Diffusion wavelets on connectome: Localizing the sources of diffusion mediating structure-function mapping using graph diffusion wavelets
Chirag Jain, Sravanthi Upadrasta Naga Sita, Avinash Sharma, Raju Surampudi Bapi

TL;DR
This paper introduces a new method using graph diffusion wavelets to better understand how brain structure relates to function, achieving high accuracy in predicting functional connectivity.
Contribution
The novel use of graph diffusion wavelets to assign region-specific diffusion scales for structure-function mapping.
Findings
The proposed method achieves an average Pearson’s correlation of 0.833 in predicting functional connectivity.
The frontal pole is associated with large diffusion scales, forming significant community structures.
Diffusion scales follow a power-law distribution, indicating a scale-free process in the brain.
Abstract
The intricate link between brain functional connectivity (FC) and structural connectivity (SC) is explored through models performing diffusion on SC to derive FC, using varied methodologies from single to multiple graph diffusion kernels. However, existing studies have not correlated diffusion scales with specific brain regions of interest (RoIs), limiting the applicability of graph diffusion. We propose a novel approach using graph diffusion wavelets to learn the appropriate diffusion scale for each RoI to accurately estimate the SC-FC mapping. Using the open Human Connectome Project dataset, we achieve an average Pearson’s correlation value of 0.833, surpassing the state-of-the-art methods for the prediction of FC. It is important to note that the proposed architecture is entirely linear, computationally efficient, and notably demonstrates the power-law distribution of diffusion…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
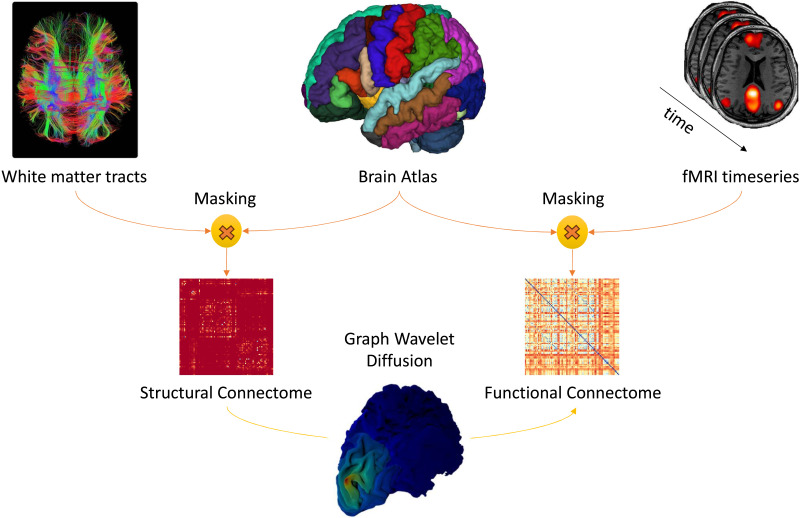 Figure 1
Figure 1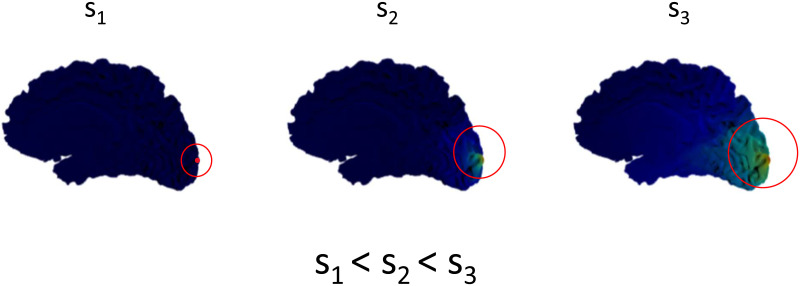 Figure 2
Figure 2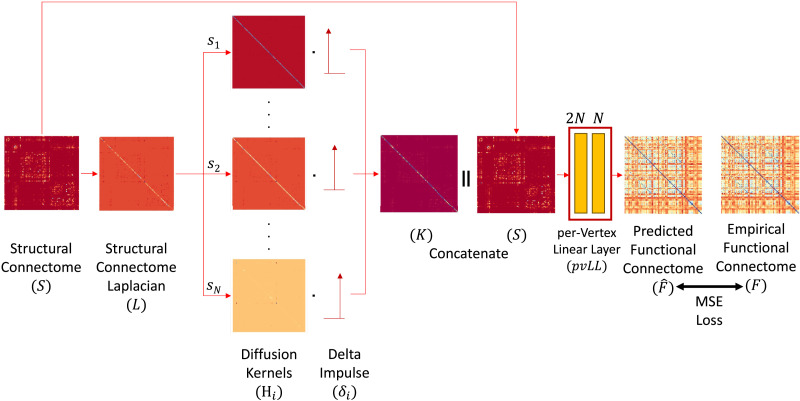 Figure 3
Figure 3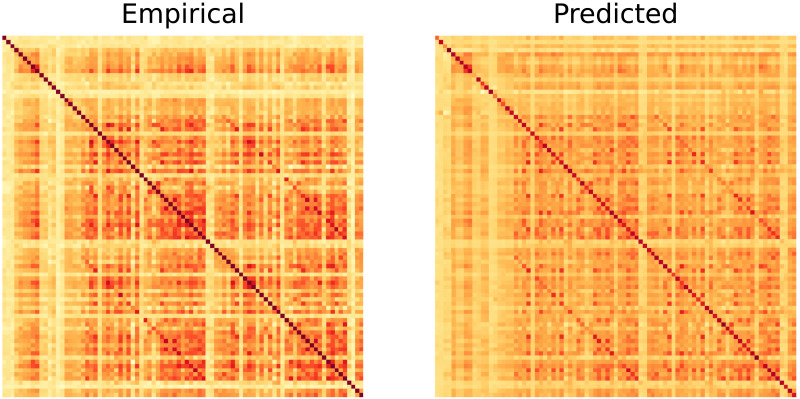 Figure 4
Figure 4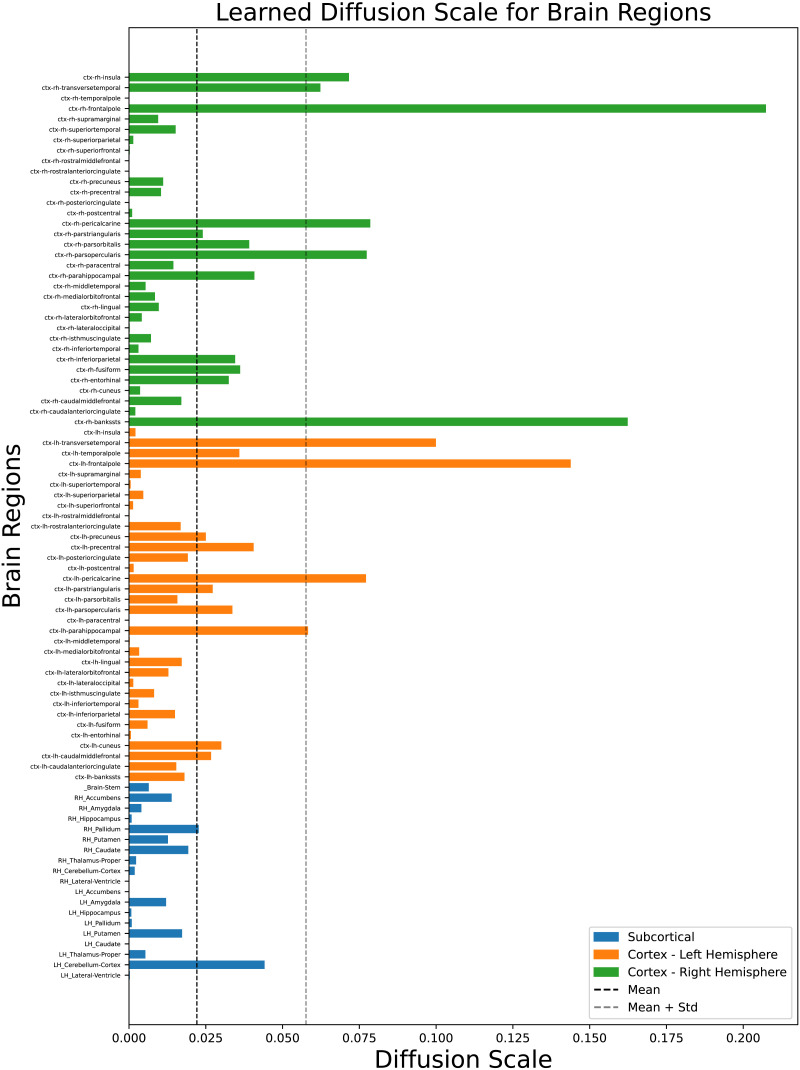 Figure 5
Figure 5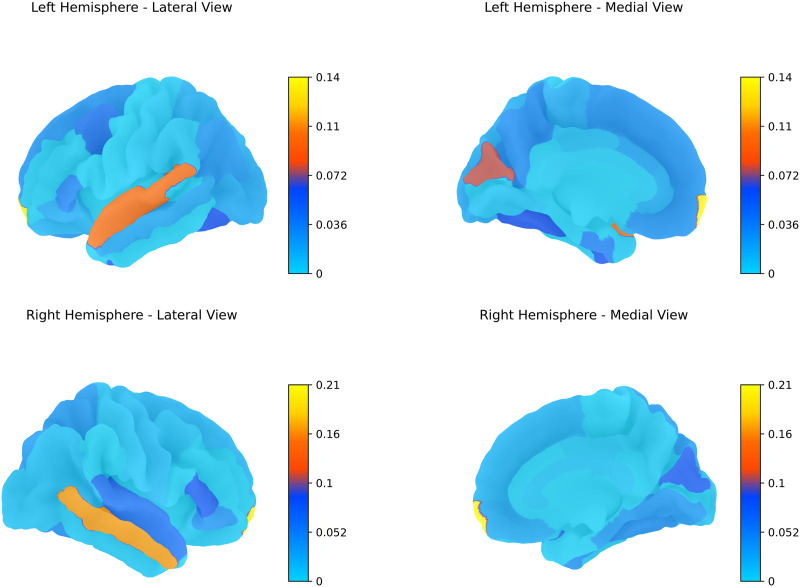 Figure 6
Figure 6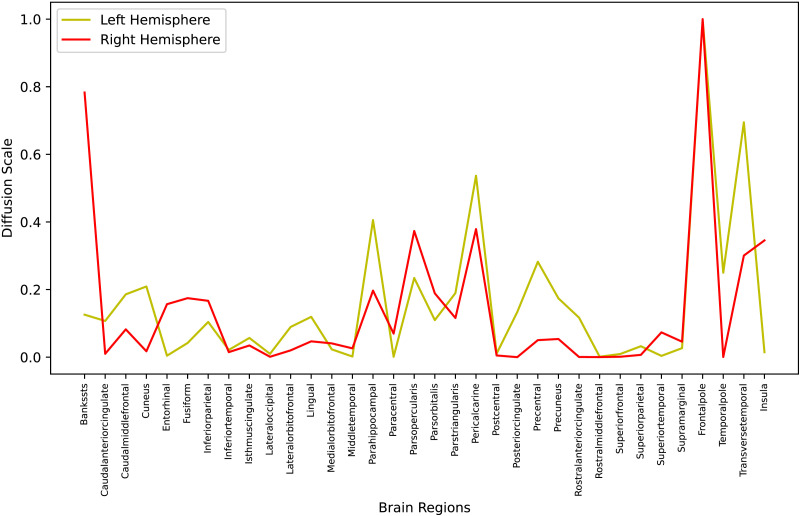 Figure 7
Figure 7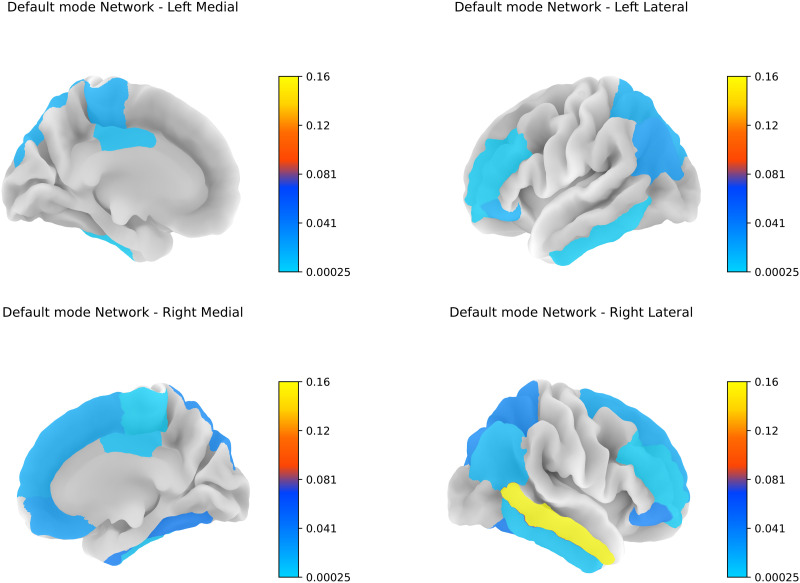 Figure 8
Figure 8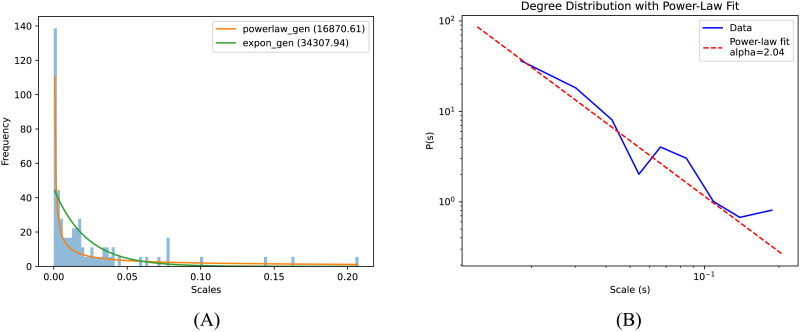 Figure 9
Figure 9|
|
|
|---|---|
| A-GHN ( |
|
| MKL ( | 0.645 |
| GNN (GCN + GTN) ( | 0.715 |
| GCN Encoder-Decoder ( |
