Doubly Robust Estimation of Marginal Cumulative Incidence Curves for Competing Risk Analysis
Patrick van Hage, Saskia le Cessie, Marissa C. van Maaren, Hein Putter, Nan van Geloven

TL;DR
This paper introduces a new method to adjust for covariate imbalance in comparing treatment outcomes in competing risk scenarios, such as breast cancer recurrence and death.
Contribution
The paper introduces a doubly robust estimator that requires correct specification of only one model for accurate results.
Findings
The doubly robust estimator performs well even when one model is misspecified.
Simulation studies show the advantages and limitations of different adjustment methods in competing risk analysis.
The methods are applied to a breast cancer cohort to estimate adjusted cumulative incidence curves.
Abstract
Covariate imbalance between treatment groups makes it difficult to compare cumulative incidence curves in competing risk analyses. In this paper, we discuss different methods to estimate adjusted cumulative incidence curves, including inverse probability of treatment weighting and outcome regression modeling. For these methods to work, correct specification of the propensity score model or outcome regression model, respectively, is needed. We introduce a new doubly robust estimator, which requires correct specification of only one of the two models. We conduct a simulation study to assess the performance of these three methods, including scenarios with model misspecification of the relationship between covariates and treatment and/or outcome. We illustrate their usage in a cohort study of breast cancer patients estimating covariate‐adjusted marginal cumulative incidence curves for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
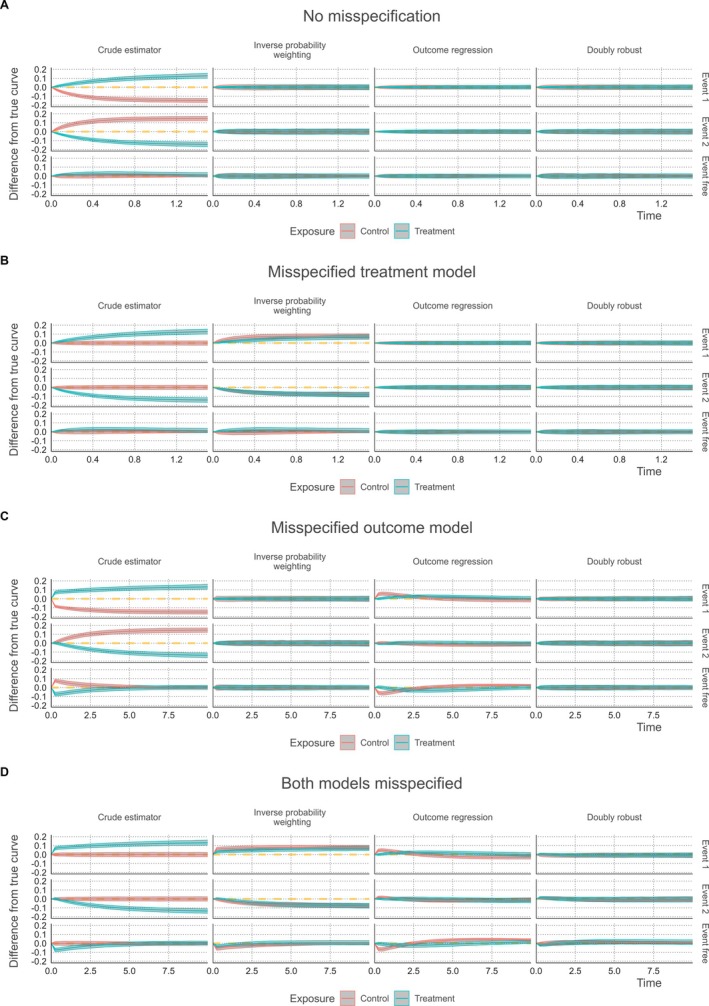 FIGURE 1
FIGURE 1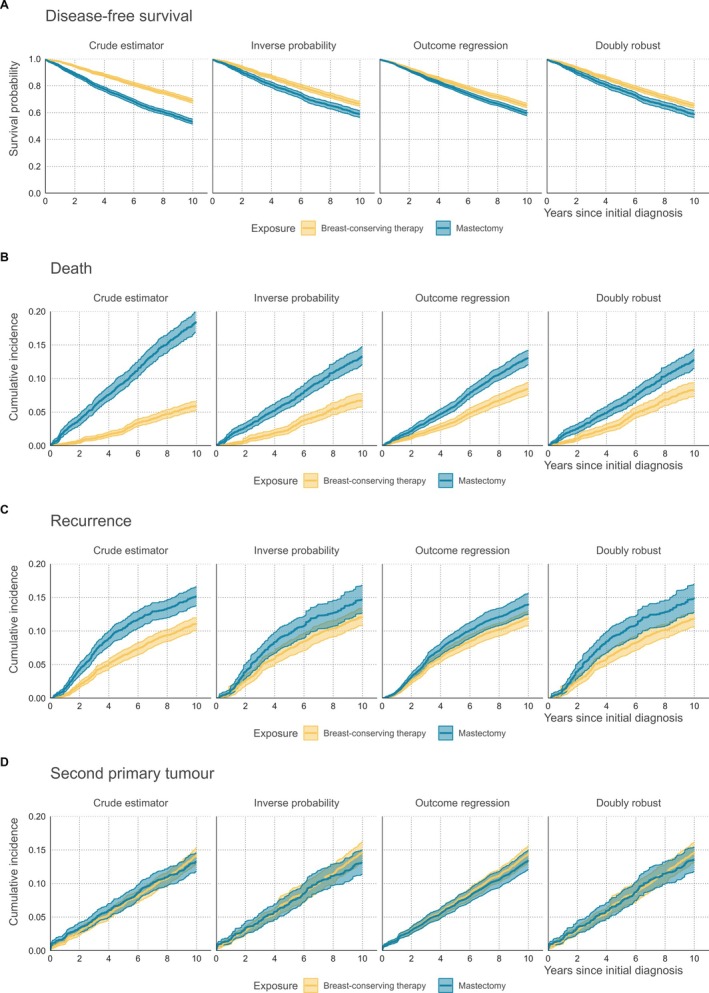 FIGURE 2
FIGURE 2| CI event 1 | CI event 2 | Event free survival | |||||
|---|---|---|---|---|---|---|---|
| 1. No misspecification ( | Bias | RMSE | Bias | RMSE | Bias | RMSE | |
| Crude estimator | Control | −0.14006 | 0.14049 | 0.14016 | 0.14067 | −0.00010 | 0.00844 |
| Treatment | 0.10121 | 0.10189 | −0.12433 | 0.12481 | 0.02312 | 0.02604 | |
| Inverse probability | Control | −0.00039 | 0.01431 | 0.00027 | 0.01306 | 0.00012 | 0.00973 |
| Treatment | 0.00029 | 0.01062 | −0.00053 | 0.01502 | 0.00025 | 0.01352 | |
| Outcome regression | Control | 0.00026 | 0.01055 | −0.00020 | 0.00992 | −0.00006 | 0.00757 |
