Verticox+: vertically distributed Cox proportional hazards model with improved privacy guarantees
Florian van Daalen, Djura Smits, Lianne Ippel, Andre Dekker, Inigo Bermejo

TL;DR
Verticox+ is an improved privacy-preserving version of the Verticox model for federated learning in survival analysis.
Contribution
Verticox+ introduces a privacy-preserving protocol to handle scenarios where survival outcomes are not locally known.
Findings
Verticox+ achieves equivalent performance to the original Verticox model.
The new protocol preserves privacy without requiring survival outcomes to be shared.
The computational and communication costs are analyzed and discussed.
Abstract
Federated learning allows us to run machine learning algorithms on decentralized data when data sharing is not permitted due to privacy concerns. Various models have been adapted to use in a federated setting. Among these models is Verticox, a federated implementation of Cox proportional hazards models, which can be used in a vertically partitioned setting. However, Verticox assumes that the survival outcome is known locally by all parties involved in the federated setting. Realistically speaking, this is not the case in most settings and thus would require the outcome to be shared. However, sharing the survival outcome would in many cases be a breach of privacy which federated learning aims to prevent. Our extension to Verticox, dubbed Verticox+, solves this problem by incorporating a privacy preserving 2-party scalar product protocol at different stages. This allows it to be used in…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
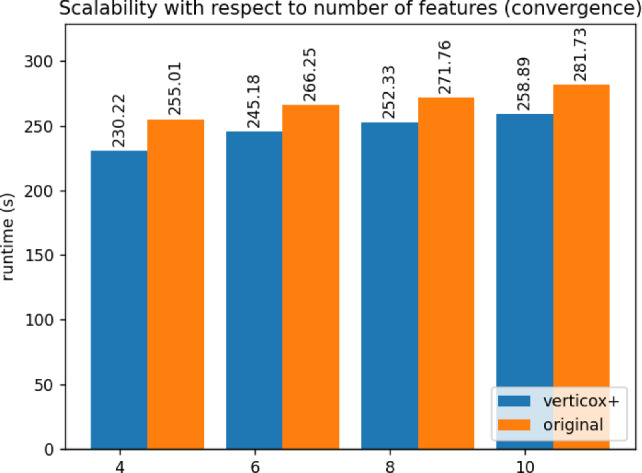 Figure 10
Figure 10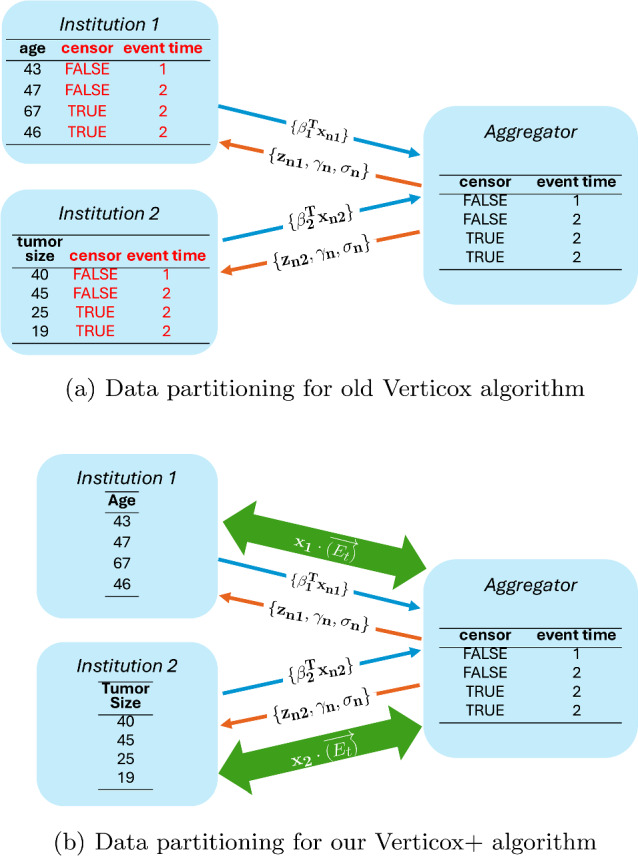 Figure 1
Figure 1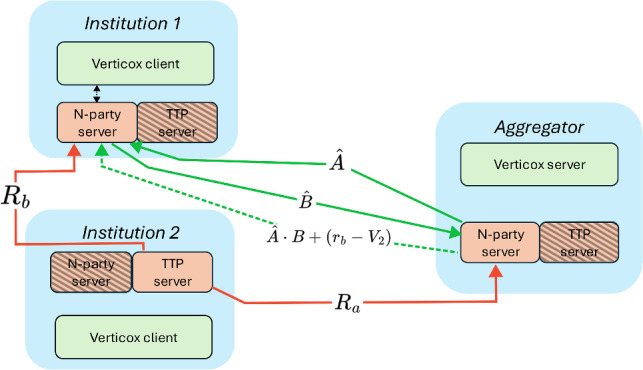 Figure 2
Figure 2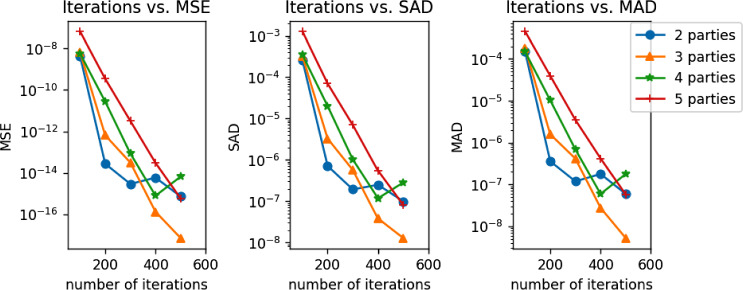 Figure 3
Figure 3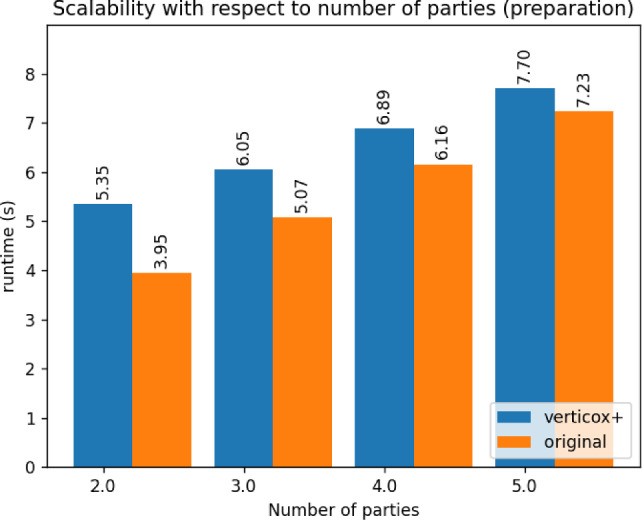 Figure 4
Figure 4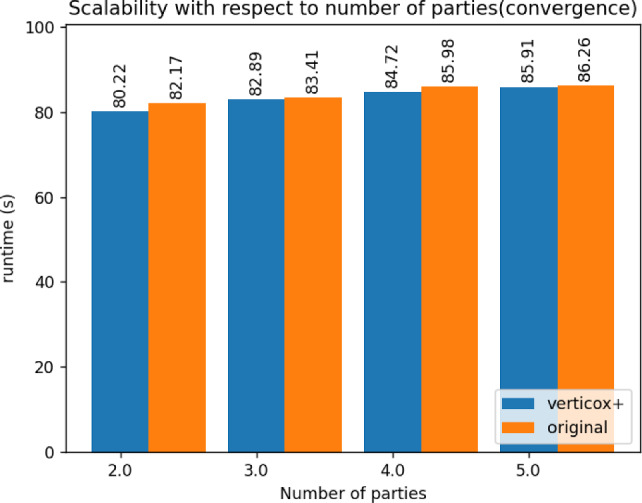 Figure 5
Figure 5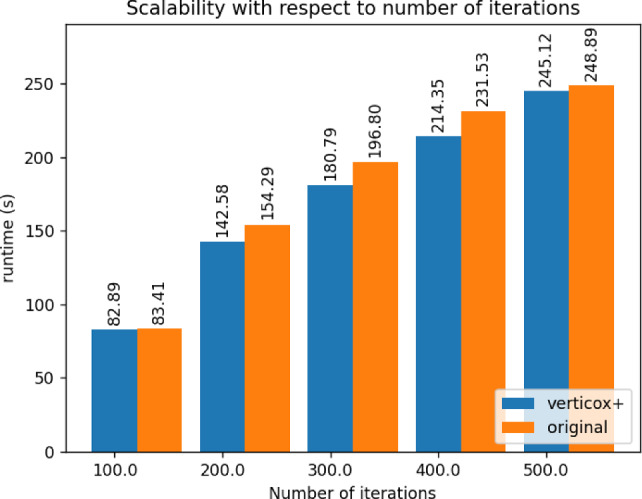 Figure 6
Figure 6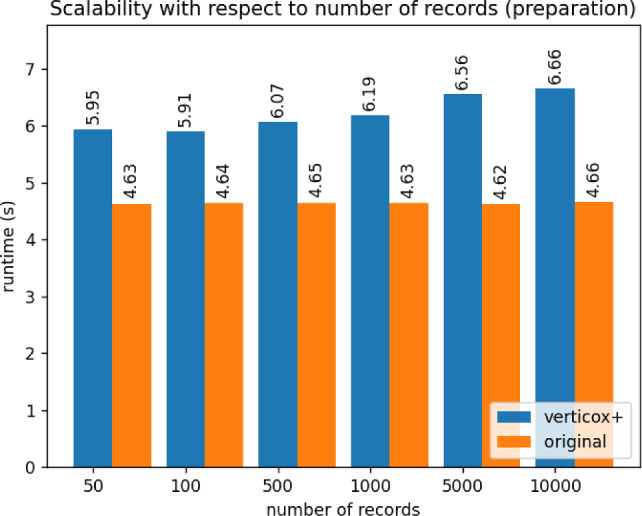 Figure 7
