Collaborative assessment of the risk of postoperative progression in early-stage non-small cell lung cancer: a robust federated learning model
Yu Liu, Xiaobei Duan, Xiaojuan Chen, Kunwei Li, Qiong Li, Ke Liu, Wansheng Long, Huan Lin, Bao Feng, Xiangmeng Chen

TL;DR
This paper introduces a robust federated learning model that effectively predicts postoperative progression risk in early-stage non-small cell lung cancer patients.
Contribution
The novel RFed model improves prediction accuracy and generalizability using federated learning across multiple centers.
Findings
RFed achieved AUC values of 0.936 to 0.970 across four centers.
The model showed greater net benefit than clinical models in Decision Curve Analysis.
Kaplan-Meier analysis confirmed improved discrimination between high- and low-risk groups.
Abstract
While the TNM staging system provides valuable insights into the extent of disease, predicting postoperative progression in early-stage non-small cell lung cancer (NSCLC) remains a significant challenge. An effective bioimaging prognostic marker for early-stage NSCLC, powered by artificial intelligence, could greatly assist clinicians in making informed treatment decisions. A total of 926 patients from four centers (A, B, C, and D) with histologically confirmed stage I or II solid non-small cell lung cancer (NSCLC) who underwent surgical resection were retrospectively reviewed. In this study, we propose a robust federated learning model (RFed) designed to predict the risk of postoperative progression in early-stage NSCLC patients. The diagnostic efficiency of the RFed model was evaluated using the area under the curve (AUC) and Decision Curve Analysis (DCA). Additionally, the model’s…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
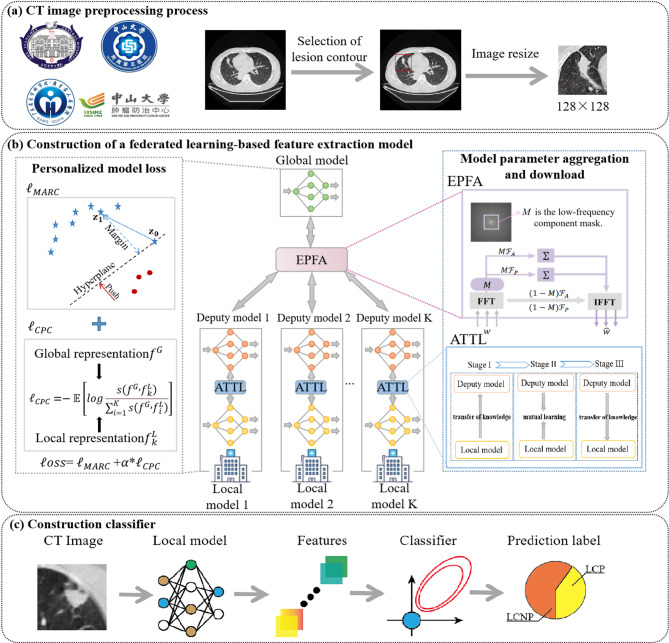 Figure 1
Figure 1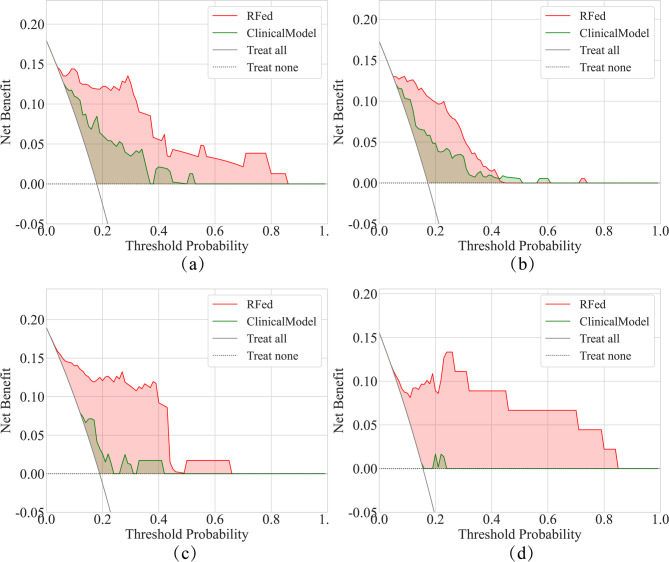 Figure 2
Figure 2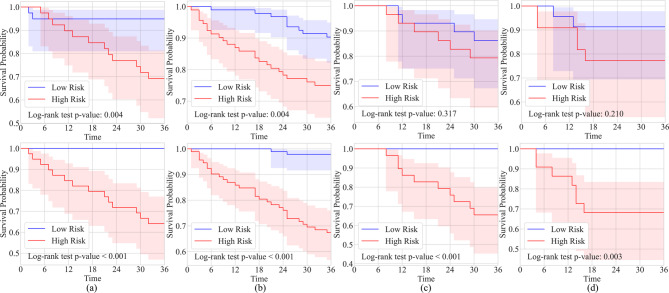 Figure 3
Figure 3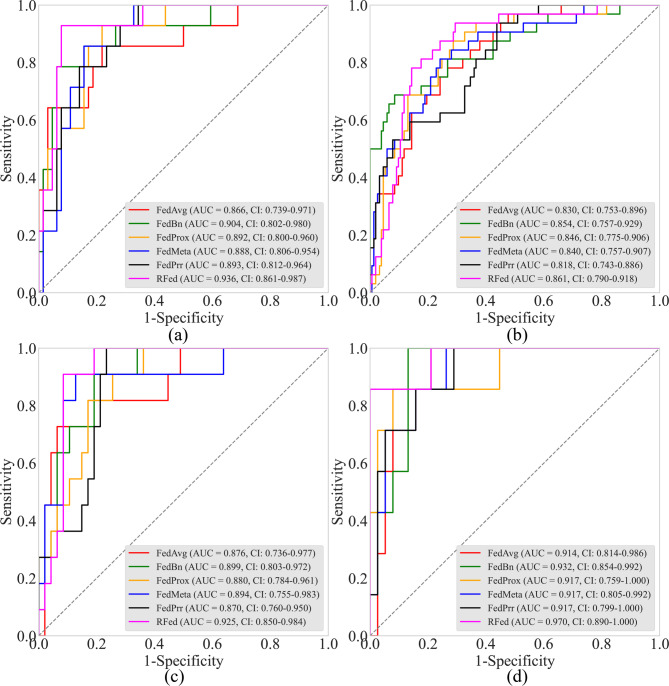 Figure 4
Figure 4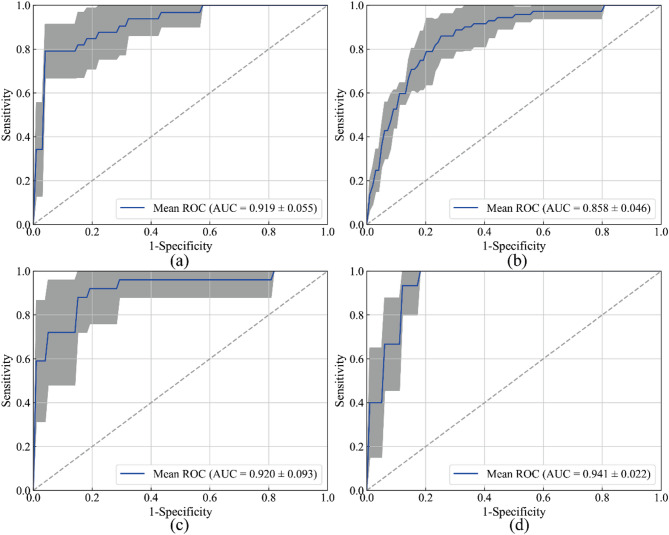 Figure 5
Figure 5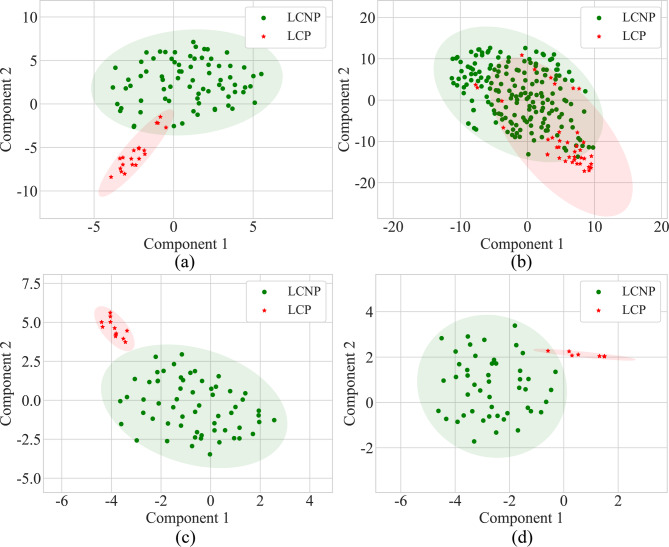 Figure 6
Figure 6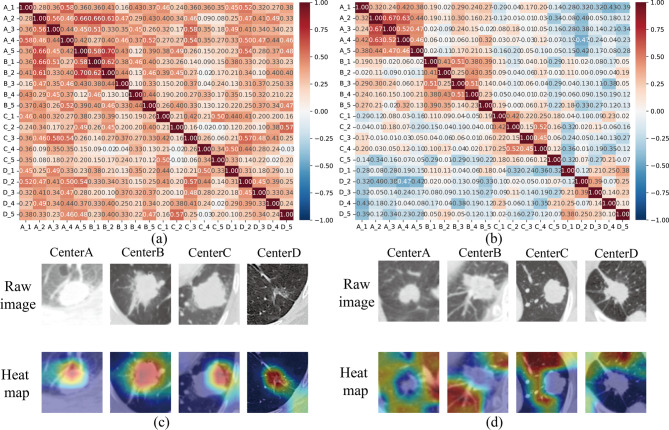 Figure 7
Figure 7- —Chongqing Big Data Collaborative Innovation Center
- —https://doi.org/10.13039/501100001809National Natural Science Foundation of China
- —GUAT Special Research Projecton the Strategic Development of Distinctive Interdisciplinary Fields
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRadiomics and Machine Learning in Medical Imaging · Lung Cancer Treatments and Mutations · AI in cancer detection
Introduction