|
| Graph wavelet diffusion |
|
|
|
|
|
| ||||
|---|---|---|---|---|---|---|---|
| Train set | Validation set | Test set | Train set | Validation set | Test set | ||
|
| 0 | 0.8332 ± 0.0014 | 0.8318 ± 0.0059 |
| 0.0220 ± 0.0004 | 0.0228 ± 0.0017 |
|
| 1 | 0.8314 ± 0.0008 | 0.8269 ± 0.0016 |
| 0.0223 ± 0.0003 | 0.0236 ± 0.0006 |
| |
|
| 0 | 0.8292 ± 0.0010 | 0.8224 ± 0.0079 |
| 0.0224 ± 0.0004 | 0.0241 ± 0.0016 |
|
| 1 | 0.8277 ± 0.0010 | 0.8237 ± 0.0039 | 0.8254 ± 0.0006 | 0.0224 ± 0.0003 | 0.0231 ± 0.0020 | 0.0228 ± 0.0003 | |
|
| 0 | 0.8200 ± 0.0006 | 0.8133 ± 0.0048 | 0.8171 ± 0.0003 | 0.0230 ± 0.0006 | 0.0241 ± 0.0017 | 0.0233 ± 0.0005 |
| 1 | 0.8237 ± 0.0019 | 0.8180 ± 0.0036 | 0.8206 ± 0.0012 | 0.0226 ± 0.0007 | 0.0237 ± 0.0016 | 0.0231 ± 0.0008 | |
|
|
|
|
|
|---|---|---|---|
| Graph wavelet |
|
|
|
| A-GHN | 244,648 | 0.233 MB | 12.88 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFunctional Brain Connectivity Studies · Neural dynamics and brain function · Opinion Dynamics and Social Influence
INTRODUCTION
The physical properties of biological entities are a key to understanding and predicting various functional capabilities. The principle of “structure determines function” has been extremely influential in molecular biology, biochemistry, and physical sciences (Alberts et al., 2002; Michael, 2021). Neuroscientists have tested this dogma on the brain and have observed that brain structural connectivity (SC) largely determines its functional connectivity (FC; Damoiseaux & Greicius, 2009; Sporns, 2013). As shown in Figure 1, the SC is derived from diffusion tensor imaging (dMRI), which captures the white matter tracts (myelinated axons) internally connecting the gray matter of the cortex. These tracts are obtained by a tractography algorithm, and then with the help of an atlas that divides the cortex in multiple regions, we can determine the strength of SC between cortical regions. The static FC is derived from functional MRI (fMRI) that is based on the blood oxygen level–dependent activity (BOLD signal) sampled across the duration of resting-state epoch. The voxel-wise BOLD signal, again with the help of the same atlas, can be converted to a region of interest (RoI)–specific signal that represents a local aggregate of oxygen concentration at different time points. Furthermore, we can calculate the Pearson’s correlation between the BOLD signal of each of the RoIs to get