HAVIT: research on vision-language gesture interaction mechanism for smart furniture
Hong Chen, Hasnul Azwan Azizan Mahdzir, Xuekun Li, Nurul Ayn Ahmad Sayuti

TL;DR
This paper introduces HAVIT, a new model for gesture recognition in smart furniture that works well even with limited data.
Contribution
HAVIT combines Vision Transformer and ALBEF to improve gesture recognition in data-scarce scenarios.
Findings
HAVIT achieved 91.83% accuracy and 0.92 AUC on a fully labeled dataset.
It maintained 86.89% accuracy and 0.88 AUC with 20% label deficiency.
The model shows strong robustness and potential for smart furniture applications.
Abstract
With the rapid development of smart furniture, gesture recognition has gained increasing attention as a natural and intuitive interaction method. However, in practical applications, issues such as limited data resources and insufficient semantic understanding have significantly constrained the effectiveness of gesture recognition technology. To address these challenges, this study proposes HAVIT, a hybrid deep learning model based on Vision Transformer and ALBEF, aimed at enhancing the performance of gesture recognition systems under data-scarce conditions. The model achieves efficient feature extraction and accurate recognition of gesture characteristics through the organic integration of Vision Transformer’s feature extraction capabilities and ALBEF’s semantic understanding mechanism. Experimental results demonstrate that on a fully labeled dataset, the HAVIT model achieved a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
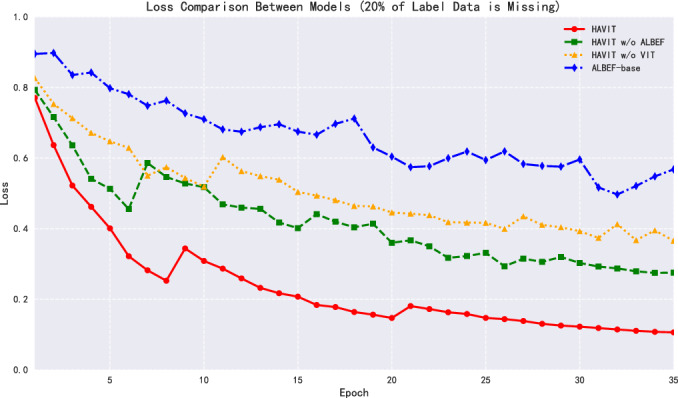 Figure 10
