A Bayesian Regularized and Annotation-Informed Integrative Analysis of Cognition (BRAINIAC)
Rong W. Zablocki, Bohan Xu, Chun-Chieh Fan, Wesley K. Thompson

TL;DR
BRAINIAC is a new model that improves cognitive predictions by integrating brain data and annotations, without assuming sparsity in brain-behavior links.
Contribution
BRAINIAC introduces a novel Bayesian method for integrative analysis of cognition with annotation-informed variance estimation.
Findings
BRAINIAC was validated through Monte Carlo simulations and real data from the ABCD Study.
Incorporating annotations improved out-of-study predictive power when applied to HCP-D data.
The model provides a principled assessment of annotation impact on feature enrichment.
Abstract
We present the novel Bayesian Regularized and Annotation-Informed Integrative Analysis of Cognition (BRAINIAC) model. BRAINIAC allows for estimation of total variance explained by all features for a given cognitive phenotype, as well as a principled assessment of the impact of annotations on relative enrichment of predictive features compared to others in terms of variance explained, without relying on a potentially unrealistic assumption of sparsity of brain–behavior associations. We validate BRAINIAC in Monte Carlo simulation studies. In real data analyses, we train the BRAINIAC model on resting state functional magnetic resonance imaging (rsMRI) and neuropsychiatric data from the Adolescent Brain Cognitive Development (ABCD) Study and use the trained model in an out-of-study application to harmonized resting-state data from the Human Connectome Project Development (HCP-D),…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
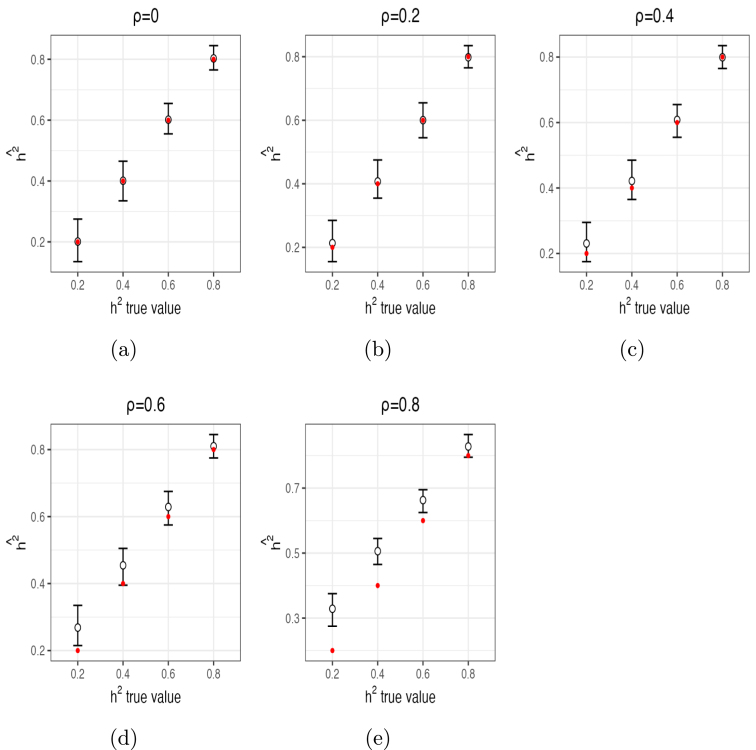 Figure 1
Figure 1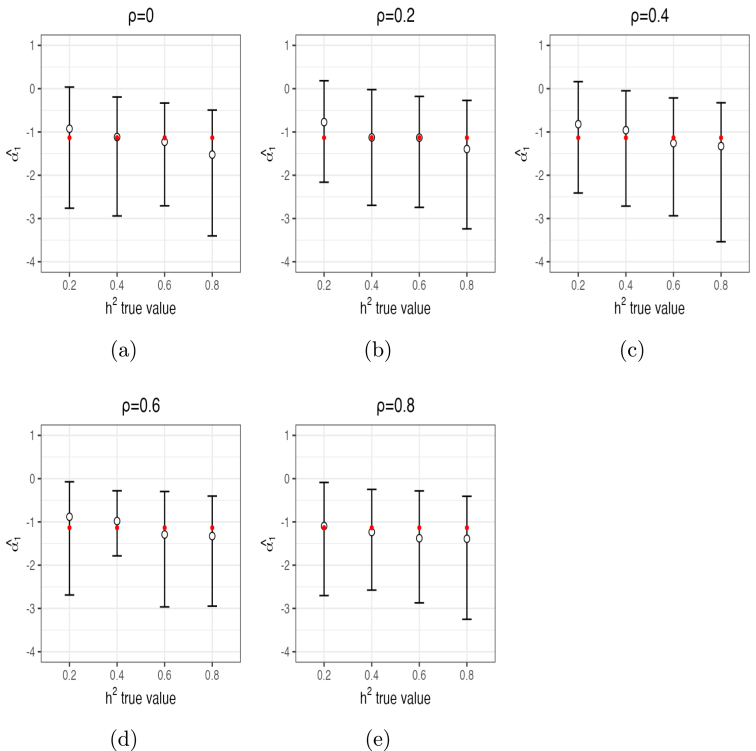 Figure 2
Figure 2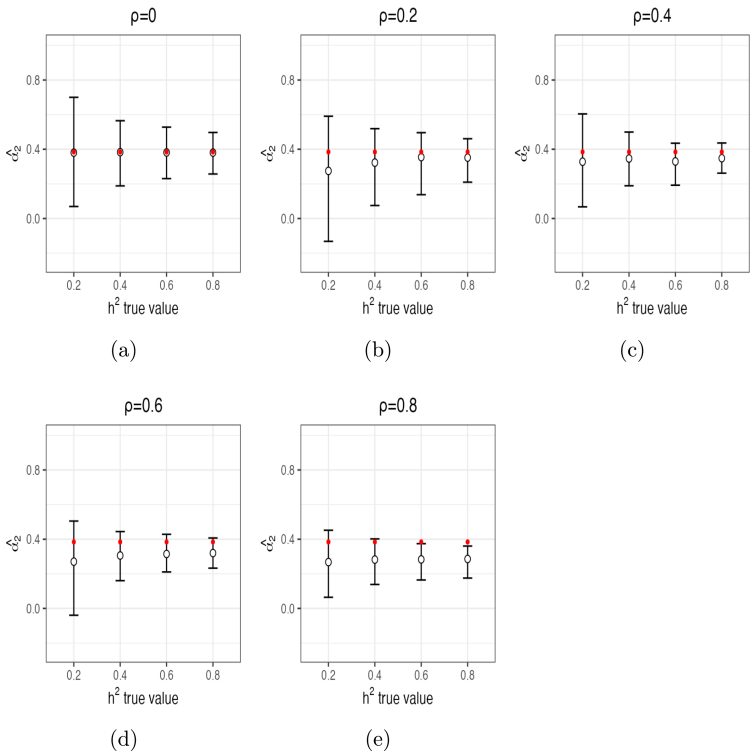 Figure 3
Figure 3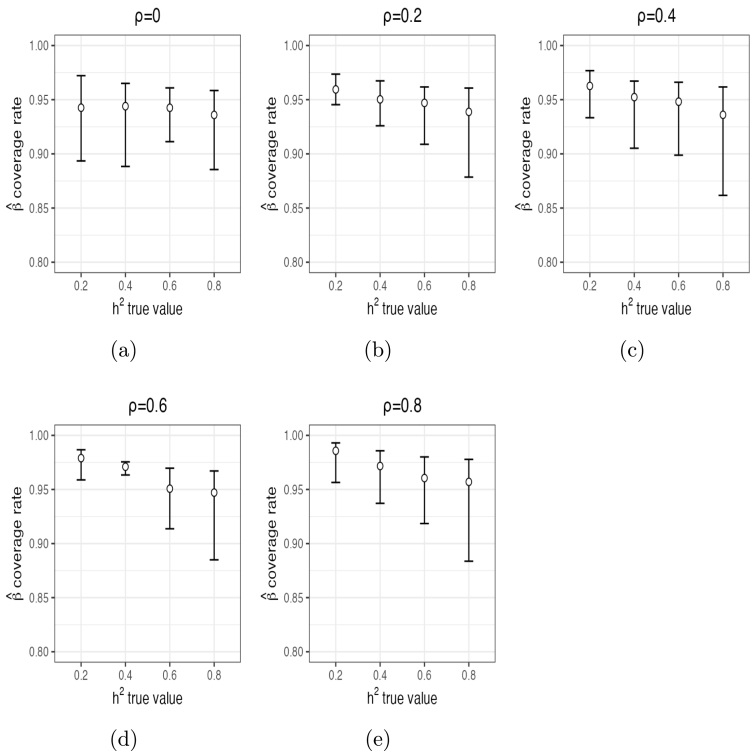 Figure 4
Figure 4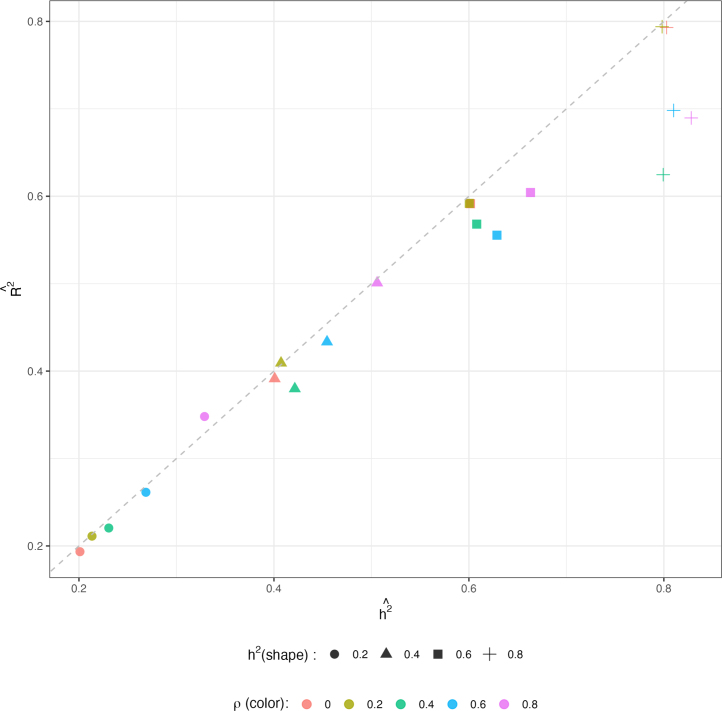 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFunctional Brain Connectivity Studies · Neural Networks and Applications · Machine Learning in Healthcare
Introduction
1
Functional Magnetic Resonance Imaging (fMRI) measures changes in blood oxygenation and blood flow related to neuronal activity, providing researchers with the means to study human brain function in vivo (Ombao et al., 2016). fMRI is safe, relatively inexpensive, and has fairly good spatial and temporal resolution. Consequently, over the past two decades fMRI has become an essential and widely-used tool for assessing the neural substrate of human behavior and development.
