The medial prefrontal cortex encodes procedural rules as sequential neuronal activity dynamics
Shuntaro Ohno, Masanori Nomoto, Kaoru Inokuchi

TL;DR
This study shows that the medial prefrontal cortex uses sequential neuron activity to encode procedural rules, updating these sequences as learning progresses.
Contribution
The study introduces a novel method, iSeq, to detect temporal neuronal sequences and reveals how rule learning dynamically reorganizes neuronal activity.
Findings
Neuronal sequences in the medial prefrontal cortex encode procedural rules during learning.
The composition of neuronal sequences changes as mice master a rule, predicting reward acquisition success or failure.
Learning procedural rules involves continuous updating of neuronal activity dynamics in the medial prefrontal cortex.
Abstract
The prefrontal cortex plays a crucial role in procedural rule learning; however, the specific neuronal mechanism through which it represents rules is unknown. We hypothesized that sequential neuronal activities in the prefrontal cortex encode these rules. To investigate this, we recorded neuronal activities in the medial prefrontal cortex of mice during rule learning using Ca2+ imaging. We utilized a method based on convolutional negative matrix factorization, iSeq, to automatically detect temporal neuronal sequences in the recorded data. As rule learning advanced, these neuronal sequences began to encode critical information for rule execution. In mice that had mastered the rule, the dynamics of neuronal sequences could predict success and failure of reward acquisition. Furthermore, the composition of cell populations within the neuronal sequences was rearranged throughout the learning…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
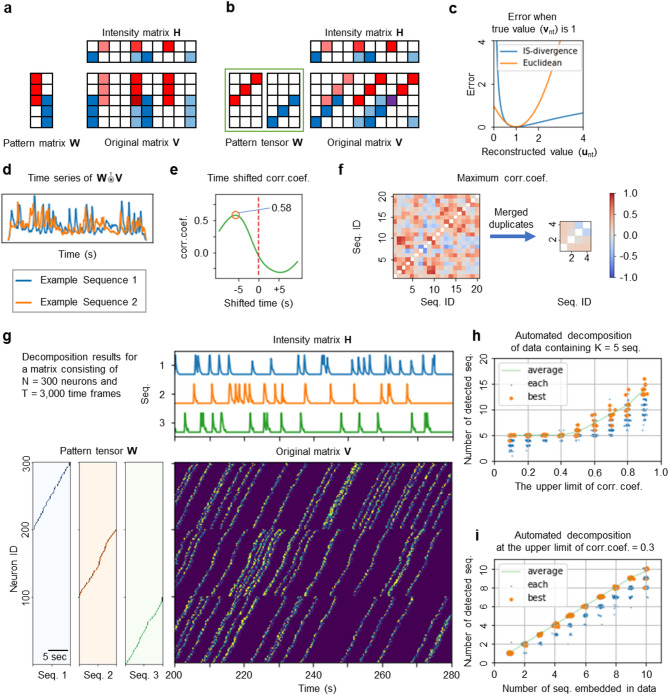 Figure 1
Figure 1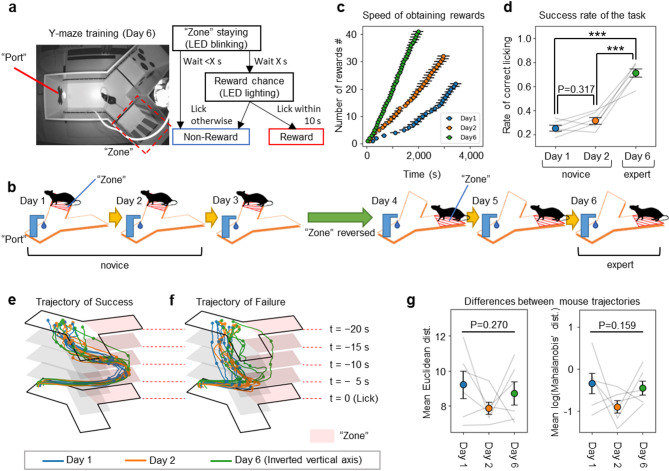 Figure 2
Figure 2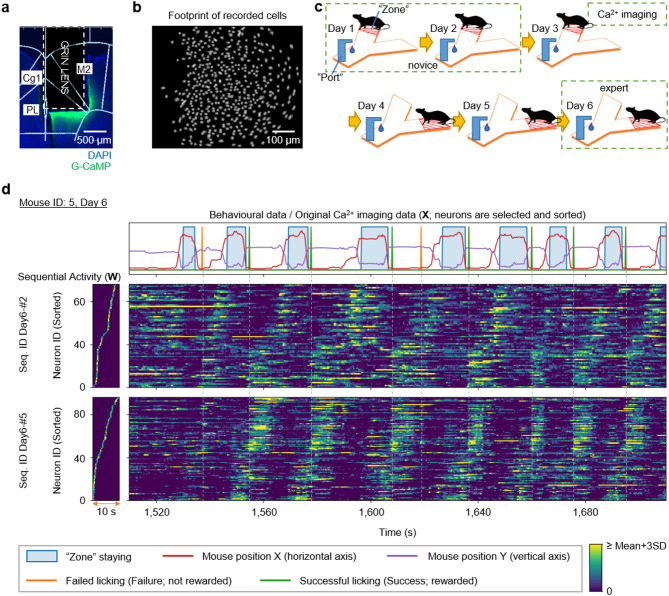 Figure 3
Figure 3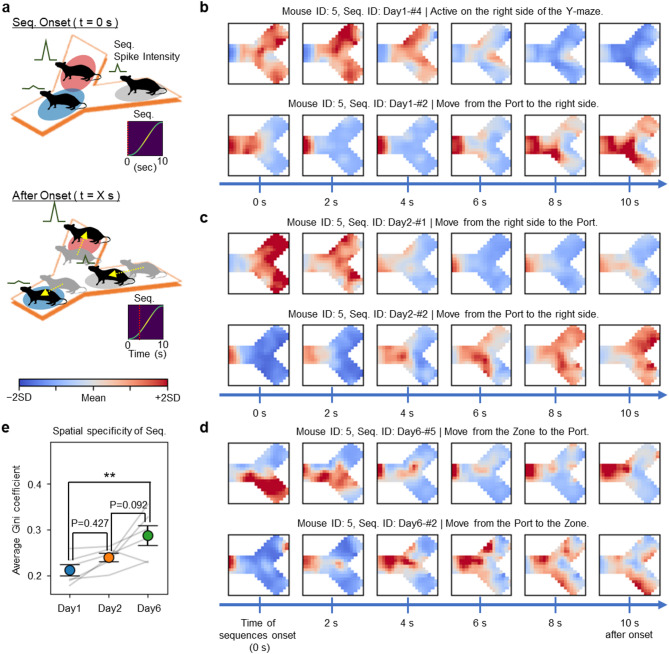 Figure 4
Figure 4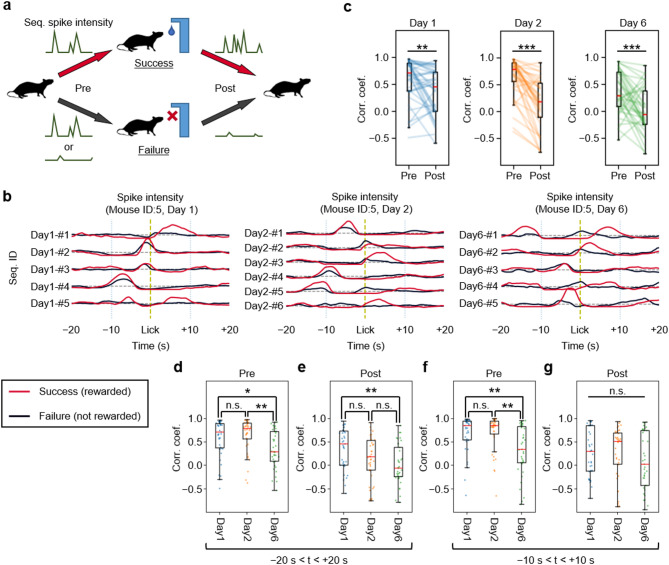 Figure 5
Figure 5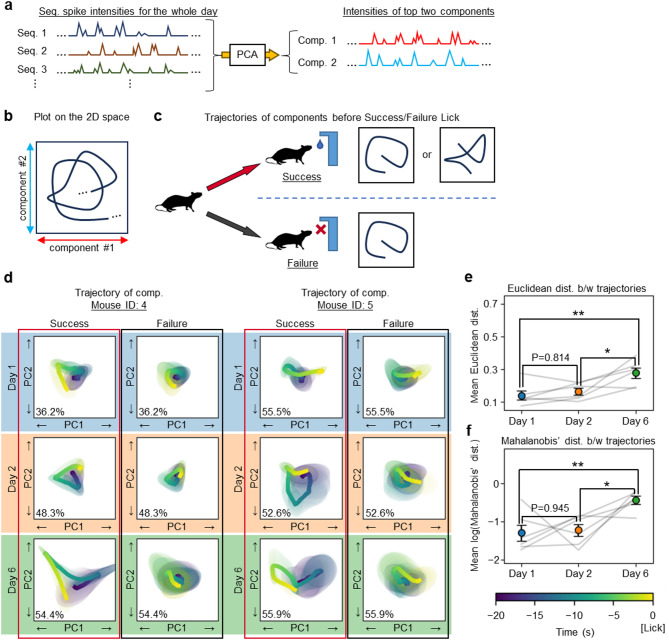 Figure 6
Figure 6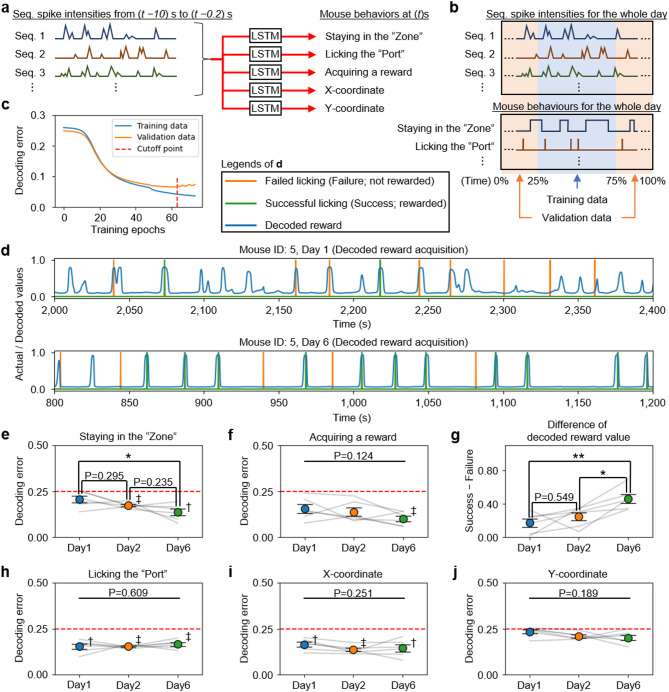 Figure 7
Figure 7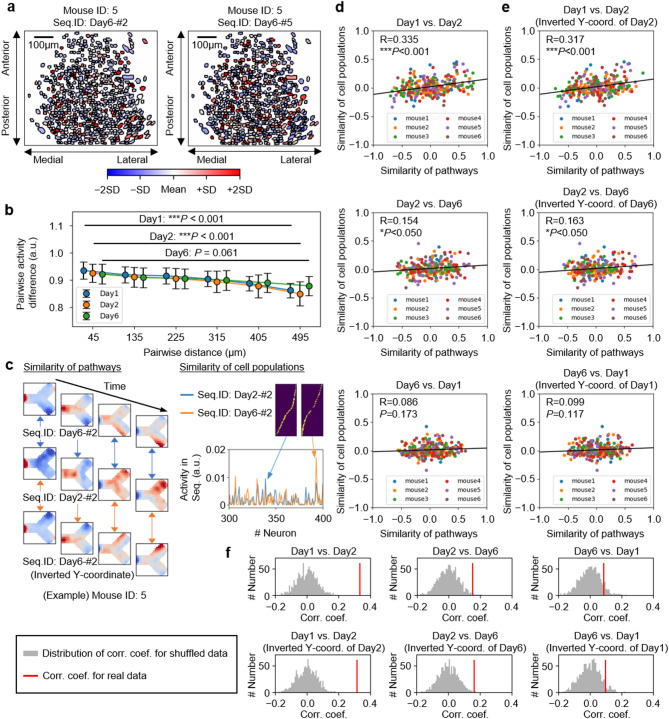 Figure 8
Figure 8- —https://doi.org/10.13039/501100001691Japan Society for the Promotion of Science
- —https://doi.org/10.13039/100007449Takeda Science Foundation
- —https://doi.org/10.13039/100009619Japan Agency for Medical Research and Development
- —https://doi.org/10.13039/100008732Uehara Memorial Foundation
- —https://doi.org/10.13039/100007428Naito Foundation
- —https://doi.org/10.13039/501100003844Inamori Foundation
- —Firstbank Of Toyama Scholarship Foundation Research Grant
- —Hokuriku Bank Grant-in-Aid for Young Scientists
- —https://doi.org/10.13039/100020051Tamura Science and Technology Foundation
- —https://doi.org/10.13039/501100003382Core Research for Evolutional Science and Technology
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural dynamics and brain function · Receptor Mechanisms and Signaling · Memory and Neural Mechanisms
Introduction
For animals to survive, it is crucial that they understand their current situation, take appropriate actions, and secure rewards such as food and safety. To efficiently obtain rewards, it is necessary to extract important pieces of information from external stimuli received in the past and actions previously taken, and to integrate these into an appropriate sequence that leads to reward acquisition. This order constitutes a procedural rule, and the individual stimuli and actions that make up this procedural rule are defined as elements of the rule.