connectivity strength based on correlation in their activity (Liu, Betzel, & Misic, 2022). Various fMRI studies have shown that brain RoIs interact to form functional networks when involved in visual (Lowe, Dzemidzic, Lurito, Mathews, & Phillips, 2000), language (Hampson, Peterson, Skudlarski, Gatenby, & Gore, 2002), or working memory (Hampson, Driesen, Skudlarski, Gore, & Constable, 2006) tasks (Skudlarski et al., 2008) and also in resting state (Biswal, Zerrin Yetkin, Haughton, & Hyde, 1995).
The white matter tracts are extracted from diffusion MRI, and the time series is estimated using functional MRI. Both are masked using a brain atlas to obtain the structural connectivity matrix and functional connectivity matrix, respectively. These connectomes are used to learn the diffusion scales using the graph wavelet diffusion process.
Mapping SC-FC is essential to understand the intricate network dynamics of the brain and its implications for various neurological disorders. This mapping allows researchers to discover biomarkers associated with diseases such as autism spectrum disorder (Chen et al., 2021), Alzheimer’s disease (Patow et al., 2023), and so forth, by analyzing deviations between predicted FC derived from SC and empirical FC data. Such studies facilitate the creation of reliable computational models of brain networks that can be tested against specific perturbations associated with a variety of diseases, ultimately improving our understanding of the neural circuitry responsible for behavioral dysfunctions. By bridging the gap between structural and functional perspectives, researchers can better elucidate the mechanisms underlying cognitive processes and pathologies, paving the way for targeted therapeutic strategies and interventions in clinical settings.
Modeling the brain as a graph through network neuroscience allows for a comprehensive analysis of its structure and function by representing brain regions as nodes and anatomical connections as edges (Bassett & Sporns, 2017; Bassett, Zurn, & Gold, 2018). This approach, applicable from micro- to macroscales, facilitates the creation of connectomes that link structure-function domains, revealing meaningful properties of brain networks (Papo & Buldú, 2024). Using graph theory techniques, we can gain insight into the complexities of brain connectivity and dynamics, enhancing our understanding of both healthy and pathological states.