Lung cancer represents a leading cause of malignancy, with non-small cell lung cancer (NSCLC) being the most prevalent subtype, accounting for approximately 85% of all cases [1, 2]. According to the National Comprehensive Cancer Network (NCCN) guidelines, anatomic lung resection and lymph node dissection are the primary surgical treatments for patients with NSCLC [3]. Despite these interventions, the rate of postoperative progression, including recurrence and metastasis, remains high, with reported rates ranging from 18 to 34% [4]. Currently, the tumor node metastasis classification (TNM) system is widely used for prognostic assessment in lung cancer patients. Unfortunately, the clinical manifestations and prognostic factors of NSCLC exhibit significant heterogeneity, leading to different outcomes even among patients with the same TNM stage [5]. Therefore, there is an urgent need to develop an accurate method capable of identifying high-risk patients prone to postoperative progression, thereby enabling early intervention (such as adjuvant chemotherapy and close follow-up) and improving patient outcomes.
In recent years, deep learning (DL) has gained considerable attention in the medical field, achieving remarkable success in diverse applications, including lung cancer prognosis [6], bladder cancer treatment [7], and preoperative grading in meningioma [8]. The development of robust and reliable DL-assisted diagnostic systems relies not only on advanced algorithms but also on the valuable knowledge extracted from large-scale datasets collected across multiple institutions [9]. However, constructing ever-larger centralized datasets is unsustainable for smart healthcare systems due to concerns over patient privacy and ethical issues.
Federated Learning (FL) [10], a distributed machine learning framework, enables multiple data owners to conduct local model training and aggregate models on a central server iteratively. Without sharing raw data, the globally aggregated model can outperform models trained on individual centers. Among existing FL approaches, personalized FL [11] is particularly suitable for medical scenarios, allowing each center to choose between the aggregated global model and local models based on their needs. However, real-world medical FL faces challenges such as data heterogeneity caused by differences in imaging devices, protocols, and regional disease characteristics. Conventional model parameter aggregation strategies can lead to performance degradation in local models after each communication. Additionally, class imbalance in medical imaging, such as postoperative progression occurring in only around 20% of NSCLC patients [12], can further hinder model performance.
In this study, we propose a robust federated learning model (RFed) designed to predict the risk of postoperative progression in early-stage NSCLC patients. Our model aims to support more informed and personalized clinical decisions, ultimately improving patient outcomes in early-stage NSCLC.
