feathered area of the body (SI), or no injury (NI). Two observers evaluated three packages (OBS1, OBS2: 6,228 image excerpts each) and OBS3 annnotated six work packages (12,456 excerpts). The percentage of the classifications in the chronological sequence of the observations was analyzed. Inexperienced observers (OBS2 and OBS3) both classified an average of 13% of the shown images as HI, 70% as SI, and 17% as…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
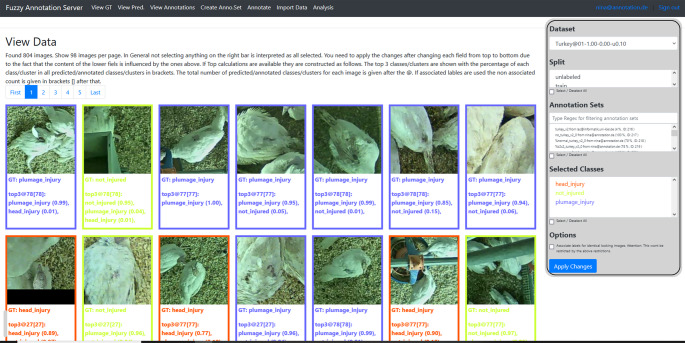 Figure 1
Figure 1 Figure 2
Figure 2- —Stiftung Tierärztliche Hochschule Hannover (TIHO) (3134)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBird parasitology and diseases · Insect and Pesticide Research
Introduction
Consecutive assessments of animals are common in scientific research. For example, previous studies evaluated the plumage in chickens (Spindler et al. 2020), footpads in turkeys (Stracke et al. 2020), and tail lesions in pigs (Brünger et al. 2019) using a scoring system assessed by human observers. However, it is well-known that these human assessments can be subjective and inaccurate due to a lack of objectivity. As Tuyttens et al. (2014) pointed out, researchers are prone to strong expectations about study results, and observers are influenced by assumptions about what is possible and what is not. This is a pitfall of the human brain, leading to favoring information that confirms previous assumptions (Nickerson 1998). Thus, recorded data and observations can be biased due to the expectations of the human observer. Observer-blinded studies are intended to reduce conscious and unconscious bias, and ensure that observers collecting data are unaware of which animals have been treated or affected by a disease, for example (Tuyttens et al. 2014).
Statistical methods to verify the reliability of human observers include inter- and intra-observer tests and examining test-retest agreement. Inter-observer reliability can be checked by training multiple humans to rate the same individual or image independently (e.g. Blömke et al. 2020). This way, the reliability between the observers can be examined in advance by calculation indices like Pearson’s and Spearman’s correlation, Krippendorff’s alpha or Cohen’s kappa. In order to make such comparisons between observers, the data is assigned to meaningful units such as scores or classes which then can serve as a so-called gold standard (Hooge et al. 2018). To characterize the behavioural pattern of animals, an ethogram is generated, which is a comprehensive description of the behavioural units and should be the starting point of every ethological study (Lehner 1996). However, many studies do not have a gold standard for comparison or collect quantitative data and instead perform a subjective visual assessment to determine and validate quantitative characteristics. Thus, without clear definitions or specifications, measuring whose evaluation is ‘more correct’ or whether an observer has rated correctly is difficult.
An intra-observer reliability test in research studies is used to verify if a human observer achieves the same result when measuring the same observation at different moments (Bokkers et al. 2012). Test-retest reliability is used to evaluate the investigation method or examine the agreement between results on the same test conducted at two different times. This type of test refers to the chance that the same outcome will be observed if the trial is repeated (Temple et al. 2013).
To improve reliability and agreement of observers training is essential (Kaufman and Rosenthal 2009). Training on the scientific question in advance is a prerequisite for observer agreement and enables its improvement. However, Schlageter-Tello et al. (2015) showed that experienced and inexperienced observers were unable to improve reliability and agreement after a short training and evaluation of the locomotion of about 600 cows. Their results suggest that, in addition to training, the experience of the observer is also an important aspect (Schlageter-Tello et al. 2015). In addition, Kazdin (1977) stated that even after training and with experience, the tendency of observers to apply the definitions of a measurement changes over time.
The present study was conducted as part of a main research project on different annotation types (Schmarje et al. 2022) and aimed to examine retrospectively whether different observers, when assessing potential pecking injuries in turkeys, tended to change their classification when repeatedly viewing the same images of injured and uninjured animals. The aim of the study was defined after the implementation of the main study, and the data was evaluated accordingly.
