Machine-learning detection of stress severity expressed on a continuous scale using acoustic, verbal, visual, and physiological data: lessons learned
Marketa Ciharova, Khadicha Amarti, Ward van Breda, Martin J. Gevonden, Sina Ghassemi, Annet Kleiboer, Christiaan H. Vinkers, Milou S. C. Sep, Sophia Trofimova, Alexander C. Cooper, Xianhua Peng, Mieke Schulte, Eirini Karyotaki, Pim Cuijpers, Heleen Riper

TL;DR
This study explores using machine learning with multiple data types to detect stress levels on a continuous scale, highlighting challenges in data quality and sample size.
Contribution
The paper introduces a preliminary exploration of multimodal machine learning for continuous stress severity detection in a lab setting.
Findings
The association between detected and observed stress scores was very weak (r2 = .154).
Classification performance was acceptable to good for the presentation task using combined features.
Large sample sizes and high-quality data are needed for reliable stress detection models.
Abstract
Early detection of elevated acute stress is necessary if we aim to reduce consequences associated with prolonged or recurrent stress exposure. Stress monitoring may be supported by valid and reliable machine-learning algorithms. However, investigation of algorithms detecting stress severity on a continuous scale is missing due to high demands on data quality for such analyses. Use of multimodal data, meaning data coming from multiple sources, might contribute to machine-learning stress severity detection. We aimed to detect laboratory-induced stress using multimodal data and identify challenges researchers may encounter when conducting a similar study. We conducted a preliminary exploration of performance of a machine-learning algorithm trained on multimodal data, namely visual, acoustic, verbal, and physiological features, in its ability to detect stress severity following a partially…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
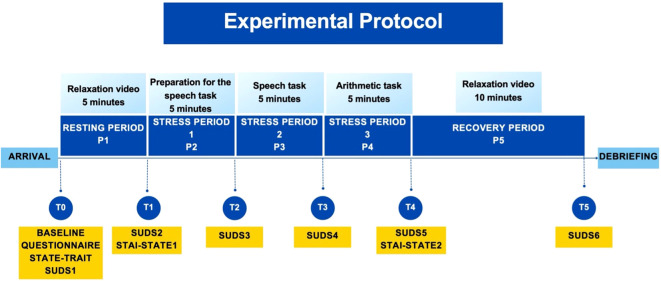 Figure 1
Figure 1| Period | r2 | r | p |
|---|---|---|---|
| Visual + Physiological | |||
| Period 1 | -1.452 | -.325 | .080 |
| Period 2 | -0.447 | -.084 | .652 |
| Period 3 | -0.374 | .075 | .689 |
| Period 4 | -0.667 | -.360 | .047 |
| Period 5 | -1.889 | -.212 | .280 |
| Visual + Acoustic + Verbal | |||
| Period 1 | -1.395 | -.296 | .112 |
| Period 2 | -1.544 | -.196 | .292 |
| Period 3 | 0.051 | .324 | .075 |
| Period 4 | -1.601 | -.597 | .000 |
| Period 5 | -1.891 | -.204 | .297 |
| Visual + Acoustic + Verbal + Physiological | |||
| Period 1 | -1.452 | -.325 | .080 |
| Period 2 | -0.447 | -.084 | .652 |
| Period 3 |
|
|
|
| Period 4 | -1.297 | -.436 | .014 |
| Period 5 | -1.889 | -.212 | .280 |
| Characteristics and Scores |
|
|---|---|
| Female | 29 (69%) |
| Born in the Netherlands | 40 (95%) |
|
| |
| Age (years) | 20.79 (2.12) |
| STAI-A-Trait (P0) | 19.69 (5.73) |
| STAI-A-State (P1) | 16.93 (4.18) |
| STAI-A-State (P4) | 21.08 (4.53) |
| SUDS (P0) | 28.10 (17.14) |
| SUDS (P1) | 21.79 (17.45) |
| SUDS (P2) | 47.95 (15.92) |
| SUDS (P3) | 43.95 (17.64) |
| SUDS (P4) | 36.05 (18.09) |
| SUDS (P5) | 22.00 (17.62) |
| Period | Accuracy | F1-score |
|---|---|---|
| Visual + Physiological | ||
| Period 2 | 0.452 | 0.564 |
| Period 3 | 0.516 | 0.571 |
| Period 4 | 0.419 | 0.100 |
| Visual + Acoustic + Verbal | ||
| Period 2 | 0.355 | 0.474 |
| Period 3 |
|
|
| Period 4 | 0.355 | 0.000 |
| Visual + Acoustic + Verbal + Physiological | ||
| Period 2 | 0.452 | 0.564 |
| Period 3 |
|
|
| Period 4 | 0.419 | 0.100 |
| Reported/predicted | Period 2 | Period 3 | Period 4 | |||
|---|---|---|---|---|---|---|
| Not stressed (predicted) | Stressed (predicted) | Not stressed (predicted) | Stressed (predicted) | Not stressed (predicted) | Stressed (predicted) | |
| Visual + Physiological | ||||||
| Not stressed (reported) | 3 | 8 | 6 | 8 | 12 | 8 |
| Stressed (reported) | 9 | 11 | 7 | 10 | 10 | 1 |
| Visual + Acoustic + Verbal | ||||||
| Not stressed (reported) | 2 | 9 | 10 | 4 | 11 | 9 |
| Stressed (reported) | 11 | 9 | 5 | 12 | 11 | 0 |
| Visual + Acoustic + Verbal + Physiological | ||||||
| Not stressed (reported) | 3 | 8 | 10 | 4 | 12 | 8 |
| Stressed (reported) | 9 | 11 | 6 | 11 | 10 | 1 |
- —Interreg North-West Europe 10.13039/100020362
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAnxiety, Depression, Psychometrics, Treatment, Cognitive Processes · Emotion and Mood Recognition · Heart Rate Variability and Autonomic Control
Introduction
1
Acute stress is considered an adaptive process preparing an individual for changes (1–3). However, in situations where the initial stress reaction is exaggerated (4) or where recovery from the initial stress response is delayed (5), stress may pose a strain on the organism (6). Repeated or prolonged exposure to situations causing acute stress over longer periods may lead to chronic stress, characterized by long-term alterations in the autonomic nervous system (ANS) and mental health (7). Such disruptions are a risk factor for many mental disorders and physical conditions, such as depression (8), anxiety (9), substance dependence (10), or cardiovascular diseases (11). Therefore, early detection of elevated acute stress is important for the prevention of its consequences (12).
