Income‐Related Inequalities in Future Health Prospects
Gustav Kjellsson, Dennis Petrie, Tom Van Ourti

TL;DR
This paper introduces a new way to measure health inequality by considering future health risks and how they differ by income.
Contribution
The novel contribution is a rank-dependent health inequality index that incorporates individual future health risk and dispersion.
Findings
The poor face worse expected future health compared to the rich.
Ignoring individual risk leads to underestimating income-related health inequalities.
Future health prospects among the poor show greater dispersion than among the rich.
Abstract
Measuring health disparities is key to monitoring health systems, but hitherto disparities in the individual risk people face about their future health has been neglected. This paper integrates individual health risk into income‐related health inequality measurement. We develop a rank dependent health inequality index that considers inequalities in each individual's expected future health and the dispersion of their future health prospects. It is useful when a social planner wants to account for risk averse preferences in the assessment of income‐related inequalities of future health prospects. The empirical application using Australian longitudinal data highlights that neglecting individual risk underestimates income‐related inequalities in future health prospects since the poor not only face worse expected future health, but also faced greater dispersion in their future health…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
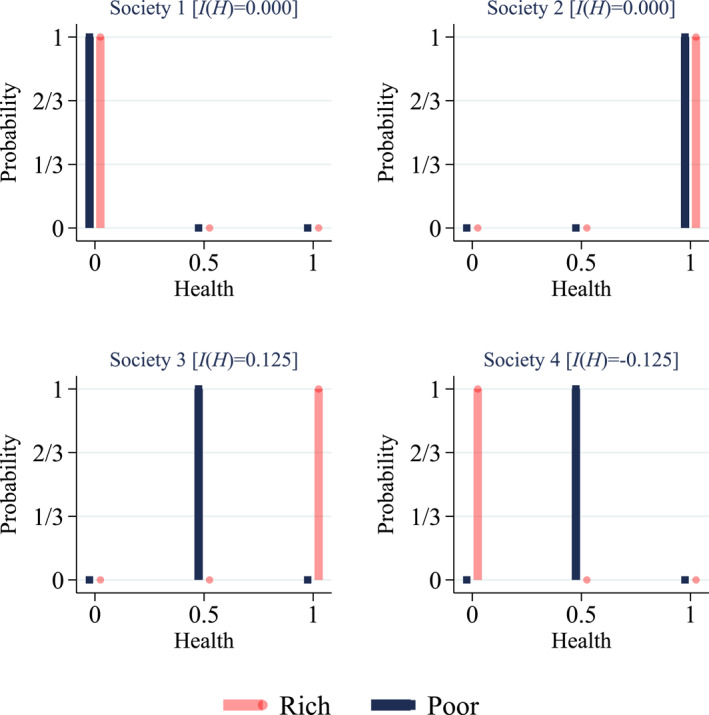 FIGURE 1
FIGURE 1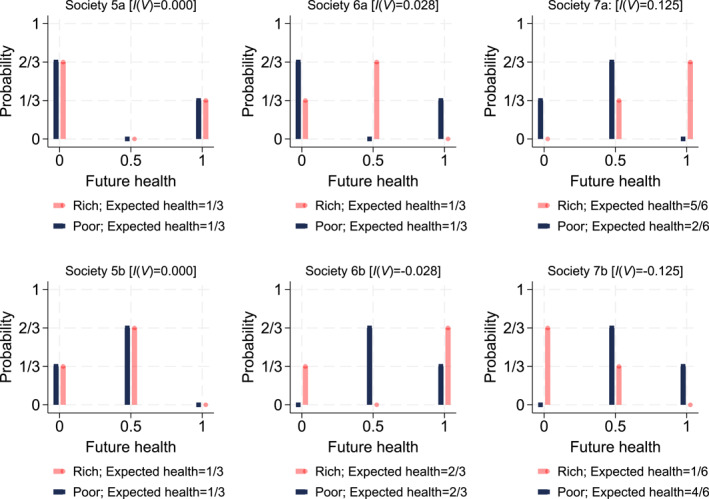 FIGURE 2
FIGURE 2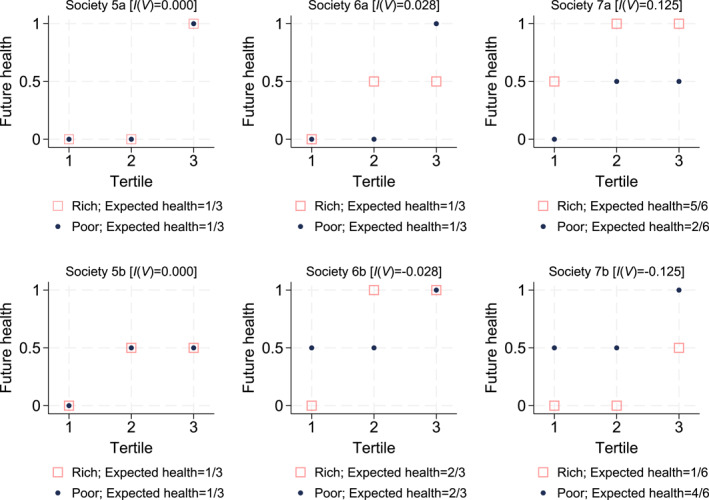 FIGURE 3
FIGURE 3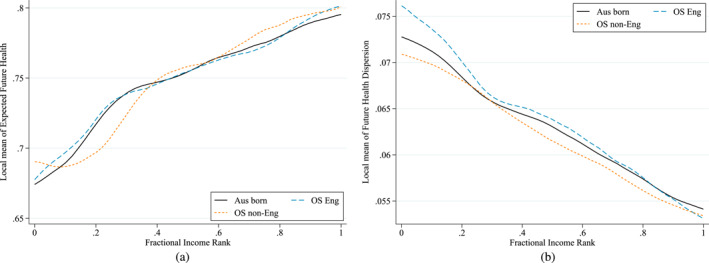 FIGURE 4
FIGURE 4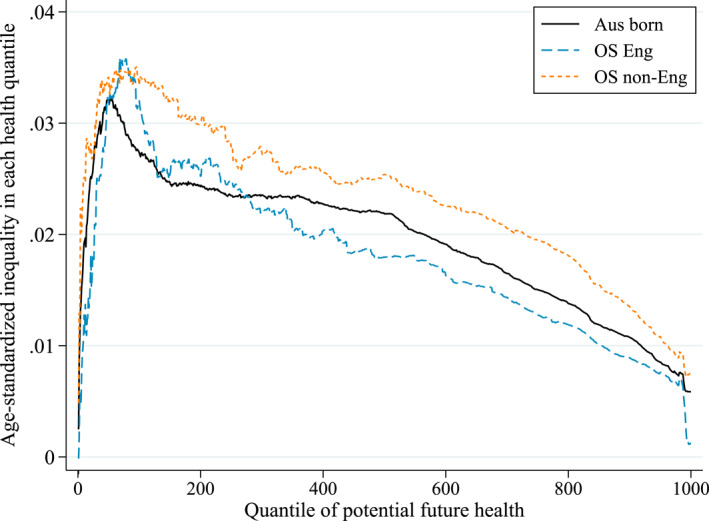 FIGURE 5
FIGURE 5| Variables ( = 12,833) | Mean | Std. Dev. |
|---|---|---|
| Health 2011 | 0.75 | 0.12 |
| Health 2019* | 0.70 | 0.22 |
| Equivalized household income ($'000s per annum)** | 54.98 | 30.49 |
| Age (years old) | 43.03 | 17.28 |
| Male | 47% | |
| Education | ||
| Less than secondary school completion (reference) | 28% | |
| Secondary school completion | 13% | |
| Post school certificate or diploma | 32% | |
| University degree or higher | 26% | |
| Unemployed | 3% | |
| Marital status | ||
| Single (reference) | 16% | |
| Married or living with partner | 70% | |
| Divorced/Separated/Widowed | 14% | |
| Smoking status | ||
| Never (reference) | 51% | |
| Current | 19% | |
| Former | 30% | |
| Risky drinker*** | 6% | |
| Country of birth | ||
| Australia [Aus born] (reference) | 76% | |
| Other English speaking country [OS Eng] | 11% | |
| Non‐English speaking country [OS non‐Eng] | 13% | |
| Age‐standardized | ||||||
|---|---|---|---|---|---|---|
| Aus born | OS Eng | OS non‐Eng | Aus born | OS Eng | OS non‐Eng | |
| Future health prospects | 0.0410 | 0.0447 | 0.0457 | 0.0227 | 0.0218 | 0.0270 |
| Due to expected health | 0.0332 | 0.0354 | 0.0373 | 0.0195 | 0.0181 | 0.0234 |
| Due to health dispersion | 0.0078 | 0.0093 | 0.0084 | 0.0032 | 0.0037 | 0.0036 |
| Sample size ( | 9783 | 1442 | 1608 | 9783 | 1442 | 1608 |
- —Australian Research Council10.13039/501100000923
- —Partner programme at the University of Gothenburg School of Business, Economics, and Law
- —Erasmus Initiative Smarter Choices for Better Health
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGlobal Health Care Issues · Health Systems, Economic Evaluations, Quality of Life · Health disparities and outcomes
Introduction
1
