A textual dataset of de-identified health records in Spanish and Catalan for medical entity recognition and anonymization
Salvador Lima-López, Eulàlia Farré-Maduell, Luis Gasco, Jan Rodríguez-Miret, Santiago Frid, Xavier Pastor, Xavier Borrat, Martin Krallinger

TL;DR
This paper introduces CARMEN-I, a Spanish and Catalan dataset of anonymized health records for training medical NLP systems in entity recognition and anonymization.
Contribution
CARMEN-I is a new multilingual clinical dataset with annotations for anonymization and information extraction.
Findings
CARMEN-I includes 2 years of anonymized clinical records from a Barcelona hospital during the pandemic.
The dataset covers multiple comorbidities and includes annotations for six clinical concept classes in a subset of 500 records.
The resource supports training and evaluation of anonymization and information extraction systems.
Abstract
The advancement of clinical natural language processing systems is crucial to exploit the wealth of textual data contained in medical records. Diverse data sources are required in different languages and from different sites to represent global health services. To this end, we have released CARMEN-I, a corpus of anonymized clinical records from the Hospital Clinic of Barcelona written during the COVID-19 pandemic spanning a period of two years. In addition to COVID-19 cases of adult patients, CARMEN-I features multiple comorbidities such as cardiovascular conditions, oncology treatments, post-transplant complications, and infectious diseases. This resource is publicly accessible together with detailed annotation guidelines and granular text-bound annotations generated in a collaborative effort between clinicians, linguists, and engineers to enable training and evaluation of automatic…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
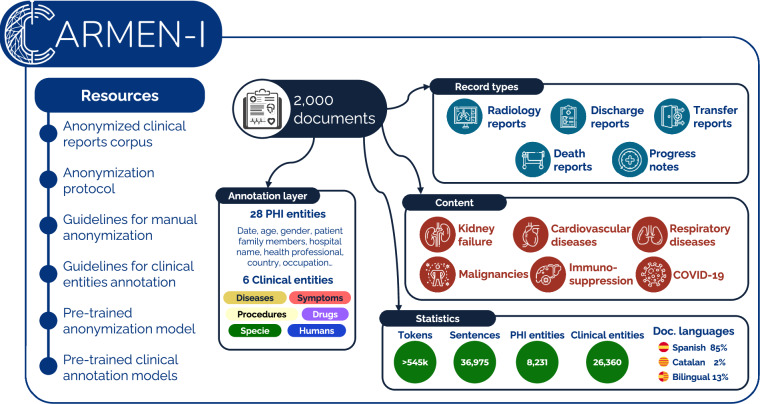 Figure 1
Figure 1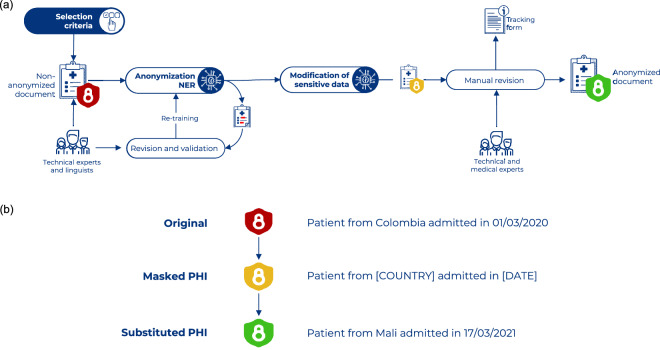 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBiomedical Text Mining and Ontologies · Topic Modeling · Machine Learning in Healthcare