Deep latent force models: ODE-based process convolutions for Bayesian deep learning
Thomas Baldwin-McDonald, Xinxing Shi, Mingxin Shen, Mauricio A. Álvarez

TL;DR
This paper introduces a new Bayesian deep learning model that uses physics-informed kernels to better capture dynamics in complex systems.
Contribution
The novel deep latent force model (DLFM) integrates physics-informed kernels derived from ODEs into deep Gaussian processes.
Findings
The DLFM effectively captures dynamics in nonlinear multi-output time series data.
DLFM performs comparably to non-physics-informed models on regression tasks.
Inducing points framework negatively impacts model extrapolation.
Abstract
Modelling the behaviour of highly nonlinear dynamical systems with robust uncertainty quantification is a challenging task which typically requires approaches specifically designed to address the problem at hand. We introduce a domain-agnostic model to address this issue termed the deep latent force model (DLFM), a deep Gaussian process with physics-informed kernels at each layer, derived from ordinary differential equations using the framework of process convolutions. Two distinct formulations of the DLFM are presented which utilise weight-space and variational inducing points-based Gaussian process approximations, both of which are amenable to doubly stochastic variational inference. We present empirical evidence of the capability of the DLFM to capture the dynamics present in highly nonlinear real-world multi-output time series data. Additionally, we find that the DLFM is capable of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1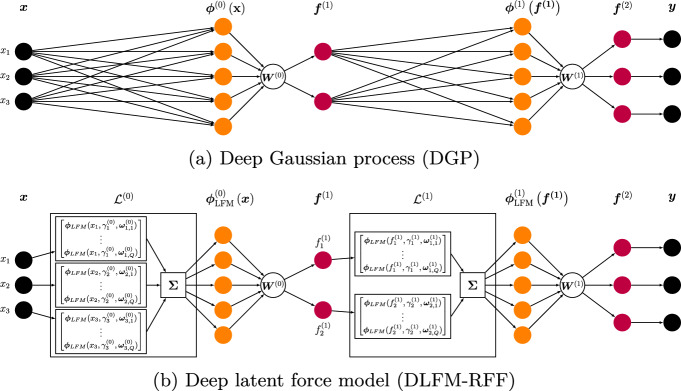 Figure 2
Figure 2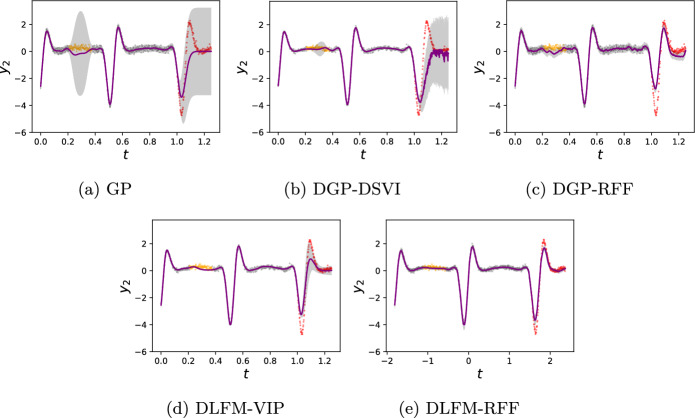 Figure 3
Figure 3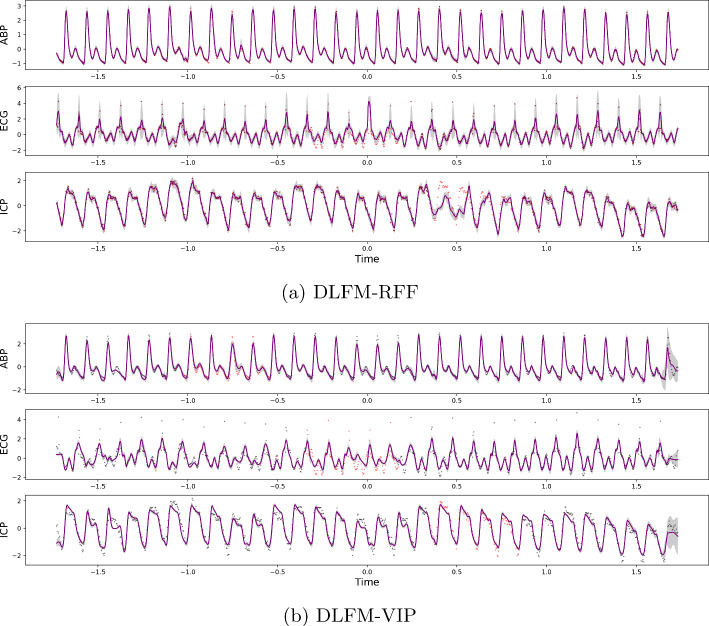 Figure 4
Figure 4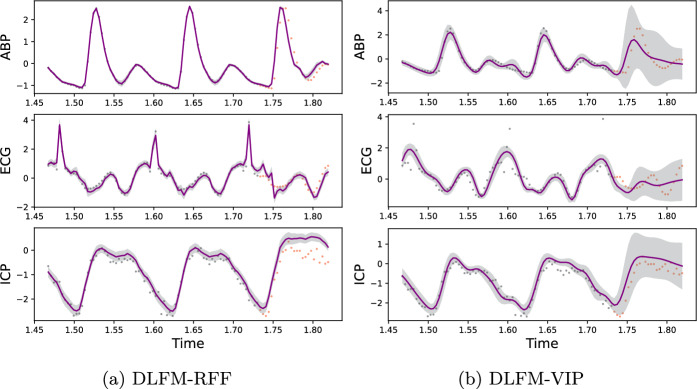 Figure 5
Figure 5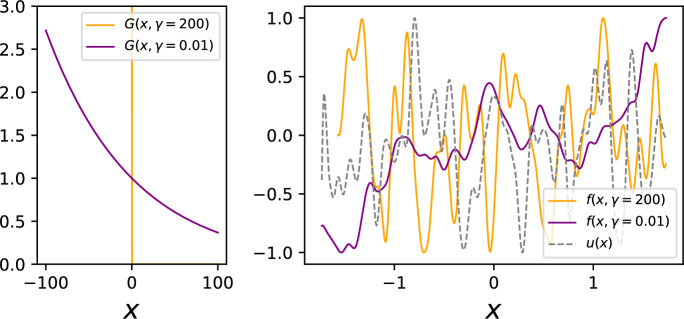 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8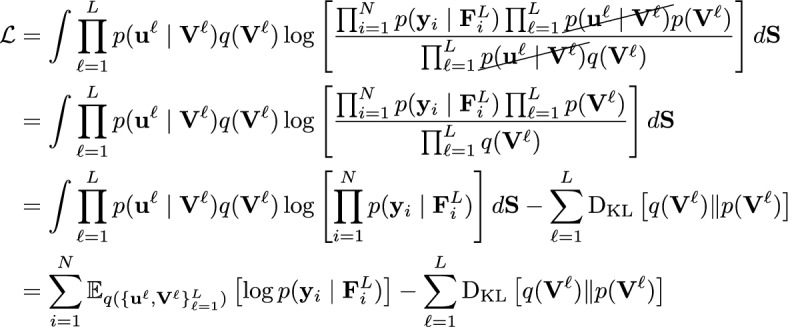 Figure 9
Figure 9- —Department of Computer Science, University of Manchester
- —https://doi.org/10.13039/501100000266Engineering and Physical Sciences Research Council
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGaussian Processes and Bayesian Inference · Model Reduction and Neural Networks · Machine Learning in Materials Science
Introduction
Across many different areas of scientific study, time-varying physical and biological processes are modelled as dynamical systems, with their behaviour described by a set of ordinary differential equations (ODEs). If the form of said system is known, and is sufficiently low-dimensional, we may attempt to model the behaviour of the system by inferring the parameters of its constituent ODEs using observational data (Meeds et al., 2019; Ghosh et al., 2021). Unfortunately, in practice, real-world systems are often sufficiently complex that it is infeasible to characterise all of the processes contained within them, let alone the interactions between these processes. Instead of forming a fully mechanistic model of a complex system, latent force models (LFMs) (Alvarez et al., 2009) construct a simplified mechanistic model of the system in question, which allows us to capture the salient features of the dynamics of the system using a (typically small) number of latent forces. This hybrid approach leverages the advantages of data-driven modelling, whilst retaining some vital advantages of mechanistic modelling, such as the ability to extrapolate outside of the training input domain.
Nonlinear dynamical systems are generally more challenging to model, often containing features such as nonstationarities which shallow models typically struggle to capture and extrapolate effectively. Whilst there has been work on integrating nonlinear differential equations into LFMs (Álvarez et al., 2019; Ward et al., 2020; Ross et al., 2021), an alternative approach to modeling nonlinear dynamics which we will consider in this work, is to utilise a deep model, formed using a composition of functions. Such architectures possess increased representational power relative to shallow models due to their hierarchical structure (LeCun et al., 2015), and furthermore, Bayesian deep models such as deep Gaussian processes (DGPs) are able to leverage this representational power whilst also providing a robust quantification of the uncertainty in their outputs. In this paper, we consider the modelling of nonlinear dynamical systems using a DGP formed from compositions of ODE-informed kernels. This approach is motivated by two key factors; firstly, many real-world systems and processes can be represented as compositional hierarchies (LeCun et al., 2015), and secondly, there is compelling evidence to suggest that shallow GP-based models are unable to optimally learn compositional functions (Giordano et al., 2022).
We introduce a generalised framework termed the deep latent force model (DLFM), a novel approach to formulating a physics-informed hierarchical probabilistic model which is summarised in Fig. 1. We present two approaches to formulating this class of model and performing computationally efficient approximate Bayesian inference. Some portions of this work have been previously published in McDonald and Álvarez (2021), therefore in the remainder of this section we will outline which portions of this paper have been previously published, and which portions are new contributions.