One of the main goals of connectomics is to understand how and to what extent brain structure influences its function. For over a decade, various studies relying on network organization have tried to establish a relationship between structure and function (Bullmore & Sporns, 2009; Honey et al., 2009; Honey, Thivierge, & Sporns, 2010). This network-based approach enables the use of graph theory methods such as random walk (Rosenthal et al., 2018) and spectral graph theory methods such as graph Fourier transform (Griffa, Amico, Liégeois, Van De Ville, & Preti, 2022), which are based on the principle of graph heat diffusion. Abdelnour, Voss, and Raj (2014) proposed that brain functional states (FC) can be predicted using a single heat diffusion kernel, a method that proved very successful and prompted further studies to rely on variants of such network diffusion models. Later, Surampudi et al. (2018, 2019) demonstrated that FC can be better explained using a linear combination of heat diffusion kernels. With the advent of geometric deep learning (GDL), methods like graph convolutional neural network (GCN; Kipf & Welling, 2016)—and graph transformer network (GTN; Yun, Jeong, Kim, Kang, & Kim, 2019)—based encoder-decoder models were used for finding better mappings (Ji, Deslauriers-Gauthier, & Deriche, 2021).
However, GCN-based learning methods are susceptible to the problem of oversmoothing, where all the node features converge to the same representation in the latent space, more so in a fully connected brain graph. Furthermore, since GDL methods lacked explainability, they were eventually integrated with graph diffusion methods (Oota, Yadav, Dash, Bapi, & Sharma, 2022, 2024) that rely on the attention mechanism for combining the heat kernels. Although incorporating attention leads to somewhat superior results compared with previous methods, they suffer from high computational complexity.
In this paper, we address the above issues by using the graph diffusion wavelets, which localize the diffusion kernel, enabling each brain region to have a unique diffusion scale. The implicit multiresolution nature of wavelets allows us to have RoI-level information of interaction in the brain. The proposed method is entirely linear, has lower space-time complexity, and, at the same time, performs better than the previous state-of-the-art (SoTA) methods. In the context of human connectomics, SC serves as the substrate for functional interactions, but the SC-FC relationship is modulated by region-specific properties such as hierarchical integration and functional specialization. By adapting diffusion scales for each RoI, our method provides biologically plausible insights into these dynamics, aligning with the evidence that structure-function coupling varies across spatial and functional hierarchies.
MATERIALS AND METHODS
Theory
The graph wavelets, with a rich history rooted in physics and mathematics, are explored in this section, where we explain graph diffusion, explain its relation to computational neuroscience, and introduce the wavelet concept. The relationship between SC and FC in the brain is complex, shaped by both local and long-range interactions. Graph diffusion wavelets offer a powerful framework for modeling this interplay, as they are inherently designed to capture multiscale diffusion processes on graphs. By leveraging graph diffusion wavelets, we can effectively map SC to FC by simulating how neural signals propagate through the structural network of the brain. A key advantage of this approach is the ability to learn diffusion scales, which provide localized insights into how information flows within and across RoIs. These scales adapt to the heterogeneity of brain dynamics, enabling the model to account for both short-range connections, which support unimodal functions, and long-range communication, critical for higher order cognitive processes. By integrating this multiscale understanding, graph diffusion wavelets provide a principled and biologically informed method to bridge the gap between SC and FC, yielding more accurate predictions while uncovering meaningful structure-function relationships.
Graph diffusion.
The heat diffusion equation is a partial differential equation that models the process of heat flow in space. For example, consider a metal rod, and one end of which is heated. The heat will flow to another, relatively cooler end, and the temperature (or any spatiotemporal signal like BOLD, x(t)) can be modeled using the classical heat diffusion (Equation 1; Wang & Solomon, 2019).
where 𝓛 is the famous Laplace-Beltrami operator. However, the graph is a discrete mathematical entity and, therefore, the equation is discretized, leading to the formulation of a Laplacian operator L = I − D^−1^A or where A is the graph adjacency matrix and D is the degree matrix. The Laplacian operator encodes spatial information of the graph, and the eigenvectors of graph Laplacian form the basis set called spatial harmonics, which is known to reconstruct BOLD data with high accuracy (Atasoy, Donnelly, & Pearson, 2016; Preti & Van De Ville, 2019). The solution x(t) = hs(x) = e^−sL^x(0) is a heat diffusion kernel that operates on y to determine the extent of diffusion after some time t parameterized by diffusion scale s. The matrix exponential can be computed as follows:
where U is the eigenvector matrix and (λ1, …, λN) are the eigenvalues of Laplacian L, where N is the number of nodes. The diffusion equation is prevalent in many branches of science (Stewart, 1999) and technology (Sharma, Horaud, Cech, & Boyer, 2011; Sharp, Attaiki, Crane, & Ovsjanikov, 2022).
Neural basis of heat diffusion.
The Wilson-Cowan equation (Wilson & Cowan, 1972) is one of the most successful models of interaction between populations of excitatory and inhibitory neurons. It is an instance of reaction-diffusion (RD) equations wherein the activity diffuses over space, and the diffusion is guided by the connection strength between elements of that space. The turing mechanism for RD systems states that the spatial modes of the Laplacian of a system are instrumental in understanding the perturbation of that system (Kondo & Miura, 2010; Van Gorder, 2021). Atasoy et al. (2016) emphasizes the use of Laplacian operator across all physical systems and specifically its utility in modeling the RD systems to eventually characterize the “connectome harmonics.” These connectome harmonics are the stationary waves associated with the graph, which can resolve the graph activity based on its spatial frequencies. The state of such system at any time is given by the heat kernel given in Equation 2.
Graph wavelets.
In signal processing, wavelets are used to localize the signal in the time domain. This allows exploration of properties of the signal for a specified time period instead of the entire time series data. Time-frequency plots are one such example that are extensively used in EEG signal processing (Cohen, 2014). Similar to time domain, we can have wavelets in the spatial domain that can localize the spatial data (like a graph). Wavelets can be applied to graphs to capture the local neighborhood of specific nodes (Coifman & Maggioni, 2006; Gavish, Nadler, & Coifman, 2010; Hammond, Vandergheynst, & Gribonval, 2011). The diffusion wavelet ψs,a(x) is defined as:
where a is the ath node and s is the scale. A graph wavelet captures the local neighborhood of a node when a unit energy is propagated from the node to the graph (Donnat, Zitnik, Hallac, & Leskovec, 2018); see Figure 2. Moreover, nodes can operate at different diffusion scales, helping us understand the role of each node within the graph. A significant limitation of the heat kernel is its lack of spatial localization, which greatly reduces its explainability, and this can be fixed by wavelets.
Visualization of diffusion on the brain surface mesh. We show the wavelet diffusion for three different scales—s1, s2, and s3—in increasing order. Note that higher diffusion scales correspond to bigger neighborhoods.
In this paper, we propose the use of graph wavelets to localize heat diffusion, providing a higher resolution view of the RD process. By associating different diffusion scales with each node, we can uncover the properties of various brain RoIs with greater precision and clarity. This approach enhances our ability to understand the intricate dynamics within the graph, like the existence of scale-free networks, offering a significant improvement over previous methods.
