Singular Value Decomposition (SVD) Method for LiDAR and Camera Sensor Fusion and Pattern Matching Algorithm
Kaiqiao Tian, Meiqi Song, Ka C. Cheok, Micho Radovnikovich, Kazuyuki Kobayashi, Changqing Cai

TL;DR
This paper introduces a new method using SVD and GD to align LiDAR and camera sensors in autonomous vehicles without manual calibration.
Contribution
A targetless pattern matching algorithm using SVD and GD for sensor fusion without requiring manual calibration targets.
Findings
The proposed method achieves up to 85% improvement in alignment accuracy.
Projection error is reduced to less than 1 pixel in experiments.
The framework maintains reliable sensor fusion under calibration drift.
Abstract
LiDAR and camera sensors are widely utilized in autonomous vehicles (AVs) and robotics due to their complementary sensing capabilities—LiDAR provides precise depth information, while cameras capture rich visual context. However, effective multi-sensor fusion remains challenging due to discrepancies in resolution, data format, and viewpoint. In this paper, we propose a robust pattern matching algorithm that leverages singular value decomposition (SVD) and gradient descent (GD) to align geometric features—such as object contours and convex hulls—across LiDAR and camera modalities. Unlike traditional calibration methods that require manual targets, our approach is targetless, extracting matched patterns from projected LiDAR point clouds and 2D image segments. The algorithm computes the optimal transformation matrix between sensors, correcting misalignments in rotation, translation, and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
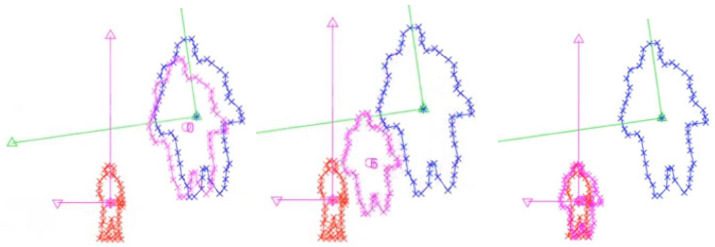 Figure 6
Figure 6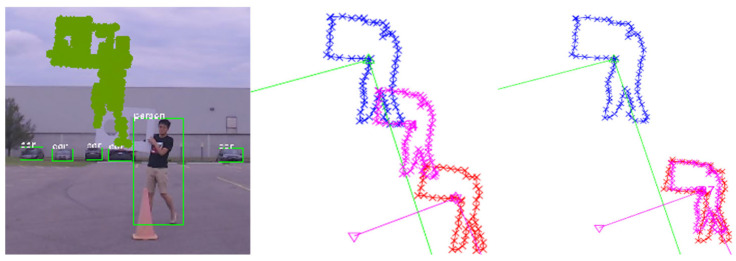 Figure 7
Figure 7 Figure 8
Figure 8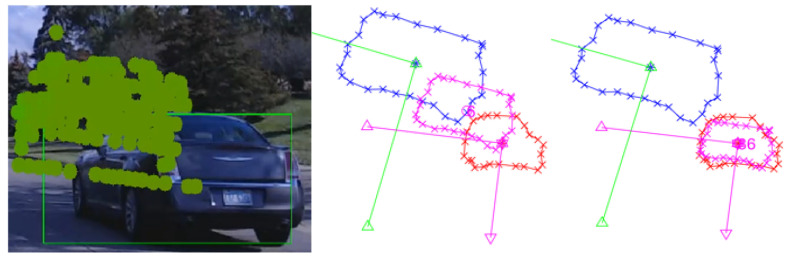 Figure 9
Figure 9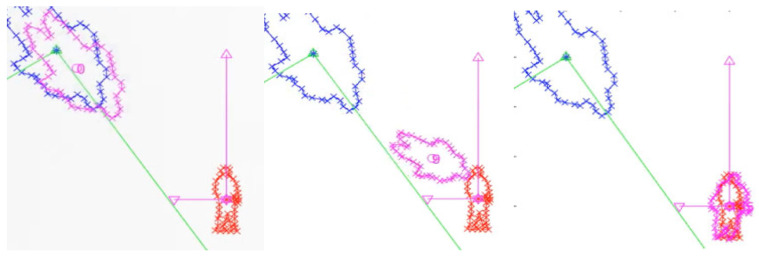 Figure 10
Figure 10- —Key Project Jilin Province Science and Technology Development Plan
- —High-end Foreign Experts Introduction Project of the Foreign Experts Bureau of the Department of Science and Technology of Jilin Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Infrared Target Detection Methodologies · Remote Sensing and LiDAR Applications
1. Introduction
Sensor fusion is a fundamental technique in robotics and autonomous systems that combines data from multiple heterogeneous sensors to achieve a more comprehensive and accurate perception of the surrounding environment. Among various sensor combinations, the fusion of Light Detection and Ranging (LiDAR) and camera data has gained significant attention due to their complementary characteristics—LiDAR provides precise geometric and depth information, while cameras capture rich semantic and visual context. This multimodal fusion enhances environmental understanding, leading to improved object detection, scene interpretation, and overall system reliability, which are crucial for Advanced Driver Assistance Systems (ADAS) and autonomous navigation [1,2,3,4].
