Economical representation of spatial networks
Fabrizio De Vico Fallani, Thibault Rolland

TL;DR
This paper introduces a new way to visualize spatial networks by reducing edge crossings, making complex systems easier to understand.
Contribution
The novel concept of progressive cost enables sparser network layouts that align with human perception and ecological principles.
Findings
Progressive cost leads to sparser networks with fewer edge crossings.
The method matches human behavior in network visualization preferences.
The approach provides an ecologically inspired criterion for modeling real-world systems.
Abstract
Network representation is crucial across various scientific, societal, technological, and artistic domains. The primary goal is to highlight patterns out of nodes interconnected by edges that are easy to understand, facilitate communication, and support decision-making. This is typically achieved by rearranging the nodes to minimize the edge crossings responsible of unintelligible and often unesthetic trends. But when the nodes cannot be moved, as in spatial and physical networks, this procedure is not viable. Here, we overcome this impasse by turning the edge crossing problem into a graph filtering optimization. By introducing the concept of progressive cost, we demonstrate that longer connections prompt the optimal solution to yield sparser networks, thereby limiting the number of intersections and getting more readable layouts. This theoretical result matches human behavior and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
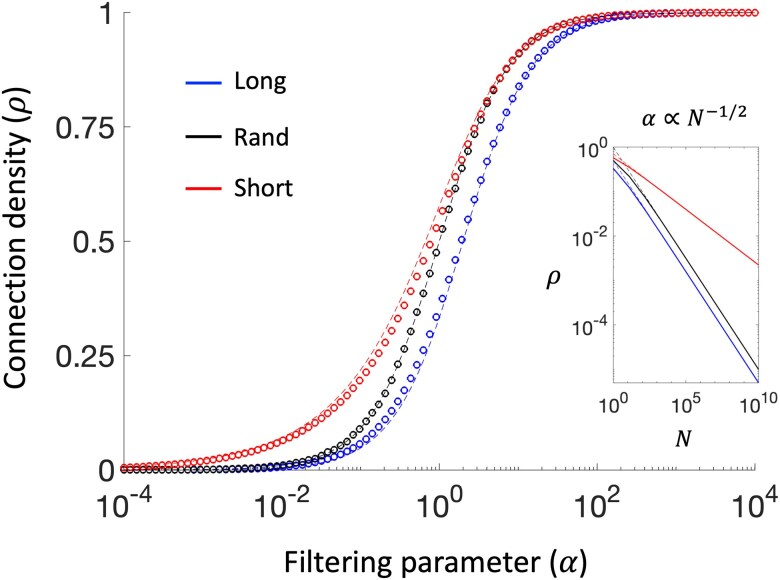 Fig. 1
Fig. 1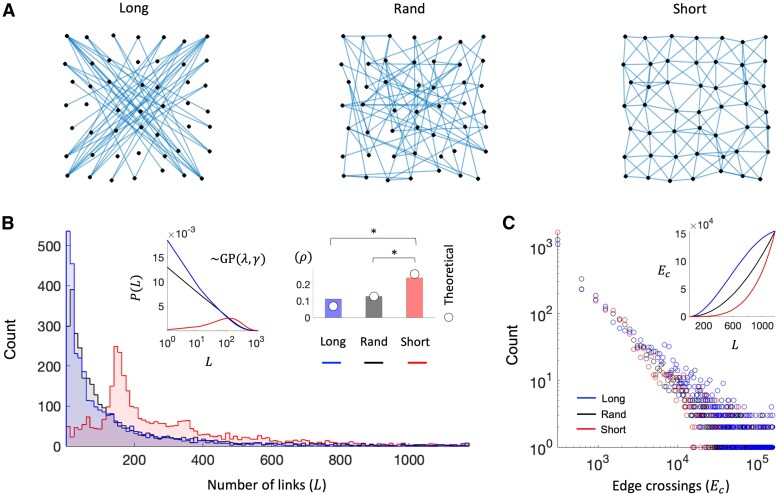 Fig. 2
Fig. 2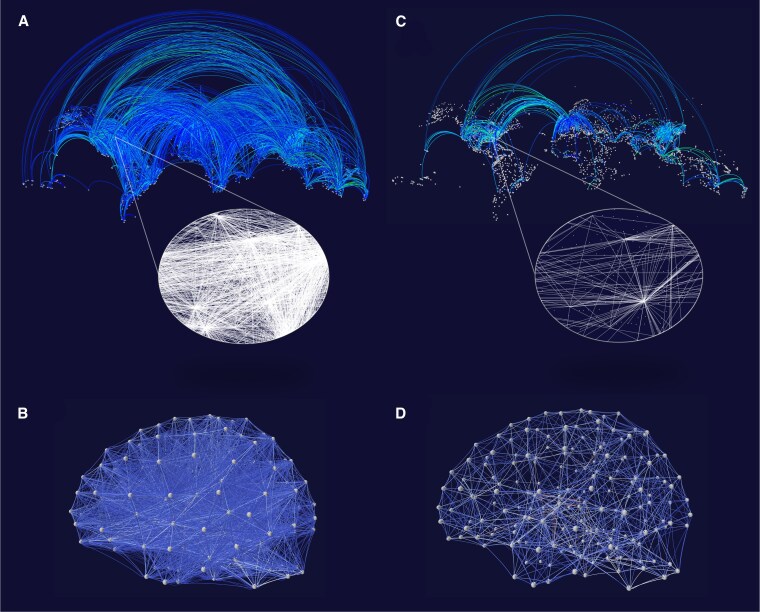 Fig. 3
Fig. 3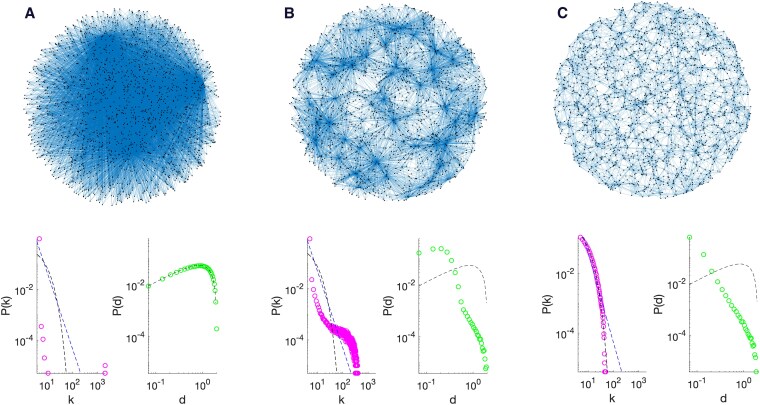 Fig. 4
Fig. 4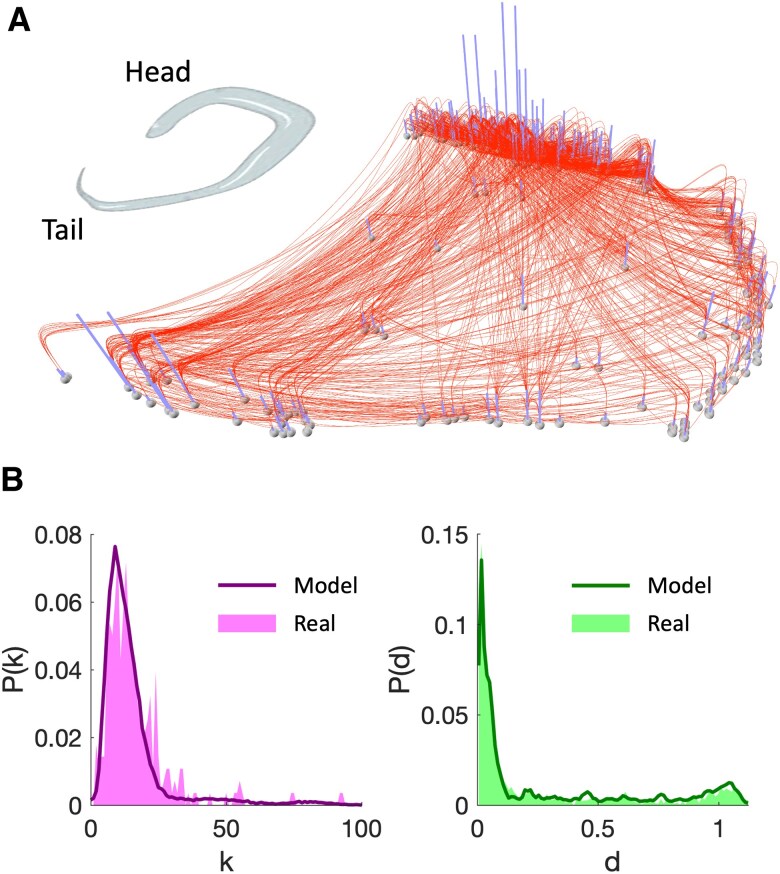 Fig. 5
Fig. 5- —Agence Nationale de la Recherche under the CRCNS NIH-ANR program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBusiness Strategy and Innovation · Digital Platforms and Economics · Complex Network Analysis Techniques
Introduction
In today’s increasingly interconnected world, information is often represented as networks made up of nodes and links. Network science provides a unified framework for analyzing and modeling interconnected systems, ranging from social and biological networks to financial and technological ones. Effectively visualizing complex information in a clear and concise manner is crucial for enhancing communication and decision-making, with wide-ranging applications across diverse fields, including mathematics, art, and medicine (1–3).