Firstly, in Sect. 3.1 we outline a random Fourier feature-based approach previously published in McDonald and Álvarez (2021). This involves the derivation of physics-informed random Fourier features, which we compute via the convolution of Fourier features corresponding to an exponentiated quadratic (EQ) latent GP prior, with the Green’s function associated with a first order ODE. These features are then incorporated into each layer of a DGP which uses weight-space approximations (Cutajar et al., 2017). In addition to the material previously published in McDonald and Álvarez (2021), in Sects. 3.1.4 and 3.1.5 we propose two new improvements to the original Fourier feature-based model, namely introducing learnable initial conditions and allowing the local reparameterization trick (used for gradient variance reduction during training) to be disabled at test time. However, the most significant additional contribution included in this paper but not present in McDonald and Álvarez (2021) is the introduction in Sect. 3.2 of a novel formulation of the DLFM and associated inference scheme based on pathwise sampling Wilson et al. (2020) and inducing points, whereby we instead perform the aforementioned convolution integral using a closed form expression for samples from the latent EQ GP. To ensure the scalability of both schemes to large datasets, stochastic variational inference is employed as a method for approximate Bayesian inference.
We provide experimental evidence that our modelling framework is capable of capturing highly nonlinear dynamics effectively in both toy examples and real world data, whilst also being applicable to more general regression problems. The experimental results provided in Sect. 5 have not been previously published in McDonald and Álvarez (2021), as they were obtained using the improved version of the Fourier feature-based model, as well as the new inducing points-based model, both of which are introduced in this paper. Finally, in Sect. 6 we present new analysis and discussion surrounding the topic of how the DLFM can be interpreted, as well as the advantages and disadvantages of using both formulations of the model in different modelling scenarios.
Background
In this section, we introduce a number of concepts relevant to this work. We begin by discussing the formulation of latent force models, a class of physics-informed Gaussian processes which form the basis of our deep probabilistic model. Additionally, we discuss two different approaches to performing approximate Bayesian inference in GPs, deep GPs and LFMs. The first approach involves using random Fourier features and weight-space GP approximations to perform stochastic variational inference, and the second is another form of variational scheme which relies upon inducing points and pathwise sampling.
Latent force models
Latent force models (LFMs) (Alvarez et al., 2009) are GPs with physically-inspired kernel functions, which typically encode the behaviour described by a specific form of differential equation. Instead of taking a fully mechanistic approach and specifying all the interactions within a physical system, the kernel describes a simplified form of the system in which the behaviour is determined by Q latent forces. Given an input data-point t and a set of D output variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{f_d(t)\}^D_{d=1}$$\end{document} , a LFM expresses each output as,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f_d(t) = \sum _{q=1}^Q S_{d, q} \int _{0}^t G_d(t-\tau )u_q(\tau )d\tau , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_d(\cdot )$$\end{document} represents the Green’s function for a certain form of linear differential equation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_q(t)\sim \mathcal{G}\mathcal{P}(0, k_q(t,t'))$$\end{document} represents the GP prior over the the q-th latent force, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_{d,q}$$\end{document} is a sensitivity parameter weighting the influence of the q-th latent force on the d-th output. Due to the linear nature of the convolution used to compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_d(t)$$\end{document} , the outputs can also be described by a GP. The general expression for the covariance of a LFM is given by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{f_d, f_{d'}}(t,t') = \sum _{q=1}^Q S_{d,q} S_{d',q} \int ^t_0 G_d(t-\tau ) \int ^{t'}_0 G_{d'}(t'-\tau ') k_q(\tau , \tau ') d\tau ' d\tau$$\end{document} .
LFMs fall within the process convolution framework for constructing GP kernels, which generally involves applying a convolution operator to a simple base GP in order to obtain an expressive covariance function (Alvarez & Lawrence, 2011). In the case of LFMs, the convolution filter has a fixed functional form \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_d(\cdot )$$\end{document} with a physical interpretation, however, this need not be the case. For example, multiple works have instead placed a GP over the convolution filter (McDonald et al., 2022; Tobar et al., 2015).
Approximate inference with random Fourier features
Since their introduction to the machine learning research community by Rahimi and Recht (2007), random Fourier features (RFFs) have been widely applied as a means of scaling kernel methods. Here we discuss their application to performing computationally efficient Bayesian inference in DGPs and LFMs, which we will leverage later in Sect. 3.1 in the context of our DLFM.
RFFs for deep Gaussian processes
Gaussian processes (GPs) are nonparametric probabilistic models which offer a great degree of flexibility in terms of the data they can represent, however this flexibility is not unbounded. The hierarchical networks of GPs now widely known as deep Gaussian processes (DGPs) were first formalised by Damianou and Lawrence (2013), with the motivating factor behind their creation being the ability of deep networks to reuse features and allow for higher levels of abstraction in said features (Bengio et al., 2013), which results in such models having more representational power and flexibility than shallow models such as GPs. DGPs are effectively a composite function, where the input to the model is transformed to the output by being passed through a series of latent mappings (i.e. multivariate GPs). If we consider a supervised learning problem with inputs denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X} = \{\textbf{x}_n\}^N_{n=1}$$\end{document} and targets denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y} = \{y_n\}^N_{n=1}$$\end{document} , we can write the analytic form of the marginal likelihood for a DGP with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_h$$\end{document} hidden layers as,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} p(\textbf{y}|\textbf{X}, \mathbf {\theta })&= \int p(\textbf{y}|\textbf{F}^{(N_h)})p(\textbf{F}^{(N_h)}|\textbf{F}^{(N_h - 1)}, \mathbf {\theta }^{(N_h - 1)}) \times ... \\ &\qquad \quad \dots \times p(\textbf{F}^{(1)}|\textbf{X}, \mathbf {\theta }^{(0)})d\textbf{F}^{(N_h)} \ ... \ d\textbf{F}^{(1)}, \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}^{(\ell )}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\theta }^{(\ell )}$$\end{document} represent the latent values and covariance parameters respectively at the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} -th layer, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell = 0,..., N_h$$\end{document} . However, due to the need to propagate densities through nonlinear GP covariance functions within the model, this integral is intractable (Damianou, 2015). As this precludes us from employing exact Bayesian inference in these models, various techniques for approximate inference have been applied to DGPs in recent years, with most approaches broadly based upon either variational inference (Salimbeni & Deisenroth, 2017; Salimbeni et al., 2019; Yu et al., 2019) or Monte Carlo methods (Havasi et al., 2018).
Cutajar et al. (2017) outline an alternative approach to tackling this problem, which involves replacing the GPs present at each layer of the network with their two layer weight-space approximation, forming a Bayesian neural network which acts as an approximation to a DGP. Consider the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} -th layer of such a DGP, which we assume is a zero-mean GP with an exponentiated quadratic kernel. Should this layer receive an input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}^{(\ell )}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}^{(0)} = \textbf{X}$$\end{document} , the corresponding random features are denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Phi }^{(\ell )} \in \mathbb {R}^{N \times 2N^{(\ell )}_{RF}}$$\end{document} and are given by,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathbf {\Phi }^{(\ell )} = \root \of {\frac{(\sigma ^2)^{(\ell )}}{N_{RF}^{(\ell )}}} \left[ \cos (\textbf{F}^{(\ell )}\mathbf {\Omega }^{(\ell )}), \sin (\textbf{F}^{(\ell )}\mathbf {\Omega }^{(\ell )}) \right] , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\sigma ^2)^{(\ell )}$$\end{document} is the marginal variance kernel hyperparameter, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{RF}^{(\ell )}$$\end{document} is the number of random features used and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Omega }^{(\ell )} \in \mathbb {R}^{D_{F^{(\ell )}} \times N_{RF}^{(\ell )}}$$\end{document} is the matrix of spectral frequencies used to determine the random features. This matrix is assigned a prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\Omega ^{(\ell )}_d) = \mathcal {N}\left( \Omega ^{(\ell )}_d \mid 0, {(l^{(\ell )})}^{-2}\right)$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l^{(\ell )}$$\end{document} , is the lengthscale kernel hyperparameter, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{F^{(\ell )}}$$\end{document} is the number of GPs within the layer, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d = 1,..., D_{F^{(\ell )}}$$\end{document} . The random features then undergo the linear transformation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}^{(\ell + 1)} = \mathbf {\Phi }^{(\ell )} \textbf{W}^{(\ell )}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}^{(\ell )} \in \mathbb {R}^{2N_{RF}^{(\ell )} \times D_{F^{(\ell + 1)}}}$$\end{document} is a weight matrix with each column assigned a standard normal prior. Training is achieved via stochastic variational inference, which involves establishing a tractable lower bound for the marginal likelihood and optimizing said bound with respect to the mean and variance of the variational distributions over the weights and spectral frequencies across all layers of the network. The bound is also optimised with respect to the kernel hyperparameters across all layers.
RFFs for latent force models
Exact inference in LFMs is tractable, however as with GPs, it scales with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {O}(N^3)$$\end{document} complexity (Rasmussen & Williams, 2006). Typically, an EQ form is assumed for the kernel governing the latent forces, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_q(\cdot )$$\end{document} , and by providing a random Fourier feature representation for this kernel, Guarnizo and Álvarez (2018) were able to reduce this cubic dependence on the number of data-points to a linear dependence. This representation arises from Bochner’s theorem, which states,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} k_q(\tau , \tau ')&= e^{\frac{-(\tau -\tau ')^2}{\ell _q^2}} =\int p(\omega )e^{j(\tau -\tau ')\omega } d\omega \\&\approx \frac{1}{N_{RF}} \sum ^{N_{RF}}_{s=1} e^{j\omega _s \tau } e^{-j\omega _s \tau '} , \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell _q$$\end{document} is the lengthscale of the EQ kernel, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{RF}$$\end{document} is the number of random features used in the approximation and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _s \sim p(\omega ) = \mathcal {N}(\omega | 0, 2/\ell _q^2)$$\end{document} . Substituting this form of the EQ kernel into the LFM covariance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{f_d, f_{d'}}(t,t')$$\end{document} leads to a fast approximation given by,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \sum _{q=1}^Q \frac{S_{d,q}S_{d',q}}{N_{RF}}&\left[ \sum _{s=1}^{N_{RF}} \phi _d(t, \theta _d, \omega _s) \phi _{d'}^*(t', \theta _{d'}, \omega _s) \right] \\ \text {where,} \quad \phi _d(t, \theta _d, \omega )&= \int _0^t G_d(t-\tau )e^{j\omega \tau } d\tau , \end{aligned} \end{aligned}$$\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _d$$\end{document} representing the Green’s function parameters. When the Green’s function is a real function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi _{d'}^*(t', \theta _{d'}, \omega ) = \phi _{d'}(t', \theta _{d'}, -\omega )$$\end{document} . Guarnizo and Álvarez (2018) refer to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi _d(t, \theta _d, \omega )$$\end{document} as random Fourier response features (RFRFs).