Materials and methods
Data acquisition and pre-processing
The study retrospectively analyzed clinical and radiological data from 926 patients across four centers who were diagnosed with solid NSCLC, underwent surgical resection, and received pathological confirmation between January 2014 and September 2019. The inclusion criteria were as follows: (1) Diagnosis of solid NSCLC confirmed by pathological examination following surgical resection; (2) Chest Computed tomography (CT) examination performed within one month prior to surgery; (3) Availability of CT images from the Picture Archiving and Communication System (PACS); (4) Regular and complete follow-up records for at least three years after surgery; (5) Pathological staging in stages I or II; (6) Image slice thickness ≤ 1.5 mm. The exclusion criteria were as follows: (1) Patients with concurrent malignancies; (2) Patients without postoperative follow-up or with a follow-up duration of less than three years; (3) Pathological staging in stages III or IV. (4)Lung cancer lesions manifested as sub-solid nodules (both of non-solid and part-solid). (5)Consolidation lesions with indistinct margins (pneumonic-type lung adenocarcinoma) and central lesions complicated with obstructive atelectasis.
The data from these four centers were randomly divided, with patients allocated to four groups for training, validation, and testing, as shown in Table 1.
Table 1. Basic information about the patients included in this studyCenterData SetDisease typeLCP vs. LCNPAge, year(Mean ± SD)Genderlongest diameter, cm(Mean ± SD)LobulatedSpiculatedSmoking historyCEAmalefemaleabsentpresentabsentpresentabsentpresentnormalelevatedA(n = 198)Train(n = 96)LCP(n = 20)62.90 ± 11.791463.50 ± 1.83119416128128LCNP(n = 76)59.07 ± 10.4844322.79 ± 1.47769403654226214Validation(n = 24)LCP(n = 5)63.20 ± 10.99412.73 ± 1.0305231414LCNP(n = 19)60.26 ± 9.271272.22 ± 1.39316109163145Test(n = 78)LCP(n = 14)69.29 ± 7.29862.59 ± 0.9131131110468LCNP(n = 64)63.48 ± 10.0135292.37 ± 1.20757343046185410B(n = 465)Train(n = 224)LCP(n = 40)61.05 ± 10.2723172.91 ± 1.78535162426142416LCNP(n = 184)60.15 ± 10.7597872.30 ± 1.7529155105791325215133Validation(n = 56)LCP(n = 10)61.60 ± 7.06733.17 ± 1.4019378282LCNP(n = 46)60.22 ± 11.1824222.31 ± 1.70739242236103610Test(n = 185)LCP(n = 32)62.09 ± 10.2921113.64 ± 1.9352713192572210LCNP(n = 153)60.28 ± 9.4582712.53 ± 1.852712678751035012033C(n = 148)Train(n = 72)LCP(n = 12)58.17 ± 13.33753.17 ± 2.441111027593LCNP(n = 60)59.32 ± 9.9931292.26 ± 2.411347402036244416Validation(n = 18)LCP(n = 3)53.67 ± 15.37122.76 ± 2.9812212130LCNP(n = 15)60.60 ± 11.40962.48 ± 1.655109696114Test(n = 58)LCP(n = 11)57.45 ± 9.31742.78 ± 1.7129565683LCNP(n = 47)56.02 ± 9.6825222.21 ± 1.77103731162720434D(n = 115)Train(n = 56)LCP(n = 8)61.13 ± 5.87532.01 ± 0.3508087162LCNP(n = 48)57.92 ± 11.2128202.12 ± 0.3504804836123612Validation(n = 14)LCP(n = 2)60.50 ± 2.12111.90 ± 1.2802022020LCNP(n = 12)65.00 ± 0.90572.01 ± 0.450120126675Test(n = 45)LCP(n = 7)57.86 ± 7.36342.36 ± 0.4107073452LCNP(n = 38)58.89 ± 11.3618201.88 ± 0.440380382513317Notes: LCP: lung cancer progression. LCNP: lung cancer non-progression. CEA: carcinoma embryonic antigen. SD: standard deviation
In order to accommodate the inputs of the deep learning model and to fully utilize its automatic feature extraction capabilities, this study used a bounding box for coarse segmentation of the region of interest (ROI) and did not use pixel-level labeling. Of course, to be precise, the All lesion was initially labeled with a bounding box by radiologist with over 10 years of experience, and then fully reviewed and validated by a second independent radiologist. This dual review process focuses on confirming the complete inclusion and correct identification of the lesion within the box, prioritizing localization suitable for deep learning analysis over fine-grained boundaries. To fit the input to the neural network, all segmented lesion images were subsequently normalized to a size of 128 × 128 pixels. A detailed description of the CT scanning parameters and the data preprocessing process is provided in Supplementary S1.
Follow-up record and definition of postoperative progression
Follow-up: (1) Chest CT scans are performed every 6–12 months during the first two years post-surgery, and annually thereafter. (2) If clinical symptoms arise, site-specific examinations are conducted as needed. (3) The study endpoint is defined by the occurrence of disease progression. Patients without progression will be followed for a minimum of three years.
The definition of progression is as follows: (1) Postoperative follow-up progression is assessed through a combination of physical examinations, imaging, and tumor marker testing [13]; (2) Local progression is identified by the appearance of lesions at the surgical margins, within the same side of the thoracic cavity, or in the mediastinum; (3) Distant metastasis refers to lesions appearing in organs outside the contralateral lung, thoracic cavity, and mediastinum [14]; (4) When clinically feasible, a definitive diagnosis is confirmed through pathological histology or cytology examinations [14]; (5) Suspected recurrent or metastatic lesions that lack histopathological confirmation but show size increase during follow-up, or decrease in size after tumor-suppressive treatment, are clinically diagnosed as recurrence or metastasis [13].
Specifically, patients who experience progression within three years are classified into the positive group, while those without progression in the same period are placed in the negative group.
Construction of a prognostic model based on robust federated learning
Traditional parameter aggregation and downloading strategy typically involve directly averaging the model parameters from multiple centers before transmitting them back. However, since parameters from different center models may represent distinct semantic patterns at the same position, direct averaging the model parameters can undermine the personalization of the models. This issue is particularly critical in early-stage NSCLC diagnosis, where multicenter data exhibit both heterogeneity and class imbalance. In such cases, directly applying global model parameters to each local model may lead to performance degradation. To address these challenges, this study proposes a robust federated learning (RFed) algorithm designed for handling multicenter, imbalanced, and heterogeneous medical images, as illustrated in Fig. 1. The RFed algorithm consists of two main components: (1) construction of a federated learning-based feature extraction model, and (2) construction of a classifier using a Bayesian extreme learning machine.
Fig. 1. The flowchart of the overall study design. (a) CT image preprocessing process. (b) Construction of a federated learning-based feature extraction model. (c) Construction of a classifier using a Bayesian extreme learning machine
(1) Construction of feature extraction model: The construction of feature extraction model introduced two key improvements: ①the model parameter aggregation and download strategy, and ②personalized model loss for handling class imbalance in samples.