| Treatment | 0.00042 | 0.00876 | −0.00055 | 0.01142 | 0.00013 | 0.01115 | |
| Doubly robust | Control | 0.00017 | 0.01296 | −0.00016 | 0.01208 | −0.00001 | 0.00968 |
| Treatment | 0.00024 | 0.01035 | −0.00049 | 0.01361 | 0.00025 | 0.01311 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Causal Inference Techniques · Statistical Methods and Inference · Statistical Methods in Clinical Trials
Introduction
1
Medical researchers are often interested in the effects of a treatment on the occurrence of a particular event in a setting where patients are at risk for more than one event. This may include the recurrence or progression of a disease, the occurrence of certain symptoms affecting the well‐being of a patient, and death due to different causes [1]. Competing risk analysis refers to studying the time until the occurrence of the first out of several possible events. Failing to properly account for the risk of occurrence of other events may lead to an overestimation of the probability of occurrence of a particular event of interest over time, also referred to as cumulative incidence [2].
In observational studies, when studying the effect of treatments we need to account for the fact that the choice of treatment observed in the data may have been influenced by the preferences of patients and clinicians [3]. The resulting imbalance of patient‐ or disease‐related characteristics between treatment groups may confound the relationship between treatment and outcome. Differences in crude cumulative incidence curves will in such cases not reflect the causal effect of treatment. Estimating the effect of treatment from observational data requires adjustment for the imbalanced characteristics using causal inference techniques [4].
Aiming for a fairer comparison between treatment groups, potential confounders are often included as covariates when modeling the relation between treatment and outcome [5]. In the setting of competing risks, this can, for instance, be done through cause‐specific Cox regression models or with the Fine and Gray model [2, 6, 7, 8]. Using these models, it is possible to estimate adjusted conditional cumulative incidence curves, representing the cumulative incidence for an individual with given treatment and covariate values (e.g., an individual with their covariate values chosen at the mean or median of observed values). However, these curves are conditional on the covariate values and do not reflect the cumulative incidence in the entire patient population.
