Advancing automatic speech recognition for low-resource ghanaian languages: Audio datasets for Akan, Ewe, Dagbani, Dagaare, and Ikposo
Isaac Wiafe, Jamal-Deen Abdulai, Akon Obu Ekpezu, Raynard Dodzi Helegah, Elikem Doe Atsakpo, Charles Nutrokpor, Fiifi Baffoe Payin Winful, Kafui Kwashie Solaga

TL;DR
This paper introduces a 5000-hour audio dataset for five low-resource Ghanaian languages to improve speech recognition and language preservation.
Contribution
The paper presents the first large-scale, validated audio datasets for Akan, Ewe, Dagbani, Dagaare, and Ikposo.
Findings
A 1000-hour validated audio corpus was created for each of the five low-resource languages.
100 hours of transcribed audio per language were generated to support ASR and linguistic research.
The dataset was collected ethically with incentives for indigenous speakers.
Abstract
Audio datasets are fundamental to the development of automatic speech-recognition (ASR) systems. However, the availability of a large corpus of audio datasets in low-resource languages (LRLs) is limited. This study addresses this gap by introducing audio speech datasets for five low-resource languages spoken in Ghana and parts of Togo. Specifically, it presents a 5000-hour speech corpus in Akan, Ewe, Dagbani, Dagaare, and Ikposo. Each language corpus includes 1000 h of validated audio speech recorded by their indigenous speakers. These audio recordings are spoken descriptions of 1000 culturally relevant images collected using a custom Android mobile application. To enhance the dataset’s utility in ASR and linguistic research 10 % of the audio recordings for each language were randomly selected and transcribed, resulting in approximately 100 h of transcription per language. This dataset…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
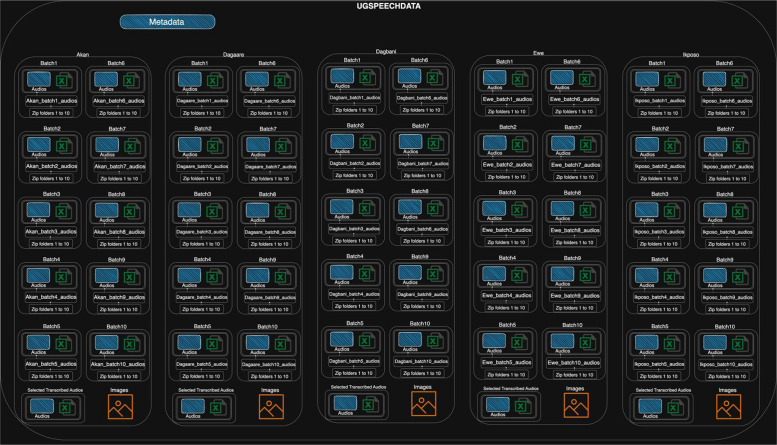 Figure 1
Figure 1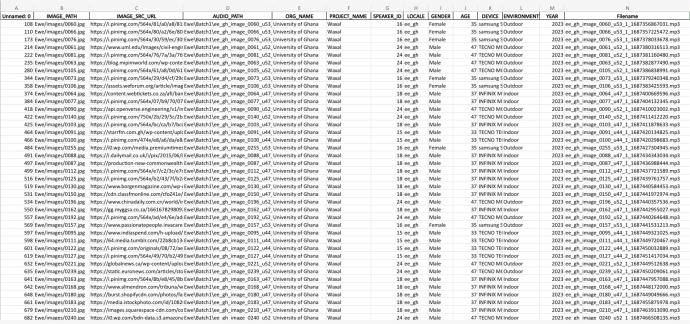 Figure 2
Figure 2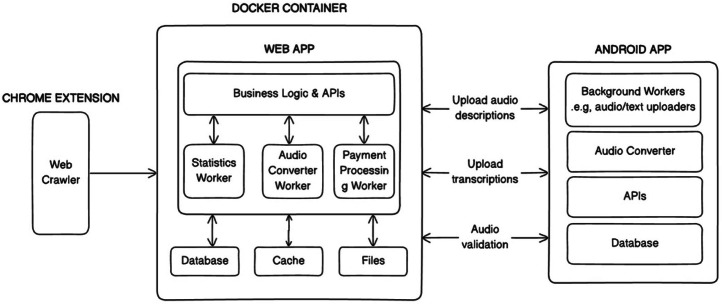 Figure 3
Figure 3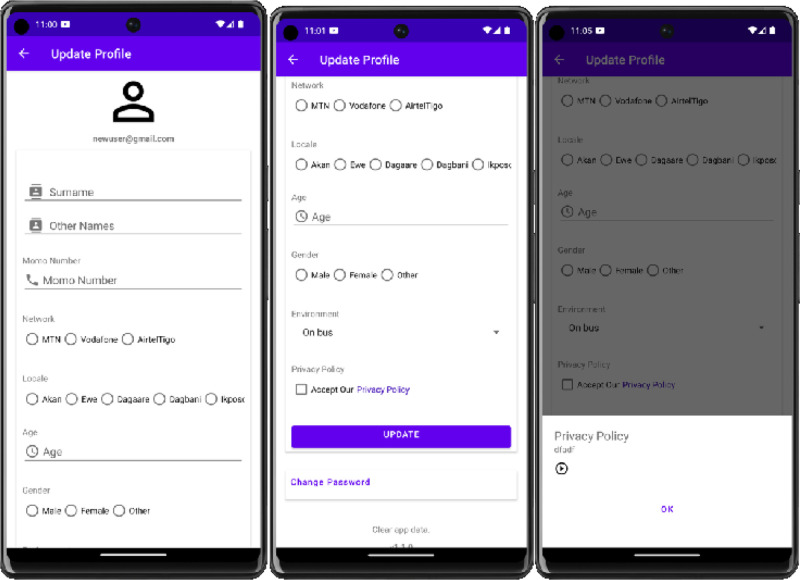 Figure 4
Figure 4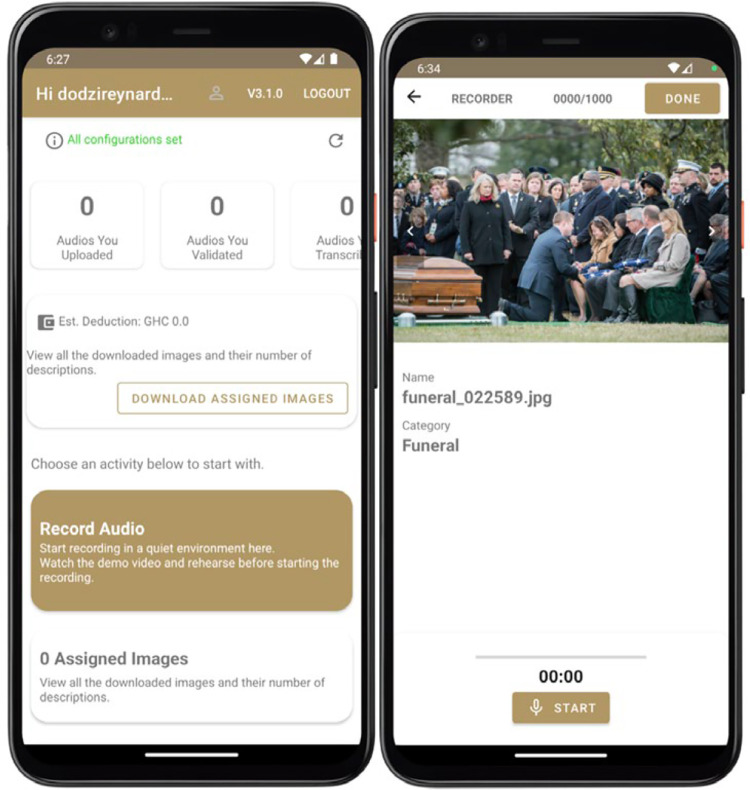 Figure 5
Figure 5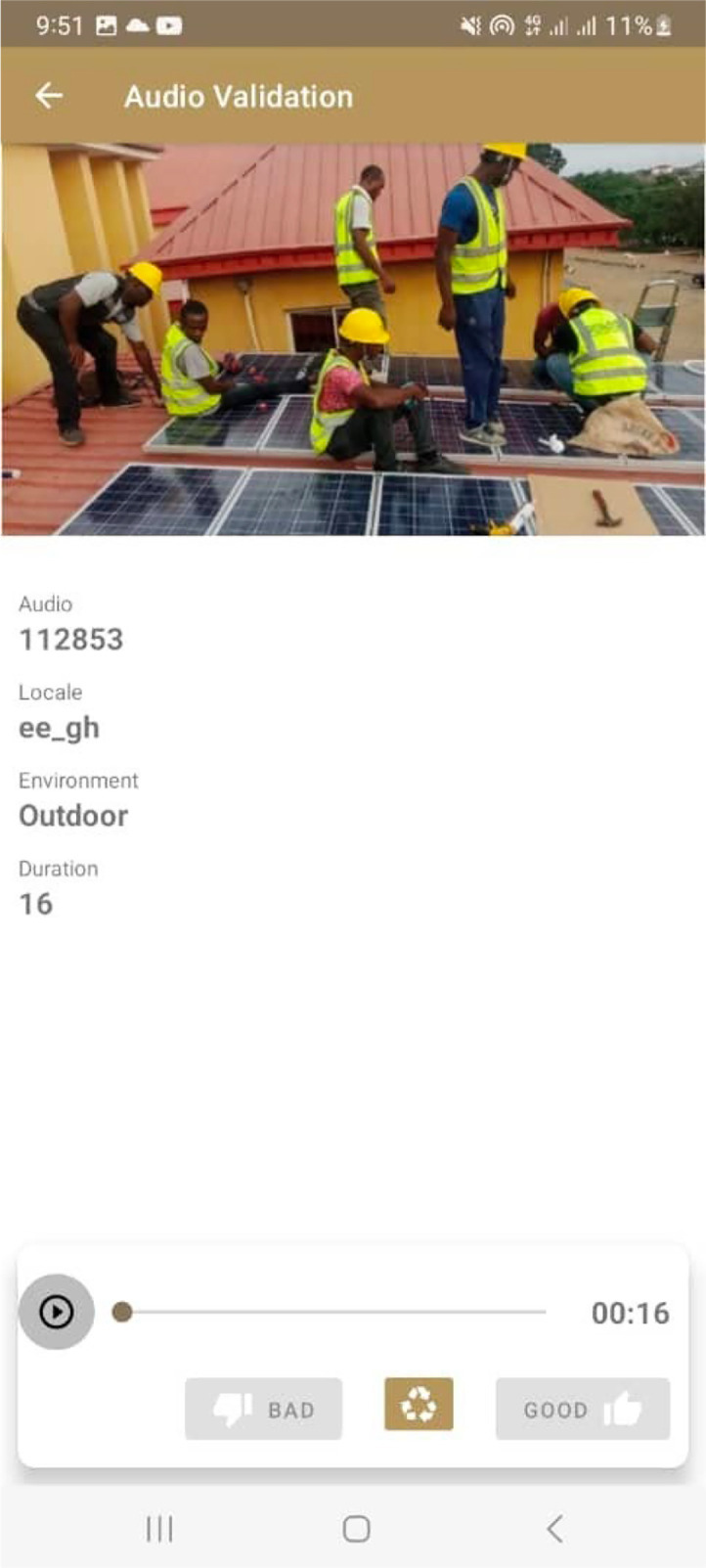 Figure 6
Figure 6 Figure 7
Figure 7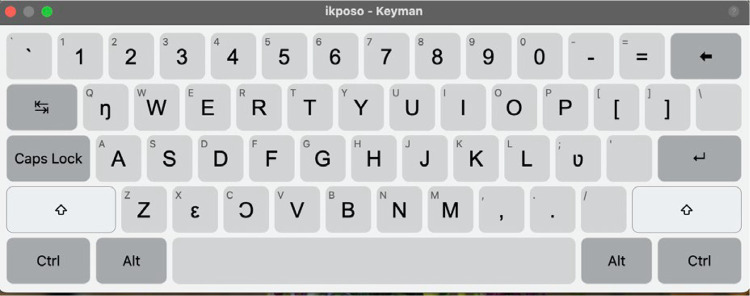 Figure 8
Figure 8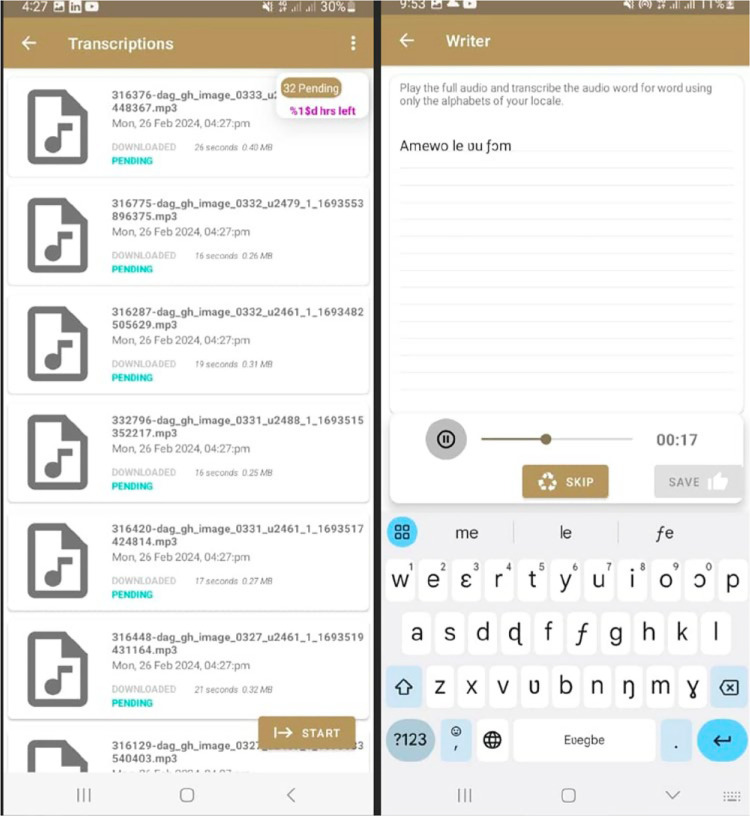 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNatural Language Processing Techniques · Speech Recognition and Synthesis · Phonetics and Phonology Research