However, over the past decade or more neuroimaging research has experienced a “replication crisis” (Button et al., 2013), wherein many published associations either do not replicate or have much smaller effect sizes in subsequent studies. It has been hypothesized that this crisis has been caused by a combination of factors, including small effects, inadequate sample sizes, high-dimensional feature spaces (with correspondingly high researcher degrees of freedom) and publication bias towards “significant” associations (Dick et al., 2021). This perfect storm of factors leads to a severe “Winner’s Curse” effect for the field as a whole (van Zwet and Cator, 2021), wherein effect sizes of replication studies tend to be much closer to zero than in initial discovery samples.
In support of this argument, it has been recently shown that effects sizes of brain–behavior relationships estimated from large-sample studies are often considerably reduced compared to those published in the past using data from much smaller samples (Dick et al., 2021, Marek et al., 2022, Miller et al., 2016). Studies such as the Human Connectome Project Development (HCP-D) (Somerville et al., 2018), the Adolescent Brain Cognitive Development (ABCD) Study (Volkow et al., 2018), and the upcoming HEALthy Brain and Child Development (HBCD) Study (Volkow et al., 2021) have greatly increased sample sizes ( 1k to 12k) compared to previous neurodevelopmental cohorts. An important consequence of larger samples is the ability to estimate brain–behavior effect sizes with more power and precision. As shown in van Zwet and Cator (2021), the degree to which subsequent published results replicate is directly related to the power of the discovery sample, determined by the underlying effect sizes and the sample size. Large neurodevelopmental samples such as that available in the ABCD Study are thus crucial for addressing obtaining accurate estimates of effect sizes.
Additionally, analyses leveraging data from these large neuroimaging cohorts suggest that brain–behavior associations, rather than being localized to a sparse set of imaging-derived features (IDFs), are widely distributed across the brain. For example, Zhao et al. (2019) found that whole-brain ridge regression of all vertices outperformed methods (e.g., LASSO) that assumed sparsity for predicting cognitive ability using the N-back task fMRI data in the ABCD Study. Thresholding associations based on levels of significance from small, under-powered studies may be giving a biased and unrealistic view of the degree to which brain–behavior relationships are localized to a small number of IDFs.
This is precisely the scenario that Genome-Wide Association Studies (GWAS) encountered over the last couple of decades (Mathieson, 2021). Candidate gene studies failed to replicate. As sample sizes became larger, it was discovered that the effect size of any single genetic locus was generally very small for most phenotypes, but that effects were widely spread across many loci.
In response, Yang et al. (2011a) proposed a variance-components analysis algorithm, termed Genome-wide Complex Trait Analysis (GCTA) for GWAS data. GCTA is designed to assess the total fraction of variance explained (FVE) for all loci in a GWAS, and can be applied when individual locus effect sizes are tiny and the number of loci far exceeds the number of subjects. GCTA requires subject-level data to fit. (Note, other FVE methods, including LD-Score Regression (Bulik-Sullivan et al., 2015) and GWASH (Schwartzman et al., 2019), work on GWAS summary statistics, typically consisting of publicly-released regression coefficients and p-values for each genetic locus). GCTA is informative in the sense that it captures the total variance explained for a given phenotype by all features en masse in a linear additive model. Conceptually, the FVE estimated from GCTA is the expected proportion of variance that could be explained using all (genomic) features simultaneously to predict outcomes in an independent replication sample, if the training sample were infinitely large, i.e., if the regression coefficients were estimated without error.
The original GCTA algorithm does not otherwise inform about which aspects of the features are related to their relative strength of prediction of the given phenotype. GCTA has been modified to allow for partitioning features into disjoint sets (Yang et al., 2011b). This allows researchers to assess relative “enrichment” across subsets of features: while effects may be spread widely across all features, per feature variance explained may be higher on average in some subsets compared to others, perhaps indicating a more central role in producing the phenotype under study. However, these methods do not currently allow for continuous annotations or for multiple characteristics of features to be evaluated simultaneously.
