Machine learning models based on routine blood and biochemical test data for diagnosis of neurological diseases
Wanshan Ning, Zhicheng Wang, Ying Gu, Lindan Huang, Shuai Liu, Qun Chen, Yunyun Yang, Guolin Hong

TL;DR
This study uses machine learning on blood test data to diagnose neurological diseases, showing high accuracy and cost-effectiveness.
Contribution
A novel XGBoost-based model using routine blood and biochemical data achieves high diagnostic accuracy for neurological diseases.
Findings
The XGBoost model achieved an AUC of 0.9782 for predicting neurological diseases.
The model distinguishing neuromyelitis optica had the best AUC of 0.9095.
Biochemical test features were most important for model predictions.
Abstract
Globally, nervous system diseases are the leading cause of disability-adjusted life-years and the second leading cause of mortality in the world. Traditional diagnostic methods for nervous system diseases are expensive. So this study aimed to construct machine learning models using the convenient blood routine and biochemical detection data for diagnosis of nervous system diseases. After the data preprocessing, 25,794 healthy people and 7518 nervous system disease patients with the blood routine and biochemical detection data were utilized for our study. We selected logistic regression, random forest, support vector machine, eXtreme Gradient Boosting (XGBoost), and deep neural network to construct models. Finally, the SHAP algorithm was used to interpret models. The nervous system disease prediction model constructed by XGBoost possessed the best performance (AUC: 0.9782). And the most…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
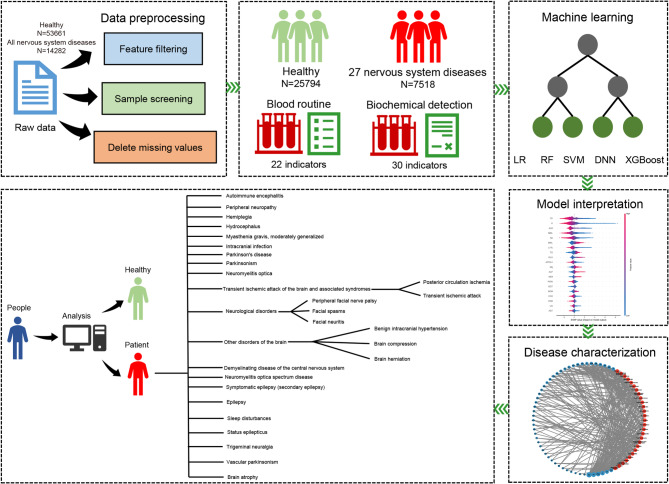 Figure 1
Figure 1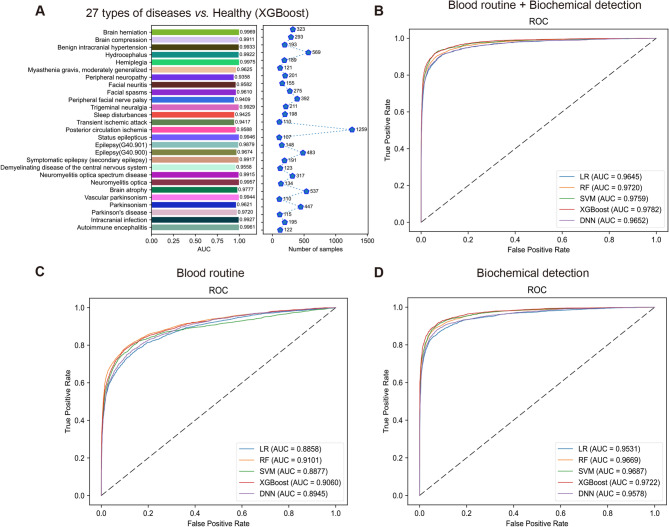 Figure 2
Figure 2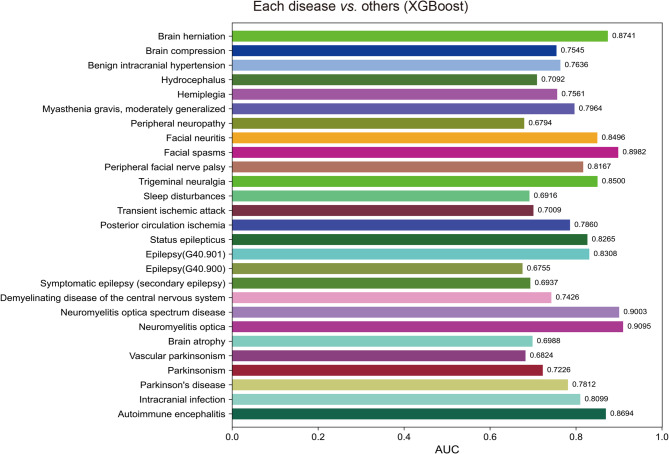 Figure 3
Figure 3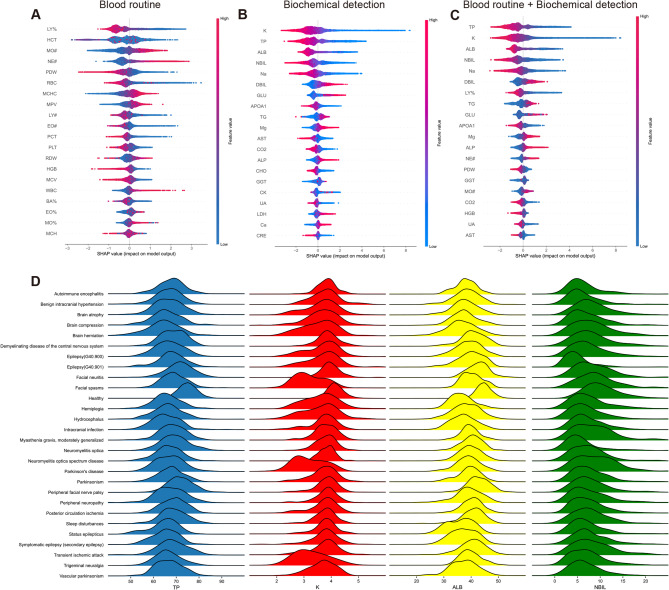 Figure 4
Figure 4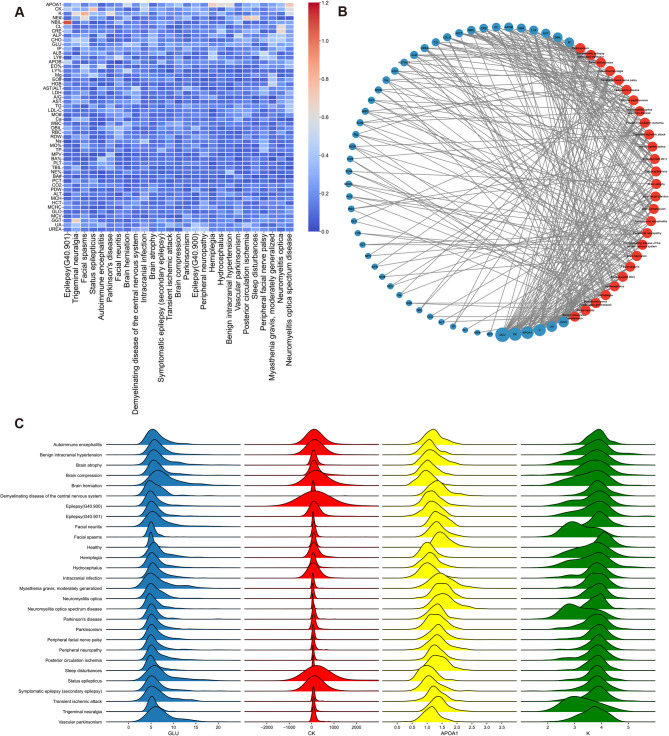 Figure 5
Figure 5- —the National Key R & D Program of China
- —the National Natural Science Foundation of China
- —the Fujian Provincial Health Technology Project
- —the Natural Science Foundation of Fujian Provincial
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Bioinformatics · Traditional Chinese Medicine Studies · Bioinformatics and Genomic Networks
Introduction
Nervous system diseases, of which the most prevalent are cerebrovascular, neurodegenerative, autoimmune, spinal cord diseases, and so on^1^. In 2021, over 3 billion people worldwide suffered from neurological disorders, affecting 43% of the global population^1^. Globally, Nervous system diseases are the leading cause of disability-adjusted life-years (DALYs, the sum of years of life lost and years lived with disability) and the second leading cause of mortality in the world^2^. Given the absence of cures for numerous nervous system diseases, a thorough comprehension of the risk factors of these nervous system diseases and the development of simple, fast, and cost-effective large-scale population screening methods is in urgent need^3^.