Numerous fusion strategies have been developed to optimize the integration of LiDAR and camera data, including fully convolutional neural networks [2], deep fusion architectures [5], and segmentation-based approaches [6,7,8]. These algorithms aim to address challenges in data alignment, improve robustness to noise, and ensure real-time performance in dynamic environments. However, the effectiveness of such methods critically depends on the accuracy of sensor calibration and the process of determining the spatial and temporal relationships between sensors.
Traditional calibration techniques often rely on manual procedures using checkerboards or custom-designed targets [9,10,11,12,13]. While these methods can achieve high precision in controlled environments, they require repetitive labor, are sensitive to installation errors, and are impractical for large-scale or long-term deployments. Moreover, calibration parameters are prone to drift over time due to environmental factors such as temperature variation, vibration, and sensor wear, degrading fusion performance unless periodic recalibration is performed [14].
To address these limitations, recent research has explored targetless calibration methods that extract features from natural scenes—such as edges, planes, or point correspondences—to estimate the extrinsic transformation between sensors [14,15,16]. However, these methods can still struggle under severe noise, occlusion, or perspective distortion. Pattern matching-based approaches represent a promising alternative by aligning geometric structures such as contours, convex hulls, or projected keypoints between modalities. Some studies apply mutual information or optimization-based matching [15], while others incorporate learned correspondences through deep models [16].
Singular value decomposition (SVD)-based methods have emerged as a mathematically robust and interpretable tool for estimating rigid transformations from point sets. The Kabsch algorithm, based on SVD, has been widely adopted in registration and poses estimation tasks due to its closed-form optimality under least-squares errors [17,18,19,20]. When combined with robust feature extraction, this technique offers a powerful framework for aligning heterogeneous sensor data.
In this paper, we introduce a novel pattern matching algorithm for LiDAR–camera fusion that leverages the strengths of SVD and iterative refinement through gradient descent. Rather than directly re-estimating intrinsic or extrinsic parameters, our method aligns projected 3D point cloud features with 2D image contours by matching spatial patterns. This strategy allows us to correct sensor misalignment without requiring calibration targets, enabling efficient, repeatable fusion correction in real-world autonomous systems. Experimental results demonstrate that our method significantly improves alignment under varying environmental and calibration drift conditions.
2. Methodology
2.1. Sensor Setup and Calibration
For development and testing, we employ a real-world sensing platform consisting of a Chevrolet (Detroit, MI, USA) Cruise vehicle equipped with an Ouster OS1-64 LiDAR (Ouster, Inc., San Francisco, CA, USA) mounted on the roof and a Logitech RGB camera (Logitech, Lausanne, Switzerland) positioned on the windshield (see Figure 1). To facilitate algorithm evaluation and simulation under controlled conditions, a simulation of the vehicle was constructed in the Robot Operating System (ROS) environment (ROS Noetic, Ubuntu 20.04). This virtual model preserves the real vehicle’s geometry and sensor placement, enabling reliable reproduction of sensor data streams and frame transformations.
As illustrated in Figure 2, the transform (TF) tree of the vehicle model defines the spatial relationships between the vehicle body and its mounted sensors using six degrees of freedom—roll, pitch, yaw, and x, y, z translations. The base_footprint frame represents the vehicle’s reference point on the ground, typically defined at the geometric center between the rear wheels. The vehicle_cam frame, corresponding to the camera’s physical location, is defined as a child frame relative to the LiDAR frame.
