The potential utility of CHATGPT4.0 as an AI assistant in the education and management of patients with Barrett’s esophagus
Frances Dang, Josh Kwon, Andy Lin, Shoujit Banerjee, Trevor McCracken, Amirali Tavangar, Shravani R Reddy, Alyssa Y Choi, Jennifer Phan, Jeffrey D Mosko, Samir C Grover, Tyler M Berzin, Jason Samarasena

TL;DR
This study evaluates ChatGPT 4.0's ability to provide accurate and empathetic information about Barrett’s esophagus, finding it preferred by patients over responses from gastroenterologists.
Contribution
The study demonstrates ChatGPT 4.0's potential as a high-quality, empathetic AI tool for patient education in Barrett’s esophagus.
Findings
ChatGPT 4.0 responses were rated as mostly accurate and preferred by patients for quality and empathy.
Patients found ChatGPT responses significantly better than those from gastroenterologists.
ChatGPT 4.0 could serve as an adjunctive tool for real-time patient education in Barrett’s esophagus.
Abstract
Chat Generative Pre-trained Transformer (ChatGPT) has emerged as a new technology for physicians and patients to obtain medical information. Our aim was to assess the ability of ChatGPT 4.0 to deliver high-quality information in response to commonly asked questions and management recommendations for Barrett’s esophagus (BE). Twenty-nine questions (14 clinical vignettes and 15 frequently asked questions (FAQ)) on BE were entered into ChatGPT 4.0. Using a 5-point Likert scale, three gastroenterologists with expertise in BE rated the 29 ChatGPT responses for accuracy, completeness, empathy, use of excessive medical jargon, and appropriateness to send to patients. Three separate gastroenterologists generated responses to the same 15 FAQs on BE. A group of blinded patients with BE evaluated both ChatGPT and gastroenterologist responses on quality, clarity, empathy and which of the two…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
