Pretraining-improved Spatiotemporal graph network for the generalization performance enhancement of traffic forecasting
Xiangyue Zhang, Chao Li, Ling Ji, Yuyun Kang, Mingming Pan, Zhuo Liu, Qiang Qi

TL;DR
This paper introduces a new pre-training method for traffic forecasting that improves long-term predictions and reduces computational costs.
Contribution
The novel ImPreSTDG method combines a Denoised Diffusion Probability Model and a Mamba module to enhance generalization and efficiency in traffic forecasting.
Findings
Experiments show the model effectively handles long-term dependencies and missing data.
The Mamba module reduces computational costs while maintaining accuracy.
The pre-training method outperforms existing models on real-world traffic datasets.
Abstract
Traffic forecasting is considered a cornerstone of smart city development. A key challenge is capturing the long-term spatiotemporal dependencies of traffic data while improving the model’s generalization ability. To address these issues, various sophisticated modules are embedded into different models. However, this approach increases the computational cost of the model. Additionally, adding or replacing datasets in a trained model requires retraining, which decreases prediction accuracy and increases time cost. To address the challenges faced by existing models in handling long-term spatiotemporal dependencies and high computational costs, this study proposes an enhanced pre-training method called the Improved Spatiotemporal Diffusion Graph (ImPreSTDG). While existing traffic prediction models, particularly those based on Graph Convolutional Networks (GCNs) and deep learning, are…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
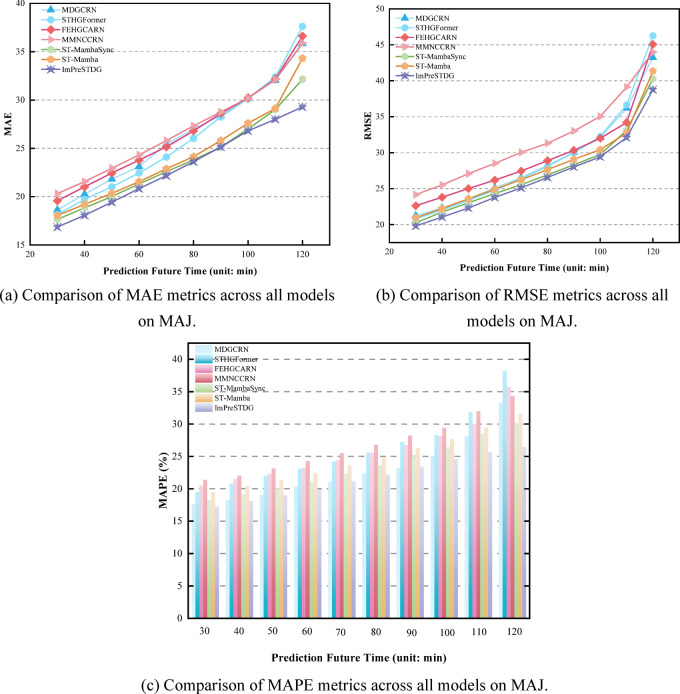 Figure 10