Specifications TableSubjectNatural Language Processing (NLP), Speech-To-Text (STT), Automatic Speech Recognition (ASR), Neural Machine Translation (NMT)Specific subject areaAutomatic Speech Recognition for Low-Resource LanguagesType of dataAudio (all recordings are in MP3 format with a sample rate of 44.1 kHz), text (audio transcriptions), imagesData collectionAudio recordings of image descriptions were collected using an Android mobile application. Indigenous speakers of each language downloaded the app and signed in using credentials provided by the research team. Upon accepting the terms in the consent form, the app allowed them to download the 1000 assigned images and to start recording descriptions of the images in their native language only.Gadgets used: Android mobile phones and tablets, laptops, microphones, and power banksData source locationCountry: Ghana and TogoRegions: Greater Accra, Central Region, Eastern Region, Volta Region, Northern Ghana, Upper West, Plateaux Region of Togo,Communities: Accra, Tampion, Nanton, Cape Coast, Winneba, Kumasi, Kwahu, Mpraeso, Anloga, Keta, Peki, Akatsi, Ho, Juapong, Kpando, Sogakope, Tamale, Jirapa, Wa, Akposokubi, Akposo Kabo, AtakpameRecording Environments: Outdoor, indoor, offices, cars, buses, studio, unspecified environments.Data accessibilityThe dataset is freely available to the public for research, academic, and educational purposes.The datasets can be assessed at: https://doi.org/10.57760/sciencedb.22298
Value of the Data
1
- •This dataset provides the first enabling step for the development of ASR technologies for Ghanaian languages. More specifically, the dataset reduces the technological inequality between high-resource and low-resource languages by enabling the development of language technologies such as ASR models for Akan, Ewe, Dagbani, Dagaare, and Ikposo. These models can be adapted for applications such as conversational AIs including question-answering (QA) systems, task-oriented dialogue systems (DS), and chatbots. In addition, since the dataset is a collection of spontaneous speech, it will most likely be more adaptable and versatile for training ASR models for the respective languages.
- •The dataset, which also includes 100 h of transcription for each language can be used to develop text-to-speech (TTS) systems that generate culturally relevant and linguistically accurate synthesized speech in the five languages. Additionally, it will provide a valuable resource for researchers working on NLP tasks such as machine translation, sentiment analysis, entity recognition, and text summarization, specifically for low-resource languages. Researchers can leverage this dataset to develop language models that improve language understanding and generation in these languages. Thus, this dataset supports a range of language-specific applications in both TTS and NLP.