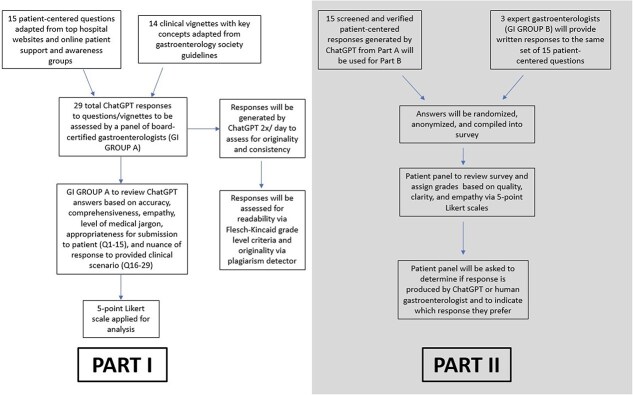 Fig. 1
Fig. 1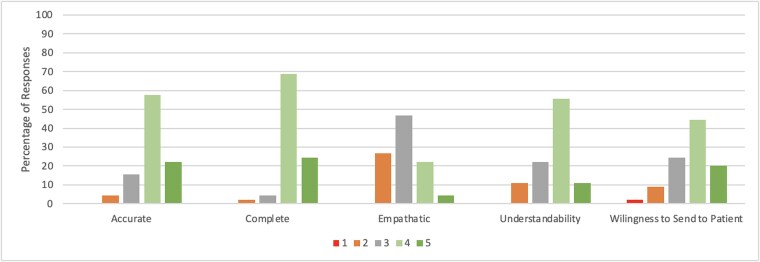 Fig. 2
Fig. 2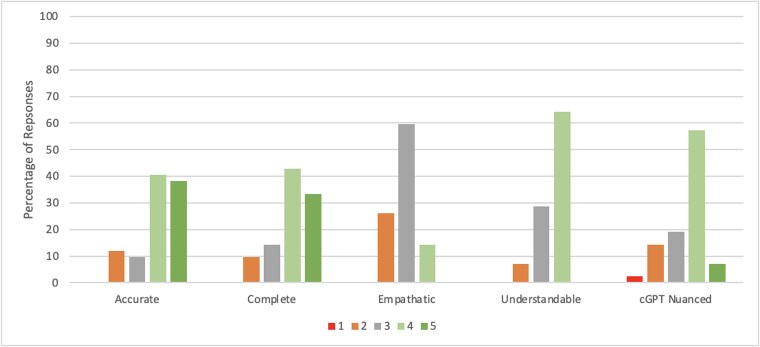 Fig. 3
Fig. 3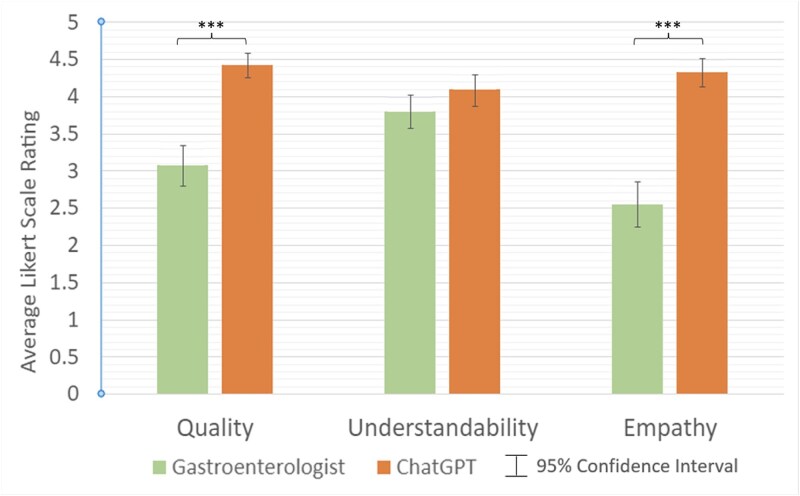 Fig. 4
Fig. 4|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
| 4.00 | 4.67 | 3.33 | 3.00 | 3.67 |
|
| 4.67 | 4.67 | 3.00 | 3.67 | 4.33 |
|
| 4.67 | 4.67 | 3.00 | 3.67 | 4.67 |
|
| 4.00 | 4.33 | 3.67 | 4.00 | 4.00 |
|
| 3.33 | 4.00 | 3.00 | 3.00 | 3.00 |
|
| 3.67 | 4.33 | 2.67 | 4.00 | 4.00 |
|
| 3.67 | 4.00 | 3.00 | 4.00 | 3.00 |
|
| 4.33 | 4.33 | 3.00 | 4.33 | 4.33 |
|
| 3.67 | 4.00 | 3.00 | 3.33 | 3.67 |
|
| 4.00 | 4.00 | 3.33 | 3.67 | 3.67 |
|
| 3.67 | 4.00 | 3.00 | 3.67 | 3.00 |
|
| 3.67 | 4.00 | 3.33 | 3.00 | 3.67 |
|
| 3.67 | 3.33 | 2.67 | 4.33 | 3.00 |
|
| 4.33 | 4.00 | 2.67 | 4.00 | 3.67 |
|
| 4.33 | 4.00 | 3.00 | 3.33 | 4.00 |
|
| 3.98 | 4.16 | 3.04 | 3.67 | 3.71 |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
| 5.00 | 5.00 | 3.67 | 4.00 | 4.33 |
|
| 3.33 | 3.33 | 2.67 | 3.00 | 2.33 |
|
| 4.33 | 3.67 | 3.00 | 3.67 | 3.67 |
|
| 4.00 | 3.33 | 2.67 | 3.00 | 3.33 |
|
| 4.33 | 4.33 | 2.67 | 3.00 | 4.00 |
|
| 4.00 | 4.67 | 3.00 | 3.33 | 3.67 |
|
| 4.33 | 4.00 | 3.00 | 4.00 | 3.67 |
|
| 4.33 | 4.00 | 2.67 | 4.00 | 3.33 |
|
| 4.00 | 3.67 | 2.33 | 3.33 | 3.33 |
|
| 2.33 | 2.67 | 2.33 | 3.33 | 2.33 |
|
| 5.00 | 5.00 | 3.67 | 4.00 | 4.00 |
|
| 4.67 | 5.00 | 3.00 | 3.67 | 4.33 |
|
| 3.33 | 3.33 | 3.00 | 4.00 | 3.67 |
|
| 3.67 | 4.00 | 2.67 | 3.67 | 3.33 |
|
| 4.05 | 4.00 | 2.88 | 3.57 | 3.52 |
|
|
|
|
| |||
|---|---|---|---|---|---|---|
| GI | ChatGPT | GI | ChatGPT | GI | ChatGPT | |
|
| 3.67 | 4.67 | 3.67 | 4.67 | 2.67 | 4.67 |
|
| 3.33 | 4.67 | 4.33 | 4.33 | 2.67 | 4.00 |
|
| 3.67 | 4.67 | 4.00 | 4.33 | 2.67 | 4.33 |
|
| 3.33 | 5.00 | 4.00 | 4.33 | 2.00 | 4.33 |
|
