Metric scale non-fixed obstacles distance estimation using a 3D map and a monocular camera
Daijiro Higashi, Naoki Fukuta, Tsuyoshi Tasaki

TL;DR
This paper improves distance estimation for non-fixed obstacles in autonomous driving using a new loss function called DifSeg with a monocular camera and 3D map.
Contribution
A novel loss function, DifSeg, is introduced to enhance distance estimation accuracy for non-fixed obstacles in autonomous driving systems.
Findings
DifSeg improved distance estimation accuracy across CARLA, KITTI, and an indoor dataset.
On KITTI, the method reduced distance estimation error by 2.14 m compared to the latest monocular depth estimation method.
The new approach focuses training on non-fixed obstacles, addressing a key limitation of previous methods.
Abstract
Obstacle avoidance is important for autonomous driving. Metric scale obstacle detection using a monocular camera for obstacle avoidance has been studied. In this study, metric scale obstacle detection means detecting obstacles and measuring the distance to them with a metric scale. We have already developed PMOD-Net, which realizes metric scale obstacle detection by using a monocular camera and a 3D map for autonomous driving. However, PMOD-Net’s distance error of non-fixed obstacles that do not exist on the 3D map is large. Accordingly, this study deals with the problem of improving distance estimation of non-fixed obstacles for obstacle avoidance. To solve the problem, we focused on the fact that PMOD-Net simultaneously performed object detection and distance estimation. We have developed a new loss function called “DifSeg.” DifSeg is calculated from the distance estimation results on…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1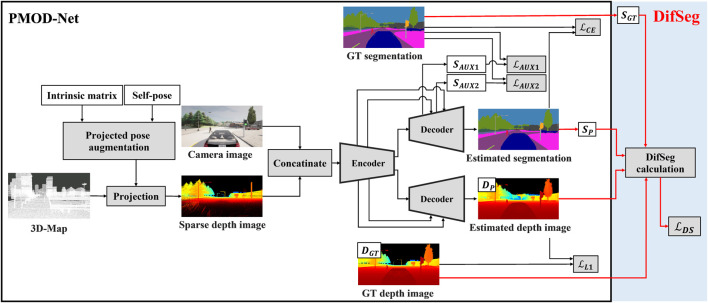 Figure 2
Figure 2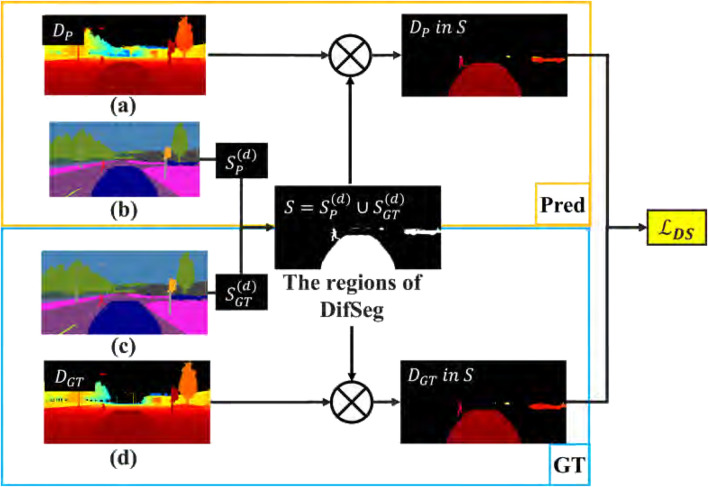 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6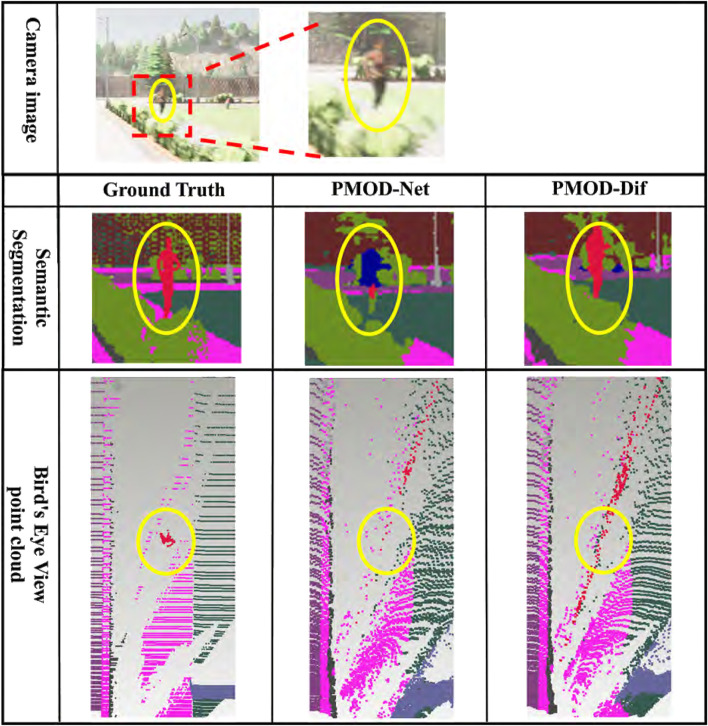 Figure 7
Figure 7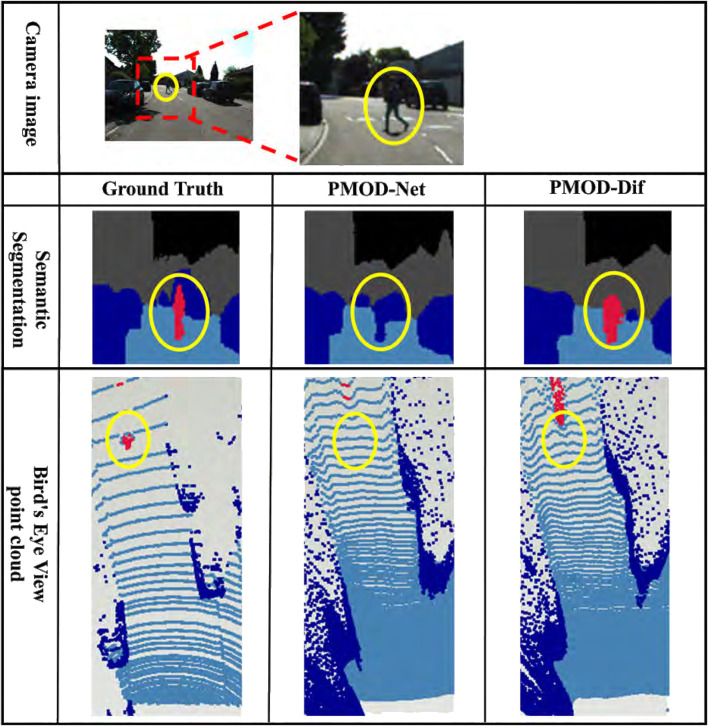 Figure 8
Figure 8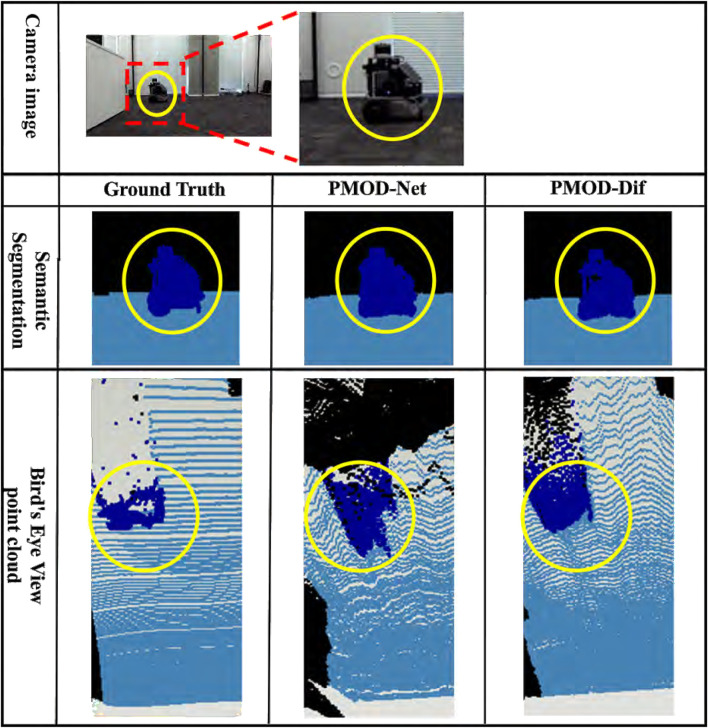 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Vision and Imaging · Image and Object Detection Techniques