The prefrontal cortex (PFC) is considered an important brain region for rule learning [1–5]. To obtain and retain procedural rule information, the PFC must be capable of representing elements of the rule [6]. Indeed, neuronal activity in the PFC encodes various pieces of information that form elements of rules. For example, neuronal representation in the PFC can be classified into distinct clusters, each encoding specific behaviour in mice [7] and individual location-rank information for sequential working memory in monkeys [8]. In addition, reward-responsive neurons have been found in the PFC of rats [9]. It is believed that, in the PFC, important sets of information for reward acquisition are selected from these representations to form procedural rules. However, the mechanisms at the neuronal level that accomplish this process are not yet fully understood.
To explore the neural mechanisms underlying rule representation, we focused on neuronal activity patterns that appear with a consistent temporal order, known as neuronal sequences. Neuronal sequences have been identified in various brain regions across species, including the hippocampus of rats [10–12], visual cortex of cats [13] and mice [14], frontal cortex of monkeys [15, 16], parietal cortex of monkeys [17] and mice [18], gustatory cortex of rats [19], and premotor cortical nucleus HVC of songbirds [20]. These activities are known to correlate with behaviours that involve sequences and spans of time, making them highly compatible with the procedural aspects of rules. Furthermore, the medial PFC (mPFC) of rats contains neuronal sequences that encode movement trajectories, which reactivate upon changes in rules [21]. Therefore, we hypothesized that in the PFC, either a single neuronal sequence or the dynamics of multiple neuronal sequences represent the procedural rules.
To validate this hypothesis, we recorded neuronal activity in the mPFC of mice during procedural rule learning using Ca^2+^ imaging. We then employed the iSeq algorithm, an enhanced version of existing methods [20, 22, 23], to automatically identify neuronal sequences in the recorded data. This revealed that the mPFC contained neuronal sequences that were activated in response to specific behaviours. As the mice learned the rule, the behavioural actions encoded by these neuronal sequences became more defined, allowing the dynamics of sequences to predict successful and unsuccessful reward acquisitions. Furthermore, in mice that mastered the rule, the neuronal sequences encoded information of crucial external stimuli and behavioural actions for rule execution. The fact that the cell populations comprising these neuronal sequences changed daily suggests that as animals learn rules, the PFC continuously updates its neuronal sequences to effectively encode behaviours crucial for reward acquisition.
Results
“iSeq” automatically detects neuronal sequences from Ca2+ imaging data
We attempted to measure neuronal activity in mice using Ca^2+^ imaging, aiming to automatically identify neuronal sequences in the data. To detect these neuronal sequences in substantial datasets of recorded neuronal activity, earlier studies often employed methods such as averaging neuronal activity across trials [10, 11, 18, 21] or using hidden Markov models [16, 19]. Here, we implemented convolutive non-negative matrix factorization (ConvNMF) [22, 23], a technique that does not refer to animal behaviour and facilitates the delineation of neuronal sequence patterns.
Basic non-negative matrix factorization (NMF) [24, 25] identifies patterns of synchronous neuronal activity [26]. This method decomposes a large two-dimensional (2D) matrix, denoted as V, which records the activity signals from hundreds of neurons across thousands of time frames, into two distinct 2D matrices: the pattern tensor W and the intensity matrix H (Fig. 1a). In W, each column vector represents a synchronously activated neuronal ensemble (population activity pattern). Conversely, the rows of H indicate the temporal variation of the activation intensity for each pattern. By expanding the dimensions of W to include a time window, ConvNMF enables the representation of sequential rather than merely synchronous activity [22, 23]. This method decomposes the original 2D matrix V into a 3D pattern tensor W and a 2D intensity matrix H (Fig. 1b). V is then approximated by matrix U, which is reconstructed through the tensor convolution [20] of W and H, detailed in Supplementary Math Note 1. In this model, V is structured by neuron and time dimensions, W by neurons, sequence count, and sequence time window, and H by sequence count and time. By defining N, T, K, and L as the dimensions of neurons, time, sequence count, and sequence time windows, respectively, V is represented as an N × T matrix, W as an N × K × L tensor, and H as a K × T matrix. The structure of each neuronal sequence is characterized by the two dimensions in W: neurons (N) and the time window of the sequence (L). Conversely, its activity intensity over time is captured in a one-dimensional vector (row) of length T in H.
Fig. 1“iSeq” automatically detects neuronal sequences from Ca^2+^ imaging data. a Schematic for detecting synchronous activity using negative matrix factorization (NMF). b Schematic for detecting sequential activity using convolutional NMF. c Comparison of Itakura-Saito (IS) divergence and Euclidean distance. d Example of overlap between two neuronal sequences and the original data. e Example of time-shifted correlations within overlaps. f Similarity across all neuronal sequences (left) and similarity after merging sequences that exceed a similarity threshold (right). g Example of decomposing synthetic data with iSeq. h Relationship between the threshold setting of iSeq and the number of detected sequences in synthetic data containing K = 5 neuronal sequences. i Correlation between the number of neuronal sequences embedded in synthetic data and the number detected by iSeq with a threshold of 0.3. Abbreviations: Corr. Coef., Correlation coefficient; Seq., Neuronal sequence
Typically, ConvNMF utilizes the Euclidean distance
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{E}_{nt}^{EUC}=\sqrt{{\left({v}_{nt}-{u}_{nt}\right)}^{2}}$$\end{document}to assess the discrepancy between matrices V and U, serving as the error function. However, we opted for the Itakura-Saito (IS) divergence [27]
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{E}_{nt}^{IS}=\frac{{v}_{nt}}{{u}_{nt}}-\text{ln}\frac{{v}_{nt}}{{u}_{nt}}-1,$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{v}_{nt}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{u}_{nt}$$\end{document} are the activity value at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} ^th^ neuron in V and U, respectively (Fig. 1c). We chose IS divergence because of its scale-invariant property [27], which is particularly advantageous for analysing data with signal-dependent noise [28]. Our recorded Ca^2+^ imaging data exhibited pronounced correlations between local mean and variance (Supplementary Fig. 1 [Additional file 1 contains Supplementary Figs., Tables and Math Notes]), indicating that the data was predominantly influenced by signal-dependent noise.
Another important consideration when using ConvNMF is that we need to preset the number of neuronal sequences to be detected (K). If the value of K is too low, some neuronal sequences may go undetected. Conversely, if the value of K is too high, it can lead to splitting what should ideally be a single neuronal sequence into multiple parts, resulting in redundancy. Prior studies have attempted to solve this by incorporating a penalty term into the error function [20, 29]. This penalty increases as the orthogonality among the detected neuronal sequences decreases, with an appropriate coefficient applied for balance. However, this method merely shifts the problem from determining K to finding the correct coefficient for the penalty term, thus making the problem more non-intuitive. Therefore, we have opted for a more direct approach.
Initially, a sufficient number of neuronal sequences were extracted. Subsequently, those determined to be identical were merged. Identity in this context is defined by the overlap (correlation) between each neuronal sequence and the original matrix V. This overlap is calculated through the transpose tensor convolution of the pattern tensor W and V (Fig. 1d and Supplementary Math Note 1). If the maximum value of the time-shifted Pearson’s correlation of these overlaps, calculated for two neuronal sequences, and exceeds a specified threshold (Fig. 1e), these sequences are considered identical and are merged (Fig. 1f). In experiments using synthetic data, the detection of an appropriate number of neuronal sequences was achieved when the threshold was set at approximately 0.3 (Figs. 1g–i and Supplementary Figs. 2a, b). Furthermore, iSeq was able to detect the correct number of neuronal sequences even in data with varying signal-to-noise ratios, when a threshold of 0.3 was applied (Supplementary Figs. 2c, d). Consequently, we consistently used a threshold of 0.3 in all subsequent calculations. In contrast, seqNMF [20] failed to identify the correct number of sequences as the level of noise increased (Supplementary Figs. 2e–g).
In addition to these methods, we developed an algorithm to ensure the convergence of the multiplicative update rules of ConvNMF (Supplementary Math Note 2). We also extended the time dimension of the intensity matrix H from T to T + L − 1 to accurately capture the influence of neuronal sequence activity prior to the recorded timestamps in Ca^2+^ imaging data (Supplementary Figs. 3a, b). Additionally, we compressed the original matrix V prior to decomposition to minimize computational complexity (Supplementary Figs. 3c–i). We compiled all these features into a software package designed for the automatic detection of neuronal sequences, which we named iSeq, in reference to its error function―the Itakura-Saito divergence.
The mice successfully learned the procedural rules of the Y-maze task
To investigate how the mPFC represents neuronal activity during procedural rule learning, mice were subjected to the Y-maze task (an additional movie file shows this in more detail see Additional file 2; see also Methods). Each mouse was individually placed in the Y-maze, in which it could freely explore (Fig. 2a, left). At the end of one arm of the maze’s branches lay the reward waiting zone, hereafter referred to as “the Zone”. Upon entering the Zone, LEDs on the maze wall were triggered to flash. If the mouse remained in the Zone for several seconds, the LEDs would switch to a continuous light, signalling the start of a 10 s period. During this time, the mouse could obtain a reward by licking a water port, referred to as “the Port”, located at the end of the trunk arm (Fig. 2a, right). The mice were not explicitly taught this rule; instead, they learned through trial and error, continuing until they either acquired 40 rewards or 1 h had elapsed. The experiment spanned 6 days, with the Zone’s location switched to the opposite arm on day 4 (Fig. 2b) to emphasize that the rule was procedural rather than location-specific.
Fig. 2. The mice successfully learned the rules of the Y-maze task. a Setup of the Y-maze on day 6 (left) and flowchart outlining the Y-maze task procedures (right). b Training schedule for the Y-maze task. c Pace of reward acquisition for mice on days 1, 2, and 6. d Success rates of reward acquisition for mice on days 1, 2, and 6 (P < 0.001; one-way RM ANOVA with Tukey post hoc test). e, f* Average 20 s trajectories leading to successful (Success; e) and unsuccessful (Failure; f) reward acquisition. g Comparison of mouse trajectories leading to Success and Failure. The Euclidean distance of average trajectories (left) and the Mahalanobis’ distance (right), taking into account the covariance of Failure trajectories (one-way RM ANOVA). Abbreviations: Dist., Distance. Data are represented as mean ± SEM
As learning progressed, the mice gradually became faster at acquiring rewards (Fig. 2c), and their likelihood of obtaining a reward when licking the port also increased significantly (Fig. 2d). On day 4, when the Zone’s location was reversed, there was a temporary decline in the pace of reward acquisition, yet it remained faster than on day 1 and comparable to day 2 (Supplementary Fig. 4a). This suggests that the mice did not perceive the task with the reversed Zone as a new challenge, but rather as a continuation of the task from the first 3 days. Furthermore, the success rate of reward acquisition on day 4 was similar to that on day 3, and there was a significant increase in the success rate from day 4 to day 5 (Supplementary Fig. 4b). This suggests that changing the task location on day 4 may have enhanced the mice’s understanding of the procedural rule of the Y-maze task.