In this paper we describe Bayesian hierarchical variance components model developed for application to fMRI data. The goals of the model are: (1) to estimate the FVE of the complete set of IDFs (which may be of much higher dimension than the number of subjects); and (2) to assess the relative enrichment of variance explained for individual features based on feature-specific “annotations”. Annotations can be multi-dimensional, and of mixed type (i.e., discrete and/or continuous). It is hoped that by expanding the variance components model to allow for feature annotations, that the model will enable expert input and hence become more useful for neurodevelopmental researchers to test hypotheses about which factors are more or less related to explaining brain–behavior associations, while preserving the ability to estimate the FVE of all features without relying on thresholding or unrealistic sparsity assumptions. Additionally, we examine the impact of the a priori assumption of independent effects, which may be less tenable in neuroimaging compared to genetic applications.
Methods
2
The BRAINIAC model
2.1
Here we present the novel Bayesian Regularized and Annotation-Informed Integrative Analysis of Cognition (BRAINIAC) model. BRAINIAC allows for both estimation of total variance explained by all features for a given neurocognitive phenotype, as well as a principled inference of the relative enrichment related to measured characteristics (“annotations”) of some features compared to others, without relying on potentially unrealistic assumptions about the sparsity of brain–behavior associations.
The GCTA algorithm (Yang et al., 2012) is based on a model like the following. Let denote a vector of behavioral phenotypes collected from participants in a Brain-Wide Association Study (BWAS). Let be the corresponding matrix of IDFs. We assume that and the columns of have been standardized. The GCTA model is given by
where is a -dimensional vector of regression parameters of per-feature association sizes and is a identity matrix. The FVE of the model is (termed the “SNP heritability” in GWAS analyses), where . Since the total variance of is unity by construction, is the variance left unexplained by the features . Thus, in the standard GCTA model, each feature explains the same amount of variance on average.
We propose an extension of the GCTA model (1) that allows for a heteroscedastic normal prior for depending on an -dimensional vector for each feature. The generative model is the same as Eq. (1), but with the prior on instead given by: (2)
The variance of is thus comprised of two components: as before, quantifies the FVE explained by all features, whereas the diagonal matrix quantifies how annotations modulate the variance explained by individual features. Here, is a matrix, where is the number of the annotations per feature and is an -dimensional vector of annotation weights. We assume the weights are unknown and hence need to be learned from the data. The matrix is scaled (so that the diagonal elements lie between 0 and 1 and sum to unity) to ensure the sum of the variances of across all features is . If , the prior of reduces to , which is equivalent to the GCTA model. Alternatively, when , the feature variances are heteroscedastic, so that some features account for more variance than others depending on the levels of , for .To complete the Bayesian model, we assign a normal prior to
The FVE is given a Beta prior defined on the interval [0,1],
where , and are hyperparameters. In applications, we often choose a large value of for a diffuse prior on . If and are both set to unity, the prior is a Uniform distribution on interval [0,1]. If there were prior information about the amount of variance explained by all brain features, we could set and appropriately to obtain a specified prior mean and variance. Bayesian inference is performed via a Markov Chain Monte Carlo (MCMC) sampling algorithm, implemented in Python and described in the Supplementary Materials. The Python code is publicly available on GitHub at https://github.com/nidaye1999/BRAINIAC.
Results
3
The Adolescent Brain Cognitive Development (ABCD) Study is the largest single-cohort long-term longitudinal study of neurodevelopment and child and adolescent health in the United States. The ABCD Study® collects observational data to characterize US population trait distributions and to assess how biological, psychological, and environmental factors (including interpersonal, institutional, cultural, and physical environments) can relate to how individuals live and develop in today’s society. The study has primary data collection at 21 research institutes across the USA. Participants include ,880 youths aged 9–10 at baseline. Details of the study design are given in Garavan et al., 2018, Dick et al., 2021. The neuroimaging protocol, including the resting state MRI (rsMRI), has been described elsewhere (Casey et al., 2018). We employed the ABCD Study data as the basis for Monte Carlo simulations as well as real data analyses, as detailed below. Data were obtained from the ABCD Study Curated Data Release 4.0 (https://nda.nih.gov/DOI 10.15154/1,523,041).
Monte Carlo simulations
3.1
Performance evaluation
3.1.1
We implemented Monte Carlo simulation studies to evaluate the BRAINIAC model performance. The goal of the Monte Carlo simulations was to examine if the posterior distributions of parameters , and were centered on their true values, and that their 95% posterior credible intervals (CI’s) contained the true parameter close to their nominal coverage level (i.e., 95% of the time). To make these simulations as realistic as possible, we extracted the rsMRI data at baseline, when participants were 9–10 years of age. If these data were missing at baseline for a given participant, we used their data from their 2-year follow-up visit if those were available.
The rsMRI features of interest were the Fisher z-transformed Pearson correlations (“connectivities”) of activation time courses between pairs of cortical regions defined by the Gordon parcellation (Gordon et al., 2016). This resulted in an approximately 1:5 ratio of participants to features. We annotated these connectivities based on whether edges connected two nodes within a specific network, where networks were chosen from a subset of ten of the networks presented in Gordon et al. (2017). Next, we reduced the set of features, only retaining those features that fell onto one of the ten networks, resulting in 14,019. To preserve the 1:5 ratio of participants to features, we subsequently randomly sampled ,804 participants, yielding the final matrix used for the simulation studies.