Approximate inference with pathwise sampling
We have seen that RFF approximations allow us to perform computationally efficient approximate Bayesian inference in both DGPs, and GPs in the process convolution framework (e.g. LFMs). However, a more widely used technique which also fulfills both of these criteria is the variational inducing points framework for approximate GP inference (Titsias, 2009). In the case of a single output regression problem for a shallow GP, this involves introducing a set of inducing inputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z} = \{\textbf{z}_i \}_{i=1}^M$$\end{document} and associated inducing variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u} \in \mathbb {R}^{M}$$\end{document} . We can then parameterise these variables using a distribution of the form \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q(\textbf{u}) = \mathcal {N}(\textbf{u} \mid \textbf{m}, \textbf{S})$$\end{document} , and optimise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{m}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{S}$$\end{document} by maximizing the aforementioned variational lower bound to the marginal likelihood (Hensman et al., 2013). As well as being pervasive throughout the GP literature, variants of this approach also form the dominant paradigm for performing inference in DGPs (Salimbeni & Deisenroth, 2017; Salimbeni et al., 2019; Blomqvist et al., 2020; Yu et al., 2019).
Performing any flavour of variational inference with GPs is predicated on the ability to obtain samples from the posterior in a computationally efficient manner, and this is also the case within the inducing points framework. Wilson et al. (2020) introduced a novel approach to doing so based on Matheron’s rule, which allows samples to evaluated at N locations with O(N) time complexity, which is a significant improvement over the typical \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N^3)$$\end{document} scaling associated with GPs. Another key benefit of their approach, which we will exploit in this work, is that the authors obtain functional samples from the GP, which allows us to apply integral and differential operators directly to the samples, in order to efficiently generate samples from complex, non-Gaussian processes. This general approach was first introduced by Ross et al. (2021) in order to generate samples from the output of a nonlinear process convolution, and has also been utilised by McDonald et al. (2023) in the context of building more expressive GP covariances.
Given a set of inducing variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}$$\end{document} (or alternatively, data), the expression for functional samples from a GP posterior presented by Wilson et al. (2020) takes the following form,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \underbrace{(f \mid \textbf{u})(\cdot )}_{\text{ posterior } } {\mathop {=}\limits ^{\textrm{d}}} \underbrace{f(\cdot )}_{\text{ prior } }+\underbrace{k(\cdot , \textbf{Z}) \textbf{K}^{-1}\left( \textbf{u}-\textbf{f}\right) }_{\text{ update } }. \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{K}$$\end{document} denotes the covariance matrix of the inducing variables with corresponding inputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{Z}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{f}=f(\textbf{Z})$$\end{document} . This expression shows that we can decompose functional samples from the posterior (conditioned on data) into functional samples from the prior, and an update term which quantifies the residual between the prior sample and the data. Wilson et al. (2020) employ a RFF representation for the prior, which reduces the computational burden of sampling considerably. However, the key insight from this work is that the pathologies associated with using RFFs in a nonstationary posterior are avoided, since only the prior (which has a stationary covariance) uses RFFs.
In Sect. 3.2, we will show how we can use this inference scheme in the context of an LFM layer, allowing us to construct a deep LFM within the variational inducing points framework.
Deep latent force models
Fig. 1A conceptual explanation of how the DLFM differs from a DGP. At each layer, we perform the operation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}^{(\ell )}\{x, G\} = \int _0^x G^{(\ell )}(x-\tau )u(\tau )d\tau$$\end{document} , where G is the Green’s function corresponding to an ODE, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u(\cdot )$$\end{document} represents an exponentiated quadratic GP prior. For example, the second operation in the model shown above would take the form, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}^{(2)}\{f_1, G\} = \int _0^{f_1} G^{(2)}(f_1-\tau )u(\tau )d\tau$$\end{document}
Deep latent force models (DLFMs) are compositions of the LFMs described in Sect. 2.1, in much the same way that DGPs are compositions of GPs. This relationship is shown in Fig. 1, which conveys the fact that DLFMs are DGPs, but with an additional convolution operation performed at each layer of the compositional hierarchy. This convolution allows us to encode the dynamics of physical systems within the covariance of the GP layer, using the Green’s function corresponding to a certain form of differential equation.
In this section, we will consider two distinct approaches to formulating a DLFM. Firstly, in Sect. 3.1, we will revisit the approach previously presented in McDonald and Álvarez (2021) which utilises the weight-space formulation of GPs and random Fourier feature approximations. In addition to reviewing this previously published work we also introduce two modifications which improve the performance of the model, namely freely optimizable initial conditions and an option to disable local reparameterization at test time. Following this, in Sect. 3.2 we propose a new approach which uses an inducing points-based framework reliant on pathwise sampling. This new formulation of the DLFM is designed to address the issues associated with using a Fourier basis to represent a nonstationary posterior, which will be discussed in further detail. Our method builds upon prior work by McDonald et al. (2023), and involves drawing functional samples from a latent GP and mapping them analytically through our convolution integral.
Deep LFMs with RFFs
Firstly we outline the variant of the DLFM previously presented in McDonald and Álvarez (2021), which utilises weight-space GP approximations and RFF-based variational inference. This model, which we will refer to as DLFM-RFF, bears a number of similarities to the DGP introduced in Sect. 2.2.1. However, rather than deriving the random features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Phi ^{(\ell )}}$$\end{document} within the DGP from an EQ kernel (Cutajar et al., 2017), we instead populate this matrix with features derived from an LFM kernel. The exact form of the features derived is dependent on the Green’s function used, which in turn depends on the form of differential equation whose characteristics we wish to encode within the model. Guarnizo and Álvarez (2018) derived a number of different forms corresponding to various differential equations, with the simplest case being that of a first order ordinary differential equation (ODE) of the form, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{df(t)}{dt} + \gamma f(t) = \sum ^Q_{q=1} S_q u_q(t)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} is a decay parameter associated with the ODE and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_q$$\end{document} is a sensitivity parameter which weights the effect of each latent force. For simplicity of exposition, we assume \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=1$$\end{document} . The Green’s function associated to this ODE has the form \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(x) = e^{-\gamma x}$$\end{document} . By using Eq. (5), the RFRFs associated with this ODE follow as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \phi (t, \gamma , \omega _s)&= \frac{e^{j\omega _s t} - e^{-\gamma t}}{\gamma + j\omega _s} , \end{aligned}$$\end{document}where compared to Eq. (5), the parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} of the Green’s function corresponds to the decay parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} . From here on, we redefine the spectral frequencies as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{q, s}$$\end{document} to emphasise the fact that the values sampled are dependent on the lengthscale of the latent force by way of the prior, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{q,s} \sim \mathcal {N}(\omega | 0, 2/\ell _q^2)$$\end{document} .
We can collect all of the random features corresponding to the q-th latent force into a single vector, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_q(t, \gamma , \varvec{\omega }_q) = \sqrt{S_q^2/N_{RF}}[\phi (t, \gamma , \omega _{q, 1}), \cdots , \phi (t, \gamma , \omega _{q, N_{RF}})]^\top \in \mathbb {C}^{N_{RF} \times 1}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\omega }_q=\{\omega _{q,s}\}_{s=1}^{N_{RF}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {C}$$\end{document} refers to the complex plane and the super index c in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }_q^c(\cdot )$$\end{document} makes explicit that this vector contains complex-valued numbers. By including the random features corresponding to all Q latent forces within the model, we obtain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c(t, \gamma , \varvec{\omega }) = [\left( \varvec{\phi }^c_1(t, \gamma , \varvec{\omega }_1\right) ^{\top }, \cdots , \left( \varvec{\phi }^c_Q(t, \gamma , \varvec{\omega }_Q)\right) ^{\top }]^\top \in \mathbb {C}^{QN_{RF} \times 1}$$\end{document} , with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\omega }=\{\varvec{\omega }_q\}_{q=1}^Q$$\end{document} . These random features will be denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(t, \gamma , \varvec{\omega })$$\end{document} to differentiate them from the features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }(\cdot )$$\end{document} computed from a generic EQ kernel.