Graph Wavelet Diffusion
For a brain region i, we write the rate equations by considering all the connected regions. The activity of diffusion in space in region j is given by i,jxj(t), where i,j is the (i, j)th entry of unnormalized SC, representing the number of tracts between ith and jth regions. The net change in activity of diffusion in space in region i is considered a linear function of the net activity of diffusion from region j, which according to Abdelnour et al. (2014) gives:
dj being the degree of node j.
where is the row-normalized SC matrix. Concatenating over i results in:
where 𝓛 = I − S. The solution for above equation is:
For multiresolution and multiscale analysis, we perform dot product with an impulse function and have a unique diffusion kernel for each node.
Without loss of generality, assume that x(0) is a unit vector and the matrix exponential can be computed through Laplacian eigen decomposition along with a diagonal heat kernel matrix (H).
where H(si) = Diag(e^−siλ1^, …, e^−siλN^). We can construct an asymmetric kernel matrix (K) by concatenating all the wavelets together.
where the symbol ‖ represents concatenation. At time t, the configuration of any given region i, based on an initial configuration, represents the FC of region i with all other regions. To obtain FC, we concatenate the asymmetric kernel and SC and pass it through a per-vertex linear layer (see Figure 3), which enables us to learn the optimal diffusion scales.
Here, pvLL() refers to the process whereby a linear layer (LL) is applied per vertex (pv) of the concatenated matrix to eventually yield a predicted FC matrix ( ). In other words, the linear layer is utilized for learning the mapping between each row of the concatenated matrix (K‖S) to each row of FC. The diffusion process utilizes the neighborhood structure, while the per-vertex linear layer performs mapping for individual nodes. This linear layer can be replaced by multilayer perceptron (MLP) by addition of an activation function, but note that our primary model is entirely linear. Furthermore, we know from literature that nonlinear MLP does not capture spatial information but helps capture high-frequency features (Sharp et al., 2022). Therefore, we incorporated the linear layer for learning the mapping. This entire flow of the graph wavelet method is depicted in Figure 3.
Flow of the graph wavelet method. 1. Calculate the normalized graph Laplacian (L) from the structural connectome (S). 2. Calculate the heat kernel for each node i, (Hi). 3. Extract the brain region from the corresponding heat kernel by localization with its dot product with the delta impulse function (δi). 4. Concatenate diffusion kernel (K) and SC (S). 5. Then, we flatten each node and estimate the predicted FC (Fˆ) using the per vertex linear layer (pvLL) for each node. 6. Lastly, we estimate the Mean Squared Error (MSE) loss by comparing the predicted and empirical FC (F) for optimization.
Training
In this section, we define the update rule for the diffusion scales and other aspects of training. We use the Adam optimizer (Kingma & Ba, 2014) along with a scheduler and the Frobenius norm of difference between predicted and empirical FC.
Forward Pass:
Since Si is constant, gradients corresponding to it will be zero.
where yi is the ith row of predicted FC matrix and W is the linear mapping. We concatenate all the yi and then calculate the loss. The loss function is defined as the Frobenius norm of difference of the predicted FC [ ] and empirical FC [Y]. When projecting a matrix onto the space of positive semidefinite matrices (like FC), the nearest positive semidefinite matrix can be computed using the Frobenius norm (Higham, 1988).
Backward Pass:
As can be seen from the update rule for the diffusion scales, the scales of RoIs are dependent on the overall FC, the linear mapping W, and the derivative of the wavelet at scale s.
Scale Selection
The question of which scales to use always persisted in the literature, right from Abdelnour et al. (2014) and multiple kernel learning (MKL; Surampudi et al., 2018) to attention graph heat network (A-GHN; Oota et al., 2024). We solve this problem by learning the scales by relying on backpropagation learning algorithm with the MSE loss function as shown in Figure 3.
Data
The dMRI and fMRI datasets are from the Human Connectome Project (HCP1200; https://www.humanconnectome.org/study/hcp-young-adult/document/1200-subjects-data-release) dataset. We assessed the 1,058 subjects provided in the HCP1200 data release (Van Essen et al., 2013). The data are processed by Zhang et al. (2018) and made available publicly at the GitHub repository (https://github.com/maxwass/brain_data_processing). They have used the Desikan et al. (2006) atlas, consisting of 68 cortical (34 from each hemisphere) and 19 subcortical brain regions. As mentioned in the repository, the 19 subcortical regions are not consistently arranged across SC and FC. We resolved this issue by reordering the FC matrix so that the correspondence between RoIs of SC and FC is maintained. This data processing step is crucial for our work since graph wavelets are first localized and then mapped to specific nodes.
RESULTS
We conduct rigorous experiments on our model, comparing it quantitatively with previous SoTA models, and also explain the patterns observed in learned diffusion scales. The plan of experiments is as follows: We undertake comparison of performance of the proposed model with respect to SoTA models and generalizability experiments on the proposed model itself. Various ablation experiments are then conducted to investigate the impact of changing the number of eigen basis vectors used for estimation of the predicted FC, effect of using an MLP layer in place of a linear output layer, and finally investigate various features of the learned diffusion scales.
Comparison With Previous Architectures
As the proposed model utilizes multiresolution, multiscale graph diffusion wavelets, we perform a comparative study on a graph diffusion-based approach that does not use deep networks such as the MKL model (Surampudi et al., 2018). Furthermore, we chose models that do not utilize diffusion but implement GDL methods such as the GCN Encoder-Decoder model (Li, Shafipour, Mateos, & Zhang, 2019) and another model that combines GCN and GTN (Ji et al., 2021). Finally, we considered a model that combines graph diffusion, heat kernels, and deep neural networks with attentional mechanism, namely, the A-GHN model (Oota et al., 2024) for comparative analysis.
All the models underwent training and testing for a total of five times on the open HCP dataset that has 1,058 subjects. For each run, the dataset was partitioned into three distinct parts: 50% was allocated for training, comprising 529 samples; 5% was designated for validation, consisting of 53 samples; and the remaining 45% was set aside for testing, encompassing 476 samples. Across these five iterations, the performance of the model was evaluated using the Pearson’s correlation coefficient (PCC) metric. The results of all the previous models were taken as reported from Oota et al. (2024); see Table 1.
As can be seen from Table 1, the average PCC for the proposed (linear) model between predicted FC and empirical FC was 0.833, indicating a strong positive relationship between the predicted and actual values. For visual confirmation, refer to Figure 4, which shows the empirical FC and predicted FC matrices for a randomly selected subject. Overall, we achieve significantly better performance as compared with A-GHN (previous SoTA) while being around four times smaller in size (number of parameters) and double in training speed. These details will be discussed further in the following sections.
Empirical FC and predicted FC matrices presented for qualitative evaluation for a randomly chosen subject.
