Pre-Warning for the Remaining Time to Alarm Based on Variation Rates and Mixture Entropies
Zijiang Yang, Jiandong Wang, Honghai Li, Song Gao

TL;DR
This paper introduces a pre-warning system for industrial processes that predicts the remaining time before an alarm triggers, using variation rates and entropy measures to improve safety.
Contribution
The novel contribution is a pre-warning method that combines variation rates and mixture entropy to estimate remaining alarm time and optimize thresholds using Bayesian estimation.
Findings
The proposed method effectively estimates remaining time to alarm using variation rates and mixture entropy.
Bayesian estimation helps determine optimal pre-warning thresholds by analyzing confidence intervals.
Numerical and industrial examples demonstrate the method's effectiveness and advantages over existing approaches.
Abstract
Alarm systems play crucial roles in industrial process safety. To support tackling the accident that is about to occur after an alarm, a pre-warning method is proposed for a special class of industrial process variables to alert operators about the remaining time to alarm. The main idea of the proposed method is to estimate the remaining time to alarm based on variation rates and mixture entropies of qualitative trends in univariate variables. If the remaining time to alarm is no longer than the pre-warning threshold and its mixture entropy is small enough then a warning is generated to alert the operators. One challenge for the proposed method is how to determine an optimal pre-warning threshold by considering the uncertainties induced by the sample distribution of the remaining time to alarm, subject to the constraint of the required false warning rate. This challenge is addressed by…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
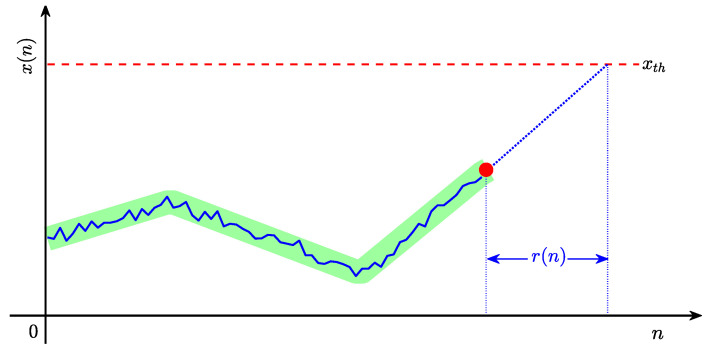 Figure 1
Figure 1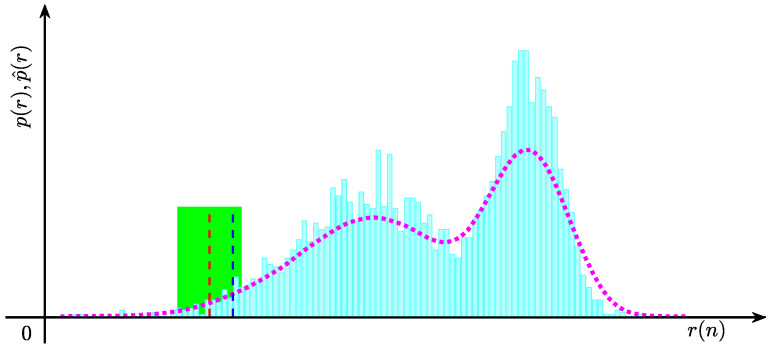 Figure 2
Figure 2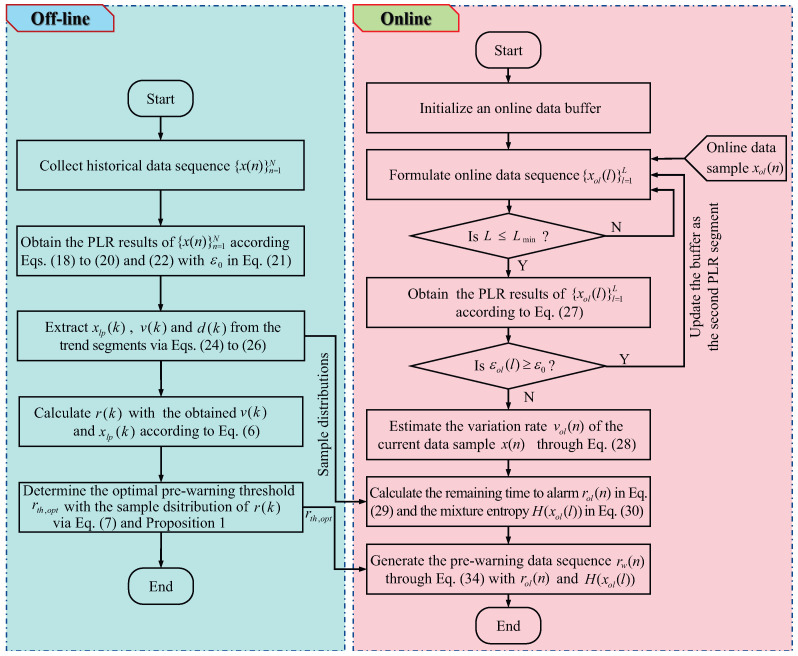 Figure 3
Figure 3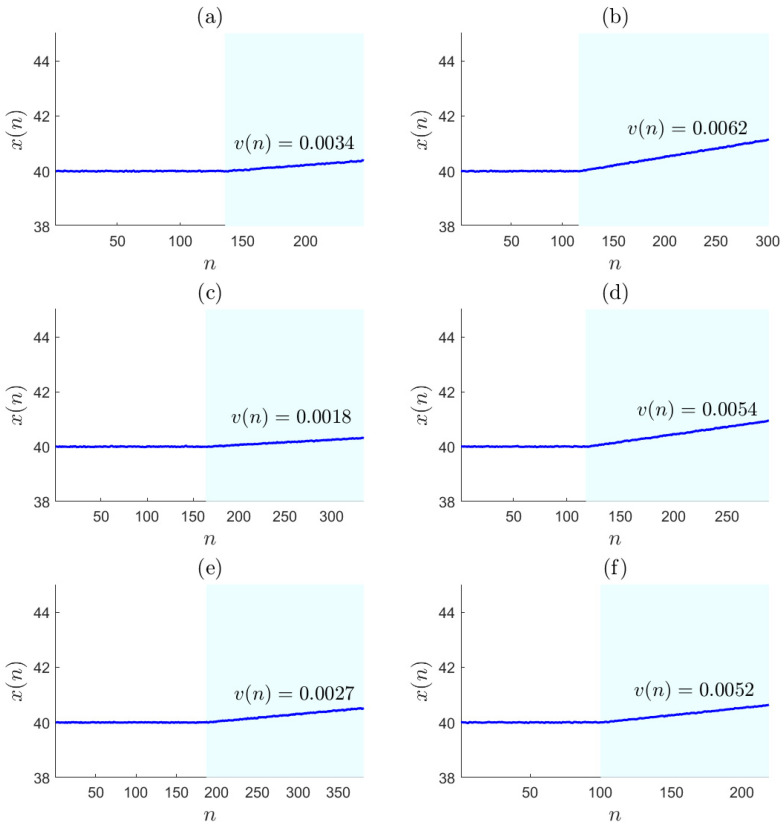 Figure 4
Figure 4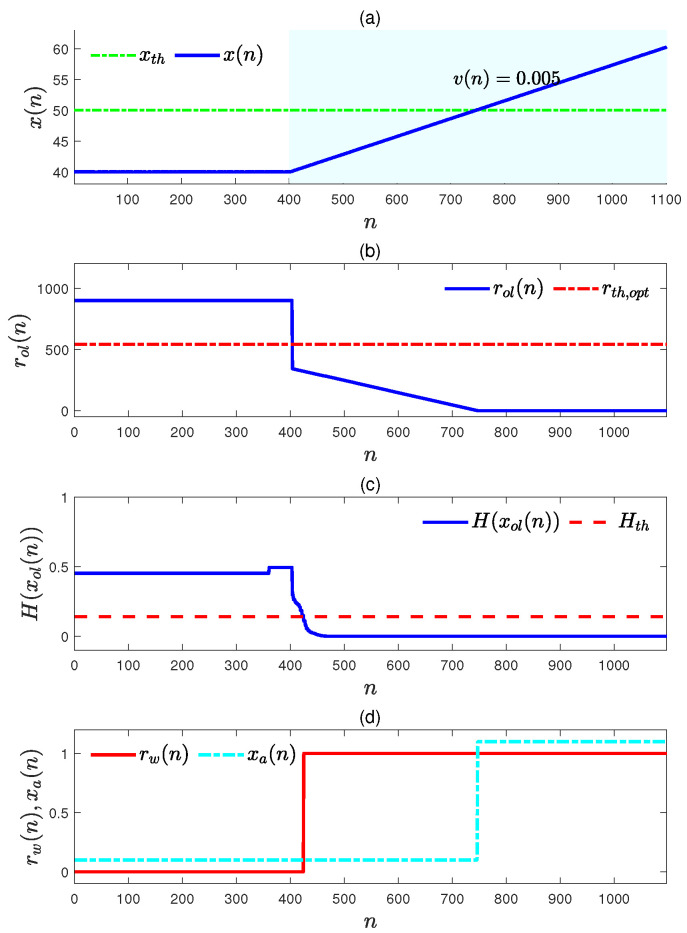 Figure 5
Figure 5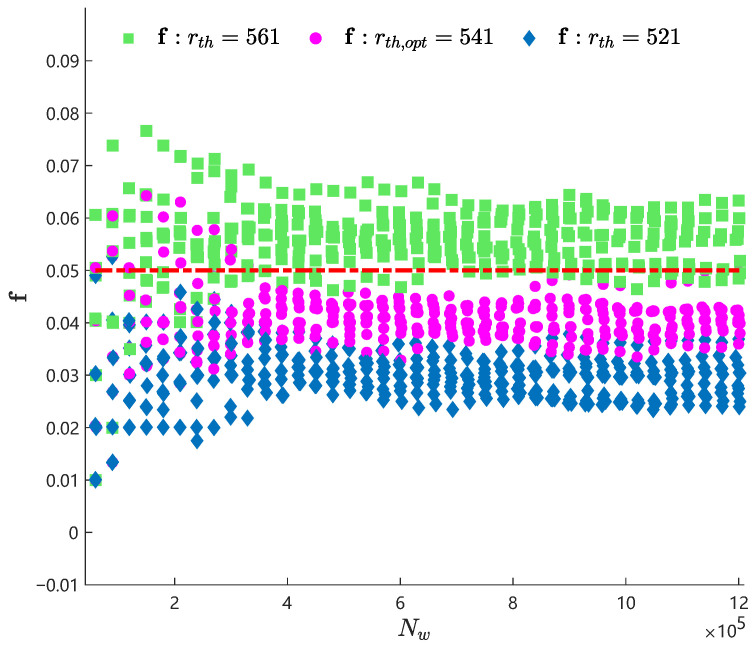 Figure 6
Figure 6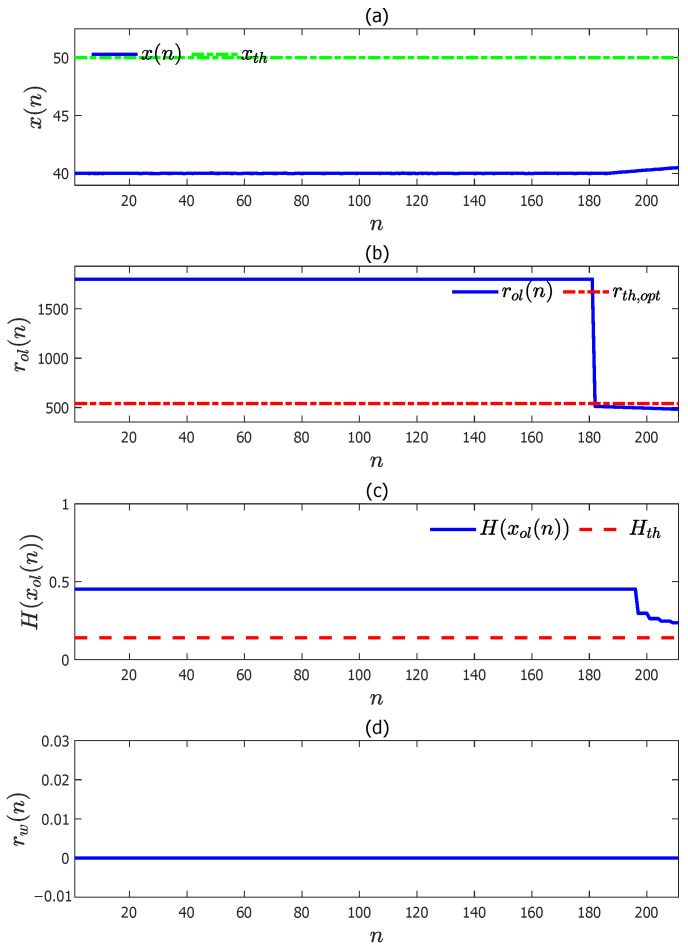 Figure 7
Figure 7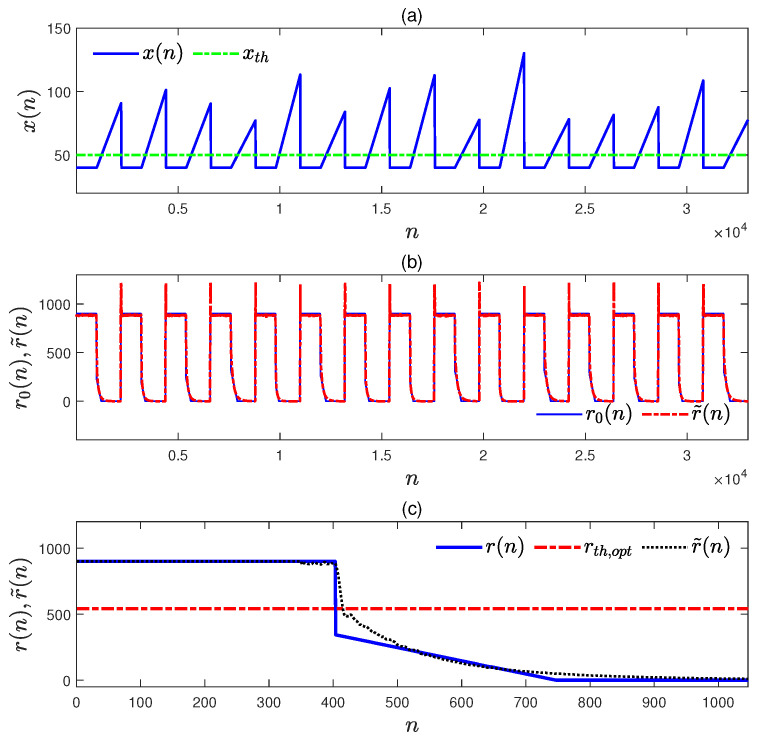 Figure 8
Figure 8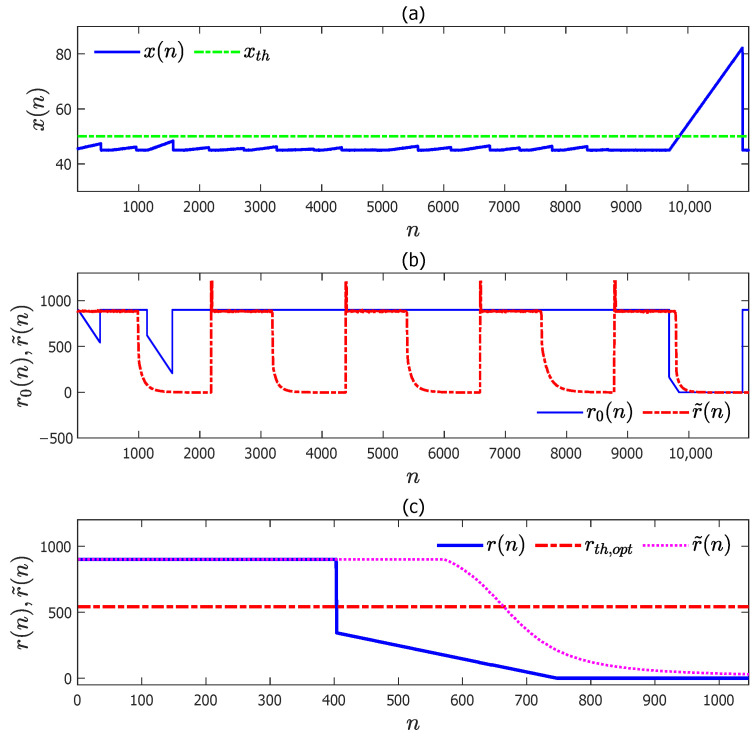 Figure 9
Figure 9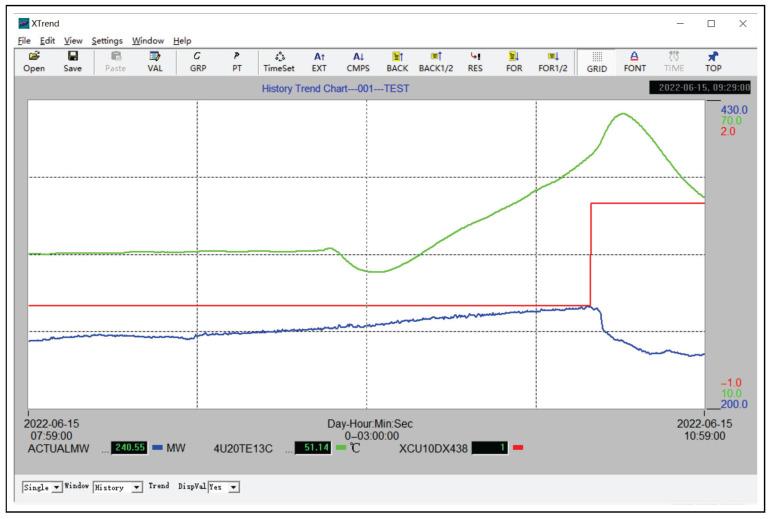 Figure 10
Figure 10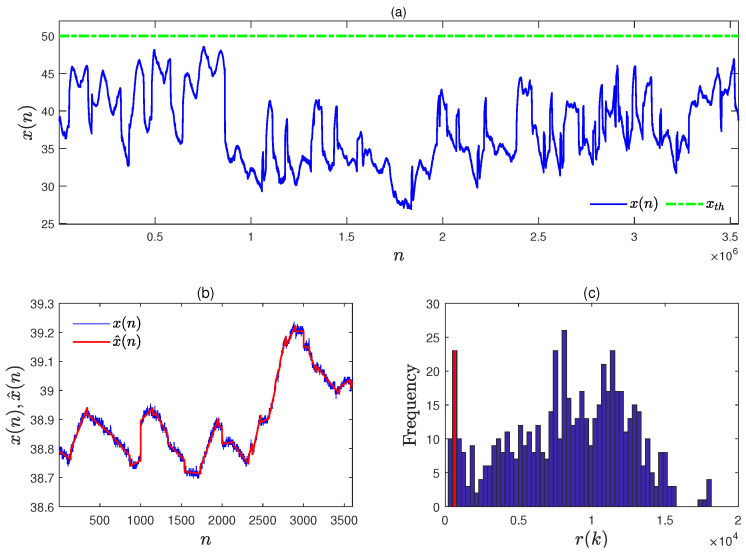 Figure 11
Figure 11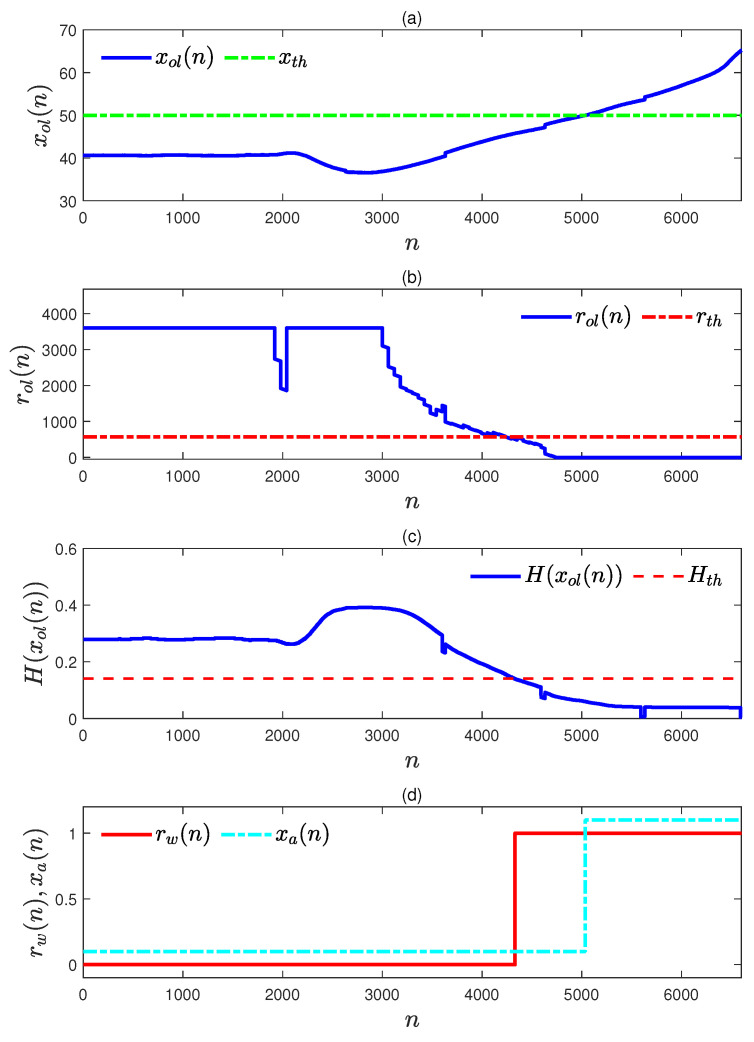 Figure 12
Figure 12 Figure 13
Figure 13- —National Natural Science Foundation of China
- —Natural Science Foundation of Shandong Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFault Detection and Control Systems · Advanced Statistical Process Monitoring · Risk and Safety Analysis
1. Introduction
Alarm systems are paramount to the safety of industrial processes [1,2] and are integrated into distributed control systems as their essential parts. With the complexity of industrial processes increasing, thousands of process variables are required to be monitored intelligently. Alarm systems monitor abnormalities in industrial processes automatically by comparing the amplitudes of process variables with their alarm thresholds. When the amplitude of one process variable is larger (or smaller) than its high (or low) alarm threshold, an alarm is triggered to notify the operators of an abnormality occurring, and then the operators take effective actions to restore the industrial process to its normal situation as soon as possible [3]. Research topics about alarm systems have been attracting attention from industrial organizations and academic societies for decades [1,2,4,5,6,7], and a large number of existing publications about alarm systems focus on alarm threshold optimization [8,9,10], nuisance alarm suppression [11,12], and alarm root cause analysis [13,14,15]. In addition to the research topics aforementioned, the pre-warning (or early warning) design is also a popular research topic about alarm systems.
