Inequality Measurement for Bounded Variables
Inaki Permanyer, Suman Seth, Gaston Yalonetzky

TL;DR
This paper introduces a new method for measuring inequality in bounded health indicators, ensuring consistent rankings across different representations.
Contribution
The paper proposes a novel axiom for ranking maximum-inequality distributions of bounded variables.
Findings
The proposed indices measure inequality as an increasing function of the observed proportion of maximum attainable inequality.
The indices rank distributions consistently when switching between attainment and shortfall representations.
Empirical results show a different picture of health inequality when using the new indices compared to traditional ones.
Abstract
Many health indicators are bounded, that is, their values lie between a lower and an upper bound. Inequality measurement with bounded variables faces two normative challenges well‐known in the health inequality literature. One is that inequality rankings may or may not be consistent across admissible attainment and shortfall representations of the variable. The other is that the set of maximum‐inequality distributions for bounded variables is different from the respective set for variables with no upper bound. Therefore, the ethical criteria for ranking maximum‐inequality distributions with unbounded variables may not be appropriate for bounded variables. In a novel proposal, we justify an axiom requiring maximum‐inequality distributions of bounded variables to be ranked equally, irrespective of their means. Then, our axiomatic characterization naturally leads to indices that measure…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
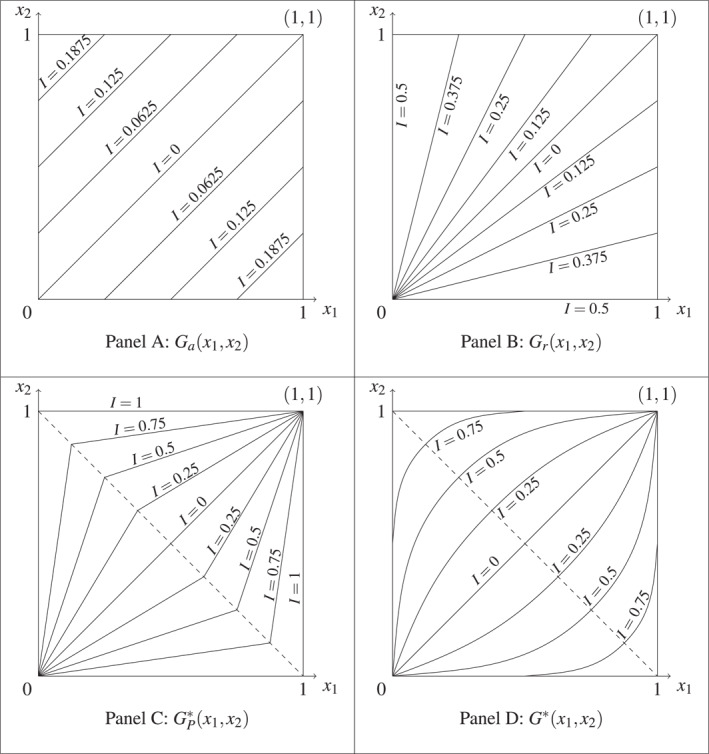 FIGURE 1
FIGURE 1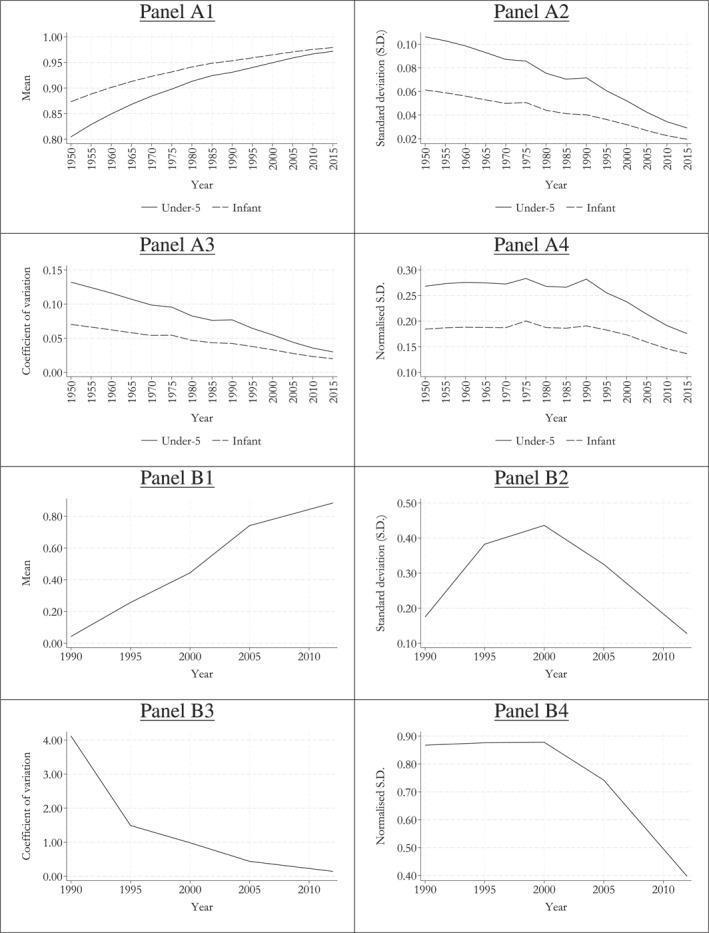 FIGURE 2
FIGURE 2- —Ministerio de Ciencia e Innovación
- —European Research Council10.13039/501100000781
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHealth Systems, Economic Evaluations, Quality of Life · Income, Poverty, and Inequality · Global Health Care Issues
Introduction
1
In his seminal contribution, Atkinson (1970) set the foundations of inequality measurement as we know it. After 5 decades, the contributions to this burgeoning field of research have expanded in multiple directions, and “inequality” can arguably be considered one of the most hotly debated topics in an increasingly globalized world, as witnessed by the popularity of several recent books on the subject (e.g., Piketty 2015; Bourguignon 2017; Atkinson 2018; Milanovic 2018; Piketty 2022; Milanovic 2023) and recent awards of the Nobel Memorial Prize in Economic Sciences. The interest in inequality measurement has gone well beyond the study of monetary or pecuniary variables. Like many non‐pecuniary variables, health indicators can only take values from a closed finite interval with fixed limits (i.e., the lower bound and the upper bound).1 Following the literature on inequality measurement, we refer to the variables with a lower bound and an upper bound as bounded variables (e.g., see Lambert and Zheng 2011).