As illustrated in Figure 3, a checkerboard calibration target with two cut-out holes was used to evaluate the alignment between LiDAR and camera data. Within the ROS RViz environment, both the LiDAR point cloud and the vehicle’s TF tree are visualized, demonstrating the spatial consistency between the 3D LiDAR data and the 2D image plane. The resulting point cloud captures distinct environmental features such as the ground surface, vertical light poles, and the calibration board itself, verifying the accuracy of the fusion setup.
To project LiDAR point cloud data onto the 2D image plane, we apply a standard extrinsic and intrinsic calibration procedure. The camera intrinsics (focal length, principal point, and distortion coefficients) and the extrinsic transformation between the LiDAR and camera coordinate frames were determined using a checkerboard target and validated in ROS. This transformation allows 3D LiDAR points , to be mapped onto 2D image coordinates using the following projection model:
where is the camera intrinsic matrix. This projected mapping enables spatial comparison between LiDAR and camera features, which is essential for the proposed SVD-based pattern matching algorithm. We employed the YOLOv5s architecture for object detection, consisting of CSPDarknet53 backbone, PANet neck, and YOLO head layers. The model was pretrained on the COCO dataset (80 object categories, 118 k images) and fine-tuned on a custom dataset of 3000 manually labeled pedestrian images captured under urban driving conditions. The input resolution was 640 × 480 pixels, using a stochastic gradient descent optimizer with a learning rate of 0.01 and batch size of 16. The confidence threshold for detection was set to 0.4 during inference. As shown in Figure 4, the CNN detection result from the camera is overlaid with the projected LiDAR point cloud on the 2D image.
2.2. Pattern Matching Algorithm
The proposed algorithm projects LiDAR point clouds onto the camera image plane, followed by the extraction of object contours and convex hulls from both modalities to capture their geometric features. Singular value decomposition (SVD) is applied to estimate the initial transformation parameters, including rotation, translation, and scale, that align the two datasets. This estimate is further refined through gradient descent (GD) optimization, which minimizes a cost function based on the residual geometric discrepancy. The combined SVD-GD approach enables robust alignment correction under varying degrees of calibration drift and sensor misalignment. Figure 5 illustrates the data preprocessing pipeline, including CNN-based object detection, LiDAR projection onto the image plane, and contour and convex hull extraction from both modalities. The extracted features are then used for SVD-based alignment and subsequent GD refinement.
The proposed pattern matching algorithm identifies and corrects sensor misalignment by minimizing discrepancies between the extracted geometric features, leading to improved fusion accuracy. By applying this algorithm, the discrepancies between the two datasets can be minimized, leading to more accurate and precise sensor fusion results.
Let the respective LiDAR and camera data at frame be denoted as matrices and , respectively, where each matrix contains the spatial features or point correspondences captured by each sensor at that frame:
With reference to the p-frame, the relative transformation from the p-frame to the q-frame can be represented by a translation vector and a rotation matrix , where
The forward kinematics relationship between the position vector and is given by
If a collection of data vectors is obtained at each frame, the dataset can be represented as a matrix, where each column (or row) corresponds to a single data vector captured at a specific frame.
Then, the matrix relationship is as follows:
The relationship between the means of the data is similarly expressed as
Let the matrix be defined as the product of the centered data matrices:
where represents the deviation of the LiDAR data matrix from its mean and represents the transpose of the deviation of the camera data matrix from its mean .
To extract the rotational relationship between the two sets of observations, we apply singular value decomposition (SVD) to , yielding
where and are unitary matrices in the minimal singular value decomposition, and is a diagonal matrix of singular values of . This decomposition allows for the estimation of the optimal rotation matrix that aligns the LiDAR and camera data in a least-squares context.
Use forward kinematics to express as
Use a similarity transformation to decompose the symmetric matrix, yielding the following relationship:
We decompose using the SVD algorithm:
It can be observed that
As a result, we find that
From the relationship , one finds that
Accordingly, the rotation matrix that aligns the LiDAR coordinate frame with the camera coordinate frame is given by:
Once the rotation matrix describing the orientation between the LiDAR and camera data is obtained, it can be used as the initial input to a gradient descent optimization function. This iterative method refines both the rotation matrix and the translation (scale) vector by minimizing a defined cost function, thereby improving the overall calibration accuracy. Upon convergence, the optimized parameters are used to update the transformation tree between the LiDAR and camera frames, resulting in a more precise estimate of their relative pose.