Common strategies for identifying biomarkers associated with central nervous system (CNS) diseases involve diverse modalities of brain imaging^4–6^ and analysis of biomarkers within the cerebrospinal fluid^7,8^. However, these methods are too costly to be used for large-scale disease screening of populations. While nervous system diseases are multifactorial, a majority of them present abnormalities in blood routine and blood biochemical tests^9,10^. For instance, parameters derived from blood routines such as neutrophil-to-lymphocyte ratio, platelet-to-lymphocyte ratio, and monocyte-to-lymphocyte ratio have undergone extensive research and have been established as highly sensitive biomarkers of nervous system diseases^11^. The low-density lipoprotein cholesterol was positively associated with the development of ischemic stroke and strongly inversely associated with intracerebral hemorrhage^10^. Current studies on neurological disease models focus on predicting the risk and prognosis of individual diseases^12–14^. However, there is limited research systematically analyzing distinguishing features between neurological disorders and their unique hematological characteristics.
Significant advancements in biotechnology and health sciences have resulted in the generation of vast quantities of data, including data from medical record systems and laboratory information systems. Doctors often emphasize important abnormal parameters while overlooking a substantial volume of other test data and the interrelationships between laboratory parameters. This tendency may lead to an underestimation of the true efficacy of laboratory data. By integrating multiple tests to analyze potential interactions, we can obtain more valuable information, which is exactly the area where machine learning (ML) excels^15^.
Research on risk prediction models for nervous system diseases is still ongoing, and it holds significant importance for human health to develop a reliable model for monitoring and preventing their occurrence. Yu et al. developed a model integrating cerebral fluid data with non-motor clinical features, such as olactory inormation, to distinguish between healthy controls (n = 138) and Parkinson’s disease (n = 290) subjects^16^. Omranid et al. identified predictive markers through AI analysis of blood transcriptomics, achieving a 97% accuracy in diagnosing multiple sclerosis^17^. Alexey S. Kononikhin et al. used human plasma protein quantitative mass spectrometry and machine learning to identify 31 proteins crucial for the differentiation of Alzheimer’s disease^18^. These studies have significantly enriched the methods for diagnosing and predicting neurological diseases, reducing the costs of large-scale population screenings to some extent, and demonstrated the feasibility of using hematological indicators for diagnosing neurological disorders. However, most diagnostic and predictive models for neurological diseases have been developed based on blood omics data, imaging data, or cerebrospinal fluid biomarkers, with few studies exploring the use of more accessible and cost-effective routine blood tests and biochemical markers for predicting neurological diseases. Tasci et al. utilized CBC data, including complete blood count with differential (CBC WBC DIFF) and numerical-CBC WBC DIFF scattergrams (which provide information on cell size and visualize it in a two-dimensional scatter plot, clearly displaying monocytes, neutrophils, eosinophils, and lymphocytes), in combination with a deep learning algorithm to aid in the diagnosis of schizophrenia (SZ)^19^. This approach achieved a remarkably high detection accuracy for SZ, inspiring us to explore the use of routine blood tests for diagnosing neurological diseases. Moreover, earlier studies have primarily focused on the prediction and diagnosis of specific nervous system diseases, so there is a lack of comprehensive investigation assessing the prediction of neurological diseases.