Figure 10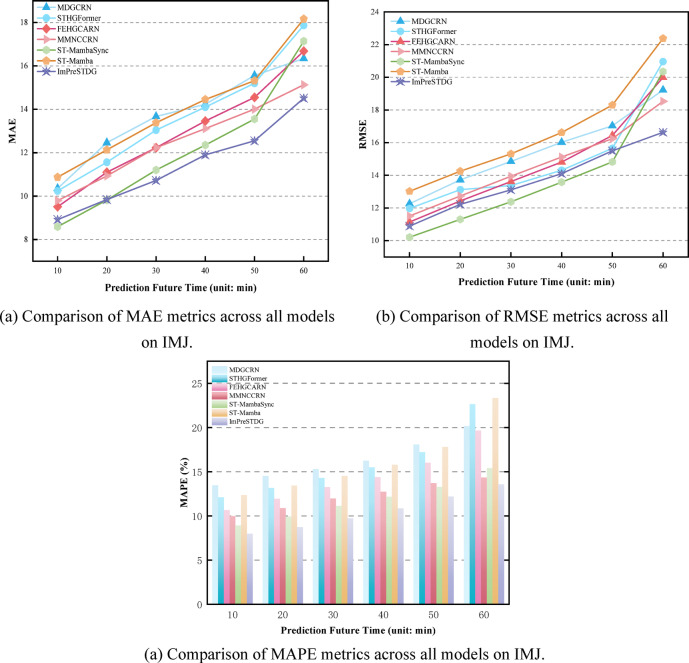 Figure 11
Figure 11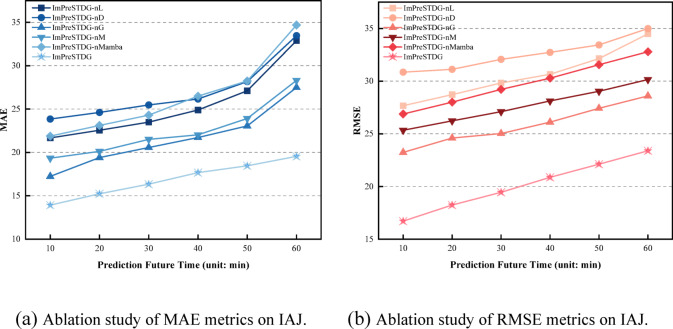 Figure 12
Figure 12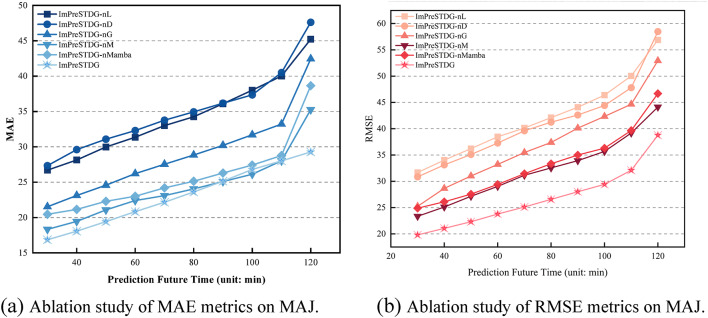 Figure 13
Figure 13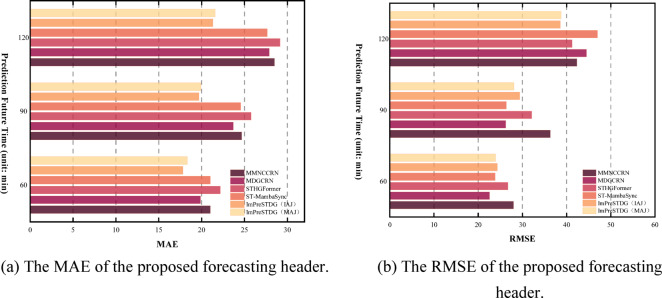 Figure 14
Figure 14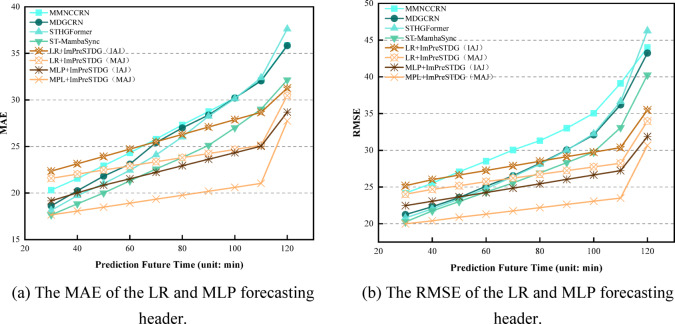 Figure 15
Figure 15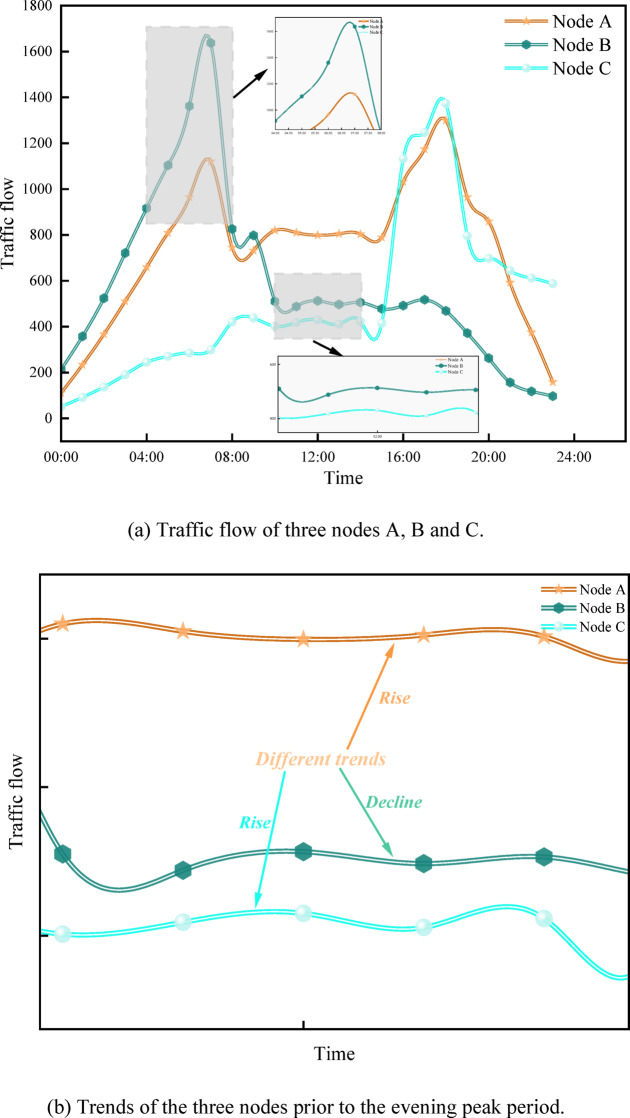 Figure 1
Figure 1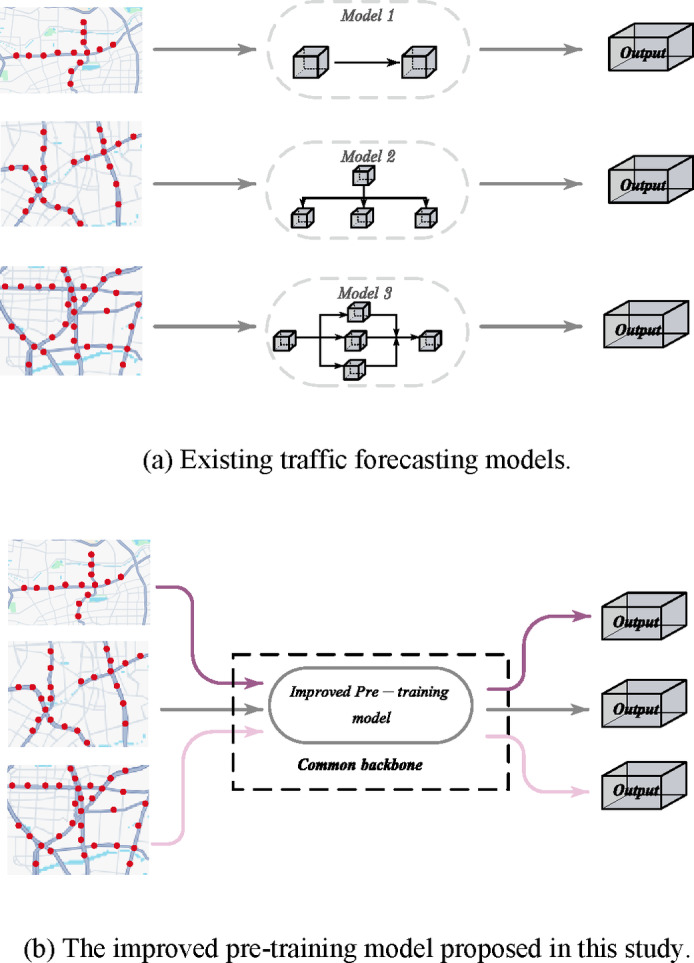 Figure 2
Figure 2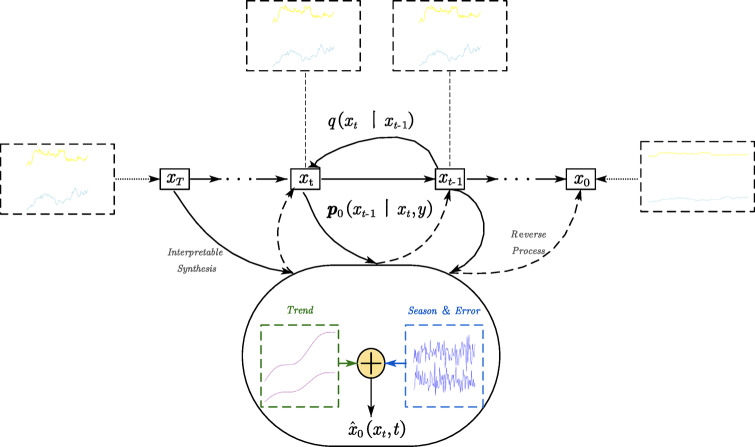 Figure 3
Figure 3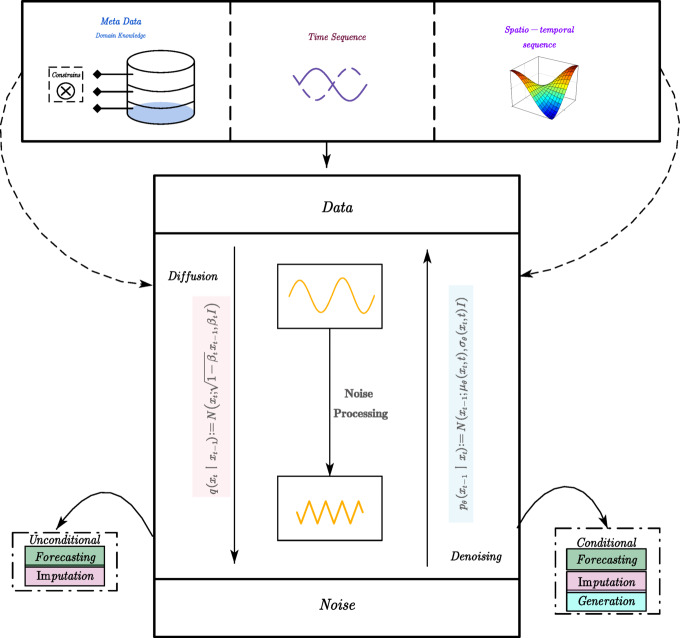 Figure 4
Figure 4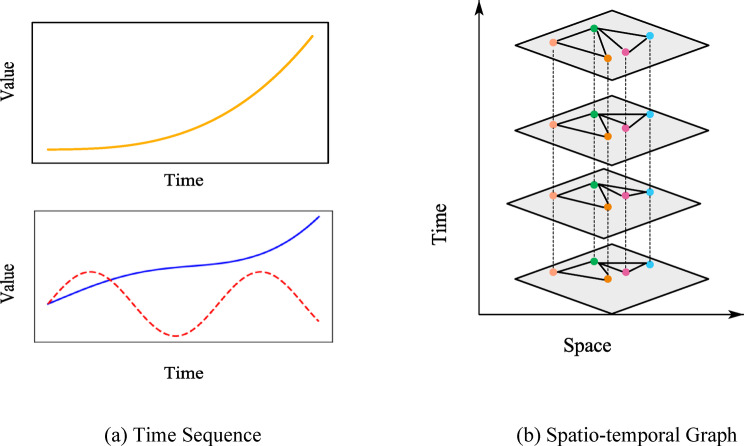 Figure 5
Figure 5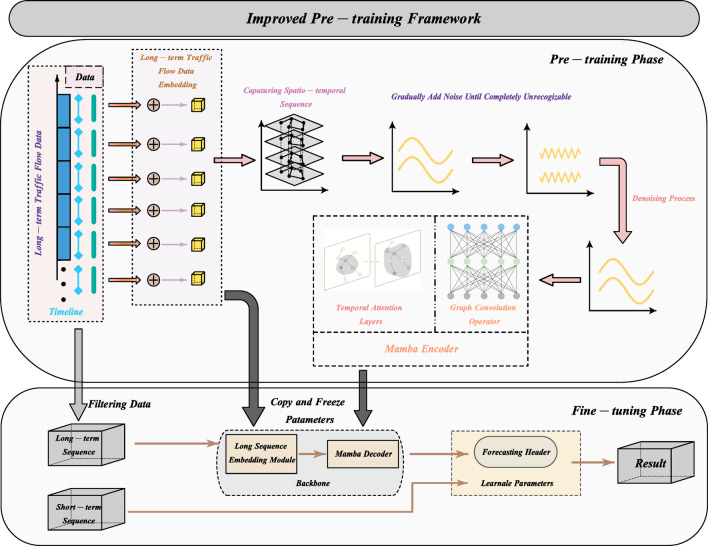 Figure 6
Figure 6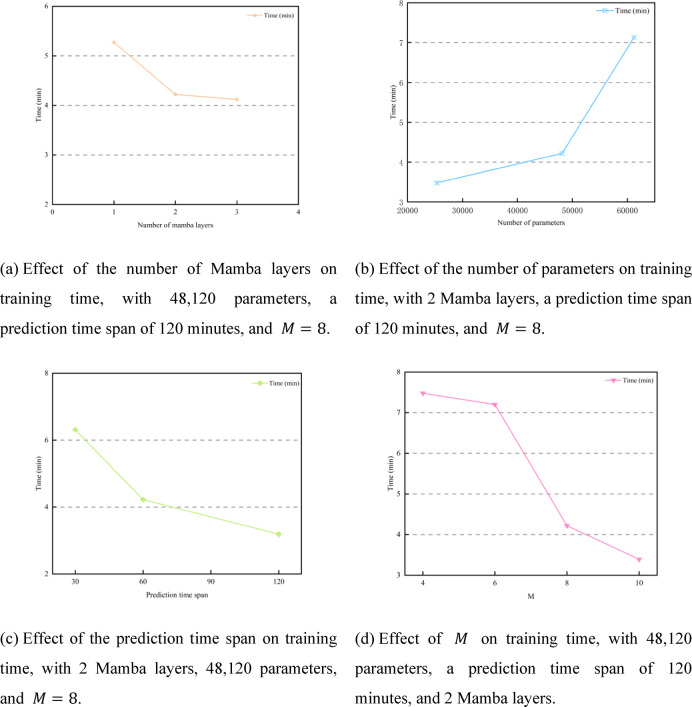 Figure 7
Figure 7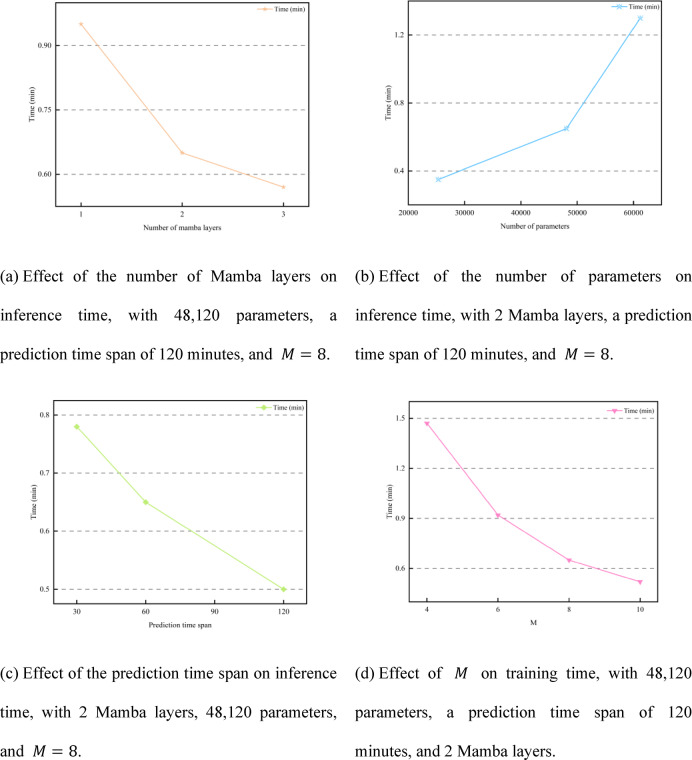 Figure 8
Figure 8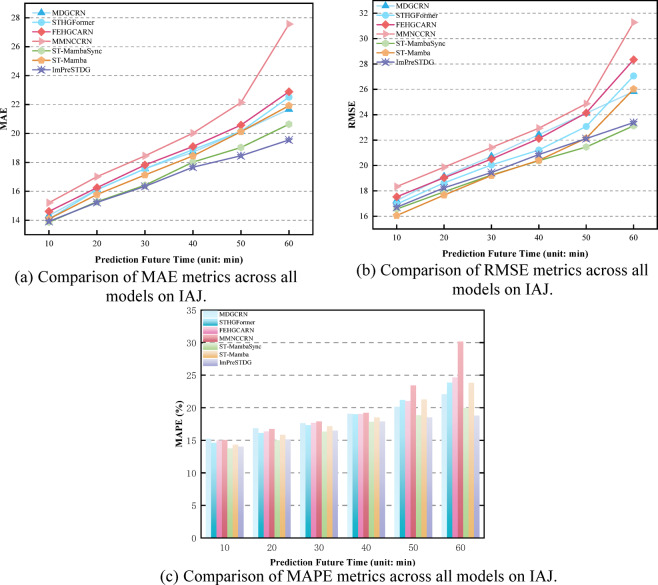 Figure 9
Figure 9- —Shandong Province innovation ability improvement project of science and technology SMES
- —Research and application of key technologies of cargo distribution and transportation based on BDS and 5G
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTraffic Prediction and Management Techniques · Transportation Planning and Optimization · Traffic control and management
Introduction
Traffic forecasting is a cornerstone of smart city development^1,2^. As a core technology of smart cities, traffic forecasting is not only crucial for optimizing traffic flow and alleviating road congestion, but also plays a significant role in reducing environmental pollution, enhancing public safety, and improving urban resource allocation. Accurate traffic forecasting, which facilitates decision-makers in responding more flexibly to changes in road conditions and enhances urban traffic efficiency^3^, is crucial for smart city development.