| 3.33 | 4.67 | 3.33 | 4.33 | 2.67 | 4.67 |
|
| 3.67 | 4.67 | 4.33 | 4.00 | 3.00 | 4.33 |
|
| 3.33 | 4.67 | 3.67 | 4.33 | 2.33 | 4.67 |
|
| 1.33 | 4.33 | 4.33 | 4.33 | 1.67 | 4.33 |
|
| 1.67 | 4.33 | 4.33 | 4.00 | 2.00 | 4.33 |
|
| 2.67 | 4.33 | 3.67 | 4.00 | 2.00 | 4.33 |
|
| 3.00 | 4.33 | 3.67 | 4.00 | 3.33 | 4.33 |
|
| 3.67 | 4.33 | 3.67 | 3.67 | 3.33 | 4.33 |
|
| 3.33 | 3.67 | 3.67 | 3.33 | 2.67 | 3.67 |
|
| 2.67 | 4.00 | 3.33 | 3.67 | 2.67 | 4.33 |
|
| 3.33 | 4.00 | 3.00 | 4.00 | 2.67 | 4.33 |
|
| 3.07 | 4.42 | 3.80 | 4.09 | 2.56 | 4.33 |
|
| <0.001 | 0.085 | <0.001 | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEsophageal Cancer Research and Treatment · Esophageal and GI Pathology · Artificial Intelligence in Healthcare and Education
INTRODUCTION
Barrett’s esophagus (BE) is a pathological disease process caused by chronic gastroesophageal reflux disease and is characterized by the replacement of squamous epithelium with metaplastic columnar epithelial tissue.1–3 BE is estimated to affect 1%–5% of people worldwide, with a greater predilection for older Caucasian males.4 Other risk factors include advanced age (>50 years old), smoking, obesity, and longstanding gastroesophageal reflux disease (GERD).3 It is estimated that 5%–12% of patients with longstanding GERD may develop BE, which is a strong predictor for the development of esophageal adenocarcinoma, as the natural course involves progression through multiple stages of dysplasia.5 As a premalignant and chronic medical condition, BE is a significant burden for patients and is associated with higher levels of depression and anxiety symptoms.6 Managing the complexities of patients with BE including different modalities for screening and prevention, treatment options, to surveillance can be time consuming, which, akin to many other GI diseases, has garnered interest in use of artificial intelligence (AI).