Several methods have been described to obtain marginal, that is, population averaged, cumulative incidence curves which account for covariate imbalance between treatment groups [9, 10, 11]. Here, we describe two popular methods to account for imbalance in baseline covariates: inverse probability weighting and outcome regression with standardization.
Inverse probability weighting is based on rebalancing the distribution of covariates between treatment groups using weighted cumulative incidence curves. To construct weighted estimators, the first step is modeling the probability of being assigned to a treatment group conditional on the set of confounders (i.e., the propensity score). Individual observations are then reweighted by the inverse of their propensity score [12]. Neumann et al. used this method within a competing risk analysis to adjust cumulative incidence curves for the imbalance in patient‐ and tumor‐related covariates between two types of treatment for Hodgkin disease [13]. Furthermore, Choi et al. illustrated that this method may provide accurate marginal cumulative incidence estimates in unbalanced data [14].
In the second method, outcome regression with standardization, the outcome is modeled as a function of both covariates and treatment using a competing risks analysis. Then, for each person, using their covariate values, two predicted cumulative incidence curves are calculated, one if the person would have been treated and one under no treatment. Marginal adjusted cumulative incidence curves per treatment group can then be obtained by averaging over the predicted curves under that particular treatment [5, 15]. Outcome regression has been previously applied in a competing risks setting by Kipourou et al. to adjust for time‐dependent covariates via a flexible regression model using cause‐specific hazard models [15, 16]. In a later study by Hu et al., this method was applied using the Fine and Gray model to study the occurrence of treatment‐related mortality and recurrence in leukemia patients [17].
Covariate adjustment methods generally rely on the assumptions of no unmeasured confounding, positivity, and consistency [18]. In addition, reweighting using propensity scores requires correct specification of the propensity score model, whereas the outcome regression approach requires correct specification of the outcome model. As a result, the robustness of these methods against various forms of model misspecification will differ. In this paper, we propose a third, doubly robust estimator, which combines the previous two methods. Doubly robust models require only one of these two models to be correctly specified [19]. Our proposal is an extension of the doubly robust approach of Wang for standard survival outcomes to the competing risks setting and makes use of pseudo‐observations to deal with censoring [20].
After verifying the doubly robust property theoretically, we compare the accuracy and precision of the proposed doubly robust method to that of the inverse probability weighting method, the outcome regression method, and to the crude Aalen–Johansen estimator in a simulation study, including various scenarios of unbalanced treatment assignment and model misspecification. To demonstrate how these methods behave in a real‐world data scenario, we apply them to a case study in breast cancer survival.
Covariate Adjustment Methods
2
Cumulative Incidence
2.1
We denote each individual by i∈{1,…,n}, with n the total number of individuals in the dataset. We assume that there are K possible events. Let T be the time to the first event, and C the censoring time. We assume C to be independent of T, that is, noninformative censoring. The observation time is defined as T*=min(T,C), and ∆∈{0,1,…,K} the event type that occurs first, with ∆=0 indicating the occurrence of censoring.
The cumulative incidence function for event k is defined as Ik(t)=P(T≤t,Δ=k). We can estimate the cumulative incidence function non‐parametrically with the Aalen–Johansen estimator I^k(t), which is a function of the estimated total survival function S^(t), representing the estimated probability to be free of any event at time t, and cause‐specific hazard functions λ^k(t):
where tj∈0<t1<…<tj<…<tJ are the distinct event times where any of the K competing events occur, dktj=∑i1Ti*=tj,Δi=k is the number of individuals failing from event k at tj, dtj=∑kdktj is the total number of failures from any cause at tj, and ntj=∑i1Ti*≥tj is the number of individuals who are still at risk at tj−.
Treatment Specific Cumulative Incidence
2.2
We now consider the situation where we have two different treatment categories denoted by z = 1 (treatment) and z = 0 (control). Extension to more treatment categories is possible. We would like to estimate treatment‐specific marginal cumulative incidence curves defined as Ikz=1(t)=PTz=1≤t,Δz=1=k, the cumulative incidence over time had all individuals of the population received treatment, and Ikz=0(t)=PTz=0≤t,Δz=0=k, the cumulative incidence function had all individuals not received treatment. The superscript notation indicates that we aim for estimating the distribution of potential outcomes, that is outcomes for individuals under treatment categories that may be different than the ones actually observed in the data.