The prior distribution from Eqs. (1), (2) assume a diagonal covariance matrix, i.e., that the are a priori independent. (Note, however, the conditional posterior of , given by Supplementary Equation (2), is normal but with a non-diagonal covariance matrix). In order to assess the sensitivity of posterior inferences to this choice of prior, simulations were performed with drawn from first-order autoregressive covariance matrices. Specifically, let and denote indices of two IDFs. In our Monte Carlo simulations, the covariance of and was then given by
where (resp. ) is the prior variance of (resp. ) from Eq. (2) and . Choosing corresponds to the BRAINIAC model. We varied to equal and 0.8. In addition, we set to values and 0.8. For each of the combinations of and , we set two of the ten-dimensional annotation weights and to represent enriched and unenriched effects. Finally, was generated from Eq. (2) described in Section 2.1. The MCMC algorithm was implemented with 10 chains per setting.
For , and , posterior mean estimates and 95% posterior CIs from 10 independent chains are shown in Figs. 1, 2 and 3, respectively. These figures demonstrate that the estimates of these parameters captured their true values accurately in most of the settings, especially with and/or . For , posterior means were quite accurate and the 95% CI’s all contained the true values of all parameters. For , estimates of were biased upwards for smaller values (average posterior mean estimate of 0.27 when and average posterior mean estimate of 0.45 when ). For , estimates of were also biased (e.g., average posterior mean estimate of 0.33 when and average posterior mean estimate of 0.51 when ). Thus, small to moderate departures from independence of only had modest impacts on the estimates of . Moderately large departures ( ) led to small upward biases for small values of , and large departures ( ) led to more substantial upward biases, especially for small values of . In contrast, estimates of (Fig. 2) were accurate even for large values of . The same is true for (Fig. 3), although this parameter was slightly upwardly biased for and a bit more for . The number of times out of the ten chains that the true value for each of the three parameters for each setting was contained in the 95% CI’s is given in Supplementary Section (1.3) Table (1). Means and 95% posterior CIs of the coverage rates for are shown in Fig. 4. Overall, the average coverage rates of ranged from 94% to 98% across all settings, matching nominal rates well.
We also computed , the empirical variance explained by all features directly from the posterior regression. This should be approximately equal to the theoretical variance explained, i.e., . The alignment between mean values of and from inter-mixed ten chains per setting are shown in Fig. 5. The values match well (lie on the diagonal) until both and , indicating that within-sample prediction accuracy of the BRAINIAC model closely tracks the true even under moderately large departures from independence, though modestly underestimating when both and are large.Fig. 1. Mean estimates (circles) of and 95% posterior CIs (error bars) from 10 chains per setting (red dots indicate true values of ).Fig. 2. Mean estimates (circles) of and 95% posterior CIs (error bars) from 10 chains per setting (red dots indicate true values of ).Fig. 3. Mean estimates (circles) of and 95% posterior CIs (error bars) from intermix of 10 chains per setting (red dots indicate true values of ).Fig. 4. Means (circles) and their 95% posterior CIs (error bars) of coverage rates for the true values based on 10 chains per setting.
Fig. 5. Mean and from intermix 10 chains per setting (combination of the color and shape indicates a setting of and true values; for example, green square implies and ; hot pink plus sign implies and ). Dash line is the diagonal line.
Out-of-sample prediction performance
3.1.2
We next evaluated the drop-off in performance in an out-of-sample prediction for a given estimate. For this simulation, we used the simplified prior of from Eq. (1). The true value of was set to 0.32, similar to the real-data analyses of crystallized intelligence described below. The matrix of rsMRI connectivities was again selected from the ABCD Study baseline data and was randomly split into a training set ( ) and test set ( ) ten different times. Each had a dimension of 8,665 × 46,360 and each had a dimension of 320 × 46,360. The outcome variables, and , were generated from Eq. (1) based on standardized and , respectively. The BRAINIAC algorithm was applied to the 10 training sets to obtain parameter estimates and , which were the median values of the MCMC chains. In-sample estimate ranged from 0.30 to 0.36, indicating reliable and stable estimates of . The squared correlation between and represented the out-sample estimate from the test sets, which ranged from 0.10 to 0.21 with median value of 0.15. This result indicates the expected drop-off in out-of-sample prediction performance due to noisy estimates of from finite training and test samples.
Application to ABCD study data
3.2
rsMRI predicting crystallized intelligence
3.2.1
For the real data analyses, we again used the resting-state MRI Fisher z-transformed Pearson correlations of activation time courses between pairs of Gordon parcels (Gordon et al., 2016). The first neurocognitive phenotype we used was the crystallized intelligence composite score (age uncorrected) assessed using the NIH Toolbox (Akshoomoff et al., 2013). We used rsMRI and NIH Toolbox data collected at the baseline visit. We retained participants passing quality control metrics and without any missing values in resting state features ( ) and crystallized intelligence ( ). We residualized both and on age at baseline, sex at birth, the first ten principal components of genetic ancestry and MRI scanner instance. The residualized and were then standardized to have zero (column) means and unit variances. The final sample size was (male: 2,737, mean [min, max] age in months: 120.0 [107,132]; female: 2,906, age: 119.5 [107–132]). The number of features was , yielding an approximate 11:1 ratio of features to participants . The annotations we used in these analyses were the assignment of cortical vertices into within-network labels, using the 13 resting state networks described in Gordon et al. (2017) including: Auditory, Cingulo-Opercular, Cingulo-Parietal, Default Mode, Dorsal Attention, Fronto-Parietal, Retrosplenial-Temporal, Somato-motor Mouth, Somato-motor Hand, Salience, Subcortical, Ventral Attention, and Visual. There was also an annotation into a “None–None” category, consisting of edges between nodes not contained in any of these thirteen named networks. The percentages of edges in each of within-network annotations are displayed in Supplementary Section (1.4) Table (2). Note, the majority of edges do not fall within any of these networks, and hence most annotations .