The designed gradient descent state is presented as
Here, and represent the LiDAR data points, which can be substituted with camera data as needed. The parameter denotes the scale factor between the LiDAR and camera data, which is initially set to 1. The major rotation angle, , is computed using the singular value decomposition (SVD) result as follows:
where is the right singular matrix obtained from the decomposition of the correlation matrix between the LiDAR and camera point sets.
The gradient descent method is a first-order iterative optimization algorithm used to minimize a cost function with respect to its parameters . At each iteration, the parameters are updated in the opposite direction of the gradient of the cost function, aiming to find the local minimum. The parameter update rule is given by
where the parameter vector to be optimized (e.g., rotation angle, scale factor, and translation), is the learning rate or step size ( ), is the gradient of the cost function with respect to , and is the cost function, typically defined as the mean squared error between transformed LiDAR data and the corresponding camera data.
The gradient of the cost function , denoted as is derived to guide the optimization process in the gradient descent algorithm. It is expressed as follows:
where and are the LiDAR data coordinates for the -th point, and are the corresponding mean values of the LiDAR data, is the scale factor between the LiDAR and camera data (initially ), and represent major rotation angles extracted from SVD-based pattern alignment, is a tuning matrix (or adjustment vector) used to scale the gradient components individually.
3. Experimental Results
3.1. Test Scenarios
To evaluate the robustness and performance of the proposed SVD-GD pattern matching algorithm, controlled misalignments were manually introduced into the system by modifying the extrinsic calibration parameters. These included rotational offsets, translation shifts, scale variations, and camera distortions, simulating practical calibration drift scenarios that may occur during long-term deployment in autonomous systems. The algorithm was tested across five representative cases. All experimental figures in this section were generated using MATLAB R2023a.
3.1.1. General Misalignment Correction (Figure 6)
In this general case, random misalignments were introduced to simulate minor calibration drift. The algorithm iteratively refined rotation, translation, and scale parameters to minimize geometric discrepancies between LiDAR and camera detections. The blue outlines represent the initial LiDAR projections, the red outlines show CNN-based camera object detections, and the pink contours illustrate intermediate stages during optimization, demonstrating convergence toward accurate alignment.
Iterative correction process of the SVD-GD algorithm. Blue: initial LiDAR projection; red: camera-based object detection; pink: intermediate results during optimization. The green and purple coordinate axes visualize the camera and LiDAR coordinate frames, respectively.
3.1.2. Checkerboard Misalignment (Figure 7)
A controlled checkerboard target with known rotational and translational offsets was used to simulate sensor misalignment. The algorithm successfully corrected these errors, aligning the LiDAR projection with the camera-detected features, despite initial calibration offsets.
Correction under checkerboard misalignment scenario. Blue: initial LiDAR projection; red: camera detection; pink: intermediate results during optimization.
3.1.3. Camera Distortion (Figure 8)
In this scenario, simulated camera lens distortion introduced additional projection errors. The algorithm effectively compensated for both geometric and projection misalignments by adjusting rotation, translation, and scale concurrently.
Correction under camera distortion scenario. Blue: initial LiDAR projection; red: camera detection; pink: intermediate results during optimization.
3.1.4. LiDAR Mounting Drift (Figure 9)
To simulate mechanical mounting shifts, positional offsets were applied to the LiDAR sensor. The algorithm successfully recovered the correct transformation despite significant positional drifts between the two modalities.
Correction under LiDAR mounting drift scenario. Blue: initial LiDAR projection; red: camera detection; pink: intermediate results during optimization.
3.1.5. Extreme Misalignment (Figure 10)
In this most challenging case, large rotational, translational, and scaling errors were introduced, including severe orientation shifts. The algorithm demonstrated strong resilience by converging to the correct transformation parameters even under extreme calibration errors.
Correction under extreme misalignment scenario. Blue: initial LiDAR projection; red: camera detection; pink: intermediate results during optimization.