Health disparities are systematically related to income, although to varying degrees across space and time (Wagstaff and van Doorslaer 2000; Cutler et al. 2012; Deaton 2013; Chetty et al. 2016). The concentration index is the main health economics workhorse for measuring these disparities. It captures the extent of health differences across individuals ranked by an indicator of socioeconomic status such as income (Wagstaff et al. 1991; O’Donnell et al. 2008, 2016). The concentration index has been used to report cross‐sectional estimates of health inequalities across countries (van Doorslaer et al. 1997), over time (Gravelle and Sutton 2003; Wagstaff et al. 2003), or how health dynamics are related to the income position of individuals (Jones and Nicolas 2004; Van Ourti et al. 2009; Allanson et al. 2010; Coveney et al. 2020; Allanson and Petrie 2021). However, inequality in the individual risk people face about their future health has received no attention in the literature on measurement of health inequality.1 In this paper we address this topic.
The literature on decisions under risk stresses that an individuals' valuation (or anticipated utility) of particular lotteries often depends on the risk involved (Quiggin 1982; Starmer 2000). The riskiness of an individual's future health prospects might thus impact on the value the individual places on it, and it may therefore be relevant to analyze how individual health risk varies across the population. When individual health risk is unequally distributed across income, a social planner—who acknowledges that individuals are on average risk‐averse—may recognize the dispersion of future health prospects as an additional source of income‐related health inequalities on top of disparities in the expected level of future health.
In this paper, we develop an index of income‐related inequalities in risky health prospects. The index can be calculated in two steps. First, the social planner values each individual's distribution of risky future health prospects. These valuations are increasing in expected future health and decreasing in the dispersion of future health prospects faced by that individual (Shalit and Yitzhaki 1984); and thus are sensitive to the trade‐off between improvements in expected future health and reductions in the dispersion of future health. In the second step, the social planner summarizes the co‐variation of the individual‐specific valuations across current income using the generalized concentration index (Wagstaff et al. 1991; Erreygers 2009). It will indicate pro‐rich inequalities when the rich face higher expected future health compared to the poor, and become more pro‐rich if the rich additionally face lower dispersion in their future health prospects. An alternative interpretation of the index considers the income‐related inequality in each quantile of each individual's health distribution, from everybody's worst possible future health outcome (the lowest health quantile) all the way up to the income‐related inequality in their best possible health outcome (the highest health quantile). If the inequality in each health quantile is given equal weight then the index collapses to the generalized concentration index which ignores individual risk, while giving more weight to inequalities at lower compared to higher health quantiles is compatible with the trade‐off that emerges under risk‐aversion. The aggregation from the lowest up to the highest health quantile further spells out that the index incorporates individual health risk (and not societal risk), that is focus is on how distributions of risky future health prospects, faced by each individual, vary by current income.