We first applied these annotations to the BRAINIAC model one at a time; in other words, for each run (single-annotation model). For each model, we ran six MCMC chains per annotation; each chain was run for 10,000 iterations with a 3,000 burn-in period and a thinning rate of ten. Posterior parameter estimates of single-annotation model from within-network are presented in Table 1. Estimates shown are the overall median value and 95% posterior credible intervals (CIs). Estimates of was highly consistent across all models. This indicates that the set of all resting state features in the model in total explains 37% of the variance of crystallized intelligence in ABCD participants after residualizing for the covariates listed above. This is a much higher total effect size than has been reported by individual features in the ABCD Study and other large neuroimaging studies (Marek et al., 2022). Note, although is not a parameter in the BRAINIAC model, it is the empirical variance explained by the features from the regression and should be close to , which in fact it is here (see Table 1). Only one within-network annotation (Default Mode Network, DMN) was significantly enriched for associations, with (95% CI: ). Thus, each edge in the DMN on average explains times as much variance compared to edges outside of the DMN. Despite being enriched for associations, most of the resting state signal for crystallized intelligence lies outside of the DMN.
Next, we examined the predictive power of the BRAINIAC model in an out-of-study application to data taken from the Human Connectome Project Development (HCP-D) study. We extracted the coefficients from the BRAINIAC model applied to the ABCD Study data (1) with no annotations ( ); and (2) using DMN as an annotation ( ). These coefficients were then applied to the resting state connectivities of HCP-D participants (male: 157, age: (186.2 [97–262]; female: 163, age: 183.0 [97–263]) processed similarly to the ABCD Study training sample, to produce polyvertex scores: and . These were then placed within separate linear regression models, including age and sex as covariates, to predict their crystallized intelligence scores. The explained 11% of the variance in crystallized intelligence over and above sex and age, whereas explained 17% of the variance in crystallized intelligence. Thus, inclusion of the DMN annotation in the BRAINIAC model improves its out-of-study predictive performance by nearly 50% over the model with no annotations.Table 1. Estimatesa from single-annotation model with 14 within-network annotations (phenotype : Crystallized Intelligence).Annotations Auditory–Auditory−0.03 (−0.39,0.10)0.37 (0.34,0.41)0.37 (0.34,0.41)CinguloOperc–CinguloOperc0.03 (−0.38,0.18)0.37 (0.34,0.41)0.37 (0.34,0.41)CinguloParietal–CinguloParietal0.00 (−0.67,0.07)0.37 (0.34,0.41)0.37 (0.34,0.41)Default–Default0.19 (0.07,0.27)0.37 (0.33,0.41)0.37 (0.34,0.40)DorsalAttn–DorsalAttn0.02 (−0.29,0.18)0.37 (0.34,0.41)0.37 (0.34,0.41)FrontoParietal–FrontoParietal0.00 (−0.41,0.14)0.37 (0.34,0.41)0.37 (0.34,0.41)None–None−0.23 (−0.75,0.05)0.37 (0.34,0.41)0.37 (0.34,0.41)RetrosplenialTemporal–RetrosplenialTemporal−0.23 (−0.83,0.04)0.37 (0.34,0.41)0.37 (0.34,0.41)SMhand–SMhand0.04 (−0.36,0.17)0.37 (0.34,0.41)0.37 (0.34,0.41)SMmouth–SMmouth−0.23 (−0.75,0.00)0.37 (0.34,0.41)0.37 (0.34,0.41)Salience–Salience−0.31 (−0.88,0.01)0.37 (0.34,0.41)0.37 (0.34,0.41)Subcort–Subcort−0.18 (−0.94,0.09)0.37 (0.34,0.41)0.37 (0.34,0.41)VentralAttn–VentralAttn0.05 (−0.62,0.17)0.37 (0.34,0.41)0.37 (0.34,0.41)Visual–Visual0.03 (−0.25,0.18)0.37 (0.34,0.41)0.37 (0.34,0.41)aEstimates ( , , ) shown are the overall median value and 95% posterior credible interval (CI) from the intermix of 6 chains per annotation. is calculated for each chain at each collected iteration for all 6 chains per annotation, the overall median and 95% CI per annotation are reported. is a vector estimate of .