Figure 7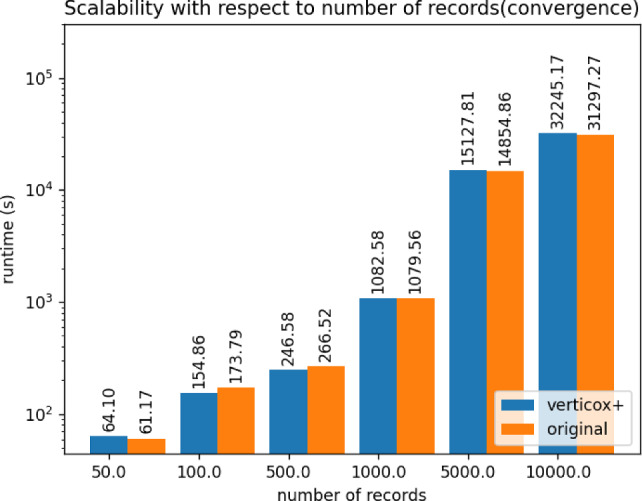 Figure 8
Figure 8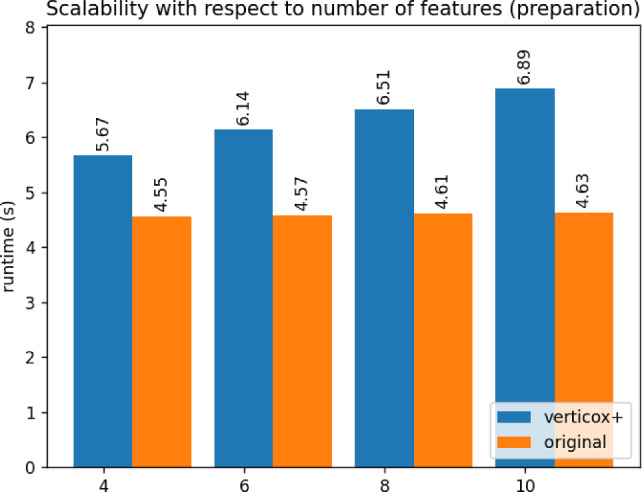 Figure 9
Figure 9 Figure 11
Figure 11 Figure 12
Figure 12- —http://dx.doi.org/10.13039/501100003246Nederlandse Organisatie voor Wetenschappelijk Onderzoek
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPrivacy-Preserving Technologies in Data · Cryptography and Data Security · Blockchain Technology Applications and Security
Introduction
Federated learning is a field that recently rose in prominence because of an increased focus on privacy by the general public as well as from legal bodies [1, 2]. In order to fulfill the stricter privacy requirements that were demanded by new laws such as the European General Data protection Regulation (GDPR) existing models were adapted and improved. Verticox is one such adaptation.
Verticox as described by Dai et al. [3] aims to provide a privacy preserving implementation of a Cox proportional hazards (CPH) model [4] in a vertically partitioned federated learning setting. Data is said to be vertically partitioned when the attributes are split between multiple parties. In contrast it is said to be horizontally partitioned when the records are split between multiple parties. Verticox utilizes an Alternating Direction Method of Multipliers (ADMM) framework [5] to preserve privacy. It can be used both for the training of a new Cox model as well as to classify a new individual.
However, Verticox relies on the assumption that the survival outcome is known locally at every party. This assumption is unfortunately not realistic as in vertically partitioned scenarios each attribute will normally only be locally known at one party, this includes the survival outcome.
A number of alternatives exist, such as the method proposed by Miao et al. [6] to compute CPH using cyclical coordinate descent, but it is still the case that outcome data needs to be shared with other parties. Kamphorst et al. [7] train a CPH model that uses secure multiparty computation [8] to compute log-partial likelihood at every iteration without revealing patient level