While there are no strict criteria for improving the readability of a network, it is generally agreed that the corresponding drawing should have minimal edge crossing, with nodes evenly distributed in the space, connected nodes close to each other, and symmetry that may exist in the graph preserved (4–6). To this end, many algorithms have been developed based on different criteria such as the spring-electrical models, the stress and strain models, as well as high-dimensional embedding and Hall’s algorithms (7). The main working strength of all these methods is the possibility to freely rearrange the node positions so as to optimize some quality function associated with the human perception.
Yet, in many real-world systems such as spatial and physical networks, the precise positioning of the nodes cannot be altered without losing information about the system’s intrinsic geometry. If rearranging the nodes is not possible, the alternative is to focus on the links, for example by bending or stretching their shape to minimize intersections (8). However, these networks might be difficult to comprehend because of the inevitable link tortuosity. In addition, while in three dimensions this approach can result in wiring patterns devoid of any crossing (9), artificial intersections persist due to the presence of multiple overlapping plans.
In general, edge crossings exponentially increase with the connection density. Notably, the longer are the connections, the higher is the likelihood of having multiple intersections. Yet, the network connections constitute basic informative units. The greater their number, the more detailed is our knowledge of the system organization. Hence, the problem of network representation can be remapped into a graph filtering optimization balancing the benefit of including as many connections as possible and the incurred cost due to their length, an indirect proxy of edge crossings.
By solving the associated analytical formulation, we reveal a nontrivial relationship between the optimal connection density and the spatial distribution of the edges within the network. We confirm this theoretical behavior using data from human responses collected from an online interactive experiment involving participants. Based on the gathered answers, we derive an unbiased criterion to filter networks and get readable representations of otherwise too dense real interconnected systems.
Drawing from these principles, we eventually introduce a benefit–cost network model that produces a continuous spectrum of realistic configurations and evaluate its ability to reproduce the spatial and topological properties of the Caenorhabditis elegans’ neuronal network.
Results
Graph filtering
A generic network can be mathematically described by a graph with N nodes and L links, or edges. Here, we considered undirected weighted graphs where each node is further equipped with a position in a Euclidean s-dimensional space. A basic characterization of such geometric graph is given by two quantities, i.e. the connection density and the spatial density δ, defined as the cumulative length of the L edges divided by the maximum when the graph is fully connected (Supplementary material - Section 1).
To measure the balance between the above quantities, we considered the general functional , where f and g are respectively increasing and decreasing functions. Because both ρ and δ are in the interval, a very simple form reads
where and are parameters tuning the importance of the connection and spatial density, respectively. Using the binomial approximation, Eq. 1 can be rewritten in terms of benefit–cost indicating that the cost per length unit is not constant but grows with the number of existing connections in the network. This behavior naturally reflects the fact that in denser graphs, the edges have a higher likelihood to produce several crossings.
Our goal was to find the optimal number of links, or equivalently the optimal connection density ρ, that maximizes J. By construction, the cumulative length, here measured by the internode Euclidean distance d, increases with the number of links. It is therefore convenient to find a formal relation between δ and ρ. Let us assume that the internode distances fall in the unitary interval, the link weights are positive and that both are unique.^a^ When the weights are randomly distributed between the nodes, they do not correlate with the actual distances. Put differently, selecting the links by their weight corresponds to randomly sample the distances. The probability to choose an edge with a given length is uniform and it is trivial to prove that the expected spatial density (Supplementary material - Section 1). However, in many real situations the edges’ weights and lengths are correlated favoring the emergence of strong short-range or long-range configurations (10, 11). Assuming perfect correlation, selecting the links by their weight will correspond to selecting the distances in the same or reverse order. Hence, the probability to pick an edge with a given length is not uniform but depends on its position in the ranking. Leveraging tools from order statistics, we show that the expected spatial density , or , depending on whether the strongest edges connect the closest or farther nodes (Supplementary material - Section 1).