Note, the out-of-study performance of and (11% variance explained without annotation, 17% variance explained with DMN as an annotation) is lower than . This is to be expected because of the finite sample size of the ABCD Study training sample. The parameter represents the theoretical upper bound of the out-of-sample variance explained if the training sample size were infinite (and hence was estimated with no error). This drop-off in performance is similar to the performance drop-off for the training and test sets observed in the Monte Carlo simulations presented above.
rsMRI predicting the P-factor
3.2.2
We next performed the same BRAINIAC analyses, but replacing crystallized intelligence with a measure of psychopathology based on the Child Behavior Checklist (CBCL) (Achenbach and Edelbrock, 1991). The CBCL has eight syndrome scales assessing different aspects of psychopathology (Anxious/Depressed, Depressed, Somatic Complaints, Social Problems, Thought Problems, Attention Problems, Rule-Breaking Behavior, Aggressive Behavior). We placed these in a Bi-Factor Structural Equation Model to obtain a unidimensional “P-factor” measure, using the lavaan package in R (Rosseel et al., 2017). Higher scores on the P-factor indicate higher levels of psychopathology. Code for computing the P-factor from the ABCD Study Release 4.0 data is available on GitHub (https://github.com/nidaye1999/BRAINIAC).
We used the exact analysis pipeline as described above for crystallized intelligence. The final sample size was (slightly differing from the crystallized intelligence analyses due to differential missingness). The BRAINIAC results are presents in Table 2. The estimates of (CI = ) were highly stable across the different BRAINIAC models. Thus, rsMRI features were less predictive of psychopathology than crystallized intelligence. No within-network annotations reached nominal significance in this application.
We performed the same out-of-study replication analysis using the harmonized HCP-D rsMRI data as described above but replacing crystallized intelligence with the P-factor computed from the CBCL syndrome scales assessed on the HCP-D participants. Since none of the annotations reached significance, we computed only the score without annotations. This resulted in FVE = 1.2%, considerably lower than the predictive performance of and for crystallized intelligence, as expected corresponding to the lower estimate for the P-factor.Table 2. Estimatesa from single-annotation model with 14 within-network annotations (phenotype : Child Behavior Checklist P-factor).Annotations Auditory–Auditory−0.08 (−0.46,0.17)0.09 (0.07,0.12)0.09 (0.07,0.12)CinguloOperc–CinguloOperc−0.01 (−0.41,0.22)0.09 (0.07,0.12)0.09 (0.07,0.12)CinguloParietal–CinguloParietal−0.28 (−1.04,0.00)0.09 (0.07,0.12)0.09 (0.07,0.12)Default–Default0.18 (−0.27,0.32)0.09 (0.07,0.12)0.09 (0.07,0.12)DorsalAttn–DorsalAttn−0.03 (−0.53,0.21)0.09 (0.07,0.12)0.09 (0.07,0.12)FrontoParietal–FrontoParietal0.18 (−0.14,0.24)0.09 (0.07,0.12)0.09 (0.07,0.12)None–None−0.09 (−0.52,0.21)0.09 (0.07,0.12)0.09 (0.07,0.12)RetrosplenialTemporal–RetrosplenialTemporal−0.13 (−0.70,0.09)0.09 (0.07,0.12)0.09 (0.07,0.12)SMhand–SMhand0.04 (−0.52,0.26)0.09 (0.07,0.12)0.09 (0.07,0.12)SMmouth–SMmouth−0.14 (−0.65,0.09)0.09 (0.07,0.12)0.09 (0.07,0.12)Salience–Salience−0.29 (−0.94,0.04)0.09 (0.07,0.12)0.09 (0.07,0.12)Subcort–Subcort−0.01 (−0.82,0.18)0.09 (0.07,0.12)0.09 (0.07,0.12)VentralAttn-VentralAttn−0.16 (−0.77,0.13)0.09 (0.07,0.12)0.09 (0.07,0.12)Visual–Visual−0.08 (−0.52,0.21)0.09 (0.07,0.12)0.09 (0.07,0.12)aEstimates ( , , ) shown are the overall median value and 95% posterior credible interval (CI) from the intermix of 6 chains per annotation. is calculated for each chain at each collected iteration for all 6 chains per annotation, the overall median and 95% CI per annotation are reported. is a vector estimate of .
Discussion
4
Here, we have presented the novel BRAINIAC model for analyzing whole-brain data associations with neurocognitive phenotypes. This model allows for estimation of the overall FVE by all imaging features simultaneously, while also allowing for systematic principled inferences regarding differences in FVE as captured by feature-level annotations. Thus, the BRAINIAC model goes beyond variance components models such as GCTA, that simply report the FVE explained by all features. By incorporating as annotations-specific aspects of the imaging derived features, we can partially localize effects and rigorously estimate and test for relative enrichment of some features compared to others.
In an application of the BRAINIAC model to the ABCD Study baseline resting state MRI data, we found that the edge connectivities in total accounted for 37% of the variance of crystallized intelligence, a much higher effect size than has been reported using IDFs individually with the ABCD Study data (Marek et al., 2022). One of fourteen within-network annotations (namely the Default Mode Network) enriched for associations with crystallized intelligence. However, since the within-DMN edges only account for 1.33% of all features in the model, the DMN still accounts for only a small fraction of the total variance accounted for by all features, underscoring the wide-spread nature of many brain–behavior associations. Nevertheless, including the DMN as an annotation lead to an over 50% improvement in out-of-study prediction accuracy compared to prediction not using this as an annotation, highlighting the potential of BRAINIAC for leveraging data from large studies such as the ABCD Study for training algorithms for powering predictions in smaller studies.