①The model parameter aggregation and download strategy.
For the model parameter aggregation and download strategy, this study employs a partially personalized Exponential Progressive Fourier Aggregation (EPFA) strategy, where low-frequency model parameters are aggregated and shared through Fourier Transform, while high-frequency parameters remain localized. This approach helps mitigate performance degradation that may arise from full model parameter aggregation in the time domain [15]. The pseudo-code of EPFA as shown in Algorithm 1. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} is the global model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} is the deputy model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T$$\end{document} is the number of communication, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} is the low-frequency mask matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} is the number of clients, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{r}}_{\text{m}\text{a}\text{x}}$$\end{document} is the threshold for the low-frequency components.
Algorithm 1 Exponential Progressive Fourier Aggregation (EPFA)1: Initialize Global model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} , deputy model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\text{r}}_{\text{m}\text{a}\text{x}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} 2: for each communication round \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t=0$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T-1$$\end{document} do3: // Client-side processing4: for each client \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k=1$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} in parallel do5: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{k}=LocalUpdate\left(D\right)$$\end{document} 6: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{A}_{k},\:{P}_{k}=FFT\left(Reshape\right({\theta\:}_{k}\left)\right)$$\end{document} 7: end for8: // Server aggregation9: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{A}_{avg}=\frac{1}{K}{\sum\:}_{k}{A}_{k}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{avg}=\frac{1}{K}{\sum\:}_{k}{P}_{k}$$\end{document} // Amplitude and phase aggregation10: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${F_{avg}} = {A_{avg}} \odot exp(j \cdot {P_{avg}})$$\end{document} // Reconstructing frequency domain parameters11: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:{r=r}_{max}*{(T-t)}^{-1}$$\end{document} // Low frequency threshold update12: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M=LowFreqMask\left(r\right)$$\end{document} // Low-frequency mask matrix13: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${F_{low}} = {F_{avg}} \odot M$$\end{document} // Extraction of low frequency components (high frequency zero setting)14: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{aggregated}=IFFT\left({Reshape}^{-1}\right({F}_{low}\left)\right)$$\end{document} 15: // Update deputy modelDand Global modelG16: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=Aggregate\left(D\right)$$\end{document} 17: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D={\theta\:}_{aggregated}$$\end{document} 18: end for
Additionally, a three-stage transfer learning strategy based on A-distance (ATTL), is designed to smooth knowledge from the global model to the local models, preventing performance regression during parameter updates. The pseudo-code of three-stage ATTL as shown in Algorithm 2. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P$$\end{document} is the personalized local model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}_{supervised}$$\end{document} denotes the cross-entropy loss function. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}_{A-distance}$$\end{document} denotes the measurement algorithm for data distribution, and the A-distance algorithm was used in this study.
Algorithm 2 Three-stage A-distance-based Transfer Learning (ATTL)1: Initialize Global model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} , deputy model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} , Personalized local model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P$$\end{document} 2: for each communication round \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t=0$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T-1$$\end{document} do3: // Stage I: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{P}$$\end{document} → \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{D}$$\end{document} transfer3: Fix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P$$\end{document} , update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} :4: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}_{D}={l}_{supervised}\left(D\right)+{l}_{A-distance}(P,D)$$\end{document} 5: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:\:D=Optimizer\left({l}_{D}\right)$$\end{document} 6: // Stage transition condition7: if AUC( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} ) > AUC( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P$$\end{document} ) then8: // Stage II: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{P}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{D}$$\end{document} mutual learning9: Update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} :10: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}_{D}={l}_{supervised}\left(D\right)+{l}_{A-distance}(P,D)$$\end{document} 11: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D=Optimizer\left({l}_{D}\right)$$\end{document} 12: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}_{P}={l}_{supervised}\left(P\right)+{l}_{A-distance}(D,P)$$\end{document} 13: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:D=Optimizer\left({l}_{D}\right)$$\end{document} 14: end if15: // Stage transition condition16: if AUC( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P$$\end{document} ) > AUC( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} ) then17: // Stage III: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{D}$$\end{document} → \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{P}$$\end{document} transfer17: Fix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} , update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P$$\end{document} :18: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}_{P}={l}_{supervised}\left(P\right)+{l}_{A-distance}(D,P)$$\end{document} 19: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:P=Optimizer\left({l}_{P}\right)$$\end{document} 20: end if21: end for
②Personalized model loss for handling class imbalance in samples.
The severe imbalance in data categories significantly affects the performance of model training. For the issue of class imbalance in federated learning, a personalized loss function is introduced, incorporating margin correction and contrastive prediction encoding.
Typically, for a classification task with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:C$$\end{document} classes, the corresponding cross-entropy loss function is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}\left({x}_{i},{y}_{i};{\theta\:}_{f},{\theta\:}_{c}\right)=-\text{l}\text{o}\text{g}\left(\frac{\text{e}\text{x}\text{p}\left({\eta\:}_{{y}_{i}}\right)}{{\sum\:}_{c=1}^{C}\text{e}\text{x}\text{p}\left({\eta\:}_{c}\right)}\right)$$\end{document}Where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{i}$$\end{document} is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} -th training data and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{i}$$\end{document} is the ground truth. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{f}\:$$\end{document} is the parameter corresponding to the feature representation learning function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{c}$$\end{document} is the parameter corresponding to classifier function. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\eta\:}_{c}$$\end{document} is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:c$$\end{document} -th class prediction score from the linear classification function as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\eta\:}_{c}={\varvec{W}}_{c}\mathcal{z}+{\varvec{b}}_{\varvec{c}}$$\end{document}Where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{W}}_{c}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{b}}_{\varvec{c}}$$\end{document} represent the weight and bias matrix corresponding to the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:c$$\end{document} -th class, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathcal{z}$$\end{document} denotes the feature that has been encoded by the feature representation learning function.
For a classification task, the classification margin of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:c$$\end{document} -th class data point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathcal{z}}_{1}$$\end{document} is calculated as [16]:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{c}=\frac{{\varvec{W}}_{\varvec{c}}{\mathcal{z}}_{1}+{\varvec{b}}_{\varvec{c}}}{\left|\left|{\varvec{W}}_{\varvec{c}}\right|\right|}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left|\left|\varvec{*}\right|\right|$$\end{document} represents the L2-norm. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${z_1}$$\end{document} is an arbitrary data point in the feature space. Thus, the prediction score \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\eta\:}_{c}$$\end{document} can be expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left|\left|{\varvec{W}}_{\varvec{c}}\right|\right|{d}_{c}$$\end{document} .