Considering this space-connection dependency, one can momentarily discard the parameter controlling the edge length (i.e. ) and obtain a simplified one-parameter functional . By substituting the above expressions in the last equation and solving , we obtain the optimal connection density for the three characteristic scenarios
Equation 2 indicate that the optimal number of links solely depends on their spatial distribution. Denser networks emerge when links tend to connect closer nodes, while sparser networks result when links tend to connect farther nodes. The solutions for long-range and short-range configurations establish the theoretical boundaries, with any other arbitrary network falling somewhere in between, i.e. . The overall filtering can be modulated by the parameter α, giving structural transitions from sparser to denser graphs. For randomly assigned links, the critical point returns networks with the maximal amount of information in terms of Shannon entropy (i.e. ). Notably, when the corresponding optimal densities tend to the values of the long-range case, while for they tend to the short-range one. For a given connection density, larger α values will preferentially filter long-range connections, while smaller values will rather keep short-distance ones (Fig. 1).
Theoretical versus empirical behavior of the optimal connection density. Dashed lines represent the analytical solutions as a function of the filtering parameter α (Eq. 2). Circle markers represent the values obtained by simulating a synthetic network with N=1,000 nodes arranged on a pseudorandom 2D unitary circle. Middle lines = no correlation between the links’ weights and lengths (rand). Lower lines = positive correlation between the edge weights and lengths (long). Upper lines = negative correlation between the edge weights and lengths (short). The inset illustrates the scaling of the solution when the filtering parameter is proportional to the typical internode distance in 2D. The inset shows the case α=1/N. Since these results only depend on the edge weight-length correlation, they stay qualitatively similar regardless of the spatial dimension, the number, and position of the nodes.
Network visualization
Graph filtering offers an effective solution to improve the readability of networks whose nodes cannot be arbitrarily rearranged to avoid line criss-cross. Long-range connections are particularly problematic as they typically intersect several edges giving unintelligible, often unesthetic, patterns. Moreover, real networks are typically represented on physical supports with limited space. This means that the larger is the network, the more difficult is to obtain a readable pattern because of the node concentration. To compensate this effect, a natural solution is to let the filtering parameter scale with the typical internode distance , where ϕ is a positive constant (12). By substituting the latter in Eq. 2, the optimal density in sufficiently big networks becomes (Supplementary material - Section 2). These expressions preserve the original filtering behavior but now scale with the inverse of the network size thus facilitating the visualization of large systems (Fig. 1 inset).
How to choose the constant ϕ in a possible unbiased way remains unknown. Without any theoretical ground, we turned this fundamental question from a human perception perspective. We realized a simple online experiment involving more than 10,000 trials from different individuals. For each trial, a fixed number of nodes was prompted on pseudorandom 2D grid and the participant was asked to keep adding edges via an interactive slider until the graph become too confusing (Materials and methods). The edge spatial distribution varied randomly across trials, enabling the added links to connect first either (i) the farthest nodes, (ii) the closest ones, or (iii) in a random fashion (Fig. 2A). Results show a general preference for very sparse networks regardless of the spatial ordering of the links and a relatively high inter-subject variability Fig. 2B). This behavior can be accurately explained by a stochastic Gamma-Poisson process (Fig. 2B left inset, Supplementary material - Section 3). Despite such heterogeneity, the connection density chosen for short-range configurations was statistically higher than that obtained in random and long-range ones (Cohen’s , Fig. 2B right inset). By fitting Eq. 2 to the actual mean ρ values, we eventually derived an unbiased estimate of the filtering constant, i.e. (Materials and methods, Fig. 2B inset).
Results from the NetViz experiment. A) Examples of networks displayed by NetViz. Depending on the type of configuration, the edges tend to connect the farthest nodes (long), the closest ones (short), or they are randomly distributed (rand). While visually the number of edges look similar across conditions they are instead rather different i.e. Llong=43, Lrand=73, and Lshort=164. B) Histograms show the distributions of the number of edges selected by the NetViz participants in different conditions. The number of users in each category is nshort=3,322, nrand=3,154, and nlong=3,163. The first inset shows the count of the links as modeled by a Gamma-Poisson process with mean λ and scale parameter γ accounting for the overdispersion of the data (Supplementary material - Section 3). Vertical bars in the second inset show the group-averaged connection density in each condition. Asterisks indicate a significant mean-difference effects size (Cohen’s |d|>0.6). In the short-range condition the average number of links (Lshort=281.87) is statistically higher than random (Lrand=150.27, Cohen’s d=0.6276) and long-range (Llong=131.83, Cohen’s d=0.7314). No statistical differences between Lrand and Llong (Cohen’s d=0.0927). White circles correspond to the theoretical connection densities from Eq. 2 with α=0.146 (i.e. ϕ=1.026) (Materials and methods). C) Distributions of the number of edge crossings Ec corresponding to the number of links selected by the users in the different conditions. No significant mean-difference effects sizes between conditions (Cohen’s |d|<0.3). The inset shows the estimated Ec associated with each value of L in the NetViz layout in the three conditions (Materials and methods).