Recently, theoretical breakthroughs in machine learning and increased computational capacity provided innovative opportunities for the detection and monitoring of stress and mental states (13, 14). Moreover, capturing biological and behavioral reactions to daily stress in the individual’s natural habitat and without extra effort, so-called passive sensing (15–17), has become easier thanks to digital devices, such as smartphones or sensory devices (18, 19). Stress detection using machine learning based on quantifiable passive-sensing data, such as electrocardiogram (ECG), facial expressions, or voice, suggests good detection potential (20–22), and has the advantage of providing real-time, objective information (23).
Most studies using passive sensing to date have detected stress dichotomously, meaning its presence or absence (24, 25), or categorically, meaning in three or more categories, such as no, low, and high stress (26, 27). Detection of stress severity on a continuous scale, rather than two or more categories, is still in its infancy. Yet, it is highly relevant for clinical practice, as it represents the nature of mental states better than categories, shows the variability among individuals and thus reflects their needs for prevention of psychopathology. Furthermore, such detection may contribute to tracking trends over time, as it captures not only simple presence or absence of the state, but also approaching or crossing over to the opposite state (28).
Thus far, very few studies have attempted to detect stress severity using machine-learning approaches based on passive-sensing data, such as heart rate or facial expressions. This may be related to barriers that need to be overcome if the detected variable, e.g., stress, is defined on a scale, rather than categorically. First, we need more detailed information about the individuals’ stress experience (29). Moreover, to acquire such detailed information, reliable and valid sensors able to distinguish subtle differences between individuals and changes over time are necessary (30). The acquired data may also be influenced by additional factors, not solely the experience of stress itself, which may hamper the interpretation. For example, an important source of variance for physiological measures, such as heart rate variability, are physical demands related to postural change, locomotion, or speech production (31). Finally, more fine-grained machine-learning approaches such as continuous stress severity detection require richer data compared to coarser approaches such as dichotomous detection (32). However, data used for machine-learning detection of mental states is often compromised by noisiness and missing information, especially in uncontrolled settings in daily life (33).
Available research on continuous stress severity detection has so far been very rare and did not provide evidence related to acute stress. (34) invited actors to mimic basic emotions, their photos were evaluated by psychologists on a scale ranging from “non-stressed” to “very stressed”, and a score on the same scale was detected by an algorithm. The relationship between the score assigned by the psychologist and the one detected by the algorithm was strong, namely *r^2^
- = .98 (35). However, mimicked emotions may be exaggerated and thus more easily recognizable than experienced acute stress (36). Another study (37) investigated a more clinical research question, namely chronic stress detection. The authors’ algorithm detected severity of self-reported chronic stress using ECG data in expectant mothers well, with a strong relationship between the detected and self-reported scores (*r^2^
- = .94). Nevertheless, as mentioned above, chronic stress manifests differently than acute stress in physiological reactions (38). Furthermore, encouraging results come from research into conditions related to stress, such as anxiety. For example, (39) predicted public speaking anxiety based on visual and acoustic data in participants who were presenting to a virtual audience, and who were subsequently trained on presenting skills, in order to present again, applying these newly-acquired skills. Anxiety was predicted with a strong relationship (*r^2^
- = .825). Hence, the abovementioned studies may serve as a base for research into acute stress severity detection. Yet, it is obvious that they cannot provide us with sufficient evidence of performance of machine-learning algorithms in stress severity detection based on passive sensing data, and more investigation is thus necessary.