AI has made significant progress over the past few years, particularly in the realm of natural language processing.7 One manifestation of these advancements, Chat Generative Pretrained Transformer 4.0 (ChatGPT), has proven itself to be a useful clinical tool for communicating with patients by generating conversational text responses to a given prompt.8 The advent of this technology has made it a potential candidate to help facilitate physician–patient communication.9–13 Within the field of gastroenterology, ChatGPT satisfactorily answered straightforward questions about diagnosis and treatment options for GERD; however, with more difficult questions, ChatGPT failed to consistently provide medically accurate responses.14 Later studies corroborated these findings for eosinophilic esophagitis (EOE) and colorectal cancer screening.15^,^16 While ChatGPT was unable to pass the American College of Gastroenterology (ACG) examination, it successfully passed the United States Medical Licensing Examination (USMLE).17^,^18 This demonstrates that although ChatGPT can access and convey a significant level of medical knowledge, it has not yet been able to deliver consistent high-quality medical responses, particularly in the world of specialty medicine.
Therefore, it must be demonstrated that ChatGPT can reliably produce medically accurate responses that gain the approval of both physicians and patients. As excessive documentation and the medical inbox are key contributors to physician burnout, AI has the potential to reduce time spent responding to patient inquiries.19 Interestingly, it may even lead to greater patient satisfaction as one recent study showed that patients believe that AI-generated responses were more empathetic and of higher quality when compared to responses from human counterparts.12 The objective of our study is to evaluate the proficiency of ChatGPT in providing medical information and management recommendations regarding BE. Novel to this study, we will also assess the quality, clarity, and empathy of AI-generated answers to common patient-centered questions pertaining to BE. We hypothesize that ChatGPT will provide accurate and empathetic information about BE in both domains of commonly asked patient questions and clinically focused vignettes.
METHODS
A total of 29 questions (15 patient-centered questions and 14 clinical vignettes) were input into ChatGPT 4.0 to generate responses in November 2023. The patient-centered questions (Q1–Q15) were derived from sections of Frequently Asked Questions of top US hospital centers and online Barrett’s patient support and awareness groups (Appendix IV). The clinical vignettes (Q16–Q29) were comprised of key clinical concepts regarding BE from updated gastrointestinal society guidelines (Appendix I). Of note, no additional prompting or guidance was provided when entering questions into ChatGPT. Each of the 29 questions was submitted twice on the same day into the ChatGPT interface to ensure consistency of responses. Figure 1 demonstrates the study protocol.
Study flowchart.
Part I of the study involves the evaluation of ChatGPT responses by a panel of gastroenterologists (JM, TB, SG) with expertise and training in BE. The expert gastroenterologists were asked to rate the responses for accuracy, completeness, empathy, and use of flowery or excessive medical jargon by means of 5-point Likert scales. For responses to the patient-centered questions (Q1–Q15), the panel was asked to rate their comfort level in sending these responses to a patient using a separate 5-point Likert scale. For the responses to the clinical vignettes (Q16–Q29), the panel was asked by means of another Likert scale to evaluate how nuanced and specific each response was to the provided clinical scenario (Appendix II). For all 29 questions, a free response comment section was provided where the panel was asked if they felt each response was ‘good’ or ‘bad’ overall and any additional comments.
Part II of the study compares the responses between ChatGPT and attending gastroenterologists from the patients’ perspective. Three board-certified attending gastroenterologists (AC, JP, SR) with expertise in BE were asked to generate responses to the patient-centered questions (Q1–Q15). The gastroenterologists were instructed to answer the questions as if they were responding to patient inquiries through a clinical messaging system (i.e. electronic health record, or EHR, inbox). The responses from both ChatGPT and gastroenterologists were then collected and randomly distributed to an anonymous, blinded panel of patients with a confirmed diagnosis of BE. For each question in the survey, there were two responses (one AI- and one gastroenterologist-generated) that were randomized in order to be presented. Using 5-point Likert scales, patients were asked to evaluate the overall quality and satisfaction with each response, the degree to which each response was easy to understand, and how empathetic or personable each response was. Patients were also asked if each answer was written by ChatGPT or a human gastroenterologist and to indicate which of the two answers they preferred. The Likert grading scales and questions used by the patient evaluators are shown in Appendix III.