- •The dataset can be integrated into multilingual AI systems to train models that are capable of handling multiple languages simultaneously or transitioning seamlessly between languages (code-switching) within the same system. Researchers can use this for tasks such as dialect detection and classification, as well as gain an understanding of how different dialects within the same language group vary phonetically and acoustically.
- •The audio and text dataset serves as a primary resource for the Ghanaian and Togolese languages. It will help preserve the linguistic diversity of these languages and contribute to the documentation of languages that are often underrepresented in global digital spaces. By making these languages digitally accessible, the dataset will help maintain their cultural relevance and continuity. Overall, this dataset supports linguistic research, language preservation efforts, cultural documentation, and contributes to language sustainability and prevention of language extinction.
- •The dataset will support education and literacy efforts, as it may be used to develop indigenous language learning tools, pronunciation guides, and interactive language courses for speakers and non-speakers of the languages.
- •The audio dataset consists of recordings performed in both indoor and outdoor environments. Hence, it provides a diverse range of acoustic environments that reflect real-world conditions. This diversity will facilitate the training of adaptive models that are robust in different environmental conditions
Background
2
Despite the plethora of automatic speech recognition (ASR) systems, low-resource languages (LRLs) particularly those spoken in Ghana and the plateaux region of Togo face a significant gap in the development of these technologies. Unlike high-resource languages, the lack of large-scale, high-quality audio datasets in these languages hinders advancements in language technologies, resulting in technological disparities between high-resource and low-resource languages. Socio-culturally, most of these LRLs remain underrepresented in global digital spaces, thus jeopardizing their linguistic preservation and cultural continuity.