Some barriers related to detecting stress severity on a continuous scale may be overcome by using a combination of data sources, such as a camera, audio recorder, and physiological sensors. Such “multimodal data” may make continuous detection more robust. First, it is not affected as much by loss in a single modality, such as background noise in voice recording, or occlusion of the face in a video, as such loss may be complemented by other data, collected from other sources (33, 40). Second, stress is a multifaceted phenomenon influencing the natural behavior of an individual, such as their voice intonations (41) or facial expressions (42), as well as their physiology (24). Therefore, multimodal data may provide a more comprehensive and holistic input (43), enhancing thus passive sensing detection in comparison to individual modalities (44).
Multimodal stress detection using passive-sensing data have applications in public health (e.g., prevention of stress-related disorders) and clinical fields, for diagnosis and to guide treatment (33, 45). When used in real-time symptom monitoring, it may show how severity of stress decreases or increases, and thus provide actionable insights to users, such as to prompt them to try to reduce stress, for example, with relaxation or breathing exercises (46). It may also capture exaggerated stress reactions or delayed recovery from stress, potentially indicating unhealthy stress responses (4, 5). Consequently, it may contribute to the indication of when to prevent an onset of a problem, when to early intervene, help understanding treatment progress, and tailor stress management strategies (47). Moreover, multimodal passive sensing may reveal (unhealthy) stress reactions before the individual is aware of them (48). It could also help exploring everyday manifestation of stress (49), and eventually lead to the identification of stress “markers”, contributing to its distinction from other mental health concepts, such as depression or anxiety (50). Multimodal passive-sensing machine-learning detection of stress severity may, if found reliable and valid, complement other valid and reliable, but more retrospective and subjective manners of stress detection, such as self-report of stressful life events and their emotional consequences (51) and ecological momentary assessment (EMA) data (52). It may also be integrated in a stress assessment together with more resource-demanding physiological measures, such as neuroendocrine (e.g., cortisol) and inflammatory markers (53, 54). Therefore, more investigation is needed.
In the current study, we aimed to explore the potential of acute stress detection based on multimodal passive-sensing data, namely acoustic (i.e., physical properties of sound), verbal (i.e., content of speech), visual (i.e., facial expressions) and physiological (i.e., ECG, electrodermal activity, and motility). We aimed to test, in a laboratory setting, whether it could detect acute stress severity indexed as a continuous score on a self-report acute stress measure. We hypothesized that we would find a significant relationship between the self-reported scores and score detected by the algorithm. Furthermore, we aimed to inform on challenges associated with this novel field of research.
Materials and methods
2
The current study was conducted as part of the IT4Anxiety project (55). This project aimed to connect research institutions to small and medium enterprises (i.e., start-ups) developing digital products, aiming at the prevention and treatment of anxiety and post-traumatic stress disorder (PTSD). The goal of the project was to provide a framework for collaboration in these sectors and thus help both to access the expertise the other sector possesses. The current project originated from the collaboration between Vrije Universiteit (VU) Amsterdam, its spin-off VU-Ambulatory Monitoring Solutions (VU-AMS), which developed an ambulatory monitoring system for the measurement of autonomic nervous system (ANS) activity, and the start-up Sentimentics, focused on development of machine-learning algorithms for detection of mental states. Given the multidisciplinary nature of the current study, we provide a glossary of terms used in the current text in Appendix A.
The protocol for the current study was preregistered at the Open Science Framework (https://osf.io/w3kh6; see Appendix B for differences between the protocol and the final manuscript). The experimental procedure was approved by the Scientific and Ethical Review Board of the Vrije Universiteit Amsterdam (VCWE, protocol number: VCWE-2022-110).
Sample size calculation
2.1
Currently, no definitive guidelines exist for power calculation in mental state detection studies. Previous studies recommended to recruit at least 100 participants to achieve satisfactory sensitivity when training and testing a prediction algorithm (56, 57). Thus, we also aimed to recruit 100 participants.
Participants
2.2
Participants were students of the VU Amsterdam, the Netherlands. They were informed about the study and recruited using SONA, a system for students who want to participate in experiments to gain study credits. Any Dutch-speaking student older than 18 years who provided informed consent was eligible for participation. No other exclusion criteria were applied.
Design and procedure
2.3
The participants took part in a laboratory experiment. They were informed that the experiment investigated the relationship between emotions and physical reactions. Upon their arrival to the laboratory, the experimenter welcomed the participants, who then signed the informed consent. They learned that their participation was voluntary, they could withdraw at any time, and how the data would be handled. The information letter and the informed consent were provided already when the participant signed up for the study, allowing thus sufficient time to the participant to reflect on their participation. After signing the informed consent, the participant was invited to sit in a cubicle, equipped with a computer, on which the whole experiment was completed. A graphic overview of the experimental protocol can be found in Figure 1, while a table with a point-by-point description of all experimental periods and pictures of the solutions used is in Appendix C.