Graph learning methods have been demonstrated to play a crucial role across various domains. Among these methods, the application of stacked capsule autoencoders (SCAE) was proposed by Hong et al. to encode the parts and poses of facial images^4^. These encoded parts and poses are subsequently utilized to train templates and reconstruct the original facial image within the decoder. In addition, the SCAE was enhanced by incorporating a locality loss function, through which the internal relationships among similar samples are exploited. To achieve this, graph regularization is employed. In this manner, geometry-aware representations with improved quality can be computed. A novel 3D human pose estimation (HPE) architecture, termed the High-Order Graph Convolution Transformer (HOGFormer), was introduced by Xie et al. HOGFormer is composed of three core components: the Chebyshev Graph Convolution (CGConv) module, the Graph-based Dynamic Adjacency Matrix Transformer (GDAMFormer) module, and the High-Order Graph Convolution (HOGConv) module^5^. These advancements in graph-based learning provide valuable references for research in traffic prediction. Machine learning and deep learning are among the most important tools for traffic forecasting^6^. Numerous studies have confirmed the feasibility and significance of machine learning and deep learning in traffic forecasting^7^. The advantage of using machine learning and deep learning for traffic forecasting lies in their ability to automatically learn nonlinear relationships from large^8^, complex historical data, capture spatiotemporal dependencies^9^, and improve accuracy through multimodal data fusion. These methods can process dynamically changing data in real time^10^, provide efficient long-term predictions, and enhance accuracy and computing efficiency through automatic feature extraction and optimization algorithms. Traffic networks are typically represented as graph structures, where nodes correspond to traffic data points and edges represent correlations. Graph convolutional neural networks are used to extract spatiotemporal features and are often integrate with other modules, such as attention mechanisms^11,12^. Although existing GCNs and deep learning models have made notable progress in capturing short-term spatiotemporal dependencies, they exhibit significant limitations when addressing long-term dependencies, such as changes in traffic patterns over hours or even days. Capturing long-term spatiotemporal dependencies is crucial for the accuracy of traffic forecasting. However, existing models have limited capacity in this area, leading to a decrease in prediction accuracy, particularly when traffic patterns undergo substantial changes. In addition, current models typically require the processing of large-scale historical datasets and real-time traffic information. This not only increases computational costs but also complicates the model training and inference processes, thereby impacting both the efficiency and scalability of the models in practical applications.
The disadvantage of using graph convolutional network methods for traffic forecasting is that it is only good at capturing short-term spatiotemporal data (the past one hour), but it is still far from enough to capture long-term spatiotemporal data (the past day or two days or even longer). This will lead to a decrease in the accuracy of the model’s traffic forecasting and misjudgment, as shown in Fig. 1. As shown in Fig. 1 (a), nodes A and C exhibit highly similar trends around 07:00. During the subsequent evening peak period, node A peaks again, while node B shows a stable or declining trend. However, while nodes A and C exhibit similar trends during the evening peak, the trend of node C prior to this period differs significantly from that of node A. As shown in Fig. 1 (b), analyzing only the 6 h before the evening peak may lead the model to incorrectly predict a traffic peak at node B due to the high similarity between nodes A and C. In a word, this analysis highlights the limitations of focusing solely on short-term traffic flow and underscores the need to consider long-term data perspectives.
Fig. 1. Traffic flow at three nodes within Linyi’s transportation network.
While current models, which can effectively capture and analyze long-term spatiotemporal data^13–16^, also increase in computational cost linearly with the continuous embedding of data, this aspect should be considered. Training strategies in natural language processing (NLP)^17,18^, which have gained widespread attention due to their effectiveness in capturing relationships within long sequences of words and sentences, are fundamental to the field. The core principle of pre-training involves masking part of the sequence data, which compels the model to reconstruct the masked portion or predict subsequent data. Capturing relationships in long sequences for traffic forecasting is similar to natural language processing, enabling the use of similar pre-training strategies. This approach leverages a unified pre-trained model backbone to handle various downstream tasks. However, directly applying NLP pre-training methods to traffic forecasting is not feasible without modification. First, in natural language processing, each word carries distinct information, and sentences composed of multiple words convey clear semantics. In contrast, each traffic data point contains limited information. Second, as shown in Fig. 1(b), each traffic data point contains numerical noise, which hinders the model’s ability to capture contextual trends. Additionally, the extremely long input sequences impose a heavy computational burden, and the temporal and spatial dependencies in traffic data must be accounted for. On the other hand, by introducing the Mamba module, a selective mechanism (selective SSM) is employed to capture multivariate correlations^19^, thereby enhancing computational efficiency.
To address these challenges, this study proposes an enhanced pre-training method, the ImPreSTDG, designed to effectively extract long-term spatiotemporal features through data masking and recovery tasks. This approach aims to improve the accuracy and practicality of traffic prediction by reducing computational costs and enhancing the model’s robustness in scenarios with missing data. The structure of this study is shown as follows. In Section II, the related literature is reviewed. In Section III, methodology of this study is introduced. In Section IV, the details of the experiment details are described. Finally, in Section V, this study is summarized and future research directions are proposed.
Related work
Although many advanced traffic prediction models, such as those based on GCN and Spatiotemporal Graph Neural Networks (STGNN), have demonstrated promising results in specific scenarios, they often struggle to adapt to diverse traffic networks and varying environmental conditions. When applied to new cities or different types of traffic data, these models exhibit limited generalization capability. Furthermore, the prevalent issue of missing data in traffic forecasting—especially due to sensor failures, extreme weather, and similar factors—further complicates model performance. Existing models often rely on complete data inputs and lack effective mechanisms for handling missing data, significantly reducing their reliability in real-world applications. In summary, this study aims to enhance the model’s generalization ability and improve its resistance to data disturbances from various sources (as shown in Fig. 2).
Fig. 2. Comparison of existing traffic forecasting models with the improved pre-trained model proposed in this study.
Traditional traffic forecasting models
Traditional traffic forecasting models form the foundational basis upon which modern predictive frameworks have been developed. These approaches, which range from statistical techniques to shallow machine learning methods and eventually to early deep learning paradigms, were initially successful in modeling short-term temporal patterns^20^. However, they have often been found inadequate when tasked with capturing the complex, high-dimensional, and nonlinear spatiotemporal dynamics that characterize real-world traffic systems.
One of the most fundamental methods that has been widely used is the K-Nearest Neighbors (KNN) algorithm, in which predictions are made based on the similarity between historical patterns. As was demonstrated by Zhang et al.^21^, KNN is capable of achieving acceptable performance under stable traffic conditions by identifying similar temporal segments from historical traffic flow data. However, because this method is entirely data-driven and lacks parametric interpretability, its effectiveness is significantly diminished when applied to volatile traffic patterns or scenarios with missing data.
In an effort to overcome these limitations, Gated Recurrent Units (GRUs) were introduced into traffic prediction tasks. A GRU-based model was proposed by Shu et al.^22^, in which nonlinear temporal dependencies are efficiently captured while computational overhead—typically associated with Long Short-Term Memory (LSTM) networks—is reduced. The model’s ability to selectively retain or discard historical information through its gating mechanisms made it particularly well-suited for short-term forecasting. Nonetheless, similar to KNN, GRU-based models do not incorporate spatial structure, as traffic time series are treated as independent sequences without consideration of the underlying connectivity among road segments. A subsequent evolution was realized with the application of Convolutional Neural Networks (CNNs), through which localized temporal features were extracted in a windowed fashion. CNNs were employed by Zhang et al.^23^ to detect temporal trends in traffic flow data, enabling the extraction of hierarchical features from large-scale datasets. However, since CNNs are inherently designed for Euclidean data structures, they are ill-suited to capture the irregular spatial topologies characteristic of road networks. Furthermore, due to their fixed receptive fields, their ability to model long-range temporal dependencies is inherently constrained.
In response to these challenges, graph-based learning approaches were explored, as they are better aligned with the non-Euclidean nature of traffic systems. A STGNN was proposed by Wang et al.^23^, in which spatial and temporal dependencies are jointly captured through the integration of graph convolutional operators with sequence modeling techniques. In their approach, nodes are defined as sensor locations and edges as roadway connections, allowing for a more dynamic representation of traffic networks. Despite these advantages, such architectures have been observed to suffer from accuracy degradation when long input sequences are used or when data is missing, largely due to their reliance on static graph structures and limited sequence modeling capacity.