Previous attempts to digitalize these languages carry inherent biases and lack the diversity and amount of data required to train ASR models to detect and learn language patterns. For instance, Akan, the second-most spoken language in Ghana [1], has an audio dataset focused on financial inclusion [2]. Similarly, the Bible remains the primary resource for Ewe [3].
This study addresses this gap by introducing a 5000-hour audio dataset consisting of recordings in Akan, Ewe, Dagbani, Dagaare, and Ikposo. The audio samples of each language were collected from their indigenous speakers. This dataset will enable the development of ASR models for these languages. It will also contribute to technological inclusivity, linguistic preservation, and educational advancement.
Data Description
3
Ghana is a multilingual country with five officially recognized languages: Akan, Ewe, Ga, Dagaare, and Dagbani [1,4]. Other languages such as Ikposo are among the endangered languages and are one of the Ghana-Togo mountain languages. The dataset is a collection of audio descriptions of 1000 different images from indigenous speakers of Akan, Ewe, Dagaare, Dagbani, and Ikposo. The same 1000 images were described for all languages, and each audio file is between 15 s to 30 s (an average size of approximately 350 KB). The uploaded dataset contains a total of 970,148 audio files (5384.28 h) and 93,262 transcribed audio files (518 h). The overall UGSpeechData dataset size is approximately 336 GB.
Fig. 1 presents a visual structure of the UGSpeechData repository. It contains a metadata folder and five language-specific folders namely, Akan, Dagaare, Dagbani, Ewe, and Ikposo respectively. The metadata folder contains five Excel files that are associated with each language, and each file contains 11 sheets corresponding to 11 subfolders (that is, Batch 1 to 10 and selected transcribed audios) of each language folder. Each language folder has 12 subfolders. For example, the Akan folder contains 12 subfolders labeled: Batch 1 to Batch 10; selected transcribed audios and images. Each batch contains an Audios folder and an Excel file. The Audios folder contains a subfolder named according to the corresponding batch number (e.g., Akan folder, Batch 1 subfolder contains a subfolder named Akan_batch1_audios), which then contains subfolders numbered 1 to 10. More specifically, each Audios folder within a batchX contains approximately 100 h of audio, and each subfolder within the Akan+batchX_audios folder contains 10 h of audio. The Excel file within each ‘batchX’ contains the metadata of the audio clips in that batch (see Fig. 2). The subfolder labeled ‘images’ contains a collection of the 1000 images that study participants described, while the subfolder labeled 'selected audios transcribed' holds approximately 104.3 h of randomly selected audio recordings which were transcribed and an Excel file containing the corresponding transcription of the audio files and other metadata. This structure is the same for the other four languages. For ease of access and downloads, all subfolders have been zipped.Fig. 1. Visual structure of the UGSpeechData repository.Fig 1:Fig. 2A screenshot of a metadata file.Fig 2:
Refer to Fig. 2 for a screenshot of a metadata file. The metadata provides details of the image path, image source URL, audio path, organization name, project name, speaker ID, locale, speakers’ gender, speakers’ age, device used in recording the audio, the recording environment, the year it was recorded, the full filename, and the shortened filename.
Akan speech corpus
3.1
The Akan dataset includes four dialectical variations namely Akuapem Twi, Asante Twi, and Fanti. They were collected from Accra, Kumasi, Kwahu, and Mpraeso. The majority of the recordings were done indoors, followed by outdoors, unspecified environments, offices, and cars. The least number of recordings were done in a studio and none in a bus. The Akan speech corpus is a collection of validated audio descriptions of different images from 2,151 Akan speakers. It includes 195,285 audio files (equivalent to 1085.63 h), out of which 18,787 audio files (104.38 h) were randomly selected and transcribed. The total size of the Akan speech corpus is 60 GB, encompassing all audio recordings, transcriptions, and metadata files. Table 1 presents details of the Akan speech corpus as found in the repository.Table 1. Summary of accepted and transcribed Akan speech corpus.Table 1:GenderTotal no audio of filesEquivalent in hoursTotal no of audio files collected by recording environmentIndoorOutdoorUnspecifiedOfficeCarStudioBusMale121,056672.5358,44752,881458139781109600Female73,952411.9639,95430,04015792159209110Others2771.1431741000000Totals195,2851085.6398,40483,095626061371318710Details of Transcribed FilesGenderTotal no of audio filesEquivalent in hoursIndoorOutdoorUnspecifiedOfficeCarStudioBusMale10,92060.674475588846691000Female786743.715147244535238200Totals18,787104.389622833350132920****0
Ewe speech corpus
3.2
The Ewe speech corpus consists of various dialectical variations of the language namely Anlo, Tongu, Wedome, and Gbi. They were collected from Accra, Anloga, Keta, Peki, Akatsi, Ho, Juapong, Kpando, and Sogakope. The recordings were done in different environments, but the majority were done outdoors, followed by indoors, in unspecified environments, offices, cars, studios, and buses. The Ewe speech corpus is a collection of validated audio descriptions of images from 1,905 Ewe speakers. It includes 203,391 audio files (1130.76 h) and 19,152 files (106.4 h) of transcribed audio. The total size of the Ewe speech corpus is 61.28 GB, encompassing all audio recordings, transcriptions, and metadata files. Table 2 provides details of the Ewe speech corpus as found in the repository.Table 2. Summary of accepted and transcribed Ewe speech corpus.Table 2:GenderTotal no of audio filesEquivalent in hoursTotal no of audio files collected by recording environmentOutdoorsIndoorsUnspecifiedOfficeCarStudioBusMale121,116673.9868,30046,1623438185093141223Female81,684453.849,85127,513331761517250121Other5912.9845494520000Totals203,3911130.76118,19674,16968072465948662144Details of Transcribed FilesGenderTotal no of audio filesEquivalent in hoursOutdoorIndoorUnspecifiedOfficeCarStudioBusMale10,87060.3943725729398210140210Female828246.0149293107114800520Totals19,152106.409301883651229014073****0