We derive the risk‐sensitive inequality index under the assumption that the social planner is able to predict individual‐specific distributions of future potential health outcomes. This includes the different potential health levels that might emerge, as well as the probabilities of each future health level faced by every individual. Our social planner takes an ex‐ante viewpoint and does not care about the health level that the individual will eventually experience in the future once individual risk is resolved. This assumption also exemplifies our explicit focus on the impact of individual risk for health inequality ex‐ante (today), rather than the impact of societal risk for the extent of future health inequality ex‐post.2 The social planner accounts for risk aversion by imposing the same valuation function onto the distribution of risky health prospects of each individual. Finally, we assume throughout the paper that the social planner considers inequality to be unchanged for absolute changes in each health prospect across all individuals, but the framework can be extended to other inequality invariance stances (Kolm 1976; Erreygers and Van Ourti 2011; Allanson and Petrie 2013; Kjellsson et al. 2015).
This paper makes two contributions to the literature on health inequality measurement. First, we extend the standard inequality measurement apparatus used by health economists such that it can account for risky health prospects. The approach is intuitive, has two equivalent interpretations and allows policy makers to monitor how individual health risk varies with an indicator of socioeconomic status such as current income. The second contribution lies in combining the newly developed measurement apparatus with data from the Australian Household, Income and Labor Dynamics in Australia (HILDA) Survey. We compare inequalities in future health prospects across three sub‐populations based on country of birth—born in Australia, born overseas in another English‐speaking country, and born overseas in a non‐English speaking country. This is of public policy relevance since Australia has a particularly large migrant population and differences in language, culture and limited knowledge of the Australian healthcare system may put them at higher risk of poorer future health prospects (Jatrana et al. 2014). We find that income‐related inequalities in the dispersion of future health prospects contribute substantially to the overall index in all three sub‐populations, even after standardizing for age which is the most important predictor of mortality and future health. This finding confirms the importance of considering the additional inequalities that arise from dispersion, on top of those arising from expected future health. Our empirical results additionally illustrate that inequalities in the dispersion of future health were most concentrated among those born overseas, while inequality in expected future health was largest among those born overseas in a non‐English speaking country.
The remainder of this paper is organized as follows. The methods of inequality measurement of risky future health prospects are laid out in Sections 2 and 3. The empirical illustration is discussed in Section 4 and Section 5 concludes.
Measuring Income‐Related Inequalities Without Risk
2
The standard approach to the measurement of income‐related health inequalities does not consider individual risk, and is based on the standard concentration index (Wagstaff et al. 1991) and its rank‐dependent generalizations (Wagstaff 2005; Erreygers 2009; Erreygers et al. 2012; Kjellsson et al. 2015; O’Donnell et al. 2016). In this paper, we use the generalized concentration index IH,Y which measures absolute health inequalities:
where H=h1,h2,…,hn and Y=y1,y2,…,yn are vectors with deterministic health and income levels. Individuals are ranked by income y1≤y2≤…≤yn, and zi=2i−1−n/n is a social weight that linearly increases with income rank from 1−n/n for the poorest individual to n−1/n for the richest individual, and equals zero for the individual with median income.
The welfare properties of the generalized concentration index are well known (Mehran 1976; Wagstaff et al. 1991; Bleichrodt and van Doorslaer 2006; Erreygers and Van Ourti 2011). The index records no health inequality when everyone experiences the same level of health. Concentration of health among the poor leads to negative values of the index (pro‐poor) and positive values indicate pro‐rich inequalities. The index satisfies the principle of income‐related health transfers which imposes that health inequality becomes more pro‐poor after a health‐transfer from a richer to a poorer person (Bleichrodt and van Doorslaer 2006); and IH,Y measures absolute inequalities and thus imposes that inequality remains unchanged when everyone's health changes by the same absolute amount.
In a scenario without individual risk, the generalized concentration index can be used to evaluate income‐related inequalities in health. Consider Figure 1 which shows four examples of hypothetical two‐person societies where individuals face no individual risk, that is with a probability of 100% they are either dead (0), in fair (0.5) or perfect health (1). In society 3, the rich individual is in perfect health and the poor individual in fair health resulting in pro‐rich inequalities as health differences favor the rich. Society 4 is an example of inequalities in favor of the poor (pro‐poor), while there are no income‐related health inequalities in a society where everyone is dead (society 1) or in perfect health (society 2).
Hypothetical societies without health risk: Probability density functions.
Introducing Individual Health Risk Into the Measurement Apparatus
3
When individuals face risk, one has to consider the full distribution of each individual's future health prospects (from their worst future health quantile to their best future health quantile) and how these individual‐specific distributions vary by income. This section first discusses the social planner's valuation of the distribution of future potential health outcomes for each individual in isolation. Next, it presents the between‐individual inequality in these valuations by income and examines the implicit value judgments of the resulting index. We end the section with an alternative, but equivalent, derivation of the index that first calculates income‐related inequalities across individuals for each future health quantile, and next aggregates these inequalities across quantiles, thereby further clarifying that the index incorporates individual, and not societal health risk.