To better accommodate temporal heterogeneity and periodic traffic behavior, a Spatio-temporal Sequence-to-Sequence Network (STSSN) was introduced by Cao et al.^24^. This model, which was built on an encoder-decoder architecture, incorporates Enhanced Diffuse Convolutional Networks (EDCNs) and Temporal Convolutional Networks (TCNs) to model both daily and weekly traffic periodicities. An encoder-decoder attention (EDA) mechanism was also integrated to enable long-range temporal modeling. However, due to its architectural complexity and dependence on clean input data, the model becomes vulnerable when applied in real-world scenarios involving sensor failures or weather-induced data interruptions.
To specifically address the widespread issue of missing data, DI-LSTM was proposed by Li et al.^25^, in which LSTM networks are combined with a temporal damping mechanism to interpolate missing values prior to forecasting. Although this model exhibits improved robustness in handling data discontinuities, its decoupling of imputation and prediction introduces the risk of error propagation between stages.
More recent efforts have attempted to integrate multiple components to better capture spatial structure and temporal dynamics. For instance, the Task Efficient Graph Attention Network (TE-GAT) has been used to enhance Di-GraphGAN for graph learning, while Temporal Context Attention (TCA) mechanisms have been introduced to dynamically reweight historical data^26^. Although such composite models offer enhanced adaptability, they often impose substantial computational demands and require carefully calibrated architectures to generalize across diverse urban networks.
In summary, while a wide range of models—from KNN to DI-LSTM—have laid the groundwork for data-driven traffic forecasting, they remain limited in their capacity to model long-range dependencies, to process non-Euclidean spatial inputs, and to function robustly in the presence of incomplete or noisy data. These limitations underscore the necessity of developing unified, pretrainable architectures that can integrate spatial reasoning, deep temporal modeling, and adaptability to real-world conditions—capabilities that are addressed by the framework proposed in this study.
Graph-based and Attention-enhanced models
To address the limitations inherent in traditional traffic forecasting methods—particularly in modeling spatial dependencies and in accommodating the non-Euclidean nature of road networks—researchers have increasingly adopted graph-based learning paradigms. In these approaches, the topological structure of traffic systems is explicitly leveraged by representing roads, intersections, or sensors as nodes, and by modeling their interconnections as edges within a graph. Among such methods, Graph Convolutional Networks (GCNs) have emerged as a foundational technique through which spatial correlations can be effectively learned from graph-structured data.
One of the early and influential developments in this direction was the introduction of STGNNs, in which GCNs are extended through integration with temporal modeling modules. For example, a model was proposed by Wang et al.^23^, in which spatial graph convolutions are combined with sequential learning units to simultaneously capture intra-temporal and inter-node dependencies within a unified framework. By moving beyond the assumptions of Euclidean space, these models are capable of learning richer representations of urban traffic dynamics. Nevertheless, several limitations remain. Many of these models rely on static or manually constructed adjacency matrices, are sensitive to the quality of the underlying graph structure, and struggle with scalability when faced with long temporal sequences or incomplete and noisy data inputs.
In response to the need for improved temporal modeling, sequence-to-sequence architectures augmented with attention mechanisms have been explored. A representative example is the STSSN)introduced by Cao et al.^24^, which incorporates EDCNs for spatial processing and TCNs for extracting temporal features. A central innovation of this model lies in its EDA mechanism, through which long-range temporal dependencies are captured while mitigating the risk of error accumulation. However, despite the sophistication of its design, STSSN remains highly sensitive to input data quality and often requires carefully customized components to adapt to varying traffic scenarios.
To address the challenge of missing or corrupted sensor data, the DI-LSTM model was proposed by Li et al.^25^, wherein a temporal damping mechanism is integrated within a recurrent framework to estimate missing values and stabilize time-series reconstructions. While this model enhances robustness to incomplete data, it treats interpolation and forecasting as two disjoint tasks, thereby risking the propagation of errors across stages and lacking a globally optimized mechanism for joint modeling.
Subsequent advancements have led to the adoption of graph attention mechanisms, which allow for adaptive, data-driven weighting of neighboring nodes. For instance, the Task-Efficient Graph Attention Network (TE-GAT), developed in conjunction with Di-GraphGAN^26^, incorporates attention layers to flexibly model traffic dynamics based on node-level interactions. When combined with the TCA module, this architecture is capable of capturing both spatial irregularity and temporal evolution in a context-aware manner. Nonetheless, the deployment of such models often results in high computational overhead due to the multiple attention layers involved, and their performance tends to be highly dependent on careful tuning across datasets or urban contexts.
Although these models collectively represent meaningful progress in learning complex spatiotemporal patterns, they continue to face three core limitations:
- Long-sequence temporal modeling remains constrained by architectural depth and computational cost, particularly in Transformer-based variants.
- Handling noisy or incomplete data is frequently treated as a preprocessing step external to the core learning pipeline, often via separate imputation modules.
- Generalization to unseen domains is weak, as many models are prone to overfitting to the structural properties of the training graph, thereby limiting their transferability.
These persistent challenges highlight the need for a unified architectural solution—one that can efficiently model long temporal sequences, inherently incorporate spatial structures, and robustly handle incomplete data, while also enabling pre-training and transfer across heterogeneous datasets. This necessity forms the foundation for the introduction of state-space modeling techniques and diffusion-based generative frameworks, both of which provide the theoretical and practical underpinnings for the pretraining strategy proposed in this study.
Pretraining and Long-sequence modeling paradigms
The increasingly complex structure of urban traffic systems has introduced significant challenges for traditional forecasting models, particularly when long-term dependencies, large-scale spatiotemporal data, and heterogeneous input conditions must be addressed. Most deep learning architectures—including recurrent neural networks, temporal convolutional networks, and even attention-based transformers—have been found to struggle in efficiently modeling long sequences, owing to computational bottlenecks, limited memory capacity, and instability in gradient propagation. Moreover, these models typically require extensive labeled datasets and frequent retraining when deployed across different domains, such as in new cities or alternative sensor networks.
A promising direction for overcoming these limitations lies in the paradigm of pretraining, which has already transformed fields such as NLP. Pretraining refers to the process through which generalized representations are learned from large-scale, unlabeled data and subsequently fine-tuned on downstream tasks with minimal additional supervision. In NLP, models such as BERT and GPT achieve this by employing masked token prediction or next-token prediction to capture global dependencies across extensive text corpora. The central advantage of pretraining is that it decouples the representation learning phase from task-specific objectives, thereby allowing models to generalize more effectively and adapt more rapidly to new scenarios.
Motivated by this success, recent research in traffic prediction has begun to explore the transferability of pretraining strategies originally developed for NLP to the spatiotemporal domain. However, the direct transfer of pretraining strategies from NLP to traffic forecasting is far from straightforward, as traffic data introduces a distinct set of challenges that complicate such adaptation. Unlike words in natural language, which inherently carry semantic meaning and contextual associations, individual traffic data points lack intrinsic semantic richness and are highly vulnerable to stochastic fluctuations induced by external disturbances—such as weather anomalies, sensor failures, or traffic accidents. As a result, the extraction of stable and context-aware representations becomes substantially more difficult. Moreover, the temporal sequences observed in traffic datasets are typically much longer and more fine-grained than those encountered in linguistic corpora. While a sentence in NLP may consist of only tens of tokens, traffic time series often span thousands of time steps, thereby imposing significantly greater computational burdens during both training and inference phases. Most critically, effective traffic forecasting necessitates the joint modeling of spatial dependencies and temporal dynamics, a requirement that standard Transformer-based pretraining frameworks—originally developed for unstructured text—are not inherently designed to fulfill. These limitations collectively underscore the need for domain-specific innovations in both model architecture and pretraining methodology, in order to fully harness the potential of self-supervised learning for traffic prediction tasks.
To address these domain-specific constraints, recent approaches have incorporated SSM and DDPM into traffic prediction pipelines. These modeling paradigms have been shown to reduce computational complexity, improve robustness against noise, and naturally support masking-reconstruction tasks that are well-suited for pretraining. By leveraging the representational flexibility of SSM and the generative learning capabilities of DDPM, these approaches aim to build more adaptable, scalable, and accurate traffic forecasting systems.
Selective state space models
To address the limitations of Transformer-based models in capturing long-term dependenciesparticularly the high computational complexity associated with attention mechanisms \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left(\mathcal{O}\left({\text{L}}^{2}\right)\right)$$\end{document} researchers have proposed SSM as a more efficient alternative for sequence modeling. An SSM characterizes the evolution of hidden states through a set of continuous-time, linear, time-invariant differential equations, which are naturally suited to dynamic systems such as traffic networks.
As outlined in a recent study^19^, the general form of an SSM can be expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\frac{\text{d}\text{h}\left(\text{t}\right)}{\text{d}\text{t}}=\text{A}\text{h}\left(\text{t}\right)+\text{B}\text{u}\left(\text{t}\right),\:\text{y}\left(\text{t}\right)=\text{C}\text{h}\left(\text{t}\right)+\text{D}\text{u}\left(\text{t}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{u}\left(\text{t}\right)$$\end{document} denotes external influences such as traffic signals or weather conditions. This formulation supports discrete-time update mechanisms, which preserve linear computational scaling with respect to sequence length^19^, thereby enabling the model to remain efficient even when applied to extended traffic sequences.
To further develop this framework, an analogy has been drawn by your work^28^ between SSM and attention mechanisms, demonstrating that linear regression in the state update process can be interpreted as a form of attention-where each prediction corresponds to a weighted sum of previous outputs:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\text{y}}} = \text{X}( \text{X}^{\text{T}}\text{X})^{ - 1} \text{X}^{\text{T}} \text{y}$$\end{document}This perspective provides theoretical support for replacing computationally intensive attention operations with more efficient state evolution functions. The Mamba module, as introduced in your paper^29^, builds upon this idea by incorporating selective mechanisms, analogous to dynamic gating, which allow the model to memorize and propagate relevant temporal signals while suppressing irrelevant ones. Such SSM offer several critical advantages that render them particularly well-suited for traffic forecasting applications. First, they facilitate the efficient modeling of long temporal sequences with linear computational complexity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left(O\left(L\right)\right)$$\end{document} , in contrast to the quadratic scaling inherent in traditional attention mechanisms. This property allows SSM to scale effectively to traffic datasets that span multiple days or weeks at high temporal resolutions. Second, their selective gating mechanisms enable dynamic adaptation to both local and global spatiotemporal patterns. As a result, these models are capable of capturing transient phenomena, such as rush-hour surges, as well as longer-term periodic trends, including daily or weekly traffic cycles. Finally, as demonstrated in prior work^30^, such models naturally accommodate the integration of exogenous variables—including weather conditions, road events, and traffic signals—through additive residual pathways. This not only enhances the model’s flexibility in diverse real-world contexts but also improves its interpretability, which is crucial for operational deployment in intelligent transportation systems.