Pre-warnings are indispensable for a special class of industrial process variables. Once alarms are triggered for these process variables, accidents with negative effects will occur. This phenomenon is referred to as alarms being accidents [16]. An essential reason for such a phenomenon is that there is too little time left for industrial plant operators to handle the occurring alarms and to take actions to avoid the upcoming accidents. Therefore, pre-warnings need to be designed to inform industrial plant operators about the remaining time of these process variables reaching their alarm thresholds.
Pre-warning-related research has been ongoing for decades [17,18], and the existing methods can be divided into univariate data-driven methods and multivariate data-driven methods [19,20]. Although the univariate data-driven methods are the origin of pre-warning methods, the associated studies are rather limited. Qu et al. [21] explored pre-warnings for pipeline leakage detection by analyzing the vibration signals through wavelet packet decomposition and support vector machine. Jiang et al. [22] established a complete ensemble empirical mode decomposition with adaptive noise to obtain components associated with early warnings, and they used decision tree and support vector machine to classify normal and abnormal states to generate early warnings. Zhang et al. [23] investigated an adaptive pre-warning method based on trend monitoring for an oil refining process, by checking if the process variables were steady or not. Jin et al. [24] formed an early fault warning method for thermal equipment by using incremental Gaussian mixture regression. He et al. [25] advocated a support vector machine ensemble model construction method to enhance the effectiveness of early warning, and they validated the method through wind turbine data and UCI benchmark datasets. Wang et al. [26] extracted cavitation features through a multi-index fusion-based method to formulate pre-warnings according to the test in the hydraulic turbine cavitation detection. Cheng et al. [27] generated early warnings for charging the thermal runaway of electric vehicle lithium-ion batteries, based on the residuals between a long- and short-term memory network and a temporal convolutional network predicting charging temperature and real charging data.
Multivariate data-driven methods have attracted much more attention. Cai et al. [28] predicted alarm events through a long short-term memory network and the Word2Vec of the natural language processing approach based on the alarm log. Geng et al. [29] proposed an intelligent early-warning method based on moving window sparse principal component analysis for abnormal detection in chemical processes. Sun et al. [30] executed pre-warning for a dry-type transformer through a temperature-based model established by the sparse Bayesian learning algorithm. Arunthavanathan et al. [31] formulated a convolutional neural network–long short-term memory network-based model for early fault detection and prognosis in multivariate process systems. Mamudu et al. [32] integrated a multilayer perceptron–artificial neural network model and a Bayesian network to offer pre-warnings in a hydrocarbon production system. Kopbayev et al. [33] performed gas leakage early detection through a convolutional network combined with bi-directional long short-term memory layer network model trained with image data. He et al. [34] presented an improved TOLOv3 algorithm to formulate a recognition and pre-warning system for tank leaks. Han et al. [35] advocated a dynamic uncertain causality graph-based method to identify the root fault cause of regenerative thermal oxidizers by incorporating expert knowledge. Song et al. [36] formulated a target detection model based on an image processing hierarchical algorithm to warn rust in transmission line connection fittings. Ali et al. [37] proposed a wavelet entropy-based multi-scale PCA–SDG methodology for industrial process monitoring. Fu et al. [38] investigated a multi-scale entropy-based feature extraction method to assign warnings for the compressor instability inception.
The limitations of the existing univariate data-driven methods lie in the facts that they do not consider the variation rates of process variables raising (decreasing) to their alarm thresholds and that they are not able to obtain the remaining time to alarm as important information for pre-warnings. The main purpose of this paper is to generate pre-warnings to inform operators about the remaining time of the process variables reaching their alarm thresholds. There are two challenges to obtaining the desired pre-warnings. First, the pre-warning threshold is determined from the historical data sequences in normal situations to meet with a required false warning rate. Second, the uncertainty of the raising (decreasing) trend should be measured mathematically in order to tell whether the pre-warnings are reliable.
A data-driven pre-warning method is proposed in this paper for the special class of univariate process variables. By extracting the last data samples, the variation rates, and the time durations of qualitative trends through the piecewise linear representation (PLR) method from a historical data sequence, the optimal pre-warning threshold is determined through a sample distribution of the remaining time to alarm, which is calculated with the obtained variation rates and the last data samples of the upward trend segments. In addition, sample distributions of the last data samples, the variation rates, and the time durations of the trend segments are obtained. For a current trend segment online, the entropies of its first data sample, variation rate, and time duration are summed with weighting factors to form a mixture entropy, and its remaining time to alarm is estimated with its variation rate and last data sample. If the remaining time to alarm is no longer than the optimal pre-warning threshold and the mixture entropy is small enough then a pre-warning is generated.
The pre-warning referred to in this paper has a different indication to those in the existing literature. The pre-warning indicates timely warnings in most of the existing literature. That is, the existing pre-warning methods define pre-warnings as having a short detection time, which is the time interval between the instants of the abnormality occurring and the warning. Although the existing methods are applied successfully in their scenarios, they do not take the variation rates to formulate predictions and do not take the remaining time to alarm as the features to formulate pre-warnings. In other words, these pre-warnings cannot indicate the remaining time to alarm, due to the fact that the variation rates of the process variables are varying. As a result, the existing methods cannot be used to generate the desired pre-warnings for the special class of industrial process variables being considered in this context.
The rest of this paper is organized as follows: Section 2 describes the problem to be solved. Section 3 presents the detailed steps of the proposed method in three subsections. Section 4 provides numerical and industrial examples to illustrate the effectiveness of the proposed method. Section 5 concludes the paper.
2. Problem Description
Given a univariate process variable x configured with a high alarm threshold and that is sampled from x in normal situations with a sampling period of h (e.g., h = 1 s), let be a historical data sequence of x. The alarm data sequence corresponding to is generated as
Suppose that x is one of the industrial process variables considered in this paper, and an alarm in x indicates an accident. Hence, a pre-warning for the remaining time to alarm is necessary. The remaining time to alarm is defined as the time span over which x increases from the current sample to its alarm threshold . To illustrate this definition clearly, a diagram is provided in Figure 1, where the blue solid curve represents a sequence of and the red dashed line is the high alarm threshold . As depicted in Figure 1, the sequence of involves three trend segments, which are covered by light-green bars and can reflect the real changes in x. The first segment shows an upward trend, the second segment shows a downward trend, and the third segment involving the current sample indicates an upward trend. The current sample is marked with the red point in Figure 1. If is believed to arrive at with the variation rate of the current trend then the remaining time to alarm can be regarded as the time span between the current sample index n and the instant of arriving at , marked by the two vertical blue dotted lines. Hence, can be calculated as
where is the variation rate of the current trend, and where is equal to the trend amplitude changing within a fixed time interval:
Here, and are data samples contained in the current trend; and are the sampling indices of and , respectively.