The general propensity to select relatively few links is in line with the intuition that good patterns should minimize the number of edge crossings (5). The distributions of the estimated values actually confirm this prediction (Fig. 2C, Materials and methods). Differently from the number of connections, the corresponding edge crossings were not statistically different between conditions (Cohen’s ). This result can be explained by the different velocity at which the values increase with the connection density. In random, we demonstrated analytically and confirmed with extensive simulations that the number of edge crossings scales with the square of the connection density, i.e. , where is the maximum when the graph is completely connected (Supplementary material - Section 4). Compared to random patterns, increases more rapidly in long-range configurations and more slowly in short-range ones (Fig. 2C inset). Therefore, by opting for a different numbers of links in long-range and short-range networks, people were actually attempting to reduce the huge difference in terms of edge crossings. Note that these results cannot be attributed to potential differences in how users navigate through the range of densities (Supplementary material, Fig. S1).
We next considered two representative real-world networks with nodes lying in a physical space, namely the worldwide airline network and the human connectome. For both networks, the edge weight measured the importance of the connection in terms of number of operated flights and interareal axonal fascicles (Materials and methods). By ranking the links in a weight-descending order and calculating the optimal density, the unbiased criterion automatically removed about the and of the weakest links from the airline and brain network respectively. This allowed for lighter and clearer connectivity structures as compared to the original networks (Fig. 3). In addition, complementary visualizations can be obtained using Eq. 2 and ranking the links according to their actual length so to emphasize the role of short-range and long-range connectivity structures (Supplementary material, Figs. S2 and S3). This is particularly efficient for very large systems, unweighted interactions, and weak spatiotopological relations (Supplementary material, Fig. S4).
Real-world networks filtered with the unbiased criterion. A) The airline route network (N=3,214, L=18,859). Nodes correspond to airports and links correspond to the number of operated flights. The link weight is coded by the color. The lighter the color, the higher the number of flights. For illustrative purposes, the network is shown on its 2D geographical representation. The height of the connections is proportional to the geodesic distance between the connected airports. The inset shows a 2D flat representation of the flights in the US SouthEast region. B) The human connectome (N=188, L=5,446). Nodes correspond to different brain regions, and links measure the number of axonal fibers between different regions (in log scale). The link weight is coded by the color. The lighter the color, the higher the number of fibers. C) Airline route network filtered with ϕ=1 and s=3 (i.e. α=1/N1/3). The optimal connection density is obtained by maximizing J and sorting the links by their actual weight (descending order). Final number of filtered connections L=915. Around 95% of the weakest connections are removed allowing to clearly visualize the main airline routes between continents. The US international airport hubs (e.g. Atlanta) become clearly visible in the filtered network (inset). D) The human connectome filtered with ϕ=1 and s=3 (i.e. α=1/N1/3). The optimal connection density is obtained by maximizing J and sorting the links by their actual weight (descending order). Final number of strongest filtered connections L=1,077. Around 80% of the weakest connections are removed allowing to clearly visualize the strong connectivity of the subcortical regions (e.g. dorsal pallidum, caudate nucleus, thalamus). All visualizations are realized with the freely available online software VIZAJ (13).
Generative models
Balancing the cost of adding links and the benefit they create is at the core of spatial network modeling (14). Based on a local version of the functional J, we introduced a spatial growth network model that optimizes the benefit of establishing connections to hubs and the increasing cost of their length. Specifically, when a new node i arrives, a link to each of the existing nodes is created with probability
where is degree of node j and is the distance between i and j, both normalized by the respective maximum values in the existing network. Note that the higher is the degree of the target node, the higher is the cost of a link per length unit ( ). In addition, because and are independent, both the model parameters α and β are needed, thus producing a wide range of behaviors.
We first implement a simple version of the model where the average node degree remains constant. This is achieved by imposing that each new node has to attach a fixed number of m edges, starting from an initial seed. The α and β parameters affect the degree and internode distance distributions, respectively. Short-range regular lattices are obtained for , while long-range star-like graphs are obtained when . By opportune parameter selection, Eq. 3 reduces to the uniform attachment model ( ) and to the preferential attachment model ( , ) (15). In these cases, the degree distributions could be analytically derived giving the typical exponential and power-law profile (Fig. 4).