Data analysis
After the surveys were completed, data were compiled in Microsoft Excel and Stata. Descriptive statistics were performed. The average Likert scale rating and standard deviation for each survey category for both Part A and Part B were calculated. For Part B, the scores for each category (i.e. quality understandability, empathy) with respect to gastroenterologist and ChatGPT-generated responses were compared using a paired T-test to assess significance and confidence interval. Inter-rater reliability was assessed using Kendall’s coefficient of concordance. Originality of answers was evaluated using Copyleaks plagiarism detector. The Flesch–Kincaid grade level (formula: 0.39 × (words/sentence) + 11.8 × (syllables/words) − 15.59) was used to assess the readability of ChatGPT and gastroenterologist-generated responses. Statistical significance was defined as p < 0.05.
RESULTS
Gastroenterologists with expertise in BE rated the 29 ChatGPT-generated responses with an average accuracy rating of 4.01 (on a 5-point Likert Scale), with 79.3% of responses marked as either completely accurate or mostly accurate with minor errors (Figs 2 and 3). The average completeness rating of all responses was 4.08 out of 5, with 85.1% of all ChatGPT responses rated as either mostly or totally complete. The average empathy scores of all responses were rated lower at 2.97 out of 5, with only 20.7% of responses rated by gastroenterologists as containing high or very high levels of empathy. The average understandability rating of all responses was 3.62 out of 5, with 65.5% of responses rated as containing low or very low levels of medical jargon or flowery language. Tables 1 and 2 provide average ratings by the panel of gastroenterologists for each question, separated by question type. There were zero responses rated as completely inaccurate, totally incomplete, very low empathy, or with very high levels of medical jargon and flowery language (i.e. the lowest possible rating on each Likert scale). The 15 patient-centered responses received an average rating of 3.71 out of 5 by the gastroenterologists when asked if they were comfortable in sending ChatGPT responses to patients, with 64.4% of ChatGPT responses evaluated as acceptable to send with either very minor or no changes or modifications. Furthermore, 64.3% of responses to clinical vignettes were identified as nuanced and specific to either most or all of the clinical scenarios provided, with an average rating of 3.52 out of 5. Inter-rater reliability using Kendall’s coefficient of Concordance was 0.55, indicating a moderate to strong level of agreement among experts.
Expert rating of ChatGPT responses to patient-centered questions. † Likert scale ratings: Accuracy: 1—Completely inaccurate, 2- Mostly inaccurate information, 3—Accurate but with multiple errors, 4—Mostly accurate with minor errors, 5—Completely accurate; Completeness: 1—Totally incomplete, 2—Basic response provided but missing key information, 3—Neither incomplete nor complete, 4—Mostly complete answer providing most necessary information, 5—Totally complete and thorough answer; Empathy: 1—Very low empathy, 2—Low empathy, 3—Average empathy, 4—High empathy, 5—Very high empathy; Understandability: 1—Very high levels of medical jargon and flowery language, 2—High levels of medical jargon and flowery language, 3—Average levels of medical jargon and flowery language, 4—Low levels of medical jargon and flowery language, 5—Very low levels of medical jargon and flowery language; Willingness to Send to Patient: 1—No, I would definitely not send this response to a patient, 2—I would only consider sending this response to a patient after significant revisions, 3—I would send this response to a patient after several key modifications, 4—I would send this response to a patient after very minor modifications, 5—I would send this response to a patient without any changes or modifications.