Dagbani speech corpus
3.3
The audio recordings for Dagbani were collected from Tamale, Tampion, and Nanton in Northern Ghana. The majority of the recordings were done outdoors, followed by indoors, in unspecified environments, offices, cars, buses, and studios. The Dagbani speech corpus is a collection of validated audio descriptions of images from 1,579 indigenous speakers. It includes 188,805 audio files (1047.21 h) and 18,200 files (101.11 h) of transcribed audios. The total size of the Dagbani speech corpus is 60.54 GB, encompassing all audio recordings, transcriptions, and metadata files. Table 3 provides details of the Dagbani speech corpus as found in the repository.Table 3. Summary of accepted and transcribed Dagbani speech corpus.Table 3:GenderTotal no of audio filesEquivalent in hoursTotal no of audio files collected by recording environmentOutdoorIndoorUnspecifiedOfficeCarBusStudioMale157,385874.36110,66442,6903293574484868Female30,413168.9615,12412,2101533691490208157Other10073.89637030664000Totals188,8051047.21126,42554,90051321329538256225Details of Transcribed FilesGenderTotal no of audio filesEquivalent in hoursOutdoorIndoorUnspecifiedOfficeCarBusStudioMale13,02672.376871568119719823947Female513028.523282432161134183819Other440.2400044000Totals18,200101.11919981133583764147****66
Dagaare speech corpus
3.4
Dagaare audio recordings were collected from Jirapa and Wa, Upper West Region of Ghana. The majority of the recordings were done outdoors, followed by indoors, and unspecified environments. No recordings were done in offices, studios, cars, and buses. The Dagaare speech corpus is a collection of audio descriptions of images from 461 speakers. It includes 190,684 audio files (1059.33 h) and 18,948 files (105.30 h) of transcribed audio. The total size of the Dagaare speech corpus is 64.81 GB, encompassing all audio recordings, transcriptions, and metadata files. Table 4 provides details of the Dagaare speech corpus as found in the repository.Table 4. Summary of accepted and transcribed Dagaare speech corpus.Table 4:GenderTotal no of audio filesEquivalent in hoursTotal no of audio files collected by recording environmentOutdoorIndoorUnspecifiedOfficeStudioCarBusMale112,610625.61100,86411,74600000Female78,053433.6363,69014,341202000Other210.08600210000Totals190,6841059.33164,55426,087402000Details of Transcribed FilesGenderTotal no of audio filesEquivalent in hoursOutdoorIndoorUnspecifiedOfficeStudioCarBusMale11,19062.177697349120000Female775843.1692083800000Other60.0250060000Totals18,948105.3014,61743298000****0
Ikposo speech corpus
3.5
Audio recordings for Ikposo were collected from Akposokubi and Akposo Kabo in Ghana and Atakpame in Togo. The majority of the recordings were done outdoors, followed by indoors, offices, unspecified environments, and studios. No recordings were done in cars and buses. The Ikposo speech corpus is a collection of audio descriptions of images from 628 indigenous speakers of Ikposo. It includes 191,983 audio files (1061.35 h) and 18,175 files (100.81 h) of transcribed audio. The total size of the Ikposo speech corpus is 60.67 GB, encompassing all audio recordings, transcriptions, and metadata files. Table 5 provides details of the Ikposo speech corpus as found in the repository.Table 5. Summary of accepted and transcribed Ikposo speech corpus.Table 5:GenderTotal no of audio filesEquivalent in hoursTotal no of audio files collected by recording environmentOutdoorIndoorOfficeUnspecifiedStudioCarBusMale98,469547.0483,80911,0951390127590000Female89,749498.6281,93663801225208000Other376515.69346003419000Totals191,9831061.35166,09117,4752615490290000Details of Transcribed FilesGenderTotal no of audio filesEquivalent in hoursOutdoorIndoorOfficeUnspecifiedStudioCarBusMale871248.40774473591142000Female934651.92825710131165000Other1170.49910026000Totals18,175100.8116,092174810223300****0
Experimental Design, Materials and Methods
4
In contrast to existing language audio datasets, where professionals read existing transcripts of the language from specific sources [[5], [6], [7]], this study provided participants with images and asked them to describe them in their own words. This approach was adopted to facilitate spontaneous and natural speech, as well as the collection of language’s diverse intonations and variations more authentically. This was achieved using a controlled crowdsourcing solution. Specifically, we developed and used an Android app (UGSpeechData app) to collect audio speech data directly from indigenous speakers of each language in their natural environment.
The UGSpeechData app comprises three systems: a web crawler, a web application, and an Android app (see Fig. 3). The web crawler extracted images from websites and populated the image database. The web application and Android app provided interfaces for admins and volunteers to manage, contribute, and validate audio recordings. These interfaces were designed to ensure real-time monitoring of the audio data collection and other related activities as well as minimize potential errors that may arise from human collation.Fig. 3. System architecture diagram.Fig 3:
The data processes are mainly done by the docker container in Fig. 3. The process begins on the user’s device, where audio is recorded in .wav format to allow real-time feedback features such as long-pause detection and ambient noise alerts. Once the recording was completed, the audio was converted into .mp3 using ffmpeg. In over 99.5 % of cases, the conversion was successful and the .mp3 was uploaded to the server. In rare instances (approx. 0.5 %), the Android OS on low-resource devices may terminate the background conversion service. After three failed attempts, the .wav file was uploaded instead.
When the audio got to the server, it was immediately registered in the database along with its metadata. A background worker service then asynchronously processed each uploaded audio file. This service: validated the integrity of uploaded audio files to detect and eliminate corrupted files; converted any remaining .wav files into .mp3; and updated audio records in the database, including replacing .wav file links with the new .mp3 versions and incrementing the count of valid audios per user.