Main features of the spatial growth network model. Synthetic networks are generated iteratively from an initial seed of N0=6 fully connected nodes. At each step, a new node is located randomly within a unitary 2D disk and attached to m=5 existing nodes. The growing process stops until the total number of nodes is N=2,000. Three representative cases are illustrated here, according to different model parameters. The top row shows an example of the resulting network, while the bottom row reports the node degree and distance distributions averaged over 100 samples and compared to known theoretical behaviors. A) α=10 and β=0. The node degree distribution (circles on left panel) indicates the presence of few giant hubs and a clear difference from exponential or power-law behavior (dashed lines). The distance distribution (circles on right panel) is instead perfectly matching the theoretical expectations for N points randomly distributed in a unitary disk (dashed line) (12). B) α=10 and β=100. Both the node degree (circles on left panel) and distance (circles on right panel) distributions show that network alters its configuration exhibiting many relatively smaller hubs and lower distances. C) α=0 and β=100. The node degree distribution (circles on left panel) follows a typical exponential behavior leading to more homogeneous node degrees as in Erdos–Renyi random networks (dashed line). The distance distribution (circles on right panel) shows that long-range connections are dramatically suppressed in favor of many short-range links.
We next evaluate the ability of the model to reproduce the main characteristics of real networks in terms of node degree and internode distance distributions. We considered the brain network of the C. elegans, for which the spatial position of the neurons, their arrival time and the synaptic connections are entirely known (Materials and methods). To reproduce the increasing average node degree during the brain development, we implemented an hidden-variable accelerated version of Eq. 3. Similar to Ref. (16), we added the new incoming nodes according to their actual arrival time and fixed their degree equal to the value of the neuronal network at the adult stage.
While several trade-offs could give the real connection density, only the combination , could also accurately reproduce the node degree and link length distributions (Fig. 5, Materials and methods). Notably, this goodness-of-fit could not be obtained when considering a constant cost per length unit (Supplementary material, Fig. S5), suggesting that the C. elegans network has developed by pondering the cost of the connections both in terms of their length and amount.
Modeled structural and spatial properties of the C. elegans neuronal network. A) Representation of the C. elegans network consisting of N=279 nodes (the neurons) and L=2,287 unweighted connections (synaptic or gap junctions). The longitudinal dimension of nodes’ location is here stretched for illustrative purposes. The height of the vertical bars is proportional to node degree and spot out the most connected nodes in the head of the nematode. B) The node degree (left panel) and distance distributions (right panel) for the real neuronal network (areas) and for the ones obtained by averaging 100 realizations of the model (solid curves) are shown. This optimal goodness-of-fit (ϵdiv=0.118) is obtained with the accelerated version of the spatial growth network model with parameters α=2.51, β=0.18.
Discussion
Many natural, social, technological interconnected systems are characterized by a large number of connections. By trimming edges in a way to preserve the essential properties of the original network, graph filtering is adopted in many fields from machine learning and network science, to social and biological network analysis (17–20). From a computational perspective, graph filtering has important consequences in terms of reduced storage requirements, faster computation, and improved scalability (21). More in general, sparsification can be used to remove spurious or irrelevant edges, improve the accuracy of the network inference and reduce the impact of noise on the analysis (22).
On the one hand, most graph filtering methods rely on statistical (e.g. bootstrapping), topological (e.g. minimum spanning tree) or combined criteria (e.g. Polya filters). As such, they neglect the actual geometry of the system determined by the physical position of the nodes. On the other hand, methods that consider the actual geometry of the graph, such as the Euclidean minimum spanning tree and relative neighborhood graph (23), generate sparse networks by keeping edges only between the spatially adjacent nodes. While the resulting skeletons match human perception, they nevertheless significantly alter the intrinsic topology, for example by constraining the actual node degree distribution.
Here, we provide a more flexible solution that seeks to preserve both the topology and geometry of the system. This is achieved by optimally balancing the benefit of keeping the largest number of connections and the cost associated with their cumulative internode distance. The idea of maximizing the trade-off between the price for adding links and the benefit that they will create, originates from the constraints imposed by the finite resources in real-word systems (14, 24). The greater the length of a connection, the more resources are required to build it. Here, we posit that such cost would also depend on the number of already deployed resources, i.e. the number of existing connections. This corresponds to a more careful consideration of how to utilize the limited remaining resources. In practice, the cost per length unit should not be constant but must increase with the connection density.
In terms of visualization, an increasing cost better reflects the occurrence of edge crossings, which tend to increase with longer edges and significantly boost as the number of connections grows. Specifically, we show that the number of intersections in a random graph displayed on a plane scales with the square of its connection density. As a result, the entire spectrum of edge crossings can be derived analytically by simply knowing the maximum when the graph is complete. By avoiding computationally intense heuristic calculations, this basic result may be further exploited to address open questions in graph theory and computational geometry (25). To create clear and visually pleasing network visuals, it is essential to reduce long-range connections, as they often result in confusing intersections. Our filtering approach supports this principle by naturally displaying fewer (or more) links depending on whether they connect distant (or adjacent) nodes, respectively. This result matches the central tendency of people when they are asked to add connections until the network becomes too confusing and establish unbiased criteria for achieving legible wiring patterns. Despite the existence of objective trends, the related variability among individuals indicates an intrinsic subjectivity in the human perception. This dichotomy can be found in other contexts, including modern art and esthetics, where factors like education, culture, and personal experience can result in considerable deviation from objective criteria (26).