Studies have shown that the decision boundary and prediction scores are correlated with the cardinality of each class, where the majority class tends to have a larger decision boundary [17, 18]. Thus, we aim to calibrate the margins to obtain balanced predictions. The adjusted margin distance is expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\>{\hat d_c}{\rm{ = }}\>\omega {\>_c} \cdot \>{d_c} + \beta {\>_c}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\omega\:}_{c}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{c}$$\end{document} are margin calibration coefficients derived from the training samples, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{c}$$\end{document} is the margin after the standard training. Thus, the calibrated logit is computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\begin{array}{l}\left|\left|{\varvec{W}}_{\varvec{c}}\right|\right|{\widehat{d}}_{c}=\left|\left|{\varvec{W}}_{\varvec{c}}\right|\right|({{\omega\:}_{c}\cdot\:d}_{c}+{\beta\:}_{c})\\\:\:\:\:\:\:={\omega\:}_{c}\cdot\:\left|\left|{\varvec{W}}_{\varvec{c}}\right|\right|{d}_{c}+{\beta\:}_{c}\left|\left|{\varvec{W}}_{\varvec{c}}\right|\right|\\\:\:\:\:\:\:={\omega\:}_{c}\cdot\:{\eta\:}_{c}+{\beta\:}_{c}\left|\left|{\varvec{W}}_{\varvec{c}}\right|\right|\end{array}$$\end{document}By combining Eqs. (1) and (5), the margin-based cross-entropy loss function is formulated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{l}}_{\text{M}\text{A}\text{R}\text{C}}\left({x}_{i},{y}_{i};{\theta\:}_{r},{\theta\:}_{o}\right)=-\text{l}\text{o}\text{g}\left(\frac{\text{e}\text{x}\text{p}\left({\omega\:}_{{y}_{i}}{\eta\:}_{{y}_{i}+{\beta\:}_{{y}_{i}}\left|\right|{\varvec{W}}_{{y}_{i}}\left|\right|}\right)}{{\sum\:}_{c=1}^{C}\text{e}\text{x}\text{p}\left({\omega\:}_{c}{\eta\:}_{c+{\beta\:}_{c}\left|\right|{\varvec{W}}_{c}\left|\right|}\right)}\right)$$\end{document}It is worth noting that this study does not explicitly introduce the imbalance ratio into the margin correction function, but rather balances the margins of the two types of samples by constructing a margin correction function (Eq. 4). by minimizing the loss function (Eq. 6) and automatically obtaining the weight parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\omega\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\beta\:$$\end{document} based on the training samples, the correction of the original margins is achieved.
In addition, to further mitigate the sample imbalance, this study extracts the fully connected layer parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{f}^{G}$$\end{document} of the global model to represent global information. The fully connected layer parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{f}_{k}^{L}$$\end{document} of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -th local model are used to represent the information of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -th local model. The contrastive predictive coding (CPC) technique is adopted to align the distance between the global model representation and the local model representations, constructing a regularization loss term to constrain the model’s learning process. The regularization loss is formulated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathcal{l}}_{\text{C}\text{P}\text{C}}\left({f}^{G},{f}^{L}\right)=-\mathbb{E}\left[log\frac{s({f}^{G},{f}_{k}^{L})}{\sum\:_{i=1}^{K}s({f}^{G},{f}_{i}^{L})}\right]$$\end{document}Where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} is the number of clients, the symbol \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathbb{E}$$\end{document} denotes the expectation operator, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{s}$$\end{document} represents some kind of similarity measure function, and cosine similarity was used in this study.
Finally, the total loss is calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\>\ell oss = \>{\ell _{{\rm{MARC}}}} + \alpha \>*{\ell _{{\rm{CPC}}}}$$\end{document}Where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} is the regularization parameter. This loss function guides local models to align with the globally balanced objective, thereby improving training performance. A detailed description is provided in Supplementary S2.
(2) construction of classifier
First, the convolutional kernels of the trained local model are utilized as feature extractors to generate feature maps for each CT image of every patient. Next, the average of all feature maps for each patient is computed to represent the patient’s final features, yielding a total of 7,616 federated learning features, as detailed in Supplementary S3. Subsequently, the maximum relevance minimum redundancy (mRMR) algorithm is employed to select the most significant features, effectively minimizing redundancy while maximizing discriminative power. Finally, a Bayesian extreme learning machine is applied to construct the final classification model.
Evaluation and comparison of models
To comprehensively evaluate the performance of RFed in a multicenter environment, various comparative experiments were conducted. First, to validate the superiority of the proposed model, several state-of-the-art federated learning methods were used for comparison, including FedAvg [10], FedBn [19], FedProx [20], MetaFed [21], and PrrFed [15]. Additionally, following previous research and referencing related guidelines [22–24], this study constructed clinical models using the Bayesian extreme learning machine algorithm, incorporating features such as the longest diameter, smoking history, lobulated sign, spiculated sign, and CEA index.
To assess the generalizability of the proposed framework, classical network architectures—ResNet34 [25], VGG16 [26], Inception-v3 [27], and Vision Transformer (ViT) [28]—were used as base models for federated learning. Furthermore, out-of-distribution generalization experiments were conducted, where models trained on data from three centers were tested on a fourth center that did not participate in the training.
Statistical analysis
To comprehensively evaluate the performance of various algorithms, this study utilized quantitative metrics such as the Area Under the Receiver Operating Characteristic Curve (AUC) and the F1 score to validate the predictive results. The F1 score, which is the harmonic mean of specificity and sensitivity, is primarily used to assess model performance in the context of imbalanced data. The Receiver Operating Characteristic (ROC) curve was employed to illustrate the overall performance of different methods. Furthermore, Decision Curve Analysis (DCA) was utilized to evaluate the clinical effectiveness of the model in predicting postoperative progression in early-stage NSCLC. These quantitative metrics and analyses offer a thorough assessment of the model’s performance and its clinical utility in predicting progression in early-stage NSCLC patients.
Additionally, to verify the degree of model improvement, Delong and Integrated Discrimination Improvement (IDI) tests were employed. Statistical analyses were performed using two-tailed tests, with a p-value of less than 0.05 considered statistically significant.
Details of the algorithm parameters and software system
The details of the algorithm parameters are as follows: the base model used is ResNet34 with a batch size of 32. Communication occurs every 50 iterations, and local model perform 5 optimization iterations between communications. The learning rate is set to 0.01, and the loss function regularization parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} is set to 0.6. Additionally, the shared low-frequency threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{max}$$\end{document} is set to 0.3. Specific ablation experiments for regularization parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:\:$$\end{document} and low-frequency threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{max}\:$$\end{document} are shown in Supplementary S4.