To determine a threshold for the remaining time to alarm, , an assumption is required that the sample distribution of does not change. This assumption is reasonable, due to the fact that the variation rates of process variables in normal situations are in certain intervals, and this fact is supported by physical balances in industrial practice, such as material balance and energy balance. Additionally, if is regarded as a random variable, a pre-warning threshold can be determined from the theoretical probability distribution of by considering a required false warning rate as
where denotes the theoretical probability of no more than the pre-warning threshold . Eventually, a pre-warning data sequence can be generated online as
The objective of this paper was to determine an optimal pre-warning threshold with the constraint of the required false warning rate and to obtain the reliable pre-warning sequence in Equation (5). Three steps can be adopted to realize this objective. The first step is to extract the last data samples, the variation rates, and the time durations of the trend segments in . The second step is to determine an optimal pre-warning threshold for the remaining time to alarm from its one sample distribution, which is obtained from the previously extracted information. The third step is to generate pre-warnings by comparing the online estimated remaining time to alarm with the optimal pre-warning threshold by considering the probability of the current trend arriving at the alarm threshold .
There are two challenges to obtaining the pre-warning sequence of the remaining time to alarm. First, as illustrated in Figure 2, an estimated probability distribution of the remaining time to alarm obtained from a sample distribution (light-blue bars) is always an approximation of the theoretical distribution (magenta dashed curve). This approximation leads to uncertainties (light-red rectangle) in the pre-warning threshold (red dashed line) determined from for a given and induces a deviation between the theoretical pre-warning threshold (blue dashed line) and the determined pre-warning threshold. If a large part of the uncertainties is located on the right side of the theoretical pre-warning threshold then the determined pre-warning threshold might result in many false pre-warnings. Therefore, the uncertainties should be considered in determining the optimal pre-warning threshold. Second, as shown in Figure 1, the current trend is not bound to increase to the alarm threshold, and it might change its direction randomly in the following time. Additionally, disturbances involved in might have large variation rates, which could result in small s in Equation (2) and make s be 1 in Equation (5). Therefore, it is necessary to measure the possibility of the current trend increasing to the alarm threshold.
3. The Proposed Method
This section presents the detailed steps of the proposed method in three subsections and makes a summary for the proposed method in the fourth subsection.
3.1. Determining the Optimal Pre-Warning Threshold
The method for determining an optimal pre-warning threshold with the constraint of the false pre-warning rate is presented here. Suppose that the last data sample of the k-th trend segment and its variation rate are obtained from , . Here, K denotes the number of the trend segments involved in . The remaining time to alarm cannot be calculated according to Equation (2) directly, due to the fact that may be larger than when the historical data sequence corresponds to abnormal conditions. If then the remaining time to alarm takes a negative value, which is contrary to the meaning of . Consequently, Equation (2) is rewritten as
where is an approximation of to reduce the effect of noise, is a significant threshold of variation rates, and indicates a significant upward trend existing. The operator takes the smallest integer more than the operand; denotes a large constant specified by users, that is, takes a constant value when and . The methods used to determine the value of and are introduced in the next subsection.
If the theoretical probability distribution of the remaining time to alarm is available then an optimal pre-warning threshold of can be determined by taking the required false pre-warning rate into consideration as
Here, is the theoretical false warning rate of being no more than . Unfortunately, the theoretical probability distribution of the remaining time to alarm cannot be provided. Hence, an alternative strategy of determining the optimal pre-warning threshold is to take advantage of a sample distribution of . With a sample distribution of , can be approximated well by the false warning rate when the number of in the sample distribution tends to infinity, that is,
Due to the number of in a sample distribution always being finite, uncertainties induced by the approximation exist in all determined s. Thereby, even if a pre-warning threshold is selected as the one that satisfies Equation (7) the actual false warning rate might be larger than . Hence, a conservative value of is selected as , which corresponds to the confidence interval upper bound of , that is,
The value of can be determined through Theorem 1:
Theorem 1. Suppose that there are M samples contained in a sample distribution of . For a given , the confidence interval upper bound of satisfies
where is a posterior probability mass function of ,
Here, is the number of satisfying ; and are random variables whose realizations are M and , respectively.
Proof of Theorem 1. If M and are regarded as realizations of random variables and , respectively, then (a simple expression of ) can be regarded as a realization of the false warning rate . Due to the fact that s are independent of each other, follows a binomial distribution for a given threshold [39]. Therefore, the conditional probability mass function of based on can be calculated as
Because there is no available knowledge about and takes a value in , a reasonable choice is to take the prior probability mass function of as a normal distribution with mean and standard variance [40,41], i.e.,
Based on Equations (11) and (12), the joint probability mass function of and is
According to the Bayesian formula, the posterior probability mass function of based on the realization of is
By taking Equation (11) into Equation (14), it can be obtained that
With the posterior probability mass function of in Equation (15), the confidence interval upper bound of the estimate about satisfies
According to the three-sigma rule of thumb, it is common to choose and in Equation (12). By taking Equation (15) into Equation (16), we are ready to obtain Equation (10). □
3.2. Extracting Features from an Historical Data Sequence
The last data samples, the variation rates, and the time durations of the trend segments contained in are extracted through a piecewise linear representation (PLR) method to support the formulation of the proposed method. The PLR method used here is an improved version of the sliding window and bottom-up method [42]. By considering the last data samples s and variation rates s used in Equation (6) and the duration times s used in the next subsection, these features of the trend segments are extracted at the same time.
The main idea of the PLR method is to approximate a data sequence with straight line segments. By pushing the historical data samples of into a buffer one by one, a data segment is contained in the buffer. Here, L is the number of data samples contained in it, , and L is no more than the buffer size W. The buffer size W is crucially important for obtaining the variation rates and the sample distribution of the remaining time to alarm. The value of W is selected as double the maximum length of the trend segments, which are obtained from a test data sequence and can reflect the trends of the test data sequence effectively. The first and latest data samples in the buffer are and . If can be approximated by one straight line segment then the PLR of is expressed as
Here, the parameters and are obtained by minimizing the sum of squared errors between and , i.e.,
The parameters and are estimated analytically as [43]
where , . Whether the data segment in the buffer can be represented by a straight line segment in Equation (17) or not is determined as
where is a separation threshold associated with the variance of noise contained in . A default value of can be determined as the significant change amplitude [44]. The variable is the Euclidean distance of to the approximating straight line segment in Equation (17), i.e.,
If is larger than for , , and if all s are smaller than for , , then is regarded as a new PLR segment and the buffer is emptied and updated as . Suppose that there are K PLR segments obtained from the historical data sequence , . To ease notations, the k-th PLR segment is denoted by , , and its PLR result and PLR parameters are denoted by , , , respectively. Here, and are the first sampling index and the data length of the k-th PLR segment.
According to the meaning of in Equation (17), it is obvious that is the variation rate of the k-th PLR segment . To determine whether a trend segment with variation rate is an upward trend, the significant threshold of variation rate in Equation (6) can be selected as the upper bound of the confidence interval of [45] (page 41 therein),
Here, is the percentile of the Student’s distribution with the freedom degree [45]. The default value of is 0.05.
For the k-th PLR segment , its last data sample and the duration time are
Additionally, the variation rate of is
When all the trend segments in are obtained, we are ready to obtain three sample distributions corresponding to the variation rate , the last data sample , and the duration time , separately. To simplify the representation of these sample distributions, the three sample distributions are denoted as , , and , respectively.