Next, we examined the behaviour of mice when approaching the Port under two conditions: (1) when the mice stayed in the Zone for the required duration and successfully obtained a reward by licking the Port during the reward chance (Success), and (2) when the mice licked the Port either before the reward chance had started or after it had ended, thus failing to obtain a reward (Failure). The trajectories of the mice during Success were nearly identical on all days (Fig. 2e). Additionally, the trajectories during Failure, across all days, differed significantly from those during Success (Fig. 2f). When comparing these trajectory differences using either Euclidean distance or Mahalanobis’ distance (which accounts for data variance) between the average trajectories during Success and Failure, no significant differences were detected across days (Fig. 2g). These results clearly demonstrate that as learning progressed, the likelihood of obtaining rewards increased, even though the trajectory of behaviours leading to successful rule completion and reward acquisition remained unchanged. Moreover, the disparity in trajectories between Success and Failure was consistent across all days.
The mPFC contains neuronal sequences that reflect reward acquisition
To assess neuronal activity in the mPFC during procedural rule learning, we employed an in vivo Ca^2+^ imaging method to monitor 347–729 neurons from each of six mice (Fig. 3a, b). To minimize brain damage due to phototoxicity during imaging, recording sessions were limited to days 1 and 2, when the mice were ‘novices’ to the task, and day 6, when they had become ‘experts’ (Fig. 3c). We recorded the change in Ca^2+^ fluorescence intensity of these neurons as video files, which were then analyzed using the HOTARU [30] system. This analysis yielded the original data matrix V, which consists of two dimensions: neurons (N) and time (T). The Ca^2+^ activity, represented by fluorescence intensity, for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} ^th^ neuron at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} was recorded in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} ^th^ row and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} ^th^ column of this matrix.
Fig. 3. The medial prefrontal cortex (mPFC) contains neuronal sequences that reflect reward acquisition. a Location of lens implantation and expression of DAPI (blue) and G-CaMP (green). b Footprints of cells recorded through Ca^2+^ imaging. c Imaging schedule during Y-maze task learning. d Example of neuronal sequences detected on day 6 in mouse ID: 5, representing the behaviour of the mouse (top) and the shape of the neuronal sequences (bottom left). For clarity, the displayed neuronal sequences underwent the sequence-sharpening operation (see Methods). Original data sorted according to the order of the neuronal sequences (bottom right). Abbreviations: Cg1, cingulate area1; PL, prelimbic cortex; M2, secondary motor cortex; Seq., Neuronal sequence
We then employed iSeq to decompose the original matrix V, collected every 3 days from six mice, into two matrices: pattern tensor W, which preserves the shape of neuronal sequences, and intensity matrix H, which captures the time series of sequential activity values. From these decompositions, we identified 4–10 neuronal sequences, each lasting up to 10 s (Supplementary Tables 1, 2 and Supplementary Figs. 5a, b). The durations of the detected neuronal sequences and the proportions of their constitutive cells did not vary across experimental days (Supplementary Figs. 5c, d). Each neuronal sequence was systematically discriminated by the mouse ID, date, and sequence ID (e.g., Seq. ID: Day1-#2 of mouse 3). Based on data from the pattern tensor W, we extracted cells comprising neuronal sequences from the original matrix V and analyzed their correlation with mouse behaviour over time (Fig. 3d). We thus discovered neuronal sequences active both before and after reward acquisition. Specifically, some neuronal sequences remained active from the moment the mouse obtained a reward (or licked the Port) until it entered the Zone (e.g., Fig. 3d; Seq. ID: Day6-#2). Additionally, other neuronal sequences were activated in anticipation of a reward (e.g., Fig. 3d; Seq. ID: Day6-#5). Importantly, iSeq extracts neuronal sequences without referring to behavioural data, making it far from trivial that the extracted neuronal sequences (shown in Fig. 3d) emerged in correspondence with behaviour. This correspondence therefore provides evidence that iSeq can uncover behaviourally relevant neuronal patterns from neuronal activity data. Furthermore, although the two neuronal sequences depicted in Fig. 3d sometimes behave as if they are part of a single large sequence, their independent activities can be distinguished, such as by their distinct responses to a Failure lick at approximately 1,530 s.
Neuronal sequences in the mPFC encode behaviours related to the procedural rule
Based on the findings from Fig. 3d, we hypothesized that individual neuronal sequences identified in the mPFC of mice correspond to specific behaviours required to complete the Y-maze task. To precisely assess the timing of neuronal sequence activation, we implemented the sequence-sharpening process (see Methods) on the pattern tensor W and intensity matrix H, which encapsulate individual neuronal sequences. Owing to the inherent nature of iSeq and ConvNMF, the activity of a single neuronal sequence can be decomposed into W and H in multiple ways (Supplementary Figs. 6a–c). Among these decomposition forms, we modified and standardized the values of W and H to depict neuronal sequences as “narrow” sequences in W (Supplementary Fig. 6a, d–e). Moreover, to emphasize the onset timing of neuronal sequence activity over its duration, we applied a high-pass filtering technique (commonly used to estimate neuronal spike activity from Ca^2+^ traces [31, 32]) to the intensity matrix H. To prevent potential phase shifts due to filtering, we extracted the low-frequency components as a moving average (Supplementary Fig. 6f). By subtracting this moving average from the original activity values and scaling based on the moving average, we derived a measure of spike-like activity referred to as the spike intensity of the neuronal sequences (Supplementary Fig. 6g).
Using data from mouse location tracking, we calculated the average spike intensity for each mouse position (Fig. 4a; top). Additionally, we time-shifted the spike intensity data relative to the location data to estimate the movement trajectories of the mouse during the occurrence of neuronal sequences (Fig. 4a; bottom).
Fig. 4. Neuronal sequences in the medial prefrontal cortex (mPFC) encode behaviours related to the rules. a Schematic for estimating mouse movement trajectories from the mouse’s location and average spike intensity of each neuronal sequence. b–d Examples of estimated mouse movement trajectories of mouse ID: 5 during the activity periods of each neuronal sequence: Day 1 (b), Day 2 (c), and Day 6 (d). Regardless of the duration of each neuronal sequence, the movement trajectories of the mouse were estimated and plotted for 10 s following the onset of the neuronal sequences. e The spatial specificity of the neuronal sequences, determined by the average Gini coefficient of the distribution of mouse positions within the estimated trajectories (**P = 0.008; one-way RM ANOVA with Tukey’s post hoc test). Abbreviations: Seq., Neuronal sequence. Data are represented as mean ± SEM
We compiled these values into what we refer to as a “location vector”, which we displayed as a heatmap formatted to match the shape of the Y-maze (Figs. 4b–d). Our findings are consistent with the idea that on all days, neuronal sequences correspond to behaviours necessary for completing the rules of the Y-maze task. Specifically, we observed neuronal sequences during movements from the Zone located at the right side to the Port to receive a reward (Figs. 4b–d; upper panels) and from the Port back to the Zone or the right side to obtain the next reward (Figs. 4b–d; lower panels). Interestingly, in mice performing the Y-maze task rule as a three-step procedure (i.e., moving to the opposite arm of the Zone (hereafter called “the Opposite”), from the Opposite to the Zone, and from the Zone to the Port), neuronal sequences corresponding to each of these three behavioural stages were detected (Supplementary Figs. 7a–c). All mice were trained under identical conditions; however, each individual developed a unique strategy for obtaining rewards, which was accompanied by the emergence of corresponding neuronal sequences. By calculating the Gini coefficient for the location vector of each neuronal sequence, we could evaluate the spatial specificity of the neuronal sequences, assessing their location bias within the Y-maze (see Methods). Our results clearly demonstrate that as rule learning progresses, the trajectories of behaviour encoded by these neuronal sequences become increasingly distinct (Fig. 4e).
The neuronal sequences of expert mice distinguish between successful and unsuccessful reward acquisition
If neuronal sequences in the mPFC encode procedural rule-related information, the activity patterns of these sequences should vary between successful (Success) and unsuccessful (Failure) reward acquisition (Fig. 5a). We calculated the average of the spike intensity for neuronal sequences 20 s before and after licking the Port in both Success and Failure events (Fig. 5b). To assess the differences in neuronal sequence activity patterns between Success and Failure, we analyzed their Pearson’s correlation. The correlation after the mouse licked the Port (post-correlation) decreased compared to before licking the Port (pre-correlation) on all days (Fig. 5c), likely due to the difference in outcomes between obtaining a reward in Success events and not obtaining one in Failure events. Of note, on day 6, the pre-correlation significantly decreased compared to days 1 and 2 (Fig. 5d). This outcome was also replicated when analysing the pre-correlation during the 10 s before the mouse licked the Port (Fig. 5f). These findings show that in the mPFC of mice that have mastered the rule, individual neuronal sequences exhibit distinct activity patterns capable of differentiating between successful and unsuccessful task completions, even before the reward is actually obtained. Additionally, when similar analyses were performed on the post-correlations, the results demonstrated variability depending on the time duration over which the correlation was assessed (Figs. 5e, g). These results were obtained using neuronal sequences detected with iSeq, with the time window L set to 10 s. We performed the same analysis using neuronal sequences detected with a shorter time window of 5 s, and obtained similar results (Supplementary Fig. 8).
Fig. 5. The neuronal sequences of expert mice distinguish between successful and unsuccessful reward acquisition. a Schematic for analysing the difference in activity patterns of neuronal sequences during Success and Failure. b Time series of the average spike intensities of each neuronal sequence during the 20 s periods before and after the mouse licked the Port, plotted separately for Success and Failure. c Changes in the correlations of spike intensities for Success and Failure before (Pre) and after (Post) the mouse licked the Port (Day 1, **P = 0.003; Day 2, ***P < 0.001; Day 6, ***P < 0.001; t-test on two related samples of scores). d Daily comparison of spike intensity correlations in the pre-lick phase, between Success and Failure (*P = 0.016; **P = 0.003; one-way ANOVA with Tukey’s post hoc test). e Same as (d), but in the post-lick phase (**P = 0.002). f Same as (d), but focused on the 10 s prior to licking (Days 1–6, **P = 0.003; Days 2–6, **P = 0.001). g Same as (e), but focused on the 10 s after licking. Abbreviations: Seq., Neuronal sequence; Corr. Coef., Correlation coefficient. The box represents the range from the first quartile (Q1) to the third quartile (Q3) of the data, with a red line indicating the median. The whiskers extend from the box to the farthest data points that are within 1.5 times the interquartile range (IQR)
The dynamics of neuronal sequences of expert mice distinguish between successful and unsuccessful reward acquisition
Furthermore, we explored whether there were differences in the overall neuronal dynamics driven by multiple neuronal sequences, rather than just individual ones, between novice and expert mice. We employed principal component analysis (PCA) to extract the first and second principal components (Fig. 6a), allowing us to represent the spike intensity of all detected neuronal sequences from each mouse on each day in a two-dimensional space (Fig. 6b). We then plotted the average trajectories of these principal components during the 20 s before licking the Port, in both Success and Failure events, defining these plotted trajectories as sequential neuronal dynamics. Our analysis focused on determining whether these dynamics were similar or differed between Success and Failure events―that is, to assess the extent to which the trajectories in Success events deviate from the trajectories in Failure events, which are used as the reference (Fig. 6c). To enable comparison of distances in the principal component subspaces obtained from different days, we independently aligned the principal component subspaces from days 1 and 2 by rotating, scaling, and translating them, such that the average trajectories of day 1 and day 2 Failure events were matched to the average trajectory of day 6 Failure events as a reference (see Methods). The results indicate that the sequential neuronal dynamics on days 1 and 2 were similar for both outcomes, whereas those on day 6 differed considerably between Success and Failure (Fig. 6d). By applying the same analytical methods as used in Fig. 2g, we observed that the distance between the dynamics of expert mice was significantly greater (Figs. 6e, f; see also Supplementary Fig. 9). Given the consistent differences in the behavioural trajectories of mice between Success and Failure across all days (Fig. 2g), the significant distinction in the sequential neuronal dynamics of expert mice is unlikely to reflect mere changes in external stimuli, such as location shifts resulting from altered behaviour. Rather, these differences suggests that the mice, at the time of executing the action sequences, had internally differentiated between Success and Failure outcomes—likely reflecting their internal representation of the rule. Nonetheless we do not exclude the alternative interpretation that the absence of an appropriate pattern of neuronal sequences may underlie the behavioural failure. We acknowledge that both mechanisms may be involved.