Higher-dimensional inputs
Although the expression for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(t, \gamma ,\varvec{\omega })$$\end{document} was obtained in the context of an ODE where the input is the time variable, we exploit this formalism to use these features even in the context of a generic supervised learning problem where the input is a potentially high-dimensional vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x} = [x_1, x_2, \cdots , x_p]^\top \in \mathbb {R}^{p\times 1}$$\end{document} . As will be noticed later, such an extension is also necessary if we attempt to use such features at intermediate layers of the composition. Essentially, we compute a vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(x_m, \gamma _m, \varvec{\omega }_m)$$\end{document} for each input dimension \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{m}$$\end{document} leading to a set of vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{\varvec{\phi }^c_{LFM}(x_1, \gamma _1, \varvec{\omega }_1),\cdots , \varvec{\phi }^c_{LFM}(x_p, \gamma _p, \varvec{\omega }_p)\}$$\end{document} . Notice that the samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\omega }_m$$\end{document} can also be different per input dimension, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_m$$\end{document} . Although there are different ways in which these feature vectors can be combined, in this work, we assume that the final random feature vector computed over the whole input vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} is given as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(\textbf{x}, \varvec{\gamma }, \varvec{\Omega }) = \sum _{m=1}^p \varvec{\phi }^c_{LFM}(x_m, \gamma _m, \varvec{\omega }_m)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\Omega }=\{\varvec{\omega }_m\}_{m=1}^p$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\gamma }=\{\gamma _m\}_{m=1}^p$$\end{document} . An alternative to explore for future work involves expressing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(\textbf{x}, \varvec{\gamma }, \varvec{\Omega })$$\end{document} as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(\textbf{x}, \varvec{\gamma }, \varvec{\Omega }) = \sum _{m=1}^p \alpha _m \varvec{\phi }^c_{LFM}(x_m, \gamma _m, \varvec{\omega }_m)$$\end{document} , with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _m\in \mathbb {R}$$\end{document} a parameter that weights the contribution of each input feature differently. Although we allow each input dimension to have a different decay parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma _m$$\end{document} in the experiments in Sect. 5, for ease of notation we will assume that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma _1=\gamma _2=\cdots =\gamma _p=\gamma$$\end{document} . For simplicity, we write \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(\textbf{x}, \gamma , \varvec{\Omega })$$\end{document} . Therefore, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(\textbf{x}, \gamma , \varvec{\Omega })$$\end{document} is a vector-valued function that maps from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^{p\times 1}$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {C}^{QN_{RF} \times 1}$$\end{document} .
Real version of the RFRFs
Rather than working with the complex-valued random features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }^c_{LFM}(\textbf{x}, \gamma , \varvec{\Omega })$$\end{document} , we can work with their real-valued counterpart by using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }_{LFM}(\textbf{x}, \gamma , \varvec{\Omega }) = [\left( \mathfrak {Re}\{\varvec{\phi }^c_{LFM}(\textbf{x}, \gamma , \varvec{\Omega })\}\right) ^\top ,$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left( \mathfrak {Im}\{\varvec{\phi }^c_{LFM}(\textbf{x}, \gamma , \varvec{\Omega })\}\right) ^\top ]^{\top }\in \mathbb {R}^{2QN_{RF}\times 1}$$\end{document} (Guarnizo & Álvarez, 2018), where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathfrak {Re}(a)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathfrak {Im}(a)$$\end{document} take the real component and imaginary component of a, respectively. For an input matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X} = [\textbf{x}_1, \cdots , \textbf{x}_N]^{\top }\in \mathbb {R}^{N\times p}$$\end{document} , the matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\Phi }_{LFM}(\textbf{X}, \gamma , \varvec{\Omega }) = [\varvec{\phi }_{LFM}(\textbf{x}_1, \gamma , \varvec{\Omega }), \dots ,$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }_{LFM}(\textbf{x}_N, \gamma , \varvec{\Omega })]^{\top } \in \mathbb {R}^{N\times 2QN_{RF}}$$\end{document} .
Composition of RFRFs
We now use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\Phi }_{LFM}(\textbf{X}, \gamma , \varvec{\Omega })$$\end{document} as a building block of a layered architecture of RFRFs. We write \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\Phi }^{(\ell )}_{LFM}(\textbf{F}^{(\ell )}, \gamma ^{(\ell )}, \varvec{\Omega }^{(\ell )})\in \mathbb {R}^{N\times 2Q^{(\ell )}N^{(\ell )}_{RF}}$$\end{document} and follow a similar construction to the one described in Sect. 2.2.1, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}^{(\ell +1)} = \varvec{\Phi }^{(\ell )}_{LFM}(\textbf{F}^{(\ell )}, \gamma ^{(\ell )}, \varvec{\Omega }^{(\ell )})\textbf{W}^{(\ell )}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}^{(\ell )}\in \mathbb {R}^{2Q^{(\ell )}N^{(\ell )}_{RF}\times D_{F^{(\ell +1)}}}$$\end{document} . As before, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}^{(0)}=\textbf{X}$$\end{document} . Figure 2 is an example of this compositional architecture of RFRFs, which we refer to as a deep latent force model (DLFM). When considering multiple-output problems, we allow extra flexibility to the decay parameters and lengthscales at the final (L-th) layer such that they vary not only by input dimension, but also by output. Mathematically, this corresponds to computing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}_d^{(L)} = \varvec{\Phi }^{(L-1)}_{LFM}(\textbf{F}^{(\ell )}, \gamma _d^{(L-1)}, \varvec{\Omega }_d^{(L-1)})\textbf{W}_d^{(L-1)}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d=1,...,D$$\end{document} .Fig. 2. An illustration of how the DLFM with random Fourier features differs from a DGP with random feature expansions, with this example containing two layers. At each layer of the DLFM-RFF, for each input dimension, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{RF}$$\end{document} random features of the form shown in Eq. (7) are computed for each of the Q latent forces. The random feature vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\phi }_{LFM}^{(\ell )}$$\end{document} is then formed by taking the sum of these features across the input dimensions. This summation is shown in the Figure by the block containing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document}
Initial conditions
In this work, we introduce an additional component to the DLFM-RFF which was not previously studied in McDonald and Álvarez (2021), a consideration of the initial conditions of our system. The analytical Green’s function we use for our first order ODE kernel is derived assuming an initial condition for the ODE of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_d(t = 0) = 0$$\end{document} . This may seem simplistic, however given that we are assuming no a priori knowledge of the form of the dynamical systems we wish to model, it is challenging to reason about a more suitable alternative. The consequence of this is that samples from the model must obey this constraint, resulting in the model having limited ability to capture large variations in the output, in regions of input space close to the origin.
We partially address this by introducing a bias term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_d$$\end{document} for each output dimension within every layer of the DLFM-RFF, which we can interpret as a learnable initial condition of the first order dynamical system we study. Learning this parameter during training allows us greater flexibility with respect to the form of the functions we can represent, as we now have a scenario where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_d(t = 0) = c_d$$\end{document} . However, we still have the restriction that all samples from the model must pass through this point.
In Sect. 3.2 we introduce another approach to addressing this in the context of our new formulation of the DLFM, which solves the problem and allows us to obtain samples which do not collapse to an initial condition at the origin.
Reparameterization trick
In McDonald and Álvarez (2021) and Cutajar et al. (2017), the local reparameterization trick (Kingma et al., 2015) is employed in order to reduce the variance of the stochastic gradients computed when performing variational approximate Bayesian inference. Whilst this is desirable during training, it is not of concern at test time, and introduces noise into the predictions generated from the model. For this reason, we introduce a new option for the DLFM-RFF which allows reparameterization to be switched off at test time.
Variational inference
As previously mentioned, exact Bayesian inference is intractable for models such as ours, therefore in order to train the DLFM we employ stochastic variational inference (Hoffman et al., 2013). For notational simplicity, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Omega }$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Theta }$$\end{document} represent the collections of weight matrices, spectral frequencies and kernel hyperparameters respectively, across all layers of the model. We seek to optimise the variational distributions over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Omega }$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} whilst also optimizing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Theta }$$\end{document} , however we do not place a variational distribution over these hyperparameters. Our approach resembles the VAR-FIXED training strategy described by Cutajar et al. (2017) which involves reparameterizing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega _{ij}^{(\ell )}$$\end{document} such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega _{ij}^{(\ell )} = (s^2)_{ij}^{(\ell )} \epsilon _{rij}^{(\ell )} + m_{ij}^{(\ell )}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m_{ij}^{(\ell )}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(s^2)_{ij}^{(\ell )}$$\end{document} represent the means and variances associated with the variational distribution over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega _{ij}^{(\ell )}$$\end{document} , and ensuring that the standard normal samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon _{rij}^{(\ell )}$$\end{document} are fixed throughout training rather than being resampled at each iteration. If we denote \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {\Psi } = \left\{ \textbf{W}, \mathbf {\Omega } \right\}$$\end{document} and consider training inputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X} \in \mathbb {R}^{N \times D_{in}}$$\end{document} and outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y} \in \mathbb {R}^{N \times D_{out}}$$\end{document} , we can derive a tractable lower bound on the marginal likelihood using Jensen’s inequality, which allows for minibatch training using a subset of M observations from the training set of N total observations. This bound, derived by Cutajar et al. (2017), takes the form,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \log [p(\textbf{y} | \textbf{X}, \mathbf {\Theta }]&= E_{q(\mathbf {\Psi })} \log [p(\textbf{y} | \mathbf {X, \Psi , \Theta })] - \text {D}_\text {KL}[q(\mathbf {\Psi }) || p(\mathbf {\Psi } | \mathbf {\Theta })] \\&\approx \left[ \frac{N}{M} \sum _{k \in \mathcal {I}_M} \frac{1}{N_{\text {MC}}} \sum ^{N_{\text {MC}}}_{r=1} \log [p(\textbf{y}_k | \textbf{x}_k, \tilde{\mathbf {\Psi }}_r, \mathbf {\Theta })]\right] - \text {D}_{\text {KL}}[q(\mathbf {\Psi })||p(\mathbf {\Psi } | \mathbf {\Theta })] , \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {D}_{\text {KL}}$$\end{document} denotes the KL divergence, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\varvec{\Psi }}_r \sim q(\varvec{\Psi })$$\end{document} , the minibatch input space is denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {I}_M$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{\text {MC}}$$\end{document} is the number of Monte Carlo samples used to estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_{q(\varvec{\Psi })}$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q(\varvec{\Psi })$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\varvec{\Psi } | \varvec{\Theta })$$\end{document} denote the approximate variational distribution and the prior distribution over the parameters respectively, both of which are assumed to be Gaussian in nature. A full derivation of this bound and the expression for the KL divergence between two normal distributions are included in the supplemental material.