All the data collection processes except participant recruitment were done using the app. They include:
- i.Image selection
- ii.Screen and select participants
- iii.Audio recording
- iv.Audio validation
- v.Audio transcription
- vi.Pay incentives to participants (recorders, validators, and transcribers)
Image selection
4.1
To capture a large variety of spoken words in the form of sentences and to overcome the challenges of manually performing sentence segmentation of audio data, participants were required to describe a set of images in their local dialect. Thus, a database of culturally relevant images was curated into the UGSpeechData app. A web crawler was used to extract images from websites such as Pinterest and Google images. This created an initial pool of 8,000 images. Stakeholders were engaged and provided with Samsung Tablets to select and validate the images. Selected images were required to be easily describable in at least three different ways between 15 s and 30 s. In addition, images were screened to ensure they were devoid of any nudity or profanity. Context specificity was another crucial consideration; thus, the majority of the selected images needed to resonate with the linguistic and cultural contexts of Ghanaians.
At the end of the image selection process, 1000 images were selected cutting across different categories. All images were 400px by 400px in size. The 1000 selected images and their associated URLs were populated into the SpeechData app image database. The image categories included but were not limited to the following: Love/Romance, Sanitation, Travel/Tourism, Weather/Climate, History/ Ethnicity, Technology, Automobile, Security, Transportation, Architecture/Construction/Furniture, Fashion/clothing, Food/Drink, Trading/commerce, Hospitality, Lifestyle, Health/Medicine, Agriculture, Economy, Entertainment, Arts/crafts, Science, Justice/Law Enforcement, Mining, Education, Governance, Leisure, Immigration, Home/Housing, Religion, Engineering, Accidents/disaster, Sports, Culture, Family, and Nature.
Participant recruitment, screening, and selection
4.2
Participants were recruited using convenience sampling, snowball sampling, and social media advertisements and visits by the research team to several villages within Ghana and Togo. Recruitment was done in three batches. We started with Akan and Ewe, then Dagbani and Dagaare, and finally Ikposo speakers. Three main groups of participants were recruited for this study, the recorders (indigenous speakers of each language who volunteered to record descriptions of assigned images), validators (indigenous and proficient speakers of each language who were selected to validate the audios based on predefined rules), and transcribers (language-specific linguist/experts who were selected from language institutions to transcribe samples of the validated audios). All participants were trained on how to use the app for their designated roles. They were provided with predefined guidelines specific to their tasks. Participants downloaded the app and were given unique login credentials (username and password).
Before recording, recorders were required to sign the consent form and provide relevant demographics, including their indigenous spoken language, age, gender, and recording environment (see Fig. 4). Demographic-related data was used for administrative purposes only and could only be accessed by the principal investigator (the lead author). In addition, the UGSpeechData app automatically retrieved the recording device's name and the timestamp of each recording.Fig. 4. Screenshot of user profile page.Fig 4:
To verify the fluency of recruited recorders in their respective indigenous languages and to ensure that they understood the recording guidelines, a screening process was conducted by selected language experts. Recorders were required to describe their first 10 assigned images using the app, and the language experts reviewed these recordings to evaluate their fluency and adherence to the following guidelines:
- i.Recordings must be done in a quiet environment without conflicting sounds.
- ii.Recordings must be in the selected language. English words were permitted if no equivalent terms existed in the language. In such instances, local pronunciation of the English word was acceptable.
- iii.Recordings must be within 15 s and 30 s without pauses longer than 3 s.
- iv.Excessive use of speech mannerisms (e.g., filler words) should be avoided.
- v.Descriptions must not start with phrases such as ‘I see, ‘ ‘in this picture,’ or ‘It looks like.’
- vi.Descriptions must not include profane or offensive words.
Recorders were selected if their descriptions of at least 8 out of the 10 images adhered to these guidelines. Once selected, restrictions in the app were removed, allowing them to download and record assigned images.
Audio recording
4.3
Selected recorders were expected to provide audio descriptions of 1000 images using the UGSpeechData mobile app. Upon logging into the app with the provided credentials, recorders downloaded the 1000 assigned images. Before each recording, the app monitored background noise levels. The record button was only activated if no background noise was detected by the app. The app allowed recorders to ‘play,’ ‘save,’ or ‘delete’ their audio descriptions. However, they could only save audio descriptions if it was between 15 s and 30 s; if there were less than three (3) seconds of pause during the description; and if there were no excessive speech mannerisms. The app also prevented duplicate recordings of the same image by a recorder. Fig. 5 shows a screenshot of the UGSpeechData home and recording page.Fig. 5. Home and recording page.Fig 5:
Upon completion of each recording, the audio files which were initially captured in .wav format were immediately converted to .mp3 format using ffmpeg and uploaded to the UG server. Real-time audio processing, such as the detection of long pauses and ambient noise, necessitated the initial use of .wav for recordings. Converting audio files to .mp3 reduced the average file size from approximately 4 MB to about 350 KB. This enabled faster uploads even in regions with limited network coverage, such as areas with only 3 G connectivity.
Participants who used their devices typically had approximately 500 MB of free storage available, which was sufficient for storing over 1000 audio files. Those who used Tablets provided by the researchers had 32 GB of storage. These limits were never reached per user. During recording, audios were automatically uploaded to the server if the recording device was connected to WIFI or had mobile data turned on. When internet connectivity was unavailable, the audio files were temporarily stored on the device. Once the internet connectivity was restored and the battery of the recording device (tablets or phones) was at least 60 % charged, a background service integrated into the Android app, triggered automatically by the Android OS ensured prompt uploads once connectivity resumed. It is important to note that users had unique IDs, and a Tablet was used to login a new user only when audios from the previous user were uploaded. Once the file was confirmed uploaded and validated by the server, it was deleted from the device storage to maintain sufficient space for continued data collection. This immediate transmission approach ensured minimal local storage consumption.
To maintain security and data integrity, all files (audio and images) were stored in the device's private internal storage. This design choice ensured:
- i.Files were inaccessible to other apps, enhancing data privacy.
- ii.Users could not access files outside the UGSpeechData app interface.
- iii.After successful upload, users had the option to delete files directly within the app; otherwise, deletion could only occur upon uninstalling the app.