3.3. Generating Pre-Warnings by Combining the Mixture Entropies
Pre-warnings are generated with a combination of the online estimated remaining time to alarm and the mixture entropy of the current trend segment. To estimate the remaining time to alarm online, the PLR method introduced in Section 3.1 is adopted to obtain variation rates online. Suppose that the online data samples contained in the buffer are and , , . Here, the parameter is a variable that is increasing with the sampling time. The last component of is the current data sample , which is denoted by . By taking Equations (19), (21), and (25) into consideration, the approximation of is
where is the minimum required length of the data samples contained in the buffer; is the approximation of the last data sample in the previous adjacent PLR segment. With in Equation (26), the variation rate of is estimated as
Here, is the variation rate of obtained from the previous adjacent PLR segment. The lengths of the PLR segments are adjusted according to the different types of gradual or abrupt process situation changes. According to Equations (21), (26), and (27), the separation threshold and the minimum required length of data samples can assure the segment length varying in different situations. For a gradual change, its corresponding variables vary smoothly, and the variable in Equation (22) might be smaller than for a large time interval, and then a large segment length can be obtained. Conversely, if there is an abrupt change, the variables vary dramatically so that in Equation (22) might be larger than in a short time interval (no less than ), and a short segment is obtained. The minimum required length of data samples, , is used to avoid wrong segmentation caused by outliers or disturbances in data sequences and to avoid inaccurate variation rates obtained from PLR. In other words, the minimum required length of data samples, , assures the data segments being trends.
Because there is no prior information about the upcoming data samples after , a conservative assumption is that is the last data sample of the current trend. Hence, the online alarm remaining time can be predicated with and as
Here, is the high alarm threshold of x in Equation (1), the operator takes the smallest integer more than the operand, and is the upper bound of the confidence interval of . The value of is determined with through Equation (23).
Although the optimal pre-warning threshold is determined in Equation (9), noise and disturbances involved in x could lead to several s in Equation (28) with a large positive value and let the corresponding s be less than the optimal pre-warning threshold . In addition, it can be concluded from Equation (28) that the trend segments tending to arrive at the alarm threshold should be in one of the following two cases: (1) the trend segment has had a large positive variation rate for a long time; (2) the trend segment starts at a large amplitude value and with a large positive variation rate. According to the information entropy theory, an entropy with a small value indicates a higher certainty [46]. To measure the certainty of trend segments tending to arrive at the alarm threshold, the information entropy as well as the conditional entropy would be the right candidates. Otherwise, by considering the two cases mentioned above, variation rates, variation time, and amplitude value are all the critical factors for determining if the trend segment arrives at the alarm threshold or not, and they are independent of each other as observed in industrial data sequences. As a result, the information entropy and the conditional entropy cannot be used here, and a mixture entropy is designed to measure the certainty of the estimated remaining time to alarm as
where , , and are weighted parameters, ; , , and are the entropies of the last data sample, the variation rate, and the duration time of the current trend segment, respectively. The recommended value for is . According to the definition of entropy, , , and can be calculated as
where , , and denote the probabilities of samples in the distributions , , and being larger than , , and , respectively.
The mixture entropy in Equation (29) obtains a small value when the trend segment tends to arrive at the alarm threshold in a higher certainty. According to the two cases of a trend segment tending to arrive at the alarm threshold, its variation rate and variation time, or variation rate and amplitude value, should be different apparently from their values corresponding to the normal situations. Hence, the probabilities of the samples more than the variation rate, the variation time, and the amplitude value in their sample distributions are small, which results in small values of and , or and in Equation (30). , , and are the information entropy of the amplitude value, the variation rate, and the variation time, respectively. Hence, the trend segment tends to arrive at the alarm threshold corresponding to in Equation (29) having a small value resulting from small values of and , or and . To declare whether a trend segment tends to arrive at the alarm threshold, it is necessary to investigate a threshold for declaring whether in Equation (29) is small enough or not. Given the two cases of a trend segment most likely to arrive at the alarm threshold aforementioned, two heuristic thresholds for can be obtained as
Here, , , and are the probabilities of , , and being more than their percent upper confidence limits, , respectively; a typical value of the parameters is 0.05. It is clear that the values of , , and are determined by their related , and is equal to on the condition that and take the same values, respectively. Nonetheless, the threshold for declaring whether in Equation (29) is small enough or not can be selected in a general form as
With the optimal pre-warning threshold in Equation (9) and the entropy threshold in Equation (32), the pre-warning data sequence is generated by comparing in Equation (28) with and comparing in Equation (29) with as
3.4. Summary of the Proposed Method
The proposed pre-warning method is composed of an off-line design part and an online application part. In the off-line part, after extracting the last data samples, the variation rates, and the time durations of the trend segments contained in the historical data sequence through the PLR method, a sample distribution of the remaining time to alarm is obtained, and the optimal pre-warning threshold is determined from this sample distribution through Bayesian estimation theory. In the online part, the last data sample, the variation rate, and the time duration of the current trend segment are extracted online to support the calculation of the remaining time to alarm and the mixture entropy, and a pre-warning is triggered when the remaining time to alarm is not longer than the optimal pre-warning threshold and the mixture entropy is small.
The pseudo-code of the proposed pre-warning method is provided in Algorithm 1. The time and the space complexity of the online application part are analyzed as follows. The time complexity of the online application part is determined by the PLR algorithm, and the number of data samples in the online buffer is not larger than the buffer size W. By considering the time complexity of the PLR method [47], the time complexity of the online application part is . The space cost of the online application part is mainly determined by the online buffer size and the PLR results of the data sequence in the online buffer, and, thus, the space complexity of the online application part is . The proposed method has been realized on a personal computer with an Intel Core i7-4770 CPU @3.40 GHz and 8 GB memory. The CPU is produced by the Intel Corporation, which is located in Santa Clara, CA, USA. The consuming time for an industrial data sample online is approximately 0.1644 s. To facilitate understanding, a flowchart of the proposed method is provided in Figure 3. Algorithm 1: Pre-warning for the remaining time to alarm
4. Examples
This section presents four numerical examples and an industrial example to show the effectiveness of the proposed method. The first numerical example is provided to illustrate the application procedures of the proposed method. The second numerical example is taken to verify the optimality of the determined optimal pre-warning threshold. The third numerical example is used to verify the necessity of the mixture entropy in pre-warning online. The fourth numerical example is available to make a comparison between the proposed method and a deep learning-based method. Finally, an industrial example is presented to show the effectiveness of the proposed method in practice.
4.1. Numerical Example A
This example is provided to verify the feasibility of the proposed method and to illustrate the application procedures. First, data sequences in normal situations were simulated to determine the optimal pre-warning threshold. Second, a data sequence in an abnormal situation was simulated to generate pre-warnings. All the simulated data sequences in the normal situations were generated with the variation rates following a normal distribution, while the abnormal data sequence was generated with a larger variation rate than its counterparts in the normal situations.
To simulate data sequences in normal situations, the basic un-noised data sequence was composed of an upward trend segment and a horizontal trend segment as
Here, and are the data lengths of in different trends. and are random integers and take uniform distributions, i.e., ∼ and ∼ ; denotes the variation rate of in an upward trend, and follows a normal distribution with mean 0.01 and variance , that is, ∼ . The basic data sequence was defined as a superposition of the basic un-noised data sequence in Equation (34) and a white noise sequence, i.e.,
where is the Gaussian white noise with zero mean and standard deviation .
A simulated data sequence corresponding to normal situations was composed of 1000 basic data sequences in Equation (35) for determining the optimal pre-warning threshold . Six simulated basic data sequences are provided in Figure 4, in which the upward trends are marked with light-blue backgrounds. A high alarm threshold was selected for the simulation data sequence as . The required false warning rate was set to 0.05, which is widely used as the probability of type I error. The PLR results of this simulated data sequence were obtained according to Equations (19)–(22) with . The last data samples s, the variation rates s, and the duration times s of all the trend segments were extracted from the PLR results, and the sample distributions , , and were obtained, corresponding to , , and , respectively.