Traditional diagnostic methods for neurological disorders are expensive. So in this study, we obtained blood routine and blood biochemical data from patients with nervous system diseases and corresponding healthy populations from the First Affiliated Hospital of Xiamen University. We compared multiple ML algorithms and conducted comprehensive feature interpretation to explore risk factors for nervous system diseases and constructed robust models for assessing the risk of developing nervous system diseases and validate their usability. Our research shows that establishing predictive models for neurological disorders using readily available blood routine and blood biochemistry data has the potential to facilitate early diagnosis and low-cost population screening for these conditions.
Methods
Data collection and processing
All the raw data we collected came from inpatients in the Department of Neurology and healthy people who had physical examinations in the First Affiliated Hospital of Xiamen University between 2018 and 2023. These data were from the hospital information system. The diagnostic information and blood routine biochemical test data of these individuals were integrated. For all patients, we screened the blood routine and biochemical test data from the first test after hospitalization as features for the construction of models, while for healthy people, we selected the blood routine and biochemical test data from the first physical examination every year as features. Because too many missing values may affect the prediction accuracy, we removed the features with a missing value ratio greater than 50%, and finally screened out 22 features from the blood routine and 30 features from the biochemical test data (Supplementary Tables 1 and 2). Diagnostic information for all patients was determined according to The International Statistical Classification of Diseases and Related Health Problems 10th Revision (ICD-10). To ensure that the sample size for each nervous system disease was sufficient, we removed nervous system diseases with fewer than 100 samples. Subsequently, to ensure the authenticity of the data, all samples with missing values were removed. In the end, 25,794 healthy people and 7518 patients with nervous system disease were used to construct our models (Fig. 1; Table 1). These data were randomly divided into a training set (70%) and a validation set (30%).
Table 1. Data distribution of diseases.ICD-10 disease codeDiseaseNumberG04.801Autoimmune encephalitis122G06.006Intracranial infection195G20.x00Parkinson’s disease115G20.x03Parkinsonism447G21.400Vascular parkinsonism110G31.902Brain atrophy537G36.000Neuromyelitis optica134G36.000 × 002Neuromyelitis optica spectrum disease317G37.900Demyelinating disease of the central nervous system123G40.800 × 004Symptomatic epilepsy (secondary epilepsy)191G40.900Epilepsy483G40.901Epilepsy148G41.900Status epilepticus107G45.004Posterior circulation ischemia1259G45.900 × 001Transient ischemic attack110G47.900Sleep disturbances198G50.000Trigeminal neuralgia211G51.003Peripheral facial nerve palsy392G51.301Facial spasms275G51.800 × 002Facial neuritis155G62.901Peripheral neuropathy201G70.004Myasthenia gravis, moderately generalized121G81.900Hemiplegia189G91.900Hydrocephalus569G93.200Benign intracranial hypertension193G93.500Brain compression293G93.501Brain herniation323ICD-10: The International Statistical Classification of Diseases and Related Health Problems 10th Revision.
Fig. 1. The flow chart of this study.
Machine learning methods
Logistic regression (LR), also known as logistic regression analysis, is a generalized linear regression analysis model, which is often used in data mining, automatic disease diagnosis, economic forecasting, and other fields. Logistic regression estimates the probability of an event occurring based on a given dataset of independent variables, and since the outcome is a probability, the dependent variable ranges between 0 and 1. Random forest (RF) is a classifier with many decision trees, which can be used to deal with classification and regression problems, as well as for dimensionality reduction problems. It also has a good tolerance for outliers and noise and has better prediction and classification performance than decision trees. Support vector machine (SVM) is a kind of generalized linear classifier that classifies data binarily according to supervised learning, and its decision boundary is the maximum margin hyperplane solved by the learning sample. eXtreme Gradient Boosting (XGBoost) is an algorithm or engineering implementation based on the Gradient Boosting Decision Tree (GBDT). XGBoost is efficient, flexible, and lightweight, and has been widely used in data mining, recommender systems, and other fields. The deep neural network (DNN) is a framework for deep learning, that is a neural network with at least one hidden layer. Similar to shallow neural networks, deep neural networks can also provide modeling for complex nonlinear systems, but the extra layers provide a higher level of abstraction for the model, thus improving the model’s capabilities. For comparing the performance of different machine learning methods, we selected LR, RF, SVM, XGBoost, and DNN to construct the model^20–24^. The LR, RF, and SVM were used through scikit-learn (version 1.3.0), XGBoost was used through the xgboost package (version 2.0.2), and the DNN by tensorflow (version 2.0.2) in python.