Valuing Risky Future Health Prospects
3.1
For a given future period, each individual faces a distribution of potential future health outcomes. We assume that the social planner is able to predict Q quantiles of this distribution (based on individual characteristics). Denote the qth future health quantile of individual i as hiq, so that hi1≤hi2≤…≤hiQ for q=1,2,…,Q. The social planner values (in the current period) individual i’s distribution of potential future health outcomes using a rank‐dependent utility function (Quiggin 1982):
and uses the same quantile weights wq for every individual. The quantile weights are positive, decrease from the worst health quantile to the best health quantile, and sum to Q, that is (1/Q)∑q=1Qwq=1. Vi thus increases more when a future health quantile in the lower part of individual i’s health distribution (a worse health prospect) improves compared to the same improvement in the upper part of the distribution (a better health prospect).
The extent to which the social planner incorporates that individuals appreciate health, and are risk‐averse is determined by the functional form of the quantile weights.3 Assuming the weights to be wq=2Q−2q+1/Q, that is strictly positive (satisfying Pareto) and linearly declining with the health quantile Q (reflecting risk‐aversion), implies that Vi corresponds to the certainty equivalent level of future health and penalizes expected health—which does not depend on the quantile weights—by the generalized Gini index of the health quantiles Di—which does depend on the quantile weights. The generalized Gini index is a standard measure of dispersion: for the same expected level of health, more dispersed future health quantiles lead to a larger penalty (Shalit and Yitzhaki 1984). This can also be seen from adding and subtracting individual i’s expected health, hi‾, to Equation (2):
Income‐Related Inequality in the Valuation of Risky Future Health Prospects
3.2
The social planner worries that the poor face less favorable distributions of future health prospects compared to richer individuals, and therefore replaces the deterministic health realizations hi in Equation (1) by the valuation function Vi. The resulting index equals the weighted sum of all future health quantiles across all individuals with the weights equaling the product of the income and quantile weights4 ^:^
and where dependence of IV,Y on Y is suppressed for notational simplicity.
Combining Equations (3) and (4) shows that income‐related inequalities in future health prospects can be decomposed into income‐related inequality in expected future health IH‾ and income‐related inequality in the dispersion of future health prospects ID:
Since IH‾ and ID uncover separate but complementary features of income‐related inequality in future health prospects, both indices might indicate opposite patterns with respect to current income (pro‐poor vs. pro‐rich inequalities). In such instances, the decomposition of the overall index I(V) in Equation (5) reveals whether inequality in expected future health outweighs that in the dispersion of future health prospects, or vice versa.5
Equation (5) further illustrates the respective roles and normative meaning of the income weights zi and quantile weights wq. As the income weights appear in IH‾ and ID, the implicit normative concern about how future health prospects vary with current income is similar for both sub‐components of the overall index. The quantile weights, instead, only appear in ID and do not matter for inequalities in expected future health; and thus determine the trade‐off between the two sub‐components of the overall index.
Both weights also determine the bounds of the overall index in Equation (4), as well as the bounds of the two components in Equation (5). For a health variable bounded between 0 and 1, such as in our empirical application, the overall index attains its maximum (minimum) value of 0.25 (− 0.25) when expected future health of all individuals above (below) the median income rank equals full (minimum) health. The bounds of the inequality index of expected health are the same as the overall index, whereas the inequality index for the dispersion of future health prospects ranges from − 0.0625 to 0.0625; the latter maximum is reached when the richest 50% of the population have certain future health and the poorest 50% of the population have a 50% chance of full health and 50% chance of zero health.6 These narrower bounds restrict the possible fraction of total inequalities that may be due to inequalities in the dispersion of future health prospects, and reflect the normative implications of linear weights for the trade‐off between inequalities in expected future health prospects and their dispersion.
Figure 2 provides a graphical illustration of our approach by adding individual risk to the hypothetical societies in Figure 1 such that individuals face two (out of three) possible future health levels with a non‐zero probability. There is no income‐related inequality in society 5a: even though the poor and rich individual face risky future health prospects, they face the same individual risk and hence there are no disparities across income. Society 5b depicts a similar situation but both individuals face lower dispersion in future health prospects. In societies 6, the poor and rich experience the same expected future health level, but face different dispersion in future health. In 6a, disparities are pro‐rich because the richer individual faces less dispersion, while the opposite pattern occurs in society 6b. In societies 7, expected health differs for the poor and rich individual. Therefore—based on expected future health—disparities are in favor of the rich in society 7a and in favor of the poor in society 7b. In both societies, rich and poor face the same dispersion of future health since we use the generalized Gini index which is a measure of absolute inequality: the health prospects of the rich individual can be obtained by adding (7a) or subtracting (7b) 0.5 units of health from the prospects of the poor individual. Thus, dispersion does not add to income‐related inequality in societies 7.
Hypothetical societies with individual health risk: Probability density functions.
While the linear income and quantile weights have been chosen to make the connection with well‐known indices in the literature—the generalized concentration index (linear income weights, Equation 1) and the generalized Gini index (linear quantile weights, Equation 3)—the framework is compatible with non‐linear weights (see Section 3.3.2 and appendix Appendix A). Non‐linear weights allow putting more or less weight on particular parts of the income distribution (Wagstaff 2002; Erreygers et al. 2012) and/or the distribution of future health prospects (Bleichrodt and van Doorslaer 2006). This has no implications for Equations (3), (4), (5), except for the third equality sign in Equation (3) and the second equality sign in Equation (5) which will no longer hold as the trade‐off between inequalities in expected future health and the dispersion of future health prospects depends on the functional form chosen for the quantile weights. Similarly, applying other functional forms for the weights will also lead to different ranges of possible fractions that the dispersion sub‐component can take as a part of the overall index.
Inequality Impact of Health Quantile Changes
3.3
This section discusses the index's response to (a) one individual experiencing a change in one particular health quantile; and (b) mean preserving transfers between different health quantiles of different individuals.