data to other parties. However, the cryptographic protocols add significantly to the computational complexity and communication overhead. As such neither alternative is practical. Finally, Lu et al. [9] propose an algorithm that executes the computation of homomorphically encrypted data at a trusted third party (TTP). However, this approach introduces a single point of failure- the TTP- which could pose a significant security risk.
In this article, we propose a new extension to Verticox, which we have dubbed Verticox+. By utilizing the privacy preserving 2-party scalar product protocol [10], we avoid the assumption made in the original Verticox implementation. We will also experimentally show that the added computational complexity of using this protocol is negligible in practice.
The rest of the article is built up as follows; first, we will discuss how the original Verticox protocol works, followed by an explanation of the privacy preserving n-party scalar product protocol. Once both protocols have been explained we will describe the improved protocol Verticox+. We will then describe our experimental validation followed by a short discussion.
The implementation of Verticox+ is available on GitHub1 and has been designed to work with the vantage6 federated learning framework [11].
Background
In the following subsections we will discuss the background of our solution. First, we will introduce Verticox, and then we will introduce the scalar product protocol.
Verticox
Verticox is a decentralized version of the Cox proportional hazards regression model where covariates can be distributed over multiple data sources. The parameters are computed without sharing raw data between the parties and the resulting model is equivalent to a centralized version of a Cox model. The original algorithm achieves this by decomposing the original optimization problem for Cox proportional hazards into subproblems that can be solved separately. This provides a layer of protection for the data against honest-but-curious adversaries with access to any of the clients or central server.