With and s, the remaining time to alarm s was calculated via Equation (6). With the obtained s and the required false pre-warning rate , the optimal pre-warning threshold was determined as via Equation (9). Because the simulation data sequences were designed according to Equation (34), the real values of the variation rate s and the last data sample s of each upward trend were known, so that the actual pre-warning threshold could be estimated from these values, and its value was 596. The optimal pre-warning threshold determined from the proposed method was very close to the actual pre-warning threshold, which clearly demonstrates the feasibility of the proposed method. To determine the threshold of the mixture entropy in Equation (32), we let the parameters and , , and was obtained.
To generate pre-warnings, a data sequence in an abnormal situation was simulated as shown in Figure 5a. The variation rate of the upward trend in this abnormal data sequence was 0.05, which is larger than the normal variation rates in Equation (34). The corresponding remaining time to alarm in Equation (28) could be obtained with in Equation (27), and the corresponding mixture entropy was calculated via Equation (29). The obtained sequence of is given in Figure 5b, and the mixture entropy is provided in Figure 5c. The pre-warning sequence was generated based on and according to Equation (33), and this is shown in Figure 5d. As a comparison, the alarm data sequence corresponding to the simulated abnormal data sequence is provided in Figure 5d also. It is obvious that the first sampling index of is much smaller than the first sampling index of ; that is, the proposed pre-warning method can perform its function as expected, and it can be concluded that the proposed method is feasible.
4.2. Numerical Example B
This example verifies the optimality of the optimal pre-warning threshold. A group of new data sequences were simulated in normal situations according to Equation (35) to validate the optimality of the optimal pre-warning threshold by checking whether its false warning rate was close to or not. The false warning rate used here is defined based on a pre-warning data sequence and its related alarm remaining time sequence as
where the operator obtains the number of the operand; is a sample of the pre-warning data sequence and is obtained as
the logical expression denotes the instant of pre-warnings being triggered, and indicates a trend segment of with a large positive variation rate. Here, is obtained with a simulated normal data sequence , which is composed of a number of basic data sequences in Equation (35). Therefore, the simulated normal data length was a random variable. Note that the mixture entropy was not considered in Equation (37), due to the fact that the mixture entropy was not used in the selection process of the optimal pre-warning threshold. A group of false warning rates for was calculated on the condition that the number of basic data sequences contained in varied from 100 to 2000 with a step of 50. The false warning rates obtained from 10 independent groups of are given in Figure 6 with magenta points. It can be observed that s are located below with the length of the simulation data sequence increasing and convergence to a value that is very close to .
The optimality of was verified by comparing its false pre-warning rates with the false pre-warning rates of and . The false pre-warning rates of and were calculated with the same simulation data sequences and in the same way. The calculated results are given in Figure 6 with green squares and cyan diamonds, respectively. Obviously, the false rates of were larger than , and, hence, resulted in a large number of false pre-warnings. On the contrary, the false rates of were smaller than , and there were much fewer false pre-warnings induced by . Although the false pre-warning rates of were smaller than the false pre-warning rates of , the pre-warnings induced by had longer time delays than . The optimal pre-warning threshold yielded more reasonable false warning rates than the two other pre-warning thresholds. Thus, the optimality of the optimal pre-warning threshold was verified.
4.3. Numerical Example C
The necessity of the mixture entropy in Equation (29) for generating pre-warnings online was verified in this case. An abnormal data sequence was designed to be similar to Equations (34) and (35). We let in Equation (34) be , and the simulated abnormal data sequence is given in Figure 7a. The abnormal data sequence contained an upward trend beginning at and ending at .
To perform pre-warnings for this abnormal data sequence with the determined optimal pre-warning threshold , the remaining time to alarm data sequence was calculated according to Equation (28) with the variation rates estimated according to Equation (27), and it is presented in Figure 7b. It is obvious that was smaller than when . If there was no mixture entropy to measure the certainty of the upward trend growing to the high alarm threshold (green dot–dash line) in Figure 7a then a false pre-warning was generated.
To avoid the false pre-warning generating pre-warnings online, the mixture entropy was calculated and plotted in Figure 7c (blue solid). It can be observed from Figure 7c that was always above the mixture entropy threshold by taking and , . Finally, the pre-warning data sequence was generated according to Equation (33) with and , and it is shown in Figure 7c with a red solid line. Obviously, there were no false pre-warnings. The correct pre-warning sequence benefited from the mixture entropy.
4.4. Numerical Example D
This example made a comparison between the proposed method and a deep learning-based method. By taking the remaining time to alarm as the feature to formulate pre-warnings, it was ready to adapt the deep learning-based method for the problem to be studied here. The deep learning-based method is based on the convolutional neural network–long short-term memory (CNN–LSTM) model for time series prediction [31].
To satisfy the data requirement in the CNN–LSTM model training, the un-noised data segments corresponding to abnormal situations were generated as
Here, is the variation rate and follows a normal distribution with mean zero and standard variance 0.03, that is, ∼ ; is the Gaussian white noise with zero mean and standard deviation 0.01. To indicate abnormal situations, all the variation rates in Equation (38) were selected as the ones larger than in Figure 5a.
The CNN–LSTM model adopted here was composed of two convolution layers (32 filters therein) and four long short-term memory layers (128 filters therein), in addition to an input layer, an output layer, an exponential linear unit layer, a batch normalization layer, a sequence unfolding layer, and a dropout layer. To ensure the quality of the CNN–LSTM model, the maximum number of epochs for training was taken as 100, and a mini-batch with 1000 observations was adopted at each iteration. The CNN–LSTM model could be trained with a simulated data sequence and its corresponding sequence of remaining time to alarm, which was calculated according to Equation (6) with the un-noised data samples and real variation rates.
For an ideal scenario, a simulated data sequence was generated to be composed of 100 abnormal data segments in Equation (38) and 100 normal data segments in Equation (34). The original data sequence and its corresponding sequence of remaining time to alarm were used to train and test an CNN–LSTM model. The proportions of the data used in training and testing were 85% and 15%, respectively. The test data sequence of and its corresponding sequence of remaining time to alarm are provided in Figure 8a and b, separately. The trained model outputs corresponding to the test data are provided in Figure 8b. It is obvious that from the trained model can well describe the sequence . The sequence of remaining time to alarm is forecasted with the trained model for the abnormal data sequence in Figure 5a, and it is denoted by in Figure 8c with the black dotted line. It is obvious that can indicate the abnormal condition effectively.
For the practical scenario, there are fewer abnormal data samples in industrial practice, and another CNN–LSTM model was trained with the data sequence composed of 5 abnormal data segments and 100 normal data segments. This CNN–LSTM model was trained in a similar manner as that in the ideal scenario. The testing results of this trained model are provided in Figure 9b, corresponding to the test data in Figure 9a. The sequence of remaining time to alarm was forecasted with this trained model for the abnormal data sequence in Figure 5a and is denoted by in Figure 9c with the black dotted line. Clearly, in Figure 9c had a long time delay to detect the abnormal condition.
By comparing the sequences of and in Figure 8c and Figure 9c, it can be concluded that the deep learning-based method has the ability to predict the remaining time to alarm on the condition that a large number of abnormal data segments can be provided for training. However, such a condition is often not satisfied in industrial practice. On the contrary, the proposed method was not confined by this condition and had a better performance than the deep learning-based method in this practical scenario.
4.5. Industrial Example
The proposed method was applied to dozens of process variables in a large-scale thermal power plant. This industrial example was used to explain the necessity of the proposed pre-warning method and to illustrate the effectiveness and the feasibility of the proposed method.