Our approach offers an alternative interpretation of spatial network modeling which currently only takes into account internode distances, but not the number of existing local connections (14). By allowing incremental penalization costs, our general model prevents extreme “rich-get-richer” effects, which might be unrealistic or at least unfeasible in many real situations with limited resources (27, 28). This aspect is not only observed in spatial networks but also in social systems where the number of possible contacts is constrained by human cognitive limits (29). We validated our hypothesis by showing that a progressive cost is essential to reproduce the main spatiotopological features of the C. elegans neuronal network such as the presence of expensive long-distance connections (30). Although our model shares similarities with other spatial network mechanisms, such as power-law economical growths (14, 16), the primary goal here was to highlight the impact of incorporating a joint distance-degree penalization as compared to considering distance alone. Notably, the specific shape of Eq. 3 establishes an equivalence between models based on attachment probabilities and benefit–cost optimization .
Our framework focuses on the number of edges to filter and unveils global relationships with their spatial length. However, a more general characterization of the specific edges’ role remains to be addressed. Identifying criteria to filter specific edges can not only predict potential effects on the structure and dynamics of the network but also offer new insights into the engineering and design of interconnected systems. Our results also resonate with recent advances in physical networks representing spatial systems whose nodes and links occupy a physical space (11). The concept of progressive cost can be for example extended to the volume of the new elements to be added, thus leading to new types of benefit–cost network models (31).
More in general, these findings can have broader implications in the study of spatial networks, from the identification of their dimension to the optimal distribution of facilities (32, 33). To conclude, we propose a criterion to visualize and analyze spatial interconnected systems that leverages both topological and geometrical properties. We hope that our work will inspire new insights across disciplines from computational geometry and data visualization to network and cognitive sciences.
Materials and methods
NetViz experiment and data analysis
We developed NetViz as an online survey to allow people interactively visualizing and selecting an arbitrary number of connections in a network https://netviz.icm-institute.org (Supplementary material - Section 5). The nodes are located on a 7 by 7 2D unitary grid and randomly shifted from their original position by a tiny factor . The resulting number of nodes ( ) ensures an optimal visual perception from a human perspective (34). To reproduce the different geometric configurations, the edges are ranked based on their length given by the internode Euclidean distance. From the longest to the shortest (long-range), from the shortest to the longest (short-range), and completely random.
Each trial starts with a preliminary window explaining the goal and conditions of the study, with no mention about the different geometric ranking. If the person proceeds with the survey, a second window opens with all the nodes prompted on the screen and the software randomly selects one of the three conditions. At this point, only the first edge is displayed according to the ranking, and a cursor slider controlling the connection density is provided^b^. Users are explicitly asked to “use the slider to keep adding connections until the graph becomes too confusing” and confirm their choice. The count of the edges is never displayed numerically. At the end of each trial, only the final number of retained edges, the explored values, the start/end time, the country from the IP address and the type of configuration are recorded (Supplementary material - Section 5). The NetViz survey is a low-risk survey, entirely anonymous. Our study was reviewed by the data protection office of the Paris Brain Institute, which determined that it does not cover any sensitive topics that would require special ethical considerations. If the subjects decided to proceed with the survey after reading the first introductory page, it is assumed they agreed to participate thus waiving the requirement for formal informed consents.
A total of users from 58 different countries have participated to the survey. Anyone capable of reading and controlling the cursor screen, with access to internet, could participate. Participants have been recruited via mailing lists, social media (Linkedin, X), printed flyers, personal contacts, and via the Prolific platform specialized for gathering reliable human responses (prolific.com) (Supplementary material - Section 5). To improve the reliability of the collected answers, we filtered the data according to the following excluding rules: number of retained edges L outside the range and elapsed time outside the range s. This resulted in a dataset of users. Among those, a negligible portion ( ) has played the game at least two times.
The data from the NetViz experiment were used to calculate of the α parameter. To this end, we considered the least square error between the theoretical connection density (Eq. 2) and the mean obtained from the real users’ choices where . To find the optimal that minimized the error, we used a numerical interior-point method with termination tolerance (35). Because the NetViz graphs were in average sparse, we bounded the search in the interval and fixed to 0 the starting point. By definition, the final filtering constant .