Impact of Number of Basis Vectors and MLP Layers
The eigen vectors that form the basis set for the Laplacian represent spatial harmonics that can be utilized for filtering purposes. It is possible to discard the basis vectors corresponding to higher spatial frequencies to evaluate their significance for FC reconstruction. Consequently, when constructing heat kernels, one can exclude the basis vectors associated with high spatial frequencies rather than using the complete basis set (U ∈ ℝ^N×k^). In Table 2, results are reported when 87, 75, and 64 low-frequency basis sets are used for computing the heat kernel. The findings indicate that higher spatial frequencies play a crucial role in the reconstruction of FC, as their exclusion leads to a noticeable decline in performance in both the PCC and MSE metrics.
When using the full set of basis vectors (i.e., all eigenvectors of the graph Laplacian), the linear layer is sufficient to model the relationship between the structural connectome (SC) and functional connectome (FC). This is because the complete set of eigenvectors captures both low-frequency (global structure) and high-frequency (localized details) components of the graph, providing the model with all the necessary information to establish the mapping effectively. However, when the number of eigenvectors is reduced to 64, the high-frequency components—associated with fine-grained, localized graph information—are no longer fully represented (reducing the Pearson’s correlation to 0.8171). This reduction creates a loss of information that the linear layer alone cannot address. In such cases, using a MLP becomes beneficial, as its nonlinear transformations compensate for the missing high-order eigenvector contributions by effectively modeling complex, nonlinear relationships between SC and FC (increasing the Pearson’s correlation to 0.8206 compared with linear layer), as shown in Table 2. This insight highlights the trade-off between the number of eigenvectors and the complexity of the model: The full basis allows for a simpler, more interpretable linear layer, whereas reduced eigenvector sets necessitate more complex models like MLPs to achieve comparable performance.
Learned Diffusion Scales
We extracted the learned diffusion scale values from 10 random runs (the train-validation-test split remains as for the five random run experiments reported earlier). We chose a larger number of runs to get a smoother estimate of the diffusion scale value. The PCC values for the predicted FCs over the 10 run experiments remain similar to those reported earlier for the five run experiments. In this section, we plot the average values of diffusion scales learned over the training epochs as shown in Figure 5, and Figure 6 imposed on the template brain surface mesh. Most of the nodes have a low diffusion rate, while few nodes display a larger scale for optimal FC prediction. Larger scale corresponds to larger neighborhood as in Figure 2, while smaller scales corresponds to small neighborhood. Note that all the diffusion scales were initialized at 0, and the increase in scale value for certain regions is based on the learning process that happens in the downstream task of mapping SC to FC.
Average diffusion scale of each brain region, with labels arranged in the order of the SC/FC matrices from bottom to top.
Average diffusion scale of each brain region overlaid on the template brain surface mesh.
Regions with lower diffusion scales, corresponding to more localized spatial signals, are predominantly unimodal, directly supporting specific functions. In contrast, the frontal pole plays a pivotal role in higher order cognitive processes such as abstract thinking, planning, decision making, and social cognition, which require coordination across diverse unimodal and multimodal brain regions. While traditional measures of SC may not capture its extensive communication network, our graph heat diffusion wavelet approach highlights the significance of the frontal pole through its association with the highest diffusion scale. This result underscores the strength of our method in uncovering region-specific structure-function dynamics, revealing the role of the frontal pole in facilitating long-range communication and higher order interactions between structure and function.
Figure 7 clearly shows that diffusion scales are largely proportional across the right and left hemispheres for most brain regions, as indicated by the closely aligned lines. However, the diffusion scales, which are learned from SC and FC matrices, are not necessarily homologically consistent between the right and left hemispheres. This inhomogeneity can arise from a range of anatomical, developmental, and functional factors. Variations in proportionality may also be influenced by the dataset distribution, which includes a greater number of right-handed individuals compared with left-handed ones. Notably, regions where the hemispheres deviate, primarily in the banks of the superior temporal sulcus (bankssts), cuneus, entorhinal cortex correspond to language learning and understanding. This pattern of diffusion scales suggests that the learned scales effectively capture the overall dynamics of the brain, providing strong evidence that our approach successfully reflects the heterogeneous nature of the structure-function relationship in the brain.
Diffusion scales across hemispheres.
We also observed that the diffusion scales learned for RoIs within the default mode network (DMN) exhibit similarity, even for regions that are geographically distant. For instance, regions represented by colors such as orange, light blue in the left hemisphere, and light blue in the right hemisphere share similar scales, reflecting their alignment in the higher dimensional functional space despite being structurally distant, as in Figure 8.
Diffusion scales across the default mode network.
Scale-Free Property
Diffusion scales correspond to the size of the neighborhood of a node in the graph. In this sense, they appear to capture similar information as node degree in a graph. It is well-known that node-degree distribution follows power-law in scale-free networks such as brain graphs (Bassett & Bullmore, 2006). It would be interesting to see if learned diffusion scale values also conform to this property. In order to test this possibility, we plot the histogram of the diffusion scale (see Figure 9A) and try to fit the power-law and exponential curves to analyze the pattern in the diffusion scales. The diffusion scale describes the spatial extent to which a node interacts with its graph, effectively controlling the neighborhood of that node. Degree distribution in a scale-free network follows a power-law, wherein a few nodes have a large degree and most nodes have a small degree (Barabási & Albert, 1999; Ciuciu, Varoquaux, Abry, Sadaghiani, & Kleinschmidt, 2012; He, 2011; He, Zempel, Snyder, & Raichle, 2010; Wang & Chen, 2003). The existence of scale-free property in the connectomes has been found previously, and our study corroborates such findings (Achard, Salvador, Whitcher, Suckling, & Bullmore, 2006; Bassett & Bullmore, 2006; Ciuciu et al., 2012; He, 2011; He et al., 2010; Ponce-Alvarez, Kringelbach, & Deco, 2023). We fit the data to the power-law and exponential curves and find that the sum of squared estimates of error for power-law is around half as compared with that of the exponential distribution as shown in Figure 9A. Based on Clauset, Shalizi, and Newman (2009), we estimate the power-law exponent as 2.04, and the corresponding log-log plot can be seen in Figure 9B.
Comparison of distribution of diffusion scales with power-law and exponential models. (A) Histogram of the learned diffusion scales with power-law and exponential distributions fitted. Values in the legends indicate the sum of squared errors to quantify the fit quality. (B) The log-log plot of the diffusion scales fits a line with a slope of −2.04.