Expert rating of ChatGPT responses to clinical vignettes related to Barrett’s esophagus. † Likert scale ratings: Accuracy: 1—Completely inaccurate, 2—Mostly inaccurate information, 3—Accurate but with multiple errors, 4—Mostly accurate with minor errors, 5—Completely accurate; Completeness: 1—Totally incomplete, 2—Basic response provided but missing key information, 3—Neither incomplete nor complete, 4—Mostly complete answer providing most necessary information, 5—Totally complete and thorough answer; Empathy: 1—Very low empathy, 2—Low empathy, 3—Average empathy, 4—High empathy, 5—Very high empathy; Understandability: 1—Very high levels of medical jargon and flowery language, 2—High levels of medical jargon and flowery language, 3—Average levels of medical jargon and flowery language, 4—Low levels of medical jargon and flowery language, 5—Very low levels of medical jargon and flowery language; Nuance/Specificity: 1—The response is extremely general and does not address the specific clinical scenario at all, 2—The response is very general and is only slightly relevant to aspects of the clinical scenario, 3—The response is neither general nor specific to the provided clinical scenario, 4—The response is both nuanced and specific to most aspects of the provided clinical scenario, 5—The response is highly nuanced and addresses all aspects of the provided clinical scenario.
In the second part of the study, the patient panel found ChatGPT responses to be of significantly higher quality compared to physician responses (4.42 vs. 3.07 out of 5, p < 0.001), with only 35.5% of ratings for gastroenterologist responses indicating high or very high quality, compared to 97.8% for ChatGPT responses (Fig. 4). Patients also found ChatGPT responses to have significantly higher empathy (4.33 vs. 2.55 out of 5, p < 0.001) when compared to gastroenterologist-generated responses. In total, 95.6% of the ratings for ChatGPT responses demonstrated high or very high empathy levels, compared to only 13.3% for gastroenterologist responses.
Patient average ratings of gastroenterologist versus ChatGPT responses. *** indicates statistical significance (p < 0.05). † Likert scale ratings: Quality: 1—Very low quality, 2—Low quality, 3—Average quality, 4—High quality, 5—Very high quality; Understandability: 1—Very difficult to understand, 2—Difficult to understand, 3—Neither easy nor difficult to understand, 4—Easy to understand, 5—Very easy to understand; Empathy: 1—Very low empathy, 2—Low empathy, 3—Average empathy, 4—High empathy, 5—Very high empathy.
When assessing understandability, patients found both ChatGPT and gastroenterologist responses to be coherent, with average scores of 4.09 and 3.8 out of 5, respectively (p = 0.085). 77.8% of the ratings for ChatGPT responses were evaluated as easy or very easy to understand, compared to 66.6% for ratings of physician responses. Table 3 summarizes the average patient rating of both human and AI responses to each question. When asked which of the two responses (AI vs. gastroenterologist) they preferred, patients selected ChatGPT responses 84.4% of the time. Regarding readability, ChatGPT responses showed an average Flesch–Kincaid reading level of 14 with an average reading ease score of 25.76, indicating a college-graduate reading level. Similarly, the average Flesch–Kincaid reading level of all gastroenterologist responses was 14 with an average reading ease score of 30.