The system is configured with Windows 11, featuring an NVIDIA RTX 4090 graphics card with 24GB of GPU memory, and utilizes CUDA 11.7 for accelerated computation. The system is powered by a 13th Gen Intel Core i9-13900 K CPU, delivering substantial processing power. For deep learning tasks, PyTorch 2.0.0 serves as the framework, with Python 3.10 as the programming environment.
Results
RFed exhibits superior diagnostic performance in early-stage NSCLC patients
Comparison with traditional clinical models
We evaluated the proposed RFed across the four centers and summarized the results in Table 2. The RFed outperforms traditional clinical models on multiple metrics. The average AUC of RFed is 0.923, which is 22.7% higher than that of the clinical model (average AUC = 0.696). The Delong test revealed significant differences between the clinical model and RFed with respect to AUC across the four centers (p = 0.052, 0.012, 0.004, 0.001). The IDI indicated that RFed exhibited significantly better prediction performance than the clinical model across the four centers (IDI = 0.314, p < 0.001; IDI = 0.187, p < 0.001; IDI = 0.148, p < 0.001; IDI = 0.427, p < 0.001).
To assess the clinical effectiveness of the model in predicting postoperative progression of early-stage NSCLC patients, DCA curves were plotted. The threshold ranges for the four centers are 0.04–0.99, 0.05–0.99, 0.02–0.99, and 0.05–0.99, respectively. This wide range of thresholds suggests that RFed has a higher net benefit in distinguishing between the LCP and LCNP groups compared to the clinical model.(Fig. 2).
Fig. 2DCA curves in four centers. (a) Center (A) (b) Center (B) (c) Center (C) (d) Center (D) Notes: RFed, robust federated learning
We further evaluated our method through statistical analysis, with the Kaplan-Meier curves presented in Fig. 3. The figure displays survival curve analyses for four centers, comparing the clinical model (first row) and the RFed model (second row). The Kaplan-Meier curves show the survival probabilities for the low-risk (blue line) and high-risk (red line) groups. The Log-rank test p-values indicate significant survival differences between the groups, with the RFed model consistently demonstrating clearer separation between the low-risk and high-risk groups compared to the clinical models. In addition, this study integrated age, gender, longest diameter, CEA, and RFed factors performed univariate and multivariate Cox regression analyses, and calculated hazard ratios with 95% confidence intervals, and as shown in Supplementary S5. In univariate Cox regression analysis, the HR (95% CI) for RFed was 4.034 (2.189–7.435) with a p-value of less than 0.001. In multivariate Cox regression analysis, the HR (95% CI) for RFed was 9.176 (2.835–29.693) with a p-value of less than 0.001. The results showed that RFed increased the independent prognostic value after adjusting for age, gender, longest diameter and CEA, and RFed outperformed clinical model in predicting postoperative risk of early-stage NSCLC patients.
Fig. 3. Kaplan-Meier curves of predicted high-risk (red) and low-risk (blue) groups. (a) Center (A) (b) Center (B) (c) Center (C) (d) Center (D) A p-value < 0.05 indicates statistical significance, and the shaded regions represent the confident intervals. The first row shows the Kaplan-Meier curves of clinical model, and the second row shows the Kaplan-Meier curves of the proposed federated learning framework. Time is measured in months
Comparison with state-of-the-art federated learning models: The results of our study demonstrate that the proposed RFed exhibits higher diagnostic efficiency when applied to data from the four centers, as shown in Table 3; Fig. 4. The AUCs obtained from the four centers are as follows: 0.936, 0.861, 0.925, and 0.970, respectively. When comparing the performance of RFed to state-of-the-art federated learning models, we observed an overall improvement in the average AUC by 2.90–5.84%. Additionally, the F1 score of RFed is relatively high overall (average F1 score: 0.598), reflecting its advantage in handling imbalanced datasets, while its performance is slightly weaker than that of MetaFed.
Table 2. Evaluation of performance between RFed and various modelsMethodAUCF1 scoreABCDMean ± SDABCDMean ± SDClinical Model0.7900.7470.6510.5940.696 ± 0.0890.4760.3710.2760.3530.369 ± 0.082FedAve0.8660.8300.8760.9140.872 ± 0.0300.5330.4890.6400.6150.569 ± 0.061FedBn0.9040.8540.8990.9320.897 ± 0.0280.6000.6380.3750.6090.556 ± 0.105FedProx0.8920.8460.8800.9170.884 ± 0.0260.5200.5250.5930.5460.546 ± 0.029MetaFed0.8880.8400.8940.9170.884 ± 0.0280.5880.5140.7500.6320.621 ± 0.086PrrFed0.8930.8180.8700.9170.875 ± 0.0370.6290.4340.5520.6670.571 ± 0.089RFed0.9360.8610.9250.9700.923 ± 0.0390.5530.5950.6110.6320.598 ± 0.029Note: RFed, robust federated learning. AUC, area under the receiver operating characteristic curve. SD: standard deviation
Fig. 4. The receiver operating characteristic curve of various federated learning algorithms. (a) Center (A) (b) Center (B) (c) Center (C) (d) Center (D) Notes: RFed, robust federated learning. AUC, area under the receiver operating characteristic curve. CI, confidence interval
RFed has good robustness and generalizability
Evaluation of reliability and targeted diagnostic utility: In this study, the sensitivity of the model was analyzed by fixing the specificity case, as shown in Table 3. Centers A and D maintained stable sensitivity until higher specificity demands, while B and C showed greater variance. All achieved > 85% sensitivity at 80% specificity (D: 85.7%). However, at the 90% specificity threshold, Hospital A had the highest sensitivity (78.6%), B and C showed moderate results (43.8% and 36.4%), and D achieved 0% sensitivity. This limitation at stringent specificity likely stems from opportunities for model refinement and the limited dataset size. Future research will expand the case cohort and develop more robust diagnostic models to address these issues. In addition, this study pooled the predicted values from the four centers and assessed the calibration performance of the model by plotting the calibration curves, as shown in Supplementary S6. The results showed that the predicted probabilities were basically consistent with the actual observed probabilities, and the overall calibration slope was 0.892, which was close to the ideal value of 1, indicating that the predicted probabilities were reasonably calibrated, trustworthy, and could be used for subsequent clinical interpretation.