The Verticox algorithm first estimates the parameters at the client-side based on the covariates that are available locally to each party. Next, an aggregation of these results is sent to a central server, which combines the results of the various parties, and further optimizes the parameters. The updated values are then passed back to the parties at the start of a new iteration. For a more detailed description of the exact techniques used we refer to reader back to the original paper [3].
Scalar product protocol
In order to solve the privacy issues that are present in the original Verticox algorithm, we use can use a privacy preserving scalar product protocol. The privacy preserving scalar product protocol is an important building block in many federated data analysis and machine learning applications. There exist several variants [10, 12–17]. Our proposed protocol requires the use of a 2-party privacy preserving scalar product protocol when dealing with vertically split data. Furthermore, we noticed that a future potential adaptation to a hybrid, that is to say both horizontally and vertically, split scenario would require a n-party protocol. To be ready for this potential future adaptation, we choose to utilize the n-party protocol variant [12] in our implementation, which is based on the 2-party protocol proposed by Du and Zhan [10]. This method introduces a third party, labeled the commodity server, to generate the random vectors that are used to encrypt the data. This server does not participate any further in the computation.
As we will be focused on vertically split scenarios we will only describe the 2-party scenario in this paper. The 2-party algorithm by proposed by Du and Zhan works as follows:
The protocol
There are two parties, Alice and Bob. Alice has a vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A$$\end{document} and Bob has another vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B$$\end{document} , both of the vectors have \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} elements. Alice and Bob want to compute the scalar product between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B$$\end{document} , such that Alice gets \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_1$$\end{document} and Bob gets \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_2$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_1 +V_2 = A \cdot B$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_2$$\end{document} is randomly generated by Bob. Namely, the scalar product of A and B is divided into two secret pieces, with one piece going to Alice and the other going to Bob. We assume that the following computation is based on the real domain.
- A Trusted Third Party (TTP) server generates two random vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_a$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_b$$\end{document} of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} , and lets \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_a + r_b = Ra \cdot Rb$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_a$$\end{document} (or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_b$$\end{document} ) is a randomly generated number. Then the TTP sends \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(R_a,r_a)$$\end{document} to Alice, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(R_b,r_b) $$\end{document} to Bob.
- Alice sends \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{A} = A + R_a$$\end{document} to Bob, and Bob sends \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \hat{B} = B + R_b $$\end{document} to Alice.
- Bob generates a random number \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_2$$\end{document} , and computes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{A} \cdot B +( r_b - V_2)$$\end{document} , then sends the result to Alice.
- Alice computes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$( \hat{A} \cdot B +( r_b - V_2)) - (R_a \cdot \hat{B} )+ r_a = A \cdot B - V_2 +(r_b - R_a \cdot R_b + r_a) = A \cdot B - V_2 = V_1 $$\end{document} For a more detailed description of the exact techniques used we refer to reader back to the original paper [12].
Verticox+
Verticox+ is an extension of Verticox that no longer a requires sharing the survival outcome data with all parties involved. By making use of the scalar-product-protocol, we have been able to isolate the outcome data to the aggregation server. We make a slight modification to the original algorithm to incorporate the scalar product protocol. Table 1 explains the notations that will be used throughout the reminder of the article.Table 1. NotationNotationDescriptionKTotal number of partiesNTotal number of records \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _{k}$$\end{document} Coefficients at party k**TNumber of distinct event times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{n} $$\end{document} Distinct event time of patient n**pIndex of iteration \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} Penalty parameter of ADMM methodzAuxiliary variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_{t}$$\end{document} The index set of records with observed events \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{nk}$$\end{document} The local feature value at index n for party n
The original Verticox pseudocode can be summarized as found in Algorithm 1. The full pseudocode can be found in original paper by Dai et al.. Note the emphasis on the requirement that outcome data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[E_1, ... E_T]$$\end{document} is present at every party.
The main privacy issue lies within solving \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _{k}^{p}$$\end{document} . This is done using Eq. 1
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \beta _{k}^{p}&=\begin{bmatrix} \rho \displaystyle \sum _{n=1}^{N} x_{nk}^{T}x_{nk} \end{bmatrix}^{-1} \cdot \\&\qquad \begin{bmatrix} \displaystyle \sum _{n=1}^{N} (\rho z_{nk}^{p-1} - \gamma _{nk}^{p-1} ) x_{nk}^{T} + \sum _{t=1}^{T}\sum _{n\in E_{t}}x_{nk} \end{bmatrix} \end{aligned}\nonumber \\ \end{aligned}$$\end{document}The problem lies in the last part of the equation: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{t=1}^{T}\sum _{n\epsilon E_{t}}x_{nk}$$\end{document} . This part has a reference to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_{t}$$\end{document} , which is the index set of samples with an observed event at time t . Therefore, for every time t we need to select the samples with an observed event. This requires the availability of outcome data at every party. In real-world use cases, this is not always possible.