Crucially, selective SSM such as Mamba demonstrate strong performance without requiring multi-head attention layers, making them especially well-suited for low-latency, real-time forecasting in smart city applications.
Denoising diffusion probabilistic models
While SSM offer efficient modeling of sequence evolution, they typically assume that the input stream is relatively complete and well-conditioned. In contrast, real-world traffic data are often incomplete, corrupted, or subject to abrupt fluctuations. To enable robust learning under such noisy conditions, your study incorporates DDPM^28,29^. DDPM are generative models designed to learn data distributions through a two-phase process:
- Forward diffusion, in which Gaussian noise is gradually added to the input data over multiple time steps.
- Reverse denoising, in which the model learns to iteratively remove noise and recover the original clean signal.
This two-phase process is illustrated in Fig. 3, which shows how a traffic signal is progressively corrupted by noise in the forward diffusion steps and then reconstructed during reverse denoising. The visualization helps convey how the model learns to restore underlying patterns through iterative refinement.
Fig. 3. In diffusion models, time series data undergo both forward and reverse diffusion processes.
As described in^29^, the forward diffusion process can be formalized as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{q}\left({\text{x}}_{\text{t}}\mid\:{\text{x}}_{\text{t}-1}\right)=\mathcal{N}\left({\text{x}}_{\text{t}};\sqrt{1-{{\upbeta\:}}_{\text{t}}}{\text{x}}_{\text{t}-1},{{\upbeta\:}}_{\text{t}}\text{I}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{\upbeta\:}}_{\text{t}}$$\end{document} denotes a variance schedule that controls the noise level. In the reverse process, the model is trained to learn a posterior distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{p}\left({\text{x}}_{\text{t}-1}\mid\:{\text{x}}_{\text{t}}\right)$$\end{document} , parameterized by a neural network. As highlighted in your study^30,31^, DDPM are particularly well-suited for traffic prediction tasks due to their inherent ability to handle noisy and incomplete data through probabilistic generative modeling. First, they can reconstruct missing values by leveraging contextual information from surrounding observations, effectively treating corrupted inputs as noise-injected segments within the diffusion framework. This enables the model to maintain robust representations even in the presence of substantial sensor outages or anomalies. Second, DDPM are highly compatible with pretraining paradigms, as the forward diffusion process—where data is deliberately corrupted—closely mimics real-world scenarios involving incomplete or disrupted traffic data. By training the model to denoise these corrupted inputs, the system learns to infer latent spatiotemporal structure without requiring fully labeled data. These characteristics collectively make DDPM an effective backbone for robust and transferable representation learning in large-scale, noise-prone traffic forecasting applications. A deeper look into the spatiotemporal modeling capabilities of DDPM is provided in Fig. 4, which visualizes how the denoising process preserves both temporal progression and spatial coherence over traffic nodes, supporting structured recovery across the network.
Fig. 4. This study provides an overview of diffusion models for time series and spatiotemporal data analysis. In the diffusion process, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{t}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{t-1}$$\end{document} are denoted as the results after noise is added at steps \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t-1$$\end{document} , respectively. The process is represented by a control step \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{t}\epsilon \left(\text{0,1}\right)$$\end{document} , an identity matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:I$$\end{document} , and a Gaussian distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N\left(x,\mu\:,\sigma\:\right)$$\end{document} over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:x$$\end{document} with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} and covariance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:$$\end{document} . During the denoising process, the data distribution is iteratively learned by modeling \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{p}_{\theta\:}\left({x}_{t-1}|{x}_{t}\right)$$\end{document} . The functions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{\theta\:}\left(\bullet\:\right)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\sigma\:}_{\theta\:}\left(\bullet\:\right)$$\end{document} are treated as the model’s learnable parameters.
To clarify the distinction between simple time series and structured spatiotemporal graph inputs, Fig. 5 compares traditional univariate and multivariate time series (5a) with graph-based representations of traffic flow (5b), highlighting how spatial relationships are explicitly encoded and preserved during the learning process. This process enables the model to establish strong priors over both short-term variability and long-term structure, even in the presence of significant input corruption. When integrated with the Mamba encoder, DDPM contributes to a multi-level representation: combining the structured temporal inference of SSM with the robustness afforded by generative modeling. Collectively, the integration of Mamba-based selective state space modeling and DDPM-based generative pretraining constitutes a complementary dual mechanism for spatiotemporal traffic forecasting. This architecture is capable of effectively learning from long, noise-prone traffic sequences by capturing both structural regularities and stochastic variations across temporal and spatial dimensions. Moreover, by decoupling representation learning from task-specific supervision, the proposed framework facilitates transfer learning across heterogeneous urban traffic datasets, thereby enabling adaptation to varying sensor distributions and network topologies. Additionally, the use of a pretrained backbone significantly reduces the retraining and adaptation burden typically required for model deployment in new environments, thus enhancing the scalability and real-world applicability of the system.
Fig. 5. Different data sequence types.
Summary and positioning of our contribution
The evolution of traffic forecasting methodologies over recent decades reflects a progressive enhancement in the modeling of spatiotemporal dynamics. Early statistical and shallow learning models—such as ARIMA, KNN, and GRU^21–23^—provided lightweight solutions for short-term prediction tasks but lacked the expressive capacity necessary to capture the nonlinear and high-dimensional patterns characteristic of modern traffic systems. These limitations motivated the development of graph-based neural networks and attention-augmented architectures^23–26^, which introduced spatial awareness and dynamic temporal reasoning into forecasting frameworks. Nonetheless, despite these advancements, such models continue to exhibit several practical deficiencies, including sensitivity to missing data, inefficiencies in handling long temporal sequences, and poor generalization across urban contexts with differing topologies or sensor configurations.
In response to these enduring challenges, the research community has increasingly turned to pretraining paradigms inspired by advances in NLP^27^, with the aim of decoupling representation learning from downstream forecasting objectives. However, as previously discussed, traffic data presents a set of unique complexities—including limited semantic granularity, high temporal resolution, and the necessity of jointly modeling spatial and temporal dependencies—which are not readily addressed by standard pretraining methods designed for unstructured text data. These domain-specific constraints necessitate the development of tailored architectural and training innovations, rather than direct adaptations of NLP-based frameworks.
To address this need, we propose a unified modeling framework that integrates two complementary strategies: SSM and DDPM^19,28–31^. The SSM component, implemented using the Mamba architecture^29,30^, enables efficient long-range sequence modeling by dynamically adapting to multi-scale spatiotemporal patterns. This allows the encoder to process long, fine-grained traffic sequences with linear time complexity, thereby avoiding the quadratic computational overhead characteristic of attention-based models. Concurrently, the DDPM module introduces a generative pretraining strategy that is specifically tailored to the properties of traffic data. By treating masked or incomplete inputs as noise-injected segments, DDPM facilitates the reconstruction of missing values and the recovery of global structure through a progressive denoising process^28–31^.
These two components collectively form the foundation of the ImPreSTDG framework, which is designed to address three critical limitations observed in current traffic forecasting research:
- A limited capacity to model long-term dependencies without incurring exponential growth in computational complexity;
- Insufficient robustness to noisy or incomplete data, particularly in scenarios involving sensor failure or environmental disruption;
- Poor cross-domain generalization, which renders model transfer across cities or networks computationally expensive and operationally inefficient.
By pretraining a scalable, robust, and transferable spatiotemporal encoder, the proposed framework enables rapid adaptation to diverse downstream forecasting tasks with minimal fine-tuning. Extensive experiments conducted on multiple real-world traffic datasets validate the effectiveness of this approach, demonstrating consistent improvements in both predictive accuracy and computational efficiency when compared to existing state-of-the-art models.
Method
Traffic network definition
In this study, the road network is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=\left(N,D\right)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N=\left\{{n}_{1},{n}_{2},\cdots\:,{n}_{K}\right\}$$\end{document} denotes the set of nodes, with each loop detector treated as a node. The number of nodes is represented by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} represents the set of edges, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i,j}$$\end{document} indicates the connection between two nodes. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\in\:{\mathbb{R}}^{K\times\:L}$$\end{document} denotes the historical traffic data of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} nodes over a historical period \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L$$\end{document} . Assuming the current time is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} , the traffic forecasting problem is formulated to learn the mapping function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f$$\end{document} , which predicts future traffic data for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{P}$$\end{document} steps using the past \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L$$\end{document} historical data:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left[{\widehat{X}}_{t+1},\cdots\:,{\widehat{X}}_{t+P}\right]=f\left(G;\left[{X}_{t-L+1},\cdots\:,{X}_{t}\right]\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left[{\widehat{X}}_{t+1},\cdots\:,{\widehat{X}}_{t+P}\right]\in\:{\mathbb{R}}^{K\times\:P}$$\end{document} represents the predicted values, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left[{X}_{t-L+1},\cdots\:,{X}_{t}\right]\in\:{\mathbb{R}}^{K\times\:L}$$\end{document} represents the historical data. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\widehat{\:X}}_{i}$$\end{document} denotes the predicted value, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{X}_{i}$$\end{document} denotes the actual traffic data at node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} .