All features were standardized prior to being used for model training. During model training, we addressed the issue of class imbalance by adjusting the class_weight parameter for LR, RF, SVM, and DNN algorithms. For LR, the class_weight mechanism increases the loss weight for minority class samples during cross-entropy loss calculation, ensuring the model pays more attention to these samples. In RF, class_weight adjusts the sample weights during tree construction, balancing the computation of information gain or Gini impurity. For SVM, the class_weight parameter assigns different penalty weights to samples of different classes in the optimization objective, amplifying the influence of minority class support vectors. In DNN, class_weight assigns weights to samples of different classes, making minority class samples more significant in loss calculations. For the XGBoost algorithm, we handled class imbalance by adjusting the scale_pos_weight parameter. This parameter modifies the gradient and Hessian calculations in the objective function, assigning a weight factor to positive samples, thereby altering the influence of positive and negative samples on model optimization.
For all five machine learning algorithms, we used grid search cross-validation (CV) combined with manual fine-tuning to identify the optimal parameters and mitigate overfitting risks. In the hyperparameter optimization process for the five algorithms, we aimed to strike a balance between computational cost and search comprehensiveness. Specifically, we designed representative and reasonable parameter grids based on the characteristics of each algorithm, ensuring robustness and reliability of the results through CV. Meanwhile, we employed parallel computing techniques to further enhance optimization efficiency. Since evaluating each hyperparameter combination typically involves extensive training and validation steps, especially during CV, the computational demand escalates rapidly. To accelerate this process, we utilized multi-core processors for parallel computation, ensuring simultaneous evaluations of multiple hyperparameter combinations, thereby significantly reducing overall optimization time. Additionally, we allocated resources judiciously in parallel computing to maintain efficiency without overloading system resources or causing performance degradation. By adopting this approach, we effectively reduced computational costs while ensuring comprehensive optimization, thereby enhancing the feasibility and efficiency of our experiments. Taking LR and SVM as examples, we optimized the following hyperparameters in detail. For LR, we focused on tuning the penalty, selecting between commonly used L1 and L2 regularization types. The parameter C was set to five values (0.5, 1, 2, 3, and 4) ranging from 0.5 (strong regularization) to 4 (weak regularization), covering typical ranges. The solver was chosen from five mainstream optimization algorithms (e.g., liblinear, saga, lbfgs). Initial experiments revealed that certain solvers were incompatible with specific parameter combinations (e.g., L1 regularization), leading us to narrow the solver range in subsequent steps to reduce computational load. For SVM, we optimized the following hyperparameters: C was set between 0.1 and 100, covering a wide range from strong to weak regularization, with the final values being 0.1, 1, 10, and 100. The kernel was limited to linear and rbf to avoid the computationally expensive poly kernel. The gamma parameter was explored within a range from 0.001 to 1, along with the scale option, to investigate the impact of kernel functions at different scales. This kernel selection strategy avoided expensive computations in high-dimensional data while balancing model expressiveness and efficiency by adjusting the gamma and C ranges. Using this methodology, we applied similar balanced strategies across all algorithms for hyperparameter optimization. On the one hand, we ensured search comprehensiveness by covering key parameters that could affect model performance. On the other hand, we controlled computational costs by reasonably limiting the search space, reducing invalid combinations, and adopting appropriate CV settings. We employed 5-fold CV, a robust evaluation method that divides the dataset into five mutually exclusive subsets. In each iteration, one subset serves as the validation set, while the remaining four subsets are used for training. This process is repeated five times, ensuring that each subset is used as the validation set exactly once. The model is trained in each iteration, and the validation performance is recorded. The average performance across the five iterations is calculated as the final performance metric. This approach maximizes data utilization, effectively assesses model generalizability, and reduces the impact of randomness from a single split. We further divided the dataset chronologically to validate the model’s generalization capability. Data from 2018 to 2021 were split into training and validation sets in a 7:3 ratio, while data from 2022 to 2023 were used exclusively as a test set.
After conducting the above series of grid search attempts, we finalized the parameter adjustments for all machine learning methods as follows. For LR, we optimized the C, penalty, and solver parameters. For instance, reducing the C value and using L2 regularization helped mitigate overfitting. For RF, the min_samples_leaf and n_estimators parameters were fine-tuned. For SVM, we adjusted the C, kernel, and gamma parameters. In XGBoost, we optimized colsample_bytree, gamma, learning_rate, max_depth, n_estimators, and subsample. To avoid overfitting, we decreased max_depth, reduced colsample_bytree, and increased n_estimators. For DNN, we adjusted the activation, number of layers, and number of neurons per layer parameters, and applied L2 regularization to the Dense layers to reduce overfitting risks. The DNN architecture used in this study consists of a four-layer structure, detailed as follows: The first layer is the input layer, with the number of neurons matching the number of input features. The second layer is a hidden layer with 64 neurons and utilizes the ReLU activation function. The third layer is also a hidden layer with 64 neurons and employs the ReLU activation function. The fourth layer is the output layer, containing a single neuron with a Sigmoid activation function, designed for binary classification tasks.
