Oil-Painting Style Classification Using ResNet with Conditional Information Bottleneck Regularization
Yaling Dang, Fei Duan, Jia Chen

TL;DR
This paper introduces a new deep learning framework for classifying oil-painting styles using a conditional information bottleneck method with ResNet, improving accuracy and interpretability.
Contribution
The novel contribution is the use of a conditional information bottleneck regularization with Rényi’s entropy estimator for oil-painting style classification.
Findings
The proposed CIB framework achieves 13.1% and 11.9% relative performance gains on the Pandora and OilPainting datasets, respectively.
The method produces disentangled latent representations that cluster semantically similar painting styles.
Abstract
Automatic classification of oil-painting styles holds significant promise for art history, digital archiving, and forensic investigation by offering objective, scalable analysis of visual artistic attributes. In this paper, we introduce a deep conditional information bottleneck (CIB) framework, built atop ResNet-50, for fine-grained style classification of oil paintings. Unlike traditional information bottleneck (IB) approaches that minimize the mutual information I(X;Z) between input X and latent representation Z, our CIB minimizes the conditional mutual information I(X;Z∣Y), where Y denotes the painting’s style label. We implement this conditional term using a matrix-based Rényi’s entropy estimator, thereby avoiding costly variational approximations and ensuring computational efficiency. We evaluate our method on two public benchmarks: the Pandora dataset (7740 images across 12…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
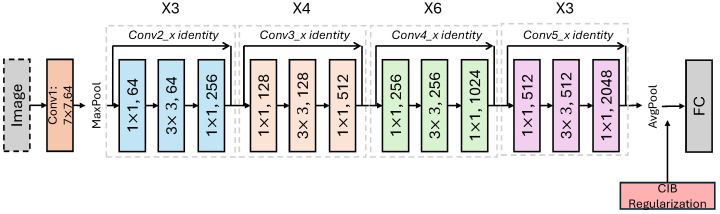 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3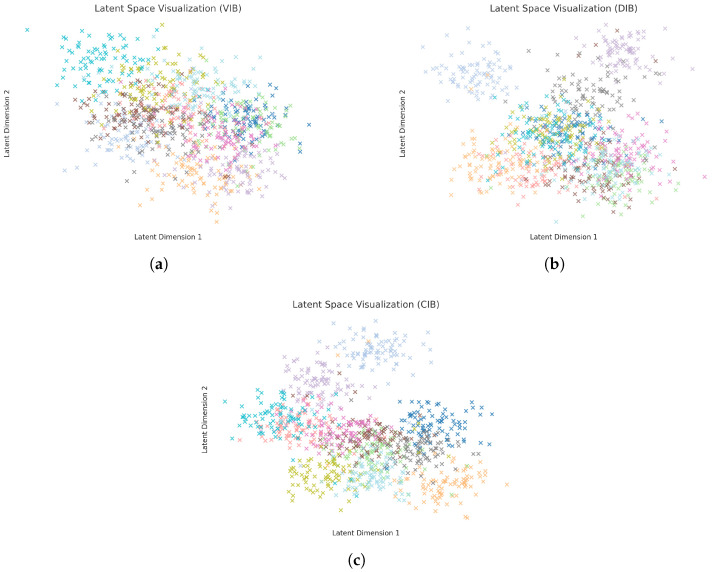 Figure 4
Figure 4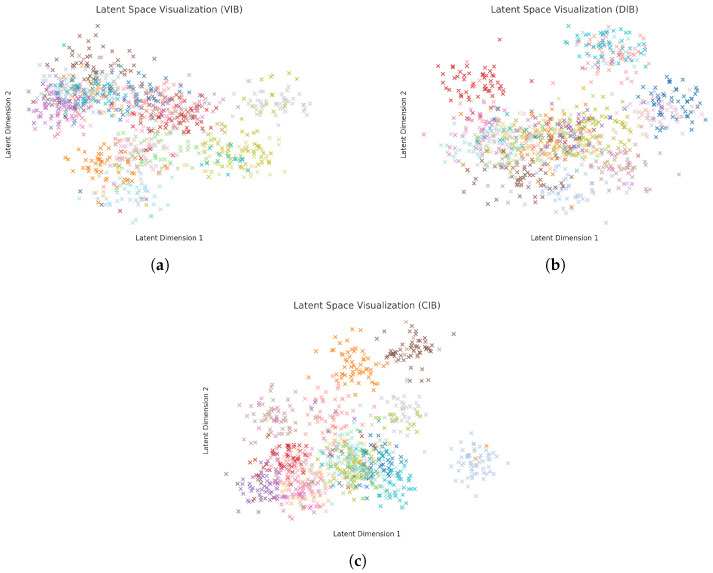 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9- —2024 Shanxi Provincial Art and Science Planning Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAesthetic Perception and Analysis · Cultural Heritage Materials Analysis · Conservation Techniques and Studies
1. Introduction
Oil painting, as a medium, has served as a cornerstone of artistic innovation for centuries, capturing the interplay of technique and cultural zeitgeist across movements, from the idealized harmonies of the Renaissance to the visceral impasto of the Baroque. Yet, the taxonomic boundaries of these styles often reside in granular, curatorially honed details: the directional thrust of a brushstroke, the optical blending of layered glazes, or the spatial rhythm of compositional geometry [1,2]. While human experts leverage decades of visual literacy to decode these cues, the rise of digitized art collections, now spanning millions of high-resolution works—demands scalable, objective tools to map stylistic lineages, detect forgeries [3,4], and democratize access to art historical narratives [5,6].