Changing One Health Quantile of One Individual
3.3.1
In case one individual experiences an increase in one quantile of her future health distribution, the sign of the income weight zi—that is whether the individual is relatively poor or rich—determines whether the inequality change is pro‐poor or pro‐rich, with more positive (negative) weights leading to larger inequality changes in favor of the rich (poor). The quantile weights do not affect the sign of the inequality change and only matter for its magnitude (as does the size of the health transfer). As quantile weights are positive and linearly declining with q, improvements in the worst possible future health outcomes will have a larger impact compared to improvements in already good possible future health outcomes of the same individual.
Mean‐Preserving Transfers
3.3.2
The impact of a mean‐preserving health transfer from a health quantile of one individual to a health quantile of another individual, or between health quantiles of the same individual, depends on the income and quantile weights of the involved individual(s) (and the size of the transfer). Transfers between health quantiles of the same individual (or between individuals with the same income) lead to more pro‐poor (pro‐rich) inequalities when the individual is poor (rich) and the transfer reduces the dispersion of the future health outcomes (i.e. Di is reduced). The opposite pattern occurs when the dispersion is increased. Health transfers between health quantiles of individuals with different incomes will generally be pro‐poor when health is donated from a health quantile of a richer individual to a health quantile of a poorer individual; while donations from a poorer to richer individual will generally be pro‐rich. However, while a health transfer from rich to poor always induces a pro‐poor change in a setting without risk,7 this does not necessarily translate to a situation with individual risk because the value placed on the health transfer may differ based on the quantiles involved. We discuss these exceptions, including potentially non‐linear income and quantile weights in appendix Appendix A.
Alternative Interpretation of the Index
3.4
The index in Equation (4) can also be obtained by first estimating income‐related inequalities across individuals for each health quantile IHq, and next obtaining the final index IV as a weighted sum of these quantile‐specific income‐related inequalities using the quantile weights:
Expressing the index in this format explicitly illustrates how inequalities in each quantile are valued differently depending on its location in the distribution. Given the restrictions imposed on wq, more weight is given to income‐related inequalities at lower health quantiles and lesser weight to inequalities in quantiles in the upper part of the health distributions. Equation (6) also reveals that the index incorporates individual, but not societal, risk as the index aggregates across quantiles and not “states of the world.” The index indeed considers how the covariance between the q‐th future health quantile and current income varies across quantiles; not on how the covariance between realized future health and current income varies across “states of the world.”
This alternative derivation can be graphically illustrated using the quantile functions (inverse distribution functions) of the risky health prospects faced by the currently rich and poor. Figure 3 repeats the hypothetical societies in Figure 2 using quantile functions rather than PDF's. For example, the second health tertile of the currently poor in society 6a equals 0, while that of the currently rich individual equals 0.5; hence inequalities in the second health tertile favor the rich. At tertile 3, inequalities favor the poor, while there are no income‐related disparities in the first tertile. The overall conclusion about the extent of disparities in risky future health prospects then depends on the importance given to the separate tertile‐specific disparities. In the context of risk aversion, more importance is given to the lower tertiles; and hence society 6a has pro‐rich disparities in risk. A similar reasoning can be applied to the other societies in Figure 3, and the resulting estimates of income‐related disparities will be identical to those obtained from the first calculation approach in Figure 2.
Hypothetical societies with individual health risk: Quantile functions.
Empirical Illustration
4
The overall inequality measure in Equation (4) assumes that the social planner is able to observe each individual's distribution of health prospects for some future period. In reality, however, the social planner will only be able to observe the realization of future health once individual risk is resolved. Thus, the empirical version of our ex‐ante approach needs to be predicted. To do this we can use the distribution of observed realizations for similar individuals, as defined by their observable characteristics, as an approximation of the health distribution individuals would have faced. We could also extrapolate into the future for individuals alive today based on the individual risk estimated for similar individuals in the past. This approach aligns with other papers that also estimate risk, such as Flores and O'Donnell (2016) who estimate exposure to the risk of catastrophic medical payment. Like Flores and O'Donnell (2016) we use quantile regressions conditioned on a set of covariates to predict individuals' future health distribution (e.g., Koenker and Bassett 1978). Since our objective is to predict each individual's health distribution based on their observable covariate set, it is the conditional and not the unconditional quantiles that are of interest here. These can be predicted using quantile regressions. Note that the covariates should be interpreted as predictors of an individual's future health distribution, and including potentially endogenous predictors still provides meaningful predictions for the social planner of the future health quantiles for each individual. If the social planner could observe additional important predictors of an individuals future health quantiles then the social planner would face less uncertainty and be better informed about the risk individuals face. While the data we use in our empirical example includes a rich set of predictors of future health prospects, one can not rule out that our estimates deviate from those that would be obtained under full information.
Data
4.1
We use the Household, Income and Labor Dynamics in Australia (HILDA) annual survey. HILDA is a household‐based panel study in Australia, which covers a large national representative sample of Australian households occupying private dwellings and includes a wide range of topics (Summerfield et al. 2014). Wave 1 (2001) consisted of 7682 households and 19,914 individuals and this was boosted in 2011 with a top up sample. Our illustration uses the sample who answered the full questionnaire in 2011 and considers their health prospects in 2019 including whether they were reported to have died before then.8 The income variable used in this study is the equivalized household income in 2011 which accounts for the number of adults and children in the household using the OECD equivalence scale.9 Our health measure is derived in terms of Quality Adjusted Life Year (QALY) weights from the SF6D and ranges from zero to one, where dead individuals are assigned a value of zero.10
The covariate set used in the predictive model includes individual characteristics in 2011: health (QALY weight), equivalized household income (expressed as the natural logarithm of 2019 Australian dollars in thousands), age (and age squared), sex, highest education qualification, unemployment status, marital status, smoking status, dummy for being a risky drinker, and immigrant status. Table 1 shows the descriptive statistics of these K covariates.