Model performance evaluation
The model was trained in the training set and then verified in the validation set. Sensitivity (Sn), specificity (Sp), positive predictive value (PPV), negative predictive value (NPV), F1 score, matthews correlation coefficient (MCC), and accuracy (Acc) were utilized for model performance evaluation. Their formulas are shown below^25–27^:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{Sn}\text{}\text{=}\text{}\frac{\text{TP}}{\text{TP}\text{\:+\:FN}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{S}\text{p\:}\text{=}\text{}\frac{\text{T}\text{N}}{\text{T}\text{N\:+\:FP}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{PPV\:}\text{=}\text{}\frac{\text{T}\text{P}}{\text{T}\text{P\:+\:FP}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{NPV\:}\text{=}\text{}\frac{\text{T}\text{N}}{\text{T}\text{N\:+\:FN}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{Acc\:}\text{=}\text{}\frac{\text{T}\text{P\:+\:TN}}{\text{T}\text{P\:+\:FN\:+\:TN\:+\:FP\:}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{F1\:score\:}\text{=}\text{}\frac{\text{2}\text{T}\text{P}}{\text{2}\text{T}\text{P\:+\:FN\:+\:FP\:}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{MCC}}\:{\text{ = }}\frac{{{\text{TP }} \times \:{\text{TN}}\:{\text{ - }}\:{\text{FP}}\: \times \:{\text{FN}}}}{{\sqrt {({\text{TP}}\:{\text{ + }}\:{\text{FP}})({\text{TP}}\:{\text{ + }}\:{\text{FN}})({\text{TN}}\:{\text{ + }}\:{\text{FP}})({\text{TN}}\:{\text{ + }}\:{\text{FN}})} }}$$\end{document}TP, TN, FP, and FN represent true positive, true negative, false positive, and false negative separately. Meanwhile, we also made use of the area under the curve (AUC) of the receiver operating characteristics curve (ROC) to evaluate the model performance comprehensively and select the best algorithm (Supplementary Fig. 1).
Model interpretation
Machine learning makes it difficult to explain the contribution of each feature due to its black-box principle, so the SHAP algorithm was introduced in this study. The SHAP algorithm assigns a SHAP value to each feature, which is used to explain the impact of the feature on the predictive model^28^. The SHAP value of each feature was computed by the shap python package (version 0.44.0).
Results
Nervous system disease prediction model construction
To ensure the accuracy of our prediction models, the number of various nervous system diseases was all over 100 (Table 1 and Supplementary Data 1). The male-to-female ratio between healthy people and nervous system disease patients was similar, all close to 1:1. The number of healthy people for 40–60 years old and nervous system disease patients for 60–80 years old were the most population, 12,828 and 3233 respectively (Supplementary Fig. 2). Subsequently, we chose five machine learning methods (LR, RF, SVM, XGBoost, and DNN) and utilized 22 features from blood routine and 30 features from biochemical detection to construct the nervous system disease prediction models. The results showed the comprehensive performance of XGBoost was the best (AUC: 0.9782; Acc: 0.9507; Sn: 0.8481; Sp: 0.9805; PPV: 0.9267; NPV: 0.9569; MCC: 0.8556; F1 score: 0.8856). Meanwhile, we also attempted to construct the models only using blood routine or biochemical detection data. We found the model performance of the blood routine combined with biochemical detection was the best (Fig. 2B-D; Table 2). Considering the imbalance for sample number among 27 nervous system diseases, we also used each nervous system disease to construct 27 models. The AUC of these models were all beyond 0.9, the highest one reached 0.9975 (Fig. 2A and Supplementary Fig. 3). These models all showed nice performance and robustness (Table 2).
Fig. 2. Construction of nervous system disease prediction model using clinical blood samples. (A) The AUC of 27 nervous system disease prediction models. ROC curves of five machine learning methods using different data. (B) Blood routine combined with biochemical detection. (C) Blood routine. (D) Biochemical detection.
Table 2. Model performance evaluation results (Nervous system diseases vs. Healthy, XGBoost).ModelAUCAccSnSpPPVNPVMCCF1 scoreNervous system disease0.97820.95070.84810.98050.92670.95690.85560.8856Autoimmune encephalitis0.99610.99790.66670.99970.93330.99820.78790.7778Intracranial infection0.99270.99680.62710.99960.92500.99720.76020.7475Parkinson’s disease0.97200.99720.48780.99990.95240.99730.68050.6452Parkinsonism0.96210.98830.45590.99770.77500.99050.58920.5741Vascular parkinsonism0.99440.99790.51610.99990.94120.99810.69620.6667Brain atrophy0.97770.99190.68670.99840.90480.99330.78440.7808Neuromyelitis optica0.99570.99780.60000.99990.96000.99790.75800.7385Neuromyelitis optica spectrum disease0.99150.99430.59380.99920.90480.99500.73040.7170Demyelinating disease of the central nervous system0.95580.99520.16670.99970.77780.99550.35870.2745Symptomatic epilepsy (secondary epilepsy)0.99170.99620.54390.99950.88570.99660.69240.6739Epilepsy (G40.900)0.96740.99100.61490.99820.86670.99270.72580.7194Epilepsy (G40.901)0.98790.99700.50000.99990.95650.99720.69040.6567Status epilepticus0.99460.99810.53330.99990.94120.99820.70770.6809Posterior circulation ischemia0.95880.97590.59900.99480.85350.98010.70350.7039Transient ischemic attack0.94170.99640.19350.99960.66670.99680.35800.3000Sleep disturbances0.94250.99320.16130.99990.90910.99330.38140.2740Trigeminal neuralgia0.99290.99770.72220.99960.92860.99810.81790.8125Peripheral facial nerve palsy0.94090.98820.35290.99790.72410.99010.50060.4746Facial spasms0.96100.99550.61450.99960.94440.99590.75990.7445Facial neuritis0.95820.99430.17390.99920.57140.99510.31320.2667Peripheral neuropathy0.93580.99290.12730.99910.50000.99380.24980.2029Myasthenia gravis, moderately generalized0.96250.99600.29270.99970.85710.99630.49960.4364Hemiplegia0.99750.99730.70910.99940.88640.99790.79150.7879Hydrocephalus0.99220.99390.82180.99780.89380.99600.85400.8563Benign intracranial hypertension0.99330.99710.67210.99960.93180.99740.79010.7810Brain compression0.99110.99530.66320.99940.92650.99590.78170.7730Brain herniation0.99690.99720.84310.99920.93480.99790.88640.8866
Classification of various nervous system diseases
To further subdivide various nervous system diseases, we constructed 27 models distinguishing a kind of nervous system disease from other nervous system diseases, such as distinguishing brain herniation from other nervous system diseases. The XGBoost was selected to construct models because of its good performance. The results showed the AUC of these models ranged from 0.6755 to 0.9095. Surprisingly, the model performance of distinguishing neuromyelitis optica (NMO) from other nervous system diseases was the best. NMO is an acute or subacute demyelinating lesion in which the optic nerve and spinal cord are simultaneously or sequentially affected. The diagnosis of NMO primarily depends on Magnetic Resonance Imaging (MRI) and serum NMO-IgG detection, not the blood routine and biochemical detection. These results indicated these models could help doctors well distinguish different nervous system diseases (Fig. 3).