Convolutional neural networks (CNNs), notably ResNet [7], have revolutionized image recognition by hierarchically encoding texture and shape. However, the direct application of ResNet to fine-grained style classification faces a critical mismatch: unlike natural objects, artistic styles are defined not by semantic content but by stylometric signatures, such as subtle variations in brushwork, localized edge contrasts, and chromatic temperature. These discriminative cues often lie in mid-to-high spatial frequency bands, making them particularly vulnerable to suppression by conventional pooling operations or invariant feature learning strategies [1]. While the information bottleneck (IB) principle [8] provides a theoretically grounded framework for learning minimal sufficient representations, unconditional variants [9] compress input features without regard to class-specific structure, often discarding style-relevant information along with redundant background content. This issue is particularly problematic in art domains, where inter-class ambiguity (e.g., between Impressionism and Romanticism) and intra-class diversity demand careful preservation of class-conditional details. To address this, we adopt the conditional information bottleneck (CIB) formulation, which explicitly encourages representations that retain only the information relevant for distinguishing between style labels, i.e., maximizing . In doing so, CIB enables the model to filter out nuisance factors unrelated to the target style label (such as background, canvas color, and object semantics), retain only the information that helps distinguish among styles (for example, brushstroke directionality in Expressionism, pointillist dot patterns in Post-Impressionism, or chiaroscuro lighting contrasts in Baroque), and mitigate overfitting to incidental patterns that may vary across artists but are irrelevant to style categories. Furthermore, compared to variational alternatives [9], CIB facilitates a more faithful disentanglement of overlapping styles by conditioning the compression process on the style label, thereby aligning the learned latent space with the stylistic structure of the dataset.
We address these limitations with a conditional information bottleneck (CIB) framework, implemented on a ResNet-50 backbone [7]. By inserting a bottleneck layer after the last block of the stage—a strategic locus preserving brushstroke-level texture before high-level semantic abstraction—we optimize a novel loss that minimizes the mutual information between input images X and latent codes Z, conditioned on style labels Y. This forces the model to discard only features statistically independent of style, unlike unconditional IB’s indiscriminate compression. Crucially, we sidestep variational approximations by computing directly via a matrix-based Rényi’s entropy estimator [10], which quantifies entropy from the eigenspectrum of Gram matrices derived from latent embeddings. This non-parametric approach not only avoids variational biases but also enables end-to-end training without auxiliary networks, yielding both efficiency and interpretability.