3.2. Quantitative Evaluation
To quantitatively evaluate the effectiveness of the proposed SVD-GD pattern matching algorithm, we measured the alignment accuracy across several real-world scenarios, including calibration drift, camera distortion, and extreme sensor misalignment. The metric used is the average 2D pixel distance or angular deviation between the projected LiDAR data and corresponding camera features, both before and after optimization. Additionally, the runtime per frame was recorded to assess computational efficiency. Table 1 summarizes the improvement in alignment accuracy and runtime performance for each test case.
4. Discussion
While the proposed SVD-GD pattern matching algorithm demonstrates strong alignment accuracy across multiple misalignment scenarios, several factors influencing sensor misalignment remain. Even though LiDAR sensors provide accurate depth measurements, practical deployment introduces relative errors between LiDAR and camera sensors due to physical installation tolerances, mounting vibrations, mechanical deformations, and thermal expansion during long-term operation. These factors result in a gradual drift of the extrinsic parameters, which can degrade fusion performance over time.
The current method relies on the availability of clear geometric features such as object contours, making it most effective when distinct objects, such as pedestrians or vehicles, are visible in the scene. Performance may degrade under severe occlusions, in highly cluttered environments, or when object detections are ambiguous. In addition, while the algorithm operates efficiently for single-object alignment (~0.4 s per frame), further optimization will be required for multi-object scenarios or real-time processing under high frame rates. Despite these challenges, the method provides a practical and adaptive solution for correcting misalignment in dynamic environments where traditional manual calibration is impractical. Despite these challenges, the proposed method offers a practical and adaptive solution for real-world autonomous systems, where continuous calibration is difficult to maintain
5. Conclusions and Future Work
This paper presented a pattern matching algorithm that maintains alignment between LiDAR and camera sensors by extracting geometric features and applying SVD-based transformation estimation with GD refinement. The proposed targetless approach was validated across multiple real-world scenarios, including sensor drift, camera distortion, and extreme misalignments, achieving alignment improvements exceeding 85% with final alignment errors reduced to sub-pixel and sub-degree levels.
By enabling continuous correction of calibration drift, the algorithm reduces dependence on repeated manual recalibration, offering long-term stability for autonomous systems operating in changing environments. Future work will focus on extending the method to handle multiple objects, improving robustness under occlusions, and integrating real-time adaptive calibration frameworks for autonomous driving applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhang F. Clarke D. Knoll A. Vehicle detection based on Li DAR and camera fusion Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC)Qingdao, China 8–11 October 201416201625
- 2Caltagirone L. Bellone M. Svensson L. Wahde M. LIDAR–camera fusion for road detection using fully convolutional neural networks Robot. Auton. Syst.201911112513110.1016/j.robot.2018.11.002 · doi ↗
- 3Zhao X. Sun P. Xu Z. Min H. Yu H. Fusion of 3D LIDAR and camera data for object detection in autonomous vehicle applications IEEE Sens. J.2020204901491310.1109/JSEN.2020.2966034 · doi ↗
- 4Zhong H. Wang H. Wu Z. Zhang C. Zheng Y. Tang T. A survey of Li DAR and camera fusion enhancement Procedia Comput. Sci.202118357958810.1016/j.procs.2021.02.100 · doi ↗
- 5Li Y. Yu A.W. Meng T. Caine B. Ngiam J. Peng D. Shen J. Lu Y. Zhou D. Le Q.V. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition New Orleans, LA, USA 18–24 June 20221718217191
- 6Zhao L. Zhou H. Zhu X. Song X. Li H. Tao W. Lif-seg: Lidar and camera image fusion for 3d lidar semantic segmentation IEEE Trans. Multimed.2023261158116810.1109/TMM.2023.3277281 · doi ↗
- 7Berrio J.S. Shan M. Worrall S. Nebot E. Camera-LIDAR integration: Probabilistic sensor fusion for semantic mapping IEEE Trans. Intell. Transp. Syst.2021237637765210.1109/TITS.2021.3071647 · doi ↗
- 8Li J. Zhang X. Li J. Liu Y. Wang J. Building and optimization of 3D semantic map based on Lidar and camera fusion Neurocomputing 202040939440710.1016/j.neucom.2020.06.004 · doi ↗