We mirror the approach of Cutajar et al. (2017) and Kingma and Welling (2014) by reparameterizing the weights and spectral frequencies, which allows for stochastic optimisation of the means and variances of our distributions over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\Omega }$$\end{document} via gradient descent techniques. Specifically, we use the AdamW optimiser (Loshchilov & Hutter, 2018), implemented in PyTorch, as empirically it led to superior performance compared to other alternatives such as conventional stochastic gradient descent.
Deep LFMs with variational inducing points
Whilst the DLFM-RFF is computationally efficient and performs well empirically, Fourier feature-based GP approximations are prone to a phenomenon known as variance starvation. As the number of observations in our training data increases, the predictions from the GP outside the domain of the training data become increasingly erratic, as the Fourier basis can only reliably represent stationary GPs, and the posterior is typically nonstationary (Wilson et al., 2020). Motivated by this, we introduce a new model formulation and inference scheme for the DLFM, which we refer to as DLFM-VIP, based on the variational inducing points framework for GP inference. This approach leverages the pathwise sampling method of Wilson et al. (2020), introduced in Sect. 2.3, which allows us to perform approximate Bayesian inference in our model in a doubly stochastic variational fashion.
Firstly, we must reformulate our model in order to incorporate inducing points. We construct each layer of the DLFM-VIP using the following generative model,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} u_q(\textbf{x})&\sim \mathcal{G}\mathcal{P}[0, k_{q}(\textbf{x}, \textbf{x}')], \qquad G^{(p)}_{d}(x_p) = e^{-\gamma _{d, p} x_p},\\ G_{d}(\textbf{x})&=\prod _{p=1}^P G^{(p)}_{d}(x_p) , \qquad G_{d, q}(\textbf{x}) = a_{d, q} G_{d}(\textbf{x}) , \\&\qquad \textbf{f}(\textbf{x}) = \int _{-\infty }^{\textbf{x}} \textbf{G}(\textbf{x}-\textbf{z})\textbf{u}(\textbf{z})d\textbf{z}, \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=1,\dots , Q$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=1,\dots , P$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d=1,\dots , D$$\end{document} . By collecting all of the Green’s functions corresponding to each distinct output and latent dimension, we form the matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{G} \in \mathbb {R}^{D \times Q}$$\end{document} , and similarly we collect all of the latent functions to form the vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u} \in \mathbb {R}^Q$$\end{document} . This model is similar to the NP-CGP proposed by McDonald et al. (2022), however instead of using a fixed functional form for the filter, they place a GP over each filter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_d^{(p)}$$\end{document} in order to perform nonparametric kernel learning.
As discussed in Sect. 3.1.4, the initial conditions associated with our Green’s function can constrain the layers of the DLFM-RFF in regions of input space close to the origin. Typically in LFMs, the convolution integral used to generate our outputs is computed with the limits \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[0, \textbf{x}]$$\end{document} , however by altering these limits to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[-\infty , \textbf{x}]$$\end{document} (as shown in Eq. (9)), we are able to circumvent the aforementioned initial condition problem entirely. In this formulation, samples from the model close to the origin may take any real value, and do not collapse to an initial condition at this point, therefore we maintain a rigorous quantification of uncertainty in this region of the input space.
Output process sampling
In order to compute samples from our output process, firstly we must produce functional samples from our latent processes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{u_q\}_{q=1}^Q$$\end{document} . To achieve this, we use the pathwise sampling approach introduced by Wilson et al. (2020), which allows us to express functional samples from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_q$$\end{document} as follows,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} u_q^{(s)}(\cdot ) =&\sum ^{B}_{i=1}w_i\phi _i(\cdot ) + k_{u_q, u_q}(\cdot , \textbf{z}_q) \textbf{K}_{u_q, u_q}^{-1}\left( \textbf{v}_q -\varvec{\Phi }\varvec{w}\right) . \end{aligned} \end{aligned}$$\end{document}In Eq. (10), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\Phi } \in \mathbb {R}^{M \times B}$$\end{document} is a matrix of features obtained by computing each of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i=1, \dots , B$$\end{document} basis functions at each of the M inducing inputs. The individual basis functions are expressed by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi _i(\textbf{x}) = \sqrt{2/B} \cos (\varvec{\theta }_i^\top \textbf{x} + \beta _i)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\theta }_i \sim FT(k_{u_q, u_q})$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _i \sim U(0, 2\pi )$$\end{document} , with FT denoting the Fourier transform of the covariance and U the uniform distribution. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{w} \in \mathbb {R}^B$$\end{document} is a vector of weights randomly sampled according to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_i\sim \mathcal {N}(0, 1)$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{u_{q}, u_{q}}$$\end{document} refers to the EQ kernel of the latent process, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}_q \in \mathbb {R}^{M \times P}$$\end{document} represents the M inducing inputs, which have corresponding outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{v}_q \in \mathbb {R}^{M \times 1}$$\end{document} . Finally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{K}_{u_{q}, u_{q}}$$\end{document} denotes the covariance matrix obtained by evaluating the kernel function of the latent process for all combinations of our inducing inputs.
Now that we are able to compute functional samples for our latent processes, we can analytically map these through our convolution integral in order to generate samples from our output process,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \left( \textbf{f}^{(s)} \mid \textbf{V}^{\textbf{u}} \right) (\textbf{x})&= \int _{-\infty }^{\textbf{x}} \textbf{G}(\textbf{x}-\textbf{z})\textbf{u}^{(s)}(\textbf{z})d\textbf{z}. \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{V}^{\textbf{u}} = \{\textbf{v}_q\}_{q=1}^Q$$\end{document} denotes all the inducing variables. Whilst omitted here for brevity, further details regarding the closed-form result of this integration and its derivation are provided in Appendix A.
These multi-output samples can then be passed as input to the next layer of the model, allowing us to form a DLFM of arbitrary depth. To make the explanation concrete, let us assume a two-layer model. The samples at layer 1 follow from Eq. (11)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \left( \textbf{f}^{(s,1)} \mid \textbf{V}^{(\textbf{u},1)} \right) (\textbf{x})&= \int _{-\infty }^{\textbf{x}} \textbf{G}_1(\textbf{x}-\textbf{z})\textbf{u}^{(s,1)}(\textbf{z})d\textbf{z}, \end{aligned}$$\end{document}For the second layer, we get
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \left( \textbf{f}^{(s,2)} \mid \textbf{V}^{(\textbf{u},2)} \right)&\left( \left( \textbf{f}^{(s,1)} \mid \textbf{V}^{(\textbf{u},1)} \right) (\textbf{x})\right) = \\&\int _{-\infty }^{\left( \textbf{f}^{(s,1)} \mid \textbf{V}^{(\textbf{u},1)} \right) (\textbf{x})} \textbf{G}_2\left( \left( \textbf{f}^{(s,1)} \mid \textbf{V}^{(\textbf{u},1)} \right) (\textbf{x})-\textbf{z}\right) \textbf{u}^{(s,2)}(\textbf{z})d\textbf{z}. \end{aligned}$$\end{document}In general, the sample at layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} follows from the samples at the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell -1$$\end{document} previous layers as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\left( \textbf{f}^{(s,\ell )} \mid \textbf{V}^{(\textbf{u},\ell )} \right) \left( \left( \textbf{f}^{(s,\ell -1)} \mid \textbf{V}^{(\textbf{u},\ell -1)} \right) \cdots \left( \textbf{f}^{(s,1)} \mid \textbf{V}^{(\textbf{u},1)} \right) (\textbf{x})\right) = \\&\int _{-\infty }^{\left( \textbf{f}^{(s,\ell -1)} \mid \textbf{V}^{(\textbf{u},\ell -1)} \right) \cdots \left( \textbf{f}^{(s,1)} \mid \textbf{V}^{(\textbf{u},1)} \right) (\textbf{x})} \textbf{G}_{\ell }\Bigl (\left( \textbf{f}^{(s,\ell -1)} \mid \textbf{V}^{(\textbf{u},\ell -1)}\right) \cdots \\ &\qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \cdots \left( \textbf{f}^{(s,1)} \mid \textbf{V}^{(\textbf{u},1)} \right) (\textbf{x})-\textbf{z}\Bigr )\textbf{u}^{(s,\ell )}(\textbf{z})d\textbf{z}. \end{aligned}$$\end{document}Variational inference
In order to perform approximate Bayesian inference in the DLFM-VIP, we once again employ stochastic variational inference. As we are now working in the inducing points framework, we follow the approach of Salimbeni and Deisenroth (2017); this differs from the DLFM-RFF inference scheme outlined in Sect. 3.1.6, but solely in how we construct our joint and variational distributions. Firstly, let us collect all of the inducing variables at the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} -th layer of the model into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{V}^{\ell } = \{\textbf{v}_q^{\ell } \}_{q=1}^Q$$\end{document} . Again, consider some input data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X} \in \mathbb {R}^{N\times P}$$\end{document} with corresponding outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y} \in \mathbb {R}^{N\times D}$$\end{document} . We can write the joint distribution of the DLFM-VIP as,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} p(\textbf{Y}, \{\textbf{u}^\ell , \textbf{V}^{\ell } \}^L_{\ell = 1}) =\prod ^{N}_{i=1} p(\textbf{y}_{i} \mid \textbf{F}_i^L) \prod ^{L}_{\ell =1} p(\textbf{u}^\ell \mid \textbf{V}^{\ell }) p(\textbf{V}^{\ell }) , \end{aligned}$$\end{document}where the likelihood is given by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\textbf{y}_{i}|\textbf{F}_i^L) = \mathcal {N}(\textbf{y}_i; \textbf{F}_i^L, \sigma ^2_y)$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}_i^L$$\end{document} is the output of the model obtained from the i-th input. The latent GPs are independent such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\textbf{u}^\ell \mid \textbf{V}^{\ell }) = \prod ^{Q}_{q=1} p( u^{\ell }_{ q} \mid \textbf{v}^{\ell }_{q})$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p( u^{\ell }_{q} \mid \textbf{v}^{\ell }_{q})$$\end{document} is a GP posterior and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\textbf{V}^{\ell })$$\end{document} represents the prior over the inducing points.