Graph convolutional network
The GCN model is a powerful tool used on graph-structured data. The connectivity of roads is represented by an adjacency matrix, capturing the topology features of road networks. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:l$$\end{document} th layer of the GCN model is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Q}^{\left(l\right)}=\left[{q}_{1}^{\left(l\right)},\cdots\:,{q}_{K}^{\left(l\right)}\right]\in\:{\mathbb{R}}^{K\times\:{O}^{\left(l\right)}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i\in\:K$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{q}_{i}^{\left(l\right)}$$\end{document} represents node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} with a length of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Q}^{\left(l\right)}$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:{Q}^{\left(l\right)}$$\end{document} is the dimension of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:l$$\end{document} th hidden layer, and if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} is the last layer, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Q}^{\left(L\right)}=P$$\end{document} . For convenience, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document} is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Q}^{\left(0\right)}$$\end{document} . The adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:A\:\in\:\:{\mathbb{R}}^{K\times\:K}$$\end{document} contains values of 0 or 1, where 0 indicates no connection between nodes and 1 indicates a connection. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{E}_{i,i}={\sum\:}_{j}A\in\:\:{\mathbb{R}}^{K\times\:K}$$\end{document} represents the diagonal degree matrix of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:A$$\end{document} . As defined by Kipf and Welling^31^, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:(l\:+\:1)$$\end{document} th convolutional layer is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{q}_{i}^{(l+1)}=\theta\:\left(\sum\:_{j\in\:sn\left(i\right)}\frac{1}{\sqrt{{\stackrel{\sim}{E}}_{i,i}{\stackrel{\sim}{E}}_{j,j}}}{q}_{j}^{\left(l\right)}{W}^{\left(l\right)}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Kn\left(i\right)$$\end{document} denotes node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n\left(i\right)$$\end{document} and its neighbors.
The equivalent matrix form is given as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Q}^{(l+1)}=\theta\:\left({\stackrel{\sim}{E}}^{-\frac{1}{2}}\stackrel{\sim}{A}{\stackrel{\sim}{E}}^{-\frac{1}{2}}{Q}^{\left(L\right)}{W}^{\left(l\right)}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:\stackrel{\sim}{A}\:=\:A\:+\:{I}_{K},\:\stackrel{\sim}{E}\:=\:E\:+\:{I}_{K}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:I$$\end{document} is the identity matrix. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Q}^{(l+1)}\:\in\:{\mathbb{R}}^{K\times\:{O}^{(l+1)}}\:\:$$\end{document} represents the output of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:(l\:+\:1)$$\end{document} th layer, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:W\left(l\right)\:\in\:\:RQ\left(l\right)\times\:Q(l+1)$$\end{document} denotes the weight parameters, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\theta\:$$\end{document} is the nonlinear activation function.
Temporal attention layers
The aim of this module is to estimate the saliency and relevance of each sequence observation. The saliency score should be based not only on the current time step’s input but also on information from neighboring observations in both directions.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{a}_{t}=\sigma\:\left({m}^{\top\:}\left({\overrightarrow{h}}_{t};{\overleftarrow{h}}_{t}\right)+b\right)$$\end{document}where, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{m}$$\end{document} is the weight vector of the fusion layer that integrates both directional layers, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b$$\end{document} is the bias term. A sigmoid function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\upsigma\:}$$\end{document} is employed as the activation function at the top layer of the attention module in Eq. (7) to constrain the attention weight to lie between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left[\text{0,1}\right]$$\end{document} .
The vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\overrightarrow{\text{h}}}_{\text{t}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\overleftarrow{\text{h}}}_{\text{t}}$$\end{document} are the hidden representations of module:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\overrightarrow{\text{h}}}_{\text{t}}=\text{g}\left(\overrightarrow{\text{W}}{\text{x}}_{\text{t}}+\overrightarrow{\text{U}}{\overrightarrow{\text{h}}}_{\text{t}-1}+\overrightarrow{\text{b}}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\overleftarrow{\text{h}}}_{\text{t}}=\text{g}\left(\overleftarrow{\text{W}}{\text{x}}_{\text{t}}+\overleftarrow{\text{U}}{\overleftarrow{\text{h}}}_{\text{t}+1}+\overleftarrow{\text{b}}\right)$$\end{document}ReLU functions are used as the activation functions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:g$$\end{document} .
Furthermore, another important role the learned attention weights play is to provide interpretability regarding the degree of salience of each time step.
Pre-training framework
The pre-training model proposed in this study offers several significant advantages. (1) Denoising Process Enhances Stability: The denoising process stabilizes the model’s ability to handle random fluctuations and noise in the data. By utilizing a denoising probabilistic model, effective representations are learned from noisy data through forward diffusion and reverse denoising, improving the model’s capacity to manage noise and missing data. This approach is especially effective in addressing the common issues of noise and missing data in traffic forecasting, such as sensor failures or environmental factors. (2) Integrating long-term and short-term historical data enhances forecasting capabilities: By employing pre-training and fine-tuning, the proposed method extracts global features from long-term historical data and integrates short-term local trends, enabling comprehensive modeling of complex spatio-temporal dependencies and significantly enhancing the accuracy and robustness of traffic forecastings. (3) Versatility and rapid deployment: The backbone network generated through pre-training is highly versatile, capable of integrating with various prediction heads to adapt to a wide range of downstream tasks. Moreover, pre-trained models can be transferred across datasets, substantially reducing retraining requirements, expediting deployment, and enhancing efficiency. (4) Efficient long-term spatiotemporal modeling: The Mamba encoder employs a selective state-space model, crucial for capturing long-term dependencies in traffic data.
Building upon the preceding discussion, the complete architecture of the proposed traffic forecasting framework—ImPreSTDG is depicted in Fig. 6. The model is constructed as a modular pipeline that sequentially integrates three core components: graph-based spatial modeling, state-space-based temporal encoding, and diffusion-based generative pretraining, culminating in a lightweight forecasting head. Each module contributes a distinct function within the overall learning framework and is formally defined in the subsequent sections.
Fig. 6. The improved pre-training framework shown in this study.
- Spatial Encoder
The raw input sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{X}\in\:{\mathbb{R}}^{\text{N}\times\:\text{T}\times\:\text{F}}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{N}$$\end{document} denotes the number of nodes, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{T}$$\end{document} represents the number of observed time steps, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{F}$$\end{document} is the number of input features, is initially processed through a graph convolutional encoder. Spatial dependencies among nodes are captured using a normalized adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\stackrel{\sim}{A}$$\end{document} . At each time step \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{t}$$\end{document} , spatial representations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{H}}_{\text{t}}\in\:{\mathbb{R}}^{\text{N}\times\:\text{D}}$$\end{document} are computed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{H}}_{\text{t}}={\upsigma\:}\left(\stackrel{\sim}{A}{\text{X}}_{\text{t}}{\text{W}}_{1}+{\text{b}}_{1}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{W}}_{1}$$\end{document} is a learnable weight matrix and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\upsigma\:}$$\end{document} denotes a nonlinear activation function. The output is a tensor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{H}\in\:{\mathbb{R}}^{\text{N}\times\:\text{T}\times\:\text{D}}$$\end{document} , which encodes localized spatial features across the sequence.
- 2.Temporal Encoder
To capture long-range temporal dependencies, we utilize a SSM instantiated via the Mamba architecture. The spatial features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{H}$$\end{document} are fed into the SSM module, which performs efficient, linear-time sequence modeling over the temporal axis:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{Z}=\text{S}\text{S}\text{M}\left(\text{H}\right)\in\:{\mathbb{R}}^{\text{N}\times\:\text{T}\times\:\text{D}}$$\end{document}The Mamba kernel dynamically selects and aggregates information across time steps through structured state transitions, enabling the model to efficiently encode both short-term variations and long-term temporal patterns.
- 3.Pretraining Decoder
In parallel with supervised learning, a DDPM is incorporated to enable self-supervised pretraining. During this phase, the input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{X}$$\end{document} is partially masked to obtain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\overline{\text{X}}$$\end{document} , which is then corrupted via a forward Gaussian diffusion process:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\overline{\text{X}}}_{\text{t}}=\sqrt{1-{{\upbeta\:}}_{\text{t}}}{\overline{\text{X}}}_{\text{t}-1}+{\epsilon}_{\text{t}},\:{\epsilon}_{\text{t}}\sim\:\mathcal{N}\left(0,{{\upbeta\:}}_{\text{t}}\text{I}\right)$$\end{document}The DDPM decoder is trained to reverse this noise injection via a denoising process:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\text{X}}} =\epsilon_{{\uptheta\:}}\left({\overline{\text{X}}}_{\text{t}},\text{t}\right)$$\end{document}This results in a pre-trained representation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{Z}}_{\text{D}\text{D}\text{P}\text{M}}\in\:{\mathbb{R}}^{\text{N}\times\:\text{T}\times\:\text{D}}$$\end{document} , which aligns with the masked input regions and supports both missing data reconstruction and regularization of the supervised training process.
- 4.Forecasting Head
The outputs from the SSM-based temporal encoder and the DDPM decoder are concatenated and passed into a Meta-Fusion Block, which consists of either a lightweight 1D convolutional layer or a spatiotemporal attention module, depending on the task requirements. The final prediction is computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\text{Y}}}=\text{M}\text{e}\text{t}\text{a}\text{F}\text{u}\text{s}\text{i}\text{o}\text{n}\left(\text{Z},{\text{Z}}_{\text{D}\text{D}\text{P}\text{M}}\right)\in\:{\mathbb{R}}^{\text{N}\times\:{\text{T}}^{{\prime\:}}\times\:{\text{F}}^{{\prime\:}}}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{T}}^{{\prime\:}}$$\end{document} denotes the forecasting horizon and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{F}}^{{\prime\:}}$$\end{document} the number of target features.
This modular architecture supports end-to-end training while also enabling the decoupling of the pretraining and fine-tuning stages. The DDPM module can be independently trained using a masked reconstruction loss and subsequently frozen during downstream forecasting. The Mambabased SSM ensures efficient long-sequence temporal modeling, even across hundreds of time steps, while the GCN module maintains spatial consistency aligned with the underlying network topology.
Experiment result and analysis
Dataset
The road traffic flow data from Linyi, Qingdao and Jinan, collected between May 1 and December 1, 2018, is used in this study. This dataset is divided into three parts: IAJ, MAJ, and MMJ. The missing values in the dataset have been preprocessed by linear interpolation to fill in the missing values. Where, 70% is used as a training set, 20% as a test set, and 10% as a validation set. To evaluate the generalization ability of the model, three public traffic datasets PeMS03, PeMS04 and PeMS07 from the PeMS system of the California Department of Transportation were selected.