Predicting Future Health Prospects
4.2
The nature of the health variable has implications on how to predict future health prospects. In our application, we need to consider that health ranges from 0 to 1 where the minimum value 0 indicates death, but the minimum value observed conditional on survival is approximately 0.3. To account for the extreme outcome, death, and restrict the possible predicted health quantiles to fall between the bounds of 0.3 and 1 when they are predicted to be alive, we estimate a two‐part model (Duan et al. 1983) for health prospects in 2019 conditional on a set of initial (2011) characteristics xik.
The first part predicts the probability of being alive in 2019, (i.e., hi>0) using a standard logit:
To restrict the predicted health quantiles to lie within the bounds of 0.3 and 1 we use a logistic quantile regression conditional on survival (Bottai et al. 2010; Orsini and Bottai 2011). In practice, we transform the health outcome onto a continuous scale between positive and negative infinity11 using a logistic transformation ghi=lnhi−0.31.001−hi, and then use this transformed variable as the dependent variable in a linear quantile regressions (conditional on survival):
We estimate Equation (8) for q=0.01,0.02,…0.99,12 and re‐transform the predicted quantiles (on the continuous scale between negative and positive infinity) back onto the bounded scale as13 ^:^
These predictions are used jointly with the individuals' predicted mortality risk from the logit model, Pˆ(mortality)=1−pˆi=1/1+expαˆ+∑k=1Kαˆkxik to obtain the distribution of possible future health outcomes (including death). We generate an approximation of the predicted future health distribution by drawing 1000 observations for each individual from the predictions of the two parts of the model.14 By probability Pˆmortality=1−pˆi these draws are assigned the value of 0, and by probability Pˆalive=pˆi these are drawn from the predictions of the 99 quantiles in Equation (9). These draws are then ordered such that hˆi1≤hˆi2≤⋯≤hˆi1000 provide the predicted 1000 quantiles for each individual's future health prospects.
Age‐Standardizing Inequality in Health Prospects
4.3
To interpret inequalities in future health prospects, it is useful to complement the index I(V) with an age‐standardized version of the index that accounts for differences in the age structure of the population. Because age is by far the most important predictor of mortality (see Section 4.4.1), a non‐standardized index will be dominated by the variation of age across income.15
Assuming the Q quantiles for each individual i can be expressed as a linear function of each individual's characteristics in the initial period, one can use Q OLS regressions (one for each quantile) to estimate (ˆ suppressed to simplify notation)16
Substituting Equation (10) into the overall inequality index in Equation (4) yields
Following the approach in Wagstaff et al. (2003), age‐standardized inequality is then obtained as IV minus the contribution of age—which equals the product of the generalized concentration index of age, Iage, and a weighted sum of the age coefficients in each quantile 1/Q∑q=1Qwqβageq—and the contribution of age2 which is similarly defined. In the same fashion, one can remove the contribution of age from income‐related inequality in expected health and health dispersion (Equation 5) and quantile‐specific income related inequalities (Equation 6).
Equations (10) and (11) also inform on the impact of unobserved predictors on the value of the index. Adding an error term to the right hand side of Equation (10), representing the true deviation from the unknown distribution due to omission of unobservable predictors,17 shows that the impact of unobservable predictors will depend on the covariance between current income and the dispersion of the error term (generalized Gini across quantiles). Since this expression depends on the underlying data and the included set of predictors, its magnitude and sign, which ultimately determines the impact on the inequality ranking, can not be known a priori.18
Application to Income‐Related Health Inequalities Among Migrant Groups in Australia
4.4
Australia has a large share of inhabitants that were born overseas: in 2011 slightly more than 75% of the population was born in Australia and less than half of those born overseas originate from other English speaking countries (Table 1). The health and health inequalities in migrant groups versus those born in Australia is of particular public policy interest because migrants may face worse future health prospects due to language and cultural barriers (Jatrana et al. 2014). This, in addition to their reduced knowledge of the Australian healthcare system, may not only reduce their use of preventive healthcare services (e.g. screening programs) (Yeasmeen et al. 2020) but may also delay their use of acute healthcare services (Bhaskar et al. 2019). This is likely to expose them to more (individual) risk in their future health prospects. The Australian healthcare system operates as a mixed public‐private model where those with private insurance or willing or able to pay higher out‐of‐pocket costs can access healthcare with shorter wait times (Cheng 2014). This means that for migrants with higher incomes, these resources may help moderate the individual risk they face. Thus, understanding the income‐related health inequalities in future health prospects of different migrant groups compared to those born in Australia is of particular interest.
We predict future health prospects for all 12,833 individuals available in the 2011 wave of HILDA using the approach of Section 4.2. We then use these predictions to compare differences in income‐related inequalities in future health prospects across three sub‐populations: those born in Australia, those born overseas in a non‐English speaking country, and those born overseas in an English speaking country. As our main aim is empirical illustration of the new overall inequality measure in Equations (4), (5), (6), we use a simple approach: the predicted future health prospects are derived from one encompassing model for all 12,833 individuals, while the inequality estimates are calculated separately for each sub‐population using the approach from the previous section.
The estimates obtained from the encompassing model and the age‐standardized inequality results are presented in subsequent sections. We also graphically represent inequality as (1) penalising income‐related inequality in expected future health with income‐related inequality in the dispersion of future health (Equation 5), and as (2) the weighted sum of quantile‐specific income‐related inequalities (Equation 6).
Mortality & Quantile Regressions
4.4.1
A snapshot of the regression results underlying the inequality estimates is provided in Appendix Table A2. We show the logit regression results for mortality by 2019 and the estimated coefficients for a sample of the quantile regressions (for quantiles at 5%, 25%, 50%, 75%, 95%) for health conditional on survival in 2019.19 The results from these regressions are used to simulate the expected health quantiles for each individual (unconditional on survival) for 2019 considering both mortality and their health quantiles conditional on survival.