Validation on two large-scale benchmarks underscores our gains: the Pandora dataset (7740 images across 12 movements, including Hellenistic frescoes and Romantic landscapes) [11] and the OilPainting corpus (19,787 works spanning 17 styles from Early Netherlandish to Post-Impressionism) [12]. Our CIB-ResNet50 achieves 64.8% accuracy on Pandora, a 7.5% absolute gain over the vanilla ResNet-50 (57.3%), and outperforms both variational IB (61.2%) [9] and deterministic IB (61.6%) [13]. Qualitatively, t-SNE visualizations reveal that CIB induces label-coherent clusters even for stylistically proximate movements (e.g., Baroque vs. Rococo), whereas baseline embeddings exhibit overlapping distributions.
Our key contributions are as follows:
- Label-Conditioned Feature Compression. A CIB mechanism that selectively prunes style-irrelevant features while preserving discriminative brushwork, color, and compositional cues, formalized through conditional mutual information.
- Non-Parametric Entropy Estimation. A training pipeline using Rényi’s -order entropy functional to compute without distributional assumptions and variational bounds, improving fidelity and eliminating auxiliary networks.
- Empirical Superiority. State-of-the-art accuracy and adversarial robustness on two oil-painting benchmarks, with ablation studies confirming CIB’s robustness to style granularity.
2. Background Knowledge and Related Work
2.1. Machine Learning Approaches for Oil-Painting Style Classification
Style classification has long been a focus of both traditional image-processing and deep learning research. Early approaches to painting-style analysis relied on handcrafted features designed to capture brushwork, color palettes, and texture. For instance, Gao et al. [14] applied sparse coding to grayscale patches in order to model local structural patterns for style discrimination. Liu et al. [15] showed that simple statistics of color histograms, such as palette entropy, can effectively distinguish painters. Berezhnoy et al. [16] employed Gabor-basis energy combined with normalized mutual information to quantify stylistic variations in Van Gogh’s oeuvre. More recently, Qian et al. [17] introduced a multi-entropy framework that jointly models block, color, and contour entropy to capture complementary cues of color, composition, and shape. Although these methods achieve competitive results, their dependence on grayscale inputs, manually selected transforms, or hand-tuned entropy measures limits their capacity to capture subtle, higher-order style characteristics inherent in complex oil paintings.
With the advent of convolutional neural networks (CNNs), researchers shifted toward end-to-end style learning. Bai et al. [18] introduced a custom CNN to extract deep style features and evaluate inter-style similarity via an information-bottleneck distance. Early attempts on the Painting-91 dataset [19] applied standard image-classification CNNs [20] to artwork classification, while Folego et al. [21] demonstrated that selecting the patch with the highest confidence score outperforms traditional voting schemes. Nanni et al. [22] showed that combining features from multiple CNN layers yields better style, artist, and architectural classification than using only the top layer, and Peng et al. [23] leveraged multiple CNNs to capture multi-scale representations. Kim et al. [24] further improved accuracy by incorporating visualized depth information of brushstrokes. Menis et al. [25] employ ensemble learning to improve classification performance. More recently, Zhang et al. [26] and Wang et al. [27] confirmed that ResNet-50 [7] provides a strong baseline for oil-painting style classification. Although deep models eliminate the need for handcrafted filters, they often conflate style-relevant cues with semantic content, such as mistaking impasto textures for foliage, and do not explicitly regulate the amount of style-specific information retained. We argue that the key to improving the generalization performance of oil-painting style classification is not to incorporate multi-scale features [23] or to combine predictions from multiple networks [25], but rather to intelligently suppress redundant information in the extracted features. Specifically, representations that include background elements, canvas color, or object semantics may mislead the model, as these factors are often irrelevant to the stylistic identity of the painting and should therefore be compressed. Two challenges, therefore, remain: (1) how to learn features that capture genuine stylistic differences across diverse artistic movements, and (2) how to control and quantify the compression of style-irrelevant information in learned representations.