Evaluation metric
Three metrics, Mean Absolute Error (MAE), Root Mean Square Error (RMSE) and Mean Absolute Percentage Error (MAPE), are introduced to measure the model’s performance in terms of prediction accuracy.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{M}\text{A}\text{E}=\frac{1}{KN}\sum_{t=1}^{K}\:\:\sum_{i=1}^{N}\:\:\left|{X}_{i\left(t\right)}-{f}_{i}\left(A,\stackrel{\sim}{X}_{t-\text{L}+1:t}\right)\right|$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{R}\text{M}\text{S}\text{E}=\sqrt{\frac{1}{KN}\sum_{t=1}^{K}\:\:\sum_{i=1}^{N}\:\:{\left({X}_{i\left(t\right)}-{f}_{i}\left(A,\stackrel{\sim}{X}_{t-\text{L}+1:t}\right)\right)}^{2}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{M}\text{A}\text{P}\text{E}\:=\frac{1}{\text{K}\text{N}}\sum_{\text{t}=1}^{\text{K}}\sum_{\text{i}=1}^{\text{N}}\left|\frac{{\text{X}}_{\text{i}\left(\text{t}\right)}-{\text{f}}_{\text{i}}\left(\text{A},\stackrel{\sim}{X}_{\text{t}-\text{L}+1:\text{t}}\right)}{{\text{X}}_{\text{i}\left(\text{t}\right)}}\right|$$\end{document}Task performance is assessed by reporting MAE, RMSE and MAPE values based on the unperturbed input. In this study, MAE, RMSE and MAPE are employed to reflect the model’s performance.
Experiment setting
Models for comparison
In the comparative experiment, several state-of-the-art models and algorithms are used to compare with the proposed model.
- MDGCRN (Multi-scale Fusion Dynamic Graph Convolutional Recurrent Network)^32^: MDGCRN is a technique for creating dynamic graphs, which can effectively capture both short-term and long-term temporal information, as well as spatial information, when combined with GRU.
- STHGFormer (Spatio-Temporal Heterogeneous Graph Transformer)^33^: STHGFormer incorporates a Heterogeneous Spatial Embedding (HSE) module to encode road network information, including diverse attributes and interactions within Heterogeneous Road network Graph (HRG). Based on the spatial information encoded by HSE, the unified SpaFormer serves as the spatial module of STHGFormer to capture the interdependencies of roads across the entire traffic network. An Adaptive Soft Threshold (AST) module is embedded in TempFormer, enabling dynamic threshold adjustment to enhance the ability to analyze complex temporal correlations.
- FEHGCARN (Fourier-enhanced heterogeneous graph convolution attention recurrent network)^34^: FEHGCARN integrates the Graph Convolutional Attention Recurrent Unit (GCARU) with a Fourier-enhanced heterogeneous graph learning module, facilitating the capture of complex relationships between nodes in the frequency domain.
- Multi-level Graph Memory Network Cluster Convolutional Recurrent Network (MMNCCRN)^35^: MMNCCRN comprises four modules: the Encoder Module (EM), Attention Module (AM), Memory Network Cluster Module (MNCM), and Decoder Module (DM). Additionally, a memory network is employed, and clustering is incorporated. By storing and memorizing patterns embedded in spatial and temporal dependencies, it aids the model in learning the underlying graph structure and discovering new hidden patterns.
- Spatial-Temporal Selective State Space Synchronization (ST-MambaSync)^36^: ST-MambaSync integrates Mamba and Transformer.
- Spatial-Temporal Selective State Space (ST-Mamba)^37^: ST-Mamba integrates an efficient Spatiotemporal Mixer (ST-Mixer) to seamlessly combine spatial and temporal data processing into a unified framework, while employing a Spatiotemporal Selective State-space (ST-SSM) block to enhance computational efficiency.
Hyperparameter settings
During the pre-training phase, the hyperparameters for long sequence embedding are set as follows: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{L}=7,\text{D}=64.\text{M}={T}_{l}/\text{L}$$\end{document} is determined by the length of 3 days of data. All hidden feature dimensions are set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{F}=\text{F}=64$$\end{document} . Optimization is performed using the Adam optimizer, starting with a learning rate of 0.001 that gradually decreased.
During the fine-tuning phase, all hidden dimensions are set to 64, and the kernel size of the spatialtemporal convolutions is set to 3. The dilation rates are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:[\text{1,2},4]$$\end{document} , respectively.
Experiment result
Tables 1, 2 and 3 show the prediction performance at different time steps across three datasets, with results reported for three time ranges for clarity. As shown in Tables 1, 2 and 3, the proposed ImPreSTDG outperforms all other methods on the three datasets, overcoming the limitations of focusing solely on short-term spatiotemporal relationships and effectively capturing long-term spatiotemporal semantics. Figs. 7, 8 and 9 visually illustrates the performance on the IAJ, MAJ and IMJ datasets.
Fig. 7. Comparison of performance metrics across all models on IAJ.
Fig. 8. Comparison of performance metrics across all models on MAJ.
Fig. 9. Comparison of performance metrics across all models on IMJ.
In contrast, other models exhibit clear disadvantages. STHGFormer incorporates several complex modules, which could increase the model’s complexity and lead to high computational resource consumption during training and inference. Despite its strong performance on the Wuhan real-world dataset, it remains uncertain whether the model will perform similarly well in other cities or across different types of traffic networks. Although MDGCRN captures spatiotemporal dependencies via dynamic graph generation, it remains highly dependent on the dynamic graph construction process. If the dynamic graph generation process is inaccurate or unable to fully adapt to the highly dynamic traffic patterns, the accuracy of the results could be compromised. FEHGCARN depends on high-quality traffic datasets to extract meaningful spatiotemporal dependencies. If the data contains noise or missing values, the model may fail to fully capture the complex spatiotemporal relationships, potentially impacting prediction accuracy. Although FEHGCARN performs well at identifying sudden traffic events, it may still have limitations in handling high-frequency, short-term traffic fluctuations, such as those caused by sudden accidents or temporary traffic controls. The memory network is a key component of MMNCCRN, enabling the model to learn graph structures by storing and retaining patterns of spatial and temporal dependencies. However, the storage capacity and update mechanism of the memory network can become bottlenecks, particularly when handling very large datasets. As the model undergoes long-term training, the memory module may encounter overload issues, negatively impacting the model’s performance and efficiency. Although ST-MambaSync enhances prediction performance by integrating the Mamba model with the Transformer, its complex architecture—incorporating multiple levels of attention mechanisms and Mamba layers—may lead to significant resource consumption, particularly when processing large-scale datasets. This could result in memory bottlenecks or prolonged computation times, negatively impacting real-time application efficiency. ST-Mamba performs well in short-term forecasting, but both ST-Mamba and STAEformer exhibit limitations in long-term forecasting, such as 24-hour predictions. During periods of significant traffic fluctuations, such as rush hours or emergencies, the model’s predictions may diverge from actual traffic flow, suggesting that further optimization is needed to handle extreme fluctuations and long-term forecasts.
Although ImPreSTDG achieved strong performance across the three indicators on the IAJ and IMJ datasets, there is a slight gap compared to other models in short-term prediction. This is because ImPreSTDG is designed to prioritize capturing long-term spatiotemporal dependencies, whereas in datasets like IAJ and IMJ, capturing short-term dependencies is more crucial. As a result, models such as STHGFormer and FEHGCAREN outperform ImPreSTDG in short-term predictions. However, despite being slightly lower in some short-term prediction indicators, ImPreSTDG demonstrates clear advantages in computational efficiency and model stability (as shown in Figs. 10, 11 and 7). By incorporating the Mamba module, the model significantly reduces computational costs when processing long-term traffic data, particularly in scenarios involving missing data and substantial environmental changes, while maintaining high prediction stability.
Fig. 10. Training time on the MAJ dataset.
Fig. 11. Inference time on the MAJ dataset.
Since long-term traffic data requires processing hundreds or thousands of historical records, the computational complexity becomes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{O}\left({\text{T}}^{2}\right)$$\end{document} , which poses a significant computational burden. To address this issue, this paper proposes a long sequence embedding module that effectively reduces the computational pressure by lowering the complexity from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{O}\left({\text{T}}^{2}\right)$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{O}\left({\text{M}}^{2}\right)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} is an adjustable parameter. As shown in Figs. 10 and 11, the control variable method is used to plot the training and inference times on the MAJ dataset. Regarding the number of Mamba layers, the optimal configuration is achieved when the number of layers is set to 2. Increasing the number of layers beyond this point leads to excessive computations and longer training times without a significant improvement in accuracy. Moreover, this increase in layers also raises the computational cost and may result in overfitting. In this study, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} is an adjustable parameter that controls the computational complexity of the long sequence embedding module. Specifically, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} represents the number of subsequences into which the long sequence data is divided. A larger value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} reduces the length of each subsequence, lowering computational complexity but weakening the time dependency that can be captured. Conversely, a smaller value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} increases the length of each subsequence, allowing for better capture of global time dependencies but at the cost of higher computational complexity. To balance the need for reduced computational complexity while capturing global time dependencies as effectively as possible, the final setting is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M=8$$\end{document} .
To evaluate the generalization ability of the model, three public traffic datasets PeMS03, PeMS04 and PeMS07 from the PeMS system of the California Department of Transportation were selected. When the prediction time spans are set to 60 min and 120 min, the results for three evaluation metrics MAE, RMSE, and MAPE are reported in Tables 4, 5 and 6, demonstrating the superiority of the proposed method.