DISCUSSION
As large language models (LLMs) continue to be refined and improved, there has been great interest in their application and integration into the medical field.20–22 Several studies have looked at the use of various versions of ChatGPT within the field of gastroenterology with variability and inconsistency in its performance. ChatGPT has been shown to accurately answer patient-centered questions in topics such as colonoscopies, cirrhosis, hepatocellular carcinoma, pancreatic cancer, and GERD, while other topics such as eosinophilic esophagitis, inflammatory bowel disease, and colorectal cancer screening highlight some of ChatGPT’s limitations.9–16^,^23 For instance, Pereyra et al. reported in a study that ChatGPT performance was both inaccurate and inconsistent when determining appropriate colorectal cancer screening recommendations on realistic clinical vignettes.16
Regarding BE, we found that ChatGPT provides adequate medical knowledge when given clinical vignettes as reviewed by three expert gastroenterologists. There were no glaring inaccuracies in ChatGPT responses; however, the content errors that ChatGPT did display involved providing non-specific recommendations that, while not harmful, were not clearly applicable, such as recommending yoga and deep breathing for stress management as lifestyle measures to prevent BE progression. ChatGPT also provided some outdated medical recommendations including esophagectomy for high-grade dysplasia and failed to mention newer therapeutic interventions like radiofrequency ablation (RFA) or endoscopic submucosal dissection. Novel therapies may handicap ChatGPT’s capability in providing up-to-date recommendations for patients as the wealth of literature is not as abundant as established treatments. Overall, ChatGPT’s ability to provide accurate medical information likely is dependent on the subject matter and this may partly explain conflicting results in the literature.14–16^,^20^,^21 Given that ChatGPT synthesizes information that is readily available on the internet, it may be able to provide higher-quality responses on medical topics with clear-cut society guidelines and a wealth of published literature. Conversely, ChatGPT may have difficulty with medical topics that involve rapidly evolving recommendations or those requiring high levels of clinical experience or nuance, which are limitations previously observed.22 Additionally, although the physician panel in our study found the ChatGPT responses to contain high levels of accuracy, one systematic literature review by Shung et al. found generally low accuracy levels in responses to gastroenterology and hepatology-related questions by LLMs, including ChatGPT 4.0.23
Our use of frequently asked patient questions simulates an interaction between patients and ChatGPT, which overall showed adequate medical knowledge and, interestingly, was preferred by patients when compared to gastroenterologist-generated responses. Compared to gastroenterologists, ChatGPT provided longer and more comprehensive responses, which patients favored in quality, empathy, and overall preference. This is congruent with a previous study by Ayers et al., demonstrating that in a forum of patient question queries, physicians overall rated chatbot responses as having higher quality and empathy.12 Given a busy clinician’s time constraints, providing long and extensive responses may not be feasible for every patient inquiry. As EHR16 inboxes have been identified as a contributor to ever-increasing physician burnout, we highlight that ChatGPT has the potential to improve physician workflow and efficiency.19
A recently published study by Garcia et al. demonstrated that when providers utilized draft replies to patient portal messages generated by an EHR-integrated LLM, there was no significant change in reply action time, write time, or read time.24 Although results from their study and ours cannot be directly compared given differences in methodology, outcomes measured, and combination of different specialties (predominantly family medicine and general internal medicine vs. a specific topic in gastroenterology), it is interesting to note that in their subgroup analysis, gastroenterology, and hepatology nurses had higher draft utilization and a trend toward time saved and positive net promoter scores.24 As our study found that >80% of ChatGPT responses were appropriate to be sent with minimal change and that there was a clear preference by patients for ChatGPT responses over gastroenterologist-generated responses; there is a promising potential value of using AI generative tools in specific practice patterns and workflows within gastroenterology. For example, many clinicians today often use premade responses or have their support staff draft replies. Use of an AI-assisted approach could potentially help relieve work burden and give back time to physicians and clinical staff to focus on other tasks. Having clinical staff review and modify AI-written drafts would allow for more consistent responses and improve communication with patients.
The results and themes from previous studies and ours suggest that in its current iteration, ChatGPT cannot perform autonomously and requires healthcare provider monitoring and input. However, a healthcare provider harnessing the power of AI ‘provider–AI hybrid’ could potentially be the answer for better care while reducing burnout.25 This has already been observed in previous studies, as utilization of AI-generated draft replies to patient portal messages resulted in improvement in assessments of burden and burnout among providers in gastroenterology and hepatology.24 As seen in prior studies, such as in ChatGPT and EOE, we found that ChatGPT provided responses at a college graduate reading level. Importantly, the American Medical Association recommends that medical information be below a sixth-grade reading level to best promote health literacy.15^,^26 However, our evaluation of gastroenterologist-generated responses also displayed a college graduate reading level, which highlights the need for both physicians and AI to tailor medical communication for each patient to ensure readability. A potential solution that was not pursued in this study is to specifically add additional prompting to the LLM so that responses are tailored to a certain reading level.