Since the number of edge crossings was not computed online, we adopted an offline reverse-engineering approach using the actual number of links selected by the users. First, for each configuration, we simulated 100 different graphs using the same NetViz layout. Then for each connection density value (i.e. 1,176 links), we calculated the actual number of edge crossings using the Bentley–Ottman algorithm (36). By averaging across samples, we then established a 1-to-1 mapping between any number of links and the related edge crossings in each spatial configuration.
Real-world network data
All the real networks used to validate our results were gathered from freely available resources. The airline network was gathered from the OpenFlights/Airline Route Mapper Route Database (https://openflights.org/data.html). Nodes correspond to airports worldwide and links to routes between nodes. The original network is directed because of the presence of few one-way flights. For the sake of simplicity, we symmetrized the corresponding adjacency matrix (i.e. ) and removed any isolated node. The final parsed network consisted of airports and weighted undirected connections. The edge weight correspond to the number of operated flights. Each node has a physical location that could be used for geographical representations in 2D or 3D.
The human connectome was obtained from the USC Multimodal Connectivity Database http://umcd.humanconnectomeproject.org. The database consists of 171 connectomes obtained from healthy individuals from diffusion weighted magnetic resonance imaging. Structural connectivity between macro regions of interest has been obtained using anatomical fiber assignment through the continuous tracking algorithm. The final parsed network consisted of brain regions and weighted undirected connections. The edge weight corresponds to the group-averaged number of anatomical fibers between nodes. Each node has a physical location that corresponds to the 3D location in the standardized MNI152 brain template (37).
The neuronal network was obtained from the map of the C. elegans connectome, consisting of 279 somatic neurons interconnected through 6,393 chemical synapses, 890 gap junctions, and 1,410 neuromuscular junctions (38). Because gap junctions often overlap with synapses and synaptic connections often are reciprocated, we considered only the backbone network, in which all the synapses and gap junctions between each pair of neurons are represented by a single undirected edge. The final network obtaining a graph with neurons and unweighted links (neuromuscular connections were excluded). Information about the growth of the neuronal network, particularly the spatial position and exact time of birth of each neuron, was reconstructed from recent literature (39).
Model parameter selection and goodness-of-fit
To determine the best parameter combination reproducing the topological and spatial properties of the neuronal network, we adopted a two-step procedure. In the first step, we aimed to find which combination reproduced the actual number of connections L of the C. elegans. To do so, we considered a same broad interval for α and β consisting of 1,000 values logarithmically spaced between and . Because of the intrinsic stochastic nature of the model, we simulated 30 networks for each parameter combination and computed their average number of links . We finally computed the relative error .
In the second step, we aimed to identify among all the possible optimal solutions, the one that best reproduced the node degree and edge length distribution . To do so, we considered all the parameter combinations that gave corresponding to differences . Next, we adopted a particle swarm optimization bounded by the found limits. For each parameter combination, we simulated 100 networks and computed their average node degree and edge length distribution . Finally, the evaluating function was , where JS is the Jensen–Shannon divergence between the average simulated and real distributions. Other main parameters were 20 particles, 400 iterations max and tolerance.
Supplementary Material
pgaf203_Supplementary_Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lima M . Visual complexity: mapping patterns of information. Princeton Architectural Press, New York, 2011. http://UWA.eblib.com.au/patron/Full Record.aspx?p=3387539.
- 2von Landesberger T, et al 2011. Visual analysis of large graphs: state-of-the-art and future research challenges. Comput Graph Forum. 30(6):1719–1749.
- 3Filipov V, Arleo A, Miksch S. 2023. Are we there yet? A roadmap of network visualization from surveys to task taxonomies. Comput Graph Forum. 42(6):e 14794.38505648 10.1111/cgf.14794 PMC 10947241 · doi ↗ · pubmed ↗
- 4Purchase HC, Cohen RF, James M. Validating graph drawing aesthetics. In: Brandenburg FJ, editor. Graph Drawing. Lecture Notes in Computer Science. Springer, Berlin, Heidelberg, 1996. p. 435–446.
- 5Purchase HC . 2002. Metrics for graph drawing aesthetics. J Vis Lang Comput. 13(5):501–516.
- 6Chen X, Tang X, Luo Z, Zhang J. 2021. Evaluating user cognition of network diagrams. Vis Inform. 5(4):26–33.
- 7Herman I, Melancon G, Marshall MS. 2000. Graph visualization and navigation in information visualization: a survey. IEEE Trans Vis Comput Graph. 6(1):24–43.
- 8Tamassia R . Handbook of graph drawing and visualization, 1st ed. Chapman & Hall/CRC, 2016.