The information bottleneck (IB) framework formalizes representation learning as an explicit trade-off between compressing the input X and preserving information about the target Y [8]. Recent extensions of IB parameterize this objective with deep neural networks, including the variational information bottleneck (VIB) [9] and the nonlinear information bottleneck (NIB) [28]. Empirically, IB methods have been shown to improve generalization in domains such as image classification [29], signal classification [30], text classification [31], and robotics [32], supported by strong theoretical guarantees [33]. However, IB approaches remain largely unexplored in the analysis of oil paintings, where variational approximations can become unstable when disentangling overlapping style attributes (e.g., Baroque versus Rococo brushwork).
Our conditional information bottleneck (CIB) approach addresses these challenges by minimizing the conditional mutual information using a matrix-based Rényi’s entropy estimator, rather than a variational bound. This explicit regularization forces the latent representation Z to retain only style-predictive information, thereby bridging classical entropy-driven style metrics [15,17] and modern deep learning. As a result, CIB delivers robust, interpretable feature compression tailored to the unique texture and compositional dynamics of oil paintings.
2.2. Information Bottleneck Principle in Deep Neural Networks
Suppose we have two random variables, X and Y, linked through their joint probability distribution . We introduce a latent variable Z, which serves as a compressed summary of X, while preserving the dependency structure . The goal of the information bottleneck (IB) principle is to learn a probabilistic encoder that captures as much relevant information about Y as possible, measured by the mutual information , while discarding irrelevant details from X by limiting . Formally, the problem can be expressed as:
where controls how much information from the input is retained in the compressed representation.
Rather than handling this constraint explicitly, the IB objective is often reformulated into a single trade-off function:
where the parameter adjusts the trade-off between compression and predictive performance. A higher encourages stronger compression, potentially at the cost of reduced predictive power.
The IB principle has both practical and theoretical impacts to DNNs. Practically, it can be formulated as a learning objective (or loss function) for deep models. When parameterizing IB with a deep neural network, X denotes the input variable, Y denotes the desired output (e.g., class labels), Z refers to the latent representation of hidden layers.
However, optimizing the IB Lagrangian is usually difficult, as it involves calculating mutual information terms. Recently, several works [9,28,34,35] have been proposed to derive some lower or upper bounds to approximate the true mutual information values. The prediction term is always approximated with the cross-entropy loss. The approximation to differs for each method. For variational IB (VIB) [9] and similar works [36], is upper bounded by:
where v is some prior distribution such as Gaussian. Depending on application contexts, can also be measured by the mutual information neural estimator (MINE) [37], which requires training an extra network network to optimize a lower bound of mutual information. More recently, [38] suggests estimating in a non-parametric way by utilizing the Cauchy–Schwarz divergence quadratic mutual information [39].
Theoretically, it was argued that, even though the IB objective is not explicitly optimized, deep neural networks trained with cross-entropy loss and stochastic gradient descent (SGD) inherently solve the IB compression–prediction trade-off [40,41]. The authors also posed the information plane (IP), i.e., the trajectory in of the mutual information pair across training epochs, as a lens to analyze dynamics of learning of deep neural networks. According to [40], there are two training phases in the common SGD optimization: an early “fitting” phase, in which both and increase rapidly, and a later “compression” phase, in which there is a reversal such that continually decrease. This work attracted significant attention, culminating in many follow-up works that tested the proclaimed narrative and its accompanying empirical observations. To date, the “fitting-and-compression” phenomena of the layered representation Z have been observed in other types of deep neural networks, including the multilayer perceptrons (e.g., [40,42]), the autoencoders (e.g., [43]), and the CNNs (e.g., [44]). More recently, Kawaguchi et al. [33], Dong et al. [45] formally established the first generalization error bound for the IB objective, showing that an explicit compression term, expressed as either or , can improve generalization. However, their conclusions are drawn solely from evaluations on standard image classification benchmarks such as MNIST and CIFAR-10. In contrast, our results, obtained in a completely new application domain and on two significantly more challenging oil painting datasets, offer complementary empirical evidence supporting the claim that the IB principle can improve generalization.