Overview of the experimental protocol.
The experiment covered the following periods (P0 – P5) of the Trier Social Stress Test (TSST) (58, 59): Welcoming of the participant to the laboratory and baseline questionnaire assessment (P0), resting period (P1), preparation for presentation (P2), presentation (P3), arithmetic task (P4), and recovery period (P5). Self-report assessments (T0 - T5) took place after each period (i.e., for example, assessment T1 took place after period P1). The experimenter was not present in periods P1, P2, and P5, but he or she was present in periods P3 and P4, when joining an online videocall from another part of the laboratory (see explanation for periods P2 – P4). Audio, video, and physiology of the participant were recorded during the whole duration of the experiment.
P1 (5 minutes) served to allow the participants’ physiological and emotional responses to stabilize (60). Five minutes were chosen as they are needed for the heart rate to return to a normal level after stress (61), and longer periods were considered frustrating by participants of our pilot study. The TSST instructions do not specify a validated activity for the resting period of TSST, only suggest emotionally neutral activities or reading. To ensure participants’ focus on the screen and to uniformly deliver the resting period activity, we decided to show a video of islands, which was found to be relaxing in a previous stress-inducing laboratory experiment (62).
In P2-P4, the stress-inducing periods of TSST was administered. This was done in its validated, online version, over a Zoom™ (version 5.16.2) call (63), together with the experimenter. TSST requires a committee of at least 2 interviewers, other than the experimenter, to be present (60). Therefore, also 2 interviewers seemingly joined the call. However, to decrease resource demands, the 2 interviewers were pre-recorded, an approach which increased stress in participants of previous similar studies (64–68). Participants were not informed that the interviewers were pre-recorded. The interviewers were one male and one female professional actor (60, 63) who provided scripted instructions to the participant throughout the TSST. The role of the experimenter was to answer questions of the participant, if there were any, create additional stress in case the participants discovered the real nature of the interviewers, and to interact with the pre-recorded interviewers in a way that suggested that they were attending live (69). The script of the TSST followed its validated protocol as well as its online version (58, 59, 63), in the Dutch translation used in previous research (68, 70).
In P2 (preparation for presentation; 5 minutes), the participant received instructions to prepare for P3, in which they had to deliver a presentation about their strengths and weaknesses as part of an interview for their ideal job. They were informed that their performance would be recorded and analyzed. They could use a notepad, which opened for the duration of P2, but which closed as soon as P2 finished. For this period, the interviewers and the experimenter switched their cameras off, and the participant was informed that they were not being watched. In P3 (presentation; 5 minutes), the participant had to deliver their presentation. The interviewers and the experimenter appeared on the screen, now dressed in lab coats. If the participant stopped speaking for more than 20 seconds, the experimenter prompted them to continue speaking. In P4 (arithmetic task; 5 minutes), the participant was instructed to subtract 13 from 1022. If they made a mistake, the experimenter asked the participant to start over from 1022. If the participant stopped speaking for more than 20 seconds, the experimenter again prompted them to continue. Finally, before P5 (10 minutes; recovery period), the video call ended, and the participant watched another relaxing video of islands.
After P5, participants were debriefed. They were informed that no analysis of their speech or math performance was conducted, that the tasks were difficult and did not reflect on the participants’ aptitude or abilities.
Materials
2.4
Baseline characteristics
2.4.1
Participants were asked about their socio-demographic characteristics (for example, age, gender, and level of education) as well as features potentially influencing stress reactions (e.g., use of medication and relaxation techniques, or mental and physical disorders).
Stress
2.4.2
A visual analogue scale (VAS) called Subjective Units of Distress Scale (SUDS) (71) was used to assess stress at T0 – T5 (i.e., before and after P1-P5). VAS has been chosen as the main outcome of the current study, as it is the recommended and validated stress measure in TSST (58, 59). It is also more feasible for repeated administration than other, more comprehensive stress measures, as it consists of only one question (“How do you feel according to the following scale?”), which can be answered on an 11-point scale, ranging from “0” (“Totally relaxed”) to “100” (“Highest distress/fear/anxiety/discomfort that you have ever felt”). The score may be further categorized into “noticeable, but not bothersome anxiety” (SUDS > 25), “bothersome anxiety” (SUDS > 50), and “very bothersome anxiety” (SUDS > 75) (72, 73). It has good psychometric properties, for example concurrent validity with stress measures (Spearman rho = .50, p <.001) (74) and clinician’s rating of general functioning (r = -.44, p <.001) (75). The SUDS has been translated into Dutch using a back-translation method recommended by the World Health Organization (76).