Verticox+ will solve this problem by making use of the scalar-product-protocol. To do that, we translate the inner sum \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{n\epsilon E_{t}}x_{nk}$$\end{document} to a scalar product: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{kt} =x_{k} \cdot \overrightarrow{(E_{t})}$$\end{document}
In this case, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overrightarrow{(E_{t})}$$\end{document} is the Boolean vector of length N that indicates for each sample whether it had an event at time t (indicated as 1) or not (indicated as 0). \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _k^{p}$$\end{document} will now be solved according to Eq. 2.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \beta _{k}^{p}&=\begin{bmatrix} \rho \displaystyle \sum _{n=1}^{N} x_{tnk}^{T}x_{tnk} \end{bmatrix}^{-1} \\ &= \begin{bmatrix} \displaystyle \sum _{n=1}^{N} \left( \rho z_{nk}^{p-1} - \gamma _{nk}^{p-1} \right) x_{nk}^{T} + \sum _{t=1}^{T} u_{kt}\end{bmatrix} \end{aligned}\nonumber \\ \end{aligned}$$\end{document}Since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{kt}$$\end{document} per time t stays constant over iterations, we will only need to compute this once at the initialization step. The rest of the algorithm will remain the same. Additionally, as this can be resolved independently for each feature, and it is known that the data is vertically split we know that even if more than 2 parties are involved in the complete analysis, only 2 parties are involved for computing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{kt}$$\end{document} at a single institution k, which limits the computational complexity introduced by its use.
A summary of the updated Verticox+ algorithm can found in Algorithm 2:
In the updated version of the algorithm, there is no longer a need to share outcome data with all collaborating parties. Figure 1a show that while the algorithm only sends aggregations back and forth between parties, it requires the outcome data (censor and event time) to be present at every institution. Figure 1b show that this is not necessary any more. When a party needs to compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{kt}$$\end{document} using the 2-party scalar product protocol it exchanges the values as shown in Fig. 2. We are making use of the implementation of the n-party scalar product protocol, which is equivalent to the 2-party protocol when combining data from 2 parties. The figure also shows that when one of the institutions needs to combine data with the aggregator (where the outcome data is located), the other institution can be used as a trusted third party. Institutions are switching roles between n-party server and TTP server depending on which party needs to calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_kt$$\end{document} .Fig. 1. In the original Verticox algorithm, the survival outcome (event time, censored) is required to be available at all parties (a), while in our Verticox+ algorithm, the survival outcome only needs to be at the central aggregator server (b)Fig. 2. When an institution needs to compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U_{kt}$$\end{document} it will perform the 2-party scalar product protocol together with the aggregator server. The other institution will take the role of TTP
Time complexity & communication overhead
In this section we will discuss the time complexity and communication overhead of Verticox+. We will start by discussing these aspects of Verticox, to provide a baseline. Afterwards we will discuss the time complexity of the n-party scalar product protocol. Finally, we will discuss the consequences of combining these two protocols.
Time complexity
Let us consider how the addition of the scalar product protocol affects the time complexity. Since the scalar product protocol has only been used at the client side, the time complexity at the server side will remain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N^{3} )$$\end{document} , which is the complexity of the Newton–Rhapson optimization.
At the client side, the original computational complexity was determined by generating and inverting matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{n=1}^{N}x_{nk} x_{nk}^{T}$$\end{document} are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(NM_{k}^{2})$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(M_{k}^{3})$$\end{document} respectively. Our adaptations add in the scalar product protocol which is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N^{2})$$\end{document} . In practice though we will see that the main bottleneck can be found in the aggregation server.
Communication cost
The original Verticox sends intermediate values \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{nk}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{\gamma }_{n}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{\sigma }_{n}$$\end{document} from the central server to the clients at every iteration. In turn, the clients send back \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{\sigma }_{nk}$$\end{document} . This results in a communication cost of 4NK. Additionally, the scalar product protocol has a cost of 4N, which will need to be run for every institution, which leads to a cost of 4NK. However, the scalar product protocol is only run once per analysis, while the intermediate values are communicated every iteration. This leads to a communication cost of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4NK + I * 4NK$$\end{document} , where I stands for the number of iterations for convergence.
Fixed precision
The n-party scalar product protocol is designed to work using integer values. However, within Verticox+ it will be used to calculate results that depend on floating point values. In order to make these values useable within the scalar product protocol we will make use of fixed-point precision. The values will be scaled by a fixed factor; this factor corresponds to the required precision (e.g. the value will be scaled by a factor 10, 000 when working with a fixed precision of 5 decimals). Once the scalar product protocol has finished the final result will be scaled back to the desired precision.
This fixed precision approach makes it viable to use the scalar product protocol even when it is necessary to work with floating point values. In principle any level of precision can be chosen, however there will be a trade-off; a greater precision will result in larger numbers being used in the scalar product protocol. This can create technical problems when it results in a number overflow error. Additionally, numbers with more digits will take longer to multiply. As such, a high precision will eventually affect the runtime performance of Verticox+. However, we experimentally determined that a fixed precision of 5 decimals is sufficient for most purposes. Furthermore, we expect the effect on the total runtime of Verticox+ to be minimal as the bottleneck is outside of the part that utilizes the scalar product protocol.