Figure 10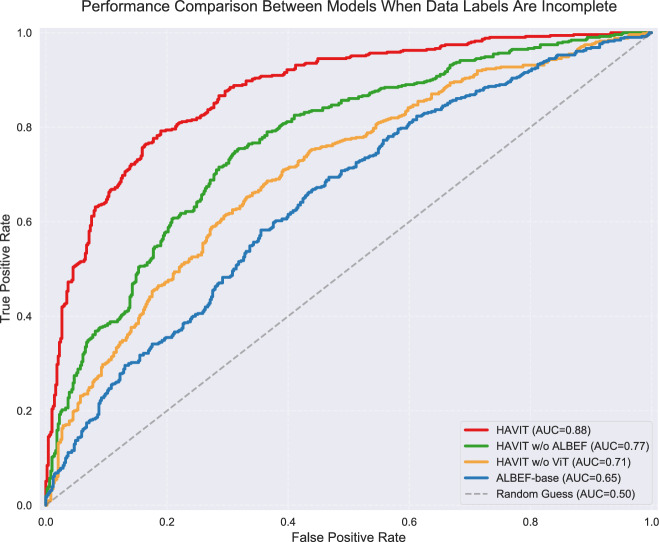 Figure 11
Figure 11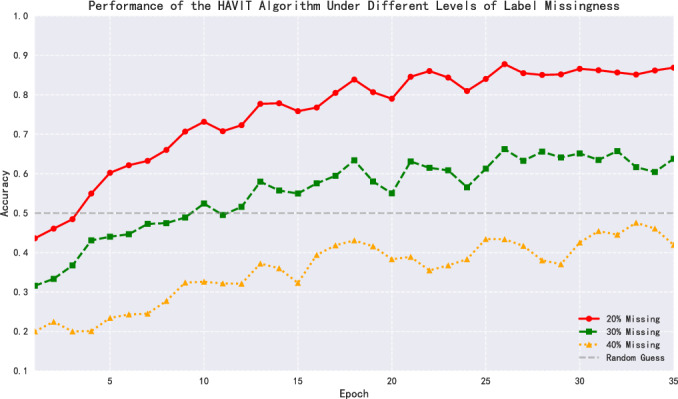 Figure 12
Figure 12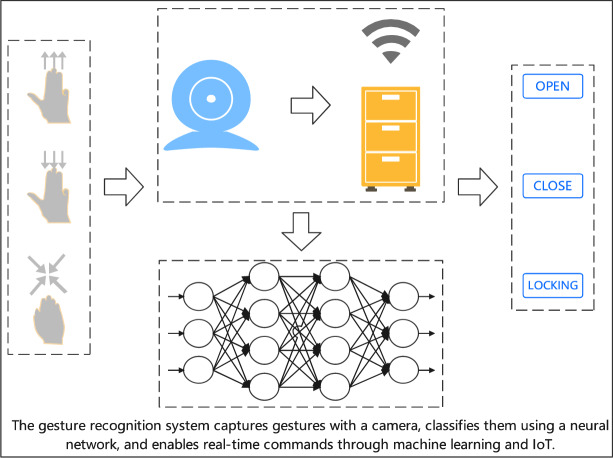 Figure 1
Figure 1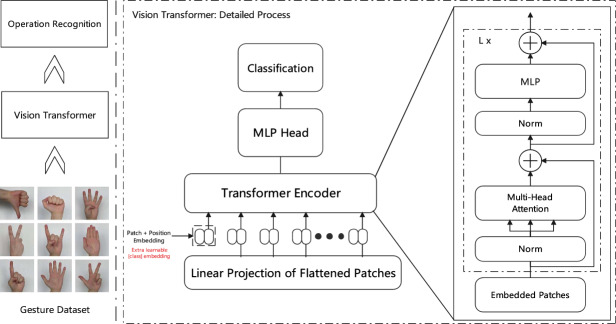 Figure 2
Figure 2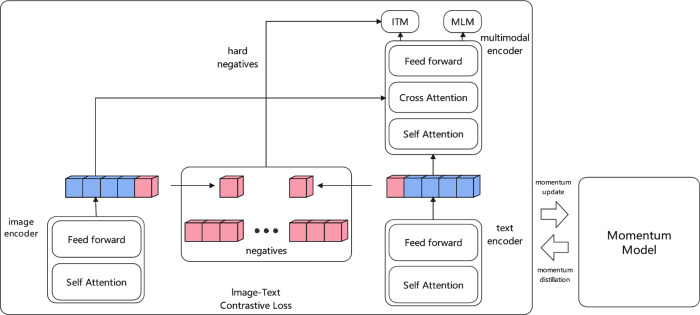 Figure 3
Figure 3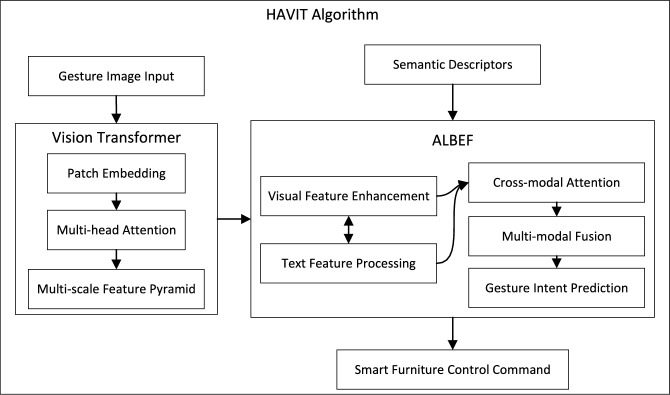 Figure 4
Figure 4 Figure 5
Figure 5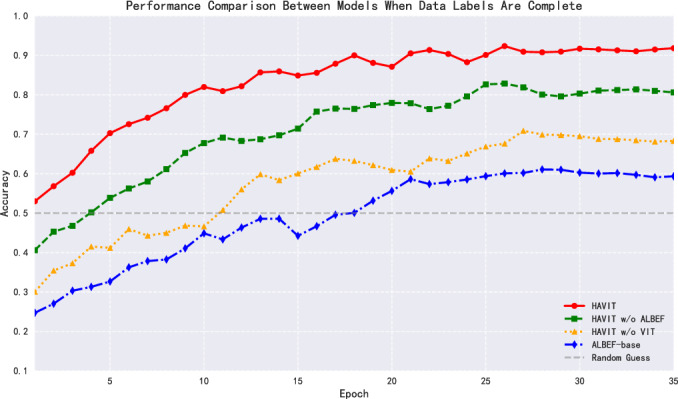 Figure 6
Figure 6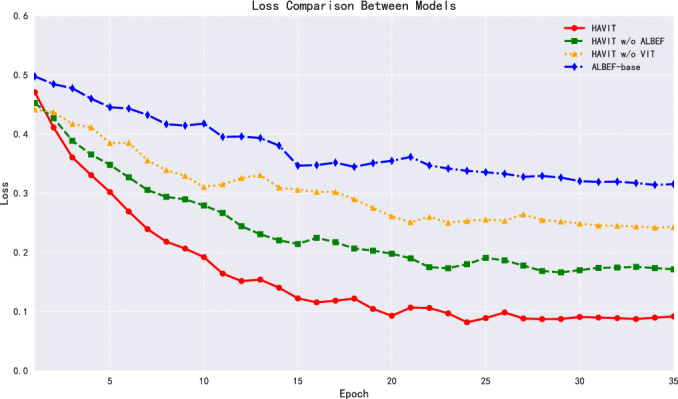 Figure 7
Figure 7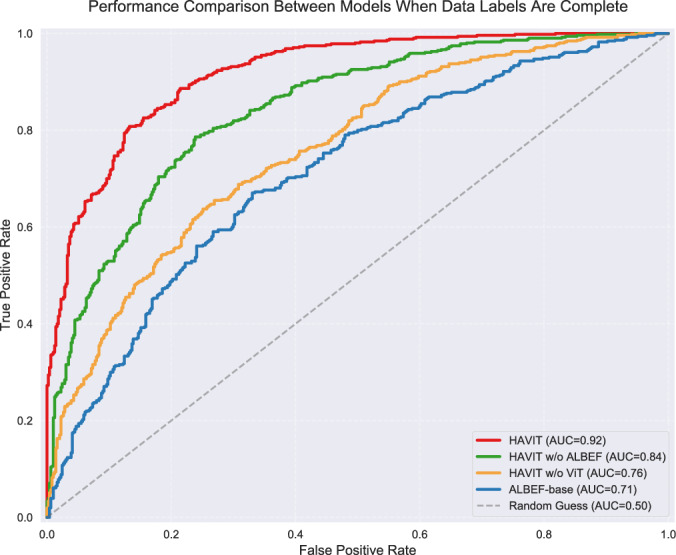 Figure 8
Figure 8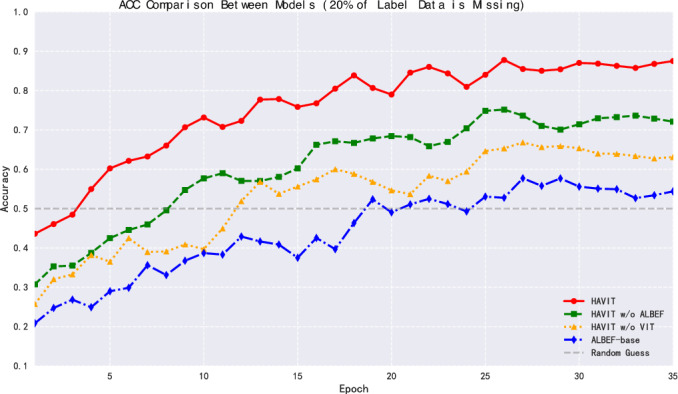 Figure 9
Figure 9 Figure 13
Figure 13Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHand Gesture Recognition Systems · Tactile and Sensory Interactions · Video Surveillance and Tracking Methods