Materials and methods
For investigations, videos from a previous study on pecking injuries in turkeys (Volkmann et al. 2021) were used which were recorded on a German research farm with female turkeys using three top-view cameras (AXIS M1125-E IP camera, Axis Communications AB, Lund, Sweden) installed approximately 3 m above the floor. For the further processing, video recordings were divided into individual frames and cut into image excerpts with 224 × 224 pixels in size showing turkey hen(s) or parts of the animal (with or without one existing injury) or objects in the stable such as a pick block. These image excerpts were made available on a web server in a zoom view for annotation (Fig. 1) and were provided as a work package (WP) with image excerpts, whereby each package in turn consisted of three annotation sets (Set 1: 804 images, set 2: 636 images, set 3: 636 image excerpts). The fact that a work package consisted of three annotation sets resulted from the main study (Schmarje et al. 2022), which investigated the impact of (semi-)supervised methods on data quality in image classification.
Fig. 1. Screenshot of the developed web server showing example image excerpts for annotation assessment
The work included the annotations of three observers, one of whom (researcher in the field of animal welfare) had prior experience with pecking injuries in turkeys (OBS1), while the other two were computer science students (OBS2 and OBS3). Before performing their individual annotations, the observers completed joint online trainings, which were led by the experienced observer. In this previous trainings, they evaluated randomly selected image excerpts (n = 4,152) together and discussed their results.
Afterwards, the three observers evaluated the work packages, which consisted of 2,076 image excerpts each, on their own and thus without further consultations. Whitin one package the observers assessed the image excerpt in the three annotation sets 1–3. The process of evaluating a work package was then repeated by the observers at a time interval of their choice (all packages were evaluated by the respective observers within one month).
During the annotation process, the observers had to assign each image excerpt to one of three different classes: ‘head injury’ (HI), ‘skin injury in the feathered area of the body’ (SI), or ‘no injury’ (NI). OBS1 and OBS2 each evaluated three work packages (in total 6,228 image excerpts each observer), while OBS3 evaluated six work packages (in total 12,456 image excerpts). Since the image excerpts in each work package were evaluated one after the other, the three observers classified the same images in the same order.
The results of their assessments were recorded, and after the main study (Schmarje et al. 2022) was completed, the corresponding hypothesis for the present study was set, which was finally evaluated. Thus, in this ‘secondary’ study it was retrospectively not possible to calculate an observer agreement based on individual image excerpts.
For statistical analyses, the classes containing ‘head injury’ (HI) and ‘skin injury’ (SI) were summarized to one named ‘injured’. The results on the frequency to which the images were assigned to the class ‘no injury’ (NI) and ‘injured’ respectively were analyzed using the SAS software (Version 9.4, Statistical Analysis Institute, Cary, NC, USA). To show a temporal effect during annotation process, a Fisher’s exact test was conducted investigating the association between the mean frequencies of the selected annotation class (‘injured’ and NI) and the work package (of the individual observer). P values of < 0.05 were considered statistically significant.
Results
The results of the individual percentage classifications of the three observers within each work package and annotation set are shown in Table 1.
Table 1. Percentage rating of the individual observers (OBS1, OBS2, OBS3) of the image excerptsOBS1OBS2OBS3WPSnSIHINISIHINISIHINI1180468.711.320.078.18.813.175.411.812.8263661.512.326.367.113.819.068.913.217.9363657.612.430.365.316.718.168.115.116.82180461.611.127.476.611.112.376.111.911.9263658.713.428.069.511.319.270.412.916.7363657.312.630.263.815.920.367.314.917.83180459.610.629.976.210.812.973.012.714.3263655.212.332.665.616.018.473.012.914.2363656.913.130.065.713.420.968.213.518.24180471.611.616.8263667.013.120.0363666.412.720.95180470.512.217.3263667.012.920.1363665.414.220.46180472.811.915.3263667.613.119.3363666.513.819.7WP work package, S number of the annotation set, n number of image excerpts, SI skin injury in the feathered area of the body, HI head injury, NI no injury
Inexperienced observers (OBS2 and OBS3) classified an average of 13% of the shown images as HI, 70% as PI, and 17% as NI. On average, OBS1 classified 12% of the images as HI, 60% as PI, and 28% as NI, thus evaluating more image excerpts with NI than the two inexperienced observers.