Income‐Related Inequality in Expected Future Health and the Dispersion of Future Health
4.4.2
We first consider, without age‐standardisation, how income (of 2011)‐related inequality in future health prospects in 2019 varies across the three migrant groups. Summary statistics for these three groups are presented in Appendix Table A3 and Table 2 shows that future health prospects are concentrated among the rich in all three sub‐populations, but most so among those born overseas in a non‐English speaking country. The estimated inequality levels in future health prospects are substantial, compared to the maximum inequality level of 0.25 and compared to the level of cross‐sectional inequality in 2011 (observed income and health levels in 2011) which was 0.0306, 0.0259 and 0.0270 for respectively those born in Australia, overseas English, and overseas non‐English.
Age‐standardized inequalities are also informative as age is the most important predictor of mortality. Once we standardize for age, the overall inequality in future health prospects almost halves as older individuals tend to be poorer and have both worse expected future health (inequality due to expected health in Table 2 reduces after age‐standardization) and higher dispersion in the distribution of future health prospects (age‐standardization reduces inequality due to health dispersion). Table 2 also depicts the decomposition into the inequality in expected future health and the inequality in health dispersion in accordance with Equation (5). Across all three sub‐populations and both before and after age‐standardization, inequality due to health dispersion contributes to overall inequality in future health prospects and thus exacerbates the level of overall inequality compared to if one only considered the inequality in expected future health. The exact magnitude of this contribution depends on the assumption of linear quantile (and income) weights (see Section 3.2), and would be different if non‐linear weights would be used. Nevertheless, the fact that health dispersion contributes to inequalities in total future health prospects illustrates the empirical relevance of our approach in the Australian migrant setting.
Figure 4a,b shed more light on how expected future health and health dispersion in 2019 vary by income rank in 2011. It shows expected future health and health dispersion predicted from Equation (10) after setting everyone's age equal to the average age of the entire Australian population (see Table 1). Since I(V), IH‾ and I(D) measure absolute inequalities, one should compare the slope (and not the height) of expected future health and health dispersion with current income rank across the three sub‐populations. In line with Table 2, the slope of expected future health is most positive for those born overseas in a non‐English speaking country meaning that good expected future health is most concentrated among the rich in this sub‐population. While this does not hold among the poorest 20% (here the slope is flatter for the non‐English overseas), it is more than compensated by the more positive slope among the richest 80%. Figure 4b further confirms that future health dispersion is concentrated among the poor, but less so among those born in Australia as its slope is less negative.
Age‐standardized expected future health and health dispersion by income rank (2019). Expected future health and health dispersion are calculated as in Equation (5) but evaluated at the average age of the entire Australian population in 2011. That is, substituting (10) into Equation (5) where age has been equalized to 43.03.
The overall index IV can also be interpreted as the weighted sum of quantile‐specific income‐related inequalities. Its age‐standardized version is obtained after combining Equations (6) and (10) and removing the contribution of age, that is 1Q∑q=1Qwq∑k=3KβkqIXk. Figure 5 illustrates how the level of age‐standardized income‐related inequality in each of the 1000 predicted future quantiles ∑k=3KβkqIXk varies across the quantiles, where q=1 is the worst and q=1000 the best quantile for all individuals in 2019. Across all three sub‐populations, the age‐standardized quantile‐specific inequalities approach zero for the worst quantiles indicating a somewhat equal distribution of the worst health outcomes as all income groups face some future chance of dying in all sub‐populations. As we move up the quantiles the inequalities rapidly increase with the poor on average having increasingly worse potential future health outcomes in these lower quantiles compared to the rich. Inequalities are highest around percentiles 5 to 10, and then start decreasing down to a level of around 0.1 in the highest quantiles (as there is some chance of good future outcomes in all income groups across all sub‐populations). Compared to the two other sub‐populations, the overseas non‐English have higher age‐standardized income‐related inequalities at almost each quantile. Despite the Australian born facing lower age‐standardized inequalities between percentiles 5 to 25 than the overseas English, overall they face higher age‐standardized inequalities in future health prospects (see also Table 2).
Age‐standardized inequality in prospective health outcomes per quantile. Quantile specific age‐standardized inequalities, measured as the generalized concentration index of each age‐standardized health quantile, is calculated following Equations (10) and (6), that is ∑k=3KβkqIXk.
We also explore the implications for income‐related inequality due to future health dispersion if the social planner could only observe a limited set of covariates to be used in the predictive model. We re‐estimated inequality due to future health dispersion along the lines of Equations (5), (6), (7), (8), (9), (10), (11) while excluding employment status, marital status, smoking status and alcohol status (and thus only including initial health, income, age, sex and education). We find only minor differences. For the age‐standardised results the income‐related inequality due to health dispersion is 0.0031 compared to 0.0032 for Australian born; 0.0046 versus 0.0037 for those born in an English speaking overseas country; and 0.0040 versus 0.0036 for those born in an non‐English speaking country. Importantly, the inequality ranking of the three sub‐populations is unaffected.
Discussion and Conclusion
5
This paper develops a framework to measure income‐related inequalities in risky future health prospects that considers not only inequalities in expected future health but also inequalities in the dispersion of individual's future health prospects. It complements existing approaches by integrating individual risk into the standard inequality measurement apparatus used by health economists.
We have then illustrated the usefulness of this framework by empirically considering differences in the inequality in future health prospects between three migrant sub‐populations in an Australian cohort. Our empirical study shows that poorer individuals are not only more likely to have worse health in the future, on average, but also more likely to face higher levels of dispersion in their future health prospects, thereby illustrating the importance of our approach. This result remains after standardizing for age. We also find that age‐standardized inequalities are highest among those born overseas in a non‐English speaking country and that the contribution of health dispersion is largest among those born overseas.