The measurement of inequality with bounded variables poses two key challenges, which are not relevant for non‐bounded variables (i.e., those with a fixed and finite lower bound but no fixed upper bound). First, when a variable is bounded, one may choose to focus either on the distribution of attainments or the corresponding distribution of shortfalls with respect to the upper bound. For instance, improvements in the coverage of public health programs could be assessed via either the percentage of vaccinated children (an achievement indicator) or the percentage of unvaccinated children (a shortfall indicator). Many well‐known inequality measures fail to rank distributions consistently when measurement switches from attainments to shortfall representations (Micklewright and Stewart 1999; Clarke et al. 2002; Kenny 2004; Erreygers 2009a; Lambert and Zheng 2011; Lasso de la Vega and Aristondo 2012; Bosmans 2016). Several solutions have been proposed in the literature to tackle this challenge, such as using absolute inequality measures (Erreygers 2009a; Lambert and Zheng 2011), indices based on both representations (Lasso de la Vega and Aristondo 2012), or using pairs of weakly consistent indices (Bosmans 2016).
Second, there is a fundamental difference between the conceptualizations of most unequal distribution (henceforth maximum inequality distribution, or MID) for bounded variables and that for non‐bounded variables (i.e., variables with no upper bound), respectively. For a non‐bounded variable, all elements in an MID, barring one, are equal to the lower bound. Inequality measurement in this context is often seen as a cake‐cutting problem (e.g., see Cowell 2011), where the most unequal distribution always involves one person owning the entire cake. For example, while dividing a cake among 10 people, an MID would contain nine people having no slice (e.g., a lower bound of zero) and a single person owning the entire cake. If, instead, there were two identical cakes of the same size, then the MID would feature nine people having no cake at all and one person owning both cakes. As the mean increases from one‐10th to one‐fifth of a cake, absolute inequality measures rank the latter MID as more unequal whereas many relative inequality measures rank these two MIDs equally, for instance.
However, such scenario can be infeasible for bounded variables like stunting and immunization rates, all with an upper bound of 1% or 100%. For a bounded variable, an MID becomes a bipolar distribution (Erreygers 2009b) or an almost‐bipolar distribution (as defined in the subsequent section). To demonstrate our point, we continue with our cake‐cutting example. Suppose there is a fixed upper bound so that no one can have more than half of a cake. When there is one cake, the MID contains eight people having nothing and two people owning half of the cake each (i.e., the upper bound); whereas, with two cakes, the MID features six people without cake and four owning half of a cake each (i.e., leading to bipolar distributions). Thus, while both in the bounded and non‐bounded settings inequality is maximized whenever the smallest share of individuals owns as much as possible, there is a fundamental domain restriction shaping the inequality‐maximizing distributions. In the MID of an unbounded variable a single individual always owns everything, whereas in the MID of a bounded variable such possibility is often precluded. How should we, then, rank the different MIDs in the context of bounded variables?
The health inequality literature has long made inroads into the challenges of assessing inequality with bounded variables (see e.g., Wagstaff 2005; Erreygers 2009a, 2009b; Erreygers and Van Ourti 2011a; Kjellsson and Gerdtham 2013), with proposals for comparing notions of inequality across distributions with different means. For instance, Wagstaff (2005) proposes dividing the concentration index by its maximum value for a given mean; while Erreygers (2009a) proposes absolute indices satisfying various scaling properties, and further proposes normalizing the variable of interest with respect to the corresponding lower‐ and upper bounds to make the interpretations of indices unit‐free. Although the merits of these two approaches and underlying value judgments have been extensively debated (Wagstaff 2011; Erreygers and Van Ourti 2011b), Kjellsson and Gerdtham (2013) seek to reconcile them by arguing that even though both approaches attempt to quantify how far a distribution is from the most unequal state, they differ in their definitions of such states.
However, we observe two gaps in this otherwise rich debate. First, despite independently mentioning some of the elements underpinning our normative proposal for ranking MIDs, the debate has not put forward our ethical justification to rank MIDs equally vis‐à‐vis each other in the context of bounded variables; namely, that inequality cannot increase applying regressive transfers to these distributions. Second, despite similar measurement aims, the debate in the health economics literature has not yet been connected to a related broad (and mostly older) inequality measurement literature (e.g., Temkin 1986; Fields 1987, 1993, 1998; Amiel and Cowell 1994; Bosmans 2007).
Building on alternative suggestions from the literature on non‐bounded variables for similar situations (Temkin 1986; Fields 1998; Bosmans 2007), we argue that, from an egalitarian perspective, the different MIDs in the context of bounded variables represent the normatively least desirable situations for correspondingly different means, because in each one of them further regressive transfers are unfeasible. Thence, our normative proposal states that all least desirable situations (i.e., the MIDs) should be considered equally unequal. We refer to this desideratum as the maximality principle. Our axiomatic characterization shows that the maximality principle naturally leads to two novel classes of normalized inequality measures, which are motivationally analogous to the normalized concentration indices of Wagstaff (2005) and Erreygers (2009b).2
Simultaneously, indices in both new classes address traditional concerns regarding the consistency of inequality rankings to alternative representations of the bounded variable (i.e., attainment vs. shortfall) by satisfying the strong consistency property (Lambert and Zheng 2011; Bosmans 2016). As an additional contribution to this literature, we show that fulfillment of the more stringent perfect complementarity property (Erreygers 2009a) is not just sufficient but also necessary for the fulfillment of strong consistency. Our two classes of indices also comply with cardinal invariance (Erreygers 2009a), a well‐established principle in the inequality measurement literature which enables comparisons of distributions with different means for interval and ratio‐scale data, and guarantees consistent inequality rankings in terms of unit consistency (Zheng 2007; Lambert and Zheng 2011) and cardinal consistency (Erreygers 2009a; Lambert and Zheng 2011).
The key distinction between our two proposed classes is that one is defined for a fixed population, while the other class, a novel contribution to the literature, enables comparisons of distributions with varying populations. The second class' novelty resides in its joint satisfaction of the maximality principle, strong consistency and the population principle (along with other standard properties). Moreover, a key feature setting both classes apart is that the relevant MIDs for fixed populations admit the case of so‐called almost‐bipolar distributions alongside the better‐known bipolar counterparts. By contrast, one of our key contributions is showing that inequality comparisons of bounded‐variable distributions with varying population sizes only admit bipolar distributions as MIDs when they comply with the population principle.
To illustrate the empirical relevance of our proposed normalized inequality measures, we study cross‐country inequality trends in under‐5 and infant survival rates between 1950 and 2015, plus the evolution of inequality in hepatitis‐B immunization rates between 1990 and 2012. For all of them, we compare the normalized standard deviation against its relative (coefficient of variation) and absolute (standard deviation) counterparts. For the two child survival rates the values of the corresponding absolute and relative indices decline throughout, along with increases in mean attainments which were already > 50% in the middle of the 20th Century. By contrast, the proposed normalized index remains stable in value until the end of the 20th Century and falls thereafter. This indicates that observed absolute and relative inequality grew at similar rates compared to their respective maximum possible values during the 20th Century and then at faster rates into the 21st Century. Meanwhile for hepatitis‐B immunization rates, when we use the relative index, inequality steadily decreases throughout, as mean attainment increases from near 0%–90% across the studied period. Instead, we observe Kuznets curves with the absolute index, whereby cross‐country inequality initially increases as mean attainment increases, reaches maximum around half way between both bounds and then decreases as mean attainment approaches its upper bound. However, the normalized standard deviation reports stable inequality values initially and then a fall, suggesting an initial stability followed by a decline in the realized proportion of maximum possible inequality for both absolute and relative inequality.