One potential limitation of any study using ChatGPT is the inherent bias of its training data. The model’s responses are based on a diverse but uncontrolled data set of information gathered from the internet, which is uncurated and may include false or outdated information. To address this challenge, there is ongoing discussion about the need to utilize refinement techniques, such as reinforcement learning from human feedback, to increase LLM accuracy.27 Other limitations to our study include its observational nature and relatively low sample size of patients. We also acknowledge that our study is limited to BE and our conclusions may not be applicable to other medical conditions. Additionally, although our study is novel in its comparison of empathy levels between ChatGPT and gastroenterologists, empathy is a nebulous concept and use of a Likert scale may not fully capture the complexity and nuance of effective patient communication. Lastly, ChatGPT boasts distinct responses to identical prompts, which limits standardization of information for patients. This is not a clear limitation as a patient aid, as different human providers may display similar incongruity when faced with identical prompts. Each question was submitted twice to ChatGPT, and we found that although the formatting of responses varied with each iteration, the content remained consistent with each query. It is worth noting that further updates in ChatGPT programming are ongoing and the responses generated in this particular version may not reflect results derived from subsequent versions of ChatGPT.
Overall, our investigation comprehensively elucidates a role for ChatGPT regarding patient inquiries on Barrett’s esophagus. We found that ChatGPT provides adequate medical knowledge when evaluated by expert gastroenterologists and overall, its responses were preferred by patients when compared to gastroenterologist-generated responses. To our knowledge, this is the first comprehensive study within a specific topic in gastroenterology demonstrating that ChatGPT is medically accurate and preferred by patients when compared to human gastroenterologists. Given inconsistencies on prior ChatGPT performance on various topics in GI, it is important that more of these studies are performed on different topics until the technology has advanced enough to consistently provide accurate and up to date medical information. Further studies are needed to reassess medical accuracy, patient satisfaction and characterize time and energy spent on EHR inbox when ChatGPT is implemented as a physician aid.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Gerson L B, Shetler K, Triadafilopoulos G. Prevalence of Barrett's esophagus in asymptomatic individuals. Gastroenterology 2002; 123(2): 461–7.12145799 10.1053/gast.2002.34748 · doi ↗ · pubmed ↗
- 2Shaheen N J, Falk G W, Iyer P G et al. Diagnosis and management of Barrett’s esophagus: an updated ACG guideline. Am J Gastroenterol 2022; 117(4): 559–87.35354777 10.14309/ajg.0000000000001680 PMC 10259184 · doi ↗ · pubmed ↗
- 3Sharma P . Barrett esophagus: a review. JAMA 2022; 328(7): 663–71.35972481 10.1001/jama.2022.13298 · doi ↗ · pubmed ↗
- 4Runge T M, Abrams J A, Shaheen N J. Epidemiology of Barrett’s esophagus and esophageal adenocarcinoma. Gastroenterol Clin 2015; 44(2): 203–31.10.1016/j.gtc.2015.02.001PMC 444945826021191 · doi ↗ · pubmed ↗
- 5Eluri S, Shaheen N J. Barrett's esophagus: diagnosis and management. Gastrointest Endosc 2017; 85(5): 889–903.28109913 10.1016/j.gie.2017.01.007PMC 5392444 · doi ↗ · pubmed ↗
- 6Treml J, Kreuser N, Gockel I, Kersting A. Anxiety and depression in patients with Barrett’s esophagus: estimates of disorder rates and associations with symptom load and treatment-seeking. Eur J Gastroenterol Hepatol 2020; 33(6): 825–31.10.1097/MEG.000000000000196033136727 · doi ↗ · pubmed ↗
- 7Nadkarni P M, Ohno-Machado L, Chapman W W. Natural language processing: an introduction. J Am Med Inform Assoc 2011; 18(5): 544–51.21846786 10.1136/amiajnl-2011-000464 PMC 3168328 · doi ↗ · pubmed ↗
- 8Open AI . https://chat.openai.com Accessed February 5, 2024.