Table 3. Sensitivity analysis under fixed specificityCenterSpecificity0.60.70.80.9A0.9290.9290.7860.786B0.9380.9060.8120.438C0.9090.9090.9090.364D0.8570.8570.8570.000
Out-of-distribution generalization of the proposed framework
To further validate the generalization ability of RFed, we also used datasets A, B, C, and D as separate testing sets, with the remaining datasets serving as training sets in each case, as shown in Table 4. The results demonstrate that the proposed federated learning framework achieves consistent and robust performance across different train-test configurations. The AUC values range from 0.770 ± 0.128 to 0.818 ± 0.009, reflecting strong discriminatory ability across all configurations. Similarly, the F1 score, ranging from 0.429 ± 0.038 to 0.473 ± 0.031, indicates reliable performance in balancing specificity and sensitivity across varying data distributions. These findings highlight the model’s strong generalization ability and adaptability to unseen datasets, validating the effectiveness of the federated learning framework in utilizing multi-center data for early-stage NSCLC prognostic diagnosis.
Table 4. Performance of the federated learning framework on different train-test configurationsCaseTraining setTesting setAUCMean ± SDF1 scoreMean ± SDCase 1AD0.8290.818 ± 0.0090.3660.373 ± 0.048BD0.8190.318CD0.8060.435Case 2AC0.7680.770 ± 0.1280.3810.429 ± 0.038BC0.7870.475DC0.7560.430Case 3AB0.7800.776 ± 0.0070.4730.460 ± 0.009CB0.7660.456DB0.7820.451Case 4BA0.8000.783 ± 0.0120.4310.473 ± 0.031CA0.7770.504DA0.7730.485Note: AUC, area under the receiver operating characteristic curve. SD: standard deviation
Effectiveness of the federated learning framework across different architectures
To validate the effectiveness of the proposed federated learning framework, three convolutional neural networks (ResNet34, VGG16, and Inception V3) and a transformer-based backbones (ViT) were chosen as base models to construct the framework, as shown in Table 5. The AUC values across all models demonstrate strong discriminatory ability, with average AUC ranging from 0.882 ± 0.054 (ViT) to 0.919 ± 0.039 (ResNet34), indicating consistently high performance across different datasets. In terms of F1 score, Inception V3 achieved the highest mean F1 score (0.630 ± 0.073), reflecting its superior ability to balance precision and recall. ResNet34 followed with an average F1 score of 0.613 ± 0.029, demonstrating stable performance. Overall, these results indicate that the proposed federated learning framework performs effectively regardless of the underlying base model. These findings validate the robust ability of the federated learning framework across different base architectures and datasets.
Table 5. Performance of different base models in the federated learning framework across centersMethodEvaluationCenter ACenter BCenter CCenter DMean ± SDVGG16AUC0.9170.8880.9190.9400.916 ± 0.019F1 score0.5710.4560.6880.2500.465 ± 0.162Inception V3AUC0.9200.8500.9230.9660.913 ± 0.042F1 score0.7140.5360.6400.7140.630 ± 0.073ResNet34AUC0.9360.8610.9250.9700.919 ± 0.039F1 score0.5530.5950.6110.6320.613 ± 0.029ViTAUC0.9130.8240.8510.9400.882 ± 0.054F1 score0.6920.4920.4210.2500.464 ± 0.183Note: AUC, area under the receiver operating characteristic curve. SD: standard deviation
To further verify the robustness of the model, the results of multi-center RFed were assessed using five-fold cross-validation. The average AUC results for cross-validation across the testing sets of four centers were 0.919, 0.858, 0.920, and 0.941, respectively. The cross-validation AUC results are shown in Fig. 5.
Fig. 5. Four center five-fold cross-validation ROC curves. (a) Center (A) (b) Center (B) (c) Center (C) (d) Center (D) The blue curve is the AUC average of the five-fold curve ROC. The gray area is the upper and lower limits of the ROC curve. Notes: AUC: Area under the curve. ROC: Receiver operating characteristics
Performance comparison of federated learning methods on other cancer data
To further validate the effectiveness of the proposed RFed algorithm, we applied it to skin cancer data alongside other federated learning methods, and the detailed information of data refers to reference [15]. The results, as shown in Table 6, demonstrate that RFed outperforms all other methods in both AUC and F1 score across all centers. Specifically, RFed achieved a mean AUC of 0.908 ± 0.035 and a mean F1 score of 0.757 ± 0.056, outperforming the next best method, MetaFed, in both metrics. These results highlight RFed’s superior performance in handling imbalanced datasets and its robustness across diverse data distributions.
Table 6. Analysis of performance on skin cancer dataMethodAUCF1 scoreABCDMean ± SDABCDMean ± SDFedAve0.8150.8230.7610.7110.778 ± 0.0450.5740.4810.5680.4420.516 ± 0.056FedBn0.8310.9640.8000.8140.852 ± 0.0650.5500.7210.5470.6210.610 ± 0.071FedProx0.8170.7010.7680.7480.759 ± 0.0420.5070.3910.5470.4600.476 ± 0.058MetaFed0.9240.9580.9030.8430.907 ± 0.0420.7820.8030.7470.6770.752 ± 0.048PrrFed0.8910.9820.8550.8410.892 ± 0.0550.7190.8530.6840.6560.728 ± 0.076RFed0.9470.9300.9000.8560.908 ± 0.0350.8330.7890.7090.6970.757 ± 0.056Note: AUC, area under the receiver operating characteristic curve. SD: standard deviation
RFed has good feature extraction and interpretable capabilities
To assess and visualize the effectiveness of feature representation, we employed the t-SNE method [29]. As shown in Fig. 6, the first row of the visualization illustrates the distribution of raw data, while the second row shows the processed feature representations after applying RFed. In the first row, it is evident that there is variability in the separation between the two classes (LCNP and LCP) across the centers in the raw data. In certain centers, such as Center A and Center D, the two classes show partial overlap, while in others, like Center B and Center C, the overlap is more pronounced, suggesting that the raw data lacks clear separability in some cases. However, after applying the federated learning framework, as shown in the second row, the class separability improves significantly across all centers. This enhancement demonstrates the ability of the federated learning framework to improve feature representation and make it more robust to data variations from different centers.
Fig. 6t-SNE visualization of class distributions across centers. (a) Center (A) (b) Center (B) (c) Center (C) (d) Center (D) Notes: LCP: lung cancer progression. LCNP: lung cancer non-progression
Exploring multi-center features helps elucidate the interactions and dependencies among features. In the federated learning framework, due to the heterogeneity of multi-center data, the center-specific features learned by local models from their respective local data exhibit biases and center-specific traits tailored to local tasks. Simultaneously, as model parameters are exchanged between centers, center-common features that are adaptable to multi-center data also emerge. To illustrate these center-specific and center-common features and their relationships, feature correlation heatmaps were generated with reference to the approach of article [30].