The rest of the paper proceeds as follows. Section 2 introduces the notation, definitions and the required well‐established properties in the inequality measurement literature. Section 3 discusses the concept of maximum inequality in the context of bounded variables and introduces the maximality principle. Sections 4 and 5 introduce and axiomatically characterize the two classes of normalized inequality measures. Section 6 provides some comparative insights of our proposed approaches in relation to the existing approaches. Finally, Section 7 presents the empirical illustration and Section 8 concludes with some remarks.
Notation and Well‐Established Principles of Inequality Measurement
2
Suppose, there are n units of analysis (e.g., people, households, municipalities, countries, etc.) such that n∈N{1}.3 Let x=x1,…,xn be an attainment distribution of n units (or an n‐dimensional attainment vector), where xi∈[L,U]∩Q+ represents unit i’s cardinally measurable attainment, which is rational and bounded between a non‐negative lower bound of L∈Q+ and some positive upper bound U∈Q++, that is, 0≤L<U.4 To simplify notation, let D=[L,U]∩Q+ denote the range of values that each xi can take, and let D=∪L≥0∪U>L[L,U]∩Q+ be the set of all admissible domains (with L and U being rational numbers).
We denote the set of all attainment distributions of size n taking values within D by Xn;D, the set of all attainment distributions of size n by Xn;•≔∪D∈DXn;D, the set of all attainment distributions taking values within D by X•;D≔∪n>1Xn;D and the set of all possible attainment distributions by X≔∪n>1∪D∈DXn;D. By definition, we exclude egalitarian distributions whose values are all equal to either bound (i.e., (L,…,L) or (U,…,U)) from our domain. The arithmetic mean function evaluated at any x∈X is denoted by μ(x). Furthermore, for any x∈Xn;D, let Xn;Dμ(x) be the set of all attainment distributions of size n taking values within D and with the same mean as x, and for any x∈X, let Xμ(x) be the set of all possible attainment distributions with the same mean as x. Henceforth, we focus on distributions with mean different from either bound, that is, L<μ(x)<U.5
Bounded variables can be represented as attainments xi for every unit of analysis i or, alternatively, as shortfalls xiS=U+L−xi, which also range between L and U. For example, if xi is the share of healthy individuals in country i, then xiS is the respective share of unhealthy individuals. In this example, L=0 and U=1, so xiS=1−xi. We denote the shortfall distribution associated with x∈Xn;D as xS=x1S,…,xnS∈Xn;D.
We now present the properties that are relevant for our characterization. An inequality index I:X→R+ is a continuous real‐valued function expected to satisfy two basic properties (Chakravarty 2009): anonymity and transfer principle, in addition to other well‐established properties. Anonymity requires that an inequality index should not depend on a reordering of attainments across units; whereas the transfer principle requires that a transfer from a richer to a poorer unit, without altering their relative positions, should decrease inequality (progressive transfer); whereas, alternatively, a transfer from a poorer to a richer unit should increase inequality (regressive transfer).6
** Anonymity: ** For some x,y∈Xn;D, I(y)=I(x) whenever y=xP for permutation matrix P.7
** Transfer principle: ** For some x,y∈Xn;D, I(y)<I(x) whenever y is obtained from x by a progressive transfer and I(y)>I(x) whenever y is obtained from x by a regressive transfer.8
Before discussing more properties, we introduce a type of function which underpins our characterization results. We refer to a real valued function f:X→R+ as strictly Schur‐convex if, for some x,y∈Xn;D, f(y)≤f(x) whenever y is majorised by x and f(y)<f(x) whenever y is majorised by x but y is not a permutation of x (Marshall and Olkin 1979, 54).9 Moreover, y is majorised by x if and only if the former distribution can be obtained from the latter through a finite sequence of progressive transfers (Arnold 1987). Therefore, strictly Schur‐convex functions play a prominent role in inequality measurement because they satisfy the transfers principle.10
The third property, equality principle, ensures that inequality is minimal and is equal to zero whenever all units feature exactly the same value, that is, x1=x2=⋯=xn.
** Equality principle: ** For any x∈Xn;D and for some λ∈Q++, I(x)=0 whenever x=λ1n.11
The fourth property, cardinal invariance (Erreygers 2009a), serves two purposes. First, it allows comparing two distributions when one is obtained from the other by changing the unit of measurement. For example, among health variables, mortality rates may be reported either on a 0–1 scale or in percentage terms 0%–100% (i.e., ratio‐scale), whereas body temperature may be reported either in degree Celsius or Fahrenheit (interval‐scale). The property requires that inequality evaluation remains unchanged when a distribution is obtained from another through a positive linear transformation. Second, although this property is sufficient but unnecessary to guarantee the consistency of inequality comparisons to positive linear transformations of the measurement unit, it crucially enables inequality comparisons of distributions with different means.
** Cardinal invariance: ** For any x∈Xn;D and for some λ∈Q++ and δ∈Q+, Iλx+δ1n=I(x), where λxi+δ∈λL+δ,λU+δ for all i.
We note from the definition of cardinal invariance that its satisfaction implies compliance with scale invariance, that is, I(λx)=I(x), whenever δ=0. Likewise, cardinal invariance boils down to translation invariance, that is, Ix+δ1n=I(x), whenever λ=1 and δ≠0. Hence, satisfaction of cardinal invariance encompasses arguably the two most popular approaches to inequality measurement with ratio‐scale data: absolute and relative.12 An inequality index is absolute if its value remains unchanged when the same amount is added to all attainments (i.e., translation invariance); whereas, an inequality index is relative if its value remains unchanged when all attainments are altered in the same proportion (scale invariance). Note that the bounds are allowed to change in both cases from L,U to λL+δ,λU+δ.
A form of inconsistency arises when inequality orderings of attainment distributions differ from their shortfall counterparts. Different properties have been proposed in the literature regarding the extent to which inequality indices, as well as partial orderings, should consistently rank attainment and shortfall distributions.13 The perfect complementarity property requires that the value of the inequality index remains unaltered when we switch between attainment and shortfall representations of the same distribution (Erreygers 2009a).14
** Perfect complementarity: ** For any x∈Xn;D, I(x)=IxS.
Likewise, the less stringent strong consistency property requires that the inequality ranking should be robust to alternative representations of the variable (Lambert and Zheng 2011).
** Strong consistency: ** For any x,y∈Xn;D, I(x)≤I(y)⇔IxS≤IyS.
The task of rendering our proposed inequality measures in compliance with strong consistency is facilitated by the remarkable equivalence between strong consistency and perfect complementarity. We know that the latter implies the former. But Proposition 1 shows that strong consistency also implies perfect complementarity.15
Proposition 1An inequality index satisfies strong consistency if and only if it satisfies perfect complementarity.