State and trait anxiety
2.4.3
State and Trait Anxiety Inventory-Alternate Form (STAI-A) (77) was administered in its Dutch version (78). STAI-A is a shorter version of the State and Trait Anxiety Inventory (STAI) (79) and introduces 10 questions focused on state and 10 on trait anxiety. The total scores can then be categorized according to respective norms into low (below the 25. percentile), high (above the 75. percentile), and normal levels of anxiety (80). STAI-A has been found to be a reliable instrument (α = .80), with results equivalent to the full version of the STAI (77). The Trait subscale was administered at T0, the first State subscale at T1, and the second State subscale at T4.
Audio and video
2.4.4
A video camera (Canon, Legria HF R86, 10 ADP, 1920x1080, 50 frames per second, 35 mbps, Dolby Digital 2ch) was used to record audio and video data. It was located below the computer screen on which the participant followed the experiment, and it was focused on the participant from their shoulders up.
Visual features
2.4.4.1
Fifty-seven visual features were extracted: 17 action units (meaning the fundamental actions of individual muscles of the face (81)), 32 parameters of the Point Distribution Model (PDM) capturing facial landmark shape variations and changes (82), and 8 parameters of the eye gaze direction. For a detailed explanation of these parameters, please see the original study on OpenFace 2.0, the software used in the current analysis (83). Visual features were extracted for all periods of the experiment, i.e., P1 – P5. As the features had to be aggregated across each of these periods, the following parameters were created for each feature: mean (M), median (Med), standard deviation (SD), minimum (MIN), maximum (MAX), skewness, kurtosis, slope, offset, and curvature of fitting a second-degree polynomial to capture temporal patterns. As a result, 570 parameters were extracted for visual features.
Acoustic features
2.4.4.2
There were 79 acoustic features related to pitch intensity and frequency, formant frequency and bandwidth, harmonic to noise ratio, zero crossing rate, Mel Frequency Cepstral Coefficients (MFCC), Linear Frequency Cepstral Coefficients (LFCC), and other parameters which capture spectral properties of audio (see Appendix D for explanations). These features were estimated for P3 and 4, i.e., the two periods in which the participants spoke. We used the same 10 aggregation methods applied to the visual features (see above), resulting in a total of 790 audio features.
Verbal features
2.4.4.3
The experiment took place in the Dutch language. The content of participants’ speech was automatically transcribed using Speech-to-Text API with a guaranteed 85% accuracy (84) and manually corrected for mistakes by a researcher, a methodology previously recommended (85, 86). The transcripts were then processed: punctuations and stop words were removed, and words were lemmatized (i.e., returned to their dictionary form). Verbal features were extracted using Bag of Words method, where the most common words are counted and used as verbal features. To encourage generalization, a word was considered if it appeared in at least three transcripts. Verbal features were extracted for P3 (64 words) and P4 (22 words), in which participants had to speak.
Physiological measures
2.4.5
Physiological data were recorded using the VU-AMS (version 5-wire 5fs) (87), a lightweight, portable ambulatory monitoring system for the non-invasive measurement of ANS activity. It records a continuous electro- and impedance cardiogram (ECG/ICG), electrodermal activity (EDA), and accelerometry signal. The ECG and ICG signal was acquired at 1000 Hz using 5 ECG electrodes (Kendall H98SG, Medtronic, Eindhoven, Netherlands) located on the chest and back of the participant (87, 88). The EDA signal was measured at 10 Hz using an EDA electrode (Type 10-W 55 GS, Movisens GmbH, Karlsruhe, Germany) placed on the thenar eminence of the non-dominant hand, and an ECG electrode on the lower arm. Participant movement was detected through a triaxial accelerometer placed on the table, so that postural changes would shift the sensor through pull on the cables but prevent loss of signal due to fall or disconnection of the device.
Physiological features
2.4.5.1
First, data were preprocessed and the signals visually inspected for noise, ectopic beats, and misplacement of R-peaks in the ECG and B- and X-points in the ICG. Then each feature was calculated using Vrije Universiteit Data Acquisition and Management Software (Version 5.4.20) for every period of interest, i.e., P1 – P5. Similarly to the visual features, the features had to be aggregated across each of these periods. Thus, where applicable, M, MIN, MAX and/or SD were used. In total, 31 parameters were extracted for each period. A more detailed overview and explanation of physiological features used in the current study can be found in Appendix E.
Analyses
2.5
Descriptive analyses were conducted in IBM SPSS Statistics (version 27). The model fitting and prediction were performed using Python 3.6 for programming, using the following libraries: OpenFace 2.0 facial behavior analysis toolkit (83), and librosa (89) for the extraction of the visual, and acoustic features, respectively. Verbal features were extracted, and regression, classification and cross-validation were conducted in SKlearn (90).