Fig. 6. The dynamics of neuronal sequences of expert mice distinguish between successful and unsuccessful reward acquisition. a Schematic for converting the time series of spike intensities from neuronal sequences into the top two principal components of sequential neuronal dynamics. b Schematic for plotting these sequential neuronal dynamics in a two-dimensional space. c Schematic for assessing whether distinct sequential neuronal dynamics occur in Success and Failure. d Plots of the sequential neuronal dynamics for mice ID: 4 and 5 during the 10 s period leading up to Success and Failure. The lines indicate the average trajectories of these dynamics. The shaded areas around the lines represent probability ellipses, statistically depicting the regions through which 50% of the sequential neuronal dynamics pass. The inset (bottom left of each trajectory) shows the sum of the explained variance ratios for the top two principal components. e, f The differences in sequential neuronal dynamics between Success and Failure were assessed by the same method as employed in Fig. 2b. Euclidean distance (e, **P = 0.008, *P = 0.026; one-way RM ANOVA with Tukey’s post hoc test). Mahalanobis’ distance (f, **P = 0.006; *P = 0.011; one-way RM ANOVA with Tukey’s post hoc test). Abbreviations: Seq., Neuronal sequence; Comp., Component; PC, Principal component; Dist., Distance; b/w, Between. Data are represented as mean ± SEM
In expert mice, neuronal sequences show improved decoding accuracy only for behaviours crucial to the procedural rule
If neuronal sequences encode procedural rule-related information, it should be possible to decode mouse behaviours from the spike intensities of these sequences. We implemented a decoder featuring an LSTM (long short-term memory) layer [33] to decode mouse behaviours from the temporal activity patterns of neuronal sequences (Fig. 7a). We assessed the decoder’s accuracy across various proficiency levels of the mice. To prevent overfitting, the data were split into training and validation datasets (Fig. 7b). Specifically, we used only the training data to train the decoder and terminated training when the prediction error on the validation data reached its minimum (Fig. 7c; see also Methods).
Fig. 7. In expert mice, neuronal sequences show improved decoding accuracy only for behaviours crucial to the rule. a Schematic for decoding mouse behaviour from the time series of spike intensities in neuronal sequences. b Schematic for dividing data into training and validation datasets. c Example of prediction error fluctuations for training and validation data, with training of the decoder halted at the epoch marked by the red dashed line, designated as the final result. d Reward values predicted by the decoder, displayed alongside the actual instances of Success and Failure for the mouse. e Daily decoding errors for “staying in the Zone” (*P = 0.014; one-way RM ANOVA with Tukey’s post hoc test). The red dashed line indicates the baseline error from the null decoder (Day 1, P = 0.84; Day 2, ‡P < 0.01; Day 6, †P = 0.02; comparison with the null decoder using a one-sample t-test with Bonferroni’s correction). f Same as (e), but for “acquiring a reward” (Day 1, P = 0.17; Day 2, P = 0.07; Day 6, ‡P < 0.01). g Differences in the outputs of the decoder predicting “acquiring a reward” at the times of Success and Failure licking (**P = 0.003; *P = 0.023 one-way RM ANOVA with Tukey’s post hoc test). h Same as (e), but for “licking the Port” (†P = 0.02; ‡P < 0.01). i Same as (e), but for the “X-coordinate” (Day 1, †P = 0.02; Day 2, ‡P < 0.01; Day 6, †P = 0.04). j Same as (e), but for the “Y-coordinate” (Day 1, P = 1.00; Day 2, P = 0.05; Day 6, P = 0.31). Abbreviations: Seq., Neuronal sequence; LSTM, Long short-time memory. Data are represented as mean ± SEM
The decoding error for critical behaviours in the Y-maze task (“staying in the Zone” and “acquiring a reward”) significantly decreased on day 6 compared to days 1 and 2 (Figs. 7d–g). Although the overall average decoding error for “acquiring a reward” did not exhibit statistically significant changes across the days, it was only on day 6 that the error was significantly lower compared to that of the null decoder (Fig. 7f; see also Methods). Additionally, when analysing the decoder’s output exclusively at the moments of licking, the results from day 6 clearly demonstrated the decoder’s ability to distinguish between Success and Failure (Fig. 7g). These results indicate that as mice learn the rule, key behaviours crucial to the rule are progressively encoded into the neuronal sequences.
Conversely, the decoding error for “licking the Port”, which does not differentiate between Success and Failure, was significantly low from day 1 and remained consistent regardless of the mice’s proficiency in the task (Fig. 7h). Although mice started learning the rules of the Y-maze task from day 1, port habituation had been initiated 2 days earlier, enabling the mice to recognize the meaning of the Port by day 1 (see Methods). Given this context, Fig. 7h indicates that information regarding the Port was already encoded in the neuronal sequences by day 1.
Regarding the decoding error for X- and Y-coordinates, no significant changes were observed across different days. Of note, the decoding error for the X-coordinate, which strongly reflects the position of the Port, consistently lower than that of the null decoder (Fig. 7i). However, the decoding error for the Y-coordinate did not differ from that of the null decoder (Fig. 7j). These findings, in conjunction with those displayed in Figs. 7d–g, indicate that the neuronal sequences are encoding information not only based on location but rather on the value of behaviours associated with the rule.
The populations of cells of the neuronal sequences are continuously updated
The cells constituting the neuronal sequences appeared to be dispersed across the field of view used for Ca^2+^ imaging (Fig. 8a). Employing a method similar to that used by Harvey et al. [18], we classified cell pairs into six groups based on their distances and analyzed the differences in their activity levels within a single neuronal sequence (Fig. 8b). Although the trend was gradual, there was a tendency for cells that were closer together to less frequently be part of the same neuronal sequence. This pattern suggests the involvement of local inhibitory neurons in the formation of neuronal sequences.
Fig. 8. The populations of cells of the neuronal sequences are continuously updated. a An example illustrating the activity intensity of cells within a single neuronal sequence and their spatial distribution. b The relationship between the spatial distance of two cells and the differences in their activity intensities within a neuronal sequence (Friedman’s test for repeated samples with Bonferroni’s correction). c Schematic showing the similarity of pathways encoded by neuronal sequences and the similarity among the cell populations composing these sequences. d Correlation between the similarity of pathways and the similarity of cell populations in neuronal sequences. The correlation coefficient R and P value (Wald’s test with t-distribution) are shown. e Same as (d), but with inverted pathway Y-coordinates on one day. f Comparison of the correlation coefficients obtained in (d) and (e) with the distribution from 1,000 simulations in which cell IDs were shuffled and recalculated. Abbreviations: Seq., Neuronal sequence; Corr. Coef., Correlation coefficient; Coord., Coordinate. Data are represented as mean ± SEM
Finally, we investigated the day-to-day consistency of the cells of neuronal sequences. Neuronal sequences of novice mice were already associated with specific behaviours (Fig. 4). However, as the mice progressed in learning, the behaviours associated with the rule became more precisely encoded within the neuronal sequences. Thus, even if certain neuronal sequences during the novice phase corresponded to behaviours similar to those in the expert phase, these sequences would likely undergo modifications as the mice’s understanding of the rules deepened. We evaluated the similarity of behaviours encoded in neuronal sequences by analysing the similarity of mouse trajectories during the activity of these sequences (Fig. 4). Additionally, we examined the correlation with the similarity of the cells of the neuronal sequences (Fig. 8c; see also Methods). Although there was a modest consistency in the sequences between days 1 and 2, there was little overlap between the sequences of novice and expert mice (Fig. 8d). Considering the reversal of the Zone’s location on day 6 compared with days 1 and 2, we also computed the correlation after inverting the Y-axes of the trajectories of one day; however, the trend did not change (Figs. 8e, f). These results indicate that the cells forming neuronal sequences are being updated daily.
Discussion
Our findings highlight the critical role of neuronal sequences in the PFC. Not only do individual neuronal sequences encode specific behaviours (Fig. 4 and Supplementary Fig. 7) but collectively, multiple sequences create dynamics that represent the procedural rule, enabling the PFC to differentiate between processes that lead to successful and unsuccessful reward acquisition (Figs. 5 and 6). As animals advance in procedural rule learning, the dynamics of their neuronal sequences increasingly concentrate on encoding behaviours essential to the rule (Fig. 7). This indicates that neuronal sequences are continuously restructured each day throughout this process (Fig. 8).
It is likely that research focusing on neuronal sequences will continue to be crucial, and the iSeq algorithm we used will prove highly valuable in this context. iSeq is not only robust to signal-dependent noise, but also requires less computational effort compared to conventional methods such as seqNMF (Supplementary Fig. 2). In order to determine the appropriate number of neural sequences using seqNMF, it is necessary to first find the penalty coefficient λ, and then search for the value of K, the number of neural sequences. Mackevicius et al. [20] recommend first identifying coefficient λ_0_ that balances the reconstruction cost with the X-ortho cost derived from the penalty term. This λ_0_ is then used as a reference point for selecting λ. Finding λ_0_ requires a large number of computations while systematically varying λ (see, for example, Fig. 9B of [20]). In this framework, the theoretical search space for λ spans the entire positive range, 0 < λ < ∞. Furthermore, after selecting an appropriate value of λ, an additional computational burden arises in determining the optimal number of neuronal sequences K. This involves testing multiple values of K, typically starting from K = 1, and evaluating each case. For each value of K, the dissimilarity metric should be computed, which itself requires substantial computation. The optimal value of K is then chosen based on the result that minimises dissimilarity. By contrast, iSeq automatically outputs the appropriate number of neuronal sequences K once a threshold for the correlation coefficient is specified. This is because the correlation threshold parameter in iSeq (ranges from 0 to 1) serves as a direct criterion for determining K. As neuroimaging technologies advance, the volume of data generated from experiments is rapidly increasing. However, iSeq can automatically detect neuronal sequences within this data, significantly decreasing the analytical workload.
iSeq is capable of automatically detecting the number of neuronal sequences K present in neuronal activity data. However, it requires the length of temporal window L of neuronal sequences to be predefined. This requirement to predefine L represents a common technical constraint shared by iSeq and earlier sequence detection method based on NMF. Thus, it is necessary to set L empirically. Previous studies have suggested that neuronal sequences in mPFC [21] and posterior parietal cortex [18] often last nearly 10 s. Based on this, we set L = 10 s in this study. Nonetheless, future work should aim to explore algorithms for optimising the length of the temporal window.
In this study, a consistent and significant finding is that the neuronal sequences in the mPFC encode the meaning of the mouse’s behaviours more strongly than merely the positional changes resulting from those behaviours. For instance, although no significant changes were observed in the differences between the movement trajectories leading to Success and Failure as a result of procedural rule learning (Fig. 2g), the trajectories of sequential neuronal dynamics in the mPFC of expert mice clearly distinguished between these outcomes (Figs. 6d–f). Additionally, even as animals learned the rule, the decoding accuracy for the X- or Y-coordinates based on sequential neuronal dynamics did not improve (Figs. 7i, j). In particular, the fact that the decoding accuracy for Y-coordinates consistently matched that of the null decoder suggests that the sequential neuronal dynamics in the mPFC do not significantly encode information regarding Y-coordinates. Conversely, the decoding accuracy for X-coordinates consistently and significantly exceeded that of the null decoder. This is likely because the X-coordinates are strongly linked to the location of the Port.
A previous study has shown that although hippocampal neurons exhibit activity characteristics that respond to the location of objects, neurons in the PFC exhibit equivalent responses to objects with the same meaning, regardless of their location [34]. Furthermore, hippocampal neurons encode absolute positions, whereas neurons in the PFC encode positions relative to the animal’s perspective [7, 21]. This supports the model suggesting that the PFC converts sensory inputs into specific behavioural outputs [35–37]. Indeed, in the PFC of macaque monkeys, only sensory inputs critical to the task are integrated into the neuronal population dynamics specific to their choices [35]. Therefore, it is more likely that the meanings of objects (rather than their identities) and the relative positions of a mouse (rather than its absolute positions), are incorporated into the populational representation of PFC neurons. In our experiments, whether the mouse was in the Zone or not was more crucial to the task than its exact X- or Y-coordinates, and thus it is conjectured that the dynamics of the neuronal sequences evolved to encode the information of the Zone as the mice learned the rule. These results strongly support our hypothesis that the PFC recognizes the meaning of stimuli and actions, selects elements crucial for reward acquisition, encodes them into neuronal sequences, and thereby represents the procedural rule.
Figure 4 and Supplementary Fig. 7 display the behaviours encoded by individual neuronal sequences. Specific neuronal sequences were active when mice performed actions corresponding to their understanding of the rule (mouse ID: 5, two steps; mouse ID: 6, three steps). These findings may suggest that neuronal sequences decompose the rule into multiple actions for encoding. This aligns with the hypothesis of “compositionality” [38–41] of the PFC, i.e., remembering complex tasks as sets of individual components enables rapid learning when faced with new tasks that share common elements. In this study, we exposed mice to only one rule; however, introducing multiple similar rules simultaneously in future experiments could enable the identification of common neuronal sequences that span across various rules.