See Appendix A1.
The aforementioned properties compare distributions with the same number of elements or population sizes. The final property, the population principle, enables the comparison of distributions with different population sizes.
** Population principle: ** For some x,y∈X•;D, I(y)=I(x) whenever y is obtained from x by a population replication.16
Maximum Inequality Distributions (MIDs) and the Maximality Principle
3
In the previous section, we discussed some well‐established properties for inequality measurement. Here, we introduce a new principle for inequality measurement in the context of bounded variables, which embodies a normative criterion for the ranking of MIDs with different means. Even though the concept of MIDs has been discussed for some types of variables and distributions in the health inequality literature (e.g., see Erreygers 2009b, for the case of bivariate distributions in concentration analysis), to the best of our knowledge they have not been characterized in relation to explicit sets of axioms for individual bounded variables. Hence, after defining the concepts of bipolar and almost‐bipolar distributions, we show that the set of distributions reflecting maximum inequality for a given mean, depends on the axioms selected to rank these distributions of bounded cardinal variables. We show that, if we consider anonymity and the transfers principle alone, then the MIDs for a given mean are either bipolar or almost‐bipolar (Proposition 2). We show in Section 5 that, if we add the population principle to anonymity and the transfers principle, then for a given mean the subset of MIDs narrows down to just bipolar distributions.
We introduce some additional necessary notation. For some n∈N{1}, let us denote a set of n−1 equally‐spaced grid points by
For example, for L=0, U=1 and n=4, G4={0.25,0.5,0.75}.
** Bipolar distribution: ** A distribution x∈Xn;D is bipolar whenever for some n′∈N such that n′<n, n′ units in x attain the value of U and the remaining n−n′ units attain the value of L.
Bipolar distributions consist of units with values at either the lower bound or upper bound exclusively, with at least one unit at each bound. Since n′ could take any value between 1 and n−1, for any bipolar distribution x∈Xn;D, μ(x) is an element in Gn. For example, with L=0 and U=1, consider distribution x=(0.1,0.4,0.7,0.8), where μ(x)=0.5 is an element in G4. An MID for x can be obtained by a sequence of regressive transfers until (or unless) no further regressive transfers are possible. Thus, the set of MIDs for x contains all possible permutations of the distribution xˆ=(0,0,1,1). All distributions in the set are bipolar since two elements are equal to the lower bound of 0 and two elements are equal to the upper bound of 1.
** Almost‐bipolar distribution: ** A distribution x∈Xn;D is almost‐bipolar whenever for some n′∈N∪{0} such that n′<n, n′ units in x attain the value of U, n−n′−1 units in x attain the value of L, and the leftover unit's attained value, which is necessarily ε=nμ(x)−n′U−(n−n′−1)L, lies between L and U.
Almost bipolar distributions consist of all units with either the lower or upper bound value, except for one unit with an interior value of ε∈(L,U). If y∈Xn;D is an almost‐bipolar distribution, then μ(y) cannot be an element of Gn. For instance, consider distribution y=(0.2,0.4,0.7,0.9), where μ(y)=0.55 with L=0 and U=1, which is not an element in G4. Again, an MID for y can be obtained by a sequence of regressive transfers until (or unless) no further regressive transfers are possible. The corresponding MIDs, in this case, are all possible permutations of the distribution yˆ=(0,0.2,1,1), with the leftover element being ε=0.2. Notably, yˆ is almost‐bipolar.
Formally, we denote the set of all possible almost‐bipolar distributions by A⊂X; the set of all possible bipolar distributions by B⊂X; and the set of all distributions that are either bipolar or almost bipolar by M=A∪B. We use subscripts n, D and • and superscript μ(x) with A, B and M as we have done for X in order to define relevant subsets. Finally, we define, for every x∈Xn;D, a partially ordered set Xn;Dμ(x),⪰n such that for any pair y,z∈Xn;Dμ(x): (1) z≻ny, which reads “z is more unequal than y,” if z is obtained from y through a sequence of regressive transfers with or without additional permutations and (2) z∼ny, which reads “z is as unequal as y” if z is obtained from y only through a sequence of permutations.
Based exclusively on anonymity and the transfers principle, Proposition 2 establishes the existence of a set of maximum‐inequality distributions (MIDs) and shows that the set of MIDs associated to any distribution x∈Xn;D contains permutations of either a bipolar or an almost‐bipolar distribution with population size n and same mean μ(x), that is, Mn;Dμ(x)=Xn;Dμ(x)∩M.
Proposition 2For any n∈N{1}, any D∈D and for any x∈Xn;D such that μ(x)∈(L,U)∩Q++, a set of maximum inequality distributions Mn,Dμ(x)=Xn;Dμ(x)∩M constituting the maximal elements of the partially ordered set Xn;Dμ(x),⪰n exists and the elements of Mn;Dμ(x) are bipolar when μ(x)∈Gn or almost‐bipolar when μ(x)∉Gn.
See Appendix A2.
It is worth noting that the elements included in Mn;Dμ(x) are unique up to permutations; that is, given any two elements x,y∈Mn;Dμ(x), then y=xP for some permutation matrix P. Even though MIDs are hypothetical distributions unlikely to be observed in practice, they do represent the benchmark case of maximum inequality against which we can compare distributions of bounded variables sharing the same mean. The latter's inequality evaluations cannot be larger than their MID's as long as an inequality index I satisfies anonymity and the transfer principle.
Comparing MIDs With Different Means
3.1
Recall from the cake‐cutting illustration for non‐bounded variables in the introduction that the ranking of the most unequal distributions (i.e., one person owning everything), with different means, depends on the selected approach to inequality measurement. For instance, such MIDs are judged equally unequal by the relative Lorenz ordering and by most Lorenz‐consistent relative inequality measures, but absolute inequality indices and partial orderings deem MIDs with higher means more unequal. By contrast and as elucidated, the concept of maximum inequality changes in the presence of an upper bound. How should we compare the MIDs of bounded variables for different means given that they all reflect maximum inequality? We draw ethical intuitions from a parallel literature assessing inequality changes for non‐bounded variables due to a sequence of population shifts between a better‐off group and a worse‐off group owing to social progress (Temkin 1986) or, analogously, between a low‐income sector and a high‐income sector owing to income growth (Fields 1987, 1993, 1998; Amiel and Cowell 1994; Bosmans 2007).
Suppose there are two groups in a society: one better off (e.g., high‐income) and one worse off (e.g., low‐income). Moreover, let everyone within each group be equally well off, so that there is no inequality within each of the two. Suppose further that there are n people in the society and consider the following n−1 situations. In the first (i.e., the initial) situation, there are n−1 persons in the worse‐off group and only one person in the better‐off group; in the second situation, one person moves from the worse‐off group to the better‐off group, and so there are n−2 persons in the worse‐off group and two persons in the better‐off group; and so on. Finally, in the (n−1)th (i.e., the final) situation, there is only one person in the worse‐off group and the other n−1 persons are in the better‐off group. As we gradually move from the initial situation to the final situation, the mean gradually improves, but how should inequality change?