For all three observers, it was observed that the proportion of images assessed as NI increased over time as the images were repeatedly evaluated (Fig. 2a-c). Consequently, the ratio of image excerpts potentially showing an injury decreased. This effect was most pronounced in OBS1, who additionally rated more than 5% of the images in the third work package as NI (WP1: 25.5% on average; WP3: 30.8% on average) (Fig. 1a). However, analyzing the mean frequencies of the annotated injury classes (‘injured’ vs. ‘no injury’), Fisher’s exact test revealed no assosiation between these classification and the work packages (all p > 0.05).
Fig. 2a–c Percentage of image excerpts which were classified by the observers (OBS1, OBS2, OBS3) as ‘no injury’ (NI). The annotation sets (Set 1–3) of the work packages were assessed one after the other
Discussion
The purpose of this study was to investigate different classifications of pecking injuries in turkeys repeatedly perfomed by observers with various prior experience.
The study results showed that the repeated performance of annotation assessments, such as the classification of pecking injuries in turkeys, can lead to variable judgments. In a study by Thomsen et al. (2008), a locomotion scoring experiment for dairy cows was repeated after one week and an additional training was carried out. At the second run, the observers showed slightly decreased intra-observer agreement by evaluating cows’ walk simultaneously in the barn. Thomson et al. (2008) assumed, that the short time between both scorings decreased the possibility that cows’ true lameness status could change from the first to the second run, and they stated that observer training seemed to have had only minor effects on agreement.
In the present study, modifying the assessment regarding potential pecking injuries may have led to a ‘deadening’ effect among the observers, as the number of animals classified as not injured decreased. It is also possible that the observers improved their view on the image excerpts over time and thus this development can be interpreted as positive learning effect. In a study on reliability and accuracy of detecting keel bone damage in hens an improvement in the palpation assessment was observed through repetition, which was recognized by comparing the results with those from radiography and sonography (Tracy et al. 2019). Furthermore, Tracy et al. (2019) observed a very large variation between the palpation results of the differently experienced observers. However, in the present study, the results of the one experienced observer (OBS1) can probably not be explained by a learning effect. Here, the experienced observer was particularly practiced and trained in assessing pecking injuries on images and yet the effect evaluating more excerpts with NI was more pronounced in OBS1 than in the computer science students (OBS2 and OBS3). Thus, it is conceivable that inexperienced, non-expert observers may be able to judge more objectively and may not hinder high-quality results in such studies but rather improve them. Of course, this depends on the complexity of the evaluation procedure. In the present study, less prior knowledge was needed than in situations where an observer is asked to judge, for example, the gait pattern means of a multistage locomotion score (Winckler and Willen 2001) or if a state of health is to be recorded based on medical expertise (Baadsgaard and Jørgensen 2003). Nevertheless, a ‘deadening’ effect is only suspected due to the altered annotations of one single trained observer. In order to verify this assumption, repeated observations should be carried out by several (experienced) participants.
When presenting the results obtained regarding the repeated judgment, it is essential to remember that there was no gold standard or ethogram included in this study. Therefore, it cannot be stated which assessment was correct and whether the changed assessment improved the results or not. However, it can be assumed that computer science students, lacking prior knowledge of pecking injuries in turkeys, resulted in less bias due to expectations in evaluating the images. Such assessment bias is likely when the observer has strong preconceptions or a vested interest in the outcome (Tuyttens et al. 2014).
One limitation of this study is the lack of an intra- and inter-reliability test between the observers. As these evaluations were only conducted after the main study (Schmarje et al. 2022) was completed, it was not possible to conduct an observer comparison retrospectively. Therefore, the results of this study should rather encourage a closer look at the possible temporal changes in the evaluation of image assessments. Nevertheless, there is no question that intra- and inter-reliability tests should be carried out in further studies. Furthermore, image assessments should be repeated, and observation changes should be considered. In an article by Risinger et al. (2002) regarding observer effects due to expectations, an example is given where the observer sees something different in a drawing depending on which similar images he/she has previously viewed. Thus, when evaluating images, the evaluation process should be performed on the same photos in a different order to avoid or detect some kind of ‘deadening’ - since the evaluation of an animal that is only slightly sick or has only a small injury can be different if one has seen many severely sick animals or severe injuries beforehand.
In summary, it is noted that the ‘deadening’ effect assumed in this brief report should be tested in further research using a different study design. Nevertheless, it is expected that, analogous to the assumptions regarding ‘deadening’ in this study, other ratings/classifications are not free from effects such as habituation, time, or tiredness. Further studies should investigate to what extent inexperienced, non-specialist observers can judge more objectively or from which number of images such as ‘deadening’ can be observed.
The reference list from the paper itself. Each links out to its DOI / PubMed record.