Recordings were done in a comfortable environment of the recorders' choosing, with the flexibility to take breaks as needed. Completing descriptions for all 1000 images took approximately four to five hours per recorder. Once a recorder completed their assigned images, they were disabled from further recording. Although 1000 images were assigned to each recorder, completing all descriptions was not mandatory. Recorders had the option to stop at any time. After 8 months of audio data collection, we received approximately 1000,000 audio recordings (5550 h) for all languages. Audios were recorded in different environments namely outdoors, indoors, car, bus, office, studio, and unspecified environments. The next step was to validate the collected audio recordings.
Audio validation
4.4
To ensure the reliability and integrity of the collected audio recordings as well as confirm adherence to the predefined guidelines, it was imperative to validate all recordings. Thus, we selected language experts from each language, and they were assigned the role of ‘validators’ in the app. These experts possessed the necessary linguistic expertise and cultural familiarity to accurately assess and determine whether an audio recording should be accepted or rejected. Each validator was assigned 240 audio files at a time and at least two validators reviewed a specific recording. In instances where there was a conflict, that is, a specific audio file was accepted by one validator but rejected by another, such a file was flagged for conflict resolution. Here, a third validator would make the final decision to either accept or reject the audio recording.
To retrieve audio files for validation, the validator will select retrieve audios for validation. The app scheduled a background service which downloaded the specified batch of audios to the validator’s device. If the device was already online, downloads commenced immediately. During validation, the audio files were played directly from the local device storage. This enabled smooth, uninterrupted playback regardless of current internet connectivity. Upon submission of the validator’s verdict to the server, each validated audio was automatically and asynchronously deleted from the local storage, freeing device space efficiently. Specifically, they would select ‘good’ if an audio met the predefined guidelines or ‘bad’ if otherwise. Refer to Fig. 6 for a screenshot of the validation page. This approach allowed validators the flexibility to download audio files during periods of stable internet connectivity and subsequently validate them at their convenience, irrespective of ongoing internet access. For example, validators could download audio batches at their workplace and perform validations offline later at home.Fig. 6. Screenshot of audio validation page.Fig 6:
At the end of the validation process, approximately 96.92 % of the audio recordings were accepted. Specifically, 970,148 audio files (5384.28 h) from 6,724 unique recorders were accepted (good), while 29,852 audio files (165.72 h) were rejected (bad). Table 6 provides demographic details of accepted audio files/recordings per language.Table 6. Distribution of demographics by gender and age per language.Table 6:LanguagesGenderNo. of recordersNo. of audio filesAge rangeNo. of recordersNo. of audio filesAkanMale1279121,05618–25138992,029Female85873,95226–3546673,439Other1427736–4516418,524Total2151195,28546–5576562556–6533381666–75101769Unspecified1383EweGenderNo. of recordersNo. of audio filesAge rangeNo. of recordersNo. of audio filesMale1076121,11618–2575156,361Female81681,68426–3560684,544Other1359136–4528732,676Total1905203,39146–5514917,17556–6571979666–75302613Unspecified11226DagbaniGenderNo. of recordersNo. of audio filesAge rangeNo. of recordersNo. of audio filesMale1172157,38518–2584995,598Female39830,41326–3548460,876Other9100736–4518925,581Totals1579188,80546–5543578556–65655566–752104Unspecified6306DagaareGenderNo. of recordersNo. of audio filesAge rangeNo. of recordersNo. of audio filesMale21378,05318–2514456,622Female245112,61026–3520688,880Other32136–457834,677Totals461190,68446–5524891256–65436866–7571304Unspecified321IkposoGenderNo. of recordersNo. of audio filesAgeNo. of recordersNo. of audio filesMale32998,46918–2519355,257Female28389,74926–3511937,737Other16376536–4511642,474Totals628191,98346–5510626,76956–655318,50066–75247332Unspecified113914Overall total6724970,1486724970,148
Audio transcription
4.5
Training datasets for automatic speech recognition (ASR) systems require transcribed audio recordings. Hence, 10 % of the validated audio recordings from each language were randomly selected for transcription. Language-specific linguists and prolific writers (hereinafter referred to as transcribers) were selected to transcribe these recordings in the five collected languages. All transcribers were university students and lecturers who were studying or teaching the respective languages at undergraduate or postgraduate levels.
Each language had 10 to 20 transcribers who were assigned audio recordings in their respective indigenous languages. If for technical issues, an audio file in a different language was mistakenly assigned to a transcriber, they were instructed to type "N/A" and skip the file. To ensure consistent and accurate transcriptions across languages, transcribers were trained and provided with a set of strict transcription guidelines. These guidelines were as follows:
- i.Use earphones and work in a quiet environment while transcribing.
- ii.Listen to 3–4 words at a time, type them, and review the transcription for accuracy. That is, ensure that what you typed matches what you heard.
- iii.Do not transcribe audio with significant background noise or secondary voices.
- iv.Do not modify or add words to the transcription.
- v.Transcribe corrections made by the speaker. For example, if a speaker says, "A red car—oh no, a yellow car", transcribe all spoken words exactly as heard.
- vi.Transcribe all comments made by the speaker, regardless of their relevance to the main content.
- vii.Transliterate English words into their phonetic equivalents in the local language.
- viii.Represent inaudible words with “…”.
- ix.Mark audio in other languages or extremely low-quality recordings as "N/A".
- x.Consolidate filler sounds (e.g., "errrrr" → "errr"; "hmmmm" → "hmmm").
- xi.Retain well-known English words or phrases (e.g., "Worldwide Web") if appropriate.
In addition, to cater to the unique characters of the languages and to enable efficient transcription, transcribers were trained on how to download and use the custom keyboards. For Akan, Dagaare, and Dagbani, the Ghana keyboard (GBoard) app was installed on the laptops of the transcribers and set as their default keyboard. Transcribers select and add their respective languages before they start transcribing.
The GBoard does not include the Ewe and Ikposo alphabets. Thus, we developed specific keyboards for these languages. The keyboard utilizes the standard QWERTY keyboard layout and incorporates all the special characters that are specific to the languages. We also designed an on-screen keyboard for transcribers who prefer a visual representation of the layout or who use touchscreen devices.