Our results show that neuronal sequences and their dynamics encode procedural rules; however, the underlying mechanisms generating these sequential activities and their effects remain unclear. A possible hypothesis is that the mPFC orchestrates procedural rule execution through the activity of neurons with diverse connectivities. The PFC is interconnected with multiple brain regions [42]. In the mPFC, sequentially activating neurons that connect to regions such as the sensory cortex (sensation), amygdala (emotion), hippocampus (memory), and motor cortex (action) could integrate processes across these areas. Neuronal sequences are likely to be particularly well suited for integrating pieces of information processed across different brain regions, compared with other population-level responses such as synchronous neuronal activity. The neuronal sequences we identified span several seconds, enabling temporally ordered representations of information processing across distinct brain regions on the timescale of the behavioural task. Therefore, the function of mPFC neuronal sequences involved in sensation, memory, and action on the timescale of the task might enable the animal to evaluate external stimuli and execute appropriate actions based on memory, thereby facilitating procedural rule-based behaviour. To optimize neuronal sequences that organise the appropriate information processing steps in the correct order for the animal to understand the task rule, it may be necessary to reconfigure the cell populations of the neuronal sequences. Investigating the mechanism of updating neuronal sequences should be a priority for future research. A previous study has shown that spike-timing-dependent plasticity (STDP) plays a role in the retention [43] and elimination [44] of neuronal sequences. Additionally, local inhibitory neurons may affect the formation of these neuronal sequences (Fig. 8b).
In conclusion, as procedural rule learning progresses, neuronal sequences in the mPFC encode behaviours critical to the rule, and their dynamics effectively represent this rule. Consequently, the cell populations forming these neuronal sequences are continuously updated to facilitate this process. Future research should aim to elucidate the mechanisms by which neuronal sequence activity triggers procedural rule-based behaviour and neuronal sequences are reconfigured to align with rules.
Methods
Animals
Naïve wild-type male C57BL/6J mice were purchased from Sankyo Labo Service Co. Inc. and maintained on a 12 h light/dark cycle at a controlled temperature (24 ± 3 °C) and humidity (55 ± 5%) with free access to food and water. Mice used in behavioural experiments were 3–5 months old. All the behavioural experiments were performed between zeitgeber ZT + 1 and ZT + 9. All experimental procedures with animals were approved by the Animal Care and Use Committee of the University of Toyama (approval numbers: A2019MED-35 and A2022MED-7) and were conducted in accordance with the Institutional Animal Experiment Handling Rules of the University of Toyama and the guidelines of the NIH.
Viral vectors
For in vivo Ca^2+^ imaging experiments, the recombinant AAV vector used was AAV_9_-SynI::janelia G-CaMP7b [45] (9.4 × 10^12^ vg/mL), which was diluted 10-fold in phosphate-buffered saline (PBS; T900, Takara Bio Inc.) before injection. The pAAV-SynI-janelia-G-CaMP7b plasmid, a gift from Douglas Kim (Addgene plasmid #104489), was previously constructed. Recombinant AAV_9_ production was performed using the minimal purification method, and the viral genomic titre was subsequently calculated as described previously [46].
Briefly, pAAV recombinant vectors were produced using AAV293 cells (240073, Agilent Tech) cultured in 15 cm dishes (Corning). Cultured cells were maintained in Dulbecco’s Modified Eagle Medium (11995-065) supplemented with 10% foetal bovine serum (FBS) (10270106), 1% 2 mM L-glutamine (25030-149), 1% 10 mM nonessential amino acid (MEM NEAA 100×, 11140-050), and 1% (100×) penicillin–streptomycin solution (15140-148, all from GIBCO Life Technologies). AAV293 T cells that reached 70% confluency were transfected using medium containing the constructed expression vector, pRep/Cap, and pHelper (240071, Agilent Technologies), mixed with the transfection reagent polyethyleneimine (PEI) hydrochloride (PEI Max, 24765-1, Polysciences Inc.) at a 1:2 ratio (W/V). After 24 h, the transfection medium was discarded, and cells were incubated for another 5 days in a maintenance medium without FBS. On day 6, the AAV-containing medium was collected and purified from cell debris using a 0.45 μm Millex-HV syringe filter (SLHV033RS, Merck Millipore). The filtered medium was concentrated and diluted with D-PBS (14190-144, GIBCO Life Technologies) twice using a Vivaspin 20 column (VS2041, Sartorius) after blocking the column membrane with 1% bovine serum albumin (01862-87, Nacalai Tesque Inc.) in PBS.
To further calculate the titre, degradation of any residual complementary DNA (cDNA) in the viral solution from production was first assured by Benzonase nuclease treatment (70746, Merck Millipore). Subsequently, viral genomic DNA was digested with proteinase K (162-22751, FUJIFILM Wako Pure Chemical) and extracted with phenol/chloroform/isoamyl alcohol (25:24:1 vol/vol), followed by precipitation with isopropanol and final dissolution in Tris-EDTA buffer (10 mM Tris, pH 8.0, 1 mM ethylenedinitrilo tetraacetic acid [EDTA]). The titre quantification for each viral solution, referenced to that of the corresponding expression plasmid, was performed by real-time qPCR using THUNDERBIRD SYBR qPCR Master Mix (QPS-201, Toyobo Co. Ltd.) with the primers 5′-GGAACCCCTAGTGATGGAGTT-3′ and 5′-CGGCCTCAGTGAGCGA-3′ targeting the inverted terminal repeat (ITR) sequence. The cycling parameters were adjusted as follows: initial denaturation at 95 °C for 60 s, followed by 40 cycles of 95 °C for 15 s and 60 °C for 30 s [47].
Stereotactic surgery for Ca2+ imaging
Mice (3–5 months old) were anaesthetised with an intraperitoneal anaesthetic injection [48] containing 0.75 mg/kg medetomidine (Domitor; Nippon Zenyaku Kogyo Co. Ltd.), 4.0 mg/kg midazolam (Fuji Pharma Co. Ltd.), and 5.0 mg/kg butorphanol (Vetorphale, Meiji Seika Pharma Co. Ltd.) and were then placed on a stereotactic apparatus (Narishige). After surgery, an intramuscular injection of 1.5 mg/kg atipamezole (Antisedan; Nippon Zenyaku Kogyo Co.), an antagonist of medetomidine, was administered to boost recovery from sedation. Mice were allowed to recover from surgery for 3 weeks in their home cages before behavioural experiments were initiated.
Viral injections were made using a 10 µL Hamilton syringe (80030, Hamilton) fitted with a mineral oil-filled glass needle and wired to an IMS-20 automated motorized microinjector (Narishige). Mice were injected with 500 nL of AAV_9_-SynI::janelia G-CaMP7 at 100 nL/min unilaterally into the right mPFC (− 2.0 mm AP, + 0.3 mm ML, + 2.2 mm DV). After 2 weeks of recovery from AAV injection surgery, the reanaesthetised mice were again placed on a stereotactic apparatus to implant a gradient index (GRIN) lens [48] (1.0 mm diameter, 4.0 mm length; Inscopix Inc.) into the centre of the injection (from the skull surface: +1.2 mm DV) using custom-made forceps attached to a manipulator (Narishige). Low-temperature cautery was used to emulsify bone wax into the gaps between the GRIN lens and the skull, and then the lens was anchored in place using dental cement. Three weeks after GRIN implantation, the mice were reanaesthetised and placed back onto the stereotactic apparatus to set a baseplate (Inscopix Inc.), as described previously [48]. In brief, a Gripper (Inscopix Inc.) holding a baseplate attached to a miniature microscope (nVista 3; Inscopix Inc.) was lowered over the previously set GRIN lens until visualization of clear vasculature was possible, indicating the optimal focal plane. Dental cement was then applied to fix the baseplate in position to preserve the optimal focal plane. Mice recovered from surgery in their home cages for 1 week before the initiation of behavioural imaging experiments.
Y-maze task
All behavioural experiments with or without Ca^2+^ imaging were performed under dim light conditions (approximately 2 lx). The behavioural apparatus, including a solenoid valve for the regulation of sucrose water delivery (LHDA2431115H, The Lee Company), video tracking sensors (VTS4, BRC), a licking port (Mouse Behaviour Port, Sanworks), and white LED tape (SOF-18 W-30-SMD, Akizuki Denshi Tsusho), was controlled. Outputs were recorded by in-house-built signal regulators and the OpenEx Software Suite (RX8-2, Tucker-Davis Technologies). OpenEx was also used to synchronize the onsets of behavioural and imaging systems.
The Y-maze context consisted of a trunk and upper and lower branching arms (wall height: 25.5 cm, path width: 12.0 cm, trunk length: 17.0 cm, branching arm length: 16.5 cm). There was a licking port (“Port”) at the end of the trunk, and an area of up to 11.5 cm from the end of either branching arm was defined as the reward chance waiting area (“Zone”). Each end was marked with a different wall pattern (a black dot or stripe). For port habituation, mice were subjected to water deprivation in their home cage from 1 day before the port habituation and Y-maze training sessions and were then rehydrated with a water bottle for 1 h after each behavioural session. Before the Y-maze training, mice were individually subjected to port habituation sessions for 2 days, in which the mice were habituated to licking the Port to drink 10% sucrose water in a small cage until they had drunk approximately 1.5 mL. The water supply from the tap of the Port was controlled so that it only delivered one 7.5 µL water drop when the animal licked the Port.
For the Y-maze training, the animal was required to learn three behaviours to obtain reward water in the Y-maze context. First, the animal needed to stay in the Zone of the arm for the appropriate time until a reward chance emerged. Second, during the 10 s reward chance, the animal needed to move to the Port. Third, the animal needed to lick the Port to drink a 25 µL water drop within the reward chance time. Otherwise, the animal failed to obtain the reward because the reward chance was not induced. The Y-maze training was composed of sequential 6-day trainings. The Zone position and time for inducing the reward chance were altered according to the day of the training session: on day 1, upper Zone for 4 s; on days 2–3, upper Zone for 5 s; on day 4, lower Zone for 5 s; on days 5–6, lower zone for 6 s.
During the training, mice were allowed to freely explore within the Y-maze context and the Port. When mice stayed in the Zone of the Y-maze arm, LED blinking (50 ms pulse, 1 Hz) started (reward chance induction phase) and continued until the reward chance was induced, provided the mice remained in the Zone. However, if the mice moved out of the Zone, the LED blinking stopped. If mice stayed within the Zone for the appropriate time, the reward chance with continuous LED lighting followed the LED blinking. Thus, during the initial learning, the animal unintentionally obtained reward water when it showed the sequential three behaviours: staying in the Zone until a reward chance emerged, moving to the lick port arm, and licking the Port within the reward chance. Mice were subjected to the Y-maze task until they acquired approximately 40 rewards or until 60 min had elapsed. The animal’s XY positions were extracted by the MATLAB program OptiMouse [49] (https://github.com/yorambenshaul/optimouse) from screen captures from the recorded movies using behavioural movie software (AG-Desktop recorder, AmuseGraphics). Ca^2+^ imaging was performed during the task only on days 1, 2, and 6 to avoid photo bleaching and phototoxicity owing to the long-exposure imaging.
Behavioural data processing
We developed image processing software in Python to adjust and align the differences in the numbers of sampled frames due to the differences in core clock frequency between the RX8-2 (Tucker-Davis Technologies) at 1017 Hz, nVista (Inscopix) at 1000 Hz, and screen capturing software (AG-Desktop recorder, AmuseGraphics) of the PC at 20.004 Hz. This procedure was performed by referring to the captured video of the computer screen during the experiment.
After one lick of the Port, the mice continued to exhibit several licking behaviours, regardless of whether they were rewarded (see Supplementary Fig. 10). This behaviour was thought to be a retrieval of the remaining water or a confirmation that the task had really failed when the reward was not obtained. Therefore, we did not count this “just in case” lick as a failed (non-rewarded) lick. Specifically, we recorded the time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} of the most recent licking event and scanned the behavioural data from the beginning. If the next licking event was associated with a reward, it was unconditionally counted as a Success event, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} was updated to the time of that licking. If the next licking event was not associated with a reward and occurred more than 10 s after \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} , it was counted as a Failure event. Regardless of whether the licking was counted as a Failure, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} was updated to the time of the most recent licking event. Accordingly, a Failure event was defined as a licking event that occurred at least 10 s after the previous licking.