We construct our variational posterior as follows,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} q(\{\textbf{u}^\ell , \textbf{V}^{\ell } \}^L_{\ell = 1}) = \prod ^L_{\ell = 1} p(\textbf{u}^\ell | \textbf{V}^{\ell })q(\textbf{V}^{\ell }), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q(\textbf{V}^{\ell }) =\prod ^{Q_{\ell }}_{ q=1} \mathcal {N}(\textbf{v}^{\ell }_{q};\varvec{\mu }^{\ell }_{q}, \varvec{\Sigma }^{\ell }_{q})$$\end{document} is a variational distribution specific to the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} -th layer, whose mean and covariance matrix are variational parameters. For the sake of clarity, we have omitted the factorisation over the layer dimensionality in the expression for the posterior. This allows us to compute the following stochastic approximation to our variational lower bound using S Monte Carlo samples,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L} = \sum ^N_{i=1} \frac{1}{S} \sum ^S_{s=1} \log p(\textbf{y}_i | \textbf{F}_i^{L^{(s)}}) - \sum ^L_{\ell = 1} \left[ D_\text {KL}[q(\textbf{V}^{\ell }) \Vert p(\textbf{V}^{\ell })] \right] , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{F}_i^{L^{(s)}}$$\end{document} is a sample from the model. A full derivation of this bound is available in the supplemental material.
Related work
Whilst the intersection of physics and deep learning has been a fruitful avenue for research for a number of years (Willard et al., 2020), to date there has been limited work on incorporating physical structure into deep probabilistic models. The work of Lorenzi and Filippone (2018) is one example, however the authors achieve this by constraining the dynamics of their DGP with random feature expansions, rather than specifying a physics-informed kernel as in our approach. Additionally, the model developed by Lorenzi and Filippone (2018) is primarily designed for tackling the problem of ODE parameter inference in situations where the form of the underlying ODEs driving the behaviour of a system are known. In contrast, the DLFM does not assume any knowledge of the differential equations governing the given dynamical system being studied, and thus we do not attempt to perform parameter inference; our aim is to construct a robust, physics-inspired model with extrapolation capabilities and the ability to quantify uncertainty in its predictions.
Physics-informed deep kernel learning (PI-DKL) (Wang et al., 2022) is another proposed approach to integrating physical priors into a probabilistic model. Unlike the work of Lorenzi and Filippone (2018) and in physics-informed neural networks (Raissi et al., 2019), PI-DKL is applicable to scenarios where we do not have complete knowledge regarding the form of the physical system we wish to model, as is our DLFM. PI-DKL uses differential operators to guide the deep kernel learning process, but the authors do not utilise the process convolution framework and pathwise sampling as we do, and nor is their model a deep GP, as the deep component is a deterministic neural network.
The new formulation of the DLFM which we introduce in Sect. 3.2 is conceptually similar to Ross et al. (2021) and McDonald et al. (2023), as both of these works map GP samples through a convolution integral analytically using pathwise conditioning (Wilson et al., 2020). The first key difference between those works and our approach is that both Ross et al. (2021) and McDonald et al. (2023) convolve one GP with another in order to obtain a more expressive GP kernel, whereas we convolve our latent GP with a Green’s function in order to encode physical structure within the model. Additionally, both of the aforementioned works are shallow, single-layer GPs, whereas we present a deep model which can be composed of an arbitrary number of layers.
One final point we wish to clarify is that although the DLFM is a deep probabilistic model composed of a series of convolved GPs, our model differs from the convolutional DGP construction outlined by Dunlop et al. (2018), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f^{(\ell + 1)}(t) = \int f^{(\ell )}(t-\tau )u^{(\ell + 1)}(\tau )d \tau$$\end{document} , which the authors argue results in trivial behaviour with increasing depth. Instead, our model takes the form, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f^{(\ell + 1)}(f^{(\ell )}) = \int _0^{f^{(\ell )}} G(f^{(\ell )} - \tau ^{(\ell + 1)})u^{(\ell + 1)}(\tau ^{(\ell + 1)}) d \tau ^{(\ell + 1)}$$\end{document} , which is more akin to the compositional construction outlined by Dunlop et al. (2018), just with a kernel which happens to involve a convolution.
Recent advances in series forecasting have also leveraged Transformer-style architectures with attention mechanisms (Vaswani et al., 2017), showing competitive results on regularly sampled datasets (Zhou et al., 2021; Wu et al., 2021; Zhou et al., 2022). We have not benchmarked these models here for two main reasons. Firstly, Transformer forecasters are usually deterministic and lack native uncertainty. In contrast, DLFM can intrinsically produce predictive distributions with calibrated uncertainty. Secondly, while recently proposed attention models have been extended to irregular data (Shukla & Marlin, 2021; Zerveas et al., 2021), these solutions do not offer a general probabilistic treatment. DLFM handles missing or unevenly spaced observations naturally through its GP backbone and convolutional kernels. A systematic empirical comparison with the last Transformer family is a valuable direction for future work.
Experiments
In this section we present experimental results which compare the empirical performance of both formulations of the DLFM to one another, and to prior work. All experiments using the DLFM-RFF were performed using the improvements discussed in Sect. 3.1.4 and 3.1.5, thus these results differ from those previously presented in McDonald and Álvarez (2021). Further details regarding the experimental setups are available in the supplemental material.
Toy experiment
Firstly, to verify that our models are capable of modelling the compositional systems which their architectures resemble, we train the DLFM-RFF and DLFM-VIP on the inputs t and noise-corrupted outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_2(t)=f_2(t) + \epsilon$$\end{document} of a system characterised by,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} f_1(t)&= \int _0^t G_1(t-\tau )u(\tau )d\tau \\ f_2(f_1(t))&= \int _0^{f_1(t)} G_2(f_1(t) - \tau ^\prime ) u(\tau ^\prime ) d\tau ^\prime , \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_1(\cdot )$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_2(\cdot )$$\end{document} denote the Green’s functions corresponding to the first order ODEs which these two integrals represent the solutions to. We evaluate an exact GP, a deep GP with random Fourier features (DGP-RFF) (Cutajar et al., 2017), a doubly stochastic variational deep GP (DGP-DSVI) (Salimbeni & Deisenroth, 2017) and both the DLFM-RFF and DLFM-VIP. The latent function is sinusoidal in nature, resulting in a signal consisting of pulses with varying amplitude. From the predictions shown in Fig. 3, we see that all five models capture the behaviour of the system well in the training regime, but only the deep models are able to extrapolate.Fig. 3. Model fits to our toy dynamical system with latent function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u(t)=\cos (0.5 t) + 6\sin (3 t)$$\end{document} . Grey, orange and red data-points represent training, imputation test and extrapolation test data respectively. Purple curves represent predictive means, and shaded areas represent \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm 2\sigma$$\end{document}
In both the imputation and extrapolation test regions, the DLFM-RFF visibly provides a better fit to the data than the DGP-RFF. By turning off reparameterization at test time, as discussed in Sect. 3.1.5, the predictive distribution of the DLFM-RFF is not subject to the noise we see in the DGP-RFF predictions. The DLFM-VIP with 20 inducing points placed evenly across the entire domain is also capable of modelling the dynamics of the system with a more realistic quantification of uncertainty than the DGP-DSVI and DGP-RFF, however, it does not capture the extremes of the function in the extrapolation regime as accurately as the DLFM-RFF is able to.
The key takeaway from this experiment is that both the DLFM-RFF and DLFM-VIP exhibit superior short-range extrapolation ability compared to the DGP-RFF and DGP-DSVI respectively, evidencing the fact that our physics-informed kernel improves our ability to perform short-range extrapolation tasks such as this regardless of the inference scheme we select.
PhysioNet multivariate time series
To assess the ability of our model to capture highly nonlinear behaviour, we evaluate its performance on a subset of the CHARIS dataset (ODC-BY 1.0 License) (Kim et al., 2016), which can be found on the PhysioNet data repository (Goldberger et al., 2000). The data available for each patient consists of an electrocardiogram (ECG), alongside arterial blood pressure (ABP) and intracranial pressure (ICP) measurements; all three of these signals are sampled at regular intervals and are nonlinear in nature. We use a subset of this data consisting of the first 1000 time steps for a single patient. We focus on two predictive tasks. Firstly, we test the ability of our models to impute missing data by removing 150 non-overlapping datapoints from each output and using these as a test set. Additionally, we also consider the challenging task of extrapolating a short distance beyond the training input domain by training the aforementioned models on the first 975 observations and withholding the remaining 25 as a test set.Table 1. Imputation test set results for each output within the CHARIS dataset, with standard error in bracketsABPECGICPNMSEMNLLNMSEMNLLNMSEMNLLDLFM-VIP0.10 (0.03)0.44 (0.08)0.34 (0.02)1.09 (0.04)0.16 (0.02)0.55 (0.06)DLFM-RFF0.05 (0.02)0.14 (0.32)0.33 (0.03)0.93 (0.04)0.09 (0.02)0.63 (0.24)DGP-DSVI0.38 (0.06)0.93 (0.07)0.38 (0.03)0.94 (0.04)0.31 (0.06)0.81 (0.08)DGP-RFF0.73 (0.02)1.18 (0.01)0.63 (0.02)1.21 (0.01)0.23 (0.02)0.73 (0.04)SLMC1.00 (0.001)1.42 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0)1.00 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0)1.43 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0)1.03 (0.001)1.44 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0)LFM-RFF1.00 (0.001)–1.01 (0.01)–0.97 (0.02)–Table 2. Extrapolation test set results for each output within the CHARIS dataset, with standard error in bracketsABPECGICPNMSEMNLLNMSEMNLLNMSEMNLLDLFM-VIP0.65 (0.19)7.55 (1.96)1.30 (0.28)1.24 (0.17)0.45 (0.14)4.35 (1.19)DLFM-RFF0.11 (0.02)3.16 (2.14)0.83 (0.09)4.03 (1.84)0.39 (0.07)7.09 (3.65)DGP-DSVI1.00 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0)1.82 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0)1.45 (0.001)1.90 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0)1.03 (0.03)1.49 (0.03)DGP-RFF1.49 (0.29)6.56 (1.32)4.54 (1.38)2.00 (0.47)0.47 (0.12)3.75 (0.83)SLMC1.04 (0.003)1.86 (0.009)1.52 (0.08)0.91 (0.02)1.05 (0.05)1.49 (0.04)
For the DLFM-RFF we use 100 random features, and for the DLFM-VIP we use 100 inducing points per layer. For both DLFMs, we use a single latent force per layer and the dimensionality of the hidden layers is set to be equal to the number of outputs in our dataset. As in the toy experiment, we once again compare our models to the DGP-RFF and DGP-DSVI. The parameters chosen for the DGP models align with the selections made for the DLFM as closely as possible in order to maintain parity. In addition to these deep models, we also evaluate the performance of a stochastic variational multi-output GP with 100 inducing points which uses the linear model of coregionalization (SLMC) (Alvarez et al., 2012). Finally, we compare to a shallow LFM with random Fourier features derived from the same first order ODE as our model (LFM-RFF) (Guarnizo & Álvarez, 2018), consisting of two latent forces and 20 random features; this setup was chosen as using more random features or latent forces did not appear to improve the performance of the LFM-RFF for this task. Given the poor performance of the LFM on the simpler imputation task, we do not include results for this model in the extrapolation setting.