Five possible ethical judgments have been discussed in the literature as the mean improves along with the shift of population from the worse‐off group to the better‐off group:
- An increase in inequality throughout;
- A decrease in inequality throughout;
- An initial increase in inequality, then a reduction after a certain point where inequality is maximized (i.e., an inverted U‐shape);
- An initial reduction in inequality, then an increase after a certain point where inequality is minimized (i.e., a U‐shape);
- No change in inequality.
Temkin (1986) and Fields (1998) both argue on the possibility for inequality to be increasing throughout (as an ever smaller number of people become victimized through the isolation of the poor) as well as the possibility for inequality to decrease throughout (reflecting a diminished elitism of the rich and the steady decrease in the number of those worse off). Temkin (1986) and Fields (1998), however, disagree on the possibilities of a U‐shape or an inverted‐U‐shape relationship. Temkin (1986) argues in favor of the possibility of an inverted‐U‐shape relationship, whereby the “isolation of the poor” judgment is claimed to dominate the “elitism of the rich” judgment when the mean is low, but the “elitism of the rich” judgment dominates at high mean levels. Meanwhile, Fields (1998) argues the exact opposite to justify a U‐shape relationship. Nevertheless, Bosmans (2007) shows that quasi‐concave inequality measures (comprising numerous relative, absolute and intermediate inequality measures) allow only the first three possibilities, that is, increasing throughout, decreasing throughout and the inverted‐U shape.
Thus, the literature features various arguments around the first four ethical judgments, in the case of non‐bounded variables, wherein none of the n−1 situations discussed above corresponds to maximum inequality (unless the two incomes are assumed unique). Importantly, a key difference emerges here for bounded variables, as for the latter each of the n−1 situations corresponds to a bipolar MID (i.e., the most unequal distribution) for a particular mean. Take the hypothetical case of 100 people (i.e., n=100), who may experience only one of the two extreme health alternatives (i.e., bounds): best health and worst health.17 Although this yields 99 bipolar MIDs, consider the following two distributions: A with 10 people experiencing best health and 90 people experiencing worst health; and B with 20 people experiencing best health and 80 people experiencing worst health. How should we compare a move from A to B? The “isolation of the poor” ethical judgment may suggest a rise in inequality as B reflects a situation with fewer people with worst health, but the “elitism of the rich” ethical judgment may suggest a reduction in inequality as 10 people previously experiencing worst health now experience best health.
A broader related question is how inequality ought to change when the mean gradually grows from the initial MID (i.e., one person with best health and 99 with worst health) to the final MID (99 people with best health and one with worst health). The most frequently used absolute inequality measures increase in value as the mean raises from the initial MID, reach their maximum values around the middle value of the mean (i.e., 50 people with best health and 50 people with worst health), and then decrease as the mean keeps growing towards the final MID; thereby depicting a Kuznets curve. Assessments based on most absolute inequality measures, thus, follow the third ethical judgment. Whichever the choice of inequality measure in the literature, we have not found compelling ethical justifications for ranking two MIDs differently despite their key common definitional trait; namely that in both distributions inequality cannot increase any further through regressive transfers (hence, we cannot even obtain one MID from another through such transfers). As is well known, we cannot transform one egalitarian distribution into another egalitarian distribution with a different mean through progressive transfers; yet we rank them equally. Hence, by analogy, we may justify ranking MIDs with different means in the same way.
As Temkin (1986, 118) eloquently stated, “two judges who accepted bribes in all of their cases might be equally corrupt, even if one tried fewer cases.” Temkin presented this argument while arguing in favor of the fifth ethical judgment. Thus, following Temkin (1986) and the aforementioned reasons, we propose considering the MIDs as equally unequal irrespective of their proportions of people with values in the lower and upper bounds. Since existing inequality indices do not satisfy the fifth ethical judgment (Bosmans 2007), we operationalize the latter with a property called the maximality principle as follows.
** Maximality principle: ** For any x,y∈Xn;D, I(x)=I(y) whenever x∈Mn;Dμ(x) and y∈Mn;Dμ(y).
The property requires that, whenever we pick any two (non‐trivial) MIDs, the corresponding levels of inequality must coincide. Stated otherwise, whenever no further regressive transfers can be performed, then we have reached maximal inequality irrespective of the mean of the distribution.
The Class of Normalized Indices for Comparisons With Fixed Population Size
4
Building on the key properties introduced in Section 2 and the maximality principle in 3, we characterize a new class of inequality indices. We show that, within our framework, inequality should be measured as an increasing function of observed inequality as a proportion of the maximum inequality level reachable given a mean attainment. Theorem 1 presents our proposed family of inequality indices for comparisons with fixed population sizes, which we call the class of normalized inequality indices.
Theorem 1For any n∈N{1} and any x∈Xn;•, an inequality index I satisfies anonymity, the transfer principle, the equality principle, the maximality principle, strong consistency and cardinal invariance if and only if there exist a positive finite constant M, a strictly Schur‐convex function f:Xn;•→R+, and an increasing function H:R→R+ such that:
where x¯=μ(x)1n is the egalitarian distribution with the same mean as x, and xˆ∈Mn;•μ(x) is an MID for x. Additionally, f satisfies the following two restrictions:
and, for some constants λ∈Q++ and δ∈Q+:
See Appendix A3.
According to Theorem 1, a normalized inequality index I(x) in our proposed class evaluated at distribution x is an increasing function (i.e., H) of any symmetric and S‐convex function f(x) evaluated at x, subtracted by its corresponding minimum possible value fx¯ evaluated at the egalitarian distribution x¯, and then normalized by the difference between its corresponding maximum possible value fxˆ evaluated at any of its uniquely associated MIDs, namely xˆ∈Mn;Dμ(x), and its corresponding minimum possible value fx¯.
For all practical purposes, we advocate using H(z)=z and M=1 in Equation (1), which yields a functionally simpler subclass of inequality indices from the class characterized in Theorem 1. Indeed, with such choices, the indices in our proposed class take the form:
Moreover, when the chosen f is an admissible traditional inequality index fulfilling the equality principle (such as the Gini coefficient or the coefficient of variation), then fx¯=0 and the ratio on the right‐hand side of Equation (4) further simplifies to:
Conveniently, the values of the inequality measures in Equations (4) and (5) range between zero in the absence of inequality (i.e., x=x¯) and one for an MID (i.e., x=xˆ). In fact, the indices in subclass (5) measure inequality as a proportion of the maximum attainable with f for a given mean. More generally, every normalized inequality index in the characterized class shares some key features, starting with increasing in value after a regressive transfer and decreasing owing to a progressive transfer.