3. Methodology
3.1. Deep Conditional Information Bottleneck for Oil-Painting Style Classification
The original IB objective improves generalization by minimizing the mutual information . In this work, we adopt an alternative information bottleneck objective, known as the conditional information bottleneck (CIB) [46], formulated as follows:
in which the compression term is replaced by the conditional mutual information (CMI) .
Adopting the conditional mutual information in place of the unconditional term offers several key advantages. Unlike , which can only be minimized by destroying all input information, admits a zero minimum—precisely satisfying the minimum necessary information (MNI) criterion by discarding only style-irrelevant variations while fully preserving style-predictive features [46]. By conditioning on the label Y, the bottleneck focuses compression on within-class nuisance factors (such as lighting, background, or canvas texture) without weakening the essential inter-style distinctions needed for accurate classification. Recent theoretical results demonstrate that controlling yields strictly tighter generalization error bounds in supervised learning than penalizing unconditional mutual information [33]. Finally, this targeted regularization sharpens the optimization signal, each sample contributes directly to eliminating only its own within-class redundancy, resulting in more stable training and more interpretable latent representations.
There are two terms in Equation (4). Minimizing the negative of is equivalent to maximizing . Note that , in which is the conditional entropy of Y given Z. Therefore,
This is just because is a constant that is irrelevant to network parameters.
Let denote the distribution of the training data, from which the training set is sampled. Furthermore, let and denote the unknown distributions that we wish to estimate, parameterized by . We have [36]:
We can, therefore, empirically approximate it by:
which is exactly the average cross-entropy loss [47].
In this sense, our objective in Equation (4) can be interpreted as a classic cross-entropy loss (The same trick has also been used in the nonlinear information bottleneck [28], squared-nonlinear information bottleneck [28] and basic variational information bottleneck [9]) regularized by a weighted conditional mutual information term . Hence, we name our framework the conditional information bottleneck (CIB).
3.2. Matrix-Based Entropy Functional and Its Gradient
The most challenging aspect of our CIB framework lies in accurately estimating . According to Shannon’s chain rule [48], can be decomposed as:
in which H denotes entropy or joint entropy.
In this work, instead of relying on variational approximation or using the popular mutual information neural estimator (MINE) [49], which may make the joint training becomes unstable or even result in negative mutual information values [50], we use the matrix-based Rényi’s -order entropy functional [10,51] to estimate different entropy terms in Equation (8). This newly proposed estimator can be simply computed (without density estimation or any auxiliary neural network) and is also differentiable which suits well for deep learning applications. For brevity, we directly give the definitions.
Definition 1. Let be a real valued positive definite kernel that is also infinitely divisible [52]. Given , each can be a real-valued scalar or vector, and the Gram matrix computed as , a matrix-based analog to Rényi’s α-entropy can be given by the following functional:
where . A is the normalized K, i.e., . denotes the i-th eigenvalue of A.
Definition 2. Given a set of n samples , each sample contains three measurements , and obtained from the same realization. Given positive definite kernels , , and , a matrix-based analog to Rényi’s α-order joint-entropy can be defined as:
where , , , and denotes the Hadamard product between the matrices A, B and C.
Now, given in a mini-batch of M samples, we first need to evaluate three Gram matrices , , and associated with variables X, Y, and Z, respectively. Based on Definitions 1 and 2, the entropy and joint entropy terms in Equation (8), all can be simply computed over the eigenspectrum of , , , or their Hadamard product. Hence, our final estimator is expressed as:
Throughout this work, we choose [10,51] and use the radial basis function (RBF) kernel to obtain the Gram matrices. For each sample, we evaluate its k nearest distances and take the mean. We choose kernel width as the average of mean values for all samples. Interested readers are referred to Appendix A for additional details and a minimal PyTorch, version 2.1.0. implementation.
As can be seen, this new family of estimators avoids explicit estimation of the underlying data distributions, making it particularly attractive for challenging problems involving high-dimensional data. In practice, computing the gradient of is straightforward using any automatic differentiation framework, such as PyTorch [53] or TensorFlow [54]. We recommend PyTorch, as its computed gradients are consistent with the analytical ones.