The results are shown in Fig. 7a for center-common features of lung cancer progression group and Fig. 7b for center-specific features of lung cancer progression group. In Fig. 7a, high correlations are observed across different centers, while the correlations within the same center are relatively lower. This pattern indicates that the center-common features capture global characteristics consistent across centers, making them well-suited for cross-center feature sharing and collaborative learning. In contrast, Fig. 7b illustrates the center-specific features, where high correlations are evident within the same center, while correlations between different centers are notably lower. For the correlation heat map related to lung cancer non-progression group, please refer to Supplementary S7. This suggests that the center-specific features reflect local characteristics unique to each center, enabling the model to effectively capture and preserve center-specific information. In addition, to investigate the interpretability and classification basis of the federated learning features for the two group, we conducted category visualization by class activation mapping [31]. In Fig. 7c and d, we present the federated feature visualization images of eight cases, including both progression group and non-progression group. The visualizations highlight that the federated learning features exhibit a higher lesion focus for the progression group compared to the non-progression group.
Fig. 7. Heat map analysis. (a) Center-common feature of lung cancer progression group. (b) Center-specific features of lung cancer progression group. (c) Class activation mapping of lung cancer progression group. (d) Class activation mapping of lung cancer non-progression group. Notes: A_1, the first feature from center A. Red areas indicate a high level of model attention, while blue areas indicate a low level of model attention
Discussion
Prognosis assessment of early-stage NSCLC is critical for improving patient outcomes by enabling timely intervention. However, in clinical practice, challenges such as data heterogeneity across multiple centers and class imbalance between positive and negative samples complicate the predictive modeling for early-stage NSCLC. To address these challenges, this study proposes a robust federated learning framework (RFed). The model exhibits exceptional diagnostic performance, strong generalizability, and effective feature extraction and interpretability capabilities. This approach has significant implications for assisting clinicians in assessing the risk of postoperative progression in early-stage NSCLC, thereby facilitating the development of personalized treatment plans tailored to individual patients.
The first key finding of this study is that the proposed RFed model can effectively associate preoperative CT images with the postoperative progression of early-stage NSCLC patients, enabling accurate assessment of the risk of recurrence or metastasis. RFed excels in handling multicenter heterogeneous data and integrating high-dimensional imaging features, allowing it to assess risks of postoperative progression that are challenging to detect visually. RFed outperformed all comparators by an average AUC of 0.923 ± 0.039 across four centers (Table 2). This performance is further validated by significant improvements in the DCA and Kaplan-Meier curves (Figs. 2 and 3), which show higher net benefits across a range of threshold probabilities (0.02 to 0.99). These results underscore the potential of RFed to enhance clinical decision-making, particularly in cases where traditional models may be less effective. Additionally, RFed’s ability to integrate diverse, heterogeneous datasets from multiple centers highlights its potential for multi-center collaborations, offering a promising solution to challenges like data privacy, which are common in real-world clinical settings.
The second key finding is that the RFed model demonstrates strong robustness and generalization, ensuring reliable postoperative risk prediction across diverse clinical settings. In the out-of-distribution generalization test, RFed maintained consistent AUC values (ranging from 0.770 ± 0.128 to 0.818 ± 0.009) and F1 scores (from 0.429 ± 0.038 to 0.473 ± 0.031) across independent test sets (Table 4). This highlights RFed’s ability to adapt to unseen data distributions, a critical feature for clinical deployment. Additionally, RFed showed flexibility when evaluated across different convolutional neural network architectures (ResNet34, VGG16, and Inception V3), with ResNet34 achieving the highest mean AUC of 0.919 ± 0.039 (Table 5). These findings emphasize RFed’s robustness and generalization, making it adaptable to various computational environments and suitable for different healthcare applications. This strong capability ultimately boosts clinical confidence in the model and enhances its potential for widespread use in personalized treatment planning and early disease screening.
The third key finding of this study underscores the RFed model’s feature representation and enhanced interpretability. T-SNE analysis demonstrated that the proposed federated learning framework significantly improved class separability across multiple centers. While the raw data exhibited variability and overlap between the two classes (LCNP and LCP), particularly in certain centers, the RFed model refined feature representations, resulting in clearer class distinctions (Fig. 6). Further analysis of multi-center features revealed that the model effectively learned both center-common features and center-specific features (Fig. 7a and b). The ability to simultaneously capture global (center-common) and local (center-specific) information enhances the model’s interpretability, providing transparent insights into the underlying factors driving predictions. In addition, by class activation mapping, the visualizations highlight that the federated learning features exhibit a higher lesion focus for the progression group compared to the non-progression group (Fig. 7c and d). This clarity enables clinicians to better understand the rationale behind risk assessments, thereby fostering trust in the model’s decisions. Consequently, this interpretability not only supports more informed and confident clinical decision-making but also ensures the model’s adaptability and relevance across diverse clinical settings, all while maintaining personalized and explainable predictions tailored to each center’s unique data characteristics.
Despite its promising results, this study has several limitations. The sample size, constrained by the availability of multi-center datasets, may limit the generalizability of the findings to broader populations. In addition, the current study only used data from a single modality, and the next step is to consider the introduction of multimodality to construct more effective diagnostic models. In addition, there are still some limitations in the current risk threshold delineation, and in the next study, we will investigate a more refined delineation of the thresholds, and even consider introducing more clinical information to further modify our thresholds and improve their clinical applicability. Addressing these limitations by expanding datasets, exploring new clinical applications, and optimizing computational efficiency will be key directions for future research.
Conclusion
The robust federated learning model effectively predicts the risk of postoperative progression in early-stage non-small cell lung cancer, offering significant clinical value for enhancing stratified management and developing precise treatment strategies for early-stage lung cancer patients.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Siegel RL, Miller KD, Fuchs HE, Jemal A, Cancer Statistics. 2021. A Cancer Journal for Clinicians. 2021;71(1):7–33. 10.3322/caac.2165410.3322/caac.2165433433946 · doi ↗ · pubmed ↗
- 2Ma L, Liao Y, Zhou B, Xi W, Per He Fed. A general framework of personalized federated learning for heterogeneous convolutional neural networks. World Wide Web. 2022;1–23. 10.1007/s 11280-022-01119-x.10.1007/s 11280-022-01119-x PMC 974310536531189 · doi ↗ · pubmed ↗