Secondly, the value of every normalized index remains unchanged across attainment and shortfall representations (i.e., satisfying strong consistency) because the condition in Equation (2) is satisfied. More precisely in terms of the subclasses in Equations (4) and (5), the condition in Equation (2) states that I(x) is strongly consistent if and only if the ratios on the right‐hand sides satisfy perfect complementarity. Thus notably, f does not need to satisfy perfect complementarity itself in order to secure the strong consistency of a normalized inequality index.
Thirdly, the value of every normalized index remains the same for two distributions when one is obtained from the other through a positive linear transformation of the measurement unit (i.e., satisfying cardinal invariance) because the condition in Equation (3) is satisfied. As with strong consistency, the condition in Equation (3) states that I is cardinally invariant if and only if the ratios on the right‐hand sides of Equations (4) and (5) satisfy cardinal invariance. Again notably, f itself does not need to be cardinally invariant in order to guarantee the cardinal invariance of a normalized inequality index.
Crucially, f admits numerous functional forms. For instance, f can take the form of absolute inequality indices in the rank‐dependent class characterized by Lambert and Zheng (2011, theorem 4) as the following two conditions hold for all its members (such as the absolute Gini index): fxS=f(x) and f(λx+δ)=λf(x). These two conditions clearly comply with the restrictions in Equations (2) and (3). Additionally, f can also adopt the forms of the absolute inequality indices in the rank‐independent class characterized by Lambert and Zheng (2011, theorem 4) if they are based on homogeneous functions (as with the variance and the standard deviation, for instance). Indeed, the following two conditions hold for homogeneous members of the rank‐independent class characterized by Lambert and Zheng (2011): fxS=f(x) and f(λx+δ)=g(λ)f(x), where g:R++→R++. Clearly, these two conditions also comply with the restrictions in Equations (2) and (3).
Every relative inequality index expressible as the product of an homogeneous Lambert‐Zheng absolute inequality index times a function of the mean, is also admissible. For instance, when f is either the Gini coefficient (which is equal to the absolute Gini index divided by the mean) or the coefficient of variation (which is equal to the standard deviation divided by the mean), we obtain fxS=μ(x)U+L−μ(x)f(x) and f(λx+δ)=λμ(x)λμ(x)+δf(x), which again, satisfy Equations (2) and (3). The same results hold for every member of the Donaldson‐Weymark class of generalized Gini indices (Donaldson and Weymark 1980), confirming their admissibility. Similarly, all measures of the Lasso de la Vega and Aristondo (2012) class based on the aforementioned absolute and relative inequality indices are also admissible.
By contrast, no members of the rank‐independent Atkinson class (Atkinson 1970) are suitable for obtaining strongly consistent normalized inequality indices. Finally, only one member of the generalized entropy class (Shorrocks 1980) is an admissible functional form for f, namely the squared coefficient of variation.18
By way of examples, we present two normalized inequality indices, which consider two popular inequality measures as admissible functional forms for f, assuming H(z)=z and M=1 as in Equation (4), and μ(x)∈Gn (meaning that only bipolar MIDs are considered).19 Also for convenience of presentation, we refer to the normalized inequality index corresponding to the admissible form f as f∗ (instead of I), in order to clarify that f∗ is derived from an admissible f.
When f is the absolute or the relative Gini index, that is, f(x)=Ga(x) or f(x)=Gr(x), then it is easy to check (see Appendix A6) that
Thus, Ga∗(x) compares Ga(x) against the maximal inequality value that such index could possibly take for any distribution with mean equal to μ(x) (which equals U−μ(x)μ(x)−LU−L when the MID is bipolar, i.e., when μ(x)∈Gn). Expectably, the normalized inequality indices derived from the absolute and the relative Gini indices coincide because the latter is a product of the former times a function depending on the mean, which cancels out. To simplify notation, such normalized Gini index will be referred to as G∗(x).
We can also derive the normalized versions of the standard deviation (f(x)=σ(x)=V(x)) and the coefficient of variation (f(x)=CV(x)=σ(x)/μ(x)). It is easy to check (see Appendix A6) that σ∗(x)=CV∗(x), that is,
Once again, the normalized version of an absolute inequality index and its relative counterpart coincide for the same aforementioned reason.
The Class of Normalized Indices for Comparisons With Varying Population Sizes
5
At least since Dalton (1920), the most popular answer to the challenge of comparing inequality across distributions with different population sizes is the population principle, which requires that identical cloning of all units should leave inequality unaltered (thereby rendering populations with different sizes comparable).20 A normalized inequality measure from the class in Theorem 1 does not comply with the population principle even when an admissible functional form of f does, because even though the replication of a bipolar MID is itself an MID, the replication of an almost bipolar MID is not an MID, based on how Proposition 2 defines an MID.21 Therefore, if we want our normalized inequality measures to fulfill the population principle we must adopt a different definition of the set of MIDs, one compliant with the population principle. Proposition 3 establishes the existence of such a set of MIDs, and shows that the set of MIDs, associated with all distributions sharing the same mean across all population sizes taking values within (L,U) is, in this case, equal to B•;Dμ(x)=X•;Dμ(x)∩B.22 Based on the transfer and population principles combined with anonymity, these MIDs are defined as the distributions that maximize inequality among all possible distributions with the same mean but varying population sizes.
Likewise, we can order distributions across all population sizes. That is, for every x∈X•;D, we can define a partially ordered set X•;Dμ(x),⪰ such that for any pair y,z∈X•;Dμ(x): (1) z≻y, which reads “z is more unequal than y,” if z is obtained from y through a sequence of regressive transfers with or without additional permutations and/or replications and (2) z∼y, which reads “z is as unequal as y” if z is obtained from y only through a sequence of permutations and/or replications.
Proposition 3For any D∈D and any x∈X•;D such that μ(x)∈(L,U)∩Q++, a set of maximum inequality distributions B•;Dμ(x)=X•;Dμ(x)∩B constituting the maximal elements of the partially ordered set X•;Dμ(x),⪰ exists and all elements of B•;Dμ(x) are bipolar.
See Appendix A4.
According to Proposition 3, in a setting compliant with the population principle, only bipolar distributions maximize inequality. Thus, the Maximality Principle introduced in Section 3 must be adapted and rewritten as follows:
** Restricted Maximality Principle: ** For any x,y∈X•;D, I(x)=I(y) whenever x∈B•;Dμ(x) and y∈B•;Dμ(y).
Again, this principle states that whenever no further regressive transfers are feasible and we have reached a bipolar distribution, then inequality is maximal (no matter what the mean of the distribution is). With this reformulated version of the maximality principle, we can now axiomatically characterize the class of normalized inequality indices compliant with the population principle:
Theorem 2For any x∈X, an inequality index I satisfies anonymity, the transfer principle, the equality principle, the restricted maximality principle, the population principle, strong consistency and cardinal invariance if and only if there exist a positive finite constant M, a strictly Schur‐convex function f:X→R+, and an increasing function H:R→R+ such that:
where x¯ is the egalitarian distribution with the same mean as x, and xˆ∈Bμ(x) is a bipolar MID for x. Besides, f satisfies the population principle and the following two restrictions:
and for any constants λ∈Q++ and δ∈Q+:
See Appendix A5.