An accident in a large-scale thermal power plant is provided in Figure 10, where data segments of three process variables with tagnames ACTUALM, 4U20TE13C, and XCU10DX438 are shown. The monitored process variable 4U20TE13C was the temperature of rotating machinery located in a coal mill, and its alarm threshold was configured as 50 °C (a high alarm threshold). As depicted in Figure 10, 4U20TE13C increased to its alarm threshold at approximately 9:34:00 and triggered an alarm at 10:20:54. This alarm caused the mill shutdown XCU10DX438 to switch on at 10:28:58, resulting in the desired active power ACTUALM decreasing by 25 MW. The time interval from the alarm being triggered to the mill shutdown was less than 15 min, which is the least time to start up a sparse mill. Clearly, the reason for the accident was that there was too little time left for the operators to start up a spare mill. Therefore, pre-warnings were necessary for 4U20TE13C.
A pre-warning was designed for 4U20TE13C, which is denoted as x for simplicity, and °C was its alarm threshold. A historical data sequence of 1 month was collected to determine the optimal pre-warning threshold . An accident data sequence in Figure 10 was taken to illustrate the pre-warning generated by the proposed method.
The optimal pre-warning threshold in Equation (9) was determined with the historical data sequence lasting for 1 month. A subsegment of is given in Figure 11a in the blue solid line, and the high alarm threshold is given in the green dot–dash line. It is worth noting that x is not a stable variable in a normal situation. Hence, it is not the same as traditional strategies to detect changes in stable variables. The PLR results of were obtained from Equation (17) to Equation (22) with the separation threshold , and some PLR results (the red solid lines) are provided in Figure 11b.
The trend segments with large enough variation rates were determined by comparing the variation rate in Equation (25) with the significant threshold of variation rate in Equation (23). That is, if the variation rate of a PLR data segment was larger than its significant threshold , this PLR data segment had a large enough variation rate. The last data samples s, the variation rates s, and the duration times s of all the trend segments were extracted from the PLR results, and the sample distributions , , and were obtained in the meantime. Furthermore, the corresponding remaining time to alarm s was calculated via Equation (6) with the s and s, and the s are provided in the histogram of Figure 11c. The optimal pre-warning threshold was determined as through Equations (9) and (10) by taking the false pre-warning rate , and the location of is marked with a red solid line in Figure 11c. Due to the fact that s are obtained from the historical data in normal situations, the false pre-warning rate is equivalent to the probability of type I errors, and is a common value for type I errors used in industrial practice [21,36]. In other words, indicates that there were 5% trend segments with large positive variation rates resulting in false pre-warnings.
By applying the proposed pre-warning method to the accident data sequence in Figure 10 with in an online manner, an effective pre-warning was triggered. For the accident data sequence in Figure 12a (a part of in Figure 10), the remaining time to alarm sequence s was obtained online through Equation (28), and the sequence of is plotted in Figure 12b. At the same time, the mixture entropy sequence of was calculated through Equations (31) and (29) with the obtained sample distributions of , , and . The pre-warning sequence was calculated via Equation (33) and provided in Figure 12c. Obviously, for the abnormal data sequence in Figure 10 the optimal pre-warning threshold reflected the abnormal correctly and generated the desired pre-warning sequence . Therefore, the feasibility of the proposed method is illustrated and validated. As a comparison, the alarm data sequence was generated according to Equation (5) and is provided with a cyan dash–dot line in Figure 12d. It can be observed that occurred at and that switched into the alarm state at . Thus, the proposed pre-warning method can alert operators much earlier than traditional alarms and provides operators much more time to address the abnormality. Hence, the proposed method is beneficial for the safety of production processes.
In addition, the performance of the proposed method was validated with the historical data sequence in normal situations lasting for three months. Benefiting from the mixture entropy combined in Equation (33), the false pre-warning rates were much less than the required value . The variation rates and the de-noised last sample of the upward trends were obtained through the online PLR method. The online variation rate was calculated through Equation (27). The online remaining time to alarm was obtained with and through Equation (28), and the pre-warning sequence was generated via Equation (33) with and . There were 8, 11, and 7 false pre-warnings out of 291, 420, and 227 trend segments with large variation rates in the three months, respectively. Consequently, the false pre-warning rates for the three months were 2.7491%, 2.6190%, and 3.0837%, according to Equation (36). The false pre-warning rates were close to the required 5%. Therefore, it can be concluded that the proposed pre-warning method achieves a satisfactory performance, in terms of false pre-warnings.
5. Conclusions
This paper proposes a pre-warning method based on variation rates and mixture entropies for a special class of industrial process variables. In the off-line stage, by extracting the information of trend segments in the historical data sequence via PLR, the proposed method determines the optimal pre-warning threshold through Bayesian estimation theory with a sample distribution of the remaining time to alarm, and it formulates the sample distributions of the variation rates, the first data sample, and the duration time. In the online stage, the remaining time to alarm is estimated with the online-obtained variation rates and the last data sample of the current trend, and the mixture entropy is calculated with the variation rate, the first data sample, and the trend length of the current trend segment, as well as their sample distributions obtained in the off-line stage. The pre-warning sequence is generated on the condition that the remaining time to alarm is no longer than the optimal pre-warning threshold and the mixture entropy is small enough.
Although the proposed method achieves the desired performance, it could be developed in three aspects. First, to reduce the number of false pre-warnings, the proposed method could be incorporated with delay timers, alarm dead-bands, or their combinations that are effective in handling nuisance alarms [48]. However, such an incorporation would result in time delays for pre-warnings. A key issue is to achieve a good balance between the false pre-warning rate and the time delay for pre-warnings. Second, the pre-warning threshold could be designed as an adaptive one, in order to deal with non-stationary and nonlinear process variables. The key issues are to determine pre-warning thresholds corresponding to different normal situations and to detect the changes of these normal situations in an online manner. Third, to draw multivariate information from industrial processes, the proposed method could be extended to generate pre-warnings by exploiting normal operating zone models to describe the geometric space of an allowable variation region of multiple related variables [49]. A key issue is to extract the variation rates of multivariate data sequences in their corresponding high-dimensional geometric space.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang J. Yang F. Chen T. Shah S.L. An overview of industrial alarm systems: Main causes for alarm overloading, research status, and open problems IEEE Trans. Autom. Sci. Eng.2016131045106110.1109/TASE.2015.2464234 · doi ↗
- 2Mustaf F.E. Ahmed I. Basit A. Alvi U. Malik S.H. Mahmood A. Ali P.R. A review on effective alarm management systems for industrial process control: Barriers and opportunities Int. J. Crit. Infrastruct. Prot.20234110059910.1016/j.ijcip.2023.100599 · doi ↗
- 3Rothenberg D. Alarm Management for Process Control Momentum Press New York, NY, USA 20092427
- 4Wang J. Hu W. Chen T. Intelligent Industrial Alarm Systems–Advanced Analysis and Design Methods Springer Singapore 2024
- 5ANSI/ISA-18. 2Management of Alarm Systems for the Process Industries ISA (International Society of Automation)Durham, NC, USA 2016
- 6Dorgo G. Tandari F. SzabóT. Palazoglu A. Abonyi J. Quality vs. quantity of alarm messages–How to measure the performance of an alarm system Chem. Eng. Res. Des.2021173638010.1016/j.cherd.2021.06.022 · doi ↗
- 7Engineering Equipment and Materials Users Association EEMUA-191: Alarm Systems—A Guide to Design, Management and Procurement Engineering Equipment and Materials Users Association London, UK 2013
- 8Gao H. Wei C. Huang W. Gao X. Design of multivariate alarm trippoints for industrial processes based on causal model Chem. Eng. Res. Des.2021609128914010.1021/acs.iecr.1c 00867 · doi ↗