In vivo Ca2+ imaging data acquisition and analysis
Ca^2+^ signals produced from G-CaMP7 protein expressed in mPFC neurons were captured at 20 Hz with nVista acquisition software (IDAS, Inscopix) at the maximum gain and optimal power of the nVista LED. Ca^2+^ imaging movies were then extracted from the nVista Data acquisition box (DAQ, Inscopix). Using Inscopix Data Processing Software (IDPS, Inscopix), movies were temporally stitched together to create a full movie that contained recordings of all sessions across all days, which was spatially down-sampled (4×) and then corrected for across-day motion artifacts against a reference frame that was chosen from any day that had a clear landmark vasculature. Further motion correction was then applied using Inscopix Mosaic software, as previously described [48]. The full movie was then temporally divided into the individual days using Inscopix Mosaic software. Each movie of individual days was then low-band-pass filtered using Fiji software [50] (NIH) to reduce noise, as described previously [26, 48]. The fluorescence signal intensity change ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varDelta\:F/F$$\end{document} ) for each day was subsequently calculated using Inscopix Mosaic software according to the formula \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varDelta\:F/F=\left(F-{F}_{m}\right)/{F}_{m}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F$$\end{document} represents each frame’s fluorescence, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{F}_{m}$$\end{document} represents the mean fluorescence of the whole day’s movie [26, 48]. Afterwards, movies representing each day were again concatenated to generate the full movie for all days in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varDelta\:F/F$$\end{document} format. Finally, cells were identified using a HOTARU automatic sorting system [30], and each cell’s Ca^2+^ signals over time were extracted in a (Ď; time × neuron) matrix format, as previously described [26, 48]. This matrix was then transposed and treated as the original matrix V.
Binning was applied every four time frames (0.2 s) to reduce the computational complexity in iSeq, which is described later. In addition, the signal intensity of the cells was scaled so that the average of the nonzero signal intensity of each cell was 1. The maximum signal intensity was capped to be within three standard deviations from the mean of the nonzero signal intensities.
Immunohistochemistry and microscopy
Immunohistochemistry was conducted as described previously [51]. Mice were deeply anaesthetised with a mixed anaesthesia solution, as described above, and perfused transcardially with 4% paraformaldehyde in PBS (pH 7.4). Their brains were removed and further post-fixed by immersion in 4% paraformaldehyde in PBS for 24 h at 4 °C. Each brain was equilibrated in 25% sucrose in PBS for 2 days and then frozen in dry-ice powder. Coronal sections of 50 μm thickness were cut on a cryostat and stored at − 20 °C in cryoprotectant solution [51] (25% glycerol, 30% ethylene glycol, and 45% PBS) until further use. For immunostaining, sections were transferred to 12-well cell culture plates (Corning, USA) containing Tris-buffered saline (TBS-T) buffer (0.2% Triton X-100 and 0.05% Tween-20).
For G-CaMP detection, after washing with TBS-T buffer, the floating sections were treated with blocking buffer (5% normal donkey serum [S30, Chemicon, USA] in TBS-T) at room temperature for 1 h. Reactions with primary antibodies were performed in blocking buffer containing rabbit anti-GFP antibody (1:500, A11122, Molecular Probes, USA) at 4 °C for 1–2 nights. After three 20 min washes with TBS-T, the sections were incubated with the secondary antibody donkey anti-rabbit IgG-AlexaFluor 488 (1:500, A21206, Molecular Probes, USA) in blocking buffer at room temperature for 3 h. Images were acquired using a Keyence microscope (BZ-9000, KEYENCE, Japan) with a Plan-Apochromat 4× or 10× objective lens.
Synthetic data generation
We specified the time (T) of the data to be generated, the number of sequences to be embedded in the data (K), and the number of cells comprising one neuronal sequence (N_s_). Then, the number of cells in the synthetic data N was K × N_s_, and finally the original matrix V with size N × T was generated.
An exponential decay model was used to simulate the Ca^2+^ activity of neurons:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:x\left(t\right)={x}_{0}\text{exp}\left(-t/\tau\:\right),$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:x$$\end{document} is the Ca^2+^ intensity of the cell, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{0}$$\end{document} is the initial Ca^2+^ intensity after the spike, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau $$\end{document} is the time constant. We expressed this in terms of a differential equation and updated it using the Euler method and also increased the Ca^2+^ intensity by 1 at each time point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} with the firing probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} . To summarize the above, we obtained the updated equation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\frac{dx}{dt}=-\frac{x}{\tau\:}+\delta\:\left(r\left(t\right)<p\right),$$\end{document}where δ is Kronecker’s delta function, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:r$$\end{document} is a random number following a uniform distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:U(0,\:1)$$\end{document} . We created K time series of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:x$$\end{document} , with each randomly time-shifted from 0 to L, which is the time window of the neuronal sequences, to obtain the time series N_s_. By combining all of these, we created the original matrix V of synthetic data, with size N × T. The values of each parameter were: N_s_ = 100, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau $$\end{document} = 2.0, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} = 0.05, and L = 50.
To reproduce the noise characteristics present in Ca^2+^ imaging data, we added multiplicative noise drawn from a gamma distribution with a mean of 1 to the synthetic data.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{noise}\left(t\right)=x\left(t\right)\cdot \:n\left(t\right),\:\:n\left(t\right)\sim\text{G}\text{a}\text{m}\text{m}\text{a}\left(k,\frac{1}{k}\right)$$\end{document}The signal-to-noise (S/N) ratio of this data is given by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} , since the noise component can be expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\epsilon\:\left(t\right)=x\left(t\right)\cdot \:\left(n\left(t\right)-1\right)$$\end{document} , and the S/N ratio is defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eqalign{{\rm{S}}/{\rm{N}} &= {{\mathbb{E}\left[ {x{{\left( t \right)}^2}} \right]} \over {\mathbb{E}\left[ {\varepsilon {{\left( t \right)}^2}} \right]}} = {{\mathbb{E}\left[ {x{{\left( t \right)}^2}} \right]} \over {\mathbb{E}\left[ {{{\left( {x\left( t \right) \cdot \left( {n\left( t \right) - 1} \right)} \right)}^2}} \right]}} \cr & = {{\mathbb{E}\left[ {x{{\left( t \right)}^2}} \right]} \over {\mathbb{E}\left[ {x{{\left( t \right)}^2}} \right] \cdot {\rm{Var}}\left[ {n\left( t \right)} \right]}} = {1 \over {{\rm{Var}}\left[ {n\left( t \right)} \right]}} = k \cr} $$\end{document}In Fig. 1 and Supplementary Figs. 2a, b, the S/N ratio was set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k=1$$\end{document} .
Benchmark
For the benchmark comparison between iSeq and seqNMF shown in Supplementary Figs. 2c–g, we used synthetic data with a length of T = 3000 time frames containing K = 5 neuronal sequences. The level of noise in the synthetic data was adjusted to produce S/N ratios of 3, 2, 1, 1/2, 1/3 (the results for S/N = 2 and S/N = 1/2 are not shown).
For each dataset, iSeq was run 10 times, and the result with the lowest reconstruction error was selected and presented as the “best”. seqNMF was run in the MATLAB environment using the code available at https://github.com/FeeLab/seqNMF. We varied the parameter λ over the range 10^− 5^ to 10^0^, as used in [20], and for each λ, the number of sequence K was varied from 1 to 10 (the results for λ = 10^− 4^, 10^− 2^, 10^0^ are not shown). For each setting, matrix factorisation was repeated 10 times, and the dissimilarity was computed. According to [20], the optimal value of K is identified as the one that minimises the dissimilarity.
iSeq
Algorithm
iSeq is implemented in Python and operates on a GPU device. iSeq is a direct extension of convolutive NMF [22, 23]. iSeq approximates the original matrix V of size N × T with dimensions of neurons and time, to the reconstructed matrix U with the same size and dimensions. U is computed by tensor convolution (see Supplementary Math Note 1) of the pattern tensor W of size N × K × L with dimensions of neurons, number of neuronal sequences, the time window of neuronal sequences, and the intensity matrix H of size K × T + L − 1 with dimensions of the number of neuronal sequences and time (Supplementary Figs. 3a, b). The number of neurons N and time T are determined from the shape of the original matrix V. The length of the time window of neuronal sequences L must be determined in advance. The number of neuronal sequences K is automatically determined by the method described in the subsection “Determination of K”.
The error between V and U is evaluated by the IS divergence [27] and is expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D\left(\mathbf{V},\:\mathbf{U}\right)=\sum\:_{n=0}^{N-1}\sum\:_{t=0}^{T-1}\frac{{v}_{nt}}{{u}_{nt}}-\text{log}\frac{{v}_{nt}}{{u}_{nt}}-1,$$\end{document}
where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{v}_{nt}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{u}_{nt}$$\end{document} are values of V and U, respectively, at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} ^th^ neuron.
Multiplicative update rules
iSeq updates the values of the pattern tensor W and the intensity matrix H to decrease \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D\left(\mathbf{V},\:\mathbf{U}\right)$$\end{document} . To guarantee the non-negativity of matrices, W and H are updated by the multiplicative update rule as follows [52]:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bf{W}}_{ \cdot \cdot l}^{t + 1} \leftarrow {\bf{W}}_{ \cdot \cdot l}^t \times {{{{\bf{V}} \over {{{\left( {{{\bf{U}}^t}} \right)}^2}}}{{\left( {\mathop {{{\bf{H}}^t}}\limits^{l \to } } \right)}^ \top }} \over {{1 \over {{{\bf{U}}^t}}}{{\left( {\mathop {{{\bf{H}}^t}}\limits^{l \to \>} } \right)}^ \top }}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{H}}^{t + 1}} \leftarrow {{\bf{H}}^t} \times {{{{\bf{W}}^t}\mathop { \circledast}\limits^ \top {{\bf{V}} \over {{{\left( {{{\bf{U}}^t}} \right)}^2}}}} \over {{{\bf{W}}^t}\mathop {\circledast}\limits^ \top {1 \over {{{\bf{U}}^t}}}}},$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{W}}^{t}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{H}}^{t}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{U}}^{t}$$\end{document} are the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} ^th^ update results of the pattern tensor W, the intensity matrix H, and the reconstructed matrix U, respectively, and the symbol “ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\times\:$$\end{document} ” and fraction represent the element-wise product and quotient of the matrix, respectively. For other symbols, see Supplementary Math Note 1. However, if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D\left(\mathbf{V},\:\mathbf{U}\right)$$\end{document} increases after the update, W and H are modified as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbf{W}}^{t+1}\leftarrow\:0.5\times\:\left({\mathbf{W}}^{t}+{\mathbf{W}}^{t+1}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbf{H}}^{t+1}\leftarrow\:0.5\times\:\left({\mathbf{H}}^{t}+{\mathbf{H}}^{t+1}\right),$$\end{document}until \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D\left(\mathbf{V},\:\mathbf{U}\right)$$\end{document} decreases to guarantee convergence of W and H. See Supplementary Math Note 2 for proof.
Determination of K
iSeq initially sets a sufficiently large value for K (= 20). For the 20 detected neuronal sequences, it calculates the overlap matrix R, which is computed as transpose tensor convolution (Supplementary Math Note 1) of the pattern tensor W and the original matrix V. Each row of R represents the time series of overlap (correlation) between each neuronal sequence and V. For each pair of rows in R, the Pearson’s correlation coefficient is calculated with a time shift of up to L − 1 time frames both forward and backward, with the maximum value designated as the sequence similarity for that pair (see Figs. 1d, e). If the sequence similarity exceeds a predefined threshold, the pairs are considered to reflect the same neuronal sequences and are merged, resulting in a reduction K. This process is repeated until the sequence similarity between all remaining neuronal sequences falls below the threshold (see Fig. 1f).
Determination of the threshold of similarity
We created 10 synthetic datasets, each with K, taking values from 1 to 10 and T = 3,000. Ten datasets with five neuronal sequences (K = 5) were decomposed by iSeq, varying the threshold of sequence similarity from 0.1 to 0.9. The decompositions with iSeq were performed 10 times for each dataset, using different random seeds. According to the number of neuronal sequences detected from the decomposition with the smallest reconstruction error \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D\left(\mathbf{V},\:\mathbf{U}\right)$$\end{document} in each calculation, five neuronal sequences were correctly detected when the correlation threshold was set within the range of 0.2–0.4. Therefore, we tentatively set the threshold of 0.3 and used the same method to decompose data containing 1–10 neuronal sequences. As a result, we decided to use 0.3 as the threshold because the correct number of neuronal sequences were detected in most of the datasets. Similar results were obtained for the datasets with T = 30,000. iSeq, with the threshold fixed at 0.3, was able to correctly detect the number of neuronal sequences even when applied to datasets with T = 3,000, in which the signal-to-noise ratio was increased or decreased threefold by adjusting the level of multiplicated noise (Supplementary Fig. 2).