When data from a perfectly randomized trial would be available, the treatment‐specific cumulative incidence curves could be estimated using the nonparametric Aalen–Johansen estimator described in Section 2.1 applied to the observed data from each treatment group. However, when treatment is not assigned randomly, results are prone to bias due to confounding, and covariate adjustment methods are needed.
To describe different covariate adjustment methods for marginal cumulative incidence functions, we consider an observational data set with Zi∈{0,1} the received treatment of individual i and with Xi a vector of confounders known at baseline. We assume that there is no unmeasured confounding and that other identifying assumptions for causality (positivity and consistency) hold [4]. More formal definitions of these assumptions are given in Appendix A.
Inverse Probability Weighting
2.3
With covariate adjustment via inverse probability weighting, we model the treatment allocation as a function of the confounders. This information is then used to rebalance the treatment groups via weighting such that the distribution of covariates becomes similar in both weighted treatment groups [12, 21]. To this end, the propensity score is used, which is the probability of an individual i being assigned treatment Zi=1, given its covariate values Xi [12, 13, 21]. The propensity score can be estimated through any classification‐based method, but is most commonly estimated through logistic regression [12]:
The corresponding inverse probability weights are calculated based on the observed treatment values Zi:
As such, individuals with covariate values which are overrepresented in a treatment group receive a smaller weight, and vice versa. This yields reweighted numbers of events of type k at tj, total number of events at tj, and numbers at risk at tj, in both treatment groups expressed as:
The weighted estimators for the overall survival function and cause‐specific hazard functions become:
Finally, combining these estimators yields the reweighted cumulative incidence estimator under treatment category z:
Point‐wise standard errors for I^IPW,kz(t) may be approximated analytically [14]. However, these methods do not account for the variation in the estimation of the propensity scores. Bootstrap methods can be used instead [22].
Outcome Regression With Standardization
2.4
In this approach, we use that the treatment‐specific marginal cumulative incidence functions can be rewritten as
with integration over the covariate distribution of the population. In the outcome regression approach, Ikz(t|x) is obtained through regression modeling. In this paper we use cause‐specific Cox proportional hazards models, modeling the effect of treatment and covariates, Z and X, on the cause‐specific hazards, but other competing risks regression models may be used as well, such as the Fine and Gray model. Integration over the covariate distribution can be approximated by averaging over the observed covariate values, that is, the empirical distribution, as follows:
In this method, the regression model is used to predict two cumulative incidence curves for every individual given their covariate values, once setting Z=1 and once Z=0. Then the average is taken over all individuals to obtain the estimated marginal cumulative incidence curves for each treatment. Standard errors can be obtained via bootstrapping or analytically (e.g., as described by Sjölander [23]).
Doubly Robust Estimation
2.5
The previous two covariate adjustment methods have different underlying assumptions. Inverse probability weighting requires correct specification of the propensity score model, whereas outcome regression requires correct specification of the outcome model. We now propose a third method using an augmented IPW estimator. Augmented IPW estimators are constructed as a weighted sum of the IPW estimator and outcome regression model. The general form of the augmented IPW estimator for the treatment specific mean of a continuous variable Y under treatment category z, that is, EYz,is
with P^Zi=z|Xi the estimated propensity score and Y^Xi,Z=z an estimate of the outcome regression model. One can see from the formula that if the propensity score model fits the data well, that is, 1Zi=z−P^Zi=z|Xi is close to zero, the estimator reduces to a regular IPW estimator. Similarly one can show that if the estimates from the outcome model Y^Xi,Z=z are close to the observed outcomes Yi in individuals with observed Zi=z, the estimator reduces to the outcome regression estimator. This results in the so called double‐robustness property: as long as either the propensity score model or the outcome regression model is correctly specified, the estimator is consistent [24, 25, 26]. A simulation study by Lunceford et al. demonstrated that this augmentation also makes the estimator generally more efficient, that is, having a smaller mean‐squared error, when compared to the propensity score weighted estimator [24]. Though Lunceford et al. noted that its efficiency does fall short when compared to a correctly specified outcome model approach.