Tables 1 and 2 contain the results of the imputation and extrapolation experiments respectively. In order to evaluate and compare the performance of each technique, we compute the per-output test set MNLL (Mean Negative Log-Likelihood) for each model, as well as the NMSE (Normalised Mean Squared Error), which was chosen as it is a common metric for evaluating time series problems. We see from the results presented that the DLFM-RFF outperforms all of the baseline methods on the imputation task across all metrics, and yields a superior NMSE to all of the baselines on the extrapolation task. On the imputation task, the DLFM-VIP also outperforms all the baseline methods across both metrics, apart from the ECG MNLL for the DGP-DSVI.
Overall the DLFM-VIP does not quite match the empirical performance of the DLFM-RFF on the imputation task (Fig. 4), however the margin is relatively small and the DLFM-VIP does appear to be slightly more stable overall, not being as prone to the large standard errors which the DLFM-RFF can suffer from. On the extrapolation task however, the DLFM-RFF does significantly outperform the DLFM-VIP in terms of NMSE. Both the DLFM-RFF and DLFM-VIP achieve relatively poor test set MNLLs on the extrapolation task, often on par with or worse than the baseline methods. In the case of the DLFM-RFF this can likely be attributed to variance starvation; it is clear from Fig. 5 that the confidence intervals are poorly calibrated given that they do not cover a significant portion of the test data. Conversely, for the DLFM-VIP, these performance issues arise because whilst the confidence intervals are arguably more realistic, the model is less capable of extrapolating the dynamics outside of the test region, as is evident from comparing the predictive means of the two DLFMs. These extrapolation results present an interesting opportunity for future work, which we will discuss in further detail in Sect. 6.2.Fig. 4. Predictions generated for each of the three outputs within the CHARIS imputation experiment, from a DLFM-RFF and DLFM-VIP. Grey dots represent training data, orange dots represent test data, the purple line represents the predictive mean of the model, and the shaded grey areas in each plot represent \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm 2\sigma$$\end{document} Fig. 5. Predictions generated for each of the three outputs within the CHARIS extrapolation experiment, from a DLFM-RFF and DLFM-VIP. Grey dots represent training data, orange dots represent test data, the purple line represents the predictive mean of the model, and the shaded grey areas in each plot represent \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm 2\sigma$$\end{document} . Here, we have zoomed in on the final 100 timesteps which includes the extrapolation region; the previous 900 training observations are not shown
UCI regression
As noted in McDonald and Álvarez (2021), whilst the DLFM was not originally designed with tabular regression problems in mind, the model is surprisingly effective in this setting, likely due to the factors discussed in Sect. 6. We consider two single-output UCI regression datasets commonly used for benchmarking deep probabilistic models, power ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=9568$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=4$$\end{document} ) and protein ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=45730$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P=9$$\end{document} ). Again, we evaluate both of our models alongside the DGP-DSVI and DGP-RFF, however for the shallow GP benchmark we now use a stochastic variational GP (SVGP) with an EQ kernel and 100 inducing points.
From the results shown in Table 3 we see that on the power dataset, both variants of the DLFM outperform the shallow benchmark in terms of both metrics, and also provide comparable results to the DGP-RFF, with slightly improved MNLL. On the protein dataset, the DLFM-RFF is unable to exceed the performance of the DGP-RFF or shallow benchmark, however the new DLFM-VIP improves upon this, exceeding the shallow benchmark in terms of both RMSE (Root Mean Squared Error) and MNLL. The DGP-DSVI is the best performing approach across both datasets and metrics. As mentioned above, the model was not devised for application to these types of problems, however the relatively strong performance of the DLFMs in this setting is related to some theoretical insights on the relationship between the DLFM and conventional DGPs, which we will discuss in Sect. 6.Table 3. Test set results on the UCI benchmarks, with standard error in bracketspowerproteinRMSEMNLLRMSEMNLLDLFM-VIP3.84 (0.03)2.77 (0.01)4.21 (0.02)2.86 (0.005)DLFM-RFF3.83 (0.03)2.78 (0.01)4.67 (0.03)2.97 (0.007)DGP-DSVI3.66 (0.04)2.72 (0.01)3.96 (0.01)2.79 (0.003)DGP-RFF3.84 (0.05)2.80 (0.01)4.03 (0.01)2.82 (0.003)SVGP3.86 (0.04)2.77 (0.01)4.33 (0.01)2.89 (0.003)
Model analysis & discussion
Both the DLFM-RFF and DLFM-VIP explicitly encode the dynamics of a linear first order ordinary differential equation within the kernel of each of their GP layers. Despite this enforced inductive bias, the results presented in Sect. 5.3 show that the DLFM still retains the generality of a conventional DGP, and achieves comparable performance on tasks where we would not necessarily expect this inductive bias to be of any use. In this section, we briefly discuss how this behaviour can be explained.
Firstly, we can explain this behaviour by considering the convolutional nature of the DLFM. In a regular DGP, the layers of the model warp the inputs, and the DLFM performs the exact same process. However, in the DLFM, due to the convolution of the GP at each layer of the model with the Green’s function, we introduce an additional degree of flexibility, which allows us to control the nature of the warping which occurs at each layer. The Green’s function can be interpreted as a filter over the GPs at each layer of the model, which not only allows us to warp the intermediate inputs but also gives us the ability to selectively filter out certain frequencies of the latent GPs, altering their degree of smoothness.
In this work, we focused on the Green’s function derived from a first-order ODE. One would ideally select the Green’s function based on known physical properties or governing dynamics of a system (e.g., decay, oscillation, diffusion). However, our primary aim was to demonstrate the general benefits of introducing structured, ODE-based inductive biases compared to conventional deep Gaussian processes (DGPs) that lack such physical structure. Our focus is not on tailoring Green’s functions to specific real-world systems but rather on evaluating whether the introduction of a general, interpretable ODE prior (e.g., via exponential Green’s functions) can improve performance across diverse tasks. As such, the scope of the analysis in this paper is limited to a single choice of Green’s function, that of the first-order ODE. We plan to explore the integration of other forms of Green’s functions related to various real-world physical systems in the future. We believe that investigating a model based on a simple ODE such as this is a valuable first step which lays the groundwork for future research in task-specific prior integration.
It is notoriously challenging to reason about a sensible choice for the kernel in the inner layers of a DGP (McDonald et al., 2022); this is further motivation for our usage of the ODE kernel, as it effectively just provides us with a more flexible approach to learning the dynamics of the latent space. Nevertheless, we can also look to interpret these findings in a more explicit manner by exploring the connection between the ODE and EQ kernels.
Decay parameter analysis
As discussed above, the ODE kernel adds useful structure to the model when required. However, this additional complexity on top of the EQ kernel of the latent GP may not always be required, thus an advantageous quality in our model would be the ability to adaptively revert to an EQ-like kernel when the physics-informed dynamics are not required. Consider the scenario where instead of using a Green’s function in our convolution integral, we use a Dirac delta function. With simplified notation for ease of exposition, this yields the result \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(x) = \int _{-\infty }^x \delta (x-\tau )u(\tau )d\tau = H(x)u(x)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H(\cdot )$$\end{document} is the Heaviside step function. As the delta function is analogous to an identity function when working with convolutions, we have simply recovered our original latent GP with EQ covariance.Fig. 6. On the left we see the Green’s function visualised for two different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} , with G(x) resembling a delta function as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} is increased. The effect of this can be seen on the right, where we have a sample from our latent GP, alongside output samples from a single layer of the DLFM-VIP for two different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} . For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =200$$\end{document} , the sample resembles the sample from the latent GP with EQ kernel, whereas for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =0.01$$\end{document} , the filter has a much more visible effect on the form of the sample
As shown in Fig. 6, as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma \rightarrow \infty$$\end{document} , our ODE Green’s function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$e^{-\gamma x}$$\end{document} forms an increasingly close approximation to a delta function, subject to a normalisation constant. This means that our DLFM behaves increasingly like a conventional DGP with EQ kernels as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} increases, and as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} is a freely optimizable parameter, the model can effectively select the extent to which the physics-informed inductive bias of the ODE kernel is required. In Fig. 6, the prior samples we show have been normalised to the range \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[-1, 1]$$\end{document} for ease of comparison; the model would be able to perform this rescaling during training through optimisation of the amplitude parameters present in each LFM layer. As previously alluded to, one caveat to note is that whilst our Green’s function approximates a delta function, it does not tend to a delta function as it does not adhere to the normalisation to unity constraint which a delta function must satisfy, as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\int _{-\infty }^{\infty } H(t) e^{-\gamma x} dx = \int _{0}^{\infty } e^{-\gamma x} dx = 1/\gamma$$\end{document} .