In our work, the bottleneck is inserted at a layer that still retains local spatial information. Specifically, for ResNet, it is added after the last block of the stage (see Figure 1).
4. Experimental Results
4.1. Dataset and Experimental Setup
The oil-painting style classification experiments are conducted on two public benchmarks. The Pandora dataset contains 7740 images distributed across 12 distinct artistic movements (ranging from ancient Greek pottery to Romanticism) (http://imag.pub.ro/pandora/pandora_download.html (accessed on 1 March 2025)) [11] (see Figure 2), while the OilPainting dataset comprises 19,787 oil-painting images spanning 17 style categories (https://mmcv.csie.ncku.edu.tw/~wtchu/projects/OilPainting/index.html (accessed on 1 March 2025)) [12] (see Figure 3). Together, these datasets cover the full sweep of oil-painting stylistic evolution, capturing rich variation in color, brushstroke patterns, texture, and compositional layout.
For each dataset, we perform a random split of 80% of the images for training and 20% for testing. All images are resized to pixels and normalized using ImageNet mean and standard deviation.
Our models are trained on an NVIDIA Tesla V100 GPU. We use a ResNet-50 backbone pre-trained on ImageNet and insert the information bottleneck module immediately after the last block of the third convolutional stage. In total, we compare six methods for style classification, including original ResNet-50, three information-theoretic approaches, and two additional architectural strategies designed to enhance generalization. The first is ResNet-50, which uses a standard classification head applied to the final global-pooling features. The second is variational information bottleneck (VIB) [9], which minimizes the mutual information via a variational approximation using a Gaussian encoder. The third approach, deterministic information bottleneck (DIB) [13], achieves the same goal by employing a deterministic compression layer. Our proposed method, conditional information bottleneck (CIB), minimizes the conditional mutual information , using a matrix-based Rényi’s entropy estimator to capture class-specific discriminative features more effectively. We also compare with two additional approaches. The first is MSCNN [23], a multi-scale CNN that extracts features at different resolutions by applying the same CNN architecture on cropped and resized versions of the input image at multiple scales. The second is Ensemble CNN [25], which produces final predictions by aggregating the outputs of three networks, VGG-16, ResNet-50, and ResNet-19, using a meta-classifier to combine their predictions.
All models are trained for 100 epochs with a batch size of 32, using the Adam optimizer (initial learning rate , weight decay ). We apply a cosine-annealing learning-rate schedule without restarts. For all IB methods, the trade-off parameter (weight on the mutual-information term) is selected from to 1. We evaluate performance using top-1 classification accuracy on the held-out test set and report the mean and standard deviation over three independent runs.
4.2. Generalization Performance
For generalization performance, we report the classification accuracy on the test sets of both datasets, as summarized in Table 1. We set the hyperparameter for the ResNet-50 backbone in our method. The ADAM optimizer is used with an initial learning rate of , which is reduced by half every ten epochs. For other IB-based comparison methods, we adopt the values as recommended in their original papers. As shown in Table 1, our method consistently outperforms existing IB approaches in terms of generalization performance across different test datasets.
4.3. Adversarial Robustness
Recently, various adversarial attack methods have been proposed to “fool” models by adding small, carefully designed perturbations. In this paper, we adopt two types of attack methods to evaluate adversarial robustness. The first is the standard baseline attack, the fast gradient sign method (FGSM) [55], which generates adversarial examples according to:
where x denotes the original clean image, is the perturbation magnitude, is the gradient of the loss function with respect to the input x, and represents the adversarially perturbed image.
The second attack method is projected gradient descent (PGD) [56], which generates adversarial examples through an iterative multi-step version of FGSM. The perturbed input at the t-th iteration, , is updated as:
where denotes the clipping function that constrains within a predefined perturbation range , and is the step size. The adversarial example is initialized as x and updated for t steps according to Equation (13). In our experiments, we set , , and for PGD attacks. Note that, 5-step PGD attacks with a step size of or are commonly used in practice [38,56].