All visual, acoustic, verbal, and physiological features for each participant were concatenated and fed into the model to detect stress severity at each of the measurement time points (T1 – T5). Data from each period were used to detect stress severity at the following time point, for example, data collected during period P1 (i.e., between the time points T0 and T1) were used to detect stress severity as assessed by the SUDS at T1. Separate analyses for each period are recommended because the TSST structure is divided into five distinct phases. Each phase is designed to elicit unique stress responses that capture the temporal dynamics of stress (61).
To assess the additive predictive power of each set of features, three different combinations of groups of features were used (1): visual + physiological features (2), visual + acoustic + verbal features, and (5) visual + acoustic + verbal + physiological features. A leave-one-out cross-validation was applied to the model, where in each iteration, data of one participant were placed aside, the rest of the data was used for the training of the model, and the resulting model was used for prediction of the stress level in the left-out participant (91). A feature selection was used, where for each iteration, 30 features with the most significant correlation with the self-reported stress severity were used in the model (meaning that not all extracted features were used for final stress detection). To avoid data leakage and ensure reliability of the results, this was also done in the training set of each iteration of cross-fold validation, meaning that different features could be selected in different iterations (92). The aim of feature selection was to prevent overfitting due to the large number of features and the small number of participants (93). Subsequently, stress levels were predicted as a continuous variable, meaning predicting a specific score on the SUDS scale, using Bayesian Ridge regression, as this linear model with a minimum number of hyper-parameters suits small datasets (94, 95). Details of the used algorithm are described in (96). This algorithm has been shown to outperform other state-of-the-art methods, and to enable feature extraction process and a novel temporal aggregation method with no initial data annotations. Additionally, it has been proposed as suitable for small sample sizes (96).
The coefficient of determination (*R^2^ *) was calculated, where values can be interpreted as strong (>.75), moderate (.5 -.75), weak (.25 -.5), or no (<.25) relationship between the predicted and the observed scores (35). We also calculated correlations (Pearson’s r) between all features and stress at T1 through T5 to provide per-parameter descriptive information to the reader. Pearson’s r may be interpreted as small, medium, or large effect for r = .10,.30, and.50, respectively (97).
Results
3
Participant characteristics
3.1
According to our preregistered protocol, we aimed at recruiting 100 participants. However, we failed due to restrictions caused the COVID-19 pandemic, which postponed the recruitment and thus caused time constraints. Eventually, recruitment was conducted between March and June 2023.
Forty-six participants joined the study, but due to technical problems in the experiment, data for only 42 participants were available. Data for some participants were only partially available, due to software issues causing some of the parts of the experiment not to start or close prematurely. Subsequently, data for 28–31 participants were available for each period (Table 1). All participants were bachelor students, most were female (69%), born in the Netherlands (95%), and did a major in psychology (88%) (Table 2).
The average scores on STAI-A-Trait and -State before and after the TSST fell into the category of normal anxiety (Table 2). The SUDS ratings, on average, ranged from minimal distress at P1 (i.e., during the resting period) to moderate distress at P2 (i.e., during the preparation for presentation). There was a visible increase in stress in P2, when the participants entered the video call, which was then slightly decreasing over the stress periods (P3-4) and eventually decreased again in the recovery period (P5).
Predicting stress as a continuous variable (regression)
3.2
When stress was measured on a continuous scale, the algorithm did not predict stress severity well in most combinations of features and time periods (Table 1). However, it predicted stress severity at P3 when all features, i.e., visual, acoustic, verbal, and physiological, were used (*r^2^
- = .154; p = .021). Still, it points to a very weak association between the predicted and observed scores.
Post-hoc analysis: predicting stress as a dichotomous variable (classification)
3.3
Since the prediction model could not fully detect patterns in the features, we also conducted a post-hoc analysis to simplify the modeling process (98). In this analysis, we treated stress as a dichotomous variable, meaning a stressed (i.e., “bothersome anxiety”, SUDS > 50) and a non-stressed group (SUDS < 50) (72, 73). We did so for P2 and P3, where higher variability of stress among participants was present. Logistic regression was conducted, and F1-measure and accuracy were computed. F1-measure ranges between 0 and 1, and its values may be evaluated as very good (>.9), good (.8 -.9), acceptable (.5 -.8), or poor (<.5) (99), where values approaching to 1 express the best trade-off between precision and sensitivity (100). Levels of accuracy also range between 0 and 1, and have been categorized as very good (>.9), good (.7 -.9), acceptable (.6 -.7), or poor (<.6) (101).
Classification results are shown in Table 3, the confusion matrix (i.e., table reporting numbers of true positives, false negatives, false positives and true negatives) is in Table 4. The algorithm reached acceptable to good performance in two cases at P3: when all but physiological (accuracy = .710, F1-score = .727) or all features (accuracy = .677, F1-score = .688) were combined.
Correlations between visual, audio, and physiological features, and stress
3.4
Appendix F shows correlations between tested features and stress. Correlations for visual features with stress at P1-P5 can be found in Supplementary Table S1, correlations between acoustic features with stress at P3 and 4 are in Supplementary Table S2, verbal features for P3 and 4 are shown in Supplementary Tables S3 and Supplementary Tables S4, respectively. Supplementary Table S5 demonstrates correlations between physiological features and stress in P1 through 5.