In addition to this we would like to note that fixed precision could potentially be used to further improve privacy guarantees. A lower precision can obfuscate records containing values that are unique at a higher level of precision. Its exact potential warrants further investigation in future research.
Experimental validation
We ran several experiments to validate our method. We implemented the algorithm in Python and Java, and ran the parties in separate Docker containers. We used a single virtual machine with Ubuntu 22.04, 8 cores with a clock speed of 1996.250 MHz and 32 GB RAM running in SURF research cloud, which is part of the Dutch national research infrastructure. As data we used part of the SEER dataset [18]. The parameters of the algorithm that we kept fixed can be found in Table 2.Table 2. Experimental parametersParameterFixed valuePenalty parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} 0.25Fixed precision of n-party protocol5Newton–Raphson precision0.00001
We ran 3 different experiments. In the first experiment, we fixed the number of records to 100 and varied the number of parties and iterations to see how that will affect runtime and accuracy. Accuracy has been measured in 4 different ways. In theory, adding the n-party protocol to the original Verticox algorithm will introduce inaccuracy into the model because the values need to be expressed in fixed-point precision. To test whether this is true in practice we ran our implementation of the original Verticox algorithm with the same parameters. We use c-index [19] to compare the predictions of the model to the ground truth. Additionally, we used 3 metrics to compare the resulting coefficients against ones that have been computed by a central Cox proportional hazards model. For this, we compute mean squared error (MSE), summation of the absolute difference (SAD), and maximum absolute difference (MAD). As can be seen in Table 3 the accuracy of the central model is identical to the accuracy of Verticox+. This is because the variables in the SEER dataset require limited precision, since they consist of values with no more than 2 digits. Looking at MSE, SAD and MAD (Fig. 3), we can see that the difference between Verticox+ and a Cox proportional hazards model learned on centralized data diminishes after a few hundred iterations.Table 3. Performance of central Cox proportional Hazards vs. Verticox+ algorithmPartiesIterationsPreparation runtimeConvergence runtimemsesadmadc-index verticox+c-index central Cox model21005.34976780.2177994.2080e–092.5862e–041.4883e–040.6344630.6338982005.254844128.4511242.7379e–147.1284e–073.5788e–070.6338980.6338983005.389899162.8279232.9245e–151.9241e–071.1896e–070.6338980.6338984005.309092200.6312225.8759e–152.4782e–071.7857e–070.6338980.6338985005.298918225.5829577.2622e–169.8687e-0085.9357e-0080.6338980.63389810005.308558394.3531626.4518e–167.4555e-0086.1778e-0080.6338980.63389831006.05024082.8930016.5099e-0093.2313e-0041.8406e-0040.6336160.6338982006.113631142.5828306.4638e–133.2763e-0061.5817e-0060.6338980.6338983006.125730180.7864343.1175e–145.6994e-0074.1506e-0070.6338980.6338984006.172221214.3498781.3309e–163.7855e-0082.7629e-0080.6338980.6338985006.029485245.1216097.1598e–181.2724e-0085.2342e-0090.6338980.63389810006.105557408.7717611.3322e–163.7714e-0082.7629e-0080.6338980.63389841006.88614684.7218145.6519e-0093.4969e-0041.4831e-0040.6338980.6338982006.924360141.2739312.7149e–112.0121e-0051.0284e-0050.6338980.6338983006.832369197.6639628.5444e–141.0257e-0066.8763e-0070.6338980.6338984006.901601228.7869647.9107e–161.1789e-0075.9357e-0080.6338980.6338985006.751254257.5532036.5969e–152.8261e-0071.7857e-0070.6338980.63389810006.864445417.9106666.0346e–167.5356e-0085.9357e-0080.6338980.63389851007.70409985.9085236.4246e-0081.2748e-0034.4972e-0040.6341810.6338982007.732730139.6562963.4136e–107.0454e-0053.9577e-0050.6338980.6338983007.673841191.0902843.1704e–126.9955e-0063.4890e-0060.6338980.6338984007.703514239.1518003.0157e–145.4475e-0074.1941e-0070.6338980.6338985007.698904266.6837735.7475e–168.0196e-0085.7432e-0080.6338980.63389810007.672942414.2289586.0121e–167.0263e-0085.9852e-0080.6338980.633898
The second experiment evaluates how runtime scales with increasing number of covariates (features) in the model. Again, we fixed the number of records to 100 and the number of iterations to 500. The number of parties has been fixed to 3. We evaluated the algorithm runtime from 2 and up to 10 features.Fig. 3. The MSE, SAD, & MAD scores of Verticox+Fig. 4. Comparison between Verticox+ and Verticox of the runtime duration of the preparation phaseFig. 5Runtime duration of Verticox+ with various numbers of partiesFig. 6Runtime duration of Verticox+ with various numbers of maximum iterationsFig. 7Runtime duration of the preparation phase of Verticox+ using various numbers of recordsFig. 8Runtime duration of the convergence phase of Verticox+ using various numbers of recordsFig. 9Runtime duration of the preparation phase of Verticox+ using various numbers of featuresFig. 10Runtime duration of the convergence phase of Verticox+ using various numbers of features
As can be seen in Figs. 4, 5, and 6, our addition of the scalar product protocol does not negatively affect the runtime. In fact, Verticox+ even has a shorter runtime for preparation as the number of parties increases. This is unexpected and likely relates to the implementation details of the n-party protocol. While we reimplemented the original Verticox algorithm in Python, the n-party protocol was actually implemented in Java. Since Java is a compiled language, it generally performs faster than the interpreter language Python. In the end, the bottleneck will not be in the preparation time, but rather in runtime of the main part of the algorithm where the model converges. In this part, Verticox+ performs the same as its predecessor (see Figs. 7 and 8).