Theorem 2 implies that the normalized inequality indices abide by the population principle (in addition to all the properties in Theorem 1) as long as f satisfies the population principle and is evaluated at any bipolar distribution with mean equal to μ(x). Good examples include the normalized inequality indices in Equations (6) and (7), already introduced in Section 4. The indices in Equations (6) and (7) can rank distributions with any mean whose value is different from either bound because both the absolute Gini index and the standard deviation (as well as the Gini index and the coefficient of variation) satisfy the population principle.
Further Comparative Insights
6
We now provide some insights into how the two proposed classes of normalized inequality indices (in Sections 4 and 5) compare with each other as well as how they both compare with standard absolute and relative measures. First, note that the two approaches to measuring normalized inequality (corresponding to the two definitions of MIDs and their respective classes of indices) bear a large degree of overlap. In fact, the formulas for normalized inequality indices compliant with the population principle (Section 5) is identical to the corresponding formulas for indices suitable for fixed population sizes (Section 4) whenever μ(x)∈Gn.23 In fact, when the population size n is sufficiently large and the decimal precision is kept fixed (as is the case in many empirical applications), the condition μ(x)∈Gn is always satisfied.
In the context of n=2, we provide insights on how the different normalized inequality measures behave and compare vis‐a‐vis each other, and with respect to standard absolute and relative inequality measures using the Gini coefficient. The non‐trivial case with n=2 lays the foundation for how the corresponding inequality indices behave for the more general case of n>2. Furthermore, the simplicity of the n=2 setting allows a neat inspection of the iso‐inequality level contours, which can be thought as the fingerprint of the corresponding inequality measures.24 Figure 1 presents the iso‐inequality contours of the absolute Gini index (Ga, Figure 1 panel A), the relative Gini index (Gr, Figure 1 panel B), the normalized Gini index based on Theorem 1 (i.e., for fixed population; GP∗ in Equation (A14) in Appendix A6, Figure 1 panel C), and the normalized Gini index complying with the population principle (the same formulation as G∗ in Equation (6), Figure 1 panel D), in the case where L=0 and U=1 (Appendix A7 shows how we arrive at these iso‐inequality contours).25
Iso‐inequality contours for the different Gini coefficient (n=2, L=0, and U=1). The figure is based on n=2 and U=1. Gax1,x2 in panel (A) is the absolute Gini index applied to an attainment distribution. Grx1,x2 in panel (B) is the relative Gini index applied to the same attainment distribution. GP∗x1,x2 in panel (C) is the normalized Gini index applied to the attainment distribution for fixed population. G∗x1,x2 in panel (D) is the normalized Gini index applied to the attainment distribution for variable population.
As is well‐known, Gax1,x2∈[0,0.25] and the iso‐inequality contours for Ga are parallel to the 45° line, while Grx1,x2∈[0,0.5] and the iso‐inequality contours for Gr are straight lines “emanating from” (or “converging to”) the origin (0, 0). In contrast, the iso‐inequality contours for the two normalized Gini indices, GP∗x1,x2∈[0,1] and G∗x1,x2∈[0,1], exhibit completely different shapes. In the case of GP∗, all level contours are made of two line segments meeting in the diagonal x1,x2∈[0,1]2|x1+x2=1, which, together, connect the points (0, 0) and (1, 1). Their shapes (though not their corresponding inequality levels) coincide with the level contours of Grx1,x2 when μx1,x2≤1/2 and with those of Grx1S,x2S when μx1,x2≥1/2 (where x1S=1−x1 and x2S=1−x2, see Appendix A7). In addition, one has that GP∗x1,x2=GP∗x1S,x2S. Lastly, the level contours G∗x1,x2=c (where c∈[0,1]) are curves that (i) are symmetrical with respect to the x2=1−x1 axis for all c∈[0,1] (i.e., G∗x1,x2=G∗x1S,x2S) and (ii) they connect the points (0, 0) and (1, 1) when c≤1/2.
As can be inferred from Figure 1 panel C, all the distributions x1,x2 lying at the border of the unit square maximize inequality (i.e., they are MIDs) when the latter is measured with GP∗x1,x2. By contrast, Figure 1 panel D shows that, when the population principle is imposed, only the bipolar distributions, namely (0, 1) and (1, 0), maximize inequality. The relative Gini index shown in panel B Gr is the only measure in Figure 1 that fails to be strongly consistent. As expected from Proposition 1, the absolute Ga and normalized Gini indices (GP∗, G∗) not only satisfy the strong consistency axiom, but also its more stringent version, perfect complementarity. This happens for all values of n≥2 and for the two normalized inequality measures explored in this paper: the normalized Gini index and the normalized standard deviation (see equations (6) and (7)). The variegated shapes of the iso‐inequality contours when moving from one inequality measure to another (see Figure 1) explain the discrepancies that might exist among them.
Empirical Illustration: Cross‐Country Inequality Trends in Three Health Indicators
7
In order to illustrate the empirical relevance of our proposal, we study the evolution of cross‐country inequality in three health indicators relevant to the United Nation's 3rd Sustainable Development Goal (SDG), “Ensure healthy lives and promote well‐being for all at all ages”: the under‐5 survival rates (indicator 3.2.1; target 3.2; SDG 3), the infant survival rates (related to target 3.2; SDG 3) and the Hepatitis B (HepB3) immunization coverage rates among 1‐year‐olds (related to target 3.3, SDG 3).26 We select the under‐five survival rate and the infant survival rate, namely the attainment complements of the respective mortality rates. The data come from the United Nations' Department of Economic and Social Welfare website.27 We obtain the survival rates by subtracting the mortality rates from 1000 and then normalizing the differences by 1000. Therefore, the survival rates also lie between zero and one. The data are available for 201 countries.
Panel A1 in Figure 2 shows the change in mean attainments for the two selected child survival indicators between 1950 and 2015, for every 5‐year period.28 All global averages display steady improvements since 1950. The mean under‐5 survival rate increases from 0.80 in 1950 to 0.97 in 2015, whereas the mean infant survival rate increases from 0.87 in 1950 to 0.98 in 2015. That is, both means lie well above 0.50 throughout the studied period.
Change in cross‐country mean and standard deviation, coefficient of variation and normalized standard deviation for the health indicators. The graphs in panels (A1–A4) are based on the data from 201 countries; whereas, the graphs in panels (B1–B4) are based on the data from 152 countries. Source: Authors' own computations.