Discussion
4
This study explored the potential of using multimodal data collected in a laboratory setting through passive sensing for machine-learning detection of self-reported acute stress severity expressed on a continuous scale. The best algorithm performance was a weak relationship between the detected and observed score (*r^2^
- = .154), when features of all modalities, meaning visual, acoustic, verbal, and physiological, were included, in the period when participants were giving a presentation. We also conducted a post-hoc analysis, in which we classified participants as stressed and non-stressed. The performance of the algorithm was then acceptable to good (accuracy up to.71) during the presentation period when using all or almost all modalities. All significant detection of stress thus took place during the presentation period, when data from all modalities could be collected. Moreover, during this period, the verbal modality provided a high variability of possible input, depending on the words the participant used, as opposed to the arithmetic task, where the participants’ speech was restricted. Moreover, we could see that combination of data from multiple modalities showed better performance than combinations of fewer data sources. In the continuous prediction, physiological features, when added to the detection, helped improve algorithm performance. However, this difference was not apparent in the post-hoc analysis (i.e., dichotomous classification) anymore.
The current study cannot be compared to previous research, as it is the first exploring the potential of continuous detection of stress by machine-learning models based on multimodal data. Evidence from the two studies attempting to detect mimicked or chronic stress (34, 37), as well as severity of conditions related to stress, such as anxiety or post-traumatic stress disorder (PTSD), suggests that moderate to strong relationship between detected and observed scores is possible even if stress is expressed on a continuous scale (39, 43, 102, 103). In the current study, we did not find such a strong relationship, which may be caused by a different outcome variable of interest than in these previous studies. Moreover, most of these studies focused on anxiety or PTSD in the community (102, 103) or clinical settings (43), thus further hampering the comparison.
Comparison between our results and previous research may thus be only based on the post-hoc dichotomous prediction, which we conducted when it became clear that our sample size prevented the algorithm from recognizing patterns in the data. Some studies used multimodal data for dichotomous detection of acute stress induced in laboratory experiments (62) used a combination of video (capturing movements, e.g., symmetry, and behavior, e.g., gestures), ECG, EDA, and foot trembling, for detection with very good performance (i.e., accuracy of up to 1) (101). 104 reported good performance (accuracy = .85) (101) when applying features related to voice, facial expressions, and ECG data. That is slightly better than detection in our post-hoc analysis, where we reached acceptable to good prediction (i.e., accuracy up to.71). The reasons for this discrepancy may be that statistical power in both studies was higher than ours due to bigger sample sizes. Even though neither of these studies recruited more participants than our study did (n = 21, and n = 20, respectively), in both studies, data from all conditions were merged in the analysis, meaning that one participant contributed to more data points, resulting thus in larger datasets (n = 108, and n = 1271, respectively). Their approach, however, does not express the temporal dynamics of stress which we aimed to reflect in our analysis by analyzing each period of the experiment separately (61).
From a methodological perspective, our study is innovative and explores potential improvements to laboratory experiment methods. To the best of our knowledge, it is the first study incorporating pre-recorded interviewers into a validated Zoom™ version of the TSST protocol (63). Although the interviewers were pre-recorded, reported stress among participants increased when they entered the video call. Thus, this method might be a viable solution to diminish resource demands of the online TSST in future studies (65, 67). In addition, the resting and recovery periods are not specified nor standardized in the TSST protocol (58, 59). We aimed at standardization by applying a method previously successfully inducing relaxation in another study applying a laboratory stress experiment (62). Finally, the results were based on long periods of time (i.e., 5–10 minutes), allowing thus more reliable estimates of stress severity, as longer recordings were suggested for precise stress detection (105).