Inference scheme comparison
We present experimental results in this work which involve making predictions in three very distinct scenarios. Firstly, the UCI experiments are an interpolation problem, where the test data used to evaluate each model is randomly sampled from across the input domain. From the results shown in Table 3, we can see that the DLFM-VIP fares well in this setting, outperforming the DLFM-RFF. Secondly, we have considered an imputation problem with the PhysioNet data, where the test data consists of non-overlapping chunks of contiguous data-points from each individual output signal. This is a challenge as the model has not been exposed to any data from these regions during training, however the model has had access to some contextual information in the form of the data-points either side of the test region, and the values of the other outputs within the test region. From the results shown in Table 1, we see that the DLFM-VIP exhibits almost comparable performance to the DLFM-RFF in this setting, and outperforms the baselines tested. Finally, we considered an extrapolation problem with the PhysioNet data, where the test data is a region entirely outside of the training domain, and the model has not has access to any of the output values within this region. As we can see from the results in Table 2 and Fig. 5, it is in this setting where the DLFM-VIP begins to struggle, failing to outperform the DLFM-RFF. This occurs regardless of whether or not we choose to fix evenly spaced inducing inputs across the entirety of the training and test domain at the first layer of the DLFM-VIP.
As noted by Rudner et al. (2020), inducing points-based GP inference methods create local approximations to the target function, which considerably limits the ability of such models to capture, and thus extrapolate, global structure within data. The two primary aims of this work were firstly to improve the interpolation abilities of the DLFM by addressing the issues associated with RFF-based posteriors, and secondly to assess whether the LFM framework would be able to overcome the aforementioned difficulties associated with extrapolating with inducing points-based models. The first aim was achieved, however we find empirically that the DLFM-VIP is only capable of performing pure extrapolation for short distances outside of the input domain, and does so with a higher degree of error compared to the DLFM-RFF.
The relative empirical effectiveness of the DLFM-RFF in the extrapolation regime may seem at odds with the fact that, as discussed in Sect. 3.2, variance starvation in Fourier feature-based GPs can cause problems outside of the training domain when the number of data-points is larger than the number of Fourier features used (which is generally the case in our experiments). We posit that the global structure imposed by the physics-informed filter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(\cdot )$$\end{document} exhibits a degree of control over the usually erratic mean predictions which can result when attempting to extrapolate with Fourier feature-based GPs experiencing variance starvation. However, the filters do not have any means of counteracting the over-confidence (Calandriello et al., 2019) which is characteristic of variance starvation, which explains the low variance in the extrapolation predictions returned by the DLFM-RFF, and the poor test set log-likelihoods on the PhysioNet extrapolation task discussed in Sect. 5.2.
In summary, whilst the DLFM-RFF and DLFM-VIP have different strengths and weaknesses, they both represent a notable improvement over their non-physics-informed DGP counterparts. A pressing issue for future work is how we can combine the advantages of these two models to obtain a model which is capable of performing accurate long-range extrapolation whilst avoiding the issue of variance starvation. In Sect. 7, we briefly discuss a possible direction for future work based on interdomain DGPs which may alleviate this issue entirely.
Computational runtimes
With respect to the number of latent forces Q and the number of features M (i.e. random features or inducing points), the complexity associated with performing inference in the DLFM-VIP is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {O}(QM^3)$$\end{document} , whereas for the DLFM-RFF it is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {O}(QM)$$\end{document} . We find empirically that the DLFM-VIP does indeed take longer to train than the DLFM-VIP. For example, for the power experiment shown in Sect. 5.3, training the DLFM-VIP for 100, 000 iterations on an 80GB NVIDIA A100 GPU with a batch size equal to the size of the dataset ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=8611$$\end{document} ) takes approximately six hours, whereas training a comparable DLFM-RFF for the same number of iterations on the same hardware would take only four hours. A discussion regarding the computational complexities of each model is included within appendix D. Additionally, an open source implementation of the models presented in this work is available at https://github.com/tomcdonald/dlfm.
An alternative to VI and RFF-based methods GP approximation methods for the construction of DGPs, are Monte Carlo (MC) methods such as those deployed in Havasi et al. (2018). Although a sampling-based approach such as this has certain attractive properties such as the ability to obtain unbiased samples from potentially non-Gaussian, even multimodal, posteriors, it is challenging to implement in practice. Convergence can be difficult to assess, and as discussed by Ustyuzhaninov et al. (2020), often unstable, in addition to the fact that inference is associated with a high computational cost. Yu et al. (2019) show this empirically, with their VI-based DGP architecture taking roughly an order of magnitude less time to train than the approach proposed by Havasi et al. (2018). Therefore, whilst we have not implemented MC-based approximate inference in the DLFM due to the fact that this would be a non-trivial task, prior work supports our assumption that the VI and RFF-based schemes likely provide improvements in computational runtime compared to what we would expect to obtain from a version of the DLFM reliant on a sampling-based inference scheme.
Comparison to non-GP approaches
We also compared the performance of the DLFM against two neural-network-based approaches, namely, variational Recurrent Neural Networks (VRNN) (Chung et al., 2015) and latent ODEs (Rubanova et al., 2019). Details are given in appendix E. Our DLFM models consistently outperformed VRNNs and latent ODEs for both interpolation (for the synthetic data) and for extrapolation (for the synthetic and the CHARIS dataset), and both in terms of RMSE and MNLL. Applying both neural-network-based models to our tasks of interpolation and extrapolation was not straightforward due to the nature of the data. The datasets we worked with contained missing values and irregularly sampled observations. Directly using both models on such data required additional modifications, such as including imputation strategies or specialized architectures, making them less immediately applicable compared to our Gaussian process-based models.
Conclusion & future work
In this work we outline the deep latent force model (DLFM), a generalised framework for performing Bayesian deep learning with physics-informed Gaussian processes. Our results show that DLFMs are able to effectively capture nonlinear dynamics in both single and multiple-output settings, as well as achieve competitive performance on benchmark tabular regression tasks. Two formulations of the DLFM are presented based on random Fourier features and variational inducing points, which are more suited to extrapolation and interpolation tasks respectively, for reasons discussed in Sect. 6.
We envision a number of avenues for future research. Firstly, the inference procedure in both models could be modified to extend the variational treatment we consider to encompass the kernel hyperparameters. Additionally, as discussed earlier, improving the extrapolation abilities of the DLFM-VIP is a key problem. Prior work on shallow LFMs with inducing points-based approximations has used periodic latent processes to address the latter problem (Moss et al., 2021), however this is not an option in the pathwise sampling setting, as the resulting convolution integral has no closed form solution. Another kernel-based solution may be to instead derive a kernel from a 2nd order ODE in order to imbue the model with more periodic long-range structure. This approach would however be more computationally intensive, and introduce more hyperparameters to estimate, which may necessitate a less biased, fully Bayesian approach to estimating these hyperparameters.
A non-trivial but potentially highly fruitful solution to this issue could involve fundamentally altering the structure of the model to mirror that of Rudner et al. (2020), who use an interdomain approach with RKHS Fourier features in order to improve the ability of DGPs to capture global structure in data. This would in effect combine the advantages of the DLFM-RFF and the DLFM-VIP, resulting in a model which can extrapolate dynamics globally whilst avoiding the problems associated with using a purely Fourier feature-based posterior.
While the UCI and CHARIS datasets used in our experiments remain widely adopted benchmarks, and their nonstationary characteristics showcase the strengths of our models, we acknowledge that these datasets have become somewhat dated. Future work will explore evaluating DLFM on more recent and large-scale benchmarks (e.g., Electricity Transformer Temperature (ETT; Zhou et al. (2021)), Traffic (Lai et al., 2018)). This would help clarify the applicability and scalability of DLFM to contemporary, real-world time series prediction tasks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alvarez, M., Luengo, D., & Lawrence, N.D. (2009). Latent force models. Artificial Intelligence and Statistics (pp. 9–16).10.1109/TPAMI.2013.8624051729 · doi ↗ · pubmed ↗
- 2Álvarez, M.A., Ward, W., & Guarnizo, C. (2019). Non-linear process convolutions for multi-output Gaussian processes. In The 22nd International conference on artificial intelligence and statistics (pp. 1969–1977).
- 3Blomqvist, K., Kaski, S., & Heinonen, M. (2020). Deep convolutional Gaussian processes. In Machine learning and knowledge discovery in databases: European conference, ecml pkdd 2019, würzburg, germany, September 16–20, 2019, proceedings, part ii (pp. 582–597).
- 4Bui, T.D., & Turner, R.E. (2014). Tree-structured Gaussian process approximations. Advances in Neural Information Processing Systems, 27
- 5Calandriello, D., Carratino, L., Lazaric, A., Valko, M., & Rosasco, L. (2019). Gaussian process optimization with adaptive sketching: Scalable and no regret. In Conference on learning theory (pp. 533–557).
- 6Chen, R.T.Q., Rubanova, Y., Bettencourt, J., & Duvenaud, D.K. (2018). Neural ordinary differential equations. S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, & R. Garnett (Eds.), Advances in Neural Information Processing Systems (Vol. 31). Curran Associates, Inc.
- 7Chung, J., Kastner, K., Dinh, L., Goel, K., Courville, A.C., & Bengio, Y. (2015). A recurrent latent variable model for sequential data. Advances in Neural Information Processing Systems, 28
- 8Cutajar, K., Bonilla, E.V., Michiardi, P., & Filippone, M. (2017). Random feature expansions for deep Gaussian processes. In International conference on machine learning (pp. 884–893).