MixingDTA: improved drug–target affinity prediction by extending mixup with guilt-by-association
Youngoh Kim, Dongmin Bang, Bonil Koo, Jungseob Yi, Changyun Cho, Jeonguk Choi, Sun Kim

TL;DR
This paper introduces MixingDTA, a new framework that improves drug–target affinity predictions using data augmentation and pre-trained models, helping overcome data scarcity in drug discovery.
Contribution
MixingDTA introduces a novel data augmentation strategy, GBA-Mixup, and combines it with a pre-trained model to improve DTA prediction accuracy.
Findings
MEETA model alone improves DTA prediction accuracy by up to 19% over existing methods.
GBA-Mixup further enhances accuracy by up to 8.4% and works across different models.
MixingDTA generalizes well for unseen drug–target pairs and identifies functionally critical residues.
Abstract
Drug–target affinity (DTA) prediction is an important regression task for drug discovery, which can provide richer information than traditional drug–target interaction prediction as a binary prediction task. To achieve accurate DTA prediction, quite large amount of data are required for each drug, which is not available as of now. Thus, data scarcity and sparsity is a major challenge. Another important task is “cold-start” DTA prediction for unseen drug or protein. In this work, we introduce MixingDTA, a novel framework to tackle data scarcity by incorporating domain-specific pretrained language models for molecules and proteins with our MEETA (MolFormer and ESM-based Efficient aggregation Transformer for Affinity) model. We further address the label sparsity and cold-start challenges through a novel data augmentation strategy named GBA-Mixup, which interpolates embeddings of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
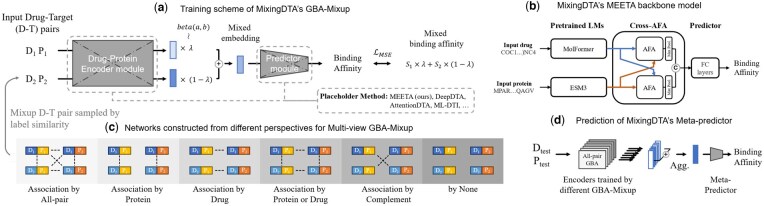 Figure 1
Figure 1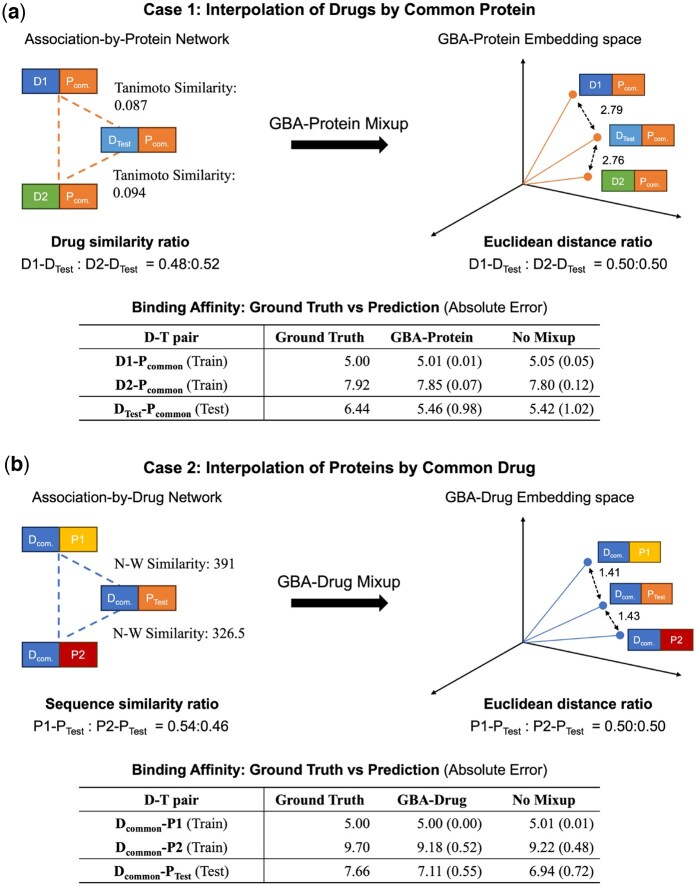 Figure 2
Figure 2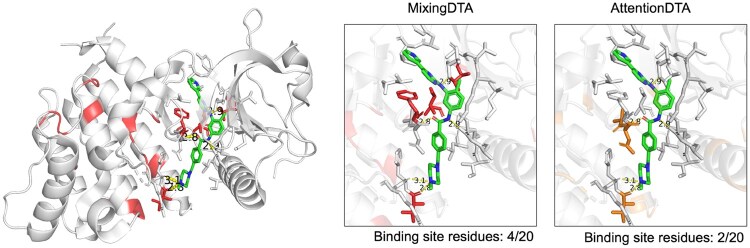 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputational Drug Discovery Methods · Machine Learning in Materials Science · Protein Structure and Dynamics