Computational Efficiency
For computational efficiency comparisons, we chose the A-GHN model as it is the best model that combines graph diffusion, heat kernels, and graph neural networks. We compare our model with A-GHN across various factors such as the number of parameters, model size, and the time taken to run on graphics processing unit (GPU). Both assume that the Laplacian spectrum is precomputed. A-GHN combined multiple diffusion scales using attention, which has an implicit quadratic time complexity. Whereas in the proposed model, we learn the fundamental diffusion scales, and the linear layer dramatically reduces the time required for training (see Table 3). We see from the results that while the performance results are superior for the proposed model, it is accomplished with a model that is four times smaller in size (number of parameters) and trains at double the speed as compared with A-GHN. More importantly, the proposed model does not compromise on the interpretability aspect. The interpretability afforded by A-GHN arises from the attention weights reflecting the importance of manually preset diffusion scales for predicting FC. On the other hand, in the proposed model, the diffusion scales are not predefined but learned and allow us to interpret region-wise differences in the scales of diffusion.
DISCUSSION
In this paper, we used the graph diffusion wavelets to perform multiscale and multiresolution analysis of the brain connectome. This method predicts the spatial extent to which the RoIs communicate in terms of the diffusion scales that range from local (fine/small communities) to global (course/large communities) scales. Instead of searching for the correct (optimal) scale by trial and error, the proposed framework allows for learning the diffusion scales using a downstream task of mapping to corresponding static resting-state FC. Our contributions are twofold: (1) We learn the SC-FC mapping with SoTA results quantified by Pearson’s correlation (0.8326) using an end-to-end linear and explainable graph wavelet diffusion, and (2) the learned diffusion scales follow a power-law distribution conforming to the well-established scale-free property of brain networks. The results suggest that the learning process of diffusion scales enables determination of neighborhood structure appropriate for estimation of FC from SC.
Learning Node-Specific Diffusion Scales
In the following, we explain how the method of graph diffusion wavelet and its application on the human structural connectome for the purpose of deriving the FC leads to tuning of RoI-specific diffusion scales. The graph diffusion wavelet is a probing mechanism that applies an impulse individually at each RoI and observes the fashion in which the impulse travels through the rest of the connectome. In other words, the wavelet captures the response of the connectome to an impulse applied at a specific RoI. Now, each RoI can communicate with other RoIs and the spatial extent of this communication is decided by the magnitude of the diffusion scale. If the diffusion scale is smaller, then the RoI forms a local communication network, and if the diffusion scale is larger, then the RoI forms a global communication network. Since the dynamics related to function reside on the structure, the diffusion scales in the model are dependent not only on FC but also on SC. Thus, the correct way to obtain the scales is by allowing diffusion at individual nodes at different scales in such a way that it gives rise to FC, unveiling the functional aspects of the individual RoIs. The localization aspect of wavelets helps in identifying the optimal scales at which the individual RoIs operate, indirectly identifying the size of communication networks regulated by the RoI.
Structural Similarity May Not Correspond to Functional Similarity
The diffusion scales as a measure of size of the communication network is not the only aspect of graph diffusion wavelets. Wavelet brings about localization of the diffusion, and each wavelet is characterized by a scale that depends on the FC. We initialize all the scales to 0, and, thus, the scales will only increase in response to the activity caused by the underlying task or, as in this case, the task of mapping SC to resting-state FC. It can be proved that two structurally identical nodes will have similar wavelet representation at the same scale (Donnat et al., 2018). But due to our downstream task, even if any two RoIs are structurally similar, different functional roles nudge them to have different scales and, thus, different wavelet representations. In other words, the functional roles of the RoIs dictate the spatial extent to which they communicate regardless of having similar neighborhoods. Such interpretations of diffusion scale reveal an interesting mechanism for information transfer in the brain. The diffusion scales are learned by the model only for the objective of prediction of FC, which enables it to encode both the structural aspect of a node and functional pattern observed in the brain.
Adaptive Selection of Diffusion Scales
Another architectural advancement over the previous methods is that the previous methods manually selected the diffusion scales for the single or multiple heat kernel models (Abdelnour et al., 2014; Oota et al., 2024; Surampudi et al., 2018). Since the scale essentially captures the relationship between structure and function, it would be appropriate for the model to learn the scales instead of manual selection. The proposed framework fills this gap of choosing the diffusion scales by learning them using backpropagation of error during training. The diffusion scale update rule can be mathematically represented by a closed-form equation, leading to an iterative update scheme. Since these scales are learned in a data-driven manner, they capture the cohort-level trend of diffusion scales.
Diffusion Scales and Scale-Free Property
The third contribution based on our results is that the brain network exhibits a scale-free architecture, characterized by the distribution of diffusion scales across its nodes. Our observations reveal that these diffusion scales adhere to a power-law distribution, indicating that a minority of nodes interact with a large number of nodes, while the majority interact with only a few. Diffusion scales serve as a proxy for degree distribution; if the degree distribution of a network follows a power-law, it may potentially be a scale-free system. The presence of scale-free properties in brain connectomes has been previously documented (Bassett & Bullmore, 2006; Eguíluz, Chialvo, Cecchi, Baliki, & Apkarian, 2005; Sporns & Kötter, 2004). This scale-free organization is crucial for optimal brain function and suggests that the brain operates at a critical point (Beggs, 2022). Several studies have shown that essential neural systems enhance the transmission, storage, and processing of information through this architecture (Marinazzo et al., 2014; Shew, Yang, Yu, Roy, & Plenz, 2011).
RoI-Specific Diffusion Scales and Resting-State Networks
Based on learned diffusion scales, we identified that the frontal pole has the largest community structure. The frontal pole of the brain plays a significant role in various resting-state networks (RSNs), particularly through its involvement in the DMN, the frontoparietal control network (FPN), and the social emotion network (SEN; Liu et al., 2013). The larger learned diffusion scale(s) that corresponds to the broader network of the frontal pole in both hemispheres can be attributed to its role in various functions inspite of its relatively smaller size (Rolls, Deco, Huang, & Feng, 2024). Other brain regions forming hubs mostly belong to the temporal lobe, which includes banks of the superior temporal sulcus, transverse temporal, and left parahippocampus. Another region belonging to the occipital lobe that has a large diffusion scale is the pericalcarine region. Although these regions are not necessarily related to DMN, they are involved in other sensory/cognitive processes such as auditory, visual, social, and memory tasks.
Scalability and Sensitivity to Noise
Consider the scalability of diffusion wavelets. To analyze this, refer to Table 3 that compares the number of learned parameters with those of A-GHN. Our model learns N diffusion kernels, and the weights of linear layer are learned in a computationally efficient manner, resulting in a training time of 7.13 s for 100 epochs. A potential bottleneck is the 87 matrix multiplications required for heat kernel calculation, but this can be parallelized with minimal GPU requirements. Alternatively, Chebyshev polynomials can approximate the heat kernel to increase speed (Hammond et al., 2011). Compared with A-GHN, which employs multiple GCNs and an attention mechanism, our method is more computationally efficient. Additionally, the proposed model is more efficient in both time and space complexity than MKL that uses the LASSO optimization algorithm for combining heat kernels.