Figure 2 panel A2 presents the trends in standard deviation since 1950 for the two child survival indicators. Predictably for standard deviation when the growth in the mean is far from egalitarian, the values decrease throughout the period as mean attainment, already well above 0.5, gets closer to its upper bound. Figure 2 panel A3 shows the evolution of relative inequality measured by the coefficient of variation. Again, predictably for this index if the growth in the mean is far from egalitarian, relative inequality decreases throughout.29
Finally, Figure 2 panel A4 presents the trends in normalized standard deviation, that is, σ∗ in Equation (7). Unlike both standard deviation (absolute) and coefficient of variation (relative), the normalized standard deviation registers a non‐upward trend for both health indicators through the first decades of the studied period. Indeed, for both indicators, the normalized standard deviation remains stable until nearly 1990, and falls thereafter. That is, in both cases, we conclude that for most of the 20th century, cross‐country inequality in the two child survival indicators remains stable compared to its maximum possible value (which was decreasing, according to the standard deviation and coefficient of variation), and then its level falls gradually in the 21st century (as maximum absolute and relative values kept decreasing with increasing means). Thus, our empirical illustration shows that normalized indices can produce different inequality trends vis‐a‐vis their traditional absolute and relative counterparts.
By way of another corroborating example, panel B1 in Figure 2 shows the change in mean attainments for HepB3 infant immunization rates. Unlike the two previous indicators, here mean attainment is observed increasing from 0.04 in 1990 (i.e., very close to the lower bound) to 0.88 in 2012 (not far from the upper bound either). Correspondingly, Figure 2 panel B2 displays a Kuznets curve for HepB3 immunization rates using standard deviation, while Figure 2 panel B3 shows a steady decline in the coefficient of variation (relative). Unless the growth in mean immunization rates remains egalitarian throughout the periods, these two inequality trends are largely predictable since the maximum values of standard deviation and the coefficient of variation describe Kuznets curves and downward sloping lines, respectively.30 But then, interestingly, Figure 2 panel B4 shows that the normalized standard deviation remains stable initially and then slopes downward throughout.
Here, the main lesson from the normalized standard deviation is that the increase in absolute inequality in immunization rates experienced during the 20th century was similar in comparison to the increase in maximum absolute inequality, hence the stability in normalized inequality. However, normalized inequality declined unabated into the 21st century. Meanwhile, we also learn from the normalized standard deviation that the observed decline in the coefficient of variation (relative) was similar in comparison to the decline in its maximum value as mean attainment grew in the 20th century; but then the coefficient of variation declined faster in comparison to its maximum possible values. In conclusion, the normalized index shows that the diffusion of HepB3 vaccination became more egalitarian as the attained proportion of maximum possible inequality decreased with the years in the 21st century (and with further increases in mean immunization rates).
Concluding Remarks
8
Bounded variables are fundamentally different from unbounded variables as the former cannot increase or decrease infinitely. Consequently, whenever the mean of a distribution moves closer to any of its bounds, the level of inequality assessed by several traditional inequality measures may fall simply because there is not enough room for variation. The concept of maximum feasible inequality with bounded variables is also quite different from maximum feasible inequality in the context of unbounded variables.31 We propose a new approach to assessing inequality for individual bounded variables relying on a new property called the maximality principle, which demands that the distributions of bounded variables reflecting maximum feasible inequality be ranked equally. We propose two new classes of inequality indices. The maximality principle leads to a type of normalization, whereby each inequality measure in our proposed classes is an increasing function of observed inequality levels compared against the maximum inequality level achievable with the same measure across all hypothetical distributions having the same mean. Furthermore, our proposed classes of normalized inequality indices evaluate inequality across attainment and shortfall representations consistently.
To illustrate the empirical relevance of our methodological proposal, we examine the evolution of cross‐country inequality in three health indicators, comparing the normalized standard deviation against its absolute and relative counterparts (i.e., standard deviation and coefficient of variation, respectively). The normalized standard deviation portrays a markedly different picture of cross‐country evolution of inequality compared to the patterns produced by the absolute and relative counterparts. More specifically, in the case of the two child survival indicators, both the standard deviation and the coefficient of variation decrease as mean attainment approaches its upper bound, but the trends based on normalized standard deviation suggest that global progress did not follow more conceivably egalitarian paths until the 1990s. By contrast, in the case of the hepatitis‐B immunization rate, for mean attainment > 50% the normalized standard deviation shows that the decline in observed inequality measured by the absolute and relative counterparts was greater than the contemporaneous decline in the corresponding maximum inequality values; thus uncovering inequality improvement above and beyond what would be expected from the predictable narrowing in maximum possible dispersion as mean attainment tends toward its upper bound.
Future research could consider the normative foundations and feasibility of classes of indices for bounded variables based on the relaxation of strong consistency in favor of inconsistent or weakly consistent inequality measurement (i.e., following Bosmans 2016), combined alternatingly with different ethical rules for ranking MIDs, including inter alia Erreygers (2009b), Bosmans (2007) and our maximality principle. Likewise, future research could explore partial orderings respecting the properties that were combined to generate the normalized inequality indices. Furthermore, there remain other measurement challenges in the context of bounded variables. For example, Lasso de la Vega and Aristondo (2012) provide conditions whose fulfillment guarantees robustness of inequality comparisons to changes in the upper bound. Though admittedly this problem is not that serious when bounds are neither arbitrary nor expected to change across time and space (e.g., in the case of indicators expressed as percentage ratios), it is nonetheless worth exploring how our proposed measurement framework could accommodate such potential concern.
Conflicts of Interest
The authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aboudi, R. , D. Thon , and S. Wallace . 2010. “Inequality Comparisons When the Populations Differ in Size.” Journal of Economic Inequality 8, no. 1: 47–70. 10.1007/s 10888-008-9104-1. · doi ↗
- 2Amiel, Y. , and F. Cowell . 1994. “Inequality Changes and Income Growth.” In Models and Measurement of Welfare and Inequality, edited by W. Eichorn , 3–27. Springer Verlag.
- 3Arnold, B. 1987. Majorization and the Lorenz Ordering: A Brief Introduction. Springer‐Verlag.
- 4Atkinson, A. 1970. “On the Measurement of Inequality.” Journal of Economic Theory 2, no. 3: 244–263. 10.1016/0022-0531(70)90039-6. · doi ↗
- 5Atkinson, A. 2018. Inequality. What Can Be Done? Harvard University Press.
- 6Bosmans, K. 2007. “Income Inequality, Quasi‐Concavity, and Gradualpopulation Shifts.” Mathematical Social Sciences 53, no. 1: 29–45. 10.1016/j.mathsocsci.2006.09.003. · doi ↗
- 7Bosmans, K. 2016. “Consistent Comparisons of Attainment and Shortfall Inequality: A Critical Examination.” Health Economics 25, no. 11: 1425–1432. 10.1002/hec.3228.26365375 · doi ↗ · pubmed ↗
- 8Bourguignon, F. 2017. The Globalization of Inequality. Princeton University Press.