In the third experiment we fixed the number of iterations to 500 and the number of parties to 3. We set the number or records to 50, 100 or 500 and timed the runtime. As can be seen in Figs. 9 and 10, the number of records does not affect the runtime significantly during the preparation phase. Convergence runtime is affected by the number of records, but not more than the original verticox.
Discussion
With the addition of the scalar product protocol to the Verticox algorithm, all data used for the analysis can stay at the source, including outcome data. Moreover, the addition of this protocol, which is potentially heavy in terms of computation, did not add significantly to the total runtime in our experiments. Neither does the additional overhead introduced by the fixed-point precision. This is because the bottleneck of the computation lies within the Newton–Raphson optimization from the original algorithm. This indicates that Verticox+ is a viable extension of the original algorithm.
There are still a couple of security issues to consider though. The Verticox+ algorithm shares record-level aggregations with the central server. That is, in every iteration the parties share their risk estimates for every record with the central server. Although this is not raw data, it is still patient level information. Additionally, it can be viewed as relatively sensitive data as it represents the risk of a given disease for a specific patient. Direct access to this information could be problematic if it falls in the wrong hands.
However, by placing the server in the care of the party that already owns the survival outcome data the practical risk is limited. Providing this party with the risk scores minimizes the privacy concerns as this party already knows the survival outcome this risk score represents, and thus would not learn anything new. This limits the risk of direct access to the risk score.
Access to the risk estimates in each iteration also opens an additional possible attack [20–22]. The aggregating party could attempt to reverse engineer the training data belonging to each other party based on the intermediate values revealed between the iterations. However, this does require the aggregating party to know which attributes are present at each other party. Additionally, reversing this information becomes more complex as the number of attributes at the other party grows.
This privacy concern could be mitigated by moving the central aggregation away from the outcome datasource and performing the central aggregation on a “neutral” server provided by a trusted third party. The outcome data would have to be queried by the central server using the scalar product protocol. Unfortunately, this means that the scalar product protocol would have to be run in every iteration, instead of only during the preparation phase. The concern is that this will add a significant increase to the total runtime. Adding this protocol with complexity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N^{2})$$\end{document} to the Newton–Rhapson optimization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(O(N^{3}))$$\end{document} will turn it into a complexity of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N^{4})$$\end{document} . Additionally, the n-party protocol will add a constant communication overhead to this part of the computation (O(6)). Although this overhead is constant, in practice the communication overhead is the bigger bottleneck when compared to the computational cost, and will add significantly to the total duration of the algorithm.
A more practical solution may be to mandate the use of a framework like Vantage6, which provides an infrastructure that explicitly limits what the aggregating party is able to do by only allowing pre-approved Docker images with vetted code to be executed. By explicitly creating this limitation, the various parties involved can establish a sufficient level of trust that no data will be leaked.
This risk, and the limitations imposed by the time complexity of the technical solutions, highlight the need for a comprehensive legal and infrastructure solutions to augment the technical privacy preserving solutions in any real world project. This also means that Verticox+ is best used in a setting where such things can viably be implemented. Implementing such solutions, and establishing the required level of trust, is difficult in an open internet of things setting, where any party is free to join. However, in a formal research setting this is indeed viable.
The scalar product protocol brings one additional privacy concern compared to the broader Verticox+ protocol. It requires a trusted third party, which can generate secret shares and aggregate the intermediate results of the protocol. However, in comparison to Lu et al. [9], the TTP has reduced privileges and does not need to process any data directly. This reduces the risks of using a TTP considerably. Additionally, similar to the previous concerns, framework such as Vantage6 is an excellent solution to set up the necessary infrastructure to ensure the reliability of the trusted third party, further limiting the potential risks.
Future work
There are currently three major limitations that we would like to improve upon. The current implementation of Verticox+ has not been made to deal with a hybrid split in the data, that is to say a split that is partially horizontal and partially vertical. While certain parts, such as the scalar product protocol, do not need any additional work to fit in a hybrid setting, we need to determine if it is possible to use the algorithm as a whole in a hybrid setting.
Secondly, the role of aggregator currently befalls to the party that owns the outcome data. If the role of aggregator could be moved to a neutral party without data, it would not know which records the intermediate values are linked to. This lowers the risk of data leaking. Lastly, we wish to improve the runtime complexity of the optimization step, for example by using a different faster optimization algorithm. This step is currently a considerable bottleneck in the algorithm, and improving it would lead to significant gains in terms of the running time of the algorithm.