Wavelet methods are recognized for their robustness to noise in the signal processing domain, where they can regularize noisy data, such as in point clouds (Hammond et al., 2011). Donnat et al. (2018) demonstrated that the difference in wavelets of nodes with equivalent neighborhoods in a noisy graph has an upper bound that depends linearly on the amount of perturbation introduced in the graph. In our perturbation studies (see the Supporting Information), we observe that when the model is trained on perturbed SC, the wavelets resist the added noise, resulting in FC reconstruction with approximately 70% Pearson’s correlation for some test subjects.
CONCLUSION
Overall, we have developed a method that leverages the graph wavelets in order to obtain explainable and efficient brain structure-to-function mapping through the multiscale, multiresolution properties. We compute a wavelet for each node operating at a unique scale and learn the node-appropriate scales during the training process. We overcome the problem of manually choosing the diffusion scales by creating an end-to-end function for efficiently and accurately modeling the relationship. The resulting model has fewer number of trainable parameters and also finds meaningful parameters associated with the brain regions. Our model not only captures the SC-FC mapping but also identifies the community structure supported by individual RoI. In the future, this study could be extended to task-based fMRI data as well as for resting-state fMRI data related to aging and neurodegenerative diseases. We expect that the diffusion scales learned in such cases could potentially be used as biomarkers.
FUTURE SCOPE
The proposed approach of using graph diffusion wavelets to predict FC from SC offers a robust foundation for exploring the intricate structure-function relationship in the brain. However, there are several exciting avenues for future research. First, while our current method operates at the macroscale, the framework can be extended to micro- and mesoscale analyses, providing finer insights into localized and long-range brain dynamics. Incorporating additional preprocessing techniques, such as global signal regression, could further refine the accuracy and robustness of FC predictions.
Additionally, the potential to move beyond static FC by modeling dynamic FC could offer a richer understanding of time-varying brain states. Expanding the approach to incorporate other observables, such as the most salient features of long-range connectivity or task-based neuroimaging data, could also broaden its applicability. Finally, integrating this method with simulations of whole-brain models and other computational techniques would enable deeper insights into how structural changes, such as those observed in neurological or psychiatric conditions, alter functional dynamics. These extensions would not only enhance the generalizability of the method but also pave the way for practical applications in personalized medicine and therapeutic planning.
ACKNOWLEDGMENTS
The authors thank Dr. Subba Reddy Oota, INRIA, Bordeaux, France for sharing the code and giving guidance related to dataset preparation, which proved to be very helpful for conducting various experiments.
SUPPORTING INFORMATION
Supporting information for this article is available at https://doi.org/10.1162/netn_a_00456. Additional material is available in the Supporting Information at https://mitp.silverchair-cdn.com/mitp/content_public/journal/netn/pap/10.1162_netn_a_00456/1/netn_a_00456_supp.pdf?Expires=1747982606&Signature=4tHq8ZgopIUgy3ZaEpHbD4ux79UM7DnU3xwNmugqWamjkFjJh5ApWGoPtd6qXqEqhXaY5LzKxMm-usRk3Nfm7R69HFpAdnbm-BFuY2q9DPDOL1MXR7yVnzmLd2v8OBJX8JkC3kA0k5qLKwI-kdwn49ViqEJEMe52k0Iv4qrLwQoqo-CPoUDwAW5Wg6Y9RuFTsctKuwqPnLXyIqvQisv6He4EhN4zkuoBbWk2z-fzwwZAl4qcvcSSu7pZRBAz2stT3kikpSzdwQSLKUx7GELm3UUU8cSvUNAIZNe0H6ZTDX1nv3xSJkQAQcfqLZ06jPToJXUuQN05RKxGu99oEA__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA.
AUTHOR CONTRIBUTIONS
Chirag Jain: Conceptualization; Data curation; Formal analysis; Investigation; Methodology; Software; Validation; Visualization; Writing – original draft. Sravanthi Upadrasta Naga Sita: Conceptualization; Investigation; Supervision; Validation; Writing – review & editing. Avinash Sharma: Conceptualization; Formal analysis; Methodology; Supervision; Validation; Writing – review & editing. Raju Surampudi Bapi: Conceptualization; Formal analysis; Investigation; Resources; Supervision; Validation; Writing – review & editing.
Supplementary Material
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abdelnour, F., Voss, H. U., & Raj, A. (2014). Network diffusion accurately models the relationship between structural and functional brain connectivity networks. Neuro Image, 90, 335–347. 10.1016/j.neuroimage.2013.12.039, 24384152 PMC 3951650 · doi ↗ · pubmed ↗
- 2Achard, S., Salvador, R., Whitcher, B., Suckling, J., & Bullmore, E. (2006). A resilient, low-frequency, small-world human brain functional network with highly connected association cortical hubs. Journal of Neuroscience, 26(1), 63–72. 10.1523/JNEUROSCI.3874-05.2006, 16399673 PMC 6674299 · doi ↗ · pubmed ↗
- 3Alberts, B., Johnson, A., Lewis, J., Raff, M., Roberts, K., & Walter, P. (2002). The shape and structure of proteins. London, UK: Garland Science.
- 4Atasoy, S., Donnelly, I., & Pearson, J. (2016). Human brain networks function in connectome-specific harmonic waves. Nature Communications, 7(1), 10340. 10.1038/ncomms 10340, 26792267 PMC 4735826 · doi ↗ · pubmed ↗
- 5Barabási, A.-L., & Albert, R. (1999). Emergence of scaling in random networks. Science, 286(5439), 509–512. 10.1126/science.286.5439.509, 10521342 · doi ↗ · pubmed ↗
- 6Bassett, D. S., & Bullmore, E. (2006). Small-world brain networks. Neuroscientist, 12(6), 512–523. 10.1177/1073858406293182, 17079517 · doi ↗ · pubmed ↗
- 7Bassett, D. S., & Sporns, O. (2017). Network neuroscience. Nature Neuroscience, 20(3), 353–364. 10.1038/nn.4502, 28230844 PMC 5485642 · doi ↗ · pubmed ↗
- 8Bassett, D. S., Zurn, P., & Gold, J. I. (2018). On the nature and use of models in network neuroscience. Nature Reviews Neuroscience, 19(9), 566–578. 10.1038/s 41583-018-0038-8, 30002509 PMC 6466618 · doi ↗ · pubmed ↗