Applying BRAINIAC to the P-factor, a measure of psychopathology, resulted in an estimated , considerably lower than for crystallized intelligence. This conforms with results from other studies examining the relationship between psychopathology and brain function using the ABCD Study rsMRI data (Karcher et al., 2021). None of the within-network annotations reached nominal significance in this example.
Simulations confirmed the good performance of BRAINIAC even when the number of features is much larger than the number of participants. A key aspect of the BRAINIAC model is the prior specification on , which is normal with a diagonal covariance matrix. In simulations we assessed the sensitivity of the results to this aspect of the prior specification, demonstrating good performance unless the departure from the independence assumption is substantial and the FVE is small.
A drawback of the current model is computational efficiency: our real-data application to the ABCD Study data took about 50 h of compute time. In future work we plan on implementing the BRAINIAC model in a more computationally efficient algorithm using a Variational Bayes algorithm. We also plan on incorporating a variety of annotations to further investigate brain–behavior relationships: while we applied the BRAINIAC model to resting state MRI associations with crystallized intelligence from the ABCD Study, the model is quite general and could be applied to a number of different modalities (e.g., task-based MRI), outcomes, and annotations (e.g., gene expression in the developing human brain). However, caution is still warranted in applying BRAINIAC to highly spatially correlated data (e.g., spatially smoothed adjacent voxels). In future work we will examine the impact of spatial smoothing on BRAINIAC estimates, e.g., using structural MRI as features.
CRediT authorship contribution statement
Rong W. Zablocki: Writing – original draft, Visualization, Software, Methodology, Formal analysis. Bohan Xu: Writing – review & editing, Formal analysis, Data curation. Chun-Chieh Fan: Writing – review & editing, Formal analysis. Wesley K. Thompson: Writing – review & editing, Writing – original draft, Supervision, Methodology, Formal analysis, Conceptualization.
Declaration of competing interest
The authors have nothing to declare.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Achenbach Thomas M.Edelbrock C.Child Behavior Checklist 1991 Burlington (vt)371392
- 2Akshoomoff Natacha Beaumont Jennifer L.Bauer Patricia J.Dikmen Sureyya S.Gershon Richard C.Mungas Dan Slotkin Jerry Tulsky David Weintraub Sandra David Zelazo Philip Viii. nih toolbox cognition battery (cb): composite scores of crystallized, fluid, and overall cognition Monographs of the Society for Research in Child Developmentvol. 78201311913210.1111/mono.12038 PMC 410378923952206 · doi ↗ · pubmed ↗
- 3Bulik-Sullivan Brendan K.Loh Po-Ru Finucane Hilary K.Ripke Stephan Yang Jian Schizophrenia Working Group of the Psychiatric Genomics Consortium Patterson Nick Mark J. Daly Alkes L. Price Neale Benjamin M.Ld score regression distinguishes confounding from polygenicity in genome-wide association studies Nature Genet.47320152912952564263010.1038/ng.3211 PMC 4495769 · doi ↗ · pubmed ↗
- 4Button Katherine S.Ioannidis John P.A.Mokrysz Claire Nosek Brian A.Flint Jonathan.Robinson Emma S.J.MunafòMarcus R.Power failure: why small sample size undermines the reliability of neuroscience Nature Rev. Neurosci.14520133653762357184510.1038/nrn 3475 · doi ↗ · pubmed ↗
- 5Casey Betty Jo.Cannonier Tariq Conley May I.Cohen Alexandra O.Barch Deanna M.Heitzeg Mary M.Soules Mary E.Teslovich Theresa Dellarco Danielle V.Garavan Hugh The adolescent brain cognitive development (abcd) study: imaging acquisition across 21 sites Dev. Cogn. Neurosci.32201843542956737610.1016/j.dcn.2018.03.001PMC 5999559 · doi ↗ · pubmed ↗
- 6Dick Anthony Steven Lopez Daniel A.Watts Ashley L.Heeringa Steven Reuter Chase Bartsch Hauke Fan Chun Chieh.Kennedy David N.Palmer Clare Marshall Andrew Meaningful associations in the adolescent brain cognitive development study Neuro Image 239202111826210.1016/j.neuroimage.2021.118262 PMC 880340134147629 · doi ↗ · pubmed ↗
- 7Garavan H.Bartsch H.Conway K.Decastro A.Goldstein R.Z.Heeringa S.Jernigan T.Potter A.Thompson W.Zahs D.Recruiting the abcd sample: Design considerations and procedures Dev. Cogn. Neurosci.32201816222970356010.1016/j.dcn.2018.04.004PMC 6314286 · doi ↗ · pubmed ↗
- 8Gordon Evan M.Laumann Timothy O.Adeyemo Babatunde Huckins Jeremy F.Kelley William M.Petersen Steven E.Generation and evaluation of a cortical area parcellation from resting-state correlations Cerebral Cortex 26120162883032531633810.1093/cercor/bhu 239PMC 4677978 · doi ↗ · pubmed ↗