Matrix decomposition with compression
We set L = 50 time frames (10 s). In the beginning, the original matrix V was compressed by binning by L time frames (Supplementary Fig. 3c). We performed 30% of the entire iteration and decomposed this compressed matrix into the mini-pattern tensor Wmini of size N × K × 2 and the mini-intensity matrix Hmini of size K × T/L + 1. The time frames for which the mini-intensity matrix Hmini had the largest value for each neuronal sequence were listed in order until they reached 10% of the total time frames of the compressed matrix (Supplementary Fig. 3d). The columns of the compressed matrix corresponding to these time frames were extracted and combined after unbinning them to create the high-density matrix (Supplementary Fig. 3e). Then, 30% of the entire iterations were performed, and this matrix was decomposed into the pattern tensor W of size N × K × L and the partial intensity matrix Hpart of size K × T_part_, where T_part_ is the number of time frames of the high-density matrix (Supplementary Fig. 3g). The overlap matrix of the pattern tensor W and the high-density matrix was then calculated, and the appropriate value of K was determined based on the aforementioned method. Then, 10% of all iterations were performed to shape the remaining neuronal sequences. Finally, the original matrix V was restored by unbinning all columns of the compressed matrix (Supplementary Fig. 3f, h), and the remaining 30% of the total iterations were performed to obtain the final decomposition result (Supplementary Fig. 3i).
We performed the above calculations 10 times and used the decomposition result with the smallest reconstruction error \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D\left(\mathbf{V},\:\mathbf{U}\right)$$\end{document} in the subsequent analysis.
Distance between trajectories
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{S}=\left\{{\varvec{s}}^{1},{\varvec{s}}^{2},\cdots\:,{\varvec{s}}^{m}\right\}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{F}=\left\{{\varvec{f}}^{1},{\varvec{f}}^{2},\cdots\:,{\varvec{f}}^{n}\right\}$$\end{document} represent the sets of trajectories corresponding to Success and Failure, respectively. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} are the number of Success and Failure events, respectively. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{s}_{t}^{k}$$\end{document} denotes the position of the mouse at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} during the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ Success event. The average Success trajectory is denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{-}{\varvec{s}}=\left\{{\stackrel{-}{s}}_{1},{\stackrel{-}{s}}_{2},\cdots\:,{\stackrel{-}{s}}_{T}\right\}$$\end{document} , and the corresponding covariance matrices are denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{\Sigma\:}}^{s}=\left\{{{\Sigma\:}}_{1}^{s},{{\Sigma\:}}_{2}^{s},\dots\:,{{\Sigma\:}}_{T}^{s}\right\}$$\end{document} , where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{-}{s}}_{t}=\frac{1}{m}{\sum}_{k=1}^{m}{s}_{t}^{k}$$\end{document}are satisfied, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T$$\end{document} represents the time length of the trajectory. Similarly, the average Failure trajectory is denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{-}{\varvec{f}}=\left\{{\stackrel{-}{f}}_{1},{\stackrel{-}{f}}_{2},\cdots\:,{\stackrel{-}{f}}_{T}\right\}$$\end{document} , and the corresponding covariance matrices are denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{\Sigma\:}}^{f}=\left\{{{\Sigma\:}}_{1}^{f},{{\Sigma\:}}_{2}^{f},\dots\:,{{\Sigma\:}}_{T}^{f}\right\}$$\end{document} . We calculated both the Euclidean distance
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${D_{EUC}} = {1 \over T}\mathop \sum \limits_{t = 1}^T {\left\| {\left. {{{\bar s}_t} - {{\bar f}_t}} \right\|} \right._2}$$\end{document}and Mahalanobis’ distance
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{D}_{Mah}=\frac{1}{T}{\sum}_{t=1}^{T}\sqrt{{\left({\stackrel{-}{s}}_{t}-{\stackrel{-}{f}}_{t}\right)}^{\top\:}{{\Sigma\:}}_{t}^{-1}\left({\stackrel{-}{s}}_{t}-{\stackrel{-}{f}}_{t}\right)}$$\end{document}to evaluate the similarity between the trajectories \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{S}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{F}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{\Sigma\:}}_{t}={{\Sigma\:}}_{t}^{f}$$\end{document} in Figs. 2 and 6, and the pooled covariance
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{\Sigma\:}}_{t}=\frac{\left(m-1\right){{\Sigma\:}}_{t}^{s}+\left(n-1\right){{\Sigma\:}}_{t}^{f}}{m+n-2}$$\end{document}was used in Supplementary Fig. 9. The Mahalanobis’ distance was compared using logarithmic transformations to normalize daily variances. Bartlett’s test was used without logarithmic transformation (**P<0.01, Figs. 2g and 6f, and Supplementary Fig. 9d) and with logarithmic transformation (P=0.523, Fig. 2g; P=0.374, Fig. 6f; P=0.612, Supplementary Fig. 9d).
Sequence-sharpening operation
To eliminate redundancy and noise in the sequence representation in iSeq and convolutive NMF, the representation of the neuronal sequences in the pattern tensor W was modified to have no width of neural activity. Originally, a single neuronal sequence was represented by a two-dimensional matrix of size N × L ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbf{W}}_{\cdot \:k\cdot \:}$$\end{document} ) within a three-dimensional pattern tensor W. However, we performed a manipulation such that for a single neuron, only one element in a row of length L would be positive, and the rest would be zero.
First, we reconstructed the neuronal activity produced by the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequence Uk from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbf{W}}_{\cdot \:k\cdot \:}$$\end{document} and part of the intensity matrix ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbf{H}}_{k\cdot \:}$$\end{document} ). Then, the sums of the time series (rows) of neuronal activity values were obtained based on Uk. This value was the relative activity intensity wint of the neurons composing the neuronal sequence, and the neuron with the largest value was referred to as the reference neuron. Subsequently, for the reference neuron and all other neurons, Pearson’s correlation was calculated for the activity time series represented in Uk, with shifts of up to L − 1 time frames both forward and backward. The amount of time shift that maximized the correlation coefficient was the relative activity timing wtim of that neuron relative to the reference neuron within this neuronal sequence. We scaled the sum of wint to be 1 and also adjusted wtim to be within the length range of L. Thus, the shape of each neuronal sequence could now be represented by two vectors for each neuron: the activity intensity wint and timing wtim. The values of the intensity matrix H were also adjusted to reconstruct approximately the same U, as the pattern tensor W was deformed.
Spike intensity
We computed a moving average of 10 s before and after for the intensity of each neuronal sequence
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{k}\left(t\right)=\frac{1}{2T+1}{\sum}_{\tau\:=-T}^{T}{h}_{k}\left(t+\tau\:\right),$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{k}\left(t\right)$$\end{document} is the intensity of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequence at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} (corresponding to the elements of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ row and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} ^th^ column of the intensity matrix H), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T=10$$\end{document} s. Based on this, we then scaled the intensity to compute the spike intensity of the neuronal sequence, as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{s}_{k}\left(t\right)=\frac{{h}_{k}\left(t\right)-{\mu\:}_{k}\left(t\right)}{{\mu\:}_{k}\left(t\right)}.$$\end{document}To avoid outliers, we modified the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{s}_{k}\left(t\right)$$\end{document} to ensure they do not exceed 1.
Location vector
We partitioned the Y-maze into 190 blocks, each 2 cm × 2 cm. The average spike intensity for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequences, when the mouse is in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b$$\end{document} ^th^ block can be calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\begin{array}{c}{l}_{b}^{k}\left(0\right)=\frac{1}{\left|{A}_{b}\right|}{\sum}_{t\in\:{A}_{b}}{s}_{k}\left(t\right)\end{array}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{A}_{b}=\left\{t|\text{A}\text{t}\:\text{t}\text{i}\text{m}\text{e}\:t,\:\text{t}\text{h}\text{e}\:\text{m}\text{o}\text{u}\text{s}\text{e}\:\text{i}\text{s}\:\text{i}\text{n}\:\text{b}\text{l}\text{o}\text{c}\text{k}\:b.\right\}$$\end{document}For the calculations, we applied a Gaussian filter covering up to 25 surrounding blocks to the mouse’s location and spike intensity data. The vector
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}^{k}\left(0\right)=\left\{{l}_{1}^{k}\left(0\right),{l}_{2}^{k}\left(0\right),\cdots\:,{l}_{190}^{k}\left(0\right)\right\}$$\end{document}represents the posterior probability of spike intensity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s$$\end{document} given the mouse location \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left(s|b\right)$$\end{document} . According to Bayes’ theorem
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left(b|s\right)=\frac{P\left(s|b\right)P\left(b\right)}{P\left(s\right)},$$\end{document}the likelihood of mouse location \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b$$\end{document} given spike intensity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s$$\end{document} is proportional to this array. Thus, using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}^{k}\left(0\right)$$\end{document} , we can estimate the distribution of the mouse’s location when the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequence occurs.
We extended Eq. (1) to define the average spike intensity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} time frames before the mouse is located in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b$$\end{document} ^th^ block:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}_{b}^{k}\left(\tau\:\right)=\frac{1}{\left|{A}_{b}\right|}{\sum}_{t\in\:{A}_{b}}{s}_{k}\left(t-\tau\:\right).$$\end{document}According to the discussion with Bayes’ theorem, we ascertain that vector
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}^{k}\left(\tau\:\right)=\left\{{l}_{1}^{k}\left(\tau\:\right),{l}_{2}^{k}\left(\tau\:\right),\cdots\:,{l}_{190}^{k}\left(\tau\:\right)\right\},$$\end{document}estimates the distribution of mouse location \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} time frames after the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequence occurs. Thus, the aggregated vector
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}^{k}=\left\{{l}^{k}\left(0\right),{l}^{k}\left(1\right),\cdots\:,{l}^{k}\left(L-1\right)\right\},$$\end{document}which combines all these vectors, predicts the mouse’s pathway during the activity period of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequence. We refer to this aggregated vector as the location vector.
Gini coefficient
To evaluate the spatial specificity of neuronal sequences, we utilized the Gini coefficient. Based on the location vector at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} , we defined the Gini coefficient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{G}^{k}\left(t\right)$$\end{document} at that time frame using the following equation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eqalign{{G^k}\left( t \right) = {1 \over {2N{{\sum}_{b = 1}^N} l_b^k\left( t \right)}}{{\sum}_{b = 1}^N} {{\sum}_{\beta \> = 1}^N} \left| {l_b^k\left( t \right) - l_{\beta \>}^k\left( t \right)} \right| \cr} $$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N=190$$\end{document} blocks. We then averaged \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{G}^{k}\left(t\right)$$\end{document} over time to calculate the average Gini coefficient for each neuronal sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{G}^k=\sum_t G^k(t)$$\end{document} . When a neuronal sequence is active at only a single block at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{G}^{k}\left(t\right)=1$$\end{document} . Conversely, if the sequence is equally active across all blocks, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{G}^{k}\left(t\right)=0$$\end{document} . In other words, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{G}^{k}\left(t\right)$$\end{document} reflects the unevenness of the vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}^{k}\left(t\right)$$\end{document} . Therefore, if a neuronal sequence exhibits high spatial specificity throughout the time frames from 0 to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L-1$$\end{document} ―that is, if the neuronal sequence occurs along specific trajectories of mouse―its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{G}^k$$\end{document} approaches 1.
Comparison of sequential neuronal dynamics
Sequential neuronal dynamics (SND) are defined as trajectories in the principal component subspace constructed from the set of detected neuronal sequences. For each mouse and each training day, we performed principal component analysis (PCA) on the entire recording period of the detected neuronal sequences and extracted the first and second principal components. For each Success event, we defined the Success-SND as the trajectory in the first and second principal component subspace over the 20 s preceding the lick. The same procedure was applied to each Failure event to obtain the corresponding Failure-SND.
The aim of this analysis was to evaluate, for each mouse on each training day, the extent to which the Success-SND were distinct from Failure-SND. This was quantified by the methods shown in the section “Distance between trajectories”.