Conclusion
In this paper, we have provided an extension to the original Verticox protocol that we dub Verticox+. The original protocol allows the user to train a Cox Proportional Hazard model in a vertically partitioned federated setting. However, the original algorithm relies on the assumption that every party involved has access to the survival outcome for each record. This is unrealistic in a vertical scenario and would most likely require this survival outcome to be shared, which represents a serious privacy concern as the survival outcome used to train a Cox proportional hazard model represents a sensitive attribute, such as a hospitalization event or death due to a certain disease. Verticox+ removes the need for this assumption by using the scalar product protocol to perform the relevant calculations in a privacy preserving manner.
Our experiments show that Verticox+ achieves comparable performance to both Verticox and a centrally trained model. This indicates Verticox+ works as intended. Additionally, our experiments show that the added overhead introduced by using the scalar product protocol is manageable as the optimization step forms a much more significant bottleneck. As such, the runtime duration is comparable to the original Verticox algorithm as well.
While Verticox+ improves the privacy guarantees, a number of practical concerns remain. The scalar product protocol relies on a trusted third party. Additionally there is a theoretical possibility of a malicious party reconstructing an approximation of the data, akin to a gradient leak attack in deep learning settings. These risks can be mitigated by applying multiple layers of security measures, such as offering access to only a small number of trusted researchers. Additionally the relevant legal frameworks also need to be established. The need for such frameworks also serves as a reminder that purely technical privacy preserving solutions are not sufficient to establish the necessary trust needed for any federated learning project.
The need for such frameworks, as well as the time complexity of Verticox+, does limit Verticox+ to certain scenarios. Scalability concerns, as well as the need for trusted third parties and a complexity of creating the necessary legal and infrastructure frameworks, means that Verticox+ is not a great fit for an internet of things scenario with many parties, all of which have an extremely low level of trust. However, in formal settings, where it is easier to vet the parties involved, and where parties have access to the technical infrastructure necessary to deal with the scalability issues, it is a great tool in the federated learning toolbox.
Summary
In this paper we have proposed an improvement to the Verticox algorithm dubbed Verticox+. Verticox+ brings improved privacy guarantees. Our experiments show that Verticox+ produces the same end-result, without a noticeable change in overhead costs.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kairouz P, Mc Mahan HB, Avent B, Bellet A, Bennis M, Bhagoji AN, Bonawitz K, Charles Z, Cormode G, Cummings R, D’Oliveira RGL, Rouayheb SE, Evans D, Gardner J, Garrett Z, Gascón A, Ghazi B, Gibbons PB, Gruteser M, Harchaoui Z, He C, He L, Huo Z, Hutchinson B, Hsu J, Jaggi M, Javidi T, Joshi G, Khodak M, Konečný J, Korolova A, Koushanfar F, Koyejo S, Lepoint T, Liu Y, Mittal P, Mohri M, Nock R, Özgür A, Pagh R, Raykova M, Qi H, Ramage D, Raskar R, Song D, Song W, Stich SU, Sun Z, Suresh AT, Tramèr
- 2Dai W, Jiang X, Bonomi L, Li Y, Xiong H, Ohno-Machado L (2020) VERTICOX: vertically distributed Cox proportional hazards model using the alternating direction method of multipliers. IEEE Trans Knowl Data Eng. 10.1109/TKDE.2020.2989301. Accessed 2021-05-26. (Accessed 2021-05-26)10.1109/tkde.2020.2989301 PMC 949159936158636 · doi ↗ · pubmed ↗
- 3Cox DR (1972) Regression models and life-tables. J Roy Stat Soc: Ser B (Methodol) 34(2):187–202. 10.1111/j.2517-6161.1972.tb 00899.x. (Accessed 2024-05-22)
- 4Shmueli E, Tassa T Mediated secure multi-party protocols for collaborative filtering. 11(2), 1–25 10.1145/3375402. (Accessed 2022-10-26)
- 5Harrell FE Jr, Lee KL, Mark DB (1996) Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med 15(4):361–38710.1002/(SICI)1097-0258(19960229)15:4<361::AID-SIM 168>3.0.CO;2-48668867 · doi ↗ · pubmed ↗
- 6Jin X, Chen P-Y, Hsu C-Y, Yu C-M, Chen T (2021) CAFE: catastrophic data leakage in vertical federated learning. In: Advances in Neural Information Processing Systems, vol. 34, pp. 994–1006. Curran Associates, Inc., https://proceedings.neurips.cc/paper_files/paper/2021/hash/08040837089 cdf 46631 a 10aca 5258 e 16-Abstract.html. Accessed 2024-05-21
- 7Wei W, Liu L, Loper M, Chow K-H, Gursoy ME, Truex S, Wu Y (2020) A framework for evaluating gradient leakage attacks in federated learning. ar Xiv. ar Xiv:2004.10397 [cs, stat]. 10.48550/ar Xiv.2004.10397 . arxiv:2004.10397 Accessed 2024-05-21