Defining the augmented IPW estimator in the context of survival analysis is challenging, as the outcome, that is, the time until event, is not observed for all individuals due to censoring. An augmented IPW estimator for the survival probability at time t in the ordinary survival setting was proposed by Wang, where the observed status indicator by time t used in the doubly robust estimator was replaced by the pseudo‐value for the survival function at that time, derived from the Kaplan–Meier estimator. We extend this approach to the setting with competing risks. Pseudo‐values that represent an individual's contribution to the cause‐specific incidence function have been formulated by Andersen and Perme [27, 28].
with I^k−i(t) the cumulative incidence by time t, estimated by the Aalen–Johansen estimator, obtained leaving out the ith observation. Our proposed doubly robust estimator of the treatment specific marginal cumulative incidence function at time t can then be expressed as
A derivation of the consistency of this estimator under correct specification of either the outcome model or the propensity model is presented in Appendix A.
Simulation Study
3
Simulation Set‐Up
3.1
Data Generation
3.1.1
A simulation study was conducted to evaluate the performance of the three methods, and their robustness against misspecification of the association between the covariates and treatment assignment and/or outcome. We simulated N individuals, i∈{1,…,N}. For each individual we simulated two independent covariates: one categorical variable with three categories drawn from a multinomial distribution with each category having an equal 1/3 probability, represented by two indicator variables X1,X2, plus a continuous covariate X3∼N(0,1). The covariate information for individual i is denoted by Xi=X1i,X2i,X3i.
We considered two competing events k∈{1,2}. In each simulation scenario we assumed a proportional hazards model for the cause specific hazard of each event:
with expλk,0 a constant baseline hazard, θk the event‐specific treatment effect on the log hazard, and βk the vector of covariate effects on the log hazard. The individual (possibly latent) event times for each event type k, Tik were generated as described by Bender et al. [29]
where Uik was drawn from a uniform distribution Uk~U(0,1). The time of the first event was derived as the minimum of the event times for the two event types: Ti=minTi1,Ti2. Censoring times Ci were sampled from a uniform distribution: Ci∼UP.20(T),P.95(T), where P.20(T) and P.95(T) were calculated for each simulation run as the 20th and 95th percentile from the empirical distribution of the event times T. This resulted in roughly 25% of censored observations under all simulation conditions. The observation time was Ti*=minTi,Ci, and the observed status δi was set to 0 if Ti>Ci,δi=1 if Ti1<Ti2 and Ti<Ci, and δi=2 if Ti1>Ti2 and Ti<Ci.
Simulation Scenarios
3.1.2
We generated four main scenarios: one scenario leading to correctly specified outcome and exposure models in the analysis (Scenario 1), one which led to misspecification in the exposure model (Scenario 2), one with misspecified outcome model (Scenario 3) and one with both models misspecified (Scenario 4). We used the following parameter values in all four scenarios: treatment effects θ1=−1, θ2=−0.5, coefficients for the covariates for the first event type β1=(1,−1,0.5), and coefficients for the second event type β2=(−1,1,−0.5). In Scenarios 1 and 2, we chose baseline hazard expλk,0=1 for both event types. These parameter choices ensured that the positivity assumption was met in each of the four scenarios. In Section S2 we show performance of the methods in an additional scenario where the positivity assumption is violated.Scenario 1 Correct specification of both the treatment and the outcome model. A logistic regression model was used to generate the probability of being assigned the active treatment Zi=1, as a function of the covariate values Xi:
with coefficients ω=(1,−1,1). Scenario 2 Misspecification of the treatment model. Next, we generated data from a scenario where individuals were assigned to treatment in a way that does not align with a logistic treatment model. We first generated data under Scenario 1 and only kept individuals with Z=1 (n1 individuals). Next we generated a large dataset where each individual was randomly assigned one of two treatments, Zi∼Bern(0.5) and selected (N−n1) individuals from this large data set with Z=0. Consequently, in the combined dataset the relationship between covariates and treatment allocation no longer follows a logistic regression model. Scenario 3 Misspecification of the outcome model. In this simulation scenario, the relationship between covariates and outcomes is misspecified, by generating a non‐linear relationship between the log hazard and the continuous covariate X3. This was done by generating latent survival times for each cause as follows:
with λk,0=2 for both event types. The treatment assignment model was the same as in Scenario 1. Scenario 4 Misspecification of both the treatment and the outcome model. In this simulation scenario, these data are generated under the conditions described both by Scenarios 2 and 3. Consequently, the relationship between covariates and treatment allocation does not follow a logistic model, and the relationship between the log hazard and continuous covariate X3 is nonlinear.
