Harpy: a pipeline for processing haplotagging linked-read data
Pavel V Dimens, Ryan P Franckowiak, Azwad Iqbal, Jennifer K Grenier, Paul R Munn, Nina Overgaard Therkildsen

TL;DR
Harpy is a new software pipeline for processing haplotagged linked-read sequencing data, enabling haplotype phasing and structural variant detection.
Contribution
Harpy introduces a modular pipeline specifically designed for haplotagging data, which existing tools cannot handle.
Findings
Harpy processes raw haplotagged data into phased genotypes and structural variant calls.
The pipeline is modular and user-friendly for researchers working with linked-read sequencing.
Harpy fills a gap in analytical tools for haplotagging data.
Abstract
Haplotagging is a method for linked-read sequencing, which leverages the cost-effectiveness and throughput of short-read sequencing while retaining part of the long-range haplotype information captured by long-read sequencing. Despite its utility and advantages over similar methods, existing linked-read analytical pipelines are incompatible with haplotagging data. We describe Harpy, a modular and user-friendly software pipeline for processing all stages of haplotagged linked-read data, from raw sequence data to phased genotypes and structural variant detection. https://github.com/pdimens/harpy.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
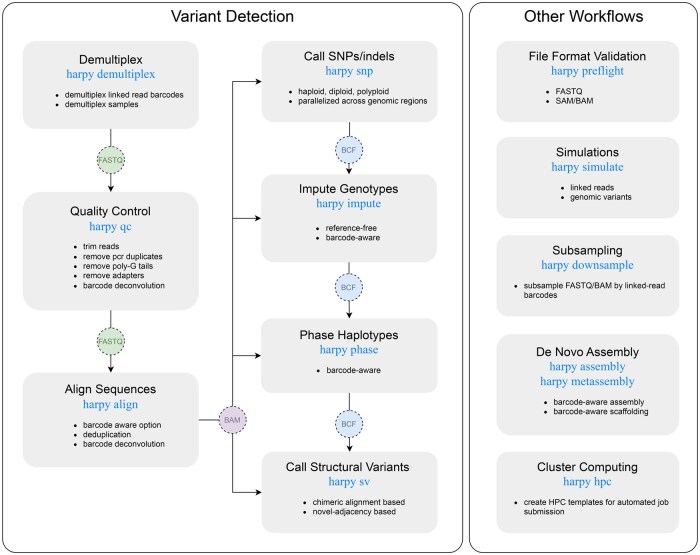 Figure 1
Figure 1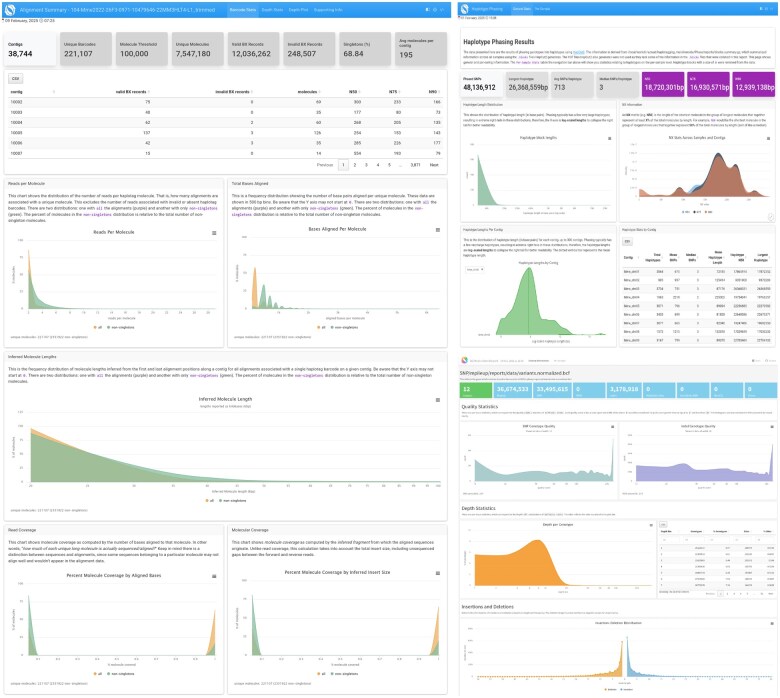 Figure 2
Figure 2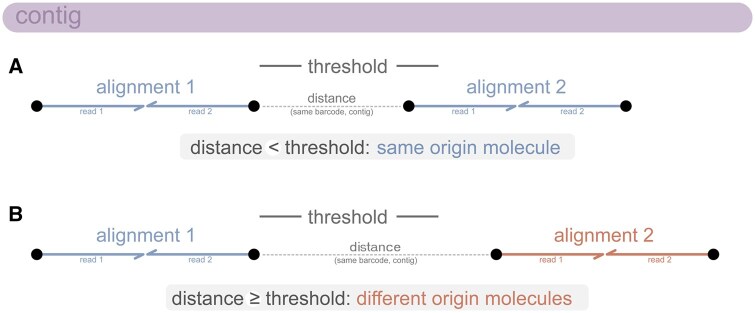 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenetic Associations and Epidemiology · Bioinformatics and Genomic Networks · Biomedical Text Mining and Ontologies