Fig. 3. The AUC of 27 models distinguishes a kind of nervous system disease from others.
Analysis of nervous system disease-specific indicators
To help us better understand the contributions of 52 features for the nervous system disease prediction model and find the nervous system disease-specific indicators, we used the SHAP algorithm to compute the contribution degree of each feature. For the constructed model only utilizing the blood routine, the top 10 features were lymphocyte percentage (LY%), hematocrit (HCT), absolute value of monocyte (MO#), absolute value of neutrophil (NE#), platelet distribution width (PDW), red blood cell count (RBC), mean erythrocyte hemoglobin concentration (MCHC), mean platelet volume (MPV), absolute value of lymphocytes (LY#), and absolute value of eosinophil (EO#) (Fig. 4A). For the constructed model only utilizing the biochemical detection data, the top 10 features were potassium (K), total protein (TP), albumin (ALB), indirect bilirubin (NBIL), sodium (Na), direct bilirubin (DBIL), glucose (GLU), Apolipoprotein A1 (APOA1), triglycerides (TG), and magnesium (Mg) (Fig. 4B). Interestingly, for the constructed model utilizing the blood routine combined with biochemical detection, only one feature from the blood routine, LY%, was one of the top 10 features (Fig. 4C). These results indicated features from biochemical detection made major contributions to predicting nervous system disease (Fig. 4D). To further validate the importance of these features, we also calculated the top 20 features ranked by four other machine learning methods. As shown in the results, although the feature rankings varied slightly across methods, there was substantial overlap among the top 20 features. This indicates that our model interpretation method demonstrates good stability (Supplementary Data 2).
Fig. 4. The top 20 features for the nervous system disease prediction model using different data. (A) Blood routine. (B) Biochemical detection. (C) Blood routine combined with biochemical detection. The red represents a high value, and the blue represents a low value. If the SHAP value is positive, it represents the positive effect of the feature on the model, and vice versa. All features are listed in order of importance from top to bottom. (D) The joyplot of numerical distributions of TP, K, ALB, and NBIL among various nervous system diseases and healthy people.
To verify whether the performance of the XGBoost was affected by redundant features, we constructed the model to distinguish nervous system disease patients from healthy individuals using only the top 10 features ranked by the SHAP algorithm (Fig. 4C). The results showed that the model constructed with the top 10 ranked features performed similarly to the model built with all 52 features (Supplementary Fig. 4).
Analysis of characteristic indicators of discrimination between various nervous system diseases
After exploring nervous system disease-specific indicators, we also hoped to further explore characteristic indicators of discrimination between various nervous system diseases. Then, we displayed the SHAP value of each feature through a heatmap. Rows and columns were clustered separately, and the more similar the features or diseases, the closer they were. We found that every nervous system disease had distinctive characteristics (Fig. 5A). At the same time, a network displaying the intersection features among various nervous system diseases showed that GLU, creatine kinase (CK), APOA1, and K were the top 4 features subdividing various nervous system diseases (Fig. 5B). Elevated GLU is often associated with diabetes, but we found that GLU could also be used to distinguish between different nervous system diseases. APOA1 is the main protein component of high-density lipoprotein (HDL) in plasma and is commonly used as a biomarker to predict cardiovascular disease. And as we can see in our results, it also has great potential for predicting various nervous system diseases. The numerical distributions of the top 4 features among various nervous system diseases and healthy people were different (Fig. 5C). The results proved our models were reliable.
Fig. 5. Analysis of specific indicators for differentiation between different nervous system diseases. (A) The heatmap displaying SHAP values of 52 features for each disease differentiation model. The positive SHAP value is added to the absolute value of the negative SHAP value to form the final SHAP value to be displayed. (B) The network showing the intersection top 10 features among different disease differentiation models. The red circles represent various nervous system diseases, and the blue circles represent various features. The larger the blue circle, the more the intersection features. (C) The joyplot of numerical distributions of GLU, CK, APOA1, and K among various nervous system diseases and healthy people.
Discussion
Diagnosing nervous system diseases relies on a comprehensive evaluation of medical history, physical examinations, and imaging studies. Nevertheless, neurological symptoms and signs can lack specificity, with clinical features frequently overlapping. Particularly in the early stages of many nervous system diseases, symptoms may be nonspecific^29,30^. Clinical reliance on imaging techniques such as Computed Tomography (CT) and MRI is common, yet economically underdeveloped regions often struggle to afford them, and they are not suitable for population-based screening as well as long-term monitoring^31,32^. Additionally, the sensitivity of imaging detection is low in the early stage of nervous system diseases. When patients seek medical care, doctors usually conduct blood routine and blood biochemical tests as part of their evaluation. Given the simplicity, accessibility, and low cost of these medical test data, we attempted to use blood routine and blood biochemical tests to establish disease prediction models.