Limitations need to be acknowledged as well. First and foremost, the combination of a small sample with the complexity of input features limited our predictive power. Larger samples are thus required to build more robust algorithms. Nevertheless, to handle this problem, we applied simpler machine-learning models, and we used feature selection to choose 30 features with the most significant correlation with the self-reported stress severity to balance it with the number of participants in our dataset. Additionally, to validate the performance, we performed a leave-one-out cross-validation. Furthermore, we added a post-hoc analysis, formulating the research question as a dichotomous problem. In this analysis, the algorithm’s performance was good, meaning that predictive power was present. Second, the generalizability of the results to natural behavior, ecologically valid or clinical contexts may be hampered, as the current study took place in a controlled, laboratory setting. Similarly, the results are limited to our sample, which mostly consisted of Netherlands-born female psychology students, thus potentially introducing selection bias. Third, the observed and detected stress in the current study was only artificially induced. Hence, caution must be taken when drawing conclusions about naturally occurring stress. Fourth, one of the included modalities were physiological data, which were observed not to have a strong relationship with self-reported stress (106). However, we deemed it still of importance to include it. While physiological data are objective markers of stress, capturing the body’s ANS activity, self-reported stress is of a subjective nature, showing stress awareness. These two pieces of information, also together with data from other modalities, such as video and audio, thus provide a more holistic picture of the individual’s stress experience. We also conducted an analysis excluding physiological measures, which did not affect the detection of stress in both main (continuous) and post-hoc (dichotomous) analysis. In the continuous analysis, it also seemed that physiological features contributed to the algorithm’s performance, as only combination of all modalities provided significant detection. However, this improvement disappeared in the post-hoc analysis, rendering thus physiological features to be the best candidates for exclusion. Finally, we used a unified relaxation method during resting and recovery periods, we thus did not let the participants simply sit in the waiting room as the protocol suggests. We also applied pre-recorded instead of in-person interviewers to provide instructions. Furthermore, we asked the participants to be seated during the whole duration of the experiment, as we needed to avoid noisiness or loss of data due to unnecessary movement, which is not uncommon in virtual versions of the TSST. However, these facts should be taken into account when interpreting our results (107).
Future research should focus on acquiring sufficient training data for multimodal algorithms, with a good “ground truth”, meaning a gold standard measure, such as a diagnostic interview or a validated self-report instrument (36), and a lot of variability (108). Currently, there has been a sharp increase in machine-learning algorithm development, and these methods keep evolving fast (109). Acquiring sufficient, rich training data may thus also help applying newer algorithms with better performance, something that was not feasible in the current study. Further laboratory experiments should include participants coming from both general and clinical populations. Then, it will be beneficial to relocate the research community’s attention towards real-life situations, such as daily stress monitoring in general populations, workplace settings or mental health care patients. Moreover, attitudes of professionals and patients towards usage of machine-learning algorithms for mental health will have to be explored through both qualitative and quantitative (user) research, as adoption of new technologies may be accompanied with reluctance, e.g., due to privacy issues (110). Finally, it is crucial to consider ethical aspects of research on machine-learning monitoring of mental states based on natural behavior, as such results may be, in extreme cases, used for privacy and human right violations (111).
Even if some results seem promising, we are currently very far from public health or clinical implementation. Only after thorough investigation, it may be explored whether validated stress detection measures may be complemented by real-time machine-learning algorithms based on multimodal data acquired through passive sensing. Low threshold and self-monitoring of daily stress in general populations may then contribute to prevention or early intervention efforts, even in situations where the individual is not yet ready to verbalize their experience. Successful measurement of severity may contribute to measurement of stress dynamics over time as well. As stress is a transdiagnostic concept, measuring of its severity, and especially delayed recovery from stress reactions, may help us detect the right moment for early intervention for potential consequences of chronic stress, such as burnout or depression. Later on, such detection may become an integrated component of digital interventions where real-time assessment is necessary or highly desirable, such as in just-in-time adaptive interventions for mental disorders (112, 113).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Selye H. The stress syndrome. AJN Am J Nursing. (1965) 65:97–9.5175587 · pubmed ↗
- 2Hoffman-Goetz L Pedersen BK. Exercise and the immune system: a model of the stress response? Immunol Today. (1994) 15:382–7.10.1016/0167-5699(94)90177-57916952 · doi ↗ · pubmed ↗
- 3Mc Ewen B. Stress: Homeostasis, rheostasis, reactive scope, allostasis and allostatic load. In: Reference module in neurosciene and biobehavioral psychology. Amsterdam, the Netherlands: Elsevier (2017).
- 4Turner AI Smyth N Hall SJ Torres SJ Hussein M Jayasinghe SU. Psychological stress reactivity and future health and disease outcomes: A systematic review of prospective evidence. Psychoneuroendocrinology. (2020) 114:104599. doi: 10.1016/j.psyneuen.2020.104599 32045797 · doi ↗ · pubmed ↗
- 5De Calheiros Velozo J Lafit G Viechtbauer Wvan Amelsvoort T Schruers K Marcelis M. Delayed affective recovery to daily-life stressors signals a risk for depression. J Affect Disord. (2023) 320:499–506. doi: 10.1016/j.jad.2022.09.136 36208689 · doi ↗ · pubmed ↗
- 6Nesse RM Young EA. Evolutionary origins and functions of the stress response. Encyclopedia stress. (2000) 2:79–84. doi: 10.1016/B 978-012373947-6.00150-1 · doi ↗
- 7Rohleder N. Stress and inflammation–The need to address the gap in the transition between acute and chronic stress effects. Psychoneuroendocrinology. (2019) 105:164–71. doi: 10.1016/j.psyneuen.2019.02.021 30826163 · doi ↗ · pubmed ↗
- 8Hammen CL. Stress and depression: old questions, new approaches. Curr Opin Psychol. (2015) 4:80–5. doi: 10.1016/j.copsyc.2014.12.024 · doi ↗