Performance Evaluation
3.2
Simulations for each scenario were repeated M=1000 times. In each scenario the sample size was N=4000. The accuracy and precision of the crude estimator of the marginal cumulative incidence curves, that is, applying the unadjusted Nelson–Aalen estimator in each treatment group, and of the three covariate adjustment methods were evaluated. We expressed performance in terms of bias, that is, the mean difference between the estimated marginal cumulative incidence and the underlying true cumulative incidence, per time point and in terms of root mean squared error (RSME), that is, the root of the mean squared difference between estimated and true cumulative incidences per time point. Derivation of the true incidence can be found in Section S1 [30]. The bias with pointwise 2.5th and 97.5th percentiles of the differences derived from the simulations, was plotted over a range of time points. We also report bias and RMSE at a time point approximately halfway during follow‐up.
Statistical Software and Packages
3.3
R statistical software (version 4.1.3) was used. The covariate adjustment methods were implemented using the package survival for the inverse probability weighting method, riskRegression for the outcome regression and doubly robust method, and prodlim to generate pseudo‐observations for competing risk [27, 31, 32]. Visualizations were produced with the ggplot2 and firatheme package [33, 34]. Performance measures and diagnostic procedures were derived using the microbenchmark, survey, and tableone packages [35, 36, 37]. The R code for the covariate adjustment methods and for the simulation study is available at https://github.com/survival‐lumc/AdjCuminc.
Results
3.4
Figure 1 depicts the deviation from the true marginal cumulative incidence curve for each estimation method in Scenarios 1–4, plotted over the range of simulated event times. The results from Scenario 1 (correct treatment and outcome model specification) illustrate substiantial bias in the naïve estimator (Figure 1A). The bias in all three covariate adjusted estimators was negligible. The RMSE of the outcome regression method was somewhat smaller compared to the propensity score‐based method and the doubly robust method (Table 1). In Scenario 2 (Figure 1B), where the treatment model was misspecified, the inverse probability weighting method yielded biased estimates. In contrast, both outcome regression and the doubly robust method were unbiased, with equal or smaller RMSE for the outcome regression method. The results for the third scenario (Figure 1C), with a misspecified outcome model, show that the incidence curves using outcome regression were biased while the other two methods were not. Even though, the RMSE was still in some situations lower for the outcome regression method than that of the other two methods (e.g., for Event Type 1 in the control group and for Event Type 2 in the treatment group at t=5.0, Table 1). Finally, we observe that none of the methods perform well in Scenario 4, when both the treatment allocation and outcome model were misspecified. The doubly robust method did not perform worse compared to the other two methods in this scenario.
Simulation results for Scenario 1, no model misspecification (A), Scenario 2, misspecified covariate effects on treatment allocation (B), Scenario 3, misspecified covariate effects on the outcome (C), and Scenario 4, both treatment allocation and covariate effects on the outcome misspecified (D). Mean difference between the true cumulative incidence of Events 1, 2, and event‐free survival and the estimated results using the naïve estimator (no covariate adjustment), inverse probability weighted estimator, outcome regression estimator, and doubly robust estimator in the two treatment groups. The bands indicate the 2.5th and 97.5th percentiles.
To summarize, the doubly robust estimator was found to be robust against misspecification of either the treatment allocation or outcome model. When both models were misspecified, the doubly robust estimator did not perform better, but also did not perform worse, than the other methods. Outcome regression was demonstrated to be the most efficient estimator when the outcome model was correctly specified.
Application to Breast Cancer Survival Data
4
Data Characteristics
4.1
The three covariate adjustment methods were applied to breast cancer survival data from a previous cohort study by van Maaren et al. [38]. These data were collected in collaboration with the Netherlands Comprehensive Cancer Organization, and consisted of 8879 patients from the Netherlands Cancer Registry of whom we selected 6538 patients who underwent either a mastectomy (i.e., surgical removal of the entire breast) or breast‐conserving therapy, and had complete information on all relevant covariates. Details on data collection, the study population, and classification and staging of cancer can be found in van Maaren et al. and Section S3 [38]. An explorative study by van Maaren et al. found patients who received breast‐conserving therapy had at least equal survival compared to patients who received a mastectomy [39]. The 2019 study compared different methods to correct for confounding, concluding that propensity score weighting, instrumental variable analysis and multivariable regression modeling all led to similar results and that assumptions of these methods have to be very carefully considered [38]. For example, unmeasured confounding could be present. Multiple event types could occur during follow‐up: locoregional and distant recurrences, second primary tumor development, and death without any such event. In the previous studies, the endpoints overall survival and “distant metastasis free survival” (censoring observations if other events occurred) were used. In our analysis, we study recurrence (including locoregional and distant recurrences), second primary breast tumors, and death as separate competing events. The aim is to shed more light on the role of confounding by studying the adjusted cumulative incidence curves for each event type separately.