In this work, the blood routine and blood biochemical data of 25,794 healthy people and 7518 patients with nervous system disease from the First Affiliated Hospital of Xiamen University were analyzed. We selected 5 kinds of ML methods (LR, RF, SVM, XGBoost, and DNN) and a total of 22 features from the blood routine and 30 features from blood biochemical tests were selected to construct a prediction model for nervous system diseases. The model demonstrated a robust predictive performance. Subsequently, we attempted to construct predictive models to distinguish among 27 common nervous system diseases. All these 27 prediction models can discriminate among multiple nervous system diseases, with particularly notable performance in distinguishing NMO (AUC = 0.9095) from other nervous system diseases.
We have developed a multivariate predictive model utilizing blood routine and blood biochemical tests. This model holds promise as a reliable method for early diagnosis and population screening of nervous system diseases. Neuroscientist Jonathan Kipnis’ work has revealed the dural sinuses as the interface for neural and immune interaction, facilitating communication between the CNS and the immune system^33^. Studies have shown that abnormal B-lymphocyte counts and immune responses in the peripheral blood may play important roles in the development of Parkinson’s disease^34^. Changes in the blood-brain barrier can facilitate the entry of peripheral blood lymphocytes into the CNS, potentially involving them in the pathogenesis of nervous system diseases. As Alzheimer’s disease and Parkinson’s disease progress, the peripheral blood lymphocyte profiles of patients undergo notable changes, affirming the significance of LY% as a predictive feature in the model^35^.
The model in this study incorporated K, Na, and Mg concentrations in blood tests by training. Sodium is the primary extracellular cation, while K and Mg are the primary intracellular cations. Metal homeostasis is critical to normal neurophysiological activity. For example, K is crucial for regulating neuronal excitability by maintaining resting membrane potential and influencing action potential dynamics. K channels help balance potassium distribution, stabilizing the neuronal environment and preventing overexcitability^36^. It is noteworthy that indicators reflecting liver function, such as DBIL, NBIL, TP, and ALB, along with markers associated with liver glucose and lipid metabolism, such as GLU and APOA1, play significant roles in predicting nervous system diseases. This suggests a close association between the occurrence of nervous system diseases and liver function through metabolic homeostasis^37^. Albumin also plays a significant role in maintaining blood-brain barrier integrity, and is particularly effective in neuroprotective contexts^38^. Subsequently, we further explored characteristic discriminative indicators among various nervous system diseases. We found that the numerical distribution of GLU, CK, APOA1, and K could serve as important features for distinguishing different nervous system diseases. Hyperglycemia increases oxidative stress and matrix metalloproteinase-9 (MMP-9) activity and leads to brain-blood-barrier dysfunction^39^. Creatine kinase is part of the phosphagen kinase family of guanidine kinases, whose primary function is to help in Adenosine 5’-triphosphate hydrolysis^40^. Patients with nervous system diseases such as amyotrophic lateral sclerosis, stroke, and epileptic seizures often exhibit elevated levels of CK in their peripheral blood. APOA1, the primary apolipoprotein component of HDL, plays a direct role in cholesterol efflux in the brain and is strongly linked to atherosclerosis and dementia^41–44^. Higher serum APOA1 level is also correlated with reduced blood-brain barrier injury and a lower risk of neuronal degeneration^45^.
While earlier research has predominantly centered on diagnosing specific neurological conditions such as Parkinson’s disease, epilepsy, Transient Ischemic Attack, and Myasthenia gravis, the development of comprehensive diagnostic models covering a broad spectrum of neurological diseases has been less common^16,46–48^. Simon Lam et al. constructed a multinomial model with demographic data, blood and urine test results, and cognitive assessments from 1,223 UK Biobank participants, achieving an 88.3% accuracy in predicting Alzheimer’s disease, Parkinson’s disease, motor neuron disease, and myasthenia gravis^49^. In our study, we performed an extensive analysis of 27 prevalent neurological diseases, developing diagnostic models through XGBoost that achieved a 95% accuracy rate. Additionally, our comprehensive approach in constructing the model included an analysis of distinctions between different neurological diseases, thereby providing physicians with improved diagnostic differentiation.
Our findings confirm that by applying machine learning to data from neurological patients, it is possible to diagnose various types of nervous system diseases using blood routine and biochemical tests, as well as differentiate between these diseases. Our ML model is capable of extracting subtle diagnostic information from blood test results, data that even the most experienced clinicians may find difficult to detect. We believe that this approach holds the potential to improve traditional diagnostic procedures, and open up a new pathway for diagnosing these diseases. It facilitates large-scale screening of at-risk populations, reduces testing costs, and supports early treatment. To further support real-world application, we added a case study to illustrate the clinical utility of our model. A 63-year-old female patient (Patient A) presented with dizziness, memory decline, and gait instability. Her blood test showed decreased K and APOA1 levels. Our model predicted a high risk (89%) of posterior circulation ischemia. This was later confirmed by MRI and Magnetic Resonance Angiography (MRA). SHAP analysis highlighted the same two features as major contributors to the prediction. This case demonstrates both the practical applicability of our model and the interpretability afforded by SHAP in guiding clinical decision-making. We also added details on model training time and hardware requirements. The XGBoost model was trained on a device with an 11th Gen Intel(R) Core(TM) i7-11800 H @ 2.30 GHz Central Processing Unit (CPU) and 16GB of Random Access Memory (RAM). The average training time was within 5 min, indicating good scalability for large-scale population screening and real-time clinical deployment. Furthermore, we expanded our discussion on the use of SHAP values. These values help clinicians interpret individual predictions by identifying the most influential laboratory indicators and their directional contributions (positive or negative). For example, elevated GLU and reduced K and APOA1 levels may indicate a high risk of posterior circulation ischemia, thus prompting further diagnostic investigation or tailored interventions. SHAP improves the transparency of machine learning predictions and provides actionable insights for personalized clinical decision-making. To facilitate the usage of our model in clinical settings, we propose developing a web application with this work. This tool would calculate and return the probability of nervous system diseases for individual patients when their relevant feature values are inputted. With this tool, our prediction model can be accessed online and easily shared with healthcare professionals [Identification and validation of an explainable prediction model of acute kidney injury with prognostic implications in critically ill children: a prospective multicenter cohort study]. However, clinical application requires multi-center validation of the model’s effectiveness. The quality of the data determines the reliability of the ML model^50^. Continuing to collect data and increasing the number of patients and blood samples may further enhance the model’s performance.