For Ewe, we incorporated the standard QWERTY keyboard layout optimized for Ewe orthography, including support for all the diacritics and tonal marks. Ewe orthography relies on the African Reference Alphabet and uses diacritics to represent tones (High, Mid, Low) and nasal vowels. The developed Ewe keyboard integrates the following diacritics to represent these tones in writing: the acute accent (‘), the Grave accent (`), the Caron (ˇ), and the Circumflex (ˆ). The Ewe alphabet consists of 30 characters including the 26 letters of the English alphabet, excluding 'c,’ ' j,’ and 'q,’ which are replaced by 'ɔ,’ 'ɣ,’ and 'ƒ,’ respectively. In addition to the standard alphabet, the Ewe keyboard includes these special characters: ɖ, ŋ, ɛ, ɔ, ɣ, ʋ. The keyboard also carters for nasal vowels, indicated by a tilde (˜). Fig. 7 is a visual representation of the Ewe keyboard.Fig. 7. Ewe keyboard.Fig 7:
Similarly, the Ikposo keyboard uses the QWERTY layout as its foundation. The Ikposo alphabet consists of 27 characters, based on the English alphabet but excluding the letters 'c', 'j', 'q', and 'x' which were replaced by ‘ɔ’, ‘ʅ ’, ‘ŋ ’, and ‘ε’ respectively. The keyboard includes the following special characters essential for writing in Ikposo: ŋ, ʋ, ε, ɔ, and ʅ. Unlike Ewe, Ikposo does not use tonal marks; therefore, the keyboard does not include any diacritics for tones. Fig. 8 is a visual representation of the Ikposo keyboard. Refer to LINK for more details on how to download and use the Ewe and Ikposo keyboard.Fig. 8. Ikposo keyboard.Fig 8:
Following the training, transcribers were given login details and assigned the role of ‘Transcribers’ in the app. To manage the workload, the app was configured to assign 240 audio files to each transcriber at a time. Transcribers were required to download and complete these transcriptions within 48 h, after which the app would automatically clear the files and allow the next batch to be downloaded. This process ensured timely completion and equitable distribution of tasks. Fig. 9 is a screenshot of the transcription page.Fig. 9. Screenshot of transcription page (Dagaare).Fig 9
A total of 93,233 (517.97 h) audio files cutting across the various recording environments and five languages were transcribed. That is, approximately 100 h of the accepted audio files per language were transcribed.
Limitations
After being trained by the research team, participants were required to know how to use an Android phone and the mobile application independently. However, given the short-term training, not all participants were competent. This may have led to early dropouts for some participants. The UGSpeechData app was only supported by Android. Thus iOS users could not participate in the study. This limitation reduced the inclusivity of the data collection process.
Furthermore, given that the languages have different dialectal variations, the absence of dialectal segmentation during the data collection process poses a limitation in categorizing data based on dialectal differences within the various languages. The dataset by language may be skewed to dialects that had more participants. This limitation may hinder the ability to analyze and interpret data concerning specific dialects. Without the ability to distinguish between dialectal variations, researchers may encounter challenges in accurately representing the linguistic diversity within the languages. Additionally, the lack of dialectal segmentation limits the applicability and relevance of the dataset for studies that specifically focus on dialectal differences and variation.
Ethics Statement
Ethical approval for this study (which was called WAXAL Project) was obtained from the Ethics Committee for Basic and Applied Sciences (ECBAS), University of Ghana. The participants were duly informed of the objectives of audio data collection and the advantages of having such a dataset. Informed consent was obtained from all the participants (recorders, validators, transcribers, and language experts). Although personal information, such as names and phone numbers, was collected, this information was used for administrative and compensation purposes only. All the participants including enumerators and language leads were duly compensated based on the number of images recorded, audios validated, and audios transcribed. This was done electronically using the UGSpeechData app to their respective mobile money accounts.
Credit Author Statement
Isaac Wiafe (Principal investigator): Conceptualization, Methodology, Data collection, Writing original draft and revisions, Project administration, Supervision, Investigation, Resources, Funding acquisition. Jamal-Deen Abdulai (Co-PI): Conceptualization, Methodology, Data collection, Supervision, Investigation. Akon Obu Ekpezu: Conceptualization, Methodology, Data collection, Project administration, Investigation, Writing – original draft and revision. Raynard Dodzi Helegah: Development and management of data collection tool, Writing original draft, Data collection and management, Investigation. Elikem Doe Atsakpo: Management of data collection tool, Data collection and management, Investigation, Writing of original draft. Charles Nutrokpor: Management of data collection tool, Data collection and management, Investigation, Writing of original draft. Fiifi Baffoe Payin Winful: Data collection and management, Writing original draft. Kafui Kwashie Solaga: Data management, development of keyboards, Writing original draft.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1USAID, “Language of instruction country profile: ghana,” no. May, pp. 1–13, 2021, [Online]. Available: https://pdf.usaid.gov/pdf_docs/PA 00XH 27.pdf.
- 2Resnik P.Olsen M.B.Diab M.The Bible as a parallel corpus: annotating the ‘book of 2000 tongues Comput Hum.331199912915310.1023/A:1001798929185 · doi ↗
- 3Agyekum K.Language shift: a case study of Ghana Sociolinguist. Stud.33200938140310.1558/sols.v 3i 3.381 · doi ↗
- 4Kimanuka U.wa Maina C.Büyük O.Speech recognition datasets for low-resource Congolese languages Data Brief.52Feb. 202410.1016/j.dib.2023.109796 PMC 1070036838076471 · doi ↗ · pubmed ↗
- 5Georgescu A.L.Cucu H.Buzo A.Burileanu C.RSC: a Romanian read speech corpus for automatic speech recognition LREC 2020 - 12th International Conference on Language Resources and Evaluation, Conference Proceedings 202066066612 no. May
- 6Ibrahim U.A.Boukar M.M.Suleiman M.A.Development of Hausa dataset a baseline for speech recognition Data Brief.40202210782010.1016/j.dib.2022.107820 PMC 879240435242895 · doi ↗ · pubmed ↗