A total of 4116 patients (63.0%) received breast‐conserving therapy, whereas 2422 patients (37.0%) underwent mastectomy. Breast‐conserving therapy is recommended for early‐stage disease when medically feasible and according to patient preferences [40, 41]. Patients in earlier stages (e.g., smaller tumor size, fewer positive lymph nodes, no multifocality, ductal histological features, etc.) more frequently received breast‐conserving therapy (see Table S2). All covariates that were previously included in van Maaren et al. were used for covariate adjustment, excluding TNM staging classifiers due to high collinearity with tumor characteristics (tumor size, number of positive lymph nodes, and tumor grade). Of the 16 patient‐, hospital‐, and tumor‐related covariates, eight differed significantly between treatment groups. As such, the comparison of crude cumulative incidence curves between treatment groups is likely to be confounded.
Comparison of Covariate Adjusted Cumulative Incidence Curves
4.2
To estimate the propensity scores, treatment allocation was modeled as a function of the covariates using logistic regression (see Figure S2 for the distribution of the propensity scores). The coefficients for the propensity score model can be found in Table S3. Considerable improvement on covariate balance was found after adjustment, with differences between covariates all within the 0.1 SEM threshold after propensity score weighting (see Figure S2). For the outcome regression approach, regression coefficients of the Cox cause‐specific hazard regression models can be found in Table S4.
We checked for deviations of the proportional hazard assumption by testing for independence between scaled Schoenfield residuals and time. For some of the covariates in the model for recurrence, the assumption of proportionality was violated (tumor size, grade, hormonal receptor status, and systemic therapy), which may be indicative of a lack of fit in this particular outcome model. This could be addressed by, for example, allowing time‐varying coefficients, but this was not further explored here. Linearity of the three continuous covariates was assessed by plotting martingale residuals; no relevant deviations were observed (Figure S3).
The estimated covariate adjusted cumulative incidence curves for each of the three event types are shown in Figure 2. The largest effects of covariate adjustment are found on the cumulative incidence of death (Figure 2B). The results were similar across the three adjustment methods, showing a lower cumulative incidence of death for patients that underwent mastectomy and a higher cumulative incidence of death for patients that received breast‐conserving therapy compared to the crude estimator. In addition, confidence bounds showed more overlap between treatment groups after adjustment (Figure 2C). Confidence bounds were wider after covariate adjustment, notably for the propensity‐score method and the doubly robust method. The confidence intervals for the treatment groups largely overlapped for secondary tumor development, both with and without covariate adjustment (Figure 2D). Based on these observations, it can be said that the imbalance in the distribution of these recorded covariates mainly impacted results for patient mortality and, to some extent, recurrence of the disease. However, it should be reiterated that the results described here are likely prone to unmeasured confounding, which has also been discussed before by van Maaren et al. and should therefore not be used to support clinical decision making.
Adjusted cumulative incidence curves for (A) disease‐free survival, that is, the probability of not experiencing any of the event types, (B) death, (C) recurrence, and (D) second primary tumor development for breast‐conserving therapy (yellow; light) or mastectomy (blue; dark). The cumulative incidence is shown for the naïve cumulative incidence estimator, inverse probability weighted estimator, outcome regression estimator, and doubly robust estimator. Confidence intervals were obtained by bootstrapping (B = 250 resamples).
Discussion
5
In this paper we introduced a doubly robust method for estimating covariate‐adjusted marginal cumulative incidence curves using pseudo‐observations and compared its accuracy and precision to that of inverse probability weighting and outcome regression. The simulation study confirmed the doubly robustness of our newly proposed estimator; it yielded unbiased results if one of the two models (for treatment or outcome) was correctly specified. In addition, when both models were misspecified, the doubly robust estimator performed similarly to the inverse probability weighted estimator and outcome regression estimator. The doubly robust estimator is therefore recommended if there is uncertainty on which model can be correctly specified.