To enable comparisons between distances obtained from different principal component subspace, we performed Procrustes alignment to standardise the scale of these subspaces. Letting the source data to be \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document} and the reference data be \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y$$\end{document} , Procrustes alignment aims to solve a problem that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop {\min }\limits_{s,R,t} \left\| {\left. {X - sYR - t} \right\|} \right._F^2$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:R$$\end{document} is a rotation matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s$$\end{document} is a scaling factor, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} is a translation vector, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\left\| {\left. \cdot \right\|} \right._F}$$\end{document} denotes the Frobenius norm. The data matrices \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y$$\end{document} are first mean-centred as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{X}=X-{\mu\:}_{X},\:\:\stackrel{\sim}{Y}=Y-{\mu\:}_{Y}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{X}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mu\:}_{Y}$$\end{document} are the mean vectors of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y$$\end{document} , respectively. Then they are normalised as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar X = {{\tilde X} \over {{{\left\| {\left. {\tilde X} \right\|} \right.}_F}}},\;\;\bar Y = {{\tilde Y} \over {{{\left\| {\left. {\tilde Y} \right\|} \right.}_F}}}$$\end{document}Under these conditions, the objective function becomes
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop {\min }\limits_R \left\| {\left. {\bar X - \bar YR} \right\|} \right._F^2$$\end{document}It is known that applying singular value decomposition
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{-}{X}}^{T}\stackrel{-}{Y}\approx\:U{\Sigma\:}{V}^{T}$$\end{document}, from which the optimal rotation matrix can be obtained as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:R=V{U}^{T}$$\end{document} . The scaling factor and the translation vector can then be obtained as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = {{{{\left\| {\left. {\tilde Y} \right\|} \right.}_F}} \over {{{\left\| {\left. {\tilde X} \right\|} \right.}_F}}},\;\;t = {\mu _Y} - s{\mu _X}R.$$\end{document}In Fig. 6, the average Failure-SND from day 6 was used as the reference data, and the average Failure-SNDs from days 1 and 2 were used as the source data. The resulting transformation parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:R$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} were then applied to the Success-SNDs from days 1 and 2 (Procrustes alignment was independently applied to the subspaces of day 1 and day 2, yielding separate transformation parameters for each day). In Supplementary Fig. 9, the reference data was the combined average of the Success-SND and Failure-SND from day 6. Similarly, we used as source data the combined average of the Success-SND and Failure-SND from day 1, and that from day 2.
Decoding the mouse behaviours
Quantifying behaviours
Staying in the “Zone”: a value of 1 was assigned when the mouse was inside the Zone, and 0 was assigned when it was outside. Licking the “Port”: a value of 1 was assigned when the mouse licked the Port, and 0 was assigned when it did not. Acquiring a reward: a value of 1 was assigned when the mouse obtained a reward, otherwise 0 was assigned. The X- and Y-coordinates represent the mouse’s X- and Y-coordinates, respectively, on a scale from 0 to 1.
Decoding protocol
The decoder was implemented using the PyTorch library [53] in Python, featuring an LSTM (long short-term memory) layer (with hidden_size = 8, num_layers = 2), a single fully connected layer, and a sigmoid function in the output layer. This decoder was trained to predict and output the behaviour of the mouse at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} , based on the time series of the spike intensities of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} neuronal sequences from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t-10.0$$\end{document} s to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t-0.2$$\end{document} s. Decoding was conducted for each mouse (mouse IDs 1 to 6) and on specific days (days 1, 2, and 6). Separate decoders were set up and trained for each of the five behaviours described above.
For training, we used only the data from 25 to 75% of the measured time (training data), whereas the data from 0 to 25% and 75–100% of the time served as validation data (Fig. 7b). Throughout the training process, we continuously monitored prediction errors for both training and validation data. A typical sign of overfitting was observed when prediction errors on training data decreased, whereas those on validation data increased. Consequently, we selected the training results from the epoch in which the prediction error on validation data was minimized as the final prediction error.
This training process was replicated 10 times for each behaviour, and the overall prediction accuracy for each behaviour was assessed based on the average of the final prediction errors.
Criteria of prediction (decoding) error
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Z$$\end{document} represent the set of behavioural data, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z\left(t\right)$$\end{document} denote the behaviour at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} . As “staying in the ‘Zone’”, “licking the ‘Port’”, and “Acquiring reward” are binary behaviours, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z\left(t\right)$$\end{document} takes values of 0 or 1. However, the frequency of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z\left(t\right)=1$$\end{document} is considerably less than that of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z\left(t\right)=0$$\end{document} . To correct for this discrepancy, we quantify the error between the actual behaviour \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z$$\end{document} and the predicted behaviour \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{z}$$\end{document} as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{E}_{bin}=\frac{\left|Z\right|}{2\left|{Z}_{0}\right|}{\sum}_{t\in\:{Z}_{0}}{\left(z\left(t\right)-\stackrel{\sim}{z}\left(t\right)\right)}^{2}+\frac{\left|Z\right|}{2\left|{Z}_{1}\right|}{\sum}_{t\in\:{Z}_{1}}{\left(z\left(t\right)-\stackrel{\sim}{z}\left(t\right)\right)}^{2}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\begin{array}{c}=\frac{\left|Z\right|}{2\left|{Z}_{0}\right|}{\sum}_{t\in\:{Z}_{0}}{\stackrel{\sim}{z}\left(t\right)}^{2}+\frac{\left|Z\right|}{2\left|{Z}_{1}\right|}{\sum}_{t\in\:{Z}_{1}}{\left(1-\stackrel{\sim}{z}\left(t\right)\right)}^{2}\end{array}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Z}_{0}=\left\{t|z\left(t\right)=0\right\},\:\:\:\:{Z}_{1}=\left\{t|z\left(t\right)=1\right\}.$$\end{document}When the decoder consistently outputs a constant value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z\left(t\right)=c$$\end{document} , this error function reaches its minimum value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.25\left|Z\right|$$\end{document} at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:c=0.5$$\end{document} . We refer to the decoder that always outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z\left(t\right)=0.5$$\end{document} as the null decoder, and it serves as the baseline for assessing predictive performance.
By contrast, “X-coordinate” and “Y-coordinate” are continuous values ranging from 0 to 1. Here, we defined the error function for them as follows (For the derivation of the coefficients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\beta\:$$\end{document} , please refer to Supplementary Math Note 3):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\begin{array}{c}E=\alpha\:{\sum}_{t\in\:{Z}_{n}}{\left(z\left(t\right)-\stackrel{\sim}{z}\left(t\right)\right)}^{2}+\beta\:{\sum}_{t\in\:{Z}_{p}}{\left(z\left(t\right)-\stackrel{\sim}{z}\left(t\right)\right)}^{2}\end{array}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Z}_{n}=\left\{t|z\left(t\right)\le\:0.5\right\},\:\:\:\:{Z}_{p}=\left\{t|z\left(t\right)>0.5\right\}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:=\frac{\left|Z\right|-\beta\:\left(4{R}_{p}-4{Q}_{p}+\left|{Z}_{p}\right|\right)}{4{R}_{n}-4{Q}_{n}+\left|{Z}_{n}\right|}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = {{\left| Z \right|\left( {\left| {{Z_n}} \right| - 2{Q_n}} \right)} \over \matrix{8\left( {{Q_p}{R_n} - {Q_n}{R_p}} \right) - 4\left| {{Z_n}} \right|\left( {{Q_p} - {R_p}} \right) \hfill \cr + 4\left| {{Z_p}} \right|\left( {{Q_n} - {R_n}} \right) - 2\left( {{Q_n}\left| {{Z_p}} \right| - {Q_p}\left| {{Z_n}} \right|} \right) \hfill \cr} }$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eqalign{{Q_n} = \sum {t \in {Z_n}} z\left( t \right),\>{R_n} = \sum {t \in {Z_n}} z{\left( t \right)^2}, \cr \>{Q_p} = \sum {t \in \>{Z_p}} z\left( t \right),\>{R_p} = \sum {t \in \>{Z_p}} z{\left( t \right)^2}. \cr} $$\end{document}Remarkably, the error function for these coordinates also reaches a minimum value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.25\left|Z\right|$$\end{document} when using the null decoder that always outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{z}\left(t\right)=0.5$$\end{document} . Considering \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z\left(t\right)$$\end{document} as a binary variable where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Z}_{n}={Z}_{0}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Z}_{p}={Z}_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Q}_{n}={R}_{n}=0$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Q}_{p}={R}_{p}=\left|{Z}_{1}\right|$$\end{document} , Eq. (3) simplifies to Eq. (2). This demonstrates that Eq. (3) is a natural extension of Eq. (2).
We employed the null decoder as a reference point and concluded that if the prediction error per data element significantly dropped below 0.25, this indicated that the neuronal sequences effectively captured behavioural information.
Consistency of neuronal sequences
The consistency of neuronal sequences was assessed by the Pearson’s correlation between the similarity of cell populations and the similarity of pathways, as detailed below.
Similarity of cell populations
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varvec{W}}^{d}$$\end{document} was defined as the pattern tensor on day \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:d$$\end{document} after the sequence-sharpening operation, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}^{d,k}$$\end{document} was defined as the relative activity intensity of the neurons consisting of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequences. The values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}^{d,k}$$\end{document} are scaled using its mean and standard deviation. The similarity between the cell populations of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequence on day \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:d$$\end{document} and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\kappa\:$$\end{document} ^th^ neuronal sequence on day \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\delta\:$$\end{document} is defined using cosine similarity as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{w^{d,k}} \cdot {w^{\delta,\kappa }}} \over {\left\| {\left. {{w^{d,k}}} \right\|} \right.\left\| {\left. {{w^{\delta,\kappa }}} \right\|} \right.}}.$$\end{document}Similarity of pathways
We defined
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}^{d,k}=\left\{{l}^{d,k}\left(0\right),{l}^{d,k}\left(1\right),\cdots\:,{l}^{d,k}\left(L-1\right)\right\}$$\end{document}as the location vector of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequence on day \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:d$$\end{document} . The values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{l}^{d,k}$$\end{document} are scaled using its mean and standard deviation. The similarity between the movement trajectory of the mouse during the activity of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ^th^ neuronal sequence on day \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:d$$\end{document} and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\kappa\:$$\end{document} ^th^ neuronal sequence on day \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\delta\:$$\end{document} was defined as the time-averaged cosine similarity:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1 \over L} \times \mathop \sum \limits_{\tau = 0}^{L - 1} {{{l^{d,k}}\left( \tau \right) \cdot {l^{\delta,\kappa }}\left( \tau \right)} \over {\left\| {\left. {{l^{d,k}}\left( \tau \right)} \right\|} \right.\left\| {\left. {{l^{\delta,\kappa }}\left( \tau \right)} \right\|} \right.}}.$$\end{document}Additionally, considering that the location of the Zone was reversed on day 4, we also computed the pathway similarity for a transformed version of the location vector, where the block labels were adjusted by inverting the Y-coordinates.
Statistics
Statistical tests were conducted using Python with scipy, statsmodels and PyTorch libraries. No statistical methods were used to pre-determine sample sizes, but our sample sizes were similar to those used in previous studies.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary Material 2
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Rubin A, et al. Revealing neural correlates of behavior without behavioral measurements. Nat Commun. 2019;10. 10.1038/s 41467-019-12724-2.10.1038/s 41467-019-12724-2PMC 680218431628322 · doi ↗ · pubmed ↗
- 2Horst NK, Laubach M. Reward-related activity in the medial prefrontal cortex is driven by consumption. Front Neuro Sci. 2013;7. 10.3389/fnins.2013.00056.10.3389/fnins.2013.00056 PMC 362288823596384 · doi ↗ · pubmed ↗
- 3Jones LM, Fontanini A, Sadacca BF, Miller P, Katz DB. Natural stimuli evoke dynamic sequences of states in sensory cortical ensembles. Proceedings of the National Academy of Sciences 2007;104:18772–18777: 10.1073/pnas.070554610410.1073/pnas.0705546104 PMC 214185218000059 · doi ↗ · pubmed ↗
- 4Smaragdis P. in Independent Component Analysis and Blind Signal Separation. (eds Carlos G. Puntonet & Alberto Prieto) 494–499 (Springer Berlin Heidelberg).
- 5Ghandour K, et al. Orchestrated ensemble activities constitute a hippocampal memory engram. Nat Commun. 2019;10. 10.1038/s 41467-019-10683-2.10.1038/s 41467-019-10683-2PMC 657065231201332 · doi ↗ · pubmed ↗
- 6Grady PDO, Pearlmutter BA. in 2006 16th IEEE Signal Processing Society Workshop on Machine Learning for Signal Processing. 427–432.
- 7Konno A, Hirai H. Efficient whole brain transduction by systemic infusion of minimally purified AAV-PHP.e B. J Neurosci Methods. 2020;346. 10.1016/j.jneumeth.2020.108914.10.1016/j.jneumeth.2020.10891432810474 · doi ↗ · pubmed ↗
- 8Aly MH, Abdou K, Okubo-Suzuki R, Nomoto M, Inokuchi K. Selective engram coreactivation in idling brain inspires implicit learning. Proceedings of the National Academy of Sciences. 2022;119:32:e 2201578119 10.1073/pnas.220157811910.1073/pnas.2201578119 PMC 937167335914156 · doi ↗ · pubmed ↗