The overall inequality measure may be decomposed into inequalities in expected future health prospects and inequalities in the dispersion of the future health distribution. As the two components may evolve in opposite directions, we encourage empirical examination of both parts separately in addition to the overall index. It may, for example, be of importance for policy decisions whether the two parts of the index develop in the same or in opposite directions. The functional form of the quantile weights determines the implicit trade‐off between inequalities in expected future health and the dispersion of health. Future empirical applications may therefore also experiment with more flexible (non‐linear) weights.
This paper is, as far as we know, the first attempt to integrate individual risk into health inequality measurement. Our empirical approach is therefore primarily an illustration, and as such there is room for improvements. We used predictions (and not causal estimates) to estimate the conditional distribution of future health prospects and while this improves the accuracy of predicted future health prospects, it also means that age‐standardizing should not be given a causal interpretation; and rather be seen as a conditional association. A related point concerns omitted predictors in the quantile regressions. While our data has a rich set of covariates to predict future health prospects, clearly we do not observe all possible predictors. If the social planner had more observable characteristics with which to predict future health quantiles then the social planner would face less uncertainty and be better informed about how the individual risk individuals face varies by current income. The extent to which the additional information would impact direction and magnitude, and importantly, the ranking of the association between risk and current income can however not be known a priori. We therefore recommend checking the robustness of the inequality ranking across populations or time by re‐estimating the index with a different covariate set. We also applied the same overlapping model to predict future health prospects for all individuals in the three migrant groups; thereby imposing that the conditional associations between the predictors and respectively mortality and future health is the same in all three groups.
We have also imposed several assumptions which require scrutiny in future research. First, our approach focuses on inequalities in risky health prospects for one future point in time, and thereby neglects health dynamics and the risk in one's future stream of health. A natural future development would be to consider the dynamics of health inequalities in a longitudinal framework (Van Ourti et al. 2009; Allanson et al. 2010), and incorporate the expected stream of future health and the health risk associated with this stream of health (e.g. lifetime QALYs; duration analyses). Modeling these dynamics and assessing the related inequalities is more complex and also requires a long panel of rich individual data, and although we have such data at hand, these are in general rare. The fact that our measurement apparatus requires data at only two points in time therefore increases its usefulness considerably. However, estimating individual risk in future health prospects using observed differences in health across individuals does ignore the possible apriori risks associated with those states of the world that did not end up eventuating. Second, our framework considers how individual risk in future health is related to current income. A potential expansion of the framework would be to also acknowledge that also future income, and not only health, are uncertain. Future work accounting for uncertainty in income would likely have to leave the rank‐dependent framework and move into a framework allowing for flexible trade‐offs between uncertainty in income and health. Finally, our approach introduces individual risk into the measurement of income‐related health inequalities, capturing how distributions of risky future health prospects, faced by each individual, vary by current income. This ex‐ante approach could be replaced by ex‐post evaluation provided the empirical method to predict future health prospects captures aggregate, or societal, risk—the “states of the world”—such that the covariance between future realized health and current income would be allowed to differ between “states of the world.” We leave such an endeavor for future research.
Conflicts of Interest
The authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abásolo, I. , and A. Tsuchiya . 2020. “Comparing Aversions to Outcome Inequality and Social Risk in Health and Income: An Empirical Analysis Using Hypothetical Scenarios With Losses.” Health Economics 29, no. 1: 85–97. 10.1002/hec.3974.31702871 · doi ↗ · pubmed ↗
- 2Allais, M. 1979. “The Foundations of a Positive Theory of Choice Involving Risk and a Criticism of the Postulates and Axioms of the American School (1952).” In Expected Utility Hypotheses and the Allais Paradox: Contemporary Discussions of the Decisions Under Uncertainty With Allais’ Rejoinder, edited by M. Allais and O. Hagen , 27–145. Springer.
- 3Allanson, P. , U. G. Gerdtham , and D. Petrie . 2010. “Longitudinal Analysis of Income‐Related Health Inequality.” Journal of Health Economics 29, no. 1: 78–86. 10.1016/j.jhealeco.2009.10.005.19954852 · doi ↗ · pubmed ↗
- 4Allanson, P. , and D. Petrie . 2013. “On the Choice of Health Inequality Measure for the Longitudinal Analysis of Income‐Related Health Inequalities.” Health Economics 22, no. 3: 353–365. 10.1002/hec.2803.22368075 PMC 3599481 · doi ↗ · pubmed ↗
- 5Allanson, P. , and D. Petrie . 2021. “A Unified Framework to Account for Selective Mortality in Lifecycle Analyses of the Social Gradient in Health.” Health Economics 30, no. 9: 2230–2245. 10.1002/hec.4373.34173290 · doi ↗ · pubmed ↗
- 6Bhaskar, S. , P. Thomas , Q. Cheng , et al. 2019. “Trends in Acute Stroke Presentations to an Emergency Department: Implications for Specific Communities in Accessing Acute Stroke Care Services.” Postgraduate Medical Journal 95, no. 1123: 258–264. 10.1136/postgradmedj-2019-136413.31097575 · doi ↗ · pubmed ↗
- 7Bleichrodt, H. , K. I. Rohde , and T. Van Ourti . 2012. “An Experimental Test of the Concentration Index.” Journal of Health Economics 31, no. 1: 86–98. 10.1016/j.jhealeco.2011.12.003.22307035 PMC 4753067 · doi ↗ · pubmed ↗
- 8Bleichrodt, H. , and E. van Doorslaer . 2006. “A Welfare Economics Foundation for Health Inequality Measurement.” Journal of Health Economics 25, no. 5: 945–957. 10.1016/j.jhealeco.2006.01.002.16466818 · doi ↗ · pubmed ↗