Our primary future goal is to establish a multi-center collaboration to enhance the diversity and generalizability of our diagnostic models across different clinical settings. Additionally, we aim to integrate advanced machine learning technologies, such as neural networks and ensemble methods, to improve the diagnostic accuracy of our models. Furthermore, we are willing to develop a real-time diagnostic tool using explainable artificial intelligence (XAI), which is expected to help healthcare providers utilize routine blood tests for immediate clinical decision-making^19^. This tool will likely increase the clinical utility of blood tests and improve patient care efficiency. These initiatives will significantly advance our diagnostic framework, potentially offering more precise and cost-effective solutions for the diagnosis of neurological diseases.
This study has the following strengths. Firstly, the data used to construct the model in this research, derived from blood routine and blood biochemical tests, originate from hospital laboratories, making them easy to obtain. This can help doctors in early diagnosis and reduce costs. Consequently, it has the potential for widespread adoption across various healthcare institutions. Secondly, the neurological disorders included are selected based on the ICD-10 codes, encompassing a total of 27 kinds of neurological diseases, making the model applicable to various healthcare institutions. Moreover, we used the SHAP algorithm to explore distinguishing features between patients with neurological disorders and healthy populations, as well as features for differentiation among various types of neurological disorders. This provides important clues for doctors when reviewing laboratory reports. Additionally, these feature indicators can assist patients and public health advisors in understanding the risk factors for neurological disease onset, thus aiding in early disease prevention.
Our study does have some limitations. Primarily, the analysis was conducted using data from a single center, which could limit the generalizability of our findings. Nevertheless, by employing standardized procedures, reagents, and technology that are widely approved, we expect that similar results could be achieved in other settings. This expectation is supported by the robust AUC values observed in our study, indicating a high level of accuracy in disease prediction. These results validate the effectiveness of our model in clinical diagnostic scenarios, even with a constrained data scope. Additionally, the retrospective nature of the study restricted the scope of information obtained from our patients. However, for our purposes, we mainly required results from routine blood tests and accurate diagnoses, which were consistently available for all patients. Owing to its proven ability to distinguish between various neurological conditions effectively, our study establishes a solid foundation for future expansions and applications in more varied clinical environments. To ensure broader applicability and acceptance within the medical community, it is crucial that future studies replicate and validate our findings across multi-center settings.
Conclusions
The present study constructed multiple models using 52 features from the blood routine and biochemical detection data for diagnosis of various nervous system diseases. Meanwhile, distinct hematologic features of various nervous system diseases also were explored. This can help doctors realize early diagnosis and prevention of nervous system diseases (Supplementary Fig. 5).
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary Material 2
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kononikhin, A. S. et al. Prognosis of Alzheimer’s Disease Using Quantitative Mass Spectrometry of Human Blood Plasma Proteins and Machine Learning. Int. J. Mol. Sci.2310.3390/ijms 23147907 (2022).10.3390/ijms 23147907 PMC 931876435887259 · doi ↗ · pubmed ↗
- 2Kriegeskorte, N. & Golan, T. Neural network models and deep learning. Curr. Biol. CB. 29 R 231-r 236 (2019).10.1016/j.cub.2019.02.03430939301 · doi ↗ · pubmed ↗
- 3Zhang, L. et al. A deep learning model to identify gene expression level using cobinding transcription factor signals. Brief. Bioinform.2310.1093/bib/bbab 501 (2022).10.1093/bib/bbab 50134864886 · doi ↗ · pubmed ↗
- 4Liu, M. et al. A computational framework of routine test data for the cost-effective chronic disease prediction. Brief. Bioinform.2410.1093/bib/bbad 054 (2023).10.1093/bib/bbad 05436772998 · doi ↗ · pubmed ↗
- 5Zhang, Z. et al. Abnormal immune function of B lymphocyte in peripheral blood of Parkinson’s disease. Parkinsonism Relat. Disord.11610.1016/j.parkreldis.2023.105890 (2023).10.1016/j.parkreldis.2023.10589037839276 · doi ↗ · pubmed ↗
- 6Ceccanti, M. et al. Creatine kinase and progression rate in amyotrophic lateral sclerosis. Cells 910.3390/cells 9051174 (2020).10.3390/cells 9051174 PMC 729108832397320 · doi ↗ · pubmed ↗
- 7Cochran, B. J., Ong, K. L., Manandhar, B. & Rye, K. A. APOA 1: a protein with multiple therapeutic functions. Curr. Atheroscler. Rep.2310.1007/s 11883-021-00906-7 (2021).10.1007/s 11883-021-00906-733591433 · doi ↗ · pubmed ↗
- 8Xia, H. et al. Predicting transient ischemic attack risk in patients with mild carotid stenosis using machine learning and CT radiomics. Front. Neurol.1410.3389/fneur.2023.1105616 (2023).10.3389/fneur.2023.1105616 PMC 994471536846119 · doi ↗ · pubmed ↗