Table 1. Prediction performance across different time steps on IAJ.ModelsIAJ (10 min/40 min/60 min)MAERMSEMAPE (%)MDGCRN14.3218.7121.6717.2322.4325.8315.2319.0722.08STHGFormer14.0818.8822.5116.9621.2227.0614.5919.0123.86FEHGCARN14.6119.1022.8917.5322.1228.3414.9719.0424.67MMNCCRN15.2120.0227.5618.3422.9431.2815.0319.2230.17ST-MambaSync13.8718.0220.6416.5720.3823.1313.7417.8219.97ST-Mamba14.0918.4521.9216.0620.4126.0214.3318.5223.83ImPreSTDG13.9217.6719.5516.7120.8723.3914.0117.8918.79
Table 2. Prediction performance across different time steps on MAJ.ModelsMAJ (30 min/60 min/120 min)MAERMSEMAPE (%)MDGCRN18.6223.1135.8321.2525.1143.2417.6220.3033.24STHGFormer18.1422.4437.6220.7924.7846.2719.5423.1038.21FEHGCARN19.5723.7836.6222.6326.1945.0520.4523.2435.75MMNCCRN20.3224.3235.8824.1728.5243.9921.3724.3034.34ST-MambaSync17.6521.3132.1520.2524.3140.2618.2421.1230.13ST-Mamba18.0421.5534.3120.9624.9141.3519.5122.4231.54ImPreSTDG16.8620.8329.2819.8123.7838.7717.2419.9026.44
Table 3. Prediction performance across different time steps on IMJ.ModelsIMJ (10 min/40 min/60 min)MAERMSEMAPE (%)MDGCRN10.3514.2316.3412.2616.0219.2213.4616.2520.17STHGFormer10.2414.1017.8711.9714.3120.9612.1115.5022.64FEHGCARN9.5113.4616.6811.1414.8119.9910.6514.3819.66MMNCCRN9.7913.1115.1311.5115.1218.539.9712.7414.34ST-MambaSync8.5912.3517.1410.2113.5820.358.9112.1715.41ST-Mamba10.8714.4518.1613.0216.6222.3812.3515.7923.34ImPreSTDG8.9211.9014.5110.8914.1016.637.9910.8513.57
Table 4. Prediction performance across different time steps on PeMS03.ModelsPeMS03 (10 min/40 min/60 min)MAERMSEMAPE (%)MDGCRN30.7935.8741.1934.6739.2646.3212.2714.0713.17STHGFormer30.1334.7340.0334.1939.2945.3911.6310.2312.33FEHGCARN31.2337.1341.2335.0339.4346.9313.3614.0613.36MMNCCRN31.9137.3142.8135.5740.4747.7714.9213.3212.52ST-MambaSync29.5734.3739.3733.4238.7244.129.4810.6812.58ST-Mamba29.8935.3940.0933.8838.4845.2810.759.8510.85ImPreSTDG29.2134.3138.8032.9838.1241.978.129.4210.62
Table 5. Prediction performance across different time steps on PeMS04.ModelsPeMS04 (10 min/40 min/60 min)MAERMSEMAPE (%)MDGCRN28.9335.8942.8934.7641.8248.8212.3313.7214.33STHGFormer30.3137.4044.4035.1142.1149.1113.0115.0115.01FEHGCARN27.7534.8741.8733.4440.5247.5211.5713.2113.07MMNCCRN29.7536.8243.8234.9742.0449.0412.7414.3614.74ST-MambaSync26.1133.1940.1932.1739.2346.2310.5112.1712.01ST-Mamba28.5335.6342.6334.8842.0149.0111.5313.7313.53ImPreSTDG25.5032.5439.5431.9839.0446.048.099.3910.21
Table 6. Prediction performance across different time steps on PeMS07.ModelsPeMS07 (30 min/60 min/120 min)MAERMSEMAPE (%)MDGCRN18.2526.2534.2528.4737.4747.4712.7213.4513.67STHGFormer19.6227.6236.6230.8539.8549.8514.2815.3415.28FEHGCARN18.8726.8734.8729.1338.1348.1312.2111.5611.89MMNCCRN17.0825.0833.0827.5936.5946.5913.3612.1912.03ST-MambaSync16.3524.3532.3526.8835.8845.8811.1710.6310.47ST-Mamba17.5325.5333.5327.9436.9446.9412.7311.5711.82ImPreSTDG15.3323.3331.3325.6734.6744.678.397.997.83
Ablation study
To further demonstrate that the full model outperforms simplified versions, the performance of model variants with different modules removed is shown in Figs. 12 and 13. Where different variations are listed as followed:
Fig. 12. Comparison of performance metrics across ablation study on IAJ.
Fig. 13. Comparison of performance metrics across ablation study on MAJ.
- ImPreSTDG-nL: the model with no Long sequence embedding.
- ImPreSTDG-nD: the model with no Denoising diffusion probabilistic model.
- ImPreSTDG-nG: the model with no GCNs operator.
- ImPreSTDG-nM: the model with no Meta fusion module in forecasting header.
- ImPreSTDG-nMamba: the model with no Mamba module.
The results show that the full model performs better than any of its abbreviated versions, indicating that each component contributes to improved performance.
Generalization on different datasets
To explore the generalization ability of the proposed ImPreSTDG method, a natural question arises: can the backbone pre-trained on the other two datasets be reused in MAJ? A case study is conducted to evaluate the accuracy of the pre-trained backbones from IAJ and IMJ on MAJ with different prediction heads. The results are presented in Fig. 14. Fig. 14 illustrates the MAE and RMSE results for the last three time steps. The pre-trained backbones from IAJ and MAJ can be reused in IMJ, outperforming other similar methods. This suggests that pre-trained backbones from high-quality datasets are transferable to other traffic scenarios. On the other hand, the validation results with the backbone pre-trained on IAJ and MAJ are shown in Fig. 15, using linear regression (LR)^38,39^ and multi-layer perceptron (MLP)^40,41^ as prediction heads, tested on IMJ.
Fig. 14. Performance of the proposed forecasting header on different datasets.
Fig. 15. The verification results of backbones pre-trained on IAJ and MAJ.
Discussion
While the proposed ImPreSTDG framework achieves competitive forecasting accuracy across multiple benchmark datasets, its broader significance lies in its practical applicability and scalability within real-world urban environments. Architecturally, the model has been purposefully designed to support modular extensibility and computational efficiency, allowing it to be readily adapted to traffic networks of varying sizes and data availability. The incorporation of a SSM—specifically, the Mamba module—ensures that temporal modeling is performed with linear computational complexity relative to sequence length, thereby enabling the handling of long historical traffic records at high temporal resolutions. This contrasts favorably with Transformer-based architectures, which typically suffer from quadratic time and memory costs.
Furthermore, the graph convolutional component operates over sparse adjacency matrices, allowing for efficient parallelization and localized computation—two critical properties for deployment within large-scale sensor networks. These architectural design choices make the model highly suitable for scalable and distributed intelligent transportation systems.
A key consideration for real-world deployment is the adaptability to domain shift, as traffic patterns can vary dramatically across cities due to differences in topology, population density, and environmental conditions. The pretraining mechanism embedded in ImPreSTDG addresses this challenge by learning robust and transferable spatiotemporal priors through denoising-based reconstruction tasks. This unsupervised strategy enables the model to acquire generalizable representations that can be fine-tuned with minimal supervision when applied to new domains. Additionally, the framework supports flexible reconfiguration of key parameters—such as sequence length and input dimensionality—without necessitating full retraining, making it adaptable to heterogeneous sensing infrastructures.
The robustness of the model to noisy or incomplete data is another crucial advantage. In operational deployments, traffic data is frequently affected by missing values, sensor malfunctions, and non-stationarities caused by external disruptions such as inclement weather or construction. The DDPM module mitigates these issues by learning to reconstruct corrupted or masked input sequences, a process that is both label-free and self-supervised, thereby facilitating continuous adaptation as new, unlabeled data becomes available and reducing long-term model maintenance costs.
From a deployment standpoint, the framework supports an offline pretraining–online inference paradigm. The computationally intensive pretraining phase can be executed on cloud infrastructure, while the lightweight forecasting head and SSM modules can be deployed at the edge to enable low-latency, real-time inference. This architecture aligns well with the distributed nature of modern transportation systems, ensuring predictions are made closer to the data source. Moreover, the modular design of the forecasting head allows it to be tailored to specific prediction tasks—such as traffic speed, volume, occupancy, or incident likelihood—thus supporting a broad array of smart mobility applications including signal control optimization, dynamic tolling, and emergency response planning.
Despite its strengths, the current framework is subject to certain limitations. The model presently operates on a static graph structure, which may be insufficient for capturing time-varying changes in road connectivity, congestion patterns, or temporary disruptions. Future research could explore the incorporation of dynamic graph construction mechanisms or adaptive edge weighting schemes. Additionally, while the DDPM component enhances noise robustness, its iterative sampling mechanism remains computationally intensive. Future work may benefit from accelerated sampling techniques or the integration of score-based diffusion alternatives to further reduce inference latency and improve deployment feasibility.
By embedding considerations of efficiency, adaptability, and robustness directly into the model’s architecture, ImPreSTDG moves beyond algorithmic novelty to offer a practical and extensible solution for real-world traffic forecasting. Its dual-path learning structure—combining generative pretraining with efficient state-space inference—positions it as a strong candidate for integration into next-generation intelligent transportation infrastructures, where predictive accuracy, resilience, and domain adaptability must be achieved simultaneously.
Conclusion
An enhanced pre-training method is introduced in this study to overcome the limitations of traditional graph neural networks in traffic forecasting. The model’s intrinsic robustness is improved without the need for extensive dataset pre-processing, unlike other methods. To fully capture long-term spatiotemporal relationships in traffic data, the proposed model includes a backbone network for long-term data processing and a prediction header for short-term data. Additionally, a pre-training strategy is designed to strengthen the backbone structure and enable the generation of generalized traffic features. Experimental results on three real-world datasets demonstrate that the proposed ImPreSTDG performs well across different scenarios. More importantly, the pre-trained backbone is compatible with various prediction headers, and when trained on high-quality data, it can be deployed on other datasets as a ready-made toolbox, highlighting the method’s importance and universality.
In future work, we will continue to focus on traffic forecasting, particularly the impact of traffic accidents. We plan to develop a “detection sentinel” mechanism to navigate and identify sudden events within the graph structure created from road information, such as changes in road network structure or node relationships due to road maintenance or traffic accidents.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Xie, Yuhong, et al. HOG Former: high-order graph convolution transformer for 3D human pose estimation. Int. J. Mach. Learn. 16.1 (2025): 599-610.
- 2Fang, Y., Qin, Y., Luo, H., Zhao, F. & Zheng, K. ST Wave+: A Multi-Scale Efficient Spectral Graph Attention Network with Long-Term Trends for Disentangled Traffic Flow Forecasting (IEEE Transactions on Knowledge and Data Engineering, 2023).
- 3Gu, Albert, and Tri Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. C. First Conference on Language Modeling. (2024).
- 4Li, L., Bi, J., Yang, K. & Luo, F. Di-Graph GAN: an Enhanced Adversarial Learning Framework for Accurate Spatial-Temporal Traffic Forecasting Under Data Missing Scenarios 120911 (Information Sciences, 2024).