We evaluate adversarial robustness on both datasets under FGSM and PGD attacks, with results summarized in Table 2, Table 3, Table 4 and Table 5. As shown, our method consistently outperforms other IB approaches, particularly under the stronger PGD attack. This suggests that by retaining more task-relevant information while effectively compressing style-irrelevant details, our model achieves better resilience against adversarial perturbations.
4.4. Latent Space Visualization
Finally, to better understand the structure of the learned representations, we visualize the latent spaces of the VIB, DIB, and our proposed CIB methods on both the Pandora and OilPainting datasets. Specifically, we extract the latent representations from the bottleneck layer and apply t-distributed stochastic neighbor embedding (t-SNE) [57] to project them into a two-dimensional space for visualization. Different colors are used to represent different style classes. The resulting visualizations are shown in Figure 4 and Figure 5.
As can be observed, for both datasets, the latent spaces produced by the standard VIB method exhibit substantial overlap between different style categories, indicating that VIB struggles to disentangle style-specific features effectively. The DIB method demonstrates moderate improvements, with partial class separation emerging, although notable overlaps still persist. In contrast, our CIB method yields a much cleaner and more structured latent organization, where samples from different style classes form compact and well-separated clusters.
These results suggest that minimizing the conditional mutual information encourages the latent space to capture more task-relevant features while discarding style-irrelevant variations. The improved structure not only aligns with the observed gains in classification accuracy and adversarial robustness but also highlights the enhanced interpretability of the learned representations achieved by our CIB framework.
5. Conclusions
In this paper, we proposed a conditional information bottleneck (CIB) framework for oil-painting style classification, where the compression regularization explicitly minimizes the conditional mutual information (CMI) . To estimate the CMI term, we adopt a matrix-based entropy functional, which avoids explicit density estimation and variational approximations, enabling stable and efficient training. Extensive experiments on two public datasets demonstrate that our CIB model consistently outperforms the standard variational information bottleneck (VIB) and deterministic information bottleneck (DIB) approaches, achieving higher classification accuracy and improved generalization performance. Furthermore, CIB enhances adversarial robustness, as the learned representations discard nuisance factors unrelated to style labels, making the classifier less sensitive to input perturbations. Qualitative analyses of the latent space show that our method produces more compact and class-aligned feature clusters, leading to greater interpretability compared to baseline bottleneck methods. These results validate the effectiveness of CIB in promoting both the utility and the interpretability of deep style representations in oil-painting analysis.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Karayev S. Hertzmann A. Trentacoste M. Han H. Winnemoeller H. Agarwala A. Darrell T. Recognizing Image Style Proceedings of the British Machine Vision Conference 2014 Nottingham, UK 1–5 September 2014
- 2Li W. Enhanced automated art curation using supervised modified CNN for art style classification Sci. Rep.202515731910.1038/s 41598-025-91671-z 40025126 PMC 11873298 · doi ↗ · pubmed ↗
- 3Mahmood T. Nawaz T. Irtaza A. Ashraf R. Shah M. Mahmood M.T. Copy-move forgery detection technique for forensic analysis in digital images Math. Probl. Eng.20162016871320210.1155/2016/8713202 · doi ↗
- 4Boccuzzo S. Meyer D.D. Schaerf L. Art Forgery Detection using Kolmogorov Arnold and Convolutional Neural Networksar Xiv 20242410.04866
- 5Bengio Y. Courville A. Vincent P. Representation learning: A review and new perspectives IEEE Trans. Pattern Anal. Mach. Intell.2013351798182810.1109/TPAMI.2013.5023787338 · doi ↗ · pubmed ↗
- 6Moyano M.Á.M. García-Aguilar I. López-Rubio E. Luque-Baena R.M. Improving Art Style Classification Through Data Augmentation Using Diffusion Models Electronics 202413503810.3390/electronics 13245038 · doi ↗
- 7He K. Zhang X. Ren S. Sun J. Deep residual learning for image recognition Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Las Vegas, NV, USA 27–30 June 2016770778
- 8Tishby N. Pereira F.C. Bialek W. The information bottleneck method Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing Monticello, IL, USA 22–24 September 1999368377