A syllable-character collaborative model for enhanced Pinyin and Chinese recognition
Zeyuan Chen, Cheng Zhong, Danyang Chen

TL;DR
This paper introduces a new model for Chinese speech recognition that improves accuracy by combining syllables and characters during training.
Contribution
The novel SCCM model uses phonetic elements and an ensemble approach to reduce recognition errors in Chinese speech.
Findings
The SCCM model reduces pinyin and character error rates compared to prior methods.
It achieves a 45.7% relative reduction in Character Error Rate on the AISHELL-1 dataset.
Abstract
In Chinese speech recognition, end-to-end speech recognition models usually use Chinese characters as direct output and perform poorly compared with other language models. The main reason for this phenomenon is that the relationship between Chinese text and pronunciation is more complex. Inspired by the learning process of Chinese beginners, who first master initials, finals, and pinyin before learning characters, we propose the Syllable-Character Collaborative Model (SCCM), which incorporates these phonetic elements into the training process. Additionally, we design a Pinyin-Ensemble module that employs an ensemble learning approach to reduce pinyin recognition errors, which in turn leads to a reduction in text recognition errors. Experiments on AISHELL-1 show that our approach not only reduces pinyin and character error rates compared to a prior end-to-end method using pinyin as…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34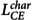 Figure 35
Figure 35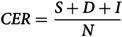 Figure 36
Figure 36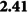 Figure 37
Figure 37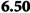 Figure 38
Figure 38 Figure 39
Figure 39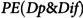 Figure 40
Figure 40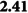 Figure 41
Figure 41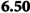 Figure 42
Figure 42 Figure 43
Figure 43 Figure 44
Figure 44 Figure 45
Figure 45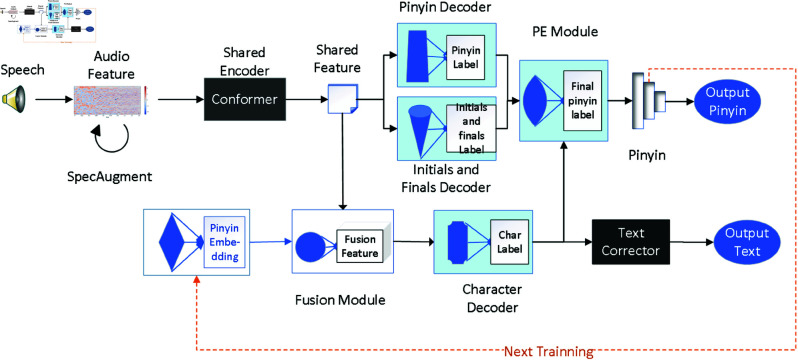 Figure 46
Figure 46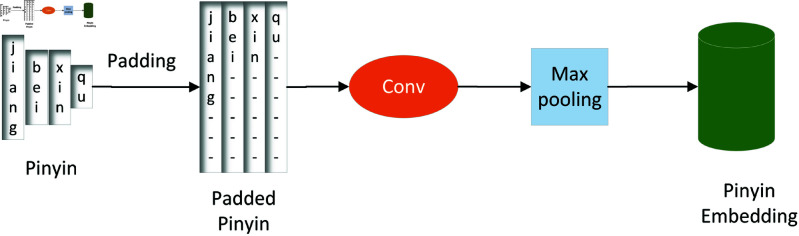 Figure 47
Figure 47 Figure 48
Figure 48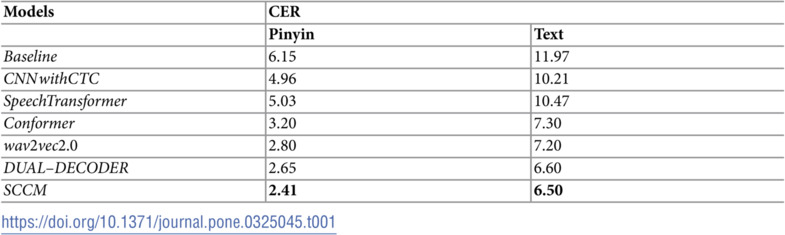 Figure 49
Figure 49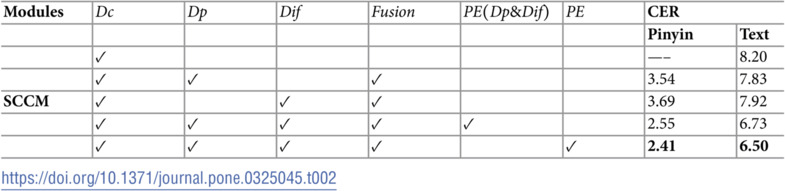 Figure 50
Figure 50Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech Recognition and Synthesis · Natural Language Processing Techniques · Topic Modeling