A disadvantage of the doubly robust estimator is its relatively high variance compared to the outcome regression estimator [42]. The variance was similar to the variance of the inverse probability weighting method, which indicates that the use of pseudo‐observations did not additionally increase the variance. This finding is similar to what was found earlier for linear outcome models and ordinary survival analysis [5, 20, 26, 42, 43]. Therefore, outcome regression is recommended if the researcher has confidence in the outcome model. The outcome model estimate is in general also less influenced by situations where there is near non‐positivity. A third limitation of the proposed doubly robust method is that the estimate for each time point is generated independently of the others and may, therefore, not guarantee a monotonous curve [26]. However, the curves showed negligible nonmonotonous deviation when the estimator was applied on the simulated data during preliminary trial runs and when the methods were applied on real‐world cancer survival data.
Another consideration is the role of censoring on the performance of these methods. In our simulation study, we have only considered a noninformative censoring mechanism. For the outcome regression method, this assumption can be relaxed to independent censoring conditional on the covariates. A caveat of the doubly robust estimator is that the modeling of pseudo‐observations requires independent censoring [28]. Therefore, it can be expected that the proposed doubly robust estimator is sensitive to dependent censoring. Extensions of pseudo‐observations to settings with dependent censoring have been proposed [44, 45], but using them in the current context has yet to be further explored.
It should be noted that simulation studies are never exhaustive. The simulation code has been made publicly available and can be readily adapted in follow‐up studies to more specifically examine the behavior of these estimators under different types of censoring and using different parameters for the outcome and treatment models.
Alternative augmented IPW estimators for causal analysis of censored data have been proposed in literature that, instead of pseudo‐observations, use inverse probability of censoring weighting to account for censoring [46, 47, 48], including the setting of competing events [49, 50]. An overview of methods focusing on standard survival data is given in Denz et al. and in Gabriel et al. [26, 51].
We used bootstrapping methods to generate confidence intervals in the breast cancer application. An analytical estimator for the variance of the doubly robust method for ordinary survival was proposed by Wang [16]; a priority for future work is to extend this to the competing risk situation.
To conclude, through our simulation study and data application we have illustrated the strengths and weaknesses of three distinct covariate adjustment approaches for treatment‐specific marginal cumulative incidence curves, emphasizing their behavior under model misspecification. With our work, we have bridged the gap between doubly robust covariate adjustment methods for standard survival curves and adjustment methods for cumulative incidence curves in competing risks settings. Future studies could further extend these methods to more complex multistate settings.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Data S1. Supporting Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1E. D. Saad , “Endpoints in Advanced Breast Cancer: Methodological Aspects & Clinical Implications,” Indian Journal of Medical Research 134 (2011): 413–418.22089601 PMC 3237237 · pubmed ↗
- 2H. Putter , M. Fiocco , and R. B. Gekus , “Tutorial in Biostatistics: Competing Risks and Multi‐State Models,” Statistics in Medicine 26, no. 11 (2007): 2389–2430, 10.1002/sim.2712.17031868 · doi ↗ · pubmed ↗
- 3M. Nørgaard , V. Ehrenstein , and J. P. Vandenbroucke , “Confounding in Observational Studies Based on Large Health Care Databases: Problems and Potential Solutions—A Primer for the Clinician,” Clinical Epidemiology 9 (2017): 185–193, 10.2147/CLEP.S 129879.28405173 PMC 5378455 · doi ↗ · pubmed ↗
- 4M. A. Hernan and J. M. Robins , Causal Inference: What if (CRC Press, 2023), 10.1201/9781315374932. · doi ↗
- 5E. Goetghebeur , S. le Cessie , B. De Stavola , E. E. M. Moodie , and I. Waernbaum , “Formulating Causal Questions and Principled Statistical Answers,” Statistics in Medicine 39, no. 30 (2020): 4922–4948, 10.1002/sim.8741.32964526 PMC 7756489 · doi ↗ · pubmed ↗
- 6J. P. Fine and R. J. Gray , “A Proportional Hazards Model for the Subdistribution of a Competing Risk,” Journal of the American Statistical Association 94, no. 446 (1999): 496–509, 10.1080/01621459.1999.10474144. · doi ↗
- 7D. R. Cox and D. Oakes , Analysis of Survival Data (Chapman and Hall, 1984), 10.1201/9781315137438. · doi ↗
- 8P. C. Austin , D. S. Lee , and J. P. Fine , “Introduction to the Analysis of Survival Data in the Presence of Competing Risks,” Circulation 133, no. 6 (2016): 601–609, 10.1161/CIRCULATIONAHA.115.017719.26858290 PMC 4741409 · doi ↗ · pubmed ↗